
Abstract
One of the key requirements to facilitate the semantic analytics of information regarding contemporary and historical events on the Web, in the news and in social media is the availability of reference knowledge repositories containing comprehensive representations of events, entities and temporal relations. Existing knowledge graphs, with popular examples including DBpedia, YAGO and Wikidata, focus mostly on entity-centric information and are insufficient in terms of their coverage and completeness with respect to events and temporal relations. In this article we address this limitation, formalise the concept of a temporal knowledge graph and present its instantiation – EventKG. EventKG is a multilingual event-centric temporal knowledge graph that incorporates over 690 thousand events and over 2.3 million temporal relations obtained from several large-scale knowledge graphs and semi-structured sources and makes them available through a canonical RDF representation. Whereas popular entities often possess hundreds of relations within a temporal knowledge graph such as EventKG, generating a concise overview of the most important temporal relations for a given entity is a challenging task. In this article we demonstrate an application of EventKG to biographical timeline generation, where we adopt a distant supervision method to identify relations most relevant for an entity biography. Our evaluation results provide insights on the characteristics of EventKG and demonstrate the effectiveness of the proposed biographical timeline generation method.
Introduction
Motivation: The amount of event-centric information regarding contemporary and historical events of global importance, such as the US elections, the 2018 Winter Olympics and the Syrian Civil War, constantly grows on the Web, in the news sources and within social media. In the literature, an event is typically described as something that happens at a specific time and location [2]. Events considered in this work are real-world happenings of societal importance, with examples including military conflicts, sports tournaments and political elections. In particular, we consider events, entities they involve and temporal relations – i.e. real-world relations between events and entities valid over a time period.
Efficiently accessing and analysing large-scale event-centric and temporal information is crucial for a variety of real-world applications in the fields of Semantic Web, NLP and Digital Humanities. In Semantic Web and NLP, these applications include timeline generation [4,17] and Question Answering [23,24]. In Digital Humanities, multilingual event repositories can facilitate cross-cultural studies analysing language-specific and community-specific views on historical and contemporary events (examples of such studies can be seen in [19,37]). Furthermore, event-centric knowledge graphs can facilitate the reconstruction of histories as well as networks of people and organisations over time [1,38]. One of the pivotal pre-requisites to facilitate effective analytics of events is the availability of knowledge repositories providing reference information regarding events, involved entities and their temporal relations.
Limitations of the existing sources of event-centric and temporal information: Currently, event representations and temporal relations are spread across heterogeneous sources. First, large-scale knowledge graphs (KGs) (i.e. graph-based knowledge repositories [14] such as Wikidata [13], DBpedia [29] and YAGO [31]) typically focus on entity-centric knowledge. Event-centric information included in these sources is often not clearly identified as such, can be incomplete and is mostly restricted to named events and encyclopaedic knowledge.
For example, as discussed later in Section 5.1, out of
Second, a variety of manually curated semi-structured sources (e.g. the Wikipedia Current Events Portal (WCEP) [50] and multilingual Wikipedia event lists) contain information on contemporary events. However, the lack of structured representations of events and temporal relations in these sources hinders their direct use in real-world applications, e.g. through semantic technologies. Overall, a comprehensive integrated view on contemporary and historical events and their temporal relations is still missing. EventKG will help to overcome these limitations.
An additional source of event-centric information on the Web are the recently proposed knowledge graphs containing events obtained from unstructured news sources using Information Extraction methods (such as [6,28,36,38,55]). These knowledge graphs are potentially highly noisy (e.g. [38] reports an extraction accuracy of only 0.55). Due to significant differences in quality and event granularity, the integration of events from these sources with the information in the established knowledge repositories such as DBpedia or Wikidata within a common knowledge graph does not appear meaningful. These event sources as well as the corresponding Information Extraction methods for unstructured news articles are out of scope of this work.
A temporal knowledge graph and EventKG: In this article we formalise the concept of a temporal knowledge graph that interconnects real-world entities and events using temporal relations valid over a time period. Furthermore, we present an instantiation of a temporal knowledge graph – EventKG. EventKG takes an important step to facilitate a global view on events and temporal relations currently spread across entity-centric knowledge graphs and manually curated semi-structured sources. EventKG integrates this knowledge in an efficient light-weight fashion, enriches it with additional features such as indications of relation strengths and event popularity, adds provenance information and makes all this information available through a canonical RDF representation. Through the light-weight integration and fusion of event-centric and temporal information from different sources, EventKG enables to increase coverage and completeness of this information. For example, EventKG increases the coverage of locations and dates for Wikidata events it contains by
EventKG was first introduced in [18]. Compared to [18], in this article we formally introduce the concept of a temporal knowledge graph, provide more details on the algorithms adopted for the EventKG generation and the corresponding evaluation results. Furthermore, we present a method that facilitates an application of EventKG to biographical timeline generation. We make EventKG, including the dataset, a SPARQL endpoint, the code and evaluation data, as well as the benchmarks created for the biographical timeline generation available online.1

An excerpt of the biographical timeline for the entity Barack Obama, generated from the EventKG knowledge graph using a proposed model trained on the Wikipedia abstracts of other entities (BS-ENC benchmark). Orange lines represent the temporal validity of the relations. Each row corresponds to a predicate characterising the relation (e.g. commander) to the specific event or entity (e.g. Iraq War).
Generation of biographical timelines using a temporal knowledge graph: A popular entity such as an influential person, a city or a large organisation can impose hundreds of temporal relations within a temporal knowledge graph. For example, the entity Barack Obama possesses
Timelines are an effective method to provide a visual overview of entity-centric temporal information, such as temporal relations in a knowledge graph [4]. In particular, biographical timelines describe significant happenings in a person’s life and typically include events of major relevance from the personal perspective such as birth, education and career. Figure 1 illustrates a biographical timeline for Barack Obama, which includes places where Barack Obama lived (first Chicago and then the White House), important events he was involved in (e.g. the Iraq War) and the major political positions he held (e.g. the President of the United States). This timeline also indicates the temporal validity of these relations.
In this article we present an approach for the generation of biographical timelines from a temporal knowledge graph. To generate such timelines, we propose a distant supervision method, where we train the relevance model using external sources containing biographical and encyclopaedic texts. With that model, we extract the most relevant biographical data from the temporal knowledge graph concisely describing a person’s life, while using features such as relation strength and event popularity information contained in EventKG, as well as predicate labels. The results of our user evaluation demonstrate that this approach is able to generate high quality biographical timelines while significantly outperforming a state-of-the-art baseline for timeline generation: our timelines were preferred over the baseline’s timelines in approximately
All events connected with Barack Obama in EventKG that started between November 4 and November 16, 2011
Most linked events in the English (EN) and the Russian (RU) Wikipedia
Overall, our contributions in this article are as follows:
We formally define the concept of a temporal knowledge graph
We present an instantiation of
We define the problem of biographical timeline generation from a temporal knowledge graph and present our method based on distant supervision.
We demonstrate the effectiveness of the proposed timeline generation method in a user study.
The remainder of this article is organised as follows: First, in Section 2 we motivate the need for a temporal knowledge graph and introduce a running example. In Section 3, we formally define the concepts of a temporal knowledge graph and a biographical timeline. Then, in Section 4, we describe EventKG, including its RDF data model and the extraction pipeline. In Section 5, we provide statistics and evaluation results of the data contained in EventKG. Our approach towards biographical timeline generation using temporal knowledge graph is presented in Section 6. The experimental setup and evaluation of the biographical timelines generated with our approach using EventKG is provided in Section 7. Related work is discussed in Section 8. Finally, we discuss our findings and provide a conclusion in Section 9.
Our society faces an unprecedented number of events that impact multiple communities across language and community borders. In this context, the efficient access to event-centric multilingual information originating from different sources, as facilitated by EventKG, is of utmost importance for several scientific communities, including Semantic Web, NLP and Digital Humanities and a variety of applications, including timeline generation, question answering, as well as cross-cultural and cross-lingual event-centric analytics.
Timeline generation is an active research area [4,17], where the focus is to generate a timeline (i.e. a chronologically ordered selection) of events and temporal relations for entities from a knowledge graph. In this article we focus on the application of EventKG to the automated generation of timelines representing people biographies. In this task, information regarding event popularity and relation strength available in EventKG in a combination with a benchmark extracted from external biographical sources can enable the selection of the most relevant timeline entries.
EventKG facilitates the generation of detailed timelines containing complementary information originating from different reference sources, potentially resulting in more complete timelines and event representations. For example, Table 1 illustrates an excerpt from the timeline for the query “What were the events related to Barack Obama between November 4 and November 16, 2011?” generated using EventKG. The last event in the timeline in Table 1 about Obama visiting Australia extracted from an English Wikipedia event list (“2011 in Australia”2
Top-4 persons mentioned jointly with the financial crisis (2007–2008) per language
An important application of EventKG is cross-cultural and cross-lingual analytics. Such analytics can provide insights on the differences in the event perception and interpretation across communities. For example, event popularity and relation strength between events and entities varies across different cultural and linguistic contexts. These differences can be observed and analysed using information provided by EventKG. For example, Table 2 presents the top-4 most popular events in the English vs. the Russian Wikipedia language editions as measured by how often these events are referred, i.e. linked to in the respective Wikipedia language edition. Whereas both Wikipedia language editions mention events of global importance, here the two World Wars, most frequently, the other most popular events (e.g. “October Revolution” and “American Civil War”) are language-specific. The relation strength between events and entities in specific language contexts can be inferred by counting their joint mentions in Wikipedia. For example, Table 3 lists the persons most related to the financial crisis in the years 2007 and 2008 in different Wikipedia language editions. This information is directly provided by EventKG. An EventKG application to cross-lingual timeline generation was presented in [17]. In this context, EventKG-empowered interfaces can be used as a starting point to identify events controversial in their cross-cultural aspects. Such events can then be analysed in more detail using tools such as MultiWiki [16] proposed in our previous work.
Another intended future application of EventKG is semantic event-centric question answering. With the provision of EventKG, it becomes possible to answer questions such as “Which events related to Bill Clinton happened in Washington in 1980?” and “What are the most important events related to Syrian Civil War that took place in Aleppo?” that are of interest for both cross-cultural and cross-lingual event-centric analytics (e.g. illustrated in [15,37]) as well as question answering and semantic search applications (e.g. [12,23,24,57]).
As a running example throughout this article, we will use the task of biographical timeline generation for the entity Barack Obama. First, we will illustrate the heterogeneity of data about Barack Obama available in the reference knowledge graphs used to populate EventKG (Wikidata, DBpedia, YAGO and Wikipedia), and the extraction and integration of this data into a canonical RDF representation in EventKG. As mentioned above, this process leads to
A temporal knowledge graph and biographical timelines
A temporal knowledge graph
A temporal knowledge graph
A temporal entity
A temporal entity
A temporal entity
A temporal relation is a binary relation of the temporal entities valid over a certain period of time. More formally:
A temporal relation
The relation identifier
Given a temporal knowledge graph
A biographical timeline is a chronologically ordered list of temporal relations involving the timeline entity and relevant to that entity’s biography.
A biographical timeline
In this article, we assume a binary notion of relevance, i.e.
The list of timeline entries in
An entity connected to e via a timeline entry
EventKG is a knowledge graph that instantiates the temporal knowledge graph defined in Definition 1, and at the same time facilitates the integration and fusion of a variety of heterogeneous event representations and temporal relations extracted from several reference sources.
A reference source is a semantic source such as a knowledge graph (e.g. Wikidata or YAGO) or a collection of articles (e.g. the French Wikipedia) used to populate EventKG.
In the following, we present the RDF data model of EventKG in Section 4.1 and its transformation into a
EventKG RDF data model
The goals of the EventKG RDF data model are to facilitate a light-weight integration and fusion of heterogeneous event representations and temporal relations extracted from the reference sources, as well as to make this information available to real-world applications through an RDF representation. The EventKG data model is driven by the following objectives:
Define the key properties of events through a canonical representation.
Represent temporal relations between events and entities (including event-entity, entity-event and entity-entity relations).
Include information quantifying and further describing these relations.
Represent relations between events (e.g. in the context of event series).
Support an efficient light-weight integration of event representations and temporal relations originating from heterogeneous sources.
Provide provenance for the information included in EventKG.
EventKG schema and the Simple Event Model: In EventKG, we build upon the Simple Event Model (SEM) [52] as a basis to model events in RDF. SEM is a flexible data model that provides a generic event-centric framework. The main rationale of SEM is to provide a simple model that can represent events and their key properties. Events within EventKG come from heterogeneous sources where they can be described at a different level of detail. SEM provides the lowest common denominator for event-centric information, whereas it still includes the key properties of events and their relations. The properties of events in the EventKG data model are not mandatory, such that we can also include under-specified events in EventKG, e.g. in case the corresponding temporal or geospatial information is missing in the reference sources. In addition to SEM, within the EvenKG schema, we adopt additional properties and classes to adequately represent the information extracted from the reference sources, to model temporal relations and event relations as well as to provide provenance information. The schema of EventKG is presented in Fig. 2 and the used RDF namespaces are listed in Table 4.

The EventKG schema based on SEM. Arrows with an open head denote rdfs:subClassOf properties. Regular arrows visualize the rdfs:domain and rdfs:range restrictions on properties. Terms from other reused vocabularies are colored green. Classes and properties introduced in EventKG are colored orange.
Namespaces used in the EventKG RDF model
EventKG is an RDF-based dataset, such that extensions to its data model are easily possible. In future work, such extensions can be performed to model confidence and uncertainty in the information extraction, integration and fusion, or to provide more fine-granular time information (using e.g. EDTF (Extended Date-Time Format) [30]).
Events and entities: SEM provides a generic event representation including topical, geospatial and temporal dimensions of an event, as well as links to its actors (i.e. entities participating in the event). Such resources are identified within the namespace eventKG-r. Thus, the key classes of SEM and of the EventKG schema are sem:Event representing events, sem:Place representing locations and sem:Actor representing entities participating in the events. Each of these classes is a subclass of sem:Core, which is used to represent all entities in the temporal knowledge graph.3
Note that entities in EventKG are not necessarily actors in the events; temporal relations between two entities are also possible.

Example of the event representing the participation of Barack Obama in his second inauguration as a US president in 2013 as modelled in EventKG. wdt:P793 is the Wikidata identifier for the “significant event” property.
In the context of this article, the term temporal relation refers to real-world relations between events and entities valid over a period of time. The set of temporal relations in EventKG includes event-entity, entity-event and entity-entity relations. Temporal relations between events and entities typically connect an event and its actors (as in SEM). A typical example of a temporal relation between two entities is a marriage. Temporal relations between entities can also indirectly capture information about events [38]. For example, the DBpedia property
Consider the difference between a wedding that is modelled as an event and a marriage between two people that can be modelled as a temporal relation.
To overcome these limitations, EventKG introduces the class eventKG-s:Relation representing relations between events and entities. This way of relation modelling facilitates flexible additional attributes describing a relation.5
See W3C Working Group Note from 12 April 2006 on defining N-ary Relations on the Semantic Web:
Other event and entity relations: Relations between events (in particular sub-event, previous and next event relations) play an important role in the context of event series (e.g. Olympic Games), seasons containing a number of related events (e.g. in sports), or events related to a certain topic (e.g. operations in a military conflict). Sub-event relations are modelled using the so:hasSubEvent property. To interlink events within an event series such as the sequence of Olympic Games, the properties dbo:previousEvent and dbo:nextEvent are used. A location hierarchy is provided through the property so:containedInPlace.
Towards measuring relation strength and event popularity: Measuring relation strength between events and entities and event popularity enables answering question like “Who were the most important participants of the US Election 2016?” or “What are the most popular events related to the Summer Olympics 2016?”. Relation strength and event popularity are of importance for many practical applications. For example, relation strength can help when using the knowledge graph to jointly disambiguate entities and events in text documents or in natural language questions in the context of question answering applications. Relation strength and event popularity can also support ranking-based applications including timeline generation and event-centric information retrieval.
Whereas the exact computation of relation strength and event popularity metrics can be application-dependent, we include two major factors required for such computations, namely links and mentions in the EventKG schema:
1. Links: This factor represents how often the description of one entity refers to another entity. Intuitively, this factor can be used to estimate the popularity of events and the strength of their relations. In EventKG the links factor is represented through the predicate eventKG-s:links in the domain of eventKG-s:Relation. eventKG-s:links denotes how often the Wikipedia article representing the relation subject links to the entity representing the object.
2. Mentions: eventKG-s:mentions represents the number of relation mentions in external sources. Intuitively, this factor can be used to estimate the relation strength. In EventKG, event KG-s:mentions denotes the number of sentences in Wikipedia that mention both, the subject and the object of the relation.
Links and mentions factors provided by EventKG are computed using sources external to the knowledge graph, such as the entire Wikipedia corpus. Having this information included directly in the knowledge graph can help the relevant applications to obtain this information efficiently and to directly use it in their computations, including (but potentially not limited to) relation strength and event popularity metrics.
Provenance information: EventKG provides the following provenance information: (i) provenance of the individual resources; (ii) representation of the reference sources; and (iii) provenance of statements.
Provenance of the individual resources: EventKG resources typically directly correspond to the events and entities contained in the reference sources (e.g. an entity representing Barack Obama in EventKG corresponds to the DBpedia resource
Representation of the reference sources: EventKG and each of the reference sources are represented through an instance of void:Dataset.7
The VoID vocabulary
Provenance information of statements: A statement in EventKG is represented as a quadruple, containing a triple and a URI of the named graph it belongs to. Through named graphs, EventKG offers an intuitive way to retrieve information extracted from the individual reference sources using SPARQL queries.
A named graph such as eventKG-g:event_kg can be expressed as a temporal knowledge graph Entities and events: Each instance of sem:Core is a temporal entity Time information for entities and events: For each temporal entity Temporal relations with known validity times: Each instance of eventKG-s:Relation that has a start or an end time in the named graphis transformed into a temporal relation Indirect temporal relations: Information regarding the temporal validity of a relation is not always explicitly provided in EventKG. However, this information can often be derived based on the existence times of the participating entities or the happening times of the events. For example, the validity of a “mother” relation can be determined using the birth date of the child entity. We refer to such relations as indirect temporal relations. Each instance of eventKG-s:Relation that represents such an indirect temporal relation is transformed into a temporal relation
EventKG generation pipeline
The EventKG generation pipeline is shown in Fig. 4.

The EventKG generation pipeline.
Input and pre-processing: First, the dumps of the reference sources in the corresponding languages are collected. Both Wikidata and YAGO provide multilingual information in a single data dump. DBpedia and Wikipedia provide language-specific dumps, so that we collect the dumps for the languages of interest, i.e. EN, FR, DE, RU and PT. The Wikipedia Current Events Portal is currently available in English only. The mapping from the Wikidata identifiers to the Wikipedia and DBpedia identifiers required for the integration is collected as part of the Wikidata dump.
As part of the pre-processing, the following information is created for each language:8
To obtain a complete list of the manually defined terms, expressions and mappings adopted in this work, please see the readme file in the open source software release provided at:
Terms: Terms is a set of terms and regular expressions used throughout the extraction process. This includes the month names, weekday names, a black list of namespaces and prefixes of the Wikipedia articles to be ignored (e.g. the prefix “Chronological_list_of_” in English) as well as regular expressions to detect titles of the Wikipedia articles representing events.
Date expressions: To extract dates from unstructured reference sources, a set of regular expressions is created. These expressions are sorted in the decreasing order of specificity, where time intervals are considered to be more specific than the individual dates or months. For example, a specific regular expression to extract a span of two dates in English is:
Example property mapping between EventKG and its reference sources
Mapping of predicates representing event relations: We define a mapping table to identify predicates that represent equivalent event relations in EventKG and its reference sources such as so:hasSubEvent and Wikidata’s “part of” property. Examples of such mappings are shown in Table 5. In this work we define the predicate mappings manually. In future work schema mapping techniques can be adopted to determine such links automatically.
Identification and extraction of events: Event instances are identified in the reference sources and extracted as follows:
Extraction of event and entity relations: We extract the following types of relations: 1) Relations with temporal validity are identified based on the availability of temporal information. Temporal relations are extracted from YAGO and Wikidata. DBpedia does not provide such information. 2) Relations with indirect temporal information: we extract all relations involving events as well as relations of entities with known existence time. 3) Other event and entity relations: we use the manually defined mapping table shown in Table 5 to identify predicates that represent event relations in EventKG such as so:hasSubEvent (e.g. we map Wikidata’s “part of” property (P361) to so:hasSubEvent in cases where the property is used to connect events), dbo:previousEvent and dbo:nextEvent as well as so:containedInPlace to extract location hierarchies. 4) Relation strength and event popularity information: For each event-entity relation we extract language-specific interlinking information from Wikipedia. In particular we extract the number of links and the number of mentions for each relation involving events. Link and mentions are extracted from each Wikipedia language edition by parsing all of its pages.
Integration: The statements extracted from the reference sources are included in the named graphs, such that each named graph corresponds to a reference source. In addition, we create a named graph eventKG-g:event_kg containing information resulting from integration and fusion. Each sem:Event and sem:Core instance in the eventKG-g:event_kg graph integrates event-centric and entity-centric information from the reference sources related to equivalent real-world instances.
The integration of entities and events obtained from knowledge graphs and Wikipedia articles is conducted using existing owl:sameAs links, as provided by the Wikidata dataset. In particular, the entities and events covered by YAGO and different language versions of DBpedia and Wikipedia are also present in Wikidata. We use owl:sameAs links to the Wikidata identifiers to represent each resource that is linked as equivalent in multiple reference sources as one resource in EventKG. That way, information regarding this resource in different reference sources, e.g. labels in different languages, is integrated. In the current version of EventKG, we do not apply any entity resolution techniques to identify missing owl:sameAs links in these reference sources. This can be addressed in future work to further increase the degree of integration.
The events in the Wikipedia event lists and WCEP do not possess unique identifiers. Such events are integrated using a rule-based approach to identify equivalent events. Two events
Fusion: In the fusion step, we aggregate temporal, spatial and type information of eventKG-g:event_kg events using a rule-based approach.
Time fusion: For each entity, event or relation with a known existence or a validity time stamp, time fusion is conducted using the following rules: (i) ignore the dates at the beginning or end of a time unit (e.g. January, 1st), if alternative dates are available; (ii) apply majority voting among the reference sources; (iii) take the time stamp from the more trusted source (in order: Wikidata, DBpedia, Wikipedia, WCEP, YAGO).
Location fusion: For each event in eventKG-g:event_kg, we take the union of its locations from the different reference sources and exploit the so:containedInPlace relations to reduce this set to the minimum (e.g. the set {Paris, France, Lyon} is reduced to {Paris, Lyon}, while France can still be induced as a location using so:containedInPlace transitively).
Type fusion: We provide rdf:type information according to the DBpedia ontology (dbo), using types and owl:sameAs links in the reference sources.
Output: Finally, extracted instances and relations are represented in RDF according to the EventKG data model (see Section 4.1). As described above, information extracted from each reference source and the results of the fusion step are provided in separate named graphs.
In the context of our running example, we now provide an exemplary overview of the EventKG generation pipeline and illustrate how exemplar relations are expressed in the EventKG model and in the TKG. We refer to individual heterogeneous instances in the input data that are not yet expressed in the EventKG schema as data items. Table 6 provides exemplary data items involving Barack Obama obtained from Wikidata, YAGO and different language editions of Wikipedia and DBpedia.
Example data items about Barack Obama extracted from different reference sources
Example data items about Barack Obama extracted from different reference sources
Identification and extraction of events. The first data item is extracted from the English Wikipedia event list in the article “2018 in the United States”. The entities “first inauguration of Barack Obama”, “United States presidential election, 2012” and “Death of Osama bin Laden” from the data items #2, #3 and #5 are identified as events using the class hierarchies in the reference sources. In this example, Obama’s first inauguration is identified as an event, because it is an instance of “United States presidential inauguration”, which can be tracked back to inauguration > key event > occurrence in Wikidata. Thus, the text event from data item #1 and the event “first inauguration of Barack Obama” are stored as event instances with additional values such as a textual description for the former and a title for the latter event.
Extraction of event and entity relations. Given the set of events, we can now detect relations between them and other entities. For example, the statement that Barack Obama was involved in his own inauguration as US president is extracted from Wikidata. This statement represents an indirect temporal relation, as it alone does not provide the required temporal validity information, which needs to be extracted from a related fact about the event. Similarly, we can extract the information that Barack Obama was a candidate of the US elections in 2012 from the French DBpedia.
With the help of Wikipedia links, we connect Barack Obama to the death of Osama bin Laden (data item #5). Given the relation
For the relation
Another type of information is coming from the temporal relations between two temporal entities: Here, the spouse relation between Barack and Michelle Obama is directly assigned a temporal validity time by Wikidata.
Integration. The entities “Élection présidentielle américaine de 2012” and “United States presidential election, 2012,” are modeled as the same event resource in EventKG, using DBpedia’s owl:sameAs link.
Fusion. There are two different dates provided for the first inauguration of Barack Obama (data item #2). While both dates are stored in EventKG together with their provenance information (i.e. as named graphs for Wikidata and YAGO), a single happening time for that event is created with our rule-based fusion approach (see Section 4.3). As the majority voting is not sufficient here, we take the date from the higher trusted source. In this case, Wikidata’s date (20 January 2009) is selected for EventKG’s named graph.
With that time information, the indirect temporal relation about Obama’s participation in his own inauguration can be transformed into the following temporal relation in the
To demonstrate the quality of the data extraction, integration and fusion steps, we first show characteristics of EventKG and provide several comparisons to its reference sources in Section 5.1. Then, we provide evaluation results based on user annotations in Section 5.2.
Number of events and relations in eventKG-g:event_kg
Number of events and relations in eventKG-g:event_kg
Number of events identified in extracted from the reference sources
Comparison of the event representation completeness in the source-specific named graphs (after integration)
In EventKG V1.1, we extracted event representations and relations in five languages – English (EN), German (DE), French (FR), Russian (RU) and Portuguese (PT) – from the latest available versions of each reference source as of 12/2017. EventKG uses open standards and is publicly available under a persistent URI9
Table 7 summarises selected statistics from the EventKG V1.1, released in 03/2018. Overall, this version provides information for over 690 thousand events and over 2.3 million temporal relations. Nearly half of the events (
We compare EventKG to its reference sources in terms of the number of identified events and completeness of their representations. The results of the event identification and extraction step in Section 4.3 are shown in Table 8. EventKG with
The most frequent event types extracted from the references sources and the percentage of the events in that source with the respective type
The most frequent event types extracted from the references sources and the percentage of the events in that source with the respective type
User-evaluated precision for the identification of events with selected reference sources
Table 9 presents a comparison of the event representations in EventKG and its reference knowledge graphs (Wikidata, YAGO, DBpedia). As we can observe, through the integration of event-centric information, EventKG: 1) enables better event identification (e.g. we can map
Over 2.3 million temporal relations are an essential part of EventKG. The majority of the frequent predicates in EventKG such as “member of sports team” (882,398 relations), “heritage designation” (221,472), “award received” (128,125) and “position held” (105,333) originate from Wikidata. The biggest fraction of YAGO’s temporal relations have the predicate “plays for” (492,263), referring to football players. Other YAGO predicates such as “has won prize” are less frequent. Overall, about
Textual descriptions
EventKG V1.1 contains information in five languages. Overall,
Evaluation of EventKG
The aim of the evaluation is to assess the effectiveness of the event identification, time fusion and location fusion steps of the pipeline.
Event identification
We manually evaluated a random sample of the events identified in the event identification step of EventKG (Section 4.3). For each reference source, we randomly sampled 100 events and manually annotated whether they represent real-world events or not. The results are shown in Table 11.
For DBpedia and Wikidata, where we rely on the event types and type hierarchies, we achieve a precision of 98% on average. On a random sample of 100 events extracted from the category names in the English and the Russian Wikipedia, we achieve 94% and 88% precision, correspondingly. One example for an entity wrongly identified as an event is the canceled project “San Francisco Municipal Wireless”, which was part of the “Cancelled projects and events” category in Wikipedia.
Time fusion
To evaluate the quality of the proposed rule-based time fusion approach, we randomly sampled 100 events from EventKG, where each event has at least two reference sources that differ in the event happening time (i.e. start and/or end time). Three users have annotated this sample by providing a start and end time for at least 20 events each. Additionally, we asked the users to denote which source they used to research the actual event dates. For our evaluation, we then checked how many of the user-given start and end dates are available in the reference sources and the joint EventKG named graph, and we computed how many of these dates are correct with respect to the user annotations.
Evaluation of EventKG’s time information. For EventKG and the reference sources, the percentage of correct, wrong and missing event dates with respect to the user annotations in our sample is shown. These are based on the random sample of events where the reference sources show disagreement between time information provided
Evaluation of EventKG’s time information. For EventKG and the reference sources, the percentage of correct, wrong and missing event dates with respect to the user annotations in our sample is shown. These are based on the random sample of events where the reference sources show disagreement between time information provided
Table 12 provides the result overview: As the time fusion does always adopt accessible time information from any reference source, all events in our random sample possess time information. Wikidata and YAGO provide the next highest coverage of time information. In terms of precision, EventKG outperforms these two reference sources by
Table 13 provides an overview of the sources most often used for finding the event dates by the users participating in the evaluation. In
Time fusion evaluation: the most frequent sources used by the users to lookup event start and end dates
Evaluation of EventKG’s location information. For each event in the sample, users judged for each location in EventKG and the reference sources whether it is correct
To evaluate the correctness of the extracted locations, we selected a random sample of 100 events with at least one location. In case of locations, multiple correct values are possible, for example South America, the United States of Colombia and the Colombia-Ecuador border are valid locations for the Ecuadorian-Colombian War. We presented all locations from each reference source to the users and for each location asked the users to verify whether that location is correct or not. Four users have annotated that sample.
Table 14 provides the result for our evaluation of the location fusion. We distinguish between the locations directly provided by EventKG and those which could be inferred using sub-location information via so:containedInPlace. We refer to this extended knowledge graph as EventKG* throughout this evaluation. EventKG and EventKG* have by far the highest coverage of locations (EventKG* finds
Table 15 lists the sources used by the users in this task. Similarly to the evaluation of the time fusion, Wikipedia and Google were the most frequently used sources, followed by domain-dependent ones such as kicker.de for locating football matches. However, in
Location fusion evaluation: the most frequent sources used by the users to lookup event locations
Location fusion evaluation: the most frequent sources used by the users to lookup event locations
The characteristics, statistics and evaluation results presented in this article refer to EventKG V1.1 released in March 2018.
In February 2019, we released EventKG V2.0 that includes a number of updates with respect to the: i) inclusion of the current content of the reference sources and extended language coverage, ii) enhanced relation fusion, iii) inclusion of geographic information, and iv) inclusion of information regarding temporal granularity. In the following we describe these extensions in more detail.
EventKG V2.0, its updated schema information and statistics are accessible online.15

Creating a timeline for a timeline entity e, after training a model from a biographical source to predict the relevance of temporal relations in the TKG for biographical timelines.
In this section, we show how EventKG can be applied as a temporal knowledge graph for the task of biographical timelines generation.
First, we present our approach based on distant supervision in Section 6.1. The features used in the relevance model are introduced in Section 6.2. Subsequently, we describe the benchmarks involved in our process to generate biographical timelines in Section 6.3 and discuss how the model is used to generate them in Section 6.4. Finally, we illustrate these steps on our running example of Barack Obama’s timeline in Section 6.5.
Approach
Given a timeline entity e for which we need to generate a biographical timeline, the number of candidate timeline entries (i.e. temporal relations involving e) is potentially very high, especially for popular entities and a large-scale temporal knowledge graph. In fact, for our set of popular persons described later in Section 7.1, EventKG contains 272.75 temporal relations per person entity on average. In order to determine the relevance of a temporal relation to the timeline entity we propose a classification approach using distant supervision. The key idea of our approach is to learn a relevance model for temporal relations using occurrences of these relations extracted from biographical sources. Examples of such biographical sources include collections of biographical or encyclopedic articles. We adopt a distant supervision approach, where we assume that a particular temporal relation r is relevant for the entity’s biography if this relation occurs in a known biographical source. An overview of the training phase and the timeline generation is depicted in Fig. 5, which illustrates the role of the TKG, the biographical and reference sources and the benchmark. Initially, we use the temporal knowledge graph and a biographical source to create a benchmark that provides relevance judgements for candidate timeline entries. We train the prediction model with features extracted for each candidate timeline entry. This includes entity type and interlinking information included in the named graphs corresponding to the reference sources of EventKG. To generate a timeline for a timeline entity e, we collect its candidate timeline entries
Relevance model
In our approach we train a classification model that identifies the relevance of a candidate timeline entry towards a biography of the timeline entity e. The candidate timeline entry is a temporal relation involving e and obtained from a knowledge graph. To train such classification models, we adopt a range of features in several categories reflecting the characteristics of the timeline entity, the entity connected to it via a temporal relation, the temporal relation and time information. In total, we consider 4 language-independent numerical features, 6 language-dependent features, as well as a number of binary features representing frequent entity types and properties in EventKG.
We illustrate the features described in the following at the example of the candidate timeline entry representing Barack Obama’s participation in his second inauguration (see Fig. 3) in Table 16.
Selected feature values for the candidate timeline entry “Barack Obama, significant event, second inauguration of Barack Obama” for the timeline entity “Barack Obama”
Selected feature values for the candidate timeline entry “Barack Obama, significant event, second inauguration of Barack Obama” for the timeline entity “Barack Obama”
Timeline entity features
The timeline entity features (TEF) reflect specific characteristics of the timeline entity e. These features address the intuition that the relevance of the particular temporal relation r for a given timeline entity e depends on the specific characteristics of e. For example, winning an award may be more important for athletes or actors than for politicians. Based on this intuition, we introduce the timeline entity features:
Timeline entity characteristics: A set of binary features denoting if the entity is an instance of the specific type (e.g. a politician or an actor).
Connected entity features
The connected entity features (CEF) take into account characteristics of the connected entity Connected entity mentions: The set of features, each reflecting the absolute number of mentions of the connected entity Connected entity mentions rank: For each reference collection, we rank the entities connected to the timeline entity e by the number of their mentions. This feature represents the rank of the specific connected entity, where the rank of 1 is assigned to the entity with the highest number of mentions. Connected entity mentions relative rank: We normalise the CEF-MR rank by the maximal rank. Connected entity represents a real-world event: A binary feature denoting whether the connected entity is an event (i.e.
Features of temporal relations
The features of temporal relations (TRF) reflect semantics of the temporal relation between the timeline entity and the connected entity. Furthermore, we consider features related to the importance and popularity of entity relations.
Property identifier: Temporal relations possess property identifiers Relation mentions: The number of co-mentions of both entities involved in the temporal relation in a reference collection (independent of relation semantics). Relation mentions rank: We rank the connected entities according to the number of their co-mentions with the timeline entity in a reference collection. This feature represents the rank of the specific connected entity involved in the relation. Relation mentions relative rank: We normalise the TRF-MR rank by its maximal rank.
Temporal features
The temporal features (TF) reflect the relevance of the temporal relations based on the time information. This includes the temporal differences in the existence time of the entities or happening times of the events involved in the relation. For example, Barack Obama gave a speech related to World War II – a historical event finished before Obama’s birth date in 1961. Here, the temporal difference in the existence times of both entities can be an indication of the low relevance of this speech for Obama’s biography. Therefore, we attempt to learn to discard the temporal relations involving events that happened too early for the entity timeline. This had been also observed by Althoff et al. [4] who implemented a rule to discard such relations. In addition to that, our temporal features could help to learn whether some events may be more relevant at specific stages of the entity’s life or existence. Furthermore, temporal features include the provenance of the temporal information by denoting whether a relation was induced from an indirect temporal relation or not.
To capture this intuition, we introduce the following temporal features:
Temporal distance (start): The temporal distance between the beginning of the existence time of the timeline entity and the start of the relation validity time Temporal distance (end): The same feature as TF-TDS, but using the entity existence end time Time provenance: This categorical feature specifies the provenance of the relation validity time. If the relation has initially been a temporal relation, the feature value is set to 3. If the temporal validity was induced from an event happening time (
To facilitate supervised model training, we require a benchmark that provides relevance judgements for temporal relations. These judgements can be obtained from the specific biographical source.
A benchmark B is a mapping of the form:
Given the large number of entities and temporal relations in the existing knowledge graphs, manual relevance judgements appear unfeasible. Therefore, we adopt an automatic approach to benchmark generation. We extract entities and temporal relations contained in the biographical sources and map them to the temporal relations in
Although the resulting benchmarks can potentially contain noisy relevance judgements due to the automatic extraction and mapping methods applied, our experimental results demonstrate that these benchmarks, used as a training set in a distant supervision method, facilitate generation of high quality timelines.
The benchmarks created in this work are publicly available online.16
We address the relevance estimation for a timeline relation r with respect to the timeline entity e as a classification problem. For each biographical source
Note that a classification model is chosen over a ranking-based approach because of two reasons: First, the timeline entries are ordered chronologically and not by their importance. Therefore, for the purpose of timeline generation we can assume that each timeline entry is equally relevant. Second, if a ranked list of timeline entries would be provided, a cut-off threshold value would still be required to decide which of the entries are to be shown.
To facilitate efficient training we limit the number of instances of the TEF-C and TRF-PI features considered. In particular, the
Our benchmark is equally divided into a training and a test set of person entities, so that the relevance judgements are obtained from the training set. We adopt a binary notion of relevance. The datasets used as biographical sources to build the classification models are presented in Section 7.1.
We use the resulting classification model to build a timeline
Running example: Barack Obama
As discussed in Section 4.4, EventKG contains many relations involving Barack Obama. In order to create a timeline of his life, we collect all relations with Obama as a subject or an object, together with their temporal validity. One example is the temporal relation about Obama’s first inauguration shown at the end of Section 4.4.
Due to the more than
Figure 1 provides a visual representation of Obama’s timeline obtained using a model trained on a Wikipedia abstracts dataset (BS-ENC) described later in Section 7.
Example data extracted from the biographical sources for Barack Obama
Example data extracted from the biographical sources for Barack Obama
In this section we first describe the biographical sources and the set of timeline entities used to create our biographical timeline benchmark used to train the classification models (Section 7.1) and to run our experiments described in Section 7.2. Then, we evaluate our approach against a baseline (Sections 7.3 and 7.4).
Benchmark: Entities and biographical sources
We collect a dataset
To train the relevance models for the biographical timeline generation, we consider the following biographical sources:
BS-BIO: Biographical articles; BS-ENC: Encyclopedic articles.
Biographical articles (BS-BIO)
Biographies of important entities (e.g. famous people) are available in form of textual descriptions from dedicated Web sources. We collect data from two publicly accessible biographical web sources (Thefamouspeople.com17
and Biography.com18). After collecting the biographical texts from both websites, they are preprocessed as follows: 1) The texts are split into sentences using the Stanford Tokenizer [32]. 2) Time expressions are collected from each sentence using HeidelTime [44]. 3) Entity mentions are identified using DBpedia Spotlight [34]. Table 17 illustrates example annotations in the BS-BIO and BS-ENC datasets extracted for the entity Barack Obama, including his birth, education and political activities. In order to map the extracted information to the temporal relations in theEncyclopedic articles (BS-ENC)
Wikipedia is a rich source of encyclopedic information. Wikipedia articles usually provide an abstract – a brief overview of the specific entity (e.g. person’s life) that typically contains important biographical sentences [9,27]. From these abstracts, we extract all the event mentions, i.e. links to the event articles, as these represent significant events in the entity’s life. For example, Table 17 shows selected events for the entity Barack Obama based on BS-ENC. In contrast to the annotations in
Statistics of the entity-related information for the entities contained in the dataset
Statistics of the dataset
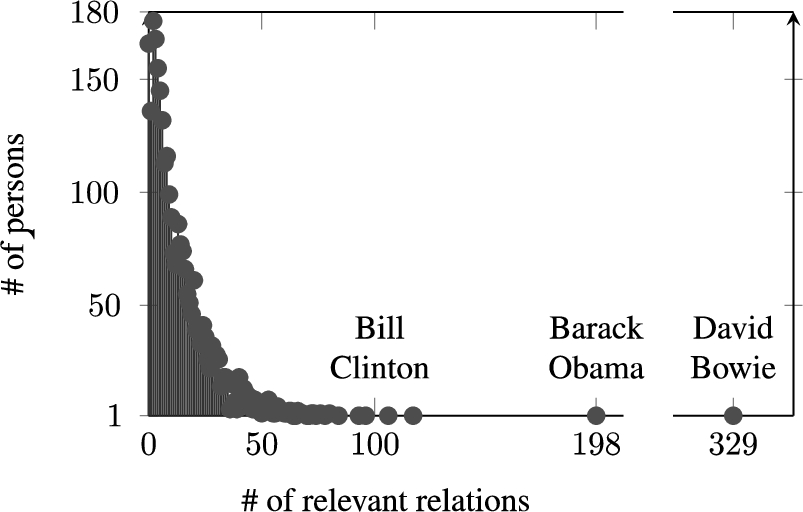
The number of person entities with the given number of relevant relations in the BS-BIO benchmark. The top-3 entities with the highest number of relevant relations are marked.
We generate a benchmark
Benchmark statistics: the number of entities and relevant temporal relations (temp. rel)
Table 20 provides the percentage of person types in the benchmarks. Actors and musical artists are the most frequent person types in both the training and test set.
Percentage of top-5 entity types in the training and test set
As our binary classifier we adopted a Support Vector Machine (SVM) due to its good generalisation ability, in particular when applied to smaller datasets. We trained this classifier on the training dataset containing
As described in Section 6.4, the timelines are generated by ordering the timeline entries classified as relevant chronologically by their start time. On average, each biographical timeline of the person entities in the test set contains 8.54 entries after training the classifier on

The number of timelines with the specific number of entries generated for the BS-BIO test set.
RPRef scores from user ratings for different timeline configurations and entity types. As users could also give a neutral rating or skip a rating, the RPRef scores do not necessarily sum up to 100%
We compare our proposed approach with the state-of-the-art Time Machine (TM) approach for timeline generation proposed by Althoff et al. [4]. The TM approach creates events from the entity-entity relations in a knowledge graph, where one entity possesses a property with a time value. Resulting events are filtered using frequency and existence time heuristics; then a greedy algorithm selects the events that maximise a relevance score. To facilitate a fair comparison, we perform the following adjustments to implement the TM baseline:
The TM approach in [4] was initially proposed for entity-centric knowledge graphs such as Freebase. Therefore, events in the TM terminology mean link structures in an entity-centric knowledge graph that vary with respect to their complexity. In EventKG, the events are connected to the entities directly via temporal relations. To facilitate the comparison, we adopt the TM baseline such that so-called “simple events” in the TM-terminology are generated. Such “simple events” in TM directly correspond to the temporal relations in EventKG. In the original TM approach, the maximal number of temporal relations on the timeline is restricted due to the visualisation constraints; i.e. these relations are ranked by their relevance and retrieved until the visualisation constraint is met. Our goal is to provide all relevant relations, such that we do not enforce any visualisation-based constraints on the number of relations. To facilitate comparison, we retrieve an equal number of relations from the baseline and our approach. TM was initially evaluated on the Freebase dataset, and the relevance scores were computed using a search engine query log and a textual corpus. We apply all methods on the EventKG data; we use the same reference sources (i.e. Wikipedia articles) to estimate the parameters related to the global importance of entities, their occurrences and temporal relations for all baselines and approaches evaluated in this article.
Evaluation of the timeline generation
The goals of the evaluation of the timeline generation are to assess the effectiveness of the proposed method for timeline generation and the role of the reference and biographical sources.
In particular, we assess:
Quality of the generated timelines in comparison to the baseline (in a user evaluation). Impact of the individual features on the timeline generation (using correlation measures). Relevance of the timeline entries with respect to the biographical source (by measuring performance of the classification model). Coverage of the timeline entries with respect to the reference sources (by measuring the mean coverage of the temporal relations in the reference sources).
Timeline quality evaluation
In order to evaluate the timeline quality we performed a user evaluation. We generated timelines for 60 popular entities of the types actors, athletes, musical artists, politicians and writers for both biographical sources BS-BIO and BS-ENC. These entities were selected from the persons in the test set described in Section 7.1 based on their popularity (measured as the link count of the corresponding Wikipedia article).
In each task, the user was presented with: (i) a task description, (ii) a timeline entity including its label and a Wikipedia link, and (iii) a pair of timelines. One timeline in the pair was generated by the specific configuration of our approach, the other timeline was generated by the TM baseline described in Section 7.3. Both timelines were visualised as illustrated in Fig. 1. Each timeline contained all entries generated by the corresponding generation method. The user could scroll and zoom within each individual timeline. In the user interface, both timelines were presented simultaneously, one above the other, in a random order. We asked the users to vote for their preferred timeline in the pair. We provided four options: two options to vote for one of the timelines, a neutral option indicating no preference for a specific timeline, and a “don’t know” option. We encouraged the users to research the timeline entity (e.g. using Wikipedia) before evaluating the timeline pair, if necessary.
Each pair of timelines was rated by three or four users each. Then, majority voting was applied. In total 11 users (graduate Computer Science students) participated in the user evaluation. A user evaluated 42 timeline pairs on average. On average, the users took 69 seconds to decide between two timelines.
We compute the rater preference
For BS-BIO, the mean number of ratings favouring our timeline is 1.50 (BS-ENC: 1.58) with a standard deviation of 0.72 (BS-ENC: 0.97), for the TM baseline the mean is 0.40 (BS-ENC: 0.59) with a standard deviation of 0.67 (BS-ENC: 0.74). The results of the paired t-test confirm statistical significance of this result for the confidence level of 99%.
Feature impact
In total, 411 features are utilised by the model during the timeline generation. In order to better understand the impact of the individual features on the classification task, we compute the correlation between the features and the benchmark judgements using the Pearson Correlation Coefficient (
PCC correlation coefficient between top-5 features and the benchmark judgments, sorted by the absolute PCC values
PCC correlation coefficient between top-5 features and the benchmark judgments, sorted by the absolute PCC values
Weighted precision and recall scores for both classes (relevant and irrelevant) for predicting the benchmark labels of the temporal relations using a 10-fold cross validation. Additionally, the F-measure as harmonic mean of precision and recall is reported. †All language-dependent features except for EN are omitted
For both biographical sources, the highest PCC is achieved for the property “born” (
We evaluated the performance of the classification models for predicting the relevance of the individual temporal relations with respect to the benchmarks presented in Section 7.1. The results of this automated evaluation using a 10-fold cross validation are presented in Table 23. In general, our models learned from the training set are generalisable to the test set, reaching F-measure values of 0.827 in the case of BS-ENC and 0.738 for BS-BIO. Across the biographical sources, the usage of all features combined leads to the best precision and recall scores. The removal of features leads to a decrease in performance: leaving out property labels or the features based on mentions leads to the biggest performance decrease.
Coverage of the reference sources
To demonstrate the gain of integrating data from multiple reference sources into EventKG, we assess the coverage of temporal relations in the biographical sources. That means, for each person in our benchmark, we compute the percentage of benchmark relations that are found in the temporal relations of a reference source. Table 24 shows the results, measured by mean coverage per person entity. For example,
Mean coverage of the temporal relations in the benchmarks per reference source and biographical source
Mean coverage of the temporal relations in the benchmarks per reference source and biographical source
The results show that there is a higher coverage for BS-ENC than for BS-BIO across all reference sources. This can be explained by the fact that the texts from BS-BIO are longer and less event links are provided: not only does the BS-BIO benchmark rely on named entity recognition, as this source does not contain any links, but events are also harder to recognise as they can be described in several ways (e.g. “first inauguration of Barack Obama” and “Barack Obama was sworn in as the president on January 20, 2009”). In general, YAGO and Wikidata clearly outperform Wikipedia and DBpedia (as DBpedia does not contain statements with validity times). Through the integration and fusion in EventKG, the coverage increases to more than
In this section, we discuss related work in the areas of event knowledge graphs and the task of biographical timeline generation.
Event knowledge graphs
To the best of our knowledge, currently there are no dedicated knowledge graphs aggregating event-centric information and temporal relations for historical and contemporary events directly comparable to EventKG. The heterogeneity of data models and vocabularies for event-centric and temporal information (e.g. [20,36,38,42,52,55]), the large scale of the existing knowledge graphs, in which events play only an insignificant role, and the lack of clear identification of event-centric information, makes it particularly challenging to identify, extract, fuse and efficiently analyse event-centric and temporal information and make it accessible to real-world applications in an intuitive and unified way. Through the light-weight integration and fusion of event-centric and temporal information from different sources, EventKG enables to increase coverage and completeness of this information. Furthermore, existing sources lack structured information to judge event popularity and relation strength as provided by EventKG – the characteristic that gains the key relevance given the rapidly increasing amount of event-centric and temporal data on the Web and the resulting information overload.
Data models and vocabularies for events: Several data models and the corresponding vocabularies (e.g. [20,38,40,42,52]) provide means to model events. For example, the ECKG model proposed by Rospocher et al. [38] enables fine-grained textual annotations to model events extracted from news collections. CAMEO [40] is a framework to model events extracted from news, in particular in the political domain. The Simple Event Model (SEM) [52], schema.org [20] and the Linking Open Descriptions of Events (LODE) ontology [42] provide means to describe events and interlink them with actors, times and places. In EventKG, we build upon SEM and extend this model to represent a wider range of temporal relations and to provide additional information regarding events.
Extracting event-centric and temporal information: Most approaches for automatic knowledge graph construction and integration focus on entities and related facts rather than events. Examples include DBpedia [29], Freebase [5], YAGO [31] and YAGO+F [10]. In contrast, EventKG is focused on events and temporal relations. In [50], the authors extract event information from WCEP. EventKG builds upon this work to include WCEP events. For the extraction of temporal information, there are several approaches to annotate both textual data [25] and relations [39,47] with temporal scopes inferred from external sources. In EventKG, we rely on the temporal information already contained in the reference sources, which gives highly precise values as shown in Section 5.2. Increasing the coverage for temporal annotations in case of missing values by using external resources is a potential extension for future work.
The question of how to model temporal data is an important question as it comes to considering time expressions of different levels of granularity or with uncertainty. Examples to tackle such issues include the use of multiple potential start and end times as in the temporal slot filling task [45] or adding uncertainty scores to temporal relations [8]. The representation of this information is facilitated through existing relational models [7], the Extended Date-Time Format (EDTF) [30] or with the Time Ontology in OWL [22]. The Simple Event Model adopted in this work supports a simple notion of temporal time spans, which is sufficient to represent temporal information provided by the reference sources of EventKG and is compatible with the time representation in these sources. Nevertheless, we see more advanced time models as a potential future extension, in particular in the context of a possible enrichment of EventKG with additional, and in particular automatically inferred, temporal information.
Extraction of events and facts from news: Recently, the problem of building knowledge graphs and datasets directly from plain text news articles [1,6,28,38], and extraction of named events from news [26,55] have been addressed. These approaches apply Open Information Extraction methods and develop them further to address specific challenges in the event extraction in the news domain. State-of-the-art approaches that automatically extract events from news potentially obtain noisy and unreliable results (e.g. the state-of-the-art extraction approach in [38] reports an accuracy of only 0.551). Furthermore, such systems provide billions of events at a very high granularity level, as typically represented in news articles. Compared to the established knowledge repositories such as DBpedia or Wikidata, such events indicate significant differences in the representation accuracy and event granularity. In contrast, contemporary events included in EventKG originate from high quality community curated sources such as WCEP and Wikipedia event lists and represent significant societal happenings at a different granularity and abstraction level, compared to news sources.
Biographical timeline generation
Existing work on timeline generation from knowledge graphs has mainly focused on the selection of relevant events or relations. The works of Althoff et al. [4] and Tuan et al. [51] come closest to our task definition. In [4], the authors create timelines for politicians, actors and athletes from the Freebase knowledge graph, adding visual and diversity constraints on the generated timelines. In [51], person timelines are generated by ranking relations extracted from Wikipedia and YAGO knowledge graphs. Similarly, in [48] entity summarisation is created based on link counts, but without taking temporal data into account. In difference to our work, in both these approaches the feature weights are handcrafted and no machine learning is involved. [9] and [27] aim at generating biographies in a natural language, that means to generate textual summaries for people, by mapping facts from knowledge graphs to one-sentence biographies. Both works incorporate neural models to learn text, but the biographies are limited to few facts such as birth dates and entity types.
Other approaches generate timelines for different use cases, for example to get an overview over news articles over a large time span [46,49] or for depicting singular events such as football matches in a very fine-grained manner [3]. For visualisation, there are approaches to transform relationship paths from knowledge graphs into sentences [4,53] and different interaction models that let a user explore the timeline [4,46,56]. In this article, we focus on the generation of timelines containing relevant temporal relations and do not limit the approach by any visual constraints. This way, the models obtained by our methods can be used in a broader range of interfaces and application scenarios.
One important subtask of the timeline generation is to judge whether a temporal relation is relevant in a certain context. This task has been addressed by other works using classification and ranking approaches. For example, to rank news articles related to a query entity, Singh et al. [43] employ a diversified ranking model based both on the aspect and temporal dimension. Approaches such as the one proposed by Setty et al. [41] impose methods to rank the importance of events, but without taking into account the specific timeline entity. In comparison to these approaches, the task addressed in our work is more specific, as it considers the relevance of individual temporal relations to a timeline entity.
Further methods to access semantic information included in knowledge graphs in an intuitive way include question answering and spatio-temporal search applications (e.g. [23,24,35,57]) and interactive query construction interfaces proposed in our previous work (e.g. [11,12]). Application of these approaches to EventKG is an interesting direction for future research.
Conclusions
In this article we presented the concept of a temporal knowledge graph that interconnects real-world entities and events using temporal relations. Furthermore, we presented an instantiation of the temporal knowledge graph – EventKG. EventKG is a multilingual knowledge graph that integrates and harmonises event-centric and temporal information regarding historical and contemporary events. EventKG V1.1 includes over 690 thousand event resources and over 2.3 million temporal relations. Unique EventKG features include the light-weight integration and fusion of structured and semi-structured multilingual event representations and temporal relations in a single knowledge graph, as well as the provision of information to facilitate assessment of relation strength and event popularity, while providing provenance. The light-weight integration enables to significantly increase the coverage and completeness of the included event representations, in particular with respect to time and location information.
We analysed the characteristics of the resulting knowledge graph and observed a significant increase in coverage compared to the reference sources. For example, EventKG V1.1 contains 50K more events than identified in Wikidata and more than 262K events than identified in the English DBpedia. Additionally, 360K events are extracted from semi-structured sources. The quality of this resulting dataset was confirmed in a manual evaluation. This evaluation indicated high precision for the event identification step (with an average precision of
Furthermore, in this article we addressed the problem of biographical timeline generation from a temporal knowledge graph. In order to generate biographical timelines from a large-scale temporal knowledge graph, we proposed a method based on distant supervision. This method uses features extracted from the temporal knowledge graph as well as a benchmark extracted from external biographical sources to train an effective relevance model. Our results of a user study and an automatic evaluation demonstrate the effectiveness of the proposed method. Our method significantly outperforms the baseline in the biography generation. According to the rater preference score, our method achieves
We make the datasets described in this article publicly available to stimulate further research in this area.
The characteristics, statistics and evaluation results presented in this article refer to EventKG V1.1 released in March 2018. In February 2019, we released EventKG V2.0, briefly described in Section 5.3. In comparison to EventKG V1.1, EventKG V2.0 includes an increased number of events, further enhances relation fusion, provides geographical information and integrates reference sources in Italian language.
In the future work, we plan to further extend EventKG to include additional sources. We would also like to explore the development of further methods and applications using EventKG.
Footnotes
Acknowledgements
This work was partially funded by the EU Horizon 2020 under ERC grant “ALEXANDRIA” (339233) and MSCA-ITN-2018 “Cleopatra” (812997), the Federal Ministry of Education and Research (BMBF) under “Data4UrbanMobility” (02K15A040) and “Simple-ML” (01IS18054).
Example queries
Here, we present example SPARQL queries to illustrate the retrieval of particular event and entity characteristics.