
Abstract
In the latest years, more and more structured data is published on the Web and the need to support typical Web users to access this body of information has become of crucial importance. Question Answering systems over Linked Data try to address this need by allowing users to query Linked Data using natural language. These systems may query at the same time different heterogenous interlinked datasets, that may provide different results for the same query. The obtained results can be related by a wide range of heterogenous relations, e.g., one can be the specification of the other, an acronym of the other, etc. In other cases, such results can contain an inconsistent set of information about the same topic. A well known example of such heterogenous interlinked datasets are language-specific DBpedia chapters, where the same information may be reported in different languages. Given the growing importance of multilingualism in the Semantic Web community, and in Question Answering over Linked Data in particular, we choose to apply information reconciliation to this scenario. In this paper, we address the issue of reconciling information obtained by querying the SPARQL endpoints of language-specific DBpedia chapters. Starting from a categorization of the possible relations among the resulting instances, we provide a framework to: (i) classify such relations, (ii) reconcile information using argumentation theory, (iii) rank the alternative results depending on the confidence of the source in case of inconsistencies, and (iv) explain the reasons underlying the proposed ranking. We release the resource obtained applying our framework to a set of language-specific DBpedia chapters, and we integrate such framework in the Question Answering system QAKiS, that exploits such chapters as RDF datasets to be queried using a natural language interface.
Keywords
Introduction
In the Web of Data, it is possible to retrieve heterogeneous information items concerning a single real-world object coming from different data sources, e.g., the results of a single SPARQL query on different endpoints. It is not always the case that these results are identical, it may happen that they conflict with each other, or they may be linked by some other relation like a specification. The automated detection of the kind of relationship holding between different instances of a single object with the goal of reconciling them is an open problem for consuming information in the Web of Data. In particular, this problem arises while querying the language-specific chapters of DBpedia [22]. Such chapters, well connected through Wikipedia instance interlinking, can in fact contain different information with respect to the English version. Assuming we wish to query a set of language-specific DBpedia SPARQL endpoints with the same query, the answers we collect can be either identical, or in some kind of specification relation, or they can be contradictory. Consider for instance the following example: we query a set of language-specific DBpedia chapters about How tall is the soccer player Stefano Tacconi?, receiving the following information: 1.88 from the Italian chapter and the German one, 1.93 from the French chapter, and 1.90 from the English one. How can I know what is the “correct” (or better, the more reliable) information, knowing that the height of a person is unique? Addressing such kind of issues is the goal of the present paper. More precisely, in this paper, we answer the research question:
How to reconcile information provided by the language-specific chapters of DBpedia?
This open issue is particularly relevant to Question Answering (QA) systems over DBpedia [21], where the user expects a unique (ideally correct) answer to her factual natural language question. A QA system querying different data sources needs to weight them in an appropriate way to evaluate the information items they provide accordingly. In this scenario, another open problem is how to explain and justify the answer the system provides to the user in such a way that the overall QA system appears transparent and, as a consequence, more reliable. Thus, our research question breaks down into the following subquestions:
How to automatically detect the relationships holding between information items returned by different language-specific chapters of DBpedia?
How to compute the reliability degree of such information items to provide a unique answer?
How to justify and explain the answer the QA system returns to the user?
First, we need to classify the relations connecting each piece of information to the others returned by the different data sources, i.e., the SPARQL endpoints of the language-specific DBpedia chapters. We adopt the categorization of the relations existing between different information items retrieved with a unique SPARQL query proposed by Cabrio et al. [12]. Up to our knowledge, this is the only available categorization that considers linguistic, fine-grained relations among the information items returned by language-specific DBpedia chapters, given a certain query. This categorization considers ten positive relations among heterogenous information items (referring to widely accepted linguistic categories in the literature), and three negative relations meaning inconsistency. Starting from this categorization, we propose the RADAR (ReconciliAtion of Dbpedia through ARgumentation) framework, that adopts a classification method to return the relation holding between two information items. This first step results in a graph-based representation of the result set where each information item is a node, and edges represent the identified relations.

RADAR 2.0 framework architecture.
Second, we adopt argumentation theory [16], a suitable technique for reasoning about conflicting information, to assess the acceptability degree of the information items, depending on the relation holding between them and the trustworthiness of their information source [14]. Roughly, an abstract argumentation framework is a directed labeled graph whose nodes are the arguments and the edges represent a conflict relation. Since positive relations among the arguments may hold as well, we rely on bipolar argumentation [13] that considers also a positive support relation.
