
Abstract
The Second World War (WW2) is arguably the most devastating catastrophe of human history, a topic of great interest to not only researchers but the general public. However, data about the Second World War is heterogeneous and distributed in various organizations and countries making it hard to utilize. In order to create aggregated global views of the war, a shared ontology and data infrastructure is needed to harmonize information in various data silos. This makes it possible to share data between publishers and application developers, to support data analysis in Digital Humanities research, and to develop data-driven intelligent applications. As a first step towards these goals, this article presents the WarSampo knowledge graph (KG), a shared semantic infrastructure, and a Linked Open Data (LOD) service for publishing data about WW2, with a focus on Finnish military history. The shared semantic infrastructure is based on the idea of representing war as a spatio-temporal sequence of events that soldiers, military units, and other actors participate in. The used metadata schema is an extension of CIDOC CRM, supplemented by various military history domain ontologies. With an infrastructure containing shared ontologies, maintaining the interlinked data brings upon new challenges, as one change in an ontology can propagate across several datasets that use it. To support sustainability, a repeatable automatic data transformation and linking pipeline has been created for rebuilding the whole WarSampo KG from the individual source datasets. The WarSampo KG is hosted on a data service based on W3C Semantic Web standards and best practices, including content negotiation, SPARQL API, download, automatic documentation, and other services supporting the reuse of the data. The WarSampo KG, a part of the international LOD Cloud and totalling ca. 14 million triples, is in use in nine end-user application views of the WarSampo portal, which has had over 690 000 end users since its opening in 2015.
Keywords
Introduction: Military history as linked data
Plenty of information about WW2 is published every year in books, articles, news, web sites and services, documentaries, and films for humans to consume. This information is scattered in various military, governmental, cultural heritage, and other organizations, making it hard to find and use. Furthermore, the information is seldom published as data for reuse in computational analyses and applications. Gathering, extracting, and harmonizing information about the war is needed in order to create comprehensive global views of the war and history but this is not a simple task. This applies also to microhistory: for example, finding out the details of what happened to a perished relative during the war can be quite tedious, involving studying and aggregating data about him/her from several registries and data sources. Without harmonized, clean data, the data analysis of large military historical datasets, such as death records, would be difficult in Digital Humanities Research [5,13]. Combining information from various sources facilitates answering the complex societal research questions of “new military history” scholars [2,6].
The initiative and publications are presented in the initiative homepage:
The WarSampo knowledge graph (KG) was published initially in 2015. The KG was first used by seven different application perspectives in the WarSampo portal, via only the SPARQL API [18]. The idea was to show that anyone could easily use the data dynamically on the client side. In 2017, by the centennial of Finnish independence, a new eighth application perspective of war cemetery data and related photographs4
A list of CIDOC CRM use cases can be found at:
Several projects have published linked data about the World War I on the web, such as Europeana Collections 1914–1918,6
Our own previous research on WarSampo first presented the vision and overview of the system especially from the use case and end-user application perspectives [18,23]. In [16] data integration was concerned from the named entity linking (NEL) point of view. The maintenance problem of the interlinked dataset has been explored in [32]. Work on creating and using individual parts of the KG has been presented in several previous publications [24,26,29,31,33,34]. This dataset description complements our other publications about WarSampo by presenting in detail the KG, including the process of maintaining the data.
This article is organized as follows. The next section presents the source datasets. Section 3 discusses how the information in the source datasets was harmonized and presents the event-based data model. The data transformation process is presented in Section 4. An analysis of the data quality is given in Section 5. The stability and usefulness of the data are discussed in Sections 6 and 7, respectively. Conclusion is provided in Section 8.
Source datasets of WarSampo, grouped by providing organization. Numbers in the article are rounded to 3 significant digits
Table 1 lists the heterogeneous source datasets of WarSampo. The data comes from several Finnish organizations, such as the National Archives of Finland, the Finnish Defence Forces, and the National Land Survey of Finland. Some source datasets have been created as part of the WarSampo project and related research. The source datasets are in different formats, e.g., spreadsheets, text, web pages, images, application programming interfaces (API), Extensible Markup Language (XML) documents, Portable Document Format (PDF) documents, and Resource Description Framework (RDF) graphs.
The core dataset of the system is the casualty database (source number 1 in Table 1) of the National Archives that contains detailed information about virtually every person killed in military action in Finland during the WW2. A key goal of WarSampo is to reassemble the life stories of the soldiers by gathering information about them via data linking. For this purpose, data about the military units (5) and their history (6), including original war diaries (2) are of central importance. Other integrated datasets include, among others, a massive collection of wartime photographs (7), memoirs of soldiers (8), historical maps (10), biographies (12), etc. In addition to people and units, historical (4, 9) and contemporary (11) places, are widely used for data linking. The semantic backbone of WarSampo is the 1050 WW2 events based on military history literature (17).
