
Abstract
In this deliberately provocative position paper, we claim that more than ten years into Linked Data there are still (too?) many unresolved challenges towards arriving at a truly machine-readable and decentralized Web of data. We take a deeper look at key challenges in usage and adoption of Linked Data from the ever-present “LOD cloud” diagram.1 Herein, we try to highlight and exemplify both key technical and non-technical challenges to the success of LOD, and we outline potential solution strategies. We hope that this paper will serve as a discussion basis for a fresh start towards more actionable, truly decentralized Linked Data, and as a call to the community to join forces.
The Linking Open Data cloud diagram, available at
Let us start with a rant, arguing that the Semantic Web may well be considered a story of failed promises with regards to decentralization:
We had hopes (as a community) to revolutionize Social Networks in a way that every data subject owns and controls their social network data in
While ActivePub has been picked up by several implementations, cf.
We envisioned a
Or, as Dan Brickley, one of the inventors of FOAF stated slightly sarcastically in personal communication: “we took one useful feature of RDF/RDFS (fine grained vocabulary composition) and elevated it to a cult-like holy law, to the extent that anyone who created a useful RDF vocabulary and wanted to keep improving it, found themselves pushed instead into combining it with dozens of other half-finished, poorly documented efforts that weren’t really designed to fit together nicely.”
The main reason for Wikidata not to prescribe existing vocabularies was to leave the community freedom to link and use what they deem useful within one consistent scheme/namespace: one of the reasons was to avoid the needed buy-in to existing ontologies the popularity of which or agreement about could shift over time. Therefore, they “left it to the community whether to choose stronger semantics (e.g., OWL) or weaker semantics (e.g., SKOS [37]) or not” (personal communication Denny Vrandec˘ić).
We put a lot of effort into
Berners-Lee et al. in their original Semantic Web article [7] promised
More specifically, we see
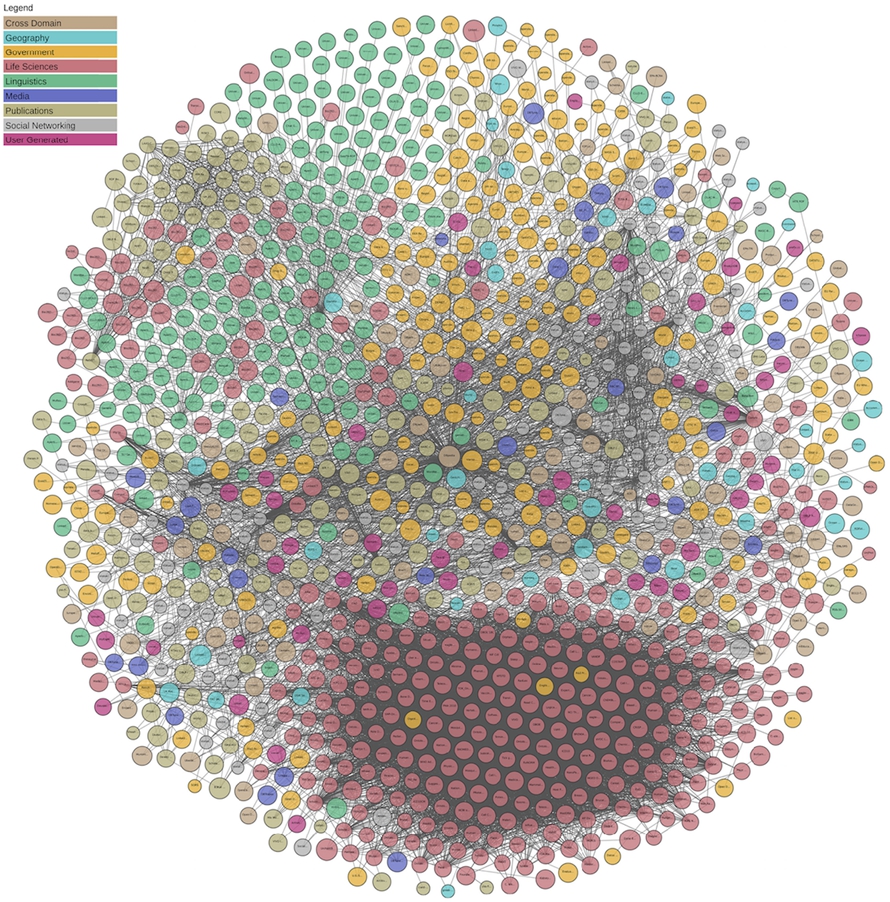
The “LOD cloud” diagram [1], from April 2018, counting 1,184 datasets.
