
Abstract
Topical profiling of the datasets contained in the Linking Open Data (LOD) cloud has been of interest since such kind of data became available within the Web. Different automatic classification approaches have been proposed in the past, in order to overcome the manual task of assigning topics for each and every individual (new) dataset. Although the quality of those automated approaches is comparably sufficient, it has been shown, that in most cases a single topical label per dataset does not capture the topics described by the content of the dataset. Therefore, within the following study, we introduce a machine-learning based approach in order to assign a single topic, as well as multiple topics for one LOD dataset and evaluate the results. As part of this work, we present the first multi-topic classification benchmark for LOD cloud datasets, which is freely accessible. In addition, the article discusses the challenges and obstacles, which need to be addressed when building such a benchmark.
Introduction
In 2006, Tim-Berners Lee [5] introduced the Linked Open Data paradigm. It refers to a set of best practices for publishing and connecting structured data on the Web. The adoption of such best practices assures that the structure and the semantics of the data are made explicit which is also the main goal of the Semantic Web. Datasets, which should be published as Linked Data, need to comply to a set of rules to ensure an easy discoverability, as well as an easy way to query information within the dataset [6]. Therefore, LOD datasets should be published adopting W3C1
The process of exploring Linked Data for a given topic is long and not intuitive. In an ideal scenario, a user decision whether to use a dataset or not, is based on the information (e.g., topic) provided in the metadata. In this setup, no initial querying of the information contained in the dataset is required. But especially in those cases when datasets do not provide metadata information about their topic/s, a lot of exploration steps are required in order to understand if the information contained in the dataset is useful or not.
The datasets in the LOD cloud 2014 belong to different domains, with social media, government data, and publications data being the most prominent areas [35]. For every dataset in the cloud, the topic is either assigned by verifying its content or by accessing the metadata assigned by the publisher. Up until now, topical categories have been manually assigned to LOD datasets either by the publishers of the datasets themselves via the
The topic of a dataset can be defined as the subject of the dataset, i.e. the subject or theme of a discourse of one of its parts.
It is very important to have a classification of datasets according to their topical domain not only to judge whether it is useful for the use case at hand or not but also as shown in [35], it is often interesting to analyze characteristics of datasets clustered by topical domains, so that trends and best practices that exist only in a particular topical domain can be identified. Link discovery also can be supported by knowing the topic of the dataset. Datasets that share the same topic, probably share equivalent instances. Topical classification is also important for coloring of the Linked Data cloud as in Fig. 1, which marks datasets according to their topical domain.
Even though the importance of topic profiling of Linked Data is undoubtful, it has not yet received sufficient attention from the Linked Data community and it poses a number of unique challenges:
Linked Data comes from different autonomous sources and is continuously evolving. The descriptive information or the metadata depend on the data publishers’ will. Often publishers are more interested in publishing their data in RDF format and do not focus sufficiently on the right meta information. Moreover, data publishers face difficulties in using appropriate terms for the data to be described. Apart from a well-known group of vocabularies, it is difficult to find vocabularies for most of the domains that would be a good candidate for the dataset at hand, as evaluated in [42].
Billions of triples is a daunting scale that poses very high performance and scalability demands. Managing the large and rapidly increasing volume of data is being a challenge for developing techniques that scale well with the volume of data in the LOD cloud.
The high volume of data demands that data consumers develop automatic approaches to assign the topic of the datasets.
Topic profiling techniques should deal with structural, semantic and schema heterogeneity of the LOD datasets.
Querying or browsing data in the LOD cloud is challenging, because the metadata is often not structured and not in a machine-readable format. A data consumer who wants to select for example, all datasets that belong to the media category faces such challenge.
Topic profiling approaches can be evaluated with topic benchmarking datasets. In general, benchmarks provide an experimental basis for evaluating software engineering theories, represented by software engineering techniques, in an objective and repeatable manner [14]. A benchmark therefor is defined as a procedure, problem, or test that can be used to compare systems or components to each other or to a standard [31]. A benchmark represents research problems of interest and solutions of importance in a research area through the definition of the motivating comparison, task sample and evaluation measures [36]. The capability to compare the efficiency and/or effectiveness of different solutions for the same task is a key enabling factor in both industry and research. Moreover, in many research areas the possibility to replicate existing results provided in the literature is one of the pillars of the scientific method. In the ICT field, benchmarks are the tools which support both comparison and reproducibility tasks. In the database community, the benchmark series defined by the TPC8
This paper presents our experience in designing and using a new benchmark for multi-topic profiling and discuss the choke points which influence the performance of such systems. In [25], we investigated to which extent we can automatically classify datasets from the LOD cloud into a single topic category. We make use of the LOD cloud data collection of 2014 [35] to train different classifiers for determining the topic of a dataset. In this paper, we also report the results achieved from the experiments for single-topic classification of LOD datasets [25], with the aim to provide the reader a complete view of the datasets, experiments and analysis of the results. Learning from the results of the previous experiments as most of the datasets expose more than one topic, we further investigate the problem of multi-topic classification of LOD datasets by extending the original benchmark by adding to some of the datasets more than one topic. Results of this new benchmark are not satisfactory due to the nature of the content of selected datasets and the topics’ choice (taken for the original benchmark). We provide a comprehensive analysis of the challenges and line out our learned lessons on this very complex and relevant task. The benchmark, together with various feature extracted from the different datasets, as well as the results of our experiments (described in this paper) are publicly available. We hope to help the LOD community to improve existing techniques for topic benchmark creation and evaluation and encourage new research in this area.
