
Abstract
When benchmarking
Introduction
The Resource Description Framework (
Regardless of whether existing data-driven benchmarks use real or synthetic datasets, the external validity of their results can be too limited, which makes a generalization to other datasets difficult. Real datasets, on the one hand, are often only scarcely available for testing, and only cover very specific scenarios, such that not all aspects of systems can be assessed. Synthetic datasets, on the other hand, are typically generated by mimicking algorithms [7,21,29,30], which are not always sufficiently realistic [15]. Features that are relevant for real-world datasets may not be tested. As such, conclusions drawn from existing benchmarks do not always apply to the envisioned real-world scenarios. One way to get the best of both worlds is to design mimicking algorithms that generate realistic synthetic datasets.
The public transport domain provides data with both geospatial and temporal properties, which makes this an especially interesting source of data for benchmarking. Its representation as Linked Data is valuable because (i) of the many shared entities, such as stops, routes and trips, across different existing datasets on the Web. (ii) These entities can be distributed over different datasets and (iii) benefit from interlinking for the improvement of discoverability. Synthetic public transport datasets are particularly important and needed in cases where public transport route planning algorithms are evaluated. The Linked Connections framework [10] and Connection Scan Algorithm [14] are examples of such public transport route planning systems. Because of the limited availability of real-world datasets with desired properties, these systems were evaluated with only a very low number of datasets, respectively one and three datasets. A synthetic public transport dataset generator would make it easier for researchers to include a higher number of realistic datasets with various properties in their evaluations, which would be beneficial to the discovery of new insights from the evaluations. Network size, network sparsity and temporal range are examples of such properties, and different combinations of them may not always be available in real datasets, which motivates the need for generating synthetic, but realistic datasets with these properties.
Not only are public transport datasets useful for benchmarking route planning systems, they are also highly useful for benchmarking geospatial [5,22] and temporal
We observed a significant correlation between transport networks and the population distributions of their geographical areas, which is why population distributions are the driving factor within our algorithm. The cause of this correlation is obvious, considering transport networks are frequently used to transport people, but other – possibly independent – factors exist that influence transport networks as well, like certain points of interest such as tourist attractions and shopping areas. Our algorithm is subdivided into five sequential steps, inspired by existing methodologies from the domains of public transit planning [20] as a means to improve the realism of the algorithm’s output data. These steps include the creation of a geospatial region, the placement of stops, edges and routes, and the scheduling of trips. We provide an implementation of this algorithm, with different parameters to configure the algorithm. Finally, we confirm the realism of datasets that are generated by this algorithm using the existing generic structuredness metric [15] and new metrics that we introduce, which are specific to the public transport domain. The notable difference of this work compared to other synthetic dataset generators is that our generation algorithm specializes in generating public transit networks, while other generators either focus on other domains, or aim to be more general-purpose. Furthermore, our algorithm is based on population distributions and existing methodologies from public transit network design.
In the next section, we introduce the related work on dataset generation, followed by the background on public transit network design, and transit feed formats in Section 3. In Section 4, we introduce the main research question and hypothesis of this work. Next, our algorithm is presented in Section 5, followed by its implementation in Section 6. In Section 7, we present the evaluation of our implementation, followed by a discussion and conclusion in Section 8 and Section 9.
Related work
In this section, we present the related work on spatiotemporal and
Spatiotemporal database systems store instances that are described using an identifier, a spatial location and a timestamp. In order to evaluate spatiotemporal indexing and querying techniques with datasets, automatic means exist to generate such datasets with predictable characteristics [26].
Brinkhoff [8] argues that moving objects tend to follow a predefined network. Using this and other statements, he introduces a spatiotemporal dataset generator. Such a network can be anything over which certain objects can move, ranging from railway networks to air traffic connections. The proposed parameter-based generator restricts the existence of the spatiotemporal objects to a predefined time period Selecting the nearest node to a position picked from a two-dimensional distribution function that maps positions to nodes. Improvement of the data-space oriented approach where the data space is represented as a collection of cells, each having a certain chance of being the place of a starting node. Selection of a network node based on a one-dimensional distribution function that assigns a chance to each node.
