
Abstract
News consumption has shifted over time from traditional media to online platforms, which use recommendation algorithms to help users navigate through the large incoming streams of daily news by suggesting relevant articles based on their preferences and reading behavior. In comparison to domains such as movies or e-commerce, where recommender systems have proved highly successful, the characteristics of the news domain (e.g., high frequency of articles appearing and becoming outdated, greater dynamics of user interest, less explicit relations between articles, and lack of explicit user feedback) pose additional challenges for the recommendation models. While some of these can be overcome by conventional recommendation techniques, injecting external knowledge into news recommender systems has been proposed in order to enhance recommendations by capturing information and patterns not contained in the text and metadata of articles, and hence, tackle shortcomings of traditional models. This survey provides a comprehensive review of knowledge-aware news recommender systems. We propose a taxonomy that divides the models into three categories: neural methods, non-neural entity-centric methods, and non-neural path-based methods. Moreover, the underlying recommendation algorithms, as well as their evaluations are analyzed. Lastly, open issues in the domain of knowledge-aware news recommendations are identified and potential research directions are proposed.
Keywords
Introduction
In the past two decades, there has been a shift in individuals’ news consumption, from traditional media, such as printed newspapers or radio and TV news broadcasts, to online media platforms, in the form of news websites and aggregation services, or social media. News platforms use a form of a recommender system to help users navigate through the overwhelming amount of news published daily by suggesting relevant articles based on their interests and reading behavior. Recommender systems have proven successful over time in numerous domains [124], ranging from music [31,106], movies [7,110], or books recommendation [36,62,77], to e-commerce [141,142,149], travel and tourism [15], or research paper recommendation [5].
In comparison to these domains, news recommendation poses additional challenges which hinder a direct transfer of traditional recommendation techniques [132]. Firstly, the relevance of news changes quickly within short periods of time and is highly dependent on the time sensitiveness and popularity of articles [84,120]. Secondly, articles may be semantically related and users’ interests evolve dynamically over time, meaning that it is not trivial to accurately capture the preferences of individual users [120]. Thirdly, common limitations of recommender systems (i.e. the cold-start problem, data sparsity, scalability), are further intensified by the greater item churn of news [39], the fact that usually user profiles are constrained to a single session [44], and that their feedback is typically collected implicitly, from their reading behavior rather than explicitly provided during a session [101]. Additionally, news articles contain a large number of knowledge entities and common sense knowledge, which are not incorporated in conventional news recommendation methods [170].
Enhancing classic information retrieval and recommendation methods with external information from knowledge bases has been proposed as a potential solution for some of the aforementioned shortcomings of recommender systems in the news domain. Knowledge graphs are directed, labeled heterogeneous graphs which describe real-world entities and their interrelations [126]. Knowledge-aware recommender systems inject information contained in knowledge graphs or domain-specific ontologies to capture information and reveal patterns that are not contained directly in an item’s features [66]. In the case of news recommendation, such knowledge-enhanced models have been developed to capture the semantic meaning and relatedness of news, remove ambiguity, handle named entities, extend text-level information with common sense knowledge, discover knowledge-level connections between news, and overcome cold-start and data sparsity issues.
Previous works provide overviews of this field from two directions. On the one hand, surveys such as [66] or [59], focus on knowledge-aware recommender systems applied to a variety of domains, such as movies, books, music, or products. Although a few of the discussed models come from the news domain, none of these works extensively review how external knowledge can be used to enhance news recommendation. On the other hand, a vast number of surveys analyze the news recommendation problem from various angles, including challenges and algorithmic approaches [11,14,47,84,94,95,120,132], performance comparison in online news recommendation challenges [43,44], user profiling [67], news features-based methods [129], or impact on content diversity [114]. However, the focus of these studies is not on the use of external knowledge resources. In contrast to existing studies, this survey focuses on categorizing and examining knowledge-aware news recommender systems, developed either specifically for or evaluated also on the news domain, as a solution for enhancing recommendations and overcoming limitations of traditional recommendation models. The analysis of such systems covers both a review of the algorithmic approaches used for computing recommendations, as well as a comparison of evaluation methodologies and a discussion of limitations and research gaps.
The contributions of the paper are threefold:
We propose a
This survey aims to provide a
We examine the limitations of existing models and open issues in the field of knowledge-aware news recommender systems, and we identify eight potential
The rest of the article is structured as follows. Section 2 introduces recommender systems and outlines challenges specific to the news domain, while Section 3 outlines the methodology used in this survey, including the search strategy, the sources, the inclusion and exclusion criteria, as well as the study execution process. Section 4 covers related work in news and knowledge-aware recommender systems. Section 5 introduces and defines commonly used notations and concepts, and analyses different aspects of knowledge-aware news recommenders. Section 6 classifies and discusses knowledge-aware news recommender systems, whereas Section 7 investigates various evaluation approaches adopted by the different models. Section 8 discusses open issues identified in the field. We close with a short summary in Section 9.
Challenges in news recommendation
Recommender systems consist of techniques that filter information and generate recommendations of items deemed potentially interesting for users, based on their preferences and past behavior, in order to help individuals overcome information overload [136]. User’s preferences are learned using either explicit (e.g. ratings) or implicit (e.g. browsing history) feedback [79]. Recommender systems are generally categorized into collaborative filtering, content-based, and hybrid methods, based on the underlying algorithm. Collaborative filtering systems recommend items liked in the past by users with similar preferences to the current user [1]. In content-based algorithms, the recommendations depend only on the user’s past ratings of items, meaning that the suggested items will have similar characteristics to the ones preferred in the past by the current user [1]. Hybrid models combine one or more types of recommendation approaches to alleviate the weaknesses of a single technique, such as the cold-start problem (which refers to the difficulty in the computation of the recommendations for new items, without ratings, or new users, without a profile) or the over-specialization issue (i.e. the lack of diversity and serendipity in results) [18].
The unique characteristics of news not only distinguish them from items in domains such as online retail, movies, music, or tourism, where recommender systems have already proven successful, but also impede the straightforward application of conventional recommendation algorithms to the task of news recommendation. A large quantity of news is published every day, with articles being continuously updated. Such a
Furthermore, the user’s interests evolve over time as individuals display both
In addition to the previously described challenges, in the news domain, users are usually not required to sign in and create profiles in order to read articles.
Another related challenge is that the users rarely provide explicit feedback in terms of likes and ratings, and, unlike for, e.g., online retail, there is no difference between looking at an item and buying an item. In turn, this
Furthermore, users often read multiple news stories in a sequence [132]. Although
News articles often describe events that occur in the world, which can be represented in terms of
Additionally, news recommendations can also be subjected to
Another significant challenge for the news domain is the existence of
Methodology
As aforementioned, this survey aims to provide a comprehensive review of knowledge-aware news recommender systems. The following subsections will describe the methodology used for conducting the study. More specifically, we firstly present our search strategy, including the platforms and queries used to retrieve relevant publications. Afterwards, we discuss the criteria for including and excluding papers from our study, followed by the description of the selection process.
Search strategy
The search strategy of our survey consists in defining a set of queries for retrieving relevant publications from a list of sources. The results are then de-duplicated, as explained in the following paragraphs.
Search queries
We defined two queries, targeting the task of (Q1) news recommendation and the usage of (Q2) external knowledge, in order to collect relevant literature. Table 1 illustrates the search strings used for each of the two queries. Keywords meant to capture (Q2) external knowledge include multiple terms referring to widely used sources of knowledge, such as knowledge graphs or ontologies. As such, the results of query (Q2) are given by the union of the results of the corresponding search strings. Since we are interested only in news recommender systems that use a form of external knowledge, the final query used in the publications’ search process represents the intersection of queries (Q1) and (Q2).
Search strings used in the search process
Search strings used in the search process
The following bibliographic databases and archives constitute the sources used for the literature search: (i) DBLP1
The results collected from the previously specified sources are then merged and de-duplicated in a threefold process. Firstly, for all the publications retrieved during the keyword-based search, we gather the associated bibtex files produced by each of the digital libraries and store them using the Zotero7
Selection inclusion and exclusion criteria
The publications retrieved during the keyword-based search need to be further filtered in order to eliminate false positives, which are irrelevant for the current survey. Consequently, a pre-defined set of inclusion criteria (Section 3.2.1) are applied to the retrieved papers in two stages, as described in Section 3.2.2.
Selection criteria
The list of inclusion criteria displayed in Table 2 was developed based on the goals of the survey in order to filter out irrelevant publications. Each criterion is composed of both an inclusion criterion (IC) and an exclusion criterion (EC). A paper needs to fulfill all inclusion criteria to be selected for the study.
Selection process
The study selection process is composed of two phases.8
The corresponding spreadsheets for both phases are available at:
Number of papers in different phases of the selection process
This section gives an overview of surveys published in the areas of news recommendation and knowledge-aware recommender systems.
News recommender systems
Several surveys on news recommender systems and corresponding issues have been conducted. A comparison and evaluation of content-based news recommenders are performed in [11]. Borges and Lorena [14] first provide a high-level overview of recommender systems in general, including similarity measures and evaluation metrics, followed by an in-depth analysis of six models applied in the news domain. A more general overview and comparison of the mechanisms and algorithms used by news recommendation approaches, as well as corresponding strengths and weaknesses, is provided by Dwivedi and Arya [47].
Özgöbek et al. [120] identify the challenges specific to the news domain and discuss twelve recommendation models according to the targeted problems, without considering evaluation approaches. In contrast to these studies, Karimi et al. [84] provide a comprehensive review of news recommender systems, not only by taking into account a large number of challenges and algorithmic approaches proposed as a solution, but also by discussing approaches and datasets used in evaluating such systems, as well as proposing future research directions from the perspectives of algorithms and data, and the aspect of evaluation methodologies.
Li et al. [94] review issues characterizing the field of personalized news recommendation and investigate existing approaches from the perspectives of data scalability, user profiling, as well as news selection and ranking. Additionally, the authors conduct an empirical study on a collection of news articles gathered from two news websites in order to examine the influence of different methods of news clustering, user profiling, and feature representation on personalized news recommendation. More recently, Li and Wang [95] analyzed state-of-the-art technologies proposed for personalized news recommendation, by classifying them according to seven addressed news characteristics, namely data sparsity, cold-start, rich contextual information, social information, popularity effect, massive data processing, and privacy problems. Furthermore, they discuss the advantages and disadvantages of different kinds of data used in personalized news recommendation, as well as open issues in the field [95].
