
Abstract
Accessing and utilizing enterprise or Web data that is scattered across multiple data sources is an important task for both applications and users. Ontology-based data integration, where an ontology mediates between the raw data and its consumers, is a promising approach to facilitate such scenarios. This approach crucially relies on useful mappings to relate the ontology and the data, the latter being typically stored in relational databases. A number of systems to support the construction of such mappings have recently been developed. A generic and effective benchmark for reliable and comparable evaluation of the practical utility of such systems would make an important contribution to the development of ontology-based data integration systems and their application in practice. We have proposed such a benchmark, called RODI. In this paper, we present a new version of RODI, which significantly extends our previous benchmark, and we evaluate various systems with it. RODI includes test scenarios from the domains of scientific conferences, geographical data, and oil and gas exploration. Scenarios are constituted of databases, ontologies, and queries to test expected results. Systems that compute relational-to-ontology mappings can be evaluated using RODI by checking how well they can handle various features of relational schemas and ontologies, and how well the computed mappings work for query answering. Using RODI, we conducted a comprehensive evaluation of seven systems.
Introduction
Motivation
Accessing and utilizing enterprise or Web data that is scattered across multiple databases is an important task for both applications and users in many scenarios [13,31]. Ontology-based data integration is a promising approach to this task, and recently it has been successfully applied in practice (e.g., [27]). The main idea behind this approach is to employ an ontology to mediate between data consumers and databases. Mappings can then be used to either export data to consumers or to translate (or rewrite) consumer queries into queries over the underlying databases on the fly. The latter approach is often referred to as ontology-based data access (OBDA).
Ontology-based data integration crucially depends on usable and useful ontologies and mappings. Ontology development has attracted a lot of attention in the last decade, and ontologies have been developed for various domains including life sciences (e.g., [3]), medicine (e.g., [16]), the energy sector (e.g., [28]), and others. Many of these ontologies are generic enough to be useful as a target ontology in a significant number of ontology-based integration scenarios.
The development of reusable mappings has, however, received much less attention. Moreover, mappings are typically tailored to relate one specific pair of an ontology and one specific database. As a result, mappings typically cannot be as easily reused as ontologies across integration scenarios. Thus, each new integration scenario essentially requires the development of its own mappings. This is a complex and time consuming process. Hence, it calls for automatic or semi-automatic support, i.e., for systems that (semi-) automatically construct useful mappings. In order to address this challenge, a number of systems that generate relational-to-ontology mappings have recently been developed [6,17,25,29,40,47,56].
Whether such generated relational-to-ontology mappings are useful in practice or not is usually evaluated using self-designed and therefore potentially biased benchmarks. This situation makes it particularly difficult to compare results across systems. Consequently, there is not enough evidence to select an adequate mapping generation system in ontology-based data integration projects. What matters at the end of the day in practice is whether the generated mappings are usable and useful for the task at hand. We therefore consider mapping quality as mapping utility with relation to a query workload posed against the mapped data.1
Utility has also been referred to as fitness for use in similar contexts in parts of the literature, cf., [58].
The RODI benchmark is composed of (i) a software framework to test systems that generate mappings between relational schemata [18] and OWL 2 ontologies [10], (ii) a scoring function to measure the utility of system-generated mappings under a query workload, (iii) different datasets and queries for benchmarking, which we call benchmark scenarios, and (iv) a mechanism to extend the benchmark with additional scenarios. Using RODI one can evaluate the quality (i.e., actual utility) of relational-to-ontology mappings produced by systems for ontology-based data integration indirectly through querying the resulting data.
To make this possible, RODI is designed as an end-to-end benchmark. That is, we consider systems that can produce mappings directly between relational databases and ontologies. Also, we evaluate mappings according to their utility for an actual query workload over real-world or realistic databases.
Apparently, such an approach has both its advantages and disadvantages. The end-to-end setup allows almost any systems that map data between relational schemata and ontologies to participate in the benchmark even if they do not support certain standards or languages. However, it also means that we cannot analyze mapping rules or other intermediate artifacts of the process directly. Our use of real-world databases and other realistic databases that closely emulate a real-world case brings the benefit of testing systems under conditions that are similar to the ones that they would encounter in real life, rather than following purely academic considerations. The same argument also holds for using a query workload. On the downside, the distribution of tasks and challenges cannot be controlled systematically and is also not backed by empirical evidence but rather built on the qualitative experience from individual applications. We compensate for the latter disadvantage by (a) including a wide range of scenarios from different application domains and by (b) allowing the benchmark to be extended by users with further scenarios and domains.
We believe that this real-world, end-to-end approach is currently the most suitable way for testing the utility of relational-to-ontology mapping generation systems.
Figure 1 schematically depicts the RODI architecture: the benchmark comes with a number of benchmark scenarios. Scenarios are initialized and set up for use by the framework. Candidate systems then read their input from the active scenario and produce mappings, which are evaluated again by our framework.

RODI benchmark overview.
In this section we summarize the main contributions of the RODI benchmark. We note that an earlier version of RODI has been introduced in [39]. In this paper we significantly extend our earlier results in several important directions: we extended the systematic analyses of challenges and related approaches; we now cover several new benchmark scenarios as well as additional test categories; we significantly extended the scope of the experimental study and now we cover seven different systems.
In the following we describe the main characteristics of RODI and highlight the enhancements with respect to its predecessor [39].
Systematic analyses of challenges and existing approaches in relational-to-ontology mapping generation: These support and explain the types of challenges tested by RODI. This paper contains an updated summary of previous work in addition to a newly added discussion of mapping approaches.
Evaluation scenarios: RODI consists of data integration test scenarios from the domains of conferencing, geographical data, and oil and gas exploration. Scenarios are constituted of databases, ontologies, and queries to check expected results. Components of the scenarios are selected in such a way that they cover the key challenges of relational-to-ontology mapping generation. The version of RODI presented in this paper contains 18 scenarios in three different domains, as opposed to only 9 scenarios from two domains in the previous version of the benchmark [39]. The newly added scenarios focus on features that are important to be tested in real-world challenges, such as high semantic heterogeneity or complex query workloads in different application domains.
The RODI framework: The RODI software package, including all scenarios, has been implemented and made available for public download under an open source license.2
Ready-to-use RODI distribution available at:
System Evaluation: We have used RODI to evaluate seven relational-to-ontology mapping systems: BootOX [25], COMA++ [2], IncMap [40], MIRROR [17], the -ontop- bootstrapper [7], D2RQ [6], and Karma [29]. The systems are chosen in a way that they cover the breadth of recent and traditional approaches in (semi-)automatic schema-to-ontology mapping generation. The insights gained from the evaluation allow us to point out specific strengths and weaknesses of individual systems and to propose how they can be improved. Compared to our preliminary experiments from [39], the study presented in this paper extends not only to twice as many benchmark scenarios as before and adds three additional systems, COMA++, D2RQ and Karma, but it also gives much greater detail on several result aspects, such as a discussion of support for 1:n and n:1 mappings, and for the first time it also includes semi-automatic experiments. In total, we present numbers for seven different reporting categories and drill-downs, as compared to only two in our preliminary study. Also, the accompanying discussion adds significant detailed insights over the earlier paper.
In the new version of RODI, we have also modified all benchmark scenarios to produce more specific individual scores rather than aggregated values for relevant categories of tests. In addition, we have extended the benchmark framework to allow detailed debugging of the results for each individual test. On that basis we now could point to individual issues and bugs in several systems, some of which have already been addressed by the authors of the evaluated systems.
First, we present our analysis of the different types of mapping challenges for relational-to-ontology mapping generation in Section 2. Then, in Section 3 we discuss differences in mapping generation approaches that impact mapping generation, and thus also need to be considered for designing appropriate evaluation approaches. Section 4 presents our benchmark suite and the evaluation procedure. Afterwards, Section 5 discusses some implementation details that should help researchers and practitioners to understand how their systems could be evaluated in our benchmarking suite. Section 6 then presents our evaluation, including a detailed discussion of results. Finally, Section 7 summarizes related work and Section 8 concludes the paper and provides an outlook on future work.
