
Abstract
A central problem in the context of the Web of Data as well as in data integration in general is to identify entities in different data sources that describe the same real-world object. There exists a large body of research on entity resolution. Interestingly, most of the existing research focuses on entity resolution on dense data, meaning data that does not contain too many missing values. This paper sets a different focus and explores learning expressive linkage rules from as well as applying these rules to sparse data, i.e. data exhibiting a large amount of missing values. Sparse data is a common challenge in application domains such as e-commerce, online hotel booking, or online recruiting. We propose and compare three entity resolution methods that employ genetic programming to learn expressive linkage rules from sparse data. First, we introduce the GenLinkGL algorithm which learns groups of matching rules and applies specific rules out of these groups depending on which values are missing from a pair of records. Next, we propose GenLinkSA, which employs selective aggregation operators within rules. These operators exclude misleading similarity scores (which result from missing values) from the aggregations, but on the other hand also penalize the uncertainty that results from missing values. Finally, we introduce GenLinkComb, an algorithm which combines the central ideas of the previous two into one integrated method. We evaluate all methods using six benchmark datasets: three of them are e-commerce product datasets, the other datasets describe restaurants, movies, and drugs. We show improvements of up to 16% F-measure compared to handwritten rules, on average 12% F-measure improvement compared to the original GenLink algorithm, 15% compared to EAGLE, 8% compared to FEBRL, and 5% compared to CoSum-P.
Introduction
As companies move to integrate data from even larger numbers of internal and external data sources and as more and more structured data is becoming available on the public Web, the problem of finding records in different data sources that describe the same real-world object is moving into the focus within even more application scenarios. There exists an extensive body of research on entity resolution in the Linked Data [30] as well as the database community [5,13]. However, most existing entity resolution approaches focus on dense data [6,19,31,32]. This paper sets an alternative focus and explores learning expressive linkage (matching) rules from as well as applying these rules to sparse data, i.e. data that contains a large amount of missing values.

Examples of attribute correspondences between product specifications: (left) specification from walmart.com, (center) centralised product catalog, and (right) specification from ebay.com.
A prominent example of an application domain that involves data exhibiting lots of missing values is e-commerce. Matching product data from different websites is difficult as most websites publish heterogeneous product descriptions using proprietary schemata which vary widely concerning their level of detail [29]. For instance in [38], we analyzed product data from 32 popular e-shops. The shops use within each product category (mobile phones, headphones, TVs) approximately 30 different attributes to describe items. The subset of the attributes that are used depends on the e-shop and even on the specific product. This leaves a data aggregator that collects product data for many e-shops into a rich schema with lots of missing values.
In [19], we presented GenLink, a supervised learning algorithm which employs genetic programming to learn expressive linkage rules from a set of existing reference links. These rules consist of attribute-specific preprocessing operations, attribute-specific comparisons, linear and non-linear aggregations, as well as specific weights and thresholds. The evaluation of GenLink has shown that the algorithm delivers good results with F-measures above 95% on different dense datasets such as sider-drugbank, LinkedMDB, and the restaurants dataset [19]. As shown in the evaluation section of this paper, GenLink as well as other entity resolution methods run into problems once the datasets to be matched are not dense, but contain larger amounts of missing values.
In order to overcome the challenge of missing values, this article introduces and evaluates three methods that build on the GenLink algorithm. First, we present GenLink Group Learning (GenLinkGL), an approach that groups linkage rules in order to cover different attribute combinations with specific rules. Next, we introduce the GenLink Selective Aggregations (GenLinkSA) algorithm which extends the original approach with selective aggregation operators to ignore and penalize comparisons that include missing values. Finally, we introduce GenLinkComb, an algorithm that combines the central ideas of the previous two into an integrated method. We evaluate all methods using six benchmark datasets: three of them are e-commerce product datasets, the other datasets describe restaurants, movies, and drugs.
The rest of this article is structured as follows: Section 2 formally introduces the problem of entity resolution. Section 3 gives an overview of the GenLink algorithm. Section 4 introduces the GenLinkGL, GenLinkSA, and GenLinkComb methods for dealing with sparse data. Section 5 presents the results of the experimental evaluation in which we compare the proposed methods with various baselines as well as other entity resolution systems. Section 6 discusses the related work.