Third, the graph of the result set obtained after the classification step, together with the acceptability degree of each information item obtained after the argumentation step, is used to justify and explain the resulting information ranking (i.e., the order in which the answers are returned to the user).
We evaluate our approach as standalone (i.e., over a set of heterogeneous values extracted from a set of language-specific DBpedia chapters), and through its integration in the QA system QAKiS [8], that exploits language-specific DBpedia chapters as RDF datasets to be queried using a natural language interface. The reconciliation module is embedded to provide a (possibly unique) answer whose acceptability degree is over a given threshold, and the graph structure linking the different answers highlights the underlying justification. Moreover, RADAR is applied to over 300 DBpedia properties in 15 languages, and the obtained resource of reconciled DBpedia language-specific chapters is released.
Even if information reconciliation is a way to enhance Linked Data quality, this paper does not address the issue of Linked Data quality assessment and fusion [6,23], nor ontology alignment. Finally, argumentation theory in this paper is not exploited to find agreements over ontology alignments [26]. Note that our approach is intended to reconcile and explain the answer of the system to the user. Ontology alignment cannot be exploited to generate such a kind of explanations. This is why we decided to rely on argumentation theory that is a way to exchange and explain viewpoints. In our paper, we have addressed the open problem of reconciling and explaining a result set from language-specific DBpedia chapters using well known conflict detection and explanation techniques, i.e., argumentation theory.
We are not aware of any other available QA system that queries several information sources (in our case language-specific chapters of DBpedia) and then it is able to verify the coherence of the proposed result set, and show why a certain answer has been provided. The merit of the present paper is to describe the proposed framework (i.e., RADAR 2.0) with the addition of an extensive evaluation over standard QA datasets.
In the remainder of the paper, Section 2 presents our reconciliation framework for language-specific DBpedia chapters, Section 3 reports on the experiments run over DBpedia to evaluate it, and Section 4 describes its integration in QAKiS. Section 5 reports on the related work. Finally, some conclusions are drawn.
The RADAR 2.0 (ReconciliAtion of Dbpedia through ARgumentation) framework for information reconciliation is composed by three main modules (see Fig. 1). It takes as input a collection of results from one SPARQL query raised against the SPARQL endpoints of the language-specific DBpedia chapters (Section 3 provides more details about the chapters considered in our experimental setting). Given such result set, RADAR retrieves two kinds of information: (i) the sources proposing each particular element of the result set, and (ii) the elements of the result set themselves. The first module of RADAR (module A, Fig. 1) takes each information source, and following two different heuristics, assigns a confidence degree to the source. Such confidence degree will affect the reconciliation in particular with respect to the possible inconsistencies: information proposed by the more reliable source will obtain a higher acceptability degree. The second module of RADAR (module B, Fig. 1) instead starts from the result set, and it matches every element with all the other returned elements, detecting the kind of relation holding between these two elements. The result of such module is a graph composed by the elements of the result set connected with each other by the relations of our categorization. Both the sources associated with a confidence score and the result set in the form of a graph are then provided to the third module of RADAR, the argumentation one (module C, Fig. 1). The aim of such module is to reconcile the result set. The module considers all positive relations as a support relation and all negative relations as an attack relation, building a bipolar argumentation graph where each element of the result set is seen as an argument. Finally, adopting a bipolar fuzzy labeling algorithm relying on the confidence of the sources to decide the acceptability of the information, the module returns the acceptability degree of each argument, i.e., element of the result set. The output of the RADAR framework is twofold. First, it returns the acceptable elements (a threshold is adopted), and second the graph of the result set is provided, where each element is connected to the others by the identified relations (i.e., the explanation about the choice of the acceptable arguments returned).
In the remainder of this section, we will describe how the confidence score of the sources is computed (Section 2.1), and we will summarize the adopted categorization detailing how such relations are automatically extracted (Section 2.2). Finally, the argumentation module is described in Section 2.3.
Assigning a confidence score to the source
Language-specific DBpedia chapters can contain different information on particular topics, e.g. providing more or more specific information. Moreover, the knowledge of certain instances and the conceptualization of certain relations can be culturally biased. For instance, we expect to have more precise (and possibly more reliable) information on the Italian actor Antonio Albanese on the Italian DBpedia, than on the English or on the French ones.
