
Abstract
In this paper we present QA3, a question answering (QA) system over RDF data cubes. The system first tags chunks of text with elements of the knowledge base, and then leverages the well-defined structure of data cubes to create a SPARQL query from the tags. For each class of questions with the same structure a SPARQL template is defined, to be filled in with SPARQL fragments obtained by the interpretation of the question. The correct template is chosen by using an original set of regex-like patterns, based on both syntactical and semantic features of the tokens extracted from the question. Preliminary results obtained using a limited set of templates are encouraging and suggest a number of improvements. QA3 can currently provide a correct answer to 27 of the 50 questions of the test set of the task 3 of QALD-6 challenge, remarkably improving the state of the art in natural language question answering over data cubes.
Introduction
Governments of several countries have recently begun to publish information about public expenses, using the RDF data model [24] in order to improve transparency. The need to publish statistical data, which concerns not only governments but also many other organizations, has pushed the definition of a specific RDF-based model, i.e., the RDF data cube model [6], whose first draft was proposed by W3C in 2012, and its current version was published in January 2014. The availability of data of public interest from different sources has fostered the creation of projects, such as LinkedSpending [14], that collect statistical data from several organizations, making them available as an RDF knowledge base, following the Linked Data principles. However, while RDF data can be efficiently queried using the powerful SPARQL language, only technical users can effectively extract human-understandable information. The problem of providing a user-friendly interface that enables non-technical users to query RDF knowledge bases has been widely investigated during the last few years. All the proposed solutions provide some systems which translate simple actions and statements entered by the user into a SPARQL query, whose result represents the answer to the intention that the user expressed through its operations. Among these systems we find those based on exploratory browsing, faceted search and by-example structured query are based on a tailored user interface, that requires user training and provides limited expressivity statistical queries (for instance limited or no support for inner select, group-by or other aggregate operators). Seeking to overcome these problems, recent work has focused on natural language interfaces which let the user type any question in natural language and translate it into a SPARQL query. While NL QA can be very user-friendly and potentially very expressive it poses many difficult research issues. In fact, while many systems only accept a controlled natural language (CNL), that is a language which is generated by a restricted grammar and vocabulary, and can be efficiently interpreted by machines, more recent work focus on free natural language question answering over RDF data.
The current state-of-the-art system for (free) question answering over Wikipedia/DBpedia is Xser [32], which was able to yield an F-score equal to 0.72 and 0.63 in 2014 and 2015 QALD challenges [31] respectively. Although its accuracy is far from being very high, Xser largely won over the other participating systems. This confirms that translating natural language questions into SPARQL queries is a really hard task.
In particular, the problem of creating NL QA interfaces for RDF data cubes is one that has received much recent attention and proven particularly challenging. Statistical question answering (SQA), meaning question answering over data cubes, is a very recent research area born thanks to the success of projects such as OpenSpending,1
In this paper we propose QA3 (pronounced as QA cube), a free natural language question answering system tailored for RDF cubes. It is based on a general tagging system and an original regex-like pattern language to describe flexible SPARQL partial templates. Their use is interleaved, that is, tagging helps the matching and filling in the correct template, but it can also be driven by the results of the matching. A question only partially tagged, or a chosen template which is incompletely filled in are signs that the question was interpreted to a limited extent or wrongly interpreted. This makes the system very flexible and tunable in its ability of trading off precision vs recall, depending on the applications. As we will see in the following, QA3 participated in the set of the task 3 of QALD-6 challenge, remarkably improving the state of the art in free natural language question answering over data cubes.
The paper is organized as follows. First, in Section 2 the model used to represent data cubes in RDF is described. Then, the approach used by QA3 is presented in Section 3, and preliminary experimental results are reported in Section 4. Section 5 reviews the related work in the area of Statistical Question Answering over RDF data. A discussion on the specific problem of answering OLAP-related questions through natural languages and lessons learned in this work, including possible improvements, are presented in Section 6. Finally, Section 7 concludes the paper, describing the ongoing work.
The RDF Data Cube Vocabulary [6] has been recently proposed as a W3C Recommendation for representing multi-dimensional statistical data using the RDF format. The model underlying this vocabulary is based on the SDMX model [29], an ISO standard for representing statistical data that can be shared among organizations.

The RDF data cube model simplified.

