
Abstract
RDF generally follows the open-world assumption: information is incomplete by default. Consequently, SPARQL queries cannot retrieve with certainty complete answers, and even worse, when they involve negation, it is unclear whether they produce sound answers. Nevertheless, there is hope to lift this limitation. On many specific topics (e.g., children of Trump, Apollo 11 crew, EU founders), RDF data sources contain complete information, a fact that can be made explicit through completeness statements. In this work, we leverage completeness statements over RDF data sources to provide guarantees of completeness and soundness for conjunctive SPARQL queries. We develop a technique to check whether query completeness can be guaranteed by taking into account also the specifics of the queried graph, and analyze the complexity of such checking. For queries with negation, we approach the problem of query soundness checking, and distinguish between answer soundness (i.e., is an answer of a query sound?) and pattern soundness (i.e., is a query as a whole sound?). We provide a formalization and characterize the soundness problem via a reduction to the completeness problem. We further develop heuristic techniques for completeness checking, and conduct experimental evaluations based on Wikidata, a prominent, real-world knowledge base, to demonstrate the feasibility of our approach.
Introduction
Over the Web, we are witnessing a growing amount of data available in RDF. As of July 2018, the LOD Cloud2
See, e.g.,

Wikidata is complete for all EU founding members.
The incorporation of completeness information can help users assess the quality of data. Over the Web, completeness information is in fact already available in various forms. For instance, Wikipedia provides a template for adding completeness annotations for lists6
E.g., see
For instance, see
For RDF data, such information about completeness is particularly crucial due to RDF’s incomplete nature. In [15], Darari et al. proposed completeness statements, metadata to specify which parts of an RDF data source are complete: for a complete part all facts that hold in reality are captured by the data source. They also provided an RDF representation of completeness statements, making them machine readable. The availability of explicit completeness information opens up the possibility of specialized applications for data source curation, discovery, analytics, and so forth. Moreover, it can also benefit data access over RDF data sources, mainly done via SPARQL queries [28]. More specifically, the quality of query answers can also be made more transparent given that now we know the quality of data sources with regard to completeness.
Query completeness When data sources are enriched with completeness information, the question naturally arises as to whether queries can be answered also completely. Intuitively, queries that are evaluated only over parts of data captured by completeness statements, are guaranteed to be complete. Consider the query “Give the EU founders” over Wikidata:9
Wikidata has internal identifiers for resources, as shown in the SPARQL query example.
Without completeness information, evaluating the query would give only query answers, for which we do not know the completeness. By having the statement that Wikidata is complete for the EU founders, we can then guarantee that the answers are complete. Darari et al. [15,16] characterized such reasoning, that is, checking whether queries can be guaranteed to be complete by completeness statements. Nonetheless, this approach is limited in the sense that the specifics of the queried graph are not taken into account in the completeness reasoning.
Let us give an example, illustrating this limitation. Suppose that in addition to the statement about all EU founders, we also have the statements that Wikidata is complete for the official languages of the following countries: Belgium, France, Germany, Italy, Luxembourg, and the Netherlands. Let us now consider the query “Give the EU founders and their official languages.” We show that the query can be answered completely by applying a data-aware approach: we enumerate the complete EU founders stored in Wikidata, and for each of them, we are complete for its languages. On the other hand, the data-agnostic approach from Darari et al. [15,16] would fail to capture the query completeness: it can be that all the EU founders are completely different than those in Wikidata, and thus, having completeness statements about the six countries above could not help in the reasoning. We argue that data-aware reasoning can provide more fine-grained insights over the completeness of query answers, which otherwise cannot be captured by relying only on the data-agnostic approach.
Query soundness While it is rather obvious to see that completeness information may guarantee query completeness, one might wonder if such completeness information can also be leveraged to check the soundness of query answers. Indeed, for the positive fragment of SPARQL, the soundness of query answers trivially holds, thanks to monotonicity. Now let us consider queries with negation. There are different ways to express negation in SPARQL, either by the explicit syntactic constructs MINUS and FILTER NOT EXISTS, which are available in SPARQL 1.1, or by combining OPTIONAL patterns with a check for unbound variables, as was the method of choice in SPARQL 1.0. The meaning of such queries on the Semantic Web has always been dubious (see, e.g., W3C mailing list discussions in [45] and [46]). The evaluation of SPARQL queries that include negation relies on the absence of some information. On the other hand, RDF, which follows the OWA, regards missing information as undecided, that is, it is unknown whether the missing information is false. Given this situation, answers to queries with negation can never be assured to be sound.
Completeness information can tackle the problem of query soundness. To illustrate this, consider asking for “countries that are not EU founders” over Wikidata:
The answers include Spain (=
Contributions An earlier version of our ideas on query completeness checking was published in the Proceedings of the International Conference on Web Engineering [19]. In that work, we provided a formalization of the data-aware completeness entailment problem and developed a sound and complete algorithm for the entailment problem. The SPARQL fragment considered in that work is the conjunctive fragment, which is the core fragment underlying all extensions [36,62]. The present paper significantly extends the previous work in the following ways:
we formulate the soundness problem for conjunctive SPARQL queries augmented with negation in the presence of completeness information, and distinguish between answer soundness (i.e., is an answer of a query sound?) and pattern soundness (i.e., is a query as a whole sound?);
we provide a full characterization of both the answer and pattern soundness problem via a reduction to the completeness problem;
we identify the bottlenecks of the completeness reasoning techniques from [19] and develop heuristic techniques for completeness reasoning;
we provide experimental evaluations based on Wikidata, a prominent, real-world data source to study the effectiveness of the proposed heuristics (and their interplay) and to validate the feasibility of our approach; and
we provide a comprehensive complexity analysis of the completeness and soundness entailment problem, include the proofs of all theorems as well as more recent related work, and improve the presentation of the theoretical parts.
A poster by Darari et al. [18] contained a result that can be interpreted as a sufficient condition for soundness in the data-agnostic setting. We now provide a distinction between so-called pattern soundness and answer soundness, a full characterization by means of a reduction to completeness checking, as well as a complexity analysis and experimental evaluations for the soundness problem.
Organization The rest of the article is organized as follows. Section 2 provides some background about RDF and SPARQL, as well as completeness statements. Section 3 motivates and formalizes the problem of query completeness and query soundness. In Section 4, we first introduce formal notions capturing aspects of completeness, then present an algorithm for completeness entailment checking based on those notions, and conclude with a complexity analysis of the completeness entailment problem. We give a characterization of the two problem variants of query soundness, that is, answer soundness and pattern soundness, in Section 5. We describe our heuristic techniques for completeness checking in Section 6, and report on our experimental evaluations for query completeness and query soundness checking in Section 7. Related work is presented in Section 8. Section 9 provides a discussion of our framework, while Section 10 gives conclusions and future work. Proofs are provided in the appendices.
In this section, we introduce basic notions of RDF and SPARQL, and provide a formalization of completeness statements. We adopt the formalization of RDF and SPARQL as in [48] and base ourselves on the formalization of completeness as in [15,16].
