
Abstract
Knowledge graph embeddings represent a group of machine learning techniques which project entities and relations of a knowledge graph to continuous vector spaces. RDF2vec is a scalable embedding approach rooted in the combination of random walks with a language model. It has been successfully used in various applications. Recently, multiple variants to the RDF2vec approach have been proposed, introducing variations both on the walk generation and on the language modeling side. The combination of those different approaches has lead to an increasing family of RDF2vec variants.
In this paper, we evaluate a total of twelve RDF2vec variants on a comprehensive set of benchmark models, and compare them to seven existing knowledge graph embedding methods from the family of link prediction approaches. Besides the established GEval benchmark introducing various downstream machine learning tasks on the DBpedia knowledge graph, we also use the new DLCC (Description Logic Class Constructors) benchmark consisting of two gold standards, one based on DBpedia, and one based on synthetically generated graphs. The latter allows for analyzing which ontological patterns in a knowledge graph can actually be learned by different embedding.
With this evaluation, we observe that certain tailored RDF2vec variants can lead to improved performance on different downstream tasks, given the nature of the underlying problem, and that they, in particular, have a different behavior in modeling similarity and relatedness. The findings can be used to provide guidance in selecting a particular RDF2vec method for a given task.
Introduction
RDF2vec [56] is an approach for embedding entities of a knowledge graph in a continuous vector space. It extracts sequences of entities from knowledge graphs, which are then fed into a word2vec encoder [31,32]. Such embeddings have been shown to be useful in downstream tasks which require numeric representations of entities and rely on a distance metric between entities that captures entity similarity and/or relatedness [44]. Examples of RDF2vec applications include knowledge graph matching [33,47,49], general machine learning involving named entities [57], entity type prediction [23,60], relation prediction [44], named entity classification [13,48], or information retrieval [28,61].
Since its inception, multiple extensions have been proposed for RDF2vec. In this paper, we analyze two recent RDF2vec extensions in more detail. They concern variations in the walk generation (named e-RDF2vec and p-RDF2vec) as well as training word2vec in an order-aware fashion (named RDF2vecoa). These extensions have been evaluated on their own on task-based datasets before [50,51]. Preliminary evaluations revealed that the flavor that is chosen influences the weight which is put on different (semantic) features – for example, e-RDF2vec spaces are considered to be more focused on relatedness while there is indication that p-RDF2vec spaces cover fine-grained similarity better. This paper presents the first comprehensive evaluation of all combinations of classic, e-RDF2vec, and p-RDF2vec, in their order aware and non-order aware variants.
Moreover, not all of the evaluations in previous papers have been fully conclusive. This poses the question: “What is actually learned?” It is not easy to answer this question since task-based evaluation are subjective in nature and blend different semantic requirements. This paper strives to achieve a deeper understanding of what knowledge graph embedding methods, such as RDF2vec, are actually capable of representing. To that end, we perform an in-depth comparison of the different variants, as well as a comparison of RDF2vec-based approaches to non RDF2vec-based ones.
While we also perform task-based evaluations with multiple variants of RDF2vec, the evaluation goes beyond single task-based discussions and tries to tackle the question more fundamentally. We use multiple description logic (DL) class constructors [52], which are used to create two benchmarks: One benchmark is based on DBpedia and one benchmark is synthetic in nature. We furthermore formulate hypotheses which of classes can be learned using which embedding method. The two benchmarks – and particularly the comparison of results between them – allow us to evaluate our hypotheses and to determine which DL class constructors are learned by which approach. Furthermore, we analyze whether the DL class constructor is actually learned or whether the approach is merely exploiting cross signals which can be found in the knowledge graphs. In our evaluation, we include not only twelve different RDF2vec configurations but also seven different state of the art embedding models.
This paper makes two main contributions: (1) An in-depth evaluation of multiple RDF2vec configurations including their combinations is performed. (2) In addition, an in-depth evaluation of existing state of the art models on completely novel tasks is run to expose their strengths and weaknesses. To our knowledge, our work is the first attempt to understand what knowledge graph embedding methods can actually represent, both with respect to RDF2vec variants as well as to other embedding methods, and, at the same time, the most comprehensive evaluation for knowledge graph embeddings in general and RDF2vec variants in particular.
While some results of this paper have already been published [50–52], the following contributions are novel:
We discuss theoretical hypotheses about the representational power of different RDF2vec based variants and test them with systematic benchmarks.
We demonstrate that information on the nature of the task for which embeddings are to be used can help to make an informed decision on an embedding model.
We provide a full comparison of twelve RDF2vec variants and seven additional baseline models.
The rest of this article is structured as follows: The following section introduces related work in the field of knowledge graph embeddings and embedding evaluation gold standards. We then discuss RDF2vec extensions in Section 3. Subsequently, we introduce a frequently used gold standard for evaluating knowledge graph embeddings through machine learning applications in Section 4. In Section 5, we introduce a broad set of description logic class constructors whereby we are interested in how far each constructor can be learned by an embedding approach. Together with the constructors, we hypothesize which RDF2vec variant may be able to cover which constructor and why. After constructors and hypotheses are introduced, a set of test cases is required to evaluate the embeddings and to validate our assumptions. Therefore, Section 6 introduces a framework which we developed to derive two gold standards, named DLCC (Description Logic Class Constructors). In Section 7 we present the obtained results, discuss them, and check the previously posed hypotheses. Lastly, this paper is concluded in Section 8 by a summary together with an outlook on future work.
All relevant artifacts (embedding models, gold standards, developed frameworks) are publicly available.1
Instructions on how to reproduce the results in this paper are available online at
Knowledge graph embeddings A knowledge graph
In this paper, the focus lies on deterministic point vector embedding approaches. The notation assumes a real vector space, this is not the case for ComplEx [65] and RotatE [62].
Numerous approaches for knowledge graph embeddings were presented in the past and multiple surveys on knowledge graph embeddings were published [8,10,44,66,69]. Cai et al. [8] distinguish five different techniques for graph embedding: (1) matrix factorization, (2) deep learning, (3) edge reconstruction, (4) graph kernel, and (5) generative model.3
Within these categories, even finer categories are presented. In this paper, we will only discuss the main classes and point to subclasses if relevant. For a complete overview of the classification system, we refer the reader to the original publication [8]. While the paper is about graph embedding in general, not knowledge graph embedding in particular, the authors list knowledge graphs as one kind of graphs under consideration for their categorization. Moreover, they do not restrict any category to a particular kind of graph. Therefore, we use this categorization as a categorization for KGE approaches.