Example of possible triples using the RDF Data Cube Vocabulary.
In the following, we briefly describe the RDF data cube model, focusing our attention on the features depicted in Fig. 1, that are the most relevant to the question answering task. A data cube, called dataset, is an instance of the class
Figure 2 depicts a set of triples that use the RDF data cube vocabulary. Assuming that the prefix

Overview of the internal steps performed by QA3.
QA3 is a system that translates natural language questions into SPARQL queries, assuming that the answer to the questions can be provided using the knowledge base (KB) “known” by the system. In particular, the KB contains a set of data cubes stored using the RDF data cube model described in Section 2. QA3 works in three steps:
the question is tagged with elements of the KB, belonging to the same dataset. This step also detects which dataset is the most appropriate to answer the question; the question is tokenized, using the Stanford tokenizer and POS tagger [19], and the tags obtained at this step are augmented using the tags obtained at the previous step. The sequence of tokens is then matched against some regular expressions, each associated with a SPARQL template; the chosen template is filled with the actual clauses (constraints, filters, etc.) by using the tags and structure of the dataset.
Figure 3 visually shows the steps performed by QA3. In the following, each step is described in more detail.
Tagging the questions with elements of the KB
The purpose of the first step of the finding the correct dataset to be queried, and finding references in the question to concepts and values in that dataset, to generate the SPARQL query in the following steps.
It must be noted that missing the correct dataset will definitely lead to a completely wrong answer, therefore accuracy in this step is of paramount importance to keep final performance acceptable. Furthermore, the problem of finding the right dataset is peculiar to the statistical question answering over linked data, since most of the other general-purpose question answering systems assume only one given KB, either a single one or the union of different KBs. In statistical QA, a system should be able to answer questions over hundreds of publicly available datasets about government spendings. For instance, the project LinkedSpending [14] currently counts about 1K datasets. In order to avoid ambiguities and non-sense, such as aggregating a measure defined in a dataset over observations defined in a different dataset, the creation of a unique big dataset from the union of all given datasets is impractical.
The idea behind the solution for this step adopted by

First, an in-memory index of all literals (labels, comments, and values) contained in each dataset is created, associating each of them to the corresponding URI in the RDF cube graph. As a simple optimization, we index multiple occurrences of the same literal only once. Although lossy, since different URIs may be associated to the same literal, this trivial compression reduces by orders of magnitudes (depending on the dataset) the footprint of the index, scaling well even for large datasets (where chances of multiple occurrences are much higher).
All textual elements, that are keys in the indexes and the question itself, are normalized, by removing the stop words and performing lemmatization by means of the WordNet lemmatizer. For maximum recall and resilience, the system also handles optional synsets, such as those provided by WordNet, although in our experiments we only used the following two equivalence classes:
After normalization, for each dataset the question is tagged with the corresponding index. Given a dataset, we are able to tag the question with linear time complexity, by applying the following approach: we lookup the index for every n-gram from the question, with n varying from 7 to 1. This way if our normalized question is composed of k words, we perform
The result of the matching between Q and the dataset D can be represented as a set of pairs
The domain in which QA3 operates is strongly structured, especially if we compare it to the domain in which general purpose question answering systems are required to work. As a consequence, the meaningful questions (i.e., questions that can be answered using the available KB) are likely to have a SPARQL translation which follows a limited set of well defined templates. For instance, following the running example in Section 2, if the user wants to know how much her city spent for public works in 2015, the question has to contain all the elements needed to detect the dataset to be used, the measure to aggregate and the aggregation function, and the constraints to be applied to restrict the computation on the observations in which the user is interested. This question, like a wide range of similar questions, can be answered by using the following SPARQL query template:
where
Another possibility is asking which department has spent the most in 2015. In this case, the SPARQL query will select the value of the dimension that represents the department, and will provide the one associated with the largest sum of money spent. Even this question, like most of the questions that can be asked in this domain, can be answered using a SPARQL query which has a structure that can be used to answer many similar questions.
