
Abstract
An ever increasing amount of event-centric knowledge is spread over multiple web sites, either materialized as calendar of past and upcoming events or illustrated by cross-media items. This opens an opportunity to create an infrastructure unifying event-centric information derived from event directories, media platforms and social networks. In order to create such infrastructure, EventMedia relies on Semantic Web technologies that ensures seamless aggregation and integration of disparate data sources, some of which overlap in their coverage. In this paper, we present the EventMedia dataset composed of events descriptions associated with media and interlinked with the Linked Open Data cloud. We describe how data has been extracted, converted, interlinked and published following the best practices of the Semantic Web.
Introduction
In their daily life, people naturally organize their personal data according to occurring events: holiday, wedding, birthday party, concert, etc. Events are indeed a natural way for referring to any observable occurrence grouping persons, places, times and activities [10]. Events are also observable experiences that are often documented by people through different media. Nowadays, social services host a large amount of information about events, illustrative media and social connections between participants. However, this information is often spread and locked in amongst these services providing limited event coverage and no interoperability of the description [3]. Aggregating these heterogeneous sources into one unified platform is the aim of the EventMedia project leveraging on the benefits of Semantic Web technologies.
One vision of the Web of Data is to organize the data silos in a structured way which can be understood by machines and easily exploited by humans. This requires the use of common vocabularies for the integration of fragmentary information into a logically coherent knowledge. To achieve this vision, a growing number of RDF datasets have been published in the Web of Data covering diverse domains such as digital libraries, government, health, media or more generally encyclopedic data. In this work, our goal is to introduce an event-domain RDF dataset and to investigate the underlying connections between event centric data on the Web. While wishing to create such dataset, we are aware that event web directories already exist such as Last.fm,1
The remainder of this paper is structured as follows. We explain how the data is collected (Section 2) and converted into an RDF model (Section 3). We present an overview of the EventMedia dataset in Section 4, and we describe how we interlinked it with the other LOD datasets in Section 5. Then, we describe two web application in Section 6, and we outline the future work in Section 7.
In this section, we describe how the data has been collected and interlinked either statically using a REST-based crawler or dynamically using a live extractor.
REST-based data crawler
Crawling data from multiple services is in general a time consuming task due to the lack of haromonization in different specifications and policies of REST APIs (Application Programming Interface). This imposes a need to create tools providing a seamless and flexible way to crawl data from multiple services. Such tools should be able to address many tasks such as policy management, requests chaining, data integration or merging response schemas. We propose a framework that supports those tasks and unifies information into a meaningful data model. This framework is composed of two main components: the Unified REST Module and the Scraping Processor as illustrated in Fig. 1. The first module is based on a RESTful service that allows for the unification of various Web APIs by exploiting their commonality in terms of described methods, inputs and responses. Each source API (e.g. Eventful API) is associated with a descriptor file which represents the API parameters such as root URL, API key, and a set of query objects. Then, each query object represents a mapping between our REST URL pattern and the source API URL pattern which describes a REST method and its input parameters. In order to manage the request chaining, we define two types of query objects: (i) the first type is related to first-order methods used to search for the main objects such as events and media, (ii) the second type is related to other methods used to fetch the descriptions of secondary objects such as artists, locations, attendees, etc. Overall, we have created three REST methods to search for events, photos and videos, respectively. These methods have as input a set of parameters such as the original sources (e.g. last.fm, eventful, etc.) and other additional filters (e.g. category, location, date, etc.). Thus, the user can request in parallel multiple Web services by specifying the list of sources into one request.

The Rest-based Crawler Architecture.
Besides the RESTful service, the Scraping Processor manages four important tasks. The first task enables multi-threading to reduce the amount of time usually required to query multiple web services. The remaining tasks deal with data processing, starting from JSON de-serialization to RDF conversion and loading into a triple store. More precisely, data retrieved is de-serialized and exported into a common schema providing descriptions of a set of objects, namely; event, location, agent, user, photo and video. Then, we use a tag-based mapping by consuming some metadata, not only to establish links between events and media, but also to enrich their descriptions with additional information from external datasets. This framework is meant to ease the addition of new APIs used to collect events and media. It also offers other REST methods to track or stop the scraping processes. Finally, a web dashboard has been developed in order to offer graphical functionalities that help monitor the scraping task. It provides practical widgets to help build a query by filtering some parameters and track the scraping process. It is available online at

