
Abstract
This paper demonstrates that the presence of blank nodes in RDF data represents a problem for distributed processing of SPARQL queries. It is shown that the usual decomposition strategies from the literature will leak information – even when information derives from a single source. It is argued that this leakage, and the proper reparational measures, need to be accounted for in a formal semantics. To this end a set semantics for SPARQL is generalized with a parameter representing execution contexts. This makes it possible to keep tabs on the naming of blank nodes across execution contexts, which in turn makes it possible to articulate a decomposition strategy that is provably sound and complete wrt. any selection of RDF sources even when blank nodes are allowed. Alas, this strategy is not computationally tractable. However, there are ways of utilizing knowledge about the sources, if one has it, that will help considerably.
Keywords
Introduction
This paper is concerned with giving a general theoretical foundation for the semantics of distributed SPARQL processing. It was inspired in part by the observation that whilst a number of distributed SPARQL processors exist already, foundational work that allows one to study their relative behaviour in a principled manner is still in short supply.
In most ways, the present study can be regarded as a sequel to [35], in which the concept of a federation scheme was first introduced. Essentially, a federation scheme is a theoretical device that captures formally the conditions under which a particular federation strategy will yield sound and complete answer sets. Contrapositively, it can be regarded as a way of characterizing the behaviour of the federation strategy in question by making theoretically explicit when it will miss answers and why. While [35] gave several examples of sound and complete ways of decomposing and evaluating a query over a set of sources, these results were valid under the proviso that the contributing sources do not employ blank nodes for encoding information. The main contribution of the present paper is to remove this restriction thus giving, for the first time we believe, a fully general declarative semantics for distributed processing of SPARQL basic graph patterns.
There is a singular tension in the Resource Description Framework (RDF) between, on the one hand, the strictly local validity of blank nodes and, on the other, the global pretensions of the data model. RDF affords a knowledge representation language for making assertions that are meant to be valid in a global or Web-wide scope. Yet, it recognizes the existence of entities that cannot be referenced outside their source of origin, and that cannot be identified across query execution contexts.
The Semantic Web community is deeply ambiguous in its attitude towards blank nodes. The Linked Data community generally shuns them – in Bizer [18] they are discussed under the heading “RDF features best avoided in the Linked Data context”. On the other hand, asserting the existence of something that one is not willing to name is generally recognized as indispensable for design patterns that rely on expressing general logical concepts such as n-ary relations, lists, sets or classes. However one sees it, there is no getting around the well-documented prevalence of blank nodes on the Web [19] – a fact which is not likely to change anytime soon.
In rough outline, the problem with blank nodes is that if a federator is to combine information across SPARQL endpoints, then it will have to join suitably small fragments of information from different sources. This in turn involves evaluating suitably small subqueries to get at all the partial answers that are required for answering the global query in full. Alas, in the process patterns may happen to be broken up that match a partial answer in a single source where a blank node figures in join position. If so, then that partial answer cannot be put back together afterwards, because the blank nodes that were previously joined will no longer be identifiable as the same node. The situation poses somewhat of a dilemma, and resolving it requires rather profound, though not too complex, amendments to the semantics of evaluating SPARQL basic graph patterns.
Admittedly, the fragment of SPARQL that consists only of basic graph patterns is a fragment that ignores many interesting and useful features of SPARQL. Yet, it is a natural fragment to start with since it is simple and mathematically well-behaved. Granted, it is an interesting question how, say, the non-monotonic features of SPARQL such as negation would alter the picture. Nevertheless, this is a question that is considered out of scope for the purposes of the present paper, though one it is hoped it will be easier to explore in the future on the basis of this paper.
The layout and specific contributions of this paper are as follows: Section 2 identifies and describes the adverse effect of blank nodes on distributed query processing, whilst Section 3 surveys related work in the area. Section 4 provides the semantic prerequisites for working out a solution to the said dilemma. This consists mainly in generalizing the SPARQL 1.1 semantics by adding a formal parameter for execution contexts to the notion of an answer set. The concept of an execution context is left largely implicit in the SPARQL 1.1 specification. In the distributed setting, it is a condition sine qua non for an adequate semantics and therefore needs to be formalized. Section 5 flexes the new semantic machinery by providing an existence theorem showing that if an answer to a query exists in a set of contributing sources taken as a whole, then there is a way to retrieve it, even when allowing for blank nodes. Section 6 reviews the federation-schemes framework as developed in [35] as a prerequisite for the subsequent section. It does not contribute any new results per se, but merely adapts the relevant concepts and definitions to the generalized semantics developed in Section 4. Finally, Section 7 ties the threads together by abstracting from the existence theorem in Section 5 a federation scheme that gives sound and complete answer sets in the absence of any knowledge about the structure of the sources, blank nodes allowed. However this section also shows that there is a rather steep price to pay for ignorance when blank nodes are involved. More specifically, it is shown that distributed query answering in the presence of blank nodes when no knowledge is available is inherently hard. Different ways to mitigate the situation are sketched based on obtaining knowledge either by regimentation of the sources or by probing them, pointing to interesting lines of future research.