RDF and SPARQL
We assume three pairwise disjoint infinite sets I (IRIs), L (literals), and V (variables). We collectively refer to IRIs and literals as RDF terms or simply terms. An RDF graph (or simply, graph) G is a finite set of triples
The standard RDF query language is SPARQL [28]. At the core of SPARQL lie triple patterns, which resemble triples, except that in each position also variables are allowed. A basic graph pattern (BGP) is a set of triple patterns. A mapping μ is a partial function
In the following, we define variable freezing, an important notion for the characterizations of completeness and soundness entailment in the subsequent sections.
(Variable Freezing).
For a BGP P, the freeze mapping
Technically, this definition is ambiguous, since there are infinitely many ways to choose the fresh IRIs and therefore there are infinitely many such mappings and corresponding prototypical graphs. In addition, the choice depends on the pattern P so that a correct notation would include a subscript P. To keep our formalism slim, we do not specify how to choose the IRIs, nor do we introduce the subscript, which would be inessential details for the arguments in the paper.
Consider the query “Give the founding members of the EU” as introduced in Section 1. The query’s BGP can be written as:
The standard query type of SPARQL is the
SPARQL with negation SPARQL queries can also include negation. We introduce notation that is concise and more convenient for our purposes than the original SPARQL syntax [28]. A
Consider the query with negation, “Give countries that are not EU founders.” The graph pattern of the query can be written as follows:
We refer to the SPARQL fragment where positive and negative parts of queries are constructed from BGPs as the conjunctive SPARQL fragment augmented with negation. Note that BGPs are the basic building blocks underlying other SPARQL extensions [36,62] as well.
We want to formalize a mechanism for specifying which parts of a data source are complete. When talking about the completeness of a data source, one implicitly compares the information available in the source with a possible state of the source that contains all information that holds in the real world. We model this situation with a pair of graphs: one graph is the available, possibly incomplete state, while another stands for an ideal, conceptual complete reference, which contains the available graph. In this work, we only consider data sources that may miss information, but do not contain wrong information.
(Extension Pair).
An extension pair is a pair
In an application, the state stored in an RDF data source is our actual, available graph, which consists of a part of the facts that hold in reality. The full set of facts that constitute the ideal state are, however, unknown. Nevertheless, an RDF data source can be complete for some parts of the reality. In order to make assertions in this regard, we now introduce completeness statements, as meta-information about the extent to which the available state captures the ideal state. We adopt the unconditional version of the completeness statements defined in [15].
(Completeness Statement).
A completeness statement C has the form
For example, we express that a data source is complete for all triples about the EU founders using the statement
For the sake of readability, we slightly abuse the notation by removing the set brackets of the BGPs of completeness statements.
An extension pair
The above definition naturally extends to the satisfaction of a set
An important tool for characterizing completeness entailment is the transfer operator, which evaluates over G all
(Transfer Operator).
Let
As an illustration, consider the statement
Motivation and formal framework
In this section, we motivate and formalize the problem of query completeness and query soundness, adapting the definitions from [15] to the data-aware setting and to the problem of soundness.
Query completeness
Given an RDF graph and a set of completeness statements, we want to check whether a query can be answered completely.
Motivating scenario

RDF graph
Consider the RDF graph
Evaluating
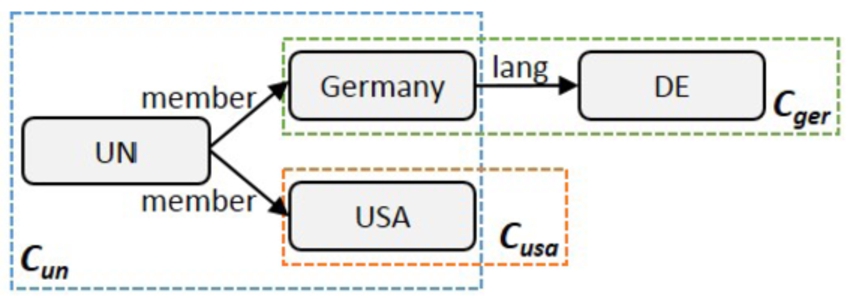
RDF graph
Let us consider the same graph as above, now enriched with completeness information, as displayed in Fig. 3. The figure illustrates the set For the sake of example, let us suppose that this is true.
First, from the statement
Our task is now transformed to checking whether
Now, only the query
In summary, we have reasoned about the completeness of a query given a set of completeness statements and a graph. The reasoning is basically done as follows: (i) we find parts of the query that can be guaranteed to be complete by the completeness statements; (ii) we produce equivalent query instantiations by evaluating those complete query parts over the graph and applying the obtained mappings to the query itself; (iii) for all the query instantiations, we repeat the above steps until no further complete parts can be found. The original query is complete iff all the BGPs of the generated queries are contained in the data graph.
Note that using the data-agnostic completeness reasoning approach of [15], it is not possible to derive the same conclusion. Without looking at the available graph, we cannot conclude that Germany and the USA are all the UN members, since it could be the case that the members are completely different items (i.e., not Germany nor the USA). Consequently, just knowing that the official languages of Germany and the USA are complete does not help in the reasoning.
When querying a data source, we want to know whether the data source provides sufficient information to retrieve all answers to the query, that is, whether the query is complete wrt. the real world. For instance, when querying for members of the UN, it would be interesting to know whether we really get all such countries. Intuitively, a query is complete over an extension pair whenever all answers we retrieve over the ideal graph are also retrieved over the available graph. We now define query completeness wrt. extension pairs.
(Query Completeness).
To express that a query Q is complete, we write
For monotonic queries, the other direction, that is,
The above definition can be naturally adapted to the completeness of a BGP P, written
Now, the question arises as to when some meta-information about data completeness can provide a guarantee for query completeness. In other words, the available state contains all data, as guaranteed by completeness statements, that is required for computing the query answers, so one can trust the result of the query. In the following, we define completeness entailment.
Let
In our motivating scenario, we have seen that the graph about the UN and the completeness statements entail the completeness of the query
Since for our SPARQL queries all variables are distinguished, the set of query answers for such a query is the same as the set of mappings satisfying the BGP. We can therefore focus on the BGPs used in the body of queries for completeness entailment. Note that here (again) the distinction between bag and set semantics collapses. The following proposition provides an initial characterization of completeness entailment, which will serve as a starting point to develop formal notions for completeness checking and an algorithm in Section 4. Basically, for a set of completeness statements, a graph, and a BGP, the completeness entailment holds, if and only if extending the graph with a possible BGP instantiation (by some mapping) such that the extension satisfies the statements, always results in the inclusion of the BGP instantiation in the graph itself.
Let
for every mapping μ such that
In other words, the completeness entailment does not hold, if and only if we can find a possible BGP instantiation (by some mapping) such that the extension satisfies the statements, but the BGP instantiation is not contained in the graph. The idea here is that, as demonstrated in our motivating example, by using completeness statements we always try to find complete parts of BGPs and instantiate them over the graph, until either all the instantiations are included in the graph (= the success case), or there is one instantiation that is not included there (= the failure case).
Here, we motivate the second main problem of this work, query soundness. The problem comes in two variants: answer soundness and pattern soundness.
