
Abstract
The Data Quality Vocabulary (DQV) provides a metadata model for expressing data quality. DQV was developed by the Data on the Web Best Practice (DWBP) Working Group of the World Wide Web Consortium (W3C) between 2013 and 2017. This paper aims at providing a deeper understanding of DQV. It introduces its key design principles, components, and the main discussion points that have been raised in the process of designing it. The paper compares DQV with previous quality documentation vocabularies and demonstrates the early uptake of DQV by collecting tools, papers, projects that have exploited and extended DQV.
Introduction
Data quality is a well-known issue accompanying information systems in every evolution from the database systems to the current Web of Data. As discussed in the recent W3C Recommendation Data on the Web Best Practices [10], “The quality of a dataset can have a big impact on the quality of applications that use it. As a consequence, the inclusion of data quality information in data publishing and consumption pipelines is of primary importance. Documenting data quality significantly eases the process of dataset selection, increasing the chances of reuse. Independently from domain-specific peculiarities, the quality of data should be documented and known quality issues should be explicitly stated in metadata.”
Aiming to facilitate the publication of such data quality information on the Web, especially in the growing area of data catalogues, the W3C Data on the Web Best Practices (DWBP) Working Group has developed the Data Quality Vocabulary (DQV) [6]. DQV is a (meta)data model implemented as an RDF vocabulary, which extends the Data Catalog Vocabulary (DCAT) [25] with properties and classes suitable for expressing the quality of datasets and their distributions. DQV has been conceived as a high-level, interoperable framework that must accommodate various views over data quality. DQV does not seek to determine what “quality” means. Quality lies in the eye of the beholder: there is no objective, ideal definition of it. Some datasets will be judged as low-quality resources by some data consumers, while they will perfectly fit others’ needs. There are heuristics designed to fit specific assessment situations that rely on quality indicators, such as pieces of data content, meta-information and human ratings in order to give indications about the suitability of data for some intended use. DQV re-uses the notions of quality dimensions, categories and metrics to let its users represent various approaches to data quality assessments. It also stresses the importance of allowing different actors to assess the quality of datasets and publish their annotations, certificates, or mere opinions about a dataset.
We claim that DQV exhibits by design a set of characteristics that have not been combined so far in quality documentation vocabularies, e.g., the Dataset Quality Ontology (daQ) [13,14], the Data Quality Management Vocabulary (DQM) [19], the Quality Model Ontology (QMO) [30] and the Evaluation Result ontology (EVAL) [31]: (1) it results from a community effort; (2) it directly re-uses standard W3C vocabularies; (3) it covers a wide range of quality requirements; (4) it embraces the minimal ontological commitment. Especially, though DQV has been originally conceived to document DCAT datasets and distributions, it can be used to document the quality of any resource published on the web. DQV can then serve as a common exchange ground between quality assessments from different parties as well as a building block to model specific quality assessments in a large spectrum of domains and applications.
This paper complements the published W3C Working Group Note [6], offering insight into the requirements and the process considered developing DQV. Section 2 explains our methodology, especially detailing the design principles adopted for the development of DQV; Section 3 presents the main components of DQV and illustrates how these components can represent the most common quality information; Section 4 compares DQV with related work; Section 5 discusses the current DQV uptake; Section 6 summarizes the contributions and outlines future activities.
Methodology and design principles
DQV has been developed under the umbrella of the W3C Data on the Web Best Practices (DWBP) Working Group, which was chartered to facilitate the development of open data ecosystems, guiding publishers and fostering the trust in the data among developers. The group worked between December 2013 and January 2017; the group discussions took place in about 135 near-weekly teleconferences and five face-to-face meetings. The group has delivered a set of best practices collected in the Data on the Web Best Practices W3C Recommendation [10] and two W3C Working Group Notes describing the RDF vocabularies: the Dataset Usage Vocabulary [36] and the Data Quality Vocabulary [6]. The efforts of the Working Group have focused on meeting requirements expressed in another W3C Working Group Note, the Data on the Web Best Practices Use Cases & Requirements [24].
This paper focuses on DQV. The design of DQV considers the requirements distilled in Section 4.2 of the DWBP Use Cases & Requirements [24] and the feedback received in response to four DQV Public Working Drafts issued towards relevant external communities. Public feedback and interactions about DQV with DWBP group members are registered in 90 public mailing list messages, in more than 30 formal issues, and over 130 formal and informal actions.1
Here we count both formal actions within the W3C process, which are assigned to group members in order to address an issue and are tracked by the W3C facilities (see
Issues. Details of all issues are documented in the Working Group’s issue tracker at
Requirements. Requirements are documented in the Use Cases & Requirements document [24]. Requirements are referred to in the text by their handles, e.g.,
In terms of guiding principles, the group has considered two fundamental principles to enable the reusability and the uptake of DQV:
a commitment to find a sweet spot between existing proposals rather than surpass them in scope or complexity;
a focus on interoperability. DQV should be easy to map to (for existing vocabularies) as well as to re-use and extend.
