
Abstract
In recent years we have seen significant advances in the technology used to both publish and consume structured data using the existing web infrastructure, commonly referred to as the Linked Data Web. However, in order to support the next generation of e-business applications on top of Linked Data suitable forms of access control need to be put in place. This paper provides an overview of the various access control models, standards and policy languages, and the different access control enforcement strategies for the Resource Description Framework (the data model underpinning the Linked Data Web). A set of access control requirements that can be used to categorise existing access control strategies is proposed and a number of challenges that still need to be overcome are identified.
Introduction
The term Linked Data Web (LDW) is used to describe a World Wide Web where data is directly linked with other relevant data using machine-readable formats [38,63]. Although the technology underpinning the LDW has been in existence for a number of years, up until now data publishers have primarily focused on exposing and linking public data. With the advent of update languages for the Resource Description Framework (RDF) data model, such as SPARQL 1.1 [101], the LDW has the potential to evolve from a medium for publishing and linking public data, to a dynamic read/write distributed data source. Such an infrastructure will be capable of supporting not only data integration of public and private data, but also the next generation of electronic business applications. However, in order to make the move from simply linking public data to using the Linked Data infrastructure as a global dataspace, suitable security mechanisms need to be put in place.
Security in general and access control in particularity have been extensively studied by both the database and the information system communities, among others. Early work on access control policy specification and enforcement within the Semantic Web community focused on: representing existing access control models and standards using semantic technology; proposing new access control models suitable for open, heterogeneous and distributed environments; and devising languages and frameworks that can be used to facilitate access control specification and maintenance. Later researchers examined access control for the RDF data model in general and access control propagation, based on the semantic relations between policy entities in particular. In recent years the focus has shifted to access control policy specification and enforcement over Linked Data. Although few authors have proposed access control strategies specifically for Linked Data [19,51,78,86], there is a large body of work on general policies languages and access control strategies for the RDF data model that could potentially be applied to Linked Data. In order to better understand the potential of existing access control mechanisms, this paper provides an overview of a number of access control models, standards, languages and frameworks. A set of access control requirements are collated from [9,22,23,72,102,104] and categorised according to four different dimensions (specification, enforcement, implementation and infrastructure) that are necessary from an access control perspective. These requirements are used not only to classify existing access control strategies but also to identify challenges, with respect to usability and understandability of access control policies and both the correctness, performance and scalability of the enforcement frameworks, that still need to be overcome.
The remainder of the paper is structured as follows: Section 2 presents relevant access control models and standardisation efforts and discusses how they have been applied to, or enhanced, using semantic technology. Section 3 details several well known policy languages and frameworks that use ontologies, rules or a combination of both to represent policies. Section 4 describes the different access control administration and enforcement strategies that have been proposed for RDF data. Section 5 presents a set of access control requirements and categorises existing access control languages and frameworks accordingly. Finally Section 6 concludes the paper and presents directions for future work.
Access control models and standards
Generally speaking the term access control is used to refer to the model, which is the blueprint that is used to guide the access control process; the policy language, which defines both the syntax and the semantics of the access control rules; and the framework, which is a combination of the access control model, the language and the enforcement mechanism. At its most basic, an access control rule (otherwise known as an authorisation) can be represented as a tuple
This section describes both well known and emerging access control models, and relevant standardisation efforts. In each instance, a description of the access control model/standard is provided, along with details of how the model/standard has been applied to or enhanced using Semantic Web technologies.
Access control models
Mandatory Access Control (MAC), Discretionary Access Control (DAC) and Role Based Access Control (RBAC) are the most prominent access control models found in the literature, and used in practice. View Based Access Control (VBAC) is a complementary access control model which grants access to sets of entities, logically structured as views. More recently researchers have proposed new access control models, that are deemed more suitable for the open, heterogeneous and distributed architecture of the web. Primary research efforts, involve using properties (relating to the subject, resource or the environment) as opposed to identities, in order to determine if access to resources should be permitted. Attribute Based Access Control (ABAC) and Context Based Access Control (CBAC) are the predominant works in this area.
In this section we present the vocabularies used to specify the access control model and provide details of the different enforcement mechanisms. A summary of the existing proposals is presented in Table 1 and the core ideas are represented on a timeline in Fig. 1.
Access Control Models – Policy Representation and Enforcement

Access Control Models – Policy Representation and Enforcement
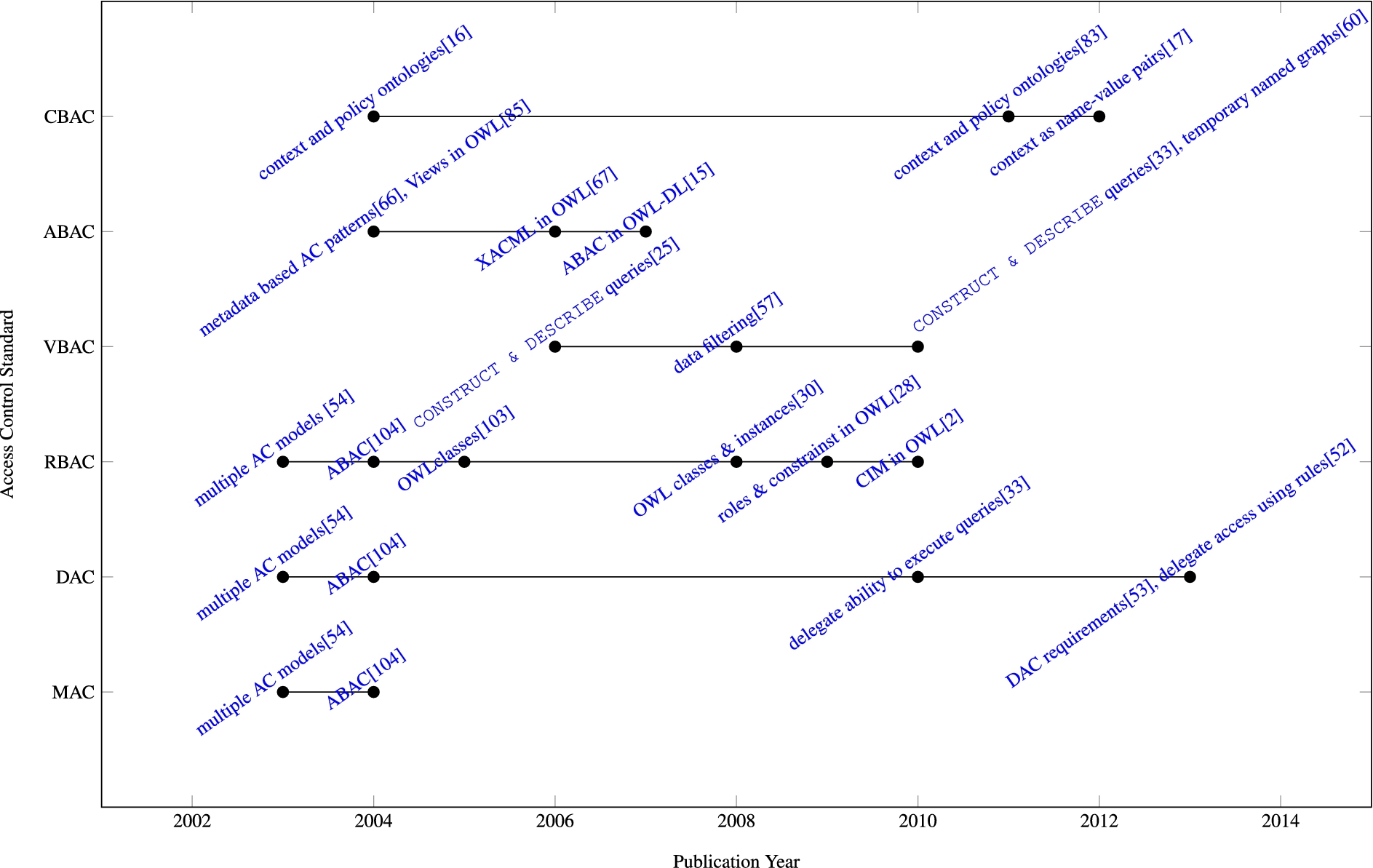
Access Control Models.
