
Abstract
The proliferation of knowledge graphs and recent advances in Artificial Intelligence have raised great expectations related to the combination of symbolic and distributional semantics in cognitive tasks. This is particularly the case of knowledge-based approaches to natural language processing as near-human symbolic understanding relies on expressive, structured knowledge representations. Engineered by humans, such knowledge graphs are frequently well curated and of high quality, but at the same time can be labor-intensive, brittle or biased. The work reported in this paper aims to address such limitations, bringing together bottom-up, corpus-based knowledge and top-down, structured knowledge graphs by capturing as embeddings in a joint space the semantics of both words and concepts from large document corpora. To evaluate our results, we perform the largest and most comprehensive empirical study around this topic that we are aware of, analyzing and comparing the quality of the resulting embeddings over competing approaches. We include a detailed ablation study on the different strategies and components our approach comprises and show that our method outperforms the previous state of the art according to standard benchmarks.
Keywords
Introduction
The history of Artificial Intelligence is a quest for the perfect combination of reasoning performance and the ability to capture knowledge in machine-actionable formats. Early AI systems developed during the ’70s like MYCIN [63] already proved it was possible to effectively emulate human reasoning in tasks like classification or diagnosis through artificial means. However, the acquisition of expert knowledge from humans soon proved to be a challenging task, resulting in what was known ever after as the knowledge acquisition bottleneck [21].
Indeed, in an attempt to address this challenge and work at the knowledge level [45], knowledge acquisition eventually became a modeling activity rather than a task focused on extracting knowledge from the mind of an expert. Along the knowledge level path came ontologies, semantic networks and eventually knowledge graphs (henceforth, KGs), which provide rich, expressive and actionable descriptions of the domain of interest and support logical explanations of reasoning outcomes. However, KGs can be costly to produce and scale since a considerable amount of well-trained human labor [25] is needed to manually encode high-quality knowledge in the required formats. Furthermore, the design decisions made by knowledge engineers can also have an impact in terms of depth, breadth and focus, which may result in biased and/or brittle knowledge representations, hence requiring continuous supervision and curation.
In parallel, the last decade has witnessed a noticeable shift from knowledge-based, human-engineered methods to statistical ones due to the increasing availability of raw data and cheaper computing power, facilitating the training of increasingly effective models in areas of AI like natural language processing (NLP). Recent results in the field of distributional semantics e.g. word2vec [41] are particularly promising ways to capture the meaning of words in document corpora as a vector in a dense, low-dimensional space. Among their applications, word embeddings have proved to be useful in term similarity, analogy and relatedness, as well as many NLP downstream tasks including e.g. classification [32], question answering [31,48,58] or machine translation [3,14,30,64]. However, the knowledge thus captured is generally hard to interpret, let alone matched to existing concepts and relations [47], i.e. the main artifacts (explicitly) represented in a KG.
In the intersection of knowledge-based and statistical approaches to NLP, many argue [17,60,62] that KGs can enhance both expressivity and reasoning power, and advocate for a hybrid approach leveraging the best of both worlds. This is particularly the case in situations where there is a lack of sufficient data or an adequate methodology to learn the nuances associated to the concepts and the relationships between them, which on the other hand can be explicitly (and extensively) represented in existing KGs.
Furthermore, recent contributions [7,16,39,50] show evidence that it is possible to learn meaning exclusively from text through NLP tasks such as language modeling and textual entailment, capturing not only lower-level aspects of the text like syntactic information but also showing a certain abstraction capability in the form of context-dependent aspects of word meaning that can be used e.g. for word-sense disambiguation. A different line of research, focused on the pragmatics of language [2,8], on the contrary argues that effectively capturing meaning requires not only taking into account the form of the text but also other aspects like the particular context in which such form is used or the intent or cognitive state of the speaker, suggesting that the text needs to be enriched in order to actually convey the required meaning to a learner. For NLP to scale beyond partial, task-specific solutions, it must be informed by what is known about how humans use language.
In this paper, we take a step further and argue that the application of structured knowledge contained in KGs can provide such necessary guidance to extract actual meaning from text. In doing so, we produce disambiguated, joint word and concept embeddings that follow a hybrid knowledge formalism involving statistic and symbolic knowledge representations. Also, we argue that the resulting representations are richer and more expressive than those produced through existing approaches based on word-only, KG and hybrid word-concept embeddings.
To support our claims we run a comprehensive set of experiments with different learning algorithms over a selection of document corpora in varying sizes and forms and evaluate our results over several NLP tasks, both intrinsic (semantic similarity, relatedness) and extrinsic (word-concept and relation prediction). We conduct an ablation study1
Systematically removing some of the information fed to our embedding learning system to determine individual contributions to the overall performance.
The paper is structured as follows. Next section provides an overview of the research context relevant to our work in areas including word, graph and sense embedding. Section 3 describes our approach to capture as embeddings the semantics of both words and concepts in large document corpora. Section 4 goes on to evaluate our results over different datasets and tasks, comparing to the approaches described in Section 2, including a comparative study and an ablation study. Next, Section 5 reflects on our findings and provides additional insight and interpretation of the evaluation results. Finally, Section 6 concludes the paper and advances next steps in our research.
This work is among the first few to study the joint learning of embeddings for words and concepts from a large disambiguated corpus. The idea itself is not novel, as Camacho-Colladas et al. [12] points out, but performing a practical study is difficult due to the lack of manually sense-annotated datasets. The largest such dataset is SemCor [43] (version 3.0), a corpus of 537K tokens, 274K of which are annotated with senses from WordNet. Although this dataset could be used with our approach to generate embeddings for the WordNet senses, results from work on word-embeddings show that the size of the corpus greatly affects the quality of the learned embeddings and that corpora in the order of billion tokens are required. In this paper we use an automatic approach for generating word-concept annotations, which makes it possible to use large corpora to learn good quality concept and word embeddings as our studies and results in Section 4 show.
Below, we discuss several similar approaches varying from those learning plain word-embeddings, to those learning sense and concept embeddings from corpora and semantic networks, and those which do not use corpora at all, but instead attempt to learn concept embeddings directly from a knowledge graph.
Word embeddings
Learning word embeddings2
Also called the Vector Space Model in the literature.
Most of the recent work in this area was triggered by the word2vec algorithm proposed in [41] which provided an efficient way to learn word embeddings by predicting words based on their context words3
or viceversa, respectively called continuous bag-of-words (cbow) and skip-gram architectures.
Sometimes also called “target” or “focus” word in the literature.
