
Abstract
We present an approach for scalable long-term preservation of data stored in relational databases (RDBs) as RDF, implemented in the SAQ (Semantic Archive and Query) system. The proposed approach is suitable for archiving scientific data used in scientific publications where it is desirable to preserve only parts of an RDB, e.g. only data about a specific set of experimental artefacts in the database. With the approach, long-term preservation as RDF of selected parts of a database is specified as an archival query in an extended SPARQL dialect, A-SPARQL. The query processing is based on automatically generating an RDF view of a relational database to archive, called the RD-view. A-SPARQL provides flexible selection of data to be archived in terms of a SPARQL-like query to the RD-view. The result of an archival query is a data archive file containing the RDF-triples representing the relational data content to be preserved. The system also generates a schema archive file where sufficient meta-data are saved to allow the archived database to be fully reconstructed. An archival query usually selects both properties and their values for sets of subjects, which makes the property p in some triple patterns unknown. We call such queries where properties are unknown unbound-property queries. To achieve scalable data preservation and recreation, we propose some query transformation strategies suitable for optimizing unbound-property queries. These query rewriting strategies were implemented and evaluated in a new benchmark for archival queries called ABench. ABench is defined as set of typical A-SPARQL queries archiving selected parts of databases generated by the Berlin benchmark data generator. In experiments, the SAQ optimization strategies were evaluated by measuring the performance of A-SPARQL queries selecting triples for archival in ABench. The performance of equivalent SPARQL queries for related systems was also measured. The results showed that the proposed optimizations substantially improve the query execution time for archival queries.
Keywords
Introduction
The importance of digital preservation research has been growing for the past ten-fifteen years. Many papers and books [9,16,24] describing problems, tools and techniques for digital preservation, have been written, and standards providing preservation models have been published [18,33]. However, most of this work focuses on preservation of file-based digital objects like documents, images, and web pages [16]. Much less work has focused on the preservation of databases and scientific data, where there is a recognized need to preserve scientific data [1,10,19,27,45]. Furthermore, preserving scientific data together with scientific publications would contribute to documenting the origin and lineage of scientific achievements [19]. For this a concept of ‘Scientific Publication Packages (SPPs)’ was introduced in [19]. The SPPs were described as composite digital objects linking experimental raw data, associated with metadata, ‘derived information’, and knowledge, including associated publications.
Scientific data, i.e. experimental and observational data, as well as data generated by instruments and sensors, reside in large datasets that are often stored in relational databases. During the research process the scientists need to select subsets of these databases (i.e. specific tables, rows, columns) to be analysed and processed in order to create a scientific model. Once the model is validated the research results are documented and published. By preserving the selected subsets of both data and publications within one digital object, future reuse, verification, and heritage [9] of the published scientific results can be guaranteed.
Selective data preservation is needed also for example in cases of medical data preservation where, in order to protect the privacy of patients, sensitive data like zip code, dates of birth, salaries, etc. should be excluded from archiving [42]. Other examples are when selecting representative geospatial data for preservation [20] or preserving web resources based on some criteria [24].
For long-term preservation of data, it is desirable for the contents of a database to be saved in a neutral format, so that it can be reconstructed and used after a very long time using current technologies for data representation, which are continuously evolving. Furthermore, preserved representations must include sufficient meta-data to retrieve, explain, reproduce, and disseminate the experiments. We propose RDF and RDF-Schema (RDFS) based neutral format as a database technology-independent format for long-term preservation of data, which provides standard meta-data representation for describing all kinds of data, including relational databases [41].
In this paper we present an approach for scalable long-term preservation of selected data stored in relational databases (RDBs) as RDF, implemented in the SAQ (Semantic Archive and Query) system. The proposed approach is suitable for archiving scientific data used in scientific publications where it is desirable to preserve only selected parts of an RDB, e.g. only data about a specific set of artefacts in the database related to some publications. For this SAQ provides selective archival of user-specified parts of an RDB using an extended SPARQL query language, A-SPARQL.
To map a relational database into RDF, SAQ automatically generates an RDF view of the relational database to be archived called the RD-view. The RD-view is defined in terms of anRDFS ontology for describing RDB schemas in general.
To select the parts of an RDB to archive, a SAQ user defines an archival query to the RD-view in A-SPARQL. For example, the classes representing the tables named product and offer in the RDB Products of the Berlin Benchmark dataset [6,7] are archived with the archival query:
In the query the result triples are stored in the data archive file ‘data.nt’. While executing the archival query, the system simultaneously produces sufficient meta-data to enable reconstruction of the selected parts of the archived RDB. These meta-data are stored in a schema archive file, ‘schema.nt’.
When an archived RDB content is to be recreated, SAQ reads the schema archive to automatically recreate the RDB schema in another RDBMS. The RDB thus created is then populated by reading the data archive and converting the read data into table rows according to the schema. This allows migration from one RDBMS to another, perhaps from different vendors. If only selected parts of the RDB are archived, a corresponding partial RDB is recreated containing only the relevant parts of the schema and data. For migrating data from RDBs to RDF repositories, the contents of the schema and data archive files can be directly loaded into an RDF repository system, e.g. [2,38,47].
For processing an archival query in A-SPARQL SAQ internally generates a corresponding SPARQL query to select the triples of the database to archive. The archival queries are straight-forward to translate into CONSTRUCT queries. As in the example, unions of sets of triples are often archived, e.g. for different classes and properties, which makes the generated SPARQL queries to become UNION CONSTRUCT queries.
