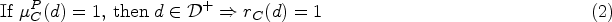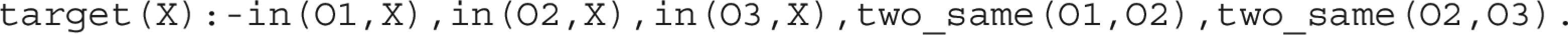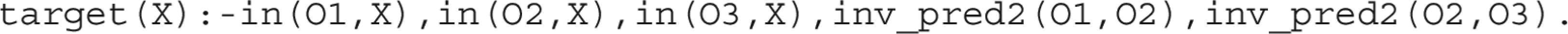The predicates used for Inductive Logic Programming (ILP) systems are usually elusive and need to be hand-crafted in advance, which limits the generalization of the system when learning new rules without sufficient background knowledge. Predicate Invention (PI) for ILP is the problem of discovering new concepts that describe hidden relationships in the domain. PI can mitigate the generalization problem for ILP by inferring new concepts, giving the system a better vocabulary to compose logic rules. Although there are several PI approaches for symbolic ILP systems, PI for Neuro-Symbolic-ILP (NeSy-ILP) systems that can handle 3D visual inputs to learn logical rules using differentiable reasoning is still unaddressed. To this end, we propose a neuro-symbolic approach, NeSy-π, to invent predicates from visual scenes for NeSy-ILP systems based on clustering and extension of relational concepts, where π denotes the abbrivation of Predicate Invention. NeSy-π processes visual scenes as input using deep neural networks for the visual perception and invents new concepts that support the task of classifying complex visual scenes. The invented concepts can be used by any NeSy-ILP system instead of hand-crafted background knowledge. Our experiments show that the NeSy-π is capable of inventing high-level concepts and solving complex visual logic patterns efficiently and accurately in the absence of explicit background knowledge. Moreover, the invented concepts are explainable and interpretable, while also providing competitive results with state-of-the-art NeSy-ILP systems. (github: https://github.com/ml-research/NeSy-PI)
Inductive Logic Programming (ILP) learns generalized logic programs from data [3,24,26]. Unlike Deep Neural Networks (DNNs), ILP gains vital benefits, including the capacity to discover explanatory rules from a small number of examples. Nevertheless, predicates for ILP systems are typically elusive and need to be hand-crafted, requiring additional prior knowledge to compose solutions. This makes the wide-scale adaption of such systems difficult and taxing. Predicate invention (PI) systems invent new predicates that map new concepts from expert-designed primitive predicates. This extends the expression of the ILP language and consequently decreases reliance on human experts [23]. A simple example is the concept of the blue sphere, which is the combination of two primitive concepts blue and sphere. Consider the visual scenes illustrated in Figure 1, where we see several objects in the scene, and the task is to reason and learn about objects’ attributes and their relations. With PI systems, the non-primitive concepts (e.g. blue sphere) are not explained in the background knowledge, but have to be learned from data. For instance, given training data, a PI system can invent new predicate defined by the following rule: , where is a variable, and are constants, and and are primitive predicates provided by experts. By using the invented predicate , ILP systems can compose rules efficiently to solve problems.
NeSy-πdiscovers relational concepts from visual scenes. NeSy-π develops relational concepts for visual scenes through iterative evaluation and invention of primitive predicates and visual scenes (on the left). The invented predicates are fed into a NeSy-ILP solver to learn classification rules. The NeSy-ILP solver creates rule candidates utilizing given predicates and performs differentiable reasoning and learning (on the right). Consequently, the classification rules can be effectively constructed with the invented predicates (best viewed in color).
Recently, a differentiable ILP framework has been proposed to integrate symbolic ILP with DNNs [10] solving rule-learning tasks on symbolic or simple visual inputs, e.g. hand-written images. In a similar vein, neuro-symbolic ILP (NeSy-ILP) systems1 that can learn explanatory rules on complex visual scenes (e.g. CLEVR scenes [13]) have shown their capability to reason and learn on abstract concepts and relations solving complex visual patterns [30]. NeSy-ILP systems outperform pure neural baselines on complex visual reasoning, since it involves inferring answers by reasoning about objects’ attributes and their relations [21]. The main drawback of the current NeSy-ILP systems is that they necessitate all predicates in advance, such as pre-trained neural predicates or manually constructed background knowledge. In addition, obtaining background knowledge is expensive as it requires human experts or the pre-training of neural modules with supplementary supervision. Consequently, this significantly restricts the flexibility of the NeSy-ILP systems across various domains. Therefore, a question arises: How can a NeSy-ILP system learn with less or no background knowledge in complex visual scenes?
To address this problem, we introduce Neuro-Symbolic Predicate Invention (NeSy-π), which can invent relational concepts from visual scenes without additional supervision or hard coding. NeSy-π provides a rich vocabulary for NeSy-ILP systems to produce effective solutions on 3D visual scenes. A briefly applying case is illustrated in Figure 1. Given positive and negative examples as visual scenes, NeSy-π performs PI finding useful relational concepts, e.g. grouping several objects and capturing their spatial relations to compose complex patterns. Given primitive predicates, NeSy-π performs the following 2 steps iteratively: (Step 1: Eval) evaluating available predicates invented in the previous steps, and (Step 2: Invent) inventing new predicates based on the evaluation scores. Additionally, we propose three novel metrics to evaluate invented predicates resulting in pruning of the redundant candidates efficiently and gain high-quality vocabulary. The invented predicates can then be fed to NeSy-ILP systems to learn explanatory classification rules.
Overall, we make the following important contributions:
We propose NeSy-π, a novel neuro-symbolic predicate invention framework compatible with NeSy-ILP systems. It extends NeSy-ILP systems by providing the capability of learning vocabularies from 3D visual scenes. NeSy-π enables them to learn using less background knowledge from human experts, mitigating the scaling bottleneck of the current NeSy-ILP systems.
To evaluate NeSy-π, we propose three metrics. These metrics measure the percentage of examples covered or eliminated by the predicates, enabling NeSy-π to efficiently discovers useful concepts.
To evaluate the ability of predicate invention using visual inputs, we propose 3D Kandinsky Patterns, extending Kandinsky Patterns [25] to the 3D world. The Kandinsky Patterns environment can generate positive and negative visual scenes using different abstract patterns. However, it has been limited to simple 2D images, and predicate invention has not been addressed. Thus we propose the first environment for the evaluation of neuro-symbolic predicate invention systems that can process complex visual scenes, filling the gap between the abstract synthetic tasks and realistic 3D environments.
We empirically show that NeSy-π solves challenging visual reasoning tasks outperforming the conventional NeSy-ILP systems without predicate invention. In our experiments, we successfully applied NeSy-π to 3D Kandinsky Patterns to invent new predicates for complex scenes, achieving higher performances than baselines. Moreover, NeSy-π produces highly-interpretable rules using invented predicates, which cannot be learned by the previous systems.
We have made our code publicly available at https://github.com/ml-research/NeSy-PI. We proceed as follows: we present the required background knowledge before introducing our NeSy-π architecture. We then illustrate the effectiveness of our approach using extensive experiments. Finally, we discuss the related work before concluding.
First-order logic and Inductive Logic Programming
Before introducing NeSy-π, we revisit the basic concepts of first-order logic and Inductive Logic Programming First-Order Logic (FOL). A Language is a tuple , where is a set of predicates, is a set of constants, is a set of function symbols (functors), and is a set of variables. A term is a constant, a variable, or a term consisting of a functor. A ground term is a term with no variables. We denote an n-ary predicate by . An atom is a formula , where is an n-ary predicate symbol and are terms. A ground atom or simply a fact is an atom with no variables. A literal is an atom or its negation. A positive literal is simply an atom. A negative literal is the negation of an atom. A clause is a finite disjunction (∨) of literals. A ground clause is a clause with no variables. A definite clause is a clause with exactly one positive literal. If are atoms, then is a definite clause. We write definite clauses in the form of . The atom A is called the head, and the set of negative atoms is called the body. For simplicity, we refer to the definite clauses as clauses in this paper.
Inductive Logic Programming (ILP). An ILP problem is a tuple , where is a set of positive examples, is a set of negative examples, is background knowledge, and is a language. We assume that the examples and background knowledge are ground atoms. The solution of an ILP problem is a set of definite clauses that satisfies the following conditions: (1) and (2) . Typically, a search algorithm starts with general clauses and incrementally weakens them through the process known as refinement. Refinement is a crucial tool for ILP when the current state clauses are overly general and result in too many negative examples being included.