These approaches have been shown to learn lexical and semantic relations. However, since they stay at the level of words, they suffer from issues regarding word ambiguity. And since most words are polysemic, the learned embeddings must either try to capture the meaning of the different senses or encode only the meaning of the most frequent sense. In the opposite direction, the resulting embedding space only provides an embedding for each word, which makes it difficult to derive an embedding for the concept based on the various words which can be used to refer to that concept.
The approach described in this paper is an extension that can be applied to both word2vec style algorithms and to co-occurrence algorithms. In this paper we only applied this extension to Swivel, although applying it to GloVe and the standard word2vec implementations should be straightforward. Applying it to FastText would be more complicated, especially when taking into account the sub-word information, since words can be subdivided into character n-grams, but concepts cannot.
A few approaches have been proposed to produce sense and concept embeddings from corpora. One approach to resolve this is to generate sense embeddings [29], whereby the corpus is disambiguated using Babelfy and then word2vec is applied over the disambiguated version of the corpus. Since plain word2vec is applied, only vectors for senses are generated. Jointly learning both words and senses was proposed by Chen et al. [13] and Rothe et al. [54] via multi-step approaches where the system first learns word embeddings, then applies disambiguation based on WordNet and then learns the joint embeddings. While this addresses ambiguity of individual words, the resulting embeddings focus on synonymous word-sense pairs,5
E.g. word-sense pairs
Another approach for learning embeddings for concepts based on a corpus without requiring word-sense disambiguation is NASARI [12], which uses lexical specificity to learn concept embeddings from Wikipedia subcorpora. These embeddings have as their dimensions, the lexical specificity of words in the subcorpus, hence they are sparse and harder to apply than low-dimensional embeddings such as those produced by word2vec. For this reason, NASARI also proposes to generate “embedded vectors” which are weighted averaged vectors from a conventional word2vec embedding space. This approach only works for Wikipedia and BabelNet, since you need a way to create a subcorpus that is relevant to entities in the knowledge base. Furthermore, although this approach should support concept embeddings for all types of words, the pre-trained embeddings we found only provided embeddings for noun concepts.6
See Section 4.4.1 for a description of and a link to the pre-trained embeddings we used.
Finally, the work that is closest to our work is SW2V (Senses and Words to Vectors) [38] which proposes a lightweight word-disambiguation algorithm and extends the Continuous Bag of Words architecture of word2vec to take into account both words and senses. Our approach is essentially the same, although there are various implementational differences: (i) we use our proprietary disambiguator; (ii) we implemented our learning algorithm as a variation of correlation-based algorithms as a consequence; and (iii) we take into account the distance of context words and concepts to the center word. In terms of evaluation, Mancini et al. [38] only reports results for 2 word-similarity datasets while we provide an extensive analysis on 14 datasets. We further analyze the impact of different corpus sizes and look into the inter-agreement between different vector spaces (a measure of how similar two vector spaces are based on the predicted distances between a set of word pairs).
Several approaches have been proposed to create concept embeddings directly from knowledge graphs, such as TransE [9], HolE [46], ProjE [61], RDF2Vec [53] and Graph Convolutions [56]. The main goal of such concept embeddings is typically graph completion. In our opinion, these approaches all have the same drawback: they encode the knowledge (including biases) explicitly contained in the source knowledge graph, which is typically already a condensed and filtered version of the real world data. Even large knowledge graphs only provide a fraction of the data that can be gleaned from raw datasets such as Wikipedia and other web-based corpora; i.e. these embeddings cannot learn from raw data as it appears in the real-world. In our evaluation we have used HolE to compare how such word and concept embeddings compare to those derived from large text corpora.
Corpus-based joint concept-word embeddings
In order to build hybrid systems which can use both bottom-up (corpus-based) embeddings and top-down (KG) knowledge, we propose to generate embeddings which share the same vocabulary as the KGs. This means generating embeddings for knowledge items represented in the KG such as concepts and surface forms (words and expressions) associated to the concepts in the KG.7
In RDF, this typically means values for
Let T be the set of tokens that can occur in text after some tokenization is applied; this means tokens may include words (“running”), punctuation marks (“;”), multi-word expressions (“United States of America”) or combinations of words with punctuation marks (“However,”, “–”). Let L be the set of lemmas: base forms of words (i.e. without morphological or conjugational variations). Note that
We assume lemmatization correctly strips away punctuation marks (e.g. lemma of “However,” is “however” and lemma of “Dr.” is “Dr.”)
In principle, we could define two vocabularies, one for the center entries and another for the context entries; however in this paper we assume both vocabularies are equal, hence we do not make a distinction.

Process for Vecsigrafo generation from a text corpus.
The overall process for learning joint word and concept embeddings in what we call a Vecsigrafo (derived from the term Sensigrafo, Expert System’s KG10
Sensigrafo, Expert System’s knowledge graph:
The disambiguated corpus can optionally be modified or
To generate embeddings for both semantic and lexical entries, we iterate through the disambiguated corpus to decide on a vocabulary V and calculate a representation of D called a co-occurrence matrix M, which is a
In standard word embedding algorithms, there is only one sequence of tokens; hence
This gives us
Our modifications are: using
This modification is useful in our case, when the row and column vocabularies are the same; where in the end you would typically take the sum or the average of both vectors as your final embeddings.
We have used Expert System’s proprietary Cogito pipeline to tokenize and disambiguate the corpora discussed in this paper. The disambiguation algorithm is proprietary; however, internal evaluations show high accuracy on small test corpora. Expert System uses a proprietary KG called
See [44] for a comprehensive survey on the topic.
To implement our approach, we extend the matrix construction phase of the Swivel [59] algorithm12
As implemented in
Example tokenizations for the first window of size
Table 1 also introduces notation we will use throughout the paper to identify embedding variations. We will use
Our approach requires a few changes to conventional algorithms for learning word embeddings, in particular the tokenization and lemmatization required to perform disambiguation affects the vocabulary. Furthermore, the introduction of concepts in the same vector space can affect the quality of word embeddings. Obviously the whole point of such a hybrid approach is to be able to learn both high quality word and concept embeddings. Hence, we posit the following research questions:
In an attempt to find answers to the research questions, we performed two studies on the resulting embeddings: an
Sources: Corpora and knowledge graphs
For better comparability, we have tried to generate embeddings using available code and the same input corpus whenever possible, although in some cases we have relied on pretrained word embeddings. In this section, we first describe the corpora we have used as well as those third parties have reported using for generating pretrained embeddings. Then, we also describe how we have generated embeddings, including relevant metadata and training parameters.
