
Abstract
Recent years have witnessed a new trend of building ontology-based question answering systems. These systems use semantic web information to produce more precise answers to users’ queries. However, these systems are mostly designed for English. In this paper, we introduce an ontology-based question answering system named KbQAS which, to the best of our knowledge, is the first one made for Vietnamese. KbQAS employs our question analysis approach that systematically constructs a knowledge base of grammar rules to convert each input question into an intermediate representation element. KbQAS then takes the intermediate representation element with respect to a target ontology and applies concept-matching techniques to return an answer. On a wide range of Vietnamese questions, experimental results show that the performance of KbQAS is promising with accuracies of 84.1% and 82.4% for analyzing input questions and retrieving output answers, respectively. Furthermore, our question analysis approach can easily be applied to new domains and new languages, thus saving time and human effort.
Keywords
Introduction
Accessing online resources often requires the support from advanced information retrieval technologies to produce expected information. This brings new challenges to the construction of information retrieval systems such as search engines and question answering (QA) systems. Given an input query expressed in a keyword-based mechanism, most search engines return a long list of title and short snippet pairs ranked by their relevance to the input query. Then the user has to scan the list to get the expected information, so this is a time consuming task [66]. Unlike search engines, QA systems directly produce an exact answer to an input question. In addition, QA systems allow to specify the input question in natural language rather than as keywords.
In general, an open-domain QA system aims to potentially answer any user’s question. In contrast, a restricted-domain QA system only handles the questions related to a specific domain. Specifically, traditional restricted-domain QA systems make use of relational databases to represent target domains. Subsequently, with the advantages of the semantic web, the recent restricted-domain QA systems employ knowledge bases such as ontologies as the target domains [30]. Thus, semantic markups can be used to add meta-information to return precise answers for complex natural language questions. This is an avenue which has not been actively explored for Vietnamese.
In this paper, we introduce the first ontology-based QA system for Vietnamese, which we call KbQAS. KbQAS consists of question analysis and answer retrieval components. The question analysis component uses a knowledge base of grammar rules for analyzing input questions; and the answer retrieval component is responsible for interpreting the input questions with respect to a target ontology. The association between the two components is an intermediate representation element which captures the semantic structure of any input question. This intermediate element contains properties of the input question including question structure, question category, keywords and semantic constraints between the keywords.
The key innovation of KbQAS is that it proposes a knowledge acquisition approach to systematically build a knowledge base for analyzing natural language questions. To convert a natural language question into an explicit representation in a QA system, most previous works so far have used rule-based approaches, to the best of our knowledge. The manual creation of rules in an ad-hoc manner is more expensive in terms of time and effort, and it is error-prone because of the representation complexity and the variety of structure types of the questions. For example, rule-based methods, such as for English [26] and for Vietnamese as described in the first KbQAS version [37], manually define a list of pattern structures to analyze the questions. As rules are created in an ad-hoc manner, these methods share common difficulties in controlling the interaction between the rules and keeping the consistency among them. In our question analysis approach, however, we apply Single Classification Ripple Down Rules knowledge acquisition methodology [10,47] to acquire the rules in a systematic manner, where consistency between rules is maintained and an unintended interaction among rules is avoided. Our approach allows an easy adaptation to a new domain and a new language and saves time and effort of human experts.
The paper is organized as follows. We provide related work in Section 2. We describe KbQAS and our knowledge acquisition approach for question analysis in Sections 3 and 4, respectively. We evaluate KbQAS in Section 5. The conclusion will be presented in Section 6.
Short overview of question answering
Open-domain question answering
The goal of an open-domain QA system is to automatically return an answer for every natural language question [21,31,63]. For example, such systems as START [23], FAQFinder [8] and AnswerBus [68] answer questions over the Web. Subsequently, the question paraphrase recognition task is considered as one of the important tasks in QA. Many proposed approaches for this task are based on machine learning as well as knowledge representation and reasoning [5,7,16,22,48,67].
Since aroused by the QA track of the Text Retrieval Conference [59] and the multilingual QA track of the CLEF conference [42], many open-domain QA systems from the information retrieval perspective [24] have been introduced. For example, in the TREC-9 QA competition [58], the Falcon system [20] achieved the highest results. The innovation of Falcon focused on a method using WordNet [17] to boost its knowledge base. In the QA track of the TREC-2002 conference [60], the PowerAnswer system [33] was the most powerful system, using a deep linguistic analysis.
Traditional restricted-domain question answering
Usually linked to relational databases, traditional restricted-domain QA systems are called natural language interfaces to databases. A natural language interface to a database (NLIDB) is a system that allows the users to access information stored in a database by typing questions using natural language expressions [2]. In general, NLIDB systems focus on converting the input question into an expression in the corresponding database query language. For example, the LUNAR system [64] transfers the input question into a parsed tree, and the tree is then directly converted into an expression in a database query language. However, it is difficult to create converting rules that directly transform the tree into the query expression.
Later NLIDBs, such as Planes [61], Eufid [51], PRECISE [46], C-Phrase [32] and the systems presented in [35,50], use semantic grammars to analyze questions. The semantic grammars consist of the hard-wired knowledge orienting a specific domain, so these NLIDB systems need to develop new grammars whenever porting to a new knowledge domain.
Furthermore, some systems, such as TEAM [29] and MASQUE/SQL [1], use syntactic-semantic interpretation rules driving logical forms to process the input question. These systems firstly transform the input question into an intermediate logical expression of high-level world concepts without any relation to the database structure. The logical expression is then converted to an expression in the database query language. Here, using the logical forms enables those systems to adapt to other domains as well as to different query languages [49]. In addition, there are many systems also using logical forms to process the input question, e.g. [6,15,18,25,33,52,56].
Ontology-based question answering
As a knowledge representation of a set of concepts and their relations in a specific domain, an ontology can provide semantic information to handle ambiguities, to interpret and answer user questions in terms of QA [27]. A discussion on the construction approach of an ontology-based QA system can be found in [4]. This approach was then applied to build the MOSES system [3], with the focus on the question analysis. The following systems are some typical ontology-based QA systems.
The AquaLog system [26] performs semantic and syntactic analysis of the input question using resources including word segmentation, sentence segmentation and part-of-speech tagging, provided by the GATE framework [11]. When a question is asked, AquaLog transfers the question into a query-triple form of (generic term, relation, second term) containing the keyword concepts and relations in the question, using JAPE grammars in GATE. AquaLog then matches each element in the query-triple to an element in the target ontology to create an onto-triple, using string-based comparison methods and WordNet [17]. Evolved from AquaLog, the PowerAqua system [28] is an open-domain system, combining the knowledge from various heterogeneous ontologies which were autonomously created on the semantic web. Meanwhile, the PANTO system [62] relies on the statistical Stanford parser to map an input question into a query-triple; the query-triple is then translated into an onto-triple with the help of a lexicon of all entities from a given target ontology enlarged with WordNet synonyms; finally, the onto-triple and potential words derived from the parse tree are used to produce a SPARQL query on the target ontology.
Using the gazetteers in the GATE framework, the QuestIO system [13] identifies the keyword concepts in an input question. Then QuestIO retrieves potential relations between the concepts before ranking these relations based on their similarity, distance and specificity scores; and so QuestIO creates formal SeRQL or SPARQL queries based on the concepts and the ranked relations. Later the FREyA system [12], the successor of QuestIO, allows users to enter questions in any form and interacts with the users to handle ambiguities if necessary.
In the ORAKEL system [9], wh-questions are converted to F-Logic or SPARQL queries by using domain-specific Logical Description Grammars. Although ORAKEL supports compositional semantic constructions and obtains a promising performance, it involves a customization process of the domain-specific lexicon. Also, another interesting work over linked data as detailed in [55] proposed an approach to convert the syntactic-semantic representations of the input questions into the SPARQL templates. Furthermore, the Pythia system [54] relies on ontology-based grammars to process complex questions. However, Pythia requires a manually created lexicon.
Question answering and question analysis for Vietnamese
Turning to Vietnamese question answering, Nguyen and Le [35] introduced a Vietnamese NLIDB system using semantic grammars. Their system includes two main modules: the query translator (QTRAN) and the text generator (TGEN). QTRAN maps an input natural language question to an SQL query, while TGEN generates an answer based on the table result of the SQL query. The QTRAN module uses limited context-free grammars to convert the input question into a syntax tree by means of the CYK algorithm [65]. The syntax tree is then converted into an SQL query by using a dictionary to identify names of attributes in the database and names of individuals stored in these attributes. The TGEN module combines pattern-based and keyword-based approaches to make sense of the meta-data and relations in database tables to produce the answer.
In our first KbQAS conference publication [37], we reported a hard-wired approach to convert input questions into intermediate representation elements which are then used to extract the corresponding elements from a target ontology to return answers. Later, Phan and Nguyen [45] described a method to map Vietnamese questions into triple-like formats (Subject, Verb, Object). Subsequently, Nguyen and Nguyen [36] presented another ontology-based QA system for Vietnamese, where keywords in an input question are identified by using pre-defined templates, and these keywords are then used to produce a SPARQL query to retrieve a triple-based answer from a target ontology. In addition, Tran et al. [53] described the VPQA system to answer person name-related questions while Nguyen et al. [34] presented another NLIDB system to answer questions in the economic survey domain.
Our KbQAS question answering system
This section gives an overview of KbQAS. The architecture of KbQAS, as shown in Fig. 1, contains two components: the natural language question analysis engine and the answer retrieval component.