A well-known matrix factorization approach is RESCAL [34]. The approach models a graph as a three-way tensor and subsequently applies tensor decomposition. DistMult [65] is a scalability improvement over RESCAL at the cost that relationships are assumed to be symmetric. ComplEx [65] extends DistMult by using complex vector spaces rather than real ones.4
Hence, for ComplEx:
RDF2vec [57] (and all its variants [50,51]) fall into the category of random walk-based deep learning: Multiple walks are performed within a graph, typically for each node, and the set of walks is then interpreted as sentences by the word2vec language embedding algorithm [31,32]. Conceptually, RDF2vec is similar to node2vec [17] and DeepWalk [43], with the difference that the latter approaches were presented in the context of homogeneous graphs, i.e., graphs with merely one edge type.
TransE [6] is a well-known edge-reconstruction approach which minimizes the margin-based ranking loss. Given a triple in the form (
Hence, for RotatE:
Since graph kernels are designed for embedding a whole graph, this category is not relevant for the article at hand. An example of generative models would be the Latent Dirichlet Allocation applied on graphs. Embedding approaches from this category, however, are not commonly used for knowledge graph embedding applications and are not further discussed in this article.
Knowledge graph embedding evaluation In the area of link prediction (or knowledge base completion), the two well-known evaluation datasets FB15k and WN18 [6] are both based on real datasets: FB15k is based on the Freebase knowledge graph [5], and WN18 is based on WordNet [15]. They were presented in the context of link prediction: Given a triple in the form (
Alshagari et al. [2] present a framework for ontological concepts covering three aspects: (i) categorization, (ii) hierarchy, and (iii) logic validation. The framework can be used for language models and for knowledge graph embeddings. The work presented in this paper differs in that it goes beyond explicit DBpedia types. The evaluation of this paper is, therefore, of analytical rather than descriptive nature. Moreover, the task sets of DLCC are significantly larger and more comprehensive.
Ristoski et al. [54] provide a collection of benchmarking datasets for machine learning including classification, clustering, and regression tasks. Later, the GEval framework [41,42] was introduced to provide a standardized evaluation protocol for this dataset. The evaluation datasets are based on DBpedia. Internally, the embeddings are processed by different downstream classification, regression, or clustering algorithms, using typical machine learning metrics like accuracy or root mean squared error (RMSE) for evaluation. The evaluation framework presented in this paper is similar to GEval in that it also evaluates multiple classifiers given a concept vector input.
Melo and Paulheim [29] provide a method for synthesizing benchmark datasets for link and entity type prediction, which are used in conjunction with a fixed ontology. Their goal is to mimic the characteristic of existing knowledge graphs in terms of distributions and patterns. However, it does not come with any specific prediction objective.
Bloem et al. [3] introduce kgbench, a node classification benchmark for knowledge graphs, which is based on real-world datasets and comes with tasks in different sizes and predefined train/test splits. Unlike DLCC, kgbench is based on real-world datasets. Therefore, it is suitable to evaluate and compare the quality of different embedding approaches on real-world tasks but does not provide any insights into what these embedding approaches are capable of representing.
In this paper, we introduce a new benchmark for node classification, i.e., Description Logic Class Constructors (DLCC), first introduced in [52], which allows for an isolated consideration of different types of node classification problems in knowledge graphs and therefore can provide insights in which problems can be tackled by a particular embedding method and which cannot.
For the experiments in this paper, we use both the established GEval benchmark as well as the rather new DLCC benchmark, in order to have an encompassing comparison of RDF2vec variants and benchmark models, with respect to both realistic problems using the widely used DBpedia knowledge graph, as well as on synthetic problems allowing to analyze the representational capabilities of the RDF2vec variants in detail.
RDF2vec has two main steps (see Fig. 1): First, sequences are extracted from a knowledge graph using random walks. In a second step, these sequences are processed by the word embedding algorithm word2vec. The algorithm considers entities and predicates from the graph as “words”, so that it produces embedding vectors for entities and predicates.
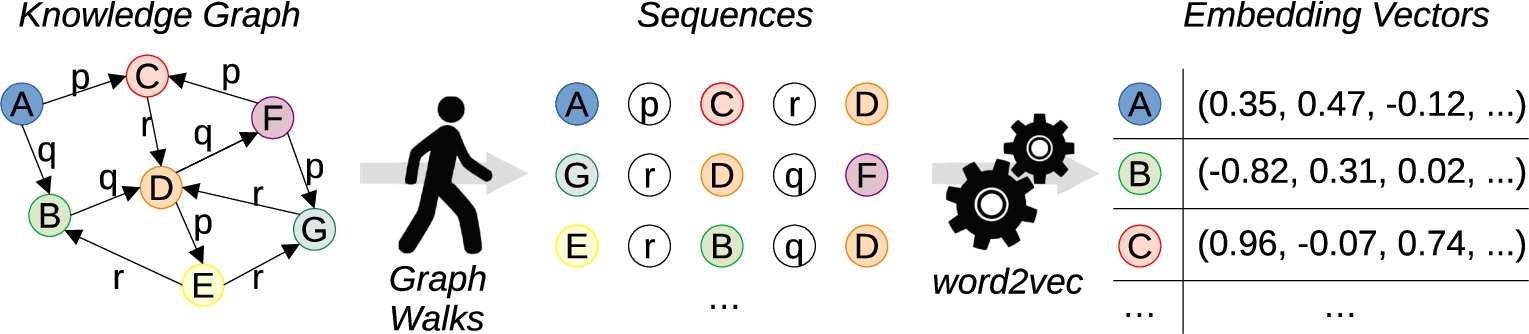
Overall workflow of RDF2vec [40].
Word2vec itself has two principle variants (see Fig. 2): context bag of words (CBOW) tries to predict a word from its context, while skip-gram (SG) tries to predict the context from a word. In both cases, a hidden projection layer is used to produce word embeddings [32].