The Snow Patrol Concert described with LODE ontology.
A recent user-centric study [3] highlights the importance of media to provide visual information which support decision making. This study motivated us to enrich event views with media by exploring the overlap in metadata between four popular web sites, namely Flickr as a hosting web site for photos and videos, and Last.fm, Eventful and Upcoming as a rich documentation of past and upcoming events. Note that explicit relationships between events and photos exist using machine tags such as
New events are taking place everyday and people keep sharing an ever-growing amount of media. Such evolution requires a real-time processing that retrieves fresh data and updates the triple store. To achieve this, we developed a live extractor which consumes the feeds provided by some Web services. More precisely, we use the Flickr feeds8
In this section, we describe our approach to generate RDF triples describing events and media using a variety of existing vocabularies such as the LODE ontology and Media Resources ontology.
The LODE ontology
The LODE ontology10
To describe media, we re-use two popular vocabularies, namely: the W3C Ontology for Media Resources11
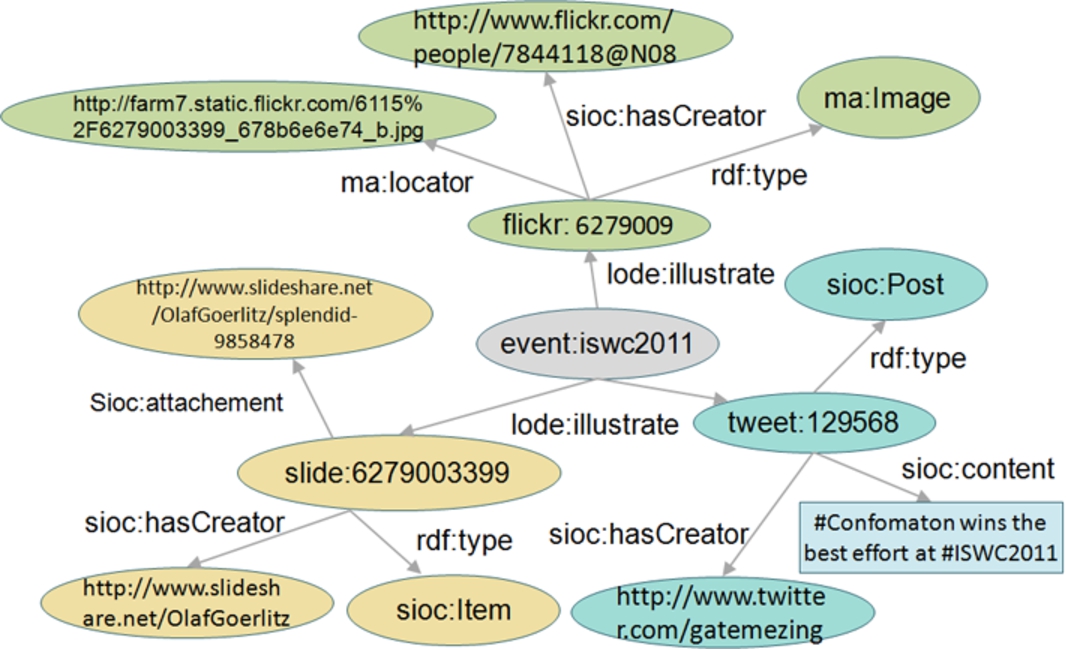
RDF modeling of photos, tweets and slides associated with the ISWC 2011 Conference.
Events are generally categorized in lightweight taxonomies that provide facets when browsing event directories. We manually analyzed the taxonomy used in various sites, namely Facebook, Eventful, Upcoming, LinkedIn,13
EventMedia is a new hub16

Overview of the EventMedia components.
Our dataset consists of more than 30 millions RDF triples. All URIs are dereferencable and served as either static RDF files serialized in N3 or as JSON by a RESTful API. The back-end of EventMedia consists of a Virtuoso SPARQL endpoint available at (
Event directories have overlap in their coverage and it is worthwhile to discover similar events so that one description can complement another. However, discovering similar events from these overlapping but heterogeneous directories imposes some challenges, well-known in instance matching. In addition, we also investigate the enrichment of EventMedia with additional information from open datasets. In our approach, we favour high precision rather than high recall since the cost of missed mapping is lower that the cost of incorrect matching. Statistics about the linksets generated are accessible at (
Number of resources per type and source in EventMedia
Number of resources per type and source in EventMedia
We create owl:sameAs links between events that reflect a high similarity in terms of their factual properties, namely: title, date, location and involved agents. It is worth noting that EventMedia is a challenging dataset due to the presence of a structural heterogeneity (e.g. missing property) and naming variations (e.g. abbreviations, misspellings, different naming conventions). The interlinking was performed using two tools: (i) SILK [4] which draws on a declarative configuration language called Silk-LSL to manually define the linkage rules; (ii) KnoFuss [8] which learns the similarity function based on a semi-supervised genetic algorithm optimizing the precision. We integrated two similarity functions into those tools, namely: a temporal inclusion metric and a string similarity metric described in [6]. The results obtained highlight the time-sensitivity of event reconciliation due to the fact that the time is differently described across multiple websites. Moreover, we note that KnoFuss achieves better performance than SILK thanks to its learning strategy. As a result, the use of KnoFuss on a manually constructed gold-standard of 300 matched events achieves high precision of about 95%, but fair recall of about 75%.
Enrichment with Linked Data
In order to enrich EventMedia, we perform several interlinking processes using SILK attempting to discover connections between agents and locations with Linked Data. In this context, the key challenge is to resolve the naming conflicts which needs to invoke additional features apart from the instance name. For example, to reconcile the agents, we decide to compare agents’ names and descriptions respectively using Jaro and Cosine functions and we set a high threshold to ensure a high precision. Several datasets have been considered such as Musicbrainz, DBpedia, Freebase and Uberblic. Hence, the agent URI which has for label “Radiohead” is interlinked with the DBpedia URI (
Event-based applications
The EventMedia dataset has been employed in some web applications designed to enable efficient browsing of an event-based space [1,5,7]. For instance, the EventMedia application [7] delivers different event-centric views (what, where, when and who) and allows users to relive experiences based on media. In fact, people wish to discover events either through invitations and recommendations, or by filtering available events according to their interests [3]. Therefore, the interface allows constraining different event properties (e.g. time, place, category) using, for example, a timeline slider control input and a map grouping markers. Once an event selected, media are presented to convey the event experience, along with social information to provide better decision support. The application is available online at
Conclusion and future work
The integration of event-centric information from social services using Semantic Web technologies has given rise to EventMedia, an open dataset continuously synchronized with recent updates. Several improvements could potentially enhance its quality and usability. Indeed, further vocabularies could be incorporated such as the Ticket Ontology to add meaningful relationships between events and related tickets, or the Allen’s vocabulary to express the temporal relationships between events in fine-grained level. Another improvement is to enrich EventMedia using other services such as Youtube, Google+ or Facebook, so that we increase the dataset coverage and more connections could straightforwardly be explored. Finally, we aim to develop a live interlinking framework that aligns in real-time every incoming stream of events with Linked Data.