
Abstract
Edge Computing is a new computing paradigm that aims to enhance the Quality of Service (QoS) of applications running close to end users. However, edge nodes can only host a subset of all the available services and collected data due to their limited storage and processing capacity. As a result, the management of edge nodes faces multiple challenges. One significant challenge is the management of the services present at the edge nodes especially when the demand for them may change over time. The execution of services is requested by incoming tasks, however, services may be absent on an edge node, which is not so rare in real edge environments, e.g., in a smart cities setting. Therefore, edge nodes should deal with the timely and wisely decision on whether to perform a service replication (pull-action) or tasks offloading (push-action) to peer nodes when the requested services are not locally present. In this paper, we address this decision-making challenge by introducing an intelligent mechanism formulated upon the principles of optimal stopping theory and applying our time-optimized scheme in different scenarios of services management. A performance evaluation that includes two different models and a comparative assessment that includes one model are provided found in the respective literature to expose the behavior and the advantages of our approach which is the OST. Our methodology (OST) showcases the achieved optimized decisions given specific objective functions over services demand as demonstrated by our experimental results.
Keywords
Introduction
As a result of the fast growth of the Internet of Things (IoT), smart cities are replete with linked sensors and computing devices used for information collection and processing [42]. Various collaborative services (e.g., smart medical assessment, smart university, elderly support) emerge as a result of the right processing and utilization of the huge data created by the Internet of Things [45]. On the basis of integrated services, it is likely that the smart city will be able to increase the Quality of Experience (QoE) of people while reducing the use of resources. Furthermore, smart cities are endowed with a robust capacity to observe, analyze, and adapt to their residents [34]. Nevertheless, because of the rapid growth of data and the limited processing capacity of endpoints, it is challenging to develop joint services that are typically time and latency-sensitive when depending purely on IoT devices. To increase the QoE in smart cities, it is essential to use additional computational resources [13]. As a result, Edge Computing (EC), which completely leverages computational resources at the network edge and can meet real-time demands, has been proposed as an effective paradigm to resolving the issue of inadequate computing resources in smart cities [57].
In order to offer ubiquitous and pervasive services, the present expansion of IoT and EC makes them possible to have a large number of devices and processing nodes located close to end-users [30]. In recent years, we have also seen the introduction of several mobile devices and applications, such as drones and Vehicular Networks (VN), each with its own unique set of capabilities. The development of this technology has made it possible for computing and sensing devices to launch applications such as Augmented Reality (AR), predictive analytics activities at the edge, intelligent vehicle control, traffic management, and interactive applications [4]. These types of services are given in response to the need for processing data being gathered by IoT devices and, then, being sent to EC nodes [63]. A range of IoT applications may offer to end users with more precise and detailed network services [18]. In this situation, an increasing number of equipment and sensors are being networked through IoT technology, and this equipment and sensors will create vast amounts of data that need additional processing, therefore delivering service providers and end users with intelligence. In the traditional Cloud computing setup, all information must be transferred to centralized servers, and after processing, the outcomes must be sent directly to the requestors, e.g., sensors or other devices. This procedure places significant stress on the network, particularly in terms of bandwidth and resource requirements for data transmission. Furthermore, when data size increases, bandwidth utilization will decline.
EC has been suggested to address the aforementioned difficulties [24,59]. The fundamental goal is to increase the processing capabilities at the network edge; specifically, computing [51], bandwidth [62], and storage resources [43] are relocated nearer to IoT systems in order to minimize core data traffic and response delay and to support resource-intensive IoT applications. In comparison to Cloud [11,25], EC nodes have limited storage and computing capabilities. Nonetheless, they are able to host a number of services that make it easier to carry out a variety of processing tasks [40]. These kinds of activities are often presented in the form of assignments that ‘request’ the processing of data (e.g., predictive analytics, explanatory-driven models). The fact that IoT and EC may work together to facilitate the implementation of collaborative activities in which nodes can collaboratively complete the tasks that have been requested is an intriguing development [22]. For instance, nodes share services or data and they even offload processing duties onto peers in certain circumstances. Because of their reduced capability for storage and computing, EC nodes are only able to host a (sub-)set of the total accessible services and the data that has been obtained. The collected data can be reported by stream monitoring e.g., the evolution of a certain phenomenon [6,27,28] and streams generated by autonomous nodes (e.g., unmanned vehicles) [29]. Upon these streams, we can support the extraction of knowledge, the detection of events or any other processing [30].
Services are essential in order to perform the processing responsibilities that have
been delegated by applications or users in the form of tasks. As a result, the
demand for services is always adjusting to accommodate the dynamic requests of
various activities/tasks. This indicates that a task can be asking for a service
that may or may not be available locally. Then, nodes have two options: Option 1: They can perform a service
replication (pull-action) from their edge neighbors or
the Cloud, but only if the service is suitable for their computing
capabilities; Option 2: They can delegate
the responsibility (push-action) to the peers/Cloud
that presently host the service(s).
The
aforementioned options deal with deciding where to transfer service in order to keep
the Quality of Service (QoS) at a high level. Because of the nature of the EC
environment and the non-static behavior of end users, it is obviously difficult to
provide an ideal migration/replication plan that can be implemented. Moreover, due
to the situations that make the local authority of the user complex, offloading
tasks involves sending them to peers or the Cloud for processing. For instance, the
node that is assigned the duty of processing as the receptor of a task could have a
high load, and as a result, it might not be able to guarantee an effective
completion within the permitted time interval that may be specified by the
requester. A strategy for the migration of services was presented in [60]; its purpose is to satisfy the service
latency requirements of EC while keeping migration costs and trip times to a
minimum. Furthermore, in [20], the authors
recommended using a reinforcement learning-based model to solve the service
migration issue.
In this paper, we focus on the pull-action leaving the initiative to EC nodes to enhance their autonomous nature and suggest that services’ replication may be optimized and controlled in the EC environment by adopting the principles of optimal stopping theory (OST) [21]. In this case, EC nodes must decide locally when it is the best time to replicate the service in order to maximize its ability to carry out the requested tasks. We have to mention that the decision for services replication is made by every EC node independently being fully aligned with the needs of the incoming tasks and the status of the node. The remaining paper is organized as follows. In Section 2, we provide a summary of the prior work as well as the rationale and our contribution, while Section 3 delves into the specifics of the proposed OST-based decision-making model. The outcomes of our performance and comparative assessment are presented in Section 4, and Section 5 draws the conclusion of this work and indicates potential avenues for further research.
Related work & contribution
Related work
The majority of the approaches for task offloading at the edge depends on the selection of whether or not the task should be processed locally or should be offloaded to peers or Cloud. The time in execution latency [26] and the amount of energy used should both be reduced as much as possible. These are the two primary goals. The work presented in [35] provides a framework for offloading computation workloads from a user device to a server hosted in EC. Our approach is different from that due to the fact that our time-optimized decision primarily considers the actual benefit of payoff which indicates the current users’ requests for specific service. In [35], the User Equipment (UE) choice on whether to offload computing tasks with the highest CPU availability for a certain application is driven by the radio network information service (RNIS), according to the current value of round trip time (RTT) between the UE and the edge node. In our method, the offloading choice ideally relies on the number of users’ requests for specific service as well as the cost of delay. Therefore, the decision of offloading is made when the dedicated time of the required service by users is finished which indicates the required service is not worth being hosted. As a result, this will optimize the edge users’ capacity.
The work in [9] presents a method for optimizing the decision-making process that an Unmanned Aerial Vehicle (UAV) uses to choose whether or not to do the compute task locally or to offload it to an edge server. The decision is made based on a series of interactions that take place between the UAV and IoT systems. During these interactions, the UAV receives feedback on the state of the network and EC server, which enables an estimation of the remaining amount of time needed to complete the task. As a result, the UAV uses this information to solve an optimization problem with the purpose of decreasing a weighted sum of delay and energy costs as much as possible. In our work, EC chooses the ideal moment that has a high payoff to perform a service replication (pull-action) from their edge neighbors or the cloud. The approach described in [1] analyses the present state of the node’s resources, which are modeled as a Markov Decision Process utilizing Q-learning for training, in order to identify which portion of the application ought to be offloaded and then moves on with an offloading decision. The primary objective is to reduce the amount of time that the offloaded applications are delayed while taking into account the mobile fog that is located nearby, the mobile fog that is located adjacent, or the Cloud as suitable offloading locations. In our work, we have examined the scenario in which the edge node only performs a service replication (pull-action) from its edge neighbors or the cloud since the edge node is static and makes this decision in a short delay as close to the real’s delay scenario.