Archival queries typically select sets of attributes of tables to archive. This corresponds to selecting sets of RDF properties in the RD-view of the database to be archived. In the example all properties of the classes representing the tables product and offer are selected for archival. Therefore, in the generated queries the property p in one or several triple patterns (s, p, o) is a variable. We call such triple patterns (TPs) unbound-property triple patterns (UPTP), and the queries having such triple patterns unbound-property queries [40]. To achieve scalable data preservation and reconstruction, we developed some special query rewriting optimizations for optimizing unbound-property queries. Archival queries can also contain conventional TPs where the properties are URIs representing RDF properties in the RD-view, which we call bound-property triple patterns (BPTP). Queries having only BPTPs are called bound-property queries, which are processed using known methods [29,30,36].
To evaluate the performance of typical archival queries a new benchmark called ABench was developed. ABench is defined as set of typical archival queries, specified in A-SPARQL, that archive selected parts of databases generated by the Berlin benchmark data generator [5]. A new benchmark was developed since the archival queries generate CONSTRUCT unbound-property queries with UNION clauses, which is not covered by any existing benchmark.
In the experiments, the SAQ optimization strategies were evaluated using ABench. The experiments showed that the proposed query rewriting optimizations substantially improve the query execution time for unbound-property queries selecting RDB contents to archive. We also compared the performance of our approach with other systems processing SPARQL queries over views of RDBs and found that the proposed optimizations improve query scalability compared with the approaches used in those systems.
The rest of this paper is organized as follows. Section 2 presents a motivating example for selective preservation of a relational database as RDF, Section 3 presents the SAQ system and the A-SPARQL language, and Section 4 the archival benchmark ABench. Section 5 describes the RD-view and the SAQ query processing steps, along with the SAQ rewriting optimizations. Section 6 evaluates the performance of the query optimizations using Abench, Section 7 describes related work, and Section 8 provides a summary.
Motivating example
A user, who has worked on analysing products with different properties, wants to preserve together with the analysis result data about analysed products having some special properties. In the example, data about products produced in Sweden and having a property
The products data resides in a RDB. Figure 1 shows a small RDB called Products, which is part of the relational Berlin benchmark dataset. The database has four tables, product, productfeature, productfeatureproduct and producer, populated with some data. The columns pnr, pfnr and prodnr are primary keys in the tables product, productfeature, and producer. The column producer in the table product references the column prodnr in the table producer as foreign key. The table productfeatureproduct is a many-to-many link table between the tables product and productfeature.

RDB Products.
To archive as RDF the selected products along with their properties and values, we define in SAQ the following archival query:
Execution of the archival query produces two N-Triples files, ‘productD.nt’ to store the archived products from the RDB and ‘productS.nt’ to store the schema archive required for recreating the parts of the RDB schema representing the archived products. The RDB reconstructed from the archival query is shown in Fig. 2. It contains only the tables, attributes and rows required to reconstruct the data archived by the query. After the reconstruction, SAQ can process SPARQL queries to the RD view of the reconstructed database.

RDB Products.
The developed SAQ system for long-term preservation of relational databases follows conceptually the OAIS reference model [33]. The OAIS model is composed by four functional units: Ingest, Archival Storage, Data Management, and Access. The Ingest unit accepts Submission Information Packages (SIPs) and generates Archival Information Packages (AIPs) for storage and management. The Archival Storage unit receives AIPs from Ingest and adds them to permanent storage. The Data Management unit provides functions for populating, maintaining, and accessing variety of meta-data stored in the repository. The Access unit provides an interface between the archive and the consumer.
An OAIS’ AIP contains Content Information, i.e. the archived data and the representational metadata, together with a Preservation Description Information (PDI). The PDI contains reference information, context information, provenance information, etc.

SAQ.
SAQ provides functionality for the Ingest component, in particularly on generating the content information in the AIPs when preserving relational database contents as RDF.
In order to preserve both schema and data from an RDB, it is important to represent not only the contents of the RDB as RDF, but also the schema. Therefore the RD-view is defined as a union of a schema view (the S-view), representing the RDB schema, and a data view (the D-view), representing the RDB contents. To allow for interoperability with other systems mapping RDBs to RDF, e.g. [4,8,13], the data view mappings conform to the direct mapping recommendations by W3C Recommendation [3].
The architecture of the SAQ system is presented in Fig. 3. The source RDB is the underlying RDB, which can be queried by SPARQL and preserved by A-SPARQL queries.
The RD-view generator automatically generates one RD-view over each source RDB by reading the database schema though a JDBC interface. The RD-view templates thereby provide general prototypes for the structure of the RD-view for any relational database, and the contents of the mapping tables provide RDB-to-RDF mappings for specific relational meta-data into RDF. An archival query is processed by the archiver and translated into a corresponding generated query in SPARQL, which is sent to the SAQ query processor. The generated query retrieves the data to archive from the RDB. Regular non-archiving SPARQL queries are sent directly to the SPARQL query processor.
The SAQ query processor executes the SPARQL queries to the RD-view by accessing the source RDB through the JDBC interface.
Archival queries have the following syntax:
where an archive specification is defined as:
An archival query is specified by an ARCHIVE statement where a data archive file and the schema archive file are specified. SAQ will create these files using the N-triples format [26]. The FROM clause specifies the URI representing the RDB to archive. The URI is assigned by the user once for each RDB.
The body of an archival query is specified by a (union of) archive specifications, which select the triples to archive. The pattern of the triples to archive is defined by an archived triple pattern (
The following are examples of some of the ABench queries:
Query A1 archives the entire database and stores it as a data archive file ‘data1.nt’ and a schema archive file ‘schema1.nt’. Query A2 archives only the RDFS classes having the URI <db:product> and <db:offer>, along with all their properties. Query A3 archives only the RDF properties having URIs <db:product_label>, <db:offer_price>, and <db:offer_webapge>. Finally, query A4 archives the property product_pNum1 for values > 214, the property product_pNum3 for values < 348, and the property review_text for values matching the string ‘time’ if the property review_rating4 > 8.