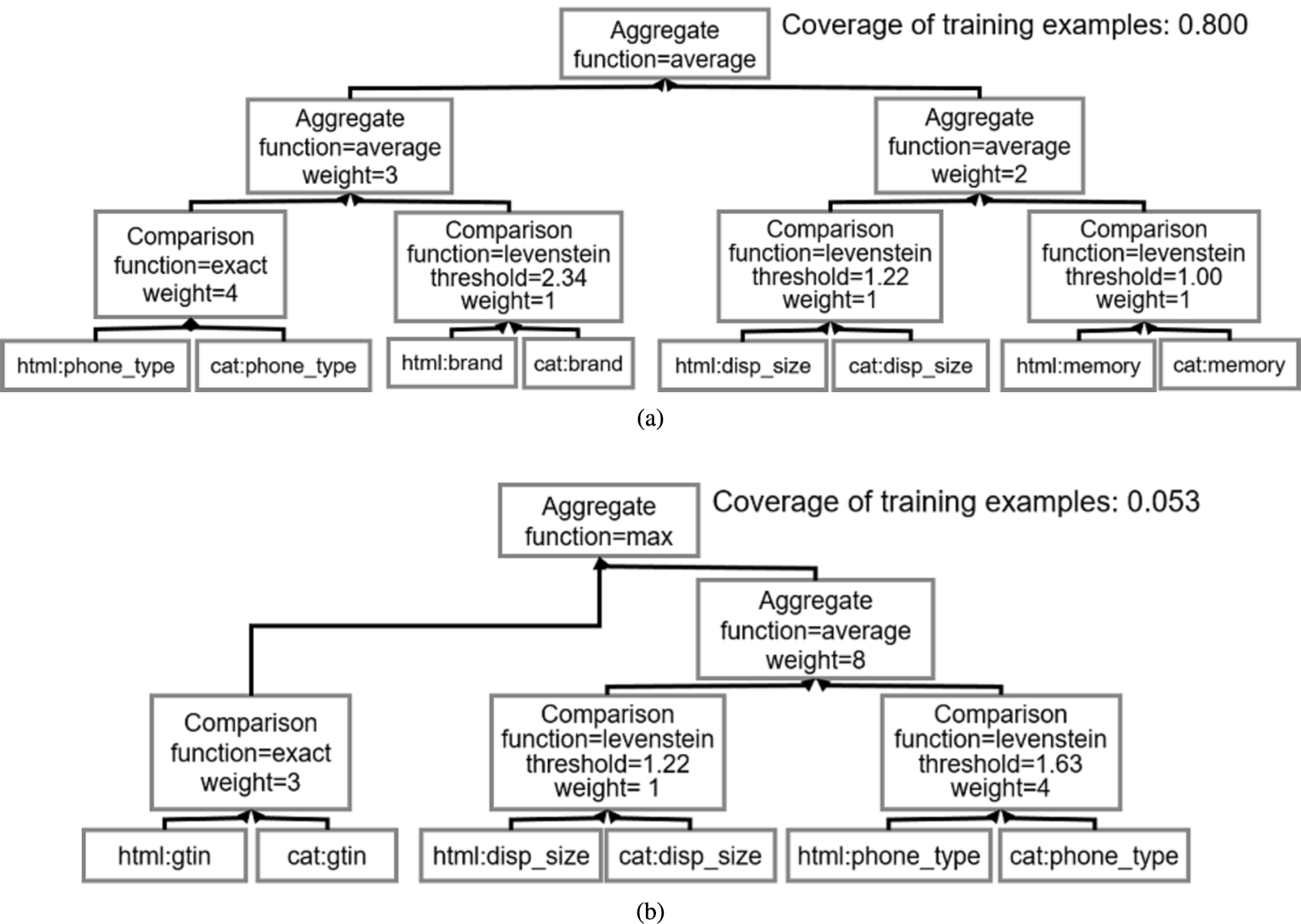
Example of two rules from the group for the phone category together with the coverage of each rule.
We consider two datasets, A the source, and B the target dataset. Each entity
Global Trade Item Number (GTIN) is an identifier for trade items, developed by GS1. – www.gtin.info/.
Additionally, we compute its complement set U defined as:
The purpose of relation
To infer a rule specifying the conditions which must hold true for a pair of entities to be part of M, we rely on a set of positive correspondences
Given the correspondences, we can define the purpose of the learning algorithm as learning matching rules from a set of correspondences:
The first argument in the above formula denotes a set of positive reference links, while the second argument denotes a set of negative reference links. The result of the learning algorithm is a linkage rule which should cover as many reference links as possible while generalising to unknown pairs.
GenLink [19] is a supervised algorithm for learning expressive linkage rules for a given entity matching task. As all three algorithms that are introduced in this paper build on GenLink, this section summarises the main components of the GenLink algorithm. The full details of the algorithm are presented in [19].
Linkage rule format
GenLink represents linkage rules as a tree built out of four types of operators: (i) property operators, (ii) transformation operators, (iii) comparison operators and (iv) aggregation operators. The linkage rule tree is strongly typed i.e. only specific combinations of the four basic operators are allowed. Figure 2 shows two examples of linkage rules for matching data describing mobile phones. The formal grammar of the linkage rule format is found in [19].
Property operators Retrieves all values of a specific property p of each entity. For instance, in Fig. 2(a) the left most leaf in the tree retrieves the value for the “phone_type” property from the source dataset.
Transformation operators Transforms the values of a set of properties or transformation operators. Examples of common transformation functions include case normalization, tokenization, and concatenation of values from multiple operators.
Comparison operators GenLink offers three types of comparison operators. The first type of operators are character-based comparisons: equality, Levenshtein distance, and Jaro–Winkler distance. The second type includes token-based comparators: Jaccard similarity and Soft Jaccard similarity. The comparison is done over a single property or a specific combination of properties. The third type of comparison operators, numeric-similarity, calculate the similarity of two numbers. Examples of comparison operators can be seen in Fig. 2(a) as the parents of the leaf nodes.
Aggregation operators Aggregation operators combine the similarity scores from multiple comparison operators into a single similarity value. GenLink implements three aggregation operators. The maximum aggregation operator aggregates similarity scores by choosing the maximum score. The minimum aggregation operator chooses the minimum from the similarity score. Finally, the average aggregation operator combines similarity scores by calculating their weighted average.