The work in [17] focuses on reducing the processing delay of all activities and the energy usage of the edge device by optimizing the task allocation decision and the central processing unit (CPU) frequency of the edge device. However, this study focuses on making decisions based on the popularity of the required service to complete the task. The authors of [16,31] studied the offloading problem decision for a multi-edge user & multi-edge node. However, in our approach, we focus on making the decision of (pull or push-action) for a single user to edge node or peer since our approach OST has strong deals with low capacity better than the approach in [16,31]. Using a time-division multiple access protocol in [50], edge users can conduct their individual activities locally or offload all or a portion of them to the Access Point (AP). Their objective is to decrease the AP’s overall energy consumption relative to the user at the network’s edge. Nevertheless, our recommended solution is subject to a choice depending on the service’s popularity and our stopping time with the maximum payoff. The study presented in [12] addresses the issue of task offloading in ultra-dense networks with the goal of reducing latency as much as possible while preserving the battery life of user equipment. On the other hand, our method provides the optimum option in terms of (pull or push-action) the service (from or to) the edge’s neighbors or peers.
The work in [23,41] primarily formulate the decision-making of offloading based on a resource scheduling factor. However, in our approach, we develop the decision of (push or pull-action) w.r.t. accumulation of the newly received tasks and cost incurring. A state-action–payoff–state-action (RL-SARSA) method is introduced in [3] to tackle the resource management issue at the edge server and make the best offloading option for reducing system cost. Moreover, the work in [49] aims to make the offload decision based on minimizing the cost. However, our work emphasizes making the decision with the greatest payoff, considering the expense cost each time that we do not make the decision of (push-action). In the study presented in [10,48], the issue of offloading computation for many users in a wireless environment with uncertainty is investigated. Nevertheless, the goal of our work is to provide the single-edge user with the best possible time in which to make a decision (push or pull-action). In [32,55], the authors examine the challenge of partial offloading scheduling and resource allocation for edge computing systems with various independent activities. The objective is to reduce the weighted total of processing latency and energy usage while satisfying the tasks’ transmission power limitations. Nevertheless, our approach enables the edge user to choose the optimal (pull-action) solution. Since the service has previously been hosted, the wait for future tasks will be reduced. The work in [15,38] investigate energy-efficient task offloading in edge computing. The goal is to reduce the amount of energy required for task offloading. However, our method focuses on making the choice at the optimal moment to host the most popular tasks, hence optimizing the edge’s capacity resource utilization.
Migration of data and services may be used to fill ‘gaps’ in the local knowledge base of a processing node. In [54], the interested reader may obtain a survey of related initiatives. When migrating services, it will be efficient to meet processing demands locally; nonetheless, a list of factors must be considered. To minimize overburdening the network, service migration may be accomplished in phases; service components should be “hooked up” to the hosting infrastructure swiftly, easily, and automatically. One of the technologies used for these reasons is Machine Learning (ML). ML may serve as the foundation for producing models that predict the movement of users and provide a proactive procedure for services migration [8]. Reinforcement learning may improve agent behavior while determining the optimal action to take [2,52]. The difficulty in depending on supervised machine learning technology is identifying the appropriate representative training data set. As a result of the raised degree of uncertainty in the corresponding decision-making, it is challenging to gather data that includes all alternative node statuses. The service migration model may alternatively be expressed as an online queue stability issue [37]. The issue may be addressed using either a Lyapunov optimization or a multi-objective optimization scheme [47,56], and the Pareto optimum solution can be determined. In the past, efforts have mostly focused on minimizing delay within the restrictions of energy usage in EC settings. However, the bulk of research efforts that aim at a user-centric service migration model is ‘affected’ by the extra time required to address the optimization issue, except if a list of assumptions is made or approximate solutions can be accepted. Using Markov chains is also a possible solution to settle the issue. Using a modified policy-iteration algorithm, the authors of [53] provide a solution to a finite-state Markov decision process. A technique based on Thompson sampling is suggested in [36] to facilitate dynamic service migration choices. The authors of [46] describe a service allocation module for networked automobiles powered by Cloud-based services. The objective is to increase the amount of autonomy of automobiles capable of picking nearby automobiles to share adopted services. The authors of [26] suggest a proactive system for determining the effective administration of services and tasks that are present/reported at EC nodes. The suggested model monitors the demand for existing services and rationalizes their management, i.e., their local presence/invocation when the demand is modified by the desired processing operations. To proactively achieve the strategic objectives of the envisioned model, a statistical inference process is initiated for each incoming task.
Rationale & contribution
Figure 1 illustrates in a simplified way the problem
of deciding whether to perform a service replication (pull-action) from their
edge neighbors or the cloud or offload (push-action) it to the cloud service to
make the necessary computation to complete the required task. Let us assume that
the starting time of recording the number of requests for a task is
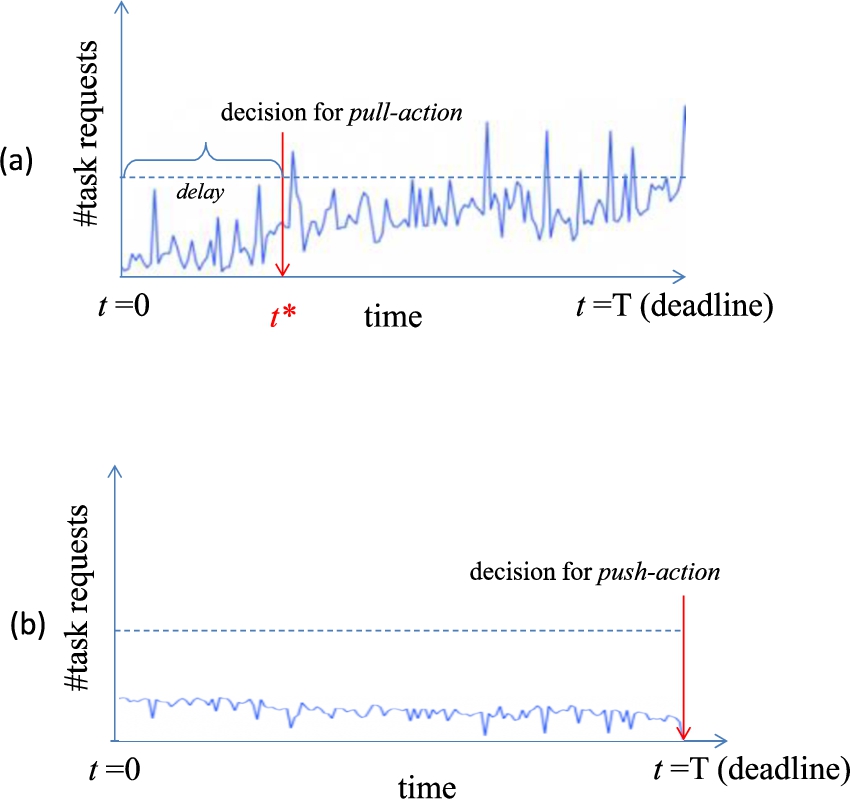
Observing the task requests rate at each time instance t to decide on (a) a high popularity or (b) low popularity of the service and act intelligently based on the history of the task requests.