In comparison to the previous general studies, Harandi and Gulla [67] investigate and categorize approaches used for user profiling in news recommendation according to the problems addressed and the types of features used. Additionally, Qin and Lu [129] survey feature-based news recommendation techniques, which they categorize into location-based, time-based (i.e. further classified into real-time and session-based), and event-based methods.
Lastly, Feng et al. [52] conduct a systematic literature review of research published in the area of news recommendation in the past two decades. They firstly classify and discuss challenges from this domain according to the three main types of recommendation techniques. Various recommendation frameworks are then categorized according to application domain, such as social media-based, semantics-based, and mobile-based systems. Even though Feng et al. [52] briefly review a small number of semantic-based recommenders, their analysis is limited to older models, and does not include any of the newer approaches of the past five years. Furthermore, the authors briefly examine evaluation approaches and datasets used, before discussing which of the numerous challenges of news recommendation have been addressed by the surveyed recommenders [52].
Although these surveys provide comprehensive overviews of news recommendation methods, domain-specific challenges, and evaluation methodologies, they do not discuss knowledge-aware models or the latest state-of-the-art recommendation methods. In contrast, our survey focuses solely on news recommender systems that incorporate external knowledge to enhance the recommendations and to overcome the limitations of conventional recommendation techniques.
Knowledge-aware recommender systems
Knowledge graphs, a type of directed heterogeneous networks, describe real-world entities (represented as nodes) and multiple kinds of relations between them (represented as edges), either spanning multiple domains (e.g. Freebase [12], DBpedia [92], YAGO [151], Wikidata [167], Microsoft Satori [10]) or focusing on a particular field (e.g. Bio2RDF [6]) [49,126]. In addition, such graphs can capture higher-order relations connecting entities with several related attributes [66].
This strong representation ability of knowledge graphs has attracted the attention of the research community working on developing and improving recommender systems for several reasons. Firstly, using knowledge graphs as side information in recommendation models can help diminish common limitations, such as data sparsity and the cold-start problem [66]. Secondly, the precision of recommendations can be improved by extracting latent semantic connections between items, while the diversity of results can be increased by extending the user’s preferences taking into account the variety of relations between items encoded in a knowledge graph [59,183]. Another advantage of using knowledge graphs as background information is improving the explainability of recommendations, to ensure trustworthy recommendation systems, by considering the connections between a user’s previously liked items and the generated suggestions, represented as paths in the knowledge graph [183].
Guo et al. [66] provide a detailed review and analysis of knowledge graph-based recommender systems, which are classified into three categories, according to the strategy employed for utilizing the knowledge graph, namely embedding-based, path-based and unified methods. In addition to comparing the algorithms used by the three types of methods, the authors also analyze how knowledge graphs are used to create explainable recommendations. Lastly, the survey clusters relevant works according to their application and introduces the datasets commonly used for evaluation in each category [66].
Recent advancements in deep learning techniques for graph data, in the form of Graph Neural Networks (GNN) [183,196], have given rise to new knowledge-aware, deep recommender systems. Gao et al. [59] are the first to provide a comprehensive overview of Graph Neural Network-based Knowledge-Aware Deep Recommender (GNN-KADR) systems, in which they analyze recommendation techniques, discuss how challenges such as scalability or personalization are addressed, and briefly summarize the domain-specific datasets and metrics used for evaluation, before suggesting a number of directions for future research.
Gao et al. [59] categorize GNN-KADRs depending on the type of graph neural network components used for recommendation. More specifically, graph neural networks are comprised of an aggregator, that combines the feature information of a node’s neighborhood to obtain the context representation, and an updater, which uses this contextual information together with the input information for a given graph node in order to compute its new embedding. According to Gao et al. [59], aggregators are divided into relation-unaware (i.e. the relation information between nodes is not encoded in the context representation) and relation-aware aggregators (i.e. the information contained in different relations is considered in the context representation). The latter category is further split into relation-aware subgraph aggregator and relation-aware attentive aggregator, depending on how the relations in the knowledge graph are modeled in the framework [59]. The first subcategory creates multiple subgraphs for each relation type found in a node’s neighborhood graph, while the second encodes the semantic information contained in the edges of the knowledge graph using weights which measure how related different knowledge triples are to the target node [59]. Similarly, updaters are also categorized into three clusters, namely context-only updaters (i.e. only the node’s context representation is used to produce its new embedding), single-interaction updaters (i.e. both the target node’s current embedding, as well as its context representation are used to obtain its updated representation), and multi-interaction updaters (i.e. different binary operators combine multiple single-interaction updaters), where the first two groups of updaters are more often encountered [59].
GNN-based recommender systems are investigated also by Wu et al. [183], who classify the recommendation models based on whether the models consider the item’s ordering (i.e. general vs. sequential methods) and on the type of information used (i.e. without side information, social network-enhanced, and knowledge graph-enhanced). According to the proposed taxonomy of Wu et al. [183], knowledge-aware models can be found only in the group of general recommender systems. In this category, four representative recommendation frameworks are examined from the aspects of graph simplification, multi-relation propagation, and user integration.
The research commentary of Sun et al. [155] consists of an extensive, systematic survey of recent advancements in recommender systems that use side information. The models, mostly hybrid techniques, are analyzed from two perspectives. On the one hand, Sun et al. [155] categorize the models according to the evolution of fundamental methodological approaches into memory-based and model-based frameworks, where the latter category is further split into latent factor models, representation learning models and deep learning models. On the other hand, the recommender systems are classified based on the evolution of side information used for recommendation, into models using structural data and models using non-structural data. The first group includes information in the form of flat features, network features, feature hierarchies, and knowledge graphs, whereas the second consists of text, image, and video features [155].
In the surveys discussed above, knowledge-aware news recommender systems are rarely analyzed. In comparison to these works, the current survey focuses on the investigation of approaches for injecting external knowledge only into the news recommendation model. To this end, it provides a categorization and an extensive overview of the knowledge-aware recommender systems developed either for or evaluated also in the news domain.
Definitions and categorization
This section firstly introduces and defines commonly used concepts and notations. Afterwards, it provides an overview of knowledge-aware news recommender systems according to multiple criteria.
Definitions
Firstly, a minimal set of concepts and notations referred to in the rest of the article are defined. Bold uppercase characters denote matrices, while bold lowercase characters generally indicate vectors. The notations used throughout this article are illustrated in Table 4, unless specified otherwise.
Commonly used notations
Commonly used notations
An
In the recent years, knowledge graphs comprising a large number of instances have been developed and utilized also in news recommender systems.
A
In the scope of this paper, we consider concepts in knowledge graphs
The
Knowledge-aware news recommendation models can be investigated according to multiple criteria, ranging from the used knowledge resource to target function types or addressed challenges.
Types of recommendation techniques
News recommendation systems generally adopt one of the three main techniques for predicting whether a user will interact with a certain article, namely content-based, collaborative filtering, and hybrid. However, content-based approaches are the most widely used in the field of news recommendation [84].
Knowledge base
The knowledge resources used by knowledge-aware recommender systems can be grouped into domain ontologies and knowledge graphs. In the remainder of the paper, these will be referred to as knowledge bases (KB), if the type of resource is not explicitly specified. The former category can be further split into self-constructed ontologies – built either from combining smaller domain ontologies or subsets of large knowledge bases (e.g. DBpedia [92], Hudong encyclopedia [177]) or directly from news articles (i.e. financial domain ontology using information from Yahoo! Finance [78]) – and controlled vocabularies used in the news domain, such as the IPTC News Codes9
In the latter category, one can distinguish between open source and commercial knowledge graphs. In the first subgroup, cross-domain knowledge graphs such as Wikidata, DBpedia, and Freebase are widely used in news recommender systems. Freebase [12] was initially launched by Metaweb in 2007, and later acquired by Google in 2010, before being shut down in 2015 [126]. The latest version of Freebase, available at Google’s Data Dumps10
WordNet [111], a large English lexicon containing nouns, verbs, adjectives, and adverbs grouped into synsets (i.e. sets of synonyms), which are further interconnected via semantic relations of antonymy, hyponymy, meronymy, troponomy, or entailment, is often used in knowledge-aware news recommender systems for word sense disambiguation. More specifically, each word in WordNet is associated with a set of senses, which denote the set of possible meanings that the word might have. For example, the noun “Jupiter” can refer to either the planet in the solar system or the supreme god of the Romans. WordNet 3.014
In the subgroup of commercial knowledge bases, Satori [10], the knowledge graph proposed by Microsoft, is the most often used one, especially by recent deep learning-based news recommender systems. Although very little information about the data contained in Satori is publicly available, it was estimated to contain in 2012 approximately 300 million entities and 800 million relations [126].
News recommendation models use knowledge bases by exploiting their different structures in order to extract either semantic, structural, or both types of information. A few knowledge-aware news recommender systems exploit only the semantic information contained in a knowledge graph or ontology, by extracting concepts or entities that appear in a news article, which will be denoted as concepts/entities only models for the rest of this article. A larger share of models however enriches the basic set of knowledge entities by expanding it with the neighborhoods of extracted entities in the knowledge graph and by considering the paths and relationships between entities (denoted as entities + paths). Another method for enhancing the set of concepts or entities extracted from a knowledge base is by taking into account its structure, namely the different types of relations between nodes in an ontology, such as synonymy or hyponymy relationships in semantic lexicons, or the distances between concepts, entities or classes (denoted as concepts + KB structure or entities + KB structure). Differently from these categories of models, the newer deep-learning-based recommendation techniques exploit simultaneously both the semantic and the structural information encoded in knowledge graphs, by means of knowledge graph embeddings (denoted as entities + KG structure).
Target function
Two main target functions can be distinguished in news recommendation models, namely click-through rate (CTR) prediction and item ranking. Models classified in the first group aim to predict the probability that the user will click on the target article, whereas methods in the second group recommend the top N most similar articles to the articles previously read by the user.
Addressed challenge
In addition to enhancing the accuracy of recommendations, knowledge-aware news recommender systems aim to address different challenges of the news domain or limitations posed by conventional recommendation techniques. Several news articles, written in different manners, using semantically related terms, can describe the same piece of news, and numerous words have different meanings depending on the context in which they are used. While humans can easily distinguish ambiguous words, or words connected via certain semantic relations, such as synonyms, this constitutes a challenge for recommendation models using text representations. Knowledge-aware recommender systems propose to remove such ambiguity from text by representing an article using only disambiguated knowledge entities or concepts from a controlled vocabulary, instead of all the terms. In turn, this leads to faster computations, since the model is required to consider a limited number of concepts or entities, which is significantly smaller than the total number of words contained in an article. Moreover, the semantic meaning of news, as well as the semantic relatedness of concepts (i.e. news describing similar or related concepts might indicate different interests of a user) can be captured by further considering the relations between the different concepts found in an article.