An archival query is straight-forward to translate into a CONSTRUCT SPARQL query. It is usually a CONSTRUCT-UNION query where unions of sets of triples are archived. For example, A3 is translated into the following generated SPARQL query:
Since archival queries always select a sub-graph from the RDF graph of the RD-view to archive, all archived triple patterns in a generated query appear both in the CONSTRUCT clause and the WHERE clause.
The translation rules from A-SPARQL to the generated SPARQL are the following:
The CONSTRUCT clause of the generated SPARQL query consists of all unique archived triple patterns defined in the TRIPLES clauses of the archive specifications.
The WHERE clause of the generated SPARQL query is a UNION of one Basic Graph Patterns (BGP) per archive specification, consisting of the archived triple pattern in the TRIPLES clause and the optional archive restrictions in the WHERE clause.
Generating the schema archive
During the execution of the generated SPARQL query, the property URIs of the triples to be archived are collected by the meta-data extractor while iterating over the result stream. When all data to archive have been processed, the meta-data extractor joins the collected properties with the S-view by issuing a schema query.
The archived content retrieved by the generated query and the corresponding meta-data retrieved by the schema query are written by the RDF converter into two N-triple files in the archive repository.
Restoring a database
Later on, when a preserved database is to be restored, the reloader reads from the archive repository the two archive files and makes the database live again by populating it into a destination RDB or alternatively a destination triple store. When an RDB is restored, the reloader first reads the schema archive in order to generate the RDB schema and then populates the destination RDB by reading the data archive. After the destination RDB is restored, it can be queried or re-archived with A-SPARQL using SAQ. When the destination DBMS is an RDF triple store system, both the schema and data archive files are loaded directly into the triple store and can there be queried with SPARQL.
The archival benchmark ABench
The archival benchmark ABench consists of archival queries that select subsets of a relational database to archive as RDF, i.e. selecting specific tables, columns, and rows for archival using A-SPARQL. The relational database is generated by the Berlin benchmark dataset generator.
Tables 1–3 list the archival queries of ABench, together with the corresponding generated queries by SAQ. The archival queries are denoted
Query A1 archives the entire database. The generated SPARQL query Q1 is an unbound-property query.
Query A2 archives the entire classes product and offer representing the entire RDB tables product and offer. The generated SPARQL query Q2 is an unbound-property UNION query of properties of the classes to archive.
Query A3 archives all values of some explicitly specified properties. Here the generated SPARQL query Q3 is a bound-property UNION query of three triple patterns, where the properties are known URIs in the WHERE clause.
Query A4 is similar to A3, i.e. it archives values of explicitly defined properties, but there are also conditions on the values of these properties. The generated SPARQL query Q4 becomes a bound-property UNION query of known property triple patterns.
Query A5 is similar to A2, but it constrains the properties of class product to archive. It retrieves the rows from table product for all attributes except those represented by the specified properties. The generated Q5 is an unbound-property query.
Query A6 archives all classes whose URIs match a defined string. The generated query Q6 is an unbound-property query. It should be executed by sending to the underlying RDB SQL queries selecting rows only from the tables represented by URIs matching the defined string.
Query A7 archives data for classes having properties whose URIs match a defined string. The generated query Q7 is an unbound-property query. It should be executed by sending to the underlying RDB SQL queries selecting rows only from the tables having attributes represented by properties that match the defined string.
Query A8 archives all properties and their values of a number of selected subjects. The generated SPARQL query Q8 is an unbound-property query with joins.
Query A9 archives all classes whose property values are literals containing a specific string. The generated query Q9 is an unbound-property query. It should be executed by sending SQL LIKE conditions on only such table attributesclass whose values are not represented by URIs.
ABench queries
ABench queries
Query A10 archives all properties of subjects related through a property to another given subject. The relationship is represented by a foreign key in the underlying RDB. The generated query Q10 is an unbound-property query. It should be executed by sending SQL queries only to tables owning a foreign key for the table represented by the given subject.
ABench queries
ABench queries
In this section, first the structure of the RD-view is presented. Then an overview of the query processing steps in SAQ is presented. Finally the SAQ query rewrite optimizations are described.
The RD-view
The RD-view is defined in SAQ in an object-oriented Datalog dialect [23] since foreign functions are used to define URIs and typed literals. A specialized RD-view for each given RDB is automatically generated by accessing the RDB catalogue. The RDB to RDF mapping in SAQ conforms to the direct mapping recommended by W3C [3], and more particularly to the augmented direct mapping proposed in[37], which is proven to guarantee information preservation.
We define a unique RDFS class for each relational table, except for link tables representing set-valued properties as many-to-many relationships. In addition, RDF properties are defined for each column in a table.
The RD-view is defined as a union of an S-view, representing the schema of the relational database, and a D-view, representing the data stored in the relational database.
The S-view represents all mappings between schema elements of the RDB and the corresponding RD-view classes and properties. It is defined in terms of six mapping tables that map relational schema elements to RDFS concepts. The system automatically generates default mappings in the mapping tables by accessing the RDB catalogue. The user can change the contents of the mapping tables to override default mappings in order to match some ontology or to limit data access. In order to guarantee unambiguous preservation the system requires unique URIs for classes and properties to be preserved.
In the used Datalog notation uppercase letters are used to denote constants while lowercase letters are used to denote variables.
The six mapping tables are the following:
The class table, cMap(T, cid) maps relational table names T to RDFS class URIs cid.
