
Abstract
Over the last years, time-efficient approaches for the discovery of links between knowledge bases have been regarded as a key requirement towards implementing the idea of a Data Web. Thus, efficient and effective measures for comparing the labels of resources are central to facilitate the discovery of links between datasets on the Web of Data as well as their integration and fusion. We present a novel time-efficient implementation of filters that allow for the efficient execution of bounded Jaro-Winkler measures. We evaluate our approach on several datasets derived from DBpedia 3.9 and LinkedGeoData and containing up to
Introduction
The Linked Open Data Cloud (LOD Cloud) has developed to a compendium of more than 2000 datasets over the last few years.1
See
Data collected from
See for example
See for example
We use bounded measures in the same sense as [18], i.e., to mean that we are only interested in pairs of strings whose similarity is greater than or equal to a given lower bound.
The contributions of this paper are as follows:
We derive length- and range-based filters that allow reducing the number of strings t that are compared with a string s.
We present a character-based filter that allows detecting whether two strings s and t share enough resemblance to be similar according to the Jaro-Winkler measure.
We evaluate our approach w.r.t. to its runtime and its scalability with several threshold settings and dataset sizes.
The rest of this paper is structured as follows: In Section 2, we present the problem we tackled as well as the formal notation necessary to understand this work. In the subsequent Section 3, we present the three approaches we developed to reduce the runtime of bounded Jaro-Winkler computations. We then evaluate our approach in Section 4. Related work is presented in Section 5, where we focus on approaches that aim to improve the time-efficiency of link discovery. We conclude in Section 6. The approach presented herein is now an integral part of LIMES.8
This paper is an extended version of [6]. We improved the scalability of the approach presented in the previous version of the paper by using tries. In addition, we provide a parallel version of the approach for additional scalability. Finally, an extended evaluation of the algorithm is presented.
In the following, we present some of the symbols and terms used within this work.
Link discovery
In this work, we use link discovery as a hypernym for deduplication, record linkage, entity resolution and similar terms used across literature. The formal specification of link discovery adopted herein is tantamount to the definition proposed in [17]: Given a set S of source resources, a set T of target resources and a relation R, our goal is to find the set
In this paper, we thus study the following problem: Given a threshold
The Jaro-Winkler similarity
Let
The Jaro-Winkler measure [30] is an extension of the Jaro distance. This extension is based on Winkler’s observation that typing errors occur most commonly in the middle or at the end of a word, but very rarely in the beginning. Hence, it is legitimate to put more emphasis on matching prefixes if the Jaro distance exceeds a certain “boost threshold”
Improving the runtime of bounded Jaro-Winkler
The main principle behind reducing the runtime of the computation of measures is to improve their reduction ratio. Here, we use a sequence of filters that allow discarding similarity computations while being sure that they would have led to a similarity score which would have been less than our threshold θ. To this end, we regard the problem as that of finding filters that return an upper bound estimate