The remaining of the article is organized as follows: In Section 2, we give the definition for topic; single and multi-topic classification. Section 3 describes the criteria for developing a sufficient and comprehensive benchmark and how our benchmark meets such criteria. In Section 4, the methodology for creating the benchmark is discussed, where the following section reports the data corpus that was used in our experiments. Section 6 describes the extraction of different features that characterize the LOD datasets and introduces the different classification algorithms used for the classification. Section 7 discusses the performance metrics used to evaluate our benchmark. In Section 8, we present the result of the experiments in order to evaluate the benchmark for multi-topic classification. Section 9 reports the analysis of the results in depth and the lessons learned, while in Section 10 the state-of-the-art in topic profiling and topic benchmarking are discussed. Finally, in Section 11, we draw conclusions and present future directions.

Linked Data (LOD) Cloud.
Given a large RDF dataset with heterogeneous content, we want to derive the topic or topics that can be understood as the subject/s of the dataset by using different feature vectors that describe the characteristics of the data.
(Topical category).
Given a set of RDF triples
(Single-topic classification).
Given a set
(Multi-topic classification).
Given a set
For creating the diagram in Fig. 1, the newly discovered datasets were manually annotated with one of the following topical categories: media, government, publications, life sciences, geographic, cross-domain, user generated content, and social networking [35].
Desiderata for benchmark
Benchmarking is the continuous, systematic process of measuring one’s output and/or work processes against the toughest competitors or those recognized best in the industry [9]. The benefits of having a benchmark are many among which:
It helps organizations understand strengths and weaknesses of solutions.
By establishing new standards and goals a benchmark helps in better satisfying the customers’ needs.
Motivates to reach new standards and to keep on new developments.
Allows organizations to realize what level(s) of performance is really possible by looking at others.
Is a cost-effective and time-efficient way of establishing innovative ideas.
[36] describes seven properties that a good benchmark should consider; accessibility, relevance, affordability, portability, scalability, clarity and solvability. In the following, we describe each of the aspects in building our benchmark.
One of the most important characteristics of the benchmark is to make it easy to obtain and use. The data and the results need to be publicly available so that anyone can apply their tools and techniques on the benchmark and compare their results with others. This characteristic is very important because it allows users to easily interpret benchmark results. A good benchmark should clearly define the intended use and the applicable scenarios. Our benchmark is understandable to a large audience and covers the topics that already exist in the Linked Open Data cloud. The developed benchmark’s cost should be affordable and comparable to the value of the results. To complete the benchmark for a single combination of the workload takes 15 to 240 minutes. The tasks consist of stand-alone Java projects containing required libraries, making thus the platform portability not a challenge for our benchmark. The benchmark should be scalable to work with tools and techniques at different levels of maturity. The documentation for the benchmark should be clear and concise. The documentation for the topic benchmarking of LOD dataset is provided at The benchmark should produce a good solution. The proposed benchmark resolves the task of multi-topic classification of LOD datasets, a task that is achievable but not trivial. Thus, our benchmark provides an opportunity for systems to show their capabilities and their shortcomings.
Benchmark development methodology
The development of the topic benchmark results in the creation of three elements:
On one hand, a benchmark models a particular scenario, meaning that the users of the benchmark must be able to understand the scenario and believe that this use case matches a larger class of use cases appearing in practice. On the other hand, a benchmark exposes technology to overload. A benchmark is valuable if its workload stresses important technical functionality of the actual systems called choke points. In order to understand and analyze choke points an intimate knowledge of the actual system architecture and workload is needed. In this paper, we identify and analyze choke points of the topic benchmarks and discuss the possibilities to optimize such benchmarks. Choke points can ensure that existing techniques are present in a system, but can also be used to reward future systems that improve performance on still open technical challenges [2].