NeSy Inductive Logic Programming. We address the problem of Neuro-Symbolic Inductive Logic Programming (NeSy-ILP) presented in 3D visual scenes, which we refer to as the “Visual ILP Problem”. The classification pattern is based on high-level concepts encompassing attributes and object relations. To solve visual ILP problems, differentiable ILP frameworks have been proposed such as ∂ILP [10] and αILP [30]. They employ a differentiable implementation of forward reasoning in first-order logic(FOL) to enable gradient-based learning of the classification rules. The optimization problem they solve to this end is , whereby is an ILP problem, represents the set of clause candidates, denote the set of clause weights, and is a loss function that returns a penalty when training constraints are breached.
Neuro-symbolic predicate invention: NeSy-π
In this section, we present the predicate invention system NeSy-π in the following steps: Section 3.1 is an overview of the system. Section 3.2 explains the clause extension, where the extended clauses are one of the inputs of the NeSy-π system. Section 3.3 explains the clause evaluation, which employs two metric proposed in this paper. The scores assigned to the clauses form the other input of the NeSy-π system. Section 3.4 presents the predicate invention and its evaluation. Section 3.5 presents the grouping module, a data prepossessing module that combines related objects into groups to simplify the problem. Section 3.6 provides the pseudo code for the system.
Architecture overview
The NeSy-π is a neuro-symbolic system to invent high-level relational concepts as predicates. The invented predicates are further be used by NeSy-ILP system for target clause searching. The workflow of solving visual ILP problem using the NeSy-π system is illustrated in Figure 2. The process is divided into two major components: the training and the evaluation. Training utilizes the training examples to search for target clauses , which satisfies two conditions: 1) and 2) , as the target clauses and selected background knowledge should entail only positive images and no negative images. During evaluation, test examples will be classified as positive or negative based on the target clauses returned during the training.
Workflow of visual scene reasoning (Train, left) during the training phase, NeSy-π learns a set of rules to describe common patterns within the given RGB-D images. This process involves using four models: a pretrained perception module (e.g. Mask R-CNN [11]) for object detection; a grouping module (GM) that fits objects to lines base on their 3D positions; NeSy-ILP as a rule learner; NeSy-π as a concept inventor. GM groups objects together (e.g. a group of objects aligned on a line) to form complex spatial relations (e.g. a check mark). (Evaluation, right) In the evaluation phase, given a test RGB-D image, the system predicts whether the image follows the set of rules (positive) or not (negative). The GM and perception module are used for image processing, while a differentiable forward reasoner is employed for reasoning purposes.
As a prepossessing step, we prepared a dataset for training a perception module, such as Mask R-CNN [11]. The dataset for perception module is similar as training examples in , which includes scenes with same object types but positioned randomly. Each scene is annotated with object labels and bounding boxes.
Once the perception module is trained, the four modules, perception module, grouping module, NeSy-ILP, and NeSy-π perform an end-to-end training, which takes training examples as input and reasons target clauses . Firstly, the perception module takes the RGB image of training example d to detect the labels and the bounding boxes of the objects, then the 3D positions of each object can then be calculated by utilizing depth map of each example d, the camera matrix K along with the labels and bounding boxes from the output of perception module. After acquiring the object positions, for providing simple and high-level descriptions of the scenes, the Grouping Module (GM) combines objects into groups based on their positions and encodes these scenes as group tensors, which capture the geometric information of the group, such as dimension scales and positions. These group tensors are then utilized as input for the NeSy-ILP system, which iteratively generates and evaluates clauses on the group tensors to identify the target clauses . In each iteration of clause searching, NeSy-ILP outputs the searched clauses and their respective evaluation scores to NeSy-π. NeSy-π then invents new predicates by taking disjunctions of the promising clauses and returns them to NeSy-ILP. By incorporating these new invented predicates, NeSy-ILP can use them in the subsequent iterations to search for new clauses with greater precision in describing the rules. The final output of the training session is the set of target clauses produced by the NeSy-ILP system.
During evaluation, the system classifies the test scenes as either positive or negative. Positive scenes satisfy the target clauses while negative scenes do not. The perception and grouping module first interpret the data into group tensors, just as during training. Then, a differentiable forward reasoner is used to classify the group tensors as positive or negative based on the target clauses .
Clause extension
We take the top-down approach for ILP, where new clauses are generated by specifying general rules [26]. We extend clauses step by step by evaluating on visual scenes to prune redundant candidates. NeSy-π begins with the most general clause for the search, e.g. the initial clause is defined as follows:
where the atom consists of the 2-arity predicate and variables , which represents the confidence of the object in the image detected by the perception module. The atom provides the probability that the image is positive based on the atoms in the clause body. is the most general clause that assesses the object’s existence in the image without imposing any property constraints, such as color or shape.
The clauses set is extended incrementally, starting with the extension of in the first step. Then a set of clauses is generated where each new clause extends the previous clause by an atom from the language 2. For instance, by adding atoms and to the body of , the clause set is generated as follows,
The clauses in are then evaluated, as introduced in Section 3.3 and only the top-scored clauses are kept for the next iteration.
Clause evaluation
We now describe the clause evaluation strategy in NeSy-π and three novel metrics to evaluate clauses efficiently for predicate invention. Given the generated clauses (described in Section 3.2), NeSy-π scores each of them using positive and negative examples . Note that each example ( or ) is given as a visual scene. For clear presentation, we prepare the following notation:
is a differentiable forward reasoning function using clause C in αILP [30]. We use it to evaluate each clause. It takes visual scene as its input, converts them to probabilistic atoms, and performs differentiable forward reasoning using clause C. We consider the output as the score for clause C. The domain of is .
represents the confidence of clause C being true for positive example
represents the confidence of clause C being true for negative example
and indicate the number of positive and negative examples in the dataset, respectively.
We introduce metric P-Measure, which is used to evaluate the performance of the clause on positive examples. The target clause has to be valid in all positive examples, thus the more positive examples that a clause satisfies, the better the clause is. On the contrary, the less positive examples that a clause satisfies, the worse it is.
P-measure The P-Measure assesses the validation of clause on positive examples, with representing the P-Measure of clause C. This value indicates the cumulative confidence of positive examples that satisfy clause C with its value in the range . Since all positive examples should satisfy the target clauses, higher P-Measure of C indicates better performance.
If all the positive examples fulfill the clause C, then the P-Measure of C equals 1. This indicates that C is a necessary condition for the positive examples, i.e. the clause C follows the implicational relationship
Similarly, we introduce metric N-Measure, which is used to evaluate the performance of the clause on negative examples. The target clause has to be invalid in all negative examples, thus the less negative examples that a clause does not satisfy, the better the clause is. On the contrary, the more negative examples that a clause satisfy, the worse the clause is.
N-measure The N-Measure evaluates the validation of clauses on negative examples. Given a clause C, its N-Measure is denoted as , measuring the inverse of the cumulative confidence of negative examples that do not satisfy C. The value of is in the range . As the target clauses are not intended to be satisfied by all of the negative examples, a higher N-Measure of C indicates better performance. The N-Measure of C is defined as follows:
If none of the negative examples satisfy C, the N-Measure of C is equal to 1. Assuming the examples are either positive or negative, if there is an example e that satisfies C, then d is a positive examples. The clause C is called a sufficient condition for the positive examples, which follows the implicational relationship
If all the positive examples are satisfied by C, and no negative examples satisfy C, then C meets the definition of the target clause. In this scenario, both the P-Measure and N-Measure of C are 1, and C is a sufficient and necessary condition of the positive examples. This follows the implicational relationship:
However, the majority of the clauses yield P and N measure scores between 0 and 1, i.e. they satisfy neither necessary nor sufficient condition. Since the sufficient and necessary condition is satisfied by and , the higher the clause resulting in both P-Measure and N-Measure scores, the closer it is to the target clause. NeSy-π utilizes a best-first approach that take the both P-Measure and N-Measure into account, resulting in the following PN-Measure.
PN-measure The PN-Measure evaluates a clause meeting the definition of the target clause. Given a clause C, its PN-Measure is denoted as , measuring the product of its P-Measure and N-Measure, which is defined as follows:
To assess a set of clauses , NeSy-π computes for each clause on the dataset, and selects the k top scoring clauses for subsequent iterations of extension or predicate invention.
Predicate invention
NeSy-π invents new predicates by using the extended clauses and their evaluations, which were described in Section 3.2 and Sec, 3.3, respectively. New predicates are defined by taking disjunctions of the extended clauses. We assume that all clauses in have the same predicate for their head atom.
(Invented Predicate).
Given a set of clauses , any subset , s.t. defines a new predicate p. The clause set is called the explanation clause set of predicate p. The meaning of p is interpreted as the disjunction of clauses in .