These enabling principles turned into design principles that others might have failed to follow, and which mirror two best practices that have been identified in our Working Group’s more general recommendations on data vocabularies [10]:
minimize ontological commitment, fitting Best Practice 16 (“Choose the right formalization level”);
re-use existing vocabularies unless there’s a good reason not to do so (Best Practice 15).
The principles above have deeply impacted the design of DQV. For example, DQV is designed to fit well into the DCAT model, but, in compliance with the minimal ontological commitment principle, it is also possible to deploy it with other models. Consequently, no formal restrictions have been imposed to restrict the domain of DQV properties to DCAT datasets and distributions. We also decided not to define the DQV elements as part of the DCAT namespace (
In adherence to the second design principle, DQV reuses standard W3C vocabularies. In particular, it reuses SKOS [7,27] to organize the Quality Dimensions and Categories into hierarchies and to represent their lexical representations and definitions (
Finally, as presented in the introduction, DQV is a data model implemented as an RDF vocabulary. The vocabulary is represented as an RDFS/OWL ontology that is accessible via the DQV namespace. This is only one of many possible representations, however. In particular, future extensions or profiles may benefit from the availability of representations of DQV axioms as SHACL or ShEx shapes.
This section describes the components of DQV. DQV relates (DCAT) datasets and distributions with different types of quality statements, which include Quality Annotations, Standards, Quality Policies, Quality Measurements and Quality Provenance. Quality information pertains to one or more quality characteristics relevant to the consumer (aka, Quality Dimensions).
The way DQV represents the quality dimensions and each kind of quality statements is shown in a separate gray box in Fig. 1 and discussed in the following sections.5
Full versions of the examples included in the following sections (including declaration of namespace prefixes) are available as RDF files at

Diagram depicting DQV classes and properties. For the sake of readability, the diagram does not include all the DQV properties.
Data quality is commonly conceived as a multi-dimensional construct [41] where each dimension represents a quality-related characteristic relevant to the consumer (e.g., accuracy, timeliness, completeness, relevancy, objectivity, believability, understandability, consistency, conciseness). For this reason, DQV relates Quality Metrics, Quality Annotations, Standards, and Quality Policies to Quality Dimensions (see the dqv:inDimension property in Fig. 1). The quality dimensions are systematically organized in groups referred to as quality categories. For instance, categories can be defined according to the type of information that is considered, e.g., Content-Based – based on information content itself; Context-Based – information about the context in which information was claimed; Rating-Based – based on ratings about the data itself or the information provider. But they can also be defined according to other criteria, which can lead to quite composite hierarchies depending on the idea of fitness for use that guides specific quality assessments.
In coherence with the principle of reusing existing vocabularies, DQV uses SKOS [27] to define dimensions and categories (
The classes dqv:Dimension and dqv:Category represent quality dimensions and categories respectively, and are defined as subclasses of skos:Concept.
Dimensions are linked to categories using the property dqv:inCategory. Distinct quality frameworks might have different perspectives over dimensions and their grouping in categories, so in accordance to the minimal ontological commitment, no specific cardinality constraints are imposed on the dqv:inCategory property.
The properties skos:prefLabel and skos:definition indicate the name and definition for dimensions and categories. SKOS semantic relations (i.e., skos:related, skos:broader, skos:narrower) are used to relate dimensions/categories. In particular, skos:broader and skos:narrower enable to model fine-grained granularities for dimensions and categories (
Example 1 shows a fragment, in the RDF Turtle syntax,6
In this paper, examples show constructs in bold when they are especially relevant for the features being illustrated.
We provide a non normative RDF representation of these dimensions and categories under the W3C umbrella at

DQV mints only one instance of quality dimension – dqv:precision – in order to tackle the
For example, qSKOS – a quite popular tool assessing the quality of thesauri – detects a set of SKOS quality issues, which is distinct from the dimensions proposed by ISO 25012 and Zaveri et al. To represent the results of qSKOS in DQV, we have mapped the qSKOS quality issues into a new classification of quality dimensions and categories published at
Quality measurements provide quantitative or qualitative information about data. Each measurement results from the application of a metric, which is a standard procedure for measuring a data quality dimension by observing concrete features in the data.