The property table, pMap(T, A, pid) maps relational column names A in table T to RDF property URIs pid.
The foreign key table, fkMap(
The many-to-many table mmMap(
The type table, typeMap(T, A, xsd) maps relational data types of relational attributes A in table T to corresponding XML Schema data types xsd.
The S-view definition itself is the same for any relational database and only the contents of the mapping tables are different. The S-view is defined as a large union of unions of sub-views representing relational schema concepts about tables, columns, types, primary keys, foreign keys, other constraints, and indexes. Since the S-view is complex but contains little data and its extent changes only when the database schema is altered, the S-view is materialized in main memory in SAQ.
Based on the S-view, i.e. on the imported RDB schema information, the system generates a D-view for each specific relational database. We opted to generate a D-view for each concrete database instead of defining a generic D-view, since this enables substantial query reduction at run time via specialization of the view definitions [29].
The D-view is defined in terms of source predicates representing the contents of relational tables, the above mapping tables, URI-construct predicates, for constructing URIs identifying rows in tables, and literal-construct predicates for constructing typed RDF literals. The D-view for an RDB is defined as a union of sub-views:
The D-view generated by SAQ for the ABench database contains the following sub-views:
67 column views; 7 foreign key views; 2 many-to-many relationship views; 8 row class views.
Query processing steps in SAQ
The main steps of the query processing in SAQ are illustrated in Fig. 4. The SPARQL parser transforms the SPARQL query into a Datalog expression where each triple pattern (TP) in the query becomes a reference to the RD-view. The view expander recursively expands each RD-view reference in the query into a disjunctive expanded RD-view. The view specializer then enables a transformation called view specialization [29]. It looks up the mapping tables in each sub-view of the D-view at query processing time to replace variables in the expanded RD-view with corresponding URIs or literals. We call such a sub-view in the D-view, where the mapping tables have been looked up, a specialized sub-view. Then, since the RD-view is defined as a union of the S-view and the D-view, each TP in the query becomes a disjunction of the materialized S-view and the specialized sub-views in the D-view.

SAQ Query processing.
The view specialization substantially reduces the disjunction for a TP depending on the TP type based on the following observations:
The disjunction for an expanded bound-property triple pattern (BPTP) with the structure (
The disjunction for an expanded unbound-property triple pattern (UPTP) with the structure (
The disjunction for an expanded UPTP structure (
Later on the query is further simplified by eliminating common sub-expressions by unifying terms [15].
The DNF-normalizer transforms the simplified Datalog query into a disjunctive normal form (DNF) predicate. The DNF-normalized query has the following structure:
A join between two BPTPs becomes a conjunction of the property conjunctions of the BPTPs.
A join between a BPTP and a UPTP becomes several disjuncts in the DNF-predicate. The disjuncts are conjunctions between the property conjunction of the BPTP and each disjunct of the expanded UPTP.
A join of two UPTPs becomes several disjuncts that combine the disjuncts of the two UPTPs.
For UNION queries, after normalization the UNION of its TPs becomes a DNF predicate containing the disjuncts of its DNF-normalized expanded TPs.
The SPARQL rewriter applies on the DNF-normalized and simplified query a number of query transformations that simplify the queries and improve the execution time. In particular, the GCT rule [40] transforms the DNF predicate into a more efficient Datalog representation by grouping those common terms in different disjuncts of the DNF predicate that can be translated to SQL. The query transformation rules are presented and evaluated below using the ABench benchmark.
Finally, the SQL generator generates an execution plan in SAQ that contains operators calling SQL. At execution time these SQL statements are sent to the RDB for execution. The generated plan also contains post-processing of such expressions that are not processed by the SQL engine, for example constructing URI objects, converting data types, and making union-all of sub-queries. All processing in the system is streamed so that no large intermediate collections are generated.
Rewrite transformations for SPARQL queries generated by ABench queries
The query rewriting optimizations for SPARQL queries selecting database parts to archive for different kinds of archival queries are described below. Since these queries often select sets of properties to archive they are mostly unbound-property queries, and therefore the query transformation optimizations for unbound-property queries are elaborated here. The processing and optimization of regular bound-property queries to an RD-view uses the techniques described in [29,30,36] and is outside the scope of this paper.
All transformations are made on the DNF normalized SAQ predicate.
To describe the SAQ rewrite transformations, we use the following terminology:
In a SPARQL query with a TP (
In a query, if the same variable is an object variable in one TP, e.g.
Table 4 shows which of the query transformations below improve the execution times of queries in ABench.
The GCT transformation
The group common terms (GCT) query transformation algorithm optimizes SPARQL queries in such a way that the RDB is accessed row-by-row instead of column-by-column. The GCT rule is applicable on queries selecting several attributes per table, in particular unbound-property queries. For example, GCT improves the performance of queries Q1, Q2, Q3, Q5, Q6, Q7, Q8, and Q10, since they all retrieve several table attributes with the same selection condition. The GCT is not applicable on queries Q4 and Q9, since they retrieve single table attributes with a single selection condition on each.
The GCT transformation is applied on a SPARQL query after DNF normalization. It factors out from the DNF predicate’s disjuncts those conjunctions of common terms that can be translated to SQL queries. After GCT, the DNF predicate becomes a disjunction of conjunctions between terms that can be translated to SQL and disjunctions of the remaining terms with the translatable terms removed. The remaining terms cannot be expressed in SQL and must be post-processed.
In general, the steps of the GCT rewrite algorithm applied on a DNF predicate are the following:
In a pre-step, normalize the variable names of the disjuncts in the DNF predicate so that the same variable names are used in equivalent predicate positions.