For the single topic classification we used as benchmark the information that is currently used in the LOD cloud, as the topic for each dataset was manually assigned, while for the multi-topic classification due to the lack of presence of a benchmark we create one. Based on the results of the single-topic classification of LOD datasets, for the development of the multi-topic benchmark we consider some criteria for the selection of the datasets such as; size, number of different data-level descriptors (called feature vectors, see Section 6.1 ), and non-overlap of topics.
We select 200 datasets randomly from the whole set of datasets contained in the LOD cloud of 2014. In the selection of the datasets, we consider small-size datasets (less than 500 triples), medium-size datasets (between 501 and 5000 triples) and big-size datasets (more than 5000 triples). As we investigate schema level information we also take into consideration the number of different attributes for each feature vector used as input in our approach. For example, if a dataset uses less than 20 different vocabularies it is considered in the group of weak-schema descriptors; using between 20 and 200 different vocabularies are considered lite-schema descriptors and datasets that make use of more than 200 vocabularies are categorized as strong-schema descriptors.
Another criteria for building our benchmark is the non-overlap of topics. The distinction between two topical categories in the LOD cloud social networking and user-generated content is not straightforward as it is not clear what datasets should go into each of them. User-generated content can cover different topical domains thus to avoid misclassification of datasets we remove this category from the list of topical categories for LOD datasets. We face the same problem when classifying datasets into the cross-domain category and any other category. Because under the cross-domain category, also datasets in life science domain, or media domain can be categorized, we removed this category from the list of topics that we used for the multi-topic classification of LOD datasets. From eight categories in the single topic experiments, in the multi-topic classification we have only six categories life science, government, media, publications, social networking and geographic.
Two researchers were involved for this task. They independently classified datasets in the LOD into more than one category. To assign more than one topical category to each dataset the researchers could access the descriptive metadata published into Mannheim Linked Data Catalog9
Distribution of number datasets per number of topics
Table 1 shows the distribution of the number of datasets by the number of topics. As we can see, in our benchmark for the multi-topic classification, most of the datasets have one or two topics, while less than
The benchmark that we build for the multi-topic classification of LOD datasets is available for further research in this topic.10
In order to build up the benchmark, which is described within this article, we made use of the crawl of Linked Data referred to April 2014 by [35]. The authors used the LD-Spider crawler originally designed by [16], which follows dataset interlinks to crawl LOD. The crawler seeds originate from three resources:
Datasets from the lod-cloud in
A sample from the Billion Triple Challenge 2012 dataset11
Datasets advertised since 2011 in the mailing list of
The crawled data contained 900129 documents describing 8038396 resources with altogether around 188 million RDF triples. To group all the resources in datasets, it was assumed that all the data originating by one pay-level domain (PLD) belong to a single dataset. The gathered data originates from 1024 different datasets from the Web and is publicly available.12
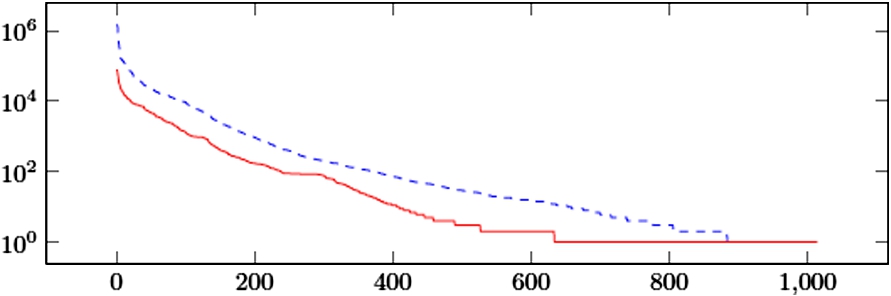
Distribution of the number of resources and documents (log scale) per dataset contained in the crawl.
The authors of the 2014 LOD cloud [35] make a distinction between the two categories user-generated content and social networking. Datasets in the first category focus on the actual content while datasets in the second category focus on user profiles and social ties.
The distribution of categories within the datasets of the LOD cloud is shown in Fig. 3. As we can see, the cloud is dominated by datasets from the social networking category, followed by government datasets. Only less than 25 datasets are included in the cloud for each of the domains media and geographic. The topical category is manually assigned to each dataset in the LOD cloud thus we consider it as a gold standard for our experiments. The imbalance needs to be taken into account for the later model learning, as some classification algorithms tend to predict better for stronger represented classes.

Topics Distribution within LOD Cloud Datasets.