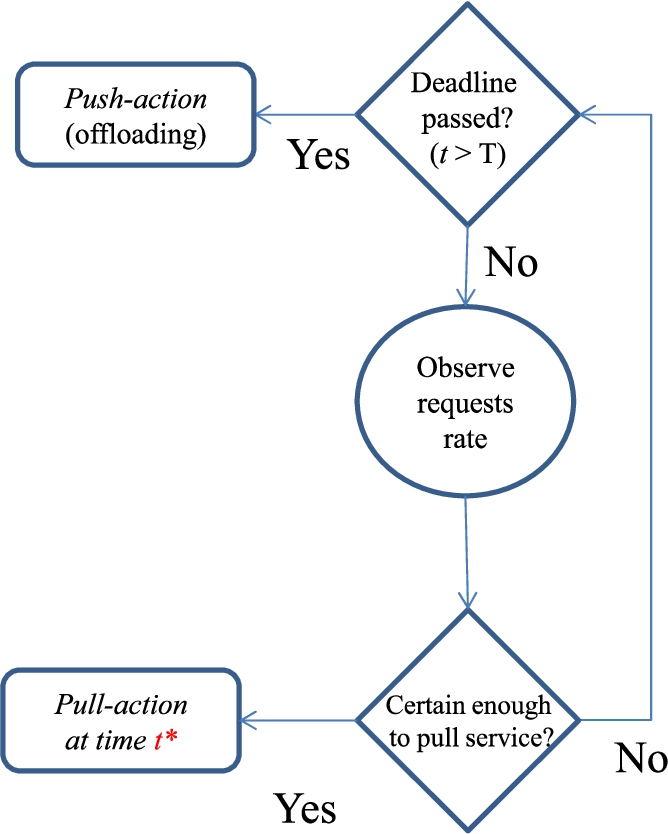
Sequential decision-making diagram on either task offloading
(push-action) or service replication (pull-action) at the best time
Our approach is adaptable to applications that use offloading decision-making
algorithms in EC environments. Our major technical contribution is: We provide a time-optimized intelligent
method that enhances the likelihood of making the decision of
service replication (pull-action) of the service with the
greatest payoff. This is reflected by the cumulative sum of the
number of task requests to the node under consideration taking
into account the incurred cost. We
provide theoretical analysis of the optimality of our model
based on the principles of the
OST. We report on a detailed
comparative evaluation of our OST-based method against the Ideal
Decision ruLe (IDL), which produces the actual maximum payoff,
and a heuristic Deterministic Rule
(DR). A comparative assessment is
provided comparing our results with the related work in [5], which is based on
the Secretary Optimal Stopping Time
problem.
In addition, Fig. 2 highlights the state-space of the decision-making. Specifically, Fig. 2 describes the mechanism of the seeking the best time for making the decision: either service replication (pull-action) or task offloading (push-action). Mainly, the decision is affected by the number of the received tasks at each time instance t for a specific service.
The rationale has as follows. The node receives a number of incoming task
requests
If the number of the received requests is high enough, therefore the
decision will be to pull the service at a time
Otherwise, the node reconsiders its decision at the next time
If the deadline T elapses, then the decision will be to push the task to a peer or the Cloud for further processing. This is the first study that we are aware of that sequential decision making, which considers the decision of pull/push-action as an OST problem in EC environments. The overall goal is to increase the possibility of making the decision of service replication (pull-action) with the greatest payoff. Moreover, since the nodes are located among the servers that have been distributed at the edge of the network, our approach will be applied to EC applications such as Virtual Networks (VN) [61], UAV [4], and data mining applications [30].
Example of the two actions: pull and push in a smart city environment.
In Section 3.1, we begin by providing an overview of the system model, and then in Section 3.2 we discuss the problem definition. In Section 3.3, the optimal stopping rule problem is introduced. Finally, in Section 3.4, we will give full details about cost-based sequential decision-making.
System model
As seen in Fig. 3, a smart city is increasingly
establishing vast IoT networks with widely distributed IoT devices that provide
vast amounts of services. In light of the vast size and extensively spread
nature of IoT networks, EC has become a strong and efficient paradigm for
providing processing capabilities to IoT devices at the network’s edge [58]. In EC, IoT services may be executed
on EC, which offers low delay and reduces the bandwidth load. Nevertheless, it
remains difficult to enhance the entire EC execution performance, for instance,
resource utilization, EC energy usage, and load balance. However, we believe
that the environment of the network is made up of a global cloud data center and
an EC system [14,33]. The EC system is constructed of M base stations as
defined in Table 1, and since each one is supplied
with some EC servers, they collectively constitute an EC node. In accordance
with it as well, we will refer to the set of EC nodes as
Notations of parameters
Notations of parameters
Within the scope of the task model, we rely on the assumption that the formation
of the user’s tasks follows a Poisson distribution with
The objective is to get as near as possible to θ. In the case
that
Based on the above interpretation, we provide the following payoff function
The rationale behind this payoff is that we desire the rate of service demands
per time t taking out the delay cost to be significantly
increasing. This expresses the likelihood that the pull-action is stochastically
a better decision than the push-action. This is because we increase our
confidence that in the (near) future we are expecting more requests for a
service in a node. Therefore, we aim at maximizing this payoff and, hence, the
corresponding likelihood. Our goal is to attain θ by maximizing
the number of the received tasks. If

Heuristic decision-making model (DR).
It is mandatory to have a base result to be compared with our fundamental
approach (OST). Therefore, we define the IDL, which measures the accumulative
sum of the received tasks from users to the node. However, each time instance
t the expected cost
We suggest the deterministic DR. DR is mainly based on calculating the number of
received tasks Y after passing the amount of
time t. In this rule, the decision of offloading is made if
Moreover, our theory has been compared to the work in [5]. Their approach is based on choosing the stopping
time using SECPRO model. The stopping time decision in [5] was based on choosing the highest value of the
received requests per time instance:
As a result, we found surprising and noteworthy results that demonstrate the superiority of our theory OST. This is what we will explain later in Section 3.3.

Secretary-based OST model (SECPRO).
Optimal stopping rule problem
The concept of optimal stopping [7]
addresses the issue of selecting a time instance to conduct a specific
action. The measure is taken to minimize an anticipated loss (or maximize an
expected payoff). A stopping rule problem is characterized by: (i) a set of
stochastic variables, whose joint distribution is presumed to be known, and
(ii) a set of loss functions
The optimal stopping time
The 1-stage look-ahead (1-sla) stopping rule (time) is defined as:
Let
The 1-sla rule provides the best solution for monotonous stopping rule issues.
See [39]. □
The edge device is required to complete making the decision of service
replication (pull-action) of the service of the number of tasks
Given the tolerance threshold θ and delay cost
The Problem 1 is resolved by establishing a model
based on the OST. Consider that the starting time
Given a series of payoff random variables
Given that
Therefore, the mechanism terminates at the first time t,
where
The 1-sla rule is optimal, since the corresponding difference is constantly
non-increasing with

Time-optimized sequential decision making (OST).
