
Abstract
The increasing number of Knowledge Graphs (KGs) available today calls for powerful query languages that can strike a balance between expressiveness and complexity of query evaluation, and that can be easily integrated into existing query processing infrastructures. We present Extended Property Paths (EPPs), a significant enhancement of Property Paths (PPs), the navigational core included in the SPARQL query language. We introduce the EPPs syntax, which allows to capture in a succinct way a larger class of navigational queries than PPs and other navigational extensions of SPARQL, and provide formal semantics. We describe a translation from non-recursive EPPs (nEPPs) into SPARQL queries and provide novel expressiveness results about the capability of SPARQL sub-languages to express navigational queries. We prove that the language of EPPs is more expressive than that of PPs; using EPPs within SPARQL allows to express things that cannot be expressed when only using PPs. We also study the expressiveness of SPARQL with EPPs in terms of reasoning capabilities. We show that SPARQL with EPPs is expressive enough to capture the main RDFS reasoning functionalities and describe how a query can be rewritten into another query enhanced with reasoning capabilities. We complement our contributions with an implementation of EPPs as the SPARQL-independent iEPPs language and an implementation of the translation of nEPPs into SPARQL queries. What sets our approach apart from previous research on querying KGs is the possibility to evaluate both nEPPs and SPARQL with nEPPs queries under the RDFS entailment regime on existing query processors. We report on an experimental evaluation on a variety of real KGs.
Introduction
Knowledge Graphs (KGs) are becoming crucial in many application scenarios [34]. The Google Knowledge Graph [24], Facebook Open Graph [17], DBpedia [13], Yago [51], and Wikidata [53] are just a few examples. Devising powerful KG query languages that can strike a balance between expressiveness and complexity of query evaluation while at the same time having little impact on existing query processing infrastructures is crucial [4]. There is a large number of KGs encoded in RDF [30], the W3C standard for the publishing of structured data on the Web [16]. To query RDF data, a standard query language, called SPARQL [26,42], has been designed. While an early version of SPARQL did not provide explicit navigational capabilities that are crucial for querying graph-like data, the most recent version (SPARQL 1.1) incorporates Property Paths (PPs). The main goal of PPs is to allow the writing of navigational queries in a more succinct way and support basic transitive closure computations. However, it has been widely recognized that PPs offer very limited expressiveness [7,10,20,46]; notably, PPs lack any form of tests within a path, a feature that can be very useful when dealing with graph data. For example, a query like find my Italian exclusive friends, that is, “my friends that are not friends of any of my friends, and are Italian” requires both path difference and tests. Surprisingly, neither are these features available in PPs nor in any previous navigational extension of SPARQL (e.g., NRE [43]). In this paper we introduce Extended Property Paths (EPPs), a comprehensive language including a set of navigational features to extend the current navigational core of SPARQL. In particular, EPPs integrate features like path conjunction, difference, and repetitions, as well as powerful types of tests. A preliminary description of the language appeared in the proceedings of the AAAI’15 conference [19].

An excerpt of a Knowledge Graph taken from DBpedia.
We introduce the main features of EPPs by describing a few examples. An excerpt of a KG is given in Fig. 1. Intuitively, an EPP expression defines a binary relation on the nodes of the graph upon which it is evaluated.
(Path difference).
Find pairs of cities located in the same country but not in the same region.
Navigational Languages such as Nested Expression (NRE) and PPs cannot express such requests due to the lack of path difference (the result has to exclude cities in the same region). With EPPs, the request can be expressed as follows (the full syntax will be presented in Section 3.1):

The symbol  denotes backward navigation from the object to the subject of a triple. Path difference
denotes backward navigation from the object to the subject of a triple. Path difference  enables to discard from the set of cities in the same country (i.e.,
enables to discard from the set of cities in the same country (i.e.,  ) those that are in the same region (i.e.,
) those that are in the same region (i.e.,  ). A SPARQL-independent evaluation pattern of the EPP expression1
). A SPARQL-independent evaluation pattern of the EPP expression1
We provide a detailed algorithm in Section 7.
 (representing one of the cities that are wanted) and then evaluates the expression from each binding. The result is the set of bindings for the variable
(representing one of the cities that are wanted) and then evaluates the expression from each binding. The result is the set of bindings for the variable  , representing the other city. From
, representing the other city. From  reaches
reaches Find pairs of cities located in the same country and in the same region.

In this case, path conjunction  enables to keep from the set of nodes satisfying the first subexpression those that also satisfy the second one. From
enables to keep from the set of nodes satisfying the first subexpression those that also satisfy the second one. From  reaches the cities
reaches the cities
(Tests).
Find pairs of cities governed by the same political party founded before 2010.

 denotes a test for the existence of a path whose parameters specify the position in the triple from which the test starts (
denotes a test for the existence of a path whose parameters specify the position in the triple from which the test starts ( denotes the object of the last traversed triple), and a path (in this case
denotes the object of the last traversed triple), and a path (in this case 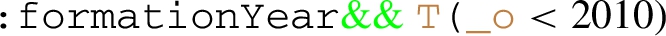 ). The path is composed by logical
). The path is composed by logical  ) of two tests. The first checks the existence of an edge
) of two tests. The first checks the existence of an edge 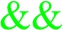 ) of two tests is performed; one checks for the existence of an edge
) of two tests is performed; one checks for the existence of an edge  ) starts from the object of the previous navigational step, that is, the object of
) starts from the object of the previous navigational step, that is, the object of 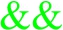 ) of two tests is evaluated. The first one checks the existence of an edge
) of two tests is evaluated. The first one checks the existence of an edge
Composing all the previous features together, we can express a more complex query.
(Path Conjunction, Difference and Tests).
Find pairs of cities located in the same country but not in the same region. Such cities must be governed by the same political party, which has been founded before 2010.

From
Example 4 cannot be expressed by using NRE-based languages or PPs. These languages lack both path difference (we want cities in the same country but not in the same region) and conjunction (additionally, they must be governed by the same political party). We have discussed in the previous examples how a SPARQL-independent algorithm can evaluate EPP expressions. However, since our primary goal is to allow powerful navigation queries on existing KGs query processing infrastructures, we devised a translation of non-recursive EPPs into SPARQL. Our approach follows the same reasoning as the translation of non-recursive PPs into SPARQL used by the current SPARQL standard [44]. The advantage of using EPPs to write non-recursive navigational queries instead of writing them directly into SPARQL is that the same request can be expressed more succinctly and without the need to deal with intermediate variables.
The SPARQL query corresponding to the translation of the EPP expression in Example 4 is shown in Fig. 2, where

SPARQL translation of the EPP expression in Example 4.
Find cities reachable from

The expression involves arbitrary length paths plus tests. The evaluation checks from the node  . Starting from
. Starting from  is evaluated to check the existence of a triple (
is evaluated to check the existence of a triple ( test, starting from it the path
test, starting from it the path  test and
test and  test. The evaluation continues from
test. The evaluation continues from  test. Overall, we reach
test. Overall, we reach
The EPP expression in Example 6 cannot be translated into a basic SPARQL query because it makes use of the closure operator ∗ (requiring the evaluation of 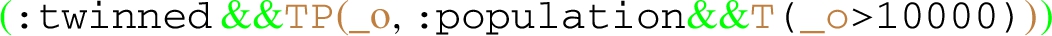 an a-priori unknown number of times). To give semantics to this kind of EPP expression we introduce the evaluation function
an a-priori unknown number of times). To give semantics to this kind of EPP expression we introduce the evaluation function
(Path Repetitions).
If restricting the number of repetitions between 1 and 2, the expression in Example 6 can be written as follows:

So far we have presented examples of isolated EPPs expressions. We now consider their usage in SPARQL.
(EPPs within SPARQL).
Find pairs of cities (A,B) and their populations such that: (i) A and B are in the same country, but not in the same region; (ii) there exists some transportation from A to B.
EPPs used inside SPARQL as for Example 8.
The query in Example 3 allows to obtain the population of the pairs of cities satisfying the EPP expression by introducing two additional patterns, where the variables
The previous example does not take the KG RDFS schema into account. When considering transportation services without specifying the exact type of service, one would be able to actually discover the connection between
The EPPs in Example 8 can be automatically rewritten into an EPP supporting RDFS reasoning as follows:
The of this query to SPARQL is reported in Fig. 4. When this query is evaluated on the graph in Fig. 1 it produces ( SPARQL translation of Example 9.
The contributions of the paper are both theoretical and practical.
We introduce two languages EPPs and iEPPs to query KGs. They have the same syntax but different semantics; one based on multisets (Section 3.2) and complying with SPARQL, and the other based on sets (Section 7.1). We perform a study on the feasibility of adding EPPs to SPARQL. To this end, we provide a translation from non-recursive EPPs into SPARQL queries (Section 4). The benefit of our translation is twofold; on one hand, it allows to evaluate nEPPs (a larger class of queries than non-recursive PPs) using existing SPARQL processors; on the other hand, the usage of our translation paves the way toward readily incorporating EPPs in the current SPARQL standard. Building upon our translation, we also show how a SPARQL query can be rewritten into another SPARQL query that incorporates reasoning capabilities and can be evaluated on existing SPARQL processors (Section 5). We perform a study on the impact of adding EPP features to SPARQL engines. To this end, we implement the nEPPs to SPARQL translation as an extension of the Jena library and an iEPPs query processor. Both are available on-line.2
We perform an extensive experimental evaluation on a variety of real data sets (Section 8).
We introduce iEPPs as a SPARQL-independent language and discuss its complexity (Section 7.2).
We report novel expressiveness results about the capability of SPARQL in expressing navigational queries. We show that SPARQL is expressive enough to capture nEPPs (Section 4.2).
We prove that the language of EPPs is more expressive than that of PPs and, as a by-product, that the fragment of SPARQL including EPPs, AND and UNION is more expressive than the fragment of SPARQL including PPs, AND and UNION (Section 6.1).
We provide a novel study about the expressiveness of SPARQL in terms of the main reasoning capabilities of RDFS (defined as ρdf [41]) when considering different navigational cores (Section 6.2). We show that SPARQL is expressive enough to capture ρdf.
The remainder of the paper is organized as follows. We provide some background definitions in Section 2. Section 3 presents the EPPs syntax and semantics. Section 4 formalizes the translation of non-recursive EPPs into SPARQL queries. Section 5 shows how EPPs support reasoning. The expressiveness of EPPs is analyzed in Section 6. The iEPPs language is described in Section 7. The implementation and the evaluation of EPPs and iEPPs are discussed in Section 8. Section 9 discusses related literature. We conclude in Section 10.
In this section we provide some background about RDF, SPARQL and SPARQL property paths. An RDF triple3
To simplify the discussion we do not consider blank nodes in this section; we will address this issue later in Section 2.4.
Let
A selection formula is defined recursively as follows: (i) If
If F is
If F is
If F is
If F is a complex selection formula then it is evaluated following the three-valued logic presented in Table 1.
Three-valued logic for evaluating selection formulas
Three-valued logic for evaluating selection formulas
We use the symbol Ω to denote a multiset and
Let 

SPARQL patterns
We now introduce SPARQL graph patterns. A graph pattern is defined recursively as follows:
A tuple from
We assume that any triple pattern contains at least one variable.
If
If
A filter constraint is defined recursively as follows: (i) If
Given a triple pattern t and a mapping μ such that
The evaluation of a SPARQL graph pattern If If If If if else If If
If


SPARQL property paths
Property paths (PPs) have been incorporated into the SPARQL standard with two main motivations; first, to provide explicit graph navigational capabilities (thus allowing the writing of SPARQL navigational queries in a more succinct way); second, to introduce the transitive closure operator ∗ previously not available in SPARQL. The design of PPs was influenced by earlier proposals (e.g., PSPARQL [3], nSPARQL [42]).

Standard query semantics of SPARQL property paths, where

Auxiliary functions used for defining the semantics of PP expressions of the form
A property path pattern (or PP pattern for short) is a tuple 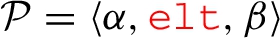 with
with  is a property path expression (PP expression) that is defined by the following grammar (where
is a property path expression (PP expression) that is defined by the following grammar (where