Answer soundness
In a nutshell, a mapping is a sound answer for a query with negation over a given graph if it continues to be an answer over all possible completions of the graph. For an example, consider the following graph pattern, asking for countries where
For the sake of example, consider the following graph about countries:
For the sake of example, suppose this is true.
Evaluating the graph pattern over the graph in the standard way results in
Let us analyze
Next, let us analyze
Last, let us analyze
In summary, our analysis established for which answers the
Consider now the graph pattern asking for countries where
Consider also the set
Let us see why
In this scenario, as opposed to answer soundness, we have reasoned for a graph pattern whether the soundness of an arbitrary answer over an arbitrary graph can be guaranteed by a set of completeness statements.
Formalization of soundness reasoning
In the following, we provide definitions of answer soundness and pattern soundness.
(Answer Soundness).
To express that a mapping μ is sound for a graph pattern P, we write
From the above definition, for
(Answer Soundness Entailment).
Given a set
In our motivating scenario we saw that for all possible completions of the graph,
Pattern soundness, as opposed to answer soundness, is concerned with a graph pattern as a whole and abstracts from any specific answers of the pattern.
(Pattern Soundness).
We express that a graph pattern P is sound by
Thus, a pattern is sound whenever all answers in the evaluation over G are also present in that over
(Pattern Soundness Entailment).
A set of completeness statements
In our motivating scenario, it is the case that
Let
In this section, we introduce formal notions and present an algorithm for checking the entailment of query completeness. We also analyze the complexity of the entailment problem.
Formal notions
First, we need a notion for a BGP with a stored mapping from variable instantiations. This allows us to represent BGP instantiations wrt. our completeness entailment procedure. We define a partially mapped BGP as a pair
Consider our motivating scenario. Over the BGP
Next, we formalize when two partially mapped BGPs are equivalent wrt. a set
Let
The above definition naturally extends to sets of partially mapped BGPs.
Consider the queries in our motivating scenario in Section 3.1.1. The equivalences discussed there can now be stated as
Next, we would like to figure out which parts of a BGP contain variables that can be instantiated completely over G wrt.
An example demonstrating why the graph is necessary to be included in the
Here we slightly abuse the notation by performing a mapping (which itself is actually a ‘reverse’ mapping) over a graph instead of a BGP.
By its construction, we are complete for the crucial part, that is,
Consider the query
Consider next the pattern
Consider now the pattern
The operator below implements the instantiations of a partially mapped BGP wrt. its crucial part.
Let
The following shows that such instantiations produce a set of partially mapped BGPs equivalent to the original partially mapped BGP, hence the name equivalent partial grounding. It holds basically since the instantiation is done over the crucial part, which is complete wrt.
(Equivalent Partial Grounding).
Let
Consider our motivating scenario. Recall from Example 5 the crucial parts of the BGPs
Evaluating the crucial parts over the graph
The corresponding equivalent partial groundings are
Generalizing from the example above, there are three cases of the operator
If
If
Otherwise, it returns a non-empty set of partially mapped BGPs, where some variables in P are instantiated.
Let us describe what these three cases mean to our completeness entailment procedure, and how their applications lead to termination. The first case corresponds to the non-existence of the query answer in any possible extension of the graph that satisfies the set of completeness statements (e.g., the USA’s official languages case). As demonstrated in Example 6, the first case removes partially mapped BGPs. This is due to the emptiness of the crucial parts. Now, for the third case, it corresponds to the instantiation of complete parts (that is, the crucial parts) of the BGP. The third case generates more specific partially mapped BGPs that are equivalent to the original partially mapped BGP.
As for the second case, it generates exactly the same partially mapped BGP as the original one. This means that the crucial part computation cannot find any more variables that can be instantiated completely. Here, we need a special treatment. We first define that a partially mapped BGP
Saturated BGPs hold the key as to whether our completeness entailment check succeeds or not: completeness of saturated BGPs is simply checked by testing whether they are contained in the graph G. Furthermore, once the repeated epg applications with the above three cases hit the saturated case (i.e., the second case), we can readily check completeness entailment.18
Essentially, it might be that the epg applications hit the first case only, that is, there are no more partially mapped BGPs that have to be checked for completeness. For this case, completeness entailment trivially holds.
Let P be a BGP,
By consolidating all the above notions, we are ready to provide an algorithm to check data-aware completeness entailment.
Algorithm
From the above notions, we have defined the

Let us now describe how Algorithm 1 works. Consider a BGP
The next proposition about the function computed by Algorithm 1 follows from the construction of the algorithm and Proposition 3.
Let P be a BGP,
From the above proposition, we can derive the following theorem, which shows the soundness and completeness of the algorithm to check completeness entailment.
Let P be a BGP,
Consider our motivating scenario. Then
From looking back at the initial characterization of completeness entailment in Proposition 1, it actually does not give us a concrete way to compute a set of mappings to be used in checking completeness entailment. Now, by Theorem 1 it is sufficient for completeness entailment checking to consider only the mappings in
Following from the aforementioned algorithm to compute saturated mappings, and Theorem 1, a corresponding algorithm for checking completeness entailment can be easily derived. In what follows we provide two simple heuristic techniques of the completeness checking algorithm: early failure detection and completeness skip. More elaborate heuristics are given in Section 6.
Early failure detection In our algorithm, the containment checks for saturated BGPs are done at the end. Indeed, if there is a single saturated BGP not contained in the graph, we cannot guarantee query completeness (recall Theorem 1). Thus, instead of having to collect all saturated BGPs and then check the containment later on, we can improve the performance of the algorithm by performing the containment check right after the saturation check (Line 6 of the algorithm). So, as soon as there is a failure in the containment check, we stop the loop and conclude that the completeness entailment does not hold.
Completeness skip Recall the definition of epg as
Complexity
In this subsection, we analyze the complexity of the problem of data-aware completeness entailment. While the complexity of checking data-agnostic completeness entailment is NP-complete [15], the addition of the data graph to the entailment increases the complexity, which is now
Deciding the entailment
One might wonder, if some parts of the inputs were fixed, what would be the complexity of the entailment problem. We answer this question in the following series of propositions.
The following proposition follows from the reduction proof of Proposition 5, in which the graph is fixed.
Let G be a graph. Deciding the entailment
Now, we want to see the complexity when the BGP P is fixed. Recall that in the algorithm, P dominates the complexity of the instantiation process in the epg operator. When it is fixed, the size of the instantiations is bounded polynomially, reducing the complexity of the entailment problem to NP-complete. Note it is still NP-hard even when the input graph G is fixed.
Let P be a BGP. Deciding the entailment
Let us now see the complexity when the set of statements
Let
Finally, the following proposition tells us that fixing both the set of statements
Let
This result corresponds to some practical cases when queries are assumed to be of limited length19
As also customary in database theory when analyzing the data complexity of query evaluation [63].
Complexity table for the data-aware completeness entailment problem with various inputs fixed (‘×’ denotes ‘fixed’)
Our complexity results with various inputs fixed are summarized in Table 1. From this complexity study, it is therefore of our interest to investigate how well the problem of completeness entailment may be solved in practice. In later sections, we will provide heuristic techniques, as well as experimental evaluations of the problem.
