
Abstract
The database of Genotypes and Phenotypes (dbGaP) allows researchers to understand phenotypic contribution to genetic conditions, generate new hypotheses, confirm previous study results, and identify control populations. However, effective use of the database is hindered by suboptimal study retrieval. Our objective is to evaluate text classification techniques to improve study retrieval in the context of the dbGaP database. We utilized standard machine learning algorithms (naive Bayes, support vector machines, and the C4.5 decision tree) trained on dbGaP study text and incorporated n-gram features and study metadata to identify heart, lung, and blood studies. We used the χ2 feature selection algorithm to identify features that contributed most to classification performance and experimented with dbGaP associated PubMed papers as a proxy for topicality. Classifier performance was favorable in comparison to keyword-based search results. It was determined that text categorization is a useful complement to document retrieval techniques in the dbGaP
Keywords
Introduction
In 2003, the National Institute of Health (NIH) required that certain funded projects include a data sharing plan. Motivated by the idea of understanding phenotypic influence on genetic disease, these policies were later expanded to include NIH funded genome-wide associated studies (GWAS).1,2 In order to facilitate implementation, a central data repository, the database of Genotypes and Phenotypes (dbGaP), was created by the National Center for Biotechnology Information (NCBI) to provide researchers access to the genotypic and phenotypic information. The database includes specific phenotype variables, statistical summaries of genetic information, and offers potential to access individual level data if approved by an NIH Data Access Committee. The database is growing at a rapid pace. In August 2011, 187 top-level studies (a study comprised of sub-studies) were archived in dbGaP, and by December 2012 there were 357 top-level studies. 3
The existence of a publicly accessible database, however, does not guarantee information is available in a suitable form for efficient retrieval, study replication, identification of control populations, or new hypothesis generation. 4 Major contributing factors to suboptimal study reuse are that phenotypic variable names are not standardized and related concepts are not effectively mapped. Approximately 130,000 variable names exist in the database and many are redundant. For example, systolic blood pressure is represented by SBP, systolic_BP, and other variations such that a string match-based search may miss these synonyms. Alternatively, if the search term “white” is entered as a keyword search instead of “Caucasian,” for example, the retrieved results for each search do not match. Genetic studies are expensive and time-consuming, hence maximizing data reuse is of paramount importance. 5
We are approaching this problem by aligning phenotype variable descriptions to a standard information model in two ways. First, our group has developed PhenDisco–-Phenotype Discoverer (http://pfindr.net/)–-a robust tool for researchers to query and upload studies in a standardized fashion by retrofitting phenotypes in dbGaP with ontologies using natural language processing. Second, we are enhancing PhenDisco by integrating automatic document classification techniques into the system. This paper is focused on the second objective as we explore approaches to automatic document classification, motivated by the need to provide enhanced search functionality to the PhenDisco system. The exploding number of scientific publications in recent decades and an increasing number of databases makes automated document classification in biomedicine extremely important to provide accurate data retrieval, organize topics of interest for research, and streamline costs of data curation.
While there is a growing body of literature in the field of biomedical text classification, a search of PubMed and Google Scholar revealed no publications about text classification applied to dbGaP We aim to (1) describe in detail the attributes of dbGaP studies, and (2) improve text categorization utilizing
Methods
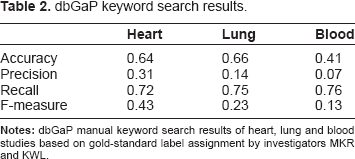
Three hundred and seventeen studies were available in dbGaP on July 1, 2012. Each title and abstract was manually reviewed and annotated by MKR and KWL into heart, lung, blood, and other categories. Interrater reliability was calculated using the R programming language (package IRR) implementation of Cohen's kappa (two raters) and Fleiss's kappa (three raters). 6 We confirmed the need for enhanced retrieval by performing a simple manual keyword search experiment. Search terms (asterisk=wildcard search) for heart studies were heart and/or card*. Lung study terms were lung and/or pulm* and/or resp*. The terms blood and/or heme* were entered for blood studies.