Note that these aggregation functions can be nested, meaning that non-linear hierarchies can be learned. For instance, in Fig. 2(a), four different properties are being compared (“phone_type”, “brand”, “memory” and “display_size”). Subsequently, two average aggregations are applied to aggregate scores from phone_type and brand, and memory and display_size, respectively. Finally, a third average aggregation is applied to aggregate scores from the previous aggregators.
Compared to other linkage rule formats, GenLink’s rule format is rather expressive, as it is subsuming threshold-based boolean classifiers and linear classifiers, hence allows for representing non-linear rules and may include data transformations which normalize the values prior to comparison [19]. Therefore, it allows rules to closely adjust to the requirements of a specific matching situation by choosing a subset of the properties of the records for the comparison, normalizing the values of these properties using chains of transformation operators, choosing property-specific similarity functions, property-specific similarity thresholds, assigning different weights to different properties, and combining similarity scores using hierarchies of aggregation operators.
The GenLink algorithm
The GenLink algorithm learns a linkage given a set of positive and negative training examples. The GenLink algorithm starts with an initial population of candidate solutions which is evolved iteratively by applying a set of genetic operators.
Generating initial population The algorithm finds a set of property pairs which hold similar values before the population is generated. Based on that, random linkage rules are built by selecting property pairs from the set and building a tree by combining random comparisons and aggregations.
Selection The population of linkage rules is bred and the quality of the linkage rules is assessed by a fitness function using the training data. The purpose of the fitness function is to assign a value to each linkage rule which indicates how close the given linkage rule is to the desired solution. The algorithm uses Matthews Correlation Coefficient (MCC) as fitness measure. MCC [25] is defined as the degree of the correlation between the actual and predicted classes or formally:
The training data consists of a set of positive correspondences (linking entities identifying the same real-world object) and a set of negative correspondences (stating that entities identify different objects). The predictions of the linkage rule is compared with the positive correspondences, counting true positives and false negatives, the negative correspondences, counting false positives and true negatives. In order to prevent linkage rules from growing too large and potentially overfit the training data, we penalize linkage rules depending on the number of operators the rules contain:
Once the fitness is calculated for the entire population, GenLink selects individuals for reproduction by employing the tournament selection method.
Crossover GenLink applies six types of crossover operators:
An in-depth discussion of the crossover operators is provided in [19].
Approaches
In [37] we have shown that the GenLink algorithm struggles to optimise attribute selection for sparse datasets. On an e-commerce dataset containing many low-density attributes the algorithm only reached a F-measure of less than 80%, in contrast to the above 95% results that are often reached on dense datasets. In the following, we propose three algorithms that build on the GenLink algorithm and enable it to properly exploit sparse attributes for matching decisions. The GenLinkGL algorithm learns a group of matching rules for the given matching task (group generation) and applies different rules from within the group to discover correspondences at runtime (group application). Next we introduce selective aggregations, new operators within the GenLink algorithm that can better deal with missing values. Finally, we introduce GenLinkComb approach which combines the central ideas of the previous two approaches into a single method.
The GenLinkGL algorithm
The GenLink algorithm lacks the capability to optimise attribute selection when dealing with sparse data. The algorithm will select a combination of dense attributes while sparse attributes will rarely be selected. This behavior influences adversely cases in which values from relatively dense attributes are missing. For instance, when matching product data describing mobile phones from different e-shops, the brand, phone type, and memory properties will be rather important for the matching decisions and these attributes will also likely be rather dense as they are provided by many e-shops. Therefore, GenLink will focus on these attributes and due to the penalty on large rules (compare Equation (5)) will not include alternative attribute combinations involving low-density properties, such as gtin, display size, or operating system. In cases in which a value of one of these dense attributes is missing, the algorithm will likely fail to discover the correct match, while by exploiting a combination of alternative low-density attributes it would have been possible to recognize that the both records describe the same product. Including all alternative attribute combinations into a single linkage rule would result in rather large rules containing multiple alternative branches that encode the different attribute combinations. Due to the penalty for large rules from Equation (5), only the most important alternative attribute combinations will be included into the rules, whereas combinations having a lower coverage will be left unused.
A way to deal with this problem could be to loosen the size penalty in Equation (5), however removing (or loosening) the penalty has the potential to result in an overfitted model. With GenLink Group Learning (GenLinkGL), we choose an alternative approach – instead of trying to grow very large rules that cover different attribute combinations, we learn sets of rules in which each rule is optimized for a specific attribute combination. The method allows us to separate more clearly the issue of avoiding overfitting rules while still being able to cover multiple attribute combinations. By combining multiple combinations of properties in a group, the learning algorithm is given the freedom to optimize matching rules not only for the most common attribute combinations, but also for less common combinations involving sparse properties, as a result increasing the overall recall. In the following, we describe how GenLinkGL combines rules into groups and later selects a rule from the group in order to match a pair of records having a specific property combination.

Generating a group of linkage rules
Group generation The basic idea of the first algorithm, presented in Algorithm 1, is that by grouping different linkage rules using different properties we could circumvent the missing values in the data. The initial group is populated with the fittest individual from the population generated by GenLink. Subsequently, an initial fitness for this group is computed using the MCC (compare Equation (4)).
