
Abstract
Recent advancements in declarative knowledge graph generation have introduced multiple mapping languages and engines, causing a shift in studies towards optimizing the knowledge graph generation process. Although these engines commonly generate the knowledge graphs from heterogeneous data sources, sharing the optimization techniques and features remains challenging due to the lack of formal operational semantics. To address this, we propose a set of algebraic mapping operators that define operational semantics for general mapping processes. This algebra, based on the SPARQL algebra, enables reuse of established definitions and strengthens the link between knowledge graph generation and query engines. To evaluate language independence we translated mapping languages ShExML and the RDF Mapping Language (RML) into our algebraic mapping plan. Our completeness evaluation shows that our algebraic operators cover the operational semantics of RML and partially support ShExML. Additional analysis is required to cover additional features of ShExML such as joining data from two input sources. For performance evaluation, our proof-of-concept algebraic mapping engine exhibits consistent and low memory usage across workloads, getting second place in the Knowledge Graph Construction Workshop's performance challenge. Algebraic mapping operators decouple mapping engines from specific languages, enabling multilingual mapping engines and allowing optimization techniques to be applied independently of the mapping process. This work lays the foundation for theoretical analysis of complexity and expressiveness of mapping languages and enforces consistency in execution semantics of mapping engines. Furthermore, aligning our algebra with SPARQL opens the door to advanced methods such as virtualization for querying heterogeneous data sources.
Introduction
There exist several use-case-agnostic and declarative mapping languages (Dimou et al., 2014; García-González et al., 2020; Iglesias-Molina et al., 2023; Lefrançois et al., 2017; Stadler et al., 2015; Sundara et al., 2012; Vu et al., 2019) to generate a Knowledge graph (KG) using the resource description framework (RDF) (Van Assche et al., 2022). Mapping rules – described using such mapping language – specify the mapping process: How to generate a KG from existing semi-structured data (Van Assche et al., 2022). These mapping languages’ increasing popularity and importance is signified by the establishment of the W3C Knowledge Graph Construction Community Group, and a diverse ecosystem of mapping engines based on these mapping languages (Van Assche et al., 2022). For example, several mapping engines based on the RDF Mapping Language (RML) (Iglesias-Molina et al., 2023) have been implemented (Arenas-Guerrero et al., 2022; Dimou et al., 2014; Haesendonck et al., 2019; Iglesias et al., 2020; Min Oo et al., 2022; Simsek et al., 2019), and there are plans to establish a RML W3C Working Group in the future (Iglesias-Molina et al., 2024).
However, these mapping languages typically provide no formal description of the operational semantics through mapping plans: The formally defined steps a mapping process should follow to generate a KG based on mapping rules. This prevents the static analysis of the mapping languages to prove the correctness of the mapping process, and analyse the expressiveness and the complexity of the mapping languages. Attempts have been made to formalize these mapping languages, however, these formalizations are mostly used in the context of proving the correctness of an optimization technique (Iglesias et al., 2023) or restricted to a particular mapping language (Asprino et al., 2023; Lopes et al., 2011). To the best of our knowledge, there is currently no research on the theoretical foundations, independent of specific mapping languages, that is applicable to multiple mapping languages.
Hence, different mapping engine implementations typically individually infer the operational semantics of the mapping plan based on the syntax of the mapping language. As a result, the operational semantics of the mapping engines are different even when using the same mapping rules. These individual inferences of the operational semantics lead to a slow-down in mapping engine development, with repetitive implementations of the same operational semantics in different flavours. Additionally, performance optimizations are scattered across different engine implementations; all incompatible with each other due to the aforementioned individual inferences of the operational semantics.
In this work, we provide such a mapping language-independent theoretical foundation by defining a set of algebraic operators for the mapping process called mapping algebra, adapting the algebra (Pérez et al., 2009) of SPARQL, an RDF data query language. These algebraic mapping operators can be composed together to form a mapping plan. We provide a proof-of-concept implementation on par – both in performance as in functionality – with existing mapping engine implementations. This shows how to translate mapping rules from multiple mapping languages into a mapping plan, and thereby providing operational semantics for mapping languages.
This approach can lead to more aligned mapping engines, and allows proving correctness across different mapping languages. Adapting the SPARQL algebra (Pérez et al., 2009) to formulate the mapping algebra allows us to maximally reuse established definitions.
The outline of this paper is as follows: In Section 2, we explore the state-of-the-art on mapping languages and their operational semantics. In Section 3, we discuss our methodology and its rationale. In Section 4, we provide the formal terms and definitions of the set of algebraic mapping operators used to construct the mapping plan. In Section 5, we introduce a reference implementation that consists of an algebraic mapping translator and a proof of concept engine. In Section 6, we provide an overview of our evaluation methodology and results, to show the viability of the algebraic mapping operators without it impeding the performance of a mapping engine. Finally, we conclude and discuss future work in Section 7.
Related Works
In this section, we provide an overview of existing mapping languages (Section 2.1) and existing formalizations (Section 2.2), and provide concluding discussions (Section 2.3).
Mapping Languages
Declarative mapping languages allow describing how to generate a KG by mapping existing data. These languages can be categorized based on the number of input data source types that they support: (i) Homogeneous mapping languages or (ii) heterogeneous mapping languages.
On the one hand, homogeneous mapping languages only support one input data source type. For example, relational databases to RDF with languages like D2RQ (Bizer & Seaborne, 2004), R2RML (Sundara et al., 2012) and SML (Stadler et al., 2015), or CSV data to RDF with TARQL (Cyganiak, 2012).
On the other hand, heterogeneous mapping languages support multiple input data source types, that is, multiple data formats (CSV, JSON, XML, etc…) and multiple data access (websocket, files, databases, etc…). Heterogeneous mapping languages can be further categorized (Van Assche et al., 2022): (i) Query-based mapping languages, (ii) dedicated mapping languages, and (iii) constraint-based mapping languages.
Query-based mapping languages extend or adapt the SPARQL syntax to map heterogeneous data to a KG, for example, XSPARQL (Bischof et al., 2012) combines XQuery and SPARQL, SPARQL-Generate (Lefrançois et al., 2017) extends SPARQL with generation-specific operators, and SPARQL-Anything (Asprino et al., 2023) applies extended SPARQL (CONSTRUCT) queries over an input data meta-model called Façade-X (Daga et al., 2021).
Dedicated mapping languages extend existing mapping languages or use custom syntax. RML (Dimou et al., 2014; Iglesias-Molina et al., 2023), xR2RML (Michel et al., 2015), and D2RML (Chortaras & Stamou, 2018) are examples of dedicated mapping languages which extend R2RML to support more than just relational databases. Amongst them, RML is the most matured mapping language, taken up by the W3C KG-Construct Community Group 1 for ongoing standardization (Iglesias-Molina et al., 2023). D-REPR (Vu et al., 2019) is the only dedicated mapping language with its own syntax.
Currently, ShExML (García-González et al., 2020) is the only constraint-based mapping language based on the ShEx (Prud’hommeaux et al., 2018) syntax with extensive modifications and with a focus on making a user-friendly language. Although ShExML itself does not use constraints internally during the mapping of data to RDF, we follow the categorization of Van Assche et al. (2022).
Formalizations
Several formalization works have been conducted to formalize the aforementioned languages. For homogeneous mapping languages, Stadler et al. (2015) provide a unified model, focussed on relational databases as input data source type. However, there are 2 limitations to their approach. First, the formalizations are only applied to the authors’ own mapping language, SML. Last, the translation of R2RML to SML – to demonstrate the completeness of their unified model – is informally described. Therefore, it is uncertain if the model is suitable for providing operational semantics for a generic mapping process. Priyatna et al. (2014) provide formalizations for the translation of SPARQL to SQL based on the mapping definitions in an R2RML document, extending the works of Chebotko et al. (2009) and improving the works of SparqlMap (Unbehauen et al., 2013). Since the formalization is not applied directly upon R2RML, it only provides partial operational semantics to R2RML.
For heterogeneous mapping languages, on the one hand, query-based mapping languages benefit from the usage of SPARQL semantics, which results in having partial operational semantics out-of-the-box. XSPARQL (Bischof et al., 2012) provides partial operational semantics on the combination of XQuery and SPARQL, using SPARQL’s semantics. Similarly, SPARQL-Anything and SPARQL-Generate extend the existing SPARQL syntax to ensure that their operational semantics inherit SPARQL’s well-defined semantics (Pérez et al., 2009). For SPARQL-Anything, it formally describes the heterogeneous input data with their RDF meta-model Façade-X (Daga et al., 2021), and uses SPARQL to query the RDF meta-model (Asprino et al., 2023), leading to SPARQL-Anything having provided formal operational semantics of its mapping process. SPARQL-Generate (Lefrançois et al., 2017) also provided the operational semantics for KG generation from heterogeneous data based on its extended SPARQL syntax.
On the other hand, dedicated mapping languages such as RML requires the authors to analyze the mapping language syntax and formulate their own operational semantics. RML Fields (Delva et al., 2021) extended RML’s syntax to also allow mapping of nested heterogeneous data, provided an informal operational semantics of how it works. Iglesias et al. (2023), and Arenas-Guerrero et al. (2022) provide formalizations for RML, used to optimize the mapping process by grouping the execution order using the concept of mapping assertions, and mapping partitions respectively. Mapping assertions are formalized using Horn clauses, whereas mapping partitions are formalized using set theory. This mismatch in formalization techniques makes it difficult to determine the similarity between the two optimization approaches. The formalizations employed in both works are successfully used to prove the optimization techniques; however, they are tailored to RML and do not introduce general operational semantics of a mapping process.
In parallel, the first author of this paper has conducted a complementary study to formally capture the semantics of mapping languages (Min Oo & Hartig, 2025). This parallel work also investigates to capture the semantics of mapping heterogeneous types of data sources to KG based on RDF, however, it focuses on providing a theoretical foundation using a variation of relational algebra, and provides an algorithm for translating RML v1.1.2 documents 2 into their algebraic expressions, thus also capturing the semantics of RML. Although this theoretical foundation is formally proven, its scope is smaller, focussing on well-defining a small set of core operators instead of more exhaustively covering current KG generation features. For example, extensions such as RML Fields (Delva et al., 2021) and Logical Targets (Van Assche et al., 2021) are not taken into consideration. Thus, this theoretical foundation has been shown to capture the semantics of RML v1.1.2 and is not yet applied to languages other than RML.
Discussion
We observe that existing formalizations are: (i) Typically partial, in the case of query-based languages that partially rely on SPARQL semantics, (ii) exclusively applicable to a specific syntax, or (iii) applicable to general mapping semantics but only capture a subset of the semantics of existing mapping languages.
The lack of operational semantics, applicable to multiple mapping languages, impedes using an optimization technique proposed in one mapping language on another mapping language. Furthermore, static analysis cannot be executed for verification of the mapping rules described using these languages. For example, mapping engines such as SDM-RDFizer (Iglesias et al., 2023) and Morph-KGC (Arenas-Guerrero et al., 2022) employ their own concept of operational semantics to optimize the mapping process. This makes it impossible to formally verify the combination of both techniques without a translation between the two operational semantics.
Methodology
In this section, we discuss our methodology for developing a mapping algebra and the rationale behind our design choices in selecting a specific set of algebraic mapping operators to represent our mapping algebra.
A mapping process can typically be decomposed into the following steps (Figure 1): (i) Data access, (ii) data querying, (iii) data transformations, (iv) data serialization, and (v) target output.

