
Abstract
The maintenance and use of metadata such as provenance and time-related information is of increasing importance in the Semantic Web, especially for Big Data applications that work on heterogeneous data from multiple sources and which require high data quality. In an RDF dataset, it is possible to store metadata alongside the actual RDF data and several possible metadata representation models have been proposed. However, there is still no in-depth comparative evaluation of the main representation alternatives on both the conceptual level and the implementation level using different graph backends. In order to help to close this gap, we introduce major use cases and requirements for storing and using diverse kinds of metadata. Based on these requirements, we perform a detailed comparison and benchmark study for different RDF-based metadata representations, including a new approach based on so-called companion properties. The benchmark evaluation considers two datasets and evaluates different representations for three popular RDF stores.
Keywords
Introduction
Within the Semantic Web community, the topic of metadata has been subject of many discussions and works for several years. These works range from the publication of different metadata vocabularies (e.g., PROV-O,1

In the context of this paper, we focus on metadata representation models (MRM) for knowledge graphs and how data and metadata are connected in the same RDF store. Knowledge graphs consist of information collected from different (data) sources, which evolve over time and can reach large dimensions. Usually, heterogeneous sources contain information about similar or equivalent entities, which represent the same real-world object. Such overlapping entities from different datasets will have common (e.g., birth year), conflicting (e.g., different heights of a mountain), and complementary property attributes (e.g., fact about an entity only available in one dataset). The process of merging these entity information into one common dataset is called knowledge fusion [8] which can include operations such as provenance tracing, conflict detection, conflict resolution, and merge. Resolving conflicting data values can be improved by metadata-based heuristics [5], e.g., prefer newer facts or prefer values from a source, which is known to ensure high data quality. Furthermore, data traceability is an important use case where not only source provenance data is recorded, but also data processing information such as results from normalization and cleaning operations, and information about applied (fusion) algorithms. Traceability can help users and developers to understand the results of Big Data systems and allows them to track erroneous statements back to its data sources and the involved algorithms, by inspecting provenance metadata. This topic has reached a political level and the EU4
is pushing for new regulations, which will force commercial solutions to add traceability of data to Big Data systems.As metadata representation model (MRM), we define a strategy of splitting an RDF triple t and its set of key-value based metadata facts m into several triples or quads, such that we can store and query metadata, for all triples individually, in an RDF Store.
Handling data and metadata alongside each other can be considered a challenging task. Since more data has to be processed, stored and indexed, a negative impact on the overall system performance might occur. However, solutions which store data and metadata in separate databases or backend types (e.g., data in an RDF store and metadata in a relational database) require complex and time-consuming join, lookup or query federation solutions. Furthermore, such setups are harder to maintain because data and metadata may be out of sync. Hence, this work will evaluate how to store metadata alongside data, using different MRMs and RDF stores. Figure 1 illustrates the main structural differences between the various MRMs, which will be explained in detail in Section 4.
The contributions of this work are as follows: We performed a thorough and comprehensive evaluation of metadata handling in RDF from several angles. As foundation for this evaluation but also as basis for a future RDF metadata performance benchmark, we defined requirements and criteria for an evaluation of metadata representation models, based on an analysis of existing RDF datasets and use cases where metadata is involved. We specified a setup motivated by a knowledge fusion use-case including a novel high degree metadata-dataset and a set of data-only and mixed benchmarking queries from different complexity classes. We validated and revised previous experimental results from the state-of-the-art, and systematically compared and evaluated several MRMs (including vendor-specific approaches and a new companion properties approach) against different RDF stores. To close the gap to previous work, we considered open questions and aspects like the MRM overhead for regular data queries, the impact of dataset specific characteristics, metadata granularity levels and meta-metadata.
The rest of the paper is structured as follows: Section 2 gives an overview about related work. Then the evaluation requirements and criteria are presented in Section 3. In Section 4 we describe different models to represent metadata and introduce companion properties. The evaluation datasets and the evaluation setup are described in Sections 5 and 6. Then the evaluation results are presented in Section 7 and compared to other studies. Finally, we conclude and discuss future work.
Related work can be separated into three groups. First several SPARQL-benchmarks exist, which try to evaluate the performance of RDF stores. Second, there is related work, which discusses or proposes MRMs, extensions of RDF or systems based on RDF to handle provenance and other metadata. The last group evaluates a set of MRMs against one or more RDF stores.
Since the presented RDF & SPARQL extensions are lacking a widespread adoption in RDF stores, RDF standard compatible MRMs have been published. This includes singleton properties [35] and nanopublications [17] which will be covered in more detail in Section 4.1 and Section 3.1.1.
This work features a novel DBpedia based dataset including high degree revision metadata, meta-metadata and a set of data-only and mixed query templates from three complexity classes. By revising and reproducing results from [22] we allow for a direct comparison of results and studying of dataset specific impacts between Wikidata and our knowledge fusion use case.
To establish a foundation for our evaluation, we define requirements and criteria for metadata usage, MRMs, and their comparison. In this section we will give a brief rundown of our requirements, and present a set of criteria, which are used to analyze, measure and compare the different MRMs. Moreover, we present an overview of metadata usage in RDF as basis for the requirements.
Metadata (requirements) analysis
In order to establish MRM evaluation requirements, an analysis of metadata usage and datasets with metadata has been conducted.
Metadata usage analysis
Several search strategies have been used to explore metadata usage. First repositories such as datahub.io,7
In addition, we requested help via the Semantic Web17
From the dataset candidates returned by our search strategies, we selected exemplary datasets with more than 5 million triples for a deeper analysis. These datasets are:
In the following section, we describe the evaluation dimensions and deduce requirements towards our evaluation to study different effects and aspects of these dimensions with regard to MRMs, but also to cover metadata handling in RDF from various angles. With respect to the latter and to close the gap to previous work, an objective of this evaluation is to also examine vendor-specific metadata extensions in large-scale capable, SPARQL 1.1 compliant RDF stores.