System architecture of KbQAS.
The question analysis component consists of three modules: preprocessing, syntactic analysis and semantic analysis. This component takes the user question as an input and returns an intermediate element representing the input question in a compact form. The role of the intermediate representation element is to provide the structured information about the input question for the later process of answer retrieval.
The answer retrieval component contains two modules: ontology mapping and answer extraction. It takes the intermediate representation element produced by the question analysis component and an ontology as its input to generate the answer.

Illustrations of question analysis and question answering.
Unlike AquaLog [26], the intermediate representation element in KbQAS covers a wider variety of question types. This element consists of a question structure and one or more query tuples in the following format: (sub-structure, question category, Term1, Relation, Term2, Term3)
We define the following question structures: Normal, UnknTerm, UnknRel, Definition, Compare, ThreeTerm, Clause, Combine, And, Or, Affirm_MoreTuples, Affirm, Affirm_3Term, and question categories: What, When, Where, Who, HowWhy, YesNo, Many, ManyClass, List and Entity. See Appendices A and B for details of these definitions.
A simple question has only one query tuple and its question structure is the sub-structure in the query tuple. A complex question, such as a composite one, has several sub-questions, where each sub-question is represented by a separate query tuple, and the question structure captures this composite factor.
For example, the question “Phạm Đức Đăng học trường đại học nào và được hướng dẫn bởi ai ?” (“Which university does Pham Duc Dang enroll in and who tutors him ?”) has the Or question structure and two query tuples where ? represents a missing attribute: (Normal, Entity, trường đại họcuniversity, họcenroll, Phạm Đức ĐăngPham Duc Dang, ?) and (UnknTerm, Who, ?, hướng dẫntutor, Phạm Đức ĐăngPham Duc Dang, ?).
The intermediate representation element is designed so that it can represent various types of question structures. Therefore, attributes such as Relation or terms in the query tuple can be missing. For example, a question has the Normal question structure if it has only one query tuple and Term3 is missing.
An illustrative example
For demonstration1
The KbQAS is available at
Given a complex-structure question “Liệt kê tất cả sinh viên học lớp K50 khoa học máy tính mà có quê ở Hà Nội” (“List all students enrolled in the K50 computer science course, whose hometown is Hanoi”), the question analysis component determines that this question has the And question structure with two query tuples (Normal, List, sinh viênstudent, họcenrolled, lớp K50 khoa học máy tínhK50 computer science course, ?) and (Normal, List, sinh viênstudent, có quêhas hometown, Hà NộiHanoi, ?).
In the answer retrieval component, the ontology mapping module maps the query tuples to ontology tuples: (sinh viênstudent, họcenrolled, lớp K50 khoa học máy tínhK50 computer science course) and (sinh viênstudent, có quêhas hometown, Hà NộiHanoi). For each ontology tuple, the answer extraction module finds all satisfied instances in the target ontology, and it then generates an answer based on the And question structure and the List question category. Figure 2 shows the answer.
The natural language question analysis component is the first component in any QA system. When a question is asked, the task of this component is to convert the input question into an intermediate representation which is then used in the rest of the system.
KbQAS makes use of the JAPE grammars in the GATE framework [11] to specify semantic annotation-based regular expression patterns for question analysis, in which existing linguistic processing modules for Vietnamese including word segmentation and part-of-speech tagging [44] are wrapped as GATE plug-ins. The results of the wrapped plug-ins are annotations covering sentences and segmented words. Each annotation has a set of feature-value pairs. For example, a word has a category feature storing its part-of-speech tag. This information can then be reused for further processing in subsequent modules. The new question analysis modules of preprocessing, syntactic analysis and semantic analysis in KbQAS are specifically designed to handle Vietnamese questions using patterns over existing linguistic annotations.
Preprocessing module
The preprocessing module generates TokenVn annotations representing a Vietnamese word with features, such as part-of-speech, as displayed in Fig. 3. Vietnamese is a monosyllabic language; hence, a word can contain more than one token. So there are words or word phrases which are indicative of the question categories, such as “phải khôngis that/are there”, “là bao nhiêuhow many”, “ở đâuwhere”, “khi nàowhen” and “là cái gìwhat”. However, the Vietnamese word segmentation module was not trained on the question domain. In this module, therefore, we identify those words or phrases and label them as single TokenVn annotations with the question-word feature and its semantic category, like HowWhy cause/method , YesNo true or false , What something , When time/date , Where location , Many number or Who person . In fact, this information will be used to create rules in the syntactic analysis module at a later stage.