In order to leverage the typical homogeneity of the structures of these questions, we implemented a system which allows the definition of a set of SPARQL templates and to automatically detect the one that should be used to provide an answer. To this end, each template is associated with one (or possibly more) regular expressions built on the tokens of the questions. The tokens are obtained using the Stanford parser [19], which tokenizes the question and annotates each token with its lemma, its POS (part of speech) tag, and its NER (named entity recognition) tag. We augment the annotations with the elements of the knowledge base (dataset, measure, dimension, attribute, literal) provided by the previous step, and with a tag representing a possible aggregate function. For the latter, we associated each aggregation function with words that users typically use to denote the function, as reported in Fig. 4.

Words used to recognize aggregate functions in questions.
Thus, for each token we have the following features:
the POS tag
the lemma
the word (i.e., the original text)
the NER tag
the KB tag (S: dataset, M: measure, D: dimension, A: attribute, E: entity, L: literal, O: none)
the aggregation tag (S: sum, A: average, M: max, N: min, O: none)
A generalized-token is defined as a 6-tuple, where the ith element represents the possible set of values for the ith feature of the actual tokens (the features are assumed to follow the order in which they are listed above). For instance, the generalized-token
A generalized-token can be followed by a

Pattern/Templates used by QA3 and an example of matching query for each template.
We describe in detail one of them, namely number 4, which is the most complex:
Each of the 6 generalized-tokens of the expression above must match subsequent chunks of the whole question. A question, seen as a sequence of tokens, matches the expression above if it consists of contiguous sub-sequences of tokens with the following properties:
any sequence of tokens (
a token with the POS tag
any sequence of tokens, whatever their POS tag, lemma, word, and NER are (
a token with any POS tag, any lemma, any word, and any NER, without any specific KB annotation (
any sequence of tokens with any POS tag, any lemma, any word, and any NER, with a KB annotation that can be a measure (
any sequence of tokens (
This expression can be matched against several questions, such as: “What is the total aid to the Anti Corruption Commission in the Maldives in 2015?”. In general, questions matching this expression ask for the computation of an aggregation function, which is represented by the token with label 1 computed over a measure, which is represented by the token with label 2. This expression also considers the possibility that the measure is implicitly denoted by the name of the dataset (this can happen, for instance, when the dataset is about a specific measure of a set of observations – expenditures of the town of Cary), or that the measure is not explicitly mentioned. In this case, we assume that a default measure is defined for each dataset. The default measure is obvious for datasets with one only measure. In case of multiple measures, our system needs to manually define the default measure for the dataset. This operation is performed just once, when a new dataset is added to the whole KB.
The questions of this kind can be translated into a SPARQL query with the following structure (template):
where
We remark that this strategy for deriving the SPARQL template is quite general and the definition of new templates is quite simple. Although capturing all the natural language questions is not possible through a finite set of patterns (for instance, none of the 7 patterns can match the QALD query “Top 3 IW Council Spending service areas?”), as we show in Section 4 we empirically found that few expressions are enough to cover most of the questions posed in a typical form.
The input to this step is the output of the previous two steps, i.e., the SPARQL query template, the dataset to be used, and the tokens with the annotations based on the KB tags. In particular, given the SPARQL template, some portions of the template must be replaced in order to obtain the final query, by using the result of the previous KB tagging. For instance, as stated above, if a literal is tagged, then it must be connected to the observation through an attribute, which is also reported in the annotation; if an entity is tagged, then it must be connected to the observation through a dimension. The dimension could be explicitly tagged in the question, but can also be derived by maintaining an index that maps every entity e to the dimensions which can take e as value.