Combining RDF2vec with more recent and advanced word embedding methods, such as FastText [4] and BERT [12], has yielded inconclusive results so far [1]. A potential reason for this is that the ratio of a corpus size extracted by random walks from a graph to the vocabulary size is far smaller than for large text corpora, on which models like BERT are trained.6
The pre-trained BERT model described in [12] is trained for 30k tokens on a corpus of 3.3B words, which makes a ratio of 110k words per token. On the other hand, extracting 500 length 4 random walks for each entity in a knowledge graph will result in a ratio of only 2.5k “words” per entity, which is two orders of magnitude smaller.

The two basic architectures of word2vec [57].
Over time, RDF2vec was extended multiple times. Generally, three kinds of extensions can be distinguished: (1) Changes in the walk generation algorithm, (2) changes in the embedding algorithm, and (3) other changes. The extensions are presented in the following paragraphs. Out of those extensions, we picked the most promising and interesting candidates and present them in more detail in the subsequent Sections 3.1 and 3.2.
Walk generation extensions One of the first extensions to the random walk generation algorithm was biased graph walks [9]. In this extension, multiple edge weighting mechanisms are proposed and evaluated to influence the walk generation. Using the predicate frequency strategy, for instance, increases the likelihood that the random walks will include predicates that are very common. While improvements in some test cases with some configurations are observable compared to the classic strategy, the overall results are inconclusive in that there is not a single best configuration for all tasks and that it is hard to determine which configuration should be used in which situation. It is also important to note that biasing walks increases the overall runtime of the RDF2vec approach since a large number of weights has to be calculated and considered during the walk configuration. While those experiments use graph-internal metrics for weighting edges, later experiments indicate that graph-external metrics for edge importance (in that case: derived from user clickstreams in Wikipedia) can be advantegeous for the resulting embeddings [63]. Other variants of walk generation include the incorporation of community hops or walklets [61], but the evidence here is mixed as well.
Most recently, entity walks and property walks were presented [51]. Those change the walk generation algorithm in terms of what graph elements are included. They are described in more depth in Section 3.1. The approaches are neutral in terms of additional embedding runtime, entity walks are even significantly faster since the vocabulary is smaller during training.
Embedding algorithm extensions The classic RDF2vec configuration is based on word2vec. RDF2vecoa [50] uses an order-aware variant [27] of the original word2vec algorithm. That approach has shown to be consistently better than the classic RDF2vec configuration in various publications [44,50].
Other extensions RDF2vec always generates embedding vectors for an entire knowledge graph. This process can be very expensive for large knowledge graphs and may be even unfeasible for very large knowledge graphs. At the same time, most tasks do not require an embedding for every concept in a knowledge graph. In many cases, the set of required embeddings can be determined ex ante – e.g. entities of type city when the task is to regress the score for the quality of living. In such instances, RDF2vec Light [45] can be used. The approach applies the walk generation algorithm only to the predefined entities and thereby reduces the required time for walk generation and training significantly. Experiments showed that the performance is comparable to the more expensive classic variant – particularly in cases where the set of entities is homogeneous and their degree is not too large.
In this paper, three different walk generation methods are evaluated: Classic walks, entity walks (e-walks), and predicate walks (p-walks). These configurations have been picked since they have previously been shown to be able to separate the paradigmatic relations of similarity and relatedness [51].7
Similarity describes in how far two concepts are similar to each other “by virtue of their similarity” [7]. Similarity and relatedness are often not clearly separated from each other (for instance in [16]). Nevertheless, there are significant differences. Dissimilar entities can even be semantically related by antonomy relationships [7]. Hill et al. distinguish the two relations by giving examples: While the concepts coffee and cup are certainly related, they are not similar; however, a mug and a cup can – in language as in the real world – almost be used interchangeably and are, therefore, similar [20].
Classic walks The originally presented RDF2vec variant generates multiple random walks for each node in the graph. A random walk of length n (where n is an even number)8
It is important to point out that not all implementations of RDF2vec share the same terminology. The two-hop sequence above would be referred to as a “walk of length 2” (i.e., counting only nodes) by some implementations, while others would consider it a “walk of length 4” (i.e., counting nodes and edges). In this paper, we follow the latter terminology.
Entity walks (e-RDF2vec) An entity walk contains only entities without any other properties. Such an approach is also known as e-RDF2vec. It has the form:
Note that in the above example, a walk of length n would comprise n entities. In the graph, the entity
Predicate walks (p-RDF2vec) A predicate walk contains only one entity together with object properties. Such an approach is also known as p-RDF2vec. It has the form:
All three walk strategies are visualized in Fig. 3.
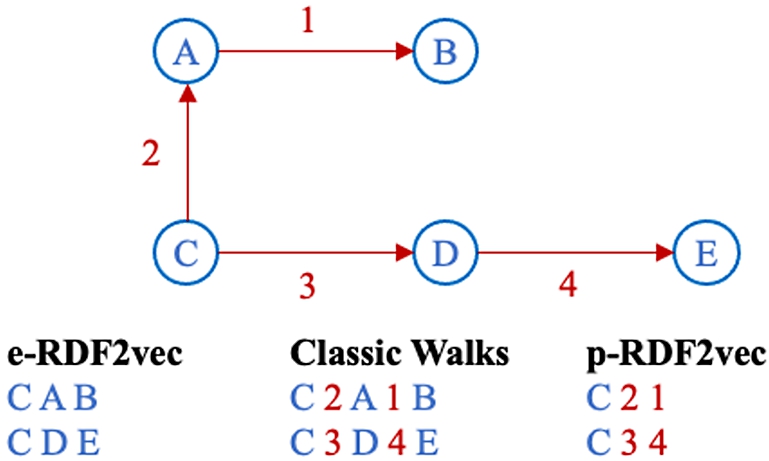
Different walk types visualized, showing walks starting from node C.
In this paper, the two original configurations (SG and CBOW) are evaluated. In addition, the order-aware variants are evaluated which are in the following denoted with the suffix “OA”. This yields four language model configurations: (1) SG, (2) CBOW, (3) SGoa, and (4) CBOWoa.