Examples of TokenVn annotations.
We also label special words, such as abbreviations of words on a special domain, and phrases that refer to a comparison, such as “lớn hơngreater than”, “nhỏ hơn hoặc bằngless than or equal to” and the like, by single TokenVn annotations.

Examples of question structure patterns.
The syntactic analysis module is responsible for identifying concepts, entities and the relations between them in the input question. This module uses the TokenVn annotations which are the output of the preprocessing module.
Concepts and entities are normally expressed in noun phrases. Therefore, it is crucial to identify noun phrases in order to generate the query tuple. Based on the Vietnamese language grammar [14], we use the JAPE grammars to specify patterns over annotations as shown in Table 1. When a noun phrase is matched, a NounPhrase annotation is created to mark up the noun phrase. In addition, a type feature of the NounPhrase annotation is used to determine whether concept or entity is covered by the noun phrase, using the following heuristics: if the noun phrase contains a single noun (not including numeral nouns) and does not contain a proper noun, it covers a concept. If the noun phrase contains a proper noun or at least three single nouns, it covers an entity. Otherwise, the type feature value is determined by using a dictionary.2
The dictionary contains concepts which are extracted from the target ontology. However, there is no publicly available WordNet-like lexicon for Vietnamese. So we manually add synonyms of the extracted concepts to the dictionary.
JAPE grammar for identifying Vietnamese noun phrases
Furthermore, the question phrases are detected by using the matched noun phrases and the question-words which are identified by the preprocessing module. QuestionPhrase annotations are generated to cover the question phrases, with a category feature that gives information about question categories.
The next step is to identify relations between noun phrases or between a noun phrase and a question phrase. When a phrase is matched by one of the relation patterns, a Relation annotation is created to markup the relation. We use the following four grammar patterns to determine relation phrases:
For example, we can describe the first question “Liệt kê tất cả các sinh viên có quê quán ở Hà Nội” (“List all students whose hometown is Hanoi”) in Fig. 4, using NounPhrase, Relation and QuestionPhrase annotations as follows: [QuestionPhrase: Liệt kêlist [NounPhrase: tất cả các sinh viênall students]] [Relation: có quê quán ởhave hometown] [NounPhrase: Hà NộiHanoi]
The phrase “có quê quán ởhave hometown” is the relation linking the question phrase “liệt kê tất cả các sinh viênlist all students” and the noun phrase “Hà NộiHanoi”.
The semantic analysis module aims to identify the question structure and produce the query tuples (sub-structure, question category, Term1, Relation, Term2, Term3) as the intermediate representation element of the input question, using the TokenVn, NounPhrase, Relation and QuestionPhrase annotations returned by the two previous modules. Existing NounPhrase annotations and Relation annotations are potential candidates for terms and relations in the query tuples, respectively. In addition, QuestionPhrase annotations are used to detect the question category.
In the first KbQAS version [37], following AquaLog [26], we developed an ad-hoc approach to detect structure patterns of questions and then use these patterns to generate the intermediate representation elements. For example, Fig. 4 presents the detected structure patterns of the two example questions “Liệt kê tất cả các sinh viên có quê quán ở Hà Nội” (“List all students whose hometown is Hanoi”) and “Danh sách tất cả các sinh viên có quê quán ở Hà Nội mà học lớp khoa học máy tính” (“List all students enrolled in the computer science course, whose hometown is Hanoi”). We can describe these questions by using annotations generated by the preprocessing and syntactic analysis modules as follows: [QuestionPhrase: Liệt kê tất cả các sinh viênList all students] [Relation: có quê quán ởhave hometown] [NounPhrase: Hà NộiHanoi] [QuestionPhrase: Liệt kê tất cả các sinh viênList all students] [Relation: có quê quán ởhave hometown] [NounPhrase: Hà NộiHanoi] [And: [TokenVn: màand]] [Relation: họcenrolled] [NounPhrase: lớp khoa học máy tínhcomputer science course]
The intermediate representation element of an input question is created in a hard-wired manner linking every detected structure pattern via JAPE grammars. This hard-wired manner takes a lot of time and effort to handle new patterns. For example in Fig. 4, the hard-wired approach is unable to reuse the detected structure pattern of the first question to identify the structure pattern of the second question. Since JAPE grammar rules were created in an ad-hoc manner, the hard-wired approach encounters common difficulties in managing the interaction among rules and keeping consistency.
Consequently, in this module, we solve the mentioned difficulties by proposing a knowledge acquisition approach for the semantic analysis of input questions, as detailed in Section 4. In this paper, this is considered as the key innovation of KbQAS.
Answer retrieval component
As presented in the first KbQAS version [37], the answer retrieval component includes two modules: ontology mapping and answer extraction, as shown in Fig. 1. It takes the intermediate representation produced by the question analysis component and a target ontology as its input to generate an answer. To develop the answer retrieval component in KbQAS, we employed the relation similarity service component of AquaLog [26].
The task of the ontology mapping module is to map terms and relations in the query tuple to concepts, instances and relations in the target ontology by using string names. If an exact match is not possible, we use a string distance algorithm [57] and the dictionary containing concepts and their synonyms to find near-matched elements from the target ontology, with the similarity measure above a certain threshold.
In case the ambiguity is still present, KbQAS interacts with users by showing different options, and the users then choose the suitable ontology element. For example, given the question “Liệt kê tất cả các sinh viên học lớp khoa học máy tính” (“List all students enrolled in the computer science course”), the question analysis component produces a query tuple (Normal, List, sinh viênstudent, họcenrolled, lớp khoa học máy tínhcomputer science course, ?). Because the ontology mapping module cannot find the exact instance corresponding to “lớp khoa học máy tínhcomputer science course” in the target ontology, it requires the user to select between “lớp K50 khoa học máy tínhK50 computer science course” – an instance of class “lớpcourse”, and “bộ môn khoa học máy tínhcomputer science department” – an instance of class “bộ môndepartment”.
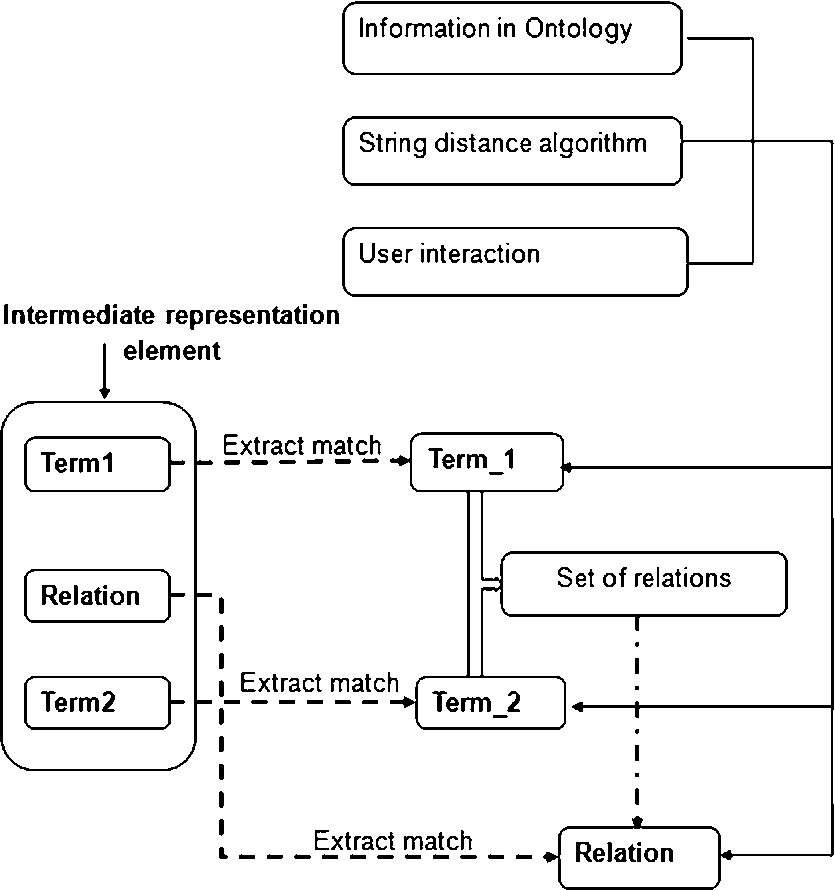
Ontology mapping module for the query tuple with two terms and one relation.
Following AquaLog, for each query tuple, the result of the ontology mapping module is an ontology tuple where the terms and relations in the query tuple are now the corresponding elements from the target ontology. How the ontology mapping module finds the corresponding elements from the target ontology depends on the question structure. For example, when the query tuple contains Term1, Term2 and Relation with Term3 missing, the mapping process follows the diagram shown in Fig. 5. The mapping process first tries to match Term1 and Term2 with concepts or instances in the target ontology. Then the mapping process finds a set of potential relations between the two mapped concepts/instances from the target ontology. The ontology relation is finally identified by mapping Relation to a relation in the potential relation set, using a manner similar to mapping a term to a concept or an instance.
With the ontology tuple, the answer extraction module finds all individuals of the ontology concept corresponding to Term1, having the ontology relation with the ontology individual corresponding to Term2. The answer extraction module then returns the answer based on the question structure and question category. See the definitions of question structure and question category types in Appendices A and B.
As mentioned in Section 3.3.3, due to the representation complexity and the variety of question structures, manually creating grammar rules in an ad-hoc manner is very expensive and error-prone. For example, such rule-based approaches as presented in [26,37,45] manually defined a list of sequence pattern structures to analyze questions. Since rules were created in an ad-hoc manner, these approaches share common difficulties in managing the interaction between rules and keeping consistency among them.
This section introduces our knowledge acquisition approach3
The English question analysis demonstration is available online at
A SCRDR knowledge base is built to identify the question structures and to produce the query tuples as the intermediate representations of the input questions. We outline the SCRDR methodology and propose a rule language for extracting the intermediate representation of a given question in Sections 4.1 and 4.2, respectively. We then illustrate the process of systematically constructing a SCRDR knowledge base for analyzing questions in Section 4.3.
This section presents the basic idea of Single Classification Ripple Down Rules (SCRDR) [10,47] which inspired our knowledge acquisition approach for question analysis. A SCRDR tree is a binary tree with two distinct types of edges. These edges are typically called except and false edges. Associated with each node in a tree is a rule. A rule has the form: if α then β where α is called the condition and β is called the conclusion.

