
Abstract
DBpedia is at the core of the Linked Open Data Cloud and widely used in research and applications. However, it is far from being perfect. Its content suffers from many flaws, as a result of factual errors inherited from Wikipedia or incomplete mappings from Wikipedia infobox to DBpedia ontology. In this work we focus on one class of such problems, un-typed entities. We propose a hierarchical tree-based approach to categorize DBpedia entities according to the DBpedia ontology using human computation and paid microtasks. We analyse the main dimensions of the crowdsourcing exercise in depth in order to come up with suggestions for workflow design and study three different workflows with automatic and hybrid prediction mechanisms to select possible candidates for the most specific category from the DBpedia ontology. To test our approach, we run experiments on CrowdFlower using a gold standard dataset of 120 previously unclassified entities. In our studies human-computation driven approaches generally achieved higher precision at lower cost when compared to workflows with automatic predictors. However, each of the tested workflows has its merit and none of them seems to perform exceptionally well on the entities that the DBpedia Extraction Framework fails to classify. We discuss these findings and their potential implications for the design of effective crowdsourced entity classification in DBpedia and beyond.
Introduction
DBpedia is a community project, in which structured information from Wikipedia is published as Linked Open Data (LOD) [26]. The resulting dataset consists of an ontological schema and a large number of entities covering, by virtue of its origins, a wide range of topics and domains. With links to many other sources in the LOD Cloud, it acts as a central hub for the development of many algorithms and applications in academia and industry. Still, no matter how popular, DBpedia is far from being perfect. Its many flaws have been subject to extensive studies and inspired researchers to design tools and methodologies to systematically assess and improve its quality [1,24,50].
In this paper, we focus on a particular class of errors, the un-typed entities. According to the statistics,1
DBpedia relies on a community of volunteers and a wiki to define and maintain a collection of mappings in different languages.4
Paid microtask crowdsourcing employs services such as Amazon’s Mechanical Turk5
In this work, we consider the problem of systematically selecting the most specific category from a tree of hierarchically organized labels through employing microtasks. We contribute with the in-depth analysis of the main crowdsourcing exercise dimensions in order to come up with suggestions for workflow design, which are grounded in existing literature in cognitive psychology, and elaborate on their implications in terms of precision and cost. To this end, we propose a workflow model consisting of a predictor, able to suggest category candidates for a given entity, as well as a crowd based error detection and correction algorithms. Using three alternative workflows, we compare the performance of an automatic predictor and two crowd based approaches: a naive predictor, where the whole ontology tree is traversed top down by the crowd and a microtask based free text predictor, that is able to make a decision based on human text input. To test our model, we run experiments on CrowdFlower using a dataset of 120 entities previously unclassified by the DBpedia community and compare the answers from the crowd with gold standard created by experts from our research group. Our experiments show that the crowd based approach achieved higher precision at lower cost compared to the workflow with automatic predictor. However, each workflow has its merit and we provide in-depth evaluation of their properties to support experts in selection decisions.
The rest of this paper is structured as follows: we start with an analysis of the state of the art in the areas of entity classification and crowdsourcing task design in Section 2. In Section 3 we present our entity classification model based on machine and human input. Section 4 is dedicated to the design of our experiments where we measure the precision and costs of our model in three alternative workflows. Section 5 discusses the evaluation results and their implications for applying human computation and microtasks to similar scenarios. Finally, we conclude with a summary of our findings and plans for future work in Section 6.
Our work on using the crowd to effectively classify DBpedia entities is closely related to entity classification techniques in general and crowdsourcing based tasks similar to the problem discussed in this paper. We take a closer look at research in these areas and review how existing methods differ from our approach or inspire it in some way.
Entity annotation and classification
Generally, entity classification can be carried out in different ways, ranging from manual annotation by experts from the corresponding domain, over hybrid approaches where human input and machine algorithms are combined, to the tools for purely automatic classification. As the expert classification is costly and time-consuming task, automatic entity classification traditionally has been part of the NER (Named Entity Recognition) research where the entity is first automatically identified and then classified [7,22,31,49] according to a number of categories. Unfortunately, such automatic algorithms, require predefined concept-based seeds for training and manually defined rules, which complexity depends on the number of involved classes. As a consequence, the classification ability is typically limited to a relatively small number of classes such as “Person”, “Location”, “Time” and “Organisation”. Those approaches are often combined with machine learning algorithms or ensembles trained on large pre-annotated datasets. However, all discussed techniques are working with a certain error margin and hence their output requires to be manually re-examined and further classified. There is a number of existing tools and APIs such as DBpedia spotlight,7
In contrast to the works mentioned above, our approach can efficiently deal with a large number of classes and keep the error margin narrow at the same time. Based on the discussed literature, in our workflows, we utilise automatic tools and algorithms as predictors for producing a small set of candidate suggestions from a large set (over 700) of DBPedia classes, hence significantly reducing the search space.