Experimental parameter setting
Experimental setup
In our experiments, we experiment with four different models: (i) The proposed
OST model. (ii) The heuristic DR model, which depends on the heuristic
factor α. In DR, the decision of pull-action is taken if
the accumulation
In the performance evaluation, we investigate the performance of the models: OST,
DR, and IDL. Also, we set the values of for each of λ,
α and θ. We assigned
In our comparative assessment, we performed the experiment over all the models,
i.e., OST, DR, IDL, and SECPRO. We set the values of λ,
α and θ. We assigned
Performance evaluation
Experiment 1
The settings for the Experiment 1 are:
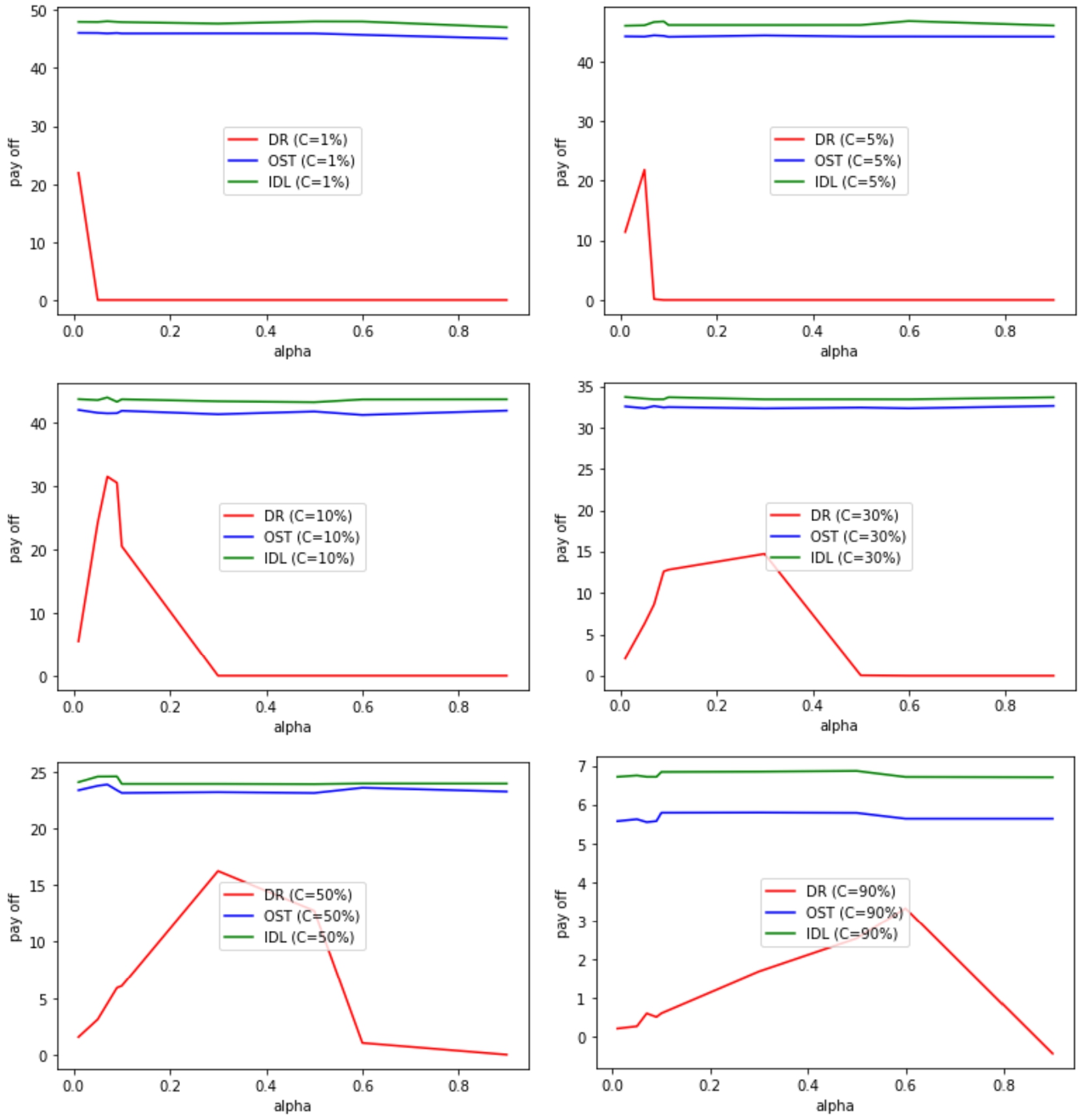
(Experiment 1) The expected payoff vs delay cost with low service
demand rate
The settings for the Experiment 2 are:
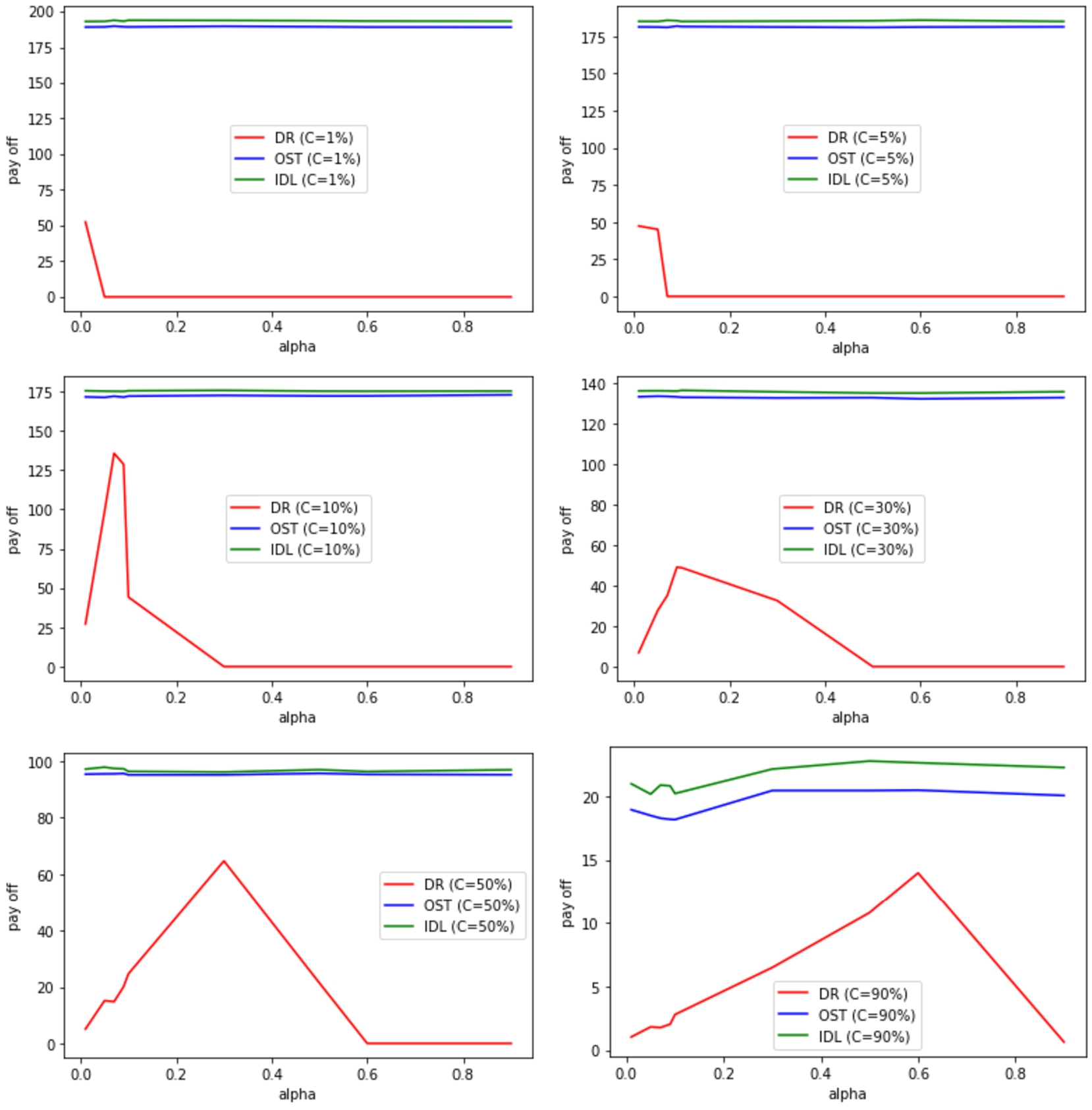
(Experiment 2) The expected payoff vs delay cost with medium service
demand rate
The settings for the Experiment 3 are:
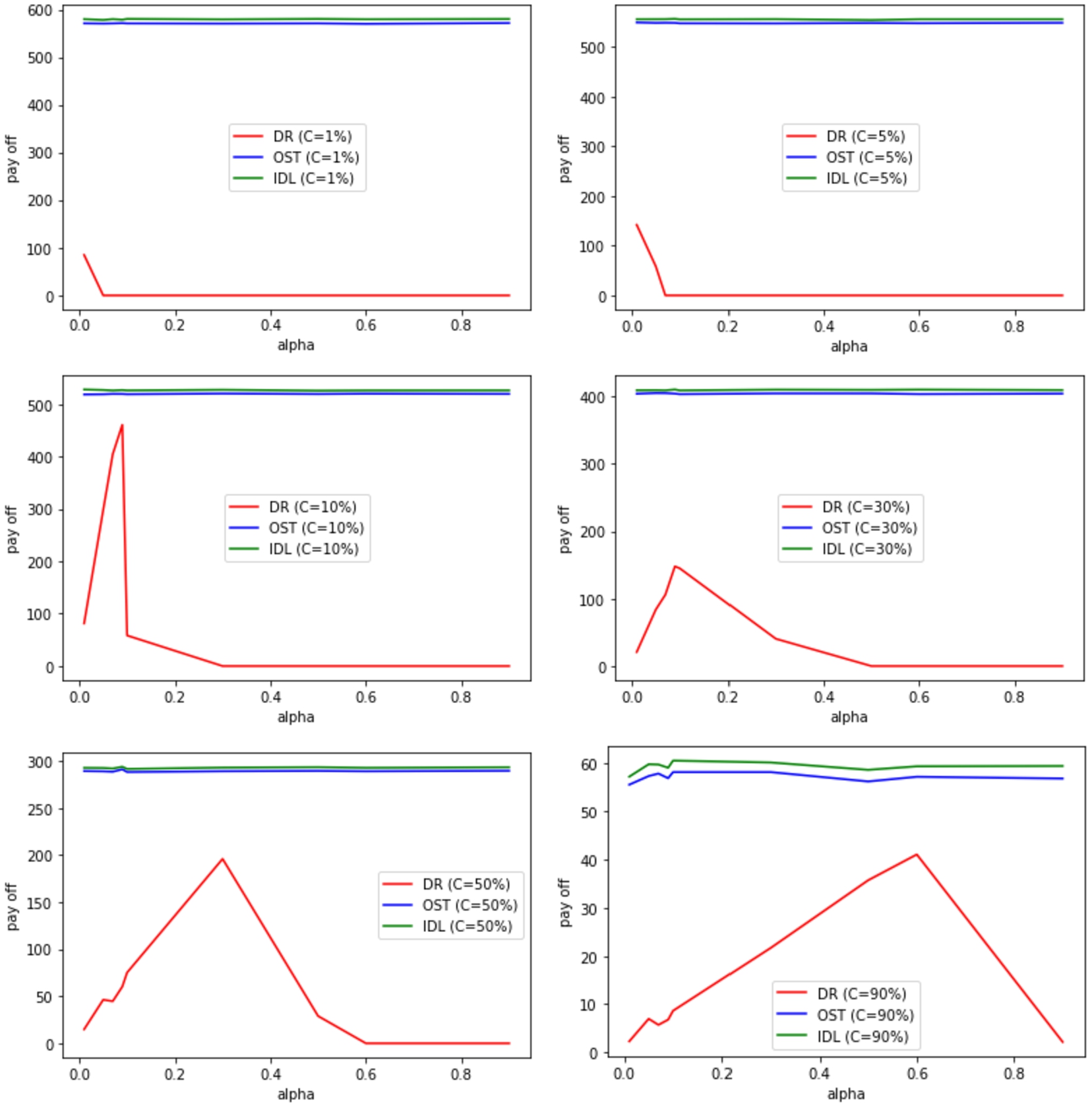
(Experiment 3) The expected payoff vs delay cost with high service
demand rate
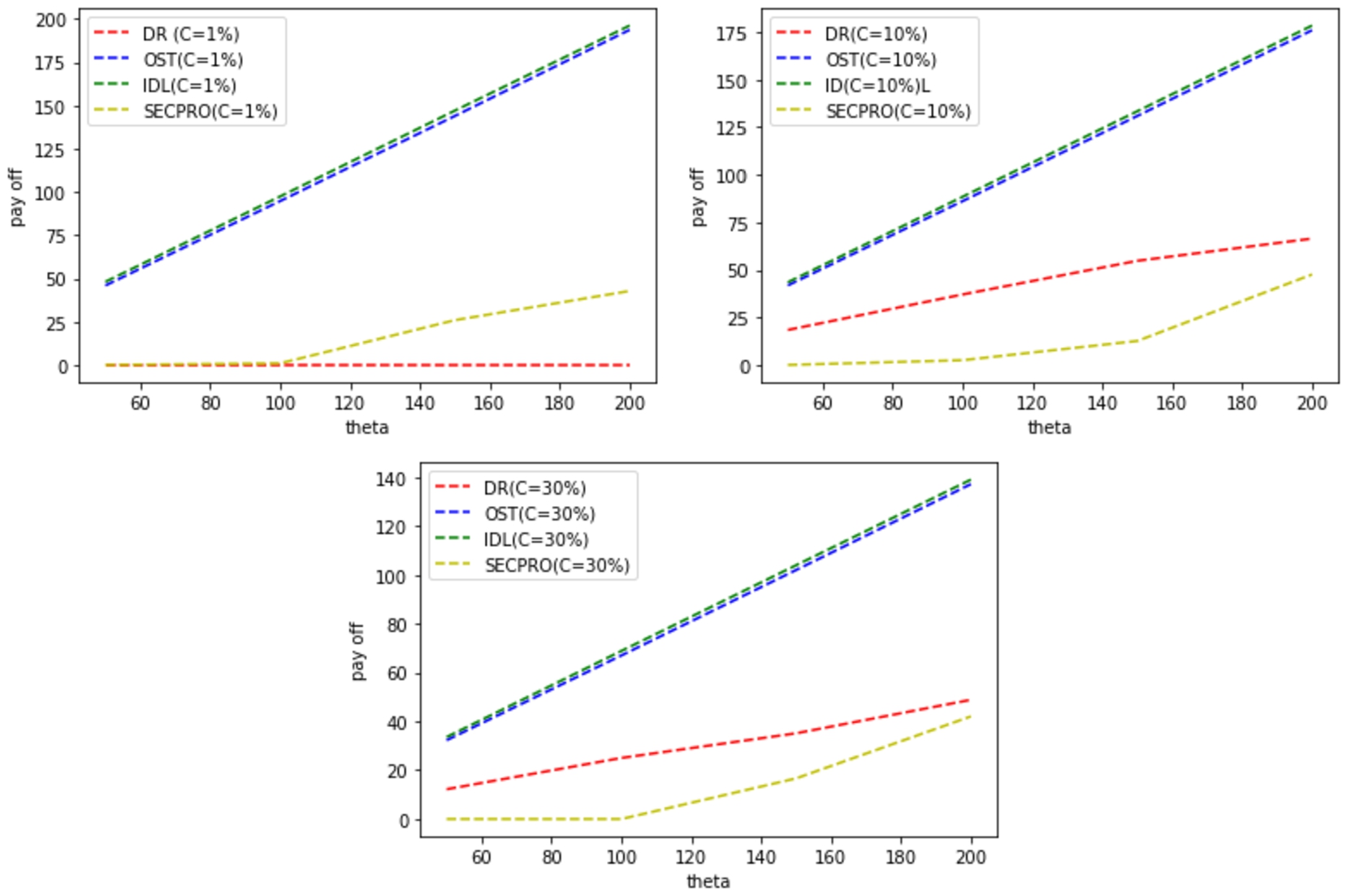
Expected payoff vs tolerance θ for diverse delay cot
values with low service demand rate
The settings for the comparative assessment experiment 1 are:
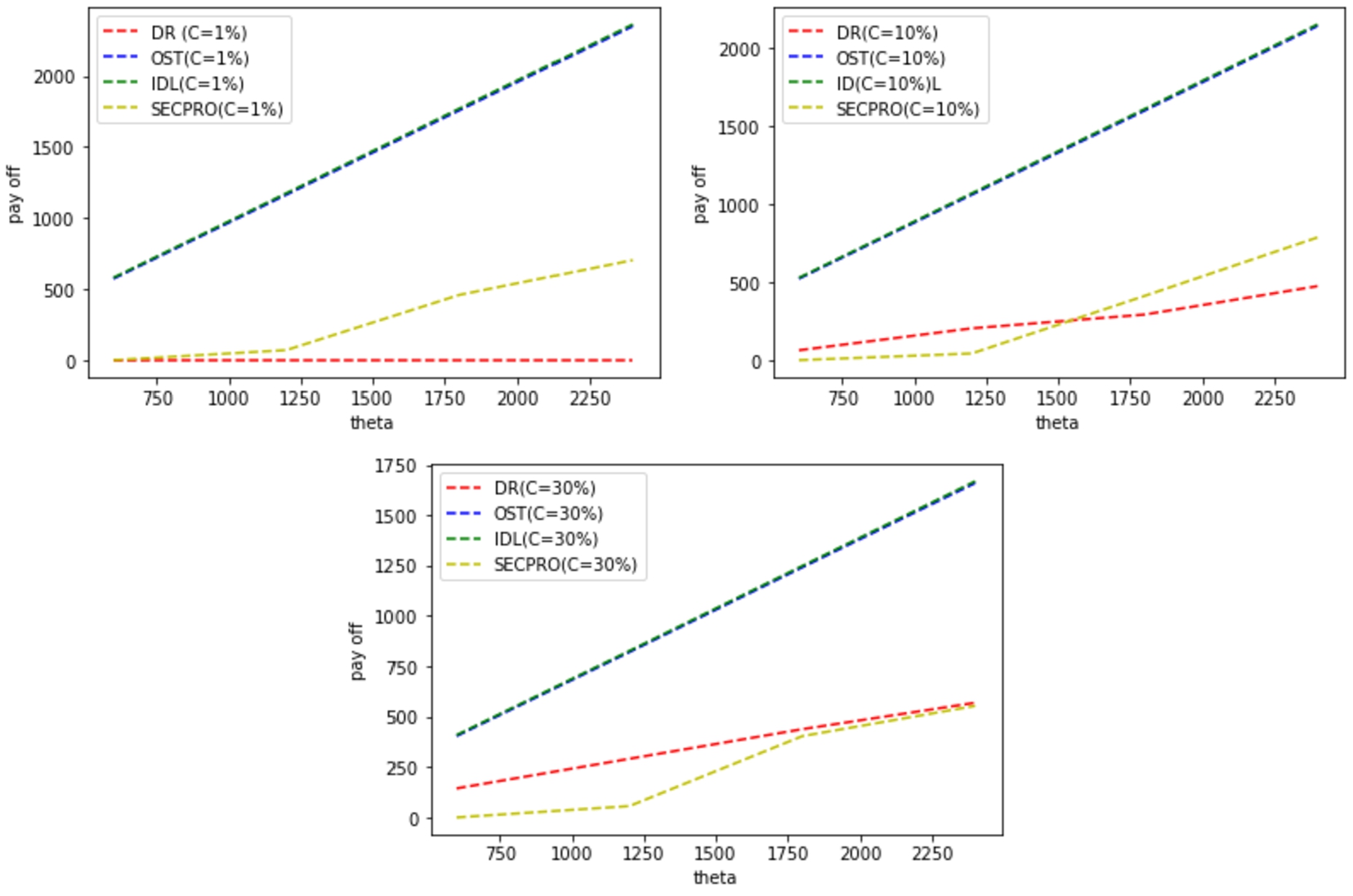
Expected payoff vs tolerance θ for diverse delay cost
values with high service demand rate
The settings for the comparative assessment experiment 2 are:
In order to test the effectiveness of our theory (OST) in the first three
experiments, where its results were compared with the IDL and another rule is
