
Abstract
Ontology-Based Data Access (OBDA) has traditionally focused on providing a unified view of heterogeneous datasets (e.g., relational databases, CSV and JSON files), either by materializing integrated data into RDF or by performing on-the-fly querying via SPARQL query translation. In the specific case of tabular datasets represented as several CSV or Excel files, query translation approaches have been applied by considering each source as a single table that can be loaded into a relational database management system (RDBMS). Nevertheless, constraints over these tables are not represented (e.g., referential integrity among sources, datatypes, or data integrity); thus, neither consistency among attributes nor indexes over tables are enforced. As a consequence, efficiency of the SPARQL-to-SQL translation process may be affected, as well as the completeness of the answers produced during the evaluation of the generated SQL query. Our work is focused on applying implicit constraints on the OBDA query translation process over tabular data. We propose Morph-CSV, a framework for querying tabular data that exploits information from typical OBDA inputs (e.g., mappings, queries) to enforce constraints that can be used together with any SPARQL-to-SQL OBDA engine. Morph-CSV relies on both a constraint component and a set of constraint operators. For a given set of constraints, the operators are applied to each type of constraint with the aim of enhancing query completeness and performance. We evaluate Morph-CSV in several domains: e-commerce with the BSBM benchmark; transportation with the GTFS-Madrid benchmark; and biology with a use case extracted from the Bio2RDF project. We compare and report the performance of two SPARQL-to-SQL OBDA engines, without and with the incorporation of Morph-CSV. The observed results suggest that Morph-CSV is able to speed up the total query execution time by up to two orders of magnitude, while it is able to produce all the query answers.
Introduction
Guided by the Open Data principles, governments and private organizations are regularly publishing vast amounts of public data in open data portals. For example, almost a million datasets are available in the European Open Data Portal (EODP),1
Most commonly used formats and percentage over the total number of datasets to expose data in mature EU open data portals in October 2019. Each dataset may be shared in different formats
Albeit extensively utilized, tabular representations imposed various data management challenges to advanced users (e.g., developers, data scientists). The lack of a unified way to query tabular data, something available in other formats (e.g., RDB, JSON, XML), hinders the integration of sources, especially those having datatype inconsistencies. Moreover, data may not be normalized, and information about relationships or column names are not always descriptive or homogeneous. Hence, data consumers are usually forced to apply ad-hoc or manual data wrangling processes to consume data via open data portals.
Following Linked Data [4] and FAIR initiatives [53] ,2
Traditional virtual OBDA approaches, usually, rely on loading tabular data into SQL-based systems (e.g., MySQL, Apache Drill, Spark SQL, Presto) to perform query translation techniques. However, the correctness and optimization of these techniques are supported by the main assumption about the existence of constraints over the source data (i.e., a good physical design of the relational database instance). Their absence during a virtual OBDA process over tabular data directly impacts completeness and performance of these techniques. Completeness is affected because of heterogeneity issues in data sources (e.g., datatype CSV columns are simply treated as string-type SQL columns). Furthermore, performance is impacted because indexes are not created based on basic relational constraints, i.e., primary and foreign key constraints are not defined in the schema. Consequently, query translation optimization techniques that commonly exploit indexes (e.g., [41,43]) may not produce the expected results whenever the constraints have not been applied, or the indexes have not been created.
OBDA annotations such as the W3C recommendation to annotate tabular data, CSVW [49] and some extensions of standard mapping rules (e.g., RML+FnO [15]) are commonly used to describe constraints over an OBDA tabular dataset. For example, we can standardize a column indicating its format, define integrity constraints, or declare data types. The majority of OBDA query translation engines [22,41] do not include this information. Those engines that have partially included the constraints (e.g., Squerall [37] parses RML+FnO mapping rules) are not fully documented; i.e., there is no explanation of how these constraints are taken into account. The definition of a workflow that includes the exploitation of these tabular annotations during a virtual OBDA process will ensure correct and optimized SPARQL-to-SQL translations.
Definition of the concept of Virtual Tabular Dataset (VTD) composed by a tabular dataset and its corresponding OBDA annotations, as well as its alignment with the current definition and assumptions of the OBDA framework [54].
Morph-CSV, a framework that implements a constraint-based OBDA workflow for tabular datasets; it receives a VTD and a SPARQL query as inputs and outputs an OBDA instance. Morph-CSV performs the following steps: (i) generation of the constraints based on information on the VTD; (ii) selection of sources and attributes needed to answer the query; (iii) pre-processing of the selected sources applying some of the constraints; and (iv) physical implementation of the corresponding RDB instance and associated schema, ensuring effectiveness of the SPARQL-to-SQL translations and optimizations. Morph-CSV is engine agnostic, i.e., it can be embedded on top of any SPARQL-to-SQL engine.
Evaluation of Morph-CSV re-using in the backend two well-known open source SPARQL-to-SQL engines: Morph-RDB [41] and Ontop [7]; two benchmarks (BSBM [5] and GTFS-Madrid-Bench [9]), and a real-world testbed from the Bio2RDF project [3] are used in the study.
The rest of the paper is structured as follows: Section 2 motivates the problem of OBDA query translation over tabular data with an example in the transport domain. Section 3 describes the identified challenges for querying and integrating tabular data, and current proposals of OBDA annotations for tabular data that address these challenges. Section 4 presents Morph-CSV, an approach for enhancing OBDA query translation over tabular data through the application on the fly of a set of constraints. Section 5 reports the results of our empirical study together with a general discussion in Section 6. We present the related work in Section 7 and our conclusions and future work in Section 8.
Since May 2017, the publication of a new directive by the EU Commission on discoverability and access to public transport data across Europe7
Consider the GTFS feeds from the metro and buses of Madrid’s city; they have several stops and stations in common. Different transport authorities create them, and the names of their stops are defined in various manners. Although these types of entities can be represented, the unique identification and relationships among them cannot be explicitly expressed. Figure 1 depicts a portion of these two GTFS feeds. As it is usual in open datasets, stop names do not follow a standard structure (e.g., “Colonia Jardin” in bus_stops.csv and “Colonia_jardin” in metro_stops.csv). A similar issue is present in closing dates, where there are multi-valued cells, and their format is not the standard one (e.g., yyyy-MM-dd). Suppose a user is interested in collecting information about bus and metro stops with the same name and information related to their closing dates during holidays; Fig. 1 presents the SPARQL query describing this request. Following the approach commonly employed by typical OBDA engines, the two files would be loaded into an SQL-system and treated as single tables. The obtained result set only contains one answer where the stop names in the two data sources are identical (“Noviciado”). However, the expected result set should include more answers by joining among the bus and metro’s stop names through the normalization of multi-valued date columns.

Motivating example. SPARQL query evaluation over two tabular data files in the transport domain through a common OBDA approach. It loads the files as single tables in an SQL-based system and uses the mapping rules for query translation. The number of results differs with respect to the expected results due to the heterogeneity of the raw data. Additionally, query performance may be affected by the join condition between the two tables, the absence of indexes and the loading of columns that are not needed to answer the input query (wheelchair).
Query’s performance may also be affected whenever a join condition is executed between the stop names of both files. Furthermore, the absence of possible indexes in these joining columns makes ineffective the typical optimizations applied in a SPARQL-to-SQL process. Nonetheless, to effectively exploit the indexes to scale-up the execution of the translated queries, the satisfaction of the unique and foreign integrity constraints should be ensured. The manual and ad-hoc definition of the relational schema representing these tables and the corresponding integrity constraints will overcome this problem. Nevertheless, this task is time-consuming, and reproducibility is not ensured. In this paper, we propose Morph-CSV, a constraint-based OBDA framework capable of exploiting standard tabular data annotations (e.g., RML or CSVW) to generate the required constraints ensure the integrity of the tabular schema in terms of unique identifiers and foreign keys. Moreover, Morph-CSV applies metadata annotation from CSVW to generate domain-specific constraints. As a result, Morph-CSV enhances query completeness and performance of SPARQL-to-SQL techniques, in compliance with OBDA assumptions.
