
Abstract
Query relaxation has been proposed to cope with the problem of queries that produce none or insufficient answers. The goal is to modify these queries to be able to produce alternative results close to those expected in the original query. Existing approaches querying RDF datasets generally relax the SPARQL query constraints based on logical relaxations through RDFS entailment and RDFS ontologies. Techniques also exist that use the similarity of instances based on resource descriptions. These relaxation approaches defined for SPARQL queries over RDF triples have proved their efficiency. Nevertheless, significant challenges arise for query relaxation techniques in the presence of statement-level annotations, i.e., RDF reification. In this survey, we overview SPARQL query relaxation works with a particular focus on issues and challenges posed by representative RDF reification models, namely, standard reification, named graphs, n-ary relations, singleton properties, and RDF-Star.
Keywords
Introduction
When a query evaluated over a dataset produces empty or insufficient answers, query issuers may try to modify the query constraints. This task is time-consuming and requires users with a profound knowledge of the data distribution and the schema of the dataset. An efficient way to cope with this problem was proposed in the domain of cooperative answering for deductive databases [12,15]. Deductive databases not only store explicit information in relational databases but they also store rules (Datalog or Prolog rules) that enable inferences based on the stored data. The original proposed idea is a relaxation method to expand the scope of the query dynamically by relaxing the constraints in the query (predicates, constants, and breaking join dependencies). The goal is to generalize the user query to produce more answers by exploiting the hierarchical structures defined in an is-a taxonomy.
The evolution of the Web to the Web of Data lead to the development of data graph structures (RDF1
SPARQL 1.1 Query Language W3C Recommendation
In this survey, we focus on SPARQL queries over RDF triples. SPARQL allows defining queries with triple patterns over which conjunctions, disjunctions, and optional patterns can be defined. With SPARQL, query issuers can use the OPTIONAL clause to specify which triple patterns can be ignored if they cannot be satisfied during the query evaluation. This idea is interesting but used to a limited extent because other forms of query relaxation can be used rather than simply dropping triple patterns defined as optionals. In particular, SPARQL query relaxation can be based on a logical relaxation of some of the query constraints by using RDFS entailment and RDFS ontologies. The major challenge of this approach, is that the number of relaxed queries grows combinatorially with the number of relaxation steps and the query size. Several approaches have been proposed to optimize the query relaxation task and generate relaxed queries efficiently. Mainly, the idea is to organize relaxed queries from the most specific to the most general and execute them in this order until obtaining k-relevant answers. But many relaxed queries may produce no new answers because they have the same answers than more specific queries. To cope with this problem, the query execution ordering can be based on the similarity of queries. This similarity can be computed using only the ontology hierarchy or using information content [38] which is based on the number of instances per class or property. Therefore the challenge is to identify the most similar relaxed queries that may produce new answers and to reduce the space of the relaxed queries that are executed until obtaining k answers.
Different query relaxation approaches use the similarity of instances based on resource descriptions. For example, similarity can be measured using an appropriate function that returns the distance between two attribute values. Such a distance can be calculated in several ways, e.g., lexical similarities (like Jaccard similarity, Jensen-Shannon divergence, cosine similarity), overlap measures, page rank scores, etc. The similarity functions are data-dependent. Thus, the necessary number of functions depends on the different data types. Calculating the similarity of instances can be very costly. Further, multi-valued predicates (triples having a subject-predicate pair with several objects) may induce additional distances to compute. Frequently, the similarity of instances is done offline before the query processing. That is because the distances to compute can be significant, and calculating them dynamically during query processing can be unrealistic.
Moreover, statements about statements, also called statement-level annotations, are increasingly used. They allow specifying that a fact is true under a particular context. Context can concern temporal aspects, provenance, trust values, scores, weights, etc. When posing queries searching for annotation values, these values may be compared. RDF reification allows making statements about statements in a generic manner. For example, Fig. 1 illustrates (a) a traditional triple that consists of two resources (nodes) related by a property relation (edge), and (b) a reified triple stating that Query_Language is a topic of an Educational_Resource “to some extent with a cosine similarity of 0.6”. In a graph, reification can be seen as defining edges about edges. Reification can be done using several syntaxes that we call models. There is for instance, standard reification [28], named graphs [4], singleton properties [32], RDF-star [17], etc.

Representation of context on labeled edge.
Existing query relaxation approaches have proved their efficiency but statement-level reification can lead to significant challenges for relaxation techniques. For instance, if a query seeks resources with the topic :Query_Language (?er, :topic, :Query_Language), relaxation might replace it with the more general class :Programming_Language. However, without considering the precise context (how relevant are the returned educational resources), less relevant educational resources could be retrieved. The same drawback would exist if a similarity of instances is used without taking into account reification. Replacing :Query_Language with a variable leads to numerous results, disregarding the topic. Varying SPARQL syntax over reified triples, depending on the reification model, affects query relaxation behavior. Additionally, performance issues may arise due to triplestore implementations and limited support for reification models.
These challenges motivate this survey on SPARQL query relaxation works with a particular focus on issues and challenges over RDF reification. The goal of this survey is to give a bird’s-eye view of the SPARQL queries relaxation approaches over RDF datasets, and compare these approaches based on various relevant criteria.
This paper is structured as follows. Section 2 presents the survey methodology. Section 3 introduces the background by providing important definitions. Section 4 reviews query relaxation strategies and studies their behaviour through a motivating example. Section 5 compares and analyzes relaxation techniques according to several aspects (query shapes, relaxed terms, optimisation strategies, experimental evaluations, etc.) and analyzes their impact when different RDF reification models are used. Finally, Section 6 discusses the main issues and challenges of applying relaxation on SPARQL queries executed over reified triples. Section 7 concludes.
To the best of our knowledge, there is no survey on SPARQL query relaxation mechanisms. In this section, we present the methodology adopted to select the publications discussed in this survey. The collection of relevant works were found using Google Scholar,6
Table of all the reviewed papers in this survey
In our paper collection process, we first screened papers based on their title, abstract, and conclusion. Then this selection was followed by another filtering based on their content. Publications cited in the state-of-the-art sections of relevant publications were also collected and analyzed.
We collected papers according to these criteria:
Papers written in English.
Papers subjected to peer review, including published journal papers, conference proceedings, book chapters, and workshops.
Papers published from 2006 and until December 2023. SPARQL became a W3C Candidate Recommendation on 6 April 2006.
A list of venues representative of the retained papers includes the International Semantic Web Conference (ISWC), the European Semantic Web Conference (ESWC), the World Wide Web Conference (WWW), and the international conference on Web Information Systems Engineering (WISE). Our intention is to include works specifically addressing the automatic relaxation of queries over RDF data within the semantic web domain. Hence, papers outside this scope or addressing other types of data structure (relational, XML, NewSQL, NoSQL, etc.) were excluded. Thus, we review 14 approaches proposed in 13 research papers (see Table 1).
Query relaxation is the task of modifying the query conditions automatically when a query fails to generate sufficient results. This task helps users generate relaxed queries that return results close to those expected in the original query. In the context of RDF, existing approaches generate relaxed queries using different techniques based on logical relaxation using ontologies, but also based on similarity of instances using a variety of similarity methods (e.g., statistical language models, probabilistic models, etc.).
There exist plenty of possibilities to relax a query. This depends on the number of elements in every triple pattern that can be relaxed and the hierarchy depth of the ontology. Before surveying existing relaxation works we introduce the background necessary to understand our analysis. The background presented in this section includes some basic definitions about Semantic Web technologies (Section 3.1), an introduction to SPARQL query relaxation (Section 3.2), and an overview of some RDF reification models (Section 3.3).
RDF, SPARQL, and RDFS entailment
The Semantic Web is built upon key technologies like RDF (Resource Description Framework), RDFS (RDF Schema), OWL (Web Ontology Language) and SPARQL (SPARQL Protocol and RDF Query Language). These technologies, standardised by the W3C, facilitate the structured representation and efficient retrieval of web-based data. RDF is a standard model for data interchange on the web. While RDFS and OWL are languages designed to represent rich and complex knowledge about things, groups of things, and relations between things. SPARQL is the standard RDF query language and protocol that allows to search, extract, and retrieve relevant information. This section provides an overview of these foundational technologies.
RDF
RDF provides the data model in the form of a graph. It extends the linking structure of the web to use IRIs to name the relationship between things as well as the two ends of the link (this is usually referred to as a “triple”). An RDF triple is a fact represented as (s, p, o) ∈ (I ∪ B) × I × (I ∪ B ∪ L), where I is the set of IRIs, B is the set of blank nodes, and L is the set of literals. An RDF graph G is a set of RDF triples.
Figure 2 shows some RDF triples (Turtle syntax, on the left) and the corresponding RDF graph (on the right) that represent the knowledge about Maya, a student enrolled in the Semantic Web course teached by Patricia and who knows Peter.

Example of some RDF triples and the corresponding data graph.
SPARQL is a query language that enables the expression of queries across of RDF data sources. Several types of queries can be defined (SELECT, CONSTRUCT, ASK, and DESCRIBE). In this article we focus on SELECT queries.
The SPARQL semantics [35] is centered on matching graph patterns of the target data graph.
Triple pattern. The simplest graph pattern is a triple pattern composed of a subject, a predicate, and an object
Using the RDF graph of Fig. 2, the graph pattern matching will return the mapping:
FILTER limits the results of a graph pattern match based on a specified constraint. FILTERs eliminate solutions when substituting values into the expression leads to either a false boolean value or an error. For example, this BGP searches for students enrolled in Web courses:
The returned mapping is:
Basic graph patterns (BGPs). A BGP is a conjunction of multiple triple patterns. A BGP can include FILTERs to limit the results of a graph pattern match based on a specified constraint.