The need to represent quality measurements and metrics emerged from the use case analysis by the DWBP Working Group and it is indicated as the
DQV represents quality measurements as instances of the dqv:QualityMeasurement class. Each measurement refers through the property dqv:isMeasurementOf to a metric which is represented as an instance of the dqv:Metric class.
dqv:QualityMeasurement encodes the metric’s observed value using the property dqv:value. The expected data type for dqv:value is represented at the metric level, using the property dqv:expectedDataType, so that implementers are encouraged to represent all measurements of a metric using the same data type. The unit of measure of dqv:value is expressed using the property sdmx-attribute:unitMeasure that is already used by RDF Data Cube (see below). The dqv:computedOn property refers to the resource on which the quality measurement is performed. In the DQV context, this property is generally expected to have instances of dcat:Dataset or dcat:Distribution as objects. However, in compliance with the minimal ontological commitment principle, dqv:computedOn can refer to any kind of rdfs:Resource (e.g., a dataset, a linkset, a graph, a set of triples).
Example 2 below describes three metrics, :populationCompletenessMetric, :sparqlAvailabilityMetric and :downloadURLAvailabilityMetric, which evaluate the two quality dimensions ldqd:completeness and ldqd:availability defined in Example 1. It also shows three quality measurements :measure1, :measure2 and :measure3 that represent the result of applying the above metrics to the DCAT dataset :myDataset and two distributions of it: CSV (:myCSVDatasetDistribution) and SPARQL (:mySPARQLDatasetDistribution).

The use of metrics checking for completeness is one of the possible approaches to indicate that data is partially missing or that a dataset is incomplete, as demanded by the
Metrics can have parameters. For example, the LusTRE project has defined a metric to evaluate the quality of a set of links between a dataset and another, from the perspective of data augmentation scenarios [3]. This metric can be applied considering a specific property in the data or values that are in a specific language, in order to produce an indicator tailored to applications that relies more heavily on this property or this language (see the discussion on Data Cube and parameters below). DQV does not propose a standard representation of such parameters. The Working Group observed that parameters for metrics were a much less mature aspect of our field, and as a consequence, the DQV Working Group Note only suggests possible approaches, on which the users might build on their solutions (see
Note that in general DQV is also agnostic about the technology adopted to implement the metrics; it does not provide any specific “language for defining metrics”. For example, DQV does not specify how the rule from Example 10 (“A dataset is available if at least one of its distributions is available”) should be represented and evaluated.
For the definition of quality metrics and measurements, DQV has adapted and revised the ontology for Dataset Quality Information (daQ) [14]. It keeps most of the daQ structure. However, daQ vocabulary is not a community standard and its guarantee of sustainability may be judged not sufficient (
Like daQ, DQV reuses the RDF Data Cube vocabulary [12] to represent multidimensional data, including statistics (

DQV users should be aware that applying Data Cube Data Structure Definitions to their quality statement datasets has a broad impact on the possible content of these. In fact, all the resources that are said to be in a quality measurement dataset (using the qb:dataSet property) are indeed expected to feature all the components defined as mandatory in the Data Structure Definition associated with the dataset. Moreover, RDF Cube imposes specific integrity constraints, for example, “no two qb:Observations in the same qb:DataSet may have the same value for all dimensions” [12]. Considering the Data Structure Definition in Example 3, the above constraint implies that it is not allowed to have two distinct measurements for the same metric, resource, and date. As a result, metrics depending on parameters shall be used with extra care so as to adhere to this constraint: data publishers will be able to represent quality measurements for the same metric, resource, and date, but they will need to include in the structure the distinct parameters that are applied. For example, if the metric depends on two extra parameters, such as :onProperty and :onLanguage (reprising the example of [3] mentioned above), the qb:DataStructure will include two qb:components in addition to those in Example 3.

All the measurements represented in a dqv:QualityMeasurementDataset conforming to such an extended structure have to indicate metric, resource, date and the extra two parameters.
Data Cube’s Data Structures are also harder to apply when quality metrics relying on different parameters are mixed together.