This section describes a set of challenges demanded be addressed whenever tabular data is queried in a virtual OBDA framework. Further, we describe relevant OBDA proposals for annotating tabular datasets and their alignment with the identified challenges.
Querying challenges under virtual OBDA for tabular data
There are specific challenges on querying tabular datasets using an OBDA approach that have not been tackled by existing techniques. We will describe those challenges and explain how they may have a negative effect in terms of completeness and performance of query-translation approaches:
Although some of the aforementioned challenges are not only specific to tabular datasets and are proposed in several data integration approaches [19,23,25] there are two main reasons why it is important to address these problems in this context: first, as we reflect in Section 1, the number of tabular datasets available in the web of data is enormous and still growing and these challenges were not taken into account in previous OBDA proposals; second, although there are declarative proposals to handle these issues in the state of the art like CSV on the Web [49] for metadata annotations, or mapping languages that include transformation functions to deal with heterogeneity (e.g., RML+FnO [15] or R2RML-F [17]), there is not yet a proposal that exploits the information from these inputs including their application in the form of constraints into a common OBDA workflow.
Properties of CSVW and RML+FnO that can be used to address the challenges of dealing with tabular data in a virtual OBDA approach
Properties of CSVW and RML+FnO that can be used to address the challenges of dealing with tabular data in a virtual OBDA approach
R2RML [13] is a W3C Recommendation for describing transformation rules from RDB to RDF and a widely used mapping language in virtual OBDA approaches. RML [18] extends R2RML; it provides support to a variety of data formats, e.g., XML, CSV, and JSON. Both languages provide basic transformation functions to concatenate strings, which are especially useful for generating URIs from columns/fields of the dataset. Recently, RML has been integrated with the Function Ontology (FnO) [14] to support other types of transformations. Additionally, for tabular data, CSVW metadata [49] is a W3C Recommendation to describe tabular datasets. Although there are other proposals in the state of the art to deal with some of the aforementioned challenges [17,33], Morph-CSV relies on these two proposals because they cover the identified challenges. Additionally, this election is supported by the fact that CSVW is a recommendation from the W3C and RML+FnO (besides being a extended version of a W3C recommendation) has been previously applied in other projects [15,37] and is widely used by several materialization engines, e.g., RMLMapper,9
In Table 2, we summarize the relevant properties from RML+FnO and CSVW that can be used to address the challenges identified in the previous section. Additionally, we provide a detailed description of these properties:
The formal framework presented in [54] defines an OBDA specification as a tuple
OBDA assumptions
Analyzing the definition of OBDA in [54] and its extension for NoSQL databases defined in [6] we identified a set of assumptions made over the framework and their impact when the dataset is tabular:
There is a native query language S typically includes a set of domain and integrity constraints. In the case of querying a tabular dataset D is an RDB instance or a NoSQL database instance, that includes an RDB wrapper able to provide a relational view over S and D. In the context of a tabular dataset
From a virtual tabular dataset to an OBDA instance
Based on the previous OBDA assumptions, we define the concepts and functions to address the problem of querying a tabular dataset in OBDA. A virtual tabular dataset is defined as a tuple A relation is defined as the subset of the Cartesian product of the domains of the attributes. The set of the attributes of each tabular relation in
The virtual tabular dataset of the GTFS of Madrid’s metro system can be defined as
Virtual OBDA for tabular data approaches. The baseline approach creates the schema and relational database instance extracting file and columns names from the tabular dataset. The proposed workflow exploits the information from the mapping rules and metadata to extracted a set of constraints and applying them over the tabular data to generate the schema and the relational database instance.
Given a
The process of applying the function
Constraints are conjunctive rules specified for tabular data that restrict the valid data in one or more tables. C is a set of constraints, where each constraint c is a logical statement that expresses the condition that needs to be satisfied by the data in order to be valid. Each constraint is applied through a function.
CSVW allows expressing a primary key constraint for a table. The function
Given an OBDA instance
Based on the preliminaries and assumptions on the OBDA framework, we now define the problem that we address in this paper and Morph-CSV, our proposed solution.

The Morph-CSV framework. Morph-CSV extends the starting phase of a typical OBDA system including a set of steps for dealing with the identified tabular data querying challenges. The framework first, extracts the constraints from mappings and tabular metadata and then, implements them in a set of operators that are run before executing the query translation and query execution phases, which can be delegated to any SPARQL-to-SQL engine. The mapping rules are translated accordingly to the modified tabular dataset to allow its access by the underlying OBDA engine.
The number of results obtained in the evaluation of the SPARQL query Q over the function The total execution time of evaluating a SPARQL query Q over
We show the workflow of Morph-CSV in Fig. 3 with the inputs and outputs of each step.

Selection of mapping rules. Based on the SPARQL query relevant rules are selected (in bold), the rest are discarded. These rules are serialized in YARRML [26].
We describe in detail the steps proposed in Morph-CSV together with an example extracted from the benchmark for virtual knowledge graph access, Madrid-GTFS-Bench, using the query shown in Fig. 4(a), the GTFS feed from the Madrid metro as source data, and the corresponding RML+FnO mapping rules and CSVW annotations.14
Resources at:
The first step performed by Morph-CSV is the extraction of the constraints that are applied to improve query execution and completeness. Morph-CSV benefits from having declarative and standard approaches to generalize this step: CSVW [49] for the metadata; and RML+FnO [15] for mapping rules and specific transformation functions. Thus, maintainability, understandability and readability of this process are improved in comparison with ad-hoc pre-processing approaches.
Most of the constraints such as PK-FK relations, datatypes or NULL values are explicitly declared in the metadata of the sources. However, there are a set of implicit constraints such as the conditions for the normalization of sources and the creation of indexes, that require complex rules to extract them and that are explained in detail in the corresponding steps. The summary of the constraints, associated functions, and properties used from OBDA annotations to extract them, are shown in Table 3.
Summary of constraints, corresponding functions and OBDA annotations applied by Morph-CSV
Summary of constraints, corresponding functions and OBDA annotations applied by Morph-CSV
The second step is to select the relevant sources to answer the input query. The baseline approach delegates this step to the RDBMS: it loads all the sources of the dataset in the RDB instance because it does not have information about which sources are going to be queried. This has a negative impact in the total execution time of a query. Taking the input mapping rules, Morph-CSV performs query unfolding, and pushes down source selection by executing the function
As usual in these approaches, we assume bounded predicates in the triple patterns.
Second, Morph-CSV runs

Source selection. Based on the selection of the rules, only the route_id and trip_id columns are selected, discarding the rest of the fields.
There are two functions for performing data normalization. The first one is the treatment of multi-values in a column. In this case, Morph-CSV performs the function
The second function is the treatment of multiple entities in the same source. Morph-CSV takes the mapping rules and executes the function

Normalization. 3NF normalization step over the routes.csv file generating other file with the data for
In this step, Morph-CSV addresses the challenge of Heterogeneity and executes three different functions:

Data preparation of route-types.csv file.
The final step before translating and executing the query is the creation of an SQL schema applying the rest of the identified constraints, and loading the selected tabular data sources. Besides the typical integrity constraints that can be extracted from CSVW annotations (PK/FK), Morph-CSV implements a rule for creating indexes in the RDB instance in order to optimize the execution of query joins. In tabular datasets, it is common that the join conditions defined in the mapping rules are based on columns that are not part of PK-FK relations; thus, they are not indexed and OBDA optimizations do not have the desired effect. To address this problem, Morph-CSV gets the
Generated schema. The schema generated by Morph-CSV extracting domain and integrity constraints from the annotations and based on the identified sources selected from the input query.
There are two main points that make the contributions of Morph-CSV relevant: (i) it incorporates the steps to the standard OBDA workflow without modifying the rest of the steps, hence, it can also benefit from optimizations in other steps of the workflow like query rewriting (reasoning) [39] or query translation (SPARQL-to-SQL) [41], and (ii) the reliance of the approach on declarative and standard annotations for OBDA allows the generalization of the proposed steps, usually solved in an ad-hoc manner, not only automatizing the process but also improving its maintainability, understandability and readability.