In order to improve the testability of Information Discovery Systems, a generic synthetic dataset generator [25] was developed that is able to generate synthetic data based on declarative graph definitions. This graph is based on objects, attributes and relationships between them. The authors propose to generate new instances, such as people, based on a set of dependency rules. They introduce three types of dependencies for the generation of instances:
Attribute values that are independent of other instances and attributes. Attribute values depending on other values of the same instance. Relationships between different instances.
The need for benchmarking
Duan et al. [15] argue that the realism of an
In this section, we present background on public transit planning that is essential to this work. We discuss existing public transit network planning methodologies and formats for exchanging transit feeds.
Public transit planning
The domain of public transit planning entails the design of public transit networks, rostering of crews, and all the required steps inbetween. The goal is to maximize the quality of service for passengers while minimizing the costs for the operator. Given a public demand and a topological area, this planning process aims to obtain routes, timetables and vehicle and crew assignment. A survey about 69 existing public transit planning approaches shows that these processes are typically subdivided into five sequential steps [20]:
In this paper, we only consider the first three steps for our mimicking algorithm, which lead to all the required information that is of importance to passengers in a public transit schedule. We present the three steps from this survey in more detail hereafter.
The first step, route design, requires the topology of an area and public demand as input. This topology describes the network in an area, which contains possible stops and edges between these stops. Public demand is typically represented as origin-destination (OD) matrices, which contain the number of passengers willing to go from origin stops to destination stops. Given this input, routes are designed based on the following objectives [20]:
The percentage of public demand that can be served.
A metric that indicates how much the actual trips from passengers deviate from the shortest path.
How many stops are close enough to all origin and destination points.
The total distance of all routes, which is typically minimized by operators.
Any other constraints the operator has, for example the shape of the network.
Existing routes may influence the new design.
The next step is the setting of frequencies, which is based on the routes from the previous step, public demand and vehicle availability. The main objectives in this step are based on the following metrics [20]:
How many stops are serviced frequently enough to avoid overcrowding and long waiting times.
How many times each line is serviced – a trade-off between the operator’s aim for minimization and the public demand for maximization.
Regulation may put restrictions on minimum and maximum waiting times between line runs.
Existing frequencies may influence the new design.
The last important step for this work is timetabling, which takes the output from the previous steps as input, together with the public demand. The objectives for this step are the following:
Total travel time for passengers should be minimized. Transfers from one line to another at a certain stop should be taken into account during stop waiting times, including how many passengers are expected to transfer. The total amount of available vehicles and their usage will influence the timetabling possibilities. Existing timetables may influence the new design.
Transit feed formats
The de-facto standard for public transport time schedules is the General Transit Feed Specification (
is a geospatial location where vehicles stop and passengers can get on or off, such as platform 3 in the train station of Brussels.
indicates a scheduled arrival and departure time at a certain stop.
is a time-independent collection of stops, describing the sequence of stops a certain vehicle follows in a certain public transit line. For example the train route from Brussels to Ghent.
is a collection of stops with their respective stop times, such as the route from Brussels to Ghent at a certain time.
In contrast to these two models, the Connection Scan Algorithm [14] takes an ordered array representation of connections as input. A connection is the actual departure time at a stop and an arrival at the next stop. These connections can be given a
In our work, generated public transport networks and time schedules can be serialized to both the
In order to generate public transport networks and schedules, we start from the hypothesis that both are correlated with the population distribution within the same area. More populated areas are expected to have more nearby and more frequent access to public transport, corresponding to the recurring demand satisfaction objective in public transit planning [20]. When we calculate the correlation between the distribution of stops in an area and its population distribution, we discover a positive correlation3
p-values in both cases

The resources (rectangle), literals (dashed rectangle) and properties (arrows) used to model the generated public transport data. Node and text colors indicate vocabularies.