Quality annotations include ratings, quality certificates and quality feedback that can be associated with data. DQV tackles these kinds of quality statements to meet the
In accordance with the principle of re-using established vocabularies, DQV models annotations by specializing the Web Annotation Vocabulary [11]. Quality annotations are defined as instances of the dqv:QualityAnnotation class, which is a subclass of oa:Annotation (
In the W3C Web Annotation data model, all annotations should be provided with a motivation or purpose, using the property oa:motivatedBy in combination with instances of the class oa:Motivation (itself a subclass of skos:Concept). For all quality annotations, the oa:motivatedBy must have as value the individual dqv:qualityAssessment defined by DQV for representing the motivation of assessing quality. Besides dqv:qualityAssessment, one of the instances of oa:Motivation predefined by the Web Annotation vocabulary should be indicated as motivation in order to distinguish among the different kinds of feedback, e.g., classifications, comments or questions (
The example below shows how to model a question about the completeness of the “City of Raleigh Open Government Data” dataset identified by the Open Data Institute (ODI) with the URI

Example 5 expresses that the “City of Raleigh Open Government Data” dataset is classified as a four stars dataset in the 5 Stars Linked Open Data rating system. The annotation :classificationQA is a user feedback that associates the dataset with the :four_stars concept where we expect the Linked Open Data 5 stars system to be represented via five instances of skos:Concept expressing the different ratings in an :OpenData5Star SKOS concept scheme. The feedback is a form of classification for the dataset, which is expressed by the oa:classifying motivation.

Example 6 expresses that an ODI certificate for the “City of Raleigh Open Government Data” dataset is available at a specific URL. :myDatasetQA is an annotation connecting the dataset to its quality certificate.
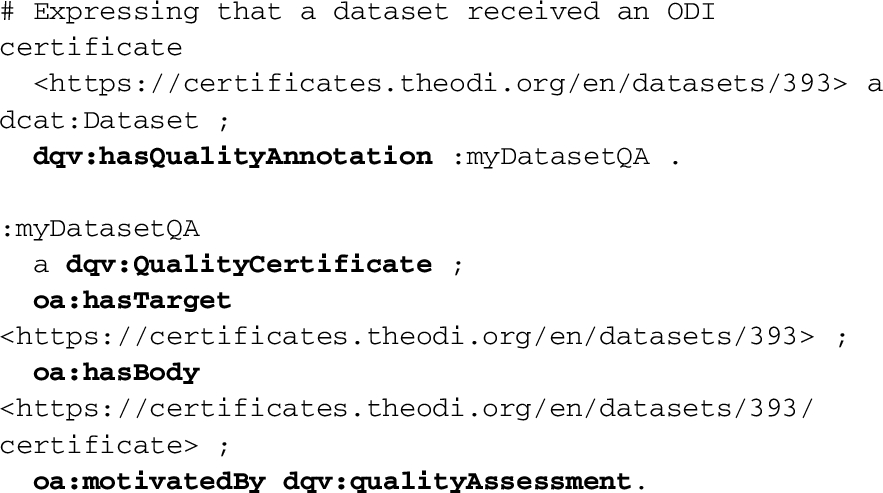
DQV users can exploit quality annotations jointly with quality metrics. For example, automatic quality checkers can complement their metric-based measurements with annotations to provide information not directly expressible as metric values (e.g., listing errors and inconsistencies found while assessing the quality metrics). Quality annotations can be also deployed when quality metrics have not been explicitly applied, for example to describe a known completeness issue of a certain dataset.
In the end, annotations can be used in conjunction with or as an alternative to other DQV components like metrics. The model is flexible and the choice to use an annotation instead of a metric might depend on the application context and the user preferences. As a rule of thumb, annotations seem a good fit for manual quality evaluations, while metrics and measurements would rather represent automatic assessments. But some metrics can be measured manually and some annotations can be generated automatically. For example, a (basic) availability evaluation may be represented as a score of 0 or 1, but still set by a human evaluator. Alternatively, availability could be expressed as an annotation with two possible concepts (“available” and “not available”), decided by an automatic agent trying to fetch the dataset at a provided URI.
Quality policies are agreements between service providers and consumers that are chiefly defined by data quality concerns.
The DWBP Working Group decided to express such policies following a discussion about Service Level Agreements (SLA) (
Example 7 below specifies that a data provider grants permission to access the dataset :myDataset of Example 2. It also commits to serve the data with a certain quality, more concretely, 99% availability in the SPARQL endpoint (seen as a DCAT data service) :mySPARQLService which provides access for :mySPARQLDatasetDistribution. Such a policy is expressed in ODRL (and DQV) as an offer assigning to the service provider (:serviceProvider) a duty on the provided service (:mySPARQLService), which is expressed as a constraint on the measurement of a quality metric (:sparqlEndpointUptime). In ODRL the odrl:assigner is the issuer of the policy statement; in our case, the assigner is also the assignee of the duty to deliver the distribution as the policy requires it. There is no recipient for the policy itself: this example is about a generic data access policy. Such assignees are more likely to be found for instances of dqv:QualityPolicy that are also instances of the ODRL class odrl:Agreement.
