
Abstract
A formal machine reader is a tool able to transform natural language text into formal structured knowledge so as the latter can be interpreted by machines, according to a shared semantics. FRED is a formal machine reader for the semantic web: its output is a RDF/OWL graph, whose design is based on frame semantics. FRED’s graph are domain- and task-independent, making the tool suitable to be used as a semantic middleware for domain- or task-specific applications. To serve this purpose, it is available both as REST service and as Python library. This paper provides details about FRED’s capabilities, design issues, implementation and evaluation.
Introduction
This paper describes FRED1
As an example of a formal knowledge graph, the text “Valentina gave Aldo a book by Charlie Mingus.” can be formalised according to OWL semantics and the OWL n-ary relation pattern,2

Formalisation for the sentence: Valentina gave Aldo a book by Charlie Mingus, based on OWL semantics and the OWL n-ary relation pattern.

FRED’s output for the sentence: Valentina gave Aldo a book by Charlie Mingus.
FRED is able to produce such a formal knowledge representation, specifically for the semantic web. The tool leverages multiple natural language processing (NLP) components by integrating their outputs into a unified result, which is formalised as an RDF/OWL graph. Such a graph is enriched with links to existing semantic web knowledge, by means of ontology alignment, entity linking techniques, as well as RDF encoding of syntactic annotations based on the Earmark [39] and the NLP Interchange Format (NIF) [23] vocabularies.
The design of FRED’s graphs is independent from any commitment on domain-specific or task-specific semantics, making the tool suitable to be used as a semantic middleware. In fact, FRED mainly targets developers of semantic applications, who can rely on FRED’s output graphs and further manipulate them (e.g. refactor or enrich) for empowering their domain- or task-specific client applications. Some examples are automatic text annotation, search engine optimisation, opinion mining, automated summarisation. Examples of applications built on top of FRED are given in Section 4.
FRED 1 is available as RESTful API (providing RDF serialisation in many syntaxes) as well as Python API (fredlib3
List of prefixes used in FRED diagrams and inline examples
FRED’s output graph is designed according to Frame Semantics [15] and ontology design patterns [20]. A frame is usually expressed by verbal phrases or other linguistic constructions. All occurrences of frames that can be recognised in an input text are formalised as OWL n-ary relations, all being instances of some type of event or situation (e.g. the class
FRED diagrams depict a subset of the generated triples, which cover the core semantics of the text.
The reader may notice that
In summary, the main contribution of FRED is to provide a novel form of machine reading. This is accomplished by addressing a number of challenges such as: performing combined NLP tasks at a same time, integrating and enriching the results of diverse NLP tasks by drawing explicit relations between them, providing a unified formal representation compliant with semantic web design and standards (i.e. OWL/RDF), providing a reference cognitive semantics for its interpretation (i.e. frame semantics).
The paper is organised as follows. Section 2 presents the main capabilities of, and design issues addressed by, FRED. Section 3 describes the FRED’s pipeline and provides implementation details. Section 4 shows the quality, importance and impact of FRED, reporting evaluation studies, community feedback, as well as examples and evaluation of applications that rely on FRED as a semantic middleware. Section 5 discusses relevant related work and the paper concludes with Section 6 that addresses open challenges and ongoing work.
FRED leverages the results of many NLP components by reengineering and unifying them in a unique RDF/OWL graph designed by following semantic web ontology design practices. In this section, the main design issues addressed by FRED are discussed and exemplified, in order to provide an overall view of its main features. In order to improve readability of figures and examples, a set of prefixes is used in lieu of namespace URIs. They are summarised in Table 1.
From Discourse Representation Structures to RDF/OWL n-ary relations
The core of FRED takes as input Discourse Representation Structures (DRSs), based on Hans Kamp’s Discourse Representation Theory (DRT) [25]. DRSs, informally called “boxes” (due to their graphical representation), represent natural language sentences, and include two parts: a set of discourse referents, and a set of conditions providing the interpretation of the discourse referents. The DRS language is within first order logic, and its discourse referents are arbitrary entities, including events modeled according to a neo-Davidsonian semantics [25].