In recent years, researchers have successfully applied human computation and crowdsourcing to a variety of scenarios that use Linked Data and semantic technologies where classification is one of the most popular tasks. The idea is to decompose tasks with higher complexity into smaller sub-tasks [37] such that each of those tasks can be solved by non-expert crowdworkers. Due to the decentralized and diverse nature of possible participants in crowdsourcing work, data validation and quality control have been an essential topic explored by many previous researchers, resulting in challenges in workflow and task design.
One challenge is to design an effective workflow and a mechanism to aggregate the sub-task outputs into a high quality final result. For example, to solve the complex authoring task using crowdsourcing platform, Bernstein et al. [4] introduce the fix-verify pattern where a task is split into multiple generation and review stages. As a popular ontology, DBpedia is a subject to a series of microtask experiments. The authors in [1] introduce a methodology to assess Linked Data quality through the combination of a contest, targeting Linked Data experts [50] and CrowdFlower microtasks. Similar to the works above, in this paper we employ the concept of combining a predicting stage (human, auto, and hybrid) and a verification stage through the CrowdFlower workers subsequently. To improve the crowdsourcing workflow and to ensure high quality answers, various machine learning mechanisms have been recently introduced [12,19,33,48]. Closely to our task, ZenCrowd [10] explore the combination of probabilistic reasoning and crowdsourcing to improve the quality of entity linking. Large scale crowdsourcing can be as well applied in citizen science projects and classification tasks as shown in [21,42]. Machine learning algorithms are often used to support the decision making of adaptive task allocation. In this work, we implement automatic algorithms, similar to that in [47], for a freetext predictor and a naive predictor to facilitate the crowd in locating promising areas within the ontology where the most specific class label for a given entity is likely to be located.
Another challenge appears in mitigating noisy answers to achieve high quality annotations. Various aspects in microtask design have been studied in the past years. Kittur et al. [23] investigate crowdsourcing micro-task design on Mechanical Turk and suggests that it is crucial to have verifiable questions as part of the task and to design the task in a way that answering the question both properly and randomly would require comparable efforts. The authors in [41] elaborate on the quality of the crowd-generated labels in natural language processing tasks, compared to expert-driven training and gold standard data. Their work suggests that the quality of the results produced by four non-experts can be comparable to the output of a single expert. Some successful citizen science applications such as Galaxy Zoo [15], do not require a high expertise level of the volunteers and the fine granularity of the workflow makes it possible for a task to be carried out through a person without a relevant scientific background. In our work, we leveraged testing questions to eliminate the potential spam user or unqualified user, and designed the task in a way such that only a little user expertise is required. FreeAssociation and Categodzilla/Categorilla [44] tools show a clear empirical evidence that variations, such as less restrictive criteria for user input, can have a positive impact on data quality. In this work we employ a hybrid free-text based predictor where user input for the most specific category is completely unrestricted. The InPhO (Indiana Philosophy Ontology) project [11] use a hybrid approach to dynamically build a concept hierarchy by collecting user feedback on concept relationships from Mechanical Turk and automatically incorporating the feedback into the ontology. The authors in [34] introduce and evaluated the Crowdmap model to convert ontology alignment task into microtasks. This research inspires us to reduce the amount of work for the crowd by using a “predictor” step, providing a shortlist of candidates instead of requiring the worker to explore the full ontology.
This literature is used as a foundational reference for the design of the microtask workflows introduced in this paper, including aspects such as instructions, user interfaces, task configuration, and validation. In contrast to solutions mentioned in the literature, the main novelty of our work lies in the systematic study of a set of alternative workflows for ontology centric entity classification. We believe that such an analysis would be beneficial for a much wider array of Semantic Web and Linked Data scenarios in order to truly understand the complexity of the overall design space and define more differentiated best practices for the use of crowdsourcing in other real-world projects under different budgetary constraints.