Breakdown of the Mapping Process: The green Labelled Steps can be Derived from Existing Query Algebra, and the orange Labelled Steps Need to be Formally Defined. The Exemplary Data Access Step can Read Data from a Relational Database, and a CSV File while the Exemplary Target Step, Writes the Generated Output to both a File and a SPARQL Endpoint.
One way to define the operational semantics of the mapping process is through the definitions of algebraic operators, similar to the query languages. It is beneficial to extend and adapt the SPARQL algebra with new algebraic operators as a foundation for defining algebraic mapping operators in a mapping algebra: (i) We already have query-based mapping languages successfully leveraging SPARQL’s semantics (Section 2.2) and (ii) this approach allows to align dedicated and query-based mapping languages, allowing for a generic mapping plan that can support multiple mapping languages.
To apply the SPARQL algebra approach, we must define the corresponding algebraic operators for the 5 steps in the mapping process (Figure 1). Formal operational semantics of the querying and transformation operators are well-defined in querying languages such as SPARQL (Pérez et al., 2009; Seaborne & Harris, 2013) and SQL. Querying operators are defined, in this work, as operators that do not change the value associated with an attribute of a data record, in contrast to the transformation operators, which derive new values through operations such as string concatenation. An example of a querying operator is SPARQL’s projection operator, which we redefine in Section 4.3 with minor modifications. The same is also done for other querying operators such as join, and rename in Section 4.7 and 4.5 respectively. Similarly, we adapt SPARQL’s extend operator (Section 4.4) to provide operational semantics for the transformation step. The remaining steps – data access, data serialization, and target output – need to be defined formally with an extended set of algebraic operators which we define in Section 4.2, 4.8, and 4.9, respectively. As shown in Figure 1, a target operator can write the generated RDF into multiple data sinks, such as a file or a SPARQL endpoint. In the original SPARQL algebra, there exists no algebraic operators which could do a fan-out operation and direct the output to multiple downstream operators. Thus, we extended SPARQL algebra with the concept of fragment (Definition 1) and the fragmenter operator (Section 4.6) for handling this situation.
In this section, we introduce our mapping algebra. We first describe the needed terms and then define the algebraic mapping operators: Source, Projection, Extend, Rename, Fragmenter, Natural join,
Preliminaries
The following pairwise disjoint infinite sets are used in the definition of mapping algebra:
Two solution mappings