Boxer versus FRED result (in two varieties labelling with either VerbNet and FrameNet frames and roles) for the sentence “People love movies”, which exemplifies the case of a box that does not add any semantics to its content, which in turn maps to a specific frame.
The DRSs taken by FRED as input are produced by Boxer [5], which performs deep parsing out of Combinatory Categorial Grammar (CCG) parse trees [47]. It also makes use of both VerbNet [27] and FrameNet [4] for frame labelling and semantic role labelling, i.e. representing event types and the relations (thematic roles) between events and their participating individuals. Figure 3(a) exemplifies a box for the sentence “People love movies” as it is returned by Boxer: the box is divided into two sections, the top section contains the discourse referents, in this case
Although the example in Fig. 3(a) is very simple, DRSs can be very complex, depending on the input text. Therefore, the problem of transforming DRSs to RDF/OWL models requires non-trivial design decisions on how to represent discourse referents and their interpreting predicates. In the case of Fig. 3(a), there is one box, which encapsulates a single event controlling all discourse referents. Therefore, the box content can be represented as an RDF/OWL n-ary relation modelling the identified event (frame), with its arguments modelled as typed individuals, and thematic roles modelled as object properties: the corresponding FRED output is shown in Figs 3(b), 3(c). Events are modelled as subtypes of the class
In the second case, the event type
Natural language text on the web is rarely such simple as “People love movies”, hence the possible configurations of boxes and their contents have a wide range of complexity. In this example, the box itself does not add any special semantics to its content, but this is not always the case. One of the design issues addressed by FRED is to assess whether a box has its own semantics or not.
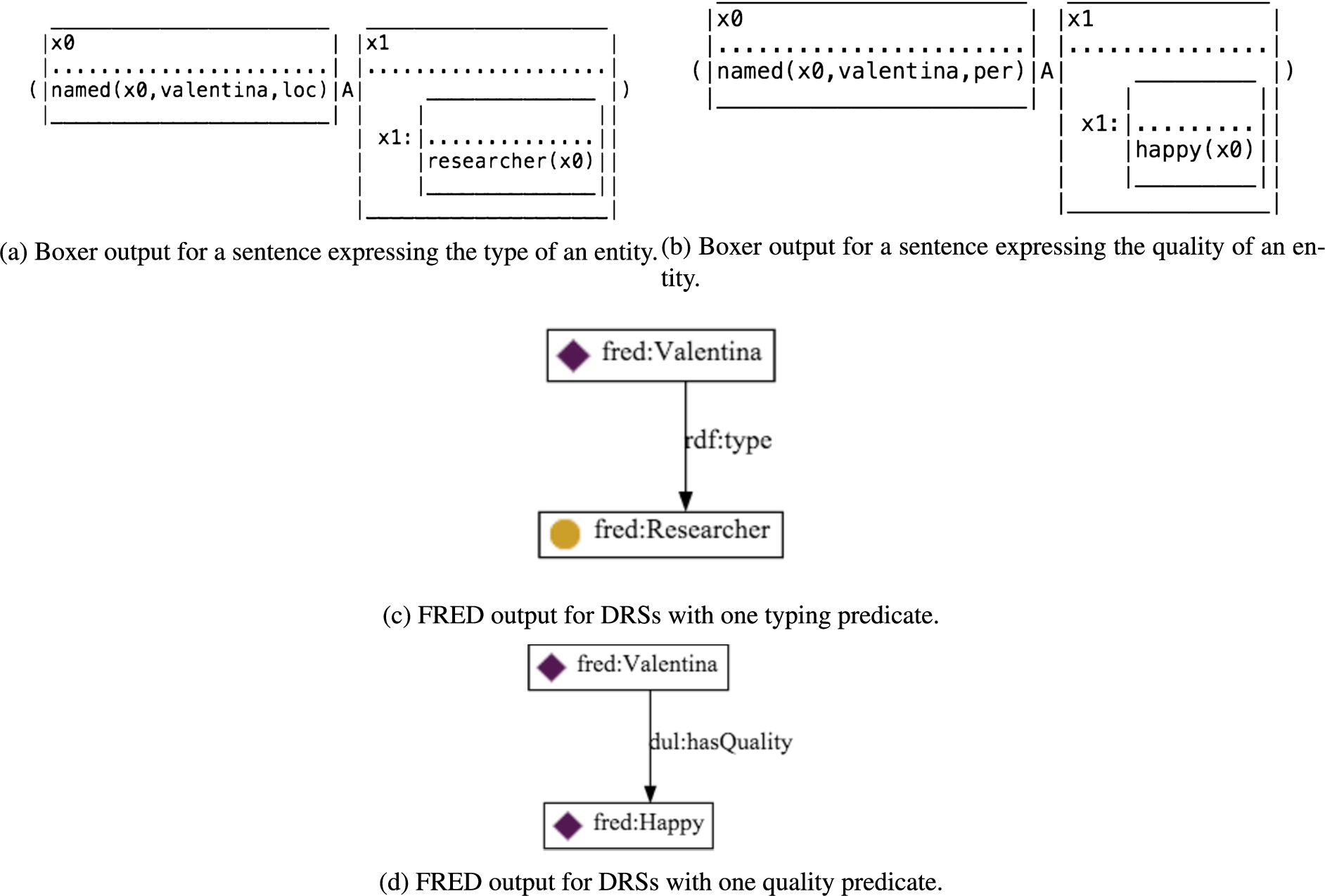
Boxer versus FRED results for examples of sentences expressing states of affairs (mostly) by means of the copula.
There are two main basic types of boxes that FRED needs to distinguish: (1) boxes only having a syntactic role in Boxer’s result, meaning that FRED only needs to focus on representing their content, and linking them to the rest; (2) boxes providing a unified relation to a complex state of affairs (usually expressed in the text by a copula), meaning that they have their own semantics to be represented. Figure 3 is an example of (1), where the content of the box is represented as an n-ary relation expressing an event