Group graph patterns (GGPs). A GGP is a collection of graph patterns enclosed within braces
AND or . allows to define the join operation over a BGP through common variables. All graph patterns are required and if one triple pattern has no binding (i.e., no solution in the data graph) then the query returns no solutions. For instance, this BGP searches for students enrolled in the Semantic Web course and which know Peter:
The graph pattern matching will return the mapping:
OPTIONAL allows to extend the solution of a BGP. If the optional part does not match, it generates no bindings but does not eliminate the solutions. This operator is useful when some data might be useful if available but not strictly required for the query result. For example, this BGP searches for students enrolled in the Semantic Web course, and if available, it returns their mailbox:
The returned mapping is:
UNION allows to define alternative or disjunctive solutions. If multiple alternatives match, it retrieves all these pattern solutions. For instance, this BGP searches for students or teachers:
The mappings returned are:
Queries can be distinguished by the shape of their BGPs into four types: star, chain, composite, and property path.
In a star query, all triple patterns share the same variable in the subject or the object. If all triple patterns are centered around the same subject, it is called a subject star-shaped query. In a chain query, the object of a triple pattern is also the subject of another triple pattern. So the same variable exists in a subject and an object. A composite query is a combination of star and chain queries. A property path query is a query whose predicate is a regular expression over a set of properties and not only one property. It allows complex paths between nodes instead of just adjacent neighboring nodes.
RDFS entailment
RDFS (RDF Schema) provides basic elements for the description of ontologies. Several RDFS concepts are included in OWL (Web Ontology Language) which is a more expressive language. RDFS constructs allow to define classes and associate properties. Properties define the relations between subject resources and object resources.
Query relaxation is frequently based on the entailment rules of RDFS13
Rule (1) defines the properties entailment through the property hierarchy.
Rule (2) specifies that when a property is inherited from another, if something relates to the superproperty, it is also entailed for the subproperty.
Rule (3) defines the classes entailment through the class hierarchy.
Rule (4) specifies that when a class inherits from another, it is entailed that instances of the subclass are also instances of the superclass.
Rule (5) entails the type of a subject in a triple from the domain of the related predicate.
Rule (6) entails the type of an object in a triple from the range of the related predicate.
Subproperty, subclass and type entailment rules of RDFS
The query relaxation explained in this section was proposed in [23] and is largely adopted by approaches using the RDFS entailment rules. We begin this section by introducing the triple pattern relaxation then the relaxation of the basic graph pattern of a query.
Triple pattern relaxation
Given two triple patterns
Property relaxation ≺sp (based on rules 1–2) replaces a property p existing in the predicate of a triple pattern with its superproperty
Type relaxation ≺sc (based on rules 3–4) replaces a class c existing in the subject or the object of a triple pattern with its superclass
Simple relaxation ≺s replaces a constant (IRI or literal) by a variable. This relaxation is frequently used when it is not possible to apply property or type relaxations.
Typing relaxation using the domain ≺d and the range ≺r (based on rules 5–6) replaces a triple pattern (?s, a, o) with (?s, type, c) if the triple (a, domain, c) exists in the ontology, or a triple pattern (s, a, ?o) with (?o, type, d) if (a, range, d) exist in the ontology.
Triple pattern deletion removes a triple pattern from the original query.
Typing relaxations using the domain and range can have several disadvantages. Adding types is not helpful if they already exist in the query. It is also not possible to use domain or range relaxations when there is a variable in the object and the subject because the links of the variables not being considered in the relaxation and other terms in the query will be lost (i.e., joins will be broken). In addition, applying these relaxations makes it hard to compare the relaxed triple pattern with the original one. Hence, measuring their similarity would need uncommon methods. For these reasons, typing relaxation is not frequently used and so it is not considered in the rest of this section.
The set of relaxed triple patterns can be represented by an acyclic relaxation graph. This graph can be a lattice-based partial order where the relation ≺ is a triple pattern relaxation. A relaxation step transforms

Relaxation lattices of triple pattern tp. ≺sc is a class relaxation, ≺sp is a property relaxation and ≺s is a simple relaxation. In (a), type relaxation is applied to :c1 once (with superclass :c1’) then simple relaxation is used (with the variable ?c1). In (b), type relaxation is applied twice (with superclass :c2’ then super-superclass :c2”) then simple relaxation is applied (with variable ?c2). In (c), type relaxation is applied to :c1 (with superclass :c1’), property relaxation to :p (with the superproperty :p’), and simple relaxation to :c2’ and :p’ (with variables ?c and ?p.)
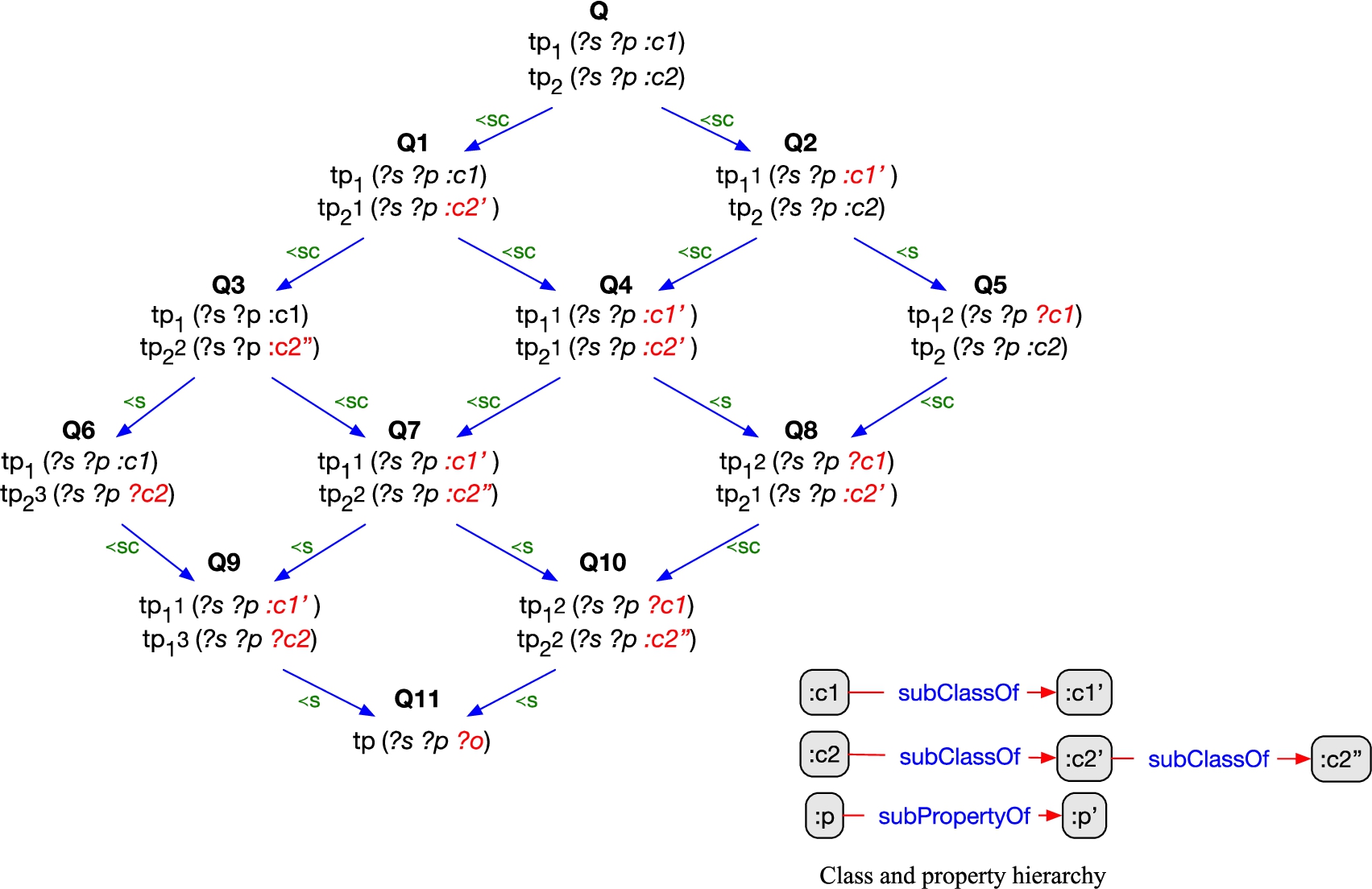
Figure 3 shows three relaxation lattices of a triple pattern
The total size of the relaxation lattice is the cartesian product of the size of each element. The size of each element can be calculated as follows, where e is an element of a triple pattern:
Let
Figure 4 shows an example of a relaxation lattice of a query Q. The basic graph pattern of Q is composed of the triple patterns of Figs 3a and 3b. The relaxation distance between two queries is the number of relaxation steps applied to the most specific query to obtain the most general relaxed query. This lattice has five levels. Relaxed queries having the same distance from the original query are part of the same level. The size of a relaxation lattice is the product of the sizes of the relaxation lattices of its triple patterns. In this example, the lattice size is twelve. If the graph pattern is composed of several triple patterns and the relaxation possibilities of each triple pattern are important, then the size of the set of queries
Information content measures
Analysing all relaxed queries existing in the relaxation lattice of a query is time-consuming and unnecessary. Information content [38], is frequently used to compute the similarity of relaxed queries to the original query. That is, to avoid the execution of an important number of relaxed queries until obtaining k-relevant results, several approaches use statistical information about the concerned dataset, such as the number of entities per class and the number of triples per property. The goal is to generate and execute relaxed queries from the most to the least similar to the original query.
Suppose
Based on information content, [21,22] propose similarity measures between terms, triple patterns and queries. These measures are used by several works because they allow ranking relaxed queries from the most to the least similar in a total order of relaxed queries.