News articles contain a large number of named entities, used to denote information regarding the events described, such as the location, actors involved, time, or what the event refers to. However, named entities are not taken into account in traditional text-based recommendation models. In contrast, knowledge-aware techniques handle named entities by extracting them from the text and enriching them with external information encoded in knowledge graphs. Furthermore, using external information for recommendation can help overcome the data sparsity and cold-start problems, as articles can be connected using relations in the knowledge graph between the entities extracted from text, such that new items without user feedback can also be included in the recommendations.
Moreover, injecting external knowledge into the recommendation model has three additional benefits. Firstly, it extends text-level information with common sense knowledge which is encoded in knowledge graphs but cannot be extracted only from an article’s text. For example, a user reading the titles of the news articles in Fig. 1 will probably know that Elon Musk and Robinhood were participants in the GameStop short squeeze event that affected GameStop, or that the New York Stock Exchange is located on Wall Street. However, a text-based recommendation model does not possess such common knowledge information. Additionally, using external information also helps the model discover latent knowledge-level connections between the news, such as the fact that the two snippets in the example from Fig. 1 are connected, although they do not appear related when considering only the words in their titles. Lastly, exploiting the knowledge-level and semantic connections between news can improve the diversity of recommendations, as the model learns to avoid recommending articles that are too semantically similar, even if they are published in different sources and have different writing styles.
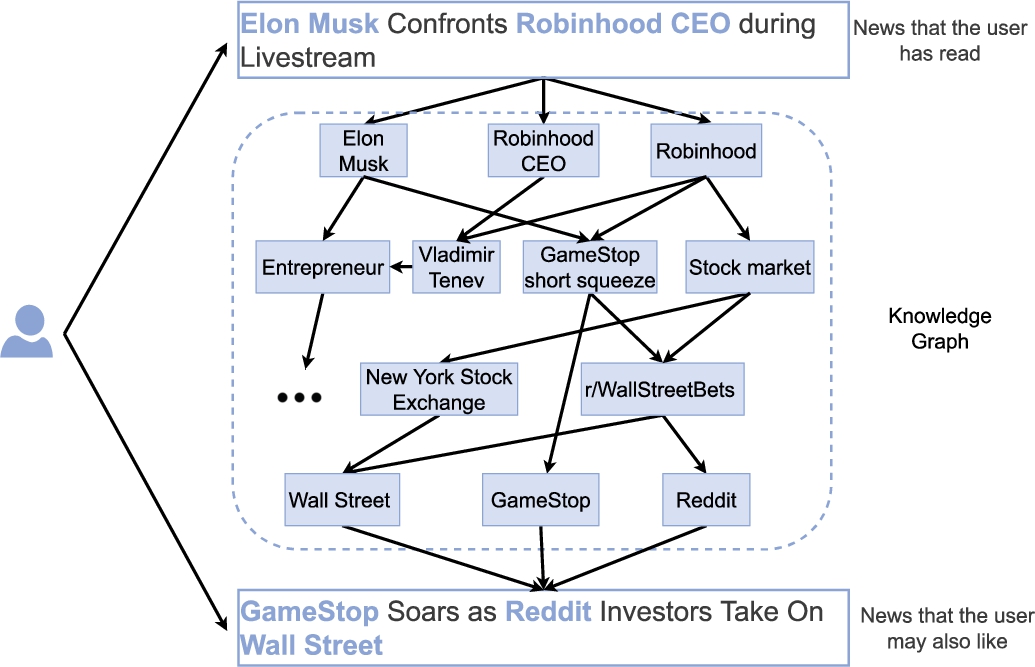
Illustration of a knowledge graph-enhanced news recommender system (reproduced from [170]).
Overview of knowledge-aware news recommendation approaches. We present the model’s category, abbreviated name, publishing year, type of recommendation technique, external knowledge resource and its used structures, target function, and challenges addressed by injecting external knowledge in the recommendation model. “Accuracy” is not explicitly mentioned as a challenge, as all discussed models aim to improve recommendations on this measure. The following abbreviations are used: NNECM = Non-Neural, Entity-Centric Methods, NNPM = Non-Neural, Path-Based Methods, NM = Neural Methods, RS = Recommender System, CB = Content-Based, CF = Collaborative Filtering, H = Hybrid, DO = Domain Ontology
Overview of knowledge-aware news recommendation approaches. We present the model’s category, abbreviated name, publishing year, type of recommendation technique, external knowledge resource and its used structures, target function, and challenges addressed by injecting external knowledge in the recommendation model. “Accuracy” is not explicitly mentioned as a challenge, as all discussed models aim to improve recommendations on this measure. The following abbreviations are used: NNECM = Non-Neural, Entity-Centric Methods, NNPM = Non-Neural, Path-Based Methods, NM = Neural Methods, RS = Recommender System, CB = Content-Based, CF = Collaborative Filtering, H = Hybrid, DO = Domain Ontology
(Continued)
(Continued)
Knowledge-aware news recommendation systems can be classified into different categories based on how external knowledge is injected in the recommendation model, on the used structures of the knowledge base, as well on how latent representations of users and articles are computed. Our proposed taxonomy, illustrated in Fig. 2, distinguishes between the methods based on how the latent representations are generated from entities and/or concepts in a knowledge base, i.e., Non-Neural Methods and methods based on neural networks (Section 6.3). We further split Non-Neural Methods into Entity-Centric (Section 6.1) and Path-Based (Section 6.2), depending on whether the recommendation approach defines the similarity between users and news articles based on distances between the concepts or entities from the knowledge base. To support readers reviewing the literature, the surveyed models are listed in Table 5 according to the aforementioned criteria.

The categorization of knowledge-aware news recommender systems. We divide existing frameworks into three categories, based firstly on how latent representations of user and news article profiles are generated, and secondly, on the type of similarity measure used.
Factorization models constitute some of the state-of-the-art recommendation techniques in various fields [9,87,147], and have already been adopted in the area of news recommendation [131,185]. Moreover, latent factor models have also been adapted to support knowledge graphs in hybrid knowledge-aware recommendation engines [30,146,154,191]. Nonetheless, as it can be observed from Table 5, factorization models are rarely used by knowledge-aware news recommender systems. More specifically, only one model from the 39 surveyed ones uses matrix factorization (see Section 6.3). Hence, we have not added a dedicated subcategory for such methods to our taxonomy.
Recommenders based on factorization models are collaborative filtering-based approaches. However, this recommendation technique is the least adopted one in the domain of news recommendation [132]. Raza et al. [132] have shown that content-based methods are the most widely used recommendation techniques in this field, followed by hybrid approaches. This phenomenon can be explained by the challenges faced by recommender systems in the news domain, explained in Section 2, such as the lack of explicit feedback (i.e. ratings), or limited amount of data available for user profiling. In turn, this affects collaborative-filtering approaches such as factorization models, which rely on a large amount of information regarding the user-item interactions in order to generate accurate recommendations.
Another categorization of knowledge graph-based recommender systems divides models into different categories based on how they utilize the knowledge graph information, namely into embedding-based methods, path-based methods, and unified methods [66]. Embedding-based methods encode the knowledge graph information by means of knowledge graph embeddings and directly use it to enhance the representations of users or items. This category is further split into models that construct knowledge graphs of items and their relations, extracted from a dataset or external knowledge base, and those that build user-item graphs, in which the users, items, and their attributes form the graph’s nodes, while user-related and attribute-related relations constitute the edges [66]. In our survey, this category overlaps with the neural-based models, which use a form of knowledge graph embedding, as it will be explained in Section 6.3. However, we do not further differentiate between neural-based recommenders depending on how the underlying knowledge graph is created.
Guo et al.’s [66] second category of path-based methods includes those recommenders that leverage connectivity patterns of entities in the user-item graph. In this context, this category has similarities with our proposed non-neural, path-based methods. However, in our case, the connectivity patterns are exploited from any source of structured knowledge base and are not restricted to user-item graphs.
The third category proposed by Guo et al. [66], namely unified methods, incorporates models that combine the first two types of techniques by leveraging both the connectivity information, as well as the semantic representation of entities and relations. This class, containing the RippleNet [168] and RippleNet-agg [169] models, overlaps again with our neural-based methods due to the neural nature of latent representations used to profile items and users.
Lastly, Sun et al. [155] classify recommender systems on two dimensions. The first dimension is concerned with the recommendation technique and differentiates between memory-based methods, latent factor models, representation learning models, and deep learning models. The second dimension focuses on the type of side information used, namely structural data (i.e. flat, network, hierarchical features, and knowledge graphs) and non-structural data, in the form of text, image, and video features. According to this categorization scheme, models classified by Sun et al. [155] under deep learning methods that use knowledge graphs as side information would correspond to neural-based methods in our taxonomy.
The following subsections analyze the knowledge-aware recommender systems presented in Table 5 according to the taxonomy introduced above. For each category of models, the overall framework, as well as representative models are investigated.
Recommender systems classified in this category represent the profiles of users and news articles using latent representations generated from concepts and/or entities in a knowledge base using non-neural methods. Generally, such representations are computed using a Vector Space Model [140], most often variants of the Term Frequency-Inverse Document Frequency (TF-IDF) model [139], modified to take into consideration side information from a knowledge base. The similarity between articles and the preference of a user for a candidate article are determined using different semantic or non-semantic similarity metrics.
Overall framework
Non-neural, entity-centric methods first create a vector representation of both the target article and the user profile, where the latter consists of the user’s reading history. Afterwards, the models compute the similarity between the two representations and recommend a list of the top N articles whose similarity scores exceed a predefined threshold. As such, the majority of techniques listed here adopt a content-based recommendation approach. We analyze these systems in terms of three differentiating factors:
Representative models
In this subsection, we discuss 12 representative non-neural, entity-centric recommendation techniques.