Data model
The source datasets of Table 1 were transformed into RDF and harmonized into a coherent whole using an event-based data model. Here the concepts in the source datasets are described using metadata schemas [12,47], e.g., DCMI Metadata Terms (DCT), and vocabulary models, such as SKOS and RDF Schema (RDFS). This section first motivates the event-based modeling approach used in WarSampo and then presents in more detail the model, the main entity types, and the properties used.11
The data model is available on GitHub:
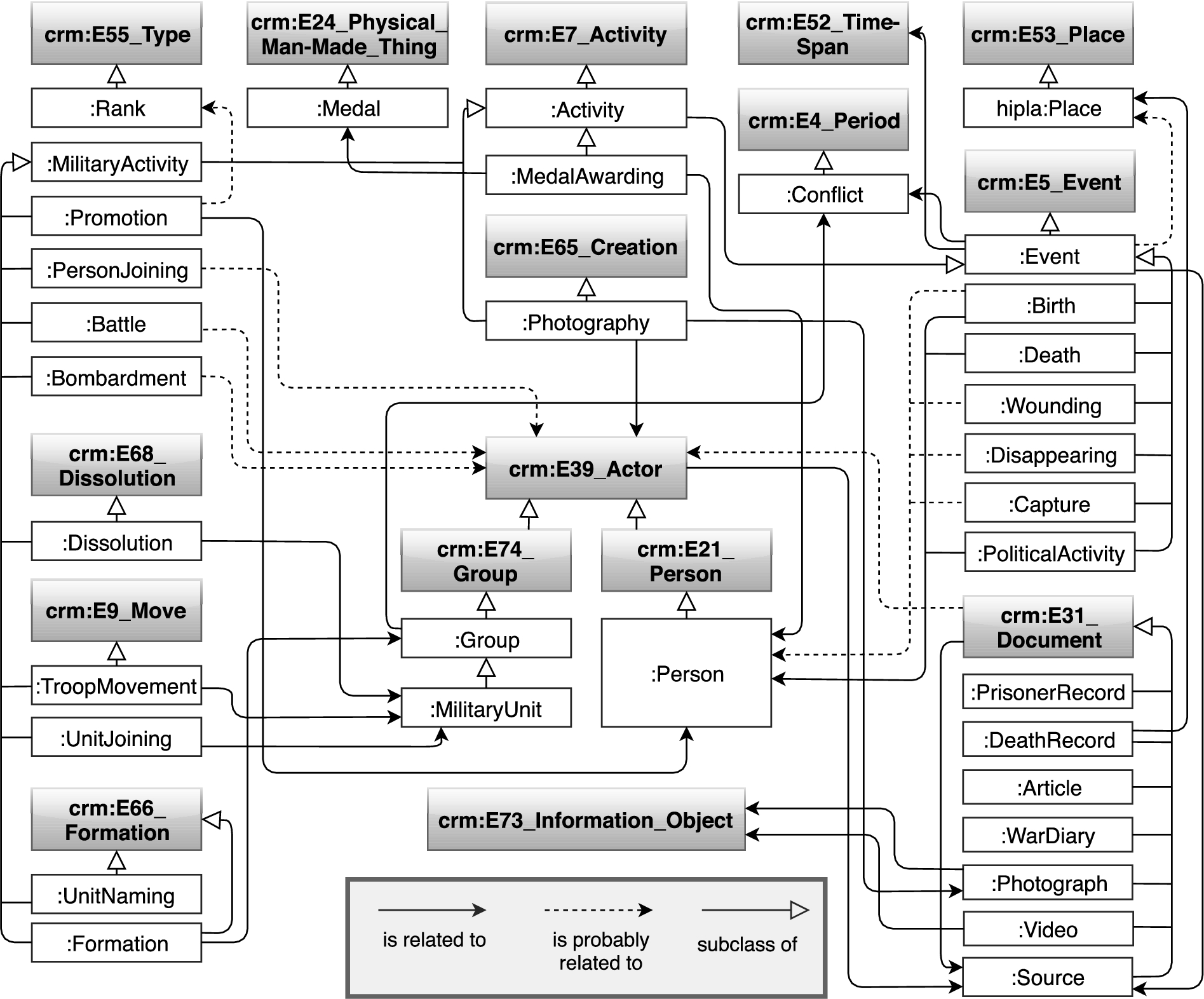
The CRM based WarSampo data model for representing military history as events.