During our investigation and based on previous work in RDF store benchmarking, we identified three main dimensions which are influencing the performance of MRMs in RDF stores:
Dataset characteristics
Each dataset differs in features such as in/out degrees of entities, property, and value distributions. These dataset characteristics have a direct impact on different evaluation metrics such as the dataset size and loading time. The datasets which are used in this evaluation should contain real-world data, since a realistic combination of these different features is difficult to reproduce in a synthetic dataset. Furthermore, the dataset should contain diverse and not just repetitive data (e.g., different data sources, annotators, dates) and cover different metadata types (e.g., date, provenance) which were seen in the metadata usage analysis. The dataset should be big enough, in order to stress the graph backend. These requirements shall ensure that the amount of (meta)data allows us to create and execute diverse search queries, for which the whole dataset can not be cached by the backend. In nanopublications we observed the concept of meta-metadata. The effect of such nested metadata should be addressed as well.
Granularity of metadata
While the dataset characteristics also include features of metadata, from our perspective the granularity level on which metadata is expressed should be considered separately. In the dataset analysis, we observed meta information which describes the whole dataset or huge parts of it, but also more fine-grained metadata for individual triples or entities. In the context of this evaluation, we defined three granularity levels:
Considering our knowledge graph and fusion use case, we were only interested in datasets which store metadata at the entity or triple level. When fusing data from different datasets into a new dataset, the source information can not be tracked using only dataset level granularity metadata. An MRM evaluation should consider both entity and triple level granularity.
In connection with metadata granularity, the support of an MRM for factorization should be examined in more detail. As factorization, we denote the capability of an MRM to represent the granularity level of metadata in an efficient way on the storage level without metadata redundancy.
Query characteristics
Besides the compatibility problem of existing data queries without rewrite, the question of the overhead of MRM usage for data-only queries remains to be answered. Therefore, an MRM evaluation should consider both data-only queries and also mixed (data-metadata) queries. Furthermore, a thorough evaluation should use queries of different complexity classes, ranging from simple to very complex queries. Finally, the complexity and structure of MRM metadata queries should be studied in terms of usability for adopters but also potential effects for RDF store query optimizers.
Evaluation criteria
Based on the analysis steps and the presented requirements and dimensions, we deduced the following criteria and give metrics for the evaluation, whenever possible.
Criteria for metadata representations
evaluates the size of the MRM and its factorization support and will be measured by triple count, as well as serialized file size and overall database size in byte. Our evaluation measures query time in ms for data-only queries for the MRMs compared to a baseline query/dataset without MRM specific triples. for a set of query templates over data and metadata we compare the execution time (in ms) We compare the number of variables, triple patterns, and additional SPARQL elements, which are necessary to query a single triple with a metadata fact, as indicators for the query usability/complexity of an MRM.
Criteria for metadata extension and SPARQL implementations
evaluates (meta)data bulk loading capacities for stores and is measured in milliseconds. evaluates integration of store-specific metadata extensions into SPARQL and validates whether stores are able to handle all SPARQL queries correctly
Additional criteria
evaluates data-only queries, which should still work after the addition of metadata without the need to rewrite them.
Metadata representation models
Within the Linked Data community different ways of representing metadata have been developed. The most common MRMs were described in [23] and [22]. Besides two additional MRMs, not evaluated in the literature so far, this work will study the same list of MRMs. In this section, we will present five RDF-compliant MRMs and we will have a brief discussion about native metadata support by graph backends. Figure 1 visualizes the major differences between MRMs and can be used as a visual reference.
RDF compliant models
In order to make it easier for the reader to understand the differences between the MRMs, a running example is used. In the example, two entities are shown with birth year values for Person p1 and p2 using the dbo:birthYear attribute. For each RDF statement metadata about the last modification date (dc:modified) exists. The presented query searches for the most current birth date for each distinct person. The abbreviated names, shown in Fig. 1, are used in the upcoming sections, to indicate that the specific realization of an MRM (as displayed in the figure) is meant. This convention allows, e.g., to distinguish between the RDF 1.1 feature “named graphs” and the MRM ngraphs, which utilizes the former.
Named graphs (ngraphs)
The Named Graph feature, which is supported by every SPARQL 1.1 compliant graph backend, allows for the assignment of one IRI for one or more triples as a graph id. The same IRI can then be used as a subject for a metadata entity, which itself can store the metadata about the associated triple(s) as predicates and objects.
The ngraphs MRM is easy to understand, since it just builds on top of the existing triple format. Hence, it is possible to reuse existing data queries. In addition, the representation is very compact (for both data and query), which can be seen in the example, the metadata can be reached by only adding the
RDF standard reification (stdreif)
As specified in the RDF standard, it is possible to create a resource which describes a triple and its subject, predicate, and object. The resource IRI can then be used to connect provenance or meta information with the triple.
Compared to the ngraphs MRM, it is not possible to reuse existing data queries out of the box. In order for them to work, a custom reasoning mechanism would have to be applied. Furthermore, each original data triple has to be represented by a resource entity, which itself consists of four statements (rdf:subject, rdf:predicate, rdf:object, and rdf:Statement). This does not only increase the dataset size, but adds more triple patterns to queries. All four components of a reified resource have to be used as triple patterns in order to find the correct reified triple in the dataset. The resource IRI can be used to access data and metadata. On the positive side it supports datasets, which use named graphs.