MAC limits access to resources using access control policies determined by a central authority [79]. The central authority is responsible for classifying both subjects and resources according to security levels. Resources are assigned labels that represent the security level required to access the resource, and only subjects with the same security level or higher are granted access. MAC was originally developed for military applications and therefore it is best suited to closed environments, where a great deal of control is required [6]. Given the open, heterogeneous and distributed nature of the web, it is not surprising that MAC has not gained much traction among Semantic Web researchers. Primary research efforts focus on: (i) defining vocabularies that can be used to support multiple access control models [54]; and (ii) using attributes to represent different credentials (e.g. identities, roles and labels) [104]. A summary of the various policy specification and enforcement mechanisms are presented below:
DAML+OIL,
An alternative strategy is proposed by Yagüe et al. [104]. Like Kodali et al. [54], the authors provide support for multiple access control models, however rather than defining an ontology the authors propose an ABAC model and discuss how it can be used to support not only MAC but also DAC and RBAC.
DQL,
Although Yagüe et al. [104] indicate that they adopt an XML based enforcement mechanism for their attribute based access control policies, they do not describe the enforcement framework.
DAC policies associate one or more subjects with sets of access rights pertaining to one or more resources. Like MAC, DAC restricts access by means of a central access control policy, however users are allowed to override the central policy and can pass their access rights on to other users, a process known as delegation [82]. According to Weitzner et al. [102], the web needs discretionary, rule based access control. Although the authors describe a motivating scenario and present a potential solution, they focus primarily on the general architecture of the system, as opposed to investigating how discretionary access control can be modelled or enforced. When it comes to intersection between DAC and RDF, research efforts to date have focused on: (i) supporting multiple access control models [54,104]; (ii) providing support for the delegated of access rights to others [33,51,53]. A summary of the various policy specification and enforcement mechanisms are presented below:
In contrast both Gabillon and Letouzey [33] and Kirrane et al. [51] focus specifically on access control delegation. Gabillon and Letouzey [33] allow users to define security policies for RDF graphs and SPARQL views (SPARQL
Role based access control
RBAC restricts access to resources to groups of users, with common responsibilities or tasks, generally referred to as roles. In RBAC, users are assigned to appropriate roles and access to resources is granted to one or more roles, as opposed to users directly [81]. The term session is commonly used to refer to the set of roles that the user is currently assuming (their active roles). Whereas, role deactivation is generally used to refer to the process whereby a user is removed from a role. Depending on the usecase, roles may be organised to form either a hierarchy or a partial order. Such structures are used to simplify access control specification and maintenance. Constraints are commonly used to enforce conditions over access control policies. For RBAC, these constraints take the form of both static and dynamic separation of duty (a user cannot be assigned to two roles simultaneously) and prerequisites (a user can only be assigned to a role if they have already been assigned another required role). When it comes to RBAC research efforts have primarily focused on: (i) modelling RBAC entities as classes [29,54,103] or instances [29]; and (ii) adapting existing vocabularies, such as the eXtensible Access Control Markup Language (XACML) [28] and the Common Information Model (CIM) [2], in order to cater for RBAC. An overview of the various RBAC policy specification and enforcement mechanisms are presented below:
OWL, www.w3.org/TR/owl-ref/.
Rather than propose a new vocabulary, Ferrini and Bertino [28] and Alcaraz Calero et al. [2] demonstrate how existing vocabularies can be modelled in OWL. Ferrini and Bertino [28] discuss how the eXtensible Access Control Markup Language (XACML),4
an attribute based access control language and framework, proposed by the Advanced Open Standards for the Information Society (OASIS), and OWL can be used to specify and enforce RBAC. While, Alcaraz Calero et al. [2] demonstrate how the Common Information Model (CIM)5CIM,
In the architecture proposed by Alcaraz Calero et al. [2] constraints are represented as rules using the Semantic Web Rule Language (SWRL).6
SRWL,
VBAC [37] is used in relational databases to simultaneously grant access to one or more relations, tuples, attributes or values. A similar approach is used in Object Oriented Access Control (OBAC) [27], where access rights are granted to sets of application objects. Primary research efforts with respect to VBAC and RDF focus on: (i) using rules to grant and deny access to views of the data [57,60]; and (ii) using SPARQL
Both Dietzold and Auer [25] and Gabillon and Letouzey [33] use a combination of rules and filters defined using SPARQL queries in order to construct a access restricted view of the data. Dietzold and Auer [25] propose access control policy specification at multiple levels of granularity (triples, classes and properties). Authorisations are used to associate filters (SPARQL
Both Dietzold and Auer [25] and Gabillon and Letouzey [33] describe how RDF data can be logically organised into views using SPARQL
Attribute based access control
ABAC was designed for distributed systems, where the subject may not be known to the system, prior to the submission of a request. ABAC grants or denies access to resources, based on properties of the subject and/or the resource, known as attributes. Primary research efforts to date focused on: (i) using rules to grant access based on attributes directly or indirectly using roles [85]; (ii) using ontologies to grant access based on attributes directly or indirectly using roles [15]; and (iii) proposing a pattern which can be used to guide the development of attribute based access control frameworks [68]. Primary research efforts with respect to ABAC policy specification and enforcement mechanisms are presented below:
Priebe et al. [ 68], inspired by software design patterns, present a Metadata-Based Access Control (MBAC) pattern, which aims to encapsulate best practice with respect to attribute based access control. In the presented pattern subjects and objects are modelled as sets of attribute/value pairs. While, authorisation subjects and authorisation resources are described in terms of required attributes and corresponding values.
Context based access control
CBAC uses properties, pertaining to users, resources and the environment, to grant/deny access to resources. In light of new and emerging human computer interaction paradigms, such as ubiquitous computing and the internet of things, access control based on context has been graining traction in recent years. Existing proposals for CBAC can be summarised as follows: (i) proposing a framework which differentiates between physical and logical context [16,59]; and (ii) using ontologies and rules to specify access control policies that take context relating to subjects, objects, transactions and the environment into consideration [83]; and (iii) using ontologies and SPARQL
Costabello et al. [17] propose a policy language that can be used to restrict access to named graphs using contextual information supplied by the requester. An access control policy is a tuple
Shen and Cheng [83] propose a semantic-aware context-based access control (SCBAC) model and demonstrate how together ontologies and rules can be used to generate authorisations. In the proposed framework an access request is represented as a tuple
Access Control Standards – Adoption and Extension

Access Control Standards – Adoption and Extension
In Costabello et al. [17], in addition to the SPARQL query that the user wishes to execute, the user provides their access credentials, in the form of a SPARQL
In recent years, there have been a number of standardisation efforts, by both the World Wide Web Consortium (W3C) and the Organization for the Advancement of Structured Information Standards (OASIS), in relation to access control for web data. This section provides a high level overview of the relevant standards and details how they have been adapted or enhanced using semantic technology. A summary of the existing work relating to each of the aforementioned standards is presented in Table 2 and the key concepts are represented in Fig. 2 using a timeline. In each instance we make the distinction between simply applying versus extending the standard.