Problem description
It seems reasonable, by default at least, to require of a distributed query processor that it neither misses nor invents answers; all and only the answers that are warranted by the sum total of information contained in the contributing sources should, if there are no overriding reasons to the contrary, be returned.
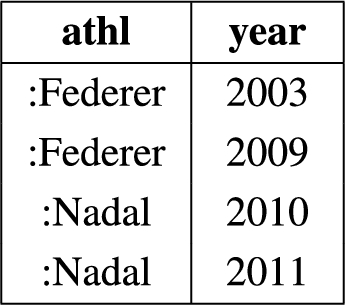
To illustrate what is meant here by ‘the sum total of information’, consider the two RDF graphs in Figs 1 and 2 respectively, call them source A and B. As should be apparent, they encode information about trophies won by Roger Federer and Raphael Nadal respectively in Grand Slam tournaments.1
It is a slightly modified version of an example from [19].

RDF source A.

RDF source B.
This answer set strictly includes that which is obtained by evaluating the query in Fig. 4 against each source separately before taking the union of the result, viz. Fig. 6. In other words, the sum of the whole is bigger than the sum of the parts. Specifically, the total amount of information contained by the two sources combined, resides not only in what each of them can contribute separately, but in also in the combination or join of elements across sources.

The union of sources A and B modulo renaming of blank nodes.

Get Grand Slam triumphs.
Answer over the merge of A and B.

Union of answers over A and B.
A distributed query processor should, in the absence of a good reason for sacrificing completeness, query the whole. That is, by combining results from partial queries evaluated separately against source A and B, it should return the table in Fig. 5 as the answer to the query in Fig. 4.
Generalizing from the present example – keeping the restriction to basic graph patterns in mind – one thus arrives at the following intuitive criterion of adequacy for a distributed query processor: the same answer should be returned as that which would be obtained were the query to be evaluated over the merge of the contributing sources. This concept of adequacy will have to be made more precise later, for there is leeway for different interpretations of it due to the appeal to the ‘sameness’ of answer sets. For now, however, and in relation to the example at hand, the question becomes: how must the query in Fig. 4 be decomposed and processed (vagueness intended) in order to satisfy the adequacy criterion?
Given the obviousness of all that has been said so far, it is somewhat surprising that there is no simple answer to this question. This is due to the fact that source A and B – as recommended by the Semantic Web Best Practices and Deployment Working Group – use blank nodes for expressing three-place predicates, in this case the predicate “X wins Y in year Z”. Due to this, the information expressed by the graphs depends on joins on blank nodes. In the distributed case, such a join, if it is not handled with special care, will quickly become a drain through which information will leak. As we shall see, this has to do with anaphoric reference being lost whenever the same blank node is processed in two separate execution contexts.
It is interesting to register that none of the more straightforward and better known query-decomposition strategies from the literature will work for this example. Consider for instance the even decomposition, so called in [35] (cf. Section 6) as implemented in DARQ [29]. This is the decomposition that evaluates each triple pattern (from the global query, let’s call it) against every source that may contain an answer for it (meaning that the RDF property from the triple pattern in question occurs in that source). For instance, the even decomposition will evaluate both of the triple patterns

Answers to

Answers to
Here, the identifiers for blank nodes have been given distinct subscripts c and d to signify that they are not to be treated as the same names. This behaviour is mandatory according to SPARQL 1.1 specification which requires every distinct query to be treated as a separate query execution context. More precisely, every query defines a distinct and sealed scope for blank node identifiers, which means that a blank node from one execution context cannot be referenced in another. From a logical point of view this is an entirely legitimate restriction. Blank nodes are similar to existential variables and existential variables are anaphors within the same quantificational context only. Nevertheless, it is detrimental for the even distribution, because join information is not preserved by the two tables. Therefore, the even distribution is not a decomposition strategy that can be relied on to remain faithful to the ‘sum total’ of information contained in the contributing sources.
The problem generalizes, for no other well-known decomposition strategy fares any better. Take the one implemented in FedX [34] for instance. The FedX decomposition is similar to DARQ except that it groups triple patterns that are satisfiable by a single source only – so called exclusive groups – into the same subquery. This strategy is studied under the name of the standard decomposition in [35].