Syntax of EPPs

Syntax of EPPs
The SPARQL standard introduces additional types of PP expressions [44]; since these are merely syntactic sugar (they are defined in terms of expressions covered by the grammar given above), we ignore them in this paper. As another slight deviation from the standard, we do not permit blank nodes in PP patterns. PP patterns with blank nodes can be simulated using fresh variables. The SPARQL standard distinguishes between two types of property path expressions: connectivity patterns (or recursive PPs) that include closure ( ), and syntactic short forms or non-recursive PPs (nPPs) that do not include it. As for the evaluation of PPs, the W3C specification informally mentions the fact that nPPs can be evaluated via a translation into equivalent SPARQL basic expressions (see [26], Section 9.3). Property path patterns can be combined with graph patterns inside SPARQL patterns (using PP expressions in the middle position of a pattern).
), and syntactic short forms or non-recursive PPs (nPPs) that do not include it. As for the evaluation of PPs, the W3C specification informally mentions the fact that nPPs can be evaluated via a translation into equivalent SPARQL basic expressions (see [26], Section 9.3). Property path patterns can be combined with graph patterns inside SPARQL patterns (using PP expressions in the middle position of a pattern).
The semantics of Property Paths (PPs) is shown in Fig. 5. The semantics uses the evaluation function  , which takes as input a PP pattern and a graph and returns a multiset of solution mappings. In Fig. 5 we do not not report all the combinations of types of patterns as they can be derived in a similar way. For connectivity patterns the SPARQL standard introduces an auxiliary function called
, which takes as input a PP pattern and a graph and returns a multiset of solution mappings. In Fig. 5 we do not not report all the combinations of types of patterns as they can be derived in a similar way. For connectivity patterns the SPARQL standard introduces an auxiliary function called
Extended property paths
We now introduce our navigational extension of SPARQL called Extended Property Paths (EPPs). We present the syntax in Section 3.1 and the SPARQL-based formal semantics in Section 3.2.
Extended property paths syntax
EPPs extend PPs and NRE-like languages with path conjunction/difference, repetitions and more types of tests. The importance of the new features considered by EPPs is witnessed by the fact that some of them (e.g., conjunction) are present in standards like XPath 2.0 [11]. Nevertheless, to the best of our knowledge no previous navigational extension of SPARQL has considered these features. As our goal is to extend the current SPARQL standard we refer the reader to Section 7 for a treatment of EPPs as a language independent from SPARQL.
(Extended property path pattern).
An extended property path pattern (or EPP pattern for short) is a tuple  with
with  an extended property path expression (EPP expression) that is defined by the grammar reported in Table 2.
an extended property path expression (EPP expression) that is defined by the grammar reported in Table 2.
EPPs introduce the following features: path conjunction ( ), path difference (
), path difference ( ), path repetitions between l and h times (denoted by
), path repetitions between l and h times (denoted by  for set, and
for set, and 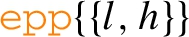 for bag semantics). EPPs allow different types of tests (
for bag semantics). EPPs allow different types of tests ( ) within a path by specifying the starting/ending positions (
) within a path by specifying the starting/ending positions ( ) of a test; it is possible to test from each of the subject, predicate and object positions in triples, mapped in the EPPs syntax to the position symbols
) of a test; it is possible to test from each of the subject, predicate and object positions in triples, mapped in the EPPs syntax to the position symbols  ,
,  and
and  , respectively. Positions do not need to be always specified; by default a test starts from the subject (
, respectively. Positions do not need to be always specified; by default a test starts from the subject ( ) and ends on the object (
) and ends on the object ( ) of the triple being evaluated. A test (
) of the triple being evaluated. A test ( ) can be a simple check for the existence of an IRI in forward/reverse direction. EPPs allow to express negated property sets by using the production
) can be a simple check for the existence of an IRI in forward/reverse direction. EPPs allow to express negated property sets by using the production  with the difference that the set of negated IRIs use the symbol
with the difference that the set of negated IRIs use the symbol 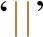 as separator instead of
as separator instead of  used by PPs. A test can also be a nested EPP, i.e.,
used by PPs. A test can also be a nested EPP, i.e.,  , which corresponds to the evaluation of the expression
, which corresponds to the evaluation of the expression  starting from a position
starting from a position  (of the last triple evaluated) and returns true if, and only if, there exists at least one node that can be reached via
(of the last triple evaluated) and returns true if, and only if, there exists at least one node that can be reached via  . In a test of type
. In a test of type  ,
,
 ). Built-in conditions are constructed using elements of the set
). Built-in conditions are constructed using elements of the set  ),
),  ) and
) and  ). We refer to non-recursive EPPs (nEPPs) as those expressions that do not include closure operators (i.e., ∗ and +) and set-semantics repetitions (
). We refer to non-recursive EPPs (nEPPs) as those expressions that do not include closure operators (i.e., ∗ and +) and set-semantics repetitions (
To clarify the intuition behind tests and positions, we introduce the function  , which projects the element in position
, which projects the element in position  of a triple t. If we have
of a triple t. If we have 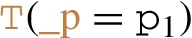 is translated to
is translated to 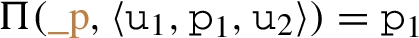 that checks
that checks  . Figure 8 shows the expression from Example 4 including default positions and positions to traverse backward edges. Note that the subexpression
. Figure 8 shows the expression from Example 4 including default positions and positions to traverse backward edges. Note that the subexpression  means that the edge
means that the edge
EPPs SPARQL-based semantics. The function
handles tests.  projects the element in position
projects the element in position  of a triple
of a triple
. Moreover,
;
and
is a fresh variable. evaluate is a function that checks if the triple t satisfies EExp

EPPs SPARQL-based semantics. The function projects the element in position of a triple
We now introduce the semantics of EPPs in terms of SPARQL. We use the function  where instead of a PP expression
where instead of a PP expression  now appears an EPP expression
now appears an EPP expression  . This semantics lays the foundations for the translation algorithm (see Section 4) that given a (concise) nEPP expression produces a semantically equivalent (more verbose) SPARQL query. In the semantics shown in Table 3 we only report the case
. This semantics lays the foundations for the translation algorithm (see Section 4) that given a (concise) nEPP expression produces a semantically equivalent (more verbose) SPARQL query. In the semantics shown in Table 3 we only report the case  is a shorthand for the concatenation (i.e., via the operator ‘
is a shorthand for the concatenation (i.e., via the operator ‘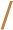 ’) of
’) of  i times. A peculiar construct of EPPs is the test
i times. A peculiar construct of EPPs is the test  , which is handled at a high level by rule R10. In particular tests make usage of the semantic function
, which is handled at a high level by rule R10. In particular tests make usage of the semantic function  and
and  denote the positions (i.e., subject
denote the positions (i.e., subject  , predicate
, predicate  or object
or object  ) of the elements of a triple that have to be projected. We now provide some examples of R11–R13 by using the graph in Fig. 1.
) of the elements of a triple that have to be projected. We now provide some examples of R11–R13 by using the graph in Fig. 1.
Consider the following EPP expression:  . This type of test is handled via rule R11 in Table 3 and considers all triples
. This type of test is handled via rule R11 in Table 3 and considers all triples  ) while the right variable (i.e,
) while the right variable (i.e, 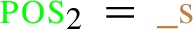 ). In particular, the set of mappings is:
). In particular, the set of mappings is:
Consider the following EPP expression:  , which is handled via rule R12 in Table 3. In this case, the triples
, which is handled via rule R12 in Table 3. In this case, the triples  ). In more detail, these triples have one among
). In more detail, these triples have one among  ) and the right variable (i.e.,
) and the right variable (i.e.,  ). Overall, the set of mappings is:
). Overall, the set of mappings is:

Auxiliary functions used to define the semantics of EPP expressions.
Consider the following EPP expression:  handled via rule R13 in Table 3. The set of triples
handled via rule R13 in Table 3. The set of triples  ) and the right variable (i.e,
) and the right variable (i.e,  ). The set of mappings is:
). The set of mappings is:
Consider the expression With Consider the EPP expression  and
and  and set-semantics repetitions (
and set-semantics repetitions ( between a minimum l and a maximum h of times. The closure operators
between a minimum l and a maximum h of times. The closure operators  and
and  are handled by setting
are handled by setting

Expression in Example 4 with positions.
Fragments of SPARQL, using the SELECT query form, considered in this paper
In the remainder of the paper we will focus on the SELECT query form and consider the SPARQL fragments shown in Table 4. These fragments are built using combinations of: (i) the operators ⋈ (
Translation of nEPPs into SPARQL
The goal of this section is to formalize and describe a translation algorithm that given a non-recursive EPPs (nEPP) translates it into a SPARQL query. Our approach follows the same line of thought as the SPARQL standard for the translation of non-recursive property paths (nPPs) into SPARQL queries. As a by-product, our study formalizes the informal procedure mentioned in the W3C specification for non-recursive PPs (see [26], Section 9.3) and does it for a more expressive language.
Translation algorithm: An overview
We now provide an overview of the translation algorithm 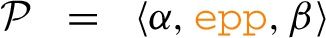 and produces a semantically equivalent SPARQL query
and produces a semantically equivalent SPARQL query
Operational tree
Let  be a nEPP pattern and
be a nEPP pattern and  . Let
. Let  9
9
Note that the  and
and  syntactic operators are omitted since they are only syntactic sugar and can be rewritten by using
syntactic operators are omitted since they are only syntactic sugar and can be rewritten by using  and
and  .
.
 is a function that associates to a pair
is a function that associates to a pair  , and test nodes that are labeled with
, and test nodes that are labeled with  . Figure 9 reports, for each type of node, its set of attributes (i.e., the domain of the functions ω and δ). The attributes
. Figure 9 reports, for each type of node, its set of attributes (i.e., the domain of the functions ω and δ). The attributes 
Node attributes in the operational tree.
Test nodes have attributes  encodes a triple traversal it has also the attributes start (
encodes a triple traversal it has also the attributes start ( ) and end (
) and end ( ) that can be valued with
) that can be valued with  ,
,  or
or  , denoting the position of beginning and ending of the traversal. Finally, test nodes
, denoting the position of beginning and ending of the traversal. Finally, test nodes  have the additional attribute
have the additional attribute  (also valued with one among
(also valued with one among  ,
,  or
or  ) that indicates the beginning of the existential test with respect to the last triple.
) that indicates the beginning of the existential test with respect to the last triple.
The root r of
If v is the root of
If v is an operational node, then c has the same type as v and all its attributes are initialized with fresh variables. Moreover,
If v is a test node and
If v is a test node, and
The operational tree for the nEPP pattern of Example 2 is shown in Fig. 11(a). Fresh variables for the attributes of a node n are generated using the template: ?