Access Control Standards.
The eXtensible Access Control Markup Language (XACML)
4
, is an OASIS standard, which is used to represent attribute based access control policies [71]. XML was chosen as the representation formalism for the policy language as it: (i) can be used to represent information in a human and machine readable manner; (ii) can easily be adapted to represent different access control requirements; and (iii) is widely supported by software vendors. The specification provides an XML schema which can be used to represent attribute based access control policies. The root of an XACML policy is a
a policy decision point, which evaluates policies and returns a response;
a policy enforcement point, which is responsible for making decision requests and enforcing the decisions;
a policy information point, which obtains attributes pertaining to subjects, resources and the environment; and
a policy administration point, which enables policies and sets of policies to be created and updated.
A number of researchers have used Semantic Web technologies to supplement the existing XACML framework. Primary research efforts include: (i) extending XACML to cater for deductive reasoning over attribute ontologies[14,66,67]; (ii) extending XACML policies with context [32]; and (iii) adapting XACML to work with roles [28].
Franzoni et al. [32] demonstrate how XACML can be extended to consider access control based on contextual properties pertaining to either the user or the application. In addition to standard access control policies, specified using XACML, the authors propose fine grained access control policies, which are used to specify the instances of a concept that a user is permitted to access. The proposed fine grained access control policies are enforced over RDF data, by expanding a SeRQL query (an alternative to SPARQL), to include triple patterns for the instances that are permitted.
Ferrini and Bertino [28] describe an extension of XACML, which uses a combination of XACML and OWL, in order to support RBAC constraints, such as static and dynamic separation of duty. Like Franzoni et al. [32], XACML policies are specified using OWL, therefore it is possible to take advantage of OWL’s out of the box reasoning capabilities. The authors propose a two layer framework where access control policies are specified using XACML and constraints and role hierarchies are represented using OWL. They further extend the XACML enforcement framework which enhances the XACML engine with Description Logic reasoning capabilities.
Web Identity and Discovery
Web Identity and Discovery (WebID),7
WebID,
FOAF,
In Berners-Lee et al. [5], the authors describe their vision of a read-write web of data and present a proof of concept. Like Hollenbach et al. [39], the authors discuss how WebID together with FOAF+SSL, can be used for authentication. It is worth noting that although Stermsek et al. [85] do not use the term WebID, they describe how attributes pertaining to a subject (commonly known as credentials), can be associated with public keys and attached to digital certificates.
WebAccessControl (WAC)9
WAC,
Platform for Privacy Preferences (P3P),10
P3P,
The Open Digital Rights Language (ODRL)11
ODRL,
General Policy Languages – Policy Representation and Enforcement

General Policy Languages – Policy Representation and Enforcement
Policy languages can be categorised as either general or specific. In the former, the syntax caters for a diverse range of functional requirements (access control, query answering, service discovery, negotiation, to name but a few), whereas the latter focuses on just one functional requirement. Two of the most well-known access control languages, KAoS [11,12,97] and Rei [48,49], are in fact general policy languages. Natural language, programming languages, XML and ontologies can all be used to express policies. XML and ontologies are two popular choices for representing policy languages as they benefit from flexibility, extensibility and runtime adaptability. However, ontologies are better suited to modelling the semantic relationships between entities. Also, the common framework and vocabulary used by ontologies, to represent data structures and schemas, provides greater interpretability and interoperability. Regardless of the language chosen, a logic based underlying formalisation is crucial for automatic reasoning over access control policies.
The work presented in this section is limited to policy languages that use ontologies, rules or a combination of both to represent general policies. A summary of the existing proposals is presented in Table 3. While, a detailed timeline is presented in Section 5.
As the objective is to provide the reader with an overview of each approach, a detailed description of well known frameworks in each category is presented. For a broader comparison of policy languages, the author is referred to a survey by Bonatti and Olmedilla [9]. The authors divide the criteria into two categories: the more theoretical criteria, which they refer to as core policy properties (well-defined semantics, monotonicity, condition expressiveness, underlying formalism) and the more practically oriented criteria, which they refer to as contextual properties (action execution, delegation, type of evaluation, evidences, negotiation support, policy engine decision, extensibility). However the criteria was devised in order to compare existing policy languages that focus on access control and trust, therefore it would need to be amended depending on the access control requirements of the specific use cases. In Section 5 we present an extended list of requirements that are derived from several papers that examine access control for RDF. Like Bonatti and Olmedilla [9], De Coi et al. [23] investigate the interplay between trust, access control and policy languages. While, Yagüe et al. [104] examine the different layers of the Semantic Web, Damiani et al. [22] and Weitzner et al. [102] focus on the access control mechanisms that are required to support new access control paradigms and Ryutov et al. [72] investigating access control requirements from a graph data model perspective.
Using ontologies it is possible to specify access control vocabularies that can easily be adopted by others. Additionally, access control policies specified using different vocabularies can be merged using existing ontology integration and merging techniques.12
Ontology integration and merging techniques,
KAoS [11,12,97] is an open distributed architecture, which allows for the specification, management and enforcement of a variety of policies. In initial versions of the language, policies were represented using DAML.13
DAML,
In a follow up paper [94], the authors discuss how description logic can be used to support policy administration, exploration and disclosure. From an administration perspective the authors are primarily concerned with subsumption based reasoning and the determination of disjointness. The former is used to investigate if one class is a more general form of another (e.g. in role hierarchies an IT manager is also an employee) and the latter is used to ensure that sets of subjects, access rights and objects are mutually exclusive (e.g. a user cannot belong to an administrative roles and a non-administrative role). Using abductive reasoning it is possible to both test constraints, and to return relevant constraints given one or more properties. Using deductive reasoning it is possible to identify and resolve conflicts at design time. The authors propose a general algorithm for conflict resolution and harmonisation, which can be used even when the entities (
One of the benefits of a rule based approach is that it is possible to support access control policies that are dependent on dynamic constraints that can only be evaluated at run time. Like ontology based approaches, access control policies are defined over ontology entities. This section examines two different rule based languages and enforcement frameworks, Rei [48,49] and Protune [7–9].
Rei
Rei [48,49] is a Semantic Web policy language and distributed enforcement framework, which is used to reason over policies, that are specified using RDFS or Prolog rules. As OWL has a richer semantics than RDFS, the authors later provided an OWL representation for their policy language [24,47]. Like KAoS, Rei is a general policy language which can be applied to agents and web services [24,46]. Although Rei policies can be represented using RDFS or OWL the authors adopt a rule based enforcement mechanism, in contrast to the description logic enforcement mechanism adopted by KAoS.
a set of ontologies, used to represent the Rein policy network, which is composed of the Rein policy language, resources, policies and metapolicies (additional rules over the policy language commonly used to specify defaults and to resolve conflicts) and access requests; and a reasoning engine, that uses both explicit and derived knowledge to determine if a request should be granted or denied.