Evaluation corpora
Evaluation corpora
Table 2 provides an overview of the corpora used for generating embeddings. To study the effect of the corpus size (and domain of the input corpus), we have used the United Nations corpus [68] as an example of a medium sized corpus that is domain specific. This corpus consists of transcriptions of sessions at the United Nations, hence the contents are domain specific with topics in politics, economics and diplomacy being predominant. We have used the English part of the corpus that is aligned with Spanish.13
Cross-lingual applications of the embeddings is not in the scope of this paper, although we discuss some initial applications in [15].
Besides the text corpora, the tested embeddings contain references to concepts defined in two KGs. The first KG is a vanilla version of Sensigrafo, our proprietary semantic network, released with Cogito Studio 14.215
Word similarity tasks using human judgment, as originally introduced by Resnik [52] for structured knowledge, are one of the most common intrinsic evaluations that are used to evaluate the quality of embeddings [5]. Although there are issues with these types of tasks [20,57], they tend to provide insights into how well learned embeddings capture the perceived semantic relatedness between words. One of our hypotheses is that introducing concepts to the vector space should help to learn embeddings that better capture word similarities; hence this type of evaluation should prove useful. Furthermore, it is possible to extend the default word-similarity task – whereby the cosine similarity between the vectors of a pair of words is compared to a human-rated similarity measure – by calculating a concept-based word similarity measure: in this case, we select the maximum similarity between the concepts associated to the initial pair of words. This intuitively makes sense since, presumably, when a pair of words is related, human raters naturally disambiguate the senses that are closest rather than taking into account all the possible senses of the words. As a matter of notation, we will append a suffix
When using word similarity datasets, there are a few details that are often not explicitly mentioned, but that can have a big effect on the results. First, there is the issue of pre-processing word pairs: some evaluation implementations will normalize the words, for example by lower-casing all words; in our studies we do not apply such normalizations, since different words in the vocabulary may match such normalized words and it is not clear which vector should then be used. A second related detail pertains handling missing values. Some implementations (especially vectorized implementations) will assign a default vector to words in the dataset which are not included in the vocabulary. This obviously will tend to degrade the results of embeddings where the vocabulary is small since they are no longer comparing the intended word pairs. On the other hand, it is more accurate to only include word pairs where both words are also in the vocabulary; however this means we also have to report how many of the word pairs have been used to produce a result, in order to be able to compare results with each other. For an example of how much this can impact results, see Fig. 2, where the curves are vectorised results which use a default embedding for missing words and the horizontal lines are the non-vectorised results which ignore pairs with missing words. The figure shows that as the coverage percentage drops, the results suffer greatly when using the vectorised evaluation method.

Word-similarity evaluation results. The x-axis are the thousands of training steps, the y-axis are the spearman’s ρ results. The lighter color curves are the actual values measured during training, while the darker color curves are smoothed values. The curves are the metrics gathered during training using a vectorized implementation. The horizontal lines are the non-vectorized results derived from the final embeddings and which do not take into account missing words from the vocabulary.
We next describe the 14 word similarity datasets that we are using in our evaluations as well as a syncon similarity dataset we generated. Results will be presented in the study sections below.
The RG-65 dataset [55] was the first one generated in order to test the distributional hypothesis. Although it only has 65 pairs, the human ratings are the average of 51 raters. MC-30 [42] is a subset of RG-65, which we include in our studies in order to facilitate comparison with other embedding methods. The pairs are mostly nouns.
Another classic word similarity dataset is WS-353-ALL [22] which contains 353 word pairs. 153 of these were rated by 13 human raters and the remaining 200 by 16 subjects. The pairs are mostly nouns, but also include some proper names (people, organizations, days of the week). Since the dataset mixes similarity and relatedness, [1] used WordNet to split the dataset into a WS-353-REL and WS-353-SIM containing 252 and 203 word pairs respectively (some unrelated word pairs are included in both subsets).
YP-130 [67] was the first dataset focusing on pairs of verbs. The 130 pairs were rated by 6 human subjects. Another dataset for verbs is VERB-143 [4] which contains verbs in different conjugated forms (gerunds, third person singular, etc.) rated by 10 human subjects. The most comprehensive dataset for verbs is SIMVERB3500 [23] consisting of 3,500 pairs of verbs (all of which are lemmatized), which were rated via crowdsourcing by 843 raters and each pair was rated by at least 10 subjects (over 65K individual ratings).
MTurk-287 [51] is another crowdsourced dataset focusing on word and entity relatedness. The 287 word pairs include plurals and proper nouns and each pair was rated on average by 23 workers. MTurk-771 [26] also focuses on word relatedness and was crowd-sourced with an average of 20 ratings per word pair. It contains pairs of nouns and rare words were not included in this dataset.
MEN-TR-3K [10] is another crowd-sourced dataset which combines word similarity and relatedness. As opposed to previous datasets, where raters gave an explicit score for pair similarity, in this case raters had to make comparative judgments between two pairs. Each pair was rated against 50 other pairs by the workers. The dataset contains mostly nouns (about 81%), but also includes adjectives (about 13%) and verbs (about 7%), where a single pair can mix nouns and adjectives or verbs. The selected words do not include rare words.
SIMLEX-999 [28] is a crowd-sourced dataset that explicitly focuses on word similarity and contains (non-mixed) pairs of nouns (666), adjectives (111) and verbs (222). This dataset also provides a score of the level of abstractness of the words. Since raters were explicitly asked about similarity and not relatedness, pairs of related – but not similar – words, receive a low score. The 500 raters each rated 119 pairs and each pair was rated by around 50 subjects.
RW-STANFORD [37] is a dataset that focuses on rare (infrequent) words. Words still appear in WordNet (to ensure they are English words as opposed to foreign words). Each of the 2,034 pairs was rated by 10 crowd-sourced workers. The dataset contains a mix of nouns (many of which are plurals), verbs (including conjugated forms) and adjectives.
Finally, SEMEVAL17 (English part of task 2) [11] provides 500 word pairs, selected to include named entities, multi-words and to cover different domains. They were rated in such a way that different types of relations (synonymy, similarity, relatedness, topical association and unrelatedness) align to the scoring scale. The gold-standard similarity score was provided by three annotators.