Length-based filters
In the following, we denoted the length of a string s with
The application of this approximation on Winkler’s extension is trivial:
Consider the pair
By using this approach we can decide in
In most programming languages, especially Java (which we used for our implementation), the length of string is stored in a variable and can thus be accessed in constant time.
The approach described above can be reversed to limit the number of pairs that we are going to be iterating over. To this end, we can construct an
For example, consider a list of strings S with equally distributed string lengths
Bounds for distinct string lengths (
)
Bounds for distinct string lengths (
An even more fine-grained approach can be chosen to filter out computations. Let
For instance, let
Calculation of
Calculation of
The naïve implementation of the character-based filter consists of checking if Eq. (10) holds true. The e function for each string is thereby represented using a map. As shown by our evaluation, the character-based filter leads to a significant reduction of the number of comparisons (see Fig. 6) by more than 2 orders of magnitude. However, the runtime improvement achieved using this implementation is not substantial. This is simply due to the lookup into maps being constant in time complexity but still a large amount of time. Instead of regarding strings as monolithic entities, we thus extended our implementation to be more fine-grained and used a trie as explained in the subsequent section.
Implementation with tries
To overcome the need to perform character index lookups for every pair of strings we use a trie-based pruning technique. We thus dub this filter the trie filter from now on. Let
We define a function
From the Jaro-Winkler version of the upper bound estimation given in Eq. (9) we obtain the following equation:
Given this value, we traverse
Consider the following example for a better understanding of how the algorithm works. The threshold parameter θ is set to 0.92. Datasets S and T are given in Table 3. We deliberately selected string of size 5 so that we can present the character filtering in a clear fashion. As both datasets contain the longest string, we set
Datasets S and T from the example
Datasets S and T from the example
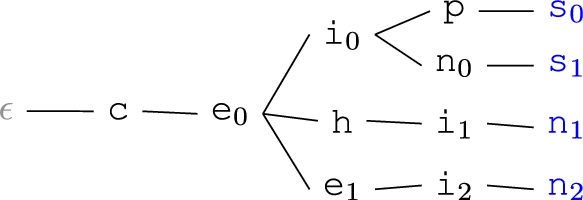
Example Trie
Nodes and their corresponding sets from the example
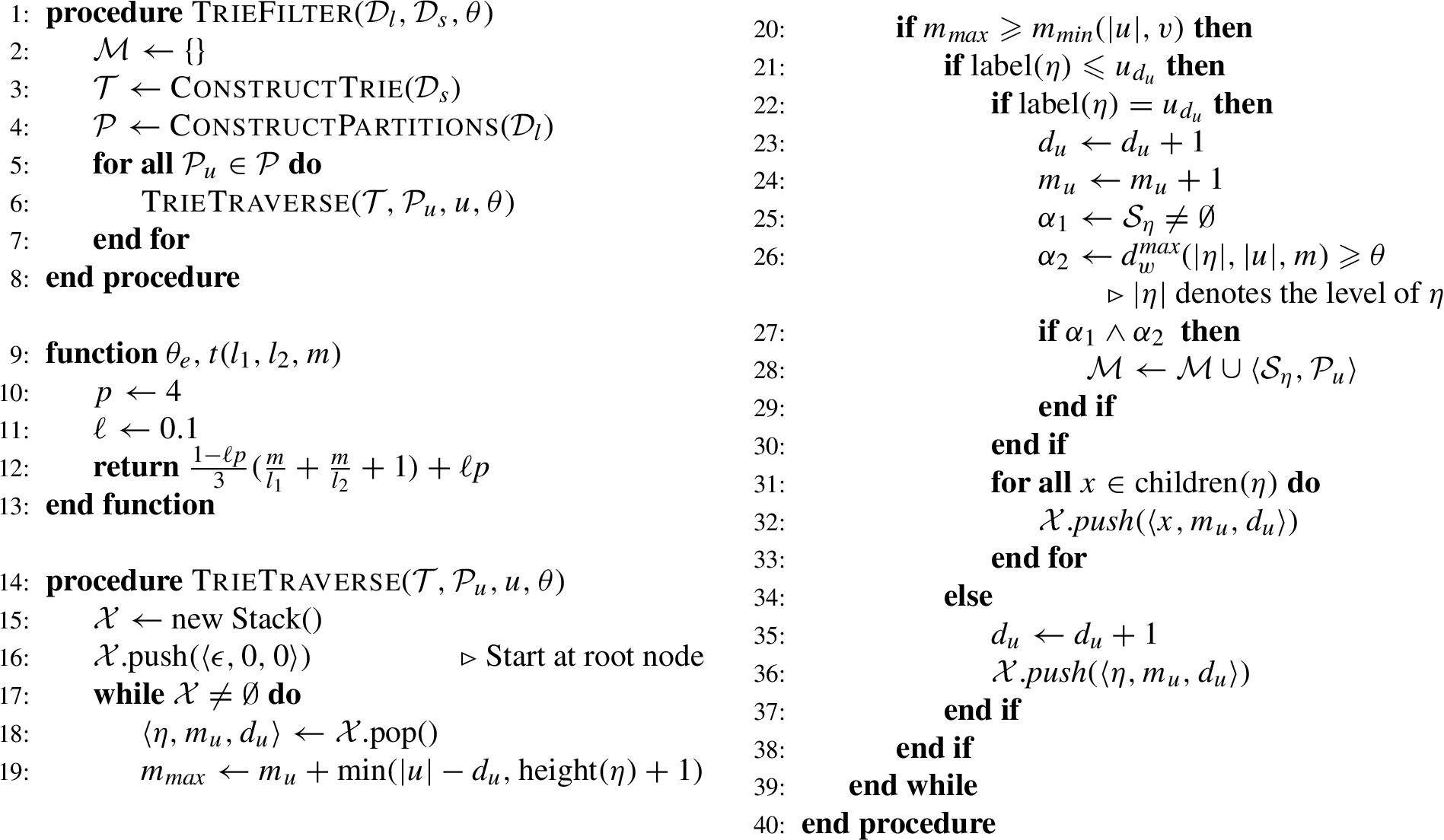
Trie filter
We select the first and only Partition
The height of a node η herein is defined as the number of edges on the longest downward path between that node and a leaf. Therefore we have
In the next iteration step, we now have
In iteration step 3
In iteration step 4 we select
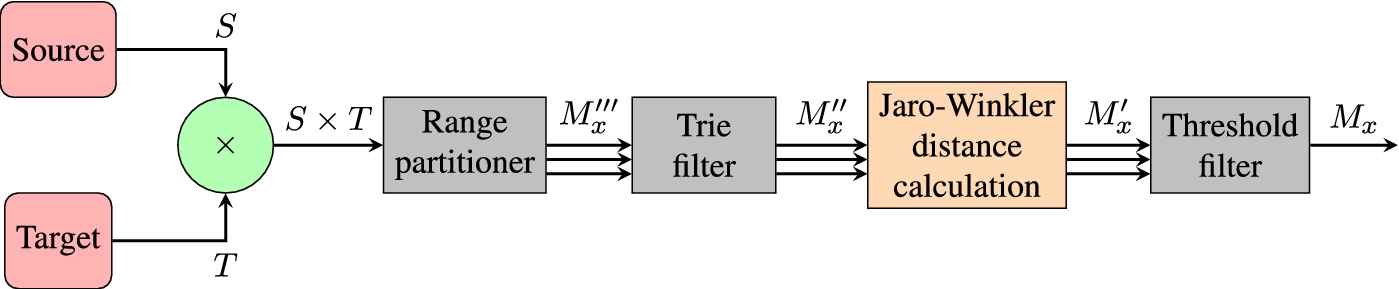
Flowchart of parallel trie filter stack.
In iteration step 5 we select
In iteration step 6 we revisit
In iteration step 7 we revisit
In iteration step 8 we select
In iteration step 9 we select
In iteration step 10 we revisit
In iteration step 11 we select
In iteration step 12 we select
Iterations 13 and 14 come about analogously to steps 11 and 12, leading to a stop of exploration at node
The set of match candidates that is forwarded to the actual Jaro-Winkler distance computation now contains
Note that using the range filter prior to the trie filter is a key requirement towards its efficiency, that is, the more equally distributed the string lengths are, the better we get in terms of reduction ratio and runtime improvement. The worst case scenario is a big dataset with very large strings over a little alphabet and little to none variation in string lengths.