Now, we are ready to define the tuple type that our algebraic operators will operate upon. Unlike querying in SPARQL, mapping languages enable users to fragment the generated data into different data sinks (e.g. multiple files or web sockets). For example, using Logical Targets (Van Assche et al., 2021), RML engines can export the generated RDF output to different data sinks according to the description provided in Logical Targets. In contrast, query languages do not allow users to specify where to export the queried data. Thus, we introduce the concept of fragments (Min Oo et al., 2023), which uses the concepts of the multiset, and the submultiset as defined by Blizard (1988). Intuitively, the multiset can be seen as an unordered bag of elements where the bag can contain duplicates of elements. Then, the submultiset can be seen as a subset,
Let
Using the definition of fragments, the core data model of the mapping algebra, the mapping tuple is defined as follows.
Let
Utilizing fragments in the mapping tuple enables mapping processes to broadcast solution mappings across multiple downstream operators. Furthermore, it enables the partitioning of the solution mappings during construction based on either user defined conditions or some abstract concept such as personal or friend’s information as shown in Table 1.
Two Mapping Tuples Describing Information Related to John.
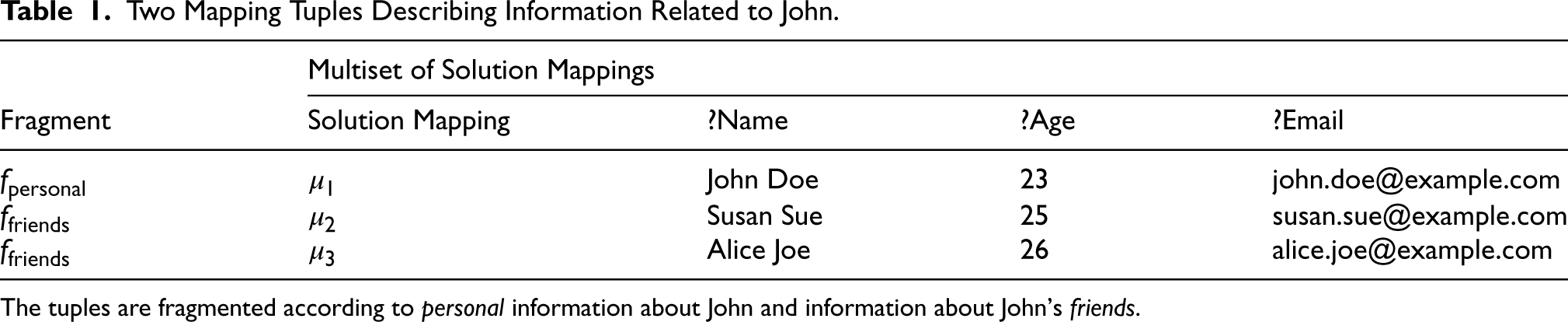
The tuples are fragmented according to personal information about John and information about John’s friends.
In an algebraic mapping plan, the source operators are the leaf nodes of the mapping plan: They generate the required mapping tuples for further processing by the downstream algebraic operators.
A way to extract data records from heterogeneous data formats needs to be defined to generate the mapping tuples. Especially, when the input data has a nested data structure. ShExML (García-González et al., 2020) enables data records extraction from nested data structures, using iterators and fields. Furthermore, it also enables referencing of data records on different hierarchical level through the use of the pushed and the popped fields 3 . RML Fields (Delva et al., 2021) expanded upon the concept of iterators and fields used in ShExML to also allow data records extraction from nested heterogeneous data formats. For example, RML Fields can extract a JSON data record in a CSV table cell using a nested reference formulation, unlike ShExML where only nested data structures of the same data format is supported. This work has been recently continued as RML Logical Views 4 .
To support the extraction of data records from a nested data structure, we define the iterators and fields, as part of the source operator, as follows. The definition is similar to the work of RML Fields.
An
Given an iterator
Given a data access configuration 
To clarify the workings of the source operator, iterator and fields, Example 1 shows how mapping tuples are generated from a simple JSON file with nested data using a source operator with its iterator and fields.

As an example, provided with an input data source such as the JSON file in Listing 1, the source operator could be configured with the following
The iterator
Representation of the Mapping Tuples Generated by the Source Operator Using Data from Listing 1.

After the source operator generates the mapping tuples from heterogeneous data sources, these mapping tuples are further processed and transformed by the intermediate algebraic mapping operators. The intermediate algebraic mapping operators are defined as follows: Projection, Rename, Extend, Fragmenter, and the various Join operators.
In SPARQL algebra, a projection restricts solution mappings to a set of variables. This is useful in reducing the amount of data that needs to be further processed by the downstream operators. The corresponding projection operator in the mapping algebra is defined as follows.
Given a set of variables


A core operation of the mapping process is the derivation of new values using existing values in the data record. For example, given a data record containing the weight and height of a person, we can calculate the body mass index of the person using their weight and height. The following definition of the extend operator enables the mapping algebra to derive new values from existing values.
Given a set of pairs

Different mapping languages can introduce different extend expressions.
Extended Mapping Tuple as Described in Example 3.

In order to avoid variable collision when processing mapping tuples, an algebraic operator must be able to rename the variables inside the solution mappings associated with the mapping tuples. The rename operator, which introduces aliasing of the existing variables in the solution mappings, is defined as follows.
Given a set of pairs of variables
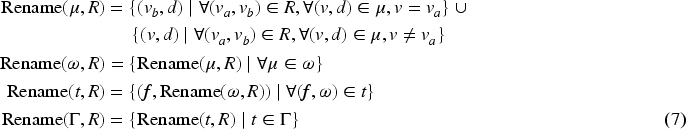

Readers may realize that the rename operator can also be derived by first extending the solution mapping with a new variable (Extension), copying the value associated with the old variable, and finally projecting away the old variable (Projection). We defined the rename operator to describe the execution of the rename operation in one operator instead of two operators. This reduces the complexity and redundancy of the generated mapping plan using the operators. The extend and project operator chain to represent the rename operator is formally defined as follows.


The aforementioned operators do not manipulate the fragments part of the mapping tuples, but only process the associated solution mappings. To manipulate the fragments of the mapping tuples, the fragment operator is defined as follows.
The


Previously defined operators are unary: They only work on a single multiset of mapping tuples
Two mapping tuples,

Natural join operator joins mapping tuples if they have common fragments, and also have equal values for all the common variables of the associated solution mapping of the fragment. It does not allow users to join mapping tuples based on the different variables of
Given a binary predicate function,
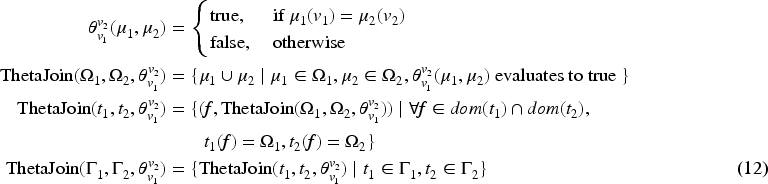
Natural and
Left outer-join operator is a binary operator that retains the solution mappings from the left multisets of mapping tuples even if the given solution mappings do not satisfy the predicate function. Other outer-join operators, such as right outer-join, and full outer-join operators, can be derived from the left outer-join operator.
Given two multisets of mapping tuples,

Mapping Tuples Generated from Another Data Source About Pets.

Output of the Natural Join Operator as Described in Example 6.

Only the common variables ?pet.name and ?pet.type are checked.
Output of

Output of Left-Join Operator as Described in Example 8.