Motivated by the GenLink algorithm, our algorithm builds a group that maximises fitness. To do this at each learning iteration, the algorithm iterates through the entire population of linkage rules and combines their individual fitness. We restrict the combination to linkage rules whose properties are not a subset of the properties of the group and include a linkage rule that has at least one new property that is not present in the group. We combine the fitness of the linkage rules by summing the number of correctly predicted instances in the training set (compare Equations (6) and (7)), calculating for each individual the percentage of the coverage of training examples in the group. Once the correctly predicted instances are summed the current fitness function is applied to the group. If the fitness of that combination is greater than the current fittest group, the new group becomes the best group. As an output the algorithm gives the fittest group.
Algorithm 1 can potentially lead to groups containing a large number of rules, up to the complete population of learned rules. In this case, the algorithm is prone to overfitting, since the population might capture the entire training set. In order to prevent this, we penalize groups containing a large number of rules:
For example, let the linkage rule in Fig. 2(a) be the fittest individual after the nth learning iteration of the algorithm. The initial group contains this linkage rule. The group would not be able to correctly predict correspondences that can only be found using a combination of the gtin, phone_type and memory properties. In the first iteration, we combine the group with the linkage rule in Fig. 2(b) which exploits the gtin property in cases in which this property is filled (coverage of training examples 0.053). As a result, the correspondences above are generated by the group leading to better fitness.

Applying a group of rules to match pairs of sparse records
Group application We use Algorithm 2 to apply a group of matching rules generated by Algorithm 1 to match pairs of sparse records. The individuals in the input group are sorted by the percentage of coverage. Sorting enables Algorithm 2 to find the more influential individual rules in less iterations. For each pair the algorithm iterates through the group of matching rules. If the pair to be matched contains the same properties as in the matching rule, the matching rule is applied. If there is no matching rule which has the exact properties as the instances, the top matching rule is applied. For instance, when matching (a) the specification from walmart.com with the product catalog and (b) the specification from ebay.com with the product catalog from Fig. 1, the algorithm would use the first rule from Fig. 2 for the a pair, but use the second matching rule from Fig. 2 for the b pair since in b one of the specifications does not have a value for the display_size attribute, however it contains a gtin attribute.
An alternative to learning groups of linkage rules specializing on a specific attribute combination each is to learn larger rules covering more attributes and apply a penalty for the uncertainty that arises from values missing in these attributes. For instance, a larger rule could rely on five properties for deciding whether two records match. If two of the five properties have missing values, the remaining three properties can still be used for the matching decision. Nevertheless, a decision based on three properties should be considered less certain than a decision based on five properties. In order to compensate for this uncertainty, we can require the values of the remaining three properties to be more similar than the values of the five properties in the original case in order to decide for a match. The GenLink Selective Aggregations (GenLinkSA) algorithm implements this idea by changing the behavior of the comparison operators as well as the aggregation operators in the original GenLink algorithm.

GenLinkSA rule for the phone category.
NULL-enabled comparison operators The original GenLink algorithm does not distinguish between a pair of different values and a pair of values containing a missing value. In both cases, the algorithm assigns the similarity score 0. This is problematic when similarity scores from multiple comparison operators are combined using the aggregation function average or minimum, as the resulting similarity score will be unnaturally low for the case of record pairs containing missing values. In order to deal with this problem, GenLinkSA amends the comparison operators with the possibility to return the value NULL: a GenLinkSA comparison operator will return NULL if one or both values are missing. If both values are filled, the operator will apply its normal similarity function and return a value in the range
Selective aggregation operators The GenLink aggregation operators calculate a single similarity score from the similarity values of multiple comparison operators using an aggregation function such as weighted average, minimum, or maximum. GenLinkSA adjusts the aggregation operators to apply the aggregation function only to non-NULL values. In order to compensate the uncertainty that results from missing values (comparison operators returning the value NULL), the similarity score that results from the aggregation is reduced by constant factor α for each comparison operators that returns a NULL value. Thus, all non-NULL similarity scores are aggregated and a penalty is applied for each property pair containing missing values. Formally, a GenLink aggregation is defined by the following:
The first argument
Given the aggregation operators, we can now define GenLinkSA’s selective aggregation operators as:
Where the uncertainty factor υ is defined as the number of NULL values multiplied by a small valued constant factor
For example, let the rule learned by the GenLinkSA algorithm be the one shown in Fig. 3 and let instances for matching be (a) the specification from walmart.com that should be matched with the product catalog and (b) the specification from ebay.com to be matched with the product catalog from Fig. 1. When matching (a) only a small penalty will be applied since for five out of six comparisons a non-NULL similarity score will be returned and only the comparison for one property (comp_os) will be penalised. On the other hand, the pair (b) will be heavily penalised since four of the six comparisons will return NULL values. Evidently, this method will discourage high similarity scores in the presence of missing values and will thus refrain from considering borderline cases with missing values as matches, resulting in a higher precision.
GenLinkGL and GenLinkSA tackle the issue of missing values differently. Namely, GenLinkGL strives to group matching rules exploiting different combinations of attributes and thus is able to apply alternative rules given that values of important attributes are missing. By being able to exploit alternative property combinations, GenLinkGL is tailored to improve recall. On the other hand, by penalizing comparisons with missing values, GenLinkSA incentivises learning matching rules that include more properties and substantially lowers the similarity scores of uncertain pairs, and by that improves precision. As the basic ideas behind GenLinkGL and GenLinkSA do not exclude each other but are complementary, a combination of both methods into a single integrated method could combine their advantages: optimize rules for alternative attribute combinations while at the same time dealing with the uncertainty that arises from missing values inside the rules. The GenLinkComb algorithm achieves this by combining the GenLinkSA and the GenLinkGL algorithms as follows: GenLinkComb uses the GenLinkSA algorithm to evolve the population of linkage rules. In each iteration of the learning process, GenLinkComb groups the learned rules together using the GenLinkGL algorithm. By being able to deal with missing values either inside the rules using the selective aggregation operators or within the grouping of rules, the GenLinkComb learning algorithm has a higher degree of freedom in searching for a good solution.