Propagation of variables and terms.
Given an operational tree for a pattern  ) makes usage of the join operator; specifically, it requires to introduce a fresh join variable in the translation. The propagation algorithm guarantees that both children of the concatenation node use the same join variable by applying the propagation rules reported in Fig. 10 (lines 25–30). By looking at Fig. 11, such rules translates to the fact that the attribute
) makes usage of the join operator; specifically, it requires to introduce a fresh join variable in the translation. The propagation algorithm guarantees that both children of the concatenation node use the same join variable by applying the propagation rules reported in Fig. 10 (lines 25–30). By looking at Fig. 11, such rules translates to the fact that the attribute
Furthermore, the propagation phase also ensures that the tests are executed on the correct position of the triple and that the endpoints are correctly selected by applying the rules reported in Fig. 10 lines 8–19. By looking at Fig. 11, the rule in lines 16–17 translates to the fact that the attribute
Generating SPARQL code
The last step of the translation algorithm takes as input the result of the previous phases, that is, an operational tree where all attribute values are filled with the correct values (i.e., RDF terms, fresh variables and the variables or terms α and β derived from the nEPP pattern as input). At this point, to generate the SPARQL code for a given nEPP pattern, the translation algorithm leverages the translation rules shown in Table 5. The translation uses two functions:
The translation algorithm applies the rules starting from the  . Path concatenation is handled via rule
. Path concatenation is handled via rule  is translated as
is translated as
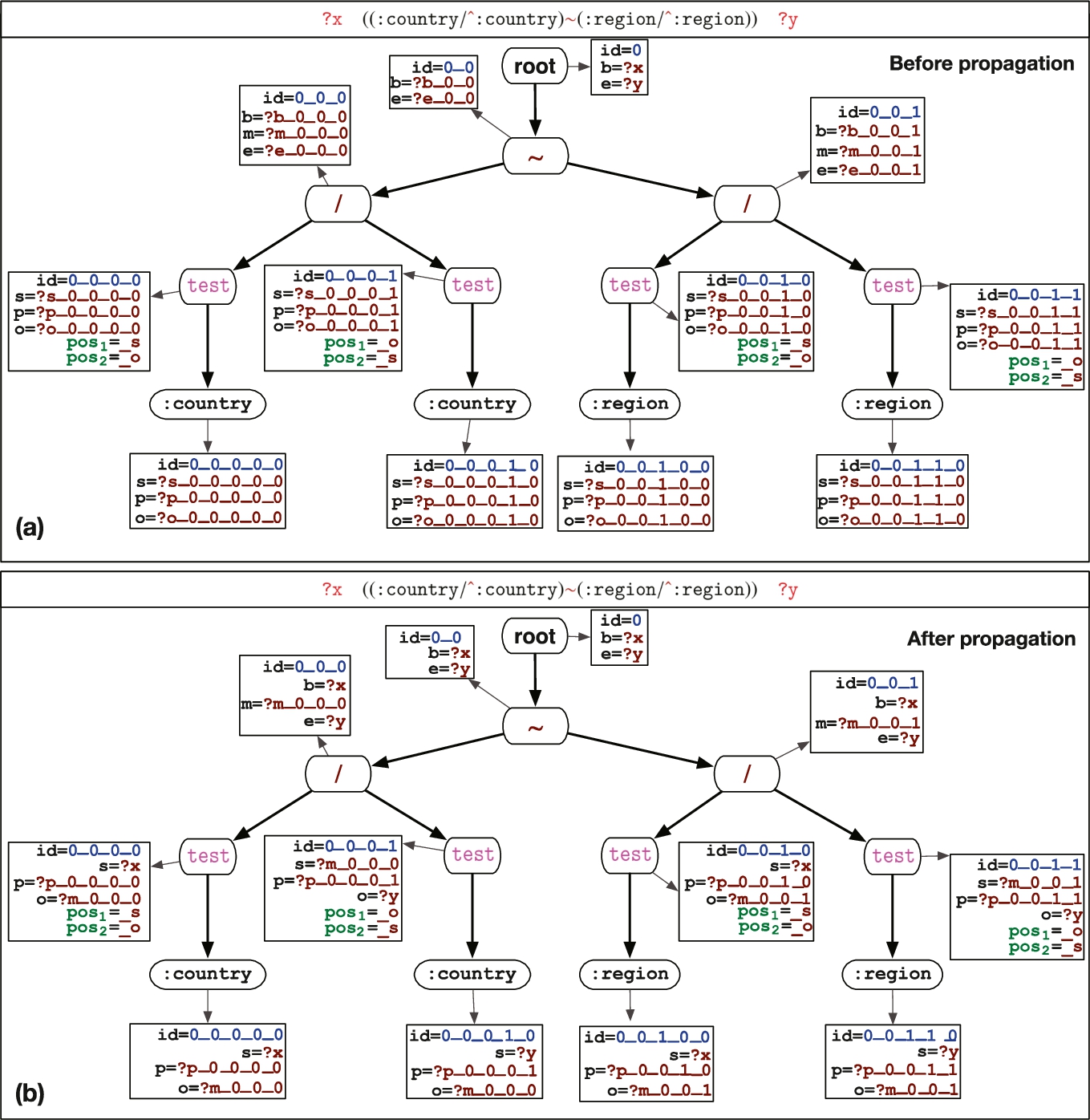
Operational tree for Example 2 before (a) and after (b) the propagation phase.
Translating nEPPs into SPARQL (code).  ). nEPPs with double-brace path repetitions (
). nEPPs with double-brace path repetitions ( ) are first translated into equivalent nEPPs via unions of concatenations
) are first translated into equivalent nEPPs via unions of concatenations

Consider the nEPP pattern in Example 2. The corresponding operational tree is reported in Fig. 11(a). The operational tree obtained after the application of the procedure  in Fig. 11(a) and (b) we can see that
in Fig. 11(a) and (b) we can see that  . Then, the node with
. Then, the node with  is visited; this triggers
is visited; this triggers  . The translation uses
. The translation uses  (e.g., 0_0_0_0) is reflected via the
(e.g., 0_0_0_0) is reflected via the