The case (2) refers to those state of affairs that are expressed neither by means of events nor as typing/quality assertions. For example, let us consider the sentence: Valentina is Gianni’s fifth daughter, from his second marriage. Figure 5 shows the results of Boxer and FRED for this sentence. In this case, the box declaring the
These basic patterns for boxes and their contents can be composed by means of formal relations such as and, or, entails between boxes. Furthermore, boxes can be nested, negated, or can include more than one event, or no events. These combinations and variety of content give rise to complex configurations that may cause the emergence of additional patterns to be handled by appropriate heuristic rules.

Boxer versus FRED result for the sentence “Valentina is Gianni’s fifth daughter, from his second marriage”, which exemplifies the case of a box carrying the semantics of a state of affairs.
RDF vocabularies for DRSs The development of FRED involved also the creation of two OWL vocabularies: one, referred by the prefix
FRED also represents modality, tense and negation in its unified OWL/RDF graph, by identifying the corresponding patterns in Boxer output. Let us consider the example sentence “Rahm Emanuel says he won’t resign over police shooting.” and its corresponding FRED graph depicted in Fig. 6.

FRED graph for the sentence: Rahm Emanuel says he won’t resign over police shooting.
Tense representation is addressed by modelling a time interval (e.g.
Modality and negation are represented with a lightweight, RDF-oriented semantics, because the underlying natural language semantics is unpredictable, and poses controversial problems from both linguistic and philosophical perspectives [8].
As far as negation is concerned, given two sentences with a similar syntactic structure, the negated scope is often ambiguous to interpret. For example, the sentence “John did not go to school by car” can be formally represented in different ways. For example (using a neo-Davidsonian first order logic style), it can be represented as:
More interpretations can be generated by swapping the negated argument.
This is why FRED only annotates (using the property
As for modality, OWL lacks formal constructs to allow the required expressivity. The approach is then similar to the one for negation. Modality in FRED can be twofold:
For the sentence of Fig. 6, the triples:
formalise the “will not resign” fragment, including modality and negation.