This section reports on the results of the empirical evaluation conducted to test the effect of respecting constraints, on the fly, during OBDA query translation over tabular data. The hypotheses we want to validate in our work are:
(H1) The application of a set of domain and integrity constraints over tabular data sources to create an RDB instance ensures the effectiveness of SPARQL-to-SQL optimizations proposed in the state of the art. (H2) Extending a common OBDA workflow with a set of additional steps to deal with the challenges for querying tabular data, does not impact negatively on the total query execution time. (H3) The exploitation of declarative and standard annotations in the process of querying tabular data in an OBDA environment, guarantees the independence of the solution and its application over different domains.
Aligned with the defined hypothesis, our aim is to answer the following research questions:
Engines The baselines of our study are two open source SPARQL-to-SQL OBDA engines: Ontop16
We modified the default configuration of Ontop extending the maximum used memory from 512Mg to 8Gb.
We name the combined engines as follows: (a) Morph-CSV: Morph-CSV+Morph-RDB, and Morph-CSV+Ontop; (b) Morph-CSV−: Morph-CSV−+Morph-RDB, and Morph-CSV−+Ontop.
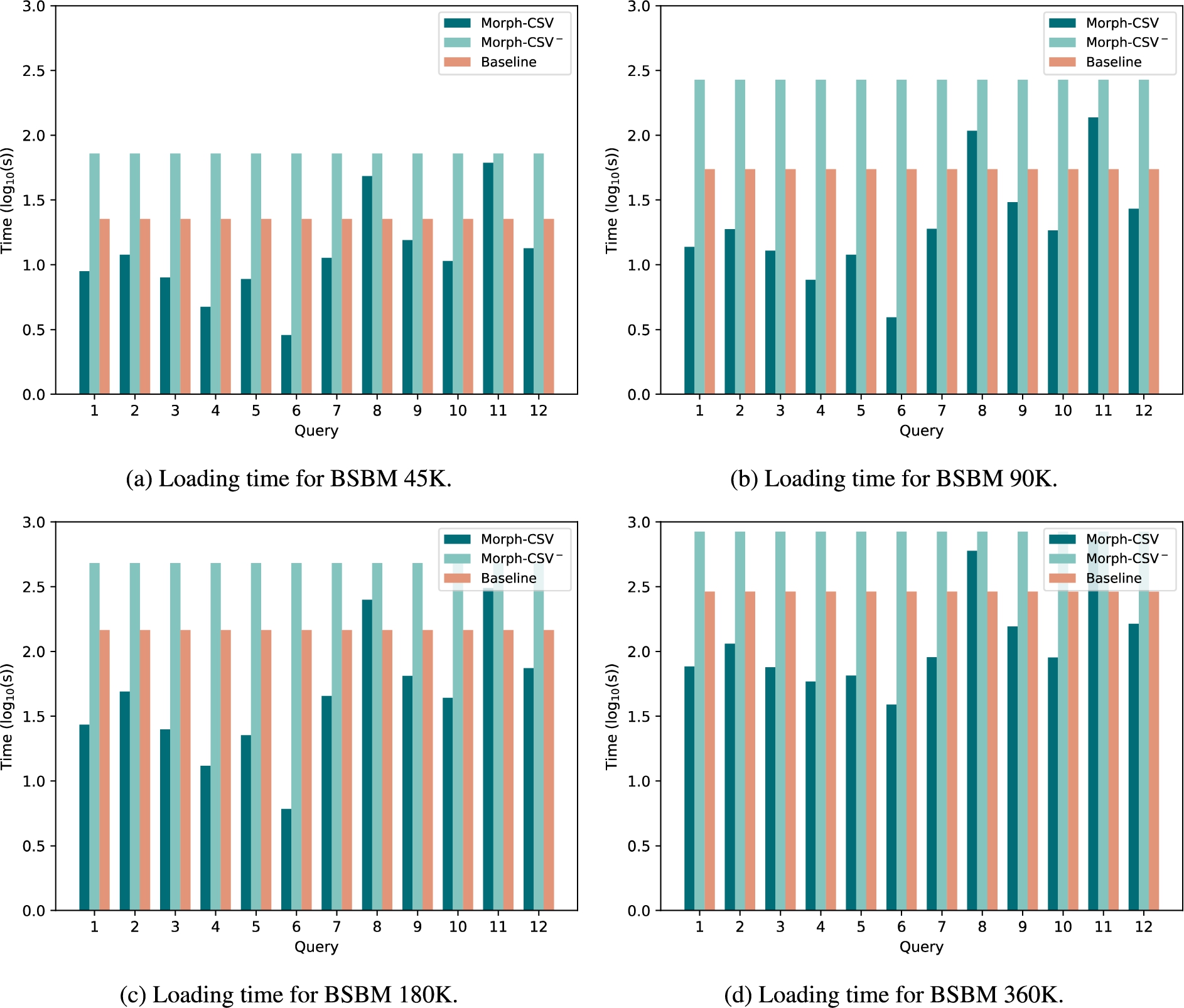
Loading time of tabular datasets in BSBM. Loading time in seconds of the tabular datasets from the BSBM benchmark with number of products 45K, 90K, 180K and 360K. The baseline approach (red columns) and Morph-CSV− (light green) are constant for each dataset and query, while Morph-CSV (dark green) depends on the query and number of constraints to be applied over the selected sources.
Metrics We measure the loading time of each query and the total query execution time (including the steps proposed by Morph-CSV or baseline when appropriate), and the number of answers obtained (see Appendix C). Additionally, we detail the times of each proposed step of our workflow in the execution of each query using Morph-CSV in both configurations (see Appendix D) following the recommendations proposed in the GTFS-Madrid-Bench [9]. Each query was executed 5 times with a timeout of 1 hour in cold mode, that means that the corresponding database is generated each time a query is going to be evaluated in order to ensure up to date number of answers. Regarding the completeness of the queries, both BSBM benchmark and GTFS-Madrid-Bench provide an RDF materialized version of the input sources that has been loaded in a triplestore (Virtuoso in the case) and used as gold standard. To analyze the completeness of each query, we compare the cardinality of the result set of each configuration against the gold standard assuming its correctness. In the case of the Bio2RDF use case, we cannot compare our results with any gold standard as the last dump version of the project [20] is not comparable with the current status of the input sources, as we declare in one of our previous works [30]. The experiments were run in an Intel(R) Xeon(R) equipped with a CPU E5-2603 v3 @ 1.60GHz 20 cores, 64GB memory and with the O.S. Ubuntu 16.04LTS.
The Berlin SPARQL Benchmark [5] is one the most popular benchmarks in the Semantic Web field that not only tests the performance of RDF triple stores, but also tests approaches that perform SPARQL-to-SQL query translations providing an RDB instance. It is the chosen benchmark to test the capabilities of many state-of-the-art OBDA engines [7,37,41].
Datasets, annotations and queries In order to test our proposal we decided to adapt BSBM, extracting the tabular data sources in CSV format from the SQL generated instances. Additionally, we create the corresponding mapping rules in RML and the metadata following the CSVW specification. We measure the loading time of the two proposals (baseline and Morph-CSV) for each query in the benchmark. Since the focus of Morph-CSV is not the improvement of the support of SPARQL features in the query translation process, we only select the queries of the benchmark that include the supported features by each engine. This means that Morph-RDB will be evaluated over the queries Q1, Q2, Q3, Q4, Q5, Q6, Q7, Q8, Q9, Q10 and Q12 and Ontop will be evaluated over Q1, Q3, Q4, Q5 and Q10, both of them using the corresponding R2RML mapping document. For the baseline approach we manually create the RDB schema without constraints.