In the following, we describe in detail the process of feature extraction, which we apply for our task in assigning more than one topic to LOD datasets. First, we present the created feature vectors, which were extracted from the datasets. In the second part of this section we describe the classification algorithms, as well as the sampling and normalization techniques which were used.
Feature vectors
For each of the datasets contained in our collection, we derive attributes/features from ten different sources (e.g., the URI of the dataset, or the used vocabulary) which are described in the following:
As vocabularies mostly describe a set of classes for a particular domain, e.g.
As a more fine-grained feature, the
Beside the class information of an entity, it might also help to have a look at the properties which are used to describe it. For example, it might make a difference, if people in a dataset are annotated with
Different vocabularies might contain synonymous (or at least closely related) terms that share the same local name but differ in their namespaces, e.g.
Using the same assumption as for the LCN feature vector, we also extract the local name of each property that is used by a dataset. This results in treating
Beside the vocabulary level features, the names of the described entities might also indicate the topical domain of a dataset. We thus extract objects (values) of
We also extract the values describing entities using the rdfs:comment property. We extract all values of the comment property and process them in the same way as with the LAB feature. All values are lowercased and tokenized at space characters, after which all tokens shorter than 3 characters or longer than 25 characters are filtered out. This property is used by only 252 datasets and not by all datasets in the cloud. This feature vector consist of 1231 attributes. In contrast to the LAB feature vector, we did not filter out tokens that were used by less than ten datasets or more than 200 datasets, because the number of the datasets that make use of the
LOV website provide metadata about the vocabularies found in the LOD cloud. Among other metadata, LOV also provides the description in natural language for each vocabulary. From this description a user can understand in which domain she could use such vocabulary. On the LOV website, there exist 581 different vocabularies,13
Numbers here refer to the version of LOV in the time when experiments for the topic classification were running (June 2016).
Another feature which might help to assign datasets to topical categories is the top-level domain of the dataset. For instance, government data is often hosted under the
We restrict ourselves to top-level domains, and not public suffixes.
In addition to vocabulary-based and textual features, the number of outgoing RDF links to other datasets and incoming RDF links from other datasets could provide useful information for datasets classification. This feature could give a hint about the density of the linkage of a dataset, as well as the way the dataset is interconnected within the whole LOD cloud ecosystem.
We extract all the described feature vectors separately from the crawled data. We are able to gather all features (except for LAB and COM) for 1001 datasets.
The classification problem has been widely studied in the database [22], data mining [29], and information retrieval communities [18]. In general the discussed approaches aim at finding regularities in patterns in empirical data (training data). The problem of classification is formally defined as follows: given a set of training records kNN is one of the oldest non-parametric classification algorithms [4]. The training examples are vectors described by n dimensional numeric attributes. In kNN classification an object is classified by a majority vote of its neighbors, with the object being assigned to the class most common among its k-nearest neighbors measured by a distance function. Choosing the right k value is done by inspecting the dataset first. In our experiments, based on some preliminary experiments on a comparable but disjunct set of data, we found that a k equal to 5 performs best. As we already know the model that was used to classify the original data in our gold standard a k equal to 5 performs better with respect to the original model. Decision Trees are a powerful set of classification algorithms that run a hierarchical division of the underlying data. The most known algorithms for building decision trees are Classification Trees, Regression Trees [20], ID3, and C4.5 [30]. The decision tree is a tree with decision nodes which have two or more branches and leaf nodes that represent a classification or a decision. Splitting is based on the feature that gives the maximum information gain or uses entropy to calculate the homogeneity of a sample. The leaf node reached is considered the class label for that example. We use the Weka implementation of the C4.5 decision tree called J48. Many algorithms try to prune their results. The idea behind pruning is that apart from producing fewer and more interpreted results, the risk of overfitting to the training data is also reduced. We build a pruned tree, using the default settings of J48 with a confidence threshold of 0.25 with a minimum of two instances per leaf. As a last classification algorithm, we use Naive Bayes. A Naive Bayesian [33] model is easy to build, with no complicated iterative parameter estimation which makes it particularly useful for very large datasets. It is based on Bayes’ theorem with independence assumptions between predictors. It considers each feature to contribute independently to the probability that this example is categorized as one of the labels. Naive Bayes classifier assumes that the effect of the value of a predictor (x) on a given class (c) is independent to the values of other predictors. This assumption is called class conditional independence. Although this classifier is based on the assumption that all features are independent, which is mostly a rather poor assumption, Naive Bayes in practice has shown to be a well-performing approach for classification [40]. Naive Bayes needs less training data and is highly scalable. Moreover, it handles continuous and discrete data and is not sensitive to irrelevant features making it appropriate for the Linked Data domain.