Mapping challenges
In the following we give a summary of our classification of different types of mapping challenges in relational-to-ontology data integration scenarios. For a more detailed discussion, please refer to [39]. As a high-level classification, we use the standard classification for data integration described by Batini et al. [5]: naming conflicts, structural heterogeneity, and semantic heterogeneity. For each of these classes, we list and briefly describe the key challenges that we have identified.
Naming conflicts
Detailed list of specific structural mapping challenges. RDB patterns may correspond to some of the “guiding” ontology axioms and language constructs. Specific difficulties explain particular hurdles in constructing mappings
Detailed list of specific structural mapping challenges. RDB patterns may correspond to some of the “guiding” ontology axioms and language constructs. Specific difficulties explain particular hurdles in constructing mappings
Typically, relational database schemata and ontologies use different conventions to name their artifacts even when they model the same domain based on the same specification and thus should use a similar terminology. The main challenge here is to be able to find similar names despite the different naming patterns. We are particularly interested in differences that are specific to inter-model matching and come on top of other naming differences, which commonly exist in other schema matching cases as well.
The most important differences in relational-to-ontology integration scenarios, compared to other integration scenarios, are structural heterogeneities. Table 1 lists all specific testable relational-to-ontology structural challenges that we have identified.
In brief, there are type conflicts resulting from normalization, denormalization or different modeling of class hierarchies, key conflicts, and dependency conflicts.
Type conflicts
Most real-world relational schemata and corresponding ontologies cannot be related by any simple canonical mapping. This is because big differences exist in the way how the same concepts are modeled (i.e., type conflicts). One reason why these differences are so big is that relational schemata often are optimized towards a given workload (e.g., they are normalized for update-intensive workloads or denormalized for read-intensive workloads). Ontologies, on the other side, model a domain on the conceptual level, albeit with different degrees of expressiveness and thus conceptual richness. Another reason is that some modeling elements have no single canonical translation (e.g., class hierarchies in ontologies can be mapped to relational schemata in different ways). In the following, we list the different type conflicts covered by RODI:
Normalization artifacts: Often properties that belong to a class in an ontology are spread over different tables in the relational schema as a consequence of normalization. Denormalization artifacts: For read-intensive workloads, tables are often denormalized. Thus, properties of different classes in the ontology might map to attributes in the same table. Class hierarchies: Ontologies typically make use of explicit class hierarchies. Relational models implement class hierarchies implicitly, typically using one of three different common modeling patterns (cf., [18, Chap. 3]). (i) The relational schema materializes several subclasses in the same table and uses additional attributes to indicate the subclass of each individual. With this variant, mapping systems have to resolve n:1 matches, i.e., they need to filter from one single table to extract information about different classes. (ii) Use one table per most specific class in the class hierarchy and materialize the inherited attributes in each table separately. Thus, the same property of the ontology must be mapped to several tables, leading to 1:n matches. (iii) Use one table for each class in the hierarchy, including the possibly abstract superclasses. Tables then use primary key-foreign key references to indicate the subclass relationship.
Key conflicts
In ontologies and relational schemata, keys and references are represented differently.
Keys: Keys in databases are usually implemented using primary keys and unique constraints, while ontologies use IRIs for individuals. The challenge is that integration tools must be able to compose or skolemize appropriate IRIs. References: While typically modeled as foreign keys in relational schemata, ontologies use object properties. Moreover, sometimes relational databases do not model foreign key constraints at all.
Dependency conflicts
These conflicts arise when a group of concepts are related among each other with different dependencies (i.e., 1:1, 1:n, n:m) in the relational schema and the ontology. Relational schemata also often model n:m relationships using an additional connecting table.
Semantic heterogeneity
Semantic heterogeneity plays a highly important role for data integration in general. Therefore, we extensively test scenarios that bring significant semantic heterogeneity.
Besides the usual semantic differences between any two conceptual models of the same domain, three additional factors apply in relational-to-ontology data integration: (i) the impedance mismatch caused by the object-relational gap, i.e., ontologies group information around entities (objects) while relational databases encode them in a series of values that are structured in relations; (ii) the impedance mismatch between the closed-world assumption (CWA) in databases and the open-world assumption (OWA) in ontologies; and (iii) the difference in semantic expressiveness, i.e., databases may model some concepts or data explicitly where they are derived logically in ontologies.
While some forms of inference on relational databases have also been given regular attention in database research, they more often take an angle of correctness and efficiency (e.g., in the case of query containment [18]) rather than knowledge systems, with only a few exceptions (e.g., [4]). For a more detailed comparison, please refer to [34]. Modern relational database systems typically also offer several possibilities to programmatically extend core database functionality with almost arbitrary business logic. They thereby enable calculations with an equivalent effect to some forms of logical inference, e.g., by using stored procedures for the purpose. These include stored procedures, triggers, UDFs, and others. For instance, a stored procedure or calculated view could list all persons based on their roles as authors (or other activities that imply the involvement of a human being), but in our experience such applications of these features are not very common in practice. We do not consider such programmatic schema extensions as they are powerful, partially non-declarative and partially non-standardized features that are difficult to analyze in the general case.
All of them are inherent to all relational-to-ontology mapping problems.
Analysis of mapping approaches
Different mapping generation systems make different assumptions and implement different approaches. Thus, a benchmark needs to consider each approach appropriately.
Differences in availability and relevance of input
Different input may be available to an automatic mapping generator. In relational-to-ontology data integration, the main difference on available input concerns the target ontology. The ontology could be specified entirely and in detail, or it could still be incomplete (or even missing) when mapping construction starts. Other differences comprise the availability of data or of a query workload.
The case where both the relational database schema and the ontology are completely available could be motivated by different situations. For example, a company may wish to integrate a relational data source into an existing, mature, Semantic Web application. In this case, the target ontology would already be well defined and would also be populated with some A-Box data. In addition, a SPARQL query workload could be known and could be available as additional input to a mapping generator.
On the other side, relational-to-ontology data integration might be motivated by a large-scale industry data integration scenario (e.g., [19,26]). In this scenario, the task at hand is to make complex and confusing schemata easier to understand for experts who write specialized queries. In this case, at the beginning no real ontology is given. At best there might be an initial, incomplete vocabulary.
Essentially, the different scenarios can all be distinguished by the following question: which information is available as input, besides the relational database? We always assume that the relational source database is completely accessible (both schema and data), as this is a fundamental requirement without which relational-to-ontology data integration applications cannot reasonably be motivated. Besides the availability of input for mapping generation, there could be additional knowledge about which parts of the input are even relevant. For instance, it may be clear that only parts of the ontology that are being used by a certain query workload need to be mapped. If so, this information could also be leveraged by the mapping generation system (e.g., by analyzing the query workload).
It has to be noted that some other and different motivations to work with relational-to-ontology mappings exist as well: for instance, a database schema might be developed or generated to serve as a storage engine for an existing ontology (e.g., [21]). We do not consider these cases but rather think of them as the inverse of what happens for relational-to-ontology mapping generation. Similarly, we consider questions of mapping evolution as a related but separate problem.
For the RODI benchmark design we consider different forms of input. In particular we vary the input database, ontology, data and queries.
Differences in the mapping process
Other differences can arise from the process in which mapping generation is approached. These can be either fully-automatic approaches or semi-automatic approaches. Truly semi-automatic approaches are usually iterative [15], as they consist of a sequence of mapping generation steps that get interrupted to allow human feedback, corrections, or other input. Their process is driven by the human perspective rather than by an automatic component. Since we want to better adjust our benchmark to the semi-automatic approaches, we first discuss different ways that are known for the semi-automatic case.
