One of the major issues encountered in the generation of knowledge bases is the integration of data coming from a collection of heterogeneous data sources. A key essential task when integrating data instances is the entity matching. Entity matching is based on the definition of a similarity measure among entities and on the classification of the entity pair as a match if the similarity exceeds a certain threshold. This parameter introduces a trade-off between the precision and the recall of the algorithm, as higher values of the threshold lead to higher precision and lower recall, and lower values lead to higher recall and lower precision. In this paper, we propose a stacking approach for threshold-based classifiers. It runs several instances of classifiers corresponding to different thresholds and use their predictions as a feature vector for a supervised learner. We show that this approach is able to break the trade-off between the precision and recall of the algorithm, increasing both at the same time and enhancing the overall performance of the algorithm. We also show that this hybrid approach performs better and is less dependent on the amount of available training data with respect to a supervised learning approach that directly uses properties’ similarity values. In order to test the generality of the claim, we have run experimental tests using two different threshold-based classifiers on two different data sets. Finally, we show a concrete use case describing the implementation of the proposed approach in the generation of the 3cixty Nice knowledge base.
In the last decade, we have witnessed to the generation of several knowledge bases that grant access to an enormous amount of structured data and knowledge. However, the generation of knowledge bases has required a tremendous manual effort to overcome several challenges. One of the typical issues in the generation of knowledge bases that integrate data from a collection of heterogeneous sources is that of automatically detecting duplicate records. Entity matching (also known as instance matching, data reconciliation or record linkage) is the process of finding non-identical records that refer to the same real-world entity among a collection of data sources [16]. Entity matching allows to identify redundant data, remove them (deduplication) and obtain unambiguous entities. Entity matching is rendered troublesome by the different data models used by the data providers, by possible misspellings, errors and omissions in data descriptions, by the use of synonyms, as well as the presence of implicit semantics in the textual descriptions. Consider as an example the case in which one record is named “Black Diamond BGWB14 Inc.” and the second record is named “Black Diamond f.s.b.”. In order to understand whether the two records correspond to the same real world entity, in addition to taking into account other properties such as the address, the state or the geographical position, it is clearly necessary to have expertise in the domain and to be able to understand the meaning of the abbreviations, as well as to rule out evident misspellings or mistakes. Nevertheless, a manual comparison from human experts is in most cases unfeasible, as matching entities requires a quadratic computational time (e.g. matching entities requires comparisons). Thus, entity matching systems typically define a metric to measure a similarity between entities. This metric can be defined through knowledge of the domain and a trial-and-error process, in a top-down manner [5,55], or can be learned from annotated examples, in a bottom-up way [21,38]. Then, the similarity is turned into a confidence score, which represents the degree of confidence in asserting that the pair of entities is a match. Finally, a threshold has to be specified, in order to convert the confidence score into a decision, namely classifying the pair as a match or not. This decision threshold introduces a trade-off between the precision, i.e. the capacity of discriminating false positives, and the recall, i.e. the capacity of individuating true positives, of the algorithm. Indeed, higher values of the threshold lead to a more selective classifier, which tends to incur in false negatives, reducing the recall of the algorithm, while lower values of the threshold produce the opposite effect. Thus, the user typically attempts to find a balance between these two measures, either manually or using more sophisticated approaches that are able to learn a configuration from annotated examples. Independently from the strategy chosen to set the final threshold, state-of-the-art systems typically rely on a single decision threshold. In this paper, we show that the combination of the predictions of an array of thresholds using ensemble learning, and, more in detail, stacked generalization, is able to break the trade-off between the precision and the recall of the algorithm, increasing both at the same time, and consequently the F-score of the algorithm. We propose a general approach called STEM (Stacked Threshold-based Entity Matching), which can be applied on top of any numerical threshold-based entity matching system. STEM is based on the principle of Stacking (or Stacked Generalization) [59], which consists in training a meta-learner to combine the predictions of a number of base classifiers. STEM creates several instances, corresponding to different values of the final decision threshold, of a threshold-based classifier. Then, the classification outputs of this ensemble of classifiers are used as a binary feature vector for a supervised learner, which is trained on a set of manually annotated data. The main goal of STEM is that of enhancing the efficiency of a threshold-based entity matching system, namely the capability of generating high-quality matches improving the precision and the recall of the classifier at the same time [26]. In order to test the generality of our claim, we run experimental tests using two different unsupervised threshold-based classifiers. The first is a Naive Bayes classifier [28,31], which follows the approach popularized by the Paul Graham’s spam filter1
http://www.paulgraham.com/spam.html
and is implemented by the open source deduplication framework Duke.2
https://github.com/larsga/Duke
The second is a linear classifier, implemented by the open source framework Silk [57],3
https://github.com/silk-framework/silk
which is currently quite widespread in the Semantic Web and Linked Data communities. The first dataset used for the experimental evaluation is that released by the organizers of the Financial Entity Identification and Information Integration (FEIII) Challenge. The second dataset is taken from the DOREMUS project, released by the instance matching track of the Ontology Alignment Edition Initiative (OAEI). In addition to these datasets, we further validate STEM by describing its implementation in a concrete use case, represented by the 3cixty project.4
https://www.3cixty.com
In this context, STEM is used on top of a Naive Bayes threshold-based classifier to match entities and remove duplicates representing places and events coming from a number of heterogeneous local and global data sources in order to create a cleaner and of better quality knowledge base, which is used to support the planning of tourist visits and to offer a digital guide for tourists when exploring the city. The novel contributions of this paper are:
We design a generic framework based on stacked generalization that is able to improve the efficiency of threshold-based entity matching systems;
We provide empirical evidence of this claim by testing it with two different threshold-based entity matching systems, showing that efficiency gain can be up to of F1 from a threshold-based classifier;
We show that STEM applied on top of a Naive Bayes classifier performs better and has a weaker dependence on the amount of manually annotated entity pairs with respect to pure machine learning approaches;
We describe the implementation of the framework in the generation of the 3cixty knowledge base, providing evidence of its efficiency on a newly generated gold standard data set.
The remainder of the paper is structured as follows: in Section 2 we describe the relevant related work in entity matching, in Section 3 we describe the problem of entity matching and of the trade-off between precision and recall, in Section 4 we describe the STEM approach and the theoretical background of the base classifiers utilized in the experimental part, in Section 5 we describe the experimental setup and the configuration process, in Section 6 we show the experimental results, in Section 7 we describe the implementation of STEM in the 3cixty project and in Section 8 we conclude the paper.
Related work
Entity matching is a crucial task for data integration [11] and probabilistic approaches able to handle uncertainty have been proposed since the 60s [36].
A survey of frameworks for entity matching is reported by Köpcke in [26], where a classification of several entity matching frameworks is done by analyzing the entity type, i.e. how the entity data is structured, blocking methods, i.e. the strategy employed to reduce the search space and avoiding the comparison of each possible pair of records, the matching method, i.e. the function utilized to determine if a pair of records represents the same real world entity and the training selection, i.e. if and how training data is used. By taking into account the matching method, entity matching frameworks may be divided in frameworks without training [5,27,55], in which the model needs to be manually configured, training-based frameworks [33,53], in which several parameters are self-configured through a learning process on an annotated training set, and hybrid frameworks, which allow both manual and automatic configuration [15,25].
The authors of the survey thoroughly compare different frameworks on a set of key performance indicators and highlight a research trend towards training-based and hybrid approach, which, in spite of the dependence on the availability, size and quality of training data, significantly reduce the effort of manual configuration of the system. The most commonly used supervised learners are Decision Trees and SVM. Training can help for different purposes, such as learning matching rules or in which order matchers should be applied, automatically setting critical parameters and/or determining weights to combine matchers similarity values [15,53,54,60]. In [51], a comparison among the most common supervised (training-based) learning models is reported together with an experimental evaluation. The authors report a high degree of complementarity among different models which suggests that a combination of different models through ensemble learning approaches might be an effective strategy. The idea of ensemble learning is to build a prediction model by combining the strengths of a collection of simpler base models. Ensemble learning can be broken down into two tasks: developing a population of base learners from the training data, and then combining them to form the composite predictor [19]. In [60] the authors report that an ensemble of base classifiers built through techniques such as bagging, boosting or stacked generalization (also known as stacking) generally improves the efficiency of entity matching systems. Another evidence of the efficiency of ensemble approaches to entity matching is reported in [9]. Ensemble learning has also been successfully applied to other fields relevant to the Semantic Web community, such as Named Entity Recognition [45,52].
In the past years, the Linked Data [6] research community has shown a great deal of interest for Entity Matching. More specifically, Entity Matching (or Instance Matching) can be seen as a part of the process of Link Discovery. Link Discovery has the purpose of interlinking RDF data sets that are published on the Web, following the evidence of recent studies that show that 44% of the Linked Data datasets are not connected to other datasets at all [49]. Link Discovery can be seen as a generalization of Entity Matching, because it can be used to discover other properties than an equivalence relation between instances. Furthermore, as remarked in [35], in Link Discovery resources usually abide by an ontology, which describes the properties that resources of a certain type can have as well as the relations between the classes that the resources instantiate. The authors of [35] report a comprehensive survey of Link Discovery frameworks, which shows that modern framework such as Silk [21,58], LIMES [37], EAGLES [38] combine manually defined match rules with genetic programming and/or active learning approaches to automatize the configuration process. A different approach is proposed by WOMBAT [50], which relies on an iterative search process based on an upward refinement operator. WOMBAT learns to combine atomic link specifications into complex link specifications to optimize the F-score using only positive examples. Another line of work is that of collective entity matching (or resolution) systems, which are not based on pairwise similarity comparison as STEM, but rather on the attempt to capture the dependencies among different matching decisions [2,13,14,40,47,61].