Sampling techniques
The training data is used to build a classification model, which relates the elements of a dataset that we want to classify to one of the categories. In order to measure the performance of the classification model build on the selected set of features, we use cross-validation. Cross-validation is used to assess how the results of the classification algorithm will generalize to an independent dataset. The goal of using cross-validation is to define a dataset to test the model learned by the classifier in the training phase, in order to avoid overfitting. In our experiments, we used a 10-fold cross-validation, meaning that the sample is randomly partitioned into ten equal sized subsamples. Nine of the ten subsamples are used as training data, while the other left is used as validation data. The cross-validation process is then repeated ten times (the folds), with each of the ten subsamples used exactly once as the validation data. The ten results from the different folds can be averaged in order to produce a single estimation. As we described in Section 5, the number of datasets per category is not balanced and over half of them are assigned to the social networking category. For this reason we explore the effect of balancing the training data. Even though there are different sampling techniques, as in [11], we explored only three of them:
We down sample the number of datasets used for training until each category is represented by the same number of datasets; this number is equal to the number of datasets within the smallest category. The smallest category in our corpus is geographic with 21 datasets.
We up sample the datasets for each category until each category is at least represented by the number of datasets equal to the number of datasets of the largest category. The largest category is social networking with 520 datasets.
We do not sample the datasets, thus we apply our approach in the data where each category is represented by the number of datasets as in the distribution of LOD in Fig. 3.
The first sampling technique, reduces the chance to overfit a model into the direction of the larger represented classes, but it might also remove valuable information from the training set, as examples are removed and not taken into account for learning the model. The second sampling technique, ensures that all possible examples are taken into account and no information is lost for training, but creating the same entity many times can result in emphasizing this particular part of the data.
Normalization techniques
As the total number of occurrences of vocabularies and terms is heavily influenced by the distribution of entities within the crawl for each dataset, we apply two different normalization strategies to the values of the vocabulary-level features VOC, CURI, PURI, LCN, and LPN:
In this normalization technique the feature vectors consist of 0 and 1 indicating the presence and the absence of the vocabulary or term.
In this normalization technique the feature vectors captures the fraction of the vocabulary or term usage for each dataset.
Table 2 shows an example how we create the binary (bin) and relative term occurrence (rto) given the term occurrence for a feature vector.
Example of bin and rto normalization
Example of bin and rto normalization
The objective of multi-label classification is to build models able to relate objects with a subset of labels, unlike single-label classification that predicts only a single label. Multi-label classification has two major challenges with respect to the single-label classification. The first challenge is related to the computational complexity of algorithms. Especially when the number of labels is large, then these approaches are not applicable in practice. While the second challenge is related to the independence of the labels and also some datasets might belong to a very large number of labels. One of the biggest challenges in the community is to design new methods and algorithms that detect and exploit dependencies among labels [23].
[38] provides an overview of different algorithms used in the multi-label classification problem. The most straightforward approach for the multi-label classification is the Binary Relevance (BR) [39]. BR reduces the problem of multi-label classification to multiple binary classification problems. Its strategy involves training a single classifier per each label, with the objects of that label as positive examples and all other objects as negatives. The most important disadvantage of the BR, is the fact that it assumes labels to be independent. Although BR has many disadvantages, it is quite simple and intuitive. It is not computationally complex compared to other methods and is highly resistant to overfitting label combinations, since it does not expect examples to be associated with previously-observed combinations of labels [32]. For this reason it can handle irregular labeling and labels can be added or removed without affecting the rest of the model.
Multi-label classifiers can be evaluated from different points of view. Measures of evaluating the performance of the classifier can be grouped into two main groups: example-based or label-based [39]. The example-based measures compute the average differences of the actual and the predicted sets of labels over all examples, while the label-based measures decompose the evaluation with respect to each label. For label-based measures we can use two metrics; macro-average in Equation (1) and micro-average given in Equation (7). Consider a binary evaluation measure B(tp, tn, fp, fn) that is calculated based on the number of true positives (tp), true negatives (tn), false positives (fp) and false negatives (fn). Let
Single-topic classification results on single feature vectors
Single-topic classification results on single feature vectors
In the first part of this section, we report the results of our experiments for the single topic classification task, using different sets of features as well as different supervised algorithms. On the one hand, the experiments show the capability of our benchmark for the single-topic classification challenges and on the other hand, lay the foundation for the next task; the multi-topic classification. The respective experiments and results are then described and presented in the second part of this section.
Single-topic classification
In a first step, we report the results for the experiments for single-topic classification of LOD datasets. This challenge has already been addressed in our previous work [25]. First, we report the results of our experiments training different feature vectors in separation in Section 8.1.1. Afterward, we combine all feature vectors for both normalization techniques and train again our classification algorithms considering the three sampling techniques and report the results in Section 8.1.2.