So, here we are after more than ten years. However, there is one lighthouse project that clearly has implemented the vision of a decentralized Semantic Web. This single project that we, as a community, hinge upon and tend to accept as a clear success to wipe away all the failed promises mentioned above is: Linked Data [9]. The promise to be able to publish structured data in a truly decentralized fashion, with a couple of simple principles to enable the automatic retrieval and integration by just “following your nose” (i.e., dereferencing HTTP links). This principle is the most powerful promise that filled the community with new enthusiasm through the so-called “LOD cloud”, cf. Fig. 1. If we measure the number of datasets published according to the four Linked Data principles [6] and that link to each other, we find evidence of growth and prosperity (cf. Fig. 2), and hope to finally make the vision of a decentralized Web of data come true. Meanwhile, indeed this “cloud” contains over 1,184 datasets, which should be considered good news.
However, as we will discuss in the present paper, there are still serious barriers to consume and use Linked Data from the “cloud”, wherein we have to question the usefulness of the current LOD cloud. Thus, we would like to take a step back and assess the situation. We call for a more principled and, in our opinion, more useful restart and for more collaboration and decentralization in the community itself.

The growth of the “LOD cloud” in number of datasets seems to indicate steady, while not rapid or even overwhelming adoption; we still have to view this as opposed to the probably much more rapid growth of other parts of the web [41].
Along these lines, in the remainder of this paper, we start with some background on the genesis of the current LOD cloud in Section 2. We will then highlight five perceived main challenges we deem important to be addressed to make Linked Data more usable and, therefore, useful. These challenges will be presented – by examples and discussing their implications – in the course of Section 3. Finally, we conclude with a call to collaboratively and openly address these challenges as a community in order to (re-)decentralize the Semantic Web again in Section 4.
The creation of a complete Web index is a never-ending story. Since the early days of the Linked Data Web, several attempts have been created and failed to sustain exhaustive Linked Data Search engines, such as Sindice [39], SWSE [30], Watson [17], Swoogle [20], just to name a few. Typically based on bespoke, crawler-based architectures, these search engines relied on either (i) collecting data published under the Linked Data principles and particularly applying the “follow-your-nose” approach enabled through these principles (i.e., find more Linked Data by dereferencing links appearing in Linked Data), and sometimes (ii) relying on “registry” or “pingback” services to collect and advertise linked data assets, such as Semantic Pingback [46]. In the meantime, unfortunately all of these search engines have been discontinued, and we are not aware of any active, public Semantic Pingback services. Recently, the LOD-Laundromat project [5] offers an URL lookup service7
Both of these more recent efforts though claim to refer to datasets in the LOD cloud. The LOD cloud diagram [1], which took a different approach, has been generated from metadata provided by the community at a (CKAN-driven) Open Data portal, namely
Still, the LOD-cloud at lod-cloud.net and the metadata at datahub.io seem to remain the single most popular entry points to Semantic Web data (with the exception of domain-specific portals such as BioPortal [44]), and therefore a bottleneck.
The metadata the LOD cloud relies on and comprises of metadata fields such as:9
Disclaimer: Note that our observations base on metadata from datahub.io collected in April 2018; since then, lod-cloud.net has discontinued on datahub.io and now provides an own form-based submission system for metadata on its Web page.
Apart from the LOD cloud, a similar effort exists to collect and register Linked Data vocabularies and document their interconnections in the Linked Open Vocabularies (LOV) project by Vandenbussche et al. [47]. As opposed to the purely metadata based approach of the LOD cloud collection, LOV relies on curation and quality checks, verification of parsable vocabulary descriptions, etc. We note that the distinction between Linked “vocabularies” and “data” is not always straightforward, with for instance the entries of the BioPortal [44], a registry of ontologies (which could by definition be considered as vocabularies), being (and, in fact, a significant) part of the LOD cloud, but not being present in LOV.