STEM is a general approach to improve the efficiency of an entity matching system, which is in principle applicable to any pairwise numerical threshold-based classifier to enhance its efficiency.
Problem formulation
The problem of entity matching can be defined as follows [17]:
Given two datasets A and B, find the subset of all pairs of entities for which a relation ∼ holds:
In this formulation, we assume that the schema mapping problem is solved, and thus:
Given a property π of the schema of A and a property ρ of the schema of B, we assume that a set of mapped properties has been defined with . In the following, when we refer to the properties , we refer to the components of the mapping , i.e. to for and for .
We assume that the comparison between a pair of entities and is carried out on a set of literal values of properties . We assume that the entity matching system is a pairwise numeric threshold-based binary classifier acting on the properties . Thus:
We define the linkage rule as a Boolean function , where indicates that the pair is deemed a match and indicates that the pair is not deemed to be a match.
The comparison of two entities is performed using a comparison vector, where the components represent atomic similarities defined over a number of literal values of the properties .
The comparison vector is then turned into a confidence vector, where each component represents the degree of confidence in stating that the pair of entities is a match given by the similarity score .
We define a confidence function which maps the confidence vector into a final score representing the confidence of the entity matching system to state that the pair of entities is a match.
We define as threshold-based classifier a linkage rule that depends on the confidence function f in the following way:
where θ is the Heaviside step function and is a given threshold.5
We assume that both f and t are normalized in the [0,1] interval, but it is intuitive to see that the same argument holds for any closed interval with , as Eq. 1 is invariant to any multiplying factor within the θ function.
The linkage rule of a threshold-based classifier has a very intuitive interpretation. A pair of entities is considered to be a match if the degree of confidence f that the pair is a match and f is above a certain threshold t. The threshold t can be defined experimentally or can be learned from a set of examples. Independently from the strategy through which it is set, the threshold t introduces a trade-off between the rate of false positives and false negatives that the algorithm will accept. To see why this is the case, let us first start from the definition of the two types of errors defined in [17], considering the variations of the confidence value . The first error, which corresponds to the probability of having false positives, occurs when an unmatched comparison is considered as a match:
Given that we consider a binary threshold-based classifier, it follows from Eq. 1 that:
which leads to:
The second error, which corresponds to the probability of false negatives, occurs when a matched comparison is not considered to be a match:
From Eq. 3, it follows that:
and thus:
The probability of true positives is similarly measured as:
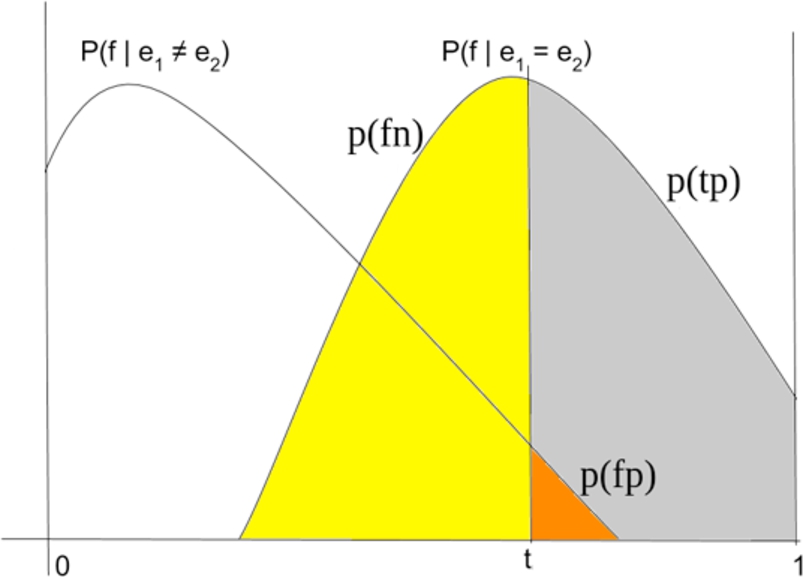
Let us now consider the graphic illustration provided in Fig. 1. Assuming that f is a meaningful confidence function, the probability density function of the values of f under the condition that , i.e. , has a higher mean and is located to the right, while , conditioned by , is located to the left. Let also be the total number of positive pairs, i.e. matching entities, and the total number of negative pairs, i.e. non matching entities, in the data. In this graphical representation, the linkage rule of Eq. 1 implies that the area of situated to the left of the vertical line corresponds to the probability of classifying a true match as a non matching pair, i.e. to the probability of producing false negatives . The number of false negatives is then given by . On the other hand, the area of situated to the right of the vertical line corresponds to the probability of classifying a false match as a match, i.e. the probability of producing false positives . Similarly to the previous case, we have that . Finally, we also have that the grey area in the graph is the probability of true positives . The number of true positives is then given by: . From Fig. 1 we can see that , and consequently , is increasing when the threshold t increases, and at the same time , and consequently , is decreasing when the threshold t increases. is also decreasing, but at a slower pace. Now, if we recall the definition of precision and recall [41]:
we can see that, when t increases, faster than , and p increases. At the same time, is growing and r decreases. Conversely, when t decreases grows and decreases, increasing r and decreasing p. Thus, the threshold t introduces a trade-off between the precision and the recall of the algorithm (we provide experimental evidence of this heuristic argument in Section 6). Note that this trade-off is not limited to Entity Matching and is well known by the Information Retrieval and Statistical Learning community, where precision-recall curves obtained through variations of the decision threshold are often used as a measure of an overall algorithm’s efficiency [29,41,42].
Graphical depiction of , and under the linkage rule Eq. 1. The vertical line represents the decision threshold t. The shape of the probability distribution has illustrative purposes.
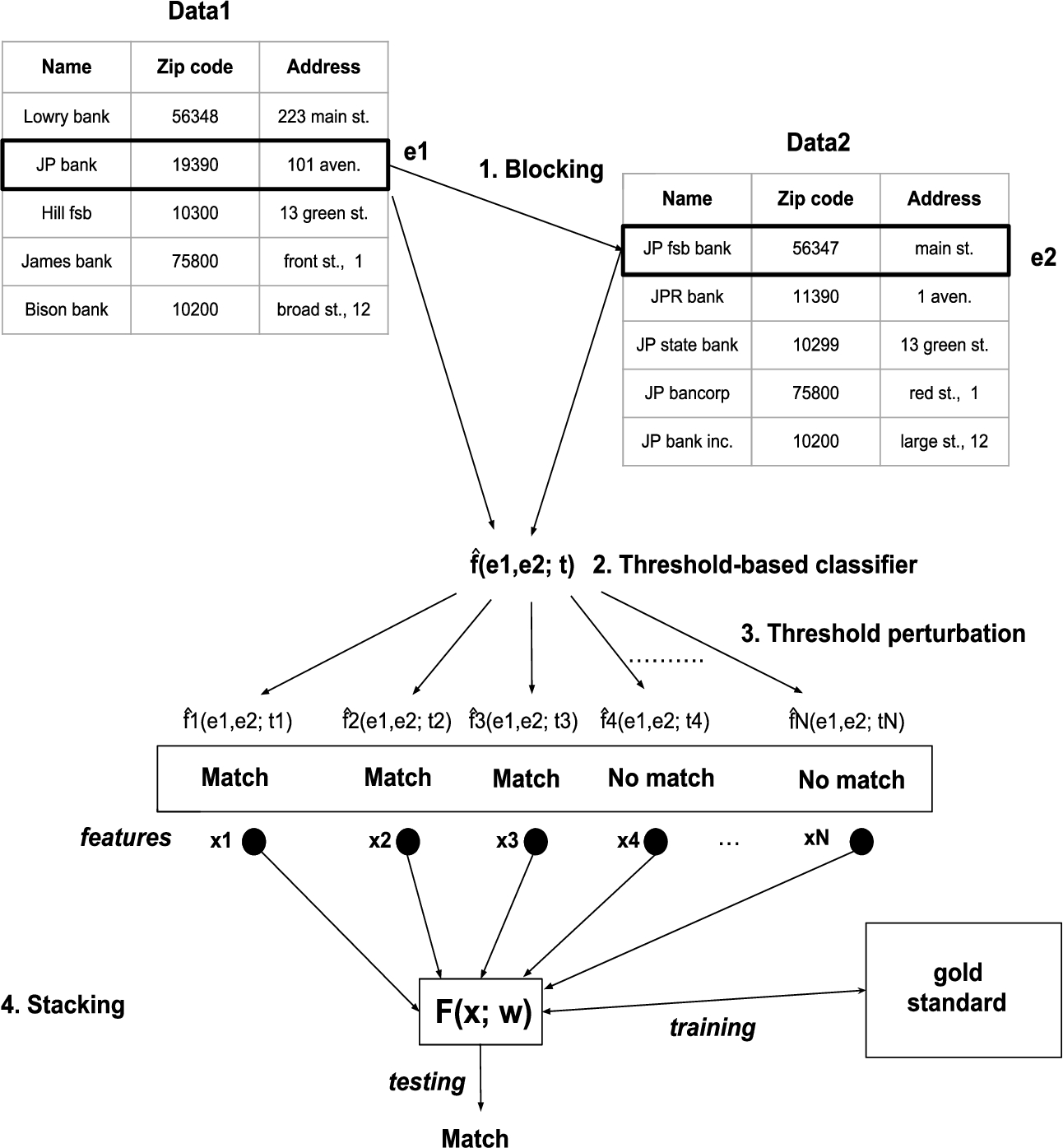
Global architecture of the STEM framework.