RDF2vec configurations of this publication
The walk generation processes and the embedding models are independent components of RDF2vec which can be freely combined. In this paper, we evaluate the following walk generation algorithms:
classic walks
entity walks
predicate walks
We combine these with the following language models:
classic word2vec (CBOW and SG)
order-aware word2vec (CBOWoa and SGoa)
This leads to the following combinations:
RDF2vec (original: classic word2vec with classic walks) RDF2vecoa (order aware word2vec with classic walks) p-RDF2vec (predicate walks with word2vec) p-RDF2vecoa (predicate walks with order-aware word2vec) e-RDF2vec (entity walks with classic word2vec) e-RDF2vecoa (entity walks with order-aware word2vec)
Since all of the above combinations can be used with the SG and the CBOW flavor of word2vec, this paper evaluates 12 variants of RDF2vec in total.
While Section 2 lists more extensions of RDF2vec, we restricted ourselves to those models listed above. In the scope of this paper, we are mainly investigating the question of which RDF2vec variant is suitable for which problem at hand. In contrast, some of the other extensions mentioned above, like RDF2vec Light, rather target computational performance improvement. Experiments in [45] suggest that the representational power of RDF2vec and RDF2vec Light are comparable.
For other extensions, like the use of graph external edge or node weights as in [63], external signals are required, which may be created for specific graphs like DBpedia, but not for others. Moreover, we expect that introducing weighted walks may change the quantitative results by putting more emphasis on certain parts of the graph than on others, but not the representational power of RDF2vec, since, with a large enough number of walks, the embedding algorithm will eventually observe all graph structures, regardless of the weights.
Machine learning gold standard
For a comprehensive understanding of the configurations presented in Section 3.3, an evaluation is performed using the machine learning task set for knowledge graph embeddings published by Ristoski et al. [54]. It is comprised of six tasks using 20 datasets in total:
Five classification tasks, evaluated by accuracy (ACC). Those tasks use the same ground truth as the regression tasks (see below). The numeric prediction target is discretized into high/medium/low (for the Cities, AAUP, and Forbes dataset) or high/low (for the Albums and Movies datasets). All five tasks are single-label classification tasks.
Five regression tasks, evaluated by root mean squared error (RMSE). Those datasets are constructed by acquiring an external target variable for instances in knowledge graphs which is not contained in the knowledge graph per se. Specifically, the ground truth variables for the datasets are: a quality of living indicator for the Cities dataset, obtained from Mercer; average salary of university professors per university, obtained from the AAUP; profitability of companies, obtained from Forbes; average ratings of albums and movies, obtained from Facebook.
Four clustering tasks (with ground truth clusters), evaluated by accuracy (ACC). The clusters are obtained by retrieving entities of different ontology classes from the knowledge graph. The clustering problems range from distinguishing coarser clusters (e.g., cities vs. countries) to finer ones (e.g., basketball teams vs. football teams).
A document similarity task (where the similarity is assessed by computing the similarity between entities identified in the documents), evaluated by the harmonic mean of Pearson and Spearman correlation coefficients. The dataset is based on the LP50 dataset [25]. It consists of 50 documents, each of which has been annotated with DBpedia entities using DBpedia spotlight [30]. The task is to predict the similarity of each pair of documents.
An entity relatedness task (where semantic similarity is used as a proxy for semantic relatedness), evaluated by Kendall’s Tau. The dataset is based on the KORE dataset [21]. The dataset consists of 20 seed entities from the YAGO knowledge graph, and 20 related entities each. Those 20 related entities per seed entity have been ranked by humans to capture the strength of relatedness. The task is to rank the entities per seed by relatedness.
Four semantic analogy tasks (e.g., Athens is to Greece as Oslo is to X), which are based on the original datasets on which word2vec was evaluated [31]. The original datasets were created by manual annotation. In our evaluation, we aim at predicting the fourth element (D) in an analogy
Table 1 shows a summary of the characteristics of the datasets used in the evaluation. It can be observed that they cover a wide range of tasks, topics, sizes, and other characteristics (e.g., balance). In this paper, the evaluation protocol as proposed in [42,54] is followed: All entities are linked to a knowledge graph. Different feature extraction methods – in this case pure knowledge graph embedding approaches – can then be compared using a fixed set of learning methods. The evaluation is performed using the GEval framework.10
Overview of the evaluation datasets
In Section 4, a gold standard was introduced. That gold standard is task-oriented, i.e., it gives an indication of which embedding configuration is suitable for a specific task – however, the gold standard is not suitable to perform a deeper analysis such as what is or can be learned.
The DLCC gold standard aims to close that gap by focusing on specific ontological constructs as targets for entity classification. The underlying idea is that if a classifier is able to separate classes created by specific ontological constructs, with entities represented by means of an embedding E, then this embedding can represent the respective ontological construct. The aim of DLCC thus is to provide a benchmark for analyzing which kinds of constructs in a knowledge graph can be recognized by different embedding methods. The construction of that benchmark is described in Section 6.
In order to analyze the representational capabilities of embedding methods, we define class labels using different DL class constructors and argue which variants of RDF2vec are capable of learning them. For each constructor, we formulate hypotheses of which variants of RDF2vec can learn the classes. More precisely, we reject the hypothesis that an embedding can learn a class if a classifier trained on positive examples (members of a class) and negative examples (non-members of a class) does not perform significantly better than random guessing.
The selection of constructors has been mainly motivated by earlier works on propositionalization of RDF for processing in data mining pipelines [39,55], which was a common approach before the emergence of knowledge graph embeddings. [24]
Ingoing and outgoing relations All entities that have a particular outgoing or ingoing relation (e.g., everything that has a location or everything that is a location of something).
We use r to denote a particular relation, whereas R denotes any relation.
Hypothesis 1a (5) and (6) can be learned by RDF2vecoa and p-RDF2vecoa. Non-oa variants cannot properly learn them because they cannot distinguish the two. e-RDF2vec variants cannot properly learn them because they cannot distinguish particular properties.
Hypothesis 1b (7) can be learned by RDF2vec, RDF2vecoa, p-RDF2vec, and p-RDF2vecoa.
Use case An exemplary use case would be entity classification. If a relation has a particular domain or range, an embedding vector capturing that information could be used to infer the corresponding class. Using such structural information for entity classification is quite common [38,60,67].