Cantandor et al. [21,23] developed a
A personalized content retrieval approach assigns a relevance measure
Following the construction of the runtime context, Cantandor et al. [23] introduce a semantic preference spreading strategy which expands the user’s initial preferences through semantic paths towards other concepts in the ontology. This contextual activation of user preferences constitutes an approximation of conditional probabilities. According to this formulation, the probability that concept
Consequently, the semantic spreading mechanism requires weighting every semantic relation r in the ontology with a value
The context-aware personalized recommendation model computes the relevance measure of an item v for user u using the expanded profiles of the user and the article, in the following way:
The weights spreading strategy addresses both the cold-start and the data sparsity problems, whereas incorporating contextual information captures the changing utility of a news article to a user based on temporary circumstances. While this model applies to single users, Cantandor et al. [23] also employ a
Semantic Communities of Interest are derived from the users’ relations at different semantic levels [23]. More specifically, each ontology concept
Cantandor et al. [23] propose two recommendation models that use the extracted latent communities of interests among users. On the one hand, model UP computes a unique ranked list of news articles based on the similarities between news and all semantic clusters, meaning that it compares a user’s interests to those of the other users and utilizes these user-user similarities to weight preferences for candidate articles. As such, the preference score of article v to user u is computed using Eq. (5):
Here
On the other hand, model UP-q generates recommendations separately for each layer by computing a ranked list for each semantic cluster. The preference between user and target article is calculated as follows:
The same context-aware and multi-facet, group-oriented hybrid recommendations are also adopted by Cantandor et al. [24] to generate
Concept Frequency – Inverse Document Frequency (
In the CF-IDF recommender, each user’s interests are represented as a vector of CF-IDF weights
The CF-IDF weights are computed similarly to TF-IDF weights. Firstly, the Concept Frequency
A major difference between the TF-IDF and CF-IDF lies in the fact that the latter considers only the ontology concepts contained in the text, instead of all the terms. Therefore, it assigns a larger value to the concepts deemed more important, and results in faster computations, as it considers a smaller amount of elements during similarity computations. In turn, this also implies that CF-IDF can assign a single representation to multi-word expressions (e.g. “Elon Musk” is one concept), compared to TF-IDF which would compute an embedding for each word individually (e.g. for “Elon” and for “Musk”). Consequently, if the concepts are disambiguated, CF-IDF can handle ambiguous terms, in contrast to TF-IDF.
The Synset Frequency – Inverse Document Frequency (
The synsets in both profiles are weighted using SF-IDF weights, obtained from TF-IDF by replacing terms with synsets s, i.e.
However, SF-IDF yields a limited understanding of the semantics of news. Therefore,
Hence, the item’s and user’s profiles, v and u, are extended according to Eqs (13) and (14), respectively.
Furthermore, SF-IDF+ not only uses extended synsets instead of synsets, as is the case for the SF-IDF model, but also assigns different weights
A similar strategy to the one proposed in SF-IDF+ is also adopted by
The Bing similarity is comparable to the Normalized Google Distance [34].
The SF-IDF+ profiles and weights are built and calculated according to Eqs (12)-(15). For the Bing component, new user and item profiles are built using sets of named entities extracted from the text with a named entity recognizer, denoted as follows:
Subsequently, the Bing search engine is used to compute the page count
The SF-IDF+ similarity
This approach of enhancing semantics-driven recommender systems with named entity similarities using the Bing page counts are prototypical also for other models, such as
An approach combining CF-IDF and SF-IDF, which aims to address the ambiguity problem by representing news articles using key concepts, synonyms, and synsets from a domain ontology, is represented by the
In Eq. (22),
In Eq. (23), the vectors
The
In comparison to item profiles of models such as CF-IDF (Eq. (8)), in Eq. (24) the total number of concepts appearing in an article’s profile is represented by the number of distinct concepts
The enclosure similarity between two concepts
The Ranked Semantic Recommendation (
Each concept
Another assumption underlying RSR [78] is that the more articles containing concept
The final rank of every concept in the user’s extended profile, denoted
A min-max normalization is applied to the extended user profile to ensure that the ranks are in the range
The Ranked Semantic Recommendation 2 (
Another difference to RSR is that RSR2 uses different weight values to determine the concepts’ ranks. The rank of a concept in the extended article representation
Non-neural, entity-centric news recommendation techniques are summarized in terms of three aspects:
Path-based methods (non-neural)
The profiles of users and news articles in non-neural, path-based recommendation methods are represented using concepts or entities from a knowledge base. Similar to the models in the previous section, some of the recommendations approaches classified here generate latent representations of these concepts or entities using non-neural methods. However, in contrast to non-neural, entity-centric recommenders, path-based ones define the user-item and item-item similarities using metrics that take into account the distance between concepts and/or entities from the knowledge base.
Overall framework
The majority of methods in this category represent a news article as a set of tuples consisting of the concepts contained in an ontology and their corresponding weights. Formally, this can be written as
Representative models
In the following, we investigate six representative recommendation techniques for this category.
Three types of partial matches between concepts were defined by Maidel et al. [105] based on hierarchical distance. A perfect match is obtained if the same concept appears in both profiles and at the same hierarchical level. For example, both the news and the user profile contain the concept ‘artificial intelligence’, found at level 1 in the ontology. However, if a concept occurs only in one of the profiles, while its parent or child is included in the other profile, a close match is reached. In this case, one can further differentiate between cases when the user’s concept (e.g. artificial intelligence) is more general than the article’s concept (e.g. deep learning), and those in which the user’s interest is more specific (e.g. user concept is graph neural networks and item concept is deep learning). Lastly, a weak match occurs if the concepts from the two profiles are two levels apart in the hierarchy, such as the user being interested in graph neural networks, whereas the article contains the concept artificial intelligence. Analogous to the previous match type, two cases are determined by the profile containing the more general concept.
A similarity score
A different approach is adopted in
The centrality score ensures that concepts with shorter and stronger connections to the top-ranked concept will be assigned higher importance than those situated further away in the ontology or having weaker relations. The centrality weight is complemented by the prestige of a concept in the ontology, a method that ranks the concepts based on their incoming relations. The more a concept is referred to via different relations by another concept (i.e. the larger its in-degree), the higher its prestige in the ontology. Consequently, the final importance score of a concept is computed as the product of centrality and prestige (denoted as rank in Eq. (30)), weighted by a constant value α assigned to the top-ranked concept:
The final weight
Similar to SF-IDF, the Semantic Similarity (
Furthermore, a subset is created from V for all pairs of synsets sharing the same part-of-speech (POS):
The final similarity score of an unread article is given by the sum of all combinations’ similarity rank
The WordNet taxonomy constitutes a hierarchy of “is-a” relationships between its nodes which, in turn, constitute synsets. As such, Capelle et al. [26] propose five semantic similarity measures to calculate the similarity rank
The two remaining metrics, of Leacock and Chodorow [90]
Similar to Bing-SF-IDF+,
Lastly, the Bing and the SS components are combined in the final BingSS similarity score using a weighted average with predefined weight α:
The similarity between the profile of a target news article and user is computed in the following way [130]:
According to Eq. (44), two concepts
In contrast to the previous models,
The shortest distance between two entities over the knowledge graph represents the shortest path length between the corresponding nodes, mathematically denoted as
Lastly, the similarity between the two articles is computed as the pair-wise shortest distance over the union of their subgraphs [83], as shown in Eq. (46).
This method provides a symmetric average minimum row-wise distance which places higher importance on the entity pairs with the highest likelihood of co-occurrence in news article. Additionally, a weighted shortest distance between the articles could be used by weighting the edges of the subgraphs and computing the sum of all the weights of the traversed edges [83]. For the weighted SED algorithm, different weighting schemes could be used, including the relation weighting scheme, which assigns edge weights based on the number of shared neighbors of two entity nodes from an article.
Summary
Non-neural, path-based knowledge-aware news recommender systems are summarized from the following perspectives:
Neural network-based methods
In recent years, the rapid advancements in the field of deep learning have also led to a paradigm shift in the domain of news recommendation. State-of-the-art knowledge-aware recommendation models combine latent representations of news articles, generated using neural networks, with external information contained in knowledge graphs, encoded by means of knowledge graph embeddings, defined below. Given a dimensionality
Frameworks classified in this category generally use a knowledge distillation process to incorporate side information in their recommendations. Firstly, named entities are extracted from news articles using a named entity recognizer. Secondly, these are connected to their corresponding nodes in a knowledge graph using an entity linking mechanism. Thirdly, one or multiple subgraphs are constructed using the linked entities, their relations, and neighbors from the knowledge graph. Afterwards, the obtained graphs are projected into a continuous, lower-dimensional space to compute a representation for their nodes and edges. Thus, these models use both the structural and semantic information encoded in knowledge graphs to represent news. Figure 3 exemplifies this process.

Illustration of the knowledge distillation process used by neural-based recommendation models (reproduced from [170]).
In contrast to models from the previous categories, the neural-based recommenders we reviewed for this survey predict the probability that a user will click on a target article, namely the click-through rate. We consider several factors underlying these recommendation models:
The architectures of 11 neural-based news recommendation frameworks are discussed in this section.
The Collaborative Entity Topic Ranking (
The user behavior component takes as input the user-news interaction matrix
The
The user-item interaction matrix is factorized into a matrix
In the following step, topic analysis is conducted at the entity level, where entities belonging to the same topic are sampled from a Gaussian distribution [193]. The third module learns knowledge graph embeddings with the TransR model [98]. The probability of observing a quadruple
The
The inner-circle in Fig. 4 exemplifies this concept. DKN takes as input the embedding of GameStop short squeeze to represent the entity, as well as its context, denoted by neighbors and associated relations, such as USA (country), or Elon Musk, Robinhood, r/WallStreetBets (participant).

Illustration of ripple sets of GameStop short squeeze in Wikidata. The concentric circles indicate ripple sets with different hops. The fading blue signifies decreasing relatedness between the center and the neighboring entities (reproduced from [168]).
One of the input elements to the recommendation model is constituted by the embedding of an entity’s context, defined in the following manner.
The
The first level in DKN’s architecture is represented by a knowledge-aware convolutional neural network (KCNN), namely the convolutional neural network (CNN) framework proposed by Kim [85] for sentence representation learning extended to incorporate symbolic knowledge in the text representations. Firstly, the entity embeddings
Secondly, the matrices containing word embeddings
The word-aligned KCNN applies multiple filters of varying sizes to extract patterns from the titles of news, followed by max-over-time pooling and concatenation of features to obtain the final representation
Additionally, DKN employs an attention network to capture the diverse interests of users in different news topics by dynamically aggregating a user’s history according to the current candidate article [170]. The second level of the DKN framework concatenates the embeddings of a target news
Given the normalized attention weights, a user i’s embedding with respect to the target article
Lastly, DKN [170] predicts the click probability of user i for news article
The recommendation model of
Secondly, the item-level attention model computes the final representation of news article
The attention weights of words are calculated as shown in Eq. (56), while those of entities and context can be computed analogously.