Similarity between terms The similarity between terms depends on their nature: class, property, constant, or variable. It is computed based on the instances of classes and properties in a dataset. Suppose that
Similarity between classes is
For example, if the subject or object of a triple pattern is a class
Notice that, the similarity between classes is zero when all the instances in the RDF dataset belong to the superclass
Similarity between properties is
For example, if the predicate of a triple pattern is a property
Notice that, like the similarity between classes, the similarity between properties is zero when all the triples in the RDF dataset belong to the superproperty
Similarity between constants and variables is
For example, if the object of a triple pattern is a constant and is relaxed to a variable
Similarity between triple patterns Given two triple patterns
Where s, p, o,
Similarity between queries Given two queries Q and
Where
This similarity function is monotone, i.e., given two relaxed queries
Relaxation based on the similarity of instances
Query relaxation based on the RDFS entailment can have effective results in queries over datasets where the hierarchies of classes or properties are rich. However, in some use cases, precise queries are posed for matching structured descriptions of resources in the RDF graphs. Relaxing these queries by replacing constants (that are actually resource instances) appearing in subjects or objects with similar resources is more appropriate than replacing them with variables (using simple relaxation). To measure the similarity among resources, similarity functions are needed to estimate the distance between resources. Different functions and methods can be used for computing the similarity between resources based on their type (numeric, string, date, etc.). For example, for dates, normalized distances can be used. For numeric values, euclidian distances can be employed, or a normalization or scaling process could also be applied to measure the relative position of one numeric value within a predefined range. String functions can be based on natural language techniques where lexical analysis is applied, like Jaccard similarity, Levenshtein distance, TF-IDF score, cosine similarity, etc.
Reification models
Throughout the development of RDF, a series of contributions have reshaped the landscape of metadata representation. Some approaches have been proposed to represent specific metadata such as RDFt [44] and tRDF [37] for the temporal annotations, or uncertain data using possibility theory [3]. But more general approaches allow to specify whatever kind of metadata such as standard reification [28], singleton property [32], n-ary relations [18], named graphs [4], RDF-star [17],
Describing and querying reified RDF triples can be complex and the impact over current relaxation works can be important. In this work, we focus on statement-level metadata, i.e., reification at the granularity of an RDF triple. In the next sections, we analyse five representative reification models, namely, standard reification, named graphs, n-ary relations, singleton properties, and RDF-star. Each approach has advantages and disadvantages. They differ in the number of necessary RDF triples, the use of particular classes or properties, the query syntax, etc. These differences have an impact on the storage volume, the query execution time, the bulk load time, and the integration to the SPARQL specification.
To highlight the main differences among the analyzed reification models, we use a running example where the RDF dataset comprises students, teachers, and courses. Students are enrolled in courses, courses are taught by teachers, and individuals may know each other. In this example, the annotated fact is the enrollment of a student into a course. We consider two annotations: the enrollment date and the type of enrollment payment (Cash or Credit Card). The query of our running example searches for students enrolled in the Semantic Web course before the 13th of September 2023 and who paid by cash.
Standard reification

Illustration of reification models with graph representations.
The standard reification method, proposed in the RDF primer standardized by W3C [28],14
Listing 2a shows our example query with standard reification. This SPARQL query contains also four triple patterns that describe the RDF statement and two triple patterns that specify the metadata values using their related predicates. Queries of this reification model are typical subject star-shaped queries.

Examples of RDF triples in different reification approaches.

Example of SPARQL queries using different reification approaches.
Carrol et al. [4] extended the RDF data model to cover RDF graphs nameable by URIs. Named graphs were proposed to describe graphs with provenance information.16
Traditionally, a triple links two resources through a relation or property. The n-ary relation model [33]17
Instead of using new classes, the singleton properties approach [32] proposes to create a unique property for associating metadata. The new property is defined with the property singletonPropertyOf. Figure 5d shows the graph representation of this model for our example. In this representation, a new node is created to represent the new property (p-200). This property is linked to the original property via singletonPropertyOf. The same property is then used as subject for all annotations. This approach needs
RDF-star
SPARQL-star allows to bind a triple pattern enclosed in angle brackets as subject or object on other triple pattern. Our query example is shown in Listing 2e. This syntax shows that with this nesting-based approach, only one triple pattern is needed to search in a reified statement. It is hard to classify the shape of SPARQL-star queries. With our example query we can identify a subject star-shaped triple pattern in the enclosed angle brackets which is used for searching matchings with the given annotations.
At the time this paper was written, the RDF 1.219
The described reification models differ in various criteria such as the number of triples (resp. triple patterns), flexibility, syntax support, and human understandability, etc.
Standard reification, n-ary relations, and singleton properties are conform to the core RDF model proposed in 2004. Named graphs represent an extension to the triple RDF model and is part of the standard RDF1.1 published in 2014. RDF-star proposes to extend the RDF specification. All models are supported in the SPARQL standard, except for RDF-star that proposes SPARQL-star as query language. However, nowadays several RDF stores support the implementation of RDF-star and SPARQL-star such as Apache Jena, Stardog, RDF4j, BlazeGraph, AllegroGraph, etc.20
Standard reification is the most costly approach since it needs
All these reification models are flexible with respect to adding new annotations to an already reified statement. Adding new annotations requires adding only one additional triple for every approach. Concerning multi-valued properties (i.e., annotations having several objects sharing the same subject-predicate pair), all models support it.
We consider the number of triple patterns and the number of overhead variables necessary to query a single triple with its metadata as indicators of query facilities. The number of necessary triple patterns follows the ranking of the number of triples. Standard reification is the model that needs the most number of triple patterns in a SPARQL query. RDF-star is the model that needs the least. From the perspective of the overhead variables, all models need only one extra variable except RDF-star that needs no extra variable to query the statement and its metadata.
The most common query shapes used to query metadata are the star and the composite shapes. N-ary relations and singleton properties use composite queries with a subject star-shaped part. Notice that the chain part of singleton properties queries is over a predicate (predicate and subject instead of the traditional object and subject). Standard reification uses typical subject star-shaped queries. Named graphs uses star-shaped queries but accessing potentially several graphs (two graphs in our example). SPARQL-star queries are nested queries that in our example contain a star-shaped triple pattern.
Standard reification, singleton properties, and n-ary relations can be considered as hardly human understandable because the reified statement is split in several forms. Consequently, it is not possible to get the reified statement in a simple maner. Named graphs is more clear since it does not break the direct links between the terms of the reified statement. RDF-star was proposed to simplify statement-level annotations so it gives a clear representation of statements and their annotations. It does not involve refactoring the statement, declaring new predicates or new classes. This facilitates human understandability.
Several works studied different reification methods and compared them according to several criteria. To mention a few, [18] focused on Wikidata and its representation in RDF using reification based on n-ary relations, standard reification, singleton properties and named graphs. [11] realized an analysis of standard reification, named graphs, n-ary relations, singleton properties, companion properties (proposed in that paper) and RDF-star in its early stages. [26] experimentally analysed the behaviour of standard reification, singleton properties, named graphs, and RDF-star over a knowledge graph with a huge number of annotations (over 70% of the used RDF dataset). [25] compared standard reification, n-ary relations, RDF-star and Qualifiers [18] (the reification model proposed for Wikidata) for three consumer scenarios: knowledge exploration, systematic querying, and embeddings for graph completion. [34] proposed REF, a benchmark (dataset and set of queries) to analyse reification models. To illustrate the utility of the benchmark, authors analysed querying performance, storage efficiency and usability on a single triplestore using three reification models (standard reification, singleton properties and RDF-star). [1] proposed StarBench (as an extension to REF), a benchmark for testing the SPARQL-star support and runtime performance. Their analysis highlighted limitations in loading the data, query parsing, correct evaluation of SPARQL-star queries, as well as contrasting query execution performance across all tested engines.
Results suggest that there is no outright winner for all comparison aspects. Standard reification and named graphs appear to have good performance. Singleton properties frequently produces poor performances. This is likely due to the high number of unique properties, and indexes of triplestores are usually not optimized with that in mind. Finally, it appear that RDF-star should be more efficiently implemented, as it is becoming part of the RDF 1.2 specification.
The next section surveys SPARQL query relaxation approaches. Even though they have proven their efficiency, RDF reification poses significant challenges and raises open questions. Is it pertinent to relax terms introduced to employ various methods of statement-based reification? Is it crucial to distinguish the part of a query that searches for annotations from the one that searches for data? Can annotation values be relaxed similarly to traditional description values? Does the higher number of triples and triple patterns necessary to describe annotations have a performance impact on query relaxation approaches?
We organise the survey of existing relaxation works in two sections. Section 4.1 analyses approaches focusing on relaxation using RDFS ontologies and entailment rules [2,10,20–24,29,30,36]. Then, Section 4.2 surveys works oriented to relaxation based on similarity of instances [7,8,19]. For each work we describe its approach, the experimental setup and evaluation conclusions. Table 3 shows analysed relaxation approaches with a brief description of their main contributions.
Table of query relaxation strategies and their descriptions
Table of query relaxation strategies and their descriptions
The SPARQL query of Listing 6 will be used as running example as much as possible. This query searches for students enrolled in the Semantic Web course who are friends of Alice and know the Semantic Web teacher. This query searches for data (triples) but also for metadata (triples with RDF reification). We use the standard reification model to faciliate our explanations. Figure 7 introduces the ontology we use in our example. The Appendix shows supplemental material about our running example. A.1 lists the example dataset. A.2 lists the used ontology in Turtle. A.3 lists the dataset closure. A.4 shows the statistics of classes (Table 8), properties (Table 9), and some query similarity scores (Table 10). The size of the query relaxation lattice is approximately two million relaxed queries. A.5 shows the relaxed queries of the first level of the query relaxation lattice composed of seventeen queries. Notice that only

SPARQL query Q used in our running example.

Ontology of our running example.
Most relaxation strategies use type relaxation, property relaxation, and simple relaxation. In general, the closure of the RDF dataset is considered. To improve the performance, dataset statistics are used to calculate similarity measures between a relaxed query and the original query.