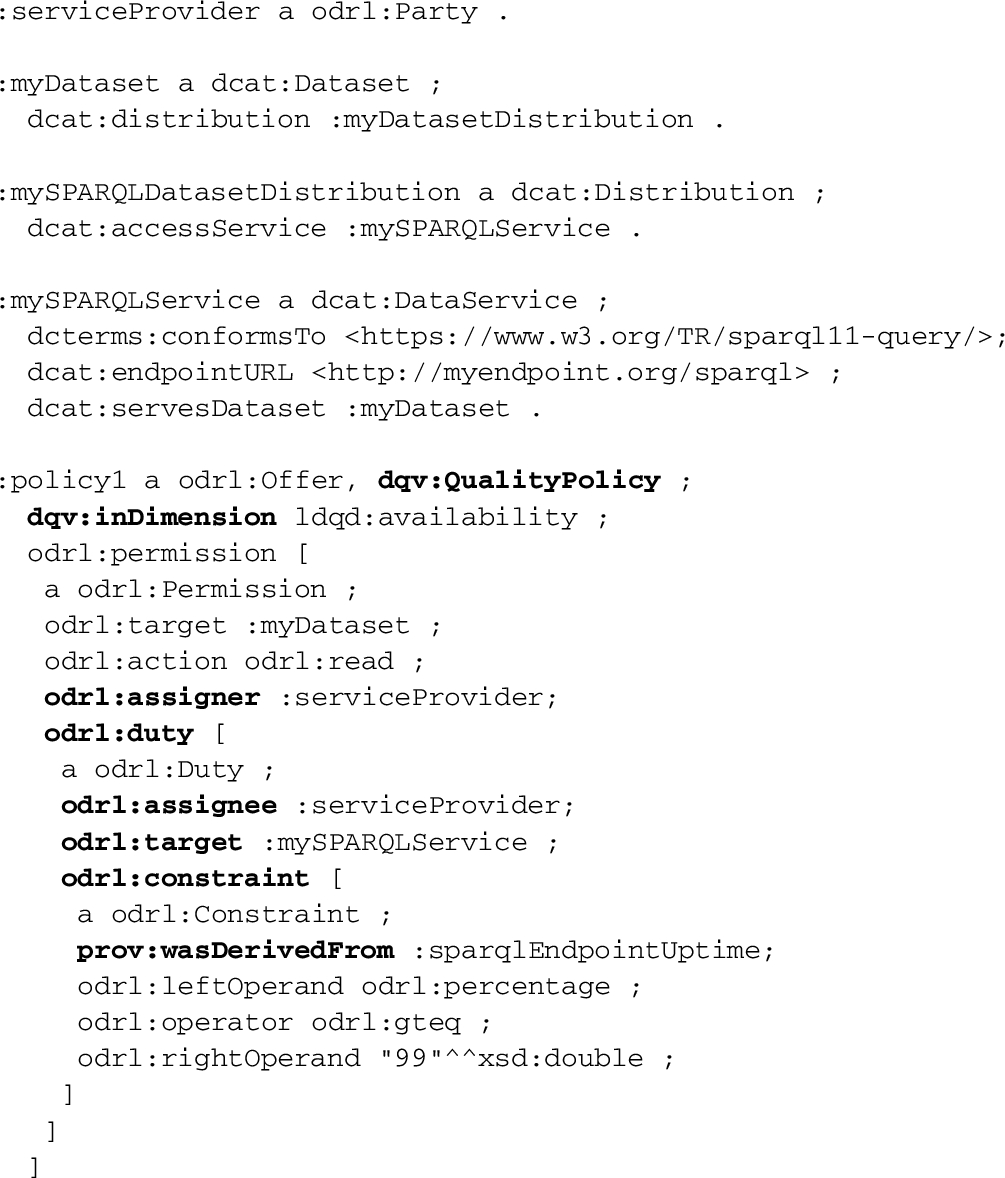
The above example slightly differs from the example originally included in the DQV Working Group Note [6]: the ODRL vocabulary has evolved since DQV was published and the expression of ODRL constraints now requires the representation of left and right operands.
Conformance to a given standard can convey crucial information about the quality of a data catalog. In particular, the modelling that a dataset’s metadata is compliant with a standard came out as a cross-cutting requirement discussing the relation of DQV with other standards (
DQV models this kind of statement by reusing the property dcterms:conformsTo and the class dcterms:Standard. This simple solution is copied from GeoDCAT-AP [18], an extension of the DCAT vocabulary [25] conceived to represent metadata for geospatial data portals. GeoDCAT-AP allows one to express that a dataset’s metadata conforms to an existing standard, following the recommendations of ISO 19115, ISO 19157 and the EU INSPIRE directive. The newly published DCAT 2 [2] has copied this pattern, too.