Relations to particular individuals All entities that have a relation (in any direction) to a particular individual (e.g., everything that is related to Mannheim).
For reasons of scalability, we restrict the provided gold standard to two hops.
Hypothesis 2a (8) can be learned by RDF2vec, RDF2vecoa, e-RDF2vec, and e-RDF2vecoa. Sub-hypothesis: It is possible that the non-oa variants learn it a bit better. However, the non-oa variants will not be able to tell closely related entities (one hop away) from less related ones (more than two hops away).13
Depending on the entity at hand, the second set might grow very large. For example, in DBpedia, half of the entities are reachable from New York City within two hops.
Hypothesis 2b (9) can be learned by RDF2vec, RDF2vecoa, e-RDF2vec, and e-RDF2vecoa, as long as the walk length allows for capturing those relations. Sub-hypothesis: It is possible that the non-oa variants learn it a bit better.
Use case An exemplary use case would be capturing entity relatedness. Two entities sharing many connections to a third entity are typically related. This can also be useful in query expansion for information retrieval [53]. The distinction between closely and vaguely related entities (sharing an entity one or two hops away) may be crucial if queries should not be expanded too much. Also in collective entity disambiguation in texts [35], this notion of relatedness can be useful: one would assume that co-mentioned entities are related, but not necessarily want to restrict the kinds of relation among them.
Particular relations to particular individuals All entities that have a particular relation to a particular individual (e.g., movies directed by Steven Spielberg).
Hypothesis 3 (10) can only be learned properly by RDF2vecoa. Non-oa variants cannot distinguish between the two.14
For example: distinguishing people influenced by Leibniz vs. people who influenced Leibniz.
Use case An exemplary use case would be capturing entity similarity. For example, two movies which have the same director and some overlapping cast can be considered similar. This can be used, e.g., in recommender systems [22] or other predictive modeling tasks.
Qualified restrictions All entities that have a particular relation to an individual of a given type (e.g., all people married to soccer players).
Hypothesis 4a (11) can only be learned properly by RDF2vecoa, and, to a certain extent, by p-RDF2vecoa.
The second case (12) is trickier. Here, the relation to the entity at hand and the type information of the related entity can only appear in two different walks, but never together (at least if the inverse relation is not explicitly contained in the graph). Hence, we assume:
Hypothesis 4b (12) cannot be learned by any RDF2vec variant.
Use case Qualified restrictions are often useful for fine-grained entity classification and thereby capture some aspects of entity similarity. For example, for distinguishing a basketball and a baseball team, it is not sufficient that both have a coach and players, but that those are of the class
Cardinality restrictions of relations All entities that have at least or at most n relations of a particular kind (e.g., people who have at least two citizenships). Here we depict only the at least variant because the corresponding classification problem is the same as the at most variant (classifying
The fact that most knowledge graphs follow the open-world assumption is ignored here.
Hypothesis 5 (14) and (15) can be learned to a certain extent by RDF2vecoa and p-RDF2vecoa. Non-oa variants cannot distinguish the two cases.16
For example: distinguishing someone who has been influenced by more than two people vs. someone who has influenced more than two people.
Use case Cardinalities often capture entity similarity aspects not expressed in other restrictions. For example, when comparing two authors in a knowledge graph of publications, both will have published papers (which makes them indistinguishable when only looking at qualified restrictions), but there is still a difference if one has published two and the other has published two hundred papers. Therefore, this distinction is useful in cases where strengths of relations, measured in their cardinality, play a role. One example are recommender engines for scientific papers [14], where highly ranked papers would be given preference over lowly ranked ones.
Qualified cardinality restrictions Qualified cardinality restrictions combine qualified restrictions with cardinalities (for example, all people who have published at least three bestsellers).
Hypothesis 6a (16) can be learned to a certain extent by RDF2vecoa.
Hypothesis 6b (17) cannot be learned by any variant of RDF2vec.
Use case Just like qualified restrictions and cardinality restrictions, these restrictions capture finer-grained aspects of entity similarity and are thus useable both for fine-grained entity classification and for predictive modeling tasks. A few examples of classification patterns were given in [36], where explanations on the cities classification task in the GEval benchmark were analyzed, and explanations like Cities which are the hometown of many bands have a high quality of living were observed, which would full into this category.
Overview of hypotheses and test cases
Table 2 summarizes the test cases that we have discussed above. While for most of them, we can formulate a hypothesis on whether or not they can be represented with a particular RDF2vec variant, we have no particular hypothesis for CBOW vs. SG.
For the twelve test cases in Table 2, we create positive examples (i.e., those which fall into the respective class) and those which do not (under closed-world semantics). For example, for tc01, we would generate a set of positive instances for which
The approach is visualized in Fig. 4: A gold standard generator generates a set of positive and negative URIs, as well as a fixed train/test split. The approach presented allows for generating custom gold standards – however, a pre-calculated gold standard is also provided. This pre-calculated gold standard can be used to guarantee reproducibility. We publish pre-calculated gold standards at Zenodo which are versioned to allow for future improvements while allowing for comparable experiments. In this paper, we use version
A user provides embeddings in a simple textual format, together with the ground truth labels for the training and the testing partition as input to the evaluator. The evaluator trains multiple classifiers and evaluates them on the selected gold standard using the provided vectors as classification input. The program then calculates multiple statistics in the form of CSV files that can be further analyzed in a spreadsheet program or through data analysis frameworks such as pandas.17

Overview of the DLCC approach [52].
There are two benchmarks: A DBpedia benchmark and a synthetic benchmark. The benchmarks are publicly available and significant efforts were made to comply with the FAIR [68] principles.18
Dataset DOI:
The gold standard generator is publicly available.19
It is important to note that the generator only needs to be run by users who want to build their own gold standards. For analyzing the capabilities of a particular knowledge graph embedding approach, it is sufficient to merely download20
DOI:
The evaluator is publicly available21
The standard user can directly download the gold standard and use the evaluation framework. To test class separability, the evaluation framework currently runs six machine learning classifiers which are commonly used together with embedding methods for node classification22
The evaluation framework is not restricted to the set of classifiers listed here. New classifiers can be easily added if desired.