The substring
Regarding the group-by variable and clause, we observe that a question requiring their use has to contain an attribute or dimension which is not bound to a value (literal or entity, respectively). Therefore, we can try to find those tokens that are tagged with a dimension/attribute X to which no value is associated. We then replace
Experimental results
We implemented the backend of QA3 [4] using Python and Java3
The Python code implementing the initial tagging step is available at
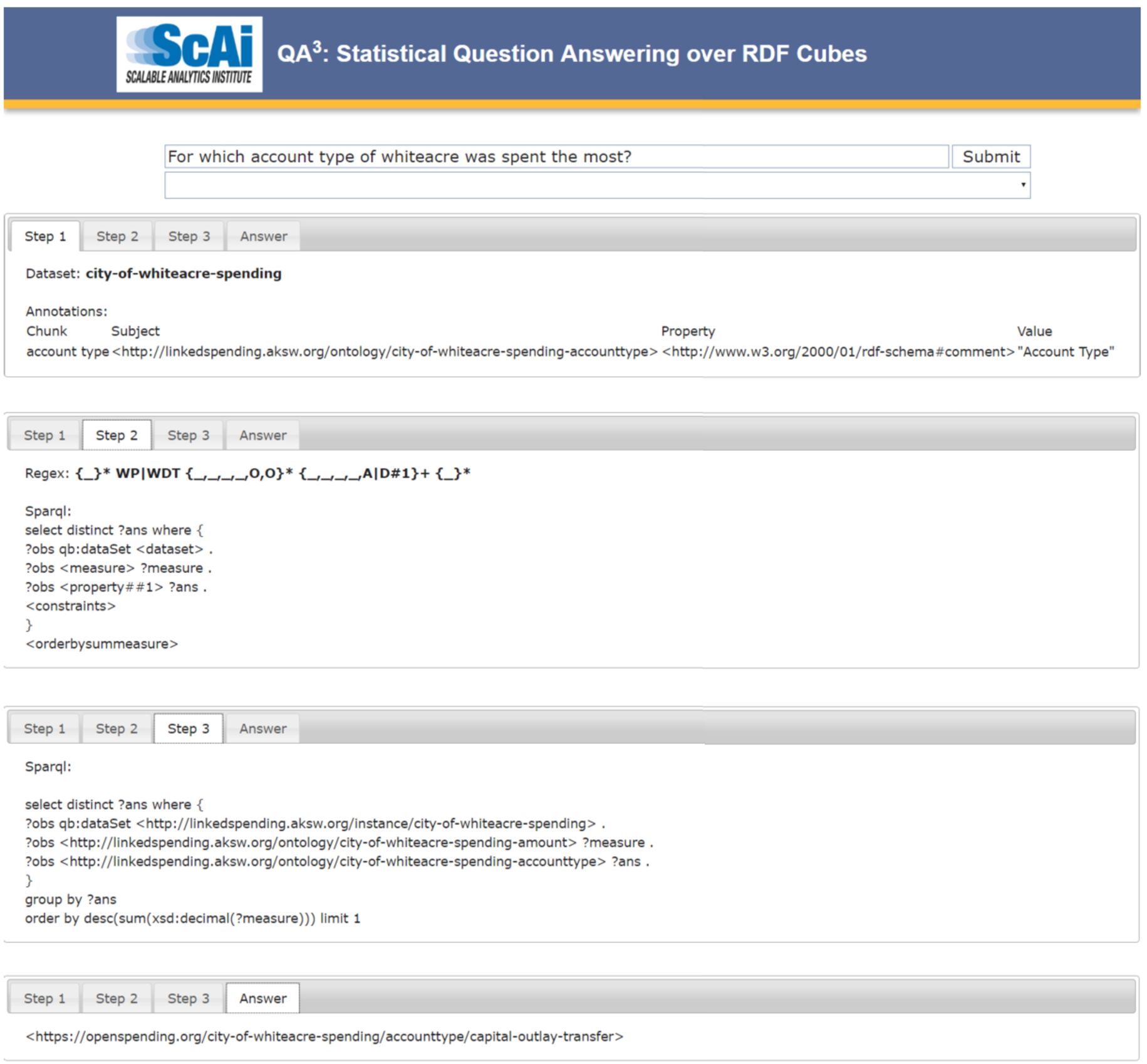
Screenshot of the QA3 web interface, showing all the steps followed by the system and the final answer for an example question taken from QALD-6.
The online system allows the user to freely type questions, but it also provides her with a quick selection of the questions of the training and test sets of the task 3 of QALD-6 challenge [31], for which the experimental outcomes are described next.

Overall results obtained by current setting of QA3 (using multiple candidate datasets) on QALD-6 training set and test.
Figure 7 reports the number of total questions (column “N”), and the results obtained by QA3 [4] over the two sets of questions, as computed by the QALD challenge, that is, averaging precision and recall for each answer, where some answers may be partially correct (e.g., those returning lists of results). Besides the average recall, precision and F1-score computed over all the questions, it is interesting to analyze the accuracy of the internal steps of QA3. In particular, for the training set, over 100 available questions, the correct dataset (column “Correct DS”) is found for 81 questions, the correct set of tags is found for 56 questions, and the correct query is generated for 47 questions. QA3 performed even better on the test set:4
Note that these results are not the official ones: they are slightly different since we did some minor improvements on the prototype after the challenge.