N-ary relation (naryrel)
In this MRM, a relationship instance is created as a resource of the subject-predicate-pair instead of the object of the triple. The object is connected to the relationship resource, using a renamed version of the predicate (appending a designated suffix). The same relationship resource is utilized, to relate meta information to the statement.23
Similar to the standard reification, an IRI can be used to access data and metadata. In the case of the nary-relation MRM, the IRI is a relation resource IRI. Due to the introduction of the relation resource IRI, one more statement per triple value has to be added. Existing data queries cannot be reused, but compared to the standard reification fewer triple patterns are required to access either data values or metadata. Furthermore, it is possible to support datasets with named graphs.
The singleton property [34] scheme uses a unique property for every triple with associated metadata. This unique property deals as a triple identifier, which can be used to describe the statement with meta information. In order to be able to reconstruct the original property of the statement, every singleton property is linked to its original predicate using a rdf:singletonPropertyOf relationship.
This unique property can be seen as a predicate resource IRI. The predicate resource IRI can be used to access metadata and the original predicate type. Since the predicate resource has the rdf:singletonPropertyOf relation, it is possible to use RDFS entailment rules to infer the original statements. When looking at the dataset triples, it is not possible to deduce the direct meaning of a triple predicate. It is always required to use the predicate resource IRI to find the associated rdf:singletonPropertyOf property and with it the original predicate. Furthermore, it is possible to support datasets with named graphs.
Companion properties (cpprop)
As was shown in [22], the singleton property representation model suffers from the fact that it creates a new property for every statement in order to create globally unique properties. This results in a very uncommon uniform distribution and large number of properties, and therefore, in increased query times. To limit the creation of new properties and to reduce the influence on the datasets property (frequency) distribution, we propose a novel MRM – companion properties.
The companion properties representation is inspired by sgprop but uses a fixed naming scheme to create a property, which is unique with respect to the subject of the statement. In order to support the naming scheme, an occurrence counter can be utilized when creating the new dataset. An individual occurrence counter is used per property p for its subject s. The occurrence count is appended as a suffix to every instance of p. Depending on the used profile, every generated property cp has at least one companion property, which is from a graph theoretic view a sibling of p with respect to s. The IRI of this companion property consists of the IRI of cp plus the additional suffix “.SID”. For each subject and companion property pair, a statement ID is created which serves as a unique metadata resource identifier for the triple s cp o .
The number of different companion property names is bound by
In contrast to the other triple based MRMs, the identifiers are not required for reconstructing the original triple. Thus it allows, likewise to ngraphs, for sharing of statement identifiers, and additionally multiple identifiers per statement. This enables companion properties to support different granularity levels.
Vendor specific models
Some of the database vendors for RDF stores have recognized and discussed the potential of adding a custom support for metadata on statement level or a native way of using statement identifiers in their backends. We investigated the online documentation of several major RDF stores and asked their vendors whether they are planning or already implemented a specific support for metadata. To the best of our knowledge, we provide a short overview of the current state at the time of writing this paper.
Blazegraph24
https://www.Blazegraph.com/product/
The Java-based graph store Blazegraph offers a feature called Reification Done Right.25
Besides the support for CONSTRUCT and DESCRIBE, Blazegraph allows data mutation for reified triples using UPDATE and INSERT queries.
To the best of our knowledge, the Virtuoso backend does not have extensions for handling metadata use cases. The community and an OpenLink employee have discussed possible extensions27
Other RDF store providers have created extensions for storing and retrieving metadata more efficiently. AllegroGraph29
After the review of the available metadata datasets, we decided based on our requirements to use the following datasets for the evaluation:
In order to reproduce and compare the work from [22], we reused the same Wikidata dump with time, geospatial and source/reference metadata for a part of the claims. The converted RDF dataset based on 2016/01/04 JSON dump contains over 81 million claims, describing around 16 million entities (out of 19 million entities in total) and using 1600 different properties. Since metadata is modelled on statement level, a statement id is kept for every claim (data triple), but 1.5 million claims have qualifiers, only. The 2.1 million qualifiers are based on 953 distinct qualifier keys (denoted as metadata key in Fig. 1). In the excerpt below, a shortened example of two different claims with metadata about the presidency of Grover Cleveland is given. Furthermore, the example illustrates the special case, where the same claim occurs more than once, but with different metadata. For a more detailed description of the data, we refer to [22].
In [14], a system has been presented, which can be used to create an RDF dataset with revision information for a Wikipedia chapter (e.g., French, German, or English). We adopted these scripts,31
Considering that on average more than 277 metadata revision statements exist per DBpedia entity, we decided not to use the complete DBpedia dataset. Therefore, we extracted data from the German and English DBpedia chapters about companies, their associated locations and persons. Focusing the dataset around companies and their related resources, helped to narrow down the dataset. Due to the different types of entity classes, this dataset still ensures a diverse distribution of entity relations within the graph. The reduced dataset contains more than 83 thousand entities (approx. 37,000 companies, 27,000 places, and 19,000 persons). Once extracted, the selected DBpedia resources were enriched with the resource revision meta information for the German and English Wikipedia chapter. The meta information comprises aggregated metadata based on all revisions of an article like the number of revisions (total, last 2 years/months), creation and last modification date, but also links to every Wikipedia revision for the article of the triples entity. In the dataset, a dedicated resource exists for every link, which contains additional information such as editor name and date of the revision. While a link to a revision remains stable, the aggregated metadata is dependent on a specific dump file created at a given point of time. We therefore save meta-metadata for this aggregated metadata in the form of a link to the used dump file. Note that storing provenance for the metadata requires reifying the metadata, too. In total over 23 million revisions are associated with the entities. More than 12,800 properties are used for data statements, but just 21 for metadata keys. The dataset is characterized by a 1:10 data/metadata ratio (10 metadata triples for a data triple) and 1:100 data/revision ratio (100 triples of revision information for one data triple). In contrast to the Wikidata dataset the number of metadata statements (948 million revision information statements and 94 million statements for aggregated metadata plus the links to the revisions) exceeds the number of data statements (9.7 million) by two orders of magnitude. This is motivated by use cases where traceability or provenance information make up a greater portion than the data itself. A fragment of the dataset which shows the full aggregated metadata for one entity, with incomplete data and revision links, is listed below.