Exclusive groups anchor the triples involved to the same execution context, so they may in fortuitous cases solve the problem. However, the example currently under consideration shows that this is not in general so. Indeed, in the cases where it is so, it comes down to luck, because exclusivity has nothing to do essentially with blank nodes. In particular, there are no exclusive groups in the query in Fig. 4 wrt. source A and B, so the even and standard decompositions are the same in this case.
As a final example, consider the decomposition strategy implemented in ADERIS [25], which is that of assigning to each selected source G the maximal subsets
Taking stock, these examples can be taken to show the following: If answering a query involves joins on blank nodes, then the granularity of the decomposition of that query matters a great deal. If the query is split too finely, then answers from a single source may be lost due to the loss of join information linking the partial answers. If on the other hand the query is split too coarsely, then cross-site joins may be lost. From a semantical point of view, distributed query answering is essentially about balancing these two opposing forces.
The delicateness of this balancing act has not been fully appreciated yet it seems: while it is reasonable to expect a distributed query processor to do better than to just collect solutions to the global query from each of the sources, it may so happen that the very attempt to do so, i.e. the attempt to harvest information by utilizing cross-site joins, is the very thing that causes it to do worse, because if there are joins on blank nodes in a contributing source, then that source will leak solutions if the global query is decomposed too finely.
As for the question of whether there even is a decomposition that can be made to work, the answer is affirmative for the example at hand at least, viz. the decomposition below:
We have the work cut out for us then: first it is necessary to show that irrespective of the shape of graphs, if a solution to a query is warranted by the merge of the contributing sources, then there is a decomposition from which that solution can be reconstructed. Secondly, it must be shown that it is possible to abstract from these particular solutions a general federation scheme that yields a correct and exhaustive answer set in the absence of any knowledge about the sources, even whilst allowing for joins on blank nodes. In order to do so, however, it will be necessary to generalize the SPARQL 1.1 semantics with an extra parameter representing execution contexts – a topic for the next section.
A tripartite classification of approaches to SPARQL federation is explicit in Görlitz and Staab [12] and implicit in Betz et al. [7] and Hose et al. [20]:
Lookup-based federation: Also known as federation-by-traversal, or follow-your-nose traversal [4], iteratively downloads and evaluates data based on links (usually as prescribed by the Linked Data principles [8]) from one dataset into another. The answer to a query is composed by cumulatively adding answers from incoming data during the traversal process. This approach is exemplified by e.g. [14–17] and [23].
Warehousing: Broadly understood, warehousing covers approaches that seek to collect or assemble all data of relevance ahead of query time into a repository that behaves as if it is a centralized single store. This area naturally shades off into cloud computing [32], distributed file systems, and big data technologies. Recent efforts in this direction focus on the use of cluster technology such as MapReduce and Hadoop e.g. [10,19,21,22,24] and [28], Spark e.g. [9] and GraphX e.g. [31].
Distributed query processing: Distributed query processing relies on analysing a query to identify a set of relevant RDF graphs – with or without the aid of statistics – to which subqueries can be assigned. Like federation-by-traversal and unlike warehousing, queries are evaluated remotely. Examples of this approach include [3,6,27,29] and [34].
If the issue were pressed, the present paper would be most naturally classified as belonging to the field of distributed query processing. However, it does not really advocate ‘an approach’ to SPARQL federation. Rather, it aims to articulate and develop a set of semantical primitives in terms of which any federation engine ought to be describable. To the authors’ knowledge it is the first foundational study of distributed query processing that allots to blank nodes a clearly described role in a strictly logico-mathematical theory.
It should be said that the tripartite classification mentioned above is very rough, and cuts across important and interesting distinctions in the literature. Conversely, there are subfields within federation that cut across it. It can plausibly be argued for instance that scalability and optimization are issues that are largely independent, or at least not tightly coupled with, any one particular approach. On the contrary, a lot of work seems to be going on here with more general significance.
To mention but a few, there is the area of adaptive query answering that explores how the evaluation of a query may be adjusted at run-time, e.g. by reordering joins [2] or by exploiting approximate membership functions reducing HTTP requests [36]. There is also a fair bit of activity in the field of caching, data replication and load balancing. For instance, [26] explores the use of replicated fragments of data graphs in order to mimimize the size of intermediate results, whereas [37,38] adresses client-server load balancing through the use of so called Triple Pattern Fragments (TPFs).
As regards, the relationship between the present theory and the SPARQL 1.1 federation extension, the two are essentially orthogonal to each other: the latter, by providing the SERVICE keyword for source selection, provides a way of evaluating different parts of a query against different endpoints, but it doesn’t tell you which parts. The present paper, in contrast, is concerned precisely with the question of which parts one can rely on to retain soundness and completeness. i.e. it is concerned with defining decompositions that are logically well-behaved.