Approach
The entity classification problem considered in this paper is a problem of selecting the most specific type from a given class hierarchy for a particular entity. As a class hierarchy can contain thousands of classes, this task is not easy to be solved manually by a few experts maintaining the dataset, especially for large entity batches such as around 1.2M un-typed entities in DBpedia.13

Representation of three workflows with human participation steps highlighted in blue.
The problem we are tackling can be formalised as follows: Let
In this section, we formally define our human computation driven model for semi-automatic entity annotation using the hierarchically structured set of labels. This starts with the definition of the terms used in our model, then covers the main tasks where human participation is involved – predictor, the subsequent error detection and error correction process, and our cost model.
(DBpedia Ontology).
The DBpedia ontology
(Candidate Nodes).
Given an entity
(Predictor and Predicted Nodes).
Let a predictor
Our assumption is that the location of an
Human computation driven error detection and correction model
The error detection and correction process in this context is to traverse
Error detection algorithm We employ a traversal Algorithm 1 with a set S of the top-scored node as a start. In case any of

Error detection

Error correction
Error correction algorithm: After the error is detected, it is possible to correct it using human assessors. Similarly to error detection, the microtask based correction Algorithm 2 starts from the set S of candidate nodes. In case a
The overall cost for entity annotation in our framework is constituted as the sum of prediction, error detection and error correction costs, more formally:
A predictor, in our case, is a module, able to produce a list of candidate classes for a given entity. Currently, all the predictors described in literature are automatic predictors, where given an entity a list of candidates along with the confidence value of the predictions is produced. In this work we employ three approaches, namely an automatic predictor
As an example for
Additionally, we propose two human computation based prediction approaches. The first
Considering the diversity of vocabulary of the crowd users, direct aggregation of their answers is not effective. To solve this issue, we leverage the freetext input to automatically calculate the closest DBpedia types based on the textual similarity between entity titles and ontology class names. We used the difflib15
For the purpose of this study, we identify three types of workflows, following the preliminary considerations presented so far. Each workflow incorporates a predictor, as well as the error detection and correction steps.
Figure 1 not only shows an overview of these three workflows, but also highlights the steps requiring human participation in blue background. In the remainder of this section we explain the workflows and their translation into microtasks in more detail.
For the
The
For the
In general, we distinguish between two types of microtasks based on their output:
The T2 variant requires the strategy to generate the list of candidates. It can be achieved through automatic tools addressing a similar task (as listed in Section 2.1), however, they impose clear bounds on the accuracy of the crowd experiments, as not all input can be processed by the automatic tools (recall) and their output can only be as precise as the task input allows (precision). Additionally, the choice of an appropriate threshold to accept or reject produced results is also a subject of debate in related literature [35,36]. Another option is to provide the crowd all possible choices in a finite domain – in our case all classes of the DBpedia ontology. The challenge then is to find a meaningful way for the crowd to explore these choices. While classification is indeed one of our most common human skills, cognitive psychology established that people have trouble when too many choices are possible. This means both, too many classes to consider [20,36] and too many relevant criteria to decide whether an item belongs to a class or not [2,17]. Miller’s research suggests that in terms of the capacity limit for people to process information, 7 (plus or minus 2) options are a suitable benchmark [30]. We hence would ideally use between 5 and 10 classes to choose from. This situation is given by the predictor

The user interface for

The user interface for
As shown in Section 3.1, all three workflows take the same input. As a result, for each workflow we first queried the DBpedia endpoint via SPARQL to obtain the name, description, and a link to Wikipedia of each entity.
CrowdFlower parameters
Task Following the advice from the literature [1], we used 5 units/rows for each task/page for each of the three workflows. The worker completes a task by categorising five entities.

Freetext: Judgement Number vs. Matched Answers.
Judgment Snow et al. [41] claim that answers from an average of four non-experts could achieve a level of accuracy parallel to NLP experts on Mechanical Turk. We hence asked for 5 judgments per experimental data throughout our experiments. In
Payment We paid 6 cents for each task consisting of 5 units. This setting took into account existing surveys [18], as well as related experiments which have similar complexity level. Tasks like reading an article and then asking the crowd to rate the article based on given criteria as well as providing a suggestion for the areas to be improved were paid 5 cents [23]. Tasks that have smaller granularity such as validating the given linked page display relevant image to the subject were paid 4 cents per 5 units [1]. In a similar vein, the complexity of our classification task is somewhere in between considering the time and knowledge it requires to complete the task.