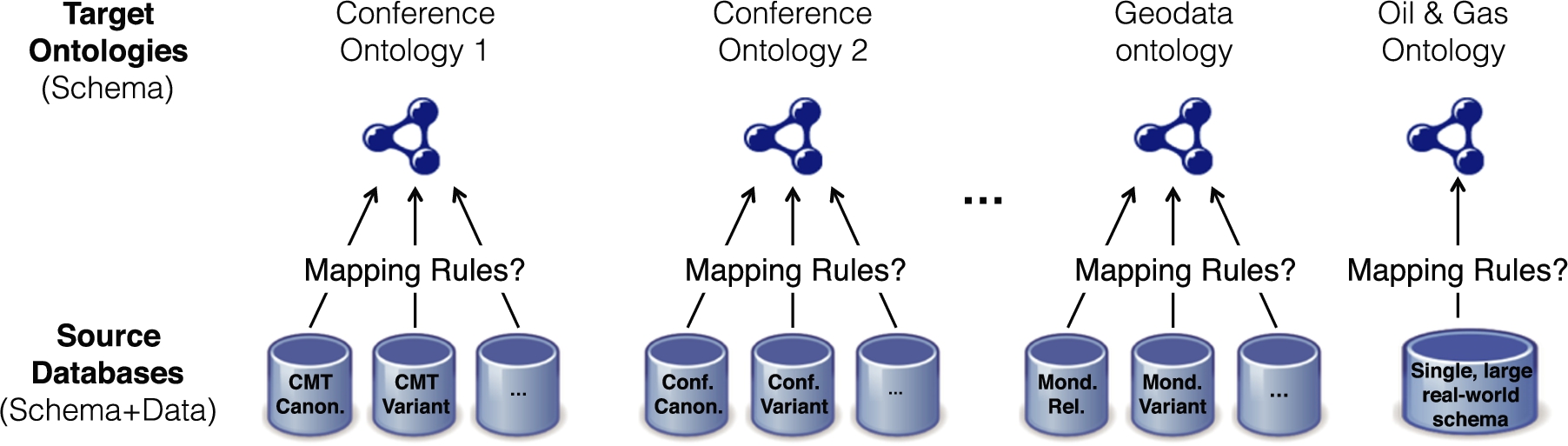
Overview of RODI benchmark scenarios.
Heyvaert et al. [20] have recently identified four different ways for manual relational-to-ontology mapping creation. Each of those directions inflicts a different interaction paradigm between the system and the user and thus solicits different forms of human input: users can edit mappings based on either the source or target definitions, they can drive the process by providing result examples or could theoretically even edit mappings irrespective of either the source or target in an abstract fashion. Some of us have also earlier identified two core user perspectives on mapping generation [38] also discussed by [20]. Moreover, while some approaches consider manual corrections only at the end of the mapping process, more thoroughly semi-automatic approaches allow or even require such input during the process.
In terms of their potential evaluation, iterative approaches of this kind must be considered according to two additional characteristics: First, whether iterative human input is mandatory or generally optional. Second, whether input is only used to improve the mapping as such, or if the systems also exploit it as feedback for their next automated iteration. Systems that solicit input only optionally and do not use it as feedback can be evaluated like non-iterative systems on a fully automatic baseline without limitations. Systems with only optional input that do learn from the feedback (if provided), can still be evaluated on the same baseline but may not demonstrate their full potential. Where input is mandatory, systems need to be either steered by an actual human user or at least require simulated human input produced by an oracle.
Next, the kind of human input that a system can process makes a difference for evaluation settings. Most semi-automatic systems either provide suggestions that users can confirm or delete, or they allow users to manually adjust the mapping. An alternative approach is mapping by example, where users provide expected results. In addition, however, some systems may require complex or indirect interactions, or simply resort to more unusual forms of input that cannot easily be foreseen.
Each mapping generation system is usually tied to one specific approach and does not allow for much freedom.
We therefore decided that an end-to-end evaluation that allows the use of different types of input is best. Since semi-automatic approaches are becoming more and more relevant, we decided to support them using an automated oracle that simulates user input where possible.
In the following, we present the details of our RODI benchmark: we first give an overview, then we discuss the data sets (relational schemata and ontologies) that can be used, as well as the queries. Finally, we present our scoring function to evaluate the benchmark results.
Overview
Figure 2 gives an overview of the scenarios used in our benchmark. The benchmark ships with data sets from three different application domains: conferences, geodata, and the oil & gas exploration domain. In its basic mode of operation, the benchmark provides one or more target ontologies for each of those domains (T-Box only) together with relational source databases for each ontology (schema and data). For some of the ontologies there are different variants of accompanying relational schemata that systematically vary some of the targeted mapping challenges.
The benchmark asks the systems to create mapping rules from the different source databases to their corresponding target ontologies. We call each such combination of a database and an ontology a benchmark scenario. For evaluation, we provide for each scenario a series of query pairs to test a range of mapping challenges as illustrated in Fig. 3. Every query pair consists of a SPARQL query (“test query”) against the ontology, and a semantically equivalent SQL query (“reference query”) against the provided SQL database. The test query runs against RDF data that results from applying the mapping rules of the matching system under consideration. The reference query is directly evaluated by RODI against the SQL database. The results are compared for each query pair and are aggregated in the light of different mapping challenges using our scoring function. For this, all query pairs are tagged with categories, relating them to different mapping challenges.
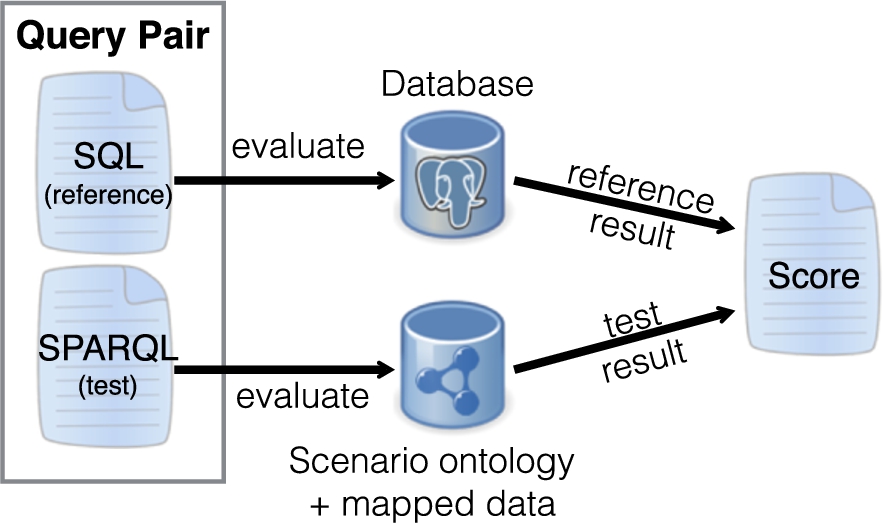
Query pair evaluation.
While challenges that result from different naming or semantic heterogeneity are mostly covered by complete scenarios, we target structural challenges on a more fine-granular level of individual query tests with a dedicated score. To this end, we add a corresponding category tag to query tests that address certain challenges. We target all structural challenges as previously listed in Table 1 in one or more scenarios.
Multi-source integration can be tested as a sequence of different scenarios that share the same target ontology. Although it has to be noted that some specific challenges in multi-source integration, especially conflicts introduced by different sources, may not become visible in sequential tests, this setup covers a wide range of multi-source mapping challenges. We include specialized scenarios for such testing with the conference domain.
In order to be open for other data sets and different domains, our benchmark can be easily extended to include scenarios with real-world ontologies and databases.
While all of our included default scenarios focus on schema-level matching, some cases in the real-world additionally demand data transformations to work fully as expected. These comprise translations between different representations of date and time (e.g., a dedicated date type versus Epoch time stamps), simple numeric unit transformations (e.g., MB vs. GB), unit transformations requiring more complex formulae (e.g., degrees Celsius vs. Fahrenheit), string-based data cleansing (e.g., removing trailing whitespace), string compositions (e.g., concatenating a first and last name), more complex string modifications (e.g., breaking up a string based on a learned regular expression), table-based name translations (e.g., replacing names using a thesaurus), noise removal (e.g., ignoring erroneous tuples), etc. Our extension mechanism (see Section 4.5) is suited to add dedicated scenarios for testing such conversions, however, we excluded them from our default benchmark for a merely practical reason: To the best of our knowledge no current relational-to-ontology mapping generation system implements any such transformation functionality to date, so there is little practical use for benchmarking it.