The DQV Working Group Note [6] includes an example to illustrate how a DCAT catalog record can be said to be conformant with the GeoDCAT-AP standard itself.
Conformance to standards can of course be also asserted for datasets themselves, not only metadata about them. The following example shows how a dataset can be declared conformant to the ISO 8601 standard, using the same basic pattern.

Finer-grained representation of conformance statements can be found in the literature. Applications with more complex requirements, such as being able to represent ‘non-conformance’ as tested by specific procedures, may implement them. The GeoDCAT Application Profile, for example, suggests a “provisional mapping” for extended profiles, which re-uses the PROV data model for provenance (see Annex II.14 at [18]). Such solutions come however at the cost of having to publish and exchange representations that are much more elaborate. At the time we considered them, it also appeared they would have to be aligned with the result of other (then ongoing) efforts on data validation and reporting thereof, for example, in the SHACL context. The DWBP Working Group therefore decided to postpone addressing such detailed conformance matters (see
The DWBP Working Group has identified a requirement for tracking provenance for metadata in general (
QualityMetadata containers can contain every kind of quality statements supported in DQV. However, they do not necessarily have to include all types of quality statements. Implementers define the granularity of containment as they see fit. For example, they might want to group together the results from the same tools, the same type of quality statements, or all quality statements from the same quality assessment campaign. In the current version, DQV leaves also open the choice of the technical means used for containment. Implementers can use (RDF) graph containment10
to assign quality statements to specific graphs, for example using RDF TriG.11
Using RDF TriG, the example below gathers a set of quality statements on :myDataset and its distributions :mySPARQLDatasetDistribution, :myCSVDatasetDistribution, including measurements (:measurement1, :measurement2 and :measurement3) and an annotation (:classificationOfmyDataset) produced during one activity (:myQualityChecking) and by one tool (:myQualityChecker).

At a lower level of granularity, DQV allows to track provenance links across quality measurements or annotations. It is possible to use PROV-O’s prov:wasDerivedFrom to indicate that a quality statement, say, a certificate, is derived from another, for example, the computation of some metric (

Note that DQV does not systematically declare its classes to be subclasses of those in the Provenance Ontology (e.g., subclassing between dqv:QualityMeasurement and prov:Entity). First, “recognizing” that some DQV resources have also a PROV-O type can be inferred by looking at the (RDFS) domain or range of the PROV-O properties applied to them. Second, we wanted to avoid limiting in any way the use of PROV-O with DQV, as well as the proliferation of instances declaring PROV-O classes without any other actual provenance statements associated with them.
The linked data community has proposed different quality documentation vocabularies in the last eight years.
The Data Quality Management Vocabulary (DQM) [19] addresses the definition of quality problems for representing quality rules and data cleansing, and defines more than 40 new classes and 56 properties embedding most common quality problems. It explicitly models data quality dimensions such as Accuracy, Completeness and Timeliness, but dimensions are hard coded in the model rather than expressed as a quality dimension framework that can be plugged in. DQM models the notion of quality score that relates to quality concepts such as Quality Metric and Measurements, but it does not include other DQV quality components such as annotations and policies. Besides, publication and (lack of) usage hints it is explorative work, which seems not maintained anymore.
The Quality Model Ontology (QMO) [30] and Evaluation Result ontology (EVAL) [31] are two ontologies defined to work together; QMO defines “a generic ontology for representing quality models and their resources” [32]; EVAL defines “a generic ontology for representing results obtained in an evaluation process” [32]. QMO and EVAL are not developed by an international working group, but they explicitly adopt the terminology used by the ISO 25010 (SQuaRE) and by the ISO/IEC 15939 standards. Similarly to DQV, they represent metrics and measurement results. However, they do not include other quality components addressed by DQV, such as annotations and policies. Nor do they reuse existing (W3C) vocabularies such as SKOS to represent quality metrics and dimensions.
The Dataset Quality Ontology (daQ) “allows for representing data quality metrics as statistical observations in multi-dimensional spaces” [13]. DQV borrows quality metrics and dimensions from daQ, but it revises the daQ solution according to the minimal ontological commitment and the reuse of best-of-breed W3C vocabularies. Besides, DQV covers quality components such as Quality feedback, certificate and policy that are not included in daQ. In the family of the ontologies around daQ, the Quality Problem Report Ontology QPRO supports the representation of quality reports that gather quality problems [15]. It does not cover quality components offered by DQV, but it can be considered as a complement to DQV for listing errors and inconsistencies found while assessing the quality metrics.
