
Abstract
Linked Data on the Web represents an immense source of knowledge suitable to be automatically processed and queried. In this respect, there are different approaches for Linked Data querying that differ on the degree of centralization adopted. On one hand, the SPARQL query language, originally defined for querying single datasets, has been enhanced with features to query federations of datasets; however, this attempt is not sufficient to cope with the distributed nature of data sources available as Linked Data. On the other hand, extensions or variations of SPARQL aim to find trade-offs between centralized and fully distributed querying. The idea is to partially move the computational load from the servers to the clients. Despite the variety and the relative merits of these approaches, as of today, there is no standard language for querying Linked Data on the Web. A specific requirement for such a language to capture the distributed, graph-like nature of Linked Data sources on the Web is a support of graph navigation. Recently, SPARQL has been extended with a navigational feature called property paths (PPs). However, the semantics of SPARQL restricts the scope of navigation via PPs to single RDF graphs. This restriction limits the applicability of PPs for querying distributed Linked Data sources on the Web. To fill this gap, in this paper we provide formal foundations for evaluating PPs on the Web, thus contributing to the definition of a query language for Linked Data. We first introduce a family of reachability-based query semantics for PPs that distinguish between navigation on the Web and navigation at the data level. Thereafter, we consider another, alternative query semantics that couples Web graph navigation and data level navigation; we call it context-based semantics. Given these semantics, we find that for some PP-based SPARQL queries a complete evaluation on the Web is not possible. To study this phenomenon we introduce a notion of Web-safeness of queries, and prove a decidable syntactic property that enables systems to identify queries that are Web-safe. In addition to establishing these formal foundations, we conducted an experimental comparison of the context-based semantics and a reachability-based semantics. Our experiments show that when evaluating a PP-based query under the context-based semantics one experiences a significantly smaller number of dereferencing operations, but the computed query result may contain less solutions.
Introduction
The increasing trend in sharing and interlinking pieces of structured data on the World Wide Web (WWW) is evolving the classical Web – which is focused on hypertext documents and syntactic links among them – into a Web of Linked Data. The Linked Data principles [5] present an approach to extend the scope of Uniform Resource Identifiers (URIs) to new types of resources (e.g., people, places) and represent their descriptions and interlinks by using the Resource Description Framework (RDF) [8] as standard data format. RDF adopts a graph-based data model, which can be queried by using the SPARQL query language [15]. When it comes to Linked Data on the WWW, the common way to provide query-based access is via SPARQL endpoints; that is, services that usually answer SPARQL queries over a single dataset. Recently, the original core of SPARQL has been extended with features supporting query federation; it is now possible, within a single query, to target multiple endpoints (via the
However, as of today, there exists no standard query language for Linked Data on the WWW, although SPARQL is clearly a candidate. A key feature that such a language should provide is navigation across the unbound, a priori unknown, graph-like environment represented by distributed Linked Data sources.
While earlier research on using SPARQL for Linked Data is limited to fragments of the first version of the language [6,16,18,38], the version 1.1 of SPARQL introduces a feature called property paths (PPs) that equips the language with navigational capabilities [15]. However, the standard definition of PPs is limited to single RDF graphs and, thus, not directly applicable to Linked Data that is distributed over the WWW.
Therefore, toward the definition of a language for accessing Linked Data live on the WWW, the following questions emerge naturally:
How can PPs be defined over the WWW?
What are the implications of such a definition?
We formalize a family of reachability-based query semantics of PP-based SPARQL queries that are meant to be evaluated over Linked Data on the WWW. This formalization approach treats navigation on the Web separate from navigation on the level of data.
We also formalize an alternative, context-based query semantics that intertwines Web graph navigation and data level navigation.
We study the feasibility of evaluating queries under these semantics. For this study we assume that query engines do not have complete information about the queried Web of Linked Data (as it is the case for the WWW). Our study shows that query evaluation under any reachability-based semantics is possible in practice and that a similarly general statement cannot be made for the context-based semantics; that is, there exist cases in which query evaluation under the context-based semantics is not possible.
We establish a decidable syntactic property of queries for which an evaluation under the context-based semantics is possible.
We provide an experimental comparison of the context-based and a reachability-based semantics. For this comparison we executed queries directly over the WWW. As its main result, our experiment shows that when evaluating a PP-based query under the context-based semantics, one experiences a significantly smaller number of dereferencing operations, but the computed query result may contain less solutions.
This article extends a preliminary version that appeared in the proceedings of the ESWC 2015 conference [21]. The extension includes: (i) the definition and analysis of a family of reachability-based query semantics for Property Paths on the Web; (ii) an experimental analysis and comparison of the different semantics; (iii) a more detailed description of the main technical results; (iv) further examples to better clarify the terminology and the main concepts of the paper; (v) a more comprehensive discussion of related work.