Evaluation
We use six benchmark datasets to evaluate the proposed methods: three e-commerce product datasets, and three datasets describing restaurants, movies, and drugs. In addition to comparing GenLinkGL, GenLinkSA, and GenLinkComb with each other, we also compare the approaches to existing systems including CoSum-P, FEBRL, EAGLE, COSY, MARLIN, ObjectCoref, and RiMOM. The following sections describe the six benchmark datasets, give details about the experimental setup, and present and discuss the results of the matching experiments.
Property densities in the Abt–Buy and Amazon–Google datasets
Property densities in the Abt–Buy and Amazon–Google datasets
Product matching datasets We use three different product datasets for the evaluation:
The dataset includes correspondences between 1081 products from Abt.com and 1092 from Buy.com. The full input mapping contains 1.2 million correspondences, from which 1000 are annotated as positive correspondences (matches). Each product is described by up to four properties: product name, description, manufacturer, and price. The dataset was introduced in [21]. Since the content of the product name property is a short text listing various product features rather than the actual name of the product, we extract the product properties Brand and Model from the product name values using the dictionary-based method presented in [39]. Table 1 shows the densities of the original as well as the extracted properties. We choose the Abt–Buy dataset because it is widely used to evaluate different matching systems [4,8].
The dataset [21] includes correspondences between 1363 products from Amazon and 103,226 from Google. The full input mapping contains 4.4 million correspondences, from which 1000 are annotated as matches. Each entity of the dataset contains the same properties as the Abt–Buy dataset. We also extract Brand and Model values from the product names using the same method as for the Abt–Buy dataset. The Amazon–Google data set has also been widely used as benchmark data set [21].
This gold standard [38] for product matching contains correspondences between 1500 products (500 each from the categories headphones, mobile phones, and TVs), collected from 32 different websites and a unified product catalog containing 150 products with the following distribution: (1) Headphones – 50, (2) Phones – 50, and (3) TVs – 50. The data in the catalog has been scraped from leading shopping services, like Google Shopping, or directly from the vendor’s website. The gold standard contains 500 positive correspondences (matches) and more than 25000 negative correspondences (non-matches) per category. Compared to the Amazon–Google and Abt–Buy datasets, the WDC Product Matching Gold Standard is more heterogeneous as the data has been collected from different websites. The gold standard also features a richer schema containing over 30 different properties for each product category.
Properties and property density of the WDC product matching gold standard, restaurants, sider-drugbank and LinkedMDB datasets. Note that properties having a density below 10% are not included into the table
Properties and property density of the WDC product matching gold standard, restaurants, sider-drugbank and LinkedMDB datasets. Note that properties having a density below 10% are not included into the table
Other entity resolution datasets In order to be able to compare our approaches to more reference systems, as well as to showcase the ability of our algorithms to perform on datasets from different application domains, we also run experiments with the three benchmark datasets that were used in [19]:
The dataset contains correspondences between 864 restaurant entities from the Fodor’s and Zagat’s restaurant guides. Specifically, 112 duplicate records were identified.
The dataset contains correspondences between 924 drug entities in the Sider dataset and 4772 drug entities in the Drugbank dataset. Specifically, there have been 859 duplicate records identified.
This dataset contains 100 correspondences between 373 movies. The authors note that special care was taken to include relevant corner cases such as movies which share the same title but have been produced in different years.
Tables 1 and 2 give an overview of densities of properties in the six evaluation datasets. If the density of a property differs in the source (A) and the target (B) dataset, both densities are reported. For the Abt–Buy and Amazon–Google datasets, we show all original property densities as well as the density of the extracted properties. The Abt–Buy and Amazon–Google datasets follow a similar distribution in which only the product name property has a density of 100%. It is worth to note that the product name property in these datasets is actually a short description of the product mentioning different properties rather than the actual product name. WDC Product Matching Gold Standard contains a small set of properties with a density above 90% while most properties belong to the long tail of rather sparse properties [38].
Baselines As baselines for the WDC gold standard, we repeat the TF-IDF cosine similarity and Paragrph2Vec experiments presented in [38]. Additionally, we learn decision trees and random forests. The first baseline, considers pair-wise cosine matching of product descriptions for which TF-IDF vectors are calculated using the bag-of-words feature extraction method. The second baseline, employs the distributed bag-of-words method to calculate Paragraph2Vec embeddings [23] for product names using 50 latent features. The embeddings are compared using cosine similarity. Decision trees and random forests are learned in Rapidminer2
Other entity resolution systems In order to set the GenLink results into context, we also ran the WDC gold standard experiments with EAGLE [34], a supervised matching system that also employs genetic programming,3

Handwritten matching rule for the headphones category.