BSBM results
Loading time The results of the load time for each query and dataset size are shown in Fig. 9. The main difference between baseline and Morph-CSV− in comparison with Morph-CSV is that while the loading time for the first two methods is constant for each size, Morph-CSV loading time depends on several input parameters such as the query and the number and type of constraints. In the case of Morph-CSV, it could be understandable that the application of a set of constraints over the raw data in order to improve query performance and completeness, would have a negative impact in the loading time. This happens in queries Q8 and Q11, where the number of sources and the application of the constraints (mainly integrity constraints), impact negatively on the loading time of the data in the RDB instance in comparison with the baseline approach. However, in the rest of the queries, the Morph-CSV steps focus on the selection of constraints, sources and columns, and on exploiting the information in query and mapping rules, improving the loading time for each query in comparison with the baseline loading time. This means that, although the engine is including a set of additional steps during the starting phase of an OBDA system, the application of these steps only over the data that is required to answer the query, has a positive impact in the total query execution time. Additionally, we can observe that Morph-CSV is able to process, apply the different constraints, and generate the corresponding instance of the RDB for any query. In the case of Morph-CSV−, applying all the constraints defined for the whole dataset each time a query has to be answered, has a negative impact in the loading time, obtaining the worst results in the loading phase.

Query execution time of tabular datasets in BSBM with Morph-RDB. Execution time in seconds of the tabular datasets from the BSBM benchmark with scale values 45K, 90K, 180K and 360K. The baseline Morph-RDB approach (red columns) is compared with the combination of Morph-CSV (dark green) and Morph-CSV− (light green) together with Morph-RDB.
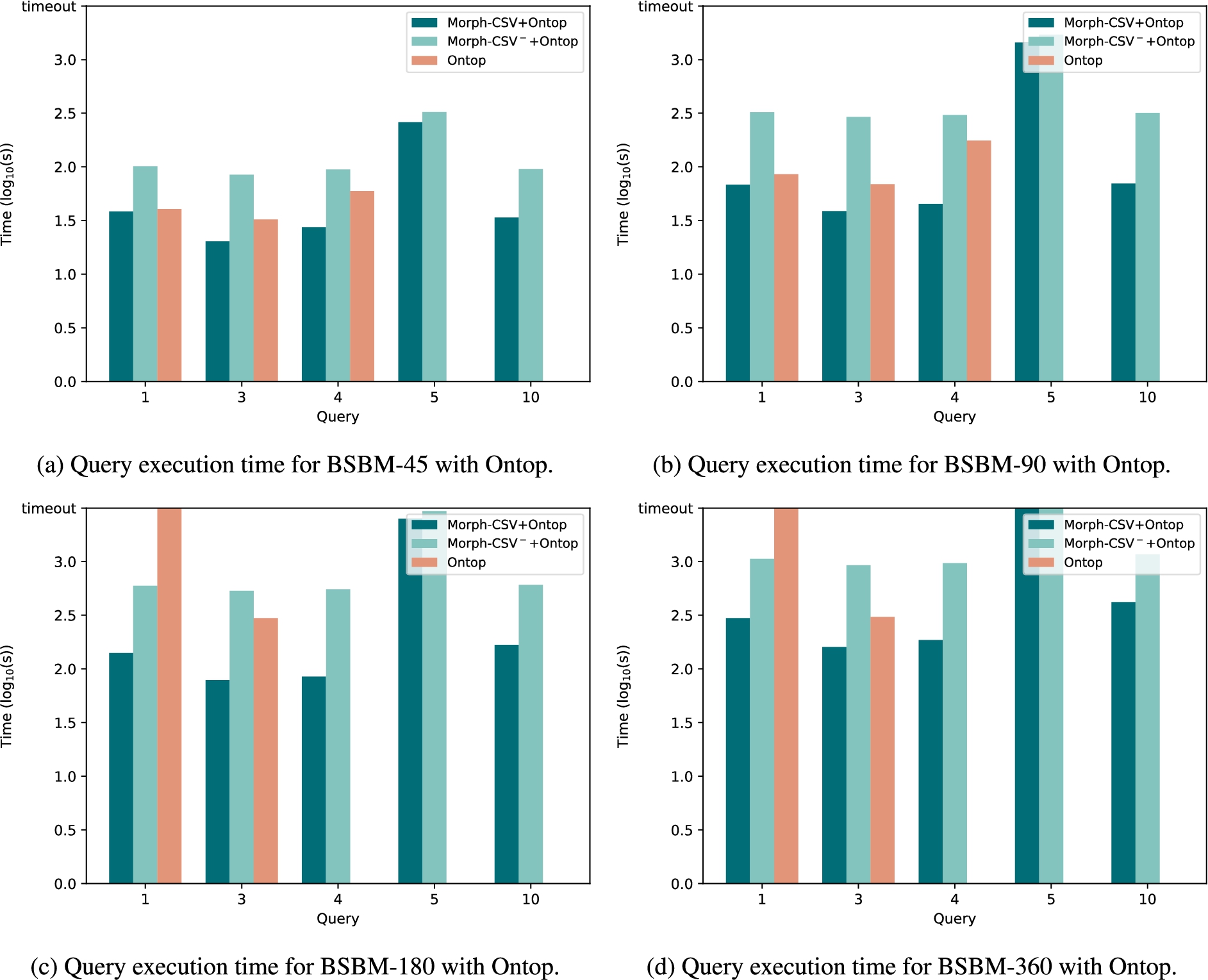
Query execution time of tabular datasets in BSBM with Ontop. Execution time in seconds of the tabular datasets from the BSBM benchmark with scale values 45K, 90K, 180K and 360K. The baseline Ontop approach (red columns) is compared with the combination of Morph-CSV (dark green) and Morph-CSV− (light green) together with Ontop.
Evaluation time with Morph-RDB The query execution time using Morph-RDB as the back-end OBDA engine is shown in Fig. 10. The first remarkable observation can be seen in query Q5. Although this query contains features supported by Morph-RDB, the engine reports an error when evaluating the query over the database generated by the baseline approach, because it is not able to evaluate the arithmetic expressions in the FILTER clauses. On the contrary, the datatype of each column in the database generated by Morph-CSV (and also Morph-CSV−) is properly defined, making it possible for Morph-RDB to evaluate the query without any problem and obtaining the expected results. Another remarkable difference is in query Q2, which contains a large number of joins, Morph-RDB reports a timeout error for 180K and 360K with the database generated by the baseline approach. However, it is still able to evaluate this query in reasonable time over the databases generated by Morph-CSV and Morph-CSV−. The effect of the application of integrity constraints in the generation of the RDB instance can also be seen in most of the queries (i.e., Q1, Q2, Q3, Q6, Q9, Q10) reducing considerably the query execution time in the database generated by Morph-CSV in comparison with the baseline approach. There are cases (i.e., Q4, Q7, Q12) where the amount of data to retrieve is large, minimizing the effect of the optimizations. Finally, there are cases where optimizations over the indexes cannot be applied (e.g. querying all the properties of a class). We observe this behavior in Q8, in which the difference between the Morph-CSV+Morph-RDB and Morph-RDB approaches is minimal and this behavior is consistent in all size of datasets. In general, Morph-CSV− obtains worse results than Morph-CSV+Morph-RDB and Morph-RDB alone. The results are understandable as this configuration has to invest time in preparing the full RDB instance for each query, executing many unnecessary steps in comparison with Morph-CSV. However, in some cases the evaluation time is better than the one obtained over the Morph-RDB configuration, where clearly the creation of indexes and integrity constraints play a key role in the performance of the query execution (see Q2).
Evaluation time with Ontop The query execution time using Ontop as the back-end OBDA engine is shown in Fig. 11. Like Morph-RDB, Ontop needs the Morph-CSV generated databases to be able to evaluate Q5 due to the arithmetic expressions of its FILTER operators. Additionally, it also fails in Q10 because it cannot process a FILTER with a date value. In the rest of the queries (Q1, Q3, Q4) we can see that the query evaluation time in Ontop with Morph-CSV is lower than the query evaluation time over the baseline database. Note that in larger databases (180K and 360K), Q1 and Q4 can only be evaluated over the databases generated by Morph-CSV. The Morph-CSV− configuration is also able to answer the queries just as the Morph-CSV standard configuration, but in comparison with this configuration, the performance is being affected due the inclusion of the additional and unnecessary steps.