The Evaluation and Report Language (EARL) [1] is a W3C vocabulary, which stems from a community effort to describe tests and their results in a general setting. EARL is not a direct competitor to DQV, as it has a minimal overlap with its requirements. EARL can be used in the context of quality assessment, and represents some information that could also be represented using DQV. For example, DCAT 2 [2] uses it to represent conformance tests and their results,14
while the latter can be expressed using DQV. This DCAT example shows however the difference of scope between EARL and DQV: as noted in Section 3.5, DCAT itself uses a different pattern for expressing conformance when complex descriptions of testing activities are not needed, and this pattern (using the dcterms:conformsTo property15
There are other works on expressing quality, such as ISO 25010 (SQuaRE) and the ISO/IEC 15939 standards. However, they are not specifically intended for use in linked data contexts. This would require some specific adaptations, and we have listed already in this section the work that we are aware of in this respect. For this reason, we consider further comparison with them out of scope for this review.
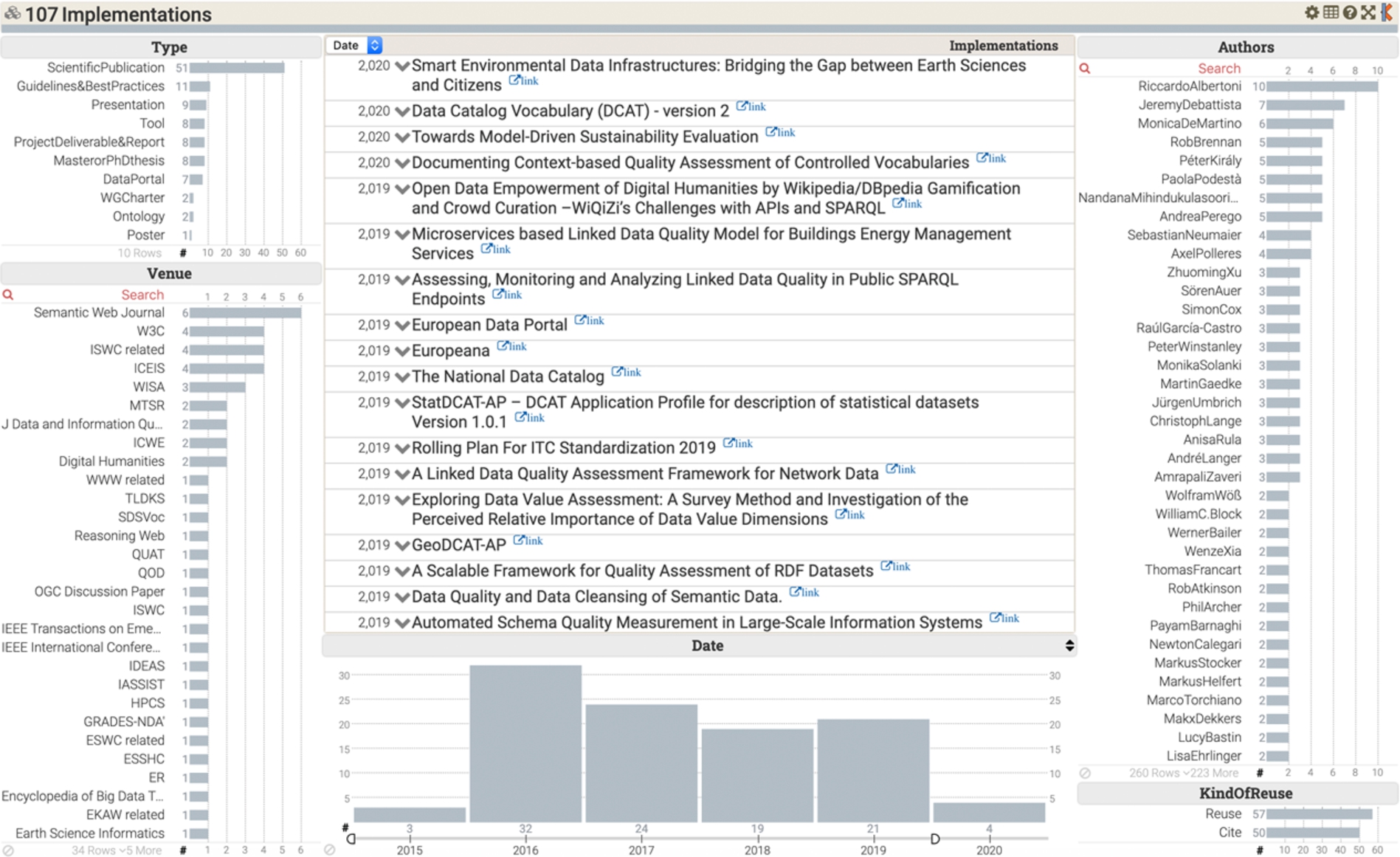
DQV implementations collected until February 2020, available at
In summary, none of the aforementioned vocabularies contemporarily exhibit the DQV characteristics, namely, (1) being the result of a community effort such as a W3C Working Group; (2) easing interoperability adopting design principles such as minimal ontological commitment and the reuse of established W3C vocabularies; (3) covering a wide spectrum of quality requirements including the representation of metrics, quality measurements, certificates, and quality annotations.