A direct comparison against the other systems described in Section 5 has been independently performed by the QALD 6 Challenge [31], as reported in Fig. 8. The best performer in this comparison is SPARKLIS,5
In fact, it is a special version of the SPARKLIS system tailored to statistical questions, as described in the related work section.
To the best of our knowledge, the only two systems that answer free natural language questions over RDF cubes are CubeQA [16], described in the next section, and our QA3. Compared to the state-of-the-art CubeQA, we get a remarkable improvement of
We also remark that F1 and F1 Global, i.e., the F1 measure computed over all questions (not only those for which the system provides an answer) are respectively
From a general point of view, querying RDF data through user-friendly interfaces is an active area of research, with quite different approaches. To the best of our knowledge most of the proposed work can be categorized into two main approaches: (1) based on ad-hoc user interfaces, and (2) question answering systems, either accepting (free) natural language or constrained natural language. Among question answering systems, it is possible to distinguish those focusing on general RDF data, with the majority of them using the DBpedia ontology, and those called Statistical Question Answering systems, aiming at querying a large number of datasets containing RDF data cubes.
Our work falls into the Statistical Question Answering category, since QA3 queries RDF data cubes by allowing users to write the query the way they like, while disambiguation and understanding are accomplished by the system.
In the following we discuss existing work on querying RDF data using the taxonomy discussed so far: (1) based on ad-hoc user interfaces, (2) question answering systems accepting natural language or CNL and (3) statistical question answering systems, specifically addressing RDF data cubes.
Per-question accuracy of QA3 (see Fig. 7 for overall accuracy)
Per-question accuracy of QA3 (see Fig. 7 for overall accuracy)
(Continued)

Comparison against other QA systems, as reported by the QALD-6 independent competition.
A number of very different interfaces to query RDF data in a user-friendly way have been proposed.
Exploratory browsing allows users to navigate through the triples of the RDF graph by starting from an entity (node) and then clicking on a property (edge), thus moving to another entity. Although the users do not need to know beforehand the exact names of properties, this approach can be effectively used only for exploring the graph in the proximity of the initial entity. Furthermore, this approach is not suitable for aggregate queries, which are the real first-class citizens in the world of RDF data cubes.
Faceted search supports a top-down search of RDF graph, by starting with the whole dataset as potential results, and enabling the user to progressively restrict the results by defining some constraints on the properties of the current result set [8,9,11,13]. This approach was recently applied to the RDF data cubes [22], following the long tradition of graphical user interfaces for OLAP analysis, based on charts representing different kinds of aggregation of the underlying data.
Another user-friendly system for querying RDF data is SWiPE [3,5,33], which makes the infobox of WikiPedia pages editable as if it was a fillable form. The user can type the constraints using the value fields of the infobox, according to the By-Example Structured Query (BEStQ) paradigm – a QBE-inspired interface to query DBpedia or similar RDF data. While this paradigm is very effective for finding lists of entities with specific properties and/or temporal constraints [33] starting from a Wikipedia page, its generalization to the RDF data cubes is not trivial.
Work on question answering over linked data
Natural language interfaces are the most challenging solutions to the problem of querying RDF data. These systems generate a SPARQL query from any user question expressed in natural language. As we stated in the introduction, the current state-of-the-art system is Xser [32], that works in two steps. In the first step, phrases are extracted from the question using a structured perceptron that can identify variables, entities, classes, and relation phrases. By means of a semantic parser, the predicate-argument structure of phrases is derived, thus obtaining the structure of the query intention. In the second step, the semantic phrases are mapped against the elements of the knowledge base (specifically, DBpedia) by using WikipediaMiner [25] for entities, and an ad-hoc lexicon that maps classes and relation phrases.
Another recent QA system is AskCO [2] that computes the answer of a natural language question by finding a source code in a RDF dataset called CodeOntology [1] that, if executed, returns the expected answer.
The difficulty of the QA task can be reduced by using a controlled natural language (CNL), i.e., a language constrained by an ad-hoc grammar that can be easily interpreted by machines, yet natural enough to be easily understood by non-technical users. Some of the CNL-based systems that participated in past QALD challenges are Squall2sparql [10] and GFmed [21].