Stacked threshold-based entity matching
In this work, we show that stacking can break the trade-off by raising both precision and recall at the same time through supervised learning. Stacking [59] (also known as stacked generalization), is based on the idea of creating an ensemble of base classifiers and then combining them by means of a supervised learner, which is trained on a set of labeled examples. In this case, the base classifiers correspond to a single threshold-based classifier with a set of different decision thresholds . The supervised learner is a binary classifier whose features are the match decisions of the base classifiers and whose output is a binary match decision, which represents the final decision of the system. Stacking requires the creation of a gold standard G containing correctly annotated entity pairs, which are used as a training set for the supervised learning approach. More in detail, the Stacking Threshold-based Entity Matching approach (Fig. 2) works as follows:
Blocking (optional): although not strictly needed, it is in practice necessary for large datasets to find good candidates using a blocking strategy, avoiding a quadratic comparison of entities (see Section 5.3 and Section 5.4).
Threshold-based classifier: start from a linkage rule based on a threshold-based classifier such as the one defined in Eq. 1
Threshold perturbation: generate an ensemble of N linkage rules where are linearly spaced values in the interval and is the perturbation amplitude
Stacking: combines the predictions corresponding to different thresholds using supervised learning.
Features: use the predictions as features for a supervised learner where w are parameters that are determined by the learning algorithm.
Training: train the supervised learner on the gold standard G, determining the parameters . This typically involves the minimization of an error function :
The shape of the error function and how the optimization is solved depends on the particular supervised learner that is chosen. In this paper, we use an SVM classifier and we thus rely on the SVM training algorithm [19]. Note that the training process only needs to be done once per dataset, as the learned model can be stored and loaded for testing.
Testing: generate the final prediction .
The intuition behind this approach is that using stacking the space of features is no longer the confidence score f as for the threshold-based classifier. The supervised learner F uses as features the set of matching decisions of the base classifiers and, by combining them in a supervised way, it is no longer tied to the trade-off introduced by the threshold t that we have described in Section 3. We show experimental evidence of the effectiveness of stacking in increasing both the precision and the recall of a threshold-based classifier in Section 6.
We now provide the descriptions of the two threshold-based entity matching systems that are used in this paper, showing that they both constitute particular cases of Eq. 1.
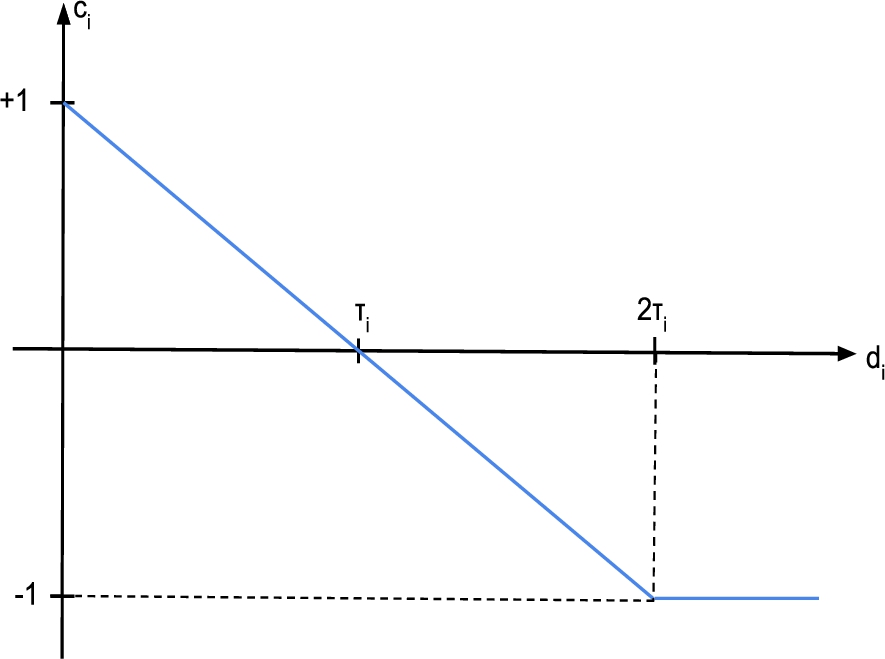
Silk function to compute property-wise confidence scores from distance values.
Linear classifier
One of the simplest models for the confidence function of a pair of entities and is that obtained by the linear combination of the components of the confidence vector introduced in Section 3. Given the set of properties and their respective values and for both entities, property-wise similarities are functions that yield a vector of similarity scores , where typically with . At this point, similarity scores are normally turned into the property-wise confidence scores , which are then linearly combined through the confidence function f. This is the case of Silk6
http://silkframework.org
[58], which is a popular Link Discovery framework, specifically built to generate RDF links between data items within different Linked Data resources. More specifically, Silk works with distances rather than with similarities and different comparators can be selected to define the distances , such as Levehnstein, Jaro-Winkler, exact comparators, Jaccard [10]. Then, distance scores are turned into confidence scores according to the rule7
(Fig. 3):
where are property-specific thresholds. Note that is a monotone decreasing function, as it depends on distances rather than on similarities values. In this way, for each property used for the comparison, a confidence score is obtained. Silk allows to combine these confidence scores in multiple ways, among which the linear combination, which is the one that has been utilized in this work:
which corresponds to the linkage rule Eq. 1 with:
The final decision threshold t corresponds to the parameter ‘minConfidence’ in Silk configuration file. This parameter, together with all the others such as property-wise thresholds or comparators, can be manually set through a trial-and-error process or they can be learnt through an active learning algorithm that is based on the approach of letting users annotate matches that produce the utmost information gain [22].
Naive Bayes classifier
Naive Bayes is a term used to describe a family of classifiers that are based on the Bayes theorem and on a particular assumption of independence among the components of the evidence vector [28,43]. In this paper, we use the formulation of the Naive Bayes classifier that has been popularized by Paul Graham’s Bayesian spam filter.8
http://www.paulgraham.com/spam.html
We now want to show that the Naive Bayes classifier can be considered as a threshold-based classifier, obeying to the decision rule of Eq. 1.
Given a set of classes with and a vector of observations , the Naive Bayes classifier aims to estimate the probability of a class given a set of observed data by applying the Bayes theorem and the conditional independence condition (from this assumption comes the adjective ‘Naive’):
In our case, we have a binary classification problem, where the decisions and and the observations are represented by the comparison vector s. Equation 14 for becomes:
Since the denominator can be rewritten as:
and then, using again the conditional independence hypothesis, factorized as:
Now, by applying Bayes theorem and , denoting with and , we have:
Finally, assuming that, a priori, and thus , we can remove the coefficients and by denoting with we obtain:
Details of the derivation can be found in [12]. Note that exactly represents the confidence score derived from the similarity value . It is also important to notice that this simplifying assumption , although widespread in practice and used in the implementation of Duke, is not necessary for a Naive Bayes classifier and can be modified with any other strategy to estimate prior probabilities.
At this point, it is necessary to specify a decision rule, that is a rule to turn the probability evaluation into a decision. A common approach is the Maximum a Posteriori (MAP) Estimation [34], namely selecting the class that maximizes the posterior probability:
which allows to define a binary linkage rule as:
which can easily be rewritten as:
Now, by adopting a decision-theoretic notion of cost, we can turn Eq. 21 into [3]:
where λ is a value that indicates how many times false positives are more costly than false negatives. From Eq. 22, it is clear that if , we require that is λ times greater than in order to consider the pair to be a match, and thus we are more keen to accept false negatives than false positives. Vice versa, if , the algorithm will tend to have more false positives than false negatives. Finally, by considering that and by using Eq. 18 we obtain the decision rule:
where . It is now easy to see that Eq. 23 can be rewritten as:
which has the same form of Eq. 1, where the combination of confidence scores has the role of the global ‘confidence function’:
We have thus shown that from a Naive Bayes classifier we can obtain a threshold-based classifier abiding by Eq. 1. As we have argued in Section 3, the threshold t rules the trade-off between the rate of false positives and false negatives that the algorithm will accept. This is evident by its relation with λ:
Thus, the higher the value of t, the higher needs to be the probability that the pair is a match for the algorithm to consider it a match. Thus, we are less likely to have false positives and more likely to have false negatives.
In the past years, Naive Bayes classifiers have been utilized in a large number of fields, such as spam filtering [31], document and text classification [30], information retrieval [28], entity matching [48] and so on. Duke9
https://github.com/larsga/Duke
is a popular open-source deduplication engine, which implements Naive Bayes classification. Duke is a flexible tool, which accepts different formats of input data, and is easy to configure through a simple XML file. For each field of each data source, the user can choose a number of string cleaners, such as functions that remove abbreviations or normalize lower/upper cases. For each property, Duke allows to select a comparator among popular string similarity measures such as Levensthein, Jaro-Winkler, exact comparators and so on [10]. The comparators thus compute, for each property, a normalized similarity score . Then, in order to turn similarity scores into a confidence score , Duke uses the heuristic function:
where and are parameters that the user can configure for each property. The rationale behind this formula of is that and , and, as Duke’s users were finding the algorithm to be too strict, a quadratic instead of a linear trend has been chosen when is larger than 0.5. After that is computed for each property, the overall is calculated through Eq. 18 and the decision is taken through Eq. 23. Similarly to the case of Silk, the final decision threshold t is a parameter that can be configured in a XML file. Duke also includes a genetic algorithm that automatizes the configuration process and in general represents a valid alternative to the manual configuration. Through an active learning approach, Duke asks to the user in an interactive way if a pair of entities should be a match or not, selecting the most informative pairs, i.e. the ones with utmost disagreement among the population of configurations [38].