For example, assume () as follows:
A predicate can be invented by disjunctively combining the first two clauses. That is, let denote the explanation clause set of , then is defined as follows
The invented predicate interprets the concept that there exists a pair of objects in the image with the same color (either blue or red). Each clause within is referred to as a variation. By taking the disjunction of the clauses, the invented predicate can be assigned true if any one of its variations is true. Similarly, another predicate can be invented by taking the disjunction of the last two clauses, can be invented by taking the disjunction of all three clauses, and so on. In total, there are predicates that can be invented from a clause set that includes at least two clauses in its explanation clause set. Due to the exponential growth rate, the invention of predicates may be restricted by a threshold, denoted as a. This threshold is defined such that , where . As a result, subsets that surpass the cardinality of a are not utilized for predicate invention. Applying the threshold a, enforces that the possible variations of concepts are within the limit of a.
The key of predicate invention in NeSy-π is to identify the explanation clause set, which is a subset of the clause set searched by the NeSy-ILP system. Due to the absence of guidance or background knowledge, the model lacks the ability to choose the optimal explanation clause set. Nonetheless, it is feasible to invent the clauses first and then evaluate them on a dataset. First, NeSy-π generates all possible clause combinations from the clause set , then evaluates each clause based on the dataset and finally selects the top-k highest-scoring new predicates.
Now we move on evaluating the newly invented predicates. Invented predicates can be evaluated using the P-Measure and N-Measure metrics as introduced in Section 3.3. Let p be an invented predicate, be the corresponding explanation clause set, and its i-th variation.
P-measure on invented predicate The P-Measure of invented predicate candidate p is utilized to evaluate the validation of an invented predicate on positive examples. The validity of predicate p increases as more positive examples are verified to hold true on it. The invented predicate is defined as the disjunction of the corresponding explanation clause set . The maximum score of the clauses in determines the evaluation score of p, which is calculated as follows
N-measure on invented predicate The N-Measure is utilized to access the validation of an invented predicate on negative examples. The fewer the number of the negative examples in which the invented predicate holds true, the stronger its performance. The invented predicate is defined by the disjunction of the associated explanation clause set , and its evaluation score is determined by the highest-scoring clause. The score of predicate p on example d is calculated as . To indicate that the higher the value, the better, the result is computed as . It is also equivalent to . The N-Measure for an invented predicate is determined in the following
PN-measure on invented predicate The PN-Measure assesses the performance of the predicate on both positive and negative examples in a quantified, objective way. This measure is derived by calculating the product of the P-Measure and the N-Measure. The formula for the PN-Measure can be written as follows:
In NeSy-ILP systems, target clauses are extended by searching for atoms within the given language. This search relies on the assumption that all the necessary atoms are present in the given language. In contrast, NeSy-π does not require such an assumption. If necessary atoms are absent from the language, the system can invent new predicates and generate new atoms.
For instance, let us consider scenes with only two colors red and blue and two shapes sphere and cube. The pattern represents the concept that three objects have same color and shape simultaneously. A possible solution for NeSy-ILP system necessitates the 3-arity predicate , which is presented as the background knowledge. The target clause can be then be obtained by extending two atoms from the initial clause
The predicate is explained by five clauses, as shown in Listing 1, which are presented as background knowledge. In NeSy-π, such kind of background knowledge is not provided, but learned by the system. An example of rules that NeSy-π might learn is illustrated in Listing 2. By updating the invented predicates for the language, NeSy-π can search for the target clause as follows:
Listing 1. Background knowledge of concept
Listing 2. Predicates invented by NeSy- that relate to concept
The predicate corresponds to the concept . It takes five clauses to explain, which are learned instead of given. The predicates and are invented predicates. The other three predicates and are given beforehand. Predicate invention enhances the system’s ability to learn new concepts with less reliance on background knowledge.
Object grouping
In a scene with numerous objects, it is often unnecessary to consider every relationship. For instance, if there are three objects on a table, it is reasonable to query whether any two of them have the same color or same shape. However, if there are 20 objects on the table, it is not necessary to investigate whether any two of them share a property. It would be more expedient to initially consider conditions such as whether more than half or all of the objects share a property. In order to gain a comprehensive understanding of an image, it is advisable to begin by accessing it at a global level, rather than delving into its particulars right away.
For complex patterns that comprise a multitude of objects, NeSy-π utilizes an object Grouping Module (GM) that can recognise line patterns in a more efficient and organised manner. The grouping module employs the position characteristics of each object to group them accordingly. It is essential to view multiple objects as a single entity in complex scenes since the number of object relationships increases at a factorial rate, specifically , with n being the number of objects in a scene. Examining relationships between different groups instead of individual objects can significantly decrease the number of relations under consideration. However, not all patterns can be fully described by line groups; rather, isolated objects must be treated individually.
Five steps are required to convert an image example to group tensors . The main procedures of the grouping module are illustrated in Figure 3. Additionally, the algorithm provides certain thresholds. ε denotes the distance threshold between an object and a group, whereas is the minimum number of objects required in each group.
Grouping module. The grouping module takes an image as input and produces the group tensors in 5 stages. (1) the perception module detects objects and encodes them as tensors ; (2) objects are chosen based on their properties to generate small groups. (3) extend each small group with as many objects as possible. (4) evaluate and select the highest-scoring groups. (5) encode groups into group tensors .
Object perception In the first step, the grouping module detects the object labels and the bounding boxes in the RGB image based on an object detector, such as Mask-RCNN [11], where N is the number of objects detected, W and H are the width and height of the image. Based on the camera matrix K, the 3D coordinates of all the pixels relative to the camera coordinate system can be calculated from the depth map . Since in RGB-D images, the pixels on and correspond to each other, each bounding box in corresponds to the same region in based on the pixel coordinate system. This allows the object surface positions to be recorded relative to the camera coordinate system. For each object there is a set of surface points. The object position can be approximated by the median number of these points. For all the objects, their positions are given by . Given and , objects can be encoded into tensors , where M is the number of properties for each object. In NeSy-π, the properties taken into account are position, color, and class. The position is specified by the 3D coordinates of the object, while both colors and classes are one-hot coded.
Group generation NeSy-π proposes an approach to gather objects into line groups based on their 3D positions. The strategy is to first generate small groups and then expand them to the maximum size. Since two points define a line, a small group is generated by two objects. The object positions can also be used to determine the corresponding line function. For N objects, small line groups are generated. As shown in Figure 3, seven objects are placed on the table in the given example, thus small groups are generated from this scene.
Group extension The groups are further extended based on their line functions. For each small group, the remaining objects not contained in the groups can be evaluated based on their distances to the line. By specifying a threshold parameter ε, the objects with have distances within ε can be extended to the groups. As shown in Figure 3, and can generate a small group. Let be the line defined by this group, the system will calculate the distance between the remaining objects to , and then compare the distances with the threshold ε. By setting a suitable threshold, is extended to the group. Similarly, the small group created by and can be extended with and .
Group evaluation Since the motivation of grouping module is to decrease the relations between objects, it is important to minimize the number of groups. After the group generation, group are generated and then expanded to their maximum potential. The group evaluation removes duplicate groups. Additionally, a minimum group size of is established, which serves as a system parameter to remove groups with fewer objects than the threshold. Choosing a smaller value of enables the explanation of rules in great detail, but at the cost of increased time and space requirements. Conversely, choosing a larger value of leads to faster reasoning, but pattern details may be overlooked. For our experiment, we opted for the smallest possible value of that still maintained acceptable reasoning times in order to enhance its robustness.
Group encoding Finally, the groups are encoded as tensors . The position of each group is determined by averaging the positions of objects within the group.
The group module is an optional module of NeSy-π. It is used for scenes with potential group structures, like lines in this given example. By generating rules at group level, the logical structures between objects can be expressed much more clearly and easily. The invented predicates are also invented at the group level.
NeSy-π algorithm
Algorithm 1 provides the pseudo code of the process of predicate invention utilizing the NeSy-ILP and NeSy-π systems. The NeSy-π system focuses on extending the initial language to the output language through the invention of new predicates. Meanwhile, NeSy-ILP is tasked with searching for target clauses.
The algorithm includes a grouping module as discussed in Section 3.2–3.5. The initial language includes all the background predicates alongside the initial clause , namely . Additionally, the camera matrix K, image dataset and the corresponding depth map are also inputs. The algorithm’s output is the extended language , which includes all invented and background predicates.