After training and evaluation, the framework outputs multiple CSV files per test case as well as higher-level aggregate CSV files. Examples of such CSV files are a file listing the accuracy per classifier and per test case or a file listing the accuracy of the best classifier per test case. In the case of DBpedia test cases where multiple domains are available per test case, the results can be analyzed on the level of each domain separately, or in an aggregated manner on the level of the test case.
We use the DBpedia knowledge graph to create test cases.24
We used DBpedia version 2021-09. The generator can be configured to use any DBpedia SPARQL endpoint if desired.
Since negative examples are generated at random, they are very likely not to fulfill any of those conditions.
Query examples for every test case in the people domain are provided in Tables 8, 9 and 10 in the appendix. The framework uses slightly more complex queries to vary the size of the result set and to better randomize results.
In total, we used six different domains: people (P), books (B), cities (C), music albums (A), movies (M), and species (S). This setup yields more than 200 hand-written SPARQL queries which are used to obtain positives, negatives, and hard negatives; they are available online26
The desired size of test sets can be configured in the framework.
The previous benchmark is realistic and well suited to compare approaches on differently typed DL class constructors.
However, the following aspects have to be considered: (1) DBpedia is a large knowledge graph, not every embedding approach can be used to learn an embedding for it (or not every researcher has the computational means to do so, respectively). (2) Depending on the DL class constructor and the domain, not enough examples can be found on DBpedia. (3) It cannot be precluded that patterns correlate, therefore, the fact that an embedding approach can learn a particular class can only be an indicator that it might learn the underlying constructor pattern, but the results are not conclusive, since the performance may also hint at the approach learning a cooccurring pattern. Correlating properties, type biases for entities, etc. may lead to surprising results in some domains.
Therefore, we complement the DBpedia-based gold standard with a synthetic benchmark. The idea is to generate a graph that contains the DL class constructors (positive and negative) of interest. The graph can be constructed to resemble the DBpedia graph statistically but can be significantly smaller (and contain a sufficient number of positives and negatives), and, by construction, side effects and correlations which exist in DBpedia can be mitigated to a large extent. However, the generator also allows for using other schema characteristics as well, which paves the way to broadly investigate the behavior of knowledge graph embedding methods for other cases as well. Unlike other synthetic data generators, like LUBM [18], we create both a schema (T-Box) and instances (A-Box), while LUBM merely creates instances given a fixed schema.
The configurable parameters are
Once the ontology is created,

Illustration of the instance generation, using the class constructor
For version

Ontology creation
Training details
RDF2vec We trained 12 RDF2vec embeddings using the configurations listed in Section 3.3. For the DBpedia benchmarks, we use version 2021-09. We generated 500 walks per entity, with a depth of 4, a window size of 5, 5 epochs, and a dimension of 200. We used the same parameters for the synthetic gold standard with the exception of
Benchmark models We trained DBpedia embeddings using seven benchmark models:
TransE [6] with L1 norm
TransE [6] with L2 norm
TransR [26]
ComplEx [65]
DistMult [65]
RESCAL [34]
RotatE [62]
The above-mentioned benchmark models were trained using the DGL-KE framework30
The results for the ML gold standard introduced in Section 4 are provided in Tables 3 (classification and clustering), 4 (regression and semantic analogies), and 5 (entity relatedness and document similarity). For each task with multiple test sets (i.e., classification, regression, clustering, and semantic analogies), we performed a Friedman test to test whether the results achieved with the different embedding methods are significantly different. The test showed significance for the tasks of classification (Q = 61.38, p = 0.000001), regression (Q = 46.18, p = 0.000279), and semantic analogy (Q = 56.84, p = 0.000007), but not for clustering. For those cases where the Friedman test shows significance, we report significance on individual comparisons of approaches according to a one-sided t-test.
Classification On the classification task, it can be observed that the order-aware RDF2vec variants lead – with few exceptions – to generally better or the same results.32
The order-aware variant significantly (
The SG variant significantly (
RDF2vec SG significantly (
TransE-L2 significantly (
Clustering Concerning the benchmark models, the overall best results are achieved using TransE with L2. Concerning the RDF2vec configurations, the results are rather inconclusive. As mentioned above, the results for clustering are not significant according to the Friedman test.
Regression Again, on the regression tasks, improvements can be observed for the order-aware variants which outperform non-order-aware variants, although not significant. Again, TransE with L2 regularization achieves the best results in most cases36
TransE-L2 significantly (
RDF2vec SGoa significantly (
Semantic analogies On the semantic analogies task, the classic RDF2vec variant with SG configuration performs best.38
RDF2vec SG significantly (
Only the differences for the order-aware and non-order-aware variants of p-RDF2vec SG and p-RDF2vec CBOW are significant (
RESCAL is significantly (
RotatE is significantly (
Entity relatedness and document similarity On the entity relatedness task, the e-RDF2vec variants perform comparatively well with e-RDF2vec SG being the best model. This is intuitive since the e-RDF2vec variant can be expected to pick up the notion of entity relatedness best. On the document similarity task, it can be observed that the p-RDF2vec variant outperforms the other RDF2vec configurations. Again, this finding is intuitive since the configuration is expected to pick up fine-grained entity similarity best – for example, for distinguishing politics from sports texts, it is not sufficient to know that both mention persons, but it is required to distinguish athletes from politicians.
ML results for classification and clustering
ML results for regression and semantic analogies
ML results for entity relatedness and document similarity
Results on the DBpedia Gold Standard (Accuracy). The best results are printed in bold. All results are significantly larger than the random baseline
Results on the Synthetic Gold Standard (Accuracy). The best result for each test case is printed in bold, statistically insignificant scores (w.r.t. a random baseline) are stated in italics. Listed are the results of the best classifier for each task and model
As outlined in Section 6.1, the DLCC benchmarks are balanced. That means that a performance significantly above 50% indicates that the model learns the constructor to some extent. It is important to highlight that Tables 6 and 7 state the best results out of six classifiers (see Section 6.2). In order to determine whether the stated result for an embedding configuration for a particular test case is significant, we performed an approximated one-sided binomial significance test with
DBpedia benchmark The results on the DLCC DBpedia benchmark (class size 5,000) are reported in Table 6. For each model, six classifiers were trained resulting in more than 2,000 classification results. At first sight, it is quickly observable that all models can learn all tasks comparatively well; all results are statistically significant. It is, furthermore, visible that the hard test cases are indeed harder.