The paper is organized as follows. Section 2 provides an overview on related work. In Section 3 we introduce the formal framework for this paper, including a data model that captures the notion of Linked Data on the WWW. Section 4 focuses on PPs, isolated from other SPARQL operators. In Section 5 we broaden our view to define PP-based SPARQL graph patterns. In Section 6 we characterize a class of Web-safe patterns and prove their feasibility. Section 7 discusses the experimental evaluation. Finally, in Section 8 we conclude.
Related work
There is an extensive body of research on the foundations of querying RDF data. An important work in this context is the investigation of SPARQL provided by Peréz et al. [30]. Other authors focused on the foundations of SPARQL query optimization [26,34].
From the perspective of graphs, languages for the navigation and specification of vertices in graphs have a long tradition (see Wood’s survey [41]). For RDF, extensions of SPARQL such as PSPARQL [2], nSPARQL [31], and SPARQLeR [23] introduced navigational features since those were missing in the first version of SPARQL. Only recently, with the addition of property paths (PPs) in version 1.1 [15], SPARQL has been enhanced officially with such features. The final definition of PPs has been influenced by research that studied the computational complexity of an early draft version of PPs [3,27]. There also already exists a proposal to extend the expressive power of PPs [11]. Other strands of research focus on studying properties of PPs such as containment [25] or supporting recursion in SPARQL [32]. However, the main assumption of all these navigational extensions of SPARQL is to work on a single, centralized RDF graph.
The idea of querying the WWW as a database is not new (see Florescu et al.’s survey [13]). Perhaps the most notable early works in this context are by Konopnicki and Shmueli [24], Abiteboul and Vianu [1], and Mendelzon et al. [28], all of which tackled the problem of evaluating SQL-like queries on the hypertext Web. While such queries included navigational features, the focus was on retrieving specific Web pages, particular attributes of specific pages, or content within them.
Our departure point is different: We aim at defining semantics of SPARQL queries (including property paths) over Linked Data on the WWW; this involves dealing with two graphs of different type; namely, an RDF graph that is distributed over an unbounded number of documents on the WWW and the Web graph in which these documents are interlinked with each other.
To express queries over Linked Data on the WWW, two main strands of research can be identified. The first studies how to extend the scope of SPARQL queries to the WWW, with existing work focusing on basic graph patterns [6,16,38] or a more expressive fragment that includes
These two strands have different departure points. The former employs navigation over the WWW to collect data for answering a given SPARQL query; here navigation is a means to discover query-relevant data. The latter provides explicit navigational features and uses querying capabilities to filter data sources of interest; here navigation (not querying) is the main focus. The context-based query semantics proposed in this paper combines both approaches.
Another line of research slightly related to our proposal is that of focused crawling. The idea is to enhance the behavior of classical Web crawlers, that consider all pages reachable from a given page, to be more selective; selectivity is obtained by considering e.g., a set of predefined topics [36] or meta data within HTML pages [29]. A more recent line of related research looks into building (domain-specific) knowledge graphs by exploiting semantic technologies to reconcile the data continuously crawled from diverse sources [35]. In a way, these approaches mimic the process of filtering performed by our approach but on a less expressive scale due to the limited expressiveness of the filtering mechanism as compared to our language. Nevertheless, our approach could be used to enable a finer-grained information filtering.
Formal framework
This section provides a formal framework for defining semantics of PPs over Linked Data. In particular, we first recall the definition of PPs as per the SPARQL standard [15]. Thereafter, we introduce a data model that captures the notion of Linked Data on the WWW.