As mentioned in the Ontop repository page,23
Query completeness In Table 7 we show the query completeness obtained with the BSBM benchmark. It is important to remark that our intention to use this benchmark is for testing performance capabilities of our proposals, the input sources are extracted from the BSBM relational model, which is a well formed and normalized RDB instance. However, there are still some cases where we identify the need of applying constraints over the relational database, which are Q5 in the evaluation over Morph-RDB and Q5 and Q10 over Ontop. In these cases, the baseline configurations of the engines are not able to answer those queries, not because they do not support a feature of the SPARQL query or cannot do it on time, but because they cannot perform the correct comparison among different datatypes in the relational database instance. We demonstrate with the application of Morph-CSV that queries can be answered and the correct number of results can be obtained. Additionally, thanks to the application of indexes and integrity constraints there are some queries such as Q1 and Q2 that can be answered by Morph-CSV configuration but not by the baseline, which means that thanks to these steps we are ensuring the effectiveness of the optimizations provided by Ontop and Morph-RDB in the SPARQL-to-SQL translation process.

Loading time of tabular datasets in GTFS. Loading time in seconds of the tabular datasets from the Madrid-GTFS-Bench with scale values 1, 10, 100 and 1000. The baseline approach (red columns) and Morph-CSV− (light green) are constant for each dataset and query, while Morph-CSV (dark green) depends on the query and number of constraints to be applied over the selected sources.

Query execution time of tabular datasets in GTFS with Morph-RDB. Execution time in seconds of the tabular datasets from the Madrid-GTFS-Bench with scale values 1, 10, 100 and 1000. The baseline Morph-RDB approach (red columns) is compared with the combination of Morph-CSV (dark green) and Morph-CSV− (light green) together with Morph-RDB.
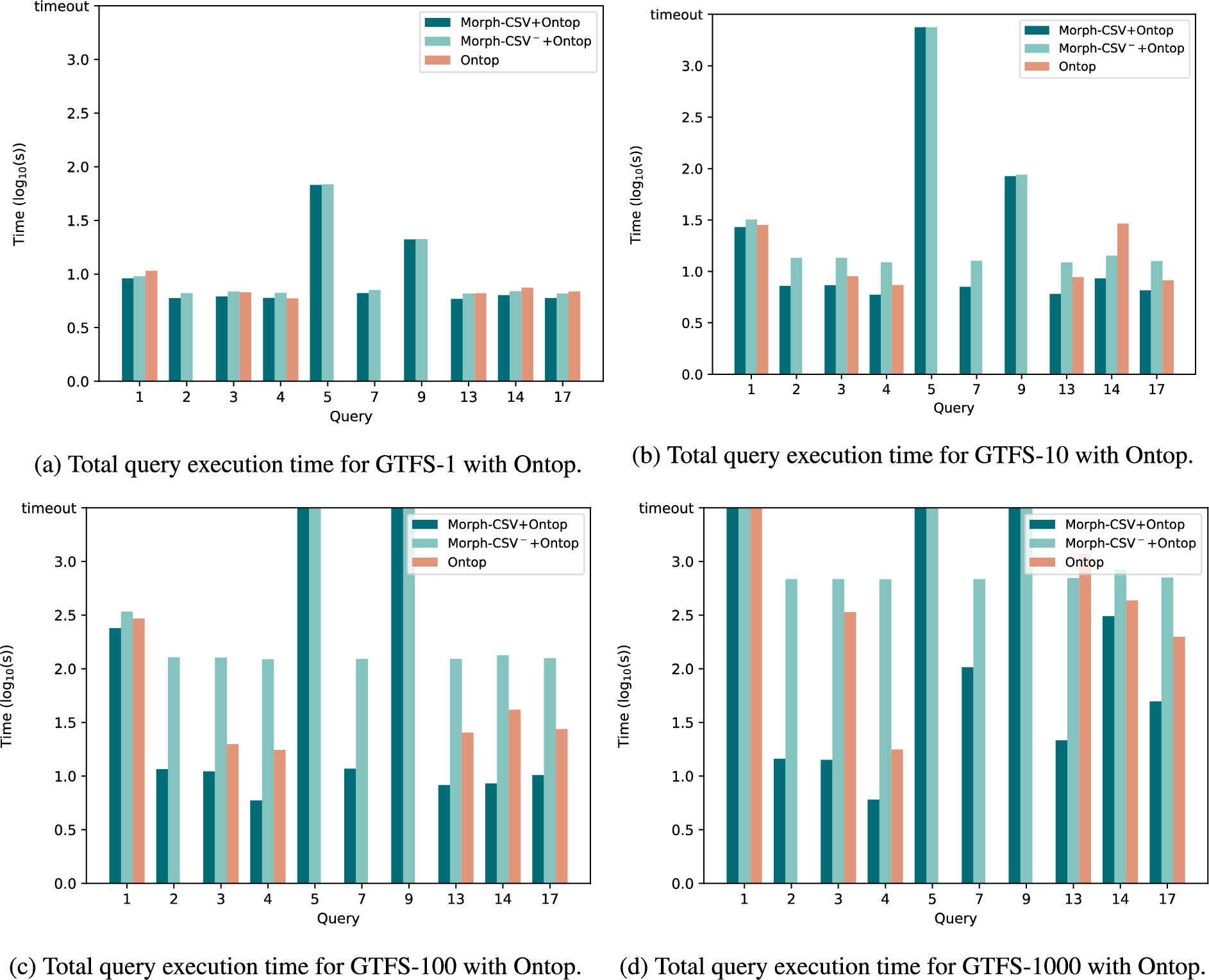
Query execution time of tabular datasets in GTFS with Ontop. Execution time in seconds of the tabular datasets from the Madrid-GTFS-Bench with scale values 1, 10, 100 and 1000. The baseline Ontop approach (red columns) is compared with the combination of Morph-CSV (dark green) and Morph-CSV− (light green) together with Ontop.
The GTFS-Madrid Benchmark [9] consists of an ontology, an initial dataset of the metro system of Madrid following the GTFS model, a set of mappings in several specifications, a set of queries according to the ontology that cover relevant features of the SPARQL query language, and a data scaler based on a state of the art proposal [34].
Datasets, annotations and queries We select the tabular sources of this benchmark (i.e., the CSV files) and we scale up the original data in several instances (scale factors 10, 100 and 1000). Each generated dataset is denoted as GTFS-S where S is the scale factor. The resources of the benchmark already include the necessary mapping rules and tabular metadata. Like our previous evaluation with BSBM benchmark, we only select the queries with features that are supported by each engine: Morph-RDB will be evaluated using queries Q1, Q2, Q4, Q6, Q7, Q9, Q12, Q13, Q14, Q17 and Ontop will be evaluated using queries Q1, Q2, Q3, Q4, Q5, Q7, Q9, Q13, Q14, Q17. The description and features of each query are also available online.24
Loading time The loading time of the GTFS-Madrid-Bench queries is shown in Fig. 12. For GTFS-1 the baseline approach clearly has better performance than Morph-CSV. However, when the size of the datasets increases, the positive effects of applying constraints become more apparent. For most of the queries, the loading time needed by Morph-CSV is lower in comparison to the loading time in the baseline approach. Additionally, similarly to BSBM, there are a set of queries where the application of integrity constraints has a negative impact on the loading time (queries Q1 and Q9). The impact of the application of all of the constraints for answering each query, presented by the configuration Morph-CSV−, clearly impacts over the performance in the loading time.