Runtimes on sample of DBpedia
While our results suggest that the approach presented above scales well on one processor, we wanted to measure how well the partitioning induced by the upper and lower length bounds given in Eqs (6) and (7) can be used to implement our approach in parallel. Let
Now given the sets
Evaluation
Experimental setup
The aim of our evaluation was to study how well our approach performs on real data. We chose DBpedia 3.9 as a source of data for our experiments as it contains data pertaining to 1.1 million persons and thus allows for both fine-grained evaluations and scalability evaluations. As a second data source we chose LinkedGeoData to evaluate how well we perform on strings that have no relation to person names. We chose these datasets because (1) they have been widely used in experiments pertaining to link discovery and (2) the distributions of string sizes in these datasets are significantly different (see Figs 7 and 8). All experiments where deduplication experiments, i.e.,
For the sake of legibility, we used the following names and acronyms for filter combination or lack thereof:

Runtimes on sample of DBpedia
Note that the trie filter implicitly contains a length filter, which is the reason why we do not evaluate the combination
In our first series of experiments, we evaluated the runtime of all filter combinations against the naïve approach on a small dataset containing 1000 labels from DBpedia. The results of our evaluation are shown in Fig. 3. This evaluation suggests that all filter setups except those containing
The runtimes on a larger sample of size
Scalability evaluation
The aim of the scalability evaluation was to measure how well our approach scales. In our first set of experiments, we looked at the growth of the runtime of our approach on datasets of growing sizes (see Figs 9 and 10). Our results show very clearly that
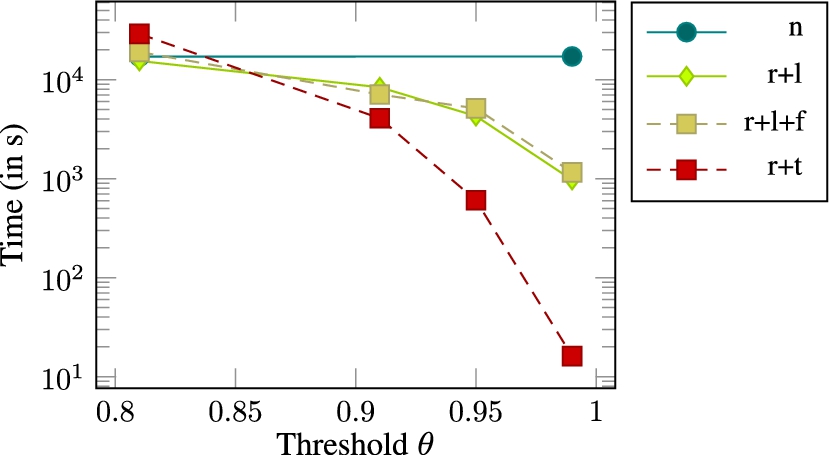
Runtimes on sample of DBpedia