Syncon-similarity dataset
Using concept-based evaluation, we can re-use the similarity rankings provided by word-similarity datasets to evaluate the quality of concepts. However, it would be better to have a dataset specifically of syncon pairs that have been ranked for similarity. Unfortunately, such a dataset would be KG-specific and we do not have a human rated dataset for Sensigrafo syncons. To still be able to generate such a dataset, we have chosen to use embeddings learned using HolE and Sensigrafo 14.2 (see Section 4.4.1 for details about how the HolE embeddings were generated). The rationale is that such embeddings reflect information encoded in the KG; i.e. vectors for syncons which are connected to each other will be close in the embedding space. We initially tried sampling random pairs; however, we noticed that most pairs had a cosine similarity of around 0. This is because most syncons pairs are not directly related via KG relations, hence HolE does not assign them a specific similarity score. In order to have a meaningful dataset, instead we devised a way to generate pairs which are somehow related to each other. The resulting dataset is called
300 pairs were randomly generated from the
200 pairs were generated by randomly picking one syncon and searching its neighbourhood for syncons with a HolE score of at least 0.4. Again, this should include various relationship types.
100 pairs were generated as in the previous method, but now for a HolE score of at least 0.5.
25 pairs were chosen from known hypernym pairs between verb concepts, as long as HolE rates them higher than 0.6.
25 pairs were chosen from known hypernym pairs between nouns concepts, as long as HolE rates them higher than 0.7.
25 pairs were chosen from known hypernym pairs between nouns, with HolE cosine similarity higher than 0.6.
140 pairs were hypernym pairs between nouns, with HolE cosine similarity scores between 0.3 and 0.4
The resulting dataset provides pairs of syncons which are similar to each other. The notion of similarity that is captured may also include other relationships in addition to hypernymy. 13 of the 815 pairs generated were duplicates; hence the final pair count.
Ablation study
In this part of the evaluation, we study how variations to Vecsigrafo-based embeddings affect the quality of the lexical and semantic embeddings. We do this by analyzing the various results using word-similarity tasks, which we extend to also take into account concept-similarity as discussed above.
By evaluating the word similarity datasets during the training process, we saw how the results improved during the first iterations and how the results stabilized towards the end of the training, see Fig. 2.16
Since some embeddings have smaller vocabularies, they were trained for less iterations overall, though in all cases we checked that training was long enough for results to converge.
Additional materials, including result data for the ablation study, are available at:
For the ablation study, we used only variations of Vecsigrafo embeddings. We chose a relatively large maximum vocabulary size of 1.5M and all embeddings were generated with 160 dimensions. We generated embeddings for the following corpora: Europarl-v7 (
Besides varying the filtering and combinations of sequences, we also used alternative disambiguation methods, described below.
Selection of statistically significant ablation differences showing effect of filtering and lemmatizing
Selection of statistically significant ablation differences showing effect of filtering and lemmatizing
For Europarl and the UN corpus, we could not measure any statistically significant differences between filtered and non-filtered embeddings. However, for Wikipedia, we measured an increased performance for
Based on these results, we can state that:
filtering the initial sequence by removing or replacing tokens based on grammar type is helpful filtering is especially helpful for large corpora and when taking the plain text in the tokens (i.e. when not applying lemmatization). when tokens are lemmatized, filtering yields no (or statistically insignificant) improvement in the resulting embeddings.
Effect of lemmatizing
In all three corpora, we see that using lemmas ( lemmatizing the tokens produces better lexical embeddings. lemmatization is especially important in small and medium corpora, but can have a positive impact even in large corpora. using lemmas instead of plain text for co-training concepts does not have a significant impact on the resulting concept embeddings.
Effect of joint lexico-semantic entry training
Selection of statistically significant ablation differences showing effect of joint lexico-semantic training
Selection of statistically significant ablation differences showing effect of joint lexico-semantic training
Co-training lexical and semantic embeddings always has a positive effect on lexical embeddings. However, co-training has a negative effect on concept embeddings for medium and large corpora, at least when measuring quality using the word-similarity datasets.
For the Europarl corpus, we measured improvements across all variants when comparing results of co-training vs. results from only lexical or semantic embeddings. For example, see the results in Table 4 for the MEN dataset. We see similar improvements for other datasets such as SEMEVAL (only concept-based), SIMLEX and SIMVERB.
For the UN corpus, we start to see a divide: co-trained lexical embeddings always perform better than lexical embeddings trained without concept information, but concept-based word similarity tests tend to be worse for concept embeddings co-trained with lexical entries than for concept embeddings trained on their own. For example, see again Table 4 for MEN. The table also shows that for the same dataset, we see some decreases for concept-based embeddings. We measured similar results for RW-STANFORD, SEMEVAL17 and SIMVERB3500.
Finally, in addition to an overall improvement due to the larger size of the corpus, for Wikipedia we see a similar trend as for the UN corpus. For MEN, we see lexical embedding improvements and concept-based semantic embedding declines as shown in Table 4. We again see similar patterns for other datasets such as RW-STANFORD, SEMEVAL17 (mostly for concept-based results) and SIMVERB3500.
These results suggest that co-training lexical and concept embeddings (using a corpus):
results in better lexical embeddings (when using a good quality disambiguator, although see below for a discussion about the effect of the disambiguation strategy)
results in poor concept embeddings for medium to large corpora, when compared to concept embeddings trained on the same corpus, but without co-training. One caveat is that this negative result for concept embeddings may be due to the evaluation method, since we are evaluating the concept embeddings using a concept-based adaptation for the word-similarity datasets. See also the section below, where we use a concept similarity dataset specifically generated to better assess the quality of concept similarity as described in the KG, as opposed to some word-similarity measure that is extended to concepts.
In this subsection, we study the effect of the Cogito disambiguator by comparing the results with embeddings generated using alternative disambiguation methods.
To get a sense of how different the results are for the alternative disambiguation algorithms, we annotated a subset of 5,000 lines of Wikipedia with the Cogito disambiguator and with the alternative disambiguators (all using Sensigrafo 14.2). Taking the Cogito disambiguator annotations as a “standard”, the Shallow Connectivity disambiguator with parameter delta 100 (as suggested in [38]) achieved 44.4 precision, 76.8 recall and 56.3 f1. Similarly,
Based on the word-similarity datasets and the
Selection of statistically significant ablation differences showing effect alternative disambiguation methods
Selection of statistically significant ablation differences showing effect alternative disambiguation methods
The most-frequent concept disambiguation (
To have a better understanding of the quality of the concept embeddings, we also evaluated them using the
The vectors derived from Shallow Connectivity disambiguation are not far behind in terms of correlation with HolE-based embeddings (we do not have any significance metrics, though); this is not surprising, since
Disambiguation by selecting the most frequent syncon for each lemma still manages to produce relatively good correlation with HolE-based embeddings. However, coverage suffers greatly, which was to be expected, since only one syncon is chosen per lemma.