Our main design objective with RODI is to provide an end-to-end testing framework that can closely mimick the challenges encountered by mapping generation in the real world. Hence, it is based on different real-world scenarios and hence it is extensible. As a consequence of this goal there is always the risk of a subjective imbalance introduced by the query workload of a certain application that we build on. RODI scores in each case reflect the query workload that is being tested and therefore may mirror some of this subjectivity. Even in scenarios where we attempt to strike a balance and vary some of the challenges we do so by modifying only the structure of the source database, not the workload. Scores are thus designed to offer a clear indication of system performance, not to provide an unquestionable source of truth. We strongly encourage users of the benchmark to look into individual test results as logged by the benchmark framework before preparing their discussion and interpretation of the results.
In the following we present the data sources (i.e., ontologies and relational schemata) as well as the combinations used as integration scenarios for the benchmark in more details. RODI ships with scenarios based on data sources from three different application domains.
We chose the conference domain as our primary testing domain since (i) it is well understood and comprehensible even for non-domain experts, (ii) it is complex enough for realistic testing, and (iii) it has been successfully used as the domain of choice in other benchmarks before (e.g., [8,12,55]). While we ship several different variants of scenarios for this domain, which vary in size and complexity, they are all built around a core fragment comprising 23 classes and 77 properties with varying additions. Corresponding databases vary in size between 32 tables and a total of 85 columns to 66 tables with 125 columns. Each scenario runs between 19 and 39 query tests.
Ontologies
The conference ontologies in this benchmark are provided by the Ontology Alignment Evaluation Initiative (OAEI) [8,12,55] and were originally developed by the OntoFarm project [52]. We selected three particular ontologies (
Relational schemata
We synthetically derived different relational schemata for each of the ontologies, focusing on different mapping challenges. We provide benchmark scenarios as combinations of those derived schemata with either their ontologies of origin, or, for more advanced testing, paired with any of the other ontologies. First, for each ontology we derived a relational schema using a canonical mapping as described in [21]: The algorithm works by deriving an entity-relationship (ER) model from an OWL ontology. It then translates this ER model into a relational schema according to textbook rules (e.g., [18]). For this paper, we extended this algorithm to cover the full range of expected relational design patterns. Additionally, we extended this algorithm to consider ontology instance data to derive more proper functionalities (rather than just looking at the T-Box as the previous algorithms do). Otherwise, the generated canonical relational schemata would have contained an unrealistically high number of n:m-relationship tables. The canonical schemata are guaranteed to be in fourth normal form (4NF), fulfilling normalization requirements of standard design practices. Thus, they already include various normalization artifacts as mapping challenges.
From the canonical schema corresponding to each of the ontologies, we created different variants by introducing different aspects on how a real-world schema may differ from the canonical one and thus to test different mapping challenges:
Adjusted Naming: As described in Section 2.1, ontology designers typically consider other naming schemes than database architects do, even when implementing the same (verbal) specification. Those differences include longer vs. shorter names, “speaking” prefixes, human-readable property IRIs vs. technical abbreviations (e.g., “hasRole” vs. “RID”), camel case vs. underscore tokenization, preferred use of singular vs. plural, and others. For each canonical schema, we automatically generated a variant with identifier names changed in this way. Restructured Hierarchies: The most critical structural challenge in terms of difficulty comes with different relational design patterns to model class hierarchies more or less implicitly. As we have discussed in Section 2.2, these changes introduce significant structural dissimilarities between source and target. We automatically derive variants of all canonical schemata where different hierarchy design patterns are used. The choice of design pattern in each case is algorithmically determined on a “best fit” approach considering the number of specific and shared (inherited) attributes for each of the classes. For instance, a small number of sibling classes would be split over several tables if they mostly used different properties but they would be rather joined together in a single table if they would mostly make use of the same set of properties. Combined Case: In the real world, both of the previous cases (i.e., adjusted naming and hierarchies) would usually apply at the same time. To find out how tools cope with such a situation, we also built scenarios where both are combined. Removing Foreign Keys: Although it is considered as bad style, databases without foreign keys are not uncommon in real-world applications. This can be a result of lazy design, or due to legacy applications (e.g., popular open source DBMS MySQL introduced plugin-free support for foreign keys just half a decade ago). The mapping challenge is that mapping tools must find the join paths to connect tables of different entities. Additionally, they sometimes even need to guess a join path for reading attributes of the same entity if its data is split over several tables as a consequence of normalization. Therefore, we have created one dedicated scenario to test this challenge with the Partial Denormalization: In many cases, schemata are partially denormalized to optimize for a certain read-mostly workload. Denormalization essentially means that correlated (yet separated) information is jointly stored in the same table and partially redundant. We provide one such scenario for the
Integration scenarios
For each of our three main ontologies,
Basic scenario variants (non-default scenarios are put in parentheses)
Basic scenario variants (non-default scenarios are put in parentheses)
As discussed before, Canonical closely mimics the structure of the original ontology, but the schemata are normalized and thus the scenario contains the challenge of normalization artifacts. Adjusted Naming adds the naming conflicts as discussed before. Restructured hierarchies tests the critical structural challenge of different relational patterns to model class hierarchies, which, among others, subsumes the challenge to correctly build n:1 mappings between classes and tables. In the Combined Case, naming conflicts and restructured hierarchies are employed and their effects are tested in combination. This is a more advanced test case. A special challenge arises from databases with no (or few) foreign key constraints (Missing FKs). In such a scenario, mapping tools must guess the join paths to connect tables that correspond to different entity types. The technical mapping challenge arising from Denormalized schemata consists in identifying the correct partial key for each of those correlated entities, and to identify which attributes and relations belong to which of the types.
To keep the number of scenarios small for the default setup, we differentiate between default scenarios and non-default scenarios. We excluded scenarios with the most trivial schema versions. In addition, we did limit the number of combinations for the most complex schema versions by including only one of each type as a default scenario. While the default scenarios are mandatory to cover all mapping challenges, the non-default scenarios are optional (i.e., users could decide to run them in order to gain additional insights). Non-default scenarios are put in parentheses in Table 2. However, they are not supposed to be executed in a default run of the benchmark.
We also include cross-matching scenarios that require mappings of schemata to one of the other ontologies (e.g., mapping a
We provide data to fill both the databases and ontologies. The conference ontologies are originally provided as T-Boxes only, i.e., no A-Box. We first generate data as A-Box facts for the different ontologies, and then transform them into the corresponding relational data using the same process as for translating the T-Box. For the technical process of evaluating generated mappings data is only needed in the relational databases. Hence, generating ontology A-Boxes would not even be necessary for this purpose alone. However, this procedure simplifies data generation since all databases can be automatically derived from the given ontologies as described before. Our conference data generator deterministically produces a scalable amount of synthetic facts around key concepts in the ontologies, such as conferences, papers, authors, reviewers, and others. In total, we generate data for 23 classes, 66 object properties (including inverse properties) and 11 datatype properties (some of which apply to several classes). However, not all of those concepts and properties are supported by every ontology. For each ontology, we only generate facts for the subset of classes and properties that have an equivalent in the relational schema in question.
Queries
For the conference scenarios, all scenarios draw on the same pool of 56 query pairs, accordingly translated for each ontology and schema, with each scenario supporting a different subset. The benchmark queries on the conference scenarios are rather simple, using either only one concept and a property of it, or one relationship and two concepts with one property each. The same query may face different challenges in different scenarios, e.g., a simple 1:1 mapping between a class and table in a canonical scenario can turn into a complicated n:1 mapping problem in a scenario with restructured hierarchies.