So, where does this leave us? We have seen a lot of resources being put into publishing Linked Data, but yet a publicly widely visible “killer app” is still missing. The reason for this, in the opinion and experiences of the authors, lies all to often in the frustrating experiences when trying to actually use Linked Data for building actual applications. Many attempts and projects end up still using a centralized warehousing approach, integrating a handful of data sets directly from their raw data sources, rather than being able to leverage their “lifted” Linked Data versions: the use and benefits of RDF and Linked Data over conventional databases and warehouses technologies, where more trained people are available, remain questionable. In the following, we will elaborate on the main reasons for this current state, as we perceive them, however, with a hopeful perspective, that is, sketching solution paths to overcome these challenges.
Reasons for LOD not yet having reached its full potential are manifold and not simple, and we do not claim to be exhaustive herein; rather, we provide a list from the experiences of the authors to help explain some major challenges in the current state of affairs around LOD. We have chosen to divide reasons into technical and non-technical underlying challenges.
Technical challenges
The current mode of collection of LOD by metadata published once-off by dataset creators has lead to mainly a nice drawing, rather than making Linked Data accessible and usable. We see the following major challenges when attempting to use Linked Data, parts of which we underpin by some preliminary analyses on the metadata from old.datahub.io. We are obviously not the first ones to recognize these as such, and will accompany them with similar analyses and references where available. Yet, we focus on challenges which we believe need a solution first, before we can dream about federated queries or optimizing query answering over Linked Data (which is what we do mostly in our research now – before addressing practical applications over several datasets in real existing Linked Data).
Availability and resource limits
As a result of a recent analysis we did over the metadata on datahub.io, we unfortunately confirmed a very low level of availability of resources, which was already identified as one of the main challenges in the biomedical domain [34]. Among the mentioned 5435 resources in the 1281 “LOD”-tagged datasets on datahub.io, there are only 1917 resources URLs that could be dereferenced. Among all the datasets only 646 dataset descriptions contain such dereferenceable (not counting links to PDF, CSV, TSV files) resource URLs. That is, almost half, 635 dataset descriptions contain no dereferenceable resource URLs that would point to data at all. We applied a best effort here, that is dereferencing both HTTP and FTP URLs with a timeout of 10 seconds awaiting a potential response, counting all 2xx return codes for a HEAD request for HTTP (and following redirects), or, resp. LIST requests for the containing directory for FTP as positives. This confirms the similar experiments by Debattista in his thesis [18, Section 9] and in a more recent article [19]; many LOD cloud datasets are indeed not even being mentioned in his quality assessment framework,10
We note that even a best effort of availability could be viewed as optimistic, if we look in a finer grained analysis of the different formats in these URLs (cf. Fig. 3). For example, concerning SPARQL endpoints, our small experiment reconfirms that, among the mentioned 444 potential SPARQL endpoint URLs in metadata, only 252 responded at all, and only 195 responded “true” to a simple
Also, some endpoint implementations returned non-SPARQL-protocol-conformant results such as

Types of URLs in the “LOD cloud” guessed by declared metadata format and suffixes.
SPARQL protocol conformant responses out of the 251 of overall 440 endpoints that responded at all
Towards a solution path In order to avoid stale or outdated datasets and SPARQL endpoints, a “live” LOD cloud would need to be producible in a regular and automated fashion. As a part of a solution path, we view regular monitoring frameworks, such as SPARQLES [48],12
Outdated, as well as non-available, data is worthless and the frustrating experiences of not finding half the resources when trying to retrieve Linked Data, rather jeopardizes the LOD initiative than inviting externals to our own close community to buy in to the ideas of Linked Data. That is, the LOD cloud itself needs to be “live” and providers that do not comply with minimal availability over a certain duration should be notified and removed. Also, notoriously outdated, stale data should not be listed.