To allow a comparison of this work with respect to different evaluation hardware and setup, we reproduced the loading and the quin query pattern experiments from [22]. In addition, we measured the execution and loading times as well as the database sizes. For this evaluation, we created a DBpedia based dataset which uses Wikipedia revision information as metadata. Combining the results of all the experiments allows us to take a more detailed look on how different MRMs perform for different datasets and use cases.
The evaluation was executed on an Ubuntu 14.04.3 server system with a 3.19.0-33 kernel, Oracle Java 1.8.0_66, Ruby 2.2.5p319, a 1.8 GHz Intel Xeon E5-2630L CPU, 256 GB RAM and a 3.6 TB hard disk drive. We used Blazegraph in version 2.1.2, Virtuoso 07.20.3215-pthreads and Stardog 4.2.3. The database configuration parameters for Virtuoso and Blazegraph were reused from [22]. According to the settings in [22], we use the recommended 6 GB Java heap memory size for Blazegraph. Blazegraph relies on the file system cache to improve disk access and the relatively small memory footprint should keep interruptions by the GC at a minimum. Furthermore, we disabled swap as per recommendation of the Blazegraph performance guide.32
According to our requirements for SPARQL integration and bulk loading we did not consider the vendor specific metadata extensions for Stardog and AllegroGraph due to their limitations. Moreover license restrictions prevent the evaluation of AllegroGraph in this work. Therefore we selected Blazegraph, Stardog (without testing the metadata extension) and Virtuoso for this evaluation.
For the experiment which is described in [22], we reused and extended the existing conversion framework. However, due to its technical design we were not able to generate cpprop representation for the Wikidata dataset.
To create the DBpedia based dataset, we developed a Java-based framework and command line utility,34
The evaluation is separated into two parts. First, datasets are loaded, and the following metrics are measured: loading time, database size, statement count. For every MRM and dataset, we created an isolated new database instance to prevent side effects. Once all the data is loaded, the second part, the query execution, is started. For each query template, we restart the backend and clear the cache. Then we run all instances of one query template sequentially.
In order to execute the queries, we adapted35
For this work, we extended the scenario, which is described in [22], by evaluating the Blazegraph feature RDR, which had not been studied for the Wikidata use case yet. In order to circumvent the limitation of RDR, that every triple needs to be unique, we do not attach the metadata directly to the data triple. Instead, we use (multiple) statement identifiers as metadata, which are then linked to the actual metadata. This is necessary, to model the Grover Cleveland example shown in Section 5. The technique is illustrated in the following example:
Wikidata loading procedure
When we looked at the original experiment webpage,36
A quin represents a data-metadata look-up query, where for a data triple pattern
For the DBpedia based dataset, we used a slightly different setup for loading and created a new set of queries, which we will introduce in this section.
DBpedia loading procedure
For the DBpedia datasets, we started pre-loading the revisions metadata first. This part of the metadata is independent of the used MRM. We then replicated this database to load the MRM-specific parts of the dataset. Unfortunately, we could use this strategy for the triple based MRM, only. Blazegraph and Stardog use a different indexing for rdr and ngraphs, which does not allow to use the triple-based pre-loaded database. For virtuoso, it was possible to reuse the database for ngraphs.
DBpedia query templates
In order to allow for a meaningful comparison between the different MRMs, we need to define a set of queries which cover different query types and complexities. As in [22], we also use query templates. But instead of applying systematic pattern based generation, we define a set of individual and heterogeneous templates (based on one template variable), which differ in complexity, the number of triple patterns and used SPARQL features. Defining criteria to measure the complexity of a query independent of the dataset is not trivial. The selectivity of a query is influenced by the query structure itself, but it is also a function of the dataset characteristics. The authors in [37] have studied complexity classes of different SPARQL elements. The conclusions are summarized in three lemmas, whereas Lemmas 2 and 3 help to judge complexity independent of dataset characteristics.
The evaluation of SPARQL queries with AND and FILTERS depends on the size of the dataset (D) and the number of triple patterns (P) in the query and is in
Establishes that UNIONs between non union-compatible basic graph patterns (BGPs) are NP-complete, where two BGPs are union compatible if they share variables.
States that OPTIONAL values increase the complexity and are PSPACE-complete.
Based on this work, we define three complexity classes for the SPARQL templates. The
In order to measure the overhead of an MRM, when executing data queries, we have created two versions for each template. The first template version executes queries over the data only and the second query template over the data and the metadata. In the results section, these queries are denoted as data (DBQ) and mixed queries (DBM) respectively. A description of the used data and mixed patterns can be seen in Table 1. We refer to the experiment website for the SPARQL syntax of the used templates and query instances.
This section presents the results of the qualitative and quantitative MRM comparison as well as the Wikidata and DBpedia experiments, which will be followed by a general discussion about findings.