Query pairs are grouped into three basic categories to test the correct mapping of class instances, instantiations of datatype properties and object properties, respectively. Additional categories relate queries to n:1 and n:m mapping problems or prolonged property join paths resulting from normalization artifacts. A specific category exists for the de-normalization challenge.
Geodata domain – mondial scenarios
As a second application domain, RODI ships scenarios in the domain of geographical data.
The Mondial database [32] is a manually curated database containing information about countries, cities, organizations, and geographic features such as waters (with subclasses lakes, rivers, and seas), mountains, and islands. It has been designed as a medium-sized case study for several scientific aspects and data models.3
Based on Mondial, we have developed a number of benchmark scenarios, which combine the Mondial OWL ontology with a series of different relational schemata. The OWL ontology is quite sophisticated, using many OWL constructs, and providing many potential challenges, e.g.:
properties whose domain is neither a single class, nor some kind of top class (like usually for the
multiple properties between the same domain and range, distinguishable by the cardinality:
properties that are functional on some subdomain, and n:m on another subdomain (e.g.,
properties that have a named union class as range: the range of
For the Mondial scenarios, we use a query workload that mainly approximates real-world explorative queries on the data, although limited to queries of low or medium complexity. The queries typically combine more than one concept, or several attributes, or several relationships with a common class. The degree of difficulty in the Mondial scenarios is therefore generally higher than in the conference domain scenarios.
There is only a single default scenario, which is based on the original relational Mondial database (42 tables, 160 columns, 60 foreign keys). It features a wide range of relational modeling patterns and it also differs from the canonical relational schema in some well-chosen aspects. With these changed aspects it mimicks a “real-life” (legacy) relational database schema:
classical relational keys/foreign keys built upon literal-valued attributes. Most of them are unary (usually, the
E.g., the above-mentioned
In addition, we have designed a systematical series of further scenarios with synthetically modified variants of the canonical relational schema. To keep the number of tested scenarios at bay, we do not consider those additional synthetic variants as part of the default benchmark. Instead, we recommend these as optional tests to dig deeper into specific patterns. These scenarios are similar to the different variants produced in the conference domain, with the additional feature that the database schema and the queries are explicitly designed to test the following crucial elements:
for all scenarios based on the canonical relational schema, all keys/foreign keys are the IRIs;
different modeling variants of the class hierarchy wrt. Water/River/Lake/Sea and Mountain/Volcano (cf. Section 2.2);
a variant where all classes mentioned in the ontology, including typically abstract ones like
different modeling variants of functional properties whose domain is a union of classes like
different modeling variants of
case-sensitive vs. case-insensitive;
a variant where all properties are n:m.
The challenges for the matching systems are not only to produce the appropriate mapping, but also to generate appropriate rules incorporating join paths, which is checked by the design of the benchmark queries. With these scenarios, the behavior of a system can be checked systematically, and even further database variants can easily be designed.
A typical (but already high-end) query is e.g.  where information from the
where information from the
Finally, we include an example of an actual real-world database and ontology, in the oil and gas domain: The Norwegian Petroleum Directorate (NPD) FactPages [49]. Our test set contains a small relational database with a relatively complex structure (70 tables, ≈1,000 columns and ≈100 foreign keys), and an ontology covering the domain of the database. The database is constructed from a publicly available dataset containing reference data about past and ongoing activities in the Norwegian petroleum industry, such as oil and gas production and exploration. The corresponding ontology contains ≈300 classes and ≈350 properties.
With this pair of a database and ontology, we have constructed two scenarios that feature a different series of tests on the data: first, there are queries that are built from information needs collected from real users of the FactPages and cover large parts of the dataset. Those queries are highly complex compared to the ones in other scenarios (by query complexity, we refer to the number of different schema elements that need to be accessed). They thus each require a significant number of schema elements to be correctly mapped at the same time to bear any results. The principled benefit of such queries is that they represent actual real-world information needs much more accurately than any simplified query workloads do. A realistic workload can thus be seen as a measure of real-world utility as opposed to simplified queries, which artifically set the bar far too low and thus may convey a false impression of actual utility. Even if today’s mapping generation systems may perform poorly on such queries, they will be the most relevant test to pass eventually. We have collected 17 such queries in scenario npd_user_ tests. In addition, we have generated a large number of small, atomic query tests for baseline testing. These are similar to the ones used with the conference domain, i.e., they test for individual classes or properties to be correctly mapped. A total of 439 such queries have been compiled in the scenario npd_atomic_tests to cover all of the non-empty fields in our sample database.
A specific feature resulting from the structure of the FactPages database and ontology are a high number of 1:n matches, i.e., concepts or properties in the ontology that require a UNION over several relations to return complete results. 1:n matches as a structural feature can therefore best be tested in the npd_atomic_tests scenario.
Extension scenarios
Our benchmark suite is designed to be extensible, i.e., additional scenarios can be easily added. The primary aim of supporting such extensions is to allow domain-specific, real-world mapping challenges to be tested alongside our more default scenarios. Extension scenarios can be added by users of our benchmark without any programming efforts. The creation and addition of scenarios is described in the user documentation of the RODI benchmark suite [42].
Challenge coverage and query category tags
Category tags used in different default scenarios, with brief description. Relevant challenges where applicable. Note, that some challenges require a check on a combination of tags or will be checked at a scenario-level, not on a query-level
Category tags used in different default scenarios, with brief description. Relevant challenges where applicable. Note, that some challenges require a check on a combination of tags or will be checked at a scenario-level, not on a query-level
The scenarios included in RODI add up to jointly cover all mapping challenges identified and discussed in the previous sections.
On a per-scenario level, they represent examples from three different application domains. They also have different degrees of complexity. This affects schema size where NPD is the largest, Mondial is in-between and Conference scenarios have different sizes from small to medium. Also, different degrees of query workload complexity are included. Query workloads are modestly complex in conference scenarios and NPD atomic tests, more demanding in Mondial, and most complex with NPD user tests. Moreover, scenarios exhibit different degrees of semantic heterogeneity. There is rather little semantic heterogeneity between conference cases of any ontology and their directly corresponding database schema. Heterogeneity is higher for Mondial and NPD. The highest degree of semantic heterogeneity is however reached for conference scenarios, where we match an ontology to a database schema corresponding to a different ontology from the same domain (cross-matching).
On a more fine-grained level, several challenges are tested through a subset of queries. We tag query tests by categories and report separate scores not only for each scenario, but also for each category in each scenario.
Table 3 shows a list of all tags that we use in our default scenarios, a brief description of their purpose, and scenarios that include them. Not all of the category tags correspond to a particular challenge. Some of them also serve to allow drill-downs into basic aspects of the schema, e.g., to separately report on class matches and property matches. However, using tags we can also report on challenges that correspond to some of the category tags in the query tests.
It is our aim to measure the practical usefulness of mappings. We are therefore interested in the utility of query results, rather than comparing mappings directly to a reference mapping set or than measuring precision and recall on all elements of the schemata. This is important because a number of different mappings might effectively produce the same data w.r.t. a specific input database. Also, the mere number of facts is no indicator of their semantic importance for answering queries (e.g., the total number of conference venues is much smaller than the number of all paper submission dates, yet the venues are just as important in a query retrieving information about any of these papers). In addition, in many cases only a subset of the information is relevant in practice and we define our queries on a meaningful subset of information needs.
We therefore observe a score that reflects the utility of the mappings with relation to our query tests as our main measure. Intuitively, this score reports the percentage of successful queries for each scenario.
However, in a number of cases, queries may return correct but incomplete results, or could return a mix of correct and incorrect results. In these cases, we consider per-query accuracy by means of a local per-query F-measure. Technically, our reported overall score for each scenario is the average of F-measures for each query test, rather than a simple percentile of successful queries. To calculate these per-query F-measures, we also need to consider query results that contain IRIs.
