
Abstract
There is a high public demand to increase transparency in government spending. Open spending data has the power to reduce corruption by increasing accountability and strengthens democracy because voters can make better informed decisions. An informed and trusting public also strengthens the government itself because it is more likely to commit to large projects. OpenSpending.org is a an open platform that provides public finance data from governments around the world. In this article, we present its RDF conversion LinkedSpending which provides more than five million planned and carried out financial transactions in 627 data sets from all over the world from 2005 to 2035 as Linked Open Data. This data is represented in the RDF Data Cube vocabulary and is freely available and openly licensed.
Introduction
A W3C design issue [4] motivates making government data available online as Linked Data for three reasons: “1) Increasing citizen awareness of government functions to enable greater accountability; 2) Contributing valuable information about the world; and 3) Enabling the government, the country, and the world to function more efficiently.” Increasing the transparency of government spending specifically is in high demand from the public. For instance, in the survey publication [13], “Public access to records is crucial to the functioning government” was rated with a mean of 4.14 (1 = disagree completely, 5 = agree completely). Open spending data can reduce corruption by increasing accountability and strengthening democracy because voters can make better informed decisions. Furthermore, an informed and trusting public also strengthens the government itself because it is more likely to commit to large projects (see [1] for details).
Several States and Unions are bound to financial transparency by law, such as the European Union1
“2. The Commission shall make available, in an appropriate and timely manner, information on recipients, as well as the nature and purpose of the measure financed from the budget […]” [14].
Our contribution is an RDF transformation of the OpenSpending3
Namespaces and prefixes used in the paper
In a time of globalization, financial data becomes an international network. RDF data with its linked nature supports a representation that takes this network nature into account. As a machine interpretable format, it lowers the access barrier for application developers. For instance, generic Linked Data tools such as OntoWiki, CubeViz and Facete provide end users with the means to explore the data and discover new insights.
Economic analysis LinkedSpending is represented in Linked Open Data, which facilitates data integration. Currencies from DBpedia and countries from LinkedGeoData are already integrated. Financial data offers further integration candidates, such as political or other statistical, policy-influencing data such as health care. This allows queries such as query 7 in paragraph 5, which asks for data sets with currencies whose inflation rates are greater than 10%.
LinkedSpending can also be used to compute economic indicators across several data sets. A possible indicator is a country’s spending on education per person where the population size can be taken from the LinkedGeoData countries linked from one or more budget data sets. One such data set is
Finding and comparing relevant data sets Government spending amounts are often much higher than the sums ordinary people are used to dealing with but even for policy makers it is hard to understand whether a certain amount of money spent is too high or normal. Comparing data sets and finding those which are similar to another one helps separating common values from outliers which should be further investigated. For example, if another country has a similar budget structure but spends way less on health care with a similar health level, it should be investigated whether that discrepancy is caused by inherent differences such as different minimum wages or a different climate or if it is due to preventable factors such as inefficiencies or corruption. While OpenSpending provides several hundreds of data sets which can be searched and it allows browsing and visualization of any single one, it does not provide a comparison function between data sets. Because of the mechanism to identify equivalent properties (see Section 4), SPARQL queries can compare different data sets, e.g. between similar structures in different countries. Query 9 in paragraph 5 shows a simple query to detect data sets which are most similar to any particular data set. This is done by calculating the number of common measures, attributes and dimensions.
OpenSpending source data
OpenSpending4
As some of them contain errors, the number of LinkedSpending data sets is slightly smaller.
The domain model of OpenSpending is a data cube (also OLAP cube, hypercube), which represents multi-dimensional statistical observations. Each cell corresponds to an observation (an instance of spending or revenue) that contains measurements (e.g. the amount of money spent or received). The context of the measurement is provided by the dimensions like the purpose, department and time of a spending item and optionally by attributes, which further describe the measured value, e.g., the unit of the measurement.
Figure 1 shows an excerpt from the model of the OpenSpending data set eu-budget with the dimension sub-programme and the measure amount. Figure 2 shows an entry that contains the actual values for the dimension and the measure of the observation.
Problems
While the data is well-structured and thus suitable for conversion without data cleaning or extensive preprocessing, it still poses problems that need to be taken into account: 1. New data sets are frequently added (approximately 50 per month) and, less often, existing data sets are modified. 2. Some data sets do not specify a value for all properties in all observations. 3. There are properties with the same name in different data sets where it is unknown if they specify the same property. 4. Data Cube is a meta model. The deep structure of the data sets is heterogeneous and described only shallowly. 5. The language of literals is varying between and even within data sets but the language used is not specified. Points 1 to 3 are addressed in the next section while points 4 and 5 are discussed in Section 8.