Allocate a hash table that, for each extracted conjunction, maintains mappings to the disjuncts from which its terms have been extracted.
For each disjunct in the DNF predicate, extract conjunctions of terms that can be translated to SQL and put them in the hash table with the entire extracted conjunction as key along with a pointer to the rest of the disjunct as value.
After the entire DNF predicate is scanned, go through the hash table and form for each key (extracted conjunction) c a conjunction between the SQL translatable predicate c and the post-processed remaining terms in the disjuncts from where c was extracted. Finally, form a disjunction of all the formed conjunctions.
The pseudo code of GCT algorithm is the following.

The function
Note that the processing is done in one pass and is therefore
The is-literal rule reduces SPARQL queries in such a way that SQL LIKE conditions are not issued on table attributes whose values are represented by URIs in the RD-view. This rule is applicable in queries where the type of an object variable in the query is restricted by some FILTER or other predicate to be a literal. For example, Q4, Q8, and Q9 restrict object variables to be literals by FILTER comparison predicates.
If an object variable is restricted to be a literal it cannot be bound to a URI by a URI-construct predicate. Therefore the is-literal rule eliminates those disjuncts from the expanded DNF normalized query where the object variable represents foreign keys or many-to-many relationships. This eliminates SQL code to access foreign keys and links, which reduces the number of generated SQL queries.
The type-match reduction
The type-match rule reduces SPARQL unbound-property queries so that SQL comparison conditions are issued only on attributes of correct literal types. For example, the LIKE predicate must be used on textual attributes of type (VARCHAR, TEXT, etc.), and arithmetic comparisons must be over numerical attributes (INT, DECIMAL, etc.). The rule reduces queries where the type of an object variable is restricted by some predicate to be of a specific literal type. For example, in Q9 the object variable value must be a literal string, which is inferred by the REGEX filter.
If an object variable is inferred to be of a specific literal type, it cannot be bound to a literal of another type by the literal-construct predicate. Therefore the type-match rule eliminates those disjuncts from the expanded DNF normalized query where the object variable represents relational column values of non-matching types. Thus SQL code to access those columns is not generated.
For example, the attribute pNum1 in table product is a number while in Q9 the variable value must be a string, and therefore the SQL code generated will not access pNum1. The generated query for Q9 contains SQL LIKE conditions only for textual attributes (i.e. of type VARCHAR, TEXT, etc.). SQL LIKE conditions for other types of attributes are not generated.
Foreign key relationship (FKR) reduction
The FKR rule reduces SPARQL unbound-property queries where a subject-object join variable is shared between two UPTPs, which requires a foreign-key constraint.
The FKR rule eliminates those disjuncts from the expanded DNF normalized query where a join subject-object variable represents values that are not foreign keys in the underlying RDB. This reduces the number of SQL queries generated. SQL queries are generated only where there is a foreign key relationship between the tables referenced by the joined UPTPs.
For example, for Q10 FKR restricts the SQL generator to SQL queries only to the tables producer, producttype and productfeature, which possess foreign keys for the table product represented by product:_2549.
Eliminate S-view reduction
The eliminate S-view rule reduces unbound-property queries so that an S-view subject is never joined with a subject constructed by the URI-construct predicate. This rule assumes that user-overridden URIs in the mapping tables are not present in the D-view. This is enforced by the system.
The eliminate S-view is not needed for bound- property queries, because there all binding patterns are of form
In contrast, the S-view will remain in UPTPs after specialization. In this case the eliminate S-view reduction is applicable when the subject variable of S-view is matched by a URI-construct predicate in a conjunction of the D-view, in which case the conjunction is eliminated. This occurs for queries where an UPTP is joined with another BPTP or UPTP on the subject or object variables. This rule is applicable on queries Q2, Q5, Q6, Q7, Q8 and Q10.
For example, Q2 is a SPARQL UNION unbound-property query where each UNION clause contains a join between the UPTP (?subject ?property ?value) and a BPTP on the variable ?subject. Both Q7 and Q10 are unbound-property queries with a join between two UPTPs on a subject variable, i.e. the variable ?subject.
Performance of archival queries
We evaluated the impact of the SAQ query rewrite optimizations for the generated SPARQL queries in ABench. We compared the performance of SAQ with Virtuoso RDF Views [13] and D2RQ [8], all systems accessing the same back-end MS SQL Server database. The experiment configuration was the following:
The measurements were made on a PC Intel(R) Core(TM), 2Quad CPU Q9400 with 2.67 GHz and 8 GB RAM running 64-bits Windows 7 Professional. The DBMS was MS SQL server 2008 R2 running on a separate machine with Intel(R) Core(TM), i5 CPU 750 with 2.67 GHz and 8 GB RAM running 64-bits Windows 7 Professional. The SQL server was configured with 6 GB for the min and max server memory. The RDB data sets were generated by the Berlin benchmark data generator and loaded into the MS SQL Server. Table 5 summarizes the RDB sizes for the experimental data sets, together with the corresponding number of triples in the SAQ RD-view and the number of query result triples for Q1–Q10. Non-clustered, non-unique indexes were put on the columns propertyNum1 and propertyNum3 in the table product, and on the column rating4 in the table review to speed up queries Q4 and Q8. For Virtuoso RDF Views, the RDF view to the underlying relational database was generated on the Virtuoso server (ver. 06.04.3132, Windows-64) using the Virtuoso Conductor tool. The SPARQL queries to this RDF view were run from a Java program, implementing a Jena Provider [46], which allows users to query Virtuoso RDF views from Java. Virtuoso was configured with the parameter NumberOfBuffers set to 340000 and the Java heap size was set to 4 GB. For D2RQ (v.08.1), the RDF view of the underlying RDBMS was generated by the D2RQ auto-generated mapping script [28]. In the generated script, we inserted the option ‘d2rq:useAllOptimizations true’ to guarantee that full optimization would be used in D2RQ. The SPARQL queries were run from a Java program calling the D2RQ Engine through Jena2 [28]. The Java heap size was set to 4 GB. The default mappings of the analysed systems SAQ, Virtuoso RDF Views and D2RQ were used.