Factorization study and qualitative MRM comparison
Wikidata experiment : The number of statements for the Wikidata dataset, its respective loading times and the final database size for the different MRMs. All loading times are in hours, whereas database sizes are in GiB
Due to the large dataset sizes for some MRMs, we decided to introduce a shared resource, which holds metadata information for one DBpedia entity. For each MRM, which does not support factorization, we link to the shared resource only once per statement, instead of attaching every metadata fact to it. This strategy allows for storing at entity level granularity metadata in a cost effective manner. For rdr, we apply this technique for the revisions, only. However, the aggregated metadata is applied on triple level, using nested rdr statements. The resulting differences are displayed with shared in Table 2. Once a shared metadata resource is introduced for each statement, the dataset sizes only vary slightly between all the MRMs. As a result the ngraphs MRM is using the least amount of space and stdreif as well as rdr the most.
When looking at the statement counts in Table 3, ngraphs can be identified as the most compact representation. Sgprop and rdr are the most compact triple based MRMs. In the Wikidata scenario, an naryrel serialization scheme similar to sgprop is used, which links the
The rankings in the DBpedia scenario shown in Table 4 are slightly different. Cpprop is the most compact representation after ngraphs, which also is reflected in the smallest database size for Virtuoso and Blazegraph. For these stores the database size difference between sgprop, stdreif and naryrel is very small, too. Except for Virtuoso, ngraphs database files are similar to the Wikidata case the biggest. While Virtuoso and Stardog can benefit from the reduced number of graph identifiers (around 0.8 million for DBpedia vs. 80 million for Wikidata) the graph overhead almost doubles Blazegraph‘s journal size. Due to an optimized scheme for naryrel, its number of statements is equal to sgprop. In contrast, rdr has more statements overhead than stdreif, because we do not use a shared resource for the aggregated metadata.
Examining the loading times of the Wikidata datasets, we observed that naryrel tends to be the slowest and stdreif followed by sgprop the fastest. Although for Blazegraph and Stardog ngraphs is rather slow, Virtuoso processed it most rapidly. Cpprop is the fastest solution for DBpedia. Ngraphs followed by naryrel perform worst. However, the loading of stdreif is slower in relation to the Wikidata experiments. The huge gap between Blazegraph’s loading times and its competitors is caused by a limited loading parallelization of the used version. Despite index updates themselves are being executed multi-threaded, the parser is not executed while the index updates are being performed. Furthermore files which could be read in parallel (nquads) are not processed in parallel and if multiple files are provided for bulk-loading these are loaded sequentially, as well. With ongoing progress of the bulkload procedure, we observed a continuously dropping rate of inserted triples per second as well as a decreasing CPU usage but an increasing time of waiting for I/O request completion. Albeit Stardog does load files in parallel and we could observe that it utilized all CPU cores, which explains the short loading times.