Finally, disambiguation using a random syncon (
Overall, these results show – somewhat surprisingly – that:
a good disambiguation method is not essential to get good quality lexical embeddings.
using simple disambiguation methods such as
the effect of disambiguation methods on the quality of concept embeddings depends on the evaluation method. Better disambiguation methods result in better concept embeddings when evaluating them using a concept similarity dataset. No such effect could be seen using a word-similarity dataset adapted to assess concepts, suggesting such evaluation tools may be inappropriate.
It is well-known that larger corpora result in better word embeddings. When comparing Europarl, UN and Wikipedia embeddings, we see a confirmation of this pattern also for Vecsigrafo-based embeddings. However, we also see some differences in terms of lexical and semantic embeddings.
When going from a small corpus (Europarl) to a medium corpus (UN), we measured mostly improvements. However, we only saw significant improvements for lexical embeddings in a few datasets, while we saw significant improvements for semantic embeddings in more cases. In MEN, we saw improvements for both lexical embeddings (on average 0.024) and semantic embeddings (on average 0.036). In WS-353 and RW we only saw significant improvements for semantic embeddings (on average 0.06 and 0.05 respectively). In SEMEVAL17 we saw improvements for semantic embeddings (on average 0.02), but decline for lexical embeddings (on average −0.02). In SIMLEX, we only saw decline for lexical embeddings (on average −0.02).
When going from the UN corpus to Wikipedia, we saw improvements across the board. The contrast is especially clear in larger word similarity datasets such as MEN, where all variants were significantly better, both statistically and in terms of absolute values, with an average increase of 0.15. Concept embeddings improve more (on average 0.18) than lexical embeddings (on average 0.13). We see similar patterns in MTurk-771, RG-65, SEMEVAL17 and WS-353. Interestingly, for some datasets, we see a decline in lexical embedding quality. This is the case for SIMLEX-999, SIMVERB3500 and RW.
For SIMLEX, the trend is clear: results are best for Europarl, then decline as the corpus size grows. We think this is due to the fact that SIMLEX gives a low rating to pairs of words which are related but not similar. word2vec algorithms, in particular Swivel, are better at learning similarity for small corpora, but as the corpus grows, the embeddings start incorporating more (semantic) relatedness, which causes the performance for this particular dataset to decrease. We note that the results are not tainted by coverage issues, since even the Europarl
For RW, we think the results are due to the coverage of the pairs in the dataset. As can be expected, small corpora will not include enough examples of rare words, hence they are not included in the vocabulary. For the
For SIMVERB3500, the issue is general poor performance of Vecsigrafo-based embeddings with spearman’s ρ scores around or below 0.2. We think this may be due to the fact that many verbs in the dataset can also refer to nouns or adjectives, which may be adding noise to the word embedding.
We also generated
To sum up:
Training on a medium corpus instead of a small corpus, improves both lexical and concept embeddings; concept embeddings improve more than lexical embeddings. Training on a large corpus instead of a medium corpus greatly improves both lexical and concept embeddings. Again concept embeddings show a higher improvement than lexical embeddings. A caveat here is that the larger corpus also increased the range of language and topics covered. Different large corpora also affect the embeddings, probably due to variance of topics and language style.
Comparative study
In this part of the evaluation, we study how Vecsigrafo-based embeddings compare to lexical and semantic embeddings produced by other algorithms.
Evaluated embeddings
Evaluated embeddings
Table 7 shows an overview of the embeddings used during the evaluations. We used five main methods to generate these. In general, we tried to use embeddings with 300 dimensions, although in some cases we had to deviate. In general, as can be seen in the Table, when the vocabulary size is small (due to corpus size and tokenization), we required a larger number of epochs to let the learning algorithm converge.
Vecsigrafo based embeddings were first tokenized and word-disambiguated using Cogito. We explored two basic tokenization variants. The first is lemma-concept with filtered tokens (“ls filtered”), whereby we only keep lemmas and concept ids for the corpus. Lemmatization uses the known lemmas in Sensigrafo to combine compound words as a single token. The filtering step removes various types of words: dates, numbers, punctuation marks, articles, proper names (entities), auxiliary verbs, proper nouns and pronouns which are not bound to a concept. The main idea of this filtering step is to remove tokens from the corpus which are not semantically relevant. We also trained a few embeddings without lemmatization and filtering. In such cases, we have kept the original surface form bound to the concept (including morphological variants) and we did not remove the tokens described above. For all the embeddings, we have used a minimum frequency of 5 and a window size of 5 words around the center word. We also used a harmonic weighting scheme (we experimented with linear and uniform weighting schemes but results did not differ substantially).
Swivel18
GloVe embeddings trained by us were derived using the master branch on its GitHub repository19
FastText embeddings trained by us were derived using the master branch on its GitHub repository20
HolE embeddings were trained by us using the code on GitHub21
Spearman correlations for word similarity datasets and
Besides the embeddings trained by us, we also include, as part of our study, several pretrained embeddings, notably the GloVe embeddings for CommonCrawl – code
Table 8 shows the Spearman correlation scores for the 14 word similarity datasets and the various embeddings generated based on the UN corpus. The last column in the table shows the average coverage of the pairs for each dataset. Since the UN corpus is medium sized and focused on specific domains, many words are not included in the learned embeddings, hence the scores are only calculated based on a subset of the pairs.
Table 9 shows the results for the embeddings trained on larger corpora and directly on the Sensigrafo. We have not included results for vectors trained with NASARI (concept-based) and SW2V on UMBC, since these perform considerably worse than the remaining embeddings (e.g. NASARI scored 0.487 on MEN-TR-3k and SW2V scored 0.209 for the same dataset, and see Table 10 for the overall average score). We have also not included word2vec on UMBC since it does not achieve the best score for any of the reported datasets; however, overall it performs a bit better than swivel but worse than vecsigrafo. For example, it achieves a score of 0.737 for MEN-TR-3k).
Spearman correlations for word similarity datasets on large corpora (UMBC, Wikipedia and CommonCrawl)
Spearman correlations for word similarity datasets on large corpora (UMBC, Wikipedia and CommonCrawl)
Aggregated word similarity results
Table 10 shows the aggregate results. Since some of the word similarity datasets overlap – SIMLEX-999 and WS-353-ALL were split into its subsets, MC-30 is a subset of RG-65 – and other datasets – RW-STANFORD, SEMEVAL17, VERB-143 and MTURK-287 – have non-lemmatized words (plurals and conjugated verb forms) which penalize embeddings that use some form of lemmatization during tokenization, we take the average Spearman score over the remaining datasets. We discuss the lessons we can extract from these results in Section 5.