(Line 1–4) Produce object tensors from the input dataset and . An object detector, like Mask R-CNN [11], is employed to identify object labels and bounding boxes in the RGB images . The 3D coordinates of all pixels can then be transformed, relative to the camera’s coordinate system, from the depth map and the camera matrix K. The 3D position of the objects can be determined by taking the median value of the corresponding region in with respect to corresponding bounding box . (Line 5–7) Group the objects based on their positions . (Line 9–12) The iteration variable N is responsible for specifying the number of groups covered by the searched clauses. The given parameter controls the maximum number of groups covered by the clauses, which is set with respect to the complexity of the training patterns. For complex Kandinsky Patterns, this parameter is set to 2, while for Alphabet Patterns, it is set to 5 or 6, as detailed in Section 4.1. Additionally, two lists are initialized. serves as a repository for invented predicates, while is the set of all background predicates in the initial language . (Line 14–17) In each iteration, a background predicate P is selected from . A new language is instantiated with no pre-existing predicate. P is the first predicate that is used to update this language. (Line 19) The for-loop spanning lines 19–38 comprises the clause extension (line 22–29) and predicate invention (line 33–37). determines the maximum length of the clauses that can be extended. (Line 22–31) Extend the clauses in the clause set for iterations. During the first iteration, the clause in serves as the initial clause. The clauses are subsequently extended with new atoms, followed by the evaluation of the whole dataset. The top-scoring clauses are retained while the rest is pruned. If a target clause has been identified, then the for loop is terminated. (Line 32–37) After the clause extension, invent the predicates. Each element in C is a subset of extended clauses , as well as an explanation clause set. The new predicates are generated from C. The evaluation of the invented predicates is based on the clauses in the corresponding explanation clause set. The score of these clauses can be obtained directly from . By limiting the number of invented predicates, only the top-k invented predicates are retained. The invented predicates are then added to the list and the language . (Line 44) The algorithm returns a language consisting of all the remaining invented predicates from .
Experimental evaluation
NeSy-π aims to aid NeSy-ILP systems such as αILP [30] in tackling visual reasoning tasks. Frequently used evaluation datasets are the 2D dataset Kandinsky Patterns [25], and the 3D dataset CLEVR-Hans [34], which is a variant of CLEVR [13]. Both datasets utilize geometry objects to represent fundamental concepts of common sense. In this paper, we propose three datasets for evaluating NeSy-π, which follow the similar dataset configuration with αILP [30]. The calibrated RGB-D camera captures all the scenes. The RGB images serve as input for the perception module. The system locates the 3D positions of the objects relative to the camera coordinate system using the corresponding depth maps and camera matrix.
Datasets
The datasets comprise synthetic images generated using the Unity game engine [35]. In every image, objects are positioned on a table and captured by a calibrated RGB-D camera. A scene in the dataset refers to an image captured by the camera. Every scene is made up of basic objects that represent logical concepts. The object categories comprise of three types: sphere, cube, and cylinder; the objects come in three colors: red, green, and blue. The size and surface texture of the objects remain consistent across all scenes. A pattern refers to a set of scenes consisting of both positive scenes and negative scenes. All of the positive scenes follow a common logical concept, while none of the negative scenes do. To examine the predicate invention performance of the NeSy-π, every pattern in the dataset is accompanied by at least one new concept not included in the initial language.
Simple Kandinsky Patterns. These patterns are designed with only a few objects. Each pattern refers to a logical concept, as indicated by the name, which is not explained by background knowledge. Close: two objects are close to each other. Diagonal: two objects are diagonally located. Same: three objects have the same shape and the same color. Two Pairs: two pairs of objects are in the scene. A pair is defined by two objects with the same color and shape.
Simple Kandinsky Patterns This dataset represents four logical patterns, as shown in Figure 4. The patterns comprises a maximum of four objects. In each pattern, several objects are placed on the table. The details of each pattern is introduced as follows:
(Close)
In positive scenes, two objects are located close to each other. The maximum distance between two objects is one-seventh of the table’s width. Negative scenes are two objects that are far apart, with a minimum distance between them of half of the table’s width.
(Diagonal)
Positive scenes require two objects to be positioned diagonally from each other, while negative scenes involve two objects being positioned horizontally.
(Three Same)
Three objects appear in scenes, positive scenes require that all objects possess the same color and shape. Negative scenes, however, involve three objects that have at least two differences in color or shape.
(Two Pairs)
In scenes with two pairs of objects, positive scenes require that each pair share the same color and shape. Negative scenes require at most one pair that shares the same color and shape.
Complex Kandinsky Patterns. These patterns are designed with at least five objects in the scenes. These objects form 2D shapes by their position. Check Mark: several objects form the shape of check mark. Parallel: multiple objects are arranged in two parallel rows. Perpendicular: multiple objects are arranged in two perpendicular rows. Square: several objects are arranged in the shape of a square.
Complex Kandinsky Patterns This dataset uses objects to represent four logical patterns, as shown in Figure 5. Compared to the simple Kandinsky patterns, the complex Kandinsky patterns consists of a considerately larger number of objects and relations among objects. The objects are ordered according to certain spatial rules, such as perpendicular, parallel and so on. The details of each pattern is introduced as follows:
(Check Mark)
In positive scenes, five to seven objects form a check mark shape. The direction of the check mark is rotated in range 0 to 45 degrees in each scene. In negative scenes, five to eight objects form two intersecting lines, with the intersection point never being an endpoint of both lines simultaneously.
(Parallel)
Positive scenes consists of six to eight objects arranged in two parallel rows. Negative scenes consist of six to eight objects arranged in two rows with an angle between them ranging from 20 to 80 degrees.
(Perpendicular)
In positive scenes, six to eight objects are arranged in two perpendicular rows. Negative scenes consist of six to eight objects arranged in two rows with angle between them ranging from 20 to 80 degrees.
(Square)
In positive scenes, several objects form the shape of a square, with consistent spacing between adjacent objects on each edge. The square size in each scene range from 3, 4, or 5 objects per edge. In negative scenes, the objects are arranged in the shape of a rectangle, with a consistent spacing between adjacent objects on each edge. The longer side of the rectangle consists of 5 objects, while the shorter side consists of 3 objects. The rectangle is located either horizontally or vertically.
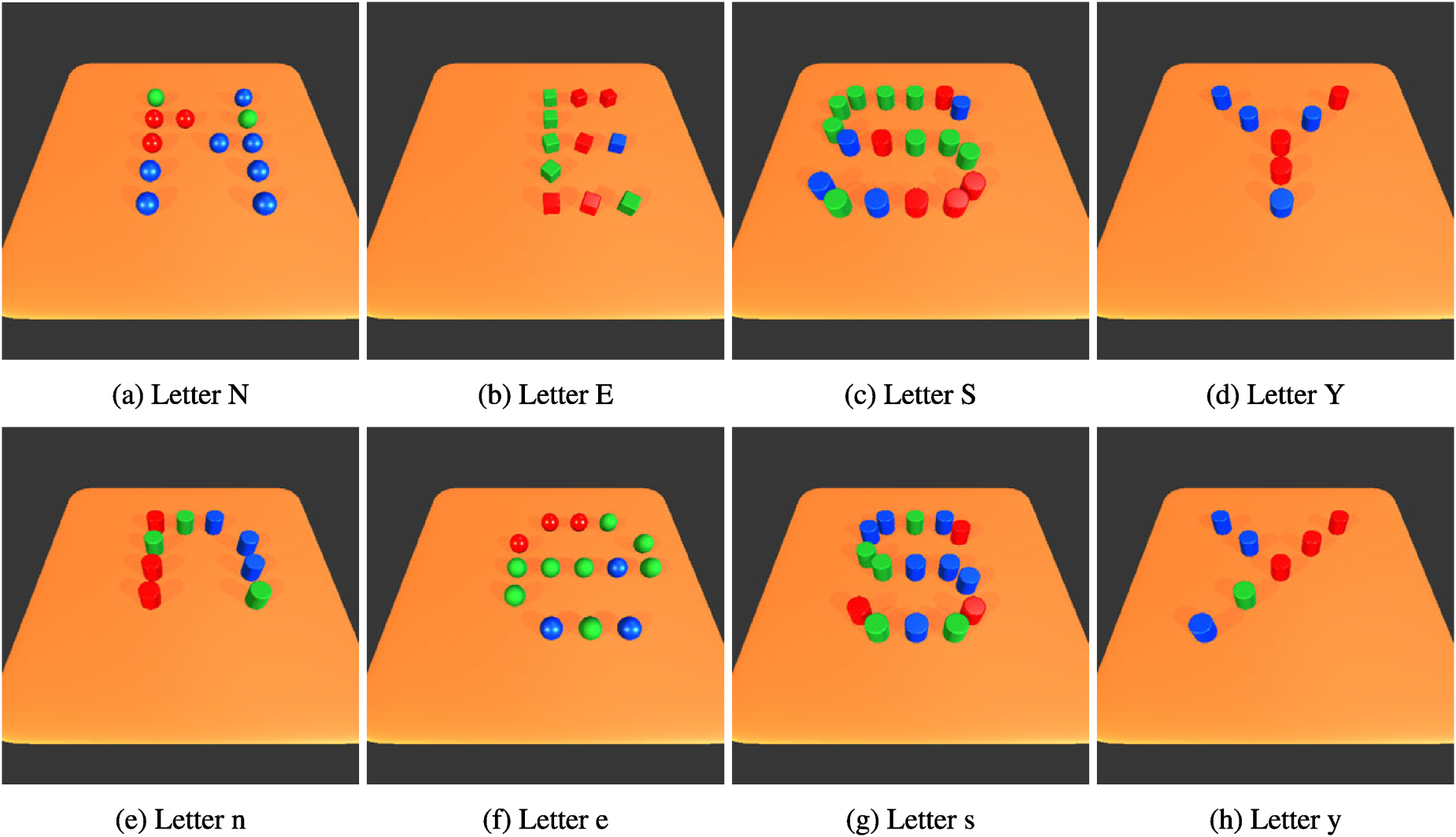
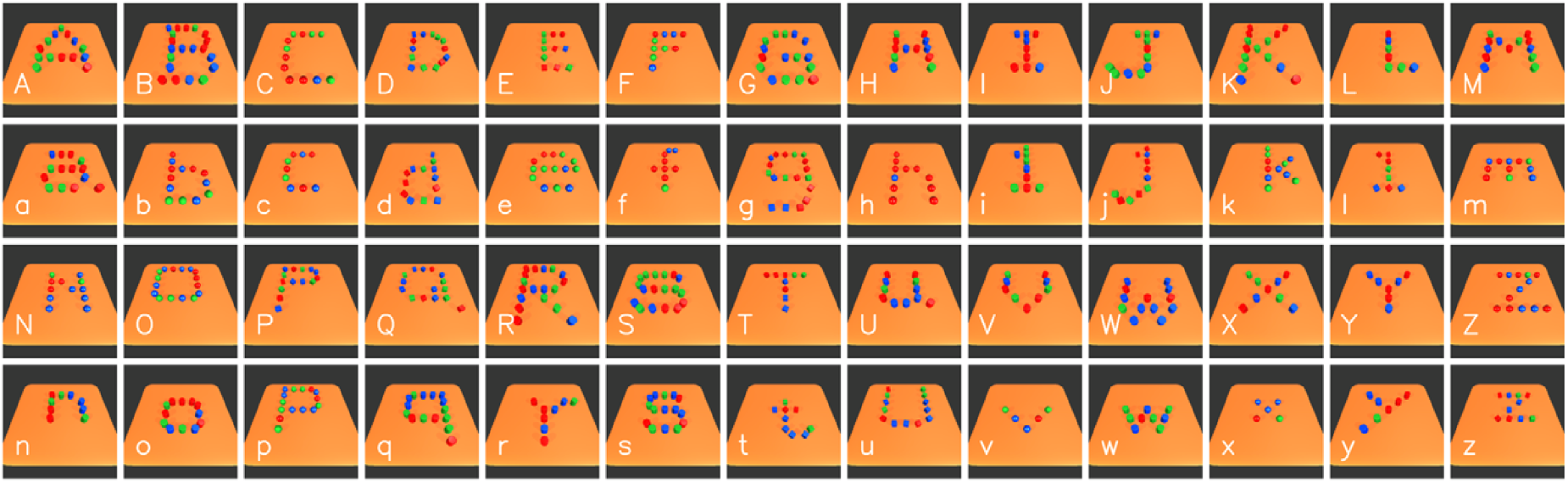
Latin Alphabet Patterns. Latin letters (including upper and lower case) consisting of multiple objects. The shape of the individual letters consists mainly of lines. For more examples, see appendix B.
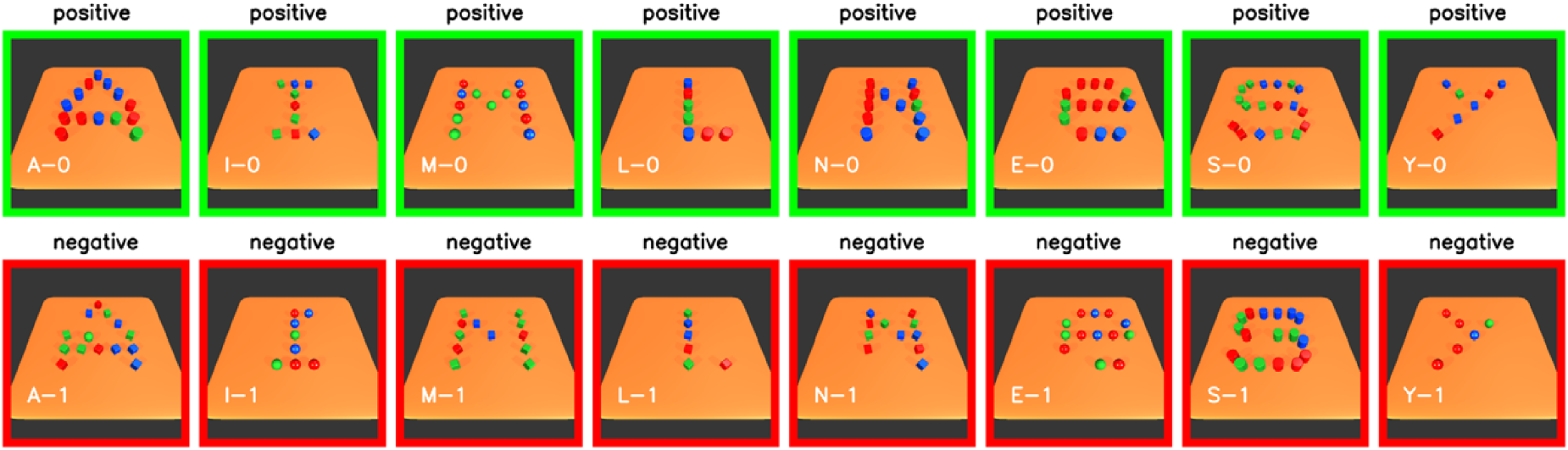
Latin Alphabet Patterns This dataset uses objects representing 26 Latin letters. Figure 6 shows some examples of the letter patterns. A complete version is shown in the Appendix B. These patterns are composed of line-based elements. In each pattern, a set of objects is placed on a table and forms the shape of a letter in the Latin alphabet. In order to introduce more variations for each pattern, letter cases (upper case and lower case) are considered, i.e. each pattern has two variations. The colors and shapes of the objects are changed randomly in each scene. The center position of all objects is also shifted slightly in each scene. The dataset of each pattern consists of the same number of positive and negative scenes. The positive scenes are created based on the two variations of that pattern, and the negative scenes are created based on the variations of all the other patterns.
Evaluation results
The experiments aim to answer the following questions:
Can NeSy-π invent useful predicates from visual scenes improving the performance of NeSy-ILP systems?
Can NeSy-π solve complex patterns that cannot be solved by the state-of-the-art NeSy-ILP baseline?
Is NeSy-π computationally efficient?
Is NeSy-π robust to unseen falsifying examples?
A1 (NeSy-π effectiveness): The background predicates utilized for solving the patterns in this work are listed in Table 1. All predicates invented by NeSy-π are based on these predicates. Moreover, no other predicates or background clauses are provided for the reasoning process. In αILP [30], certain concepts such as are explained using a set of background clauses, but no such clauses are provided for reasoning in NeSy-π. However, certain background predicates necessitate parameters determination for precision purposes. The parameter decides the precision of the distance predicate (). For example, means that the distance between two objects can be characterized from () to () with W as the table width. Similarly, the precision of the direction predicate () is determined by the parameter , while the precision of the slope predicate () is determined by the parameter . These parameters determine the granularity of the concepts that can be handled in the system.
Background predicates for solving logical patterns.
Predicate
Description
Evaluate whether the object/group exists in the image .
Evaluate whether the object/group is of the form .
Evaluate if the object has color .
Evaluate whether the direction of object/group corresponds to the object/group falls within the range of ϕ.
Evaluate whether the distance between the object and falls within the range of ρ.
Evaluate whether the slope of object group falls within the range of .
Pattern Close. The logic of the pattern is that two objects are close to each other. Left: two positive (green border) and two negative (red border) examples of the pattern Close. Right: learned target clauses and the corresponding invented predicates of the pattern Close. The distance precision parameter is given as 20. The predicate evaluates if the distance of and in range ( of table width).
Figure 7 shows an example of the learning result for the simple Kandinsky pattern close. The target clause is searched by αILP, and the used predicate is invented by NeSy-π, which can be interpreted by the distance between object O1 and O2 is in the rangeto. The invented predicates that are not used in the target clauses are not listed in the figure. Appendix B shows the corresponding target clauses and the invented clauses of the rest patterns.
Table 2 shows the evaluation result of all simple Kandinsky patterns based on the proposed metrics in Section 3.3. NeSy-π has successfully invented new predicates and found the promising target clauses for all simple patterns, resulting in PN-Measure values over higher than the baseline model αILP, with the exception of the diagonal pattern at only . This is due to the limited variations in the diagonal pattern compared to others. Only two variations exist in the positive scenes (since a square has two diagonals), and two variations exist in the negative scenes (forming a row either at the top or bottom of the table). Other patterns, such as close, have randomly changed object distances within a specified range. Consequently, there are many more variations in these patterns. PN-Measure is a balanced measurement that considers both positive and negative examples simultaneously. Therefore, the outperforming of PN-Measure does not guarantee the outperforming of both P-Measure and N-Measure.