Summarising we found that for Stardog and Virtuoso the MRMs are competitive w.r.t. loading times. For Blazegraph the variance is much higher, but seems to be dataset dependent. When it comes to database sizes ngraphs files are significantly larger for Stardog and Blazegraph. If Virtuoso in combination with ngraphs or the other MRMs is used, the choice is of no consequence for disk space.
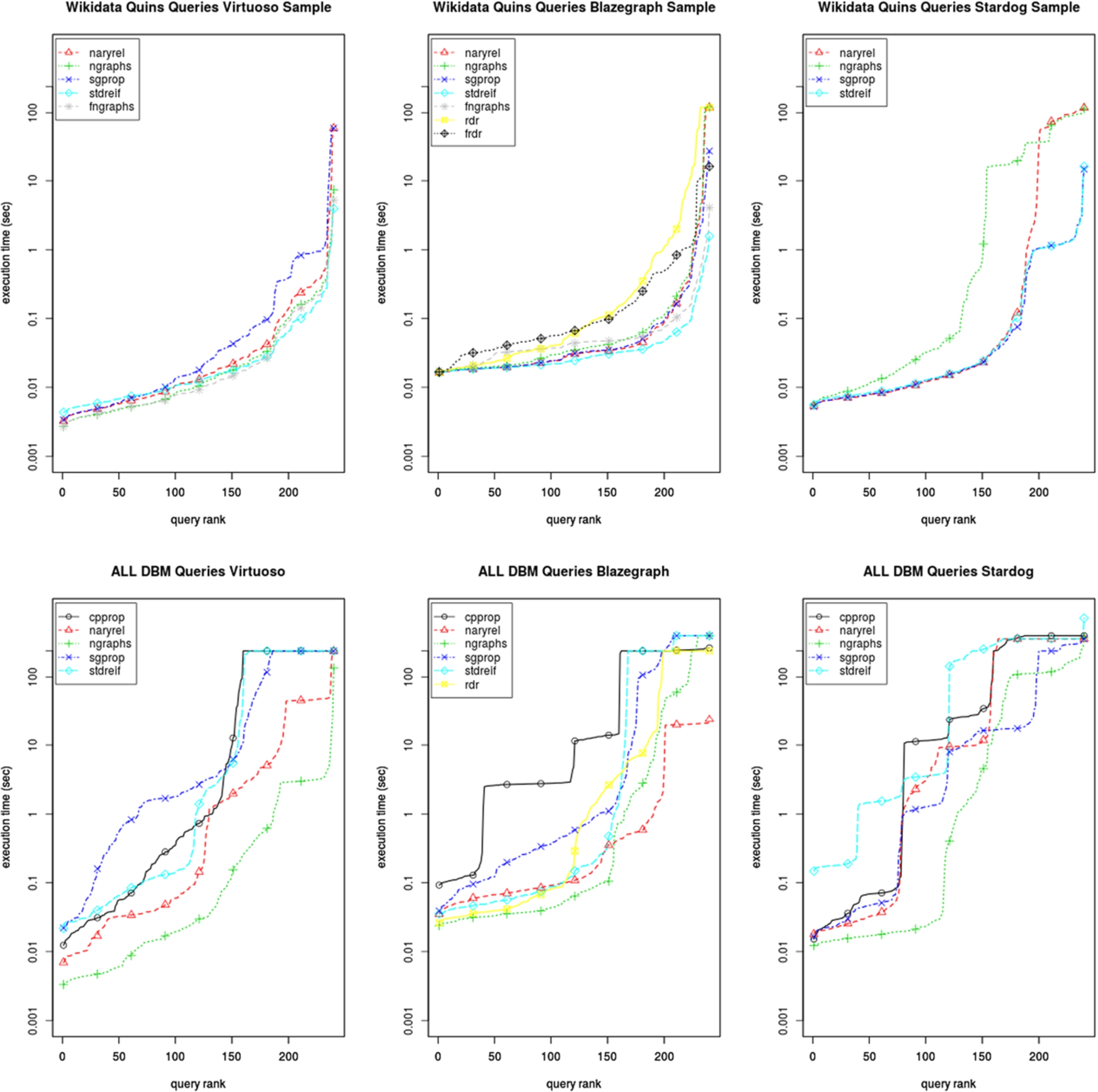
In Fig. 2, we can identify stdreif as best solution for Blazegraph for the Wikidata use case; no single timeout occurs. In Virtuoso, stdreif also exhibits a good performance for queries having an execution time longer than 30 milliseconds. For queries faster than that, the additional number of joins caused by the 4 triple patterns has a greater impact on the execution time. While the singleton property is the worst performer for Virtuoso, in Blazegraph there is no huge difference between sgprop, naryrel, and ngraphs. Moreover, sgprop is the best model for Stardog but with no significant difference to stdreif. Though naryrel is faster for simple queries in Stardog, it is not competitive for challenging queries. Surprisingly ngraphs is exceptional slow. Since the Stardog code is not publicly available and we could not find documentation about indexing techniques and other database internals, we can only guess that the database structures for named graphs lead to performance issues for a high number of graphs. The rdr feature which is used to encode the statement identifier and not the metadata directly (caused by the data model of Wikidata as mentioned before), cannot benefit from its indexing strategy. It is the worst performing MRM for the Wikidata use case. Generalising over all quin queries and stores, stdreif performs best.

Considering the mixed Queries for the DBpedia dataset, ngraphs is the clear winner, as can be seen in Fig. 2. For the triple based MRM, naryrel exhibits the best performance in Virtuoso. We can in theory observe the same behavior for Blazegraph. Unfortunately, the naryrel queries for Blazegraph do not return the full number of results. This explains why the queries are executed quickly and why naryrel seems to even outperform ngraphs. Blazegraph showed issues evaluating queries with multiple

Looking at the overhead of MRMs for regular data queries (Fig. 3), ngraphs is the closest to the baseline for the majority of queries against Virtuoso. For queries faster than two seconds, cpprop is competitive with the other triple MRMs. In spite of this, for stdreif and cpprop followed by sgprop occur many timeouts for complex queries. Summing all query execution times, naryrel is the best triple MRM for Virtuoso. In contrast to that naryrel and ngraphs MRMs introduce the most overhead in Stardog, though to the latter is performing well for short queries. Cpprop is the best option. Likewise, sgprop shows similar good results as for mixed queries in Stardog. While there is a significant overhead for queries shorter than one second, rdr is outstanding for challenging data queries. Cpprop deals as second-best option in Blazegraph. Stdreif and ngraphs show almost the same behavior. Sgprop appears as the slowest MRM. Note that naryrel returns incomplete result sets for a fraction of Blazegraph’s queries, as already mentioned for mixed queries.
To examine the influence of the dataset and the type of metadata, we compared the DBpedia related mixed simple queries to a query pattern from the quins experiment. The
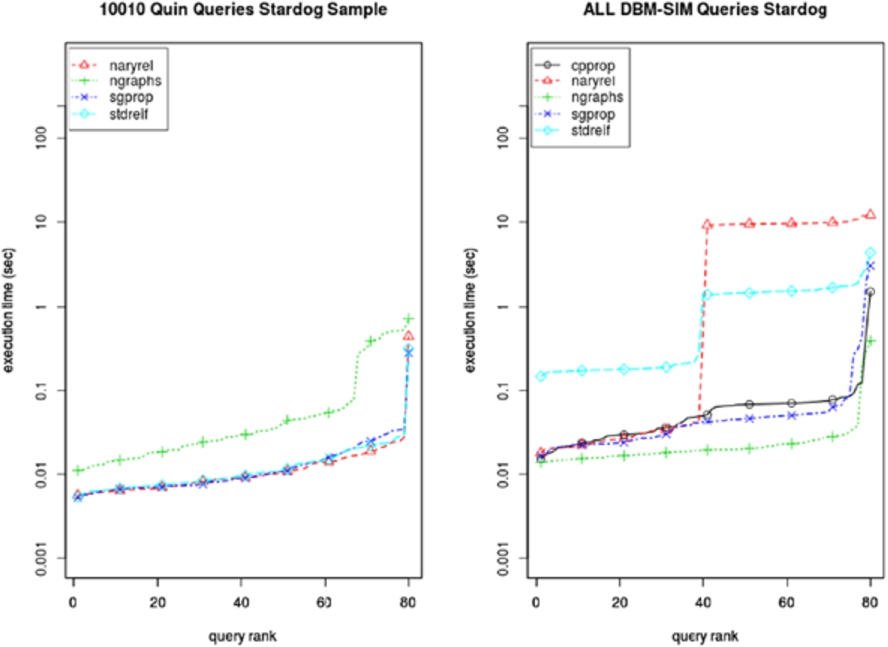
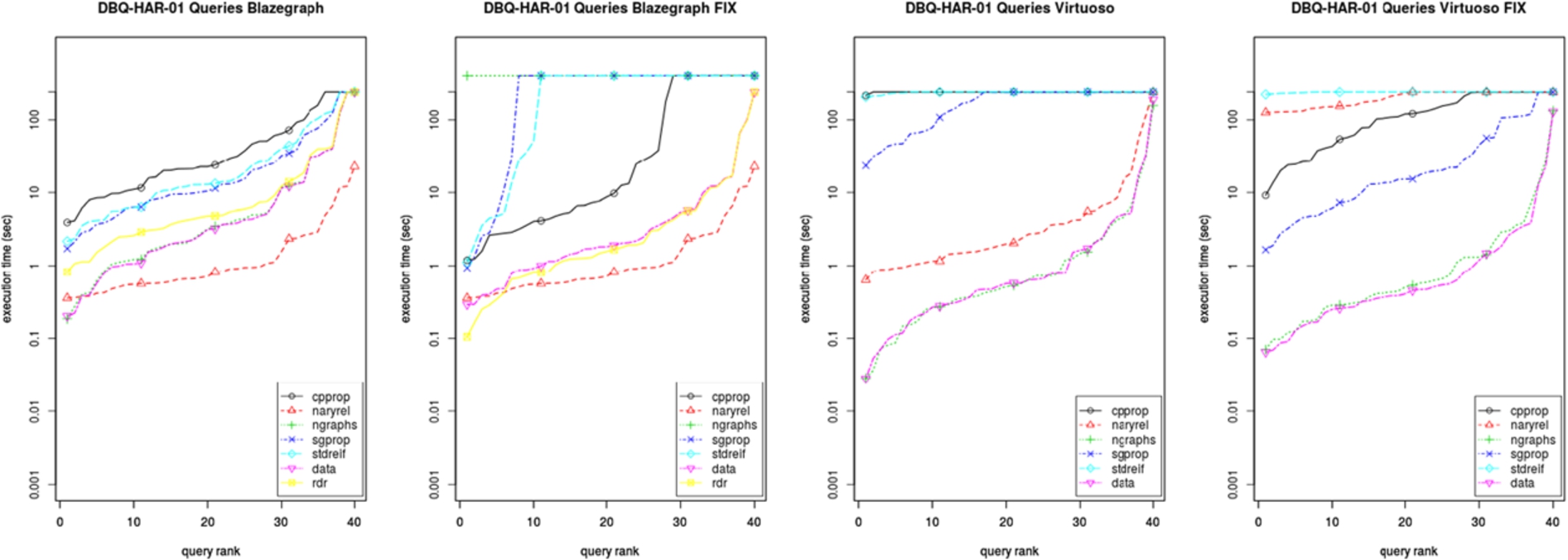