The situation in terms of dataset sizes have changed dramatically since the early days of semantic search engines, where relatively small amounts of triples could be feasibly managed in a single triple store: few datasets generated from big databases reach dramatic sizes. For instance, the latest edition of DBpedia (2016-10), consists of more than 13 billion triples, Wikidata comprises +5B triples and the whole LOD-Laundromat project, which attempts to process and cleanse the accessible part of the LOD cloud, reports at the moment 38.8B indexed triples.
We also note that, to the best of our knowledge, current triple stores on commodity servers do not scale up to more than 50B triples, apart from lab experiments on hardware probably not yet available to most research labs in our community. AllegroGraph and Oracle triple stores have reported dealing with up to 1 trillion triples.14
Cf.
We already see the number of triples reported on the LOD cloud diverging from what a simple
The same number is returned on a query for quads, i.e.
In addition to that, it is mostly impossible to indeed retrieve all triples from a SPARQL endpoint, due to result size restrictions that many endpoints apply, either in the form of timeouts or only returning a certain maximum number of results/triples. For details, Buil et al. [14] discusses some of these restrictions, and also explains, why in general they cannot be trivially circumvented (e.g., by “paging” results with
Another potential challenge in terms of size and scalability is the amount of duplicates in current dumps. As an example, the PubMed RDF dump from Bio2RDF we mentioned above (cf. Footnote 17) consists of +7.22B nquads spread over 1151 dump files. A lot of triples are actually duplicated across these dump files from the same dataset. Downloading all of these and de-duplicating them locally both wastes bandwidth and makes processing such dumps unnecessarily cumbersome.
Towards a solution path It seems that in order to avoid both such discrepancies and bottlenecks for downloads and query processing, a combination of (i) dumps provided in HDT [21], a compressed and queryable RDF format, as well as (ii) Triple Pattern Fragments (TPF) endpoints [49] as the standard access method for Linked Datasets could alleviate some of these problems The Triple Pattern Fragments interface – essentially limits queries to an endpoint to simple triple matching queries which offloads processing of complex joins and other operations to the client-side, while still not having to download complete dumps. HDT,19
As an additional starting point, work on load balancing under concurrency for SPARQL endpoints [38] also promises better resource management on server-side query processing. Eventually, we expect lots of room for research and potential solutions to the challenges for truly decentralized, scalable linked data querying, by combining client-side and server-side query processing in a demand-driven manner.
While the current metadata available on the LOD cloud does not tell us a lot about how to access single datasets, over time, various dataset description formats and mechanisms have been proposed, namely (i) VoID descriptions, (ii) (Semantic) Sitemaps, and (iii) SPARQL service endpoint descriptions. In the following, we analyze their state of use in the LOD cloud.
The Vocabulary of Interlinked Datasets (VoID) had been designed as a minimalistic entry point for describing datasets and how to access them, containing properties for locating dumps (
There are various problems with this approach: firstly, different datasets hosted under one common domain/server cannot provide different dataset descriptions; as illustration, obviously for Github hosted data,
We tested all hosts from URLs that provided non-error results.
(Semantic) sitemaps XML Sitemaps22
SPARQL service endpoint descriptions according to the SPARQL1.1 specification, “SPARQL services made available via the SPARQL Protocol SHOULD return a service description document at the service endpoint when dereferenced using the HTTP GET operation without any query parameter strings provided. This service description MUST be made available in an RDF serialization, MAY be embedded in (X)HTML by way of RDFa [RDFA], and SHOULD use content negotiation [CONNEG] if available in other RDF representations.” Yet, out of the 251 potential respondent endpoint addresses mentioned above only 136 respond to this recipe, out of which in fact 63 return HTML (mostly query forms), even if attempting CONNEG.23
with sending an
We note that while some of these mentioned HTML responses might contain RDFa, it is still an extra step to extract and parse and each such extra step will bloat a potential consuming client unnecessarily. Similarly, when attempting to find data dumps, without a semantic sitemap or a VoID file in place, our best guess would be to guess and try parsers from “format” descriptors in the metadata or from filename suffixes. An additional complication here are compressed formats, where attempting different decompression formats (gzip, bzip, tar, zip, just to name a few), sometimes even used in combination, further complicate accessibility. Some of the the guessed formats we found in all URLs are listed again in Fig. 3 above.