As the output of Boxer does not tag compound terms explicitly, FRED extracts them by recognising two main patterns in the input DRSs. Given a compound term “term1 term2” the two predicates forming it (“term1” and “term2”) can be represented by Boxer either as a dependency relation (i.e.
FRED creates a class representing the compound term, e.g.,
based on the rationale that the modifier of the main concept (“police”) provides a distinguishing feature to the more specific class. This feature used to be called in ancient logic differentia specifica, and can be either a quality (typically expressed by an adjective or an adverb), or another concept (typically expressed by a noun). In the latter case, a new class is created for the concept, e.g.
The case of adjectives and adverbs expressing a differentia specifica is different from nouns. Adjectives in particular have an unpredictable and unstable semantics as nicely explained by Morzycki in [35]. FRED represents such modifiers (i.e. adjectives) as qualities of the modified term by means of the DOLCE property
intersective: the adjective that modifies a noun can be independently predicated of the individual, via entailment. For example, in a graph formalising the sentence: “Roberto Bolle is an Italian dancer.”, we would find the following triples:
subsective: the adjective that modifies a noun cannot be independently predicated of an individual via entailment. For example, referring to Fig. 5, we find the following triples:
where the quality does not modify the individual, but the class: it is represented as an intensional quality, exploiting the “punning” pattern available in OWL2.
In the special case of Fig. 5, the fragment fifth daughter is part of a “periphrastic expression”, which leads to a special representation in FRED, as explained in the next section:
Generating periphrastic relations
There are many cases of relations that are expressed (and annotated by NLP tools) by means of prepositions, e.g. of, with, for, in, etc. Naming an object property in a semantic web graph with one of those terms, e.g. of, results meaningless and identical to many other relations that actually may mean a completely different concept. For example, of from “survivor of” has a different meaning (closer to among) from the of from “sister of”. In those cases FRED performs a paraphrasing task by identifying the noun to be associated with the preposition, and putting it before the preposition in order to form the label of the resulting relation. For example, the sentence “He was the only survivor of the expedition.” would be formalised by generating the following triples:
Named entity recognition, entity linking, and coreference resolution
Named Entity Recognition (NER) is used for identifying elements in a text that should have a corresponding OWL individual in the graph. FRED also integrates the results of Entity Linking (EL) performed on the input text for enriching its output graph with
Co-reference resolution and role propagation output is used for merging nodes, for example in Fig. 6 the reader may notice that the individual
Word sense disambiguation for ontology alignment
FRED produces RDF/OWL ontologies having classes (and related taxonomies) depending on the lexicon used in the text. FRED exploits word sense disambiguation (WSD) in order to provide a public identity to these classes by identifying equivalent or more general concepts from WordNet and BabelNet [36], and by creating alignments, where appropriate. WSD also enables FRED to generate alignments to two top-level ontologies: WordNet “supersenses” and a subset of DOLCE+DnS Ultra Lite (DUL) classes. For example, the term programming language is formalised by the following alignment axioms:
Since Wikipedia is rich in “conceptual” entities, EL is also used for disambiguating the sense of words after a process of contextualisation and formal interpretation: if a text segment annotated by EL was originally annotated by FRED as an
Other FRED’s capabilities
Multilinguality FRED takes as input a text in one of 48 different languages, it translates it in English and then processes it for producing its corresponding graph. Therefore, the resulting graph always has English labels. As for the translation, FRED currently relies on Bing Translation APIs.7
If the input language is different from English, the input text must be preceded by the tag <BING_LANG:lang>, where lang is the code for the language.8The website

FRED pipeline.
Textual annotation grounding As part of its OWL/RDF output, FRED provides annotations that link text fragments to their corresponding graph elements. These annotations are expressed by means of the Earmark vocabulary [39] and the NLP Interchange Format (NIF) [23].