Evaluation time with Morph-RDB The query execution time with Morph-RDB as the back-end OBDA engine is shown in Fig. 13. Analyzing the results, we generally observe that the incorporation of Morph-CSV in the workflow of OBDA enhances query performance. With respect to the results of each query, we can observe that on the one hand the behavior of the engine over simple queries (Q1, Q2, Q7, Q12 and Q17) is similar. This is understandable as the selected data sources needed to answer the query do not include the application of several constraints (e.g. there are no joins in the query). On the other hand, in the case of complex queries such as Q4, Q6, Q9, Q13 and Q14, where several tabular sources are needed to answer the queries, the application of constraints has a better impact in comparison to the baseline approach. Similar behavior is shown over Morph-CSV−, where the complexity of the GTFS data model, with many sources, columns and relations among them, has a clear impact on the total execution time of each query, obtaining worse performance than the baseline in most of the cases. However, for example, in the case of query Q9, Morph-RDB is not able to evaluate the query over the 10th scale database generated by the baseline approach, while in the case of the database generated by Morph-CSV and Morph-CSV−, the query can be answered in reasonable time. In general, due the complexity of GTFS model, we can observe that for small datasets (GTFS-1), the cost of applying the proposed steps of Morph-CSV impacts total execution time. However, when the size of the dataset increases, the baseline approach is impacted due to the fact that it has to load all of the input data sources in the RDB before executing the query, low performance is reported for GTFS-100 and GTFS-1000, including timeout in some queries of the latter. Thanks to the application of the constraints and to the source selection step, for Morph-CSV together with Morph-RDB, the return of the results of the queries has a high performance most of the time. In the cases where Morph-CSV reports a timeout (e.g., Q1 in GTFS-1000); it is because the extremely high number of obtained results cannot be handle by Morph-RDB.
Evaluation time with Ontop The experimental evaluation of the query execution in Ontop as the back-end OBDA engine is shown in Fig. 14. This engine is more strict with datatypes in the RDB in comparison with Morph-RDB, and it is why Q2, Q5, Q7 and Q9 produce a failure in the execution over the databases generated by the baseline approach. All these queries have a FILTER clause on a specific datatype (e.g., date, integer, etc) and Ontop proceeds to check the domain constraints before executing the queries. Morph-CSV solves this problem by exploiting the annotations from the metadata and defines the correct datatypes of each column before evaluating the query. For the queries that can be answered by both approaches (Q1, Q3, Q4, Q13, Q14, Q17), the absence of integrity constraints has a negative impact in Ontop, resulting in lower execution time over the databases generated by Morph-CSV. However, similar to the evaluation over Morph-RDB, the complexity of the GTFS data model with a larque quantity of domain and integrity constraints to be applied over the whole dataset, makes that the behavior observed over Morph-CSV− is being impacted, hence, obtaining worse results that Morph-CSV configuration and the baseline in most of the cases. Finally, in the case where Ontop is not able to evaluate the query under the defined threshold, we report it as a timeout.
Query completeness In the same manner as BSBM benchmark, the focus of the GTFS-Madrid-Bench is on testing the performance and scalability issues of virtual OBDA and OBDI engines. The input dataset is also well formed and normalized. The completeness results of the evaluation are shown in Table 5, where as we describe before, Morph-RDB has a mechanism to infer the datatypes of the database using the rr:dataType annotation from R2RML, which allows the engine to answer the queries of this benchmark without the need of applying datatype constraints over the RDB instance. However, Ontop does not include such a mechanism and it needs the declaration of the correct datatypes over the RDB instance, which has a negative impact in the execution of many queries of the benchmark, that cannot be answered using the baseline database but they retrieve the correct results including Morph-CSV (or Morph-CSV−) in the pipeline.
Use case: The Bio2RDF project
Bio2RDF is one of the most popular projects that integrates and publishes biomedical datasets as Linked Data [3]. Its community has actively contributed to the generation of those datasets using ad-hoc programming scripts, such as PHP. In our previous work [30] we proposed an alternative way of generating the datasets using a set of declarative mapping rules to improve the maintainability, readability and understanding of the procedure. In comparison with the other benchmarks where the focus of the evaluation was the improvement of the query evaluation time, this real use case contains multiple heterogeneity challenges that, for example, enforce the application of ad-hoc transformation functions (i.e., mappings in the form of RML+FnO). Thus, with this use case we want to demonstrate the benefits of exploiting declarative annotations (metadata and mappings) over the raw data in order to improve query completeness and the need of incorporating the proposed steps for executing queries over real world data sources.
Dataset, annotations, and queries Tabular datasets in CSV or Excel formats cover over 35% of the total datasets in the Bio2RDF project [30]. In order to test the capabilities of Morph-CSV, we select a subset of the tabular datasets guaranteeing that they cover all of the identified challenges. Additionally, as far as we are aware, there is no standard benchmark over the Bio2RDF project; we also propose a set of SPARQL queries in order to exploit the selected data. Their main features are shown in Appendix B).

Query execution time of tabular datasets in Bio2RDF with Morph-RDB. Execution time in seconds of the tabular datasets from Bio2RDF of Morph-CSV and Morph-CSV− using Morph-RDB as back-end engine. The baseline is not reported as the loading over the RDB instance reports an error.
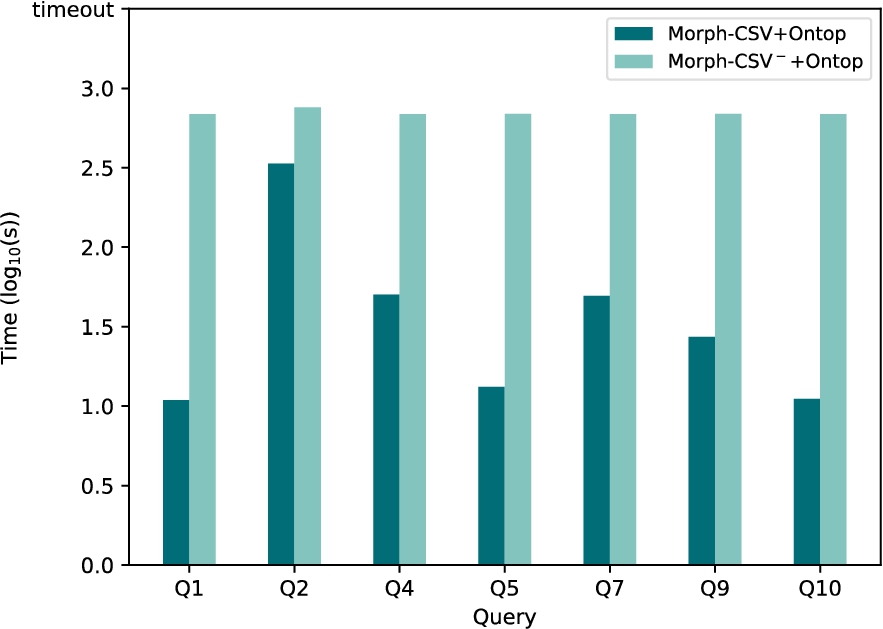
Query execution time of tabular datasets in Bio2RDF with Ontop. Execution time in seconds of the tabular datasets from Bio2RDF of Morph-CSV and Morph-CSV− using Ontop as back-end engine. The baseline is not reported as the loading over the RDB instance reports an error.
The results obtained for query evaluation in Bio2RDF are shown in Fig. 15 with Morph-RDB as back-end engine and in Fig. 16 with Ontop. The detailed results obtained by Morph-CSV and Morph-CSV− are shown in Table 10 and the completeness in Table 6. Analyzing the obtained results, we can observe that there are no results for the baseline approach, this means it was not possible to create an RDB schema and load the input data manually. The main reasons are the heterogeneity problems of a real use case that do not exist in the previous evaluations. GTFS and BSBM have well formed and standard source data models. Problems such as the absence of column names, multiple formats of same datatype in different files (numbers, dates) and the use of delimiters inside the column data, make it impossible to generate the baseline approach without a manual and ad-hoc pre-processing step. However, exploiting declarative annotations, Morph-CSV is able to apply the proposed workflow to this dataset, and successfully answer the proposed queries with both back-end OBDA engines. Similar to the previous benchmarks, loading the complete dataset for answering the input query (Morph-CSV− configuration) has an negative impact on the total execution time. We can observe that for the proposed queries, most of the total evaluation time of each query is spent in the loading process, as the total execution time in Morph-CSV− is pretty similar for all the queries. Contrary, query execution is benefited by this previous step obtaining the results in reasonable time for all of the queries.
Discussion of experimental results
We have run an experimental evaluation to analyze what are the effects on the use of declarative annotations to extract and apply constraints to enhance virtual OBDA approaches. We have tested our approach over three different cases: (i) a well known benchmark (BSBM) from the e-commerce domain; (ii) a benchmark focused on a virtual OBDA approach for the transport domain; and (iii) a real use case from the biological domain. We describe the main conclusions and findings based on the results obtained:
Related work
In this section, we first refer to previous works in data integration systems that precede the OBDA approach. Then, we refer to the general techniques used in systems that handle raw data. Next, we describe current Ontology Based Data Integration (OBDI) systems that handle tabular data. Finally, we describe existing tabular annotation languages and the use of transformation functions in mappings.