To trust and reward the data sources, we need to calculate the reliability of the source with respect to the contained information items. In [10], an apriori confidence score is assigned to the endpoints according to their dimensions and solidity in terms of maintenance (the English chapter is assumed to be more reliable than the others on all values, but this is not always the case). RADAR 2.0 assigns, instead, a confidence score to the DBpedia language-specific chapter depending on the queried entity, according to the following two criteria:
Wikipedia page length. The chapter of the longest language-specific Wikipedia page describing the queried entity is considered as fully trustworthy (i.e., it is assigned with a score of 1) while the others are considered less trustworthy (i.e., they are associated with a score Entity geo-localization. The chapter of the language spoken in the places linked to the page of the entity is considered as fully trustworthy (i.e., it is assigned with a score of 1) while the others are considered less trustworthy (i.e., they are associated with a score Such table connecting a country with its language can be found here:
Cabrio et al. [12] propose a classification of the semantic relations holding among the different instances obtained by querying a set of language-specific DBpedia chapters with a certain query. More precisely, such categories correspond to the lexical and discourse relations holding among heterogeneous instances obtained querying two DBpedia chapters at a time, given a subject and an ontological property. In the following, we list the positive relations between values resulting from the data-driven study in [12]. Then, in parallel, we describe how RADAR 2.0 addresses the automatic classification of such relations.
i.e., same value but in different languages (missing i.e., initial components in a phrase or a word. E.g., i.e., a value contains in the name the class of the entity. E.g., i.e., an expression referring to another expression describing the same thing (in particular, non normalized expressions). E.g.,
Based on WikiData, a free knowledge base that can be read and edited by humans and machines alike,
i.e., ontological geographical knowledge. E.g., i.e., reformulation of the same entity name in time. E.g.,
For instance, we extract the property “today” connecting historical entity names with the current ones (reconcilable with GeoNames). We used Wikipedia dumps.
i.e., a constituent part of, or a member of something. E.g.,
i.e., relation between a specific and a general word when the latter is implied by the former. E.g.,
i.e., a name of a thing/concept for that of the thing/concept meant. E.g.,
i.e., pen/stage names pointing to the same entity. E.g.,
Royo [25] defines both relations of meronymy and hyponymy as relations of inclusion, although they differ in the kind of inclusion defined (hyponymy is a relation of the kind “B is a type of A”, while meronymy relates a whole with its different parts or members). Slightly extending Royo’s definition, we joined to this category also the relation of metonymy, a figure of speech scarcely detectable by automatic systems due to its complexity (and stage name, that can be considered as a particular case of metonymy, i.e., the name of the character for the person herself).
to detect when a musician plays in a band, and when a label is owned by a bigger label.
for the broader term relation between common names.
in particular the datasets connecting Wikipedia, GeoNames and MusicBrainz trough the
for the part of, subclass of and instance of relations. It contains links to GeoNames, BNCF and MusicBrainz, integrating DBpedia
contains hierarchical information in: infoboxes (e.g. property

Example of (a) an AF, (b) a bipolar AF, and (c) example provided in the introduction modeled as a bipolar AF, where single lines represent attacks and double lines represent support.
Moreover, in the classification proposed in [12], the following negative relations (i.e., values mismatches) among possibly inconsistent data are identified:
i.e. unrelated entity. E.g., i.e. different date for the same event. E.g., i.e. different numerical values. E.g.,
At the moment no tolerance is admitted, if e.g. the height of a person differs of few millimeters in two DBpedia chapters, the relation is labeled as numerical mismatch. We plan to add such tolerance for information reconciliation as future work.
The reader may argue that a machine learning approach could have been applied to this task, but a supervised approach would have required an annotated dataset to learn the features. Unfortunately, at the moment there is no such training set available to the research community. Moreover, given the fact that our goal is to produce a resource as precise as possible for future reuse, the implementation of a rule-based approach allows us to tune RADAR to reward precision in our experiments, in order to accomplish our purpose.
This section begins with a brief overview of abstract argumentation theory, and then we detail the RADAR 2.0 argumentation module.
An abstract argumentation framework (AF) [16] aims at representing conflicts among elements called arguments, whose role is determined only by their relation with other arguments. An AF encodes, through the conflict (i.e., attack) relation, the existing conflicts within a set of arguments. It is then interesting to identify the conflict outcomes, which, roughly speaking, means determining which arguments should be accepted, and which arguments should be rejected, according to some reasonable criterion.