Learning result on Simple Kandinsky Patterns.α is the baseline approach based on αILP [30], π is the proposed approach using αILP with NeSy-π, Δ is the improvement in percentage calculated as , #Inv_Pred is the number of invented predicates used in the target clauses.
P-Measure
N-Measure
PN-Measure
Pattern
# Object
# Image
α
π
Δ
α
π
Δ
α
π
Δ
# Inv_Pred
Close
2
100
0.43
1.00
132.56%
1.00
0.91
−9.00%
0.43
0.91
111.63%
1
Diagonal
2
100
0.87
1.00
14.94%
1.00
1.00
0.00%
0.87
1.00
14.94%
1
Same
3
100
0.50
0.92
84.00%
0.67
1.00
49.25%
0.34
0.92
170.59%
2
Two Pairs
4
100
0.64
0.96
50.00%
0.68
1.00
47.06%
0.44
0.96
118.18%
2
Pattern Check Mark. The logic of the pattern is that several objects form a shape of check mark. The number of objects on the right side of check mark changes randomly from 3 to 5 in each scene. Left: two positive (green border) and two negative (red border) examples of pattern Check Mark. Right: learned target clauses and the corresponding invented predicates of the pattern Check Mark. The predicate evaluates if the direction of and in range .
A2 (Complex Patterns): For the complex Kandinsky patterns, NeSy-π uses the Grouping Module to gather the objects into groups. The predicates are invented on the group level. In the experiment, the maximum group number of the grouping module, i.e. the parameter N in Algorithm 1, is given as 5. The dataset Complex Kandinsky Patterns uses objects representing basic line relations and other basic geometry shapes. The given background knowledge is the given predicates shown in Table 1, and the line grouping module explained in Section 3.5.
Figure 8 lists the learned target clauses and the corresponding invented predicates of the pattern check mark. The target clause is described by 2 invented predicates. The used invented predicate is explained as follows: the group O2 is either in the direction,,, orof O1, which corresponds to the direction ranges , , , and respectively. The predicate is explained as follows: the distance between two groups is in the rangeto, which corresponds to the distance ranges with W as the table width. Appendix B shows the learned clauses of the remaining three complex Kandinsky patterns. Table 3 shows the scores of each pattern based on proposed metrics. NeSy-π improves the scores in both P-Measure and N-Measure with using 1–2 invented predicates in the target clauses.
Learning result on Complex Kandinsky Patterns.α is the baseline approach based on αILP [30], π is the proposed approach using αILP with NeSy-π, Δ is the improvement in percentage calculated as , #Inv_Pred is the number of invented predicates used in the target clauses.
P-Measure
N-Measure
PN-Measure
Pattern
# Object
# Image
α
π
Δ
α
π
Δ
α
π
Δ
# Inv_Pred
Check Mark
5–6
100
0.66
0.93
40.91%
0.90
0.99
10.00%
0.59
0.92
55.93%
2
Parallel
6–8
100
0.33
0.93
181.82%
1.00
1.00
0.00%
0.33
0.93
181.82%
1
Perpendicular
6–8
100
0.63
0.92
46.03%
0.88
1.00
13.64%
0.55
0.92
67.27%
2
Square
8–16
100
0.50
0.83
66.00%
0.72
1.00
38.89%
0.36
0.83
130.56%
1
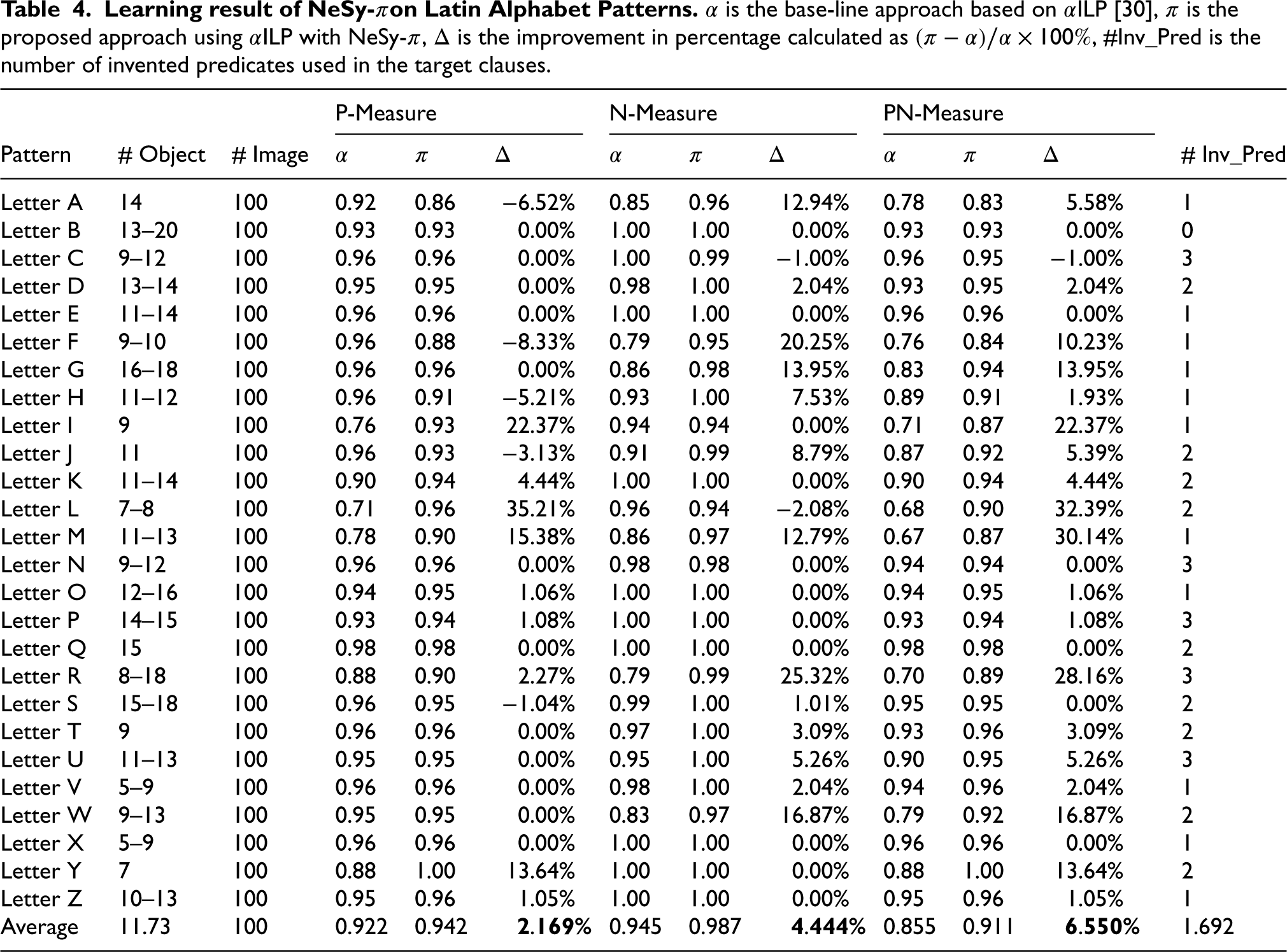
Learning result of NeSy-πon Latin Alphabet Patterns.α is the base-line approach based on αILP [30], π is the proposed approach using αILP with NeSy-π, Δ is the improvement in percentage calculated as , #Inv_Pred is the number of invented predicates used in the target clauses.