Three machine learning algorithms used successfully for text classification in the past were applied in this work: naïve Bayes (NB), support vector machines (SVM), and the C4.5 decision tree learning algorithm (Weka v. 3.6.8 using default parameters). The NB algorithm is frequently utilized for text classification with good results despite its assumption that features are independent. The SVM algorithm is commonly used because it is robust and resilient to over-fitting. Decision tree algorithms are another commonly applied tool, but incur the risk of mistakes early in the training process. 7
Below we describe the experiments in detail. First, we explain the study metadata features. Second, we detail text classification experiments integrating
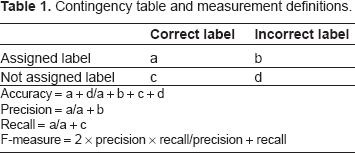
Contingency table and measurement definitions.
dbGaP keyword search results.
Metadata features
Each dbGaP study Web page is organized into descriptive sections (Fig. 1). The sections are: study description, authorized access, publicly available data, study inclusion/exclusion criteria, molecular data, study history, selected publications, disease related to study (MeSH terms), links to other NCBI resources, authorized data access requests, and study attribution (principal/co-investigators and funding source). We focused on journal publications, MeSH terms, principal/co-investigators, and funding source as these features have been shown to increase classification accuracy in previous studies.810
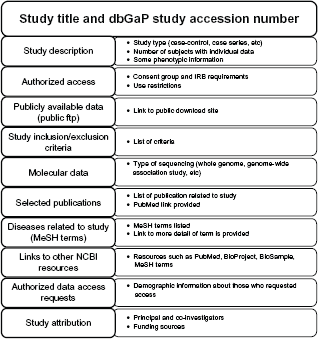
Metadata features of studies in dbGaP.
n-gram and metadata experiments
The first set of experiments used
Metadata for each study was automatically extracted from the dbGaP website (http://www.ncbi.nlm.nih.gov/gap) using Python scripts. For our first set of experiments we employed unigrams, bigrams, and the study metadata (journals, MeSH terms, principal and co-investigators, and funding source). Accuracy, precision, recall, and F-measure were calculated using Weka.
Feature selection experiment
Our next experiment focused on feature set optimization. Yang and Pedersen have shown that feature selection (in particular the χ
2
and information gain feature selection algorithms) can improve classification accuracy for some text classification tasks.11,12 We used the Weka implementation of the χ
2
feature selection algorithm in this work. All
PubMed experiment
Due to the relative paucity of training data in dbGaP, our last experiment examined feasibility of using study-associated PubMed indexed articles as a representation for topicality (eg, if 20 PubMed heart studies are associated with a dbGaP study, but only one lung study, then the study is likely to be a heart study). A similar method was applied to classifying company and university websites with some success by Ghani et al.
13
To develop our training corpus, MKR manually chose 100 PubMed articles associated with dbGaP studies at random in each category of heart, lung, and blood and 300 PubMed studies unrelated to heart, lung, or blood topics for a total of 600 PubMed studies. A binary classifier was used for each category. For example, a study would be categorized as heart or other, lung or other, and blood or other. In each dbGaP study, the associated PubMed studies are found in the selected publications section under which the study authors, title, and journal article are recorded with a PubMed hyperlink. Of the chosen studies, approximately 60 PubMed studies directly associated with dbGaP studies in each category of heart, lung, and blood. However, not all dbGaP studies have an associated PubMed study; therefore, 40 studies with the same topicality were chosen at random from the PubMed database (with same search terms used in the keyword experiments), for a total of 100 studies per heart, lung, and blood category. MC and KWL categorized MKR's chosen studies and inter-rater reliability was calculated using Fleiss’ Kappa for three raters. Each discrepant classification was assigned a label after discussion and majority vote. A corpus was created from the PubMed study title and abstract and categorized using NB and SVM classifiers with
Results
We detail our results in four sections. First, we report on some salient characteristics of the dbGaP metadata. Second, we describe the
Metadata features
In this section we report details of four types of metadata associated with dbGaP studies: journals, MeSH terms, principle and co-investigators, and funding sources.