The translation continues until no more nodes of the operational tree have to be visited and gives:
Languages and translations into SPARQL for plain RDF
Languages and translations into SPARQL for plain RDF
Conciseness. EPPs enable to write navigational queries in a more succinct way as compared to SPARQL queries using triple patterns and/or union of graph patterns. Given a nEPPs expression containing a number of fragments (e.g., concatenation, union, predicates) it is interesting to note that its corresponding translation in SPARQL is always more verbose. Consider for instance the nEPPs pattern
Benefits. EPPs coupled with the translation procedure bring a significant practical advantage as compared to other navigational extensions of SPARQL (e.g., nSPARQL, cpSPARQL). On one hand, nEPPs can be evaluated over existing SPARQL processors. On the other hand, the machinery presented in this paper could potentially extend the SPARQL standard in an elegant and non-intrusive way; one would need to use our translation algorithm instead of that currently used by the SPARQL standard.
By analyzing the translation algorithm presented in the previous section and the translation rules reported in Table 5, it is possible to identify the precise SPARQL fragment that can express nEPPs.
nEPPs can be expressed in the SPARQL fragment
In the remainder of this section we analyze for different navigational cores, the SPARQL fragment necessary for its rewriting. The results of the analysis are reported in Table 6. The table shows in the first column (
The most interesting result that emerges from the table is that the fragment
The full EPPs language can be incorporated in SPARQL using the
We observe that the complexity of evaluating queries in most of the fragments reported in Table 6 has been studied in the literature. The fragments not including
The aim of this section is to study the support that EPPs can give to querying under entailment regimes (Section 5.1) with particular emphasis on how to support the entailment regime on existing SPARQL processors (Section 5.2).
Capturing the entailment regime
In this paper we focus our attention on the
The
rule system. Capital letters
,
,
,
, and
, stand for meta-variables to be replaced by actual terms in
The
Given a SPARQL pattern
The intended meaning of two semantics differs with respect to the data graph on which the evaluation is performed. In particular,
Most of existing SPARQL processors handle (variants of) ρdf reasoning in the following way: first, compute and materialize the finite polynomial closure of the graph G and then perform query answering on the closure via RDF simple entailment regime [25]. It is interesting to point out that materializing all data by computing the closure
Encoding of ρdf inference rules via EPPs

Encoding of ρdf inference rules via EPPs
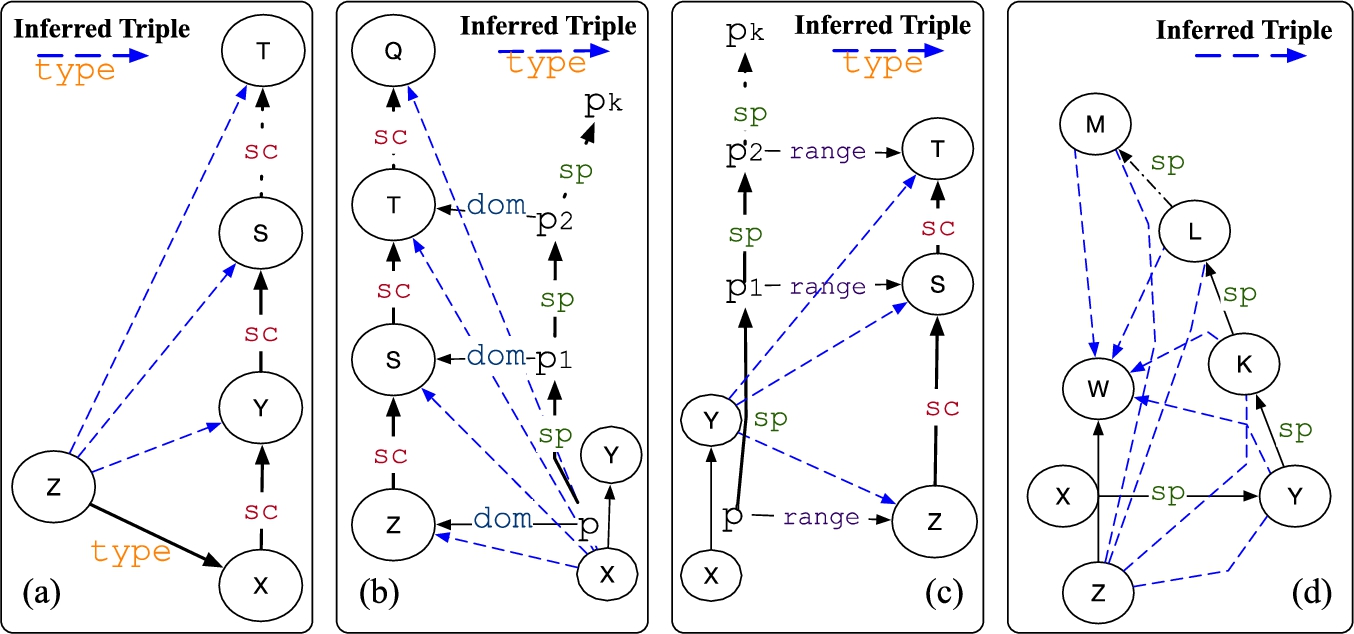
Similarly to nSPARQL [42], cpSPARQL [3] and others approaches (e.g., [12,32]), we identified for each inference rule in the fragment considered, ρdf in our case), an EPP expression encoding it. The translation rules are shown in Table 8. Whenever one wants to adopt the ρdf entailment regime, it is enough to rewrite the input pattern according to these translation rules. The result of the evaluation of the rewritten pattern on G is the same as the result that would be obtained by first computing the closure
Given a triple pattern
The proof follows from the fact that rules in Table 8 encode the reasoning rules shown in Table 7. This is immediate to see for rules R1–R4. R5 is composed by the union of three expressions, each capturing one of the three possible ways (shown in Fig. 12(a)–(c)) to derive a  ) of two tests. The second test just checks for triples where p is the predicate; the first performs an existential test (i.e., it uses the nested EPP construct
) of two tests. The second test just checks for triples where p is the predicate; the first performs an existential test (i.e., it uses the nested EPP construct  ) composed by a conjunction (via
) composed by a conjunction (via  ) of two tests, the first moves to the predicate position of a triple and travels up the property hierarchy (via *) while the second checks that the object reached is p. □
) of two tests, the first moves to the predicate position of a triple and travels up the property hierarchy (via *) while the second checks that the object reached is p. □
We observe that our translation rules are indeed a translation into the language of EPPs of the NRE expressions that have been shown to capture all the RDFS inferences in Perez et al. [42] (Lemma 5.2). Lemma 22 shows that for an arbitrary pattern there exists a rewriting allowing to capture
The idea behind our approach, follows from the observation that closure operators appearing in Table 8 only involve single predicates i.e.,  ,
,  ,
,  ,
,  . Such types of expressions are property paths that (taken alone) can be evaluated via the
. Such types of expressions are property paths that (taken alone) can be evaluated via the  ) used in Table 8. We refer to this variant of the translation algorithm as
) used in Table 8. We refer to this variant of the translation algorithm as
Given a triple pattern
The result follows from Lemma 22 which shows that the EPPs rewriting of the
The above result tells us that an algorithm to perform query-based reasoning works in three steps: (i) apply the translation function
The aim of this section is to provide novel results about the expressive power of EPPs as compared to PPs (Section 6.1) and the expressiveness of the SPARQL standard in terms of
Expressive power of extended property paths vs. property paths
We now investigate the expressiveness of EPPs as compared to PPs. We use the evaluation function  (Fig. 5) or EPP
(Fig. 5) or EPP  (Table 3). The semantics of the evaluation will be clear from the context. In the next theorem we prove that the language of EPPs is strictly more expressive than PPs.10
(Table 3). The semantics of the evaluation will be clear from the context. In the next theorem we prove that the language of EPPs is strictly more expressive than PPs.10
Even if such result could be obtained by adapting standard results about NREs, we provide, for the sake of completeness, a complete constructive proof.
There exists an EPP pattern
 that cannot be expressed as a PP pattern
that cannot be expressed as a PP pattern
 .
.