Adding execution contexts to the SPARQL semantics
The formal developments that follow are based on the set version of the SPARQL 1.1 semantics as defined in [5] – or at any rate, as far as it goes. We say “as far as it goes”, because that semantics is designed for the case where a single query is evaluated against a single source in a single execution context. But what is distinctive about the distributed setting, is that the overall answer to the distributed query is assembled from partial answers to partial queries each one of which represents a distinct execution context. These contexts matter a great deal from a semantical point of view as they constitute disjoint name spaces for blank nodes, which in turn influences the semantics of joins.
Execution contexts are not formally defined in the SPARQL 1.1 semantics, which therefore lacks the expressive power to define distributed query processing. However, the following passage provides a fairly robust basis for a formal reconstruction: “Since SPARQL treats blank node identifiers in a results format document as scoped to the document, they cannot be understood as identifying nodes in the active graph of the dataset. If DS is the dataset of a query, pattern solutions are therefore understood to be not from the active graph of DS itself, but from an RDF graph, called the scoping graph, which is graph-equivalent to the active graph of DS but shares no blank nodes with DS or with [the query]” [13].
The scoping graph mentioned here is a purely theoretical construct – it is just another namespace for blank nodes. In other words, SPARQL distinguishes between the scopes of a query, the queried data and the result, stipulating that blank nodes cannot be shared between them. This has important formal ramifications that will be explored shortly, after the requisite semantic concepts have been introduced.
The following notational conventions will be adopt-ed from here on: curly braces are omitted from singletons in set-theoretic expressions as well as from arguments of functions if no confusion is likely to ensue, e.g.
Turning now to RDF specifics, let I, B and L denote pairwise disjoint infinite sets of IRIs, blank nodes, and literals respectively. In conformity with the nomenclature of [5],
Turning now to SPARQL queries, let V be an infinite set of variables. Variables are denoted by lower case letters in the range of x to z with a question mark prepended. Variables may also be counted as terms, in which case they too are denoted
A basic graph pattern (BGP) is either
a singleton a union
Thus,
Following [5], SPARQL queries will be identified with basic graph patterns. In other words, the distinction between the syntax and the semantics of SPARQL queries will deliberately be blurred. Concretely, this means that queries will be treated as sets of triple patterns rather than as syntactic entities in and of themselves. This is mathematically convenient and simplifies formal developments without loss of precision. Abiteboul et al. [1] establishes precedent in this respect.
In the SPARQL 1.1 specification answers to simple conjunctive queries aka. basic graph patterns are formalized in terms of solution mappings, which are partial functions μ of type
Let G be an RDF graph, and P a BGP. Let
Here
This is the standard definition of answer sets as it looks in the set version of the SPARQL 1.1 semantics. Yet, keeping the SPARQL 1.1 specification’s notion of a scoping graph in mind, it is already not entirely accurate – not even for a single source and a single execution context. For if a solution
An RDF graph
The concept of an RDF homomorphism that figures in this definition will be defined shortly. Henceforth, whenever two answer sets are said to be the same, this is intended to mean that they simply entail each other, i.e. that they are simply equivalent, represented symbolically as  .
.
The upshot of this is that even in the single-source case, SPARQL semantics can be seen to have an equivalential basis, and is thus not really expressible in terms of membership alone. This is not all bad news. On the contrary, it fits hand-in-glove with distributed query processing, for as soon as the equivalential basis of answer sets over a single source is made formally explicit it generalizes straightforwardly to answer sets obtained by combining solutions from different execution contexts.
The notational apparatus will have to be amended slightly. Starting with a countably infinite set of contexts
Returning now to RDF homomorphisms:
Given two RDF graphs
This definition differs from the standard only in that the range of functions has been extended with the new (countable) set of blank nodes. As for the concept of an execution context, viz. the following definition:
An execution context is a bijection
The idea now, is to let the partial map μ, as defined in the standard semantics, figure merely as the mathematical relationship between a graph pattern and a graph that is to be portrayed by solutions proper. Stated differently, μ is no longer considered a solution per se, rather a solution
Given a
Generalizing Definition 4.2 accordingly yields.
Let
The following pair of lemmas is unglamorous but important:
An execution context c is an RDF homomorphism from
Suppose
By Definition 4.5(1) and (2), we then have
Therefore
The converse of a context c is an RDF homomorphism.