The main objective of a mimicking algorithm is to create realistic data, so that it can be used to by benchmarks to evaluate systems under realistic circumstances. We will measure dataset realism in high-level by comparing the levels of structuredness of real-world datasets and their synthetic variants using the coherence metric introduced by Duan et al. [15]. Furthermore, we will measure the realism of different characteristics within public transport datasets, such as the location of stops, density of the network of stops, length of routes or the frequency of connections. We will quantify these aspects by measuring the distance of each aspect between real and synthetic datasets. These dataset characteristics will be linked with potential evaluation metrics within RDF data management systems, and tasks to evaluate them. This generic coherence metric together with domain-specific metrics will provide a way to evaluate dataset realism.
Based on this, we introduce the following research question for this work: “Can population distribution data be used to generate realistic synthetic public transport networks and scheduling?” We provide an answer to this question by first introducing an algorithm for generating public transport networks and their scheduling based on population distributions in Section 5. After that, we validate the realism of datasets that were generated using an implementation of this algorithm in Section 7.
In order to formulate an answer to our research question, we designed a mimicking algorithm that generates realistic synthetic public transit feeds. We based it on techniques from the domains of public transit planning, spatiotemporal and
Figure 1 shows the model of the generated public transit feeds, with connections being the primary data element. We consider different properties in this model based on the independent, intra-record or inter-record dependency rules [25], as discussed in Section 2. The arrival time in a connection can be represented as a fully intra-record dependency, because it depends on the time it departed and the stops it goes between. The departure time in a connection is both an intra-record and inter-record dependency, because it depends on the stop at which it departs, but also on the arrival time of the connection before it in the trip. Furthermore, the delay value can be seen as an inter-record dependency, because it is influenced by the delay value of the previous connection in the trip. Finally, the geospatial location of a stop depends on the location of its parent station, so this is also an inter-record dependency. All other unmentioned properties are independent.
In order to generate data based on these dependency rules, our algorithm is subdivided in five steps:
These steps are not fully sequential, since stop generation is partially executed before and after edge generation. The first three steps are required to generate a network, step 4 corresponds to the route design step in public transit planning and step 5 corresponds to both the frequencies setting and timetabling. These steps are explained in the following subsections.
Region
In order to create networks, we sample geographic regions in which such networks exist as two-dimensional matrices. The resolution is defined as a configurable number of cells per square of one latitude by one longitude. Network edges are then represented as links between these cells. Because our algorithm is population distribution-based, each cell contains a population density. These values can either be based on real population information from countries, or this can be generated based on certain statistical distributions. For the remainder of this paper, we will reuse the population distribution from Belgium as a running example, as illustrated in Fig. 2.

Heatmap of the population distribution in Belgium, which is illustrated for each cell as a scale going from white (low), to red (medium) and black (high). The actual placement of train stops are indicated as green points.
Stop generation is divided into two steps. First, stops are placed based on population values, then the edge generation step is initiated after which the second phase of stop generation is executed where additional stops are created based on the generated edges.

Placement of train stops in Belgium, each dot represents one stop.
Population-based For the initial placement of stops, our algorithm only takes a population distribution as input. The algorithm iteratively selects random cells in the two-dimensional area, and tags those cells as stops. To make it region-based [8], the selection uses a weighted Zipf-like-distribution, where cells with high population values have a higher chance of being picked than cells with lower values. The shape of this Zipf curve can be scaled to allow for different stop distributions to be configured. Furthermore, a minimum distance between stops can be configured, to avoid situations where all stops are placed in highly population areas.
Edge-based Another stop generation phase exists after the edge generation because real transit networks typically show line artifacts for stop placement. Figure 3(a) shows the actual train stops in Belgium, which clearly shows line structures. Stop placement after the first generation phase results can be seen in Fig. 3(b), which does not show these line structures. After the second stop generation phase, these line structures become more apparent as can be seen in Fig. 3(c). In this second stop generation phase, edges are modified so that sufficiently populated areas will be included in paths formed by edges, as illustrated by Fig. 4. Random edges will iteratively be selected, weighted by the edge length measured as Euclidian distance.5
The Euclidian distance based on geographical coordinates is always used to calculate distances in this work.