RDB sizes and number of result triples for Q1–Q10 when using SAQ
RDB sizes and number of result triples for Q1–Q10 when using SAQ
The following notation is used in the performance diagrams:
In all cases, the time spent in executing the query by the relational database followed by post-processing was measured, thus not including the time for preparing the SPARQL query by the respective system. The measured times did not include the back-end DBMS query optimization time by excluding a first warm-up execution. The actual measurements were made five times and the mean values plotted. The standard deviation was less than 10% in all measurements.
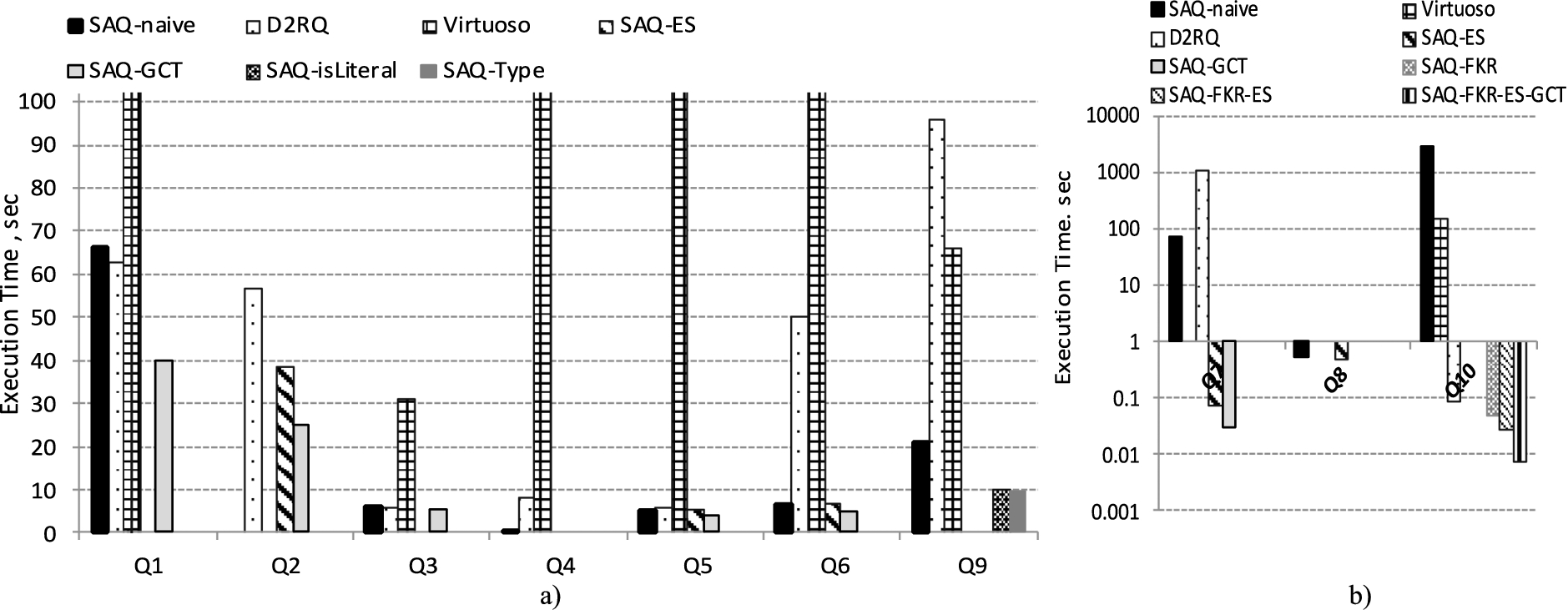
Query Performance for Q1–Q10, RDB1 = 184 MB.
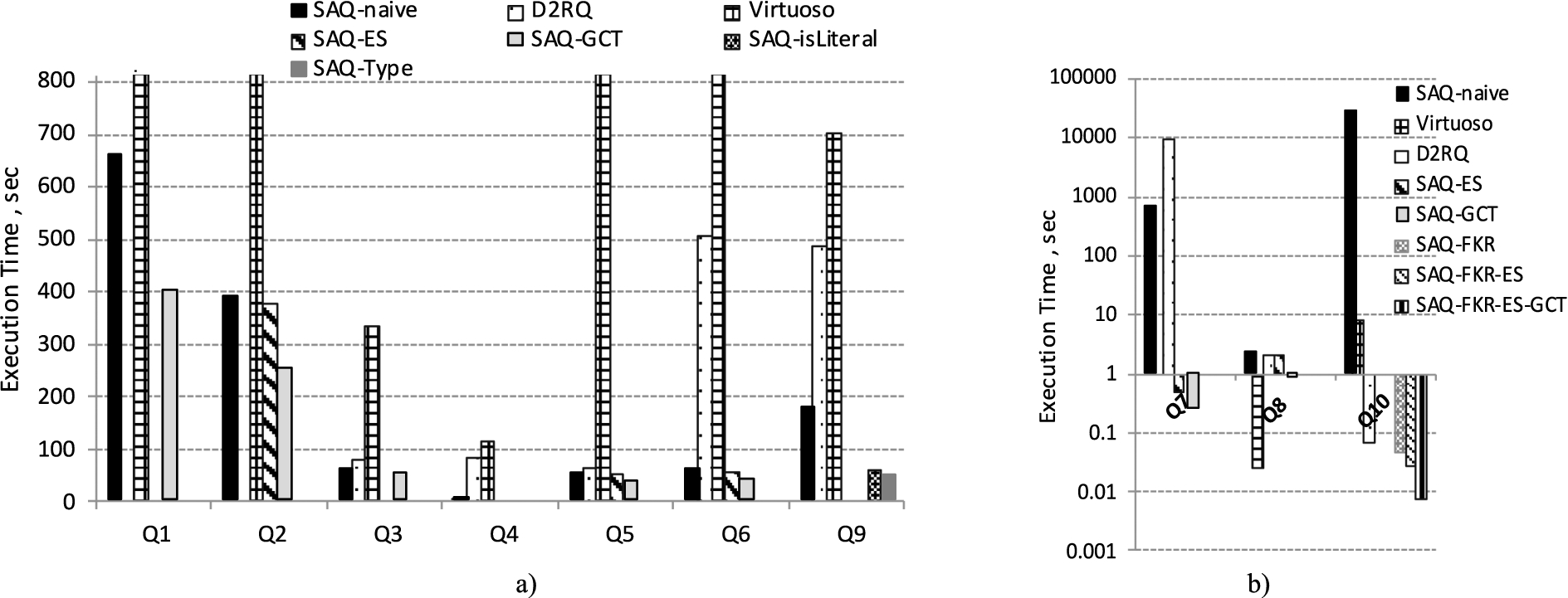
Query Performance for Q1–Q10, RDB2 = 1.8 GB.