Results of experiments on single feature vectors
For the first experiment, we train a model to classify LOD datasets in one of the eight categories described in Section 5. In this experiment we consider VOC, LCN, LPN, CURI, PURI, DEG, TLD and LAB feature sets applying the approach described in Section 6. For the above mentioned feature sets, we train the different classification techniques as depicted in Section 6.2 with different sampling techniques (cf. Section 6.3) and different normalization techniques (cf. Section 6.4).
In Table 3 we report the results (accuracy) of the different feature sets based on the selected algorithms (using 10-fold cross-validation) with and without sampling. Majority Class is the performance of a default baseline classifier always predicting the most dominant topic in the corpus: social networking. As a general observation, the schema-based feature sets (VOC, LCN, LPN, CURI, PURI) perform on a similar level, where LAB, TLD and DEG show a relatively low performance and in some cases are not at all able to beat the trivial baseline. Classification models based on the attributes of the LAB feature vector perform on average (without sampling) around
Single-topic classification results on combined feature vectors
Single-topic classification results on combined feature vectors
In the second experiment, we combine all attributes from all feature sets that we used in the first experiment and train classification models.
As before, we generate a binary and relative term occurrence version of the vocabulary-based features. In addition, we create a second set (binary and relative term occurrence), where we omit the attributes from the LAB feature sets, as we want to measure the influence of this particular feature, which is only available for less than half of the datasets. Furthermore, we create a combined set of feature vectors consisting of the three best performing feature vectors from the previous section.
Table 4 reports the results for the five different combined feature vectors:
Combination of the attributes from all eight feature vectors, using the rto version of the vocabulary-based features. (This feature vector is generated for 455 datasets.)
Combination of the attributes from all eight feature vectors, using the bin version of the vocabulary-based features. (This feature vector is generated for 455 datasets.)
Combination of the attributes from all features, without the attributes of the LAB feature vectors, using the rto version.
Combination of the attributes from all features, without the attributes of the LAB feature vectors, using the bin version.
Includes the attributes from the three best performing feature vectors from the previous section based on their average accuracy: PURIbin, LCNbin, and LPNbin
We can observe that when selecting a larger set of attributes, our model is able to reach a slightly higher accuracy of
Multi-topic classification
In this section, we report the results from the experiments for multi-topic classification of LOD datasets. First, we report the results of using the different feature sets in separation, similar as we did for the single-topic classification in Section 8.2.1. Afterward, we report the results of experiments combining attributes from multiple feature sets in Section 8.2.2.
Results of experiments on single feature vectors
In this section, we report the results for classifying LOD datasets in more than one topical category described in Section 2, that we define as multi-topic classification of LOD datasets.
Similarly, as for the single topic experiments, we also apply our classification algorithms on different feature vectors, taking into account also the different sampling and normalization techniques described in Section 6.3 and Section 6.4. Also for the multi-topic classification of LOD datasets, we use a 10-fold cross-validation. For our first experiment, we consider the LCN, LPN, CURI and PURI feature vectors as from the results of the experiments on the single topic classification they perform better with respect to the other feature vectors.
Multi-topic classification results on single feature vectors
Multi-topic classification results on single feature vectors
Multi-topic classification results on single feature vectors
Table 5 and Table 6 show the micro-accuracy in terms of precision, recall and F-measure achieved by our classification algorithms. Focusing on the algorithms, the best results precision-wise are achieved using k-NN, without sampling with a
Multi-topic classification results on combined feature vectors
In the second experiment for the multi-topic classification of LOD datasets, we combine the feature vectors that we used in the first experiment and train again our classification algorithms. Table 7 shows the results of ALL feature vector and the combination CURI and PURI, as well as LCN and LPN.
From the results we can observe that when selecting a larger set of attributes, our model is not able to reach a higher performance than using only the attributes from one feature vector (
The proposed method scales well with respect to the number of features used as input to the classifier. The experiments were run on a Macbook Pro on a 2.9-GHz Intel i7 Intel core processor with 8 GB of RAM. The fastest experiment took about 15 minutes training kNN on all features vector on down-sampling on binary normalization technique. The longest experiment took about 4 hours (240 minutes) trained using J48 decision tree on all features vector on up-sampling on relative term occurrence normalization technique. The complexity of algorithms such as kNN, Naive Bayes and J48 is linear with respect to the number of features in input. While in the latest version of LOD (April 2017) the number of datasets has increased with over than 50%, there is a need on further verifying the number of the new features with respect to the version of LOD used in this paper. However dimensionality reduction techniques such as features selection, or extraction can be applied in order to reduce the number of features in consideration for the classifier.