Illustration of the second phase of stop generation where edges are modified to include sufficiently populated areas in paths.
The next phase in public transit network generation connects the stops that were generated in the previous phase with edges. In order to simulate real transit network structures, we split up this generation phase into three sequential steps. In the first step, clusters of nearby stops are formed, to lay the foundation for short-distance routes. Next, these local clusters are connected with each other, to be able to form long-distance routes. Finally, a cleanup step is in place to avoid abnormal edge structures in the network.
Short-distance The formation of clusters with nearby stations is done using agglomerative hierarchical clustering. Initially, each stop is part of a seperate cluster, where each cluster always maintains its centroid. The clustering step will iteratively try to merge two clusters with their centroid distance below a certain threshold. This threshold will increase for each iteration, until a maximum value is reached. The maximum distance value indicates the maximum inter-stop distance for forming local clusters. When merging two clusters, an edge is added between the closest stations from the respective clusters. The center location of the new cluster is also recalculated before the next iteration.
Long-distance At this stage, we have several clusters of nearby stops. Because all stops need to be reachable from all stops, these separate clusters also need to be connected. This problem is related to the domain of route planning over public transit networks, in which networks can be decomposed into smaller clusters of nearby stations to improve the efficiency of route planning. Each cluster contains one or more border stations [4], which are the only points through which routes can be formed between different clusters. We reuse this concept of border stations, by iteratively picking a random cluster, identifying its closest cluster based on the minimal possible stop distance, and connecting their border stations using a new edge. After that, the two clusters are merged. The iteration will halt when all clusters are merged and there is only one connected graph.
Cleanup The final cleanup step will make sure that the number of stops that are connected by only one edge are reduced. In real train networks, the majority of stations are connected with at least more than one other stations. The two earlier generation steps however generate a significant number of loose stops, which are connected with only a single other stop with a direct edge. In this step, these loose stops are identified, and an attempt is made to connect them to other nearby stops as shown in Algorithm 1. For each loose stop, this is done by first identifying the direction of the single edge of the loose stop on line 8. This direction is scaled by the radius in which to look for stops, and defines the stepsize for the loop the starts on line 10. This loop starts from the loose stop and iteratively moves the search position in the defined direction, until it finds a random stop in the radius, or the search distance exceeds the average distance of between the stops in the neighbourhood of this loose stop. This random stop from line 12 can be determined by finding all stations that have a distance to the search point that is below the radius, and picking a random stop from this collection. If such a stop is found, an edge is added from our loose stop to this stop.

Reduce the number of loose stops by adding additional edges
Figure 5 shows an example of these three steps. After this phase, a network with stops and edges is available, and the actual transit planning can commence.

Example of the different steps in the edges generation algorithm.
Generator objectives The main guaranteed objective of the edge generator is that the stops form a single connected transit network graph. This is to ensure that all stops in the network can be reached from any other stop using at least one path through the network.
Given a network of stops and edges, this phase generates routes over the network. This is done by creating short and long distance routes in two sequential steps.
Short-distance The goal of the first step is to create short routes where vehicles deliver each passed stop. This step makes sure that all edges are used in at least one route, this ensures that each stop can at least be reached from each other stop with one or more transfers to another line. The algorithm does this by first determining a subset of the largest stops in the network, based on the population value. The shortest path from each large stop to each other large stop through the network is determined. if this shortest path is shorter than a predetermined value in terms of the number of edges, then this path is stored as a route, in which all passed stops are considered as actual stops in the route. For each edge that has not yet been passed after this, a route is created by iteratively adding unpassed edges to the route that are connected to the edge until an edge is found that has already been passed.