Completeness of queries with projections The above formalization deals with the completeness of queries with no projections (that is, where all variables in the BGP are distinguished). One may wonder, what happens when not all variables are distinguished? The answer depends on whether bag or set semantics is used.
With bag semantics, due to the monotonicity of BGPs, and answer-multiplicity being preserved, our results immediately transfer to queries with projections: a query with projections is complete if and only if the projection-free version of the query is complete.
We do not know a characterization of completeness for queries with projections under set semantics. Nevertheless, Theorem 1 derives a sufficient condition for completeness in this case: whenever the BGP of a query with projections is complete, then the query is also complete under set semantics.
In this section, we leverage completeness reasoning for checking answer and pattern soundness.
Checking answer soundness
We will use data-aware completeness reasoning to judge whether an answer obtained by evaluating a graph pattern over a graph is sound.
Remember the motivating scenario of answer soundness in Section 3.2.1. Consider the mapping
In contrast, consider the mapping
The main theorem of this subsection generalizes the observations of the example. Intuitively, it states that the soundness of some answer-mapping of a graph pattern over a graph is guaranteed exactly if all the graph pattern’s
Let G be a graph,
In fact, Theorem 2 holds for a wider class of graph patterns than defined in this article. We only need the positive part of the pattern to be monotonic, that is, a mapping remains a solution over all extensions of the graph G. We do not make this formal to keep the exposition simple.
Complexity From Theorem 2, the check of whether an answer is sound wrt. a set of completeness statements and a graph can be reduced to a linear number of data-aware completeness checks (as discussed in Section 4). From this, it follows that the complexity of the answer soundness entailment problem is in
Checking pattern soundness
As shown in our motivating scenario, it might be the case that completeness statements guarantee the soundness of a graph pattern as such, that is, all answers returned by the graph pattern are known to be sound, no matter the specifics of the graph. To characterize pattern soundness, we follow the same strategy as before: we reduce the problem of soundness checking to completeness checking.
First, we generalize completeness statements to conditional completeness statements, which express the completeness of a BGP under the condition of another BGP. Given two BGPs P and
Though redundancies may occur in the left-hand side due to the projection, for our characterizations here the ⊆ operation is done under set semantics. Hence, the redundancies are ignored.
This means that the conditional completeness statement is satisfied by the extension pair, whenever the evaluation of the BGP P over the graph G contains the evaluation of P under the condition of
For a set
In the motivating scenario of pattern soundness, it holds that
The following lemma states that the soundness of a graph pattern can be guaranteed if each BGP of the
Let
One might wonder whether the converse of the above lemma also holds. However, the following counterexample shows that it does not.
Consider the following graph patterns:
Taking a closer look, one notices that both graph patterns in fact contain redundancies, which can be checked via query containment under set semantics (written
To identify such redundancies, we associate to each pattern
The BGP
The BGP
With this notion in place, we can obtain the main theorem of this subsection. The theorem states that given an NRF graph pattern, the check of whether it is sound can be reduced to checking whether each BGP among the
Let
In the motivating scenario of pattern soundness, it holds that
Complexity If P is a graph pattern (which may have negated parts) and
For that purpose we introduce a relationship between patterns with negation of which the relationship between a pattern and its NRF is a special case. We say that two graph patterns P,
for every
for every
Note that negation-similarity is in NP, since it can be checked by guessing for every
Negation-similarity is a key-property here because it preserves equivalence.
Negation-similar graph patterns are equivalent.
With this background we can design an NP soundness check for patterns P by, intuitively, first guessing
Let P be a graph pattern. Then there exists a graph pattern
We can obtain such a
Now we have all ingredients in place for an NP-algorithm that checks whether a set of completeness statements nondeterministically drop negated patterns from P; nondeterministically drop atoms from the remaining negated patterns; verify that the resulting pattern verify that
Clearly, the first two steps can be performed in nondeterministic polynomial time. As seen above, also, negation-similarity can be checked in nondeterministic polynomial time. Finally, by Proposition 10, the completeness checks in Step (iv) can be reduced to a linear number of
If the resulting
NP-hardness is clear, since Theorem 3 also shows that completeness checking can be reduced to soundness checking.
Soundness checking of graph patterns is NP-complete.
From a practical viewpoint, one may expect graph patterns of queries and BGPs of completeness statements to be short, potentially allowing for a feasible soundness check. Section 7 reports an experimental investigation of pattern soundness checking in practical cases.
Soundness of queries with projections We have provided a full characterization of the soundness of queries with negation where no projections are involved (or where the projection is over all variables in the query body). One may wonder whether our characterization here can also be used for queries with negation that involve generic projections (that is, where some variables can be non-distinguished). The next example shows that in general, the condition from Theorem 3 is not a necessary condition for pattern soundness entailment of queries with projection.
Consider the following boolean query, which asks whether there is some triple that cannot be right-shifted.
We do not know a characterization of pattern soundness for queries involving projections. Nevertheless, Theorem 3 still gives a sufficient condition for soundness in this case.
Combining soundness and completeness reasoning A graph pattern with negation can be both sound and complete. Theorem 3 characterizes when a graph pattern P in NRF is sound wrt. a set
So far, we have formally characterized completeness entailment, and, for soundness entailment, provided a reduction to completeness entailment. In this section we investigate how completeness checks can actually be implemented in practice. A vanilla implementation of completeness reasoning over a Wikidata-based experiment setting took about 15 s on average for a single completeness check, whereas query evaluation took just about 1 ms. Such a considerable overhead over query evaluation may hinder the adoption of our completeness framework in practical settings. This motivates the need for heuristic techniques that may provide speed-ups. In this section we discuss several possible heuristics for completeness checking, then evaluate their performance in the next section in a realistic setting based on Wikidata.
Before delving further into the discussion of heuristic approaches for completeness checking, we provide basic practical assumptions underlying the development of the heuristics. Our first assumption concerns the length of completeness statements. Similarly to queries, which in many practical cases consist of a limited number of triple patterns [5,58,59], we conjecture that also completeness statements would be of limited length. At the same time, it is conceivable that the number of completeness statements is large in practice, in particular since big KBs such as Wikidata may have many parts of data that are actually complete. Nevertheless, for a given query, most statements are likely to be irrelevant. For example, the statement “All players of Arsenal” is irrelevant to the query “Give founders of the EU.” Consequently, an efficient implementation should filter out such irrelevant statements. Moreover, as users are likely to provide completeness statements for similar topics, we introduce generic completeness templates. By providing a compact representation of completeness statements, completeness templates enable multiple statements to be processed simultaneously. We also provide a heuristic called prioritized evaluation, which tunes the way the crucial part is computed in data-aware completeness reasoning (cf., Eq. (1)).
In the next subsections, we first provide a heuristic technique for a simpler problem, that is, data-agnostic completeness checking, followed by several heuristic techniques for data-aware completeness checking.