The set of accepted arguments of an argumentation framework consists of a set of arguments that does not contain an argument conflicting with another argument in the set. Dung [16] presents several acceptability semantics that produce zero, one, or several consistent sets of accepted arguments. Roughly, an argument is accepted (i.e., labelled in) if all the arguments attacking it are rejected, and it is rejected (i.e., labelled out) if it has at least an argument attacking it which is accepted. Figure 2(a) shows an example of an AF. The arguments are visualized as nodes of the argumentation graph, and the attack relation is visualized as edges. Gray arguments are the accepted ones. Using Dung’s admissibility-based semantics [16], the set of accepted arguments is
However, associating a crisp label, i.e., in or out, to the arguments is limiting in a number of real life situations where a numerical value expressing the acceptability degree of each argument is required [14,17,18]. In particular, da Costa Pereira et al. [14] have proposed a fuzzy labeling algorithm to account for the fact that arguments may originate from sources that are trusted only to a certain degree. They define a fuzzy labeling for argument A as
Since we want to take into account the confidence associated with the information sources to compute the acceptability degree of arguments, we rely on the computation of fuzzy confidence-based degrees of acceptability. As the fuzzy labeling algorithm [14] exploits a scenario where the arguments are connected by an attack relation only, in Cabrio et al. [10] we have proposed a bipolar version of this algorithm, to consider also a positive, i.e., support, relation among the arguments (bipolar AFs) for the computation of the fuzzy labels of the arguments.
Let
We follow da Costa Pereira et al. [14] choosing the max operator (“optimistic” assignment of the labels), but the min operator may be preferred for a pessimistic assignment.
Let
Such an α may also be regarded as (the membership function of) the fuzzy set of acceptable arguments where the label
A bipolar fuzzy labeling is defined as follows,11
For more details about the bipolar fuzzy labeling algorithm, see Cabrio et al. [10].
A total function
When the argumentation module receives the elements of the result set linked by the appropriate relation and the confidence degree associated to each source, the bipolar fuzzy labeling algorithm is applied to the argumentation framework to obtain the acceptability degree of each argument. In case of cyclic graphs, the algorithm starts with the assignment of the trustworthiness degree of the source to the node, and then the value converges in a finite number of steps to the final label. Note that when the argumentation framework is composed by a cycle only, then all labels become equal to 0.5.
Consider the example in Fig. 2(b), if we have
BAF:
,
,
,
BAF:
Statistics on the dataset used for RADAR 2.0 evaluation
The fact that an argumentation framework can be used to provide an explanation and justify positions is witnessed by a number of applications in different contexts [2], like for instance practical reasoning [27], legal reasoning [3,4], medical diagnosis [19]. This is the reason why we choose this formalism to reconcile information, compute the set of reliable information items, and finally justify this result. Other possible solutions would be (weighted) voting mechanisms, where the preferences of some voters, i.e., the most reliable information sources, carry more weight than the preferences of other voters. However, voting mechanisms do not consider the presence of (positive and negative) relations among the items within the list, and no justification beyond the basic trustworthiness of the sources is provided to motivate the ranking of the information items.
Notice that argumentation is needed in our use case because we have to take into account the trustworthiness of the information sources, and it provides an explanation of the ranking, which is not possible with simple majority voting. Argumentation theory, used as a conflict detection technique, allows us to detect inconsistencies and consider the trustworthiness evaluation of the information sources, as well as proposing a single answer to the users. As far as we know, RADAR integrated in QAKiS is the first example of QA over Linked Data system coping with this problem and providing a solution. Simpler methods would not allow to cover both aspects mentioned above. We use bipolar argumentation instead of non-bipolar argumentation because we have not only the negative conflict relation but also the positive support relation among the elements of the result set.
In this section, we describe the dataset on which we evaluate the RADAR framework (Section 3.1), and we discuss the obtained results (Section 3.2). Moreover, in Section 3.3 we describe the resource of reconciled DBpedia information we create and release.
Dataset
To evaluate the RADAR framework, we rely on the dataset presented in Cabrio et al. [12], the only available annotated dataset of possibly inconsistent information in DBpedia language-specific chapters to our knowledge. It is composed of 400 annotated pairs of values (extracted from English, French and Italian DBpedia chapters), a sample that is assumed to be representative of the linguistic relations holding between values in DBpedia chapters. Note that the size of the DBpedia chapter does not bias the type of relations identified among the values, nor their distribution, meaning that given a specific property, each DBpedia chapter deals with that property in the same way. We randomly divided such dataset into a development (to tune RADAR) and a test set, keeping the proportion among the distribution of categories.12
The dataset is available at
Table 3 shows the results obtained by RADAR on the relation classification task on the test set. As baseline, we apply an algorithm exploiting only cross-lingual links (using WikiData), and exact string matching. Since we want to produce a resource as precise as possible for future reuse, RADAR has been tuned to reward precision (i.e., so that it does not generate false positives for a category), at the expense of recall (errors follow from the generation of false negatives for positive classes). As expected, the highest recall is obtained on the surface form category (our baseline performs even better than RADAR on such category). The geo-specification category has the lowest recall, either due to missing alignments between DBpedia and GeoNames (e.g. Ixelles and Bruxelles are not connected in GeoNames), or to the values complexity in the renaming subcategory (e.g., Paris vs First French Empire, or Harburg (quarter) vs Hambourg). In general, the results obtained are quite satisfying, fostering future work in this direction.