By Lemma 4.2, c is a homomorphism which by Definition 4.4 is bijective. Hence
Taking stock so far, there is no longer such a thing as the set of answers to a BGP P over a graph G, strictly speaking. When blank nodes are involved there are infinitely many distinct such sets, one for each context c. These sets are all simply equivalent, though, which just means that they answer the query in essentially the same way:
If
By Lemmas 4.2 and 4.3 c is an RDF homomorphism from  . By similar reasoning
. By similar reasoning 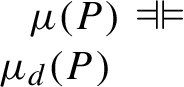 , and by the property of euclideanness for equivalence relations
, and by the property of euclideanness for equivalence relations
Corollary 4.4 thus expresses formally what was hinted at in Section 2 when it was said that the ‘sameness’ of answer sets would have to be made precise.
Turning now to distributed query answering and its semantics, its formalization is a matter of generalizing the ⋈ relation to apply to answer sets from different sources and parametrized by different execution contexts:
There is in general no context e such that
It suffices to argue the case where
What this means is that there is in general no algebra on contexts and sources that allows one to reduce
As a consequence of this, there are two different things that need to be recognized as solutions to a query: first, any solution to the query over a single source, and secondly, any solution obtained by joining partial answers from different sources or contexts. Call the latter intercontextual joins, and let them be denoted with ρ. Intercontextual joins generalize cross-site joins: whereas a cross-site join is an intercontextual join, the converse does not necessarily hold. The ρ notation will be used primarily as a convention for indicating in the relevant parts of a proof or line of reasoning that an appeal to a context is neither required nor apt. We have:
Let
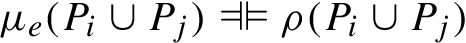 .
.
By Definition 4.6(2) it suffices to show the property for a  for an arbitrarily chosen e, and
for an arbitrarily chosen e, and  for the same e. From the former it follows by Theorem 4.1 that there is a pair
for the same e. From the former it follows by Theorem 4.1 that there is a pair
For A) it suffices to show that
For B) the reasoning is entirely similar to A) so suppose for reduction that there is a term
As this argument can obviously be extended to all finite unions of BGPs by a straightforward induction, it is in effect akin to a soundness result: as long as execution contexts do not share blank node identifiers with one another or with RDF graphs, and as long as the scope of RDF graphs are treated as mutually exclusive, distributed query processing, understood as assembling intercontextual joins across sources and contexts, never produces solutions that are not warranted by the union of those sources.
To recapitulate briefly, the point of introducing an explicit parameter for execution contexts is to be able to reason about the total information content held by a set of answers each of which was generated by a different query over a distinct source – the total information content being given by the join over all these sets. Now, as each query will set up a separate scope for blank node identifiers that is disjoint from all others, answer sets cannot in the distributed case be joined freely. In particular, any join on blank nodes, if it spans two or more execution contexts, must be deemed a false positive. Conversely, any join on blank nodes that refers to a single context is ok. In other words, execution contexts is essentially a way to keep tabs on legitimate and illegitimate joins.
The present section is concerned with the first of the tasks that were defined towards the end of Section 2 which, having introduced execution contexts into the SPARQL semantics, it is now possible to address: the aim is to show that irrespective of the shape of graphs, if a solution to a query is warranted by the merge of the contributing sources, then there is a decomposition from which that solution can be reconstructed.
The investigative strategy that is adopted here is to reverse-engineer the problem by showing that every solution over the merge of the contributing sources induces a decomposition that fits the bill. More specifically, the idea is to let those parts of the given solution that have joins on blank nodes dictate how the corresponding query pattern is to be decomposed; for if a graph pattern is connected by blank nodes, it must derive from a single source, so the subquery that matches it must be grouped and evaluated in a single execution context.
Thus, we shall be interested in those subpatterns
(b-connectedness).
Let G and
It is worth noting that, in the limiting case, the definition makes every triple pattern that, parameterized by
The definition of a b-connected set (wrt.
(b-component).
Let
Note that b-connected sets are RDF graphs, whereas b-components are SPARQL query patterns. Consider the following example:
Consider the merge of the RDF graphs A and B in Fig. 3 and the query in Fig. 4. Let
Now, Example 5.1 seems to indicate otherwise, but it is a fact of some importance that
Put
The significance of this is that one cannot limit ones’ view to connected subqueries when searching for a complete federation scheme. There will be more to say about this in the next section.
For stocktaking and for the sake of contrast, it might be instructive to review a couple of cases that are excluded by Definitions 5.1 and 5.2: First of all, and rather obviously, a maximal b-connected set is not the same as a set which is maximally such that each pair of triples is connected by a blank node. Consider Fig. 9, where for simplicity we let the properties
Considering how blank nodes are renamed in each execution context, one can appreciate why it is
Elaborating on this example a bit, the lopsidedness of the concept of pairwise b-connectedness could be counteracted by stipulating instead that a b-connected set is one in which all pair of triples are connected by an undirected path where all interior nodes on the path are blank nodes. It is easily verified that the only subgraph of Fig. 9 which is maximal in this respect is the entire graph, as this example demands.