Journals
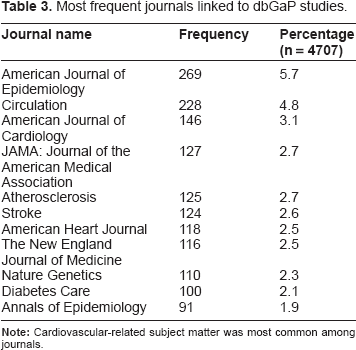
There were 4707 journals publications linked to all dbGaP studies. Of these, 606 were unique instances. The mean number of articles per dbGaP study was 15.4 ± 101.81, ranging from 0–1514. The journals most frequently linked to dbGaP studies were of general topicality, cardiology, epidemiology, or stroke (Table 3).
Most frequent journals linked to dbGaP studies.
Medical Subject Heading terms
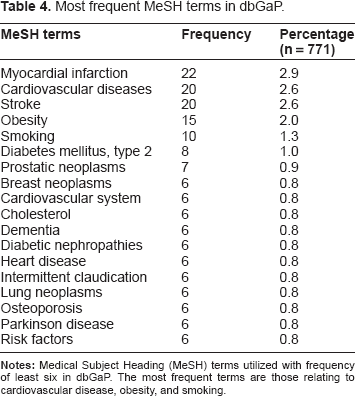
On average, dbGaP studies are associated with 2.24 ± 5.46 Medical Subject Heading (MeSH) terms, ranging from 0–69. There were 771 total terms, with cardiovascular disease, stroke, obesity, and smoking being the most common topics. Terms with a frequency of at least six are represented in Table 4.
Most frequent MeSH terms in dbGaP.
Principal and co-investigators
There were 903 principal investigators and co-principal investigators associated with studies in dbGaP On average each investigator was associated with a mean of 3.99 ± 8.22 distinct studies. Fifty-one investigators were associated with three or more dbGaP studies.
Funding sources
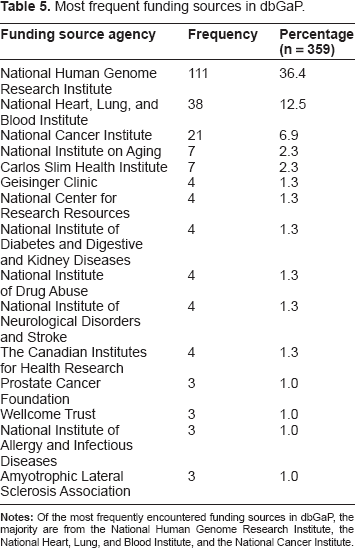
The funding agency most frequently linked to dbGaP studies supported 111 studies. The mean number of studies supported per funding body was 3.44 ± 0.93 ranging from 1-111. Studies were predominately funded by the National Human Genome Research Institute (36%) and the National Heart, Lung, and Blood Institute (12%). The most frequent funding sources are listed in Table 5.
Most frequent funding sources in dbGaP.
n-gram and metadata experiments
Results from the
Inter-rater agreement
MKR and KWL manually classified dbGaP studies into the categories of heart, lung, and blood. Cohen's Kappa score was 0.86, 0.72, and 0.77, respectively indicating acceptable agreement. The discrepancies were reviewed, discussed and a final category was determined.