Preliminaries
We assume four pairwise disjoint, countably infinite sets
A property path pattern (or PP pattern for short) is a tuple

SPARQL algebra operators over multisets of solution mappings,
As can be seen from this grammar, we have two base cases for PP expressions, namely, arbitrary IRIs and expressions of the form
The SPARQL standard introduces additional types of PP expressions [15]. Since these are merely syntactic sugar (they are defined in terms of expressions covered by the grammar given above), we ignore them in this paper. As another slight deviation from the standard, we do not permit blank nodes in PP patterns (i.e.,
As an example of a PP pattern consider
In addition to a syntax for the queries of interest, we have to introduce the standard semantics of these queries. The SPARQL specification defines this semantics by an evaluation function (see below) that returns multisets of so called solution mappings; such a mapping is a partial function
To refer to the domain of a solution mapping μ (i.e., the set of variables for which μ is defined) we write
We represent a multiset of solution mappings by a pair
To define the aforementioned evaluation function we also need to introduce several operators of the SPARQL algebra, which is defined over multisets of solution mappings. That is, for two such multisets,

Auxiliary functions used for defining the semantics of PP expressions of the form
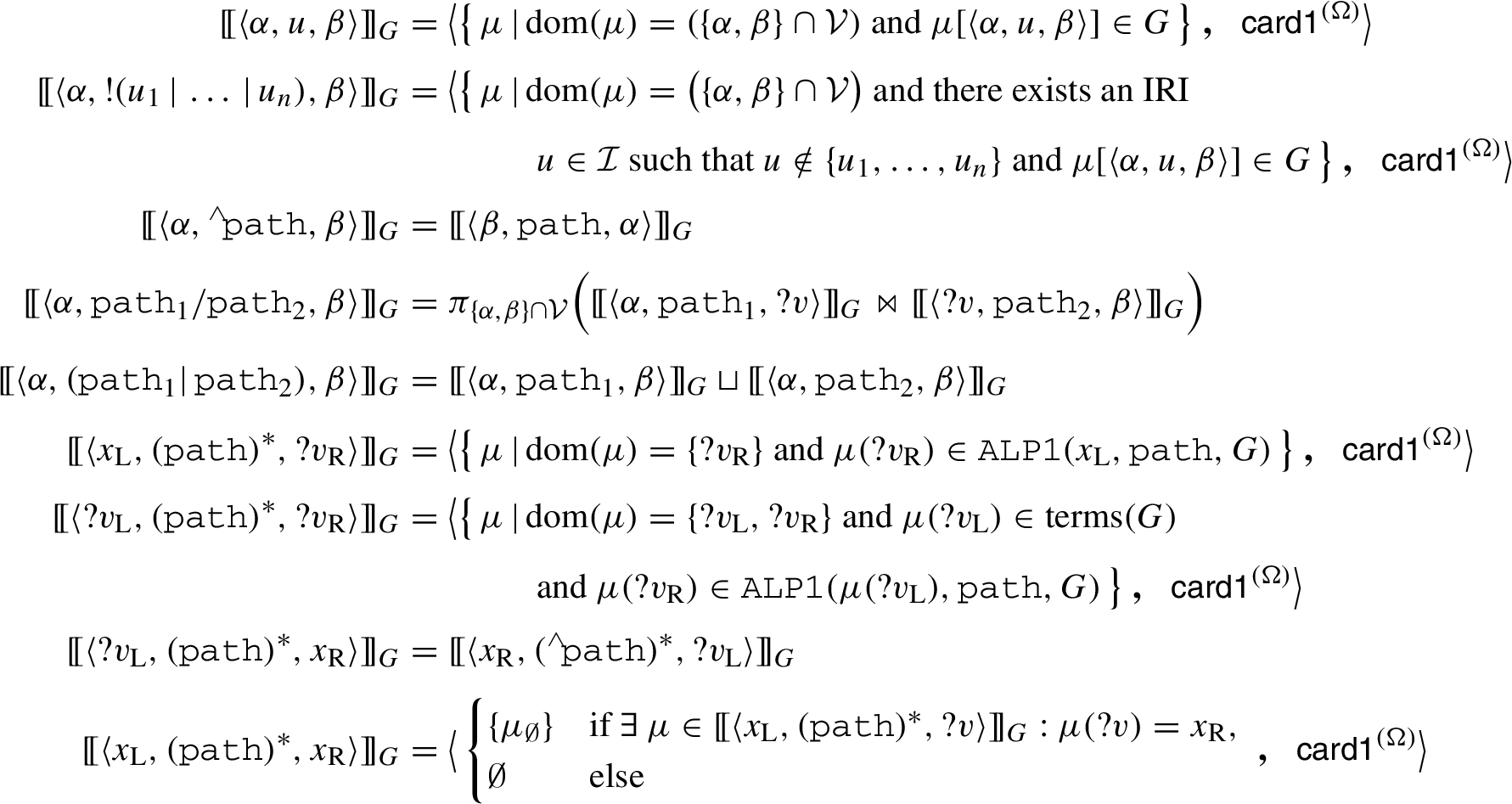
Standard query semantics of SPARQL Property Paths, where
We are now ready to define the evaluation function that formalizes the standard semantics of PP patterns.