Data-agnostic completeness checking
We now address a heuristic technique for data-agnostic completeness checking, originally proposed in [16], which can also be leveraged for pattern soundness checking, thanks to the characterization in Theorem 3. The theorem states that pattern soundness checking can be reduced to the (data-agnostic) checks of whether a set
A simple way (yet efficient, as we will show in Section 7) to implement such subset queries is to build a hashmap of all statements where the key of C is
Consider the following set
… …
The corresponding hashmap is as follows, where the keys are sets of terms occurring in the completeness statements, and the values are sets of completeness statements with those terms:
Consider the query
A potential, theoretical drawback of this heuristic technique is that when queries are long, the number of term subsets generated for hashmap lookups would become large. More precisely, the number of term subsets grows exponentially with the query length (i.e., number of triple patterns). Nevertheless, as discussed above, we expect that queries in the real world are of limited length [5,58,59].
For the data-aware setting, reasoning needs also access to the data graph. The previous heuristic of data-agnostic reasoning, which leaves out statements whose terms are not among the terms of the query, is no more applicable, since parts of the statements can now be mapped to the data graph. We present three heuristic techniques: completeness templates, partial matching, and prioritized evaluation. Their individual and combined impacts on reasoning time are reported in Section 7.
Completeness templates
Templates support users in creating completeness statements about similar topics, as they occur for instance in IMDb, which reports completeness for movie cast and crew,21
See e.g.,
See e.g.,
A key part of the algorithm for data-aware completeness checking, given a statement set
That is, when those mappings are projected to the meta-variables of the template, the projected mappings exist in Ω.
Given a BGP P, a graph G, and a set
The proposition holds basically because the mappings that result from the evaluation of a template over
While the above heuristic technique concerns a data structure, called completeness templates, that bundles similar completeness statements, here we develop a heuristic for filtering out irrelevant completeness statements. In the previous data-agnostic heuristic technique, we perform so-called subset matching: for each statement, collect the set of terms of the BGP and check if this is a subset of the set of terms of the query BGP. This technique is no more applicable because a part of the BGP of a statement can also be matched to the data graph.
For data-aware completeness reasoning, it is sufficient for a completeness statement to be relevant for a query if the statement partially captures the BGP of the query, which in the worst case means to capture just a single triple pattern of the query. This is shown in the computation of the crucial part (Eq. (1)), where the transfer operator is evaluated over the union of the prototypical graph and the data graph, and then is intersected with the BGP of the query. Thus, the notion of relevance needs to be adapted for the data-aware case: A completeness statement may potentially be relevant for a query, if there is at least one triple pattern of the statement which is more general than a triple pattern of the query. The notion of generality is defined as follows: a triple pattern
Let us first sketch a way how to retrieve such partially matched statements. Again, we rely on hashmaps. We use each triple pattern of a statement as a hashkey, by which the statement can be retrieved. Thus, a statement with three triple patterns, for example, can be retrieved in three different ways. To find statements that are potentially applicable to a frozen BGP
Technically, the predicate can be a variable too. Yet, in relation to completeness statements, we believe that to be complete for all possible relationships between two entities might not be reasonable in practice. Hence, only non-predicate terms are generalized.
Let us formalize the above sketch. Our main goal here is partial matching: retrieving only completeness statements having a triple pattern that can potentially be mapped to a triple in a frozen BGP
Next, we index completeness statements according to (the signatures of) their triple patterns. For this purpose, we define a mapping M from signature triples to sets of completeness statements such that the signature triple is in the signature of the statement’s BGP:
Now, we are ready to define the operator
Given a BGP P, a graph G, and a set
This means that instead of taking all the statements in
Partial matching can also be leveraged immediately to support completeness templates: we simply take the (uninstantiated) statements of the completeness templates for building the hashmap in partial matching (that is, the C part in the template
An important operator in checking data-aware completeness is the crucial-part operator,
To formalize the above idea, we define prioritized evaluation of a BGP over a pair of graphs
Consider the BGP
Next, in the prioritized evaluation of a BGP
The algorithm with pruning proceeds as follows. For each non-empty subset
The above discussion concerns the prioritized evaluation of the transfer operator that uses plain completeness statements. For completeness templates, the template-based transfer operator
Trade-offs of the heuristics A potential benefit of the templates are that they can be used to group (possibly many) similar completeness statements into one, and hence we can reduce the number of evaluations in the transfer operator. A potential drawback of using templates are that since their BGPs are by construction more general than completeness statements, the evaluation of the template’s BGP over the data graph may return many results which have to be checked for compatibility wrt. the set Ω of mappings of the template.
As for partial matching, in principle it may filter out many completeness statements (and templates). Still, a potential drawback is that when the statements contain many overlapped parts to each other, then partial matching may consider many partially matched completeness statements, too. Hence, the reduction of the number of completeness statements that need to be considered in completeness reasoning might not be substantial.
As for prioritized evaluation, using it alone can still be expensive when there are a large number of completeness statements that need to be considered. Combining prioritized evaluation with completeness templates may provide a remedy to the generality of the BGPs of the completeness templates, since in this case, the BGPs of the templates have to be checked first if they may capture parts of the query, and only if so, they can be evaluated over the graph.
In Section 7, we will study how such trade-offs may behave in a practical setting, for all possible combinations of heuristics (that is, they may be applied alone, or together).
In this section, we report on our experimental evaluation of query completeness and query soundness reasoning. We have proposed in Section 6 three heuristic techniques for completeness reasoning, namely completeness templates, partial matching, and prioritized evaluation. Consequently, the practical impact of these techniques (and their interplay) on completeness reasoning needs to be validated. Furthermore, in the light of the query soundness problem, we want to study the performance of answer and pattern soundness checking in a realistic setting. The goal of our experimental evaluation is therefore two-fold:
To study how effective are completeness templates, partial matching, and prioritized evaluation, as well as their combinations, for completeness reasoning; and to show the feasibility of soundness reasoning (which in turn reduces to completeness reasoning) in a realistic setting.
Query completeness evaluation
In this subsection, we first describe the experimental setup, followed by the discussion of the results of the experiments.
Experimental setup

Comparison of completeness checking using different heuristic settings. The x-axis is the query length, and the y-axis is the runtime in ms.
Given the three heuristic techniques for completeness reasoning, that is, completeness templates (
As for completeness reasoning, there are three ingredients: graph, queries, and completeness statements. While machine-readable completeness statements in the wild are yet to appear, we aim to make our setup as realistic as possible. We take Wikidata as the graph for our evaluation. More specifically, we use the monolingual, direct-statement fragment (i.e., the fragment without qualifiers, references and non-English labels) of the Wikidata dump released in April 2018. The graph consists of around 491 mio triples (= 57 GB in the uncompressed NT format). We choose Wikidata mainly because of its popularity and good quality.
As for the experiment queries, they have to use the same vocabulary as the Wikidata graph described above. We therefore generate the experiment queries based on human-made, openly available queries on the Wikidata query page.25
If the number of mappings is below 20, then we just take all the mappings.