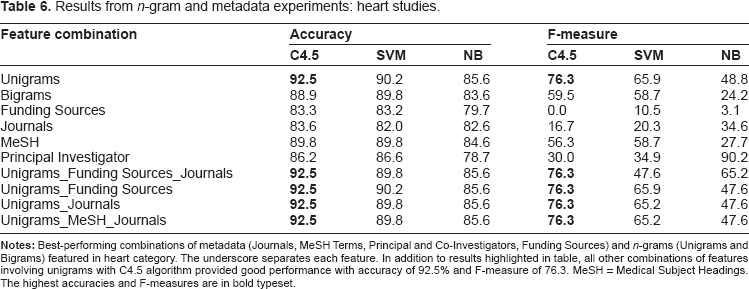
Heart studies
There were 46 heart studies in the database. The best performing algorithm was the C4.5 approach with accuracy of 92.5% and F-measure of 76.3. The second-best performing algorithm was SVM with 90.2% accuracy and F-measure of 65.9. The unigram feature yielded the best result regardless of the metadata feature combination (Table 6). This is substantial improvement over the keyword search accuracy of 64% and F-measure of 43.
Results from
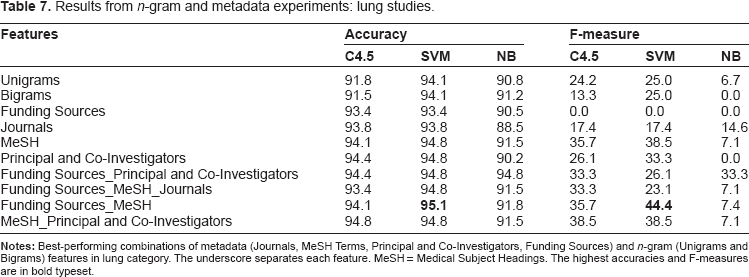
Lung studies
There were 20 studies classified as lung in the dbGaP database. In this case, the C4.5 algorithm performed adequately with regards to accuracy, but was not the highest overall performing learning algorithm in terms of F-measure. The SVM classifier achieved the highest overall score of 95.1% for accuracy and 44.4 for F-measure when the metadata features funds, MeSH terms, and journals were combined (Table 7). Similar to heart studies, this was a noticeable improvement over keyword search for lung studies, which provided an accuracy of 66% and F-measure of 23.
Results from
Blood studies
There were 28 blood studies in the training set. The best performing classifier was SVM in conjunction with MeSH features, with 92.1% accuracy and 33.3 F-measure. The best performing combination of features was unigrams, funds, and journals with an accuracy of 92.1% and F-measure of 29.4 as shown in Table 8. The scores decreased as increasing features were added likely due to over-fitting of the model. While the results did not increase to the degree of the heart and lung cases, there was an improvement over keyword accuracy of 41% and F-measure of 13.
Results from
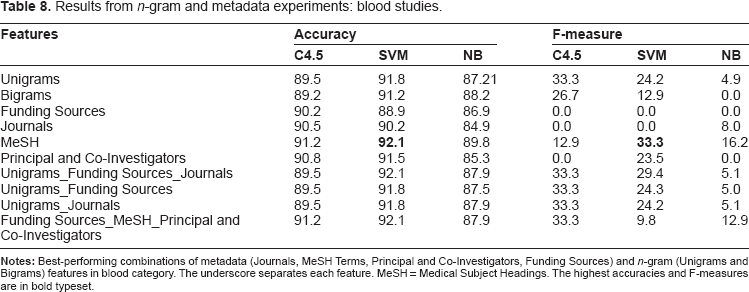
Feature selection experiment
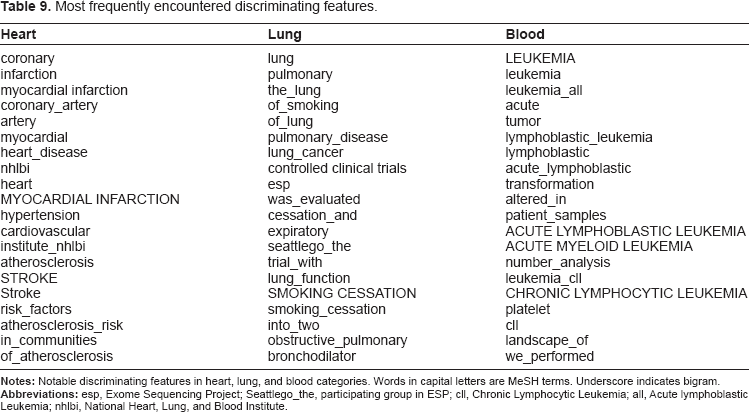
Although the unigrams and metadata feature-based classifiers out-performed the keyword search available in dbGaP, we continued with the feature selection experiment to attempt further performance increase. The 20 most discriminating features in each category as determined by the χ 2 feature selection algorithm are noted in Table 9. Performance of the SVM and NB learning algorithms was improved by determining the optimal number of features in cross-validation experiments (Table 10). For heart studies, the threshold was 500 features with best performance by SVM algorithm (F-measure, 83.1). In lung studies the threshold was 2400 features with best results by NB algorithm (F-measure, 78.8). The blood study threshold was 2200 features with best performance by NB algorithm (F-measure, 72.7). All groups achieved substantial improvement, particularly over keyword search (Fig. 2).