The authors propose a distributed enforcement architecture, whereby each entity is responsible for specifying and enforcing their own policies. Rein is capable of acting as a server or a client. In server mode, Rein retrieves the relevant policies; requests the credentials necessary to access the resource; and verifies the credentials against the policies. Whereas in client mode, the server returns a link to a policy which the client must satisfy; the Rein client generates a proof that the requester can satisfy the policy; and forwards the proof to the server. In order to cater for scenarios where part of the policy is private and part is public, the authors propose a hybrid approach, where Rein acts both as a client and a server. For example, if a company offers a discount for a product/service, the policy will request proof of a valid discount (i.e. the public part), however the details of the relevant discounts will not be disclosed (i.e. the private part). The details of how such a hybrid approach would work in practice are left to future work.
Using Rein it is possible to combine and reason over different access control policies, metapolicies and policy languages. Policies are expressed using either RDFS or OWL, and inference over both data resources and policies is performed using an N3 reasoner, known as Cwm.14
Cwm,
In Kagal et al. [49], the authors discuss how conflict resolution can be achieved using metapolicies. Priority policies are used to indicate dominance between policies or policy rules. While, precedence policies are used to specify a default grant or deny, for policies, sets of actions or sets of entities satisfying specific conditions. In order to guarantee that a decision can always be reached, the authors propose a partial order between metapolicies. Given Rei allows for policies to contain variables, conflicts need to be resolved at run-time, as opposed to design-time, in the case of KAoS.
Protune [7–9] is a policy language which was proposed by the Research Network of Excellence on Reasoning on the Web, known as REWERSE.15
REWERSE,
Decision predicates are used to specify the outcome of a policy. Provisional predicates are used to represent the conditions the requester must satisfy. By default the system supports two conditions: requests for credentials and request for declarations. Both credentials and declarations are used to assert facts about the requester, however credentials are certified by a third party, whereas declarations are not. Abbreviation predicates, which are composed of one or more provisional predicates, are used to represent abstractions of the conditions listed in the body of the rule, simplifying policy specification and maintenance.
It is also possible to extend the language with custom predicate categories. Ontologies are used to associate evidences (descriptive requirements of what is needed to meet the conditions) with access conditions. Evidences of this nature facilitate negotiation.
In protune metarules are used to specify constraints and to drive negotiation decisions. For instance using metarules it is possible to attach a provisional predicate to an action in order to specify the actor who is permitted to execute the action, or to assign sensitivity levels to predicates and rules that can be used for policy filtering (i.e. to remove the sensitive parts of the policy).
The negotiation handler is responsible for sending conditions to the requester and providing responses to conditions that were requested. The execution handler is used to interact with external systems and data sources. The inference engine is tasked with both enforcing policies (deduction) and retrieving evidences (abduction). How-to queries (provide a description of the policy). What-if queries (give foresight into potential policy outcomes). Why queries (give explanations for positive outcomes). Why-not queries (give explanations for negative outcomes).
Like Rei, Protune can be used as a client, as a server, or both. Protune-x is a key component of the Protune framework, which provides policy explanations in controlled natural language. Using verbalization metarules it is possible to specify in controlled natural language how domain-specific atoms have to be rendered. For example using the following rule it is possible to explain that Y is the password of X:
Protune is developed in Java with a Prolog reasoning component, which is compiled into Java byte code.
A hybrid approach to policy specification and enforcement can be used to exploit the out of the box deductive capabilities, of an ontology based approach, and the runtime inference capabilities, of a rule based approach. This section describes Proteus [92] which uses a combined approach to policy enforcement and examines an alternative approach, presented by Kolovski et al. [56] which demonstrates how description logic based access control policies can be extended with defeasible logic rules.
Proteus
Proteus [92] uses a hybrid approach to access control policy specification. The authors examine early versions of KAoS and Rei, and highlight the strengths and weaknesses of both ontology based and logic based policy languages and frameworks. Like KAoS the authors use ontologies to model both domain information and policies. Such an approach allows for conflict resolution and harmonisation at design time. Like Rei, the authors adopt a rule based approach in order to support dynamic constraints and run time variables. For example, to support access control based on dynamic context pertaining to the requester or the environment. Like Protune, policy descriptions are used to facilitate partial policy disclosure and policy negotiation.
The policy installation manager is responsible for loading ontologies, access control policies, contextual information and quality constraints. The reasoning core performs reasoning over policies, context and quality constraints in order to determine which policies are currently active. The policy enforcement manager intercepts action requests, collects relevant contextual information and interacts with the reasoning core in order to determine if access should be granted or denied. The context manager collects state information pertaining to system entities and forwards this contextual information to the reasoning core.
The authors provide details of their prototype which is implemented in Java with a Pellet reasoner. The proposed solution supports incremental reasoning via an OWL application programming interface and SPARQL queries.
Kolovski et al. [56]
Kolovski et al. [56] demonstrate how together description logic and defeasible logic rules, known as defeasible description logic [36], can be used to understand the effect and the consequence of sets of XACML access control policies.
The proposed XACML analysis prototype is implemented on top of Pellet (an open source description logic reasoner).
Access Control for RDF – Policy Representation and Enforcement

Access Control for RDF – Policy Representation and Enforcement
This section presents the different access control mechanisms that have been used to protect RDF data. In particular, it focuses on the specification of access control policies, the different enforcement mechanisms, the simplification of administration using different reasoning strategies and the alternative techniques used to return partial query results. A summary of the existing proposals is presented in Table 4. While, a detailed timeline is presented in Section 5.
Specification of access control for RDF
Over the years several researchers have focused on specification of access control policies over RDF data. A number of authors [1,31,41,70] define access control policies based on RDF patterns, that are mapped to one or more RDF triples. Others [17,33,57] propose view based access control strategies for distributed RDF data. Whereas, [17,18,74,76–78,86,87,100] propose access control ontologies.
RDF patterns
Triple patterns are triples that can potentially contain variables in the subject, predicate and object positions. From an access control perspective triple patterns are used to match multiple triples.
In Reddivari et al. [70] two predicates policy specific conditions relate to the access control policies, for example a user can only add instances if they added the class. triple specific conditions correspond to the triple specified in the authorisation, for example if an authorisation governs a triple then all triples associated with a subProperty relation are governed by the same policy. agent specific conditions use properties of the user to limit the authorisation, for example it is possible to limit access to users who are managers in a specific company division.
Abel et al. [ 1] , Flouris et al. [31] and Kirrane et al. [51,53] also use RDF triple patterns to expose or hide information represented as RDF. However, Abel et al. [1] and Flouris et al. [31] go beyond simple graph patterns by allowing the graph pattern to be constrained by a
Jain and Farkas [41] also use triple patterns to specify access control policies, however the authors build on the approach proposed by Reddivari et al. [70], by demonstrating how RDFS entailment rules can be used to derive access rights for inferred triples (see Section 4.4).
Views and named graphs
An RDF graph is a finite set of RDF triples. Named graphs are used to collectively refer to a number of RDF statements. A collection of RDF graphs, which can include a default graph and one or more named graphs is known as an RDF dataset.