A part of the SCRDR tree for English question analysis.

The graphic user interface for knowledge base construction.
Cases in SCRDR are evaluated by passing a case to the root node of the SCRDR tree. At any node in the SCRDR tree, if the condition of the rule at a node η is satisfied by the case (so the node η fires), the case is passed on to the except child node of the node η using the except edge if it exists; otherwise, the case is passed on to the false child node of the node η. The conclusion given by this process is the conclusion from the node which fired last.
Given the question “Who are the partners involved in AKT project ?” and the SCRDR tree in Fig. 6, it is satisfied by the rule at the root node (0). Then it is passed to node (1) using the except edge. As the case satisfies the condition of the rule at node (1), it is passed to node (2) using the except edge. Because the case does not satisfy the condition of the rule at node (2), it is then passed to node (3) using the false edge. As the case satisfies the conditions of the rules at nodes (3), (5) and (40), it is passed to node (42), using except edges. Since the case does not satisfy the conditions of the rules at nodes (42), (43) and (45), we have the evaluation path (0)-(1)-(2)-(3)-(5)-(40)-(42)-(43)-(45) with the last fired node (40). Given another case of “In which projects is enrico motta working on”, it satisfies the conditions of the rules at nodes (0), (1) and (2); as node (2) has no except child node, we have the evaluation path (0)-(1)-(2) and the last fired node (2).
A new node containing a new exception rule is added to an SCRDR tree when the evaluation process returns an incorrect conclusion. The new exception node is attached to the last node in the evaluation path of the given case as an except edge if the last node is the fired node; otherwise, it is attached as an false edge.
To ensure that a conclusion is always reached, the root node, called the default node, typically contains a trivial condition which is always satisfied. The rule at the default node, the default rule, is the unique rule which is not an exception rule of any other rule. For example, the default rule “if
In the SCRDR tree from Fig. 6, the rule at node (1) (simply, rule 1) is an exception rule of the default rule 0. Rule 2 is an exception rule of rule 1. As node (3) is the false-child node of node (2), the rule 3 is also an exception rule of rule 1. Furthermore, both rules 4 and 9 are also exception rules of rule 1. Similarly, all rules 40, 41 and 46 are exception rules of rule 5 while all rules 42, 43 and 45 are exception rules of rule 40. Therefore, the exception structure of the SCRDR tree extends to 5 levels, for examples: rules 1 at layer 1; rules 2, 3, 4 and 9 at layer 2; rules 5, 7, 21 and 22 at layer 3; and rules 40, 41, 46 and 50 at layer 4; and rules 42, 43, 44 and 45 at the layer 5 exception structure.
A rule is composed of a condition part and a conclusion part. A condition is a regular expression pattern over annotations using JAPE grammars in GATE [11]. It can also post new annotations over matched phrases of the pattern’s sub-components. As annotations have feature-value pairs, we can impose constraints on the annotations in the pattern by specifying that a feature of an annotation must have a particular value. The following example shows the posting of an annotation over the matched phrase:

Every complete pattern followed by a label must be enclosed by round brackets. In the above pattern, the label is
The conclusion part of a rule produces an intermediate representation containing the question structure and the query tuples, where each attribute in the query tuples is specified by a newly posted annotation from matching the rule’s condition, in the following order: (sub-structure, question category, Term1, Relation, Term2, Term3)
All newly posted annotations have the same RDR prefix and the rule index so that a rule can refer to annotations of its parent rules. Examples of rules and how rules are created and stored in an exception structure will be explained in details in Section 4.3.
Given an input question, the condition of a rule is satisfied if the whole input question is matched by the condition pattern. The conclusion of the fired rule produces the intermediate representation element of the input question. To create rules for matching the structures of questions, we use patterns over annotations returned by the preprocessing and syntactic analysis modules.
Knowledge acquisition process
Our approach is language-independent, because the main focus is on the process of creating the rule-based system. The language-specific part is in the rules itself. So, in this section, we illustrate the process of building a SCRDR knowledge base to analyze English questions. Figure 7 shows the graphic user interface to construct SCRDR knowledge bases.
We reused the JAPE grammars which were developed to identify noun phrases, question phrases and relation phrases in AquaLog [26]. Based on Token annotations which are generated as output of the English tokenizer, sentence splitter and part-of-speech tagger in the GATE framework [11], the JAPE grammars produce NounPhrase,4
Here annotations are generated without any concept or entity type information.
For illustrations in Sections 4.3.1 and 4.3.2, we employed a training set of 170 English questions,5
In contrast to the example in Section 3.3.3 with respect to Fig. 4, we start with demonstrations of reusing detected question structure patterns.

Examples of annotations.
For the question “Who are the researchers in semantic web research area ?”, we can represent this question using NounPhrase, QuestionPhrase and Relation annotations as shown in Fig. 8 as follows: [QuestionPhrase: Who] [Relation: are the researchers in] [NounPhrase: semantic web research area]
Supposed we start with a knowledge base containing only the default rule

UnknTerm question structure and one query tuple (RDR1_.category1, RDR1_QP.QuestionPhrase.category, ?, RDR1_Rel, RDR1_NP, ?)
If the condition of
When node (1) fired, the input question has one query tuple where the sub-structure attribute takes the value of the category1 feature of the RDR1_ annotation; the question category attribute takes the value of the category feature of the QuestionPhrase annotation which is in the same span as the RDR1_QP annotation. In addition, the Relation and Term2 attributes take values of the strings covered by the RDR1_Rel and RDR1_NP annotations, respectively, while Term1 and Term3 are missing. The example of firing the question at node (1) is displayed in Fig. 7.
Assume that, in addition to
For the question “Which universities are Knowledge Media Institute collaborating with ?”, the following annotation-based representation is constructed: [RDR1_: [RDR1_QP: Which universities] [RDR1_Rel: are] [RDR1_NP: Knowledge Media Institute]] [Relation: collaborating with]
We have the evaluation path of (0)-(1)-(2) with the last fired node (1). However,

Normal question structure and one query tuple (RDR3_.category1, RDR1_QP.QuestionPhrase.category, RDR1_QP, RDR3_Rel, RDR1_NP, ?)
In the knowledge base, node (3) containing
Subsequently, another question makes an addition of rule
For the question “Who are the partners involved in AKT project ?”, we have an annotation-based representation as follows: [RDR3_: [RDR1_QP: Who] [RDR1_Rel: are] [RDR1_NP: the partners] [RDR3_Rel: involved in]] [NounPhrase: AKT project]
We have the evaluation path (0)-(1)-(2)-(3) and node (3) is the last fired node. But

Normal question structure and one query tuple (RDR5_.category1, RDR1_QP.QuestionPhrase.category, RDR1_NP, RDR3_Rel, RDR5_NP, ?)
As node (3) is the last node in the evaluation path, node (5) containing
The process of adding the rules above illustrates the ability of quickly handling new question structure patterns of our knowledge acquisition approach against the ad-hoc approaches [26,37]. The following examples demonstrate the ability of our approach to solve question structure ambiguities.
For the question “Which researchers wrote publications related to semantic portals ?”, the following representation is produced: [RDR5_: [RDR1_QP: Which researchers] [RDR1_Rel: wrote] [RDR1_NP: publications] [RDR3_Rel: related to] [RDR5_NP: semantic portals]]
This question is fired at node (5) which is the last node in the evaluation path (0)-(1)-(2)-(3)-(5). But

Clause question structure6
A Clause structure question has two query tuples where the answer returned for the second query tuple indicates the missing Term2 attribute in the first query tuple. See more details of our question structure definitions in Appendix A.
The extra annotation constraint of hasAnno requires that the text covered by an annotation must contain another specified annotation. For example, the additional condition in
A whole string is also considered as its substring.
In the knowledge base, node (40) containing
For the question “Which projects sponsored by eprsc are related to semantic web ?”, we have part-of-speech and annotation-based representations as follows: Which/WDT projects/NNS sponsored/VBN by/IN eprsc/NN are/VBP related/VBN to/TO semantic/JJ web/NN [RDR40_: [RDR1_QP: [QuestionPhrasecategory = QU-whichClass: Which projects]] [RDR1_Rel: sponsored by] [RDR1_NP: eprsc] [RDR3_Rel: are related to] [RDR5_NP: semantic web] ]
The current knowledge base generates an evaluation path (0)-(1)-(2)-(3)-(5)-(40)-(42)-(43) with the last fired node (40). However,