We note that by manual inspection, some endpoint addresses or accessibility of datasets could be recovered, but since we emphasize on machine accessibility, manual “recovery” seems an undesirable option.
Towards a solution path We feel that as for automatic findability, Semantic Sitemaps with pointers to a VoID description, with concrete pointers to primarily a dump, preferably in HDT as well as (optionally) a pointer to a SPARQL endpoint (or TPF endpoint) should be the commonly to be agreed upon practice. We note here, that the use of HDT makes this task even simpler, as indeed the Header part of an HDT dump file holds a place for metadata descriptions about the dataset readily.24
In fact, some automatically computable VoID properties are already computed and included in HDT’s header per default, and it is possible to add additional properties such as pointers to (SPARQL or Linked Data fragments) endpoints, or used namespaces within this header, as a single point of access through an HDT dump file.
The Linked Data principles define rough guidelines on derefenceability and linkage of datasets, yet in order for RDF datasets, once downloaded, to be truly machine-processable and being able to traverse and interpret those links fruitfully, more detailed guidelines seem to be indispensable: in an early approach, Hogan et al. proposed the “Pedantic Web” [29] alongside with the discontinued tool, RDFAlerts, to check and assess the quality, dereferenceability, and finally syntactical (e.g. use of ill-defined literals) logical consistency (in terms of RDFS/OWL inferences, use of literals in place of object properties, availability of definitions for used properties and classes, etc.) of RDF datasets. A lot of these checks though, were not necessarily designed to scale to datasets of billions of triples, or, resp., should be reassessed in terms of feasibility: HDT could serve as a basis for scalable, out-of -the-box implementations of such checks on a dataset level [26].
For example, link counts in the LOD cloud diagram, which shall indicate in how far one dataset links to another dataset, could be checked and computed automatically. To the best of our knowledge, these links and their strength, have been created so far from datahub.io’s metadata field to which namespace a URI belongs, or to which dataset a namespace belongs
As for 1, we note that in many cases it is not even clear entirely purely from the RDF data which part of the URIs in a dataset denote namespaces: namespaces and qnames in RDF have no special status as in XML, they simply denote prefixes; while certain “recipes” for such prefixes exist, such as most commonly used ‘/’ and ‘#’ prefixes, some ontologies use completely different recipes to separate identifiers from prefixes. In fact, various datasets “mint” URIs with differing recipes, for instance, we find the prefix scheme
In this case, what is the namespace prefix? It seems intuitive that this URI minting scheme refers to UNIPROT which indeed means the dereferenceable URL
Now, at a closer look this example25
Which is one of many, we emphasize it is not our intention to point fingers to anyone!
In fact, the “#-namespace” in our example,
At
While – depending on the serialisation – namespaces could be filtered out based on being explicitly represented (e.g., marked with XML namespaces in RDF/XML or by @prefix declaration in Turtle, respectively, this seems not to be a reliable way of recognizing all used namespaces within an RDF datadump in a declarative machine-readable manner. Plus, as the example illustrates, even if we had all namespaces occurring within a dataset, various URL schemes used refer to either non-dereferenceable or non-RDF publishing third-party namespaces, that cannot be simple assigned to “belonging” to a single dataset. More issues about URI schemes and namespaces and term (non-)re-use have been described in [26,33,35].
Last, but not least, as an open problem, links in one dataset always refer to a particular version of the linked dataset, which cannot be guaranteed to persist or being dereferenceable in the future. For more sustainable Linked Open Data, we therefore deem versioned Linked Data as well as archives a necessity.