Results of the system on relation classification
Results of the system on relation classification
Since we consider text mismatch as a negative class (Section 2.2), it includes the cases in which RADAR fails to correctly classify a pair of values into one of the positive classes. For date and numerical mismatches,
We applied RADAR 2.0 on 300 DBpedia properties – the most frequent in terms of chapters mapping such properties, corresponding to 47.8% of all properties in DBpedia. We considered ∼5 M Wikipedia entities. The outcoming resource, a sort of universal DBpedia, counts ∼50 M of reconciled triples from 15 DBpedia chapters: Bulgarian, Catalan, Czech, German, English, Spanish, French, Hungarian, Indonesian, Italian, Dutch, Polish, Portuguese, Slovenian, Turkish. Notice that we did not consider the endpoint availability as a requirement to choose the DBpedia chapters: data are directly extracted from the resource.
For functional properties, the RADAR framework is applied as described in Section 2. In contrast, the strategy to reconcile the values of non-functional properties is slightly different: when a list of values is admitted (e.g. for properties
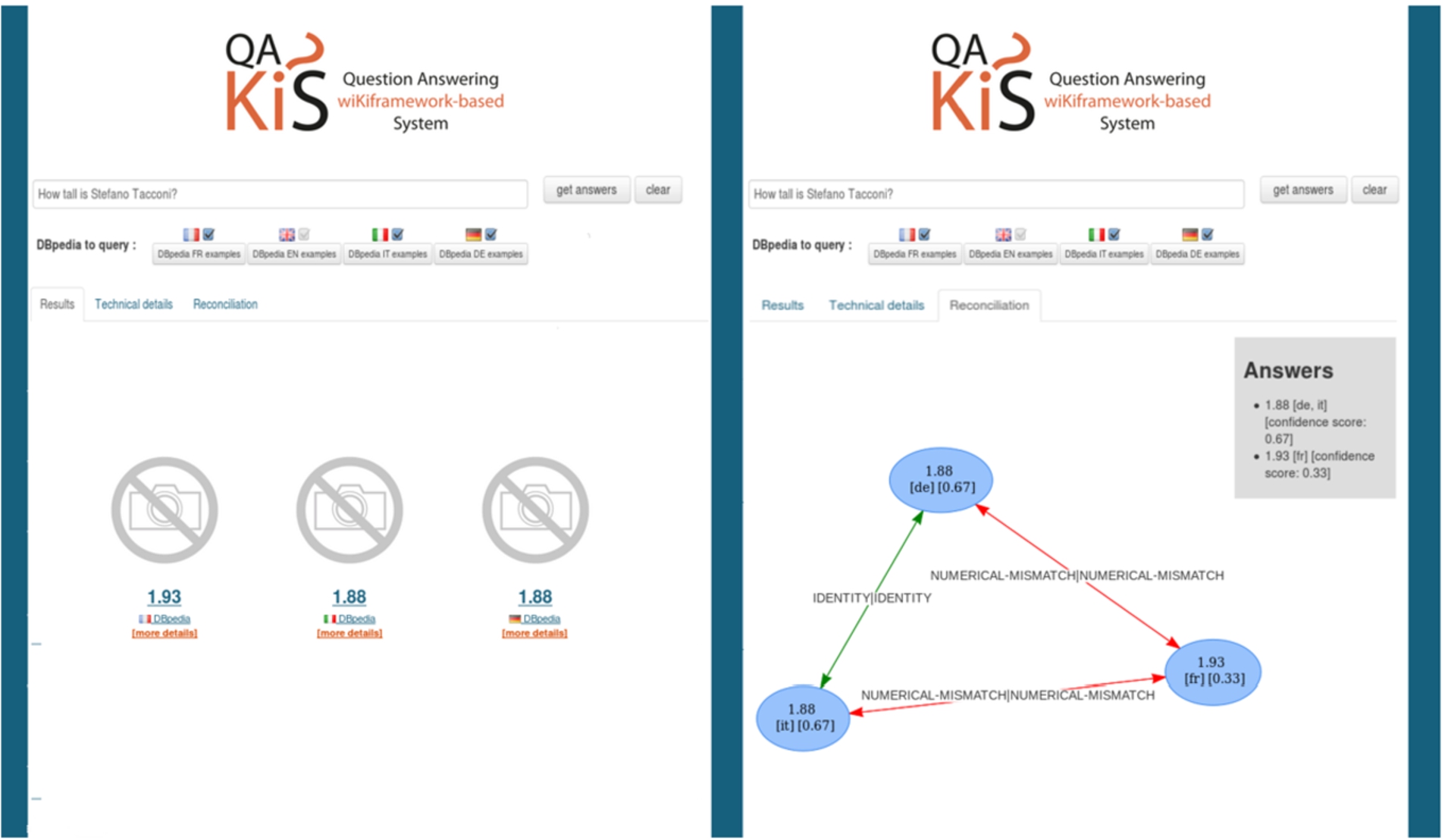
QAKiS + RADAR demo (functional properties).