On the DBpedia gold standard, it can be seen that p-RDF2vec is rather suitable for similarity-based constructors (tc1, tc2, tc3, tc6) while e-RDF2vec is doing better on relatedness-oriented constructors (tc04, tc05).
Moreover, we can observe that it seems easier to predict patterns involving outgoing edges than those involving ingoing edges (cf. tc02 vs. tc01, tc08 vs. tc07, tc10 vs. tc09, tc12 vs. tc11). Even though the tasks are very related, this can be explained by the learning process which often emphasizes outgoing directions: In RDF2vec, random walks are performed in forward direction; similarly, TransE is directed in its training process. On the DBpedia benchmark, it is observable that the TransE-L2 configuration performs, overall, best scoring first place in 9 out of 20 cases.
Figure 6 depicts the simplicity per domain of the DBpedia gold standard in a box-and-whisker plot. The simplicity was determined by using the accuracy of the best classifier of each embedding model without hard test cases (since not every domain has an equal amount of hard test cases), i.e., the difficulty for a test case t and an embedding model e is

Simplicity of the DBpedia Gold Standard (Size Class 5000).
Synthetic benchmark The results on the synthetic benchmark (class size 1,000) are reported in Table 7. Again, for each model, six classifiers were trained whereby only the best performing classifiers’ results are discussed. RDF2vec configurations are performing very well on this gold standard being the best performing embedding model in 10 out of 12 cases. In terms of the best RDF2vec configuration, the classic CBOW variant achieves the best results in five cases.
The intuition that p-RDF2vec is doing better on similarity-based constructors while e-RDF2vec is doing better on relatedness-oriented constructors can again be observed: This time e-RDF2vec is not able to learn tc02 and tc03 which is intuitive since the approach does not learn the notion of predicate types. On tc04 and tc05, on the other hand, the e-RDF2vec approach performs very well (much better than p-RDF2vec).
The best benchmark model is RESCAL. RotatE produces insignificant results than significant results more often – the model outperforms pure guessing in only a third of the cases.
The overall most complicating test case is tc07. Similarly, more than half of the models are not significantly able to learn tc08. This is remarkable since the constructors can be almost perfectly predicted on the corresponding DBpedia gold standards. Hence, we can reason that handling qualified restrictions is a very intricate task. The second hardest group of tasks is those involving cardinalities (tc10-tc12).
DBpedia benchmark vs. synthetic benchmark The comparison of the DBpedia and the synthetic benchmark is particularly intriguing. We can see that the synthetic benchmark is much harder to solve since the results are drastically lower in most cases. While there are no insignificant results on the DBpedia gold standard, there are many for the synthetic one – particularly when it comes to the benchmark models. Many class constructors that are easily learnable on the DBpedia gold standard are hard on the synthetic one. Moreover, the previously reported superiority of RDF2vecoa over standard RDF2vec [44,50] cannot be observed on the synthetic data.

Excerpt of DBpedia.
Figure 7 shows an excerpt of DBpedia, which we will use to illustrate these deviations. The instance
The example can also explain the advantage of RDF2vecoa on DBpedia. Unlike standard RDF2vec, this approach would distinguish the appearance of
Finally, Fig. 8 shows the aggregated number of the best classifiers for each embedding on each test case. It is visible that on DBpedia, MLPs work best followed by random forests and SVMs. On the synthetic gold standard, SVMs work best most of the time followed by naïve Bayes and MLPs. The differences can partly be explained by the different size classes of the training sets (MLPs and random forests typically work better on more data).
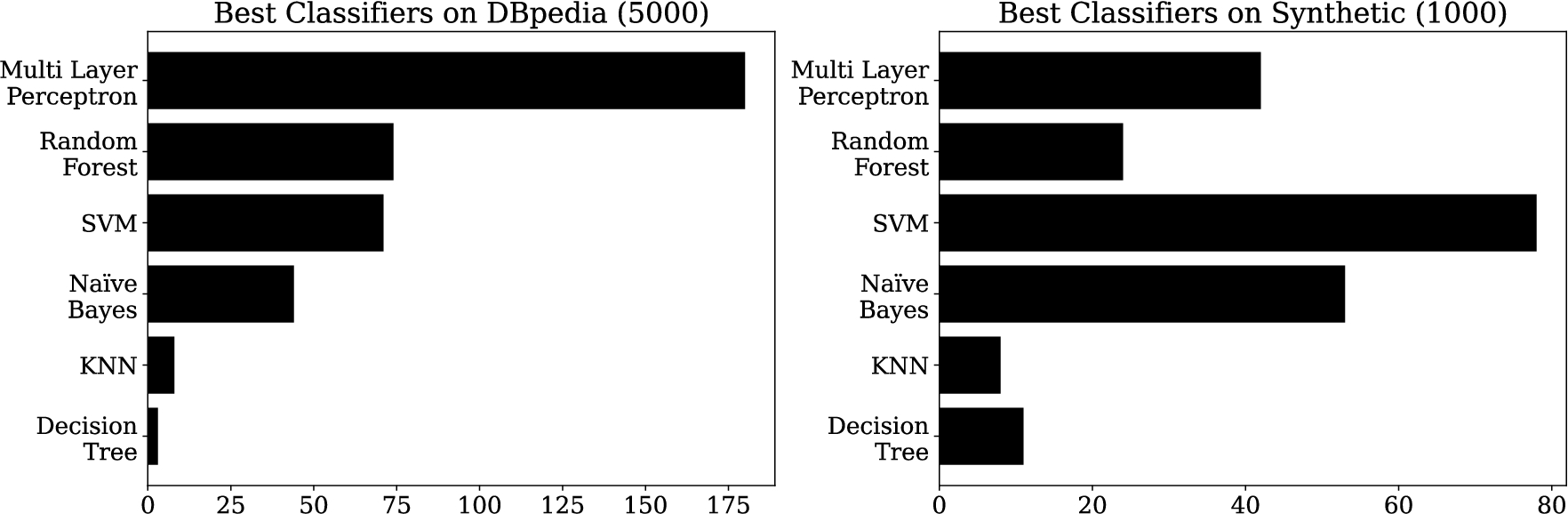
Best DLCC classifiers on DBpedia and synthetic. It is important to note that the total number of test cases varies between the two gold standards – therefore, two separate plots were drawn.