As mentioned before, we implemented an additional client side timeout in the benchmarking framework. For both Blazegraph and Stardog, it is crucial to use this second timeout as fallback to continue benchmarking. For challenging queries these Java based stores had issues terminating the query within the specified database timeout of 240 seconds. If huge parts of the dataset are being processed, several Java Objects are created. The garbage collection seems to be the reason that both stores struggle and get unresponsive. The framework therefore waits up to 400 seconds to let the store clean up memory and properly terminate the timed-out query before executing the next query. In [22], it had already been reported that subsequent queries did time out non-deterministically. Having a closer look at this issue revealed that challenging queries, which are supposed to be aborted by the database (due to database timeout), continue to run up to several minutes. As a result the original Wikidata setup effectively ran several queries in parallel, which increased the backend pressure even more and caused the timeout of subsequent queries. The client timeout helps to reduce such domino effects by giving the backend a period of 160 seconds to abort the query and enforce the database timeout. However, even this additional timeout is too short for stopping every challenging query. Therefore, a second plateu at 400 seconds can be observed in the plots for various MRMs. Despite this, we observed both databases transitioning into an undefined state after executing a number of queries. The backends were still running, but did not respond to any command or activity and did not consume CPU time. For several query templates, this was non-deterministic and rerunning the experiment for the query template solved the issue. The garbage collection overhead and problems can be tackled by using off-heap data structures. For Blazegraph a so-called analytic query mode exists, leveraging a custom (off-heap) memory management. Yet, for the rewritten Blazegraph naryrel queries several attempts did not succeed. According to the Blazegraph issue-tracker not all database components and query execution stages utilize this memory management. Likewise, for Stardog, we were not able to run the original HAR-01 templates. Splitting its 3 pairwise OPTIONAL clauses into 6 clauses resolved this issue. Further investigation revealed that due to sub-optimal query optimization and planning, Stardog performs several loop joins and finally exceeds memory. As already stated, internal server errors occurred for subsequent sgprop and cpprop HAR-02 queries, starting at random positions in the queries. After submission of this work a native memory management, trying to address GC issues, has been integrated in the Stardog 5 release (July 2017).
In order to allow for a comparison of Stardog for this template, we decided to use the rewritten template for the other backends as well. Figure 6 illustrates the significant changes in runtime behavior between this template variations. The fix leads to an improvement for sgprop and cpprop for Virtuoso. As a result Blazegraph’s performance for sgprop, cpprop and especially ngraphs, declined sharply but increased for rdr. This observation exposes a major problem. The performance of an MRM is not just dependent on its structure, the complexity of the query and database architecture details like data structures and indices. In practice, the way how the template query is expressed and how BGP’s are ordered or grouped may have a huge impact on the performance. Depending on the structure, the query optimizer may choose an improper join order. Thus, an MRM based on many joins (e.g., cpprop) has a higher risk that unfavorable join orders are used in the query plan.