The word similarity datasets are typically used to assess the correlation between the similarity of word pairs assigned by embeddings and a gold standard defined by human annotators. However, we can also use the word similarity datasets to assess how similar two embedding spaces are. We do this by collecting all the similarity scores predicted for all the pairs in the various datasets and calculating the Spearman’s ρ metric between the various embedding spaces. We present the results in Fig. 3; darker colors represent higher inter-agreement between embeddings. E.g. we see that
Word-concept prediction
One of the disadvantages of word similarity (and relatedness) datasets is that they only provide a single metric per dataset. In [15] we introduced Word-prediction plots, a way to visualize the quality of embeddings by performing a task that is very similar to the loss objective of word2vec. Given a test corpus (ideally different from the corpus used to train the embeddings), iterate through the sequence of tokens using a context window. For each center word, take the (weighted) average of the embeddings for the context tokens and compare it to the embedding for the center word using cosine similarity. If the cosine similarity is close to 1, this essentially correctly predicts the center word based on its context. By aggregating all such cosine similarities for all tokens in the corpus we can (i) plot the average cosine similarity for each term in the vocabulary that appears in the test corpus and (ii) get an overall score for the test corpus by calculating the (weighted by token frequency) average over all the words in the vocabulary.
Table 11 provides an overview of the test corpora we have chosen to generate word and concept prediction scores and plots. The corpora are:
webtext [36] is a topic-diverse corpus of contemporary text fragments (support fora, movie scripts, ads) from publicly accessible websites, popular as training data for NLP applications.
NLTK gutenberg selections26
Europarl-10k. We have created a test dataset based on the Europarl [33] v7 dataset. We used the English file that has been parallelized with Spanish, removed the empty lines and kept only the first 10K lines. We expect Europarl to be relatively similar to the UN corpus since they both provide transcriptions of proceedings in similar domains.
Figure 4 shows the word prediction plots for various embeddings and the three test corpora. Table 12 shows (i) the token coverage relative to the embedding vocabulary (i.e. the percentage of the embedding vocabulary found in the tokenized test corpus); (ii) the weighted average score, this is the average cosine similarity per prediction made (however, since frequent words are predicted more often, this may skew the overall result if infrequent words have worse predictions); (iii) the “token average” score, this is the average of the average score per token. This gives an indication of how likely it is to predict a token (word or concept) given its context if a token is selected from the embedding vocabulary at random, i.e. without taking into account its frequency in general texts. As with previous results, we will draw conclusions about these results in Section 5.

Inter-embedding agreement for the word similarity datasets in the same order as Table 10. Embeddings that do not mention a corpus, were trained on Wikipedia 2,018.
Word (and concept) similarity and prediction tasks are good for getting a sense of the embedding quality. However, ultimately the relevant quality metric for embeddings is whether they can be used to improve the performance of systems that perform more complex tasks such as document categorization or knowledge graph completion. For this reason we include an evaluation for predicting specific types of relations in a knowledge graph between pairs of words, following recent work in the area [34,65,66]. At Expert System, such a system would help our team of knowledge engineers and linguists to curate the Sensigrafo.
To minimize introducing bias, rather than using Sensigrafo as our knowledge graph, we have chosen to use WordNet since we have not used it to train HolE embeddings and it is different from Sensigrafo (hence any knowledge used during disambiguation should not affect the results). For this experiment, we chose the following relations.
Datasets We built a dataset for each relation by (i) starting with the vocabulary of
Training Next, we trained a neural net with 2 fully-connected hidden layers on each dataset, using a 90% training, 5 validation, 5 test split. The neural nets received as their input the concatenated embeddings for the input pairs (if the input verb was a multi-word like “go up”, we took the average embedding of the constituent words when using word embeddings rather than lemma embeddings). Therefore, for embeddings with 300 dimensions, the input layer had 600 nodes, while the two hidden layers had 750 and 400 nodes. The output node has 2 one-hot-encoded nodes. For the HolE embeddings, the input layer had 300 nodes and the hidden layers had 400 and 150 nodes. We used dropout (0.5) between the hidden nodes and an Adam optimizer to train the models for 12 epochs on the verb group dataset and 24 epochs on the entailment dataset. Also, to further avoid the neural net to memorize particular words, we include a random embedding perturbation factor, which we add to each input embedding; the idea is that the model should learn to categorize the input based on the difference between the pair of word embeddings. Since different embedding spaces have different values, the perturbation takes into account the minimum and maximum values of the original embeddings.
Overview – test corpora used to gather word and concept prediction data
Overview – test corpora used to gather word and concept prediction data
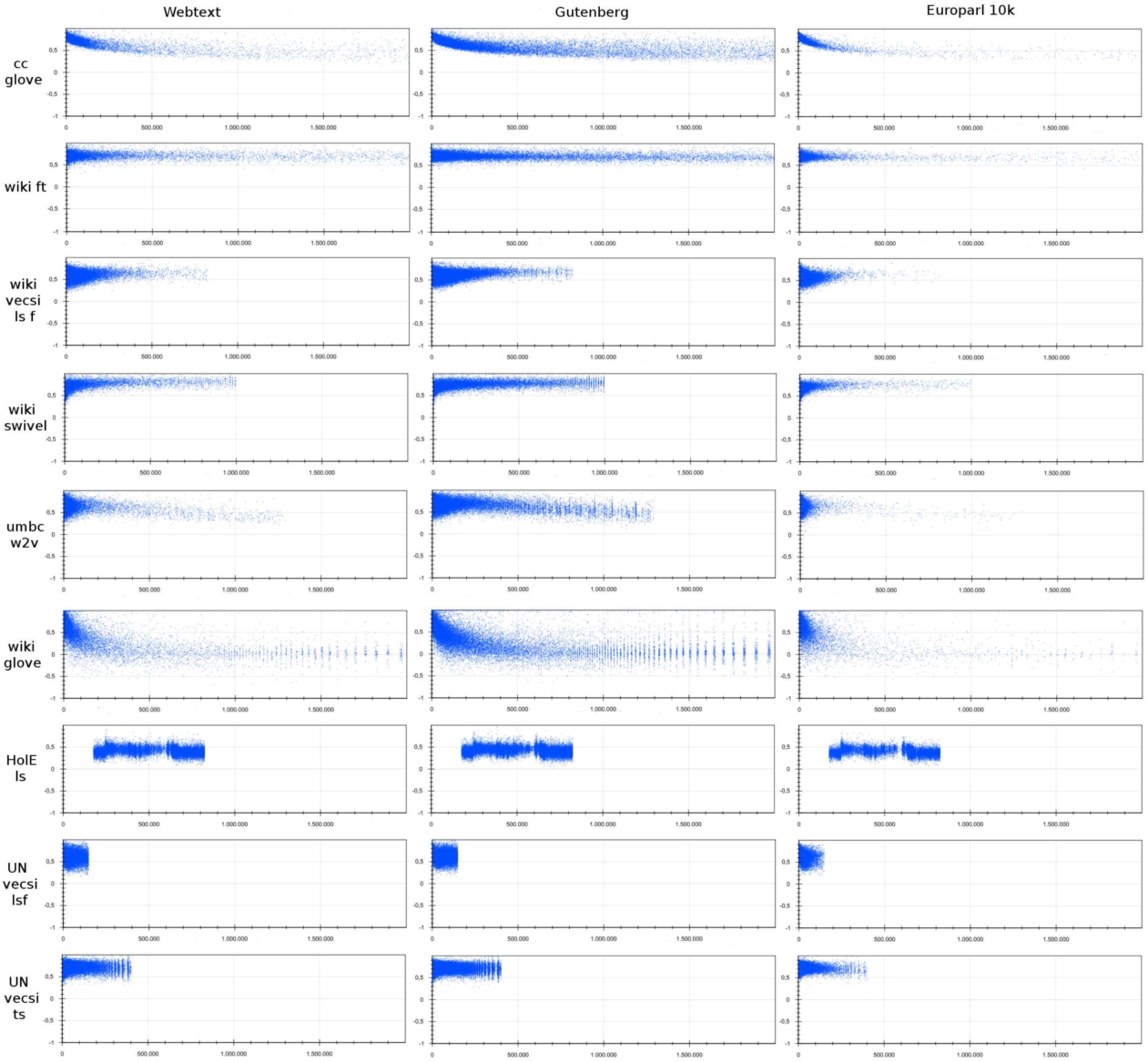