Extension of the OPTIONAL clause with a RELAX clause
Hurtado et al. [23,24,36] propose a RELAX clause as a generalization of the OPTIONAL clause of SPARQL for conjunctive queries. These works use four types of relaxation: type relaxation, property relaxation, typing relaxation (using the domain and range rules), and simple relaxation. Simple relaxation includes dropping triple patterns (similar to the OPTIONAL clause of SPARQL), replacing constants with variables, and breaking join dependencies. Breaking join dependencies consists in generating new variable names for a variable that appears in multiple triple patterns. These works perform the breadth-first traversal of the relaxation lattice of a query and return the answers in a ranking order according to the relaxation distance. But the queries that are on the same relaxation level are not distinguished.
It is worth noting that the approach introduced in [23] focused on single triple pattern queries or simple chain queries. [24] extends their relaxation approach by addressing graph patterns (using the product of the relaxation lattices of the graph pattern). Then, [36] extended the application of ontology-based relaxation from graph patterns to property path queries. To do this, authors convert a property path query into a chain query. Once a chain query is obtained, the query relaxation is done as usual. For instance, the property path ex:friendOf/ex:knows of our running example will produce two triple patters, and ex:friendOf will be relaxed to ex:knows. This will interestingly result in obtaining extra answers. In our example dataset, this relaxation will return the student Maya who knows Peter, who in turn, knows Alice.
The RELAX clause proposed in these works has interesting constraints. A triple pattern whose predicate term is in the RDFS vocabulary cannot be relaxed except for type-triple-patterns (i.e., triple patterns having rdf:type in the predicate). This kind of triple pattern will be relaxed only with Rule 4 (rdfs9) of Table 2, where a class is replaced by a superclass in the object. Applied to our running example, the metadata part of our example query would not be relaxed except for the triple pattern
We remark that the works by Hurtado et al. propose theoretical concepts and algorithms but do not include experimental evaluations of their contributions.
Ranking model based on Bayesian networks
Huang et al. [20] propose an approach to rank the relaxed queries according to their similarities to the original user query, and an original method to compute similarity values using Bayesian networks. The goal is to identify a set of relaxed queries to obtain k-relevant answers. This work considers type relaxation, property relaxation, typing relaxation and simple relaxation. It focuses on relaxing predicates and objects within the context of subject star-shaped queries to find similar entities.
The similarity of a relaxed query to the original query is measured based on the difference of their estimated results, i.e., their selectivity, or more concretely
This approach allows to discard relaxed queries with empty results. Our first observation is that as this approach focuses on star-shaped queries, the data part of our example query will be analyzed separately from the (related) metadata part (reification). Triple patterns like
Experimental setup The experiments conducted use Jena21
Evaluation Experimental results show that this relaxation strategy can avoid some unneccessary relaxations by considering the real data distribution, i.e., relaxations giving empty results are avoided. However, the experiments carried out do not present a comparison with other state-of-the-art contributions. Thus, there is no confirmation of the better performance brought by this work compared to other contributions.
[21,22] proposed the query similarity measures introduced in Section 3.2.3. [22] proposes and evaluates three query relaxation strategies: Best First Strategy (BFSR), Optimized Best First Strategy (OBFSR) and Batch-based Relaxation Strategy (BR). These strategies are based on the best-first traversal strategy of the query relaxation lattice and execute the relaxed queries in a ranking order according to similarity measures to generate the k-relevant answers for a query.
BFSR selects the best-relaxed query (based on the similarity measures) from the relaxed queries at every level of the query relaxation lattice until enough answers are obtained.
OBFSR is an optimization of BFSR that checks the usefulness of relaxed queries and skips unnecessary relaxed queries. It considers the join dependency between the triple patterns and the data distribution in the dataset to prune the relaxation lattice. OBFSR will prune the lattice by avoiding the evaluation of relaxed queries in cases where classes and properties are relaxed to their superclasses and superproperties that do not have new instances. Coming back to our running example, a relaxed query with the class ex:Person instead of ex:Teacher in
BR studies the problem of relaxing queries as a batch-based process to accelerate the query processing. The proposed idea is to execute relaxed queries as a group (batch) and skip some unnecessary relaxed queries for obtaining k-relevant answers. It improves OBFSR by considering the cases where the answers of a relaxed query are included in the answers of another query. The batch size is the number of relaxed queries that need to be executed to obtain k-relevant answers. BR excels when users require a large number of approximate answers, making it ideal for scenarios emphasizing result quantity over precision. In our running example, if
Although these algorithms rank relaxed queries based on similarity scores, distinguishing between relaxed queries can still be challenging. Consider two relaxed queries generated by simple relaxation. Despite both queries may yield distinct answers, it would be difficult to distiguish them if they have same similarity measures (see last line of Table 10 in the Appendix A.4).
Experimental setup These algorithms were evaluated using Jena TDB.22
Evaluation Experiments showed that when the user asks for few answers, BR will behave as OBFSR and BFSR. OBFSR is more efficient than BFSR since it prunes the lattice and saves more time. However, no difference in results quality is observed according to the type of queries used in the experiments. This means that the type of queries do not have an impact on the quality of results obtained by these strategies. The experiments carried out do not present a comparison with other state-of-the-art contributions.
Fokou et al. [10] present three approaches that focus on optimizing the relaxation process by investigating the failure causes of relaxed queries. Authors argue that executing relaxed queries in a similarity-based ranking order lacks of efficiency because queries are relaxed without identifying their failure causes. The failing sets of triple patterns in a query are called Minimal Failing Subqueries (MFS). Identifying the MFSs (i.e., the set of MFS) of a query is an NP-hard problem. In [9,29], authors propose efficient methods to computate the MFSs of a failing query. Discovering MFSs of a query Q roughly consists in (1) finding an MFS of Q, (2) computing the maximal queries not containing the MFS determined in the first step, and (3) repeating the first two steps until no more MFS are found. [10] proposes three different strategies based on failing subqueries, MFS-Based Search (MBS), Optimized MFS-Based Search (O-MBS), and Full MFS-Based Search (F-MBS). These strategies rank relaxed queries based on the similarity function described in Section 3.2.3. The three proposed strategies use different levels of information about failing queries.
MBS explores every query in a queue of relaxed queries totally ordered according to their similarity measures. The failure causes of the original query Q are identified, i.e., MFSs. If a relaxed query contains an MFS of Q, then it is considered as failing. MBS prunes the query relaxation graph with the identified failing queries. This strategy improves the query relaxation efficiency but its limitation is that it does not discover all failing subqueries because it focuses only on the failing causes of the initial query. When applying MBS to our running example, the only MFS consists of
O-MBS optimizes MBS by focusing on the MFSs that are not repaired. MFS existing in a query must be relaxed (i.e., repaired), otherwise, the query fails in producing results. Relaxed queries where the MFS are not relaxed are considered unnecessary. Intuitively, a relaxed query
F-MBS extends the O-MBS strategy by discovering all failing causes of every relaxed query. Although this extended strategy discovers all possible failing subqueries, its drawback is that it can take more execution time compared to the O-MBS strategy. This strategy will skip all queries in the Appendix A.5 except
Experimental setup These three algorithms were implemented in Java using Jena TDB and Virtuoso.23
Evaluation According to the experiments, O-MBS is the best strategy since it minimizes the computation time and the number of executed queries in most cases. O-MBS is a good compromise between MBS and F-MBS. However, these experiments do not show a comparison between these proposed algorithms and other state-of-the-art contributions.
Mebrek et al. [29] introduced an approach named CADER for handling failing queries. Unlike all previous proposed relaxation techniques, CADER relaxes the constraints of a query only by eliminating triple patterns. It does not use any ontology-based relaxation or query similarity. However, this approach also aims to optimize the relaxation process by studying the failure causes of the relaxed queries similar to the works described in Section 4.1.4 but in different manner. It involves two main steps: (1) determining the MFSs, and (2) exploring these failing subqueries to compute the set of maximal succeeding subqueries (XSSs). The basic idea of identifying MFSs consists in decomposing the initial query into the smallest subqueries (one triple pattern) and evaluating those queries until finding the largest queries with empty answers. In [10], the idea is to start with queries having the largest number of triple patterns and progressively move to those with the smallest number. The iterative browsing performed by CADER is more efficient since it reduces the exponential search space, resulting in the evaluation of fewer queries. If a query fails to give answers, then all its proper superqueries will fail. Consequently, evaluating these superqueries becomes unnecessary. Regarding the second step, this approach models the query relaxation problem as a hitting set problem. Given a collection of subsets (i.e., answers calculated in the step 1), the hitting set problem is finding the smallest subset that intersects (hits) every set in the collection. This is performed by discovering the MFSs and searching for their hitting sets which correspond to the complement set of XSSs. Hence, the set of succeeding queries are the set of maximal subqueries that succeed to give answers, and these queries are just generated by eliminating some triple patterns from the original query (the MFSs).
By applying CADER on the motivating example, it will identify the MFS of the original failing subquery that was determined in Section 4.1.4 (i.e.,
Experimental setup CADER has been implemented in Java with the Jena library. The experiments are carried out using datasets from DBpedia and LUBM. Several experiments were performed to compare the proposed approach with the LBA and MBA algorithms proposed in [9]. Queries of varying types (star, chain, and composite) were generated over the DBpedia and LUBM dataset. The LUBM tested queries were borrowed from [9].
Evaluation CADER behaves the best regardless the types of queries in terms of execution time.
Query relaxation using property paths and SHACL constraints
Lahmam Bennani et al. [2] propose two original predicate relaxations. The first one, relaxes a predicate to a predicate+, where + is a property path operator. The second one relaxes a predicate with another predicate based on the same domain and range constraints. The idea is to relax a property with another whose domain or range includes the subject or object in the triple pattern. To generate this relaxation, the SHACL constraints language [27] is used because it provides more expressive domain and range constraints than RDFS. Similarities are computed like in Section 3.2.3. This work explicitly uses weights to give priority to some triple pattern relaxations. However, the similarity is set to 0 when relaxing predicates using domain and range restrictions and to 1 when relaxing to a property path. This gives property path relaxations more preference. Simple relaxation is not used in this work. Only predicates and objects are relaxed. Suppose that there exist two constraints that say that only a student can enroll in a course and only a teacher can enroll in an employee meeting. In that case, SHACL shapes can be defined for identifying these constraints and defining the allowed domain and range of the predicate related to enroll. This approach will work on relaxing the predicate while still satisfying these constraints.