Different mapping generators will typically generate different IRIs for the same entities represented in the relational database, e.g., by choosing different prefixes. F-measures for query results containing IRIs are therefore calculated w.r.t. the degree to which they satisfy structural equivalence with a reference result. For practical reasons, we use query results on the original, underlying SQL databases as technical reference during evaluation. Structural equivalence effectively means that if same-as links were established appropriately, then both results would be semantically identical.
Formally, structural equivalence and fitting measures for precision and recall are defined as follows:
(Structural tuple set equivalence).
Let
For instance,
(Tuple set equivalence w.r.t. ontology).
Let O be a target ontology of a mapping,
Then,
With the same example as just before, the two tuples are structurally equivalent, iff http://my#john is not already defined in the target ontology. Finally, we can define precision and recall:
(Precision and recall).
Let
Then the precision of the test set
Table 4 shows an example with a query test that asks for the names of all authors. Result set A is structurally equivalent to the reference result set, i.e., it has found all authors and did not return anything else, so both precision and recall are 1.0. Result set B is equivalent with only a subset of the reference result (e.g., it did not include those authors who are also reviewers). Here, precision is still 1.0, but recall is only 0.5. In case of result set C, all expected authors are included, but also another person, James. Here, precision is 0.66 but recall is 1.0.
Example results from a query pair asking for author names, e.g., SQL: SELECT name FROM persons WHEREperson_type=2 SPARQL: SELECT ?name WHERE {?p a :Author; foaf:name?name}

Example results from a query pair asking for author names, e.g., SQL:
To aggregate results of individual query pairs, a scoring function calculates the averages of per query numbers for each scenario and for each challenge category. For instance, we calculate averages of all queries testing 1:n mappings. Thus, for each scenario there is a number of scores that rate performance on different technical challenges. Also, the benchmark can log detailed per-query output for debugging purposes.

RODI framework architecture.
With RODI, we can test mapping generators that work in either one or two stages: that is, they either directly map data from the relational source database to the target ontology in one stage (e.g., [2,40]). Or, they bootstrap their own ontology, which they use as an intermediate mapping target. In this case, to get to the full end-to-end mappings that we can test, the intermediate ontology and the actual target ontology should be integrated via ontology alignment in a second stage. Two-stage systems may either include a dedicated ontology alignment stage (e.g., [25]) or they deliver the first (intermediary) stage only [6,7,17]. In the latter case, RODI can step in to fill the missing second stage with a standard ontology alignment setup [48].
Our tests check the accuracy of SPARQL query results. Queries ask for individuals of a certain type (or their aggregates), properties correlating them, associated values and combinations thereof, sometimes also using additional SPARQL language features such as filters to narrow down the result set. This means that mapped data will be deemed correct if it contains correct RDF triples for all tested cases. For entities, this means that systems need to construct one correctly typed IRI for each entity of a certain type. For object properties, they need to construct triples to correctly relate those typed IRIs, and for datatype properties, they need to assign the correct literal values to each of the entity IRIs using the appropriate predicates. Systems do therefore not strictly need to understand or to produce any OWL axioms in the target ontology. However, our target ontologies are in OWL 2, using different degrees of expressiveness. Axioms and other language constructs in the target ontology can be important as guidance to identify suitable correspondences for one-stage systems. Similarly, if two-stage systems construct expressive axioms in their intermediate ontology, this may guide the second stage of ontology alignment. For instance, if a predicate is known to be an object property in the target ontology, results will suffer if a mapping generation tool assigns literal values using this property. Also, if a property is known to be functional it might be a better match for an n:1 relation than a non-functional property would be.
Framework implementation
In this section, we discuss some implementation details in order to guide researchers and practitioners to include their system in our benchmarking suite.
Architecture of the benchmarking suite
Figure 4 depicts the overall architecture of our benchmarking suite. The framework requires upfront initialization per scenario. Artifacts generated or provided during initialization are depicted blue in the figure. After initialization, a mapping tool can access the database (directly or via the framework’s API) and the target ontology (via the Sesame API4
Unless a mapping system under evaluation decides to skip individual steps, i.e., to implement them independently, in the evaluation phase, the benchmark suite will: (i) read submitted R2RML mappings and execute them on the database, (ii) materialize the resulting A-Box facts in a Sesame repository together with the target ontology (T-Box), (iii) optionally apply reasoning through an external OWL API [22] compatible reasoner to infer additional facts that may be requested for evaluation, (iv) evaluate all query pairs of the scenario on the repository and on the relational database, and (v) produce a detailed evaluation report. Additionally, as mentioned in Section 4.8, RODI also provides support to (two-stage) systems that require assistance to align their generated ontology with the target ontology. Information about how individual steps are invoked can be found in RODI’s user documentation [42].
We evaluate query results as described in Section 4.7 by attempting to construct an isomorphism ϕ between the query result set and the reference results. Technically, we use the results of the SQL queries from query pairs to calculate the reference result set. For each SQL query in a query pair, we flag attributes that together serve as keys, so keys can be matched with IRIs rather than with literal values. Obviously, literal values need to be exact matches. IRIs always need to match the same unique value from the database in each matching tuple. But the unique values used in the tuple can be different from the string components that make up an IRI. For instance, a tuple describing a person might have a synthetic integer ID column in the relational database, whereas corresponding person IRIs are composed of a namespace prefix and the persons’ first and last names, with an additional suffix added only where several different persons share identical names.
For constructing ϕ, we first index all individual IRIs (i.e., IRIs that identify instances of some class) in the query result. Next, we build a corresponding index for keys in the reference set. For both sets we determine binding dependencies across tuples (i.e., re-occurrences of the same IRI or key in different tuples). As a next step, we narrow down match candidates to tuples where all corresponding literal values are exact matches. After this step, we have a set of tuple pairs from the two result sets that are candidates for being structurally equivalent, because all their literals are identical. Finally, we check for these candidates to be actually structurally equivalent, i.e., we also check for viable correspondences between keys (in the reference tuples) and IRIs (in the matching result tuples). As discussed, the criterion for a viable match between a key and an IRI is that for each occurence of this particular key and of this particular IRI in any of the tuples, both need to be matched with the same partner. In principle, the same IRIs (and keys) can appear in any number of tuples and in different positions of each tuple. A simple example for such a query with repeated occurences of the same IRI in several positions of the result tuple could be a request for papers with their authors and reviewers (where each author and reviewer may appear in many different tuples and the same person’s IRI may appear as an author in one tuple and as a reviewer in another). All occurences of all IRIs in any tuple need to match the same keys in all cases for a structurally equivalent overall match. Hence, we can have transitive n-hop dependencies between n tuples or even cyclic dependencies. The step of finding viable matches across all tuples therefore corresponds to identifying a maximal common subgraph (MCS) between the dependency graphs of tuples on both sides, i.e., it corresponds to the MCS-isomorphism problem.6
The MCS isomorphism problem is a well-studied optimization problem and is known to be NP-hard.
Finally, we count tuples that could not be matched in the result and reference set, respectively. Precision is then calculated as
RODI offers different ways at different levels of detail to look into test results. By default, for each scenario a report of different scores will be provided. Output formats can be chosen between tabular format and a human-readable log. For each of the reports, a break-down into categories used within the corresponding scenario is included. To better understand the details of category composition for each scenario, users can lookup the corresponding queries, which are stored in human-readable text files.
In addition, a debug mode of the benchmark supports detailed per-query test output. When enabled, one report for each query test will be produced and includes details that fully explain test criteria, including full provided and expected results and any gaps between them. This information can be used, together with the database and ontology from a scenario, to understand exactly where and why a certain system has failed any of the tests, or tests associated with a particular score.