However, it is not too difficult to rig up another graph which shows that this time we have overshot our target insofar as the latter concept is not discriminating enough. Consider the graph Fig. 10. There is a path of the kind described between every pair of triples, so the graph itself is the only connected component according to this latter concept of connectedness. However,

Counterexample 1.
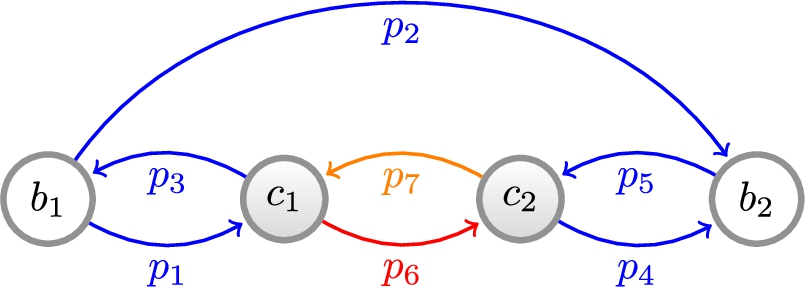
Counterexample 2.
It will be convenient to have a notation that assembles all the b -components that a particular solution induces:
The set of b-components of P relative to
The next two lemmas record some important properties about f as so defined.
According to Definition 5.1 the empty set is not b-connected, hence any
The right-to-left inclusion is trivial. For the converse suppose
It remains to show that the elements of
f is a function.
Let
The combined significance of these two lemmas may be explained as follows: Lemma 5.2 fixes a single set
Let P be a query,
 for any execution context c.
for any execution context c.
Put
In words, Lemma 5.3 demonstrates that every element
Suppose
 and
and
 . Then
. Then
 .
.
Suppose the conditions of the theorem hold. Since  . By Theorem 4.1, this in turn reduces to demonstrating the existence of an RDF homomorphism from left to right and one from right to left. By the supposition of the theorem the property holds for each of the component patterns. That is, there is a pair of RDF homomorphisms
. By Theorem 4.1, this in turn reduces to demonstrating the existence of an RDF homomorphism from left to right and one from right to left. By the supposition of the theorem the property holds for each of the component patterns. That is, there is a pair of RDF homomorphisms
For
It remains to verify that
For
Suppose that either
Suppose for contradiction and without loss of generality that
The verification that
It may be worthwhile to pause to register what it is that makes this proof work: it is essentially a question of building larger RDF homomorphisms from smaller ones. This requires certain simple conditions to be met, most importantly that the union of functions be a function. Since the smaller functions in question are RDF homomorphisms, and RDF homomorphisms by definition map IRIs and literals to themselves, the only way this could go wrong is if the mapped element were a blank node. However, this cannot happen for the left to right direction, since execution contexts have disjoint ranges, and it cannot happen for the right to left direction since the solutions in question do not share blank nodes. Thus the theorem flows from two things: the relativization of answer sets to execution contexts and the splitting of queries into b-components.
It is now possible to prove the converse of Theorem 4.6 and the main result of this section:
Let
 .
.
Suppose the conditions of the corollary hold. Put 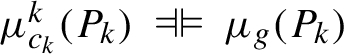 . By extension of Lemma 5.4 to finite unions it follows that
. By extension of Lemma 5.4 to finite unions it follows that  . Therefore, selecting
. Therefore, selecting
Whereas Theorem 4.6 says that cross-site joins can never be incorrect, provided that tabs are kept on execution contexts, Corollary 5.5 states that every solution to a query P returned by the merge of the contributing sources is contained in the join of the separate evaluation of the cells of some decomposition of P. Thus there is always a solution distributed in the contributing sources if there is a solution in their union modulo renaming of blank nodes – i.e. in their merge.
What Corollary 5.5 does not say, is how to obtain this decomposition when we do not know the structure of the sources. It was only possible to prove that a decomposition exists by assuming prior knowledge of a solution that could be used to partition the query. However, different solutions may require different decompositions. Yet, all solution cannot be assumed to be available if federation is to produce information one does not already possess. It remains, therefore, to abstract from Theorems 4.6 and 5.5 a general federation scheme that will deliver all solutions, and only solutions, over any set of contributing sources in the absence of any knowledge about them. For this, we shall need the concept of a federation scheme.