DR. They were all tested on different parameters, which start from normal
requests to medium requests and end with dense requests. Moreover, the results
of our approach (OST) are amazing, which prove the effectiveness of the theory.
As shown in Figs 9, 10 and 11, it obvious that Fig. 9 represents
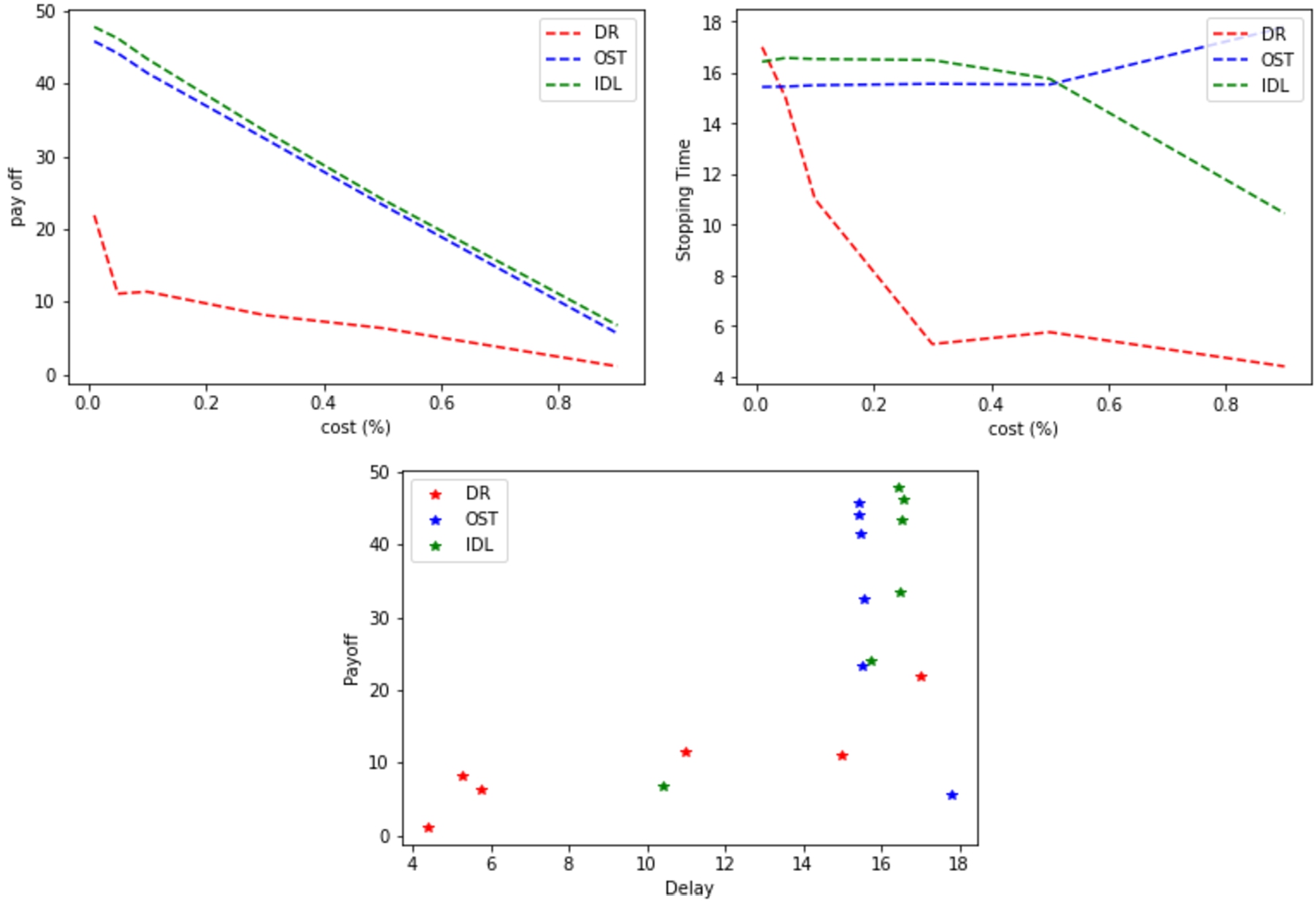
Expected payoff vs cost and delay for OST, IDL (low service demand rate
In Fig. 9, we see the results of our theory (OST), which are very close to IDL, and this is illustrated in the graphic that presents cost versus payoff. However, after increasing the cost to more than (0.5) cost in the figure that shows the cost versus the Stopping time, we find there is a small difference, and despite that, our approach obtains a delay time less than IDL in all results where the cost is (0.5) or less, and this is what makes it unique.