Now, for the completeness statements, we generate them in a similar way as we generate the experiment queries. The only difference is that, in the second step above, instead of taking randomly 20 of the mappings, we obtain randomly 50% of the mappings to create completeness statements. This is to ensure the generation of a large number of completeness statements. In this setting, we also naturally represent completeness statements by completeness templates as follows: we take the extracted BGP as the template’s BGP, and the projected mappings as the template’s mappings. We generate in total 693,928 completeness statements with the average statement length (i.e., the number of triple patterns in the BGP of completeness statements) of 2.4. Moreover, these statements are represented by 65 completeness templates.
Implementation The reasoning program and experiment framework are implemented in Java using the Apache Jena library.27
Figure 4 summarizes the results of the experiments. The figure shows the runtime comparison of completeness checking using different heuristic settings. The x-axis is the query length, whereas the y-axis shows the runtime in ms, and is in log-scale. We also add the query evaluation time to provide an orientation as to how completeness checking may compare to query evaluation.
In general, we observe that completeness checking using all heuristics (that is, the
Let us now observe the performance of combining the heuristics. Adding partial matching on top of completeness templates provides a runtime improvement, as can be seen from the
Overall, our experimental evaluation has answered the question as to how effective are heuristic techniques (and their combinations) for completeness checking. Partial matching, though seeming promising for short queries, tends to have a negative effect for long queries. Templates and prioritized evaluation are best applied together. Using all the three heuristics brings the advantages of each heuristic into one.
Query soundness evaluation
Here, we describe the setup of the experiments, and then discuss the results of the experiments.
Experimental setup
From the characterizations in Section 5, we are able to check query soundness by reducing it to query completeness checking. Pattern soundness checking can be reduced to data-agnostic completeness checking, for which we proposed a heuristic technique in Section 6.1 that is based on the term-relevance principle. As for answer soundness checking, we also reduce it to the problem of data-aware completeness checking. In Section 7.1, we have shown that not only using all the heuristics of completeness templates, partial matching, and prioritized evaluation yields runtime improvements over a plain implementation of a completeness reasoner, but also that the approach where all these heuristics are applied in combination performs the best. Given these improvement techniques for completeness checking, we want to study the feasibility of soundness checking in a realistic setting. Additionally, we want to know how pattern soundness checking compares to answer soundness checking, and how soundness checking compares to query evaluation.
For experimentally evaluating query soundness, we (again) require three ingredients: graph, queries, and completeness statements. We use the Wikidata graph that is described as before in the experiments in Section 7.1. For the experiment queries, now we need queries with negation. Similarly as before, we take Wikidata queries,28
Completeness statements We used two different methods of generating completeness statements depending on whether we wanted to perform either answer soundness or pattern soundness checking. As for the generation of statements for answer soundness, we wanted to perform it in such a way that there will be a variety of sound and possibly unsound answers. So, we generated the statements as follows: (i) given a query, we evaluated the query and obtained all the answer-mappings; (ii) for 25% of these answer-mappings, we applied them to the BGP of each
In this setting, we can naturally represent completeness statements by completeness templates (see Section 6.2). We took the BGP of the
In the particular case of
We fixed an ordering.
For the generation of statements for checking pattern soundness, we simply transformed the union of the positive part and each BGP of the
We had five different cases for our experimental evaluation by combining different query sets and completeness statements:
The number of statements
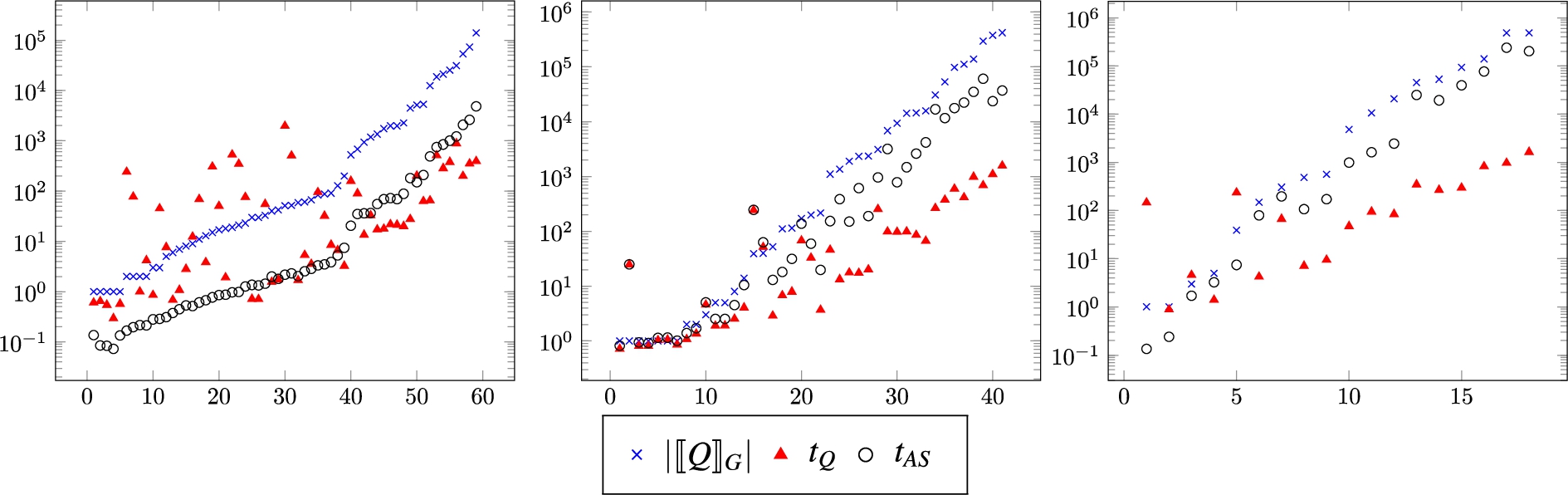
Comparison between the number of query answers (
In each case, to perform answer soundness checking, we did not use the statements generated based on pattern soundness since that would have made all the answers sound. On the other hand, to perform pattern soundness checking, we also used all the statements generated based on answer soundness, as otherwise there would have been too few statements (= the number of queries per case). We measured the runtime of soundness reasoning for both pattern and answer, and also that of query evaluation. For each case, we removed the measurements where the query evaluation returned 0 answers, as answer soundness checking would have become trivial. Each measurement was repeated 15 times and we took the median. Moreover, to get the result summary of each experiment case, we also took the median over the case’s results. We used median to avoid the effect of extreme values (that is, some queries returned a large number of results, up to about 490,000 results). The experiments were done on a PC with an Intel Core i7 3.6 GHz-processor, a 16 GB memory, and an HDD of 1 TB.
Table 2 summarizes the results of the soundness reasoning experiments for five cases. In the table, query evaluation time ranges from 20 ms to 89 ms. Pattern soundness checking always takes less than 0.3 ms. The term-relevance principle is likely to help rule out irrelevant completeness statements before performing the actual pattern soundness checking. Note that the pattern soundness checking time for the
As for answer soundness checking, we observe that the runtime ranges from 2 ms to 592 ms. The
Let us look more closely at answer soundness checking. Figure 5 shows the comparison between the number of query answers, query evaluation time, and answer soundness checking time for cases
To summarize, we have performed an experiment evaluation for soundness checking over a realistic setting based on Wikidata. Soundness checking using the heuristic techniques as proposed in Section 6 has been validated to be feasible for our experiment cases. To get an idea of how long soundness checking may take without using any heuristics, we perform vanilla answer soundness checking for the
Related work
In this section, we discuss related work for query completeness and query soundness.