In addition, predicates will be transformed into property paths (for example, ex:teaches+, ex:knows+, etc.).
Experimental setup This work was evaluated over a dataset named Brick which its ontology is composed of building representations. A set of basic conjunctive queries were defined for this dataset. In the experiments, two scenarios are considered. In the first scenario, all the weight values for computing the similarity measure are 1, while in the second scenario, there is a willingness to relax a set of triple patterns in the original query. As a result, lower weights are assigned to some triple patterns to prioritize relaxation over these specific patterns.
Evaluation Experimental results show that a relaxation time less than 1 ms was observed for most of the queries. However, these experiments do not present a comparison with other state-of-the-art contributions. Furthermore, the results of the two considered scenarios for weight assignments demonstrated that assigning weights could facilitate the retrieval of more answers at lower levels of the relaxation graph.
License-aware query relaxation
Moreau et al. [30] proposes FLiQue, a license-aware query processing strategy that uses query relaxation to deal with contradictions among licenses. This is the only relaxation approach among the proposed works that deals with license conflicts in a federation of SPARQL endpoints. When two or more licensed datasets participate in evaluating a (federated) query, to be reusable, the query result must be protected by a license compliant with each license of the involved datasets. If a license conflict is detected, FLiQue dynamically discards datasets of conflicting licenses. As this solution may generate an empty query result, the original user query is relaxed with ontology-based relaxation technique (O-MBS proposed in Section 4.1.4). Thus, given a SPARQL query and a federation of licensed datasets, the goal is to guarantee a relevant and non-empty query result whose license is compliant with each license of involved datasets. The challenge is to limit the communication cost when the relaxation process is necessary. To reduce the overhead induced by the distributed query relaxation process, FLiQue uses data summaries, statistics, and descriptions of data. It uses a compatibility graph of licenses that can be produced with CaLi [31], a lattice-based model for license orderings. FLiQue searches for licenses that are compliant with each license of the datasets that can participate in the query evaluation. Subfederations that avoid license conflicts are defined if no compliant license exists in the original federation. If no subfederation can execute the query, then the O-MBS approach is used to produce and propose relaxed queries. This work does not propose a new query ranking strategy (queries are ordered by similarity like in O-MBS), but it is able to propose queries ordered by their licenses, from the less to the most restrictive license.
The FLiQue approach can be applied to our example and its behaviour would be similar as for O-MBS. The difference is that FLiQue can be also used in a federation of endpoints and can deal with the exponential number of possibilites wich depend on the instances of each dataset.
Experimental setup FLiQue was implemented in Java using Jena and CostFed [41], an index-assisted federated engine for SPARQL endpoints which relies on a join-aware triple-wise source selection by considering URI prefixes. The conducted experiments for the evaluation of FLiQue use Virtuoso endpoints and LargeRDFBench [40], a benchmark for a federation of SPARQL endpoints. This benchmark contains 32 federated queries (14 simple queries, 10 complex queries, and 8 large queries). Queries were executed over a federation of 11 interlinked endpoints.
Evaluation The experiments aim to demonstrate FLiQue’s ability to preserve licenses during federated query processing. For every query, experiments were carried out to compare the time to get the first result of the query with and without FLiQue. FLiQue shows a constant overhead due to checking the license conflicts. According to the experimental results, FLiQue succeeds in limiting the communication costs during the relaxation of federated queries whose results set cannot be licensed. However, LargeRDFBench is not ideal for this evaluation since the benchmark queries contain a lot of variables and very few classes. In addition, the potential for relaxation is poor due to the short depth of the hierarchies of the ontologies concerned by LargeRDFBench datasets.
Relaxations based on similarity of instances
Next works propose relaxation approaches that concentrate on rewriting queries based on instance similarities. They focus on discovering entities similar to the ones specified in the user query. RDF graphs describe entities, thus, similarities can be identified according to numeric or symbolic distances among entities’ descriptions.
Statistical language model relaxations
Elbassouni et al. [7] see the query relaxation problem as the entity-relationship-oriented counterpart of query expansion in traditional keyword-search settings. It uses NLP techniques, particularly statistical language models, to relax queries. This is performed by learning the probability of word occurence. In the same way, probability of occuring two entities together in the same triple in the dataset, is learned. Then similar entities are detected based on this statistics. This work proposes to rewrite triple patterns using similar entities and similar relations. Similarities are calculated using the entity descriptions existing in the knowledge graph. Each entity generates a document containing the triples where the entity appears as subject or object. Each relation generates also a document containing the triples where the relation appears as predicate. Then unigrams and bigrams are defined from each document. Unigrams correspond to all entities, and bigrams correspond to all entity-relation pairs. Language models are then estimated by combining unigrams and bigrams using linear interpolation smoothing from the corpus (i.e., the knowledge graph). The language model of each entity or relation becomes a probability distribution. The distance between the language models of every pair of entities allows to identify similar entities. The similarity score between any two distributions is computed using Jensen-Shannon divergence. Thus, for each entity, this approach computes a ranked list of similar entities. This processing is conducted offline prior to online query processing. Three types of relaxations are proposed: (1) replacing entities (subjects or objects) and properties with other related entities and properties, (2) replacing entities and properties with variables, and (3) removing triple patterns or making them optional. External information sources could be also used in this work to relax entities and predicates.
In our query example, the course ex:Semantic_Web can be replaced with the course ex:Databases by estimating their statistical language models. This estimation can be done from some common information about these two courses in the dataset, such as that both are taught by ex:Patricia. Concerning RDF reification, reified triples may induce errors because, for instance, in standard reification the subject is an identifier not an entity. But, it is possible that in a query relaxation, the subject of triple patterns like
Experimental setup The effectiveness of this relaxation approach was evaluated in two experiments. The first one evaluated the quality of relaxations of entities and relations. The second one evaluated the quality of the final results obtained from the original and relaxed queries. The experiments were conducted over two datasets. The first dataset was derived from the LibraryThing community, and the second dataset was derived from a subset of the Internet Movies Database (IMDB).
Evaluation Experiments based on human evaluations were conducted to evaluate the quality of the relaxations and relaxed query results. Evaluators studied the quality of these relaxations and how close they were. The same was carried out for the relations. The evaluators agreed with the ranking results of the entity and relations relaxations. indicating the good performance of this contribution in relaxing entities and relations. This work does not report a comparision with other approaches.
Relaxations of heterogenous resources descriptions
Hogan et al. [19] focus on entity-lookup queries using similarities of RDF terms. They address vague queries executed over heterogenous and incomplete data. Vague means that the query issuer may be not sure about the query constraints. When queries yield no results, this approach proposes rewriting them with similar constraints. This work introduces a generic framework to calculate distance scores between resources based on their structured descriptions. This process is conducted offline before online query processing. The target queries are subject-star shaped queries where only objects are relaxed. The framework maps entity values to relaxation scores using multiple distance functions. These scores range from 0 to 1, where 1 indicates no interchangeability, and 0 indicates perfect interchangeability. For instance, distance(:blue, :navy) might be 0.2, suggesting :navy as a good relaxation for generic :blue. The choice of the distance functions depends on attribute types, such as normalized distances for numeric attributes or Levenshtein distance for string attributes. Background knowledge, including similarity tables, can also be used. This approach positions the original query as the reference point and maps entities into an n-dimensional space. The closest entity value to the query is chosen. An overall relaxation score is computed for each entity based on its distance from the original query, facilitating result ranking. Users can assign vagueness scores to attribute-value pairs to control relaxation by property. It also proposes a concurrence measure that matches RDF resources based on the cardinality of property-value pairs in the dataset.
Considering our running example, a query that searches students enrolled in a “very easy” course, will give no answer as in our dataset there are no courses described as very easy (only easy and hard). But, if we use the Levenshtein distance, “easy” can replace “very easy” because “easy” is closer to “very easy” than “hard”.
Experimental setup The proposed relaxation framework was tested against the vehicles dataset of the EADS project (European Aeronautic Defence and Space Company) which is considered a small dataset. The effectiveness of this framework was also evaluated over three small queries. These queries were defined from their expression in natural language. Then, handmade, the expressions were transformed into SPARQL queries with vagueness scores. Transforming natural language phrases automatically into queries is out of the scope of this paper.
Evaluation Top 5 approximate answers of each query were collected and evaluated using scores based on root-mean-square deviation. From these observations, it was deduced that this approach has a weakness due to the functions declared in the framework. This weakness states that different functions may produce very similar values. Therefore, it becomes challenging to compare these values and determine the most suitable relaxation, making it difficult to distinguish the most relevant answers.
Partitioning-based relaxation
Ferré [8] proposes a strategy for finding approximate answers and optimizing the evaluation of relaxed queries. This work allows query relaxation to be applied effectively on large queries and not only on queries with few triple patterns. The usage of ontology in relaxing queries is not mandatory. Thus, this strategy is considered instance-based relaxation but it can also behave like an ontology-based relaxation approach. The foundation of this strategy is Formal Concept Analysis [13], a mathematical theory for deriving implicit relations between objects based on common attributes. In the context of semantic web queries, objects refer to RDF nodes, and attributes are the properties or characteristics associated with these nodes. When we formulate a query in the semantic web, it essentially acts as a description of RDF nodes. The query specifies certain conditions or properties that we are interested in when searching for information in a knowledge graph. Consider two classes in a knowledge graph, such as Course and Talk. These classes may have common properties, like duration, topic, and audience. Instances of these classes are the specific nodes in the graph, and when these instances share similar properties, they can be grouped together as part of a broader concept. For instance, if there are instances of both classes Course and Talk with same duration, topic, and audience, these instances could be identified as part of a broader concept – let’s call it EducationalEvent. In this context, the query represents a description of RDF nodes, and relaxed queries symbolically describe similar nodes. This work relies on symbolic similarity rather than numeric measures and utilizes relaxation distance to establish a partial ordering instead of a total ordering.