The most relevant concept that predates the OBDA data integration approach is that of mediator [52], defined in the early 90’s by Wiederhold. In the proposed architecture for information systems, mediators form a middle layer that makes user applications independent of the data resources. The idea is to transform heterogeneous data sources into a common data model, which can then be processed and integrated. Classical examples of systems that implemented the original mediator architecture were TSIMMIS [10], Information Manifold [42], and GARLIC [45]. The problem of inconsistent formats is not new, and in general mediators may convert attributes of several sources into a common format. The TSIMMIS [10] architecture includes a Constraints Manager component which handles integrity constraints across different sources. It supports the definition of the interfaces that a source supports for the constraint (e.g., a trigger), the specification of the desired constraint, and the specification of the strategy for enforcing the constraint or for detecting violations. Information Manifold [42] is an integration system for heterogeneous sources on the Web. It uses source content and capabilities descriptions in order to prune the space of sources that are accessed to answer a query. Garlic [45] is a system that provides an integrated view over legacy data sources. Each source or repository has its own data model, schema, programming interface, and query capability. Each Garlic object has an interface and may have several implementations, corresponding to different data sources. The system uses these implementations to optimize and execute a query. Both these systems neither handle domain constraints nor constraints across sources.
The work presented in [50] provides a toolkit for the generation of wrappers for web-accessible heterogeneous sources (may be represented as HTML tables) through the description of their capabilities. It provides an specification language to define the capability for each source, and generates a wrapper according to this specification. It also provides a graphical interface for specifying domains of input attributes and built-in operators to manipulate the data that is extracted. Similarly to this work, the Morph-CSV framework takes into account the specification of domain constraints and transformation functions, but using established standards for tabular annotations and mapping function definitions.
Throughout the years these ideas have evolved from the use of description logics [8] to the use of ontologies as a common model for data access [7], what is called Ontology-Based Data Access. Most of the works proposed under this framework are focused on providing access to relational databases [7,41,46] and optimizations on the SPARQL-to-SQL translation process. In this context, the term constraint has been used in [27], where the authors defined two new properties extending the concept of OBDA instance. They propose a set of optimizations during SPARQL-to-SQL translation with techniques that take into account these constraints. However, the main assumptions made over the OBDA framework (e.g, the data source is an RDB o has an RDB wrapper, or the schema contains a set of constraints) are maintained. There are other works such as [6,38] that apply the OBDA framework over document-based databases, i.e., MongoDB. Morph-CSV follows an OBDA approach including the exploitation of additional information from mappings, tabular metadata and queries for tabular datasets.
Related to our work are those approaches that allow querying directly information stored in flat files [28], Drill,25
Current OBDI open source systems that take tabular data as input are Ontario [22] and Squerall [37]. Ontario is a federated query processing approach for heterogeneous data sources. In its source selection step, Ontario uses source descriptions named RDF Molecule Templates [21] which keep information on the sources. The system handles tabular data among other formats, and implements a virtualization approach of query answering techniques for efficient execution. Similarly, Squerall is also an OBDI system that takes as its inputs data and mappings and uses a middleware to aggregate the intermediate results in a distributed manner. Although the aforementioned systems evaluate queries against raw tabular data, they do not exploit the constraints declared in annotations or mapping rules.
CSV on the Web (CSVW)26
Another area related to our work is the definition and application of data transformation functions. An approach independent of a specific implementation context is described in [16]. It enables the description, publication and exploration of functions and instantiation of associated implementations. The proposed model is the Function Ontology and the publication method follows the Linked Data principles Previous works related to this topic focus on developing ad-hoc and programmed functions. For example, R2RML-F [17] allows using functions in the value of the
In this paper, we have presented an extension of the common OBDA specification to address the problem of query translation over tabular data. We describe and evaluate Morph-CSV, a framework that exploits the information of mapping rules and metadata OBDA annotations to extract and apply a set of relevant constraints. It pushes down the application of these elements directly over the raw data in order to improve query evaluation and query completeness. One of the main contributions of this proposal is that it can be used together with any OBDA framework. From the set of experiments that we have performed with two existing state-of-the-art OBDA engines (Morph-RDB and Ontop), we can see that the use of those engines inside the Morph-CSV framework brings several positive impacts: more queries can be answered and less time is needed to answer most queries.
The definition, application and optimization of new functions and constraints to address other challenges for querying tabular data is one of the main lines for future work [30]. We also want to study the performance of the proposed workflow over OBDA distributed query systems such as the ones proposed in [22,37]. More in detail, we want to analyze if the outcomes of the proposed steps by Morph-CSV can help in distributed environments where physical design of knowledge graphs are being proposed [24,44] to enhance query performance (i.e., deciding which input sources have to be transformed to RDF and which ones have to be maintained in their original format). Additionally, one of the possible future work lines is the comparison of the proposed approached, that exploits semantic web technologies and annotations, against non-semantic web solutions that provide support to deal with the identified challenges for querying tabular data (e.g., Apache Drill, Presto, Spark, etc.). The results obtained can also be useful to machine learning approaches that identify when the application of the integrity constraints is needed or not, as we observe that there are special cases where it can have a negative impact. We will also study the challenges for querying other data formats (e.g., XML, JSON) in an OBDA context and extend our approach to incorporate them. We also want to remark the importance of having standard and shared methods and vocabularies to publish metadata of raw data on the web, available for tabular data but not for tree data formats such as XML and JSON. Finally, we will adapt this proposal for a materialization process and study its effects comparing it with previous proposals. We also want to study how the materialization process can be improved when historical versions of the same RDF-based knowledge graph are needed, for example, analyzing which input sources have been changed or not, to decide which parts of that knowledge graph have to be generated again.
Footnotes
Acknowledgements
We are very thankful to Anastasia Dimou, Ben de Meester and Pieter Heyvaert (the RML team), who helped us in the initial discussions about the main contributions of our approach and in the creation of (YARR)RML mappings. We are also very thankful to the developers of Morph-CSV: Jhon Toledo and Luis Pozo-Gilo. The work presented in this paper is supported by the Spanish Ministerio de Economía, Industria y Competitividad and EU FEDER funds under the DATOS 4.0: RETOS Y SOLUCIONES – UPM Spanish national project (TIN2016-78011-C4-4-R) and by an FPI grant (BES-2017-082511).
Morph-CSV algorithm
The Morph-CSV algorithm exploiting the mapping rules and metadata to enhance virtual ontology based data access for tabular datasets.