Let P be a PP pattern and let G be an RDF graph. The evaluation of P over G, denoted by
Consider the following RDF graph:
As another example, consider PP pattern
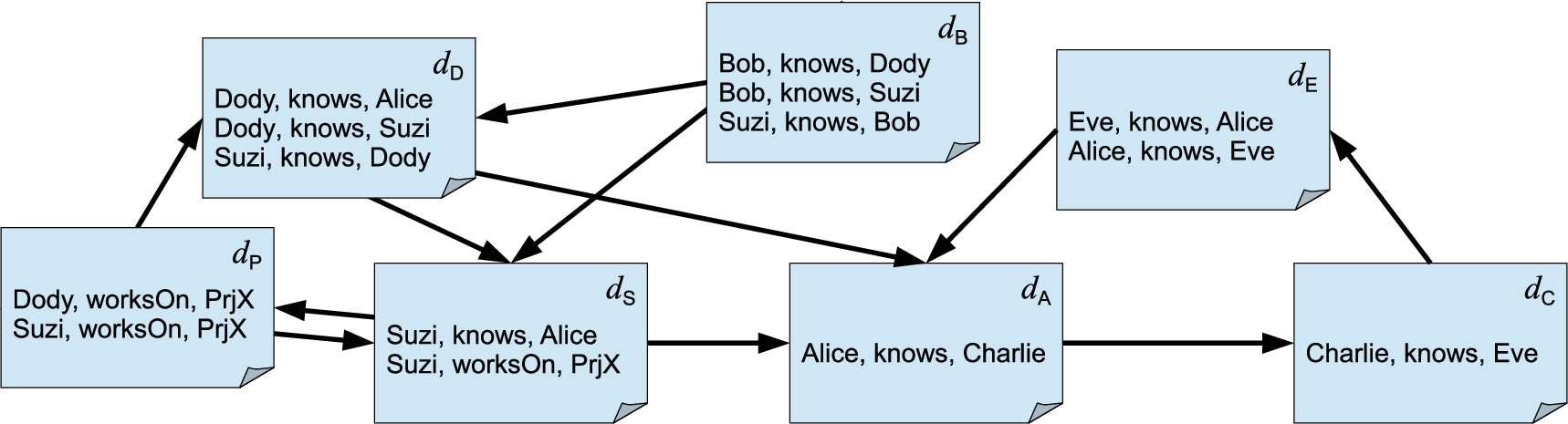
The link graph of our example Web of Linked Data
The standard query semantics of PP patterns – as introduced in the SPARQL specification and presented in the previous section – defines the result expected from evaluating such a pattern over a (single) RDF graph. Since the WWW is not an RDF graph, this standard definition is insufficient as a formal foundation for evaluating PP patterns over Linked Data on the WWW. As a basis for providing a suitable definition we need a data model that captures the notion of a Web of Linked Data. To this end, we adopt the data model introduced in our earlier work [18].
For this model we assume an infinite set
Assume a special symbol ⊥ such that
Observe that the function
For the subsequent discussion we introduce a few additional concepts: Given a Web of Linked Data
As a running example for the remainder of this paper, we assume a small Web of Linked Data
We emphasize that the link graph, as well as the two elements D and
We are now ready to formalize query semantics that define PP patterns as queries over a Web of Linked Data (and, thus, over Linked Data on the WWW).
This section introduces three alternative query semantics, each of which defines an expected query result for any PP pattern over any Web of Linked Data.
Full-web query semantics
As a first approach we may assume a semantics that is based on the standard evaluation function for PP patterns (cf. Definition 2) and defines expected query results in terms of all data in a queried Web of Linked Data. The following definition captures this approach, which we call a “full-Web query semantics” [18].
Let P be a PP pattern,
Recall our example Web
We emphasize that the full-Web query semantics is mostly of theoretical interest. In practice, that is, for a Web of Linked Data
Given the limited practical applicability of the full-Web semantics, our earlier work introduces reachability-based semantics that restrict the scope of queries and expected results to “reachable” documents [18]. In the following, we adapt this idea for PP patterns.
Informally, a set of reachable documents of a Web of Linked Data W contains all the documents that can be reached by traversing recursively a well-defined set of data links in the link graph of W. To specify what data links belong to such a set, we introduce the notion of a reachability criterion [18], which we define formally as a function
Let P be a PP pattern, let There exists an IRI there exist (another) document
Notice how the second condition restricts the notion of reachability by ignoring any data link that does not satisfy the given reachability criterion. In earlier work we define several concrete reachability criteria [18], including
Another, more restrictive criterion that is commonly used in practice [19,38], is
For any triple
By using our previous example pattern
Given the notion of reachability criteria, we define a family of reachability-based semantics for PP patterns: Let P be a PP pattern, let Consider Under
Reachability-based query semantics as introduced in the previous section impose a clear conceptual separation between navigation over the link graph of a queried Web of Linked Data – which serves the purpose of discovering and retrieving reachable documents – and standard PP-based navigation over the data obtained from all reachable documents. That is, there exists no correlation between paths of triples that match PP expressions and paths of data links that connect reachable documents to seed documents.
At this point it is interesting to also explore an alternative approach in which navigation on the link graph correlates with PP patterns in queries. To this end, we introduce another semantics that interprets PP patterns as a language for navigation over Linked Data on the WWW (i.e., along the lines of earlier navigational languages for Linked Data such as NautiLOD [10]). We refer to this semantics as context-based.