Only the variables ?pet.type and ?animal_type are checked for equality and all solution mappings from
The aforementioned join operators have a limitation where they cannot merge mapping tuples without comparing the actual data values in the solution mappings. In order to collect mapping tuples from multiple operators, without data value comparisons, we need to define a
Given two multisets of mapping tuples,

The aforementioned operators process and transform the mapping tuples generated from heterogeneous data sources, they do not define how to process the mapping tuples to the target data format.
Serializer Expression
A serializer expression,
Provided with the serializer expression

Note that, similar to the rename operator, the serialize operator is defined as a fixed chaining of a Projection operator (Section 4.3) after the Extend operator (Section 4.4). We defined the serialize operator to describe the execution of the serialization operation in one operator instead of two operators. This reduces the complexity and redundancy of the generated mapping plan.

Output of the Serialize Operator as Described in Example 9.

Finally, depending on the configuration of the data sink, the serialized data is written to heterogeneous data sinks such as files, websockets or Apache Kafka topics. In mapping algebra, the fragments of the mapping tuple determine where the associated solution mappings will be written to.
Provided with a target fragment

Given the input mapping tuples shown in Table 11 as
As a reference implementation utilizing the aforementioned algebraic mapping operators, we implemented an algebraic mapping translator and a proof-of-concept engine. The translator translates mapping rules in different mapping languages to a uniform mapping plan consisting of the algebraic mapping operators, while the proof of concept engine executes the mapping plan to generate RDF statements from heterogeneous data sources. As our mapping algebra extends the SPARQL algebra (and thus naturally aligns with query-based mapping languages), we choose RML and ShExML from the categories of dedicated mapping languages and constraint-based languages, respectively, to implement our translation algorithms described in Section 5.1 and Section 5.2. We specifically generate the mapping plan for the following versions: (i) RML v1.1.2 (Dimou et al., 2014) 9 , and (ii) ShExML v2020 (García-González et al., 2020).
We choose RML v1.1.2 as RML is the prevalent declarative mapping language (Van Assche et al., 2022) – as evidenced by its ongoing support via the W3C Knowledge Graph Construction Community Group 10 – and the v1.1.2 version is mature with large implementation coverage 11 . The more recent version of RML (Iglesias-Molina et al., 2023) is backwards compatible with the previous version 12 , hence, we do not expect breaking changes. We choose ShExML v2020 as it is independent of the other major mapping language families used in this work
This selection thus shows that our mapping algebra covers the semantics of at least one mapping language from the 3 categories of mapping languages mentioned in Section 2: RML-based languages are represented by RML v1.1.2 to compare against ShExML, and SPARQL-based languages are represented by the algebra definitions on which we based our algebraic operators on. This way, we ensure that our approach is not dependent upon a single mapping language.
Our proof-of-concept is used to demonstrate current coverage and practical feasibility of our proposed mapping algebra, but is not exhaustive in its current form, specifically concerning the ShExML translation. Syntactic sugar such as Query declarations are not supported since it is used to make the ShExML document more human-readable and do not add or change mapping steps. We currently only support one ShExML transformation operation (string concatenation), and no joins. We do not support the ShExML v2020 join – currently known as substitution 13 – since it was defined with the usage of both the UNION and the JOIN keywords without detailed clarification on the operational semantics (García-González et al., 2020).
The algebraic mapping translator is implemented in Rust 14 and utilizes Sophia (Champin, 2020) as a library for handling RDF types. The translator 15 is called “Algebraic Mapping Loom: Weaving Mapping Languages” (“AlgeMapLoom”, v0.4.0), and contains different modules to implement a mapping language translator. The decision to use Rust as the implementation language is to leverage Rust’s cross compilation capabilities to enable the usage of the translator code on multiple operating systems. Furthermore, Rust has a rich ecosystem of libraries to support the generation of bindings for multiple programming languages, enabling developers to use the translator engine’s API from within their code. The output of the AlgeMapLoom translator is a graph data structure that is compliant with the Graphviz 16 format in DOT language 17 . For ease of implementing the algebraic mapping engine, we also provide a JSON output of the translated mapping plan together with the JSON schema 18 .
The proof-of-concept algebraic mapping engine 19 is implemented in JavaScript, called “RMLWeaver-JS” (v0.1.1), to show that the translated mapping plan is mapping and programming language agnostic. For this work, we only support processing CSV files 20 with RMLWeaver-JS. As the mapping plan is source-independent – except for the extensible source operator – only supporting CSV files is sufficient to prove the working of our proof-of-concept. We used the reactive programming paradigm 21 when implementing RMLWeaver-JS to ensure that input data is processed in a streaming manner, resulting in lower memory usage. The following sections give an overview of the respective algorithms used to translate RML and ShExML into a mapping plan consisting of algebraic mapping operators.
RML Translation
RML v1.1.2 describes how triples maps (TPs) are used to generate RDF statements. A TP is linked to a source – called logical source in RML – which provides the necessary data to generate the RDF statements described by the TP. Multiple TPs can have the same RML logical source. For translating a logical source to a Source operator (Section 4.2), we extract the iterators and fields related to a logical source from the TP, as described in the work on RML Fields (Delva et al., 2021). Then, all triples maps are grouped according to their associated Source operators. The grouped TPs are then iterated over individually and the associated term maps 22 are translated into corresponding Projection, Join, Extend, Serialize.
For each term map (subject, predicate, and object maps), the references 23 are extracted as projection attributes to create projection operators. The created Projection operators are applied directly after the previously created Source operators. This results in a partially projected mapping plan, used throughout the rest of the algorithm to build the final mapping plan representing the mapping process described by the RML document.
Once the Projection operators are created, the TPs are partitioned into groups with and without referencing object map 24 to be further translated into sub-mapping plans with and without joins.
For TP with referencing object maps, a Fragmenter operator and a Join operator is created to join the partially projected mapping plan involving the child and parent TP for each referencing object map associated with the TP. The Fragmenter operator is created with the fragment mapping,
Then, information about the term maps are utilized to create extend expressions. For example, a constant-valued term map with the term type IRI is translated to generate a nested extend expression (Definition 7) where an IRI data typing extend expression is applied to the return value of the constant value generating extend expression (e.g. irify(constant(value))). The new variable,
Finally, the Serialize operator is created based on the combination of term maps for the TP. Subject, predicate, object, and graph maps are used to generate quad patterns 26 with variables for each term.
The proposed RML logical target (Van Assche et al., 2021) is partially supported: Only the default logical target is interpreted by creating a default Target operator that pipes the generated RDF quads to the terminal’s standard output, for all the mapping tuples having the default fragment.
ShExML Translation
Unlike RML, ShExML documents 27 have a structure split into two blocks: (i) declarations and (ii) generators. The declarations block contains individual lines defining sources, iterators, prefixes, and expressions. The declarations have the following structure: ¡type¿ ¡variable¿ ¡statement¿. Each declaration is aliased with a variable which can be used within other declarations – introducing interdependency between different declarations. Thus, it is important to group related declarations together to generate our mapping plan. The generators block contains shapes and graphs, which in turn can contain nested shapes. The syntax for defining the graphs and shapes are the same with the ShEx specifications 28 with some modifications by ShExML.
First, unique combinations of the source and the iterators variables, used inside the ShExML expressions’ statements, are used to generate the algebraic Source operators. One Source operator is generated for each unique combination of a source and an iterator variables. The generated Source operator is grouped with the variables of the expression definitions, which reference the same source as the Source operator. This results in pairs where every Source operator is paired with a set of expression variables. We shall annotate the set of expression variables as
For each pair of Source operator with
RDF QPs are derived from the shapes and graphs in the generator block of ShExML document. These RDF QPs also contain metadata such as RDF data type or term type (IRI, Blank node, Literal) to aid in the generation of the value to be bound to the variables in the RDF QP. RDF QPs are generated, and added to the set of RDF QPs, if the subject node and the object node of a ShExML shape references one of the expression variables