The performance of SAQ for the SPARQL queries generated by the archival queries in Abench is described below. Figures 5–7 show the execution times for Q1–Q10 in seconds for different database sizes, SAQ strategies and other systems compared.
Table 6 summarizes the speed-up of the different rewrite optimizations in SAQ compared with
Impact of GCT
The performance
The GCT optimization also somewhat improves bound-property queries selecting RDF properties that represent attributes in the same table, such as Q3. With GCT the properties are retrieved by a single SQL query per table, rather than one query per property without GCT. Thus for Q3 the number of SQL queries is reduced from 3 to 2.
Impact of eliminate S-view
The eliminate S-view reduction (
Impact of is-literal, type-match, and FKR
The improvement by the is-literal reduction (
The type-match reduction (
The FKR reduction (

Query Performance for Q1–Q10, RDB3 = 9 GB.
Speed-up (in times) for the SAQ rewrite optimizations and number of SQL queries sent to the RDB compared with SAQ-naive
The bound-property queries Q3 and Q4 are processed by
Query performance of other systems
To analyse how the other systems process ABench queries, we measured their performance and, in addition, inspected what SQL queries were sent to the relational database.
For D2RQ, some measurements caused Java exception GC overhead limit exceeded and they are therefore not presented in Figs 6 and 7. Similarly,
Query performance of D2RQ
For
Normally for bound-property queries such as Q3 and Q4, and for the unbound-property queries with one UPTP and no filter such as Q2, Q5 and Q8,
For Q2, Q5 and Q8, despite
For Q4,
For Q1, which selects all RDB tables,
To process Q6,
For Q7,
Q9 is processed by
Query performance of Virtuoso
The debug logging of
The bound-property UNION query Q3 with no filters is processed by
For the bound-property UNION query Q4, which has a filter on each selected property,
For the selective unbound-property query Q8,
For the unbound-property queries Q2, Q5 and Q6,
Query Q7 could not be processed by
The text matching query Q9 is processed by
Finally, for Q10
Related work
The related work on preservation of relational databases, mapping relational databases to RDF, and query processing of unbound-property queries is reviewed.
Long-term preservation of relational databases
Testbed [12], SIARD [43] and RODA [31] are projects that have developed strategies for long-term preservation of relational databases based on XML. In both Testbed and RODA the data and metadata of relational databases are preserved as XML. SIARD has an own format for preservation which is based on XML and SQL1999, and the industry standard ZIP. In contrast, in SAQ we use RDF to represent the relational database to archive. Both XML and RDF are neutral data formats that don’t rely on current DBMS technology and provide hardware and software independence. These make both of them suitable for long-term preservation of databases. However, RDF has the following advantages comparing to XML. In RDF the identifiers are URIs which are universal global unique identifiers that allow identifiers from one database or table to be linked with identifiers from other data. Data can be represented as XML in many different ways depending on a defined DTD or XML schema [44] while the RDF-Schema (RDFS) in RDF provides standard meta-data representation for describing all kinds of data, including relational databases [41]. Furthermore, representing relational data as RDF allows migration from RDBs to RDF repositories which are gaining increasing popularity compared to XML native repositories.
In the above mentioned related approaches the entire relational database, both the data and schema are migrated into XML or XML based format and stored in a file. By contrast, in SAQ we provide selective archival of user-specified parts of a relational database as RDF using an extended SPARQL query language, A-SPARQL.
CSV is a recommended data format for long-term preservation of structured data in Florida Digital Archive [32] and Library Archives Canada [22]. We have not considered CSV format since the CSV dumps provided for archiving relational databases do not include meta-data, which is important to reconstruct archived databases.
Mapping and querying relational databases as RDF
Virtuoso RDF Views [13,14], D2RQ [4,8], and SquirrelRDF [36] are other systems that allow mapping of relational tables and views into RDF to make them queriable by SPARQL. These systems implement compilers that translate SPARQL directly to SQL. In contrast, SAQ first generates Datalog queries to a declarative RD-view of the relational database, and then transforms the SPARQL queries to SQL, based on logical transformations. We have shown that query transformations on this representation significantly improve performance for SPARQL unbound-property queries selecting RDB contents to archive.