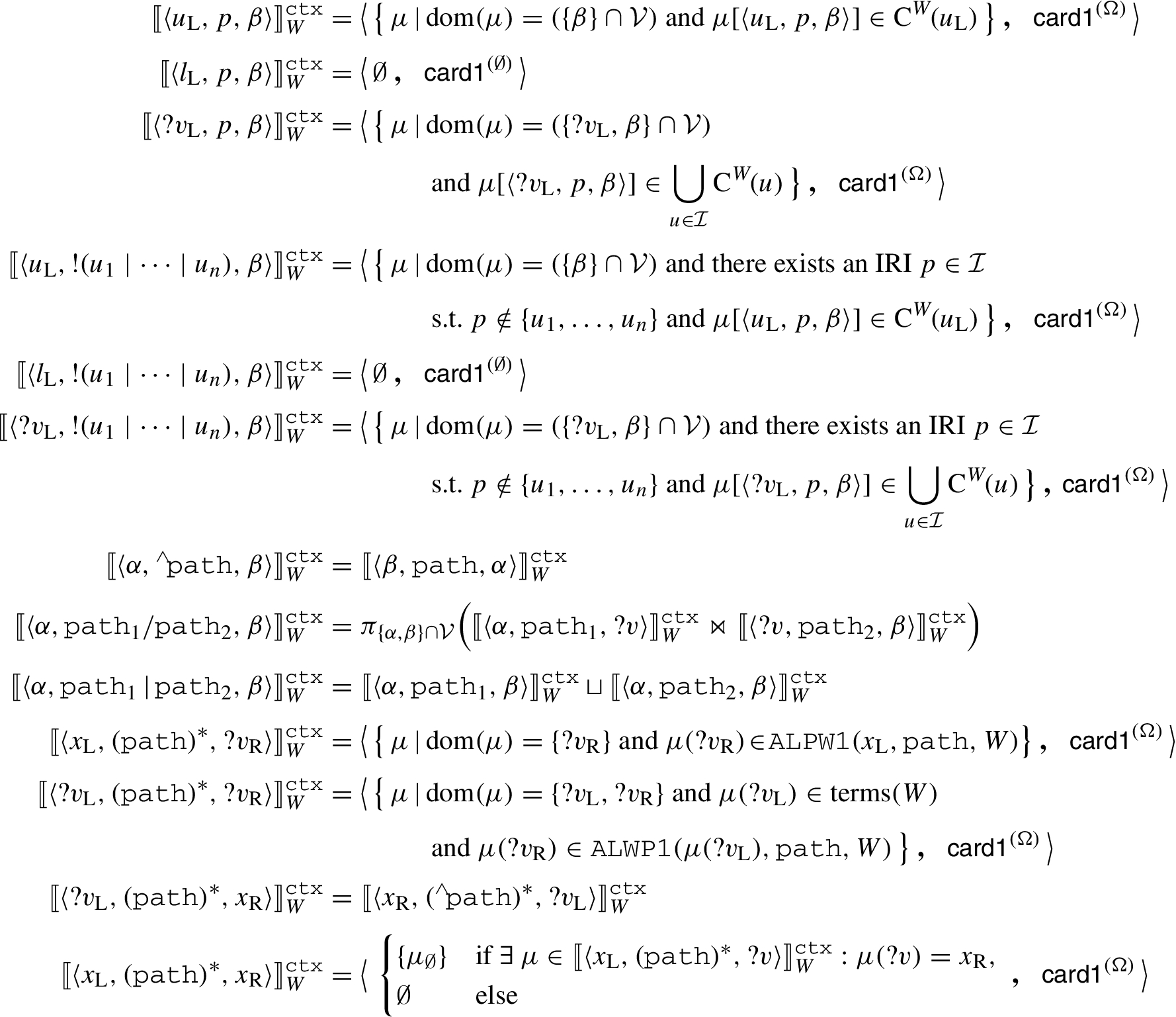
Context-based semantics of property paths over a Web of Linked Data;
The main idea of this query semantics is to restrict the scope of searching for any next triple of a potentially matching path to specific data within specific documents on the queried Web of Linked Data.
To formalize these restrictions we introduce the notion of a context selector. Informally, for each IRI that can be used to retrieve a document, the context selector returns a specific subset of the data within that document; this subset contains only those triples that have the given IRI as their subject (such a subset of triples resembles Harth and Speiser’s notion of “subject authoritative triples” [16]). Formally, for any Web of Linked Data
Informally, the context-based semantics uses the notion of a context selector to restrict the scope of PP patterns over a Web of Linked Data as follows. Assume a sequence of triples
Given a PP pattern P and a Web of Linked Data

Auxiliary functions used for defining context-based query semantics.