Computational complexity
A crucial point for entity matching systems, which are often used to find matching entities among datasets with large numbers of instances, is their computational complexity. The stacking approach introduced by STEM adds an overhead to the runtime performance of the base classifier due to the generation of the ensemble of predictions and to the learning process. More in detail, the computational complexity of STEM in the current sequential implementation can be roughly approximated with:
where N is the number of features, n is the number of instances of the first dataset, m is the number of instances of the second dataset, g is the size of the training set and k is the size of the test set. depends on the nature and the configuration of the base classifier, especially on the blocking strategy. Let us assume that the base classifier adopts a smart blocking strategy such as that of Silk, we can assume that [57]. depends on the supervised learner that is used and depends on the training and the testing time . The training and testing processes can easily be decoupled, for instance saving the trained model to a file and loading it subsequently for testing. However, in this section, we discuss the worst case in which we need to first train and then test the model. In this paper, we use a kernel SVM10
http://scikit-learn.org/stable/modules/svm.html
classifier as a supervised learner, whose complexity may vary depending on a number of practical factors depending on the specific implementation. However, as a rule of thumb, it is reasonable to assume [7,8] that: and . To summarize, we can then say that:
In our experiments, we have that , and, by using cross-validation, we have that . In practice, we observe that when the number of features N grows, the time for generating the predictions quickly surpasses the time of stacking, i.e. (see Section 6 for an example). Note that the time could be reduced to by parallelizing the generation of the predictions of the N base classifiers, which we leave as a future work.
Experimental setup
As we have explained in Section 4, the STEM approach is general and can be utilized on top of any threshold-based entity matching system. In this paper, we have implemented it and evaluated through two different open source frameworks, Duke and Silk, which are based respectively on a Naive Bayes and on a linear classifier. In Section 5.3 and in Section 5.4, we describe the configuration process of these frameworks inside STEM. The software implementation of STEM, the configuration files and the data used for the experiments are publicly available on github.11
https://github.com/enricopal/STEM
Datasets
The first dataset utilized for the evaluation of the proposed approach is that released by the organizers of the Financial Entity Identification and Information Integration challenge of 2016 (FEIII2016).12
https://ir.nist.gov/dsfin/index.html
The purpose of the challenge is that of creating a reference financial-entity identifier knowledge base linking heterogeneous collections of entity identifiers. Three datasets have been released:
FFIEC: from the Federal Financial Institution Examination Council, provides information about banks and other financial institutions that are regulated by agencies affiliated with the Council.
LEI: contains Legal Entity Identifiers (LEI) for a wide range of institutions.
SEC: from the Securities and Exchange Commission and contains entity information for entities registered with the SEC.
In this paper, we focus on the Entity Matching of entities of the FFIEC database and the SEC database, as it proved to be the most challenging one. The gold standard, which can be seen as a benchmark for the evaluation of the systems as well as a set of annotations to create a supervised system, has been created by a panel of experts of the field. The gold standard contains 1428 entity pairs, with 496 positive and 932 negative examples. The dataset is available online.13
A second evaluation of the STEM approach is performed on the dataset released by the DOREMUS project14
http://www.doremus.org/
in the context of the instance matching track of the Ontology Alignment Evaluation Initiative 2016 (OAEI201615
http://islab.di.unimi.it/im_oaei_2016/
). The Instance Matching Track of the OAEI 2016 aims at evaluating the efficiency of matching tools when the goal is to detect the degree of similarity between pairs of items/instances expressed in the form of OWL Aboxes. The DOREMUS datasets contain real world data coming from two major French cultural institutions: the French National Library (BnF) and the Philharmonie de Paris (PP). The data is about classical music works and is described by a number of properties such as the name of the composer, the title(s) of the work, its genre, instruments and the like. We focused our evaluation on two tasks, whose description we report here:
DOREMUS 9-heterogeneities: “This task consists in aligning two small datasets, BnF-1 and PP-1, containing about 40 instances each, by discovering 1:1 equivalence relations between them. There are 9 types of heterogeneities that data manifest, that have been identified by the music library experts, such as multilingualism, differences in catalogs, differences in spelling, different degrees of description.”
DOREMUS 4-heterogeneities: “This task consists in aligning two bigger datasets, BnF-2 and PP-2, containing about 200 instances each, by discovering equivalence relations between the instances that they contain. There are 4 types of heterogeneities that these data manifest, that we have selected from the nine in the Nine hererogeneities task and that appear to be the most problematic: 1) Orthographical differences, 2) Multilingual titles, 3) Missing properties, 4) Missing titles.”
To the reference links provided by the organizers, we add 20 and 123 false links respectively for the DOREMUS 9-heterogeneities and the DOREMUS 4-heterogeneities gold standards, to enable the supervised learning approach implemented by STEM that necessitates both positive and negative entity pairs.
A third dataset used in the experimentation of the STEM approach is derived from the 3cixty Nice Knowledge Base. This knowledge base contains Nice cultural and tourist information (such as Place-type entities) and it is created with a multi datasource collection process, where numerous entities are represented in multiple sources leading to duplicates. This creates the need of matching and the resolution of the entities. Further details of the making of the knowledge base with the selection of the gold standard is detailed in Section 7, while in this section we report the statistics of the gold standard that drove the entity matching task.
For the FEIII and the DOREMUS datasets, we assume that the Unique Name Assumption is true, meaning that two data of the same data source with distinct references refer to distinct real world entities. For 3cixty this is clearly not the case, as we are matching the dataset with itself to detect duplicates.
A summary of the datasets statistics is reported in Table 1 and of the matching tasks in Table 2.
Datasets summary
Dataset
Domain
Provider
Number of entities
Format
FFIEC
Finance
Federal Financial Institution Council
6652
CSV
SEC
Finance
Security and Exchange Commission
129,312
CSV
BnF-1
Music
French National Library
32
RDF
PP-1
Music
Philharmonie de Paris
32
RDF
BnF-2
Music
French National Library
202
RDF
PP-2
Music
Philharmonie de Paris
202
RDF
3cixty Nice places
Culture and Tourism
3cixty Nice Knowledge Base
336,900
RDF
Matching tasks summary
Dataset 1
Dataset 2
Gold standard pairs
Challenge
Task
FFIEC
SEC
790
FEIII2016
FFIEC-SEC
BnF-1
PP-1
52
OAEI2016
DOREMUS 9-heterogeneities
BnF-2
PP-2
325
OAEI2016
DOREMUS 4-heterogeneities
3cixty Nice places
3cixty Nice places
756
-
-
Scoring
To evaluate the efficiency of the algorithm we have used the standard precision p, recall r and f measures [41]. These measures, if not specified otherwise, have been evaluated through a 4-fold cross validation score process. Given the ambiguity of the definition of p, r and f when performing cross validation [18], we hereby specify that we have used:
where are the four folds. The computation of the precision score depends on the closed/open world assumption, i.e. whether we assume that all correct matches are annotated in the gold standard or not. In practice, it is normal to have in the gold standard only a fraction of all the real matching entities and we thus follow, by default, the open world assumption. In this case, when a pair of entity is considered to be a match by STEM and is not present in the gold standard, we are unable to determine whether this is due to a false positive or to a missing annotation and we simply ignore it in the scoring. In the case of the experiments with DOREMUS datasets, where the organizers of the challenge claim to have annotated all the true matches, we follow the closed world assumption. In this case, every match that is not annotated in the gold standard is considered as a false positive.
Duke
Entity format: Duke is able to handle different formats for input data, such as .csv (comma separated value) or .nt (n-triples). In the first case, an entity is represented by a record in a table. In the second case, an entity is a node in a Knowledge Base.
Blocking method: we reduce the search space for the entity matching process from the space of all possible pairs of entities using an inverted index, in which property values are the indexes and the tuples are the documents referred by the indexes. The lookup of a tuple given a value has, therefore, a unitary cost. We reduce the search space to a small subset of the most likely matching entity pairs that satisfy a given Damerau-Levenshtein distance [4] for each value pair of the tuples, and we considered the first m candidates.17
We empirically set the distance to 2 and the number of potentially retrievable candidates to 1,000,000 (conservative boundary).
Configuration: the first step of the implementation consists in configuring Duke. Duke is built by default on top of a Lucene Database,18
https://lucene.apache.org
which indexes the records through an inverted index and does full-text queries to find candidates, implementing the blocking strategy. The Lucene Database can be configured in Duke by setting a number of parameters such as the max-search-hits, that is the maximum number of candidate records to return or min-relevance, namely a threshold for Lucene’s relevance ranking under which candidates are not considered. Duke then allows to select a number of properties to be taken into account to establish if a pair of entities match, such as name, address, zip code. Duke requires to specify a mapping between the fields of the data sources and those on which the comparison has to be performed, e.g. “LegalName → NAME, LegalEntityAddress → ADDRESS, LegalEntityCode → ZIPCODE”. In this case, we have manually configured Duke during the participation to the FEIII2016 challenge and the choice of cleaners, comparators is reported in [39].
Silk
Entity format: Silk is specifically built to deal with RDF formats, such as .ttl (turtle) or .nt (n-triples), where entities are represented as nodes in a Knowledge Graph. However, it allows to convert data from a variety of formats, such as .csv (comma separated values).
Blocking method: Silk implements a multidimensional blocking system, called MultiBlock [23], which is able to not lose recall performance. Differently from most blocking system that operates on one dimension, MultiBlock works by mapping entities into a multidimensional index, preserving the distances between entities.