And question structure and two query tuples (RDR45_.category1, RDR1_QP.QuestionPhrase.category, RDR1_QP, RDR1_Rel, RDR1_NP, ?) and (RDR45_.category2, RDR1_QP.QuestionPhrase.category, RDR1_QP, RDR3_Rel, RDR5_NP, ?)
As illustrated in Sections 4.3.1 and 4.3.2, using the set of 170 questions from AquaLog [26], we constructed a knowledge base of 59 rules for question analysis. Similarly, in this section, we illustrate the process of adding more exception rules into the knowledge base to handle DBpedia and biomedical test questions.
For the DBpedia test question “Which presidents of the United States had more than three children ?”, the following representations are constructed: Which/WDT presidents/NNS of/IN the/DT United/NNP States/NNPS had/VBD more/JJR than/IN three/CD children/NNS [RDR27_: [RDR10_: [RDR10_QP: Which presidents] [Preps: of] [RDR10_NP: the United States]] [RDR27_Rel: had more than] [RDR27_NP: three children]]
The last fired node for this DBpedia question is node (27). However, the conclusion of rule

Clause question structure and two query tuples (RDR67_.category1, RDR10_QP.QuestionPhrase.category, ? , RDR67_NP, ?, RDR67_Compare) and (RDR67_.category2, RDR10_QP.QuestionPhrase.category, RDR10_QP, ?, RDR10_NP, ?)
Given the question,
For the biomedical test question “List drugs that lead to strokes and arthrosis”, we have the following representations: List/NN drugs/NNS that/WDT lead/VBP to/TO strokes/NNS and/CC arthrosis/NNS [QuestionPhrase: List drugs] [RDR1_: [RDR1_QP: that] [RDR1_Rel: lead to] [RDR1_NP: strokes and arthrosis]]
The last fired node for this biomedical question is node (1). However,