Gabillon and Letouzey [33] highlight the possible administration burden associated with maintaining access control policies that are based on triple patterns. They propose the logical distribution of RDF data into views using SPARQL
Ontology concepts
Sacco and Passant [76,77] and Sacco et al. [78] demonstrated how an extension of the Web Access Control vocabulary known as the Privacy Preferences Ontology (PPO) can be used to restrict access to an RDF resources, statements and graphs. An access control policy is composed of:
a restriction in the form of an RDF resource, statement or graph; a condition which provides specific details of the restriction, for example an access privilege, for example a SPARQL
A follow-up paper Sacco and Breslin [74] extends the original PPO to allow access to be restricted based on a dataset or a particular context. The authors also provide support for more expressive authorisations (in the form of negation and logical operators), and a broader set of access privileges (
An alternative access control vocabulary called Social Semantic SPARQL Security for Access Control (S4AC) is presented in Villata et al. [100]. Like Sacco and Passant [76] they extend the WAC to cater for fine grained access control over RDF data. Their proposal is tightly integrated with several social web and web of data vocabularies. The authors define access control policies for named graphs, which can also be used to grant/deny access to sets of triples. S4AC provides support for logical operators and a broad set of access privileges (
In contrast Steyskal and Polleres [86] discuss how an alternative vocabulary known as the Open Digital Rights Language (ODRL) 2.0 ontology can be used to specify access policies for Linked Data. The ODRL vocabulary is more general than the WAC vocabulary, and thus in addition to standard access control policies the authors demonstrate how ODRL can be used to represent common licenses and policies that require payment. In a follow-up paper [87], the authors propose a formal semantics for ODRL, which can be used as the basis for rule based reasoning over ODRL policies.
Enforcement of access control for RDF
Over the years several researchers have focused on the modelling and enforcement of access control over RDF data. Existing proposals can be summarised as follows: (i) demonstrating how access control can be enforced on top of RDF Data [33,70]; and (ii) enforcing access control over access control policies represented as RDF using SPARQL
Policy layer
Reddivari et al. [70] define a set of actions required to manage an RDF store and demonstrate how access control rules can be used to permit or prohibit the requested actions. The actions are organised into four categories:
The proposed RDF Store Access Control Policies (RAP) framework checks the policy to ensure that the action is permitted, temporarily allows the action, and afterwards checks the policy to ensure that the inferences are allowed. The authors propose default and conflict preferences that can simply be set to either permit or deny.
Like Reddivari et al. [70], Flouris et al. [31] propose a default policy and a conflict resolution strategy. They formally define the semantics of the individual access control statements and the entire access control policy, and present the different possible interpretations for the default semantics and the conflict resolution. A flexible system architecture that demonstrates how the access control enforcement framework can be used with disparate RDF repositories and query languages is presented. The system is implemented using Jena ARQ, Jena SDB with a Postgresql back-end and Sesame.
Gabillon and Letouzey [33] describe an enforcement framework, whereby users define security policies for the RDF graph/views that they own. Users may delegate rights to other users by specifying an authorisation which grants
SPARQL ASK queries
Sacco and Passant [76,77] and Sacco et al. [78] describe the formal semantics of the PPO and present a detailed description of their Privacy Preferences Manager (PPM), which can be used to enforce access control using SPARQL
Like Sacco and Passant [76], Villata et al. [100] use SPARQL
LDP,
BTC2012,
Inference is a process whereby new data is derived from data which is known or assumed to be true. Section 3 discussed how deduction and abduction can be used to simplify both policy specification and maintenance. However, inference can also be used to deduce information, which users should not have access to, commonly known as the inference problem. Both Thuraisingham [91] and Nematzadeh and Pournajaf [62] highlight the need for security mechanisms to protect against such unauthorised inference. Although this is not a new problem, the authors argue that with advances in current data integration and mining technologies, the problem is further magnified. According to Qin and Atluri [69], if the semantic relationship between entities is not taken into account it may be possible to infer information which has been restricted, or access control policies may not exist for the inferred information making this information inaccessible.
Existing reasoning proposals focus on: (i) demonstrating how access rights can be inferred for new triples deduced based on RDFS inference rules [41,50,58,65]; (ii) the propagation of access rights based on authorisation subjects, access rights and resources [3,43,69,72]; (iii) proposing a flexible authorisation framework [51,53]; and (iv) examining use cases where it is desirable to grant access to data which has been inferred from unauthorised data [4].
RDFS inference
When it comes to RDFS inference, there are two different strands of research. The first infers access rights for triples that are inferred using RDFS entailment rules [41,50]. Whereas the second uses RDFS entailment rules to propagate permissions for triples that already exist [58,65].
While, Kim et al. [50] demonstrate how together authorisations and RDFS inference rules can be used to generate new authorisations as opposed to simply access control annotations in the case of Jain and Farkas [41]. An authorisation is defined as a four tuple
directly associated with triples; inferred using RDF inference rules; propagated using RDF inference rules; or assigned a default label.
The authors demonstrate how the RDFS
Lopes et al. [ 58] demonstrate how AnQL an extension of the SPARQL query language can be used to enforce access control, by rewriting using the requesters credentials to rewrite a SPARQL query to an AnQL query. A follow-up paper [52] demonstrates how custom rules can be used to support multiple access control models and demonstrate how rules can be used to propagate permissions: based on hierarchies of authorisation subjects, access rights and resources; to triples with the same subject; and using resource typing.
Papakonstantinou et al. [65] evaluate their prototype over both ProgresSQL and MonetDB relational databases. Based on their performance evaluation of both the inference and propagation rules, the authors concluded that more efficient storage and indexing schemes are required.
Propagation of authorisations
Early proposals for the propagation of authorisations focused on reasoning over ontology concepts [69]. Subsequent work by Javanmardi et al. [43,44] focused not only on ontology concepts but also on reasoning over ontology properties and ontology instances. An alternative strategy which is proposed by Ryutov et al. [72,73], takes a more abstract approach by propagating policies based on nodes and edges in a semantic network.
The Semantic Based Access Control Model (SBAC) proposed by Javanmardi et al. [43,44], builds on the work presented in Qin and Atluri [69], by catering for access control policy propagation, not only based on the semantic relations between ontology concepts, but also based on the relations between concepts, properties and individuals. Like Qin and Atluri [69], OWL vocabularies are used to represent the authorisation subjects, permissions and objects, however the authorisations themselves are specified using rules. The authors propose the propagation of access rights based on seven different types of inference, from:
concept to concept (where classes are deemed related based on some vocabulary, for example concept to individual (where an entity is a type of class, for example if employee is a class and JoeBloggs individual to individual (using properties such as property to concept (if access is granted to the property access should be granted to the classes governed by property to property (where properties are deemed related based on some vocabulary. For example property to individual (where an entity is a type of property, for example if roles is a property and manager is of concept to property (where access is granted to a concept it should also be granted to all properties relating to that concept).
The authors describe how the aforementioned semantic relations can be reduced to subsumption relations and propose a general propagation strategy for subsumption relations among subjects, permissions and objects. In the case of subjects and objects, both positive and negative access rights propagate from subsumee to subsumer. However, in the case of permissions positive access rights propagate from subsumee to subsumer, while negative access right propagate from subsumer to subsumee.
Although an architecture is presented by Javanmardi et al. [43], very little detail on the actual enforcement mechanism is supplied. Follow-up papers by Ehsan et al. [26] and Amini and Jalili [3] build on previous work, by providing for an access control model with formal semantics and an enforcement framework, which is suitable for distributed semantic aware environments (for example Semantic Web, Semantic Grid and Semantic Cloud Computing). Policy rules, in both the conceptual and individual levels, are specified using a combination of deontic and description logic, which they refer to as using the parallelisation facilities of the tableaux system; adopting a proof based approach where the requester presents authorisation rules that demonstrate they can access the requested resource; and materialisation of inferred relations in advance.