Additionally, we provide a comparison to handwritten Silk rules. These rules are composed of up to six properties for each product category and were written by the authors of this article using their knowledge about the respective domains as well as statistics about the datasets. As an example, the handwritten rule that was used for matching headphones, shown in Fig. 4, implements the intuition that if the very sparse properties html:gtin or html:mpn match exactly, the record pair should be considered as a match. If these numbers are not present or do not match, the rule should fall back to averaging the similarity of the properties html:model, html:impedence and html:headphone_cup_type giving most weight to html:model.
Available aggregation, comparison, and transformation functions. The transformation functions are used only for non-product datasets
GenLinkGL, GenLinkSA, and GenLinkComb The GenLinkGL, GenlinkSA, and GenLinkComb algorithms were implemented on top of the Silk Framework.5
GenLink (GL/SA/Comb) parameters
GenLink and its variants as well as EAGLE were trained on a balanced dataset consisting of 66% of the positive correspondences and the same number negative correspondences. The systems were tested afterwards using the remaining 33% of the correspondences. For training FEBRL, we calculated TF-IDF scores and cosine similarity for all pairs given in the dataset. As with GenLink and EAGLE, FEBRL was trained on 66% of the data and evaluated on the rest. For the experiments on the Abt–Buy and Amazon–Google datasets, all systems were trained using the original as well as the extracted attribute-value pairs.
Preprocessing The restaurants, movies, and drugs datasets have an original density of over 90%. In order to use them to evaluate how the different approaches perform on sparse data, we systematically removed 25%, 50% and 75% of the values. More precisely, we first randomly sample 50% of properties (not including the name property) and for those we randomly select 25%, 50% and 75% of the values and removed the rest, thus introducing greater percentage of null values in the datasets. We do not remove values from all properties since we want to create a similar sparseness distribution as we found in the product datasets. We do not remove the name property since it is the only reliable identifier for a human, i.e without it even a human cannot decide whether two entities are the same.
Table 5 gives an overview of the matching results on the WDC gold standard. Moreover, we compare results of: (i) the baselines, (ii) handwritten matching rules, (iii) the GenLink algorithm, (iv) GenLinkGL, (v) GenLinkSA, and (vi) GenLinkComb. In addition, we compare to the GenLink results with three state-of-the-art matching systems: (i) EAGLE [34], (ii) FEBRL [21], and (iii) CoSum-P [44].
Matching results per category for the WDC product matching gold standard
Matching results per category for the WDC product matching gold standard
As expected, the baselines perform poorly within each product category. Specifically, TF-IDF could not capture enough details of a given entity. Paragaph2Vec, improves on TF-IDF by considering the semantic relatedness of words. Decision trees reach similar results as handwritten rules. Using random forests further improves the results on all three datasets. As shown by Ristoski et al. [40], decision trees and random forests can reach even better results when combined with more sophisticated feature extraction methods.
EAGLE [34] and GenLink [19] improve on the baselines since they have the ability to optimise the thresholds for comparisons and the weights within aggregations. FEBRL [8] outperforms handwritten rules in all product categories. Because of FEBRL’s SVM implementation is optimized for entity resolution, the system seems to be able to capture more nuanced relationships between data points than the handwritten rules. The main difficulty of the FEBRL is recall.
Interestingly, the unsupervised method CoSum-P [44] outperforms FEBRL in two out of three product categories (phones and TVs). The CoSum-P graph summarization approach is able to successfully generalise entities based on pair-wise pre-computed property similarities into super nodes. However, having no supervision (ability to learn from negative examples) the algorithm suffers from lower precision due to the inability to distinguish between closely related entities. For instance, “name: iphone 6; memory: 16gb” and “name: iphone 6s; memory: 16gb” would give a high pre-computed similarity score, and thus will be considered a match. Without negative evidence it is very hard for the approach to differentiate between these two products.
GenLinkGL, GenLinkSA, and GenLinkComb consistently outperform CoSum-P, FEBRL, and the handwritten rules, according to the Friedman [non-parametric rank] test [15] with significance level of
The Friedman [non-parametric rank] test was performed on the averaged F-measure results.
Category wise, the headphones category proves to be an easier matching task obtaining the best results with 94% F-measure. Headphones have a smaller number of distinct properties and therefore e-shops tend to more consistently describe products with the same attributes compared to the other two categories. The TVs and phones category reach similar F-measures of 83.8% and 84.9% respectively.
Standard deviation of the GenLink algorithms on the WDC dataset
Table 6 shows the averaged results of the algorithms and their standard deviation values. The stability of GenLink and GenLinkSA is improved by GenLinkGL and GenLinkComb.
Comparison of the learned matching rules In order to explain the differences in the results of GenLinkSA, GenLinkGL, and GenLinkComb, we analyze and compare the rules that were learned by the three algorithm for matching mobile phones. Figure 3 shows the GenLinkSA rule that was learned. As we can see, the rules uses six properties which are combined using a hierarchy of average aggregations. Within the hierarchy, more weight is put onto a branch containing four properties, as well as on the properties brand and phone_type within this branch. The GenLinkGL algorithm has learned a group consisting of 12 matching rules that use 15 distinct properties for matching phones. Table 7 shows the top five rules learned by GenLinkGL sorted by their coverage. More than 50% of the rules contain the model (phone_type) and the display size (disp_size) attributes. It is interesting to examine the coverage of the learned rules: The first rule was applied to match 80% of the pairs in the training data. The second rule was only used for 5% of the cases, the next rule for 2% and so on, meaning that the data contained one dominant attribute combination (the one exploited by the first rule) while by specializing on alternative combinations (like the second rule involving the gtin property) still improves the overall result. Furthermore, most of the learned matching rules use similar combinations of aggregation functions (average aggregation). The only exception is the second rule which uses the property gtin. Namely, the gtin property by itself is enough to identify the specific product, thus the maximum aggregation function is used. For matching phones, the GenLinkComb algorithm has learned a group that only consists of five matching rules which use 10 distinct properties. Meaning that the algorithm achieves a better F1-performance using less rules and less properties compared to GenLinkGL. Table 8 shows the rules that were learnt by the GenLinkComb algorithm, again sorted by coverage. Interestingly, the rules have a more homogenous coverage distribution (three rules with a coverage of over 0.2) than the GenLinkGL rules. Instead of generating rules for exotic, low-coverage property combinations as GenLinkGL does, GenLinkComb generates less rules which exploit more properties each and uses the selective aggregations and the uncertainty penalty to deal with missing values within these properties. The property composition also supports this argument: The robust property composition of GenLinkComb suggests that the learned matching rules in the group contain more nuanced differences, while GenLinkGL has more irregular property composition.
Properties, comparisons, aggregations, and training example coverage of the top 5 rules for phone category learned by GenLinkGL
Properties, comparisons, aggregations, and training example coverage of the top 5 rules for phone category learned by GenLinkComb
Amazon–Google and Abt–Buy results In order to also evaluate the algorithms on datasets having a lower number of distinct properties (see Table 1), we apply the algorithms to the Amazon–Google and Abt–Buy datasets. The results of these experiments are shown in Table 9 and Table 10. As reference systems, the best performing approaches found in literature are listed in the lower part of the tables. Table 9 shows the results for the Amazon–Google dataset. GenLinkComb outperforms the commercial system COSY [21] which uses manually set attribute similarity thresholds. CoSum-P [44] shows comparable results to GenLinkComb. As the datasets only have a low number of properties and as these properties often contain multi-word texts, the token-similarity based approach of CoSum-P can play its strength, leading to better relative results compared to the results on the WDC gold standard (Table 5).
Table 10 shows the results for the Abt–Buy dataset. As within the previous experiments, GenLinkComb shows the best performance in terms of F-Measure. Both, FEBRL’s SVM classifier [8] and MARLIN [4]9
Results from experiments with FEBRL and MARLIN are published in [21].
Product matching results for the Amazon–Google dataset
Product matching results for the Abt–Buy dataset
Generally, for all datasets we can conclude that our methods have difficulties to find the correct matches when dealing with severely sparse data (density: 25%). Additionally, GenLinkComb and GenLinkSA have similar performance and both tend to outperform GenLinkGL for every dataset for the sparser settings. In contrast, when the datasets have 75% density, our methods perform close to the results of reference systems achieved on the datasets with more than 90% property density.
Table 11 gives results on the matching experiment done on the Restaurant dataset. GenLinkSA and GenLinkComb perform closest to the reference systems, while GenLinkGL does not show any improvement on this dataset. Due to low number of attributes in the dataset, GenLinkComb and GenLinkGL show little improvement compared to the other methods. Consequently, GenLinkComb and GenLinkGL cannot find enough matching rules with alternative attributes to group, making GenLinkComb to boil down to GenLinkSA and GenLinkGL to boil down to GenLink. Density wise, all three methods follow the same downward trend when the datasets get sparser, keeping the relative improvements of GenLinkSA and GenLinkGL in comparison to GenLink.
Results for the restaurants dataset
Results for the restaurants dataset
Table 12 shows the matching results for the Sider-Drugbank dataset. Even though we systematically lowered the quality of the dataset, GenLink still outperforms the state-of-the-art [18,43] systems for the case of 75% property density. With that said, GenLinkGL and GenLinkSA reach considerably better results in recall and precision respectively. When the data become severely sparse, like in the case of 25% density, our methods show an increase of 5% in F-measure compared to GenLink. Similar to the Restaurant dataset, GenLinkComb does not improve over GenLinkSA as again the grouping algorithm can not find suitable rules with alternative attributes for grouping.
Results for the Sider-Drugbank dataset
Table 13 gives results on the matching experiment done on the LinkedMDB dataset, which contains more properties compared to the other two datasets. In this case GenLinkComb outperforms other variations of GenLink even when data spareness is severe. Unlike with the Restaurants and Sider-Drugbank datasets GenLinkComb successfully finds rules with alternative attributes to group and thus increases the F-measure by 5% compared to GenLinkSA.
Results for the LinkedMDB dataset
Average runtimes on the WDC gold standard
Table 14 shows the average training as well as application runtimes in seconds of GenLink and its variants as well as EAGLE and CoSum-P on the WDC gold standard. The experiments have been conducted using an Intel® Xeon CPU with 6 cores available while the Java heap space was restricted to 4 GB. On average, it took GenLink and GenLinkSA approximately 6 minutes to learn a matching rule using the maximum number of iterations (see Table 4 for the exact configuration), while it took GenLinkGL and GenLinkComb 8.5 minutes to learn a group of rules. Similar to GenLink, EAGLE learns a matching rule for the same dataset in just under 6 minutes. However, when comparing application runtimes, GenLink and its variants are at least 24.3 times slower than EAGLE. This result is explained by the fact that GenLink and its variants in their current implementation do not apply any blocking. Compared to CoSum-P, GenLink and its variants are between 7 and 35 seconds slower.