Thirdly, the user-level self-attention module computes the final representation of the user i’s history
Fourthly, the vector representation of the user and the target news article are combined using a multi-head attention module [163] with ten parallel attention layers. Lastly, the output of the fourth module is passed through a fully connected layer to calculate the user’s probability of clicking the candidate article.
A different approach is constituted by
Giving the knowledge graph
The k-hop
The user’s interests in certain entities are extended from the initial set along the edges of the knowledge graph, as shown in Fig. 4. The further the hop, the weaker the user’s potential preference in the corresponding ripple set becomes since entities that are too distant from the user’s initial interests might introduce noise in the recommendations. This behavior is exemplified in Fig. 4 by the fading color of the concentric circles denoting ripple sets. The closer a neighboring entity is to the center seed, the more related the two are assumed to be. In practice, this is controlled by the number H of hops considered [170].
In the first step, RippleNet calculates the probability
The 1-order response
Equations (60) and (61) theoretically illustrate the preference propagation mechanism of RippleNet, through which the user’s interests are spread from the initial set
An inward aggregation version of this model, denoted
In RippleNet-agg, higher-order proximity information is captured by encoding the ripple sets in the final prediction function at the item-end, compared to the user-end, as it was the case in the original RippleNet model. To this end, the topological proximity structure of a news article v is defined as the linear combination of its one-hop samples ripple set
Lastly, the representations of the entity
Although the aggregation function in Eq. (62) is represented by the sum operation followed by a nonlinear transformation σ, this could be replaced by a
In contrast to previous models, the Multi-task feature learning approach for Knowledge graph Recommendation (
MKR is composed of three modules. The recommendation component uses as input two raw feature vectors
The features of news article v are computed using L cross&compress units, as follows:
The module outputs the probability of user u clicking on candidate news v, computed using a nonlinear function which takes as input latent features of the user
The goal of the KGE module is to learn the vector representation of the tail entity of triples in the knowledge graph. For a triple
The two task-specific modules are connected using cross&compress units which adaptively control the weights of knowledge transfer between the two tasks. The unit takes as input an article v and a corresponding entity e from the knowledge graph. The cross operation constructs a cross-feature matrix
Afterwards, the compress operation projects the cross features matrix back into the latent feature spaces
Although such units are able to extract high-order interactions between items and entities from the two distinct tasks, Wang et al. [172] only employ them in the model’s lower layers for two main reasons. On the one hand, the transferability of features decreases as tasks become more distinct in higher layers. On the other hand, both item and user features, as well as entity and relation features blend together in deeper layers of the framework, which deems them unsuitable for sharing as they lose explicit association.
The Interaction Graph Neural Network (
The knowledge-based component jointly learns knowledge-level and semantic-level representations of news, similar to KCNN. More specifically, the embedding matrices of words, entities, and contextual entities are stacked before applying multiple filters and a max-pooling layer to compute the representation of news. In contrast to DKN, in IGNN the embeddings of entities and context, obtained with TransE [13], are not projected into the word vector space before stacking. However, as observed by Wang et al. [170], this simpler approach disregards the fact that the word and entity embeddings are learned using distinct models, and hence, are situated in different feature spaces. In turn, this means that all three types of embeddings need to have the same dimensionality in order to be fed through the convolutional layer. Nonetheless, this might be detrimental in practice, if the ideal vector sizes for the word and entity representations differ.
Higher-order latent collaborative information from the user-item interactions is extracted using embedding propagation layers that integrate the message passing mechanism of GNNs [128] using the IDs of the user and candidate news as input. This strategy is based on the assumption that if several users read the same two news articles, this is an indication of collaborative similarity between the pair of news, which can then be exploited to propagate information between users and news. The propagation layers inherit the two main components of GNNs, namely message passing and message aggregation. The former passes the information from news
The latter component aggregates the information propagated from the user’s neighborhood with the current representation of the user, before passing it through a LeakyReLU transformation function, namely
The KCNN results in a content-based representation of news and of users, where the latter is the result of a mean pooling function applied to the embeddings of the user’s previously read articles. Similarly, the k propagation layers result in another k representations of user and news. Lastly, the inner product between the final user and news representations, obtained by concatenating the two kinds of embeddings, is used to determine the user’s preference for the candidate news.
In addition to using side information to extract latent interactions among news, the Self-Attention Sequential Knowledge-aware Recommendation system (
The encoder of the sequential-aware component of Saskr is composed of an embedding layer, followed by multi-head self-attention and a feed-forward network. The embedding layer projects an article’s body in a d-dimensional latent space, by combining, for each piece of news i, its article embedding
The article’s embedding can be obtained in two ways. On the one hand, it can be computed as the sum of the pre-trained embeddings of its words, weighted by the corresponding TF-IDF weights, as
These representations are then fed into a multi-head self-attention module [163], to obtain the intermediate vector
Given the embedding
The knowledge-aware module uses external knowledge from a knowledge graph to detect connections between news. The knowledge-searching encoder extracts entities from the body of articles and links them to predefined entities in a knowledge graph for disambiguation purposes. The set of identified entities is additionally expanded with 1-hop neighboring entities. The contextual entities are embedded using word embeddings pre-trained with a directional skip-gram model [150]. The resulting contextual-entity embedding matrix
The final recommendation score for candidate news article
Liu et al. [100] propose a Knowledge-aware Representation Enhancement model for news Documents (
In Eq. (73),
The next, context embedding layer encodes the dynamic context of entities from a news article, determined by their position, frequency, and category. The entity’s position in the article (i.e. in the title or body) is encoded using a bias vector
The entities’ representations are aggregated into a single vector in the information distillation layer, by means of an attention mechanism that takes into account both the context-enhanced entity vectors and the original embedding of an article to compute its final representation. More specifically, the attention weights
The knowledge-aware document vector
In addition to injecting external knowledge into the recommendation model, the Topic-Enriched Knowledge Graph Recommendation System (
Firstly, the KG-based news modeling layer is composed of three encoders and outputs a vector representation for each given article. The word-level news encoder learns news representations using their titles without considering latent knowledge features. The first layer of the encoder projects the titles’ sequence of words into a lower-dimensional space, while the bidirectional GRU (Bi-GRU) layer encodes the contextual information of a news title. Bi-GRU obtains the hidden state of an article by concatenating the outputs of the forward and backward gated recurrent units (GRUs) [91]. This is followed by an attention layer which extracts more informative features from the vector representations by giving higher importance to more relevant words. Hence, the final representation of news article
The knowledge encoder extracts topic information from the news titles through three layers [91]. The concept extraction layer links each news title with corresponding concepts in a knowledge graph using an “is-a” relation. Afterwards, the concept embedding layer maps the extracted concepts to a high-dimensional vector space, while the self-attention network computes a weight for each word in the news title according to the associated concept and topic. For example, in the news title from Fig. 1, Elon Musk will have a higher attention weight in relation to the entrepreneur, than with the programmer, concept. The layer’s output is then concatenated with the news embedding vectors obtained from the word-level encoder.
The third, KG-level news encoder firstly performs a knowledge distillation process. The resulting subgraph is enriched with 2-hop neighbors of the extracted entities, as well as with topical information distilled by the knowledge encoder [91]. Therefore, not only are knowledge entities from the text disambiguated and their contextual information is taken into account but also adding topical relations among entities decreases data sparsity by connecting nodes not previously related in the knowledge graph. The topic and knowledge-aware news representation vector are computed with a graph neural network [171]. The final news embeddings are obtained by concatenating the word-level and KG-level representations.
Secondly, the attention layer computes the final user embedding by dynamically aggregating each clicked news with respect to the candidate news. This step is accomplished as in DKN, by feeding the concatenated embedding vectors of the user’s click history and the candidate news into a DNN. Lastly, the user’s probability of clicking on the target article is computed in the scoring layer using the dot product of the user’s and article’s feature vectors.
In the next step, the words
The textual-level and semantic-level article embeddings are concatenated and integrated with user features to obtain the final article embedding
Neural-based news recommendation systems are summarized by focusing on four distinguishing aspects:
Evaluation approaches
This section analyses approaches used for evaluating the surveyed knowledge-aware news recommender systems, as well as potential limitations concerning the reproducibility and comparability of experiments.
Evaluation methodologies
The type of evaluation methodology depends on the target function of the recommendation models and the user data. In this context, the surveyed recommender systems were typically evaluated either through offline experiments based on historical data, through online studies on real-world websites, or in laboratory studies. Frameworks based on an item-ranking target function usually use an online setting or laboratory experiment. In these scenarios, participants are asked to annotate news articles recommended to them by the model based on their relevance to the user’s profile. In turn, the user profile is either created during the experiment or predefined and assigned to the participants by the evaluators. Once the annotations are obtained, the performance of the model is evaluated by comparing the predicted recommendations against the truth values provided by the annotators. In contrast, systems that target the click-through rate are evaluated through experiments in an offline setting, using data comprising of logs representing users’ historical interactions with sets of news.
Table 6 provides an overview of evaluation settings in terms of datasets and metrics used. As it can be observed there, all models are evaluated using different types of information retrieval accuracy measures, such as precision, recall, F1-score, or specificity. The performance of some of the more recent, neural-based systems is also evaluated in terms of rank-based measures, such as Normalized Discounted Cumulative Gain, Hit Rate, or Mean Reciprocal Rank. Generally, these metrics are computed at different positions in the recommendation list to observe the recommender’s performance based on the length of the results list. Moreover, for non-neural, entity-centric methods, the authors use statistical hypothesis tests, such as the Student’s t-test, to measure the significance of the experimental results.