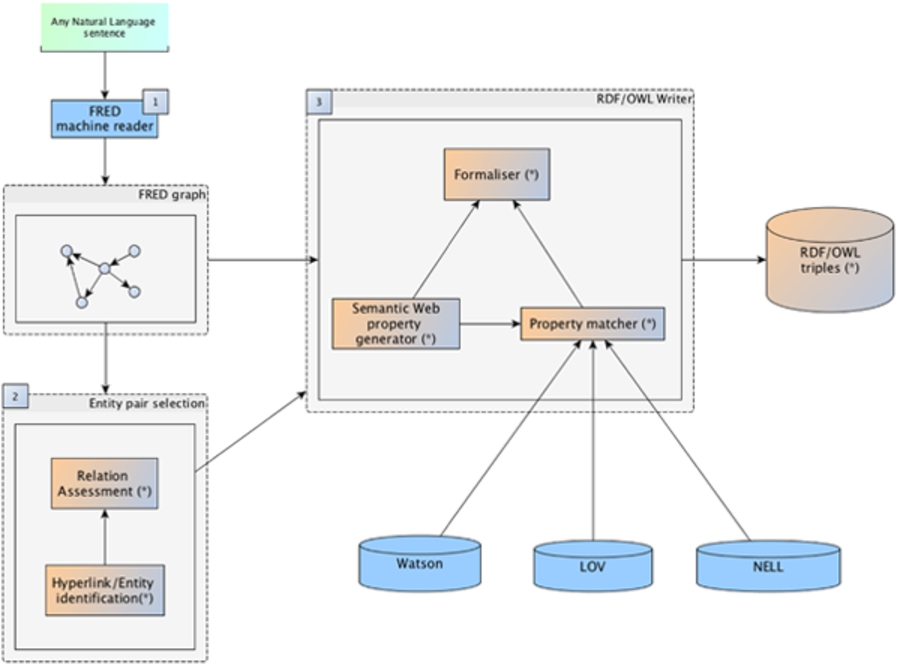
FRED pipeline is depicted in Fig. 7. In this section, the pipeline is described by providing details about the actual components that realise its implementation. The FRED pipeline is characterised by three main phases: text processing, heuristic-based triplification, and RDF graph enrichment.

Output of the second phase of FRED pipeline (heuristic triplification) for the sentence: “Rahm Emanuel says he won’t resign over police shooting.”
FRED takes as input a text in natural language (NL). It can be a short text (to be processed at once) or a corpus of NL documents; at the moment, the latter is available only by using the fredlib Python API. The input text is processed and transformed into DRSs. This processing includes also frame detection and semantic role labelling (based on VerbNet [27] and FrameNet [4]), identification of relations between frames, named entity recognition (NER) and coreference resolution (CRR). Boxer [5] is in charge of producing DRSs (see Section 2 for more details about Boxer) nevertheless, after observing a significant number of cases during FRED implementation and experience of usage, it emerged that Boxer’s pronoun CRR capability is limited. For this reason FRED also integrates CoreNLP9
Implementation This phase is implemented as a Python software component that uses system calls for getting Boxer, TAGME and CoreNLP outputs, integrate them in an internal representation and pass the result to the next component.