Moreover, we carried out a merge and a light-weight reconciliation of DBpedia classes applying the strategy called “DBpedia CL” in [24] where “CL” stands for cross-language (e.g., Michael Jackson is classified as a
We integrate RADAR into a QA system over language-specific DBpedia chapters, given the importance that information reconciliation has in this context. Indeed, a user expects a unique (and possibly correct) answer to her factual natural language question, and would not trust a system providing her with different and possibly inconsistent answers coming out of a black box. A QA system querying different data sources needs therefore to weight in an appropriate way such sources in order to evaluate the information items they provide accordingly.
As QA system we selected QAKiS (Question Answering wiKiFramework-based System) [8], because it allows i) to query a set of language-specific DBpedia chapters using a natural language interface, and ii) its modular architecture can be flexibly modified to account for the proposed extension. QAKiS addresses the task of QA over structured knowledge-bases (e.g., DBpedia) [7], but taking into account also unstructured relevant information, e.g., Wikipedia pages. It implements a relation-based match for question interpretation, to convert the user question into a query expressed in a query language (e.g., SPARQL), making use of relational patterns (automatically extracted from Wikipedia), that capture different ways to express a certain relation in a language. The actual version of QAKiS targets questions containing a Named Entity (NE) related to the answer through one property of the ontology, as Which river does the Brooklyn Bridge cross?. Such questions match a single pattern.
In QAKiS, the SPARQL query created after the question interpretation phase is sent to the SPARQL endpoints of the language-specific DBpedia chapters (i.e., English, French, German and Italian) for answer retrieval. The set of retrieved answers from each endpoint is then sent to RADAR 2.0 for answer reconciliation.
To test RADAR integration into QAKiS,13
Demo at

QAKiS + RADAR demo (non-functional properties).
Looking at these examples, the reader may argue that the former question can be answered by a simple majority voting (Fig. 3), and the latter can be answered by a grouping based on surface forms (Fig. 4), without the need to introduce the complexity of the argumentation machinery. However, if we consider the following example from our dataset, the advantage of using argumentation theory becomes clear. Let us consider the question Who developed Skype?: in this case, we retrieve three different answers, namely Microsoft (from FR DBpedia), Microsoft Skype Division (from FR DBpedia), and Skype Limited (EN DBpedia). The relations assigned by RADAR are visualized in Fig. 5. The answer, with the associated weights, returns first Microsoft (FR) with a confidence score of 0.74, and second, Skype Limited (EN, FR) with a confidence score of 0.61. Note that this result cannot be achieved with simple majority voting nor with grouping based on surface forms.

Example about the question Who developed Skype?
To provide a quantitative evaluation of RADAR integration into QAKiS on a standard dataset of natural language questions, we consider the questions provided by the organizers of the QALD challenge (Question Answering over Linked Data challenge), now at its fifth edition, for the DBpedia track.14
We extract from this reference dataset of 359 questions, the questions that the current version of QAKiS is built to address (i.e. questions containing a NE related to the answer through one property of the ontology), corresponding to 26 questions in QALD-2 training set, 32 questions in QALD-2 test sets, 12 in QALD-4 test set, 18 in QALD-5 training set, and 11 in QALD-5 test set. The discarded questions require either some form of aggregation (e.g., counting or ordering), information from datasets different than DBpedia, involve n-ary relations, or are boolean questions. We consider these 99 questions as the QALD reference dataset for our experiments.