Squall2sparql [10], is a CNL system that translates queries written using its SQUALL language into SPARQL. The translation is based on about 100 rules of a Montague grammar. The chunks of the SQUALL sentence must be annotated by the user, and written in a form that enables the direct mapping to elements of the knowledge base. The language enables users to both query and update the knowledge base, and uses all the SPARQL features. Therefore, its Squall2sparql interface to RDF seems to push the CNL idea to its extreme, inasmuch as it achieves the greatest expressive power, but the need to manually annotate the chunks of the sentences severely limits its usability – a fact recognized by the author who proposes the use of a meta-level interface to guide the user in writing annotated questions.
GFMed [21] is a CNL system specialized for the biomedical domain. It is based on the Grammatical Framework [28], which enables the definition of grammars by means of an abstract syntax and one or more concrete syntaxes. The abstract syntax defines the concepts that can be expressed as non-terminal symbols and the rules for their composition. The concrete grammar defines how the trees specified through the abstract syntax are linearized into sentences of a specific language (e.g., English, SPARQL, etc.). The possibility of defining more concrete syntaxes allows GF to serve as a powerful tool for translating sentences from one language to another. The GFMed system consists of a GF program that defines a grammar allowing to pose questions over the knowledge bases such as DrugBank, Diseasome and SIDER. The GF program is completed with a post-processing procedure for handling literals, that can not be defined using the concrete syntax. GFMed proved to be very accurate on the biomedical questions of QALD-4. The main limitation of this approach is the need to write the grammar rules for all the concepts of the underlying the dataset, which can be a very hard task for large ontologies such as DBpedia.
Therefore, while the accuracy of both systems is very high, the former suffers from usability issues, since the user needs to type non-natural phrases in the question, and the latter has scalability problems, since the number of rules of its grammar depends on the size of the knowledge base.
Authors in [23] also proposed CANaLI, a system that overcomes the above issues, yet providing high accuracy. CANaLI relieves the usability issues derived from the use of a CNL by means of an interactive interface having no scalability issues, since it combines a restricted set of rules, which do not depend on the knowledge base, with the use of an index, queried at run-time to find the tokens that are consistent with the grammar of the CNL and the semantics of the knowledge base.
None of the previously proposed systems, either based on full or controlled natural language, has been specialized for question answering over RDF data cubes. As also discussed next and in Section 6, RDF data cubes pose specific problems not arising in general question answering, therefore it is not known how to adapt the above systems to handle statistical question answering.
Work on statistical question answering over RDF data cubes
Question answering over RDF cubes is a brand new challenge, which raises issues different from those of question answering on a “general” knowledge base [15]. In fact, questions in this context are likely to be very specific, i.e., oriented towards extracting statistical information. Thus, a system called to interpret these questions must be as accurate as possible in interpreting specific features of the typical OLAP queries, such as different kinds of aggregation or constraints on the dimensions. Furthermore, questions on statistical data are more sensitive to misinterpretations. For instance, while a partial interpretation of a general question might also yield an acceptable answer (maybe with non-perfect precision), an aggregation query missing a constraint is likely to yield a totally wrong answer.
Although datasets, benchmarks and problem definition have been proposed only recently, there are already two other existing works that focused on Statistical Question Answering over Linked Data. The first system is called CubeQA [16], and reached an average 0.4 F-measure at Task3 of QALD-6 challenge, as described in the previous section. The system has a lightweight template module that matches the kind of question (what, how much, when, etc.) against a table that provides the expected result type (countable, uncountable, date, etc.). This improves the results provided by the main step, consisting of parsing the query and creating a tree. Elements of the tree are matched against a pre-computed index that allows to find the most probable dataset and dimensions and generate the corresponding SPARQL query.