P-Measure
N-Measure
PN-Measure
Pattern
# Object
# Image
α
π
Δ
α
π
Δ
α
π
Δ
# Inv_Pred
Letter A
14
100
0.92
0.86
−6.52%
0.85
0.96
12.94%
0.78
0.83
5.58%
1
Letter B
13–20
100
0.93
0.93
0.00%
1.00
1.00
0.00%
0.93
0.93
0.00%
0
Letter C
9–12
100
0.96
0.96
0.00%
1.00
0.99
−1.00%
0.96
0.95
−1.00%
3
Letter D
13–14
100
0.95
0.95
0.00%
0.98
1.00
2.04%
0.93
0.95
2.04%
2
Letter E
11–14
100
0.96
0.96
0.00%
1.00
1.00
0.00%
0.96
0.96
0.00%
1
Letter F
9–10
100
0.96
0.88
−8.33%
0.79
0.95
20.25%
0.76
0.84
10.23%
1
Letter G
16–18
100
0.96
0.96
0.00%
0.86
0.98
13.95%
0.83
0.94
13.95%
1
Letter H
11–12
100
0.96
0.91
−5.21%
0.93
1.00
7.53%
0.89
0.91
1.93%
1
Letter I
9
100
0.76
0.93
22.37%
0.94
0.94
0.00%
0.71
0.87
22.37%
1
Letter J
11
100
0.96
0.93
−3.13%
0.91
0.99
8.79%
0.87
0.92
5.39%
2
Letter K
11–14
100
0.90
0.94
4.44%
1.00
1.00
0.00%
0.90
0.94
4.44%
2
Letter L
7–8
100
0.71
0.96
35.21%
0.96
0.94
−2.08%
0.68
0.90
32.39%
2
Letter M
11–13
100
0.78
0.90
15.38%
0.86
0.97
12.79%
0.67
0.87
30.14%
1
Letter N
9–12
100
0.96
0.96
0.00%
0.98
0.98
0.00%
0.94
0.94
0.00%
3
Letter O
12–16
100
0.94
0.95
1.06%
1.00
1.00
0.00%
0.94
0.95
1.06%
1
Letter P
14–15
100
0.93
0.94
1.08%
1.00
1.00
0.00%
0.93
0.94
1.08%
3
Letter Q
15
100
0.98
0.98
0.00%
1.00
1.00
0.00%
0.98
0.98
0.00%
2
Letter R
8–18
100
0.88
0.90
2.27%
0.79
0.99
25.32%
0.70
0.89
28.16%
3
Letter S
15–18
100
0.96
0.95
−1.04%
0.99
1.00
1.01%
0.95
0.95
0.00%
2
Letter T
9
100
0.96
0.96
0.00%
0.97
1.00
3.09%
0.93
0.96
3.09%
2
Letter U
11–13
100
0.95
0.95
0.00%
0.95
1.00
5.26%
0.90
0.95
5.26%
3
Letter V
5–9
100
0.96
0.96
0.00%
0.98
1.00
2.04%
0.94
0.96
2.04%
1
Letter W
9–13
100
0.95
0.95
0.00%
0.83
0.97
16.87%
0.79
0.92
16.87%
2
Letter X
5–9
100
0.96
0.96
0.00%
1.00
1.00
0.00%
0.96
0.96
0.00%
1
Letter Y
7
100
0.88
1.00
13.64%
1.00
1.00
0.00%
0.88
1.00
13.64%
2
Letter Z
10–13
100
0.95
0.96
1.05%
1.00
1.00
0.00%
0.95
0.96
1.05%
1
Average
11.73
100
0.922
0.942
2.169%
0.945
0.987
4.444%
0.855
0.911
6.550%
1.692
Furthermore, we have also analyzed the more intricate dataset Alphabet Patterns, which consists of 5 to 20 objects. The learning result of certain letters on NeSy-π with αILP systems are shown in appendix B. Table 4 illustrates the best learning result of each patterns on two systems. NeSy-π shows an average PN-Measure score of 0.911, exhibiting a improvement compared to αILP. The average P-Measure is 0.942 and N-Measure is 0.987. Certain letters achieves even to improvement on PN-Measure, such as letter I, L, M and R. Some letters achieves only minor or even negative improvement, that is because the baseline model αILP already achieves high scores (mostly higher than 0.9), thus the improvement spaces left to the NeSy-π are limited, such as letter D, H, K. In addition, NeSy-π does not guarantee a higher PN-Measure comparing to αILP alone, such as letter C. That is because the clauses are extended in a best-first approach in each step. The predicates in two systems are different, thus the best atoms for extension in two systems can be different. It is possible that a clause with invented predicates achieves high score in the previous steps, but increases only minor score in the following steps. In this case, the target clauses still contain the invented predicate, but its measurement can be smaller than the clause without invented predicate. In total, there is 1 pattern that does not invent any predicate, 11 patterns invent one predicate, 9 patterns invent two predicates and 5 patterns invent three predicates. On average, 1.65 new predicates are invented to describe each pattern.
A3 (NeSy-π efficiency): NeSy-π can improve the time efficiency for αILP system. The invented predicates improve the expressiveness of the language so that the rules can be expressed by shorter clauses. Consequently, the algorithm needs fewer iterations to search the target clauses, thereby improving the time efficiency.
In Figure 9, the graph displays the runtime for each alphabet pattern. The height of each bar represents the corresponding letter’s run-time, with the color indicating the number of groups N covered by the respective target clause. The fewer groups the target clause covers, the fewer iterations the algorithm requires. Figure 9 (c) and (d) show the ranking of the training time in descending order. On average, the NeSy-ILP method requires 64 minutes and 47 seconds to solve one letter, while the αILP method takes 126 minutes and 28 seconds to solve one letter. Therefore, NeSy-π is roughly twice as fast. On the other hand, it is apparent that fewer iteration N adheres to the less training time. The letter B has the highest iteration and also the longest training time. On the other hand, letters such as U, X have the fewest iterations and, as a result, have the fastest training time. On average, αILP with NeSy-π module requires 0.46 fewer iterations than αILP alone.
Time consumption on Alphabet Patterns. Time consumption of the individual letters in descending order. The red dashed lines show the average time for each plot. The colors of the bars differ according to the number of groups covered by the target clauses. (A). Grouping time of αILP. (B). Grouping time of αILP with NeSy-π. (C). Training time of αILP. (D). Training time of αILP with NeSy-π.
A4 (NeSy-π robustness): In this experiment, we show that NeSy-π is robust to falsifying patterns that have not seen in the training phase, i.e. NeSy-π exhibits robustness in distinguishing similar positive and negative examples in the dataset, achieving high accuracy despite their similarity.
Dataset. In order to evaluate the robustness of the learned clauses, another test dataset for the alphabet patterns is generated with similar positive and negative scenes. The positive scenes are still generated from the original letter patterns. However, the negative scenes are generated by intervening the positive scenes, i.e. randomly removing one object from the positive patterns, as shown in Figure 10. Such negative patterns are not seen by the model during training. To solve this task correctly, models need to be keen on small violations of the learned logical concepts.
Result.Figure 11 shows the evaluation result for the robustness test dataset. In comparison to the efficiency result in A3, when negative examples with similar patterns as positive examples are used, NeSy-π performance on N-Measure decreases from 0.98 to 0.77. Additionally, none of the test image patterns were seen by the model during the training period, and they are also very similar to the positive patterns (with only one object removed). In addition, when the robustness test dataset is applied to the clauses acquired through αILP, the N-Measure average is approximately 0.70, as demonstrated in the right plot of Figure 11. In this case, the NeSy-π attains a higher N-Measure.
Examples of robustness test dataset. The top row displays a selection of the original letter patterns. The bottom row shows negative letter patterns with one object randomly removed. To solve this dataset correctly, the model needs to be robust to the falsifying negative scenes not appeared in the training phase.
NeSy-πis robust to unseen falsifying examples. The evaluation of Alphabet pattern’s robustness is presented. Left: the NeSy-π performance in distinguishing negative examples is evaluated on two test sets. The purple line is based on a test set with dissimilar patterns as the negative examples, where different letters are used as negative examples. The orange line use a test set with similar patterns as negative examples, where one object is randomly removed from the same letters used as negative examples. Right: the performance of αILP and NeSy-π on the test set, where negative examples using similar patterns as positive patterns. The N-measure of NeSy-π achieves a higher average score compared to αILP.
Related work
We revisit relevant studies of NeSy-π.
Inductive Logic Programming and Predicate Invention. Inductive Logic Programming (ILP) [3,22,24,26] has emerged at the intersection of machine learning and logic programming. ILP learns generalized logic rules given positive and negative examples using background knowledge and language biases. Many symbolic ILP frameworks have been developed, e.g., FOIL [27], Progol [22], ILASP [19], Metagol [6,8], and Popper [4], showing their advantages of learning explanatory programs from small data. To handle uncertainties in ILP, statistical ILP approaches have been addressed, e.g. Markov Logic Networks [28] with their structure-learning algorithm [15]. Predicate invention (PI) has been a long-standing problem for ILP and many methods have been developed [2,5–7,12,17,33], and extended to the statistical ILP systems [16].
Recently, differentiable ILP frameworks have been developed to integrate DNNs with logic reasoning and learning [10,29–31]. ∂ILP [10] is the first end-to-end differentiable ILP solver, where they learn rules by gradient descent. ∂ILP can perform predication invention to compose solutions with less inductive biases. ∂ILP-ST [29] extends it by incorporating efficient search techniques developed for symbolic ILP systems, enabling the system to handle more complex rules using function symbols. To this end, Neuro-Symbolic ILP systems that can handle complex visual scenes as inputs have been developed. αILP [30] performs differentiable structure learning on visual scenes, however, these extended differentiable ILP systems do not support predicate invention. NeSy-π extends this approach by providing the predicate invention algorithm, leading them to learn from less supervision and background knowledge. Many other neuro-symblic systems have been established, e.g. DeepProbLog [20], NeurASP [37], SLASH [32] for parameter learning and FFNSL [9] for structure learning. NeSy-π could be integrated to these systems to allow predicate invention from complex visual scenes.