We run the questions contained into our QALD reference dataset on the English, German, French and Italian chapters of DBpedia. Since the questions of QALD were created to query the English chapter of DBpedia only, it turned out that only in 43/99 cases at least two endpoints provide an answer (in all the other cases the answer is provided by the English chapter only, not useful for our purposes). For instance, given the question Who developed Skype? the English DBpedia provides Skype Limited as the answer, while the French one outputs Microsoft and Microsoft Skype Division. Or given the question How many employees does IBM have?, the English and the German DBpedia chapters provide 426751 as answer, while the French DBpedia 433362. Table 5 lists these 43 QALD questions, specifying which DBpedia chapters (among the English, German, French and Italian ones) contain at least one value for the queried relation. This list of question is the reference question set for our evaluation.
We evaluated the ability of RADAR 2.0 to correctly classify the relations among the information items provided by the different language-specific SPARQL endpoints as answer to the same query, w.r.t. a manually annotated goldstandard, built following the methodology in Cabrio et al. [12]. More specifically, we evaluate RADAR with two sets of experiments: in the first case, we start from the answers provided by the different DBpedia endpoints to the 43 QALD questions, and we run RADAR on it. In the second case, we add QAKiS in the loop, meaning that the data we use as input for the argumentation module are directly produced by the system. In this second case, the input are the 43 natural language questions.
Table 4 reports on the results we obtained for the two experiments. As already noticed before, the QALD dataset was created to query the English chapter of DBpedia only, and therefore this small dataset does not capture the variability of possibly inconsistent answers that can be found among DBpedia language-specific chapters. Only three categories of relations are present in this data – surface forms, geo-specification, and inclusion – and for this reason RADAR has outstanding performances on it when applied on the correct mapping between NL questions and the SPARQL queries. When QAKiS is added into the loop, its mistakes in interpreting the NL question and translating it into the correct SPARQL query are propagated in RADAR (that receives in those cases a wrong input), decreasing the total performances.
Results on QALD relation classification
Results on QALD relation classification
Notice that in some cases the question interpretation can be tricky, and can somehow bias the evaluation of the answers provided by the system. For instance, for the question Which pope succeeded John Paul II?, the English DBpedia provides Benedict XVI as the answer, while the Italian DBpedia provides also other names of people that were successors of John Paul II in other roles, as for instance in being the Archbishop of Krakow. But since in the goldstandard this question is interpreted as being the successor of John Paul II in the role of Pope, only the entity Benedict XVI is accepted as correct answer.
When integrated into QAKiS, RADAR 2.0 outperforms the results obtained by a preliminary version of the argumentation module, i.e. RADAR 1.0 [10], for the positive relation classification (the results of the argumentation module only cannot be strictly compared with the results obtained by RADAR 2.0, since i) in its previous version the relation categories are different and less fine-grained, and ii) in [10] only questions from QALD-2 were used in the evaluation), showing an increased precision and robustness of our framework. Note that this evaluation is not meant to show that QAKiS performance is improved by RADAR. Actually, RADAR does not affect the capacity of QAKiS to answer questions: RADAR is used to disambiguate among multiple answers retrieved by QAKiS in order to provide to the user the most reliable (and hopefully correct) one.
One of the reasons why RADAR is implemented as a framework that can be integrated on top of an existing QA system architecture (and is therefore system-independent), is because we would like it to be tested and exploited by potentially all QA systems querying more than one DBpedia chapter (up to our knowledge QAKiS is the only one at the moment, but given the potential increase in the coverage of a QA system querying multiple DBpedia language-specific chapters [7], we expect other systems to take advantage of these interconnected resources soon).
QALD questions used in the evaluation (in bold the ones correctly answered by QAKiS; x means that the corresponding language specific DBpedia chapter (EN, FR, DE, IT) contains at least one value for the queried relation; dbo means DBpedia ontology)
The present paper is an extended version of our previous work [9–11] introducing RADAR 1.0. The following common points are present: the idea of using argumentation theory to detect inconsistencies over the result set of a question answering system exploiting DBpedia, and the bipolar extension of the original fuzzy labeling algorithm [14] to judge an argument’s acceptability in presence of both support and attack relations. However, the present paper presents a substantial extension with respect to this preliminary work. More specifically, the main enhancements are reported in the following:
RADAR 2.0 exploits the categorization we introduced in [12], as mentioned in Section 2.2. However, the work presented in [12] is purely theoretic and the contribution here is to study how to make RADAR 2.0 match these linguistic relations with respect to the DBpedia use case. Moreover, the categorization of the possible relations holding between the information items we adopt here is different (more linguistically-motivated) and more fine-grained than the one we used in [10]. This fine-grained categorization allows for a more insightful justification graph.