Actual Jaro-Winkler computations, measured on sample of DBpedia

String length distribution of

String length distribution of

Runtimes for growing input list sizes (DBPedia).

Runtimes for growing input list sizes (LinkedGeoData).
The second series of scalability experiments looked at the runtime behaviour of our approach on a large dataset with
In the third series of experiments we looked at the speedup we gain by parallelizing
We compared our approach with SILK2.6.0. To this end, we retrieved all
We ran SILK with -Dthreads = 1 for the sake of fairness.
Runtimes (in seconds) of our approach (OA) and SILK 2.6.0

Speedup of parallel algorithm (DBPedia,

Speedup of parallel algorithm (DBPedia,
The work presented herein is related to record linkage, deduplication, link discovery and the efficient computation of Hausdorff distances. An extensive amount of literature has been published by the database community on record linkage (see [7,12] for surveys). With regard to time complexity, time-efficient deduplication algorithms such as PPJoin+ [32], EDJoin [31], PassJoin [13] and TrieJoin [29] were developed over the last years. Several of these were then integrated into the hybrid link discovery framework LIMES [17]. Moreover, dedicated time-efficient approaches were developed for LD. For example, RDF-AI [27] implements a five-step approach that comprises the preprocessing, matching, fusion, interlink and post-processing of data sets. [19] presents an approach based on the Cauchy-Schwarz that allows discarding a large number of unnecessary computations. The approaches HYPPO [15] and
In addition to addressing the runtime of link discovery, several machine-learning approaches have been developed to learn link specifications (also called linkage rules) for link discovery. For example, machine-learning frameworks such as FEBRL [2] and MARLIN [1] rely on models such as Support Vector Machines [3] and decision trees [25] to detect classifiers for record linkage. RAVEN [20] relies on active learning to detect linear or Boolean classifiers. The EAGLE approach [21] combines active learning and genetic programming to detect link specifications. KnoFuss [22] goes a step further and presents an unsupervised approach based on genetic programming for finding accurate link specifications. Other record deduplication approaches based on active learning and genetic programming are presented in [5,9].
Conclusion and future work
In this paper, we present a novel approach for the efficient execution of bounded Jaro-Winkler computations. Our approach is based on three filters which allow discarding a large number of comparisons. We showed that our approach scales well with the amount of data it is faced with. Moreover, we showed that our approach can make effective use of large thresholds by reducing the total runtime of the approach considerably. We also compared our approach with the state-of-the-art framework SILK 2.6.0 and showed that we outperform it on all datasets. In future work, we will test whether our approach improves the accuracy of specification detection algorithms such as EAGLE. Moreover, we will focus on improving the quality of matches. To this end we will split input strings into tokens and use a hybrid approach as proposed by Monge and Elkan [14], which adds to complexity of the algorithm, hence allowing for further runtime improvements. Furthermore, we will extend the parallel implementation with load balancing.