Flexible reasoning framework
Kirrane et al. [51,53] demonstrate how authorisations based on quad patterns together with stratified Datalog rules can be used to enforce DAC over the RDF data model. An RDF quad pattern is an RDF quad with optionally a variable V in the subject, predicate, object and/or graph position. A quad pattern is a flexible mechanism which can be used to grant/restrict access to an RDF quad, a collection of RDF quads (multiple quads that share a common subject), a named graph (arbitrary views of the data), specific classes or properties. The authors describe how the hierarchical Flexible Authorisation Framework proposed by Jajodia et al. [42], which is composed of authorisations, propagation policies, conflict resolution rules and integrity constraints, can be extended to cater for the RDF graph data model. They describe how together pattern matching and propagation rules can be used to ease the maintenance of access control policies for linked data sources; and show how conflict resolution policies and integrity constraints can ensure access control policy integrity. Propagation policies can be used to simplify authorisation administration by allowing for the derivation of implicit authorisations from explicit ones. Rather than propose a conflict resolution strategy the authors provide a formal definition for a conflict resolution rule that can be used to determine access given several different conflict resolution strategies. For example conflict resolution policies based on the structure of the graph data system components; the sensitivity of the data requested; or contextual conditions pertaining to the requester. Integrity constraints are used to restrict authorisation creation based on the existing relationships between SPARQL operations and RDF data items. For example,
Safe reasoning
When it comes to reasoning over restricted data, there is a general consensus that any information that can be inferred from restricted data should also be restricted. An alternative viewpoint is presented by Bao et al. [4]. The authors focuses on a number of use cases where it is desirable to grant access to information that has been inferred from restricted data:
a calendar showing the existence of an appointment without revealing specifics; a booking engine sharing partial hotel details; and a pharmacy confirming that the patients drugs are reimbursable without disclosing details.
The open world assumption is used to ensure that users cannot distinguish between information which does not exist and information with is inaccessible. The authors stipulate that, the knowledge base should not lie, the answers given should be independent of any previous answers and it should not be possible to infer any restricted data. The authors propose a safe reasoning strategy is based on the notion of conservative extension. Essentially the reasoner keeps a history of the answers to all previous queries. For each subsequent query, the history is consulted, in order to verify that unauthorised information cannot be inferred by the requester.
Partial query results
A number of the access control mechanisms for RDF data that have been presented, demonstrate how their access control can be enforced on top of SPARQL queries. However, the solutions examined thus far either grant or deny access to the entire query. This section examines how data filtering [25,60] and query rewriting [1,14,17,32,64] can be used to return partial query results when access to some of the results is restricted by an access control policy.
Data filtering
Dietzold and Auer [25] examine access control requirements for an RDF store from a semantic wiki perspective. The authors propose access control policy specification at multiple levels of granularity (triples, classes and properties). In addition, they define three atomic actions (
Mühleisen et al. [60] describe a Policy-enabled Linked Data Server (PeLDS), which uses WebID to authenticate users. The policy language caters for the specification of access control policies for particular triple patterns, resources or instances, using SWRL rules. An OWL ontology is used to identify the rule types (
Query rewriting
Existing query rewriting strategies involve: limiting the query to a specific named graph [17]; rewriting a view so that it considers propagation rules and both instance and range restrictions [57]; and creating bindings for variables and adding them to the query
Franzoni et al. [32] propose a query rewriting strategy, which is used to grant/deny access to ontology instances. The authors rewrite queries to take into account contextual information, pertaining to the user or the environment. A fine grained access control (FGAC) policy is defined as a tuple:
target is the resource that the policy relates to; property is a path expression, which either directly or indirectly relates to the target; attribute is the user attributes, that are bound to the path expression variables; and operator is the filter condition.
The authors propose a two tiered approach to access control enforcement. Access control policies are used to determine if access should be granted or denied. FGAC policies are only applied if access is granted. If the query contains one ore more FGAC policy targets, the query is rewritten to include the path expression and a
Chen and Stuckenschmidt [14] present a query rewriting strategy, which can be used to restrict access to data represented using ontologies. The authors focus on restricting access to instance data. Access control policies are used to deny access to specific individuals or to grant/deny access to instances associated with a given class or property. When access is prohibited to specific individuals, a
Oulmakhzoune et al. [64] propose a query rewriting strategy for SPARQL queries. In the presented modelling, both positive and negative authorisations are composed of sets of filters that are associated with simple conditions or involved conditions. Given a SPARQL query the algorithm examines each individual basic graph pattern (BGP). In the case of simple conditions, when authorisations permit/deny access to a single triple pattern, the following query rewriting strategy is applied: If all authorisations that match the triple pattern, permit access to the triple pattern, no action is required; If all authorisations prohibit access to the triple pattern, the triple pattern is deleted; Otherwise, if the BGP is converted to an
Access control requirements for Linked Data
More recently, the focus has shifted to the specification and enforcement of access control over Linked Data. Costabello et al. [19], Sacco et al. [78] and Kirrane et al. [51] describe how their policy languages and frameworks can be used in conjunction with Linked Data, and Steyskal and Polleres [86] discuss how ODRL can be used to specify access policies for Linked Data. However, any of the access control mechanisms examined thus far could potentially be used (albeit to a lesser or greater extent) to enforce access control over Linked Data.
This section provides a summary of existing requirements for RDF data, and uses these requirements to categorise existing access control strategies that have been proposed for RDF. As the work presented in Section 2 focused on extending existing access control models and standards as opposed to enforcing access control over RDF, the analysis is limited to the policy languages presented in Section 3 and the different access control strategies described in Section 4.
The requirements presented below are derived from several papers that examine access control for RDF from a number of perspectives. Yagüe et al. [104] examine the different layers of the Semantic Web and how the technologies and concepts can be applied to access control. Both Damiani et al. [22] and Weitzner et al. [102] focus on the access control mechanisms that are required to support new access control paradigms where user privacy is a key requirement. De Coi et al. [23] and Bonatti and Olmedilla [9] investigate the interplay between trust, access control and policy languages. While, Ryutov et al. [72] focus more on the data model, investigating access control requirements from a graph perspective, as opposed to the traditional hierarchical approach. We also consider the set of access control guidelines devised by the W3C Linked Data Platform Working Group (LDP)18
LDP,
Although it would also be interesting to examine the access control requirements arising from emerging Linked Data access strategies (e.g. Linked Data Fragments) and novel languages for navigating and consuming triples on the Web (e.g. nSPARQL), as these technologies are still evolving such an investigation is left to future work.
To ease referenceability the access control requirements are categorised under the headings specification, enforcement, administration and implementation.