Query completeness Data completeness concerns the breadth, depth, and scope of information [65] and is deemed to be one of the most significant data quality dimensions [6]. In the field of relational databases, Motro [41] and Levy [35] were among the first to investigate data completeness. Motro modeled completeness of an available database instance in terms of its relationship with a hypothetical, unknown instance that represents the real world. This model has been taken up in the present paper by the notion of extension pairs. Motro also defined completeness constraints, which correspond to our completeness statements and developed a sound technique to check query completeness of conjunctive queries in the data-agnostic setting. Levy generalized completeness constraints to local completeness statements, which correspond to the conditional statements in Section 3.2.2 and are more expressive than the statements in the framework studied here.
Razniewski and Nutt [54] further extended this work by reducing completeness reasoning to containment checking, for which many algorithms are known, and by characterizing the complexity of reasoning for different classes of conjunctive queries. While their investigations were largely at the schema level (that is, data-agnostic), they also showed that for conditional statements the combined complexity of completeness checking in the data-aware setting is
This line of work on data-agnostic reasoning was later continued by Darari et al. [15,16], incorporating orthogonal aspects such as time-awareness and federation. In contrast, the present work focuses on more restrictive, yet also more intuitive unconditional completeness statements, for which it provides an in-depth complexity analysis and implementation techniques for data-aware reasoning. The problems of answer and pattern soundness are also completely new. In [53], Razniewski et al. proposed completeness patterns and defined a pattern algebra to check the completeness of queries. The work incorporated database instances, yet provided only a sound algorithm for completeness checking. In our work, a sound and complete algorithm for data-aware completeness checking and a comprehensive complexity analysis of the checking are given.
On a more abstract level, Fürber and Hepp [23] distinguished three types of completeness: ontology completeness, concerning which ontology classes and properties are represented; population completeness, referring to whether all objects of the real-world are represented; and property completeness, measuring the missing values of a specific property. Those three types of completeness together with the interlinking completeness, i.e., the degree to which instances in the dataset are interlinked, are considered to be the bases of the completeness dimension for RDF data sources [66]. Our work considers completeness statements which are built upon BGPs, and hence have more flexibility in expressing completeness (e.g., “complete for all children of the US presidents who were born in Hawaii”). Mendes et al. [38] proposed Sieve, a framework for expressing quality assessment and fusion methods, where completeness is also considered. With Sieve, users can specify how to compute quality scores and express a quality preference specifying which characteristics of data indicate higher quality. Ermilov et al. [21] presented LODStats, a statistics aggregation of RDF datasets published over various data portals such as data.gov, publicdata.eu, and datahub.io. They discussed several use cases that could be facilitated from such an aggregation, including coverage analysis (e.g., most frequent properties and most frequent namespaces of a dataset). As opposed to Sieve and LODStats, our work puts more focus on describing completeness of data sources, and leveraging such completeness descriptions for checking query completeness (and soundness). In the context of crowdsourcing, Chu et al. [10] developed KATARA, a hybrid data cleaning system, which not only cleans data, but may also add new facts to increase the completeness of the KB; whereas Acosta et al. [1] developed HARE, a hybrid SPARQL engine to enhance answer completeness. As opposed to our work, KATARA and HARE cannot be used to check whether queries are complete in the sense that all answers are returned, as they concentrate more on increasing the degree of KB and query completeness.
Galárraga et al. [25] proposed a rule mining system that is able to operate under the Open-World Assumption (OWA) by simulating negative examples using the Partial Completeness Assumption (PCA). The PCA assumes that if the dataset knows some r-attribute of x, then it knows all r-attributes of x. This heuristic was also employed by Dong et al. [20] (called Local Closed-World Assumption in their paper) to develop Knowledge Vault, a Web-scale system for probabilistic knowledge fusion. Our completeness statements are in fact a generalization of the assumption used in the above work.
Query soundness The use of negation in querying can be traced back to Codd’s relational calculus [12], where a tuple is included in the complement of a relation if it is not explicitly given in the relation. Reiter [56] and Clark [11] generalized this to rule-based systems. They assumed that the failure to find a proof of a fact implies that the negation is true, and called this the closed-world assumption (CWA). SPARQL, the standard query language for RDF, supports negation by such a non-existence check [28,52]. However, since the semantics of RDF imposes the open-world assumption (OWA) [29], there remains a conceptual mismatch when negation in SPARQL over RDF datasets is evaluated in a closed-world style. In other words, there is a missing gap between the normative semantics of negation in SPARQL, which is based on the negation-as-failure (‘negation from the failure to find a proof of the fact’) [57], and the classical negation (‘the negated fact truly holds’) [26] due to RDF’s openness. Moreover, the fact that RDF is a positive language, means that one viable way of having negated facts in RDF is by imposing some (partial) completeness assumption over RDF data: whenever P is complete, then all facts not in P are false.
In the Semantic Web, Polleres et al. [49] first observed this mismatch. They proposed to restrict the scope of negation to particular data sources, thus limiting the search for negative information. In their work, no assumption was made as to whether the knowledge in these data sources is complete. In description logics (DLs), Lutz et al. [37] proposed closed predicates, that is, concepts and roles that are interpreted to be complete, to enable a combination between open- and closed-world reasoning. A similar concept was also employed by Analyti et al. [2]. They proposed ERDF, an extended RDF that supports negation, as well as derivation rules. ERDF allows one to have local closed-world information via default closure rules for properties and classes. As opposed to these two approaches, which considered only a simple partial CWA over atomic classes and properties (e.g., all cars, all child relationships, …), our work supports more expressive completeness information in the sense that we can use BGPs to capture completeness. From the practical side of the Semantic Web, negation is featured in test queries of many popular SPARQL benchmarks such as SP2Bench [61], Berlin SPARQL Benchmark (BSBM) [7], and FedBench [60], in which the closed-world assumption (CWA) is employed. Our work does not only provide formalizations, but also optimization techniques for checking the soundness of queries with negation, for which we have experimentally shown to improve the feasibility of the soundness checking in realistic settings based on Wikidata.
More recently, Gutierrez et al. [27] proposed an alternative semantics for SPARQL based on certain answers. They argued that the proposed semantics is more suitable to capture RDF peculiarities, such as OWA, unique name assumption (UNA), and blank nodes. For queries with negation, they showed that the queries do not have certain answers, since more facts can be arbitrarily added to falsify the query answers. In our work, we combine between open- and closed-information in RDF, enabling SPARQL queries with negation to have answers that are guaranteed to remain. That is, when queries are guaranteed to be sound by completeness statements, new data that might be added to the graph is restricted by the statements, hence the answers will not be falsified.
Weak monotonicity The open-world semantics of RDF has led to the question which type of queries appropriately reflects this fact. Arenas and Pérez noted that for positive graph patterns, that is, patterns composed by the operators AND, UNION, and FILTER, the semantics of SPARQL reflects the open-world semantics in that the answers for such a pattern are exactly the certain answers [3].