And question structure and two query tuples (RDR80_.category1, RDR80_QP.QuestionPhrase.category, RDR80_QP, RDR1_Rel, RDR80_NP1, ?) and (RDR80_.category2, RDR80_QP.QuestionPhrase.category, RDR80_QP, RDR1_Rel, RDR80_NP2, ?)
Given the question,
Experiments
In KbQAS, the question analysis component employs our language-independent knowledge acquisition approach, while the answer retrieval component produces answers from a domain-specific Vietnamese ontology. So we separately evaluate the question analysis and answer retrieval components in Sections 5.1 and 5.2, respectively.
Experiments on analyzing questions
This section indicates the abilities of our question analysis approach for quickly building a new knowledge base and easily adapting to a new domain and a new language. We evaluate both our approaches of ad-hoc manner (see Section 3.3.3) and knowledge acquisition (see Section 4) on Vietnamese question analysis, and then present the experiment of building a knowledge base for processing English questions.
Question analysis for Vietnamese
We used a training set of 400 questions of various structures generated by four volunteer students. We then evaluated our question analysis approach on an unseen list of 88 questions related to the VNU University of Engineering and Technology, Vietnam. In this experiment, we also compare both our ad-hoc and knowledge acquisition approaches for question analysis, using the same training set of 400 questions and test set of 88 questions.
Time to create rules and number of successfully analyzed questions
Time to create rules and number of successfully analyzed questions
With our first approach it took about 75 hours to create rules in an ad-hoc manner, as shown in Table 2. In contrast, with our second approach it took 13 hours to build a Vietnamese knowledge base of rules for question analysis. However, most of the time was spent looking at questions to determine the question structures and the phrases which would be extracted to create intermediate representation elements. So the actual time to create rules in the knowledge base was about 5 hours in total.
Number of exception rules in each layer in our Vietnamese knowledge base for question analysis
The knowledge base consists of the default rule and 91 exception rules. Table 3 details the number of exception rules in each layer where every rule in layer n is an exception rule of a rule in layer
Table 2 also shows the number of successfully analyzed questions for each approach. By using the knowledge base to resolve ambiguous cases, our knowledge acquisition approach performs better than our ad-hoc approach. Furthermore, Table 4 provides the error sources for our knowledge acquisition approach, in which most errors come from unexpected question structure patterns. This can be rectified by adding more exception rules to the current knowledge base, especially when having a large training set that contains a variety of question structure patterns.
Number of incorrectly analyzed questions accounted for the knowledge acquisition approach
For another example, our knowledge acquisition approach did not return a correct intermediate representation element for the question “Vũ Tiến Thành có quê và có mã sinh viên là gì ?” (“What is the hometown and student code of Vu Tien Thanh ?”) because the existing linguistic processing modules for Vietnamese [44], including word segmentation and part-of-speech tagging, were not trained on the question domain. So these two modules assign the word “quêhometown” as an adjective instead of a noun. Thus, “quêhometown” is not covered by a NounPhrase annotation, leading to an unrecognized structure pattern.
Number of rules in the question analysis knowledge bases for Vietnamese (#RV) and English (#RE); number of Vietnamese test questions (#TQ) and number of Vietnamese correctly answered questions (#CA) corresponding to each question structure type (QST)
Regarding a question structure-based evaluation, Table 5 presents the number of rules in the Vietnamese knowledge base and number of test questions, corresponding to each question structure type. For example, the cell at the second row and the fourth column of Table 5 means that, in 7 test questions tending to have the UnknRel question structure, there are 4 test questions correctly analyzed.
For the experiment in English, we firstly used a set of 170 English questions,8
Test results of the knowledge base of 59 rules for question analysis on DBpedia and biomedical domains
Table 6 presents evaluation results of analyzing the test questions from the DBpedia and biomedical domains, using the knowledge base of 59 rules for question analysis. It is not surprising that most errors come from unknown question structure patterns. Furthermore, just as in Vietnamese, the existing linguistic processing modules in the GATE framework [11], including the English tokenizer and part-of-speech tagger, are also error sources, leading to unrecognized structure patterns. For example, such questions as “Which U.S. states possess gold minerals ?” and “Which drugs have a water solubility of 2.78e-01mg/mL ?” are tokenized into “Which U . S . states possess gold minerals ?” and “Which drugs have a water solubility of 2 . 78 e- 01 mg / mL ?”, respectively. In addition, such other questions as “Which river does the Brooklyn Bridge cross ?”, “Which states border Utah ?” or “Which experimental drugs interact with food ?” are tagged with noun labels for the words “cross”, “border” and “interact” instead of verb labels.
Test results of the English knowledge base of 90 rules for question analysis on DBpedia and biomedical domains
To correct the question analysis errors on the two sets of test questions, we spent 5 further hours to add 31 exception rules to the knowledge base. Finally, in total 12 hours, we constructed a knowledge base of 90 rules for English question analysis, including the default rule and 89 exception rules. The new evaluation results of question analysis on the DBpedia and biomedical domains are presented in Table 7.
Table 8 shows the number of exception rules in each exception layer of the knowledge base while the number of rules corresponding to each question structure type is presented in Table 5.
Number of exception rules in layers in our English knowledge base
As the intermediate representation in KbQAS is different from AquaLog, it is difficult to directly compare our knowledge acquisition approach with the ad-hoc question analysis approach in AquaLog on the English domain. However, this experiment on English questions shows the abilities to quickly build a new knowledge base and easily adapt to a new domain and a new language.
As illustrated in Section 4.3, this experiment also presented a process of building a knowledge base for question analysis without any concept or entity type information. However, we found that the concept or entity type information in noun phrases is useful and can help to reduce ambiguities in question structure patterns. When adapting our knowledge acquisition approach for question analysis to anther target domain (or language), we can simply use the heuristics presented in Section 3.3.2 and a dictionary to determine whether a noun phrase is a concept or entity type. The dictionary can be (automatically) constructed by extracting concepts from the target domain and their synonyms from available semantic lexicons such as WordNet [17].
To evaluate the answer retrieval component of KbQAS, we used the ontology modeling the organizational structure of the VNU University of Engineering and Technology, as mentioned in Section 3.2, as target domain. This ontology was manually constructed by using the Protégé platform [19]. From the list of 88 questions, as mentioned in Section 5.1.1, we employed 74 questions which were successfully analyzed by the question analysis component.
Questions successfully answered
Questions successfully answered
The performance result is presented in Table 9. The answer retrieval component produces correct answers for 61 out of 74 questions, obtaining a promising accuracy of 82.4%. The number of correctly answered questions corresponding to each question structure type can be found in the third column of Table 5. Out of those, 30 questions can be answered automatically without interaction with users. In addition, 31 questions are correctly answered with the help from the users to handle ambiguity cases, as illustrated in the first example in Section 3.4.
Questions with unsuccessful answers
Table 10 gives the limitations that will be handled in future KbQAS versions. The errors raised by the ontology mapping module are due to the target ontology construction lacking a full domain-specific conceptual coverage and some relationships between concept pairs. So specific terms or relations in query tuples cannot be mapped or are incorrectly mapped to the corresponding elements in the target ontology to produce the ontology tuples. Furthermore, the answer extraction module fails to extract the answers for 7 questions because: (i) Dealing with questions having the Compare question structure involves specific services. For example, handling the question “sinh viên nào có điểm trung bình cao nhất khoa công nghệ thông tin ?” (“Which student has the highest grade point average in the faculty of Information Technology ?”) requires a comparison mechanism to rank students according to their GPA. (ii) In terms of four Clause structure questions and one Affirm_MoreTuples structure question for which KbQAS failed to return answers (see Table 5), combining their sub-questions triggers complex inference tasks and bugs which are difficult to handle in the current KbQAS version.
In this paper, we described the first ontology-based question answering system for Vietnamese, namely KbQAS. KbQAS contains two components: natural language question analysis and answer retrieval. The two components are connected by an intermediate representation element capturing the semantic structure of any input question, facilitating the matching process to a target ontology to produce an answer. Experimental results of KbQAS on a wide range of questions are promising. Specifically, the answer retrieval module achieves an accuracy of 82.4%.