Benchmark results
Evaluated systems
We have performed an in-depth analysis using RODI on a wide range of systems. Those include current contenders in the automatic segment (BootOX [19,25,27] and IncMap [37,40,41]), more general-purpose mapping generators (-ontop- [7], MIRROR [17] and D2RQ [6]), as well as a much earlier, yet state-of-the-art system in inter-model matching (COMA++ [2]). In a specialized semi-automatic series of experiments, we have also evaluated Karma [29,53], which does not support a fully automatic mapping generation mode and works with a sophisticated model of human intervention. As a consequence, it requires a specific experimental setup. Note that BootOX, -ontop-, MIRROR and D2RQ are two-stage systems (see Section 4.8), that is, they do not generate mappings targetting the ontology provided in each RODI scenario and they generate their own (putative or bootstrapped) ontology instead. BootOX includes a built-in ontology alignment system which allows to integrate the bootstrapped ontology with the target (scenario) ontology. In order to be able to evaluate -ontop-, MIRROR and D2RQ with RODI, we also aligned their generated ontologies with the target ontology in a similar setup to the one used in BootOX.
BootOX (
IncMap (
MIRROR (
The -ontop- Protege Plugin (
COMA++ (
D2RQ platform (
Karma is one of the most prominent modern relational-to-ontology mapping generation systems. It is strictly semi-automatic, i.e., there is no fully automatic baseline that we could use for non-interactive evaluation. In addition, Karma’s mode of iterations is designed to take advantage mostly from integrating a series of data sources to the same target ontology. Karma is therefore not well suited for single-scenario evaluations. We therefore only evaluate Karma in a dedicated line of experiments that suit its specifications.
We conduct benchmark default experiments as described in Section 4 for all systems except Karma. This includes a selection of nine prototypical scenarios from the conference domain, one from the geodata domain and two from the oil & gas domain, as well as six different cross-matching (conference) scenarios. For all of these main experiments, we observe and report overall RODI scores as well as specific selected scores in individual categories.
Overall scores in default scenarios (scores based on average of per-test F-measure). Best numbers per scenario in bold print
Overall scores in default scenarios (scores based on average of per-test F-measure). Best numbers per scenario in bold print
In addition, we perform two different semi-automatic experiments on selected scenarios for Karma and IncMap, respectively. For Karma, we had to conduct experiments with an actual human in the loop to perform steps that Karma could not automate. With IncMap, we could simulate human feedback by responding to suggestions by taking a response from the benchmark that indicates changes in mapping quality. In both semi-automatic cases, we chiefly observe the number of interactions.
Table 5 shows scores for all systems on all basic default scenarios. At first impression we can observe that all tested systems manage to solve some parts of the scenarios, but with declining success as scenario complexity increases.
For instance, relational schemata in the conference “adjusted naming” scenarios follow modeling patterns from their corresponding ontologies most closely, and all systems without exception perform best in this part of the experiments. Quality drops for all other types of scenarios, i.e., whenever we introduce additional challenges that are specific to the relational-to-ontology modeling gap. The drop in accuracy between Adjusted Names and Restructured hierarchies settings is mostly due to the n:1 mapping challenge introduced by one of the relational patterns to represent class hierarchies which groups data for several subclasses in a single table. In the most advanced conference cases, systems lose further due to the additional challenges, although to different degrees. Good news is that some of the actively developed current systems, BootOX and IncMap, could improve their scores compared to previous numbers recorded in January 2015 [39]. A somewhat disappointing general observation, however, is that measured quality is overall still modest compared to results that are known from ontology alignment tasks involving some of the same ontologies (cf. [8,12,55]). This is disappointing, especially while state-of-the-art ontology alignment software is employed in some of the systems. It could indicate that the specific challenges in relational-to-ontology mapping generation can not convincingly be solved with the same technology that is successful in ontology alignment, but may call for more specialized approaches.
Overall scores in cross-matching scenarios (scores based on average of per-test F-measure). Best numbers per scenario in bold print
Overall scores in cross-matching scenarios (scores based on average of per-test F-measure). Best numbers per scenario in bold print
While all of the conference scenarios test a wide range of specific relational-to-ontology mapping challenges, they do so in a highly controlled fashion, on schemata with at best medium size and complexity, and using a largely simplified query workload. For instance, queries in the conference domain scenarios would separately check for mappings of authors, person names, and papers. They would not, however, pose any queries like asking for the names of authors who did participate in at least five different papers. The huge difference here is that, if two out of three of these elements were mapped correctly, the simple, atomic queries would report an average score of 0.66, while the single, more application-like query that correlates the same elements would not retrieve anything, thus resulting in a score of 0.00. None of the systems managed to solve even a single test on this challenge. This kind of real-world queries that mimick an actual application query workload, are precisely what we focus on the remaining default scenarios, which are set in the geodata and oil & gas exploration domains. Consequently, scores are lower again in those scenarios. In the geodata scenario, only a minority of query tests could be solved. Detailed debugging showed that the reason for this lies in the more complex nature of queries, most of which go beyond returning simple results of just a single mapped element. In the oil & gas case, the situation becomes even more problematic. Here, the schema and ontology are again a bit more complex than in the geodata scenario, and so is the explorative query workload (“user queries”). None of the systems was able to answer any of these queries correctly after a round of automatic mapping. To retrieve meaningful results, we added a second scenario on the same data, but with a synthetic query workload of atomic queries (“atomic”). On this scenario, results could be computed but overall scores remain low due to the size and complexity of the schema and ontology with a large search space as well as many 1:n matches.
Table 6 showcases results from the most advanced scenarios in the conference domain. All of them are built on the “combined case” scenarios, i.e., they contain a mix of all of the standard relational-to-ontology mapping challenges except for denormalization and lazy modeling of constraints. In addition, they increase the level of semantic heterogeneity by asking for mappings between a schema derived from one ontology to a rather different, independent ontology in the same domain. Scores are generally lower than in the basic conference cases discussed above. Reasonable scores can still be achieved by some systems. Also, the overall trend of performance between the systems mostly remains the same as in the basic scenarios, with a few exceptions. Somewhat surprisingly, COMA loses out more than other contenders. Even more, the performance of BootOX is noticeably low compared to the baseline results from basic scenarios in Table 5. This is unexpected as BootOX essentially applies ontology alignment technology that has proven itself in tasks with high semantic heterogeneity [1]. It could, again, be an indicator that out-of-the-box ontology alignment techniques could not take the same leverage that they do when aligning original ontologies.
The big picture shows that two of most specialized and also actively developed systems, BootOX and IncMap, are leading the field. Among those two, BootOX is at a clear advantage in scenarios where the inter-model gap between relational schema and ontology is small (e.g., “adjusted naming”). IncMap is gaining ground when more specific inter-model mapping challenges are added. MIRROR, -ontop- and D2RQ generally show weaker results. It has to be noted, though, that these systems have been originally designed and optimized for a somewhat different task than the full end-to-end mapping generation setup tested with RODI. MIRROR and -ontop- also fail to execute some of the scenarios due to technical difficulties. For MIRROR in particular, we have encountered a number of so far unresolved difficulties that may also have a detrimental effect on MIRROR scores. COMA keeps up well, given that it is no longer actively developed and improved. Also, while COMA has been constructed to support inter-model matching in general, it has not been explicitly optimized for the specific case of relational-to-ontology matching.
As part of our detailed analysis of the results we could also identify, and partially even fix, a number of technical shortcomings in tested systems. For instance, we encountered issues with MIRROR in certain multi-schema matching cases on PostgreSQL and implemented a solution in exchange with the authors of the system. In another example, IncMap’s poor performance in the geodata scenario could in part be explained by its failure to understand the specification of property domains and ranges as a union of several concrete classes. This pattern lead IncMap to skipping such properties altogether. While not yet fixed, the observation points to concrete technical improvements in IncMap. In BootOX, incomplete and unfavorable reasoning settings were detected and fixed.