This paper proposes two algorithms: Answers partitioning and Lazy join.
Answers partitioning. This algorithm is the relaxation core of this work. It starts from a general query and progressively adds triple patterns to create more specific queries, efficiently eliminating irrelevant answers. This approach contrasts with traditional top-down approaches in query relaxation. The choice of triple patterns is free from the set of triple patterns in the original query.
Lazy join. The Lazy join algorithm is proposed to optimize the evaluation of the relaxed queries generated by the Answers partitioning algorithm. Unlike the traditional approaches, this algorithm passes reversely from the relaxed queries to the more specific queries. This guarantees less complexity since the newly generated answers are a subset of the previous one. This approach is advantageous for queries with multi-valued properties, as it avoids the explosion in join size.
This approach starts initially with a single partition defined by the fully relaxed query, i.e., the query with an empty body and the set of all possible answers. In addition, a set of candidate triple patterns is identified, containing all the triple patterns from the initial query that failed to produce enough results. Then each partition will be split in two parts by using a triple pattern as discriminating criteria generating a binary tree. As the choice of triple patterns is free, in our running example, the triple pattern (?student rdf:type ex:Student) could be chosen first. Based on this, the initial partition is split into two partitions. The first partition consists of a relaxed query that contains only this triple pattern and a set of answers that validate this query (ex:John, ex:Maria, and ex:Maya). While the second partition will remove this triple pattern and the results will be the complement of the results of the first partition. The algorithm stops when no partition can be split further. This algorithm is anytime because a partition is defined at all time so it can be stopped at any level. The partitions can be split in any sequence, enabling the adoption of either depth-first or breadth-first strategies, or the application of heuristics. The selection of the splitting triple pattern is also unrestricted and remains independent from one partition to another.
Experimental setup This approach was implemented in OCaml.24
Recently, authors published a java implementation for the Answers Partition and Lazy Join algorithms but no experiments are published
Evaluation The experimental results showed the efficiency of these algorithms in query relaxation over the small queries. In addition, it was proved that these algortihms are capable of exploring the search space in the absence of ontological definitions for queries having up to 1500 triple patterns. But still some strategies must be considered for choosing the proper cluster to split and the splitting element that allow to retrieve good results at earlier levels of relaxations.

Global query relaxation process of the two types of analyzed works (ontology-based and similarity of instances).
The relaxation processes of analyzed works share several common aspects. Figure 8 groups those relevant aspects from both types of analyzed works. The starting point is a query with empty or not enough answers. On the left part of the figure, the ontology-based relaxation process will logically relax the query constraints based on the class and properties hierarchies but also the domain and range descriptions existing in the ontology. Simple relaxation is not based on the ontology but it allows to generalize constraints by replacing terms with variables. As the number of relaxation possibilites is huge (generating all the relaxation possibilitites of the query relaxation lattice is a NP-hard problem), partial orders are calculated to rank queries by relevance. To reduce the search space of the most relevant relaxed queries (cf. doted box in Fig. 8), it is possible to calculate the similarity of relaxed queries using the information content (dataset statistics). This allows to identify relevant query rankings so that the query relaxation lattice will be pruned (unrelevant queries are discarded). Then, there is an iteration process where relevant queries are generated and evaluated until reaching k-relevant answers.
On the right part of Fig. 8, the general approach of the similarity of instances process is shown. This approach needs a potentially costly offline process such as building probabilistic language models or defining relaxation scores for every pair of entity values using various distance functions. This enables efficient relaxation of entities, relations, or object-terms during query execution. Then during query execution, the relaxation process can be done efficiently to relax entities, relations or object-terms.
If we generally position the SPARQL query relaxation contibutions, Hurtado et al. [23] initially introduced the concept of relaxing a triple pattern by extending the OPTIONAL clause using RDFS entailment rules and ontology. Building upon this foundation, [24,36] extended the scope to handle not only individual triple patterns but also SPARQL queries and property path queries. Huang et al. [20] contributed by proposing a ranking strategy. Their approach aimed at ordering relaxed queries and distinguishing them based on their similarity to the original query. To address the challenges posed by the search space, [10,22] made significant improvements by introducing optimizations. These optimizations helped in reducing the search space during query relaxation. [29] stands out in terms of efficiently computing the failing relaxed queries. Moreau et al. [30], added the data distribution aspect at considering a federation of SPARQL endpoints instead of the traditionally single SPARQL endpoint. Some notable works [7,19] proposed approaches to relax queries in the absence of explicit ontological definitions. Finally, the partitioning-based work [8] introduced optimized algorithms, showcasing efficiency in similarity search for large queries in situations where ontological information is absent.
Analyzed works are organized in two parts, the first one focuses on ontology-based relaxation and the second one on instances-based relaxation. Our first observation is that most of the works are included in the first part (see the first eleven lines of our tables). Only three out of the fourteen analyzed approaches propose instances-based relaxations. Notice that from these three works, [8] can also use ontology-based relaxation. This section compares the fourteen reviewed approaches with an analysis of relevant aspects about query relaxation. We begin by drawing a general comparison in Section 5.1. In Section 5.2 we compare reviewed approaches based on particular aspects of the query relaxation process. In Section 5.3 we analyze and compare their experimental evaluations. Section 5.4 positions the query relaxation in the context of RDF reification. Our analysis is summarized in comparative tables (Tables 4, 5, and 6) where  means the comparative criteria is satisfied,
means the comparative criteria is satisfied,  means that it is more or less satisfied, and
means that it is more or less satisfied, and  indicates absence of information.
indicates absence of information.
Query relaxation is a costly process because numerous relaxed queries can be evaluated before obtaining the most relevant k answers. The necesary information for the query processing relaxation is the RDF dataset (to evaluate candidate queries), the ontology (to relax queries in ontology-based relaxation), dataset statistics (to optimize the relaxation processing cost). Depending on the kind of relaxation, analyzed approaches use some or all this information.
Concerning the SPARQL query characteristics of relaxed queries, in general only BGPs are relaxed (set of conjunctive triple patterns). These works do not focus on relaxing FILTER, or UNION queries. The OPTIONAL operator allows somehow a relaxation of the query constraints as the OPTIONAL triple patterns are joined only if triples are mapped. Analyzed works do not relax OPTIONAL triple patterns. One work proposes instead an extension of this operator with a RELAX clause.
All works are able to relax star-shaped queries. And only one approach is able to relax property path queries. This observation has a logical explanation because the most used queries in real applications are star-shaped queries. Property path queries are relatively new (since SPARQL 1.1.), and they can be complex to evaluate. Concerning the relaxed terms (subject, predicate, object), all of them can be relaxed.
General comparison of analysed works

General comparison of analysed works
Next paragraphs detail our general comparison that is summarized in Table 4.
The second column of Table 4, shows the necessary information of analyzed works. During the query relaxation process, all analyzed works access the RDF dataset instances to evaluate relaxed queries and progressively obtain k-relevant answers. Dataset statistics are used to calculate the similarity of queries based on information content in [10,30]. This technique allows to rank queries so that unrelevant queries are ignored. Thus, it allows to avoid evaluating an important number of relaxed queries.
Third column of Table 4, shows that most of the works are able to relax the three main query structures: star, chain, and composite queries. All works relax star queries. [19,20] focus exclusively on subject star-shaped queries. [23] is limited to the relaxation of single triple patterns. But the extension of this work in [36] also proposes to relax regular path queries.
Dataset summaries are also used to limit the communication overhead in a federated environment in [30], where a federation of SPARQL endpoints participate in evaluating relaxed (federated) queries. In [20], the RDF dataset is used to build Bayesian networks which help in estimating the similarity measure of every relaxed query. All approaches of the first set of works, except for CADER, need the dataset ontology. CADER analyzes the original triple patterns of a user query to identify the maximal subsets of non failing triple patterns.
Concerning the second part of the contributions, based on the RDF dataset, [7] produces probabilistic language models. [19] uses the RDF dataset to map every pair values with distance functions. During the relaxation process, [8] access the RDF dataset to define partitions. As an option, [8] can use the dataset ontology. None of these works use dataset statistics.
The fourth column of Table 4 shows that subjects are relaxed by almost all analyzed works. [2,19,20] do not relax subjects. Predicates are relaxed by almost all works. All analyzed works relax objects of triple patterns. [19] relaxes only objects with its framework of mapping functions with similarity distances among object values. [29] does not relax queries ontologically, it only eliminates failing triple patterns.
Ontology-based query relaxation is made dynamically as an online process. Even if the relaxation possibilities can be huge, O-MBS and BR ([10,22]) proposed optimized strategies to prune the query relaxation lattice. Furthermore, the ontology-based relaxation proposed in [2], shows that it is also possible to relax using SHACL constraints. [2] also demonstrates that weighting triple patterns in the query similarity calculation can lead to obtaining more efficiently the k-relevant answers at earlier levels of the relaxation lattice.
Relaxation based on the similarity of instances needs, in general, an initialization phase that is an offline process. That is because techniques to define similarities are data-type dependent, and some distance functions are costly. Distance functions may involve processing external information (canonical representations, dictionaries, similarity tables, etc.), but also processing statistical models (NLP and machine learning techniques). This initialization phase should be done periodically for datasets that change over time. While for ontology-based relaxation, changes in the dataset have no impact on the computation of relaxed queries. Only dataset statistics need to be updated to calculate precisely the similarity of queries. For a federated environment, the indexes allowing to discard empty joins between distant sources must also be updated.