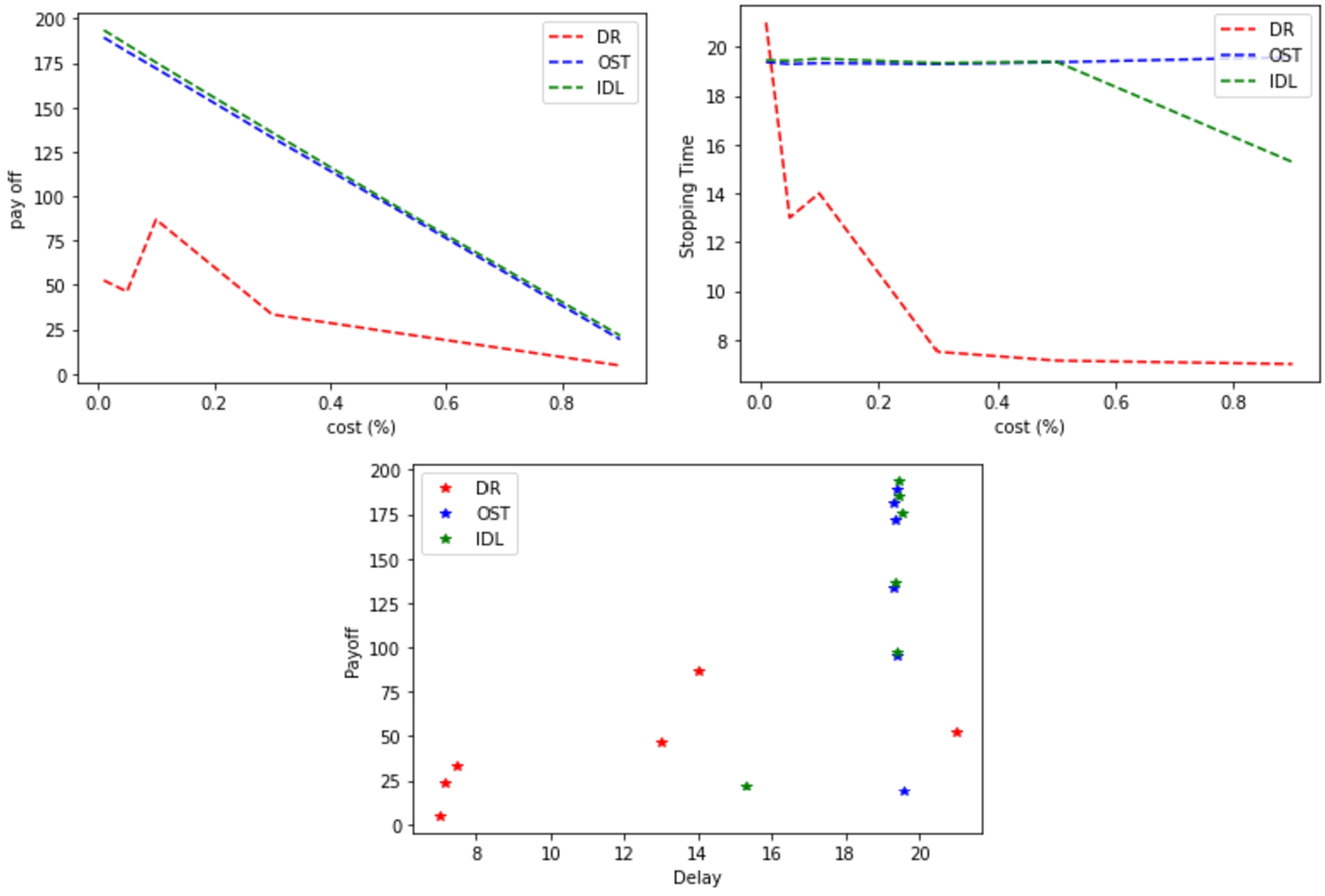
Expected payoff vs cost and delay for OST, IDL (medium service demand
rate
In Fig. 10, the receiving of requests were
increased by making
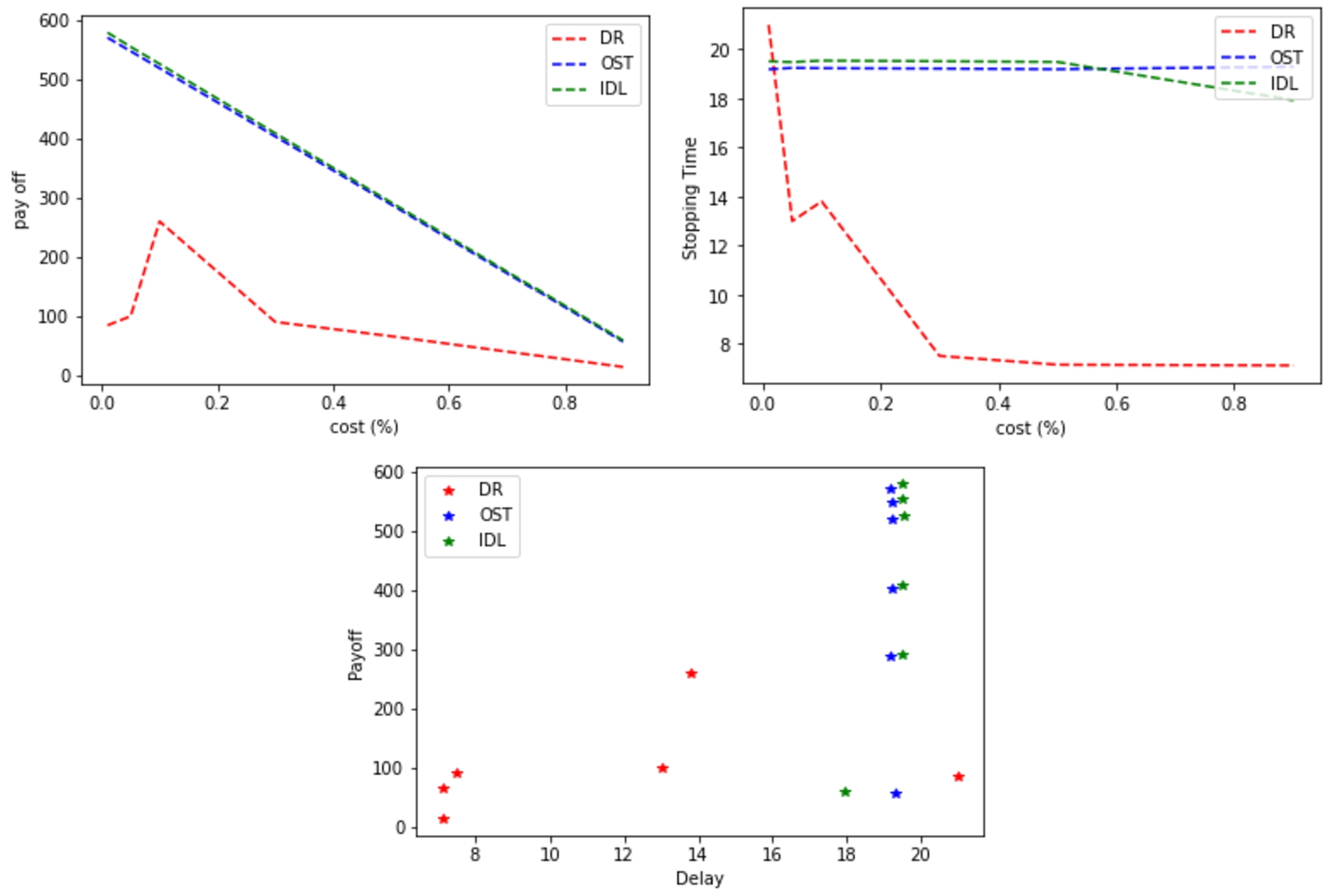
Expected payoff vs cost and delay for OST, IDL (high service demand rate
Figure 11 shows the robustness and effectiveness
of our theory (OST). It is shown clearly OST’s ability to deal with heavy
demands where
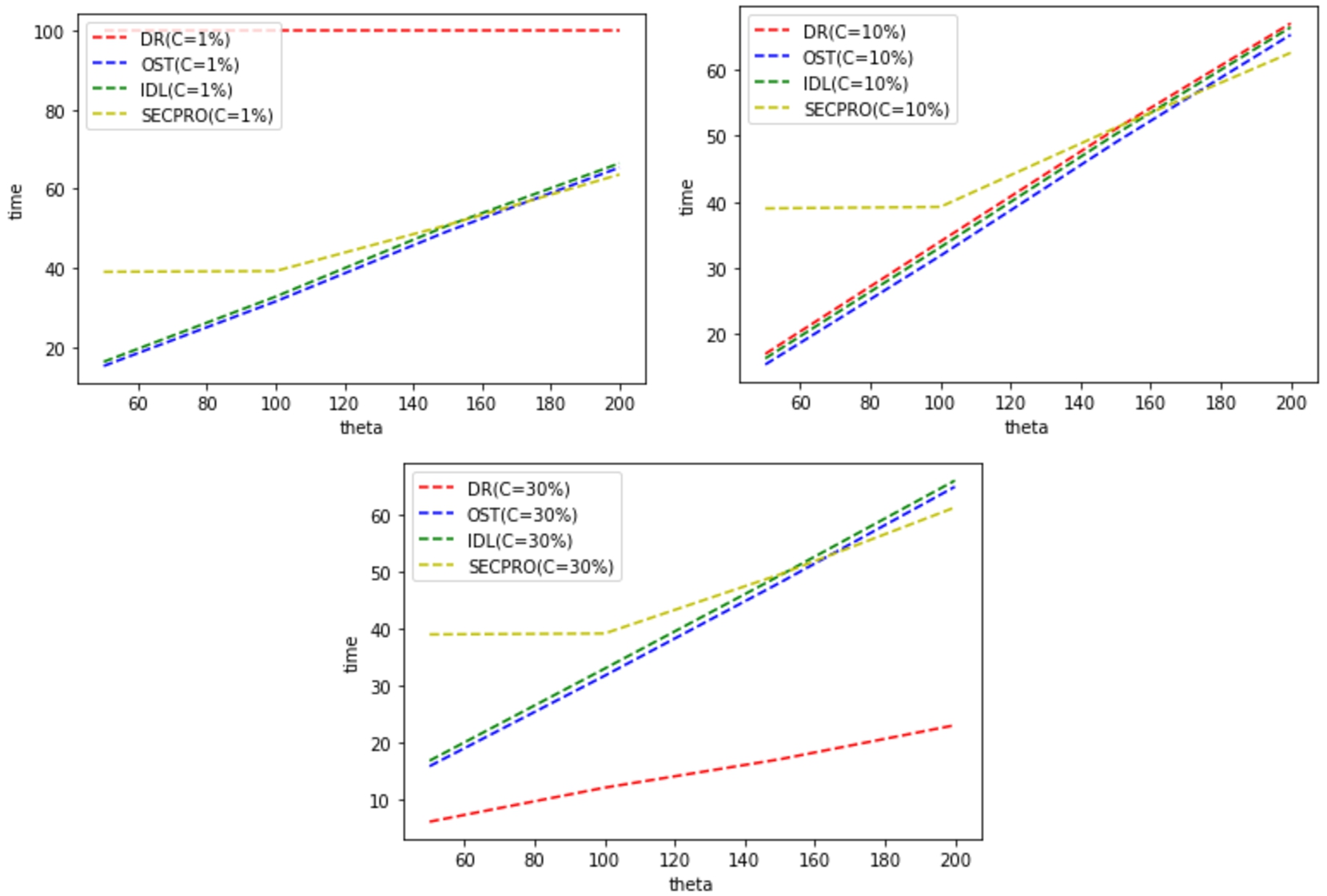
Expected delay (time to decision) vs tolerance θ for
diverse cost values (low service demand rate
Moreover, we tested the effectiveness of our theory (OST) in the fourth &
fifth experiments, where its results were compared with the three methodologies
which are IDL, DR, and SECPRO. They were all tested on two different parameters,
which are low & high requests. Moreover, the results of our approach (OST)
are brilliant, which proves the effectiveness of our theory OST. As shown in
Figs 12 and 13, it is obvious that Fig. 12 represents
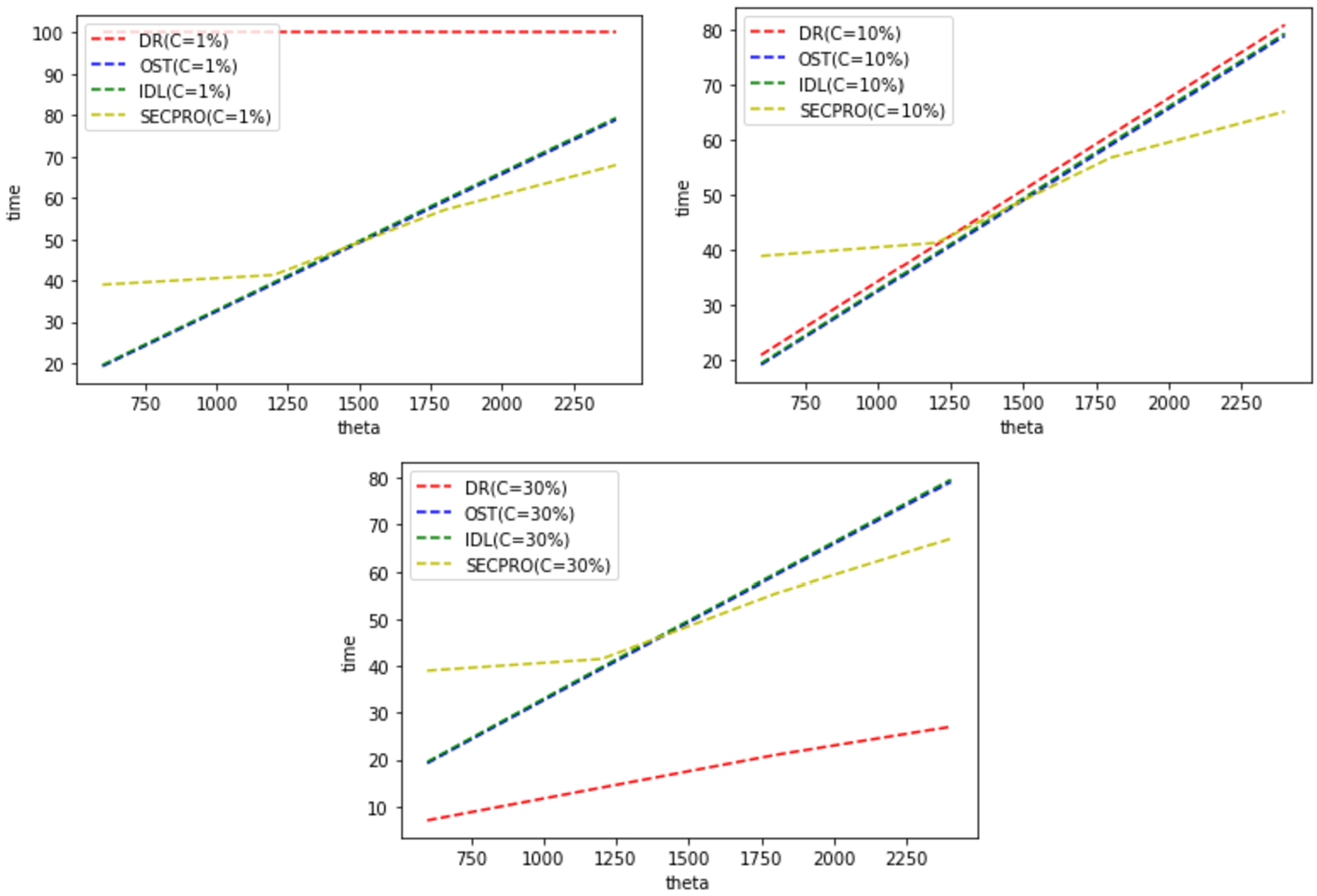
Expected delay (time to decision) vs tolerance θ for
diverse cost values (high service demand rate
We provide a superior decision-making approach for users in EC that is based on the Optimal Stopping Theory. When using and adopting the OST in time-optimized decision-making for a service replication (pull-action) in EC environments, we offer a comprehensive review of the process. Based on the results of our experimental assessments, the OST model performs more effectively than the other approaches, which are suitable for use in Edge nodes, and do not demand for a significant amount of resources. Moreover, the highest payoff is obtained by our models, which outperform alternative baseline solutions. In further work, our aim is to analyze how the characteristics of mobile applications and data timeliness affect our OST models and build new ones that take these limitations into account.
Footnotes
Acknowledgements
The authors would like to thank the Saudi Prime Minister of Defense (Crown Prince Mohammad Bin Salman), the Royal Saudi Air Force, Senior Engineer Mohammad Aleissa, Saudi Arabia, and the Saudi Arabian Cultural Bureau in the UK for their support and encouragement.
Conflict of interest
The authors have no conflict of interest to report.