Configuration: Silk can easily be configured through an XML file. To configure the blocking algorithm, it is sufficient to specify the number of blocks, which we have empirically set to 100. A set of properties onto which the matching is based needs to be specified and then, for each of them, the user can select among a large number of ‘transformators’ (comparable to Duke’s cleaners) to pre-process and normalize strings. The choice of transformators and comparators has been based on the result obtained with Duke in the participation to the FEIII challenge and a similar configuration file has been produced for Silk. A manual configuration to optimize the f score has been used also for the DOREMUS data in the context of the OAEI challenge [1].
Stacking
Differently from the previous steps, which are mainly based on low-level string similarity measures, the supervised learner can implicitly learn semantic similarities from the human annotations of the gold standard. The stacking process is implemented through a Python script that executes Duke or Silk a number N of times, editing the threshold t through uniform perturbations of amplitude a, automatically modifying Duke’s or Silk’s configuration file. Then, the script saves Duke’s or Silk’s outputs and turns them into a training set for a supervised learner with pairs on the rows and N features on the columns.
The user may choose different supervised learners for the stacking layer. What we have experimentally found to work better, given the small number of features, is an SVM with a RBF kernel [19]. In many cases, such as the default one, the learning algorithm leaves a number of parameters (so-called “hyper parameters”) to be determined. Let be a supervised learner where θ is the vector of hyper parameters (C and γ in the case of SVM with RBF kernel). In order to optimize the efficiency of the algorithm with respect to these hyper parameters, we have trained the algorithm on an array of possible values of θ and selected as the vector that optimized 4-fold cross validation score (grid search cross validation [20]).
For what concerns the number of features N, it is reasonable to expect that higher values tend to increase the efficiency of the algorithm up to a saturation point, where no further predicting power is added by an additional instance of the base classifier. Actually, we observe that increasing the number of features can also lead to efficiency decrease, as a typical overfitting problem. This saturation point will typically depend on the amplitude a of perturbation, as with small intervals we expect it to occur earlier. This will also depend on the size of the datasets and its complexity, so no one-fits-all solution has been individuated. As we will see in the experiments though, and appears to be a good rule of thumb.
Results
STEM vs threshold-based classifiers
In this section, we first provide evidence of the trade-off between precision and recall introduced by the decision threshold and then we show that STEM is able to increase the precision and the recall of the base classifiers at the same time. In the following, we refer to the STEM approach implemented on top of Duke as STEM-NB and to that implemented on top of Silk as STEM-LIN.
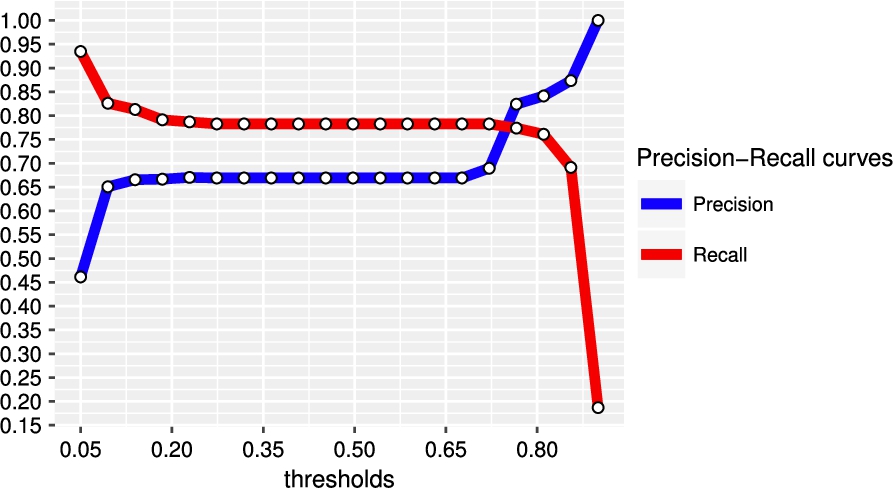
Precision and recall curves as functions of the threshold t for Duke on the FEIII dataset. It clearly shows the trade-off between and introduced by the Naive Bayes classifier decision rule Eq. 23.
Results of STEM-NB vs Duke for and different values of N across different datasets
Base classifier
N
FFIEC-SEC
DOREMUS 4-heterogeneities
DOREMUS 9-heterogeneities
p
r
f
p
r
f
p
r
f
Duke
n/a
0.88
0.77
0.82
0
0.46
0.57
0.51
0
0.48
0.66
0.55
0
STEM-NB
5
0.90
0.98
0.94
12%
0.89
0.98
0.93
42%
0.97
1.0
0.99
44%
STEM-NB
10
0.93
0.97
0.95
13%
0.89
0.98
0.93
42%
0.94
1.0
0.97
42%
STEM-NB
20
0.94
0.97
0.95
13%
0.89
0.99
0.94
43%
0.87
1.0
0.93
35%
Results of STEM-LIN vs Silk for and different values of N across different datasets
Base classifier
N
FFIEC-SEC
DOREMUS 4-heterogeneities
DOREMUS 9-heterogeneities
p
r
f
p
r
f
p
r
f
Silk
n/a
0.57
0.67
0.59
0
0.45
0.43
0.43
0
0.46
0.81
0.58
0
STEM-LIN
5
0.77
0.81
0.79
20%
0.82
0.93
0.86
43%
0.89
1.0
0.94
36%
STEM-LIN
10
0.78
0.83
0.80
21%
0.75
0.66
0.69
28%
0.89
1.0
0.94
36%
STEM-LIN
20
0.77
0.84
0.81
22%
0.75
0.60
0.64
21%
0.87
1.0
0.93
35%
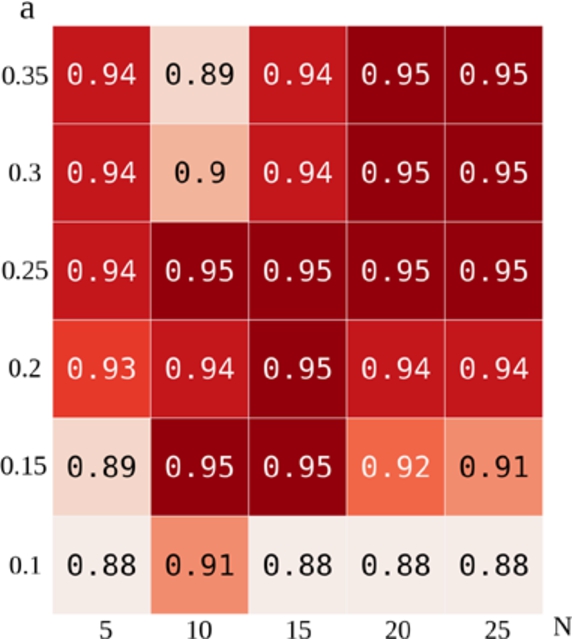
The premise of this work is that the threshold t in decision rule Eq. 1 introduces a trade-off between precision and recall. In Section 3 we have provided a heuristic argument of why this should be the case and now we provide experimental results. In Fig. 4, we report the precision and recall obtained by running Duke on the FFIEC-SEC dataset for a set of 20 equally spaced threshold values . The graph clearly shows the trade-off between precision and recall of the algorithm ruled by the threshold t. The trend for both curves is non-linear, with moderate changes in the central part and sudden variations at the sides. The typical configuration process of a threshold-based classifier attempts to find a balance between the two metrics, in order to maximize the F-score of the algorithm. Then, using STEM, both metrics can be increased at the same time using stacking. In Table 3 and Table 4 we support this claim by reporting respectively the results obtained using STEM-NB and STEM-LIN on FFIEC-SEC, DOREMUS 4-heterogeneities, DOREMUS 9-heterogeneities tasks, varying the number of features N. The value of the perturbation amplitude a has been fixed to following the analysis reported in Fig. 5, which shows that this value allows to reach with only 10 configurations and limits the dependence on the value of N. The plot also shows that the saturation effect tends to occur sooner when a is small, as this corresponds to a denser and therefore less informative sampling of the interval.
F1 score for different combinations of a and N on the FFIEC-SEC dataset for STEM-NB.
In Table 3, we can observe that, for the FFIEC-SEC task, even with a small number of features , stacking leads to a significant increase of the F-score of the algorithm (12%), obtained by increasing both precision and recall at the same time. Increasing the number of features N tends to increase the efficiency, with a saturation effect as the number gets larger. Indeed, going from to only grants a gain and no difference of efficiency is observed from to . A similar behavior is observed for the DOREMUS tasks, where the big efficiency leap is given by the introduction of stacking, whereas raising the number of features N grants small improvements in the case of 4-heterogeneities and decreases the efficiency in the case of 9-heterogeneities. A similar behavior is observed for all the experiments that we have done.
To show that the increase of efficiency is not dependent on the particular threshold-based classifier, we have run the same experiments using STEM-LIN and reported the results in Table 4. In this case, we can observe that, although absolute values are lower, the increase in efficiency given by the stacking layer is equally or even more important, achieving a on the F-score with only in the FFIEC-SEC task and a and for DOREMUS tasks. Also in this case, both precision and recall are increased at the same time and a saturation effect can be detected as N grows. In general, it seems that the saturation effect occurs earlier for DOREMUS tasks, as in three cases out of four with we already reach the peak efficiency and the fourth case the efficiency only increases by . This is probably due to the fact that DOREMUS datasets are smaller and thus a model with too many features tends to overfit the data.