Overview of evaluation settings. We list the model’s category and abbreviated name, datasets used, and reported evaluation metrics and setup information. The abbreviations used in the table are the following: Eval. = Evaluation, Acc = Accuracy, P = Precision, R = Recall, F1 = F1-score, NDGC = Normalized Discounted Cumulative Gain, RMSE = Root Mean Square Error, MAE = Mean Absolute Error, ROC = Receiver Operating Characteristic, PR curves = Precision-Recall curves, AUC = Area Under the Curve, NDPM = Normalized Distance-Based Performance measure, HR = Hit Rate, MRR = Mean Reciprocal Rank, Kappa = Kappa statistics, Student’s t-test = One-tailed two-sample paired Student t-test, ESI-RR = Expected Self-Information with Rank and Relevance-sensitivity [56], EILD-RR = Expected Intra-List Diversity with Rank and Relevance sensitivity [162], PROCS = processing steps, DS = data split, PARAMS = parameters, All available = PROCS + DS + PARAMS + CODE
Overview of evaluation settings. We list the model’s category and abbreviated name, datasets used, and reported evaluation metrics and setup information. The abbreviations used in the table are the following: Eval. = Evaluation, Acc = Accuracy, P = Precision, R = Recall, F1 = F1-score, NDGC = Normalized Discounted Cumulative Gain, RMSE = Root Mean Square Error, MAE = Mean Absolute Error, ROC = Receiver Operating Characteristic, PR curves = Precision-Recall curves, AUC = Area Under the Curve, NDPM = Normalized Distance-Based Performance measure, HR = Hit Rate, MRR = Mean Reciprocal Rank, Kappa = Kappa statistics, Student’s t-test = One-tailed two-sample paired Student t-test, ESI-RR = Expected Self-Information with Rank and Relevance-sensitivity [56], EILD-RR = Expected Intra-List Diversity with Rank and Relevance sensitivity [162], PROCS = processing steps, DS = data split, PARAMS = parameters, All available = PROCS + DS + PARAMS + CODE
(Continued)
In comparison to the relatively uniform usage of evaluation metrics, the type of datasets used for evaluation varies significantly among recommender systems. The majority of non-neural models can be clustered into two groups, depending on the dataset used for their evaluation. As shown in Table 6, semantic-aware context recommenders are evaluated using the News@hand architecture described in [22]. Most of the remaining models are incorporated in the Hermes News Portal [54]. The authors of a few of the path-based, non-neural recommender systems construct their own datasets using news articles collected from websites such as the New York Times, or Sina News,16
Overview of evaluation datasets. We list the model’s category and abbreviated name, the dataset’s source, language, time frame, as well as the number of users, items, and interactions. An entry annotated with “*” denotes that the statistics were approximated by us based on the data provided by the authors. The abbreviations used in the table are the following: # = number of, N/A = not applicable
(Continued)
The datasets used to evaluate neural-based frameworks consist of user interaction logs gathered from websites such as Bing News,22
As it can be further observed in Table 7, which summarizes the statistics of the used evaluation datasets, the number of users and items contained in these datasets varies widely. Non-neural models are evaluated on small datasets, usually with less than 1000 articles, with the exception of the semantic contextualization systems, tested with nearly 10,000 items. In contrast, neural-based methods are mostly evaluated on over 1 million click logs from more than 100,000 users and items.
Another critical finding is that in many cases, datasets are not described clearly enough. In a fourth of the cases, the data source is not specified. Moreover, the language of the dataset is rarely mentioned explicitly. While the language can easily be deduced from monolingual news websites, this does not hold true for international news platforms, leading to an unknown language in more than half of the cases.
Table 6 also lists the type of information provided by each model with regards to the evaluation setup. Replicating experiments requires not only access to the data used, but also knowledge of how the data was split and processed for training and evaluation, and which values were used for the different parameters and hyperparameters of the model. Moreover, differences in the models’ implementation, especially of neural-based models, can further influence the results obtained when reproducing experiments. Hence, access to the original implementation constitutes an important factor for the comparability and reproducibility of results.
However, as it can be observed in the last column of Table 6, only 5 out of the 40 surveyed papers provide all this information. For both sub-categories of non-neural models, generally only the data split and some of the parameters or processing steps are specified. Even when some processing steps are explained in the paper, not enough details are provided regarding how procedures such as named entity recognition or entity linking were performed. Moreover, systems in these categories each propose their own evaluation setups, without following a uniform procedure.
In contrast, most papers describing a neural-based framework offer extensive details regarding their evaluation settings and model architecture. This phenomenon could be explained in two ways. On the one hand, since all neural-based models are deep learning architectures, hyperparameters play a central role in their performance. On the other hand, most of the approaches in this family have been published in the recent past, and there has been a trend in the recent years in the academic community to make implementation details available when publishing a research paper in order to facility reproducibility.
Nonetheless, important aspects which would increase the comparability of experiments are still neglected in some works. Often, the entity extraction and linking processes are not thoroughly explained, meaning that if no implementation details are available, it would be impossible to reproduce the exact steps of the original experiments. Nonetheless, all the previously discussed knowledge-aware news recommender systems use a form of named entity recognition and linking in order to identify entities and concepts in the news articles and to map them to a knowledge base. However, almost none of the papers explicitly mention how these steps are performed and implemented. Other important steps required by any news recommender system, such as general text pre-processing, which can heavily influence the data representation, and ultimately, the generated recommendations, are also not discussed. In addition to the recommendation module itself, such steps constitute important dimensions that may differ between systems, and in turn, choices in their design and implementation may lead to great differences in performance. In Saskr, for example, the authors offer few details on the construction of the news-specific knowledge graph used, and no specification of the news data source.
Overview of evaluated features and components. We report the model’s category and abbreviated name, the features evaluated and the components evaluated during an ablation study, if one was conducted. The abbreviations used in the table are the following: dim. = dimension, emb. = embedding, init. = initialization, # = number of
Overview of evaluated features and components. We report the model’s category and abbreviated name, the features evaluated and the components evaluated during an ablation study, if one was conducted. The abbreviations used in the table are the following: dim. = dimension, emb. = embedding, init. = initialization, # = number of
(Continued)
Another significant factor to be considered in the evaluation and comparison of recommender systems is how different model features and components affect its performance. All of the surveyed papers compare their knowledge-aware news recommendation models against baselines which do not incorporate side information in order to illustrate the gains of a knowledge-enhanced system. In addition to evaluating a model against baselines and state-of-the-art systems, it is also necessary to understand the effect of different features and modules on the recommender’s performance. To this end, the choice of knowledge resource is critical for a knowledge-aware model. However, none of the papers compare their model’s performance using different knowledge bases to determine the extent to which the resource itself influences results.
As it can be seen in Table 8, only 6 out of 16 papers describing non-neural, entity-centric systems evaluate their model’s parameters. In these cases, the threshold values determining which articles are suggested to the user are empirically tested. In the case of non-neural, path-based recommenders, only the authors of ePaper [105], BingSS [27], Kumar and Kulkarni [88] and SED [83] evaluate the influence of different parameters or user profile initialization on the model’s performance. In comparison, the evaluation of neural-based systems involves parameters sensitivity analysis, as well as experiments with different initialization, training or embedding strategies. Such extensive experiments could also be influenced by the type of models, since neural network architectures comprise of several components, and are more sensitive to hyperparameters and design choices than models from the first two categories.
An additional finding is that few works perform an ablation study to determine the contribution of each component to the overall system. In the case of semantic-aware context recommenders, the authors analyze variants of the model obtained by removing either the contextualization of user preferences, the extension of user and news profiles, or both. Werner and Cruz [179] investigate different similarity metrics and recommendation techniques, while BKSport’s authors examine the performance of the recommender when taking into account only semantic similarities, only content similarities, or both. Colombo-Mendoza et al. [35] similarly experiment with two network-based feature learning algorithms and different similarity metrics. Wang et al. [170] remove not only the knowledge component during the ablation study, but also experiments with different types of knowledge graph embedding models. Additionally, DKN’s performance was tested using different transformation functions, as well as with and without the attention module. The authors of MKR evaluate the contribution of its cross&compress units by replacing them with different modules, while those of IGNN examine the effectiveness of the embedding propagation layers by comparing different model variants which use them either to enhance the news, the user, or both representations. Lee et al. evaluate the improvements of using side information in TEKGR by analyzing the effect of its KG-level and knowledge encoders. Similarly, KRED’s authors conduct an ablation study in which they remove each of KRED’s entity representation, context embedding and information distillation layers. KCNR’s performance is analyzed with and without the user preference prediction module, and the influence of the preference propagation in the knowledge graph by considering different k-hop neighbor information. KG-RWSNM’s authors perform an ablation study on the impact of the social network information, while MUKG’s recommender performance is examined given varying degrees of data sparsity. Lastly, Sheu and Li [145] examine CAGE’s performance without the knowledge graph or with different knowledge graph embedding models.
Overall, this investigation of evaluation approaches shows that there is no unified evaluation methodology to produce comparable experiments. Moreover, the datasets used for evaluation are freely chosen by the authors, and there is no clear benchmark set of datasets used by all the systems. Although an effort has been made in recent years to provide more details on the evaluation setup, model architectures and choice of parameters, there is often still too little information specified for critical processing steps. In conclusion, we argue that only some of the most recent, neural-based approaches could be replicated given the available data, whereas the remaining methods cannot be reproduced in accordance to the original implementations. In this context, knowledge-aware news recommendation models lack reproducibility and comparability, standards which have been strongly encouraged in other fields of machine learning.
Open issues and future directions
Existing works have already established a strong foundation for knowledge-aware news recommender systems. In this section, we firstly discuss which fundamental challenges of news recommendation have already been addressed by knowledge-aware models, then identify and elaborate on several open issues in the field, and propose promising research directions.
In addition to general challenges for recommender systems, such as the cold-start, data sparsity, personalization, diversity, or privacy issues [143], news recommenders systems face additional domain-specific challenges, as explained in Section 2. Data sparsity and cold-start problems have clearly been addressed by the injection of external information from a knowledge base into the recommendation module, as such information enriches the initial data available about items and users. Similarly, the
However, the backbone of knowledge-aware recommender systems is represented by the recognition and disambiguation of named entities in the articles, a plain task for humans, but difficult for automatic systems. While knowledge representations obtained from identified entities in the text have been claimed to provide a solution for many shortcomings of traditional recommender systems, this is only true if such entities have been firstly disambiguated correctly and knowledge about them has been created and stored in knowledge bases. In turn, this passes the problem to the entity linking and knowledge graph construction components, which are most often not thoroughly discussed by the existing works, as shown in Section 7.3. Moreover, these components themselves are being subjected to the same challenges of resolving ambiguities and discovering knowledge-level connections as a knowledge-unaware recommender system. If such knowledge is extracted automatically, the problem is pushed further down the pipeline, whereas if human experts are involved, the challenge becomes how to create structured knowledge in the face of the high churn of the news domain. Overall, these problems have not been tackled in the existing literature, although they pose significant problems for deploying a high-performing system as an effective solution in the real world. Therefore, we strongly believe that future research should not only be concerned with achieving increased performance on benchmark datasets while ignoring the additional challenges that a real-world application of the recommender system would pose, but should instead also try to address these open questions.