Namespaces of WarSampo classes and their main properties

WarSampo main entity types with instance counts and linkage between the instances. Events have associated time spans that are not depicted in the figure.
The used CRM classes and their subclasses are presented in Fig. 1 and the used namespace prefixes in Table 2. The class structure was designed and extended iteratively, as the amount of source datasets and links between them increased. In Fig. 1, the RDFS subclass relation is represented with a white headed arrow. The relationships between class instances are presented with various properties in the KG, which are divided into two categories based on their certainty: 1) relations that are generated directly from the source dataset information (solid arrows), e.g., a birth event created from a person’s birth date in a death record, and 2) relations that are generated using entity linking methods (dotted arrows), e.g., to link a person mentioned in the caption of a photograph. Entity linking methods use heuristics and produce a small amount of erroneous links, which is discussed in Section 5.
CRM has an internal way of representing the types of entities, with the property crm:P2_has_type. However, the common way of representing specific types in LD is by introducing classes and subclasses for each specific type, and using rdf:type to state that a resource is an instance of a class. This approach is used in WarSampo, as it is more expressive, allowing multiple inheritance. In WarSampo, CRM is extended by creating new subclasses for representing the military history domain. The modeling decision is based on the need to use custom properties for the subclasses, that would not be valid for a whole CRM class. This facilitates interoperability with other systems based on CRM.
Events are represented strictly as subclasses of crm:E5_Event depicted on the right in Fig. 1. Also the other core classes in the data model are from CRM. However, for some information in the source datasets, modelling them using CRM is not feasible, e.g., marital statuses, or nationalities, as the way to model them with CRM is using groups and events, which is not in line with how people intuitively organize this kind of information [35]. In such cases, the information is annotated using simple SKOS vocabularies.
Literal names of the WarSampo resources are represented using properties skos:prefLabel and skos:altLabel, instead of the more verbose CRM label appellations, as there is no metadata available about the appellations in the data sources. Information sources are given with the property dct:source, and textual descriptions with dct:description. The data model can be extended with new CRM subclasses as needed, e.g., when integrating new datasets into the KG.
DOs define the basic concepts used in populating metadatasets and are shared by them. DOs include, e.g., ontologies for subject matter concepts (keyword thesauri), places, people, and events.
MDSs describe objects or other things in an application domain in terms of a metadata schema. Collection metadata in libraries, museums, and archives, or their harmonized aggregated versions are typical examples of MDSs.
The person resources are modeled as instances of :Person, a subclass of crm:E21_Person. Names are expressed using foaf:familyName and foaf:firstName. Person resources are further enriched with events created from the source information, e.g., :Birth, :Battle, :Death, :PersonJoining, :Promotion, or :MedalAwarding.
During the WW2, changes were made to the army hierarchy: the unit identification codes and unit names were changed occasionally in order to confuse the enemies, and different units have even used identical names. The army hierarchy, including the temporal changes made in it, is modeled with :UnitJoining events that link a unit into its superior unit [34].
The DRs are modeled as instances of :DeathRecord, which is a subclass of crm:E31_Document. From each DR, there is a crm:P70_documents relation to the corresponding person instance. The DRs are described with custom properties that correspond to the columns of the source spreadsheet, while each DR corresponds to a spreadsheet row. The DR properties convey information about, e.g., the person’s occupation, the number of children, marital status, and burial place, using custom SKOS vocabularies. The property values are linked, when possible, to corresponding shared DOs (e.g., Places).
The PRs contribute new person instances and extend the person data model with the capturing events. The PRs often contain multiple values for a property, and source annotations for property values, modeled as RDF reifications.
Each event is an instance of :Event or one of its subclasses (e.g., :PoliticalActivity, :Battle, :Bombardment). Events are described with textual representations via dct:description, time spans, and places of occurrence, if applicable, linking the events to Places DO. The events are linked to actors by several properties, e.g. crm:P11_had_participant, crm:P14_carried_out_by, and crm:P100_was_death_of. Time spans are instances of crm:E52_Time-Span and are represented using the properties crm:P82a_begin_of_the_begin and crm:P82b_end_of_the_end to describe the beginning and end times respectively.