Annotation properties in FRED. The fred:offset_28_36_daughter offset is shortened as “offset”
Annotation properties in FRED. The
In this phase a first version of the graph is created. The component in charge of this task is implemented as a manager of ~100 heuristics that remove redundancies, associate a OWL/RDF representation to each identified pattern in the input DRSs (described in Section 2), and combines them. At this stage, FRED performs taxonomy induction, variable reification, role propagation, periphrastic relation extraction, frame and situation modelling, semantic role labelling, lightweight representation of negation and modality, tense modeling, and representation of both individual and intensional qualities. Figure 8 shows the result of this phase for the sentence “Rahm Emanuel says he won’t resign over police shooting.”. The reader may notice that the type assigned by Boxer is kept in this preliminary model and represented by means of a
Implementation This phase is realised by a set of Python modules that implement the heuristics described in Section 2. The resulting component is deployed as a REST service, meaning that it is possible to programmatically access the output of the heuristic-based triplification. Additional triples are generated in order to annotate the fragments from a text with the semantic entities that are extracted from the text, jointly with their syntactic part-of-speech annotations. The Earmark [39], NIF [23], and semiotics.owl10
The result of the previous phase is the input for the final phase, which has the goal to further enrich the graph with links to existing semantic web resources and textual annotations, as well as to enrich compositional associations (
Implementation The third phase is implemented as an independent Java software framework, named K~ore. K~ore is a modular set of Java components, each accessible via its own RESTful interface. All components are implemented as OSGi [38] bundles, components and services based on Apache Felix.11
Additional implementation and deployment details FRED is also released as a Python API named fredlib, which relies on the K~ore REST services, and allows to query FRED with a user-specified corpus, also enabling the manipulation of the resulting graph. More specifically, a Python function hides details related to the communication with the FRED service, and returns the user a FRED graph object that is easily manageable. FRED graph objects expose methods for extracting qualified parts (motifs) from the graph. These methods include functions for extracting the set of individual and class nodes, equivalence axioms, typing axioms, categories of FRED nodes (i.e. events, situations, qualities, general concepts) and categories of edges (roles and non-roles). In addition, fredlib supports rdflib12
FRED’s quality and impact can be assessed from different perspectives: (i) its ability to perform specific knowledge extraction tasks such as event detection, taxonomy induction, etc. (ii) its popularity in terms of reuse and citations by a wider community of developers; (iii) its performance as a semantic middleware, based on the evaluation of applications built on top of it.
Rigorous evaluation
As far as (i) is concerned: [43] reports FRED performance on the frame detection task showing that it is one order of magnitude faster than Semafor [11] (see Fig. 9), i.e. the best state-of-art tool at the time. Table 3 summarises the accuracy performance of the two tools: FRED and Semafor have comparable precision values for frame detection, while the value of recall is lower for FRED. Nevertheless, it has to be noted that Semafor was trained on the FrameNet reference corpus, which put it in strong advantage with respect to FRED. As additional functionality compared to Semafor, FRED provides a formal representation of the identified frame occurrences.

Time to provide answers in function of the number of sentences per document as reported in [43].
Frame detection task: performance comparison between FRED and Semafor as reported in [43]
A further study [16] reports a comparison between information extraction tools, including FRED. The author defines a number of basic semantic tasks by providing a correspondence between NLP tasks and semantic web terminology. Table 4 reports the list of tasks with a brief explanation of such correspondences: each NLP task is informally associated with a corresponding OWL-based semantics by indicating the type of triples that may be produced starting from its output.
Summary of basic semantic tasks
As many of the analysed tools provide a non-RDF output, in order to allow their comparison, a manual conversion to RDF graphs was performed, based on a reference translation table. The study compares fifteen tools (including FRED) by assessing their coverage of, and performance on, the listed tasks against a gold standard of 524 triples produced from a news text. The result shows that FRED has the largest coverage of tasks and best accuracy performance for some of them. Table 5 summarises this evaluation analysis, the reader can refer to [16] for a detailed description of each tool (here we only provide an external reference for each of them), and to online updated data14
The table reports a value for each basic task indicating that a certain tool addresses that task (coverage) with a certain accuracy performance. Accuracy is computed as the sum of true (positive and negative) results over the sum of all (true and false) results. If a value is not present it means that it was either not computed or not computable (i.e. task not addressed), yet a “–” sign indicates “not addressed” while a “+” sign indicates “addressed”.