Second column of Table 5 summarizes the type of the relaxation applied when ontology relaxation is employed. Ontology relaxation is a way of relaxing queries by generalizing the initial query exploiting the ontology hierarchy. Only the contributions proposed in [20,23,24,36] mention using typing relaxation using the range and the domain. We recall that this kind of relaxation can be impractical to calculate the query similarity or when types already exist in the initial query. But, [23,24,36] do not use query similarity. Comparison of query relaxation approaches

Most of the relaxation approaches use type and property relaxations except the contributions that focus on similarity of instances [7,19] and the one that only consists of eliminating triple patterns [29].
Third column of Table 5 indicates that all the analyzed aproaches use simple relaxation except [2]. This relaxation replaces the value of a term (instance or constant) with a variable. This will lead to finally obtaining the most general query that is composed of a triple pattern with only variables.
Fourth column of Table 5 higlights the second set of analyzed works that focus on the similarity of intances. Queries are relaxed based on the similarity between the dataset instances and not on the ontology hierarchy. The similarity of instances is frequently computed using NLP techniques like word embedding, clustering, or probabilistic models. Several distance functions are often used to compute the semantic similarity between different entity values. That is because the similarity of instances is data-type dependent.
Fifth column of Table 5 shows that some contributions propose techniques to prune the query relaxation lattice that can be huge (cf. Section 3.2.2). This process is relevant for performance reasons. [10,22] studied the failure causes of relaxed queries. MBS and O-MBS can discover some relaxed queries that do not give answers without evaluating them (partial pruning). While F-MBS finds all the minimal failing subqueries of relaxed queries. FLiQue uses O-MBS but also a join-aware triple-wise source selection to prune unnecessary relaxed queries. OBFSR and BR also prune the lattice by studying the cases where a superclass or a superproperty does not contribute with additional answers. But BR executes relaxed queries in a batch. With the increase of the number of relaxed queries to be executed, it is more likely that these queries are subsumed by others in a batch. Hence, BR could skip these queries and outperforms BFSR when users expect more approximate answers.
Sixth column of Table 5 shows that few contributions propose techniques to avoid redundancy. When a query Q is relaxed to Q’, the relaxed query Q’ may have common answers with Q leading to redundancy during the query processing. This redundancy is caused by the inheritance of classes and properties. Fetching same answers from the dataset several times is time and memory consuming. Hence it is a good advantage for the relaxation approach to be optimized to avoid redundancy. Relaxation approaches proposed in [8,23,24,36] and the BR algorithm [22] make efforts to reduce redundancy. [23,24,36] avoid redundancy by considering the logical subsumption between queries. The lazy join algorithm proposed in [8] also results in calculating non-redundant answers by optimizing joins. The BR algorithm [22] skips the execution of relaxed queries that result in redundant answers by estimating the selectivity of the queries.
When a user query produces not enough results, the query relaxation possibilites can be huge. To propose the most close results to the user expectations, almost all analyzed works use techniques for query ranking. This is shown in the last column of Table 5. The query relaxation lattice is a partial order. The relaxation distance between two queries gives a hint about the semantic similarity of their results. But the relaxed queries at the same level of the lattice can not be compared. Hence additional information can be used to be able to compare all the relaxed queries. The similarity of queries is used as a measure that allows to obtain a total order of relaxed queries. This measure is based on information content (cf. Section 3.2.3). [23,24,36] rank queries according to their relaxation distance. Similarity of queries based on information content is used by [2,10,20,22,30]. [2] extends the similarity calculation by proposing simple similarity measures for relaxations using SHACL constraints (for domain and range constraints) and when a predicate is relaxed into a property path (into a predicate+). Other works employ different ways of computing similarity, such as word embeddings methods [14], symbolic similarity [8], numeric distance functions [19], and JS-divergence between statistical models [7]. CADER [29] does not consider ranking queries. It just discovers the set of relaxed queries, without any order.
SPARQL query relaxation has been used in solving real-world problems. Among the surveyed works, [19] addresses the need for approximate answers in a real scenario, specifically in police post-incident analysis. In this context, data is gathered and integrated for providing a more complete and insightful view of the incident or scenario under investigation. In addition, [2] seeks to enable interoperability and efficiency in smart buildings and building management systems. [2] allows applications to dynamically discover and interact with building resources, optimizing energy management, fault detection, occupant comfort, and scalability while reducing the need for hard-coded references to specific data sources. However, the remaining works do not focus on specific real-world scenarios.
Concerning the experimental evaluations reported in analyzed works, they vary in the used dataset size, the number of experimented queries, and the size of the queries (number of triple patterns in a BGP). Dataset used across analyzed works can be classified into three distinct dimensions, reflecting the diverse scales and issues of RDF data they encompass. The size of the dataset crossed with the potential relaxation allowed by the ontology poses important challenges of scalability. Exploring all the possibilities of relaxation of the query relaxation lattice is not possible but the limits of instances and ontology-hierarchies makes algorithms to reach an end point.
Small-scale datasets EADS, MONDIAL, and the Brick dataset contain a modest number of RDF triples, enabling controlled experiments and specific evaluations.
Medium-scale datasets A number of reviewed works chose to evaluate query relaxation on medium-scale datasets, including LUBM10, LibraryThing, and subsets of the IMDB dataset. These datasets strike a balance between complexity and manageability, presenting a realistic representation of query scenarios in various domains.
Large-scale datasets Our survey also covers works that tackle the challenges of large-scale RDF datasets. Datasets such as LUBM100, DBpedia, and LargeRDFBench contain extensive RDF triples, allowing for evaluating the scalability and efficiency of query relaxation techniques under substantial data volumes.
Comparison of experimental evaluations

Comparison of experimental evaluations
Table 6 shows the comparison of the relaxation approaches based on the experimental evaluations. [23,24,36] do not involve implementations and experiments for validation. These works analysed the theoretical part of query relaxation as they were the first to propose relaxing using RDFS entailment and RDFS ontologies.
The second column of Table 6 underlines a clear tendency to evaluate query relaxation with the LUBM benchmark. That is because LUBM proposes a well designed OWL ontology containing interesting class and property hierarchies which are necessary to experiment with ontology-based relaxation. CADER uses two datasets (LUBM and DBpedia) to compare the experimental results with LBA and MBA algorithms proposed in [9]. Besides using LUBM for ontology relaxation, [8] uses MONDIAL to study the performance of the proposed approach in presence of multi-valued properties. The brick-based relaxation [2] uses a different dataset concerning the brick-based building as it targets particular applications. FLiQue uses LargeRDFBench that composes a federation of 11 real interlinked datasets. FLiQue highlights the fact that the ontologies of these datasets are not deep enough to allow interesting query relaxation. At the time, LargeRDFBench was the only benchmark for federated queries. [7] tested their approaches on parts of the LibraryThing and IMDB datasets. These datasets were automatically parsed and converted into RDF triples in this work. [19] uses an existing a structured dataset describing car instances. The dataset was modelled and transformed into RDF triples by the authors using the Hepp’s Vehicle Sales Ontology.27
The third and fourth columns of Table 6 show heterogeneous number of queries and number of triple patterns used for the experimental evaluations. First, we remark that LUBM queries used in the experiments were different. Each concerned work defined different queries depending on the experimental goals. CADER [7] was evaluated with the greatest number of queries but we recall that the query relaxation consists in dropping failing triple patterns (MFS). The number of triple patters goes from 2 to 15. [21] experimented with five subject star-shaped queries having from three to four triple patterns. [22] and [10] used seven LUBM queries. [22] used queries with a maximum of five triple patterns and one MFS. The maximum number of executed relaxed queries is 8, 9, and 16 queries for k equals to 10, 50, and 150, respectively.
[10] defined queries involving until 15 triple patterns and up to 4 MFSs (k was set to 50 answers). This number of triple patterns lead to more than 1000 executed queries. O-MBS and F-MBS reduce the necessary number of queries to be executed to about 80 queries. [2] was experimented over small and simple queries (up to 8 triple patterns). FLiQue [30] was experimented with 32 federated queries with two up to twelve triple patterns. At most, 69 relaxed queries were generated for the queries needing relaxation. Nevertheless, at most 3 queries were executed for every initial query. We recall that these benchmark queries contain numerous variables in both subjects and objects, with very few classes in objects. (they are all star and composite queries). Thus the relaxation opportunities are mostly concentrated in the properties.
[7,19] focus on studying the performance in terms of the quality of results. Thus, the number of triple patterns was not important (one to four triple patterns). [7] defined 40 evaluation queries for each dataset. Top-5 relaxed queries were generated for each evaluation query. [19] defined three vague queries run against the vehicles dataset where five relaxations were also generated for each query.
The partitioning-based approach [8] defined sets of small queries (up to 21 triple patterns) and large queries (up to 1505 triple patterns) for the experiments. Small queries were tested to study the efficiency of the proposed algortihms in different execution modes (limit to relaxation distance and computation time). Large queries were used to prove the efficiency of the proposed algorithms in relaxing queries in the absence of ontology with thousands of triple patterns in a matter of minutes (thanks to the efficiency of similarity search). When large queries (having triple patterns up to 248) were tested over the MONDIAL dataset, a maximum of 117 relaxed queries were computed in less than 270 seconds. However, for queries (having triple patterns up to 1505) tested over LUBM, a maximum of 52 relaxed queries were computed in less than 540 seconds.
It is hard to position the efficiency of analyzed works due to the lack of availability of source codes and experimental prototypes. Indeed, analyzed works barely position experimentaly their contributions to state-of-the-art works. CADER was compared experimentally with algorithms proposed in [9] (LBA and MBA algorithms). The experiments proved a better behaviour of CADER in terms of execution time regardless the shape of queries. The algorithms proposed in [10], were compared as a whole with the BFSR algorithm [22]. Experiments revealed that BFSR executes more queries until finding k answers than the proposed algorithms in [10]. For queries with more than ten triple patterns, more than 1000 queries were executed for BFSR, while only about 80 queries were executed in the case of the algorithms based on MFS with k set to 50.