Quality control We created test questions for all jobs and required contributors to pass a minimum accuracy rate (we use
Contributors CrowdFlower distinguishes between three levels of contributors based on their previous performance. The higher level of contributors required, the longer it takes to finish the task, but might be with higher quality. In our experiment, we choose the default Level1 which allow all levels of contributors to participate in the classification task. We used this level for all three workflows.
Aggregation For the T2 tasks we used the default option (aggregation=’agg’),23
The validated and aggregated results may be leveraged in several ways in the context of DBpedia. Freetext suggestions signal potential extensions of the DBpedia ontology (concepts and labels) and of the DBpedia Extraction Framework (mappings). Applying the freetext workflow gives insights into the limitations of entity typing technology, while the way people interact with the naive workflow is interesting not only because it provides hints about the quality imbalances within the DBpedia ontology, but also for research on Semantic Web user interfaces and possible definition of new mapping rules for entity typing.
Overview of the E1 Corpus
Overview of the
In this section, we will evaluate the performance of proposed workflows as depicted in Fig. 1. Overall, we obtained three different workflows, namely:
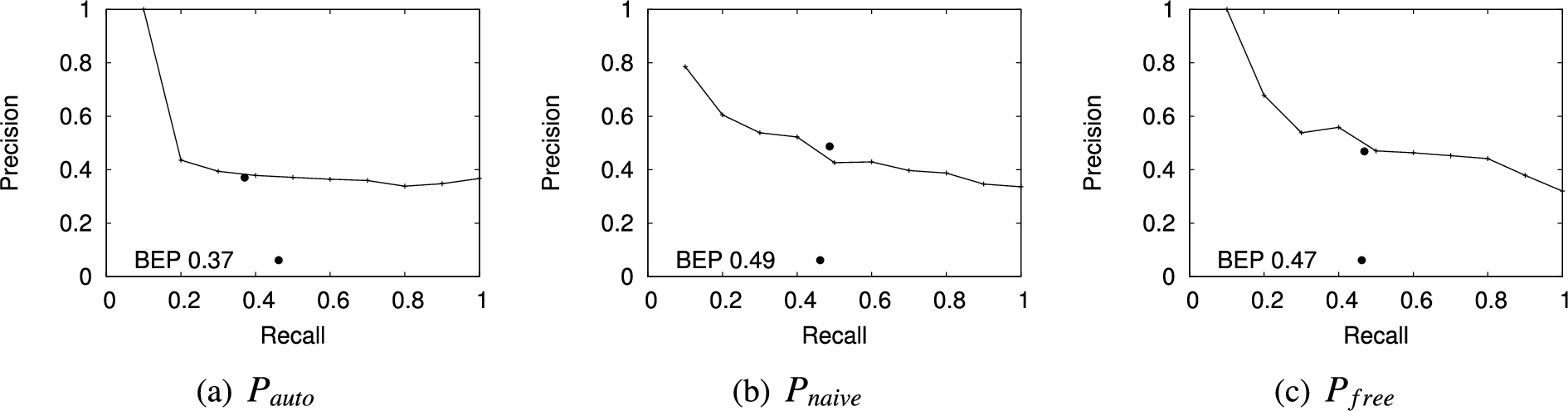
Precision-recall curves for the output of the different predictors with respect to our gold standard.
For our experiments we uniformly at random choose 120 entities which were not classified so far by the DBPedia. The authors of the paper annotated these entities manually to obtain a gold standard. The annotators worked independently and achieved an agreement of 0.72 measured using Cohen’s kappa.24
Table 1 provides the overview on the composition of the resulting gold standard corpus with respect to general categories. “Place” and “Organisation” are the most present categories with respectively 20 and 16 entities in the dataset, corresponding to one of their child categories. For 18 entities that no appropriate category in the ontology could be found by the experts, those were labelled as “owl:Thing”.
For each workflow we assess their properties in our experiments with respect to quality, effectiveness and costs. The accuracy of the predictor matching our gold standard will provide information about the predictor effectiveness for real applications. The accuracy of the human based error correction with respect to our gold standard will provide insights into what quality can be expected from the crowd in general.