To check whether all MRMs are consistent, we compared result sizes. We discovered that a few template queries returned incorrect results. Virtuoso evaluates the FILTER EXISTS expression in HAR-02, which contains an optional variable, as false if the variable is unbound. As opposed to this, Blazegraph and Stardog evaluate this condition as true. We therefore added bound conditions to the queries. A similar issue arise for fngraphs queries in Stardog, which we therefore excluded. Virtuoso shows different results, if strings (containing numbers only) are compared to integers.
The results in [13] show a complete different picture. Regarding sgprop, Virtuoso performed best, Stardog was 3 to 4 times slower than Virtuoso and Blazegraph was much slower than both of them. As the used nary-relation serialization is really different in structure, it is hard to compare with our naryrel results, but instead it makes more sense to compare the trends with stdreif model. Stardog clearly outperformed Blazegraph (5 times slower) and Virtuoso (around 2 to 20 times slower) for queries against this standard reification variant. Several factors may explain the different outcome. The dataset is rather small and from another domain, the evaluation setup differs and the used storage backends have received major updates.
Conclusion and future work
To summarize, this work defined requirement-based criteria to drive an evaluation of different approaches for metadata handling in three prominent RDF stores. Furthermore, a systematic comparison of several MRMs and its corresponding queries was presented. Based on previous work, additional datasets and use cases which elaborated different aspects about dealing with metadata in RDF datasets were created. Additionally, we introduced a novel metadata representation model called Companion Properties, which has been proven to be a good alternative to existing triple based MRMs for DBQ Queries, even outperforming ngraphs in Stardog. Unfortunately, it did not perform well for challenging DBM queries. Substituting
The results clearly show, that ngraphs outperforms the other MRMs for challenging mixed queries, which confirms the results presented in [22] for more complex templates than the quin queries. As long as the use case or source dataset does not require the usage of quads, ngraphs is the most suitable solution. In case existing datasets rely on named graphs, naryrel turned out to be a very good alternative for Virtuoso. With the used Blazegraph version, it was not possible to finish the Blazegraph naryrel experiments due to an unresponsive backend. In contrast to [22], we were not able to confirm performance problems with sgprop. It is the best triple MRM for Stardog and it seems to be a more reliable replacement for naryrel in Blazegraph. Stdreif performs good in Blazegraph and Stardog for simple queries, but it has shortcomings in Stardog and for challenging queries in all tested stores. This is not in line with findings in [22], where stdreif had been reported as competitive to ngraphs. The obtained results indicate that metadata characteristics have an impact on the ranking of the MRMs. Ngraphs and rdr support queries against meta-metadata much better than the other MRMs. In general, rdr can compete with ngraphs, if the metadata is on statement level granularity and does not require logical units of metadata facts.
In addition, experimental results show that the MRM ranking differs between data-only and mixed query scenarios. Moreover, ngraphs and rdr offer the best trade-off for both, mixed and data query workloads. When the query templates were created, the query optimizers were strongly impacted by even minimal structural changes in the queries. After investigating incomplete or wrong query results, we encountered the presented SPARQL implementation errors and variations in the used stores. Therefore an adoption of existing SPARQL test suites to check for these errors is advisable. Besides, memory and stability issues for Stardog and Blazegraph were observed, which were caused by garbage collection pressure. Improving query (plan) optimizers and memory management is ongoing work for upcoming major releases of Stardog and Blazegraph. Therefore, it could be interesting to repeat these experiments in the future, in order to evaluate the impact of such changes on the query execution performance.
Future work
With regard to benchmarking MRMs, there are many aspects that required to be studied in the future, e.g., parallel query workloads with multiple users. Depending on whether high throughput or low latency are required, it would be interesting to evaluate, which factors influence the performance of a parallel execution. If multiple query operators are evaluated in parallel, this can improve execution performance of an individual query, but it can result in higher costs, which in turn can potentially decrease the overall system performance, if many queries are run in parallel. Hence, a future work could validate, whether the results are also valid for parallel workloads.
In the performance evaluation of this paper (and to the best of our knowledge also in previous MRM studies), the queries are read-only. Having Big Data systems in mind, we can think of scenarios, where data is streamed (added and changed) continuously into the database. Changing metadata of a triple using a shared statement identifier (ngraphs & cpprop) is more complex than for other MRMs. So MRMs optimized for fast reading and factorization, may perform worse in update scenarios. Moreover, the study reported in this paper could be extended to other datasets to gain a better insight into dataset characteristics impact. By using additional datasets and update queries in combination with formalized scores and evaluation procedures, the performance evaluation could be extended to a general-purpose benchmarking framework for metadata handling in RDF stores. Furthermore, the mixed queries used in this evaluation are characterized by selecting and filtering (e.g., for confidence) of metadata. Therefore, metadata has a supportive role for the data parts of a query. We think, it could be interesting to study queries with patterns evaluating metadata statements over different entities or using other more elaborated metadata-centric query patterns, in order to find out whether similar results can be observed. On top of this, different ways in how to query a specific MRM need to be analyzed in more detail. For cpprop and naryrel, other SPARQL expression can be used to reduce the number of joins or BIND statements. Additionally, the injection of query hints during the transformation of a template for an MRM can help to support the query plan selection. In order to improve metadata handling, combinations of MRMs can be considered as well. For the purpose of backwards compatibility and performance, it seems reasonable to use a triple MRM for the first metadata level but ngraphs for meta-metadata. Moreover, rdr could be combined with an adopted version of cpprop to logically tie metadata facts, which belong to the same group. As these queries would require users to have detailed knowledge of the applied MRMs, the usability could be improved by using a SPARQL proxy. Such a service could (similar to our query transformation framework) use special MRM-independent annotations within a query, to translate it into the appropriate format. To go one step further, a more sophisticated metadata-aware system could be developed, which enables unified querying, regardless the used MRMs, granularity levels, and metadata levels.