In this section, the hypotheses stated in Section 5 are verified and discussed. We treat the hypotheses as non-exclusive. That is, we accept the hypotheses if there is significance that the stated configurations can indeed learn the corresponding class constructor; in cases where we hypothesize that the constructor can be learned by neither configuration, we reject the hypothesis if a single approach can learn the constructor. However, we do not want to mislead the reader: We underestimated which other configurations are also capable of learning constructors. We, therefore, encourage the reader to not just check which hypotheses are accepted but to also follow the reasoning. Hence, we use the hypotheses as structured discussion points for a deeper analysis.
Hypothesis 1 The hypothesis can be accepted. It has to be acknowledged though that – with the exception of e-RDF2vec – all RDF2vec configurations perform rather well.
Hypothesis 1a/1a’ In fact, out of all RDF2vec configurations, RDF2vecoa and p-RDF2vecoa are performing best on tc01 and tc02 for DBpedia. On the synthetic gold standard, this can similarly be observed albeit the improvement of order aware variants does not account for all RDF2vec variants. The previously discussed directionality bias in the training likely leads to better results on tc01 compared to tc02.
Hypothesis 1b Particularly on tc03 (synthetic), it is visible that e-RDF2vec cannot really learn the constructor: None of the configurations performs significantly better than random guessing. As expected, once the directionality restriction is lifted, the results generally improve.
Hypothesis 2 The hypothesis can be accepted. Again, however, it has to be noted that even the p-RDF2vec configuration performs well on tc04 and tc05. While performing worse than the other configurations, p-RDF2vec is still able to a small extent to learn the constructor as witnessed by the results on the synthetic gold standard. The sub-hypotheses, stating that non-order-aware variants perform better than order-aware variants, can be rejected. On DBpedia, significant increases can be observed when using the order-aware variant. Although there are multiple cases of non-oa variants slightly outperforming order-aware variants on the synthetic gold standard, there is, overall, also not enough evidence to accept this hypothesis.
Hypothesis 3 The hypothesis can be accepted. Particularly on the hard tc06 test case, the classic RDF2vec configuration with the order-aware training component performs best. It has to be admitted though, that on the synthetic gold standard the e-RDF2vec variant performs very well. A reason for this may be the fact that domain/range restrictions can also be found in the synthetic gold standard which allows to reason on a likely predicate given an object entity.
Hypothesis 4 The hypothesis can only be partially accepted.
Hypothesis 4a The RDF2vecoa configuration is indeed the best performing configuration on tc07 for both gold standards. A look at the synthetic gold standard reveals that p-RDF2vec cannot learn this constructor.
Hypothesis 4b While we assumed that this constructor cannot be learned by any configuration, there is indication that at least to a small extent, classic and p-RDF2vec can learn to recognize the constructor. In both cases, the p-RDF2vecoa configuration achieves the overall best result. The improvement of the order aware component can be explained since only this component can detect the inverse usage of the relationship.
Hypothesis 5 The hypothesis can be accepted. On DBpedia, p-RDF2vec and classic RDF2vec can learn cardinality restrictions. On the synthetic gold standard, this is only true for RDF2vec classic and CBOW p-RDF2vec configurations. From the rather low score (in the 60ies in terms of accuracy), it can be seen that learning cardinality is rather hard.
Hypothesis 6 This hypothesis can only partially be accepted since multiple configurations are capable of learning tc12. What can be concluded when comparing hypothesis 6 to hypothesis 5 is that the addition of the type restriction makes the test cases harder to solve: This can be seen when comparing the scores for tc09 versus tc11 and tc10 versus tc12. e-RDF2vec can surprisingly learn the constructors on DBpedia (even well) – but a look at the synthetic gold standard reveals that it can neither learn tc11 nor tc12 when correlations are mostly removed. This finding is intuitive since e-RDF2vec is unaware of the actual predicates within a graph (it is merely aware of their existence).
Conclusion
In this paper, we presented an extensive evaluation of 12 RDF2vec variants and benchmark models using the established GEval and the newly introduced DLCC benchmark.
DLCC is used to analyze embedding approaches in terms of which kinds of classes they are able to represent. It comes with an evaluation framework to easily evaluate embeddings using a reproducible protocol. All DLCC components, i.e. the gold standard, the generation framework, and the evaluation framework, are publicly available. Significant efforts were made to comply with the FAIR [68] principles.42
Dataset DOI:
By analyzing the performance of different RDF2vec variants on a pattern-by-pattern-basis, the findings of this paper can provide some guidance on which embedding method to use for which downstream task. For example, for identifying related items (e.g., for knowledge-based recommender systems [22] or collective entity disambiguation [35]), approaches performing well on tc04 and tc05, like e-RDF2vec, are preferable, while for entity classification based on structural features [37], approaches performing well on tc01-tc03, tc07, and tc08, i.e., mostly the p-RDF2vec variants, are preferable. With such considerations, users of RDF2vec can make more informed decisions on which variant to choose, as an alternative to blindly trying all available variants.
Furthermore, we have shown that many patterns using DL class constructors on DBpedia are actually learned by recognizing patterns with other constructors correlating with the pattern to be learned, thus yielding misleading results. This effect is less prominent in the synthetic gold standard. We showed that certain DL class constructors, especially qualified restrictions and cardinality constraints, are particularly hard to learn. Such insights open an interesting way to new developments in knowledge graph embeddings, since they point to conceptual shortcomings of methods instead of using pure leaderboard-based methods for assessing embedding methods.
In the future, we plan to extend the systematic evaluation by adding more gold standard datasets. The synthetic dataset generator also allows for more interesting experiments: We can systematically analyze the scalability of existing approaches, or study how variations in the synthetic gold standard (e.g., larger and smaller ontologies) influence the outcome.
Footnotes
Acknowledgements
The publication of this article was funded by the Ministry of Science, Research and the Arts Baden-Württemberg and the University of Mannheim.