Prediction quality
In our quality concerned experiments, we employ precision which measures the portion of correctly classified entities among all entities classified by the predictor. Our quality measures are the precision-recall curves as well as the precision-recall break-even points for these curves. The precision-recall graph provides insights in how much precision it is possible to gain in case only a certain amount of recall is required. Typically, the head of the distribution achieves better precision due to the fact that the values correspond to the higher confidence of the predictor. The break-even point (BEP) is the precision/recall value at the point where precision equals recall, which is equal to the F1 measure, the harmonic mean of precision and recall, in that case. The results of the experiments for predictors described in Section 3.1.2 are shown in Fig. 5. The main observations are:

Precision at confidence level curves for the output of the different predictors with respect to our gold standard.
The precision of the human computation based methods was generally higher when compared to the automatic method. Also the automatic method did not produce any results for around 80% of the entities, whilst human computation based predictor provided suggestions for all entities with certain quality.
We standardized the confidence level of each predictor to the range [0.0–1.0] and plotted the output quality at different confidence levels in terms of precision in Fig. 6. As expected from previous results, high confidence levels above 0.9 for
In comparison to
Error detection quality and costs
Having received the output of a predictor, we tested whether the crowd was able to identify prediction errors and empirically determined the costs for this detection in terms of the number of questions needed to be answered on average. The graphs provide insights into the quality of the predictor outputs with respect to crowd decisions and can provide decision support to include or exclude the error detection step in real applications. We do not test error detection for
Cost overview for different workflows
Cost overview for different workflows
In the last step, we apply our algorithm to correct the errors produced by the predictors. Similar to the previous section, we measure the costs for the correction as the number of questions needed to be answered on average. Table 2 provides an overview of the costs.
The quality of human output
Finally, we measure the quality of the workflows as a whole to estimate the effort to be invested by experts in post-processing. Figure 7 shows the precision-recall curves of the human based result correction for

The overall output quality of the workflows.

Precision at different Options List Size with the
Crowdsourcing tasks We decided to limit the number of top-options shown to the user to 7 as recommended in the literature. Longer lists may contain the correct result with higher probability, however would also require more interaction and effort in complexity for a crowd worker to process. In order to show the possible influence of the option number on the prediction quality, we plot the correspondence in Fig. 8 where we vary the list size on the logarithmic scale from top 1 to the maximum of 740 possible categories and measure the predictor BEPs’ on the basis of the gold standards. As we can observe, the precision improves only slightly with the growing list size, indicating no meaningful advantage for the lists containing more than 7–10 options.
Are unclassified entities unclassifiable?
As noted earlier, there were significant differences in the performance scores achieved in the experiments using different workflows. Especially notable is that existing NLP tool could only classify 45% of the randomly selected entities (54 out of 120) with a precision of only 0.37. Human-based approach can achieve relatively higher 0.49 to 0.47 precision, but still a large portion of the entities are not classified to the correct specific type. To some extent, this indicates that untyped entities have certain characteristics which make them difficult to be classified.
Firstly, we observed that their types are quite diverse and not within the most popular classes.25
Secondly, the imbalanced structure of DBpedia ontology also makes the classification of untyped entities whose boundary between subtle categories are not well defined. For example, “Hochosterwitz Castle” is a “Castle” which would be the most specific category for this entity, however, Castle is a child category of Building, which is a child type of ArchitecturalStructure that has many child types such as Arena, Venue and Pyramid, leading the user to choose none of the children of “ArchitecturalStructure” as they did not see any fits. Similarly, among all 18 entities that are instances of “Place”, only 5 of them are correctly classified to the most specific category because of the unclear and over-defined sub-categories. “Place” and “Area” are both immediate first level types under “owl:Thing”, which create a lot confusion in the first place as we observed from the crowd contributed classification. Also categories such as “Region”, “Locality” and “Settlement” are difficult to be differentiated.