Long-distance In the next step, longer routes are created, where the transport vehicle not necessarily halts at each passed stop. This is done by iteratively picking two stops from the list of largest stops using the network-based method [8] with each stop having an equal chance to be selected. A heuristical shortest path algorithm is used to determine a route between these stops. This algorithm searches for edges in the geographical direction of the target stop. This is done to limit the complexity of finding long paths through potentially large networks. A random amount of the largest stops on the path are selected, where the amount is a value between a minimum and maximum preconfigured route length. This iteration ends when a predetermined number of routes are generated.
Generator objectives This algorithm takes into account the objectives of route design [20], as discussed in Section 2. More specifically, by first focusing on the largest stops, a minimal level of area coverage and demand satisfaction is achieved, because the largest stops correspond to highly populated areas, which therefore satisfies at least a large part of the population. By determining the shortest path between these largest stops, the route and trip directness between these stops is optimal. Finally, by not instantiating all possible routes over the network, the total route length is limited to a reasonable level.
Trips
A time-agnostic transit network with routes has been generated in the previous steps. In this final phase, we temporally instantiate routes by first determining starting times for trips, after which the following stop times can be calculated based on route distances. Instead of generating explicit timetables, as is done in typical transit scheduling methodologies, we create fictional rides of vehicles. In order to achieve realistic trip times, we approximate real trip time distributions, with the possibility to encounter delays.
As mentioned before in Section 2, each consecutive pair of start and stop time in a trip over an edge corresponds to a connection. A connection can therefore be represented as a pair of timestamps, a link to the edge representing the departure and arrival stop, a link to the trip it is part of, and its index within this trip.
Trip starting times The trips generator iteratively creates new connections until a predefined number is reached. For each connection, a random route is selected with a larger chance of picking a long route. Next, a random start time of the connection is determined. This is done by first picking a random day within a certain range. After that, a random hour of the day is determined using a preconfigured distribution. This distribution is derived from the public logs of iRail,6
Stop times Once the route and the starting time have been determined, different stop times across the trip can be calculated. For this, we take into account the following factors:
Maximum vehicle speed ω, preconfigured constant. Vehicle acceleration ς, preconfigured constant. Connection distance δ, Euclidian distance between stops in network. Stop size σ, derived from population value.
For each connection in the trip, the time it takes for a vehicle to move between the two stops over a certain distance is calculated using the formula in Equation (4). Equation (2) calculates the required time to reach maximum speed and Equation (3) calculates the required distance to reach maximum speed. This formula simulates the vehicle speeding up until its maximum speed, and slowing down again until it reaches its destination. When the distance is too short, the vehicle will not reach its maximum speed, and just speeds up as long as possible until is has to slow down again to stop in time.
Delays Finally, each connection in the trip will have a certain chance to encounter a delay. When a delay is applicable, a delay value is randomly chosen within a certain range. Next to this, also a cause of the delay is determined from a preconfigured list. These causes are based on the Traffic Element Events from the Transport Disruption ontology,7
Generator objectives For trip generation, we take into account several objectives from the setting of frequencies and timetabling from transit planning [20]. By instantiating more long distance routes, we aim to increase demand satisfaction as much as possible, because these routes deliver busy and populated areas, and the goal is to deliver these more frequently. Furthermore, by taking into account realistic time distributions for trip instantiation, we also adhere to this objective. Secondly, by ensuring waiting times at each stop that are longer for larger stations, the transfer coordination objective is taken into account to some extent.
In this section, we discuss the implementation details of
The main requirement of our system is the ability to generate realistic public transport datasets using the mimicking algorithm that was introduced in Section 5. This means that given a population distribution of a certain region, the system must be able to design a network of routes, and determine timely trips over this network.
The gtfs files that are written by p od igg , with their corresponding sub-generators that are responsible for generating the required data. The files in bold refer to files that are required by the gtfs specification
The

Sample of a
We designed
All sub-generators store generated data in-memory, using list-based data structures directly corresponding to the
In order to easily observe the network structure in the generated datasets,

Visualization of a generated public transport network based on Belgium’s population distribution. Each route has a different color, and dark route colors indicate more frequent trips over them than light colors. The population distribution is illustrated for each cell as a scale going from white (low), to red (medium) and black (high). Full image:
Because the generation of large datasets can take a long time depending on the used parameters,
Finally,
Configuration parameters for the different sub-generators. Time values are represented in milliseconds
(Continued)
Time distributions are based on public route planning logs [9].