Note how Definition 15 uses the context selector to restrict the data that has to be searched to find matching triples (e.g., consider the first line in Fig. 5).
Coming back to the example PP pattern
There are two points worth emphasizing regarding Definition 15: First, we define the context-based semantics such that it resembles the standard semantics of PP patterns in Section 3.1 as close as possible. To this end, the part of our definition that covers PP patterns of the form
However, due to this requirement, there exist PP patterns whose (complete) evaluation under context-based semantics is infeasible when querying the WWW. The following example describes such a case.
Consider the following PP pattern
It is not difficult to see that the issue illustrated in the example exists for any triple pattern that has a variable in the subject position. On the other hand, triple patterns whose subject is an IRI do not have this issue. However, having an IRI in the subject position is not a sufficient condition in general. For instance, the PP pattern
A question that arises is whether there exists a (decidable) property of PP patterns that can be used to distinguish between patterns that do not have this issue (i.e., evaluating them over any Web of Linked Data is feasible under the context-based semantics) and those that do. Another question is whether any of the aforementioned reachability-based semantics has a similar problem, and, more generally, how do these semantics compare to the context-based semantics?
We come back to these questions in Sections 6 and 7, after introducing the more general case of PP-based SPARQL queries in the next section.
After considering PP patterns in isolation, we now turn to a more expressive fragment of SPARQL that embeds PP patterns as the basic building block and uses additional operators on top. In this section, we define the resulting PP-based SPARQL queries; we specify their syntax and formalize Web-aware semantics that extend the above defined semantics of PP patterns.
By using the algebraic syntax of SPARQL [30], we define a graph pattern recursively as follows:1
For this paper we leave out other types of SPARQL graph patterns such as filters, subqueries, assignments (
Any PP pattern
If
For any graph pattern P, we write
An example of a graph pattern that combines two PP patterns using the
By using PP patterns as the basic building block of graph patterns, we can readily carry over any of the above defined query semantics to graph patterns. To this end, let Let P be a graph pattern and let W be a Web of Linked Data. For any Note that the definition uses the algebra defined in Fig. 1. If P is a PP pattern If P is of the form If P is of the form If P is of the form
Given the different semantics for evaluating (PP-based) graph patterns over a Web of Linked Data, we now study formally whether such evaluations are possible in practice over Linked Data on the WWW.
To this end, we first recall from Section 4.1 that, under full-Web semantics, evaluating PP patterns over the WWW is not possible in practice because, for the tuple
Based on this observation, we define a notion of Web-safeness of graph patterns; with this notion we capture whether it is possible for a graph pattern to be evaluated completely over Linked Data on the WWW under a given semantics.
For any The algorithm computes During its execution, the algorithm looks up only a finite number of IRIs (that is, conceptually, the algorithm invokes function Neither the set D nor the set
Unsurprisingly, as already discussed in Section 4.1, it follows from the results in our earlier work [18] that, under full-Web semantics, none of the graph patterns considered in this paper is Web-safe.
In the following, we study Web-safeness of graph patterns under the other Web-aware query semantics.
Independent of what reachability criterion (and seed IRIs) one chooses, for every reachability-based semantics we can show the following positive result.
Given an arbitrary reachability criterion c and any finite set
As a basis to prove Theorem 21, we first focus on PP patterns, for which we show the following lemma.
Given an arbitrary reachability criterion c and any finite set
We prove the lemma by providing Algorithm 1. It is easily verified that this algorithm has the desired properties (as listed in Definition 20). Note that the execution of this algorithm consists of two consecutive phases: a data retrieval phase (lines 1 to 12) and a standard result computation phase (line 13). During the data retrieval phase the algorithm incrementally discovers all documents that are

Computation of the S-seeded evaluation of a PP pattern P over any Web of Linked Data under c-semantics (where
Given Lemma 22, it is trivial to prove Theorem 21.
Theorem 21 is a direct consequence of Definition 19 and Lemma 22. That is, given multisets of solution mappings computed for PP patterns, combining such multisets as per the algebra operators does not require any more URI lookups (or any other kind of access to the queried Web of Linked Data) and can be done by any algorithm that implements these algebra operators. □
We emphasize that, while Algorithm 1 is sufficient for proving Lemma 22 and, thus, Theorem 21, it is perhaps not a very efficient algorithm to use in practice. Systems might instead implement traversal-based execution approaches to evaluate PP patterns under reachability-based semantics [19,38]; the processing of IRIs from the Open list (used in the algorithm) can be parallelized by a multi-threaded implementation; additionally, assuming a suitable invalidation policy, documents may be cached and reused for later queries [17].