STEM vs supervised learning on similarity values
In this section, we discuss the second claim of the paper, namely the comparison of a hybrid approach such as STEM with a system that performs machine learning ‘from scratch’. More in detail, we have compared STEM to a number of commonly used machine learning algorithms, using similarity values as features. In addition to verifying whether STEM performs better than the other systems in absolute, the intent is also to see whether it is less dependent on the amount of annotated training data. Indeed, given the quadratic nature of the entity matching problem, in most real usage scenarios, annotating a comprehensive gold standard (such as those of FEIII and DOREMUS) is an extremely time consuming endeavour and the user is able to annotate just a small fraction of all possible entity pairs. Therefore, it is interesting to see how an entity matching system performs with a small amount of annotated training pairs. To this end, we have studied how STEM performs at the variation of the amount of training data with respect to an SVM classifier with a RBF kernel, a random forest and a logistic classifier. In order to avoid possible size effects on the scores, we have split the FEIII data in two halves, according to the stratified sampling technique, i.e. keeping constant the proportion of matching and non matching pairs in the two parts. The first half is used as training data and the second half is used as test data. Then, we randomly extract a fraction z of training data from 0.1 to 0.9, train the systems and score them on the test set, which remains the same. For each value of z, we repeat the extraction 50 times and we compute the average value. Using the FEIII datasets and the STEM-NB implementation, values of have been computed using the same comparators with the same configuration of STEM-NB. The configuration procedure of the machine learning classifiers is the same as that described in Section 5.5, namely a grid search hyper parameters optimization has been used to maximize 4-fold cross validation scores, setting C and γ for SVM, ‘n_estimators’ for the random forest and the regularization constant C for logistic regression.19
http://scikit-learn.org/stable/user_guide.html
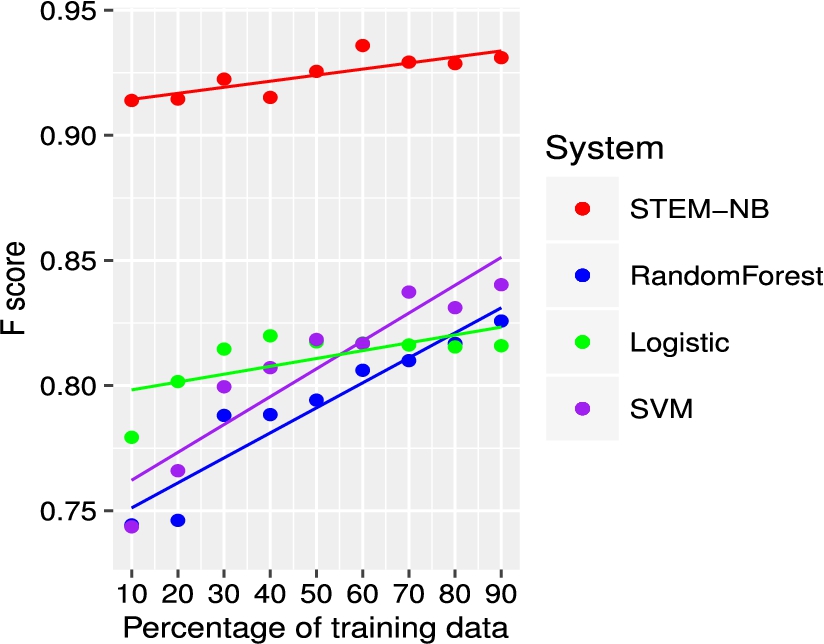
The result of the experiment is depicted in Fig. 6. We can see that STEM-NB performs better than any other classifier in absolute terms, reaching a peak of 0.931 when 90% of the training data is used. Moreover, it shows little dependency on the amount of training data, producing 0.914 with only 10% of the training data. SVM performs better than the other pure machine learning approaches when 90% of training data is used, but decreases fast when annotated examples are reduced. In Table 5, we report, for each classifier, the quantitative estimation of the dependency of f from the fraction of training data z, obtained through the statistical estimation of the angular coefficient m of a linear fit of the points (i.e. the straight lines of Fig. 6). What we can observe is that more complex models such as SVM and Random Forest tend to depend more on the amount of training data, while a simple linear model such as logistic regression is performing well even with a small amount of training data. The logistic model is even less dependent on the training data than a hybrid approach such as STEM, but it is not comparable in terms of absolute efficiency. STEM thus represents a model that is complex enough to achieve good efficiency in absolute terms and it is also able to maintain it with a little amount of training data.
F-score at the variation of the percentage of training data used. STEM-NB is compared to an SVM classifier, a Random Forest and a logistic classifier.
Dependency on the amount of training data. ‘Min’ and ‘Max’ represent respectively the minimum and maximum F-score and ‘m’ represents the angular coefficient of a straight line interpolating the points of Fig. 6
Classifier
min
max
m
STEM-NB
0.91
0.93
SVM
0.74
0.84
Random Forest
0.74
0.83
Logistic
0.78
0.82
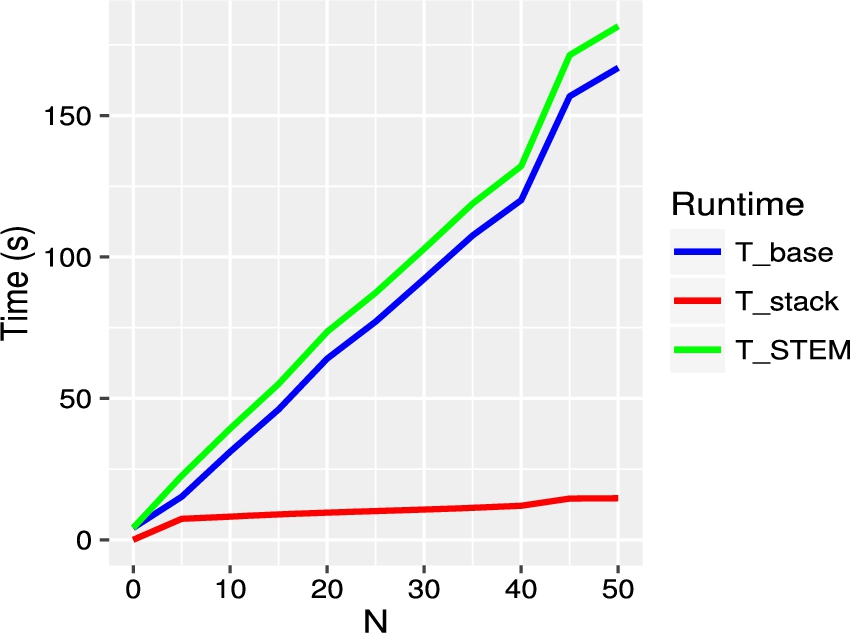
Runtime for STEM-NB on DOREMUS 4-heterogeneities task with increasing number of features N.
Runtime performance
In Section 4.3 we have discussed the computational complexity of STEM, which can be summarized as . We have also argued that we observed that the time required to run the ensemble of base classifiers is longer than the time required for the stacking layer. In this section, we show an example of such a behavior measuring the runtime of STEM-NB on the DOREMUS 4-heterogeneities dataset with increasing number of features N. In Fig. 7, we can see that the time required to generate the features quickly becomes much more significant than the time required for stacking . A similar behavior has been observed for all the datasets under consideration, suggesting that a parallelization of the feature generation process would greatly improve the runtime performance of STEM as a whole. In general, we also observe a linear trend in both the components and , which implies a linear trend for the total time , consistently with what we expect from Section 4.3.
3cixty knowledge base generation
In this section, we describe the implementation of STEM in the generation of the 3cixty Nice knowledge base, introducing first the key components of the 3cixty data chain.
Overview 3cixty is a semantic web platform that enables to build real-world and comprehensive knowledge bases in the domain of culture and tourism for cities. The entire approach has been tested first for the occasion of the Expo Milano 2015 [46], where a specific knowledge base for the city of Milan was developed, and is now refined with the development of knowledge bases for other cities, among those Nice. These knowledge bases contain descriptions of events, places (sights and businesses), transportation facilities and social activities, collected from numerous static, near- and real-time local and global data providers, including Expo Milano 2015 official services in the case of Milan, and numerous social media platforms. The generation of each city-specific 3cixty knowledge base follows a strict data integration pipeline, that ranges from the definition of the data model, the selection of the primary sources used to populate the knowledge base, till the entity matching used for distilling the entities forming the final stream of cleaned data that is then presented to the users via multi-platform user interfaces. A detailed description of the technology leading to the creation of the knowledge base is summarized in [56]. In the remainder of this section we introduce the data model and the data sources used in 3cixty. We then detail the entity matching process, which is performed using STEM, describing the experimental setup, gold standard, and results.
Data Model The 3cixty ontology design principle has focused on optimizing the coverage of the terminology in the context of culture and tourism. For each entity to model, such as Place-type and Event-type, we looked for existing knowledge resources (keyword search) in LOV,20
We established a rigid search mechanism where two domain experts analyzed the ontology resources that resulted from the search. In detail, they first agreed on a set of keywords to be utilized in the search. The set contains: Event, Place, Transportation, Tourism, Culture, City, Smart City. Then, each expert analyzed the results of the search through the different platforms noting in a spreadsheet the classes and related properties most valuable for the vertical domain of the 3cixty knowledge bases. The two experts compared manually the two spreadsheets and resolved any conflict of representation by optimizing the following selection criteria:
the popularity of classes/properties based on usage data,
Once consensus was reached, classes and predicates were taken and added to the 3cixty data model, which therefore consists in a constellation of existing ontologies. We re-used some classes and properties from the following ontologies: dul,24
A few additional classes and properties have been created to describe travel distances: we defined origin, distance, travel time, the nearest metro station and bike station. Details are available in [44].