Default delays are based on the Transport Disruption ontology (
In this section, we discuss our evaluation of
Metric In order to determine how closely synthetic
Coherence values for three gold standards compared to the values for equivalent synthetic variants
Results When measuring the coherence of the Belgian railway, buses and Dutch railway datasets, we discover high values for both the real-world datasets and the synthetic datasets, as can be seen in Table 3. These nearly maximal values indicate that there is a very high level of structuredness in these real-world datasets. Most instances have all the possible values, unlike most typical
While the coherence metric is useful to compare the level of structuredness between datasets, it does not give any detailed information about how real synthetic datasets are in terms of their distance to the real datasets. In this case, we are working with public transit feeds with a known structure, so we can look at the different datasets aspects in more detail. More specifically, we start from real geographical areas with their population distributions, and consider the distance functions between stops, edges, routes and trips for the synthetic and gold standard datasets. In order to check the applicability of
In order to construct distance functions for the different generator elements, we consider several helper functions. The function in Equation (5) is used to determine the closest element in a set of elements B to a given element a, given a distance function f. The function in Equation (6) calculates the distance between all elements in A and all elements in B, given a distance function f. The computational complexity of χ is
Stops distance For measuring the distance between two sets of stops
Edges distance In order to measure the distance between two sets of edges
Routes distance Similarly, the distance between two sets of routes
Connections distance Finally, we measure the distance between two sets of connections
When serializing time in milliseconds, we set ϵ to 60000.
Computability When using the introduced functions for calculating the distance between stops, edges, routes or connections, execution times can become long for a large number of elements because of their large complexity. When applying these distance functions for realistic numbers of stops, edges, routes and connections, several optimizations should be done in order to calculate these distances in a reasonable time. A major contributor for these high complexities is χ for finding the closest element from a set of elements to a given element, as introduced in Equation (5). In practice, we only observed extreme execution times for the respective distance between routes and connections. For routes, we implemented an optimization, with the same worst-case complexity, that indexes routes based on their geospatial position, and performs radial search around each route when the closest one from a set of other routes should be found. For connections, we consider the linear time dimension when performing binary search for finding the closest connection from a set of elements.
Metrics In order to measure the realism of each generator phase, we introduce a realism factor ρ for each phase. These values are calculated by measuring the distance from randomly generated elements to the gold standard, divided by the distance from the actually generated elements to the gold standard, as shown below for respectively stops, edges, routes and connections. We consider these randomly generated elements having the lowest possible level of realism, so we use these as a weighting factor in our realism values.
Results We measured these realism values with gold standards for the Belgian railway, the Belgian buses and the Dutch railway. In each case, we used an optimal set of parameters24
Realism values for the three gold standards in case of the different sub-generators, respectively calculated for the stops

Stops for the Belgian railway case.

Edges for the Belgian railway case.

Routes for the Belgian railway case.
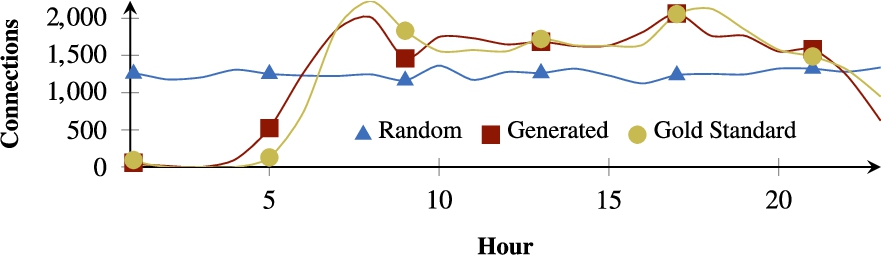
Connections per hour for the Belgian railway case.