Lessons learned
In the following, we discuss the results achieved by our experiments and analyze the most frequent errors of the best performing approaches.
Single-topic classification
The best performing approach is achieved by applying Naive Bayes trained on the attributes of the NoLabbin feature vector using up sampling. This approach achieves an accuracy of
Confusion Matrix for the NoLABbin feature vector
Confusion Matrix for the NoLABbin feature vector
The most common confusion occurs for the publication domain, where a larger number of datasets are predicted to belong to the government domain. A reason for this is that government datasets often contain metadata about government statistics which are represented using the same vocabularies and terms (e.g., skos:Concept) that are also used in the publication domain. This makes it challenging for a vocabulary-based classifier to distinguish those two categories apart. In addition, for example the
The third most common confusion occurs between the user-generated content and the social networking domain. Here, the problem is in the shared use of similar vocabularies, such as foaf. At the same time, labeling a dataset as either one of the two is often not so simple. In [35], it has been defined that social networking datasets should focus on the presentation of people and their inter-relations, while user-generated content should have a stronger focus on the content. Datasets from personal blogs, such as www.wordpress.com however, can convey both aspects. Due to the labeling rule, these datasets are labeled as user-generated content, but our approach frequently classifies them as social networking.
In summary, while we observe some true classification errors, many of the mistakes made by our approach actually point at datasets which are difficult to classify, and which are rather borderline cases between two categories.
Evaluation of benchmark criteria
In the following, we discuss the results achieved by our experiments on the multi-topic classification of LOD datasets and analyze the most frequent errors of the best performing approach. As from the results on Section 8.2.1 and Section 8.2.2 for the multi-topic classification of LOD datasets the best performing approach in terms of harmonic mean is achieved training the LCN using Naive Bayes on no sampling data with a performance of
Consider the problem of classifying the datasets with three labels, e.g., government, publication and geographic. One of the datasets belonging to these topics is europa.eu. Our model classifies it as belonging to publication and government. The model is not able to predict geographic as the third topic. Even though this dataset contains some geographical data for all countries in the European Union, for example http://europa.eu/european-union/about-eu/countries/member-countries/italy_en the amount of geographic data with respect to the government and publication data is smaller. In this small amount of geographical data, the classifier could not find similar attributes as those used for training, considering them to be noise and not assigning a topic.
For the datasets that have more than three topics, it is even harder for the classifier to predict all labels, especially if there are few examples (instances) belonging to each topic and if they use similar vocabularies to define also instances that belong to other topics.
The results discussed above indicate that only schema-level data are not a good input to the classifiers. For this reason we also exploit the text information in these datasets extracting the LAB and COM feature vectors as described in Section 6.1. Later, we manually checked the text from LAB and COM feature vectors for the datasets in the gold standard to understand if this information could be a good input. We were able to find significant text only for 15 datasets (out of 200 in the gold standard) while for all the others, the text was not in English, or rather it contained acronyms, or was encoded. The number of datasets containing significant text is very low thus, we did not further continue testing LAB and COM feature vectors as input for the classifier for the multi-topic classification of LOD datasets.
Except of LAB and COM, also the VOCDES feature vector was not considered in our experiments. From 1438 vocabularies that are used in LOD, only 119 have a description in LOV. From 119 vocabularies with a description, 90 of them are used in less than ten datasets, while 5 of them are used in more than 200 datasets. For this reason we did not use the description of vocabularies in LOV as a feature vector for our classifiers.
In Table 9 we summarise the errors and possible solutions in determining the datasets to use for benchmarking LOD.
Related work
Topical profiling has been studied in data mining, database, and information retrieval communities. The resulting methods find application in domains such as documents classification, contextual search, content management, product classification and review analysis [1,3,24,27,28,37]. Although topical profiling has been studied in other settings before, only a few methods exist for profiling LOD datasets. These methods can be categorized based on the general learning approach that is employed into the categories unsupervised and supervised, where the first category does not rely on labeled input data, the latter is only applicable for labeled data. Moreover, existing approaches consider schema-level [8,12,19] or data-level information [10,13] as input for the classification task. In [34] the topic extraction of RDF datasets is done through the use of schema and data level information.