The geographical data within WarSampo is modeled with a simple schema [19], which contains properties for the place name: coordinates, a polygon, a place type, and part-of relationship of the place. Each place is an instance of a subclass of crm:E53_Place. The Finnish Place Name register is used as an external DO, served on a separate endpoint.15
The process of creating the WarSampo KG started with the creation of shared DOs [16], shown on the top of Fig. 3. The MDSs created from the source datasets, were then linked to the DOs. Some of the early DOs, i.e., 5610 people, military units, military ranks, and medals, have involved manual work, and the processes used to create them are not repeatable. This is also true for person record specific lightweight ontologies used by the death records and the prisoner records. These DOs are maintained directly in RDF and a repeatable data transformation pipeline was built on top of those.
To create a harmonized view of the wars, it is vital to reconcile the entities in the source datasets, by using the shared DOs. In most cases, the reconciliation is based on probabilistic NEL [15], in which a small number of erroneous or missing links is not considered a problem. As a general principle, we have tried to link more rather than less, focusing on recall rather than precision. This enables us to provide at least the relevant links for the users of the data to find more information that they might be interested in. If we emphasized precision more, some relevant information might not be found. We trust in the users’ ability to evaluate the links and give feedback if a link is wrong. In some cases, like when disambiguating references to people, we pursued to maximize both recall and precision.
When NEL is used to link literal values to resources, the original values are preserved with a separate property, in order to provide enough information for the user of the data to evaluate whether the generated link might be incorrect.
If the source datasets are updated, the pipeline can be used to update the KG. By recreating the KG, the pipeline also handles change propagation caused by changes in the MDSs or DOs [32,43], which may cause other parts of the KG to need to adapt to the changes or the linking between resources may become invalid. Several of the data transformation processes employ Docker to increase reproducibility [7].
Figure 3 shows the data transformation pipeline, and links created by the entity linking to the DOs. The boxes represent structured data and the cylinders RDF data, with the yellow color depicting DOs and the green color depicting MDSs. The boxes from which the processes start show the corresponding source numbers from Table 1.

The 5-step WarSampo data transformation process. Dashed arrows represent entity linking, while solid arrows convey data flow.
Because of the interlinking between datasets, different change propagation scenarios emerge when updating the source datasets and DOs. The general strategy for handling the change propagation scenarios is to 1) transform DOs, 2) transform the datasets which both link to the Person DO and create new person instances, and 3) transform datasets that link to the DOs, but do not alter them. The steps shown in Fig. 3 are:
The place transformation processes convert three source CSV16
Comma-separated values format.
The Casualties transformation process transforms the CSV file into RDF death records, and links them to the DOs of military ranks, military units, occupations, places, and people [31]. The death records are matched to already existing person instances using probabilistic record linkage [14], with a logistic regression based machine learning implementation. New person instances are created in the Persons DO for the death records that don’t match any existing person.
The Prisoners of War dataset transformation process [33] is similar to the previous step, and links to the same DOs.
The war and political events originate from OCR’d texts, which are then structured into CSV files. This step takes the CSV files as input, transforms them into RDF, and links entities to the DOs [18].
Photograph metadata is transformed from a CSV file into RDF, enriched by images using the data provider’s API, and linked to the DOs of military units, people, and places.
The resulting WarSampo KG consists of 14 300 000 triples, separated into multiple DOs and MDSs. The URIs minted in the data transformation pipeline are stable over consecutive runs. For example, the person registers contain a column containing a local identifier for each person record, used to mint the WarSampo URIs for the entities.
The home page of the KG:
The public SPARQL endpoint:
The WarSampo SPARQL endpoint is hosted on an Apache Jena Fuseki21
The platform provides dereferencing of URIs for both human users and machines, and a generic RDF browser for technical data users, where a user is redirected if a WarSampo URI is visited directly with a web browser. The WarSampo URIs are of the form
Given a URI, e.g., of the commander-in-chief Mannerheim (
The KG is also available in Zenodo, with an associated canonical citation [30]. The KG is licensed by the open Creative Commons Attribution 4.0 license.
The WarSampo KG is based on the heterogeneous source datasets that are considered being of high quality, since most datasets originate from established national authorities. The data has not been corrected or amended in any way, but only converted into RDF and linked as they are.
The KG adheres to the 5th star level of the 5-star LD publishing principles [1]. In addition, the LDF platform provides an explicit schema and an online documentation26
The NEL of event descriptions to the DOs of people, military units, and places, is accomplished with
The person record linkage of death records results in 620 death records linked to some of the 5600 pre-existing person instances, while for the remaining 94 100 death records, new person instances are created.
The person record linkage of prisoner records results in 1255 PRs linked to some of the 99 700 pre-existing person instances, while creating 2945 new person instances in the Persons DO.