Execution times when increasing the number of stops, routes or connections.
Metrics While performance is not the main focus of this work, we provide an indicative performance evaluation in this section in order to discover the bottlenecks and limitations of our current implementation that could be further investigated and resolved in future work. We measure the impact of different parameters on the execution times of the generator. The three main parameters for increasing the output dataset size are the number of stops, routes and connections. Because the number of edges is implicitly derived from the number of stops in order to reach a connected network, this can not be configured directly. In this section, we start from a set of parameters that produces realistic output data that is similar to the Belgian railway case. We let the value for each of these parameters increase to see the evolution of the execution times and memory usage.
Results Figure 11 shows a linear increase in execution times when increasing the routes or connections. The execution times for stops do however increase much faster, which is caused by the higher complexity of networks that are formed for many stops. The used algorithms for producing this network graph proves to be the main bottleneck when generating large networks. Networks with a limited size can however be generated quickly, for any number of routes and connections. The memory usage results from Fig. 12 also show a linear increase, but now the increase for routes and connections is higher than for the stops parameter. These figures show that stops generation is a more
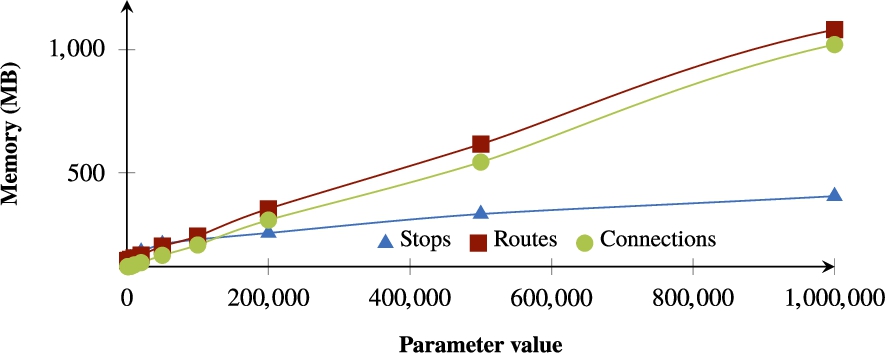
Memory usage when increasing the number of stops, routes or connections.
An important aspect of dataset generation is its ability to output various dataset sizes. In
Discussion
In this section, we discuss the main characteristics, the usage within benchmarks and the limitations of this work. Finally, we mention several
Characteristics
Our main research question on how to generate realistic synthetic public transport networks has been answered by the introduction of the mimicking algorithm from Section 5, based on commonly used practises in transit network design. This is based on the accepted hypothesis that the population distribution of an area is correlated with its transport network design and scheduling. We measured the realism of the generated datasets using the coherence metric in Section 7.1 and more fine-grained realism metrics for different public transport aspects in Section 7.2.
Usage within benchmarks
A synthetic dataset generator, which is one of the main contributions of this work, forms an essential aspect of benchmarks for (
Storage of entities.
Storage of stops, stations, connections, routes, trips and delays.
Storage of links between entities.
Storage of stops per station.
Storage of connections for stops.
Storage of the next connection for each connection.
Storage of connections per trip.
Storage of trips per route.
Storage of a connection per delay.
Storage of literals.
Storage of latitude, longitude, platform code and code of stops.
Storage of latitude, longitude and label of stations.
Storage of delay durations.
Storage of the start and end time of connections.
Storage of sequences.
Storage of sequences of connections.
Find instances by property value.
Find latitude, longitude, platform code or code by stop.
Find station by stop.
Find country by station.
Find latitude, longitude, or label by station.
Find delay by connection.
Find next connection by connection.
Find trip by connection.
Find route by connection.
Find route by trip.
Find instances by inverse property value.
Inverse of examples above.
Find instances by a combination of properties values.
Find stops by geospatial location.
Find stations by geospatial location.
Find instances for a certain property path with a certain value.
Find the delay value of the connection after a given connection.
Find the delay values of all connections after a given connection.