The relations holding between the elements of the result set are here automatically extracted with the application of more robust techniques than in [10]. More precisely, the way RADAR 2.0 extracts these relations in an automated way is different from the way RADAR 1.0 extracts them: RADAR 2.0 adopts external resources to improve the extraction of the correct relation, such as MusicBrainz, the BNCF (Biblioteca Nazionale Centrale di Firenze), DBpedia and Wikipedia, GeoNames, and WikiData.
While in [11] only data from QALD-2 has been used, here we use all data available from the QALD challenges (all editions), and the Italian chapter of DBpedia is added as RDF dataset to be queried with QAKiS (not present in our previous works on the topic). Moreover, the results presented in this paper show a higher precision with respect to the results obtained with RADAR 1.0 and reported in [10] (
Differently from [10] where no resource resulted from the inconsistencies detection process, here we generate a resource applying the proposed framework to 15 reconciled language-specific DBpedia chapters, and we release it.
State-of-the-art QA systems over Linked Data generally address the issue of question interpretation mapping a natural language question to a triple-based representation (see [21] for an overview). Moreover, they examine the potential of open user friendly interfaces for the Semantic Web to support end users in reusing and querying the Semantic Web content. None of these systems considers language-specific DBpedia chapters, and they do not provide a mechanism to reconcile the different answers returned by heterogenous endpoints. Finally, none of them provides explanations about the answer returned to the user.
Several works address alignment agreement based on argumentation theory. More precisely, Laera et al. [20] address alignment agreement relying on argumentation to deal with the arguments which attack or support the candidate correspondences among ontologies. Doran et al. [15] propose a methodology to identify subparts of ontologies which are evaluated as sufficient for reaching an agreement, before the argumentation step takes place, and dos Santos and Euzenat [26] present a model for detecting inconsistencies in the selected sets of correspondences relating ontologies. In particular, the model detects logical and argumentation inconsistency to avoid inconsistencies in the agreed alignment. We share with these approaches the use of argumentation to detect inconsistencies, but RADAR goes beyond them: we identify in an automated way relations among information items that are more complex than
We mentioned these works applying argumentation theory to address ontology alignment agreements as examples of applications of this theory to open problems in the Semantic Web domain. Actually, the two performances cannot be compared to show the superiority of one of the two approaches, as the task is different.
Conclusions
In this paper, we have introduced and evaluated the RADAR 2.0 framework for information reconciliation over language-specific DBpedia chapters. The framework is composed of three main modules: a module computing the confidence score of the sources depending either on the length of the related Wikipedia page or on the geographical characterization of the queried entity, a module retrieving the relations holding among the elements of the result set, and finally a module computing the reliability degree of such elements depending on the confidence assigned to the sources and the relations among them. This third module is based on bipolar argumentation theory, and a bipolar fuzzy labeling algorithm [10] is exploited to return the acceptability degrees. The resulting graph of the result set, together with the acceptability degrees assigned to each information item, justifies to the user the returned answer and it is the result of the reconciliation process. The evaluation of the framework shows the feasibility of the proposed approach. Moreover, the framework has been integrated in the question answering system over Linked Data called QAKiS, allowing to reconcile and justify the answers obtained from four language-specific DBpedia chapters (i.e. English, French, German and Italian). Finally, the resource generated applying RADAR to 300 properties in 15 DBpedia chapters to reconcile their values is released.
There are several points to be addressed as future work. First, the user evaluation should not be underestimated: we will soon perform an evaluation to verify whether our answer justification in QAKiS appropriately suits the needs of the data consumers, and to receive feedback on how to improve such visualization. Second, at the present stage we assign a confidence score to each source following two criteria, however another possibility is to let the data consumer itself assign such confidence degree to the sources depending on the kind of information she is looking for. Finally, the proposed framework is not limited to the case of multilingual chapters of DBpedia. The general approach RADAR is based on allows to extend it to various cases like inconsistent information from multiple English data endpoints. The general framework would be the same, the only part to be defined are the rules to extract the relations among the retrieved results. Investigating how a module of this type can be adopted as a fact checking module is part of our future research plan.