Word and concept prediction plots. The horizontal axis contains the word ids sorted by frequency on the training corpus; although different embeddings have different vocabulary sizes, we have fixed the plotted vocabulary size to 2M tokens to facilitate comparison. Since HolE is not trained on a corpus, hence the frequencies are unknown, the vocabulary is sorted alphabetically. The vertical axis contains the average cosine similarity between the weighted context vector and the center word or concept.
Aggregate word prediction values. The coverage refers to the percentage of tokens (words and concepts) in the embedding vocabulary that were found in the test corpus. The “w avg” is the average cosim weighted by token frequency and “t avg” is the average cosine similarity for all the token predictions regardless of their frequency in the corpus
Results Table 13 shows the results of training various of the embeddings:
For GloVe and FastText only the optimal results, based on the larger corpus (cc, wiki), are shown.
The main finding was that the vecsigrafo-based embeddings learnt from the medium-sized UN corpus outperform the rest at the prediction of both target relations. Surprisingly the vecsigrafo UN embeddings also outperformed the Wikipedia-based embeddings; a possible explanation for this is the greater specificity of the UN corpus compared to Wikipedia, which spans across a large variety of topics. This could provide a stronger signal for the relation prediction task since there are less potentially ambiguous entries and the model can better leverage the relational knowledge explicitly described in the KG.
Based on the data gathered and presented in the previous section, we now revisit our research questions and discuss the results.
Optimal configuration for learning Vecsigrafo embeddings
The ablation study presented in the previous section, produced various insights into how various options affect the quality of the resulting embeddings. Filtering the input sequences by grammar type is optional in terms of quality of the embeddings: it never hurt the measured quality of embeddings, although improvements were only clearly significant when learning plain text tokens. However, for large corpora,
Entailment and verb group average prediction accuracy and standard deviation over 5 training runs
Entailment and verb group average prediction accuracy and standard deviation over 5 training runs
Overall, the results show that the
Obviously, since Cogito and Sensigrafo are proprietary technology, they are not available to the wider community. However, the results from Table 5 suggest that most of the benefits of the Cogito disambiguator can still be retained using alternative disambiguation methods such as
Our results show that evaluating lexical embeddings is fairly straightforward given the large number of word-similarity datasets which are available. Our results show that
Vecsigrafo (and sw2v) compared to conventional word embeddings
From Tables 8 and 10 we can draw the conclusion that, for the UN corpus (a medium sized corpus):
For larger corpora such as Wikipedia and UMBC:
Either concept-based or lemma-based similarity.
Concept-based only.
We were surprised to see how NASARI concept embeddings (based on lexical specificity) compare poorly to the other embeddings. This was unexpected, since results in [12] were very good for similar word-similarity tests, although restricted to a few of the smaller (and thus less stable) datasets. We note that the pre-trained embeddings we used only provide embeddings for concepts which are nouns even though the method should support concepts for verbs and other grammar types. However, even for noun-based datasets we could not reproduce the results reported in [12]: for MC-30 we measured 0.68 ρ vs 0.78 reported, for SIMLEX-999-Nou we measured 0.38 instead of 0.46 and WS-353-SIM it was 0.61 instead of 0.68. An explanation for the different results may be that we do not apply any filtering by POS, as this is not specified in the concept-based word-similarity evaluation method. Instead, we find all the concepts matching the words in the word pair and return the maximum cosine similarity, regardless of whether the concepts are nouns or verbs. Also, since we do not have access to the full BabelNet, we used the REST API to download a mapping from words to BabelNet concepts. It may be the case that [12] used an internal API which performs a more thorough mapping between words and concepts, which affects the results.
In terms of inter-embedding agreement, from Fig. 3 we see that, even if those concepts are derived from a different semantic net (BabelNet and Sensigrafo),
Furthermore, we clearly see that for the medium sized corpus, all lexical embeddings tend to have a high inter-agreement with each other, but less so with lexical embeddings trained on larger corpora. For larger corpora, both lexical and concept embeddings show high inter-agreement with other similar embeddings even when trained with other corpora. For such large corpora, we see that the method used to train the embeddings (Vecsigrafo, FastText, SW2V, etc.) or the method used to predict word similarity (word-based vs concept-based) have a higher impact on the measured inter-agreement.
From the word prediction plots (Fig. 4) and results (Table 12, we see very different learning patterns for the various word embedding algorithms:
GloVe tends to produce skewed predictions excelling at predicting very high-frequency words (with little variance), but as words become less frequent the average prediction accuracy drops and variance increases. This patterns is particularly clear for GloVe trained on Common Crawl. The same pattern applies for
FastText produces very consistent results: prediction quality does not change depending on word frequency.
word2vec applied to UMBC has a pattern in between that of FastText and GloVe. It shows a high variance in prediction results, especially for very high-frequency words and shows a linearly declining performance as words become less frequent.