Meta rules, which define a template for rules to be generated, have been used for dealing with new predicates in (NeSy) ILP systems [10,14]. NeSy-π achieves memory-efficient predicate invention system by performing scoring and pruning of candidates from given data, and this is crucial to handle complex visual scenes in NeSy-ILP systems since they are memory-intensive [10].
Visual Reasoning. The machine-learning community has developed many visual datasets with reasoning requirements. Visual Question Answering (VQA) [1,18,36] is a well-established scheme to learn to answer questions given as natural language sentences together with input images. VQA assumes the programs to compute answers are given as a question, however, NeSy-π learns the programs from scratch using positive and negative examples. Kandinsky Patterns [25] are proposed as an environment to generate images that contain abstract objects (e.g. red cube) to evaluate neural and neural-symbolic systems. In a similar vein, CLEVR-Hans [34] has been developed, where the task is to classify 3D CLEVR scenes [13] based on classification rules that are defined on high-level concepts of objects’ attributes and their relations. These datasets can be used to evaluate various models on visual reasoning, however, they do not involve with predicate invention, thus it is not trivial to evaluate predicate invention systems using them. The proposed 3D Kandinsky Patterns extends these studies by having predicate invention tasks at its core, and it is the first to evaluate neuro-symbolic systems in terms of the ability of predicate invention.
Conclusion
We proposed Neural-Symbolic Predicate Invention (NeSy-π), which discovers useful relational concepts from complex visual scenes. NeSy-π can reduce the amount of required background knowledge or supplemental pre-training of neuro-symbolic ILP frameworks by providing invented predicates to them. Thus NeSy-π extends the applicability of neuro-symbolic ILP systems to wide range of tasks. Moreover, we developed 3D Kandinsky Patterns datasets, which is the first environment to evaluate neuro-symbolic predicate invention systems on 3D visual scenes. In our experiments, we have shown that (i) NeSy-π can invent useful predicates from visual scenes improving the performance of NeSy-ILP systems, (ii) NeSy-π can solve complex patterns that cannot be solved by the state-of-the-art NeSy-ILP baseline, (iii) NeSy-π is computationally efficient, and (iv) NeSy-π is robust to unseen falsifying examples. Developing a differentiable approach to fine-tune the given parameters is a promising avenue for future work. Also taking an unsupervised approach for predicate invention is another interesting future direction.
Spatial neural predicates explanation by examples. Left: directions of red circle with respect to green circle denoted by symbols . The red circle is in the direction of . Right: distance of red circle to the green circle denoted by the symbols . The red circle is located at the distance of . For 3D KP, we assume all the object placed on a flat surface with same height. Thus their positions can be mapped to 2D space with ignoring the axis denoting the height. The positions of each object can be evaluated from depth map of 3D scenes.
Simple Kandinsky patterns from top to bottom: Diagonal, Three Same, Two Pairs. In each patterns, two positive (green border) and two negative examples (red border) are shown in left side. The target clauses searched by NeSy-α and the predicates invented by NeSy-π are listed on the right side.
Complex Kandinsky patterns from top to bottom: parallel, perpendicular, square. In each patterns, two positive (green border) and two negative examples (red border) are shown in left side. The target clauses searched by NeSy-α and the predicates invented by NeSy-π are listed on the right side.
Latin Alphabet Patterns. Latin letters (including both upper and lower cases) constructed by multiple objects. The shape of each letter is mainly composed of lines.
Alphabet Pattern N and E from top to bottom: letter N, E. In each patterns, upper and lower case examples are shown in left side. The target clauses searched by NeSy-α and the predicates invented by NeSy-π are listed on the right side.
Alphabet Pattern S and Y from top to bottom: letter S, Y. In each patterns, upper and lower case examples are shown in left side. The target clauses searched by NeSy-α and the predicates invented by NeSy-π are listed on the right side.
Footnotes
Experiment setting
More experiment result
Figure 13 shows the learning result on Simple Kandinsky Patterns (Diagonal, Three Same, Two Pairs). Two positive and two negative images are given as examples in the left side. The target clauses searched by αILP and the predicated invented by NeSy-π are listed on the right side.
Figure 15 shows the examples of each letter patterns in Alphabet Pattern Dataset. Each letter includes its upper and lower case examples. Figure 17 shows the learning result on some of the Alphabet Patterns.
Notes
References
1.
AntolS.AgrawalA.LuJ.MitchellM.BatraD.ZitnickC.L.ParikhD., Vqa: Visual question answering, in: International Conference on Computer Vision (ICCV), 2015.
2.
AthakraviD.BrodaK.RussoA., Predicate invention in Inductive Logic Programming, in: 2012 Imperial College Computing Student Workshop, OpenAccess Series in Informatics (OASIcs), Vol. 28, Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany, 2012, pp. 15–21.
CropperA.MorelR.MuggletonS.H., Learning higher-order programs through Predicate Invention, in: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020, pp. 13655–13658.
EvansR.GrefenstetteE., Learning explanatory rules from noisy data, J. Artif. Intell. Res.61 (2018), 1–64. doi:10.1613/jair.5714.
11.
HeK.GkioxariG.DollárP.GirshickR., Mask R-CNN, in: 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988. doi:10.1109/ICCV.2017.322.
12.
HocquetteC.MuggletonS.H., Complete bottom-up Predicate Invention in meta-interpretive learning, in: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, (IJCAI) International Joint Conferences on Artificial Intelligence Organization, 2020, pp. 2312–2318.
13.
JohnsonJ.HariharanB.Van Der MaatenL.Fei-FeiL.ZitnickC.L.GirshickR., Clevr: A diagnostic dataset for compositional language and elementary visual reasoning, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2901–2910.
14.
KaminskiT.EiterT.InoueK., Exploiting answer set programming with external sources for meta-interpretive learning, Theory and Practice of Logic Programming18(3–4) (2018), 571–588. doi:10.1017/S1471068418000261.
15.
KokS.DomingosP., Learning the structure of Markov logic networks, in: International Conference on Machine Learning, 2005.
16.
KokS.DomingosP.M., Statistical Predicate Invention, in: International Conference on Machine Learning (ICML), 2007.
17.
KramerS., Predicate Invention: A Comprehensive View 1, 2007.
18.
KrishnaR.ZhuY.GrothO.JohnsonJ.HataK.KravitzJ.ChenS.KalantidisY.LiL.ShammaD.A.BernsteinM.S.Fei-FeiL., Visual genome: Connecting language and vision using crowdsourced dense image annotations, Int. J. Comput. Vis.123(1) (2017), 32–73. doi:10.1007/s11263-016-0981-7.
19.
LawM.RussoA.BrodaK., Inductive learning of answer set programs, in: Logics in Artificial Intelligence – 14th European Conference (JELIA), FerméE.LeiteJ., eds, Lecture Notes in Computer Science, Vol. 8761, 2014, pp. 311–325.
MaoJ.GanC.KohliP.TenenbaumJ.B.WuJ., The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision, in: International Conference on Learning Representations (ICLR), 2019.
22.
MuggletonS., Inverse entailment and progol, New Generation Computing, Special issue on Inductive Logic Programming13(3–4) (1995), 245–286.
23.
MuggletonS.BuntineW.L., Machine invention of first order predicates by inverting resolution, in: Proceedings of the Fifth International Conference on Machine Learning, ML’88, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1988, pp. 339–352. ISBN 0934613648.
24.
MuggletonS.H., Inductive Logic Programming, New Gener. Comput.8(4) (1991), 295–318. doi:10.1007/BF03037089.
ShindoH.NishinoM.YamamotoA., Differentiable Inductive Logic Programming for structured examples, in: Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), 2021, pp. 5034–5041.
SkryaginA.StammerW.OchsD.DhamiD.S.KerstingK., Neural-probabilistic answer set programming, in: International Conference on Principles of Knowledge Representation and Reasoning (KR), 2022.
33.
StahlI., Predicate invention in ILP – an overview, in: Machine Learning: ECML-93, BrazdilP.B., ed., Springer, Berlin Heidelberg, 1993, pp. 311–322. doi:10.1007/3-540-56602-3_144.
34.
StammerW.SchramowskiP.KerstingK., Right for the right concept: Revising neuro-symbolic concepts by interacting with their explanations, in: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 3619–3629.
35.
Unity Technologies, Unity, https://unity.com/.
36.
WuQ.TeneyD.WangP.ShenC.DickA.Van Den HengelA., Visual question answering: A survey of methods and datasets, Image Vis. Comput.163 (2017), 21–40. doi:10.1016/j.cviu.2017.05.001.
37.
YangZ.IshayA.LeeJ., NeurASP: Embracing neural networks into answer set programming, in: International Joint Conference on Artificial Intelligence (IJCAI), BessiereC., ed., 2020, pp. 1755–1762.