Query features
Query features of the evaluation of Morph-CSV. Domain constraints are described based on the function performed by Morph-CSV and reflect the number of the columns where that functions has been applied. Improvement functions (duplicates, source selection) are always applied
| Query | Query characteristics | Constraints | # Sources | |
|
|
||||
| Integrity | Domain | |||
|
|
||||
| Q1 | 4 TP | – | 3 DataType, 4 Sub | 1 |
| Q2 | 5 TP, 2 OPT, 1 Filter | 1 INDEX | 3 DataType, 5 Sub | 1 |
| Q3 | 5 TP, 3 OPT, 1 Filter | 1 INDEX | 4 DataType, 5 Sub | 1 |
| Q4 | 9 TP, 1 Join, 4 OPT | 2 PK, 1 FK | 7 Sub | 2 |
| Q5 | 5 TP, 2 Join, 1 Filter | 2 PK | 2 DataType, 2 Sub | 2 |
| Q6 | 3 TP, 1 Join, 1 Filter | 2 PK, 1 FK | – | 2 |
| Q7 | 15 TP, 5 Join, 5 OPT, 1 Filter | 6 PK, 5 FK | 3 DataType, 8 Sub | 6 |
| Q8 | 14 TP, 4 Join, 3 OPT | 6 PK, 5 FK | 3 DataType, 8 Sub | 6 |
| Q9 | 7 TP, 5 Join, 1 OPT, 1 Filter | 5 PK, 3 FK | 2 DataType, 3 Sub | 5 |
| Q10 | 4 TP, 1 Join, 1 Filter | 2 PK, 1 FK | 2 Sub | 2 |
| Q11 | 10 TP, 3 Join, 3 Filter (1 not exists) | 3 PK, 2 FK | 2 DataType, 2 Sub | 3 |
| Q12 | 10 TP, 3 Joins | 4 PK, 3 FK | 1 DataType, 4 Sub | 4 |
| Q13 | 6 TP, 1 Join, 1 OPT | 1 PK, 1 FK | 1 DataType, 3 Sub | 1 |
| Q14 | 8 TP, 3 Join, 1 OPT | 4 PK, 3 FK | 1 DataType, 3 Sub | 3 |
| Q15 | 3 TP, 1 Filter | 1 PK, 1 FK | 4 DataType, 11 Sub | 1 |
| Q16 | 8 TP, 3 Join, 2 Filter | 4 PK, 2 FK | 2 DataType, 2 Sub | 3 |
| Q17 | 9 TP, 2 Join | 3 PK, 2 FK | 1 DataType, 4 Sub | 3 |
| Q18 | 8 TP, 1Union, 3 Join | 4 PK, 3 FK | 1 DataType, 3 Sub | 4 |
|
|
||||
| Q1 | 4 TP | – | 3 Sub | 1 |
| Q2 | 4 TP, 1 Join, 1 Filter | 1 PK, 1 INDEX | 7 Sub | 2 |
| Q3 | 4 TP, 1 Join | 1 PK, 3 INDEX | 5 Sub | 3 |
| Q4 | 4 TP, 1 Join | 1 PK, 1 INDEX | 7 Sub | 2 |
| Q5 | 5 TP, 1 Join | 1 PK, 2 INDEX | 6 Sub | 2 |
| Q6 | 4 TP | – | 2 Sub | 1 |
| Q7 | 6 TP, 1 Join, 2 Filter | 1 PK | 1 DataType, 4 Sub, 1 Create | 1 |
|
|
||||
| Q1 | 5 TP, 3 Join, 1 Filter | 3 PK, 2FK | 7 DataType, 1 Sub | 3 |
| Q2 | 15 TP, 3 Join, 3 OPT | 4 PK, 3 FK | 10 DataType, 12 Sub | 4 |
| Q3 | 7 TP, 3 Join, 2 Filter, 1 OPT | 3 PK, 2FK | 8 DataType, 3 Sub | 3 |
| Q4 | 12 TP, 1 Union, 6 Join, 2 Filter | 3 PK, 2FK | 2 DataType, 4 Sub | 2 |
| Q5 | 7 TP, 2 Join, 2 Filter | 2 PK, 1FK | 6 DataType, 3 Sub | 2 |
| Q6 | 2 TP, 1 Filter | – | 1 Sub | 1 |
| Q7 | 14 TP, 5 Join, 1 Filter, 2 OPT | 5 PK, 4 FK | 11 DataType, 2 Sub | 5 |
| Q8 | 10 TP, 2 Join, 4 OPT | 3 PK, 2 FK | 8 DatatType, 8 Sub | 3 |
| Q9 | DESCRIBE, 1 TP | – | – | 1 |
| Q10 | 7 TP, 3 Join, 2 Filter | 3 PK, 3 FK | 7 DatatType, 2 Sub | 3 |
| Q11 | 2 TP, 1 Union | 11 PK, 11 FK | 29 DataType, 53 Sub | 11 |
| Q12 | CONSTRUCT, 9 TP, 2 Join | 3 PK, 2 FK | 6 DataType, 7 Sub | 3 |
Query completeness
Query completeness over multiple sizes of a BSBM dataset. The absence of a value means that the OBDA engine does not support the features of the SPARQL query
| Engines/Queries | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q12 | Total |
|
|
||||||||||||
| Virtuoso | 10 | 19672 | 10 | 10 | 5 | 3 | 580691 | 20 | 450000 | 10 | 900000 | 1950431 |
| Morph-RDB | 10 | 19672 | 10 | 10 | 0 | 3 | 580691 | 20 | 450000 | 10 | 900000 | 1950426 |
| Morph-CSV & Morph-RDB | 10 | 19672 | 10 | 10 | 5 | 3 | 580691 | 20 | 450000 | 10 | 900000 | 1950431 |
| Ontop | 10 | – | 10 | 10 | 0 | – | – | – | – | 0 | – | 30 |
| Morph-CSV & Ontop | 10 | – | 10 | 10 | 5 | – | – | – | – | 10 | – | 45 |
|
|
||||||||||||
| Virtuoso | 10 | 38665 | 10 | 10 | 5 | 5 | 1161448 | 20 | 900000 | 10 | 1800000 | 3900183 |
| Morph-RDB | 10 | 38665 | 10 | 10 | 0 | 5 | 1161448 | 20 | 900000 | 10 | 1800000 | 3900178 |
| Morph-CSV & Morph-RDB | 10 | 38665 | 10 | 10 | 5 | 5 | 1161448 | 20 | 900000 | 10 | 1800000 | 3900183 |
| Ontop | 10 | – | 10 | 10 | 0 | – | – | – | – | 0 | – | 30 |
| Morph-CSV & Ontop | 10 | – | 10 | 10 | 5 | – | – | – | – | 10 | – | 45 |
|
|
||||||||||||
| Virtuoso | 10 | 69434 | 10 | 10 | 5 | 9 | 2168792 | 20 | 1800000 | 10 | 3600000 | 7638300 |
| Morph-RDB | 10 | timeout | 10 | 10 | 0 | 9 | 2168792 | 20 | 1800000 | 10 | 3600000 | 7568861 |
| Morph-CSV & Morph-RDB | 10 | 69434 | 10 | 10 | 5 | 9 | 2168792 | 20 | 1800000 | 10 | 3600000 | 7638295 |
| Ontop | timeout | – | 10 | timeout | 0 | – | – | – | – | 0 | – | 10 |
| Morph-CSV & Ontop | 10 | – | 10 | 10 | 5 | – | – | – | – | 10 | – | 45 |
|
|
||||||||||||
| Virtuoso | 10 | 137359 | 10 | 10 | 5 | 18 | 4337584 | 20 | 3600000 | 10 | 7200000 | 15275026 |
| Morph-RDB | 10 | timeout | 10 | 10 | 0 | 18 | timeout | 20 | 3600000 | 10 | timeout | 3600078 |
| Morph-CSV & Morph-RDB | 10 | 137359 | 10 | 10 | timeout | 18 | timeout | 20 | 3600000 | 10 | timeout | 3737437 |
| Ontop | timeout | – | 10 | timeout | 0 | – | – | – | – | 0 | – | 10 |
| Morph-CSV & Ontop | 10 | – | 10 | 10 | timeout | – | – | – | – | 10 | – | 40 |
Detailed loading times for Morph-CSV
Detailed results of Morph-CSV over Bio2RDF
| Step/Query | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Morph-CSV− |
| Selection | 3.705 | 3.749 | 3.777 | 3.714 | 3.732 | 3.787 | 3.719 | 3.775 | 3.712 | 3.632 | 48.088 |
| Normalization | – | – | 0.194 | – | – | 0.212 | – | 0.301 | – | – | 38.577 |
| Preparation | 0.903 | 123.798 | 0.580 | 7.414 | 0.628 | 126.852 | 8.457 | 2.660 | 5.531 | 0.555 | 253.461 |
| Creation & Load | 0.318 | 131.912 | 0.113 | 34.569 | 0.994 | 147.659 | 32.203 | 0.901 | 8.968 | 0.790 | 265.301 |
| M. Translation | 0.541 | 0.542 | 0.546 | 0.534 | 0.548 | 0.560 | 0.535 | 0.539 | 0.543 | 0.552 | 0.693 |
| Total | 5.467 | 260.000 | 5.211 | 46.231 | 5.901 | 279.071 | 44.915 | 8.176 | 18.756 | 5.529 | 606.121 |