After finding that under any reachability-based semantics all graph patterns are Web-safe, we now come back to the context-based semantics for which we know from Example 17 that Web-safeness cannot be assumed in general. We begin our analysis by providing the following example, which extends Example 17.
Consider the following graph pattern:
The example illustrates that some graph patterns are Web-safe under context-based semantics even if some of their sub-patterns are not. Consequently, we are interested in a decidable property that enables us to identify Web-safe patterns under context-based semantics, including those whose sub-patterns are not Web-safe.
Buil-Aranda et al. study a similar problem in the context of SPARQL federation where graph patterns of the form
The set of strongly bound variables in a graph pattern P, denoted by If P is a PP pattern, then
If P is of the form If P is of the form If P is of the form
Given the definition of strongly bound variables, we observe that one cannot identify Web-safe graph patterns by using only this notion of strong boundedness.
Cases of the recursive definition of the conditionally bound variables of a graph pattern P w.r.t. a set of variables
Consider graph pattern
We conjecture the following reason why strong boundedness cannot be used directly for our problem. Consider the types of graph patterns that combine two sub-patterns (by using operators such as
Based on this observation, we introduce the notion of conditionally bound variables, which is based on particular relationships between sub-patterns due to which the result of one sub-pattern may be used to evaluate another sub-pattern in a more well-behaved manner (along the lines of Example 23). This notion shall turn out to be suitable for our case.
Let
The conditionally bound variables in the PP pattern
As another example consider the graph pattern
We note that for the pattern
A graph pattern P is Web-safe under context-based semantics if
Before proving Theorem 29 in the remainder of this section, we emphasize the following observation.
Due to the recursive nature of Definition 26, the condition
To prove Theorem 29 we aim to provide an algorithm that evaluates graph patterns recursively by passing (intermediate) solution mappings to recursive calls. To capture the desired results of each recursive call formally, we introduce a special evaluation function for a graph pattern P over a Web of Linked Data W that takes a solution mapping μ as input and returns only the solutions of P over W that are compatible with μ (recall from Section 3.1 that the compatibility of two solution mappings,
Let P be a graph pattern, let W be a Web of Linked Data, and let
The following lemma shows the existence of the aforementioned recursive algorithm.
Let P be a graph pattern and
The algorithm computes
During its execution, the algorithm looks up only a finite number of IRIs (that is, conceptually, the algorithm invokes function
Neither the set D nor the set
Before proving the lemma (and Theorem 29), we point out two important properties of Definition 31. First, it is easily seen that, for any graph pattern P and Web of Linked Data W,
Let
Recall that for any IRI u and any Web of Linked Data W, every triple in the context

EvalCtxBased
We use Lemma 33 to prove Lemma 32 as follows.
We prove Lemma 32 by induction on the possible structure of graph pattern P. To this end, we provide Algorithm 2 and show that this (recursive) algorithm has the desired properties for any possible graph pattern (i.e., any case of the induction, including the base case). In this paper we focus on a fragment of the algorithm and highlight essential properties thereof. This fragment covers the base case (lines 1–11) and one pivotal case of the induction step, namely, graph patterns of the form
For the base case (i.e., PP patterns of the form
For PP patterns of the form
We are now ready to prove Theorem 29.
Suppose P is a graph pattern such that
While the condition given in Theorem 29 is sufficient to identify graph patterns that are Web-safe under context-based semantics, the question that remains is whether it is a necessary condition (i.e., whether it can be used to decide Web-safeness of all graph patterns under context-based semantics). Unfortunately, the answer is no as the following example shows.
For the graph pattern
The example illustrates that “only if” cannot be shown in Theorem 29. It remains an open question whether there exists an alternative condition for Web-safeness that is both sufficient and necessary (and decidable) and, thus, can be used to decide Web-safeness of all graph patterns under context-based semantics.
In the previous section we have shown that, when querying Linked Data on the WWW, it is possible for PP-based graph patterns to be evaluated completely under any reachability-based semantics, and, similarly, under the context-based semantics (assuming, for the latter, we use only patterns that have been identified to be Web-safe). Hence, we have shown that – based on these semantics – one can build a system that answers PP-based SPARQL queries over the WWW in a well-defined manner. At this point, a natural question that arises is:
How do these query semantics compare when actually used in practice?
To achieve empirical insights related to this question we conducted an experimental comparison of the context-based semantics and a reachability-based semantics. For this comparison we selected

Comparison between context-based semantics and (reachability-based)
In the remainder of this section, we specify the experimental setup, describe the experiments, present the measurements, and discuss the experimental results.