A Simple Mapping Plan Generated from the Mapping Process Described by the Resource Description Framework Mapping Language (RML) Document in Listing 3.
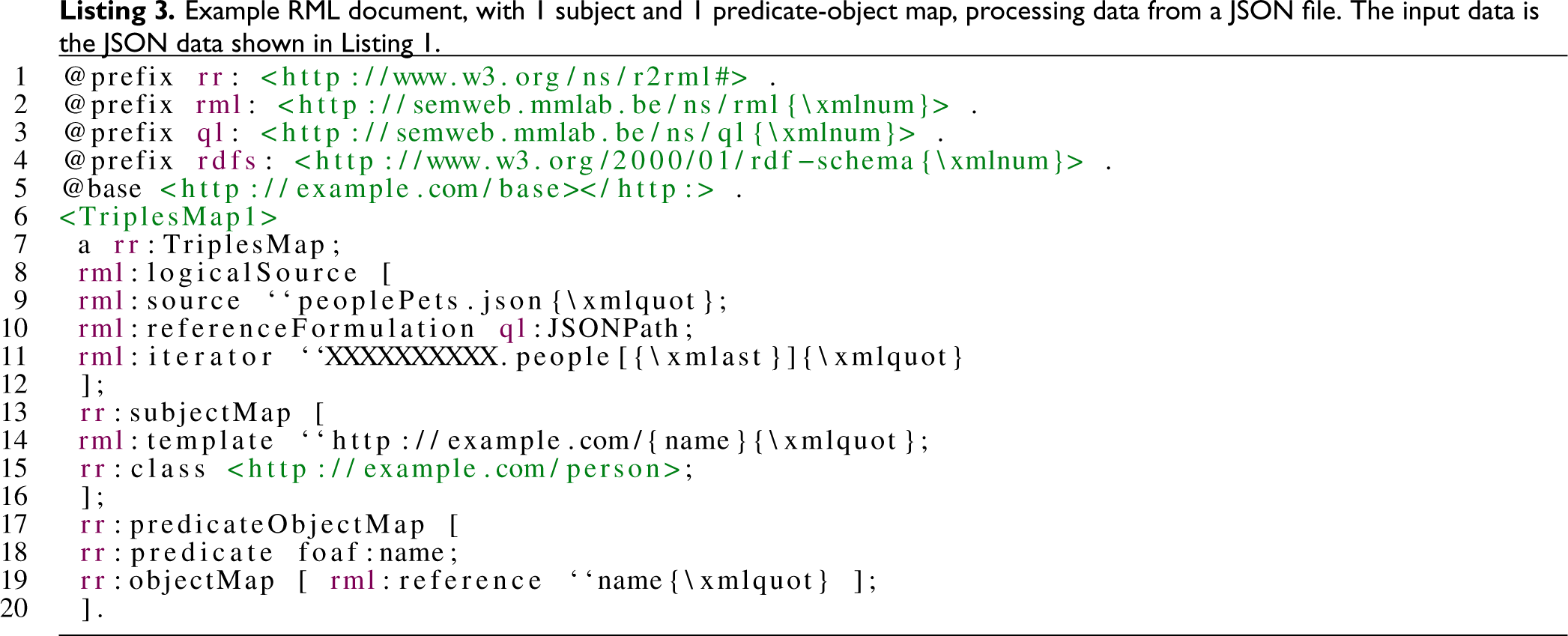
Once the RDF QPs are generated, we generate the relevant algebraic mapping operators based on the type of expression declarations with expression variable
Basic expressions
31
are translated after the transformation expressions. Basic expressions in ShExML behave just like a Rename operator (Section 4.5), where the values generated from the ¡statement¿ are aliased with the associated expression variable. Thus, a Rename operator is generated, with the rename pairs derived from the basic expressions whose
Afterwards, the extend expressions (Definition 7) for type casting, derived from the metadata of the generated RDF QPs, are generated and paired with the corresponding variable in the RDF QP. For example, an IRI type casting statement is generated for a subject node and paired with the variable of the subject node in the RDF QP. The generated pairs of variables and extend expressions are used to create an Extend operator, with typecasting extend expressions. The created Extend operator is applied after the previous step.
Finally, the previously generated RDF QPs are used to generate the Serialize operator. Since ShExML can not specify targets, the default Target operator is created to pipe the generated RDF quads to the terminal’s standard output.
When applying the aforementioned algorithms to translate RML and ShExML documents, a mapping plan is generated. Figures 2 and 3 shows an example mapping plan generated from an RML document (Listing 3 and 4 respectively) using the algorithm described in Section 5.1, and Figure 4 shows the mapping plan generated from a ShExML document (Listing 5) using the algorithm described in Section 5.2.
RML Translation Result
When translating an RML document (Listing 3), the Projection operator projects the attributes referenced by the term maps in RML. The projected attribute is name, referenced in the subject map’s template and the object map’s reference. The Extend operator contains pairs of attributes and extend expressions for the generation of the terms required for the mapping process. In Figure 2, the Extend operator binds the variable
Translating the RML document in Listing 3 does not produce the Fragmenter nor the binary operators such as
ShExML Translation Result
There are two major differences between the mapping plan generated by RML translation and the ShExML translation. First, ShExML translation generates a Rename operator as part of the mapping plan due to the basic expression on line 12 in Listing 5. Lastly, the Extend operator has an extra variable binding for the generation of a constant IRI term namely ¡http://example.com/person¿. This arises from the ShExML translation algorithm (Section 5.2) which generates extend expressions for both the subject and the object nodes in ShExML’s shapes and graphs block. The other operators are semantically similar to those generated from the RML document.
Evaluation
This work introduces the definitions of algebraic mapping operators. We conduct an empirical evaluation of the algebraic mapping operators, using the aforementioned RML and ShExML mapping languages (Section 5). We implemented a reference algebraic mapping engine for the evaluation. Two types of empirical evaluation are carried out for this work: (i) Completeness of the defined algebraic mapping operators and (ii) the impact on performance of a mapping engine utilizing algebraic mapping operators. The first evaluation shows that this work is sufficient to create complete mapping engines. The second evaluation shows that utilizing algebraic mapping operators results in performance of real-world mapping engines comparable to the state of the art. Figure 5 shows an example execution pipeline consisting of AlgeMapLoom-rs and RMLWeaver-JS used to translate and execute RML document. The same pipeline setup is also used for ShExML evaluation.
Completeness of Algebraic Mapping Operators
Evaluating the completeness of the algebraic mapping operators is done by translating test cases, provided by the RML and ShExML reference implementations, into a mapping plan using the defined algebraic mapping operators. We then execute the generated mapping plan with our reference implementation, RMLWeaver-JS, and check the output of our implementation against the output of the reference implementations of RML and ShExML.