Summary of evaluation results for basic tasks indicating accuracy values in the interval [0,1] with 1 expressing the best possible accuracy
Besides rigorous evaluation, FRED’s quality is supported by evidence of its impact in the community (ii). A public forum in the software engineering community, stackoverflow.com, contains independent discussions about extending FRED’s usage to other platforms (Python, C#).15
More literature shows the impact of FRED beyond semantic technology circles: a 2014 study about dealing with big data for statistics made by the United Nations Economic Commission for Europe18
“The knowledge extraction from unstructured text is still a hard task, though some preliminary automated tools are already available. For instance, the tool FRED (
Since FRED is a semantic middleware (iii) its quality is primarily assessed by evaluating the performance of applications that depend on it. This is a hard task to address because a rigorous methodology would require to assess the performance of each such application both with and without using the middleware. Nevertheless, we argue that FRED’s impact as a middleware can be demonstrated by showing successful results of applications depending on it that address a broad range of tasks, hence reducing the possibility that their individual success is only due to other factors. In support to this claim, it has to be noted that all tools discussed in the next sections strongly depends on FRED’s output: the core of their logic relies on heuristics defined based on FRED’s graph design. In other words, these tools are specialisations of FRED for specific domains or tasks. The reminder of this section is dedicated to briefly describe three such tools addressing different tasks and their performance. Notably, FRED has been used also in [24] to automatically extract the meaning of citations in scientific research articles, and in [32] for supporting a semantic web approach to textual knowledge reconciliation.
Semantic sentiment analysis
Sentilo19
Figure 10 shows the pipeline of Sentilo. Its extension to FRED includes
an ontology for opinion sentences for enriching FRED graphs; SentiloNet, a novel (frame-based) lexical resource that enables the evaluation of opinions expressed by means of events; a novel scoring algorithm for opinion sentences.
Sentilo is accessible as both REST service and web application featuring a graphical user interface.
An evaluation conducted on a corpus of open-rating reviews about hotels, reported in the cited papers, shows high accuracy of the system for the different addressed tasks: holder detection (

Pipeline of Sentilo (taken from [44]).
Legalo21
Pipeline of Legalo. Numbers indicate the order of execution of a component in the pipeline.
Figure 11 depicts the pipeline implemented by Legalo. The system also relies on external resources such as Watson22
Tipalo26

Pipeline of Tipalo. Numbers indicate the order of execution of a component in the pipeline.
The work on Open Information Extraction (OIE, [13]) is the foundation of machine reading, which relies on an open domain and unsupervised paradigm. The main antecedent to OIE is probably the 1999 Open Mind Common Sense project [46], which adopted an ante-litteram crowdsourcing and games-with-purpose approach to populate a large informal knowledge base of facts expressed in triplet-based natural language. Another OIE project is Never Ending Language Learning (NELL) [31], a learning tool that since 2010 processes the web for building an evolving knowledge base of facts, categories and relations. In this case there is a (shallow) attempt to build a structured ontology of recognised entities and predicates from the facts learnt by NELL. Ontology learning [9] aims to address a similar task as machine reading: it uncovers statistical regularities in linguistic features from large corpora, which could justify e.g. subsumption or disjointness relations, in order to generate logical axioms. However, the results are typically sparse, and apply shallow parsing only. Works such as [5,33] assume an axiomatic form, and make the extraction process converge to that form. In these cases, although the output is formalised, its transformation to semantic web languages is far from being straightforward.
FRED provides a means to perform machine reading where the result is formally represented according to semantic web standards and design, carrying the semantics of cognitive linguistics frame and enabling automatic reasoning and reuse from other software agents. We call this variety of OIE Open Knowledge Extraction [42].
Most research work in the area of natural language processing (NLP) is relevantly related to machine reading. NLP research is characterised by the fact that the developed methods focus on specific tasks such as relation extraction, named entity recognition, frame detection, semantic role labeling, etc. Furthermore, the formal representation of NLP methods’ results is mostly overlooked in their development. Therefore, two among the challenges for advancing the state of the art in machine reading are: (i) to address combined NLP tasks at the same time and (ii) to identify a unified formal representation for the output. Among FRED’s merits is the ability to address these challenges: it leverages different existing NLP methods and unifies their results into a formal representation.