Data sources The 3cixty knowledge bases contain information about places, events, artists, transportation means, and user-generated content such as media and reviews. The knowledge bases are built using three types of data sources:
local sources usually offered by city open data portals,
global sources such as social media platforms,
editorial data generated by experts of the domain.
The selection of the sources follows a strict protocol that involves two teams of experts who analyze and rank the data sources at disposal to decide which ones were important to be selected for being included in the knowledge base. The teams are both composed of two researchers in the field of data integration and the Semantic Web and two local data experts, knowledgeable of technicalities concerning data publishing, integration and data exploitation. The experts are asked to maximize a 3-objective function: data semantics, instance coverage, and real-time update. The output of such an investigation leads to a survey, which is cross-validated by two domain experts who decide by consensus and iterate in checking existing and new data sources according to the aforementioned objectives, updating the list continuously.
Data reconciliation The data reconciliation problem is addressed via both category reconciliation and instance reconciliation. The rationale of having both types of reconciliation is to improve the quality of data perceived by the final user by removing both category and instance duplicates. In both cases, the reconciliation processes have been applied to the two main topical types of entities in the knowledge base: Events and Places. Such a stage is at the core of the knowledge base creation, since the consumption of the data from the knowledge base is highly polarized by a clean feed of data where no duplicates or near-duplicates are shown.
Reconciling categories has the objective to reduce sparsity in the use of different labels for the same category groups. We addressed the process by using two category thesauri (implemented in skos) as pivots: the Foursquare taxonomy31
https://developer.foursquare.com/categorytree
for Places, and the taxonomy used in [24] for Events. The alignment, led by two experts of the domain, has established a set of links from the gathered categories, using skos:closeMatch and skos:broadMatch. An automatic process is then used to identify links according to the exact match of the found categories with the alignment defined by the experts.
Given two data sources, namely A and B, an instance reconciliation process looks at identifying data instances that are similar according to their semantics and thus linking them with links. In 3cixty, we have implemented the instance reconciliation task using STEM. To do so, we have first generated a gold standard for training the STEM stacked machine learning (Section 7.1), and then validated its efficiency (Section 7.2).
Using the findings reported in [24] we have listed the instance fields used for the entity matching process, in detail: for Place-type instances the set , where is the place name, are the geographic coordinates according to a fixed bounding box, and in plain text. For Event-type instances the set , where is the place name, are the geographic coordinates according to a fixed bounding box, and when the event starts and ends.
Gold standard creation
Given the generality of the STEM approach and the data model of the different 3cixty knowledge bases, we have generated a gold standard from the 3cixty Nice KB, i.e. the knowledge base built for the Nice area, to be used to benchmarking the performance of STEM and to be utilized as training set for the other city knowledge bases.
The gold standard has gone through a process of identifying, with a random sampling, a small portion of Place-type pairs32
For the sake of brevity we report the entity matching process of the Place-type entities.
to match, totaling 756 pairs. This accounts to a tiny fraction of the entire set of possible pairs (order of possible pairs); then, two human experts rated each as a match or as no-match. The annotation process was divided in two steps: i) individual annotation, i.e. each expert performed annotations separately; ii) adjudication phase, i.e. the two experts compared the annotations and resolved eventual conflicts.
This has prompted the creation of a gold standard that accounts 228 match and 528 no-match pairs.33
We aim to share the Gold Standard once the paper is published to foster the reuse and experimental reproducibility.
Experimental results
Similarly to what has been done in Section 6.1, we compared STEM with Duke. In order to put Duke in the best conditions, we let it learning the best configurations using the active learning built-in function, just giving as input the instance fields to be utilized in the matching task and the gold standard created by the two experts.
The built-in active learning function works as follows: it iterates multiple times changing the configurations of the comparators aiming to minimize the matching error rate. Such a process prompts the creation of a configuration file summarizing the best Duke settings for the dataset used.
Having observed that it performs better than STEM-LIN (Section 6), we have then deployed STEM-NB using Duke configured as above and we conducted a 4-fold cross validation. Table 6 shows the results of the experiments. We can observe how STEM with five classifiers holds better results than a single run of Duke with a of . We can also observe how the boost STEM introduces is slightly reduced with an increasing number of Duke instances N, similarly to what observed for DOREMUS data. As we mentioned earlier in the paper, this is the typical overfitting problem, where introducing additional complexity in the model does not provide better learning. As a general suggestion, seems to be enough to obtain a consistent increment of efficiency with respect to the baseline without overfitting the data. The matching process with took approximately 3 hours on a laptop with 4 cores and 12GB of RAM.
Results of STEM-NB vs Duke on the 3cixty Nice dataset for and different values of N
Base classifier
N
p
r
f
Duke
n/a
0.76
0.65
0.70
0
STEM-NB
5
0.90
0.92
0.90
20%
STEM-NB
10
0.76
0.81
0.78
8%
STEM-NB
20
0.79
0.81
0.79
9%
Conclusion
In this paper, we have proposed a framework for stacking threshold-based entity matching algorithms. We have argued and then shown empirically that the final decision threshold, which converts the confidence score of a threshold-based classifier into a decision, introduces a trade-off between the precision and the recall of the algorithm. Using stacking, we have demonstrated that this trade-off can be broken, as the combination of the predictions of an ensemble of classifiers with different threshold values can raise both metrics at the same time, resulting in a significant enhancement of the matching process. This enhancement is not bound to the type of classifier nor to the dataset used, as we observe consistent results for both a linear and a Naive Bayes classifier on three different datasets. Generally, using five classifiers is enough to obtain a consistent increase in performance and increasing the number of classifiers N can easily lead to overfitting, providing small improvements or even decreasing the accuracy of the predictions.
STEM is independent from the configuration process of the threshold-based classifier. Indeed, we have provided three experimental evaluations and in two of them we have manually configured the system, whereas in the third we have used an active learning approach. A further advantage of the STEM approach is the little dependency on the amount of training data, as we have shown that it can reach high levels of performance even with a small fraction of annotated data. STEM has allowed to greatly improve the data reconciliation process of the generation of the 3cixty knowledge base, proving to be accurate, reliable and scalable, as the reconciliation process lasted roughly 3 hours. STEM is computationally more expensive than a single threshold-based classifier, as it involves running several instances of the threshold-based classifier and then training a supervised learner on top of their matching decisions. Among these two components of the total STEM runtime, we observe that for the datasets that we have used in this work, the first is the most expensive step. Thus, as a future work, we plan to improve the computing time of the software using a parallel and/or distributed implementation to allow the simultaneous execution of processes. We also plan to extend the ensemble process to other relevant parameters and to other threshold-based entity matching systems and to experiment different supervised learners.
Footnotes
Acknowledgements
This work was partially supported by the innovation activity 3cixty (14523) and PasTime (17164) of EIT Digital Cities.
References
1.
M.Achichi, M.Cheatham, Z.Dragisic, J.Euzenat, D.Faria, A.Ferrara, G.Flouris, I.Fundulaki, I.Harrow, V.Ivanovaet al., Results of the ontology alignment evaluation initiative 2016, in: 11th ISWC Workshop on Ontology Matching (OM), 2016, pp. 73–129.
2.
M.Al-Bakri, M.Atencia, J.David, S.Lalande and M.-C.Rousset, Uncertainty-sensitive reasoning for inferring sameAs facts in linked data, in: 22nd European Conference on Artificial Intelligence (ECAI), IOS Press, 2016, pp. 698–706.
3.
I.Androutsopoulos, J.Koutsias, K.V.Chandrinos and C.D.Spyropoulos, An experimental comparison of naive Bayesian and keyword-based anti-spam filtering with personal e-mail messages, in: 23rd International Conference on Research and Development in Information Retrieval (SIGIR), 2000, pp. 160–167.
4.
G.V.Bard, Spelling-error tolerant, order-independent pass-phrases via the Damerau-Levenshtein string-edit distance metric, in: 5th Australasian Symposium on ACSW Frontiers, 2007.
5.
O.Benjelloun, H.Garcia-Molina, D.Menestrina, Q.Su, S.E.Whang and J.Widom, Swoosh: A generic approach to entity resolution, The VLDB Journal – The International Journal on Very Large Data Bases18 (2009), 255–276. doi:10.1007/s00778-008-0098-x.
6.
C.Bizer, T.Heath and T.Berners-Lee, Linked data – the story so far, in: Semantic Services, Interoperability and Web Applications: Emerging Concepts, 2009, pp. 205–227.
7.
L.Bottou and C.-J.Lin, Support vector machine solvers, Large Scale Kernel Machines3(1) (2007), 301–320.
8.
C.-C.Chang and C.-J.Lin, Libsvm: A library for support vector machines, ACM Transactions on Intelligent Systems and Technology (TIST)2(3) (2011), 27.
9.
Z.Chen, D.V.Kalashnikov and S.Mehrotra, Exploiting context analysis for combining multiple entity resolution systems, in: Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, 2009, pp. 207–218.
10.
W.Cohen, P.Ravikumar and S.Fienberg, A comparison of string metrics for matching names and records, in: KDD Workshop on Data Cleaning and Object Consolidation, Vol. 3, 2003, pp. 73–78.
11.
W.W.Cohen, H.Kautz and D.McAllester, Hardening soft information sources, in: Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2000, pp. 255–259. doi:10.1145/347090.347141.
12.
E.Croot, Bayesian spam filter, http://people.math.gatech.edu/~ecroot/bayesian_filtering.pdf – Last visited: 10 January 2017.
13.