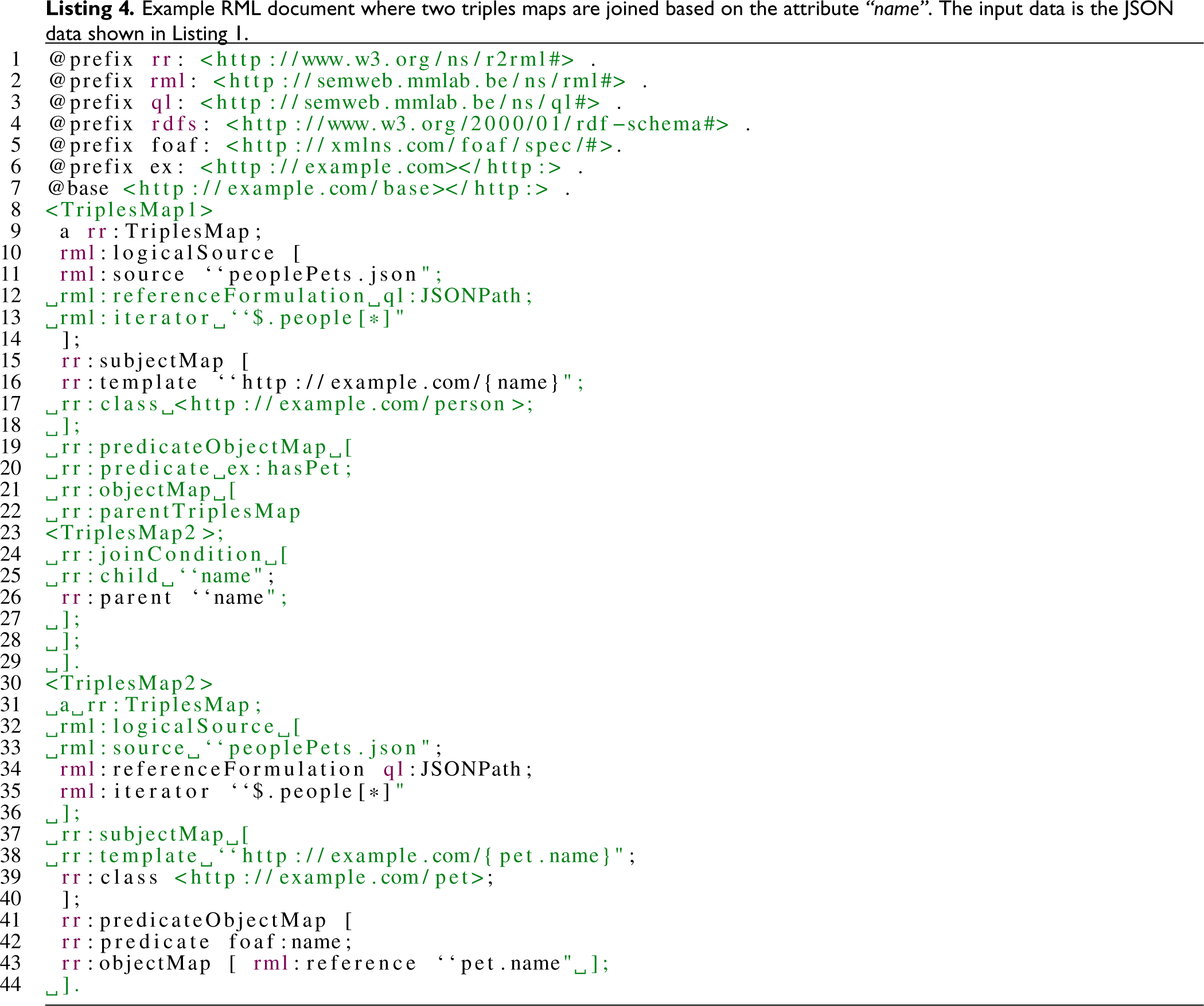
A Mapping Plan with Joins Generated from the Resource Description Framework Mapping Language (RML) Document in Listing 4.

A Mapping Plan Generated from the ShExML Document in Listing 5.
For RML, we use the RML v1.1.1 specification conformance test cases. Since RMLWeaver-JS only supports processing CSV files, we only chose the test cases using CSV files as input data source. The test cases for RML are available at the RMLWeaver-JS repository: https://github.com/RMLio/rmlweaver-js/tree/v0.1.1/test/rml-mapper-test-cases-csv.
For ShExML, the test cases provided with the reference implementation utilize heterogeneous data formats and sources such as a mix of JSON and XML or SPARQL endpoints. Since RMLWeaver-JS only supports input data files in CSV format, we adapted the test cases to utilize only CSV files as input. ShExML reference implementation’s test cases evaluates multiple features of the ShExML language per test case. Therefore, we also split up the existing test cases into multiple smaller test cases to conduct a more granular evaluation of RMLWeaver-JS’s execution of ShExML documents. For example, ShExML test case called MultipleElementTest tests for the usage of both multiple Iterators, and multiple Basic Expressions statements. We split it into two smaller test cases which evaluates the usage of multiple iterators and multiple basic expressions statements separately. This resulting set of test cases for ShExML are available at the RMLWeaver-JS repository: https://github.com/RMLio/rmlweaver-js/tree/v0.1.1/test/shexml.

Algebraic Mapping Engine Pipeline where an RML Document is First Translated into an Algebraic Mapping Plan which is used to Generate the KG. RML: Resource Description Framework Mapping Language; KG: Knowledge Graph.

RMLWeaver-JS produces the same output as the reference RML implementation 32 for all 39 out of the 39 RML CSV test cases (100%), covering 100% of the operational semantics of the RML CSV test cases (Table 12).
Our Solution Supports 65% of ShExML v2020 Features and 100% of RML v1.1.1 Features.