The DQV Working Group Note editors, who are the authors of this paper, maintain a list of projects, papers, guidelines and data services reusing DQV16
Summary of the DQV implementations collected until February 2020
For example, 51 scientific papers have mentioned the DQV (e.g., [3,8,9,16,33,38]), 25 of which have directly reused it (e.g., [5,29,35]). In particular, Radulovic et al. [32] adopt the DQV to model the quality of linked data datasets at different levels of granularity (IRI, statement, graph, dataset). The Aligned project combines DQV with the W3C SHACL Reporting Vocabulary,17
11 international guidelines/best practices suggest DQV for documenting the quality of open data. For example, the StatDCAT Application Profile [17] recommends dqv:QualityAnnotation to document ratings, quality certificates, feedback that can be associated to datasets or distributions. The W3C Spatial Data on the Web Best Practices [37,39] reuses DQV to describe the positional accuracy of spatial data.
8 tools use DQV to encode the results of their elaborations. For instance, qSKOS [26] maps its quality metrics to DQV;20
7 data services have published quality metadata adopting DQV: the Linked Thesaurus fRamework for Environment (LusTRE)22
International working groups such as the W3C Dataset Exchange Group (DXWG), the RDA WDS/RDA Publishing Data Interest Group and the WDS/RDA Certification of Digital Repositories Interest Group28
DQV is a (meta)data model implemented as an RDF vocabulary, whose original motivation is the documentation of the quality of DCAT Datasets and Distributions. DQV is a community effort developed in the W3C DWBP Working Group, which gives it high visibility and status. In addition, and more than other proposals for expressing quality information, it specifically embraces design principles meant to favor its reusability and uptake. The adoption of minimal ontological commitment has led us to avoid unnecessary domain restrictions, for DQV can be applied to any kind of web resource, not only DCAT Datasets and Distributions. The reuse of consolidated design patterns from other standard vocabularies has minimized the number of new terms defined in DQV and it is expected to shorten its learning curve. These factors seem to have facilitated a number of DQV reuses, which is encouraging considering the recency of DQV.
As DQV is a Working Group Note, it is not a final recommendation and can be seen as a work in progress. As its editors, we are committed to support the adoption of DQV and consider issues and questions arising from the reuse of DQV in specific use cases and projects. We are especially interested in feedback from DQV adopters about barriers or requirements, which might have been disregarded in this first specification round. From the feedback received so far, we are considering the following future activities:
define a default ShEx schema and/or SHACL shape to help adopters to understand the (few) constraints that apply by default to DQV data and potentially help them to create their own profiles/extensions of DQV, including additional constraints that their applications may need;
publish a JSON-LD context [22] to facilitate the use of DQV in a JSON environment;
include a notion of severity for the discovered quality issues;
define DQV mappings with metadata models (or extensions of such models with DQV elements) adopted in domain specific portals, such as INSPIRE;
develop consumption tools such as a visualizer;
develop registries (possibly equipped with APIs) for the dimensions and metrics coming from different quality frameworks and the alignments between them.
Besides these, some already started work is likely to bring new lines of activity around DQV: The ongoing DCAT revision carried out within the W3C Data Exchange Working Group [2] explicitly considers DQV providing examples and guidance to document dataset and distribution quality. In addition, the recently launched Google Dataset search29
Footnotes
Acknowledgements
The authors thank Jeremy Debattista for contributing to the design of Quality Measurement, and for his support in understanding the daQ Ontology; Nandana Mihindukulasooriya for contributing to Quality Policy; Makx Dekkers and Christophe Guéret for driving the discussions in the early stage of DQV specification. They also thank the DWBP Working Group chairs Hadley Beeman, Yaso Córdova, Deirdre Lee, the staff contact Phil Archer, and gratefully acknowledge the contributions made to the DQV discussion by all members of the Working Group and external commenters, in particular, the contributions received from Andrea Perego, Ghislain Auguste Atemezing, Carlos Laufer, Annette Greiner, Michel Dumontier, Eric Stephan.
Finally we would like to acknowledge the contribution of Amrapali Zaveri, who worked on mapping the ISO and linked data quality dimensions. We feel lucky this work gave us the opportunity to collaborate with her. She was a brilliant, enthusiastic researcher and will be missed.