The objective of the experimental comparison is to identify the differences between the studied semantics in terms of (i) number of dereferencing operations performed to evaluate a query and (ii) number of solutions in the respective query results, including duplicates (which are possible in our bag semantics as Example 13 illustrates). Hereafter, we refer to these metrics as (i)
For the experiments, which we conducted during the days of November 16–28, 2015, we used a prototypical implementation of the studied semantics to execute PP-based SPARQL queries directly on the WWW. To avoid overloading Web servers we introduced a delay of 3 seconds between dereferencing operations. While we did not use any client-side caching of retrieved documents, there may have been Web caches (proxy servers) between our prototypical query clients and the Web servers that host the data discovered and retrieved during the execution of our test queries. Measurements reported in the following are the average of five executions with rounding to the next integer.
Experiments and measurements
We conducted two different experiments considering two different topical domains of Linked Data on the WWW, namely, distributed social network data (D1) and encyclopedic data about influence relationships between people (D2). Within these domains we focus on navigational queries that we express using PP patterns. The particular queries used for the experiments can be found in Appendix. In the following, we describe the experiments and the queries in more detail, and we present the measurements.
Experiment on D1
In our first experiment we considered the distributed social network of FOAF profiles [14]. Such FOAF profiles typically are RDF documents that people make available online to provide Linked Data that describes themselves in terms of their interests, their works, and, most important for our experiment, references to other people they know. Such references are expressed using triples with the IRI3
For the compact representation of IRIs in this section we use the following two prefixes. foaf: <
In this experiment we use the IRI of Nuno Lopes4
By looking at Fig. 7(a), we notice that, under the context-based semantics,
The effect of taking into account more data can be observed by looking at our
The only exception, where the query result under both semantics is the same, is the distance-1 query. This query consists only of a single triple pattern with the seed IRI as subject,

Comparison between context-based semantics and (reachability-based)
For our second experiment we considered influence relationships between people described in Linked Data that is made available by the DBpedia project [4]. In particular, we focused on the relationships expressed by triples with the IRI
Due to the availability of these bidirectional data links, the query results under both semantics are the same for each of the six queries (cf. Fig. 8). In contrast, the
Our experiments indicate that choosing one of the two tested query semantics over the other may have a significant impact in practice. Considering the size of query results first, our experiments show that there are cases in which the query result computed under the context-based semantics is smaller than under the (reachability-based)
First, since it is based on the context selector (cf. Section 4.3), the context-based semantics ignores all the triples from any given document that have a subject IRI different from the IRI whose lookup resulted in retrieving the document. Ignoring such triples significantly decreases the number of paths (of triples) that can be found to match a given PP expression.
Second, the context-based semantics is designed to be very selective in the way the queried Web of Linked Data has to be traversed. More precisely, every traversal step is the result of first discovering a triple in the data of the current context document such that this triple can be used as a next step along a path that eventually may match the given PP expression. As a consequence of enforcing such a behavior, the traversal may not reach some documents that are reached under the
Our first experiment shows that this may happen in particular if the region of the Web that a query focuses on has a very heterogeneous link structure with many unidirectional links. On the other hand, if the link structure is more homogeneous, with mostly bidirectional links, then the query results under both semantics are more likely to coincide. Our second experiment presents an extreme case of such a scenario.
The downside of potentially larger query results that may be expected under
The significantly smaller number of dereferencing operations may be seen as a crucial advantage of the context-based semantics over the
Concluding remarks
This paper studies the problem of extending the scope of the Property Paths feature in SPARQL to query Linked Data that is distributed on the WWW. We have investigated reachability-based query semantics, which decouple navigation from querying. Additionally, we have proposed a different interpretation for PPs over the Web via the context-based query semantics. An interesting finding regarding this latter semantics is that there exist queries whose evaluation over the WWW is not possible in practice. We studied this aspect using a notion of Web-safeness and introduced a decidable syntactic property for identifying queries that are Web-safe under the context-based semantics. Moreover, we have presented an experimental evaluation that compares the two semantics on different datasets showing that the context-based semantics incurs in a lower number of dereferencing operations that will have an impact on the running time.
We believe that the presented work provides valuable input to a wider discussion about defining how the SPARQL language can be used for accessing Linked Data on the WWW. There are several directions for future research including an investigation of the relationships between navigational queries and SPARQL federation, as well as an exploration of techniques based on which query execution systems may implement efficiently the machinery developed in this paper.
Footnotes
Acknowledgements
We thank the ESWC reviewers and the SWJ reviewers for their valuable feedback. Olaf Hartig’s work has been funded by the German Government, Federal Ministry of Education and Research under the project number 03WKCJ4D. Giuseppe Pirrò’s work has been funded by the Cyber Security Technological District financed by the Italian MIUR.
Queries used in the evaluation
This appendix provides the queries used in our experiment. These queries use the following prefixes: