
Abstract
Understanding complex societal events reported on the Web, such as military conflicts and political elections, is crucial in digital humanities, computational social science, and news analyses. While event extraction is a well-studied problem in natural language processing (NLP), there remains a gap in semantic event extraction methods that leverage event ontologies for capturing multifaceted events in knowledge graphs. In this article, we aim to compare two paradigms to address this task of semantic event extraction: the fine-tuning of traditional transformer-based models versus the use of large language models (LLMs). We exemplify these paradigms with two newly developed approaches: T-SEE for transformer-based and
Introduction
Event extraction (EE) aims to identify and classify events and their relations in text, including Web sources such as social media, news websites, and online encyclopedias like Wikipedia. Typically, this extraction process is conducted without relying on pre-existing knowledge structures or further structuring of extracted data. In contrast, the goal of semantic EE is to leverage an existing event ontology to lift unstructured text into a structured representation capturing the essence of the event, including its type (e.g. presidential election ) and relations to entities (e.g. < US presidential election 2020 , successful candidate , Joe Biden >). Specifically, semantic EE aims at enriching knowledge graphs to make event information more accessible, that is, by adding events that are not yet contained in the knowledge graph because (i) the input texts are about recent events or (ii) the events of that type are considered out of domain (e.g. if the knowledge graph only contains more coarse-grained event types). Practical applications of event knowledge graphs include event-centric visualisations (Gottschalk & Demidova, 2020; Latif et al., 2021), biography generations (Gottschalk & Demidova, 2019a), event narrativisation (Porzel et al., 2022) and question answering over event-related information (Souza Costa et al., 2020).
Semantic extraction operates at a critical juncture of the Semantic Web and natural language processing (NLP) technologies:
The Semantic Web offers rich event ontologies such as LODE (Linking Open Descriptions of Events, Shaw et al., 2009) and the simple event model (Van Hage et al., 2011) to represent events. However, cross-domain knowledge graphs such as DBpedia (Auer et al., 2007) and Wikidata (Erxleben et al., 2014) typically focus on named events, such as political summits and natural disasters and lack adaptability to diverse expressions in text-based event descriptions. In addition, relation extraction and link prediction for knowledge graph population typically suffer from noisy data (Ji et al., 2022; Li et al., 2019a; Shirai et al., 2023) and require the presence of the related entities in the knowledge graph (Stoica et al., 2020) and are thus not applicable for extracting relations of newly identified events. NLP employs named entity recognition and EE techniques to identify finer-grained, transient events like individual meetings or transactions (Xiang & Wang, 2019) from text. However, traditional NLP methods often deconstruct the task of semantic EE into smaller sub-tasks such as event detection (Mehta et al., 2019; Zheng et al., 2021), and argument extraction (Li et al., 2021; Ma et al., 2022; Wang et al., 2019) with each garnering their specific benchmark datasets (Ebner et al., 2020; Wang et al., 2020) typically not bound to semantic event ontologies.
This divergence results in a critical gap, creating a need for semantic EE, blending structured, ontology-based classification with the adaptability to handle a wide range of event types – from transient interactions to significant historical occurrences.
Although some efforts have been made towards semantic EE (Guo et al., 2023a; Rospocher et al., 2016), Guan et al. denote that the construction of event knowledge graphs still suffers from the unsatisfactory performance of existing EE methods, especially for argument extraction (Guan et al., 2022). Most methods still fall short in delivering an integrative approach that works across various domains and effectively accommodates sufficiently rich and diverse ontologies (Hamborg et al., 2019; Wang et al., 2021b; Zhou et al., 2021) centring instead around aged NLP benchmark datasets such as ACE05 (Linguistic Data Consortium, 2005) or conversely on highly specific domains (Davani et al., 2019; Xu et al., 2021).

Example of semantic event extraction for an event mentioned in the Wikipedia article ‘2017 UEFA European Under-21 Championship Final’ using classes and properties in Wikidata. The figure shows a text (top-left), a set of queries consisting of an event class and a property (bottom-left), and the extracted event triples (right).
In this article, we introduce two approaches for semantic EE, which follow the same structure but two different paradigms: transformer-based architectures and large language models (LLMs). 2
Event classification: Approached as a multilabel classification problem, Relation extraction: Utilising a span prediction transformer model, we target class-specific relations to construct a nuanced representation of events. In our example, we extract relations such as (
In this way, we aim to contribute to the ongoing discourse on the potential and limitations of leveraging LLMs for information extraction (IE) and knowledge engineering, particularly in cases where LLMs may uncover information beyond the predefined ground truth or existing knowledge graphs.
We outline the underexplored area of semantic EE, situated at the Semantic Web and NLP intersection. We present We provide two new semantic EE datasets created from Wikipedia, Wikidata, and DBpedia: Wikidata-SEE and DBpedia-SEE. We demonstrate the efficacy of We perform an extensive manual annotation of the predictions of
We formally define the problem of semantic EE to bridge the gap between granular, structured information and the adaptability required to capture a wide variety of events.
In the context of this work, an event is an occurrence of societal importance, typically happening at a specific time and location, involving a set of participants. Examples of events include military conflicts, such as the Second World War, political shakeups, such as Brexit, but also more fine-grained events, such as the battles and air raids in the Second World War or specific football games.
We model information regarding entities (representing real-world events and real-world objects such as persons or locations) and their relations in an event knowledge graph. The classes and properties within the knowledge graph are defined by an event ontology:
Event Ontology
An event ontology
Classes and properties in an event ontology are uniquely identified by an Internationalized Resource Identifier (IRI).
5
Specifically, the property
Other example properties describe the location and number of participants of events. Examples of event classes include final as a sub-class of sporting event .
Based on an event ontology, we formally define an event knowledge graph as follows:
Event Knowledge Graph
An event knowledge graph
In a relation
We define the task of semantic EE as follows:
Semantic EE
Given an event ontology
Identifying its event class relation Extracting a set of relations from
These relations, and the classes they involve, must adhere to the properties and classes of O.
Figure 1 illustrates an example text (
Assumptions
To perform semantic EE given the defined problem statement, we propose methodologies that employ transformers and LLMs based on the following assumptions:
Tasks and Models
Task representation: Following Definition 3, we frame semantic EE as a two-step task: event classification followed by relation extraction. This decomposition is assumed to be effective and meaningful for capturing events and their relations. Further, we directly intertwine the tasks of event detection and event classification: event classification detects and classifies events at the same time, that is, there are no events without event class. Task dependency: Relation extraction depends on the results of event classification. This dependency is intentional, as event classes determine which relations to extract. Consequently, we assume errors to propagate across the entire pipeline, so any misclassifications naturally affects relation extraction results. This error propagation needs to be reflected during evaluation. Model selection: We assume that both transformer-based models and LLMs are suitable for semantic EE.
Transformers: Fine-tuned transformer models (e.g. Bidirectional Encoder Representations from Transformers, BERT) are assumed to generalise effectively for event classification and relation extraction when trained on high-quality, ontology-aligned datasets. LLMs: LLMs are assumed to generate structured outputs reliably when prompted with event ontologies. However, we acknowledge LLMs’ sensitivity to prompt design and their tendency to hallucinate relations not present in training data, requiring careful validation.
Event ontology scope: The selected event ontology must comprehensively define event classes and properties for the target domain. We assume the event ontology is extracted from a knowledge graph (e.g. Wikidata) and filtered to exclude overly specific or metadata-like entries. As described in our evaluation setup in Section 5.1.1, we use two event ontologies for training and evaluation, extracted from DBpedia and Wikidata. Data availability: Training data must consist of texts annotated with events, classes, and relations aligned with the event ontology. As described in our evaluation setup in Section 5.1, we use two datasets for training and evaluation. They contain triples from DBpedia and Wikidata, respectively, both linked to texts from Wikipedia. An example of a text annotated with Wikidata triples is given in Table 1. Annotation quality: In order to generate such large-scale datasets, we assume distant supervision during dataset creation to link triples to Wikipedia texts, acknowledging potential noise in annotations. Consequently, even despite a cautious dataset creation process, ground truth annotations may still contain omissions or inaccuracies, particularly in large-scale datasets. Further, annotations can vary regarding granularity (e.g.
dbo:SportsEvent
vs.
dbo:TennisTournament
) and completeness. This assumption motivates to perform manual validation of the evaluation results as we do in Section 6.
Example of an Annotated Text as Required in a Dataset Required for Training and Evaluating a Semantic Event Extraction Model. This Example Is Based on Figure 1 Using Wikidata as the Target Event Ontology.

Example of an Annotated Text as Required in a Dataset Required for Training and Evaluating a Semantic Event Extraction Model. This Example Is Based on Figure 1 Using Wikidata as the Target Event Ontology.
The given text
Setup: As described above, the evaluation setting requires a training and evaluation dataset and needs to assess the quality of event classification, relation extraction and their combination in semantic EE. Metrics: Metrics must reflect pipeline-wide performance, including error propagation. Therefore, we compute precision, recall and F Error analysis: We assume manual error analysis is critical to identify phenomena like event ambiguity, type misalignment, and annotation discrepancies, which automated metrics may overlook.
T-SEE : Transformer-based Semantic Event Extraction
In this section, we present
Through a three-step procedure of event classification, relation extraction and event modelling, we ensure comparability with To allow seamless integration into the Semantic Web, the whole architecture of
Figure 2 offers a visual summary of
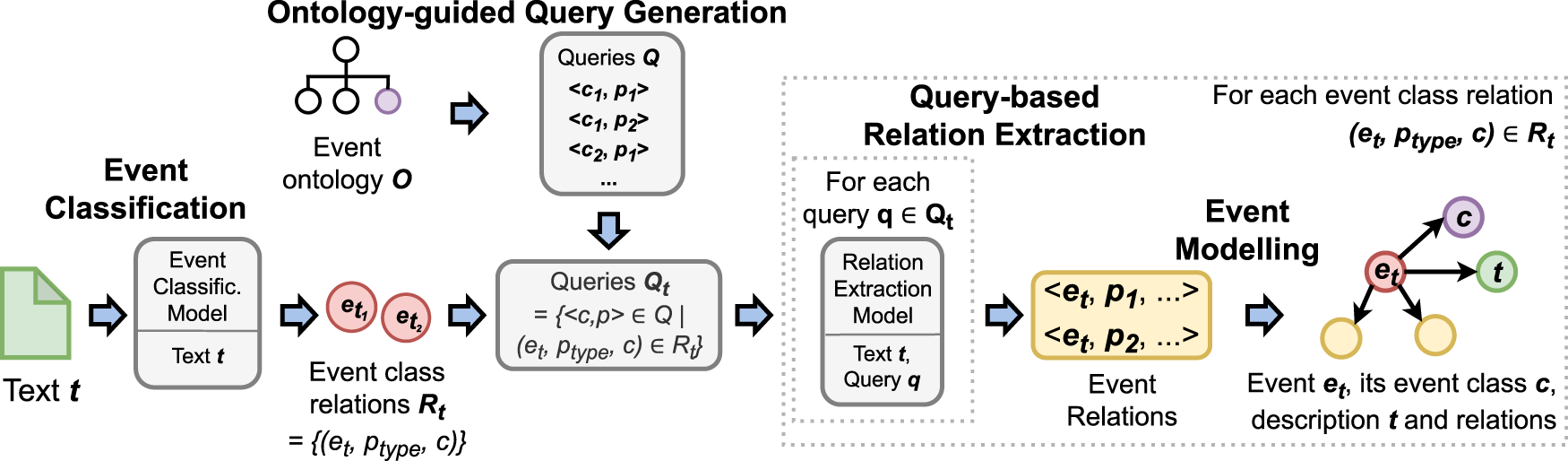
Overview of transformer-based semantic event extraction (
Event classification: We formulate event classification as a multilabel classification problem and apply it to a given text Query-based relation extraction: For each identified event, we extract its relations using a transformer-based extraction model and a subset of Event modelling: We transform the extracted event information into triples and add them to the event knowledge graph
With this process,
In the following, we describe

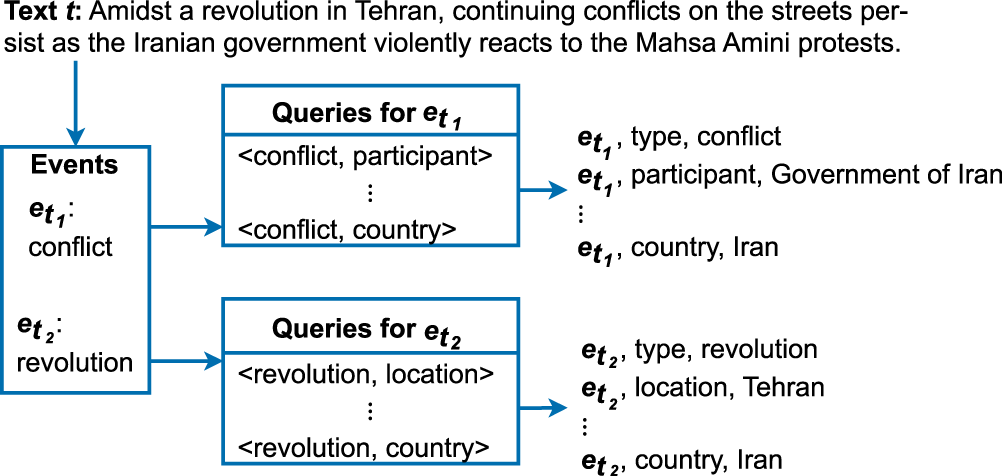
Example of event classification and query-based relation extraction on a sentence in the Wikipedia article ‘Mahsa Amini protests’.
The query generation step is a preprocessing step that creates a set of queries
Given an event ontology
Example
Figure 4 shows an example Wikidata SPARQL query to extract Wikidata properties commonly (more than

SPARQL query on Wikidata to extract Wikidata properties commonly (more than
Using such SPARQL queries, we can generate queries used by
Example Queries Extracted From the Wikidata Ontology.

Given a text
Specifically, the input to our event classification model is a sequence of tokens derived from
The hidden states are then passed through a dropout layer to reduce the number of connections between the pre-trained layers and the downstream layers, effectively forcing the downstream layers to learn more robust and generalisable representations of the input data. Finally, a fully connected layer and a sigmoid activation function are used in the output layer, generating a probability distribution over the possible event classes in the input text.
Additionally, we conduct threshold optimisation on a validation set. Prior work on multilabel classification, such as binary relevance methods (Tsoumakas & Katakis, 2007), often employs a fixed decision threshold (usually
Example
In our example, the event classification model receives the whole text shown in Figure 3 (‘Amidst a revolution in Tehran, continuing conflicts on the streets persist as the Iranian government violently reacts to the Mahsa Amini protests’.) as an input and returns two event classes ( conflict and revolution ) corresponding to the two events in the text.
Training
To train
Query-Based Relation Extraction
Given the text
We leverage BERT (Devlin et al., 2019) as the base of
Specifically, we encode the text
As shown in line 14 of Algorithm 1, each selected query
Example
For our predicted event classes
conflict
and
revolution
, the queries in
Training
To train our query-based relation extraction model, we use a corpus of texts with event mentions and their relations with properties in the event ontology
Event Modelling
In the event modelling step, we materialise the extracted event information as triples and enrich the event knowledge graph with them (lines 17 and 18). Precisely, for each text Type relation for Description of Relations extracted with our query-based relation extraction.
This process is repeated for all texts in an input corpus and the events extracted within them, after which the ontology-mapped relations can be transformed into RDF triples. As described in Definition 3, the event modelling step creates new triples of events not yet represented in the target knowledge graph
For representing the provenance and explicitly providing the source of the semantic event representation, further information could be added, for example, a URL pointing to the source text and a description of the extraction method. To do so, sources can be directly linked to a source statement in Wikidata. 10 Another option would be to use the PROV-O ontology (Hoekstra & Groth, 2015).
Example
Figure 3 illustrates relations extracted for the example events conflict and revolution . Given the conflict event, the following relations are created:
We provide examples of generated RDF triples in Section 5.6.
L-SEE : LLM-based Semantic Event Extraction
In this section, we present
Figure 5 offers a visual summary of

Overview of large language model-based semantic event extraction (
Event classification: We perform event classification as a multilabel classification problem by prompting an LLM to detect events and their classes in a text Relation extraction: We prompt the LLM to extract relations of all identified events. Event modelling: We transform the extracted event information into triples and add them to the event knowledge graph

For event classification (line 7 in Algorithm 2),
The event classification LLM prompt template is shown in Figure A.1 in the Appendix, where
Instruction: Explicitly defines event classification and the operational definition of an ‘event’. Example: Illustrates the task with a one-shot example, including a sample text, identified event classes, and explanations to clarify expectations. Output options: Explicitly lists the full set of potential outputs, that is, the set of all event classes Task: Specifies the input text
Relation Extraction
For relation extraction (line 11 in Algorithm 2),
The relation extraction LLM prompt template is shown in Figure A.2 in the Appendix. For our condensed example in Table 2,
Instruction: Defines the task (relation extraction), specifies expected property-value formats (e.g. temporal or spatial attributes), and mandates valid JSON output. Semantic constraints enforced through data type conventions ensure consistency for downstream processing. Example: Provides a one-shot demonstration with a text snippet, event classes, properties, and a corresponding JSON output to model structured responses. Task: Presents the input text
Event Modelling
The event modelling step (lines 14 and 15 in Algorithm 2) follows the procedure outlined in
Evaluation
In this section, we introduce two new datasets for semantic EE and compare
Datasets
We introduce two new large-scale datasets that currently stand as the largest and most diverse datasets for the task of semantic EE and follow our assumptions states in Section 2.1: DBpedia-SEE and Wikidata-SEE. They are available online.
11
DBpedia-SEE and Wikidata-SEE serve as training and test corpora for semantic EE based on event ontologies of DBpedia and Wikidata. To comply with the definition of semantic EE in Definition 3, each dataset belongs to an event ontology
Event Ontology Extraction
In the first step, we extract relevant event classes and their properties from DBpedia and Wikidata to create two event ontologies. The main reason why we extract event ontologies from DBpedia and Wikidata instead of using event ontologies such as LODE (Shaw et al., 2009) and the Simple Event Model (Van Hage et al., 2011) is that we do not only require an event ontology but also a large corpus of events modelled with such ontology, as available in the DBpedia and Wikidata knowledge graphs. Further reasons are as follows: (i) we focus on cross-domain knowledge graphs, with DBpedia and Wikidata being well-established cross-domain knowledge graphs yet inherently incomplete and bear potential for extension (Shenoy et al., 2022), (ii) as described in Section 1, we focus on named events and (iii) to create our evaluation datasets (see next Section 5.1.2), we utilise Wikipedia links which can be directly mapped to Wikidata and DBpedia entities.
Filtering Protocols and Thresholds
To ensure the quality and relevance of the event classes and properties extracted from Wikidata and DBpedia, we apply stringent filtering protocols. Specifically, we restrict event classes and properties to those used in the context of events and apply a minimum threshold for event classes (
While we try to keep manual interventions minimal and to be as consistent as possible in our annotations, for the remaining events and properties, we need to manually filter out overly specific event classes and metadata properties. Specifically, for Wikidata, we filtered out the following three types of event classes and properties:
Event classes specifically about a country (we still consider their parent classes. For example, instead of ‘UK Parliamentary by-election’, there still is ‘by-election’). Examples are:
Turkish general election (wd:Q22333900) Spanish Grand Prix (wd:Q9208) Sydney International (wd:Q248952) Classes that are wrongly categorised as event classes in Wikidata. Examples are:
communications satellite (wd:Q149918) space telescope (wd:Q148578) crewed spacecraft (wd:Q7217761) Properties that do not represent real-world relations (e.g., identifiers). An example is:
X username (wdt:P2002)
Statistics of the resulting DBpedia and Wikidata event ontologies are shown in Table 3. For example, the Wikidata event ontology has
Statistic of the Extracted DBpedia and Wikidata Event Ontologies.

SEE = semantic event extraction.
To extract texts and the RDF triples representing mentioned events, we follow a distance-label generation process. 13 The individual texts are sentences extracted from articles in the English Wikipedia describing events. 14 Event classes and relations are extracted by exploiting existing links to events and their DBpedia or Wikidata representations.
Figure 6 illustrates the distance-label generation process at an example: The Wikipedia article ‘Turkish involvement in the Syrian civil war’ has a link to the event ‘Operation Euphrates Shield’ which has a relation to Syria and is also mentioned in the same text. Consequently, we select the text, the event class military operation . 15 , and the country relation to Syria

Example illustrating how we label texts with events and relations. The Wikipedia text on the left links to the Wikidata event on the right side, which also has a relation to an entity mentioned in the text:
As delineated in Table 4, DBpedia-SEE includes 42,648 texts, and Wikidata-SEE contains 37,988 texts, where each text contains at least one annotated event and its corresponding relations. Together, these datasets feature over 80,636 uniquely annotated events and 111,663 relation instances, making them the most extensive repositories for training and evaluating EE models to date.
Statistic of our Datasets for Semantic Event Extraction.

Statistic of our Datasets for Semantic Event Extraction.
SEE = semantic event extraction.
DBpedia-SEE and Wikidata-SEE distinctly surpass existing benchmarks for the task of semantic EE due to their use of RDF annotations, their focus on general-domain events with societal impact and the coverage of both event detection and relation extraction annotations. Datasets such as SuicideED (Guzman-Nateras et al., 2022), SCIERC (Luan et al., 2018) and GENIA (Ohta et al., 2002) only cover very domain-specific events. MAVEN (Wang et al., 2020) and MINION (Pouran Ben Veyseh et al., 2022) only provide annotations for event detection, not relation or argument extraction. The existing larger event datasets like GDELT (Leetaru & Schrodt, 2013; Li et al., 2022) are less structured and not in RDF. 16 In a comparison to the ACE05 (Linguistic Data Consortium, 2005) dataset typically used for EE, our datasets DBpedia-SEE and Wikidata-SEE:
are freely available
ACE05 is only available for $4,000.00 to non-members of the Linguistic Data Consortium. have wider coverage of event domains
for example, ACE05 does not have sport-related events use RDF classes and properties have a large number of event classes and properties
DBpedia-SEE: Wikidata-SEE: ACE05: provide a large number of texts
DBpedia-SEE: 42,648 texts Wikidata-SEE: 37,988 texts ACE05:
These attributes amplify the datasets’ potential for semantic EE, which can not be performed with other existing datasets.
With our distantly labelled datasets DBpedia-SEE and Wikidata-SEE, we are able to (i) train
In our experiments, we split the datasets into training, test, and validation sets using
Evaluation Setup
Next, we describe our evaluation setup, that is, baselines and metrics.
Baselines
We compare
The selection of baselines for our study is carefully considered but constrained by the availability and adaptability of existing EE methodologies due to the following reasons: (i) despite their valuable contributions, several works do not provide any accessible implementations (Huang et al., 2023; Li et al., 2020; Liu et al., 2022b), which is a critical barrier to replication and further research. (ii) The usability of many EE frameworks is hampered by a lack of comprehensive documentation and a dependency on specific or proprietary datasets, notably the ACE05 dataset (Du & Cardie, 2020; Hsu et al., 2022; Liu et al., 2019a; Lu et al., 2023). Other methodologies like DEGREE (Hsu et al., 2022) and the question-answering paradigms by Du and Cardie (2020) and Lu et al. (2023) necessitate additional, task-specific inputs such as argument and description queries, complicating their integration into diverse research settings. Similarly, Liu et al. (2019a) and ChatIE (Wei et al., 2023) are hindered by very limited documentation and strict data formatting requirements. (iii) CLEVE (Wang et al., 2021b) cannot be adapted to our definition of semantic EE due to its presupposition of argument type knowledge. (iv) Frameworks like AllenNLP (on which DyGIE++ (Wadden et al., 2019) is built) have been discontinued, and (v) the substantial computational resources required for models like the 10-billion parameter Deepstruct (Wang et al., 2022) model further limit their viability.
Given these considerations, we have chosen
Metrics and Setting
To evaluate
We judge the accuracy of event classification using precision, recall, and F
Analogously, we use the same metrics for evaluating relation extraction, where relations are only considered to be correct if connected to a correctly classified event via the correct property and to the correct entity or value.
In this section, we report the results of
Event Classification
Table 5 shows the evaluation results of
Precision (P), recall (R) and F
Scores for Event Classification on DBpedia-SEE and Wikidata-SEE.
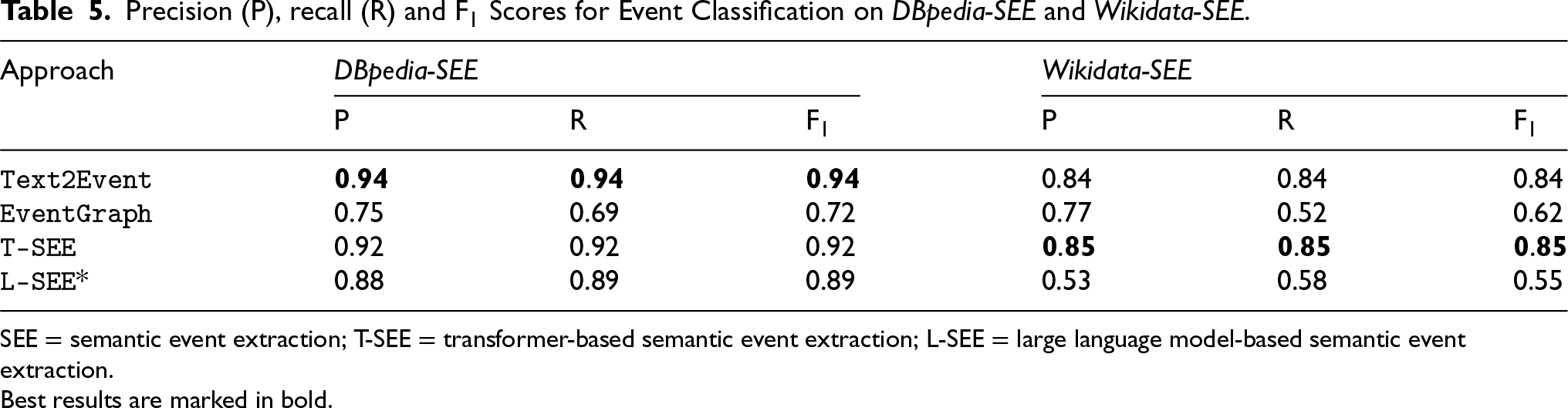
Precision (P), recall (R) and F
SEE = semantic event extraction; T-SEE = transformer-based semantic event extraction; L-SEE = large language model-based semantic event extraction.
Best results are marked in bold.
The performance of
Table 6 presents the relation extraction performance of
Precision (P), Recall (R), and F
Scores for Relation Extraction on DBpedia-SEE and Wikidata-SEE.

Precision (P), Recall (R), and F
SEE = semantic event extraction; T-SEE = transformer-based semantic event extraction; L-SEE = large language model-based semantic event extraction.
Best results are marked in bold.
Given the sequential structure of
For
Similarly, on Wikidata-SEE,
Example Result
Finally, we provide example RDF triples of an event extracted with

Example of RDF triples generated from the Wikipedia article ‘1991 Monte Carlo Open’ using the Turtle syntax.
To address the variability of the LLM in generating outputs for identical inputs, we evaluate the consistency of
Our analysis reveals a high level of consistency for both event ontologies, as summarised in Table 7. For DBpedia-SEE, we observe an average Fleiss’
Consistency Analysis Results of L-SEE for Event Classification and Relation Extraction.

Consistency Analysis Results of
L-SEE = large language model-based semantic event extraction; SEE = semantic event extraction.
The few cases demonstrating disagreement across LLM executions for event classification and relation extraction can be attributed to the design and complexity of the two tasks and the event ontologies. There is a stronger agreement for DBpedia-SEE compared to Wikidata-SEE due to the lower number of classes and properties (see Table 3): with a lower number of event classes to select from, there naturally is a higher chance of agreement. This also explains the consistency observed for relation extraction where the prompts include a small number of properties (
In order to implement our multilabel classification model, we leverage a pre-trained uncased BERT base model.
19
The model is fine-tuned for
To generate the training data, we extract Wikipedia articles using the MWDumper. 20 For entity linking, we use the Spacy Entity Linker, 21 a named entity linking tool specifically designed for Wikidata.
For
Comparison of T-SEE and L-SEE
A significant finding of our evaluation is the worse performance of
Manual Evaluation
In this section, we aim to understand the differences between the two paradigms of transformer-based architecture versus using LLMs for semantic EE. Therefore, on top of the automatic evaluation performed in Section 5, we perform a comparison of
We create DBpedia-SEE100 – a subset of DBpedia-SEE with
Table 8 shows the results of evaluating
Evaluation of T-SEE Versus L-SEE on DBpedia-SEE100 Before and After Manual Assessment.

Evaluation of
TP = true positives, FP = false positives, FN = false negatives; SEE = semantic event extraction; T-SEE = transformer-based semantic event extraction; L-SEE = large language model-based semantic event extraction.
After manual assessment,
These results underscore the strengths and limitations of both methodologies. While
To understand the differences in behaviours between
Our manual annotation process has unveiled a structured classification of errors, which we have divided into three principal categories:
Extraction Inaccuracies
Errors arising from the model’s inability to accurately interpret information within texts:
Omissions or missing events/relations: The event or its relations are not extracted. Type misalignment: An inappropriate type of entity or value is selected for a given property. Granularity mismatch: The model’s predictions lack the specificity of the ground truth, for example, categorising an event broadly as
dbo:SportsEvent
rather than the more specific
dbo:TennisTournament
. Erroneous extraction: The extraction of incorrect properties or values, leading to a misrepresentation of the factual content.
Annotation Discrepancies
Errors stemming from inconsistencies, errors or omissions in the ground truth:
Imprecise event class: The model’s predictions provide a more detailed event classification. Imprecise property: The model predicts property values with greater accuracy than the ground truth, such as specifying the exact match score when the ground truth only acknowledges the victory. Annotation error: The presence of omissions or inaccuracies within the ground truth itself, such as neglecting to annotate the specific date of a match or other pertinent details.
Other Anomalies
Errors arising from other sources:
Event ambiguity: The model struggles to distinguish between multiple distinct events described within a single sample, which may lead to conflated or mixed property assignments. Processing error:
Examples of Errors
We provide four semantic event representations generated by
Figure 8) – ground truth extracted from dbr:Black_Monday_(1360)
Omission: Annotation error: On the other hand, Example of an omission error and an annotation error.

Type misalignment: The commanders are incorrectly identified and assigned to group entities instead of individuals. Specifically, Processing error: In the entity linking process, ‘Lebanese militia Hezbollah’ is wrongly linked to three entities. Example of type misalignment and processing errors.

Imprecise event class: Erroneous extraction and event ambiguity: The same tennis tournament did not happen in Wuhan and in Beijing; Example of an imprecise event class, an erroneous extraction and event ambiguity.

Event ambiguity: The date ‘1961-01-01’ indicates confusion between multiple events. Specifically, this is because the event annotated in the ground truth is derived from the link tied to the string ‘previous election’, referring to
dbr:1959_Ontario_general_election
. Erroneous extraction: The use of
dbo:secondLeader
to indicate a chronological successor is highlighted in red, illustrating a misunderstanding of the property, as
dbo:secondLeader
is meant to instead describe second ranking in a competition. Annotation error: The relation using the
dbo:affiliation
property is missing in the ground truth. Example of event ambiguity, erroneous extraction and an annotation error.

On the basis of our error taxonomy, we annotated each semantic event representation generated by
First, we categorise errors into extraction inaccuracies, annotation discrepancies, and other anomalies to clarify our approaches’ error landscapes. Figure 12 visualises these error profiles for

Distribution of error categories for
Figure 13 provides a detailed analysis of the error types. As can be seen in the figure, different error types manifest with varying frequencies across

Distribution of error types for
For
Misunderstanding and Type Misalignment errors, with
Conversely,
Upon a more nuanced examination, especially after correcting for annotation errors, the performance landscape shifts. Initially,
In summary, while
As indicated in Section 5.2.2, for
Misformatted output: The LLM-generated JSON strings of Non-existing event classes: In Invalid properties: In 1191 cases, a property was identified which is not part of the event ontology (e.g.
Effect of Text Characteristics on Semantic EE
To get a sense of
Text Characteristics
We employ a collection of strategies to generate meaningful subsets of the dataset, each aimed at isolating different factors that could influence
We assess samples for semantic diversity. The semantic diversity of a text is measured by the variety of verb phrases and their arguments, approximated by the count of unique verb lemmas in the text. Samples with high semantic diversity are chosen for this subset, aiming to test the model’s understanding of varied semantic contexts and its ability to extract a broad range of event semantics. This strategy sorts the samples by the length of the text. Samples are then selected from the sorted list, prioritising those with the longest texts. Samples of this subset are generated based on the count of geographical entities identified by the Spacy NLP pipeline (i.e. ‘GPE’ and ‘LOC’ labelled entities) in each text. To assess the model’s proficiency in dealing with texts containing diverse geographical references, we select samples with the highest counts of such entities. We identify texts with temporal expressions using the Spacy library and extract where they are most frequently occurring. As temporal expressions can be crucial for event understanding, this subset evaluates This subset focuses on the diversity of named entities. We again utilise the Spacy library to extract named entities and then sort and select samples with the widest range of entities. This subset tests the model’s ability to accurately recognise and categorise entities in the context of events. Samples with intricate syntactical constructions are selected to challenge
In the following, we detail the outcomes of this analysis, demonstrating

Large language model-based semantic event extraction (

Large language model-based semantic event extraction (
For comparison, we also include the full dataset performance in our analysis. The distinctly strongest relation extraction performance on the full dataset suggests that we have successfully sampled parts of our data that The results suggest that longer sentences pose significant challenges, with lower macro metrics for event classification and even more pronounced difficulties in relation extraction. This indicates that We observe notable difficulties, highlighting
This analysis underscores
With our comparison of
Mimicry of dataset characteristics: Our analyses, for example, in Tables 6 and 8 and Figure 12, clearly demonstrate that the results of methodologies fine-tuned on the target datasets (
Distantly labelled datasets: Training a transformer-based architecture requires the availability of large training data, that is, texts annotated with RDF triples. Therefore, we opted for the automated extraction of two new datasets. The use of distantly labelled datasets without human annotations such as DBpedia-SEE and Wikidata-SEE for semantic EE or datasets for relation extraction (Elsahar et al., 2018; Goodrich et al., 2019; Han et al., 2020; Yao et al., 2019) overcomes the issues of training data dimensionality but always comes with questions regarding dataset quality.
24
Specifically, we identified a large number of false positives when evaluating
Ontology guidance: We took care of carefully guiding both our approaches through our event ontologies. By fine-tuning a transformer-based architecture, adherence to the ontology can be enforced, for example, by explicitly classifying into the event classes pertinent to the event ontology. For an LLM, in contrast, while we prompted for the specific event classes and properties, we still observed cases of invalid event classes or properties as discussed in Section 6.3.1. Also, our examples demonstrated cases of type misalignment and a misunderstanding of the semantic definition of a property ( dbo:secondLeader in Example 4), demonstrating the need to control the outputs of an LLM. The improvement in the precision of LLM-based semantic EE is a major future direction for LLM-based semantic EE, for example, through the provision of property descriptions within the prompt.
Complexity: Setting up a transformer-based architecture and its fine-tuning requires the availability of rich training data, computing and time resources. Setting up an LLM, in contrast, requires access to an LLM and careful prompt engineering, that is, potentially easier-to-obtain resources.
Real-world applications: Given the capability of LLMs to adapt to different inputs and data characteristics, we assume that LLM-based approaches are well-suited under more complex, real-world conditions and to explore low-resource scenarios.
Related Work
Knowledge graphs have, as a form of structured human knowledge, drawn a lot of research attention from both academia and the industry (Ji et al., 2022). With a great deal of event information worldwide, it is essential to bring entities and events together through event-centric knowledge representations (Guan et al., 2022), with EE and relation extraction being key technologies for accessing event knowledge (Xiang & Wang, 2019).
Event Knowledge Graphs
Event knowledge graphs represent knowledge about happenings with societal impact in an event ontology and interlink them with connected entities (Guan et al., 2022). We distinguish between two types of event representations as follows:
Named events: The predominantly entity-centric information of popular cross-domain knowledge graphs such as DBpedia, YAGO, and Wikidata represent events as named events such as ‘Brexit’ and ‘World War II’. Named events are also the core component of EventKG (Gottschalk & Demidova, 2018), a multilingual event-centric temporal knowledge graph, part of the Open Event Knowledge Graph (Gottschalk et al., 2021) that integrates event-related data sets from multiple application domains. GDELT (Leetaru & Schrodt, 2013) and ICEWS are two datasets of global political events encoded using the CAMEO framework (Gerner et al., 2002), that is, not in RDF. Unnamed events: Works that address unnamed events specifically deal with the identification of texts describing events and with the semantic annotation of these texts. For example, Rospocher et al. (2016) build knowledge graphs from news articles, and Zhang et al. (2020) develop a large-scale English event knowledge graph extracted from several sources such as reviews, news, and social media. For the task of event modelling, Yao et al. (2020) propose a weakly supervised approach to extract event relation tuples from text and build an event knowledge base, not focusing on event-entity relations.
All event knowledge graphs require the availability of an event ontology, with popular examples including LODE (Shaw et al., 2009), the Simple Event Model (Van Hage et al., 2011) and more as discussed by Piryani et al. (2023). Relevant patterns for event representation are presented by Carriero et al. (2021) and Krisnadhi and Hitzler (2017), focusing on the spatio-temporal extent of events, the role of their participants and recurring events. In this article, we extracted event ontologies from their vocabularies to allow the population of the well-established cross-domain knowledge graphs DBpedia and Wikidata.
With
Event Extraction
EE is a critical task in constructing and populating entity-centric knowledge graphs, with recent advancements significantly diversifying the methodologies employed (Du et al., 2021; Lu et al., 2021; Xu et al., 2021). Earlier approaches have relied on sentence-level pipelines for extracting event triggers and their corresponding argument roles (Du & Cardie, 2020; Liu et al., 2020; Yang et al., 2019a), employing sequence-to-structure generation paradigms like Text2Event (Lu et al., 2021) and multi-task frameworks such as DyGIE++ (Wadden et al., 2019), which utilise contextualised embeddings and dynamic span graph updates. Other studies have extended the scope to document-level EE (Lou et al., 2021; Zheng et al., 2019) or ventured into open-domain EE without predefined event classes (Liu et al., 2019b; Rusu et al., 2014), which, while broadening the applicability, faces challenges due to the absence of a well-defined event ontology.
Innovations in the field have introduced contrastive pre-training frameworks like CLEVE (Wang et al., 2021b), which capitalise on large unsupervised datasets and their semantic structures to enhance EE’s efficacy, demonstrating marked improvements in both supervised and unsupervised settings. Similarly, EventGraph (You et al., 2022) has presented a joint framework that conceptualises events as graphs, facilitating the simultaneous detection and extraction of multiple events and their intricate interrelations, thereby achieving state-of-the-art results in event trigger and argument role classification.
Deepstruct, on the other hand, tries to leverage the structural understanding capabilities of language models through task-agnostic pretraining, allowing for zero-shot knowledge transfer across a wide array of structure prediction tasks and setting new benchmarks on numerous datasets (Wang et al., 2022). With DEGREE (Hsu et al., 2022), authors propose a data-efficient, generation-based model for EE that capitalises on semantic guidance from manually designed prompts and the joint prediction of triggers and arguments, showcasing robust performance in low-resource settings. ONEEE (Cao et al., 2022), on the other hand, utilises a one-stage framework for fast overlapping and nested EE.
A notable shift in EE methodology is the adoption of a question-answering paradigm (Du & Cardie, 2020), which mitigates the prevalent issue of error propagation seen in conventional approaches by facilitating end-to-end argument extraction, including for roles not encountered during training. Following this line, QGA-EE (Lu et al., 2023) has refined the QA-based approach by integrating context-aware question generation, thus accommodating multiple arguments for identical roles and surpassing prior single-task models in performance metrics.
In light of the new methodologies and progress in EE, the research community has also focused on the specific subtasks of EE. For example, with PAIE (Ma et al., 2022), authors devise a prompt tuning approach to document-level event argument extraction similar to the already established question-answering paradigm in EE work. Older work on event argument extraction, such as HMEAE (Wang et al., 2019), a hierarchical approach to argument extraction utilising concept correlation among argument roles, have, in turn, inspired approaches such as DEGREE that aim to resolve issues such as poor handling of the encoding of the labels semantics and other weak supervision signals.
Prompt-based approaches have been explored for event argument extraction, leveraging the ability of pre-trained language models to generate structured outputs. For example, Peng et al. (2024) propose Event Co-occurrences Prefix Event Argument Extraction (ECPEAE), which incorporates co-occurrence information of multiple events in a sentence to improve argument extraction accuracy (Peng et al., 2024b). This method uses a co-occurrence event prefix module to encode template information for all events in the input, enabling the model to leverage causal relationships between events. While ECPEAE focuses on sentence-level event interactions,
The other subtask of EE, event detection, has also received attention with the DRC framework (Zhao & Yang, 2022) trying to compete with trigger-based models as a way of exploring methods of event detection robust to less annotated real-world domains, an area we examine in our work as well. Similarly, recent work has introduced retrieval-augmented prompting for event detection, leveraging LLMs to improve performance in both high- and low-resource settings (Shiri et al., 2024). This approach constructs automatic retrieval-augmented prompts to provide LLMs with structured extraction guidelines, enhancing their ability to detect events without relying solely on trigger words. These advancements align with our exploration of methods for event detection in less-annotated domains.
Other research exploring ontology and schema-based approaches to EE has yielded promising innovations. Notably, Huang et al. (2024) introduce a multi-graph representation for EE, using graph neural networks to model event interactions and improve extraction accuracy (Huang et al., 2024). This graph-based approach contrasts with
These developments reflect a broader trend towards more adaptable, efficient, and comprehensive models for EE, underlining the field’s evolution towards leveraging advanced language model capabilities and innovative problem-solving frameworks.
LLM-based IE
The field of IE has traditionally relied on rule-based and statistical methods to extract structured information from text. However, the emergence of LLMs has opened up new avenues for tackling IE tasks with remarkable capabilities in understanding and generating natural language. This section reviews recent advancements in using LLMs for IE, particularly focusing on unstructured IE and EE.
General IE with LLMs
A few years ago, LLMs were still in their early stages of development, with limited capabilities for tackling complex tasks like IE. While early works explored LLM-based approaches for IE (e.g. Peters et al., 2018), these models faced challenges due to limited model capacity, data inefficiency, and limited adaptation. However, significant advancements in recent years have addressed these challenges, driven by the rise of the transformer architecture (Vaswani et al., 2017) enabling long-range dependencies. Large-scale pre-training pushed things further with BERT (Devlin et al., 2019) and GPT-3 (Brown et al., 2020), allowing LLMs to learn general language understanding capabilities and adapt to specific IE tasks through fine-tuning with smaller labelled datasets. Finally, the growing availability of powerful computing resources like GPUs and TPUs (Jouppi et al., 2017) has enabled the training of larger and more complex LLM models, further enhancing their ability to handle complex IE tasks.
Unstructured IE with LLMs
In 2022, Dunn et al. showed how a pre-trained LLM can extract structured information from scientific abstracts (Dunn et al., 2022). In 2023, Polak and Morgan (2024) expanded on the early promises of unstructured IE with ChatExtract, demonstrating that a significant amount of up-front effort, expertise, and coding may be fully automated using an advanced conversational LLM. By leveraging prompts and follow-up questions, ChatExtract achieves high accuracy and efficiency in extracting materials data, showcasing the potential of LLMs for automated knowledge extraction from scientific literature.
In the same year, Wei et al. proposed ChatIE, a multi-turn QA framework for zero-shot IE demonstrating good performance across a number of datasets, three tasks, and two languages (Wei et al., 2023). Li et al. systematically analysed ChatGPT across seven detailed IE tasks (Li et al., 2023a) including EE. The authors show that while ChatGPT underperforms in standard IE tasks compared to BERT-based models, it excels in OpenIE settings, as confirmed by human evaluators. However, a notable concern is the model’s overconfidence in its predictions, leading to calibration issues. This is further confirmed in the comprehensive survey by Liu et al. (2023), in which the authors evaluate the capabilities and applications of ChatGPT (versions 3.5 and 4) against the backdrop of current state-of-the-art models in NLP. The article highlights ChatGPT’s advancements in large-scale pre-training, instruction fine-tuning, and reinforcement learning from human feedback, which collectively enhance its adaptability and performance across a myriad of NLP tasks. A detailed comparison of ChatGPT with existing state-of-the-art models reveals that while ChatGPT excels in multitask learning and shows promising results in some NLP tasks, it falls short in multilingual capabilities and specialised tasks when compared to dedicated models. Moreover, stability and consistency emerge as areas where ChatGPT does not yet match the performance levels of state-of-the-art models, which could impact its reliability in critical applications.
LLM-based EE
LLMs have recently been utilised for the task of EE. In general, as already mentioned, Li et al. (2023a) evaluate the performance of ChatGPT on a number of IE tasks, revealing an increasingly worse performance as the complexity of the evaluated task increases, where the worst performance is reported on the task of EE.
A comparison between LLMs and traditional methods have been conducted on several tasks related to EE: according to Kirti et al. (2023), authors explore prompt-based learning with GPT-4 for detecting factual events in literary narratives. The study concludes that while BiLSTM with BERT embeddings excels in event detection within literary texts, GPT-4 shows promise in prompt-based learning approaches, particularly in few-shot settings. Sharif et al. (2024) conducted an in-depth analysis of ChatGPT’s performance on the task of characterising information-seeking events, where ChatGPT underperformed compared to transformer models like XLNet, especially in domain-specific contexts requiring extensive knowledge.
Zhan et al. introduce GLEN (Li et al., 2023b), a large-scale general-purpose event detection dataset that significantly expands the ontology of event types. While InstructGPT underperformed compared to other baselines in their experiments, the authors attribute this to the limited input length and lack of fine-tuning, with only
Peng et al. (2024) introduce CsEAE, a model that combines small language models (SLMs) and LLMs for document-level event argument extraction (Peng et al., 2024a). CsEAE incorporates co-occurrence-aware and structure-aware modules to handle semantic boundaries between events and reduce interference from redundant information. The authors also demonstrate that insights from SLMs can enhance LLM performance via supervised fine-tuning and prompt engineering. This work aligns with
Liu et al. (2024) propose EventRL, a framework that enhances LLM-based EE using reinforcement learning with outcome supervision (Gao et al., 2024). EventRL improves extraction accuracy by rewarding the LLM based on its alignment with human-annotated triggers and arguments. While EventRL focuses on refining LLM outputs through external feedback,
While the early attempts at utilising LLMs for the complex task of EE have shown mixed results, with LLMs often underperforming in comparison to traditional methods, especially in domain-specific contexts, there is a clear trajectory of improvement. As LLMs continue to evolve, gaining the ability to handle larger context windows and as researchers refine their prompting techniques – such as breaking down the task into simpler sub-tasks as demonstrated in
LLM-Based Knowledge Graph Population
The use of LLMs for the population of knowledge graphs has also been explored recently. For example, Mihindukulasooriya et al. experimented on ontology-driven triple extraction from sentences (Mihindukulasooriya et al., 2023), while Yao et al. performed instruction tuning for the tasks of triple classification, relation prediction and entity link prediction (Yao et al., 2023). In another innovative approach, AutoKG leverages a multi-agent-based approach employing LLMs and external sources for KG construction and reasoning (Zhu et al., 2024). Zhang et al. propose KoPA, which ingests entity and relation embeddings into LLMs (Zhang et al., 2024c).
These papers about LLM-based IE present a glimpse into the rapidly evolving field of LLM-based IE. While promising results have been achieved, further research is needed to address challenges such as factual correctness, bias mitigation, and adapting LLMs to specific domains and tasks. As research progresses, LLMs are set to play a key role in the future of IE, enabling efficient and accurate knowledge extraction from vast amounts of unstructured text data.
Conclusion
In this article, we compared two paradigms for semantic EE: fine-tuning transformer-based architectures as exemplified by our approach
Both approaches consist of two main steps: event classification and relation extraction, where
In our evaluation, we first introduced two new datasets for semantic EE. Then, we compare
Consequently, we derive a set of phenomena to be regarded when performing semantic EE, including the role of distantly labelled datasets and the event ontology.
In future work, we plan to further improve
Footnotes
Acknowledgements
This work was partially funded by the Federal Ministry for Economic Affairs and Energy (BMWE), Germany (‘ATTENTION!’, 01MJ22012D). The publication of this article was funded by the Open Access Fund of Leibniz Universität Hannover.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.