Towards a solution path We feel that in order to avoid such issues, established best practices for Linked Data publishing would need to provide more guidelines for URL minting and reuse. Namespace and ID minting should probably be restricted to machine-recognizable patterns (such as strict adherence to ‘/’ and ‘#’-namespaces), with dereferenaceable namespace URLs). Ownership of a namespace could – for instance – be restricted to pay-level-domain, that is, definition of namespaces being restricted to the own pay-level domain, and URL and namespace schemas given a clear machine-readable ownership relation. We leave a concrete definition of such a machine-readable and assessable ownership open for now, but refer to similar concepts and thoughts about URI “authority” having been discussed before in the context of ontological inference by Hogan in his thesis [28, Section 5] as a potential starting point. Hogan’s thesis also contains some details on scalable implementations of the above-mentioned checks that have been described in RDFAlerts [29] earlier, which we believe could be implemented directly and efficiently on top of indexed compressed formats HDT, which we leave to future work on our agenda for now.
As for archiving and versions, we refer to [23] and references therein in terms of starting points. While no standard exists at this point for how to publish versioned RDF archives, let us again refer to possible HDT-based solutions, particularly enabled through the recent extension of HDT to handle nquads [22].
Even if we will be able to solve all the above technical challenges, there are several more pertinent issues in the critical path to the success of LOD. Many non-technical challenges should be fixed in order to stimulate adoption of linked data, a non-exhaustive list of which we briefly describe hereafter.
Completeness/consistency
Several well-known and important RDF datasets are missing in the LOD cloud. For example, EBI RDF [31] is not there (plus various other well-known data bases from the biomedical and life sciences domain [34]), which have gone through the effort of publishing RDF, but not taken the additional hurdle of manually adding and updating their metadata in yet another centralized catalog such as datahub.io. For similar reasons, Wikidata is not a dataset in the LOD cloud, although it is clearly linked well with several datasets present.
Overall, the burden of manually and pro-actively needing to provide and maintain LOD cloud metadata on the publisher-side has proven unsustainable.
Trust
Besides the pervasive issues of availability and reliability, developers are rightfully worried that published data in the cloud is not kept up to date, and as such these technical issues might overall give rise to (or have already given rise to, possibly) doubts on the technologies and principles of Linked Data. Stale datasets, while still available, but with outdated, once-off RDF exports of in the meantime evolved databases, likewise raise trustworthiness issues in Linked Data.
While it seems to have been a sufficient incentive to “appear” in the LOD cloud to publish datasets adhering to Linked Data principles, a similarly strong incentive to sustain and maintain quality of published datasets seems to be missing. It is therefore important for us as a community to keep the LOD project up and alive and maintained, by creating sustainable publishing and monitoring processes.27
with the questionable alternative to re-brand under another name after an “LOD winter” from unfulfilled expectations.
We note that not only trust in the LOD cloud itself, but also mutual trust between LOD providers may be a problem that is difficult to circumvent. For instance the presence of various different unlinked “RDF dumps” or LOD datasets arising from exports of the same legacy database (BIOMODELS given as one illustrative example of many above) could be potentially related to many of our exports and datasets being created in isolation, by closed groups, without incentives for collaboration, sharing infrastructures, and evolving those exports jointly. This issue can only be solved by a more collaborative, and truly open governance.
Documentation and usability
Besides the technical issues discussed above, usability issues and documentation standards have been long overlooked in many Linked Data projects. Industry-strength tools to consume and use Linked Data with sufficient documentation are still under-developed.
We believe this issue can be ameliorated by: (1) better metadata for describing the datasets; (2) better documentation for using the datasets, including sample queries; (3) better tool support for enabling reuse of existing vocabularies; and (4) Supporting and promoting developer-friendly formats, such as JSON-LD.
In addition, in terms of positive examples, apart from the aforementioned HDT and TPF projects, useful SPARQL query editing tools such as YASGUI [43] or Wikidata’s query interface, have appeared in the last two years; we need more tools like those.
Funding & competition
Last, but not least, while the EU and other funding agencies have supported the creation of a Web of data greatly, we also feel that there are problematic side effects which need discussion and counter-strategies:
cross-continental research initiatives are not being funded EU project consortia are typically being judged by complementary partner expertise
Both these factors prevent research groups working on overlapping topics collaboratively, and rather stimulate an environment of isolated closed research than open collaboration to jointly build sustainable solutions and address the issues mentioned so far.