Specification requirements – A = attributes, C = context, O = obligation, P = permission
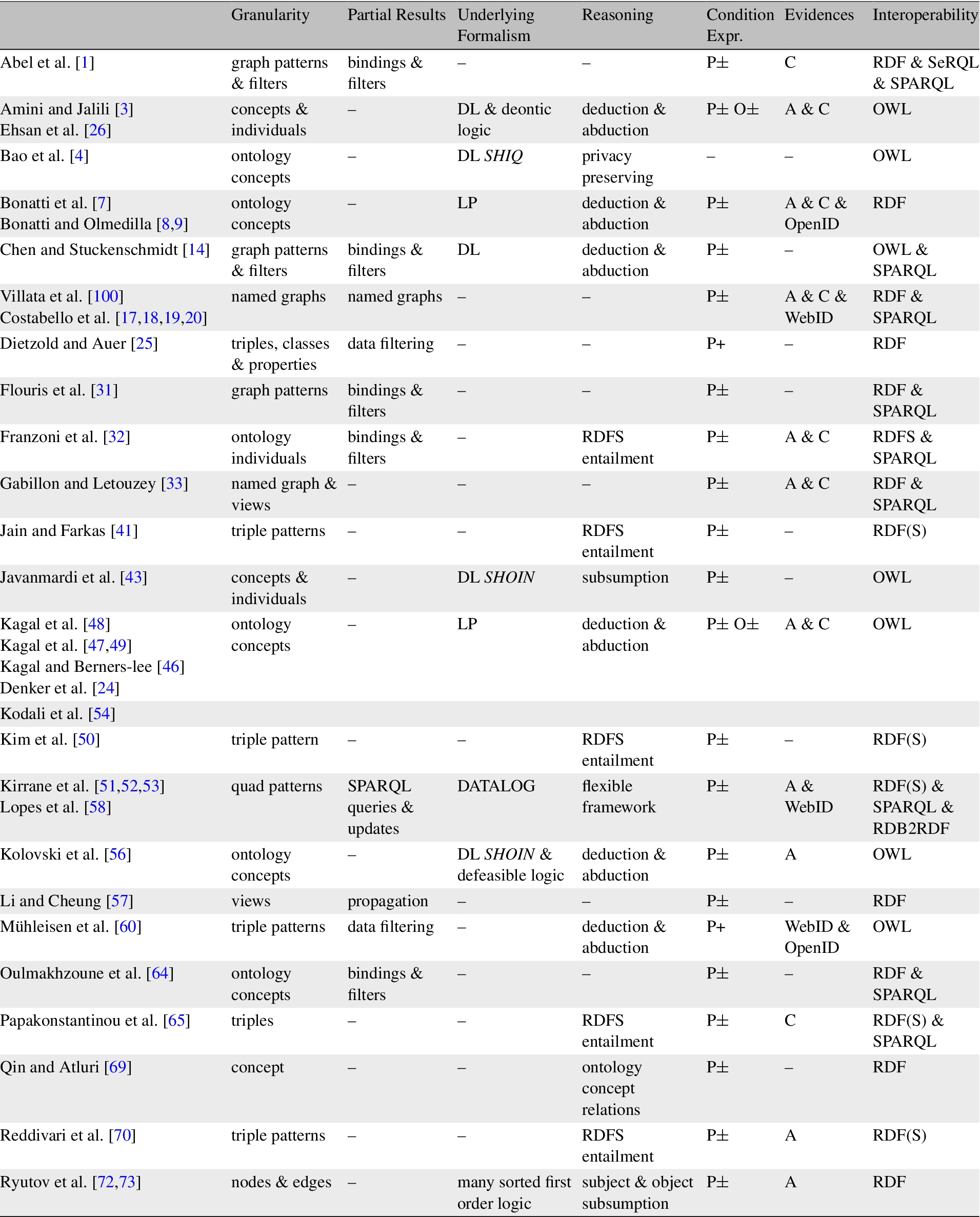
Generally speaking, access control policy specification requirements relate to the types of policies that can be expressed, and the interoperability of the chosen representation format. An overview of each of the requirements relating to access control specification is presented below and a summary of existing proposals is depicted in Table 5 and the corresponding timeline is represented in Fig. 3. One requirement, which was not included is

Access Control Specification.
OpenID,

Access Control Enforcement.
Enforcement requirements

Access control enforcement requirements refer to constraints that are placed on the policy language or mechanisms that assist the requester to complete their request. An overview of the requirements is presented below and a snapshot of existing support for said requirements is presented in Table 6 and the corresponding timeline is represented in Fig. 4.
Administration requirements

Administration requirements

Access Control Administration.
This section presents a number of access control requirements that are necessary to simplify the specification and maintenance of access control policies. An overview of the requirements is presented below and a summary of current support is presented in Table 7 and the corresponding timeline is represented in Fig. 5. Although a number of researchers indicate that they provide some level of support for these requirements, generally speaking research efforts seem to focus more on the specification and enforcement mechanisms, and very little detail is supplied.
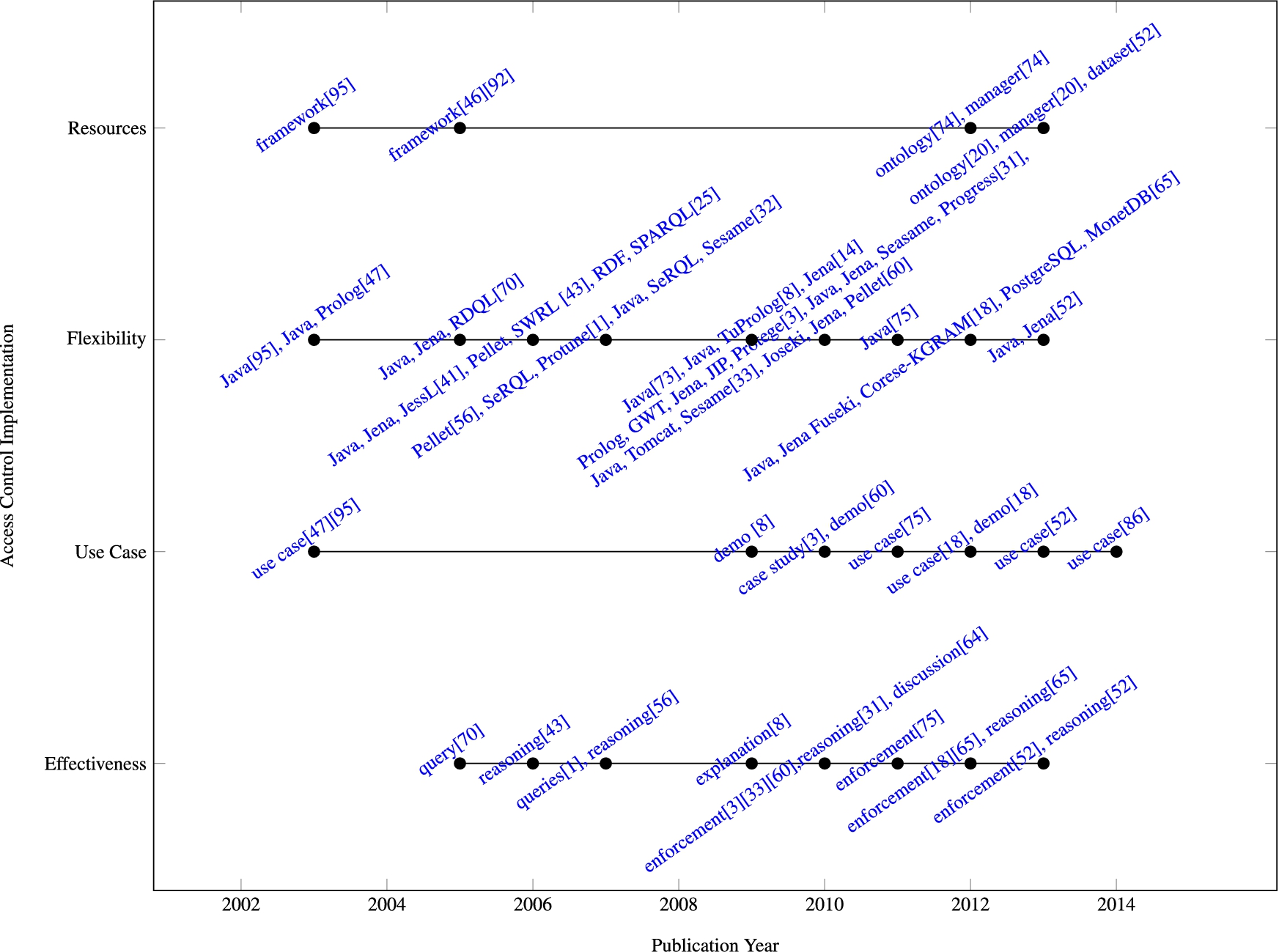
Access Control Implementation.