As an additional feature that supports querying incomplete information, SPARQL offers the OPT constructor that binds variables if they can be matched to the data, and leaves them unbound otherwise. Patterns with OPT are not necessarily monotone because adding triples to a data graph may lead to bindings for variables that were not bound previously. Such patterns may however be weakly monotone, that is, for every answer mapping returned over the smaller graph there is an answer over the larger graph that extends it. Thus, weakly monotone patterns do not lose information when new information becomes available, although they may not preserve the shape of answers.
While not all patterns with OPT are weakly monotone, this is the case for the class of well-designed patterns [3]. It has been shown, though, that there also weakly monotone patterns beyond the well-designed patterns. Arenas and Ugarte have investigated patterns that are weakly monotone over potentially infinite graphs and characterized them by applying interpolation techniques from first-order logic [4].
In the presence of incomplete data, OPT can be interpreted in two different ways. For example, the pattern
Darari et al. have characterized completeness of well-designed patterns in the data-agnostic setting [15,16]. We conjecture that techniques from that work and from the current paper can be combined to reason about the completeness of well-designed patterns in the presence of data.
Discussion
Here we discuss issues related to our framework: creation of completeness information, no-value information, blank nodes, and RDFS extension.
Creation of completeness information Our framework relies on the availability of machine-readable completeness information. We found a widespread interest in collecting completeness information in various forms, for example on Wikipedia, IMDb, and OpenStreetMap. The techniques we develop may serve as an incentive to standardize such information and to make it available in RDF, since then not only is such information useful for managing data quality, but also for assessing query quality in terms of completeness and soundness.
Ideas for approaches to automating the generation of completeness information were collected in [55]. Galárraga et al. [24] investigated various signals, such as popularity, update frequency, and cardinality, that can be used to identify complete parts of a KB via rule-mining techniques. Mirza et al. [39,40] developed techniques for relation cardinality extraction from text, which can be leveraged to generate completeness statements in the following way: when the extracted cardinality of a relation matches with the relation count in a KB, then a completeness statement can be generated. COOL-WD is a collaborative, web-based system for managing and consuming completeness information about Wikidata, which currently stores over 10,000 real completeness statements [51], and is available at
No-value information Completeness statements can also be used to represent no-value information. Such information is particularly useful to distinguish between a value that does not exist due to data incompleteness or due to its inapplicability. Wikidata, for instance, contains about 19,000 pieces of no-value information over 269 properties.30
As of Feb 18, 2017.
SPARQL fragment In this paper we have focused on conjunctive SPARQL, that is, SPARQL without
Blank nodes The use of blank nodes in RDF has been a controversial topic in the Semantic Web community [13,47]. In Linked Data applications, blank nodes add complexity to data processing and data interlinking due to the local scope of their labels [22,30]. With respect to SPARQL, there are semantic mismatches with the RDF semantics of blank nodes, e.g., when
For the former usage, completeness of a topic that contains a blank node is contradictory, as we argue that completeness statements should capture only “known and complete” information. For instance, one may state that a graph is complete for triples of the form
For the latter case, Skolemization as a way to systematically replace blank nodes with fresh, Skolem IRIs may be leveraged with almost interchangeable behavior [14,29,31], except that Skolem IRIs have a global scope instead of a local scope. This way, completeness statements can capture n-ary relation information encoded originally with blank nodes, and completeness reasoning (which involves SPARQL queries) behaves well (i.e., no semantic mismatches as per [32]). Nevertheless, in practice Semantic Web developers often tend to directly use IRIs instead of blank nodes for representing auxiliary resources, for instance by Wikidata [22].31
For instance, the resource IRI of Wikidata for the marriage between Donald Trump and Ivana Trump is http://www.wikidata.org/entity/statement/q22686-f813c208-48b2-9a72-3c53-cdaed80518d2.
RDFS extension RDFS [8] adds lightweight semantics to describe the structure and interlinking of data, usually sufficient for Linked Data publishers [30]. Main RDFS inference capabilities consist of class and property hierarchies, as well as property domains and ranges [30,43], which are widely used in practice [50]. Darari et al. [15] formalized the incorporation of RDFS in data-agnostic completeness reasoning. Using a similar technique as in [15], it is also relatively easy to extend our data-aware completeness reasoning framework with the RDFS semantics. The idea is that we strengthen our syntactic characterization of computing the epg operator (see Section 4.1) via the closure operation wrt. RDFS ontologies [43]. More precisely, in the crucial part, the closure has to be computed before and after the
Extending the completeness and soundness characterizations to relational databases Our completeness and soundness results are based on RDF and SPARQL, which are the triple-based data model and triple-pattern-based query language for the Semantic Web. However, analogous algorithms, characterizations and complexity results can also be formulated and proved for relational databases if we generalize triples to n-ary relations and conjunctive patterns to projection-free conjunctive queries. The completeness statements in this paper can be generalized in two ways. One way is to view them as so-called query completeness statements, which state that a given query is complete (see [42]), where the query in this case is projection-free. Another way is to see them as collections of local completeness statements (see [35,54]). The proofs for the analogous results would be similar to the ones given here. This class of completeness statements, however, has not yet been considered in the relational setting, while they arise naturally in the Semantic Web context.
The open-world assumption of RDF and the closed-world evaluation of SPARQL have created a gap on how we should treat the completeness and soundness of query answers. This paper bridges the gap between RDF and SPARQL via completeness statements, metadata about (partial) completeness of RDF data sources. In particular, we have introduced the problem of query completeness checking over RDF data annotated with completeness statements. We also developed an algorithm and performed a complexity analysis for the completeness problem. Then, we formulated the problem of soundness for SPARQL queries with negation, and characterized it via a reduction to completeness checking. We proposed optimizations for completeness checking, and provided experimental evidence that our techniques are feasible in realistic settings over Wikidata for both query completeness and soundness problems.
Our current approach tackles the core fragment of SPARQL, and can be easily adapted to provide sufficient characterizations of richer fragments (e.g., involving union, arithmetic filter, or—for queries with negation—the selection operator), setting a solid basis for future investigations into the full characterization of those fragments. Also, while the current completeness statements are constructed using BGPs, one might wonder what happens if richer constructors are added, to enable statements like “Complete for all students who were born after 1991 and who do not speak German.” On the practical side, the availability of structured completeness information remains a core issue. We hope that our work provides a further incentive for standardization and data publication efforts in this area. Another future direction is to study how (Semantic) Web data publishers and users perceive the problem of completeness, and how they want to benefit from data completeness. Extensive case studies may be conducted in various application domains like healthcare, economics, or government. The purpose is to analyze whether our approach is sufficient or not for their requirements, and if not, on which side it can be improved. Last but not least, we want to study how the soundness of queries with the
Footnotes
Acknowledgements
Werner Nutt has been partially supported by the project TaDaQua, funded by the Free University of Bozen-Bolzano. Sebastian Rudolph has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771779). We thank Sebastian Skritek, Martín Ugarte, and the anonymous reviewer for their valuable feedback.