The system closest to SAQ is Ultrawrap [35,36] where, like in SAQ, an RDF view over a relational database is generated as a union of sub-views. While the RDF view in Ultrawrap is defined in SQL in a specific SQL dialiect, in SAQ the view is defined in an object-oriented Datalog dialect and thus it is independent on the RDBMS. Furthermore, since the view in Ultrawrap is defined in a concrete RDBMS the query optimizations are also dependent on the RDBMS, and thus the performance measurements in [36] show different results in different systems. By contrast, in SAQ the proposed optimizations are made in the SAQ query processor and are not dependent on the back-end RDBMS.
Unlike SAQ, neither D2RQ, nor Virtuoso, nor Ultrawrap includes the schema view in the RDF view of RDBs. The inclusion of the S-view is very important when archiving relational databases, since the database schema is needed to reconstruct an archived database. The logical rewrites of SAQ enable scalable processing over full RDF views, including the schema part.
Optimizing unbound-property queries and disjunctive queries
We did not find any published data on how D2RQ compiles SPARQL queries into SQL. The documentation on Virtuoso is very limited. However, by using the profiling tool of the DBMS and the debug logging of Virtuoso, we were able to analyse what queries were actually sent to the underlying RDB. This showed that neither D2RQ nor Virtuoso uses optimization for unbound-property queries similar to the SAQ rewrite optimizations GCT, is-literal and type-match. D2RQ uses an optimization similar to FKR to process queries with a join variable shared between two UPTPs, such as Q10.
SquirrelRDF also allows SPARQL queries to relational tables, but it does not support unbound-property SPARQL queries.
Ultrawrap tries to completely translate SPARQL to semantically equivalent SQL, without any pre- or post-processing. This is problematic for unbound-property queries, and in [36] the authors state that a SPARQL unbound-property query “doesn’t have a concise, semantically equivalent SQL query”. In contrast, SAQ generates an execution plan where SQL queries are submitted to an RDB, and then streamed post-processing constructs URIs, RDF literals, and triples. We could not find any published data on how Ultrawrap translates SPARQL unbound-property queries to SQL. Nevertheless, there are experimental results with Ultrawrap on unbound-property queries in [36] and it can be concluded from these that Ultrawrap has no special optimizations. It is shown in [36] that an Ultrawrap query for unbound-property query performs worse than a “Native SQL” query, i.e. a translated SQL query did not exploit the relational model as well as a native query.
Rather than semantic transformations directly on the original SPARQL code, SAQ makes all query transformations on Datalog expressions. The advantage with this approach is that it is a very general, well understood, and easy to extend with new transformation rules, if so needed. We have shown that the approach is possible without loss of efficiency.
Work on optimizing disjunctive database queries in general is described in [11,21,25]. The closest work to GCT is the combinatorial algorithm [25], which merges disjuncts with common sub-expressions in general disjunctive logical expression in order to avoid repeated evaluation of the same predicate on the same tuple. In contrast, the purpose of GCT is to group in a DNF predicate query fragments that can be translated to SQL, and GCT is therefore a simpler linear algorithm. The idea of bypass evaluation of disjunctive queries in [11,21] is based on implementing specialized operators that produce two output streams: the true-stream of the tuples that fulfil the operator’s predicate and the false-stream of the tuples that do not match. The main benefit of the technique of bypass evaluation is in eliminating duplicates by avoiding unnecessary join operators. The purpose of GCT is not duplicate elimination, but to rewrite complex disjunctive queries for faster execution.
Conclusions and future work
An approach was presented for selective scalable long-term archival of RDBs as RDF in terms of SPARQL queries, implemented in the SAQ system. The proposed approach is suitable for archiving research data used in scientific publications where it is desirable to preserve only selected parts of an RDB. The archival of user-specified parts of a RDB is specified using an extension of SPARQL, A-SPARQL, having an archival statement for selective archival.
The SAQ system for long-term preservation of relational databases follows conceptually the OAIS reference model. In particular, this work concentrates on the functionality of the Ingest component in the OAIS model on generating the content information when preserving relational database content as RDF.
To evaluate the performance of typical archival queries, the ABench was defined that archives selected parts of databases generated by the Berlin benchmark data generator. In experiments, the SAQ optimization strategies were evaluated by measuring the performance of A-SPARQL queries selecting triples for archival queries in ABench.
SAQ automatically generates an RDF view of an RDB called the RD-view. The RD-view can be queried and archived with A-SPARQL queries that are translated into SQL queries sent to the RDB. An archival query internally generates a corresponding CONSTRUCT SPARQL query. Since the archival query usually selects sets of attributes of tables to archive, the generated CONSTRUCT SPARQL query is typically an unbound-property or UNION query. To achieve scalable data preservation and recreation for such queries, SAQ uses some special query rewriting optimizations presented in this paper.
Using ABench queries and data generated by the Berlin benchmark generator, the rewriting optimizations were experimentally shown to improve query execution time compared with naïve processing. Compared with not using the optimizations, they reduce the number of SQL queries to execute and retrieve data in relational row order rather than in column order. The performance of SAQ was compared with that of other systems that support SPARQL queries to views of existing relational databases. It was shown experimentally that SAQ with the rewrite optimizations performs better than those systems for all queries returning large results. In general, the SAQ optimizations are useful not only for archival queries, but also for unbound-property and UNION queries.
Future work will include defining and evaluating new query rewrites for further improving the performance, for example for free text searches of RDB when data are archived based on LIKE. Another extension would be to perform the archiving based on what is reachable from a set of root data nodes, i.e. based on SPARQL queries with path expressions [17].