In addition, we proposed a question analysis approach for systematically building a knowledge base of rules to convert the input question into an intermediate representation element. Our approach allows for systematic control of interactions between rules and keeping consistency among them. We believe that our approach is important especially for under-resourced languages where annotated data is not available. Our approach could be combined nicely with the process of annotating corpora where, on top of assigning a label or a representation to a question, the experts just have to add one more rule to justify their decision. Incrementally, an annotated corpus and a rule-based system can be obtained simultaneously. Furthermore, our approach can be applied to open-domain question answering where the technique requires an analysis to transform an input question into an explicit representation of some sort. Obtaining a question analysis accuracy of 84.1% on Vietnamese questions and taking 12 hours to build a knowledge base of 90 rules for analyzing English questions, the question analysis experiments show that our approach enables individuals to easily build a new knowledge base or adapt an existing knowledge base to a new domain or a new language.
In the future, we will extend KbQAS to be an open-domain question answering system which can answer various questions over Linked Open Data such as DBpedia or YAGO. In addition, it would be interesting to investigate the process of building a knowledge base for question analysis, which directly converts the input questions into queries (e.g. SPARQL queries) on Linked Open Data.
Footnotes
Acknowledgements
This work is partially supported by the Research Grant No. QG.14.04 from Vietnam National University, Hanoi (VNU). Most of this work was done while the first two authors was at the VNU University of Engineering and Technology. The first author is supported by an International Postgraduate Research Scholarship and a NICTA NRPA Top-Up Scholarship.
Definitions of question structure types
We define question structures types: Normal, UnknTerm, UnknRel, Definition, Affirm, ThreeTerm, Affirm_3Term, Affirm_MoreTuples, Compare, And, Or, Combine, Clause as follows:
∙ A Normal structure question has only one query tuple in which Term3 is missing.
∙ An UnknTerm structure question has only one query tuple in which Term1 and Term3 are missing.
∙ An UnknRel structure question has only one query tuple in which Relation and Term3 are missing. For example, the question “List all the publications in knowledge media institute” has one query tuple (UnknRel, QU-listClass, publications, ?, knowledge media institute, ?).
∙ A Definition structure question has only one query tuple which lacks Term1, Relation and Term3. For example, the question “What are research areas ?” has one query tuple (Definition, QU-who-what, ?, ?, research areas, ?).
∙ An Affirm structure question is a question which belongs to one of three types Normal, UnknRel and UnknTerm, and has the YesNo question category. For example, the question “Is Tran Binh Giang a PhD student ?” has the Affirm question structure and one query tuple (UnknRel, YesNo, PhD student, ?, Tran Binh Giang, ?).
∙ A ThreeTerm structure question has only one query tuple where Term1 or Relation could be missing. An example for this structure type is illustrated in Fig. 2.
∙ An Affirm_3Term structure question is the question which belongs to ThreeTerm and has the YesNo question category. For example, the question “số lượng sinh viên học lớp K50 khoa học máy tính là 45 phải không ?” (“45 is the number of students enrolled in the K50 computer science course, is it not ?”) has the Affirm_3Term question structure and one query tuple (ThreeTerm, ManyClass, sinh viênstudent, họcenrolled, lớp K50 khoa học máy tínhK50 computer science course, 45).
∙ An Affirm_MoreTuples structure question has more than one query tuple and belongs to the YesNo question category. For example, the question “tồn tại sinh viên có quê ở Hà Tây và học khoa toán phải không ?” (“Is there some student enrolled in the faculty of Mathematics, whose hometown is Hatay ?”) has the Affirm_MoreTuples question structure and two query tuples (Normal, YesNo, sinh viênstudent, có quêhave hometown, Hà TâyHatay, ?) and (Normal, YesNo, sinh viênstudent, họcenrolled, khoa Toánfaculty of Mathematics, ?).
∙ A Compare structure question is a question which belongs to one of three types Normal, UnknRel and UnknTerm, and it contains a comparison phrase which is detected by the preprocessing module. In this case, Term3 is used to hold the comparison information. For example, the question “sinh viên nào có điểm trung bình cao nhất khoa công nghệ thông tin ?” (“Which student has the highest grade point average in the faculty of Information Technology ?”) has the Compare question structure and one query tuple (Normal, Entity, sinh viênstudent, điểm trung bìnhgrade point average, khoa công nghệ thông tinfaculty of Information Technology, cao nhấthighest).
∙ An And or Or structure question contains the word “màand” (“vàand”) or “hoặcor”, respectively, and it has more than one query tuple (i.e. two or more sub-questions). The And type returns the final answer as an intersection (i.e. overlap) of the answers of the sub-questions, while the Or type returns the final answer as an union of the answers for the sub-questions.
For example, the question “Which projects are about ontologies and the semantic web ?” has the And question structure and two query tuples (UnknRel, QU-whichClass, projects, ?, ontologies, ?) and (UnknRel, QU-whichClass, projects, ?, semantic web, ?).
The question “Which publications are in knowledge media institute related to compendium ?” has the And question structure and two query tuples (UnknRel, QU-whichClass, publications, ?, knowledge media institute, ?) and (Normal, QU-whichClass, publications, related to, compendium, ?).
The question “Who is interested in ontologies or in the semantic web ?” has the Or question structure and two query tuples (UnknTerm, QU-who-what, ?, interested, ontologies, ?) and (UnknTerm, QU-who-what, ?, interested, semantic web, ?).
However, such question as “Phạm Đức Đăng học trường đại học nào và được hướng dẫn bởi ai ?” (“Which university does Pham Duc Dang enroll in and who tutors him ?”) contains “vàand”, but it will have the Or question structure and two query tuples (Normal, Entity, trường đại họcuniversity, họcenroll, Phạm Đức ĐăngPham Duc Dang, ?) and (UnknTerm, Who, ?, hướng dẫntutor, Phạm Đức ĐăngPham Duc Dang, ?).
∙ A Combine structure question is constructed from two or more independent sub-questions. Unlike the Or structure type, the query tuples in the Combine type do not share the same term or Relation. For example, the question “Ai có quê quán ở Hà Tây và ai học khoa công nghệ thông tin ?” (“Who has hometown of Hatay, and who enrolls in the faculty of Information Technology ?”) has the Combine question structure and two query tuples (UnknTerm, Who, ?, có quê quánhas hometown, Hà TâyHatay, ?) and (UnknTerm, Who, ?, họcenroll, khoa công nghệ thông tinfaculty of Information Technology, ?).
∙ A Clause structure question has two query tuples, where the answer returned for the second query tuple indicates the missing Term2 attribute in the first query tuple. For example, the question “số lượng sinh viên học lớp K50 khoa học máy tính lớn hơn 45 phải không ?”10
This is the case of our system failing to correctly analyze due to an unknown structure pattern.
In general, Term1 represents a concept, excluding cases of Affirm, Affirm_3Term and Affirm_ MoreTuples. In addition, Term2 and Term3 represent entities (i.e. objects or instances), excluding the cases of Definition and Compare.
Definitions of Vietnamese question categories
In KbQAS, a question is classified as one of the following classes: HowWhy, YesNo, What, When, Where, Who, Many, ManyClass, List, and Entity. To identify question categories, we specify a number of JAPE grammars using the NounPhrase annotations and the question-word information given by the preprocessing module.
∙ A HowWhy-category question refers to a cause or a method, containing a TokenVn annotation covering such strings as “tại saowhy” or “vì saowhy” or “thế nàohow” or “là như thế nàohow”. This is similar to Why-questions or How is/are questions in English.
∙ A YesNo-category question requires a true or false answer, containing a TokenVn annotation covering such strings as “có đúng làis that” or “đúng khôngare those” or “phải khôngare there” or “có phải làis this”.
∙ A What-category question contains a TokenVn annotation covering such strings as “cái gìwhat” or “là gìwhat” or “là những cái gìwhat”. This question type is similar to What is/are questions in English.
∙ A When-category question contains a TokenVn annotation covering such strings as “khi nàowhen” or “vào thời gian nàowhich time” or “lúc nàowhen” or “ngày nàowhich date”.
∙ A Where-category question contains a TokenVn annotation covering such strings as “ở nơi nàowhere” or “là ở nơi đâuwhere” or “ở chỗ nàowhere”.
∙ A Who-category question contains a TokenVn annotation covering such strings as “là những aiwho” or “là người nàowho” or “những aiwho”.
∙ A Many-category question contains a TokenVn annotation covering such strings as “số lượnghow many” or “là bao nhiêuhow much/many” or “bao nhiêuhow much/many”. This question type is similar to How much/many is/are questions in English.
∙ A ManyClass-category question contains a TokenVn annotation covering such strings as “số lượnghow many” or “là bao nhiêuhow much/many” or “bao nhiêuhow much/many”, followed by a NounPhrase annotation. This type is similar to How many NounPhrase-questions in English.
∙ An Entity-category question contains a NounPhrase annotation followed by a TokenVn annotation covering such strings as “nàowhich” or “gìwhat”. This type is similar to which/what NounPhrase-questions in English.
∙ A List-category question contains a TokenVn annotation covering such strings as “cho biếtgive” or “chỉ rashow” or “kể ratell”, or “tìmfind” or “liệt kêlist”, followed by a NounPhrase annotation.