Lastly, ambiguous entities unsurprisingly caused disagreement [3]. This was the case with “List” and specific types such as the “1993 in Film”,26
Taking naive workflow where we present maximum of 7 types (including a “NoneOfAbove” option) in one step as an example, the aggregated outcome shows that 33 entities are categorised as “other” after traversing the DBpedia class tree top-down from “owl:Thing”, with none of the DBpedia categories being chosen. This also contributes to the ongoing debate in the crowdsourcing community regarding the use of miscellaneous categories [3,13]. In our case, using this option elicited a fair amount of information, even if it was used just to identify a problematic case. [13] discuss the use of instructions as a means to help people complete an entity typing task for microblogs. In our case, however, we believe that performance enhancements would be best achieved by studying the nature of unclassified entities in more depth and looking for alternative workflows that do not involve automatic tools in cases which we assume they will not be able to solve. A low hanging fruit is the case of containers such as lists, which can be identified easily. For the other cases, one possible way to move forward would be to compile a list of entity types in the DBpedia ontology, which are notoriously difficult, and ask the crowd to comment upon that shortlist instead of the one more or less ’guessed’ by a computer program. Another option would be to look at workflows that involve different types of crowds. However, it is worth mentioning that for the 120 randomly chosen untyped entities from DBpedia, 18 of them don’t fit in any DBpedia types based on our gold standard which indicate there is a need to enhance the ontology itself.
Popular classes are not enough
As noted earlier, entities which do not lend themselves easily to any form of automatic classification seem to be difficult to handle by humans as well. This is worrying, especially if we recall that this is precisely what people would expect crowd computing to excel at, enhancing the results of technology. However, we should also consider that a substantial share of microtask crowdsourcing applications addresses slightly different scenarios: (i) the crowd is either asked to perform the task on their own, in the absence of any algorithmically generated suggestions; or (ii) it is asked to create training data or to validate the results of an algorithm, under the assumption that those results will be meaningful to a large extent. The situation we are dealing with here is fundamentally new because the machine part of the process does not work very well and distorts the wisdom of the crowds. These effects did not occur when we used free annotations. An entity such as “Brunswick County North Carolina”29
It became evident that in case the predicted categories are labelled in domain-specific or expert terminology, people tend not to select them. While under the unbound condition they are comfortable using differentiated categories, the vocabulary has to remain accessible. For example, Animal (sub-category of Eukaryote) is used more than Eukaryote. In all three workflows, if the more general category is not listed, participants were inclined towards the more specialized option rather than higher-level themes such as Person, Place, and Location. This could be observed best in the freetext workflow. Such aspects could inform recent discussions in the DBpedia community towards a revision of the core ontology.
It has been observed that crowdsourcing microtasks sometimes generate noisy data which either is submitted deliberately from lazy workers or from the crowd whose knowledge of the task area is not sufficient enough to meet certain accuracy criteria. Test question is a good way to help minimize the problems caused by both cases such that only the honest worker with basic understanding are involved in the tasks. In our experiment, we did not specially use control question to prevent spam, instead we use test question to recruit qualified workers. Although the test question approach requires about 10% additional judgments to be collected, it does give good inputs in which the definite spam is rare and negligible.
Conclusion and future work
In this paper, we are the first to propose a crowdsourcing based error detection and correction workflows for (semi-) automatic entity typing in DBpedia with selection of the most specific category. Though our framework employs DBpedia ontology, in principle it can also be applied to other classification problems where the labels are structured as a tree. In our second contribution we propose a new microtask based free text approach for the prediction of entity type. This predictor provides good results even for entities where automatic machine learning based approach fails and naive full ontology scans are necessary. We empirically evaluated the quality of the proposed predictors as well as the crowd performance and costs for each of the workflows using 120 DBpedia entities that are chosen uniformly at random from the set of entities, not yet annotated by the DBPedia community.
While upper levels of the DBpedia ontology seem to match well the basic level of abstraction coined by Rosch and colleagues more than 30 years ago [32], contributors used more specific categories as well, especially when not being constrained in their choices to the (largely unbalanced) DBpedia ontology. The experiments also call for more research into what is different about those entities which make the hard cases and in our discussion we gave some suggestions for improvement.
In our future work we plan to investigate how the quality of semi-automatic predictors can be further improved to reduce the costs for correction to a minimum. More work can be done in the design of the microtasks especially in terms of the option choice displayed to the user. Finally, there is a lot to be done in terms of support for microtask crowdsourcing projects. The effort invested in our experiments could be greatly reduced if existing platforms would offer more flexible and richer services for quality assurance and aggregation (e.g., using different similarity functions).
Footnotes
Acknowledgements
This work is supported by the EPSRC under SOCIAM grant EP/J017728/1, and the European Commission under grant agreement 688135 (STARS4ALL).