Related work
Entity resolution has been extensively studied under different names such as record linkage [1,6,17,32], reference reconciliation [12], and coreference resolution [24,31]. In the following, we review a set of representative entity resolution methods with respect to their ability to deal with sparse data. For a broader comparison of the approaches along different criteria, please refer to the following surveys [5,7,16,30,42]. Entity resolution methods can either be unsupervised [9,10,26,35,44] or supervised [4,8,19,31,32].
Unsupervised methods CoSum [44] and idMesh [10] are two examples of unsupervised entity resolution methods. CoSum and idMesh are both treating entity resolution as a graph summarisation problem, i.e. they generate super-nodes by clustering entities and in the case of CoSum by applying collective matching techniques. Both approaches employ sophisticated generic similarity metrics. Nevertheless, dues to not using negative evidence, they run into problems for cases in which small syntactic differences matter, such as product type Lul5X versus Lul6X. As shown by the good results of CoSum-P [44] on the Amazon–Google dataset (see Section 5.3), unsupervised approaches can excel in use cases that involve rather unstructured, textual data. But due to not using domain-specific evidence, they reach lower relative results for use cases that require domain-specific similarity metrics and attribute weights. Missing values boil down to missing edges in the graph summarisation setting, meaning that the algorithms decide using less evidence. Nikolov et al. [35] propose an unsupervised entity resolution method for the context of the Semantic Web. They present a genetic algorithm for matching, similar to EAGLE [34] and GenLink [19]. However, instead of using reference links as basis for calculating fitness, the authors propose a “pseudo F-measure”; an approximation of F-measure based on indicators gathered from the datasets. Specifically, the fitness function proposed by the authors assumes datasets to contain no duplicates. This assumption is violated by many real world datasets. For instance, the WDC dataset contains multiple offers for the same product all originating from eBay.
Supervised methods Supervised entity resolution methods learn binary classifiers to determine whether two records refer to the same real-world object. Such binary classifiers can be categorised into threshold based boolean classifiers and linear classifiers. An example of an approach using boolean classifiers is presented in [2]. The method is based on the assumption that the entity resolution process consists of iterative matching and merging which results in a set of records that cannot be further merged with each other. Examples of approaches using linear classifiers are MARLIN (Multiply Adaptive Record Linkage with INduction) [4] and FEBRL (Freely Extensible Biomedical Record Linkage) [8] which both employ support vector machines (SVMs). While there are numerous studies that propose approaches for handling missing values in SVMs, for instance [36], these optimizations are often expensive and are not used by MARLIN and FEBRL. Limes [33] and Silk [19] are examples of supervised entity resolution systems that focus on combining expressive linkage rules with good runtime behavior. Both Limes and Silk learn linkage rules using genetic programming, i.e. EAGLE [34] and GenLink. As demonstrated throughout this paper, both methods do not handle missing values well as the learned linkage rules focus on dense attributes.
Another direction of research is collective entity resolution. For instance, Bhattacharya and Getoor [3] propose a relational clustering algorithm that uses both property and relational information between the entities of same type to determine correspondences. However, the employed cluster similarity measure depends primarily on property value similarity. Larger amounts of missing values will thus unsettle the measure. [27] and [41] both use probabilistic models for capturing the dependence among multiple matching decisions. Specifically, conditional random fields (CRFs) have been successfully applied to the entity resolution domain [27] and are one of the most popular approaches in generic entity resolution. On another hand, a well-founded integrated solution to the entity-resolution problem based on Markov Logic is proposed in [41]. However the approach applies the closed-world assumption, i.e. whatever is not observed is assumed to be false in the world.
Matching product data An important application domain of entity resolution is matching product data. Kannan et al. [20] learn a logistic regression model on product features that are extracted using a dictionary-based approach. Similarly, [22] extend the FEBRL approach from [21] with more detailed features. Finally, in [39], the authors compare various classifiers for product resolution (SVMs, Random Forests, Naive Bayes) on features extracted using a dictionary-based method as well as CRFs. [40] extends this work by using latent semantic features and shows that such features can significantly improve the results of traditional machine learning methods for entity resolution.
Conclusion
This article has introduced three methods for learning expressive linkage rules from sparse data. The first method learns groups of matching rules which are each specialized on a specific combination of non-NULL attributes. Moreover, we introduce new operators to the GenLink algorithm: selective aggregation operators. These operators assign lower similarity scores to record pairs with missing values which in turn boosts precision. Finally, we presented a method that integrates the central ideas of the previous two methods into a combined method. We evaluate the methods using six different datasets: three e-commerce datasets (as this domains often involves sparse data), as well as three datasets from other domains that were used as benchmarks in previous work. We show improvements of up to 16% F-measure compared to handwritten rules, on average 12% F-measure improvement compared to the original GenLink algorithm, 15% compared to EAGLE, 8% compared to FEBRL, and 5% compared to CoSum-P. In addition, we show that the method using groups of matching rules improves recall up to 15%, while selective aggregation operators improve precision of up to 16%.
As a general conclusion, the high gains in F-measure clearly show that identity resolution systems should take sparse data into account and not only focus on dense datasets. When benchmarking and comparing systems, it is important to not only use dense evaluation data, but also test on datasets with varying attribute density such as the WDC gold standard [38].