Swivel with standard tokenization also shows mostly consistent predictions; however very frequent words show a higher variance in prediction quality which is almost the opposite of GloVe: some high-frequency words tend to have a poor prediction score, but the average score for less frequent words tends to be higher. The same pattern applies to Vecsigrafo (based on swivel), although it is less clear for
By comparing the word-prediction results between
First, on average word prediction quality decreases by using Vecsigrafo, which is surprising (especially since word embedding quality improves significantly based on the word-similarity results as discussed above). One possible reason for this is that the context vector for Vecsigrafo-based predictions will typically be the average of twice as many context tokens (since it will include both lemmas and concepts). However, the results for
Second, both UN-based Vecsigrafo embeddings outperform the wiki-based Vecsigrafo embedding for this task. When comparing
Other results from the word-prediction study are:
Most embeddings perform better for the gutenberg test corpus than for webtext. The only exceptions are
The training and test corpora matter: for most embeddings we see that the token average for Europarl is similar or worse than for webtext (and hence worse than for Gutenberg). However, this does not hold for the embeddings that were trained on the UN corpus, which we expect to have a similar language and vocabulary as Europarl. For these embeddings –
Finally and unsurprisingly, lemmatization clearly has a compacting effect on the vocabulary size. This effect can provide practical advantages: for example, instead of having to search for the top-k neighbours in a vocabulary of 2.5M words, we can limit our search to 600K lemmas (and avoid finding many morphological variants for the same word).
From the verb relation prediction results in Fig. 13, we see that, once again,
Table 10 shows that for KG-based embeddings, the lemma embeddings (
The inter-embedding agreement results from Fig. 3 show that HolE embeddings have a relatively low agreement with other embeddings, especially conventional word-embeddings. Concept-based HolE similarity results have a relatively high agreement with other concept-based similarities (Vecsigrafo, sw2v and NASARI).
Results from the word-prediction task are consistent with those of the word-similarity task. HolE embeddings perform poorly when applied to predicting a center word or concept from context tokens.
In Fig. 4 we see that the first 175K words in the HolE vocabulary are not represented in the corpus. The reason for this is that these are quoted words or words referring to entities (hence capitalized names for places, people) which have been filtered out due to the
Conclusions and future work
In this paper we presented Vecsigrafo, a novel approach to produce corpus-based, joint word-concept embeddings from large disambiguated corpora. Vecsigrafo brings together statistical and symbolic knowledge representations in a single, unified formalism for NLP. Our results, based on the largest and most comprehensive empirical study in the area that we are aware of, show that our approach consistently outperforms word-only, graph and other hybrid embedding approaches with a medium size and large training corpora, leveling out with sub-word approaches (FastText) only in the presence of much larger corpora.
Word embeddings have shown to learn lexical and semantic relations but, staying at the level of words, they suffer from word ambiguity and brittleness when it comes to capture the different senses in a word. As a consequence, these methods usually require very large amounts of training text. Previous lemmatization and word-sense disambiguation of the training corpora enables Vecsigrafo to capture each sense much more efficiently, requiring considerably smaller corpora while producing higher quality embeddings. In the case of graph embeddings, these approaches are limited to the knowledge explicitly described in the knowledge graph, which is just a condensed interpretation of the domain according to a knowledge engineer. Vecsigrafo, on the other hand, learns from the way language is used in actual text and uses this knowledge to complement and extend the knowledge graph. Compared to previous semantic embeddings, Vecsigrafo explicitly provides embeddings for knowledge graph concepts, can be used with different knowledge graphs, and covers not only nouns but also all the lexical entries that are semantically relevant.
In this paper we have provided a detailed insight on our approach and the different aspects it comprises, including an ablation study that drills down on the effects of filtering over raw text based on grammatical information, entities and other criteria, the effects of (and different approaches to) lemmatization, the impact of jointly training lexical and semantic embeddings, the effects of applying different disambiguation strategies and the impact of training corpora of different sizes and characteristics. As the ablation study showed, looking at the improvements obtained in each specific word similarity benchmark over the different ablations confirmed that in general larger training corpus size would produce better lexical and semantic embeddings. However, the embeddings produced by large corpora like Wikipedia were outperformed by those obtained from UMBC, which is similarly sized but has a different structure, suggesting that corpus size is an important factor to consider but not the only one when it comes to balance the quality of lexico-semantic embeddings. The study also showed that jointly learning embeddings for words and concepts contributed to improve the quality of both compared to each individual case. A detailed analysis for each individual word similarity benchmark and their properties, e.g. in terms of number of contributors and similarity/relatedness pairs, contributed to identify the nuances of these conclusions, as discussed in the paper.
We also proposed two mechanisms that have proved useful to provide a deeper understanding on the quality of the resulting embeddings. Word (and concept) prediction plots allow overcoming some of the main limitation of word similarity benchmarks, which only provide a single metric per dataset, by using the embeddings to predict a word based on its context in three additional test corpora. On the other hand, inter-embedding agreement leverage the results from the word similarity benchmarks to assess how similar two embedding spaces are, allowing to identify trends over the different algorithms and corpora.
Our ongoing research seeks to enrich, validate and extend the coverage of existing knowledge graphs for NLP, as well as to explore cross-lingual, cross-modal scenarios that span across related areas of AI, with a focus on multimodal machine comprehension [24]. At Expert System we are currently applying Vecsigrafo in different tasks aimed at optimizing Cogito, assisting our team of knowledge engineers and linguists in increasingly cost-efficient ways. Some examples include the increasingly automated extension and curation of our knowledge graph, Sensigrafo, extending cross-lingual capabilities over more than 14 languages currently supported by Cogito, and enhancing the disambiguation algorithm with evidence captured from document corpora.
We hope that the algorithms and analysis reported in this paper, as well as the resources that we generated in doing so, will inspire further research to better understand and leverage the interplay between knowledge graphs and distributional semantics in cognitive tasks, supporting a new breed of hybrid methods for knowledge-based NLP. To assist this purpose, we have also created a tutorial,30
Tutorial on Hybrid Techniques for Knowledge-based NLP, available at:
Footnotes
Acknowledgements
The research presented herein was funded by Expert System, the EU Research and Innovation Horizon 2020 programme (project DANTE-700367) and the Spanish Centre for the Development of Industrial Technology, CDTI (project GRESLADIX-IDI-20160805). We gratefully acknowledge their continued support.