graph used to prove Theorem 24.
Consider the EPP pattern Consider the graph G in Fig.
13
and let We proceed by induction on the construction of the PP expression If If If If If If If  and the graph G in Fig. 13. We have that
and the graph G in Fig. 13. We have that  (step 1 of the + operator). Moreover, no other mappings can be obtained by evaluating further steps because of the self loops. We claim that for every PP pattern
(step 1 of the + operator). Moreover, no other mappings can be obtained by evaluating further steps because of the self loops. We claim that for every PP pattern  the following property holds: either
the following property holds: either  we have that either
we have that either or
or .
. . We start with the base cases:
. We start with the base cases:
Let  is of the form
is of the form  then: (i) if u=
then: (i) if u= is
is  or
or  then: (i) if
then: (i) if  because of the self-loops present at each node; (ii) otherwise
because of the self-loops present at each node; (ii) otherwise  .
. is of the form
is of the form 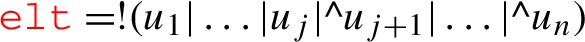 then
then  ,
,  be PP expressions; assume that it holds that either: (i)
be PP expressions; assume that it holds that either: (i)  or (ii)
or (ii)  for
for
□ is of the form
is of the form  then
then  and the claim follows from the properties of the algebra.
and the claim follows from the properties of the algebra. is of the form
is of the form  then
then  and the claim follows from the properties of the algebra.
and the claim follows from the properties of the algebra. is of the form
is of the form  then
then  as a consequence of the evaluation of the base step of the Kleene operator.
as a consequence of the evaluation of the base step of the Kleene operator. is of the form
is of the form 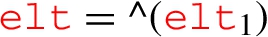 then
then 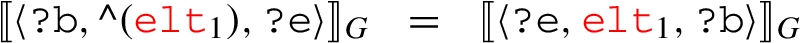 and the claim follows from the properties of the algebra.
and the claim follows from the properties of the algebra.
By relying on Claim 25, the result follows since all the mappings in
Languages and their translation into SPARQL for reasoning
To continue our expressiveness analysis, we now show that using EPPs as navigational core in SPARQL increases the expressive power of the language.
There exists a
Consider the following Consider the graph G in Fig.
13
and let We prove the theorem by structural induction on the construction of the pattern If Consider now the case of  and the graph G in Fig. 13. Let us indicate by
and the graph G in Fig. 13. Let us indicate by  the EPP pattern in
the EPP pattern in  is a single property path pattern then by virtue of Theorem 24 and Claim 25 we have that either
is a single property path pattern then by virtue of Theorem 24 and Claim 25 we have that either 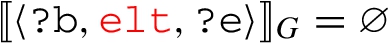 or
or  and thus, the property holds.
and thus, the property holds.
By relying on Claim 27, the result follows since all the mappings in
We now study the expressiveness of SPARQL in terms of ρdf reasoning when considering various navigational cores. Table 9 mimics the expressiveness study in Table 6 where the second column describes the language produced to support query-based reasoning as described in Section 5. We can notice that, in general, supporting reasoning requires a more expressive language in the rewriting. For the basic case  ), (conjunction of) tests (
), (conjunction of) tests ( ), and closure (
), and closure (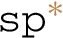 ). Note that the closure operator is only applied to a single predicate, i.e.,
). Note that the closure operator is only applied to a single predicate, i.e.,
Interestingly, when considering more expressive forms of navigational patterns such as non-recursive property paths (nPP), and non-recursive EPPs (nEPP), the fragment needed to capture ρdf in the translation remains the same. The situation changes when moving to navigational patterns with recursion, that is, PPs and EPPs. In this case, the current SPARQL standard is not enough expressive to capture query-based ρdf reasoning. To give an intuition for such a limitation, consider the EPP expression  , where
, where

A graph about transportations.
The interesting conclusion that can be drawn by observing Table 9 is that

Set-basd semantics for EPPs.
The aim of this section is to study EPPs as an independent language. The advantage of defining EPPs as a navigational language independent from SPARQL stems from the fact that the SPARQL-based semantics and translation discussed in Section 3.2 and Section 4 only apply to KGs based on RDF while the proposed language can be used to query arbitrary KGs. To this end, we give a set-based semantics in Section 7.1 and present an evaluation algorithm along with a complexity analysis in Section 7.2.
Formal semantics of EPPs based on sets
The semantics of EPPs based on sets for both recursive and non-recursive EPPs is shown in Fig. 15. It leverages two evaluation functions. The first,  given an
given an  expression and a graph G returns the pairs of nodes that are linked by paths conforming to
expression and a graph G returns the pairs of nodes that are linked by paths conforming to  . The second
. The second  , given a test
, given a test  , a graph G and a triple
, a graph G and a triple
Evaluation algorithm
The aim of this section is to study whether the semantics in Fig. 15 can be implemented in an efficient way. In what follows we show an efficient evaluation algorithm, that has been implemented in a custom query evaluator, and discuss its complexity. The presented evaluation algorithm for iEPPs expressions is similar to those of other navigational languages such as nested regular expressions [43] and NautiLOD [20]. The algorithm starts by invoking  and a node n. If
and a node n. If  is non recursive (i.e., it does not contain the closure operators
is non recursive (i.e., it does not contain the closure operators  and
and  ) then it is given as input to the function
) then it is given as input to the function  .
.

The result of the evaluation of an iEPP expression
The
We assume G to be stored by its adjacency list. In particular, for each The function  from a node n is a set of nodes
from a node n is a set of nodes  . To study the complexity of the evaluation algorithm we introduce the decision problem
. To study the complexity of the evaluation algorithm we introduce the decision problem  , a pair of nodes
, a pair of nodes 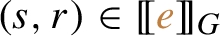 .
.
 , where
, where
 be the size of the iEPP expression
be the size of the iEPP expression  .
. in input; if such sub-expressions are not recursive (i.e., do not contain
in input; if such sub-expressions are not recursive (i.e., do not contain  ,
,  ),
),  times. The base cases (lines 17–21 of function
times. The base cases (lines 17–21 of function  is recursive, the function
is recursive, the function  . As for nested expressions, memoization enables to mark nodes of the graph satisfying a given subexpression. Path conjunction and difference, corresponding to intersection and difference of sets of nodes respectively (line 12 and 14 of
. As for nested expressions, memoization enables to mark nodes of the graph satisfying a given subexpression. Path conjunction and difference, corresponding to intersection and difference of sets of nodes respectively (line 12 and 14 of  . □
. □
This section reports on an experimental evaluation meant to investigate different aspects of the EPP language discussed in the previous sections. Section 8.1 investigates the performance of our translation algorithm (see Section 4) in terms of running time, and compares it with that of translations routinely performed by existing SPARQL processors. We focused on running time since it offers a reasonable summary of the overall performance of a query processing system being based on the iEPPs evaluation algorithm or SPARQL evaluation algorithm. In Section 8.2 we compare the running time of a custom processor implementing the evaluation algorithm for iEPPs (see Section 7) with the running time of the Jena ARQ SPARQL processor. Finally, in Section 8.3 we discuss the impact of using query-based reasoning (see Section 5) both in terms of running time and number of results. All the experiments have been performed on an Intel i5 machine with 8 GBs RAM. Results are the average of 30 runs (queries were run in a random order each time) after removing the top and bottom outliers.
Translation running time
Our primary objective is to make practical the immediate adoption of EPPs as a query language for KGs. This objective is fulfilled by using our translation from nEPPs to SPARQL as front end to any existing SPARQL processor. To investigate the performance of the translation algorithm presented in Section 4, we show that our nEPPs to SPARQL translation performs comparably to the existing translations routinely performed by SPARQL processors.

Time of the translation of Jena ARQ (SPARQL2Algebra) and nEPPs (nEPPS2SPARQL) vs query length (number of path steps).
We compared our translation algorithm with the SPARQL syntax to SPARQL algebra (referred to as
While this suggests that the cost of our approach could be up to twice the cost of a direct nEPPs to algebra translation, keep in mind that we are comparing initial phases of query processing and these are typically much faster than subsequent phases. As an example, in Jena ARQ the
We now compare the running time of the custom EPP processor implementing the iEPPs evaluation algorithm discussed in Section 7.2 against the translation-based approach described in Section 4 using Jena ARQ as underlying SPARQL query processor. This experiment gives insights about the pros and cons of evaluating EPPs using existing SPARQL processors as compared to the usage of the iEPPs custom query processor. In the experiments, we used a portion of the FOAF dataset extracted from the BTC2012 dataset12

Query time for simple and
We created 4 groups  ) and path alternatives (
) and path alternatives ( ); the second group also includes nesting (
); the second group also includes nesting ( ); the third group includes path difference (
); the third group includes path difference ( ) and concatenation (
) and concatenation ( ); finally, the fourth group leverages path conjunction (
); finally, the fourth group leverages path conjunction ( ) and concatenation (
) and concatenation ( ). These groups of queries allow to investigate the trade-off between expressiveness and running time. Indeed, one expects that queries in
). These groups of queries allow to investigate the trade-off between expressiveness and running time. Indeed, one expects that queries in
For
The huge advantage of using nEPPs is that navigational queries can be written in a succinct way. Anecdotally, while the nEPPs asking for mutual friends (simple entailment) at distance 3 contains ∼200 characters, the SPARQL query (obtained from the translation) contains ∼700 characters; moreover, writing navigational queries directly in SPARQL requires to deal with a large number of variables that need to be consistently joined. We want to point out that the translated SPARQL queries have been automatically generated. It may be the case that manually written equivalent queries can be shorter. Nevertheless, there are cases in which the EPPs syntax always introduces benefits (beyond those already introduce by PPs). As an example, path repetitions (used e.g., in Q5–Q12) available in EPPs (and not in PPs) always allow a significant reduction in the expression size. Indeed, the conversion of path repetitions into PPs requires to use alternative paths having an increasing number of concatenation operators. As an example,
We now move to a larger scale evaluation of the query-based reasoning approach described in Section 5. The goal is to compare the running time of queries with and without reasoning support. Even in this case we considered running time since it offers a reasonable summary of the overall performance of a query processing system. We also investigate the number of results returned. Among the ρdf inference rules (see Table 8) we considered the two most interesting, that is, R5 that allows to derive new

Query time (y-axis) for simple and
Datasets used for the evaluation of query-based reasoning
DBpedia is a large dataset with limited RDFS usage, Yago/LDCache makes extensive usage of RDFS predicates while LinkedMDB does not use RDFS. LinkedMDB and Yago have been loaded into a BlazeGraph13
Figure 18(a), (c), (f) report the running times on the RDFS rule R5 on 50 different queries that count the number of results by randomly picking 50 entities in Yago, DBpedia, and LinkedMDB, respectively. Detailed results are available in Appendix A. We observe that the additional time introduced by the query-based reasoning approach is reasonable and there are a few exceptions (in DBpedia) where plain RDF query execution takes more time. As expected, there is some variation in DBpedia while the additional time is much larger in Yago. Note that query answering under the entailment regime in some cases takes less time; this can be explained by the fact that it requires the usage of the
Average number of results for plain RDF and ρdf
Figure 18(b), (d), and (e) further investigate the benefit of query-based reasoning. We created 150 additional queries for R6; 100 for DBpedia by considering two properties, that is,
In other words, queries using R5 are more involved than those using R6. R6’s impact in terms of running time is lower than R5; this also reflects on the average speed-up now is 1.18 for
Comparison with Closure Computation. An additional advantage of the query-based approach is that it can benefit from space optimization if one would work with the transitive reduction15
Tools like Slib (
The idea of graph query languages is to use (variants of) regular expressions to express (in a compact way) navigational patterns (e.g., [10,14,15,40]). Angles and Gutierrez [5], and Wood [54] provide surveys on the topic, Barceló provides a detailed overview of research in the field [9] while Angles et al. [4] describe a recent proposal. Our goal with EPPs is to extend the navigational core of SPARQL (i.e., PPs) and make the extension readily available for existing SPARQL processors.
SPARQL navigational extensions
Proposals to extend SPARQL with navigational features have been around for some time. Notable examples are PSPARQL [3] and nSPARQL [43] that tackled this problem even before the standardization of property paths (PPs) as SPARQL navigational core. From the practical point of view, the need for RDF navigational languages is witnessed by projects like Apache Marmotta16
 ), path difference (
), path difference ( ), negation of tests (
), negation of tests ( ), nesting (
), nesting ( ), tests over nodes (
), tests over nodes ( ), usage of positions (
), usage of positions ( ), path repetitions ({l,h}), entailment regime, and closure operator (
), path repetitions ({l,h}), entailment regime, and closure operator ( ). Additionally, we consider how expressions in each of the languages are evaluated, the support for reasoning (we focus on RDFS and in particular the ρdf fragment [41]) and the support for query-based reasoning (QBR); finally, we also report whether the language is implemented.
). Additionally, we consider how expressions in each of the languages are evaluated, the support for reasoning (we focus on RDFS and in particular the ρdf fragment [41]) and the support for query-based reasoning (QBR); finally, we also report whether the language is implemented.
Comparison of EPPs with other navigational extensions of SPARQL
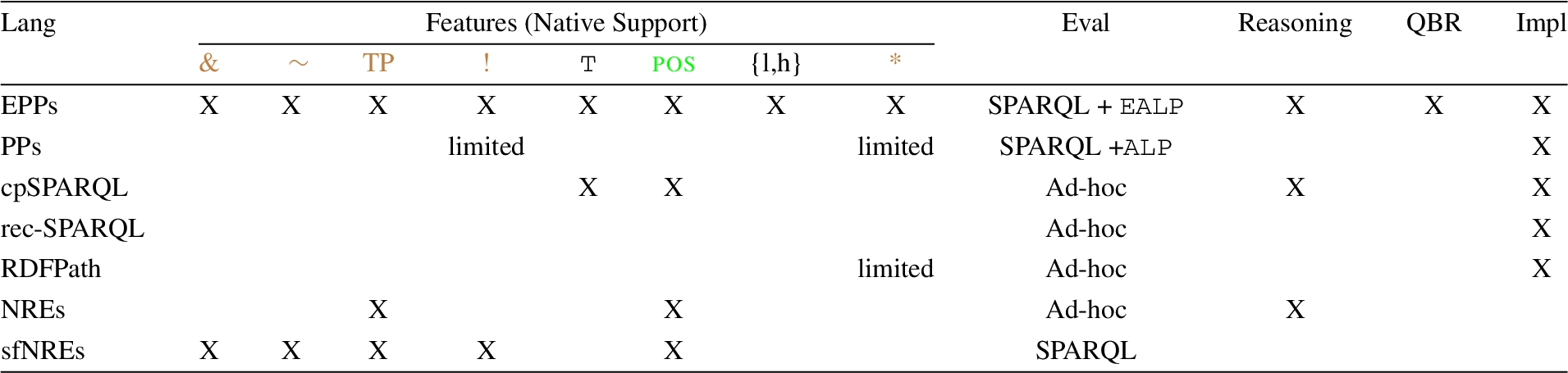
RDFPath is more focused on specific types of queries (i.e., shortest paths) and their efficient implementation in MapReduce and it has fewer features than all the other languages considered. Path conjunction/difference are natively supported only by EPPs and sfNREs while nSPARQL, cpSPARQL and rec-SPARQL require the usage of the SPARQL algebra (i.e.,  for conjunction). Nevertheless, this does not allow to use path conjunction inside the closure operator where the number path conjunction evaluations is apriori not bound. As a side note, we also mention that queries that resort to the SPARQL algebra for conjunction are more verbose. Finally, nSPARQL, cpSPARQL and rec-SPARQL do not support path difference. Test negation (
for conjunction). Nevertheless, this does not allow to use path conjunction inside the closure operator where the number path conjunction evaluations is apriori not bound. As a side note, we also mention that queries that resort to the SPARQL algebra for conjunction are more verbose. Finally, nSPARQL, cpSPARQL and rec-SPARQL do not support path difference. Test negation ( ) is only supported by PPs (e.g., via negated property sets) and EPPs; nesting is supported by all languages except PPs and rec-SPARQL. However, only EPPs allow to test node values in a nested expression (see Example 6). Node tests are supported in limited form by cpSPARQL; EPPs allow logical combination of tests representing nesting and tests representing (in)equalities of node values. As a matter of fact, none of these extensions can express the Italian exclusive friends query mentioned in the Introduction. EPPs support path repetitions; this feature (called curly brace form) is in the agenda of the SPARQL working group.17
) is only supported by PPs (e.g., via negated property sets) and EPPs; nesting is supported by all languages except PPs and rec-SPARQL. However, only EPPs allow to test node values in a nested expression (see Example 6). Node tests are supported in limited form by cpSPARQL; EPPs allow logical combination of tests representing nesting and tests representing (in)equalities of node values. As a matter of fact, none of these extensions can express the Italian exclusive friends query mentioned in the Introduction. EPPs support path repetitions; this feature (called curly brace form) is in the agenda of the SPARQL working group.17
A crucial difference between EPPs and related research is that we tackle the problem of extending the SPARQL language in the least intrusive way. We show that there exists a precise fragment of SPARQL that is expressive enough to capture non recursive EPPs (nEPPs), that is, EPPs that do not use closure operators (i.e., * and
Reasoning is not supported by PPs, sfNREs, RDFPath, and rec-SPARQL. Along the same line of NREs (and nSPARQL) and cpSPARQL, we focus on how EPPs can support SPARQL queries with embedded reasoning capabilities [23]. We focus on the
Another difference with related proposals concerns the implementation of the language. To foster the adoption of EPPs and show its feasibility, we make EPPs available to users and developers in different forms: (i) as an implementation independent from SPARQL; (ii) as a front-end to SPARQL endpoints (for nEPPs) and (iii) as an extension to the Jena library. Further information along with pointers to the source code is available on the EPPs’s website.18
Finally, our study includes two novel expressiveness aspects. The first concerns the expressive power of the current SPARQL standard in terms of navigational features (see Section 6). We show that the language of EPPs is more expressive than SPARQL PPs; as a by-product we show that using EPPs as navigational core in SPARQL increases the expressive power of the whole SPARQL language. The second aspect concerns the expressiveness of SPARQL also in terms of query-based reasoning capabilities when considering the
Besides SPARQL navigational extensions there exist other graph languages like GraphQL [28] the Facebook query language and
CONSTRUCT query forms
Reutter et al. [46] proposed to enhance the expressive power of SPARQL via the introduction of recursions in a similar way to SQL. The idea is to alternate CONSTRUCT queries (that materialize in a graph the portion of data needed in each recursive call) and SELECT queries to project only parts of interest. This approach, which is currently not available in standard SPARQL implementations could be used to materialize the portion of the graph needed to capture RDFS inferences. Both data materialization and changes required to SPARQL processors (to support recursion) go against the idea of EPPs that provide expressive SPARQL navigational queries (also under the ρdf entailment regime) with no materialization and no changes to existing SPARQL processors.
Concluding remarks
We introduced EPPs, a significant extension of property paths, the current navigational core of SPARQL, the standard query language for querying KGs based on RDF. We underlined several practical advantages of adopting such an extension. Our study also offers interesting theoretical observations, among which: (i) we identified a precise fragment of SPARQL that can capture non-recursive EPPs thus providing an indirect analysis of the navigational expressiveness of SPARQL; (iii) we have studied the expressiveness of EPPs as compared to PPs; (iii) we have also studied the expressiveness of SPARQL with respect to the
Footnotes
Detailed experiments in Section 8.3
(Continued)
| Seed entity | QId | Result count | Time (ms) | ||
|
|
|
||||
| No reasoning | No reasoning | ||||
| yago:Acheron_Boys_Home | Q24 | 0 | 1 | 106.18 | 110.22 |
| yago:Acheron,_Victoria | Q25 | 0 | 5 | 96.06 | 115.61 |
| yago:Achimota_School | Q26 | 0 | 2 | 120.28 | 128.43 |
| yago:Acme,_Washington | Q27 | 0 | 2 | 106.37 | 121.53 |
| yago:Acquaviva_Picena | Q28 | 0 | 1 | 102.37 | 115.10 |
| yago:AD_Torreforta | Q29 | 0 | 1 | 108.07 | 123.47 |
| yago:Ada,_Croatia | Q30 | 0 | 3 | 91.96 | 113.06 |
| yago:Adabay_River | Q31 | 0 | 1 | 112.62 | 120.61 |
| yago:Adaganahalli | Q32 | 0 | 1 | 91.23 | 118.95 |
| yago:Adair,_Idaho | Q33 | 0 | 3 | 111.64 | 114.51 |
| yago:Adak_Airport | Q34 | 0 | 1 | 111.93 | 122.05 |
| yago:Adak,_Alaska | Q35 | 0 | 3 | 91.31 | 116.07 |
| yago:Adakanahalli | Q36 | 0 | 1 | 105.41 | 121.67 |
| yago:Adakatahalli | Q37 | 0 | 1 | 108.14 | 99.44 |
| yago:Adalin_River | Q38 | 0 | 2 | 102.34 | 107.79 |
| yago:Adam_&_Steve | Q39 | 0 | 1 | 100.46 | 111.54 |
| yago:Adam_Airport | Q40 | 0 | 1 | 97.71 | 102.69 |
| yago:Adam_Orris_House | Q41 | 0 | 1 | 108.72 | 104.87 |
| yago:Adam’s_Green | Q42 | 0 | 2 | 93.65 | 111.36 |
| yago:AdOn_Network | Q43 | 0 | 1 | 114.73 | 128.12 |
| yago:AFI_Conservatory | Q44 | 0 | 2 | 110.62 | 123.65 |
| yago:ALZ_(steelworks) | Q45 | 0 | 1 | 98.44 | 110.07 |
| yago:APSA_Colombia | Q46 | 0 | 1 | 92.99 | 121.10 |
| yago:ASFA_Soccer_League | Q47 | 0 | 1 | 106.14 | 128.73 |
| yago:ASTM_International | Q48 | 0 | 2 | 103.31 | 125.01 |
| yago:ATP_Challenger_Guangzhou | Q49 | 0 | 1 | 108.21 | 111.38 |
| yago:ATP_Challenger_La_Serena | Q50 | 0 | 1 | 122.51 | 113.77 |
Queries of experiments in Section 8.2
Queries used in Section 8.2
|
|
|
| Q1 |
|
| Q2 | |
| Q3 | |
| Q4 |
|
| Q5 | ( |
| Q6 | ( |
| Q7 | |
| Q8 | ( |
| Q9 | |
| Q10 | |
| Q11 | ( |
| Q12 |