In contrast, our approach is extremely general in the first steps, based on entity and property recognition within the query. We do not create a tree, trying instead to tag as many numbers and words (either single or multiple words) in the question as possible. We do this for each possible dataset, using an in-memory index. We then rank solutions according to a score, and the one with higher rank is chosen. Rank increases according to the portion of the question that has been interpreted/understood (tagged); also, ranking decreases on the number and size of recognized entities (multiple word tagging is preferred). We then use an original template system, with an ad-hoc language, that exploits NLP to express SPARQL templates based on the grammar structure of the query. We also propose partial templates, that (if matched) establish a portion of the SPARQL query (e.g. a new triple pattern, the use of group by over a given attribute, or the use of a specific aggregate function). The matching templates are then used together to generate the final SPARQL query. An interesting fact related to our approach is that each step we run provides insights on how well it has been performed. For instance, if a large portion of the question is not tagged, it means that most of it was not understood and, therefore, chances of obtaining the right answer in the following steps are low. In these cases, we can maximize precision over recall, not providing an answer. The same optimization can be applied for the template-based mechanism, since some templates are mutually exclusive (e.g. either SUM or COUNT can be used as a final aggregate function). Furthermore, the template mechanism is very simple and it easily allows new patterns to be input in order to answer more advanced questions. These techniques result in a sensible increment of the precision and recall of our QA3 over CubeQA, as certified by the QALD-6.
A very different approach is presented in the work by Sébastien Ferré [8,9]. Based on the adaptation [11] of the general purpose Faceted Search system called SPARKLIS [8,9], the system allows users to incrementally add new constraints. In particular, disambiguation and most of the semantically difficult tasks are not done automatically but left to the user. Although SPARKLIS takes care of also generating a natural language question that helps users to verify that the input constraints are leading to what she is willing to search for, this system cannot be considered a Natural Language approach to Question Answering. One peculiarity of the SPARKLIS system is therefore that achieved precision and recall strongly depend on the user who interacts with the system. According to the QALD-6, the system has been tested by two users with different skill level, and in both cases SPARKLIS achieved a higher F-measure than both CubeQA and our QA3.
Discussion
In this section we discuss the lessons we learned from implementing a system tailored for the specific task of statistical question answering.
Analytical vs. flat model
As previous work already noticed [15,18], there are good reasons why an analytical-aware representation of the data should be published instead of a flat one. In DBpedia, especially if we focus on the Yago categories, information needed to answer the question “What is the 2014 public transportation budget of Frankfurt?” may be found in triples like the following:
Unfortunately, this representation may not be useful for statistical reasoning or analytics, e.g. “In which year Frankfurt had the higher public transportation budget” or “What is the average public transportation budget in Germany”, because some data needed to filter or to aggregate is “hidden” within the property name.
The adopted solution in literature is an ad-hoc form of reification where a specific OLAP ontology is used [6]. This data model must be taken into account by any question answering system, as the matching between the question and the data follow a different path. In particular, answers need to be derived from statistical observations, selecting the appropriate dimensions among many, and values often need to be further processed, e.g., by applying aggregation.
This inherent structure of data naturally poses a limitation to the form of reasonable questions that a QA system working in this domain should handle. As a consequence, a solution like QA3, based on a simplified view of the natural language, has proven to provide good results. The approach presented in this paper is driven by a highly constrained and regular nature of the model underlying statistical observations and therefore it cannot be easily generalized to KBs with a more flat and general schema like DBpedia.
Handling multiple datasets
One of the most important decisions to take while designing a statistical QA system is how to handle the multitude of datasets. Questions in task 3 of QALD-6 testbed all refer to one dataset per query. In fact, more complex queries (such as comparisons among countries or cities) could be answered by two different subqueries, each using one dataset only. Pointing to the right dataset is of paramount importance because the result will be definitely wrong otherwise. We learned that the first phases of the system, that recognize references to properties and entities within the question, are very important to exclude a vast number of datasets unrelated to the question. Still, given the similarities among some datasets contents (e.g., between
Scalability
In terms of time performance, our implementation scales linearly with the number of datasets. With in-memory indexes it is acceptable for the 50 datasets used at QALD, but both time and memory resources required for, e.g., thousands of datasets, can be demanding. In any case, QA3 can be adapted to scale to tens of thousands of datasets by substituting the
Precision-recall trade off
Every step in QA3 is associated with an internal score that represents our confidence in that specific decision/interpretation. For instance, a small percentage of tagged tokens, more datasets matching the question, or finding more than one template for a given question, they are all cases that can be weighted to negatively affect the score. Going further with low scores leads to higher recall but potentially lower precision, and the converse is also true. The system can be therefore tailored for a specific application and/or coupled with a user interface that interacts with the user asking for more (potentially wrong) results. In order to improve recall, another improvement would be to “guess” correct references to constraints, properties and measures required by a template but missing, by exploiting tagged entities/observations. This can be done, e.g., by ranking features associated to each entity [7].