Lack of collaboration may in other cases also just be caused by the disconnect of research communities. This is for instance exemplified by the Semantic Web in Life Sciences community, for instance, seemingly having recently started efforts very similar to SPARQLES [48] in building up a completely independent SPARQL endpoint monitoring framework [52],28
Available at
So, is Linked Data doomed to fail? In this paper we did not present a lot of new insights, but our deliberatively provocative articulation of rethinking Linked Open Data and its principles. It is not too late to counteract and join forces. We hope that our summary of problems and challenges, reminders of valuable past attempts to address them, and outline of potential solution strategies can serve as a discussion basis for a fresh starts ahead towards more actionable Linked Data. Yet, we should not conceal there is still a lot of research to be done and open problems to work on, for instance in demonstrating how the sketched solution paths can be realized at Web scale.
On the bright side, specific communities, such as the biomedical community have been very successful in using OWL and Semantic Web technologies for the management of large biomedical vocabularies and ontologies, for a detailed overview of successes in this area we refer to [33,34]. Main factors for success projects are: (1) Having a dedicated and very active development team behind it with continuous funding over several years; (2) Actively building a strong community of domain users from different areas, and using their needs as the driver for the ontology development; (3) Having an exemplary documentation, about both ontology, but also about how to use Linked Data in applications targeted to domain users, as well as documentation about the processes for building and maintaining collaboratively generated Linked Data sources; (4) Using a principled approach for developing the underlying ontology and maintaining the vocabularies used; (5) Using automated pipelines to check and ensure data and vocabulary quality.
Our hope is that the Linked Data community can learn from such specific projects, and that it will try to apply some of the same approaches that proved to be so successful. We believe the community needs to work on those by joining forces, rather than by competition. We also argued that HDT, a compressed and queryable dump format for Linked Datasets, could play a central role as a starting point to address some (but not all) of the technical challenges we have outlined, i.e., implicitly suggesting a “fifth” Linked Data principle [6]: 5. Publish your dataset as an
In fact, we would argue that more principled Linked Data publishing could allow to auto-generate LOD clouds from a set of HDT dumps, which to demonstrate is on our agenda for future work. While we admit of course that HDT is not the only possible solution to this problem, what we aim at emphasizing here is the necessity for a principled approach to overcome the obvious synchronization problems arising from separate maintenance of metadata outside of the actual knowledge source in current dataset catalogues: an interesting very recent initiative in this context is the DBpedia Databus project,29
currently in public beta, which aims at providing an end-to-end pipeline easing auto-extraction, metadata-generation and publishing of Linked Data Knowledge Graphs at scale.Apart from technical challenges, other issues arose, that seem equally important, such as the establishment of collaborative and shared research infrastructures to guarantee sustainable funding and persistence of Linked Data assets, as we have seen many promising efforts and initiatives mentioned in this paper having discontinued unfortunately. In the meanwhile, we also emphasize that initiatives like the recently US-founded “Open Knowledge Network”30
Footnotes
Acknowledgements
A preliminary version of this work [![]() ] was presented at the DESEMWEB2018 workshop: we thank the participants and particularly Dan Brickley, Sarven Capadisli, Amrapali Zaveri, and Denny Vrandec˘ić for their comments on this first revision. Axel Polleres’ work was supported under Stanford University’s Distinguished Visiting Austrian Chair program. Javier Fernández’ work was supported by the EC under the H2020 project SPECIAL and by the Austrian Research Promotion Agency (FFG) under the project “CitySpin”. Maulik Kamdar, Tania Tudorache, and Mark Musen were supported in part by the grants GM086587, GM103316, and U54-HG004028 from the US National Institutes of Health.
] was presented at the DESEMWEB2018 workshop: we thank the participants and particularly Dan Brickley, Sarven Capadisli, Amrapali Zaveri, and Denny Vrandec˘ić for their comments on this first revision. Axel Polleres’ work was supported under Stanford University’s Distinguished Visiting Austrian Chair program. Javier Fernández’ work was supported by the EC under the H2020 project SPECIAL and by the Austrian Research Promotion Agency (FFG) under the project “CitySpin”. Maulik Kamdar, Tania Tudorache, and Mark Musen were supported in part by the grants GM086587, GM103316, and U54-HG004028 from the US National Institutes of Health.