Most frequently encountered discriminating features.
Optimal number of features.

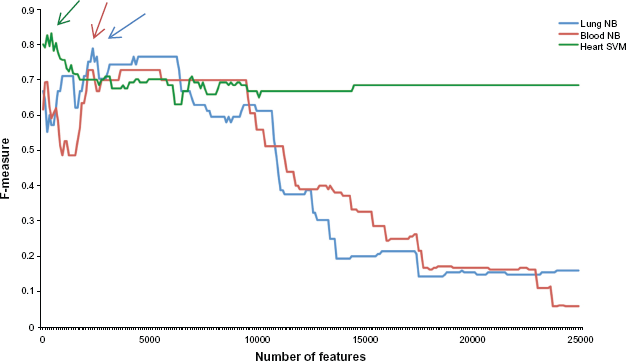
F-Measure feature selection thresholds: heart, lung, blood.
PubMed experiment
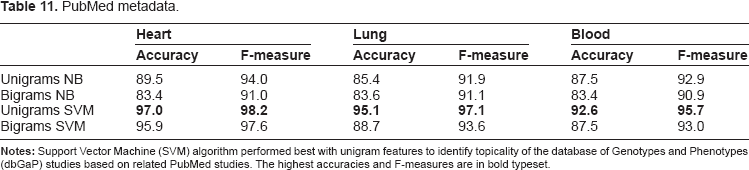
We found PubMed studies effective metadata to represent topicality of dbGaP studies (Table 11). The SVM algorithm using unigrams achieved the highest F-measure for heart, lung, and blood studies (98.2, 97.1, and 95.7, respectively). Accuracy was also highest with the SVM algorithm and unigrams (97.0, 95.1, and 92.6, respectively).
PubMed metadata.
Inter-rater agreement
Inter-rater agreement was calculated across three raters (MKR, KWL, and MC). Both MKR and KWL have a background in clinical medicine, while MC's background is in informatics. The Fleiss’ Kappa for
Discussion
For all categories–-heart, lung, and blood–-we found that text classification methods improved document identification compared to keyword based approach. By utilizing
Text classification of biomedical-related documents is an active area of research and our dbGaP database results are comparable to previous approaches in the literature. Donaldson et al
14
identified PubMed literature on the topic of protein-protein interactions using an SVM algorithm, gaining a classification accuracy of 90%.
14
Dobrokhotov et al
15
used probabilistic classification to classify and rank PubMed literature according to human genes of interest, achieving 59% precision and 69% recall.
15
Miotto et al
16
applied classification and regression trees (CART) and artificial neural networks (ANN) machine learning algorithms to PubMed abstracts to identify allergen cross-reactivity papers, finding that a bag-of-words document representation performed best overall.