P.Cudré-Mauroux, P.Haghani, M.Jost, K.Aberer and H.De Meer, idMesh: Graph-based disambiguation of linked data, in: Proceedings of the 18th International Conference on World Wide Web, 2009, pp. 591–600. doi:10.1145/1526709.1526789.
14.
X.Dong, A.Halevy and J.Madhavan, Reference reconciliation in complex information spaces, in: Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, 2005, pp. 85–96. doi:10.1145/1066157.1066168.
15.
M.G.Elfeky, V.S.Verykios and A.K.Elmagarmid, TAILOR: A record linkage toolbox, in: Proceedings. 18th International Conference on Data Engineering 2002, 2002, pp. 17–28. doi:10.1109/ICDE.2002.994694.
16.
J.Euzenat and P.Shvaiko, Ontology Matching, Springer, 2013.
17.
I.P.Fellegi and A.B.Sunter, A theory for record linkage, Journal of the American Statistical Association64 (1969), 1183–1210. doi:10.1080/01621459.1969.10501049.
18.
G.Forman and M.Scholz, Apples-to-apples in cross-validation studies: Pitfalls in classifier performance measurement, ACM SIGKDD Explorations Newsletter12 (2010), 49–57. doi:10.1145/1882471.1882479.
19.
T.Hastie, R.Tibshirani, J.Friedman and J.Franklin, The elements of statistical learning: Data mining, inference and prediction, The Mathematical Intelligencer27 (2005), 83–85.
20.
C.W.Hsu, C.C.Chang, C.J.Linet al., A practical guide to support vector classification, http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf – Last visited: 10 January 2017, 2003.
21.
R.Isele and C.Bizer, Learning linkage rules using genetic programming, in: Proceedings of the 6th International Conference on Ontology Matching, Vol. 814, 2011, pp. 13–24.
22.
R.Isele and C.Bizer, Active learning of expressive linkage rules using genetic programming, Web Semantics: Science, Services and Agents on the World Wide Web23 (2013), 2–15. doi:10.1016/j.websem.2013.06.001.
23.
R.Isele, A.Jentzsch and C.Bizer, Efficient multidimensional blocking for link discovery without losing recall, WebDB, 2011.
24.
H.Khrouf, V.Milicic and R.Troncy, Mining events connections on the social web: Real-time instance matching and data analysis in EventMedia, Web Semantics: Science, Services and Agents on the World Wide Web24 (2014), 3–10. doi:10.1016/j.websem.2014.02.003.
25.
H.Köpcke and E.Rahm, Training selection for tuning entity matching, in: QDB/MUD, 2008, pp. 3–12.
26.
H.Köpcke and E.Rahm, Frameworks for entity matching: A comparison, 69 (2010), 197–210.
27.
L.Leitão, P.Calado and M.Weis, Structure-based inference of XML similarity for fuzzy duplicate detection, in: Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, 2007, pp. 293–302. doi:10.1145/1321440.1321483.
28.
D.D.Lewis, Naive (Bayes) at forty: The independence assumption in information retrieval, in: Machine Learning: ECML-98, 1998, pp. 4–15. doi:10.1007/BFb0026666.
29.
C.D.Manning and H.Schütze, Foundations of Statistical Natural Language Processing, Vol. 999, 1999.
30.
A.McCallum, K.Nigamet al., A comparison of event models for naive Bayes text classification, in: AAAI Workshop on Learning for Text Categorization, Vol. 752, 1998, pp. 41–48.
31.
V.Metsis, I.Androutsopoulos and G.Paliouras, Spam filtering with naive Bayes – which naive Bayes?, in: CEAS, 2006, pp. 27–28.
32.
N.Mihindukulasooriya, G.Rizzo, R.Troncy, O.Corcho and R.Garcia-Castro, A two-fold quality assurance approach for dynamic knowledge bases: The 3cixty use case, in: International Workshop on Completing and Debugging the Semantic Web, 2016.
33.
B.Mikhail and R.J.Mooney, Adaptive duplicate detection using learnable string similarity measures, in: Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2003, pp. 39–48.
34.
K.P.Murphy, Machine Learning: A Probabilistic Perspective, MIT Press, 2012.
35.
M.Nentwig, M.Hartung, A.C.N.Ngomo and E.Rahm, A survey of current link discovery frameworks, Semantic Web Journal (2015), 1–18.
36.
H.B.Newcombe and J.M.Kennedy, Record linkage: Making maximum use of the discriminating power of identifying information, Communications of the ACM5 (1962), 563–566. doi:10.1145/368996.369026.
37.
A.C.N.Ngomo and S.Auer, Limes – a time-efficient approach for large-scale link discovery on the web of data, Integration15 (2011).
38.
A.C.N.Ngomo and K.Lyko, Eagle: Efficient active learning of link specifications using genetic programming, in: Extended Semantic Web Conference, 2012, pp. 149–163.
39.
E.Palumbo, G.Rizzo and R.Tröncy, An ensemble approach to financial entity matching for the FEIII 2016 challenge, in: DSMM’16: Proceedings of the Second International Workshop on Data Science for Macro-Modeling, 2016.
40.
H.Pasula, B.Marthi, B.Milch, S.Russell and I.Shpitser, Identity uncertainty and citation matching, in: Advances in Neural Information Processing Systems, 2002, pp. 1401–1408.
41.
D.M.Powers, Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation, Journal of Machine Learning Technologies (2011).
42.
V.Raghavan, P.Bollmann and G.S.Jung, A critical investigation of recall and precision as measures of retrieval system performance, ACM Transactions on Information Systems (TOIS)7 (1989), 205–229. doi:10.1145/65943.65945.
43.
I.Rish, An empirical study of the naive Bayes classifier, in: IJCAI Workshop on Empirical Methods in Artificial Intelligence, 2001, pp. 41–46.
44.
G.Rizzo, O.Corcho, R.Troncy, J.Plu, J.C.Ballesteros Hermida and A.Assaf, The 3cixty knowledge base for Expo Milano 2015: Enabling visitors to explore the city, in: 8th International Conference on Knowledge Capture (K-CAP), 2015.
45.
G.Rizzo, M.Erp and R.Troncy, Benchmarking the extraction and disambiguation of named entities on the semantic web, in: 9th Edition of the Language Resources and Evaluation Conference (LREC’14), 2014.
46.
G.Rizzo, R.Troncy, O.Corcho, A.Jameson, J.Plu, J.C.Ballesteros Hermida, A.Assaf, C.Barbu, A.Spirescu, K.Kuhn, I.Celino, R.Agarwal, C.K.Nguyen, A.Pathak, C.Scanu, M.Valla, T.Haaker, E.S.Verga, M.Rossi and J.L.Redondo Garcia, 3cixty@Expo Milano 2015: Enabling visitors to explore a smart city, in: 14th International Semantic Web Conference (ISWC), Semantic Web Challenge, 2015.
47.
F.Saıs, N.Pernelle and M.-C.Rousset, L2r: A logical method for reference reconciliation, in: Proc. AAAI, 2007, pp. 329–334.
48.
S.Sarawagi and A.Bhamidipaty, Interactive deduplication using active learning, in: 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Vol. 3, 2003, pp. 269–278.
49.
M.Schmachtenberg, C.Bizer and H.Paulheim, Adoption of the linked data best practices in different topical domains, in: International Semantic Web Conference, 2014, pp. 245–260.
50.
M.A.Sherif, A.-C.N.Ngomo and J.Lehmann, WOMBAT – a generalization approach for automatic link discovery, in: European Semantic Web Conference, 2017, pp. 103–119. doi:10.1007/978-3-319-58068-5_7.
51.
T.Soru and A.C.N.Ngomo, A comparison of supervised learning classifiers for link discovery, in: 10th International Conference on Semantic Systems, 2014, pp. 41–44.
52.
R.Speck and A.C.N.Ngomo, Ensemble learning for named entity recognition, in: International Semantic Web Conference, 2014, pp. 519–534.
53.
S.Tejada, C.A.Knoblock and S.Minton, Learning object identification rules for information integration, Information Systems26(8) (2001), 607–633. doi:10.1016/S0306-4379(01)00042-4.
54.
S.Tejada, C.A.Knoblock and S.Minton, Learning domain-independent string transformation weights for high accuracy object identification, in: Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2002, pp. 350–359. doi:10.1145/775047.775099.
55.
A.Thor and E.Rahm, MOMA – a mapping-based object matching system, in: CIDR, 2007, pp. 247–258.
56.
R.Troncy, G.Rizzo, A.Jameson, O.Corcho, J.Plu, E.Palumbo, J.C.Ballesteros Hermida, A.Spirescu, K.Kuhn, C.Barbu, M.Rossi, I.Cellino, R.Agarwal, C.Scanu, M.Valla and T.Haacker, 3cixty: Building comprehensive knowledge bases for city exploration, in: Web Semantics: Science, Services and Agents on the World Wide Web, 2017.
57.
J.Volz, C.Bizer, M.Gaedke and G.Kobilarov, Silk – a link discovery framework for the web of data, in: 2nd Workshop About Linked Data on the Web, Madrid, Spain, 2009.
58.
J.Volz, C.Bizer, M.Gaedke and G.Kobilarov, Discovering and maintaining links on the web of data, in: International Semantic Web Conference, 2009, pp. 650–665.
H.Zhao and S.Ram, Entity identification for heterogeneous database integration – a multiple classifier system approach and empirical evaluation, Information Systems30 (2005), 119–132. doi:10.1016/j.is.2003.11.001.
61.
L.Zhu, M.Ghasemi-Gol, P.Szekely, A.Galstyan and C.A.Knoblock, Unsupervised entity resolution on multi-type graphs, in: International Semantic Web Conference, 2016, pp. 649–667.