The integration between NLP and semantic web (often referred to as “semantic technologies”) is progressing fast. Most work has been opportunistic: on one hand exploiting NLP algorithms and applications, such as named-entity recognisers and sense taggers, to populate semantic web datasets or ontologies, or for creating NL query interfaces; on the other hand exploiting large semantic web datasets and ontologies (DBpedia, YAGO, Freebase) to improve NLP algorithms. For example, Alchemy API,28
Relation extraction and question answering are mostly domain-dependent and supervised: they use a finite vocabulary of predicates (e.g. from the DBpedia ontology), and rely on their extensional interpretation in data (e.g. DBpedia) to either link two entities recognised in some text (as in [26,28]), or to find an answer to a question, from which some entities have been recognised (as in [30]). FRED performs a different form of relation extraction: it identifies what terms convey the semantics of a relation and creates a formal representation for them in the form of an OWL object property. Currently it is partly independent from any existing source of properties, which leads its behaviour to generate redundancies. However, its goal is not to detect existing relations, but to formalise the ones it recognises as such. An extension of its capabilities to cope with redundancies may be desirable as future work.
As the integration between NLP and semantic web is becoming tighter, clearer practices about how to represent linguistic data are strongly desirable. Some work propose linked data versions of linguistic resources such as WordNet31
This paper describes FRED: a tool able to provide a formal representation of natural language text based on semantic web design principles and technologies. After providing a detailed description of FRED’s architecture and capabilities, the paper reports on its impact by showing both rigorous evaluations and independent quotes from a wider community of researchers, adopters and practitioners. These references demonstrate that FRED currently stands as the non-commercial tool having the largest coverage of formally defined tasks, and, to our knowledge, the largest coverage for the semantic web specifically. The final aim motivating FRED development is to support natural language understanding.
FRED currently responds to a very important challenge: to leverage existing natural language methods and tools in order to obtain a unified, formalised representation of both facts and concepts expressed by a natural language text. Most natural language tasks are addressed by specialised tools separately, and the semantic assumptions behind their output is neither harmonised nor formalised in most (if not all) cases. The main issues implied by developing FRED were to identify such a unified formal interpretation, and to minimise the heuristic rules needed for producing a sound formal result, when combining the diverse discourse patterns.
There are still important open issues in dealing with discourse phenomena: they are more diverse and broader than what can be currently extracted and represented. Some of the challenges depend on implicit knowledge, others on ambiguity, and some more depend on higher order modal and conceptual structures.
Ongoing work for extending FRED is dealing with some of them, for example certain kinds of coercion, adjective semantics, polarity, sentiment, frame composition, a subset of presuppositions and paraphrases, etc. For some (e.g. polarity, sentiment) very promising results have been achieved [21,44].
The current state of the art for machine reading, either grounded in the semantic web or not, is still at an early stage when compared to the grand vision of natural language understanding. Two relevant examples of difficult tasks are: (1) the accurate extraction of implicit discourse relations and conventional implicatures, which do not only require background knowledge, but also reasoning on that knowledge in a way close to the appropriate discourse level [22]; (2) the recognition of cultural framing out of real world facts, as in political discourse, which requires the extraction, representation, and reasoning over high-level frames (attitudes, values, metaphors), which tend to control the factual frames that are currently the most complex grasp offered by automated discourse representation.
A current focus of our work is creating large repositories of FRED graphs, using typed named graphs and reconciliation techniques [32] for the cases when the source texts are related for some reason, e.g. with news series, large texts, abstracts of categorised scientific articles, etc. The final goal is to produce a large repository of knowledge graphs that can be used to perform deep and formal annotation of large archives of documents, and to automatically produce formal relations between them. Another ongoing evolution of FRED is in the area of robot-human interaction, where FRED graphs extracted from natural language dialogues need to be grounded to physical environments.
Footnotes
Acknowledgements
The research leading to these results has received funding from the European Union Horizon 2020 Framework Programme for Research and Innovation (2014–2020) under grant agreement 643808 Project MARIO Managing active and healthy aging with use of caring service robots. It was also funded by the EFL (Empirical Foundations of Linguistics) LabEx of Sorbonne Paris Cité (France).