Score break-down for queries on different match types with adjusted naming conference scenarios. ‘C’ stands for queries on classes, ‘D’ for data properties, ‘O’ for object properties
Score break-down for queries on different match types with adjusted naming conference scenarios. ‘C’ stands for queries on classes, ‘D’ for data properties, ‘O’ for object properties
Score break-down for queries that test n:1 matches in restructured conference domain scenarios. 1:1 and n:1 stands for queries involving 1:1 or n:1 mappings among classes and tables, respectively
Score break-down for queries that require 1:n class matches on the Oil & Gas atomic tests scenario
All systems struggle with correctly identifying properties as Table 7 shows. A further drill-down shows that this is in part due to the challenge of normalization artifacts, with systems struggling to detect any properties that map to multi-hop join paths in the tables. Mapping data to class types appears to be generally easier for all contenders. BootOX is performing best in most cases with all kinds of properties, with IncMap coming in second. This represents a change over the previous versions of both systems benchmarked earlier, where IncMap was clearly leading on properties [39].
Tables 8 and 9 show the behavior of systems for finding n:1 and 1:n matches between ontology classes and table content, respectively. We highlight the n:1 case in restructured conference scenarios and 1:n matches in the oil & gas scenario as they include the highest number of tests in their respective categories. In both cases results are staggering with all systems failing the large majority of tests. For 1:n matches the situation is slightly better than it is with n:1 matches. This is not particularly surprising in general, as 1:n matches can be composed in mapping rules by adding up several correct 1:1 matches. A correct mapping of n:1 matches between classes and tables, on the other side, usually requires the much more challenging task of filtering from the table that holds entities of different types.

Karma multi-source integration counting human interactions.
We have also conducted semi-automatic, iterative experiments on RODI scenarios with two different systems, Karma and IncMap. While IncMap was also evaluated in the main line of experiments before on its fully automatic mode, Karma does not support such a baseline mode and always requires human intervention in different forms. This is mainly due to Karma’s need for so called Python transformations, essentially tiny Python scripts, to mint entity IRIs. In contrast to class and property matches, Karma does not learn those transformations. Also, both systems work according to completely different semi-automatic processes. Karma is designed for multi-source integration and learns from human interactions in one scenario to provide suggestions in the next ones. IncMap, on the other side, adjusts its suggestions after simple yes/no feedback during one single scenario but has no memory between any two scenarios.
For these reasons, a direct experimental comparison between the two systems is not feasible. Instead, we run a separate dedicated experiment for each of them and identify similarities and differences in performance in the following discussion.
With Karma, we ran three experiments, each of which consists of a series of three related scenarios on the same target ontology. This translates to three different source schemata that Karma needs to integrate in a row. As Karma cannot produce any results completely automatically, we conducted this experiment interactively and recorded the number of human interactions needed to complete the mapping for each of the data sources. Figure 5 shows that in all cases the total number of required interactions drops for later data sources over previous ones. The drop in manual class matches and property matches is made possible by type learning. Python transformations remain approximately constant across subsequent data sources as no learning support and suggestions are available for these transformations.
Due to the manual input, mappings resulting from Karma’s semi-automatic process are generally of high quality and did mostly reach scores close to 1.0 (cf. Table 10).
For IncMap, we ran a series of regular single-scenario tests, but in an incremental, semi-automatic setup [36]. That is, for each of the scenarios, we simulated human feedback in the form of choosing a suggestion from shortlists of three suggestions, each. To simulate this kind of feedback we simply used the benchmark as an oracle to identify the best pick. We observed how the score achieved by IncMap’s mappings changes after a number of iterations, i.e., we report a score at k human interactions [35].
Table 11 shows those scores for three conference domain scenarios, before feedback (
Note that these changes in score are based on feedback during several iterations on the same scenarios. It would be most interesting to see an evaluation of a system that combines the approaches of Karma and IncMap. From the results available from these two systems so far, it becomes clear that either approach has its own benefits. A direct comparison is not possible, though, as both follow a fairly different kind of process (multi-source vs. single-source) and also request different forms of human input (e.g., Python transformations in Karma).
Semi-automatic Karma mappings: generally very high scores thanks to human input
Semi-automatic Karma mappings: generally very high scores thanks to human input
Impact of incremental mapping: scores for IncMap after k interactions in adjusted naming scenarios
Mappings between ontologies are usually evaluated only on the basis of their underlying correspondences (usually referred to as ontology alignments). The Ontology Alignment Evaluation Initiative (OAEI) [8,12,55] provides tests and benchmarks of those alignments that can be considered a de-facto standard. Mappings between relational databases are typically not evaluated by a common benchmark. Instead, authors typically compare their tools to one or more of the industry standard systems (e.g., [2,14]) in a scenario of their own choice. A novel TPC benchmark [43] was recently created to close this gap. However, no results are reported so far on the TPC-DI website. To the best of our knowledge, no benchmark to measure specifically the quality of inter-model relational-to-ontology mappings was available before the original release of RODI [39].
Similarly, evaluations of relational-to-ontology mapping generating systems were based on one or several data sets deemed appropriate by the authors and are therefore not comparable. In one of the most comprehensive evaluations so far, QODI [56] was evaluated on several real-world data sets, though some of the reference mappings were rather simple. IncMap [40] was first evaluated on a choice of real-world mapping problems based on data from two different domains. Such domain-specific mapping problems could be easily integrated in our benchmark through our extension mechanism.
A number of papers discuss different quality aspects of relational-to-ontology mapping generation in a more general way. Console and Lenzerini have devised a series of theoretical OBDA data quality checks w.r.t. consistency [9]. As such, these could also be used to judge mapping quality to a certain degree. However, the focus of this work is clearly different. Also, the approach is agnostic of actual requirements and expectations and only considers consistency of data in itself. A more multi-dimensional approach has been proposed by Westphal et al. [57]. Their proposals do not include a single, globally comparable scoring measure, but rather a collection of different measures, which could be sampled and combined as suitable or applicable in different scenarios. Tarasowa et al. propose a similarly generic approach to quality measurement on relational-to-ontology mappings [54]. Dimou et al. [11] have proposed unit testing as a generic and domain-independent quality measure for relational-to-ontology mappings. Impraliou et al. [23] present a benchmark composed by a series of synthetic queries to measure the correctness and completeness of relational-to-ontology query rewriting. The presence of complete and correct mappings is a prerequisite to their approach. Mora and Corcho discuss issues and possible solutions to benchmark the query rewriting step in OBDA systems [33]. Mappings are supposed to be given as immutable input. The NPD benchmark [30] measures performance of OBDA query evaluation. Neither of these latter two papers, however, address the issue of measuring mapping quality.
A comprehensive overview of relational-to-ontology efforts, including related approaches of automatic mapping generation, can be found in the two surveys [46,51].
Conclusion
We have presented a novel benchmark suite RODI that allows to test the quality of system-generated relational-to-ontology mappings. The prime application area of RODI is ontology-based data integration. RODI tests a wide range of data mapping challenges that are specific to relational-to-ontology mappings, and which we identified in this paper.
Using RODI we have conducted a thorough evaluation of seven prominent relational-to-ontology mapping generation systems from different research groups. We have identified strengths and weaknesses for each of the systems and in some cases could even point to specific erroneous behavior. We have communicated our observations to the authors of BootOX, IncMap, MIRROR, D2RQ and -ontop- and most of them already used our feedback to improve their systems and the quality of the computed mappings. Overall, the systems demonstrate that they can cope well with relatively simple mapping challenges. However, all tested tools perform poorly on most of the more advanced challenges that come close to actual real-world problems. Thus, further research is needed to address these challenges.
Future work includes repeated evaluations of a growing number of relational-to-ontology mapping generation systems. It would be particularly interesting to evaluate semi-automatic tools in a more comprehensive way, and to directly compare different tools under identical settings. Additionally, we expect several of the tested systems to address issues pointed by our evaluation with RODI. Another avenue of future work includes the extension of the benchmark suite, e.g., by adding scenarios from other application domains relevant for ontology-based data integration.
Footnotes
Acknowledgements
This research is funded by the Seventh Framework Program (FP7) of the European Commission under Grant Agreement 318338, “Optique”. Ernesto Jimenez-Ruiz, Evgeny Kharlamov and Ian Horrocks were also supported by the EPSRC projects MaSI3, Score!, DBOnto and ED3.