It is hard to reproduce the experimentally analysed works due to the lack of availability of prototypes and source codes. There exist only source codes for [10],28
OCaml
Several methods exist to define statement-level annotations. In this article we focus on standard reification, named graphs, n-ary relations, singleton properties, and RDF-star (cf. Section 3.3). In this section, we analyse the feasability of applying analyzed query relaxation approaches to RDF datasets using these reification methods under different perspectives.
Analyzing the syntax support, RDF-star, being a recent proposal, is not currently supported by existing relaxation proposals. Indeed, the nested capability of RDF-star and named graphs is not considered in query relaxation. The other reification methods can be syntactically supported but triple patterns querying metadata will be relaxed in the same manner as triple patterns querying data. However, relaxing classes and properties that specify the reification method, such as rdf:singletonPropertyOf, rdf:Statement, rdf:subject, rdf:object, rdf:predicate and the n-ary relation ex:Enroll_relation in Listing 1, is not meaningful. Moreover, the query shape of typical queries for standard reification are star-shaped queries, and for n-ary relations and singleton properties, they are composite queries with a subject star-shaped part. This enables the application of most relaxation methods to these reification models. Table 7 shows for each existing relaxation method and reification model, which combinations are technically applicable with minimal modifications.
Uncertain knowledge graphs have been addressed in the work [6]. They proposed algorithms in the context of empty answers. Their approach explains the reasons for the failure. There, the only metadata provided is a trust score related to each triple. They applied their algorithms over three reification models: standard reification, named graphs, and N-Quads. The experiments showed that query execution times are significantly longer on the named graph and reification implementations in comparison with the quad filter implementation.
Applicability of existing relaxation works with respect to reification models

Applicability of existing relaxation works with respect to reification models
The following paragraphs analyze these and other comparative aspects in more details.
Queries for standard reification, n-ary relations and singleton properties can be relaxed with existing relaxation approaches. However, current works cannot relax SPARQL-star and named graphs queries because of their nested approach, i.e., the subject or the object can be a triple pattern or a graph.
All relaxation approaches can relax star-shaped queries. Thus all of them can deal with standard reification where queries are typical star-shaped ones with the subject variable searching for instances that are of type Statement. The n-ary relations and singleton properties induce composite queries. Except for [20] and [19], all relaxation works are able to relax composite queries where objects and predicates can be relaxed.
Relaxation based on ontologies over queries including metadata constraints will apply relaxation over the terms related to the reification model or the metadata value itself. The ontology hierarchy of classes and properties used in annotations is not rich and relaxing them will not have any positive effect in the relaxation process. It has no sense in logically relaxing terms like rdf:singletonPropertyOf, rdf:type, rdf:Statement, rdf:subject, rdf:object, rdf:predicate and the n-ary relation ex:Enroll_relation and the property ex:enroll_value in Listing 1. Simple relaxation, where a variable would replace terms (instance or the constant) in the subject or the object of a metadata triple pattern would have a better effect. Using relaxation approaches based on similarity of instances will be more efficient over the annotation values. These approaches will relax values giving empty answers with similar or closer values. We notice, however, that none of the works use range of values. Using range of numeric values would be an interesting relaxation for annotation values.
Querying data and its metadata produces, in general, queries with numerous triple patterns and joins. As the number of triple patterns increases, the complexity of the computation of relaxed queries increases. Some works can deal with BGPs having until 15 triple patterns. [8] experimented with a very large number of triple patterns but only with the similarity of instances approach, not the ontology-based relaxation. Ontology-based relaxation poses serious challenges when the ontology hierarchy is rich. Moreover, RDF-star and named graphs are the most compact models and could be the most efficient during query relaxation from the complexity point of view because they do not add terms and triple patterns exclusively for the reification syntax. Unfortunately, there is no relaxing approach designed either for SPARQL-star or named graph queries.
The metadata type (numeric, string, date, URIs, etc.) is relevant for the relaxation based on the similarity of instances. The similarity functions to estimate the distance of resources is data-type depend. Estimating the distance of all the resources in a graph is a costly process that is frequently done offline. Thus, data types used in annotations may have an impact on the initialisation phase for techniques based on the similarity of instances.
Conversely to ontology-based relaxation, the relaxation approaches based on similarity of instances need an offline initialization phase before the online query processing. The initialization phase can be costly in time and its complexity depends on the size of the dataset. In general, adding statement-based annotations to RDF graphs increases the dataset volume. Except for named graphs and RDF-star, other reificaton models need several triples to include a statement-based annotation. This volume will impact the first phase of relaxation approaches based on similarity of instances. Besides, the shape of the RDF graph depends on the reification model (see Fig. 5). Thus, approaches like the one based on statistical language model relaxation [7] or the partitioning-based relaxation [8] would be seriously impacted.
On the other side, ontology-based relaxation approaches are independent of the size of the dataset during relaxation process, i.e., they depend on the class and property hierarchies of the ontology. Except for n-ary relations where one class definition is necessary by annotated statement, the performance of reification over ontology-based approaches would be insignificant. At the evaluation level, the relaxation works [10,30] that use dataset statistics will also not be affected at this level.
Regarding the evaluation of relaxed queries, depending on the query engine and reification model, the size of the dataset can cause performance issues (see Section 3.3.6).
After surveying existing SPARQL query relaxation strategies, we cannot assert that a relaxation approach can be directly applied to RDF reification. Several adaptations should be done. Each analyzed relaxation approach needs to be modified to understand the semantics of reification. The relaxation approaches could be enhanced to distinguish data and metadata in a query and identify reification patterns. This should be accompanied with understanding the semantics of reification patterns and treat it differently from regular triples. Particular attention should be paid to the chain part of composite queries because the relation of the data and the metadata parts of the query should not be broken. This could involve developing specialized similarity measures or scoring mechanisms for reification triples. This would ensure that the reification semantics are better retained during relaxation.
Applying query relaxation over queries whose constraints concern data and metadata (statement-level annotations) opens several issues. Current relaxation techniques are not proposed for querying metadata. Here is a summary of our observations. (1) Logical relaxation over the terms related to the reification model or the metadata value itself has in general no sense. That is, logically relaxing terms like rdf:singletonPropertyOf, rdf:type, rdf:Statement, rdf:subject, rdf:object, rdf:predicate does not generate relevant answers. (2) Metadata values are not taken into account in the query ranking function that allows gathering the k-relevant answers closest to the original query. In ontology-based approaches, object-values are replaced by variables. (3) Current relaxation techniques are defined for equality of values but metadata constraints can include intervals of values in a range. Relaxation approaches based on similarity of instances can be efficient over annotation values but in general they do not consider ranges of values. (4) The representation of different RDF reification models leads to different forms of the RDF graph. Graphs representing instances with reification vary and will be consequential to approaches based on the similarity of instances that use graph-based approaches to calculate instances’ similarity. (5) Syntactically, RDF-star and named graphs are not supported by current query relaxation approaches. Indeed, the nesting aspect of these reification models is not considered.
Hence, we consider that new query relaxation contributions should be proposed to deal with queries querying data and metadata. A query rewritting process is necessary to distinguish the query constraints (which triple patterns concern data and which ones metadata) because relaxing metadata triple-patterns (i.e., triple patterns about annotations) does not have the same goal as relaxing other triple patterns. However, the joins between the data and metadata part should be preserved (not broken down).
Both, ontology-based relaxation and similarity of instances, are necessary to query data and metadata. Depending on the application goals, these techniques may be combined. Querying data and metadata increases the query size which leads to the increase of the query relaxation lattice. Thus, optimal methods to prune this relaxation lattice should be used. If as we suggest, the terms related to the reification models are not logically relaxed, the query relaxation lattice will decrease. New relaxation approaches should take care about not breaking the relation of the metadata part of the query from the data part. Metadata values should play a role in the query ranking strategies that allow pruning the relaxation lattice but also gathering the k-relevant answers closest to the original query. Thus, new functions to calculate the similarity of queries should be proposed. Experimental evaluations to compare existing works will be done in the future works. Among the instance-based works, particular interest lies in evaluating the partitioning-based approach, especially considering its non-specific targeting of particular application scenarios or query shapes. While for the ontology-based works, O-MBS and the batch relaxation strategy proposed in [10,22] stand out as particularly interesting candidates for comparison. Their focus on composite queries and effective optimizations makes them compelling choices for evaluation. Regarding the datasets, it would be motivating to compare these works using Wikidata since it is a diverse and extensive knowledge base, covering a wide range of domains. Both conjuctive and non conjunctive queries could be the target of these experimental evaluations.
Finally, current works should also be extended to cover the syntax and the nesting aspect of named graphs and RDF-star. Besides, existing query engines can deal efficiently with named graphs and extensions taking into account this representation can be effective, but that is not the case for RDF-star. SPARQL query engines should be improved to make possible query relaxation over RDF-star datasets.
Conclusion
Applications querying reified triples may face the problem of empty or insufficient answers. Query relaxation approaches have been proposed to solve this problem but none of them is appropriate for metadata triple-patterns. In this paper, we provided an overview and comparative analysis of existing contributions focusing on SPARQL query relaxation. We also analysed and compared the syntaxes of some relevant reification models. Then, we underlined the potential effects of query relaxation approaches over reified triples. This survey has revealed that at the moment, no query relaxation solution deals with RDF triples and their annotations. Therefore, we pointed out some challenges and open issues in relaxing SPARQL queries under the lens of RDF reification, which we hope will open the doors to new inspiring contributions.
Footnotes
Acknowledgements
This work has received a French government support granted to the Labex Cominlabs excellence laboratory and managed by the National Research Agency in the “Investing for the Future” program under reference ANR-10-LABX-07-01.