The concept of a federation scheme was first introduced in [35] as a mathematical abstraction for reasoning about the distributed query answering process. It is meant to highlight the two complementary aspects of this process, which may be taken to consists respectively in decomposing a query over a set of sources and in assembling an answer to it from the partial answers returned by each contributing source. A federation scheme is thus a pair
The soundness and completeness of a federation scheme is a relationship that holds wrt. a set of sets of contributing sources – or, in a more suggestive terminology, a set of selections of contributing sources: the federation scheme specifies how a graph pattern is to be distributed and evaluated over a set/selection of sources. Conversely the set of selections defines the permissible ways of choosing sources over which to distribute the decomposed query, where permissible means that soundness and completeness of query answering is preserved. Stated differently one might say that the set of sources specify in semantic terms the assumptions about the structure of the data that is built into the federation scheme.
The present section recalls the essentials of this formal framework, and generalizes it to the new equivalence-based semantics for distributed queries as set out in the previous section.
The minimal amount of knowledge one needs about a set of sources in order to distribute a query over them, is their signatures. Here a signature is understood essentially as the set of concrete predicates of an RDF graph or of a SPARQL pattern. The following definition covers both cases:
Let S be a BGP or a set of RDF triples. The signature of S written
Note that variables and blank nodes do not add to the signature of a graph pattern, and that blank nodes do not add to the signature of an RDF graph. Using signatures to route subqueries is a common stratagem in the literature (cf. [11] and [34]).
If P is non-empty, then
It is a simple consequence of Definitions 6.1 and 6.2 that if
A decomposition function is a binary function δ that takes a set of RDF graphs if
Note that this definition does not necessarily partition P, it all depends on the signature of the sources. Clause (1) prevents a decomposition function from behaving erratically when it comes to assigning subqueries to sources. That is, a BGP is only assigned to sources that can potentially answer it. Clause (2) ensures that the value of a decomposition function on any selection of sources
Examples of decomposition functions
Section 2 mentioned the notion of an exclusive group of a query P relative to a selection of sources The subpattern of BGP P that is exclusive to an RDF graph G, relative to a set of RDF graphs
The following theorem, the proof of which can be found in [35], gives examples of decomposition functions:
Let
Even decomposition:
Standard decomposition: either
Prudent decomposition: either
Then δ is a decomposition function in the sense of Definition 6.3 .
The effect of the second clause under the prudent decomposition is to avoid useless cartesian products in cells of the decomposition, something that is not excluded by the standard decomposition. The reader may wish to consult [35] for more detail.

Query LS5 from FedBench.
Consider the query in Listing 1. This is query LS5 from the FedBench suite [33] which asks for all drugs from Drugbank, together with the URL of the corresponding page stored in KEGG and the URL to the image derived from ChEBI.
The signature of the query divides among the FedBench datasets as specified in Table 1. Presupposing this division, Table 2 gives the even, standard and prudent decompositions respectively. Blocks in a column correspond to subqueries and are labelled with the datasets to which that subquery is assigned. For instance, the standard decomposition assigns the subquery consisting of line 2 and 3 to KEGG, since 2 and 3 form an exclusive group for it. The non-exclusive triple pattern in line 4, in contrast, is assigned to both KEGG and ChEBI.
Decomposition of the signature of query LS5
Decomposition of LS5 over KEGG, ChEBI and Drugbank
The standard- and prudent decompositions of LS5 over KEGG, ChEBI and Drugbank are identical for this particular selection of datasets. The difference between them is revealed by reducing the selection to ChEBI and Drugbank only, viz. Table 3. Here, the standard decomposition assigns the subquery consisting of line 4, 5 and 6 to ChEBI, since this larger set now constitutes an exclusive group for ChEBI. Note, however, that its join-graph is not connected since none of the variables in line 4 occur in line 5 or 6. Therefore, the prudent decomposition divides
Decompositions of LS5 over ChEBI and Drugbank
Turning now to the notion of an evaluation rule, it suffices to define it abstractly as a function that produces a set of answers, in the form of intercontextual joins (cf. the previous section), from a decomposition:
(Evaluation rule).
An evaluation rule is a function
Obviously, this definition hides great variety. Next:
A federation scheme is a pair
The following particular evaluation rule is a generalization to a semantics parametrized by contexts of the so-called collect-and-combine rule from [35]:
Put
The collect and combine rule is relatively simple if one looks beyond the bureaucracy that comes with execution contexts. It takes each element in a decomposition, executes it against each source that covers its signature, and collects the results. Then it forms the coordinatewise join of the resulting set. Peeking ahead to the next section, this rule turns out to be too simple for the case where blank nodes are involved, but may serve as a concrete example to aid intuition.
The reader should note that in order to be completely precise formally, the set
Completeness
Recapitulating briefly, the properties of soundness and completeness are relations that hold between federation schemes on the one hand and sets of selections of RDF graphs on the other. The former specifies how a graph pattern is to be distributed and evaluated, the latter defines the permissible ways of selecting sources over which to distribute the decomposed query.