Our Solution Supports 65% of ShExML v2020 Features and 100% of RML v1.1.1 Features.
The features are aligned across the two languages in terms of their functionality in mapping heterogeneous data to RDF. For example, string operations in ShExML is equivalent to the usage of template-valued term maps in RML. RML: resource description framework Mapping Language; RDF: resource description framework.
For the ShExML test cases, RMLWeaver-JS generates the same output as the reference v0.5.1 ShExML implementation 33 .
Table 12 shows the number of features supported by RMLWeaver-JS in execution for both RML v1.1.1 and ShExML v2020. RMLWeaver-JS supports 16 out of 23 (65%) of ShExML features, and supports 11 out of 11 (100%) of RML v1.1.1 features. The exhaustive alignment of all ShExML features (such as Joins) to the introduced mapping algebra is future work. All testing code and results are published on GitHub 34 .
To show that the implementation of an algebraic mapping engine does not have a large negative impact on the performance, we participated (Min Oo et al., 2024) in the first part of the performance track of the 2024 KG Construction Challenge 35 . We highlight results of that participation in this paper, put it in context with the other participating mapping engines, and align the results with learnings concerning our proposed mapping algebra.
The performance track’s first part evaluates the mapping engines’ performance when handling diverse KG construction parameters with synthetic datasets, using RML mapping rules. Mapping engines are evaluated by changing the following properties of the data: The number of data records, data properties, duplicates, empty values, and input files. It also changes the following properties of the mapping rules: The number of subjects, predicates and objects, and finally, the number and type of joins used. For the measurements, the following metrics of the participating mapping engines are measured: (i) maximum RAM usage (GB), (ii) CPU usage (s), and (iii) execution time (s). The interpretation of CPU usage is as follows: 100% CPU usage is achieved when the CPU usage time (in seconds) equals the product of the execution time and the number of CPU cores available on the machine. In our evaluation setup, 100% CPU usage is four times the execution time as our machine has 4 cores available.
There are 5 mapping engines, including RMLWeaver-JS, participating in the performance track of the challenge. The engines can be classified into two major groups: Those based on data processing frameworks (e.g. Apache Spark and Flink), and those without using data processing frameworks. RPT-Sansa (Stadler & Bin, 2024), Mapping-template (Scrocca et al., 2024), and RMLStreamer (Min Oo et al., 2022) are based on Apache Spark 36 , Apache Velocity 37 , and Apache Flink 38 data processing frameworks respectively. The other 2 engines are FlexRML (Freund et al., 2024a, 2024b), implemented in C++, and our JavaScript implementation RMLWeaver-JS.
All the engines are evaluated on a virtual machine provided by the organizers, which has a standardized specification to ensure a fair evaluation. Each engine is provided with its own separate virtual machine for evaluation. The virtual machine has a 64 bit architecture, and it is configured with an Intel(R) Xeon(R) Gold 6161 CPU at 2.20GHz with 4 cores, 16765 MB of RAM memory, and 150 GB of storage space. The operating system of the machine is Ubuntu 22.04.03 LTS. The execution of the experiment is done using the tools provided by the challenge organizers (Van Assche et al., 2024), isolated via Docker container 39 .
Since the results are significantly more verbose than the completeness evaluation in Section 6.1, we present our results and discuss their causes separately.
Results
The full results of the challenge for KG parameters can be found on Zenodo 40 by downloading the file System-Results-Challenge-2024.zip. These results are based on the submissions by the authors of their respective engines. Thus, we can not conclude whether the engine failed at executing the test case or the results are omitted from the list. We skip the presentation of the results for duplicates and empty values test cases, since RMLWeaver-JS does not deduplicate the generated triples nor handle empty values in the columns by ignoring them. We discuss the results of the other test cases and compare our performance against the other participants in the following paragraphs.
Table 13 shows the engines’ performance when the number of TM and predicate-object maps (POM) in the RML document changes, while the input dataset size stays the same. For the other engines, there is no difference in CPU usage and execution time increase when compared to RMLWeaver-JS. Where for FlexRML execution time shortens and CPU usage maximizes for the test case with 3 TM and 5 POM, for RMLWeaver-JS execution time and CPU usage increases across the test cases. It even has a 4-fold increase for execution time and CPU usage for the test case with 15 TM and 1 POM.
FlexRML is the Most Performant Engine When Constructing Knowledge Graph from Varying Triples Maps and Predicate-Object Maps.

FlexRML is the Most Performant Engine When Constructing Knowledge Graph from Varying Triples Maps and Predicate-Object Maps.
Note: Best performance highlighted in bold.
It performs best when the number of TMs is closer to the number of CPU cores on the machine. TM: triples map; RML: resource description framework Mapping Language; POM: predicate-object map.
Table 14 shows the results of the test cases to evaluate the performance impact by increasing the number of columns in the input CSV dataset. RMLStreamer and RMLWeaver-JS maintain constant memory usage, while for the other engines memory usage increases with the number of columns. RMLWeaver-JS maintains the lowest memory usage amongst engines for the 10 and 30 columns CSV data records test cases. For all engines, execution time and CPU usage increases with the number of columns. Mapping-template is the fastest in terms of execution time and lowest CPU usage. FlexRML is only slightly faster, by 0.08 seconds, than Mapping-template for the first test case with 1 column CSV data records.
Number of Properties in CSV Data Records has Little to no Impact on the Memory Usage of RMLWeaver-JS.

Note: Best performance highlighted in bold.
RML: resource description framework Mapping Language.
Table 15 contains the results of the test case with increasing number of CSV data records. For the test case with 10K rows, FlexRML is the fastest engine (1.23 seconds) using the lowest memory (0.4 GB) while Mapping-template’s CPU usage is the lowest at 0.55 seconds. Once the number of rows reaches 100k, Mapping-template becomes faster than FlexRML and uses noticeably less CPU time (8 times less than FlexRML), but memory usage increases with 0.44 GB compared to the 10k rows test case. However, Mapping-template fails to produce any results for 10M rows of CSV data. Throughout the experiment, RMLWeaver-JS maintains a constant memory usage of approximately 0.5 GB even for the 10M rows test case. RMLStreamer uses the same amount of memory of around 6.1 GB for both 100k and 10M rows of CSV data. This is similar to the amount of memory RMLStreamer uses for the test cases in Table 14.
RMLWeaver-JS Manages to Keep Memory Usage Constant Around 0.5 GB with Increasing Input Data Size, While flexRML is the Fastest.