Several challenges have only been partly addressed by the surveyed works. For example, recommenders that construct user and item profiles based on ontological concepts take into account a smaller amount of data than those that use the full-text of news articles. Therefore, computations are faster and the negative effect of the large volume of data characterizing news recommendations is diminished. However, as it will be explained in Section 8.2, it remains unclear what is
Nevertheless, a large number of news-specific challenges are not yet tackled by knowledge-aware news recommender systems. Issues related to the
In the remainder of this section we elaborate on the identified open issues and propose future research directions.
Comparability of evaluations
Zhang et al. [194] have observed that the entire field of recommender systems lacks a unified evaluation methodology or benchmark datasets, which are common, e.g. in the domains of computer vision or natural language processing to ensure a fair comparison of models. A similarly troubling finding with regards to the reproducibility of research published in the area of recommender systems has been discussed by Dacrema et al. [37]. The authors compared numerous works published in recent years at prestigious conferences in the domain of neural, collaborative filtering-based recommendation approaches and found that less than a half could be reproduced. Moreover, the majority of the proposed methods were equally good or even outperformed by simpler methods, due to methodological issues such as the choice of baselines, propagation of weak baselines, or the poor tuning of these baselines [37].
The findings of Section 7.3 have shown that currently, knowledge-aware news recommender systems also hardly produce comparable experiments. While neural-based methods have a higher degree of reproducibility, the other models do not provide enough details on their evaluation methodology in order to be accurately replicated and verified. Another important observation is that none of the deep learning models have been compared against recommenders from the non-neural approaches. Nonetheless, comparability of evaluations is essential for benchmarking different models, which in turn, drives advancements in the field. Therefore, we argue that the field of knowledge-aware news recommender systems needs a stricter and more unified evaluation approach, including common benchmark datasets, clear processing steps, unification of evaluation metrics, usage of comparable resources and hyperparameters of pre-trained models, and ablation studies.
As discussed above, while natural language processing methods, in particular entity recognition and linking, play a crucial role in processing new texts, their effect is rarely documented. In the realm of ablation studies, we would encourage to investigate those effects more thoroughly (e.g. by exploiting different entity linking methods), and to also investigate interaction effects between the natural language processing methods, recommendation methods, and the knowledge resource used.
Overall, all these steps would ensure that models are not only fairly and transparently compared against each other without great variations in parameter settings, but would also indicate whether the improvement of a new model over the state-of-the-art results is determined by the system’s architecture, or simply, by a better-tuned set of hyperparameters. Similar studies that can serve as an example for the field of news recommendation have been conducted for graph neural networks [48] or knowledge graph embeddings [138].
Lastly, we believe that a comparison between non-neural and neural-based knowledge-aware news recommender systems is needed to compare and understand the strengths and weaknesses of all existing approaches for incorporating external knowledge into news recommendations.
Scalability of news recommenders
The continuously increasing amount of news published daily, as well as the growing number of online news readers and their desire to receive news content in a timely manner [132] constitute a constant challenge for any news recommender system, which requires scalability in order to be applied in real-world scenarios. Several techniques, ranging from fast clustering to dimensionality reduction, have been proposed to address the scalability issue. For example, Li et al. [93] proposed a scalable news recommender system which firstly clusters news articles based on their content in order to reduce the amount of similarity computations required for personalized recommendation. A combination of three approaches has been adopted by Das et al. [39] to improve the scalability of a recommender system dealing with millions of users and articles from Google News. A MinHash-based user clustering algorithm and Probabilistic Latent Semantic Indexing [70], both adapted for large-scale dataset scalability using the MapReduce framework [41], were employed by Das et al. [39] to cluster dynamic news datasets. These methods were combined with an item covisitation technique for extracting user-item relations to generate personalized news recommendations.
However, the injection of external information in the recommender systems further enlarged the scale of the datasets that need to be processed by the model, particularly in the case of frameworks using knowledge graphs as side information. As shown in Sections 6.2 and 6.3, such models obtain scalability using subgraphs, constructed by sampling fixed-sized neighborhoods. While this approach ensures that the recommendation model scales arbitrarily regardless of the size of the full graph, by not considering the entire graph at once, it is possible to ignore relevant neighbors of a node when gathering its contextual information. Hence, the sampling strategy used for defining a node’s neighborhood during subgraph construction influences the efficiency of the model. Overall, it can be concluded that knowledge-aware news recommender systems ensure scalability by sacrificing knowledge graph completeness. In this context, a promising research direction would be to investigate how to balance scalability and knowledge graph completeness in each downstream application scenario. To this end, we believe that an analysis of the effect of sampling strategy and neighborhood size on the robustness of the system and quality of the recommendations, as performed in [169], should be conducted for a larger variety of recommenders.
Explainability of recommendations
Providing explanations for the results generated by a recommender system helps users to understand why a certain item has been recommended to them by the model. In turn, this can increase the users’ trust in the system. For example, LISTEN, a model designed to explain rankings generated by a news recommendation model [158], explains the ranking of recommendations by identifying the most important features contributing to the current ranking and providing them to the user in a human interpretable form. The importance of features is determined by disrupting their values, one at a time, and observing how the change affects the ranking. In this case, a significant feature value will substantially change the ranking [158].
Although the workings and outputs of deep learning-based recommender systems are intricate and often not easily interpretable by non-expert users, attention mechanisms have recently alleviated the lack of interpretability of neural models. Attention weights not only provide insights into the inner functioning of a system but also serve as explanations for which features in a user’s or item’s profiles have contributed to the model’s recommendation. In this context, the Dynamic Explainable Recommender was designed by Chen et al. [32] to increase the accuracy of user modeling by taking into account the dynamic nature of user’s preferences, while providing recommendation explanations. More specifically, the model utilizes time-aware gated recurrent units to encode the user’s dynamic preferences and sentence-level convolutional neural networks to represent items based on the information captured in their reviews. The review information of different items is combined using a personalized attention mechanism, which learns the relevant pieces of information from a review according to the user’s current preferences, thus being able to explain the generated recommendations tailored to the user’s current state [32]. A different approach for balancing the accuracy and explainability of recommendations was adopted by Gao et al. [57], who built a rating prediction model using an attentive multi-view learning framework based on an explainable deep hierarchy. An attention mechanism connects adjacent views denoting different levels of features representing a user’s profile. Personalized explanations are generated from these multi-level features using a constrained tree node selection solved with dynamic programming [57].
Incorporating knowledge graph information into recommender systems has been used not only to improve recommendation accuracy, but also to increase the explainability of results, as paths capturing user-items interactions in the knowledge graph could illustrate which semantic relations and entities contribute to a particular recommendation given the input user profile [76,175,186]. As such, reasoning over the knowledge graph can reveal possible user interests and provide explanations for why a certain article has been recommended to the reader. Another means of using a knowledge graph to provide users with human-readable explanations for a recommender’s prediction was proposed by Ma et al. [104]. Their method learns inductive rules from an item-centric knowledge graph, which encodes items associations in the form of multi-hop relational patterns. The induced rules are incorporated in the recommendation module to address the cold start problem and provide explainability.
A growing number of recent news recommenders employ graph neural networks as components in the framework. However, these deep learning models are often seen as black-box models, whose interpretability is concealed to regular users. The GNNExplainer proposed by Ying et al. [190] is a model-agnostic approach for explaining predictions of any GNN-based model. The method takes as input a trained GNN and a prediction and generates an explanation in the form of a compact subgraph of the input graph and a small subset of node features with the highest impact on the given prediction. Computing explanations require optimizing the subgraph structure, such that its mutual information with the GNN’s prediction is maximized. Given the increasing usage of graph neural networks in news recommender systems, the GNNExplainer could be used to provide explanations for knowledge-aware news recommendations.
Hitherto, to the best of our knowledge, an explainable knowledge-aware news recommender system has not yet been designed. Providing explanations for online news readers remains thus an open problem. Therefore, we believe this is a noteworthy avenue which should be explored in future research.
Fairness of recommendations
Nowadays, news recommender systems have an increasing influence over people’s lives, by controlling which articles a reader is exposed to. This has raised concerns about biases that might be amplified by such systems. Yao and Huang [189] identified two types of biases inherent in recommender systems, namely observation bias, and population imbalance bias.
Observation bias is determined by feedback loops that prevent the model from learning how to predict items that are dissimilar to the previously recommended or consumed ones [51]. Content-based recommenders generate suggestions that are similar to the ones in the user’s history, while collaborative filtering systems recommend items liked by similar users. In both cases, the model learns to make predictions based on its past actions, since users cannot provide feedback for items that are not recommended to them, thus reinforcing the recommender’s algorithmic behavior [51]. In the context of news recommendation, observation bias has given rise to the hypothesis that readers become trapped inside filter bubbles – states in which they are exposed only to the news that supports or amplify their opinions [123]. In turn, this might lead, in the long run, to opinion polarization and self-radicalization of individuals through online media [119].
Bias stemming from imbalanced data is a systematic bias caused by societal or historical discrimination, which occurs when different categories of users are represented in unequal proportions in the data used for training a recommender system [189]. For example, population imbalance bias would occur if a recommender would suggest technology news mainly to men and cooking articles to women.
Several techniques have been designed for fair recommender systems in general. For example, Beutel et al. [8] proposed using pairwise comparisons as a metric for measuring the ranking fairness of a recommender system. Moreover, they introduce a pairwise regularization method to improve the model’s fairness property during training. Burke et al. [19] identify multiple stakeholders of a recommender system and distinguish between different types of fairness depending on the corresponding stakeholder group, namely consumer-centered, provider-centered, or both. The authors propose using the concept of balanced neighborhoods combined with a sparse linear model to obtain a desirable trade-off between fairness of results and personalization of recommendations [19].
Wu et al. [181] proposed using decomposed adversarial learning and orthogonality regularization to diminish unfairness caused by the biases of sensitive user attributes, such as gender, in news recommendation. More specifically, during training, the model learns two types of user embeddings: bias-aware ones that capture biases encoded in sensitive attributes describing the user’s behaviors, and bias-free ones that capture attribute-independent information related to the user’s interests. Adversarial learning is used to ensure that the bias-free embeddings do not contain information from the sensitive user attributes, while orthogonality regularization ensures that the two types of representations are orthogonal to each other. Lastly, fairness-aware news recommendations are computed using only the bias-free user embeddings [181].