simplified excerpt of an OpenSpending model.

simplified excerpt from an OpenSpending entry.
The RDF DataCube vocabulary [5], i.e. an RDF variant of the previously explained data cube model, is an ideal fit for the transformed data.
First and foremost, this vocabulary provides the backbone structure for every LinkedSpending data set, see Fig. 3. Each data set is represented by an instance of
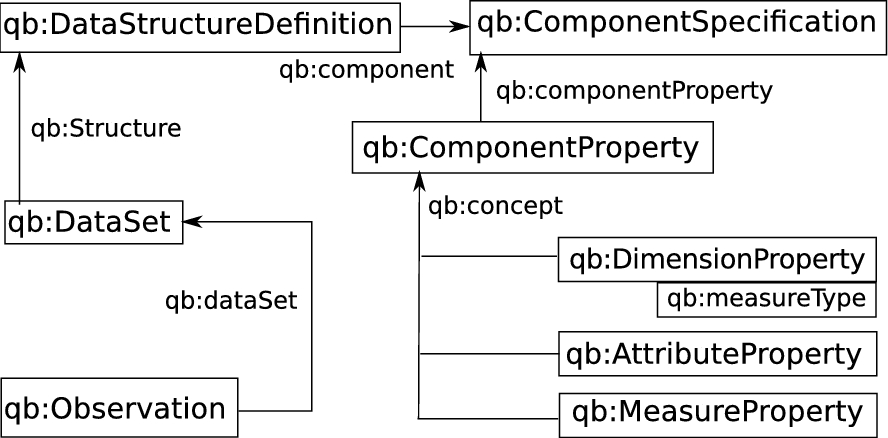
Used RDF DataCube concepts and their relationships.10
Simplified version of the structure described in [5].
Conversion of OpenSpending to LinkedSpending classes and instances

RDF DataCube vocabulary modelling excerpt of data set
Transformation All of the OpenSpending data sets describe observations referring to a specific point or period in time and thus undergo only minor changes. New data sets, however, are frequently added. Because of this, the huge number of data sets and their size, an automatic, repeatable transformation is required. This is realized by a program11
Written in Java, available as open source at https://github.com/AKSW/openspending2rdf.
JSON path (
Equivalent component properties (dimensions, attributes and measures) are identified as follows: A configuration file optionally specifies the mapping of data set and property name to an entity in the LinkedSpending ontology. By default, the property URI is derived from the property name. Properties with the same name in different data sets not having a mapping entry that states otherwise are assumed to represent the same concept and thus given the same URL.13
Although that has the possibility of mismatches, such a mismatch has not been spotted yet. Still, evaluating and, if necessary, improving the automatic matching is part of future work.
Use of established vocabularies In addition to the standard vocabularies, RDF, RDFS, OWL and XSD, the DCMI vocabulary is used for source and generation time metadata. The data sets are modelled, first and foremost, according to the RDF Data Cube vocabulary, which specifies the structure of a data cube. LinkedSpending follows the RDF Data Cube recommendation to make heavy use of the SDMX model for measures, attributes and dimensions. The data sets are very heterogeneous but there are some properties which are commonly specified and thus modelled with established vocabularies. The year and date, a data set and an observation refers to, respectively, is expressed by
Currencies are taken from DBpedia [9] and countries are represented using the vocabulary of LinkedGeoData [16], a hub for spatial linked data. Some amount of data is imported from LinkedGeoData countries and DBpedia currencies. Because of the limited number of countries and currencies, and property values imported per country and currency, the amount of data is too small to consider federated querying. As most countries and currencies are stable in the medium term, this data needs to be updated only infrequently.
Interlinking There are two possibilities to align entities to another vocabulary: 1) to use the entities directly and 2) to create an own RDF resource with interlinks, like
Error handling The OpenSpending API lists 732 data sets with 627 of them having a LinkedSpending equivalent. The discrepancy is caused by loss in several stages. To prevent timeouts and to reduce the impact of disrupted connections, the source data set is downloaded in several parts with a maximum number of entries. These parts are then merged so that each file corresponds to exactly one data set. Data sets without observations are removed and the remaining data sets are transformed, noting the missing values for all component properties. If the first 1000 values are all missing, the transformation is aborted, otherwise a
Sustainability The data conversion process is controlled by a web application14