The authors of [12] try to define the profile of datasets using semantic and statistical characteristics. They use statistics about vocabulary, property, and datatype usage, as well as statistics on property values, such as average strings length, for characterizing the topic of the datasets. For classification, they propose a feature/characteristic generation process, starting from the top discovered types of a dataset and generating property/value pairs. In order to integrate the property/value pairs they consider the problem of vocabulary heterogeneity of the datasets by defining correspondences between terms in different vocabularies. This can be done by using ontology matching techniques. Authors intended to align only popular vocabularies. They have pointed out that it is essential to automate the feature generations and proposed the framework to do so, but do not evaluate their approach on real-world datasets. Also, considering only the most popular vocabularies, makes this framework not applicable to any dataset or to datasets that belong to any kind of domain. In our work, we draw from the ideas of [12] on using schema-usage characteristics as features for the topical classification, but focus on LOD datasets.
Authors in [10] propose the application of aggregation techniques to identify clusters of semantically related Linked Data given a target. Aggregation and abstraction techniques are applied to transform a basic flat view of Linked Data into a high-level thematic view of the same data. Linked Data aggregation is performed in two main steps; similarity evaluation and thematic clustering. This mechanism is the backbone of the inCloud framework [10]. As an input, the system takes a keyword-based specification of a topic of interest, namely a real-world object/person, an event, a situation, or any similar subject that can be of interest for the user and returns a part of the graph related to the keyword in input. Authors claim that they evaluated the inCloud system by measuring user satisfaction and system evaluation in terms of accuracy and scalability but do not provide any experimental data. In our approach we do not imply any matching algorithm, but use schema-based information to assign the topic.
[8] introduced an approach to detect latent topics in entity relationships. This approach works in two phases: (1) A number of subgraphs having strong relations between classes are discovered from the whole graph, and (2) the subgraphs are combined to generate a larger subgraph, called summary, which is assumed to represent a latent topic. Topics are extracted from vertices and edges for elaborating the summary. This approach is evaluated using DBpedia dataset and explicitly omits any kind of features based on textual representations and solely relies on the exploitation of the underlying graph. Thus, for datasets that do not have a rich graph, but instances are described with many literal values, this approach cannot be applied. Differently from [8], in our approach we extract all schema-level data. In this approach only strong relations between classes are discovered from the whole graph, while in our approach we do not consider the relation between classes but extract all classes and all properties used in the dataset.
In [13], authors propose an approach for creating dataset profiles represented by a weighted dataset-topic graph which is generated using the category graph and instances from DBpedia. In order to create such profiles, a processing pipeline that combines tailored techniques for dataset sampling, topic extraction from reference datasets, and relevance ranking is used. Topics are extracted using named-entity-recognition techniques, where the ranking of the topics is based on their normalized relevance score for a dataset. These profiles are represented in RDF using VOID vocabulary and Vocabulary of Links.15
Automatic identification of topic domains of the datasets utilizing the hierarchy within Freebase dataset is presented in [19]. This hierarchy provides background knowledge and vocabulary for the topic labels. This approach is based on assigning Freebase types and domains to the instances in an input LOD dataset. The main challenge in this approach is that it fails to identify the prominent topic domains if in Freebase there are no instances that match entities in the dataset.
Some approaches propose to model the documents (text corpora) containing natural language as a mixture of topics, where each topic is treated as a probability distribution over words such as Latent Dirichlet Allocation (LDA) [7], Pachinko Allocation [21] or Probabilistic Latent Semantic Analysis (pLSA) [15]. As in [34], authors present TAPIOCA,16
A benchmark is a mandatory tool in the toolbox of researchers allowing us to compare and reproduce the results of different approaches by researchers all over the world. In this paper, we discussed the problem of the creation and evaluation of a benchmark for multi-topic profiling for datasets being part of the LOD cloud. Comparing the performance of the multi-label classification (multiple topics get assigned to one dataset) with the performance of the single-label classifcation approach (only one topic gets assigned), we identify that on our benchmark this task shows larger challenges as the latter one. The error analysis of the misclassified cases showed that many datasets use same or very similar feature sets to describe entities. Moreover, the distribution of the datasets for each topical category highly influences the classifier. The distribution of instances belonging to different topics within a dataset is also highly influencing the classifier. If the dataset contains only a few instances belonging to a topic, our classifier consider this information as noise. The multi-topic benchmark is heavily imbalanced, with roughly half of the data belonging to the social networking domain. Moreover, some datasets belonging to a specific topic such as bbc.co.uk belonging to the media category, make use of specific vocabularies such as bbc vocabulary. Our learning classifier learned the model on specific vocabularies, thus it fails to assign the same topical category also to other datasets belonging to the same category but not using such vocabularies.
As future work, when regarding the problem as a multi-label problem, the corresponding approach would be a classifier chains, which make a prediction for one category after the other, taking the prediction for the first category into account as features for the remaining classifications [41]. Another direction is the application of stacking, nested stacking or dependent binary methods [26].