Symeonidis et al. [156] propose a popularity-based and a distance-based novelty-aware matrix factorization technique to address the problem of filter bubbles created by recommender systems. Novelty-aware matrix factorization introduces in the classic regularized matrix factorization model a soft constraint that controls how new items are being recommended. In the popularity-based recommendation setting, the novelty of an item is defined as the inverse of its popularity, with items being more novel the fewer people are aware of them. In the case of distance-based recommendations, an item is considered novel if the topic category to which it belongs does not comprise many other items with which the user has already interacted in the past [156]. However, this approach focuses on systems based on matrix factorization, which are not used by knowledge-aware news recommender systems, as discussed previously.
In the field of news recommendation, Gharahighehi et al. [61] address the news recommendation task from a multi-stakeholder perspective and adopt a hypergraph learning method in order to take into account multiple stakeholders and counteract the negative effect of popularity bias on the recommendations. The stakeholders involved in the news recommendation scenario and their interactions are modeled by means of a hypergraph, thus enabling the direct computation of the relatedness between different stakeholders, represented as vertices of the hypergraph. Moreover, the authors introduce a temporal-aware learning approach which dynamically updates the weights given to the different stakeholders in order to increase recommendation fairness [61].
However, these methods have been developed for traditional recommender systems and do not consider biases that might stem from the knowledge resource used as side information. Moreover, none of the surveyed models investigates whether filter bubbles arise when using external knowledge resources for recommendations. Hence, given the importance of these topics, investigating how fairness can be incorporated into knowledge-aware news recommender systems, as well as examining if filter bubbles are created and how their effect can be diminished, represent promising directions for future works in this field.
Another related problem is that of fake news, which can be propagated by recommender systems using news data whose credibility has not been verified. In this context, numerous fake news detection algorithms have already been proposed [103,164,165]. Additionally, knowledge graphs can also be used to detect whether the news is fabricated [46,121,157]. Nonetheless, none of the surveyed works is concerned with the potential propagation of fake news by the recommender system or ways to mitigate it. Therefore, we conclude that incorporating a fake news detection module, potentially based on knowledge graphs, represents an important avenue for research that would contribute to reducing the spread of fake news and misinformation by knowledge-aware news recommendation algorithms.
Multilingual and multi-modal news recommendation
Today, online news comes in various shapes. Next to online newspapers, internet users increasingly consume their news in the form of podcasts or videos, most often using a mix of text, audio, and video modalities [116]. Given that observation, multi-modal recommendation methods are likely to gain more traction but are rarely observed so far [132]. Here, knowledge-based recommenders would be an interesting opportunity, since knowledge-based content representations and multi-modal knowledge graphs [102] could be used to form links between news present in different modalities. Moreover, given the strong trend of neural recommendation methods in the field, multi-modal embedding models [115,159] could be an interesting pathway towards developing such recommendation techniques [153].
Multi-lingual news consumption is also quite frequent. According to a study from 2014, 36% of all internet users in the European Union “frequently” and even 81% “occasionally” consume news and information online in more than one language [42]. While many knowledge graphs are inherently multi-lingual, and the use of identifiers for concepts and entities can help to bridge the gap between documents in different languages, all of the approaches surveyed in this document are monolingual. Like multilingual neural language models can be applied to the task of cross-lingual news recommendation [180], we also foresee the development of knowledge-based multi-lingual news recommenders.
Multi-task learning for recommendation
Multi-task learning [29] is a transfer learning-based paradigm which aims to exploit similarities across different tasks in order to improve the generalization performance of a model. The model is trained for multiple related tasks in parallel and domain-specific information is transferred between tasks to prevent overfitting on a single downstream application [195]. This approach has proven successful in numerous applications, ranging from computer vision to speech recognition and natural language processing [137].
Multi-task learning has also been employed by recommender systems from different domains [118]. In the case of recommender systems using knowledge graphs as side information, the quality of recommendation might be negatively affected by missing facts in the knowledge graph as the user’s preferences may be ignored if they are not captured by existing entities and relations. Recent works have shown that jointly learning a model for both recommendation and knowledge graph completion can result in improved recommendations [25,96]. Similarly, in the field of knowledge-aware news recommendation, Wang et al. [172] have used this paradigm to jointly train a model for the tasks of news recommendation and knowledge graph embedding, while Liu et al. [100] jointly trained a knowledge-aware representation enhancement model for news documents on a variety of tasks, ranging from item recommendation to local news prediction.
Taking into account the advantages of the multi-task learning paradigm, we believe that utilizing transfer knowledge from tasks such as entity classification or link prediction for knowledge-aware news recommendation is a promising direction to pursue in the future.
Sequential and timely recommendations
Readers consume news in sequences and prefer updates about ongoing and developing stories, rather than repeated or highly similar articles. Taking into account sequential dependencies between articles has been addressed in news recommendation generally by means of recurrent neural networks (RNNs) [125]. More recent approaches combine RNNs with attention modules. For example, Zhu et al. [197] use an attention-based RNN as a sequential information extractor that can automatically model the dynamic history sequential features used to represent a user’s clicked articles, while Bai et al. [4] use a combination of RNNs and attention to build a sequence-aware, user-based collaborative filtering recommender system. However, knowledge-aware sequential news recommender systems have been rarely proposed so far. In this context, we believe that enhancing existing sequential news recommenders with side information from a knowledge base is an interesting research avenue towards tackling this problem.
In addition to consuming articles sequentially, readers prefer recent and up-to-date news. Not only does an article’s relevance diminish over time, but the news is constantly updated and superseded by more popular pieces of information. In turn, this means that recommendations that are based not only on the text content of news, but also on knowledge entities and side information, need to ensure the timeliness of the information contained in external knowledge bases. However, many large knowledge graphs quickly become outdated and do not contain the latest information about world events [50].
In this context, one approach to address this issue is the inclusion of temporal constraints to model the limited validity of knowledge base items determined by the dynamic nature of events described in the news. Among the existing recommender systems, the ones included in the Hermes News Portal [17,26–28,40,55,64,71,112,161] support knowledge base updates. More specifically, the Hermes framework not only provides the functionality for specifying temporal constraints of news items, but it also incorporates updates to the knowledge base based on event rules, meant to reflect changes of real-world events [53]. A similar strategy of updating the ontology used for recommendation is adopted in Magellan [45], in which erroneous statements or outdated facts are removed from the ontology if the lifespan of the corresponding relations in the ontology – updated with every repetition in a news story – are not refreshed for a certain period of time. Another technology that could be adopted by news recommenders based on ontologies is tOWL [109], namely an extension of the OWL Description Logic language used to model ontologies. tOWL enables temporal representations through the introduction of time points and relations between them, as well as timeslices that can represent complex temporal aspects, such as process state transitions [109].
Furthermore, we encourage a shift from static towards temporal knowledge graphs that capture temporal dynamics of entities and the relations [81] between them. This could help knowledge-aware news recommenders overcome the problem that the validity of any facts contained in static knowledge graphs is constrained to a specific time period. Temporal knowledge graphs have gained traction in the latest years in the field of recommender systems. For example, Xiao et al. [187] proposed a temporal knowledge graph, which is incrementally constructed from user-item interactions and related auxiliary information, and used for recommendation. Similarly, Mezni [107] leverages a temporal knowledge graph to build a time-aware recommender system for service recommendation. Therefore, we believe that using temporal knowledge graphs is not only a potential solution to ensure the timeliness of external data injected in the recommendation module, but also a highly promising direction for future research in the field of knowledge-aware news recommendation.
Changing user preferences
In addition to preferring timely news, readers also have preferences that evolve over time. On the one hand, short-term preferences are determined by current trends, popularity, and context of certain news and events, such as the local elections in a country. On the other hand, long-term preferences evolve more slowly and are motivated by socio-economic and personal factors, such as an interest in climate change [67]. However, as it can be observed from Section 6.3, neural knowledge-aware news recommender systems learn single representations of users that do not differentiate between the two types of user interests. In turn, this can be detrimental for the generated recommendations, as users might not only want to see news regarding the latest events, but also read articles related to their long-term interests.
The LSTUR model proposed by An et al. [3] takes into account both kinds of preferences when constructing user profiles. More specifically, long-term representations are given by the embeddings of user IDs, while short-term preferences are captured from the users’ recently browsed news using a GRU. The two representations can either be concatenated to obtain the final user representation, or the long-term user representation can be used to initialize the hidden state of the GRU network for the short-term representation module [3].
Another approach has been proposed by Hu et al. [73]. Their model, GNewsRec, uses a GNN on a heterogeneous user-news-topic graph to learn the user’s long-term interest encoded as high-order relationships between users, items, and topics in the graph. To capture the short-term user preferences, the authors employ an attention-based long short-term memory [69] on the user’s reading history.
Given the existing research already conducted to account for changing user interests in news recommendation, we believe that incorporating techniques that are able to differentiate between short-term and long-term user preferences in knowledge-aware news recommenders is a pathway worth pursuing to ensure diversity of recommendations and user satisfaction.
Conclusion
In this survey paper, we have extensively reviewed knowledge-aware news recommender systems. We propose a new taxonomy for classifying existing recommenders, based on how the latent representations are generated for the users’ and articles’ profiles using concepts and entities from a knowledge base, as well as on the type of similarity metric used. According to the classification scheme, we categorize knowledge-aware news recommender systems into non-neural and neural-based frameworks, with the former category further divided into entity-centric and path-based methods. Representative models from each category are summarized and thoroughly analyzed. Moreover, we discuss and compare evaluation approaches used by existing publications and identify limitations in terms of comparability and reproducibility of experiments. Lastly, we identify and examine open issues in the field and propose future research directions that could drive progress in this domain. We hope this survey can serve as a comprehensive overview of knowledge-aware news recommender systems, clarifying key aspects of the field and uncovering open problems and corresponding promising directions to pursue in future studies.
Footnotes
Acknowledgements
The work presented in this paper has been conducted in the ReNewRS project, which is funded by the Baden-Württemberg Stiftung in the Responsible Artificial Intelligence program. The publication of this article was funded by the Ministry of Science, Research and the Arts Baden-Württemberg and the University of Mannheim.