View of the data set
Performance The transformation of a data set takes less than an hour on average on a 2 GHz virtual machine, using less then 2 GB of RAM.
The data is published using OntoWiki [2]. The interface for human and machine consumption is available at
It can be explored by viewing the properties of a resource, its values and by following links to other resources (see Fig. 5). Using the SPARQL endpoint15
Faceted search offers a selection of values for certain properties and thus slice and dice of the data set according to the interests on the fly. For example, depicted in Fig. 6 is all Greek police spending in a certain region. Visualization supports discovery of underlying patterns and gain of new insights about the data, for example about the relative proportions of a budget (see Fig. 7). We set up the RDF DataCube Browser CubeViz [15] as part of the human consumption interface.
Licensing All published data is openly licensed under the PDDL 1.0. in accordance with the open definition.17
Technical details of the LinkedSpending data set

Faceted browsing in CubeViz by restricting values of dimensions.

CubeViz visualization of the Romanian budget of 2013.
LinkedSpending consists of 627 data sets (continually growing) with more than five million observations total. The amount of observations of the individual data sets varies considerably between two (spendings in Prague of about 5000 CZK for an unknown purpose) and 242 209 (“Spending from ministries under the Danish government”). Table 4
The links are inflated as they originate in observations instead of data sets, which allows better querying and tool support.
This analysis relates to version 0.1, which contains less data sets.
There is only one data set with no dimensions which a test data set on OpenSpending, as a data cube with no dimensions is not useful.

Histogram of measures, attributes and dimensions (version 0.1). 217 data sets have exactly one measure (clipped bar).
Example queries Table 5 contains queries for common use cases: Queries 1–6 are basic queries. Query 7 uses the interlinking to DBpedia currencies by querying over two different graphs.22
Parts of DBpedia and LinkedGeoData describing countries and currencies have been integrated in the SPARQL endpoint. With federated querying however, nearly the whole LOD cloud can be queried.
In this case, the “Hauptfunktion” and “Oberfunktion” are unique to the
The TWC Data-Gov Corpus [6,7] consists of linked government data from the Data-gov project. However, it only contains transactions made in the US and does not overlap with OpenSpending. The publicspending.gr project generates and publishes [17] public spending data from Greece based on the UK payment ontology and without using statistical data cubes. The UK government expenditure dataset COINS24
Amount of data for version 2014-3. All values are rounded to the nearest integer
As shown in Section 4, we converted several hundreds of financial data sets to RDF and, as shown in Section 5, we published them as Linked Open Data in several ways. However, we recognise a few shortcomings and our goal is to enrich the meta data with the help of domain experts and to refine the structure of the individual data sets. Furthermore, we plan to improve the automatic configuration of CubeViz.
Multilinguality RDF itself provides support for multilingualism, which is one of its key advantages to other representation formats. The source data does not contain language tags, however, and the languages used do not always match the country, the data refers to. Automatic language detection on single labels did not yield a satisfying precision and it is not possible to increase the precision of the language detection by combining the estimates about several labels of an observation as their language is not always identical. We plan statistical examinations of the relations between labels of different entities and more complex schemes based on those examinations, which can achieve language detection with a higher precision. Additionally, we plan to automatically translate all literals to several languages.
Individual modelling Because the source data is already structured, the transformation of all the data sets without the need of text extraction and in an automatic way was feasible. On a deep level however, there is much unmodelled structure that is unique to each data set or at most shared between several of them, for instance the categorization of spending into several specific “plans” in German budgets. Because of the amount of data sets, modelling all details, and thus also improving the internal and external connectivity, requires either a large-scale cooperation or a crowd-driven approach, which we did not perform yet.
Examplary SPARQL queries for typical use cases
Interlinking Extensive interlinking of referenced entities to the all-purpose knowledge base of DBpedia provides additional context. Coded property values, such as the budget areas healthcare and public transportation, can be interlinked with their respective DBpedia concepts. This enables the usage of type hierarchies and thus new ways of structuring the data and provides more meaningful aggregations and new insights.
Question answering We plan to develop a question answering system that allows accessing statistical Linked Data in the form of RDF Data Cubes using natural language questions [8]. LinkedSpending is used both as the first knowledge base and for performance evaluation.
Footnotes
Acknowledgements
Special thanks goes to the people behind the OpenSpending project, including Friedrich Lindenberg for suggesting the conversion.