Find instances by inverse property path with a certain value.
Find stops that are part of a certain trip that passes by the stop at the given geospatial location.
Find instances by class, including subclasses.
Find delays of a certain class.
Find instances with a numerical value within a certain interval.
Find stops by latitude or longitude range.
Find stations by latitude or longitude range.
Find delays with durations within a certain range.
Find instances with a combination of numerical values within a certain interval.
Find stops by geospatial range.
Find stations by geospatial range.
Find instances with a numerical interval by a certain value for a certain property path.
Find connections that pass by stops in a given geospatial range.
Find instances with a numerical interval by a certain value.
Find connections that occur at a certain time.
Find instances with a numerical interval by a certain value for a certain property path.
Find trips that occur at a certain time.
Find instances with a numerical interval by a certain interval.
Find connections that occur during a certain time interval.
Find instances with a numerical interval by a certain interval for a certain property path.
Find trips that occur during a certain time interval.
Find instances with numerical intervals by intervals with property paths.
Find connections that occur during a certain time interval with stations that have stops in a given geospatial range.
Find trips that occur during a certain time interval with stops in a given geospatial range.
Plan a route that gets me from stop A to stop B starting at a certain time.
This list of choke points and tasks can be used as a basis for benchmarking spatiotemporal data management systems using public transport datasets. For example,
Limitations and future work
In this section, we discuss the limitations of the current mimicking algorithm and its implementation, together with further research opportunities.
Memory usage The sequential steps in the presented mimicking algorithm require persistence of the intermediary data that is generated in each step. Currently,
Realism We aimed to produce realistic transit feeds by reusing the methodologies learned in public transit planning. Our current evaluation compares generated output to real datasets, as no similar generators currently exist. When similar generation algorithms are introduced in the future, this evaluation can be extended to compare their levels of realism. Our results showed that all sub-generators, except for the trips generator, produced output with a high realism value. The trips are still closer to real data than a random generator, but this can be further improved in future work. This can be done by for instance taking into account network capacities [20] on certain edges when instantiating routes as trips, because we currently assume infinite edge capacities, which can result in a large amount of connections over an edge at the same time, which may not be realistic for certain networks. Alternatively, we could include other factors in the generation algorithm, such as the location of certain points of interest, such as shopping areas, schools and tourist spots. In the future, a study could be done to identify and measure the impact of certain points of interest on transit networks, which could be used as additional input to the generation algorithm to further improve the level of realism. Next to this, in order to improve transfer coordination [20], possible transfers between trips should be taken into account when generating stop times. Limiting the network capacity will also lead to natural congestion of networks [8], which should also be taken into account for improving the realism. Furthermore, the total vehicle fleet size [20] should be considered, because we currently assume an infinite number of available vehicles. It is more realistic to have a limited availability of vehicles in a network, with the last position of each vehicle being of importance when choosing the next trip for that vehicle.
Alternative implementations An alternative way of implementing this generator would be to define declarative dependency rules for public transport networks, based on the work by Pengyue et. al. [25]. This would require a semantic extension to the engine so that is aware of the relevant ontologies and that it can serialize to one or more
Streaming extension Finally, the temporal aspect of public transport networks is useful for the domain of
p od igg in use
Finally,
Conclusions
In this article, we introduced a mimicking algorithm for public transport data, based on steps that are used in real-world transit planning. Our method splits this process into several sub-generators and uses population distributions of an area as input. As part of this article, we introduced
Results show that the structuredness of generated datasets are similar to real public transport datasets. Furthermore, we introduced several functions for measuring the realism of synthetic public transport datasets compared to a gold standard on several levels, based on distance functions. The realism was confirmed for different regions and transport types. Finally, the execution times and memory usages were measured when increasing the most important parameters, which showed a linear increase for each parameter, showing that the generator is able to scale to large dataset outputs.
The public transport mimicking algorithm we introduced, with
Footnotes
Acknowledgement
We wish to thank Henning Petzka for his help with discovering issues and providing useful suggestions for the