16
In 2007, Wang et al
9
used a NB text classifier to demonstrate improved automated document classification in an immune epitope database. Features used were authors, journal, and MeSH headings with a sensitivity (precision) of 95% and specificity of 51.1%.
9
In 2008, Poulter et al
17
created an information retrieval system for Medline with a NB classifier incorporating MeSH terms and journals titles to retrieve articles of interest in specific domains. The average precision varied from 0.69 to 0.92 depending on the topic.
17
In 2009, Conway et al
18
demonstrated that a combination of
In our experiments, the highest accuracy and F-measure overall for heart studies was based upon the unigram feature alone. This was attributed to the fact that the heart category contained the highest number of studies and the most homogenous diagnoses, such as coronary artery disease and myocardial infarction. For lung studies, the funding source was the most discriminating attribute. One possible explanation for this was the relatively small size of the lung document training set, and to explore this we reviewed the C4.5 classifier output. We discovered many terms used to determine decision nodes were not specific to lungs such as the name of the clinical trial, whereas the heart study output better captures cardiac medical terms(Fig. 3). In regard to the blood studies, we speculate that the lower performance was because their topicality is comprised of heterogeneous terms including clotting disorders, leukemia, and platelets.
C4.5 decision tree nodes to determine heart vs. lung label.
In regard to the inter-rater reliability of classifying the PubMed experiments, MKR and KWL's scores were more aligned because of their clinical backgrounds and experience with manual classification. The categorization of studies is not straightforward. There are diagnoses that may belong to multiple categories and require clinical expertise to determine appropriate classification. For example, although stroke involves the neurologic system, it is generally thought of as a cardiovascular disorder. Other indistinct diagnoses are pulmonary embolism and pulmonary hypertension. Although the root cause of embolism is typically a blood coagulation abnormality, and pulmonary hypertension is vascular in origin, these can be considered lung diseases as recognized by the American Lung Association. This concept of classifying studies into only one category when in reality diagnoses may fall under multiple categories, is a shortcoming of our methods. This is something to be addressed in the future as we optimize the algorithms and is important to consider when deciding which researchers will perform manual categorization of training corpus documents as domain knowledge has a decisive role.
Conclusion
Although relatively small, the number of studies in dbGaP is rapidly increasing. We demonstrated that using a document classifier based on
In future work, we plan to employ features derived from MetaMap 21 and other natural language processing tools in order to further improve classification accuracy and integrate this into the PhenDisco system. We plan to expand these experiments in topicality and build classifiers for other conditions of interest to dbGaP users (eg, asthma, chronic obstructive pulmonary disease, myocardial infarction, diabetes, etc.). The methods presented in this paper are not only suitable for dbGaP, but can also add structure to new databases or retrofit existing databases.
Author Contributions
MKR conceived of the study, collected and analyzed data, and drafted the manuscript. KT and AK performed machine learning experiments and data analysis. KWL performed manual classification analysis. MC participated in study design and helped draft the manuscript. All authors read and approved the final manuscript.
Funding
The authors were funded in part by NIH grants UH2HL108785 and T15LM011271 (MKR).
Competing Interests
Author(s) disclose no potential conflicts of interest.
Disclosures and Ethics
As a requirement of publication the authors have provided signed confirmation of their compliance with ethical and legal obligations including but not limited to compliance with ICMJE authorship and competing interests guidelines, that the article is neither under consideration for publication nor published elsewhere, of their compliance with legal and ethical guidelines concerning human and animal research participants (if applicable), and that permission has been obtained for reproduction of any copyrighted material. This article was subject to blind, independent, expert peer review. The reviewers reported no competing interests.
Footnotes
Acknowledgements
We thank Dr. Lucila Ohno-Machado for review of the manuscript. We thank Dr. Hyeon-eui Kim (University of California, San Diego), Dr. Wendy Chapman (University of California, San Diego), Dr. Son Doan (University of California, San Diego), and Julianne Iacuaniello for helpful discussion.