Note: Best performance highlighted in bold.
RML: resource description framework Mapping Language.
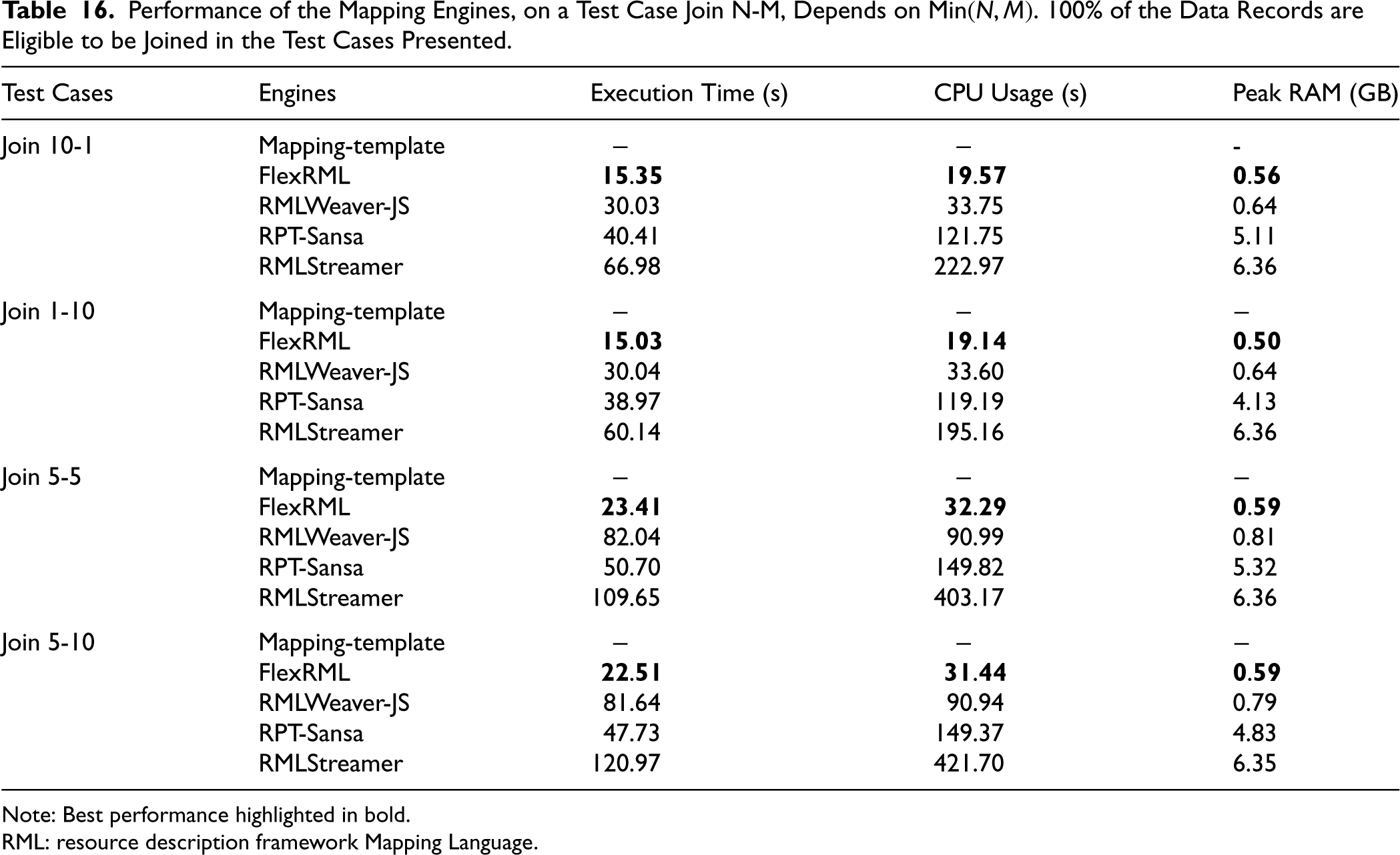
Table 16 provides the measurements of evaluating on the join related test cases where 100% of the data records are eligible to be joined. All engines maintain similar performance across test cases Join N-M based on min
Performance of the Mapping Engines, on a Test Case Join N-M, Depends on Min
Note: Best performance highlighted in bold.
RML: resource description framework Mapping Language.
Analysing the results presented in Section 6.2.1 reveals several potential improvements for implementing a more efficient algebraic mapping engine.
Compared to the other engines, RMLWeaver-JS exhibits an abnormal behaviour for the test cases where the number of TMs and POMs changes inversely in the RML document (Table 13). For example, RMLWeaver-JS is the only engine with a significant spike in execution time from 11.26 seconds to 42.57 seconds for the test cases 1TM 15POm, and 15TM 1POm respectively. This can be explained due to the manner in which AlgeMapLoom (Section 5) translates the RML document into the algebraic mapping plan used by RMLWeaver-JS. The test cases include multiple TMs, each with its own definition of a logical source, all referring to the same CSV data file and using the same iterator. Due to the lack of detection for semantically similar data sources, the interpreter generates a distinct source operator for each logical source definition identified. In the specific test case of 15 TMs and 1 POM, a total of 15 source operators are generated, with each TM associated with one of these source operators. RMLWeaver-JS is implemented in JavaScript without worker threads, thus inherently single-threaded and can only execute one task at a time. Thus, processing the CSV data file 15 times instead of just once is done sequentially. This results in a noticeable increase in both execution time and CPU usage.
For the test cases regarding increasing number of properties and records, RMLWeaver-JS and RMLStreamer managed to maintain constant memory even if the input data columns or rows increase. This consistent memory usage is due to the way both engines process data. On one hand, RMLStreamer – built on the Apache Flink stream processing framework – processes input CSV rows one at a time. Consequently, RMLStreamer maintains a constant memory usage of around 6.1 GB, even for inputs with a higher number of columns and records. On the other hand, RMLWeaver-JS, implemented based on reactive programming paradigm, also processes the input CSV records one at a time, leading to the same constant memory usage. The substantial difference in memory usage, with RMLWeaver-JS using around 0.5 GB and RMLStreamer using approximately 6 GB, is due to the overhead of the underlying Apache Flink framework. Apache Flink allocates a fixed amount of heap memory for the Java Virtual Machine on which RMLStreamer is executed. Thus, RMLWeaver-JS has a lower memory usage than RMLStreamer due to the implementation not relying on data processing frameworks.
As observed in Table 16, all engines demonstrate the same performance across two different test cases in Join N-M, depending on the min
Summarizing the results, RMLWeaver-JS achieved the second place for the Track 2 performance challenge in KG Construction Workshop, handing first place to FlexRML (Van Assche et al., 2024). This achievement shows that it is possible to implement a performant algebraic mapping engine in JavaScript for web browsers, potentially empowering web clients and servers with KGs generated from heterogeneous data sources.
Conclusion
In this paper, we presented a mapping language-independent mapping algebra consisting of algebraic mapping operators Source, Projection, Extend, Rename, Fragmenter, Natural join,
In our parallel work, we focussed on a provable theoretical foundation for core operators applied to RML v1.1.2, allowing us to prove equivalence classes, and thus, theoretical optimizations for RML v1.1.2 engines (Min Oo & Hartig, 2025). In this journal article, we focus on a more exhaustive set of language-agnostic operators, allowing us to build end-to-end language-agnostic engines.
For future work, we will investigate to which degree we can apply the theoretically founded operators and data model definitions of our parallel work into the more exhaustive data model and operators of this work, given the difference in scope and theoretical grounding (i.e., relational algebra in our parallel work versus SPARQL algebra in this work). The resulting mapping algebra could further be used to develop a formal mapping language with a formal grammar. Such a language will benefit from the operational semantics already defined by the algebra. To formalize the operators not investigated in our parallel work, the Algemaploom-rs output adhering to a specific JSON schema can serve as an inspiration.
We will exploit this mapping algebra for mapping process research: Translating mapping rules – in multiple mapping languages – into mapping plans conforming to our mapping algebra opens the door to static analysis of mapping rules, for example, for verification and optimization. After further completion of our proof-of-concept implementations, for example, researching the alignment of the join semantics in ShExML with our mapping algebra, we will investigate a mapping plan optimizer to improve the mapping process regardless of the mapping language used. We will start by considering existing optimizations, such as mapping partitions (Arenas-Guerrero et al., 2022) and mapping assertions (Iglesias et al., 2023), and we will exploit the theoretical equivalence classes found in our parallel work (Min Oo & Hartig, 2025) (i.e., projection pushing for intermediate result size reduction): These can be expanded towards our presented operators to have a more comprehensive set of optimization rules in our language-agnostic engine. We will present and benchmark these optimizations in a unified mapping algebra model.
With the advent of this mapping algebra and algebraic mapping engines, users are no longer locked into using a specific mapping language for KG generation. The performance across languages will become consistent by having an algebraic mapping engine that is multilingual, hence mapping language design can focus on functionality, decoupled from performance.
Footnotes
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.