Implementation requirements generally refer to non-functional requirements. As with any software system, non-functional requirements hold the key to the adoption of a tool or technology. Although a number of authors indicate that the solutions they propose are flexible or extensible, seldom do researchers evaluate these claims. Table 8 and the corresponding timeline is represented in Fig. 6 provide an overview of the technologies adopted and indicates the evaluations performed. Where applicable a link to the ontology, framework, dataset or demo is provided under the heading ‘Available Resources’.
Implementation requirements
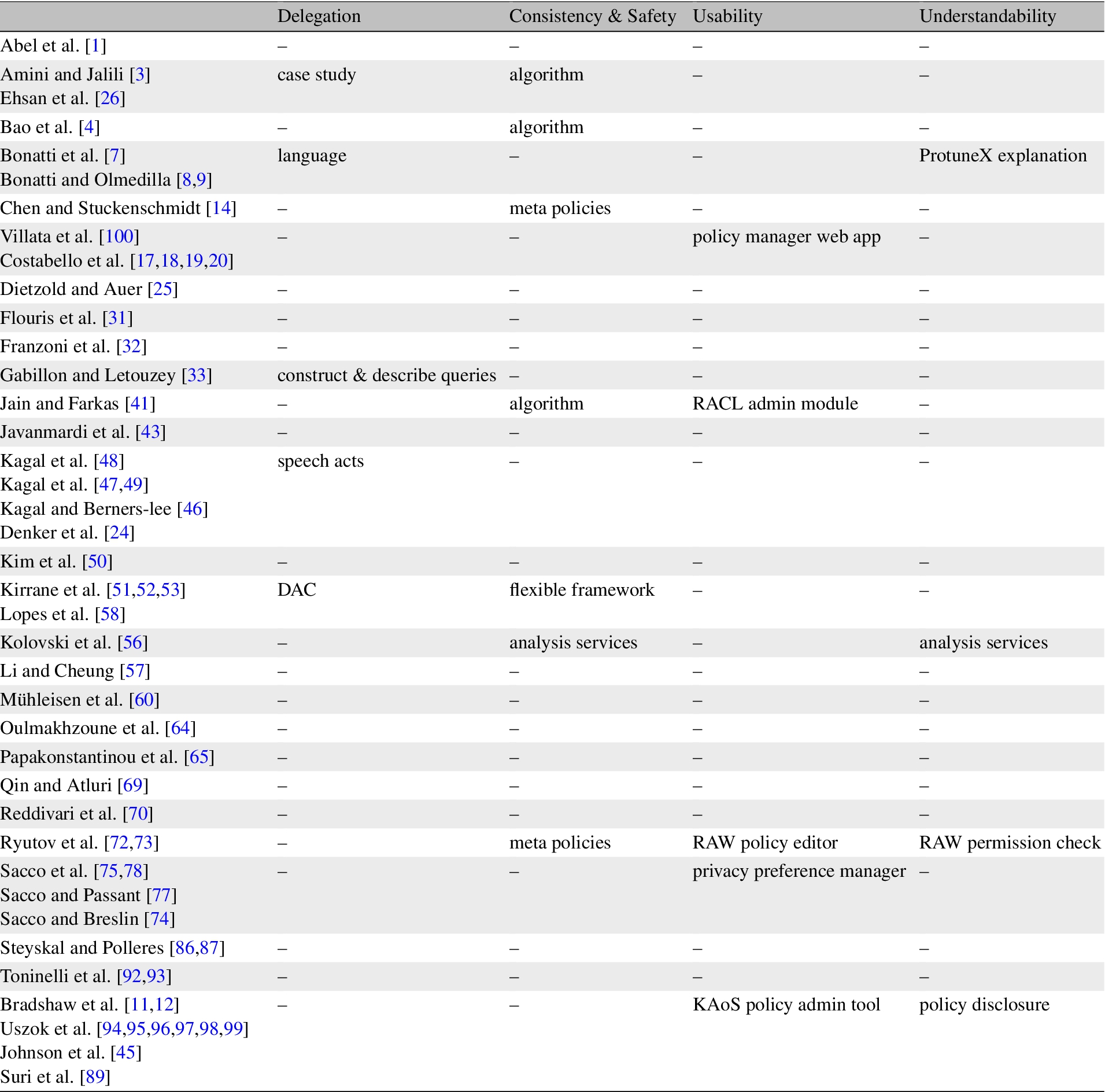
Implementation requirements
This paper provided an overview of relevant access control models (MAC, DAC, RBAC, VBAC, ABAC, CBAC) and standardisation efforts (XACML, WebID, WAC, P3P, APPEL, ODRL), and described how they have been either enhanced by/applied to RDF. A number of well known policy languages, that adopt ontology based, rule based and combined ontology and rule based access control enforcement mechanisms were examined in detail. Several different strategies that have be used to specify access control over RDF (triple patterns, views, named graphs and ontologies) and various reasoning, filtering and query rewriting strategies were presented. Finally, a set of requirements for Linked Data, based on several papers that examine access control for RDF from a number of perspectives, were derived. These requirements were subsequently used to classify the various access control specification, enforcement and administration strategies that have been proposed for RDF data.
Based on this analysis a number of gaps with respect to access control for Linked Data, which still need to be addressed were identified:
Access control administration in general, and over large datasets in particular, can become extremely difficult to manage. Access control policies may be composed of authorisations specified at multiple levels of granularity. In addition, permissions may be inferred or propagated using different inferencing mechanisms, making the task of administration even more cumbersome. An interesting avenue for future work, would be to investigate if graph based data clustering and visualisation techniques, such as those proposed by [61], can be used to assist systems administrators to examine the interplay between authorisations and rules, and also determine the impact of new authorisations.
The benefits associated with explanations are two fold: (i) they allow the requester to understand what is required of them and (ii) they enable the policy owner to troubleshoot potential issues with existing policies. However, when it comes to explanations in particular and negotiation in general, there is a fine line between usability and security. As such, different levels of detail may need to be relayed to the requester depending on the context. In order to devise guidelines for access control explanations, it would be beneficial to examine the different reasons for access denial and the potential security impact associated with both single and multiple explanations.
In order to work in practice, both access control enforcement and administration need to be effective from both a performances and a correctness perspective. Although a number of authors have conducted access control performances evaluations using the BSBM dataset, when it comes to access control for RDF data there is currently no general access control benchmark. In addition, there is a pressing need for general mechanisms that can be used to verify the correctness of proposed access control strategies.