Insight into the internal scores
QA3 already provides the user with information about the results of the three processing steps (see Fig. 6), including the potential failures. This helps the advanced user getting an idea on how reliable the final answer, when generated, is. Showing a failure rather than an empty answer has usually some advantages, in particular when the expected answer is represented by a set. Although QA3 uses some internal scores in the process of obtaining the final SPARQL query, they are not currently surfaced to the user. Having some scores associated with each step may help the user to get an idea about the quality of the answer. However, simply outputting the internal scores currently in use might be confusing for the user, since the score are meaningful only a relative basis. For instance, we choose the database among a list of candidates because it has the highest score computed as coverage of the NL question in input with the elements of the KB. This cannot be easily recast in terms of an absolute probability that formally justifies the selection of the database chosen by our system. Nevertheless, users will find the relative scores provided by the system useful. In particular, the current feedback provided in the “Step 1” tab of Fig. 6, that is, the list of words/phrases recognized and interpreted within the input question, can shed much light and show to the user whether the important parts of her question were recognized and taken into account by the system.
An interesting approach, which might be investigated in future work, is based on the re-generation of the natural language question associated with the (possibly wrong) SPARQL query computed by QA3, showing the NL question the system is actually answering [27].
Expressiveness of the patterns
Perhaps the most important lesson we learned is that having detailed patterns is very important (if the question contains “average of …”, this must be taken into account) but also that specific patterns may support only few questions. One naive approach may be to generate all possible patterns and generate its natural language representation, then trying the best matching with the current question. The exponential explosion in the search space needs to be addressed, perhaps with original compact representations. As described in the paper, we instead developed small, possibly overlapping patterns that may occur together in the same question. These can be seen as “features” in the question, each associated with a fragment of SPARQL. The combination of the features found in the question leads to the complete SPARQL query, unless the features cannot combined together (in this case another alternative is taken).
We believe that having a good, comprehensive set of these features, that is, question patterns associated with SPARQL fragments, may lead to high precision and recall. A possible path to further reduce the search space may be to exploit results in learning connections between semantic representations and natural language expressions of those semantics [12,20,26,30]. Our future work is to extend and improve our manually-crafted set of patterns using machine learning techniques. In particular, the QALD-6 testbed, containing both the natural language questions and the SPARQL queries, can be used as input to statistical learners that can learn, e.g., that “average of …” can be associated to the SPARQL fragment
Conclusions
In this paper we have presented QA3, a system supporting statistical question answering over RDF data cubes. The system combines the syntactical tags obtained using the Stanford tokenizer and POS tagger with semantic tags derived by QA3 from the available knowledge base. An extensible set of regular expressions, defined over the tokens, is used to detect the query template to be used. The template is then filled in by using the previously found KB tags. We remark that this approach is effective in the context of RDF data cubes because the meaningful questions naturally tend to follow structured patterns, while most of the effectiveness would be lost in a more general context (e.g., questions posed on DBpedia KB), where the variability of the structure of meaningful question is much higher. The preliminary results are encouraging, and we are currently working on improving all the three steps of the translation process used by QA3. In particular, since the wrong annotations often do not enable all the placeholders in the query template to be filled in, the performances are likely to be improved by considering additional datasets and tagging results, whenever the choice of one dataset does not yield a valid SPARQL query. This is likely to provide a correct answer to some of the questions for which the correct dataset is assigned the same quality measure as other wrong datasets, and even to some questions for which a wrong dataset is initially detected as the best candidate. Low scores in the first step must be appropriately weighted with the higher scores obtained in the later steps.
The tagging system could be also improved by allowing an approximate matching. This possibility, however, is not obvious since while the approximate matching will improve the recall of the tagging, it could also worsen the precision. A more sophisticated handling of synonyms, taking care of a fuzzy semantic relativity could also improve the answers of questions expressed with different terms with respect to the one found in the dataset.
Finally, we are also working on improving the set and internal language of SPARQL templates, in order to enable the use of more advanced SPARQL features (es., the
Footnotes
Acknowledgements
This research was supported in part by a 2015 Google Faculty Research Award, NIH 1 U54GM 114833-01 (BD2K) and Sardegna Ricerche (project OKgraph, CRP 120).