One will want the federation scheme in question and the selection of sources to be perfectly matched, meaning that if a global query is processed according to the scheme it will neither invent solutions nor ignore any that are warranted by the sum total of information in the contributing sources. Recalling that sameness of solutions is defined in terms of simple equivalence, this gives the following definition of the soundness and completeness of a federation scheme wrt. to a set of selection of sources:
Let 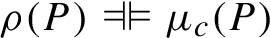 . It is sound if the converse holds.
. It is sound if the converse holds.
This definition differs from that of [35] where soundness and completeness is defined in terms of set-inclusion as
Taking sets of selections of sources (that is, sets of sets of sources) as the semantic correlate of decomposition schemes facilitates the formalization of different degrees of knowledge about the structure and content of the sources that a query is distributed over. At the extreme end of this spectrum one finds the zero-knowledge case, i.e. the case where nothing is known about the tributary sources apart from their respective signatures. The zero-knowledge case, of course, corresponds to the absence of any restriction on how to make a selection of sources to distribute a query over, i.e. it corresponds to the set of all selection of sources. Stolpe [35] proves the following:
Suppose δ is the even-, standard or prudent decomposition. Then
However, Theorem 6.2 does not generalize. That is, neither the even-, standard nor prudent decomposition guarantees completeness of query answering under the collect-and-combine rule when blank nodes are allowed (the reader may wish to refer back to the example in Section 4).
Summary of notation
Consider the following distribution function and evaluation rule:
Let
It is immediate by this definition, that if
Let
It should be evident that
The federation scheme
For completeness, let  . Now, by Corollary 5.5 there is a partition
. Now, by Corollary 5.5 there is a partition  . We need to show first of all that this partition is an element of
. We need to show first of all that this partition is an element of  implies that
implies that
As for the soundness direction of the proof, this is just Lemma 4.6, so the proof is complete. □
A few comments on this result are in order: Although the completeness of
When one cannot make any assumptions about the structure and content of the contributing sources, there seems to be no other solution than to evaluate all the possible partitions of the original query that involves only cells whose signature is covered by a source. Indeed, this can easily be seen to be not only a sufficient, but also a necessary condition for completeness, for if one of these partitions is skipped it is straightforward to tailor a selection of sources that correspond to just that partition.
Alas, in the limiting case where
The obvious remedy for this is to make sure that one has some knowledge about the sources, either by imposing requirements on them or by probing them. By ‘probing’ is here understood an initial round of queries, typically but not necessarily SPARQL ASK queries, designed to detect patterns in the data, typically concerning the placement of blank nodes, that can be exploited for decomposing the global query.
Recall that
A set of RDF graphs
To be sure, uniformity is a lot to ask for. It is a global requirement that demands that the same type of information be encoded by the same graph pattern in all the sources where it occurs. Uniformity does not, however, limit the space of eligible patterns. That is, it does not say anything specific about how the data must look, only that an encoding pattern must be employed consistently across all contributing sources. This need not be as strict as it sounds, since it will be the case for instance if each source is individually consistent in this sense and if in addition the contributing sources all provide solutions to different subpatterns.
From a theoretical point of view, uniformity is interesting for two reasons: first, a very limited amount of probing suffices. In fact, a single solution to the global query is enough to determine a sound and complete federation scheme. Secondly, the evaluation rule
(Induced distro).
Let
Let
Soundness is already established. For completeness, suppose  . Clearly there is a
. Clearly there is a
Summing up, one might say that Theorems 7.1 and 7.2 constitute different extremes of a combinatorial spectrum. The former gives a complete federation scheme in which the number of required partitions of a query grows exponentially in the size of the query, whereas the latter gives a federation scheme where the number of required partitions is constant with
Of course, with perfect knowledge about the structure of the sources, probing will not be necessary at all. A perfect knowledge-case would be one where the contributing sources could be expected to conform to a predefined schema e.g. a resource shape [30]. In such a case, distributed query processing can be done efficiently without having to sacrifice the expressive power that comes with blank nodes.
Exploring the space between Theorems 7.1 and 7.2 should provide a rich field for future research.
It has been demonstrated that the presence of blank nodes in RDF data represents a problem for distributed processing of SPARQL queries. Even though the facts of the matter are fairly simple, they seem as yet to have slipped by unnoticed, and none of the usual decomposition strategies from the literature solve it.
To mend the situation, this paper has introduced a semantics for distributed query processing in which the notion of an execution context is explicit. This makes it possible to keep tabs on the naming of blank nodes across execution contexts, which in turn makes it possible to articulate a decomposition strategy that is provably sound and complete wrt. any selection of RDF sources even when blank nodes are allowed. Alas, this strategy is not computationally tractable. However, there are ways of utilizing knowledge about the sources, if one has it, that will help considerably.