The precision of the person record linkage of both the death records and prisoner records was manually evaluated to be 1.00, based on randomly selecting 150 links from the total of 620 links for death records, and 200 links from the total of 1260 links for the prisoner records. The information on the person records and the person instances was compared, and all of the records were interpreted to be depicting the same actual people with high confidence.
KOKO is a collection of Finnish core ontologies, which are merged together:
YSA is a general thesaurus in Finnish, covering all fields of research and knowledge, containing common terms and geographical names for content description:
There are 3360 external links to the digitized Kansa Taisteli magazine service29
Linkage to other datasets of the global LOD Cloud31
The KG is mature enough to be relatively static, with only minor error corrections predicted to happen in the near future. New DOs can be added to the ontology infrastructure, without affecting the existing DOs, as the DOs are separated into distinct components, which are handled separately in the transformation pipeline.
The URIs of the Casualties MDS have been revised after initial release, stemming from the MDS originating from a time before the WarSampo infrastructure, and it had URIs which were not in the WarSampo namespace. In 2018, the MDS was revised to be fully integrated into WarSampo: the namespace was changed, the schema was revised, and the used source dataset was updated. The Casualties transformation process (step 2 in Fig. 3) was revised to be fully repeatable and to use person record linkage that is able to adapt to changes in the pre-existing Persons DO. Currently, the used WarSampo URIs can be considered stable.
The KG is versioned using semantic versioning 2.0.0,32
WarSampo KG major and minor version history
The Linked Data Finland platform, on which the KG is hosted, is actively maintained by the authors of this article and has been operational since 2014.
The WarSampo KG has been accessed and used by 690 000 end users through the WarSampo Portal, corresponding to more than
Based on the experiences of the National Archives of Finland, the main data provider for WarSampo, users of military history data portals can be divided into three groups: academic researchers, military history enthusiasts, and private citizens. The first group has the widest range of needs regarding the data, but they often have the best skills to handle and refine the data by themselves. The focus of academic research seems to be shifting from a macro level towards individual and social aspects of war [2,6]. In the future, end-user studies could be conducted to get a more complete understanding of the users, their motivations, and needs.
Wikidata has linked some Finnish person instances to WarSampo with a distinct WarSampo property, e.g., the commander-in-chief C. G. E. Mannerheim.35
Parts of the KG, especially the Places DO and historical maps have been reused in the Finnish historical place and map service Hipla36
Finally, the KG was used for enriching data in the external semantic web applications Norssi High School Alumni [20], and BiographySampo [21].
Another problem is data maintenance: data modeled with CRM is considerably difficult to edit directly, due to verbosity and high level of interlinking between resources. Our solution is to support maintenance of the source datasets, which can be repeatedly integrated into the KG using the data transformation pipeline.
The data transformation practices have evolved during the project, and only later datasets are integrated into the KG with repeatable processes. Also modeling conventions have improved, and there are slight variations in how information from different source datasets is modeled.
The transformation pipeline handles most change propagation scenarios, but in some rare cases the initial DOs need manual updates. For example, if the Places DO changes, the initial state of the Persons DO may need to adapt to the changes, as there are references to e.g., municipalities of birth.
In entity linking, disambiguating some entity types without much context information has been found difficult. For example, place names are usually unambiguous on the municipality level, but automatically disambiguating the names of villages, farms, and lakes can not be done reliably due to high amount of synonymy. Furthermore, place names are often used also as surnames, which is a source of confusion in NEL from free text.
The amount of open, structured, and digitized source datasets about the war is limited. In WarSampo, the focus is on the fallen soldiers, and not much is known about the soldiers who survived the war, except for the high ranking officers who can be considered public figures. In the future, plenty of new material will become available through digitization, raising privacy concerns regarding the people who might still be alive.
The WarSampo project has transformed a number of previously isolated source datasets into a harmonized KG. Besides the large number of links between entities, also whole new entities have been extracted from textual content, e.g., people from photograph descriptions, and military units from war diaries.
The WarSampo KG enables queries that were not possible before: for example fetching all WW2 data related to a specific place, or constructing the history of a single soldier based on corresponding military unit information. By publishing shared domain ontologies and data about WW2 for everybody to use in annotations, future interoperability problems can be prevented before they arise.
Footnotes
Acknowledgements
Our work has been funded by the Finnish Ministry of Education and Culture, the National Archives of Finland, the Association for Cherishing the Memory of the Dead of the War, the Memory Foundation for the Fallen, the Finnish Cultural Foundation, the Academy of Finland, and Teri-Säätiö.
Erkki Heino and Eetu Mäkelä have previously contributed to the data model and data transformation processes.
The authors wish to acknowledge CSC – IT Center for Science, Finland, for computational resources.