
Abstract
Graph Neural Networks (GNNs) are now a standard tool for modelling graph structured data in applications such as molecular property prediction, drug discovery, recommender systems, and citation networks. However, despite their strong predictive performance, they still suffer from the black box problem. Most existing explainability methods focus on local-level explainability, explaining individual predictions. They highlight important nodes and edges but don′t capture how the model behaves globally across a dataset. As a result, global-level explainability remains an open challenge. In this paper, we extend our previous work on Functional Semantic Activation Mapping (FSAM) to investigate how varying the number of GNN layers affects both representation quality and predictive performance. Across several datasets, increasing depth may improve accuracy but does not necessarily enhance semantic coherence. In some cases, performance gains coincide with a decline in semantic quality, suggesting that spurious patterns may drive correct predictions for wrong reasons. FSAM layer-wise activation tracking allowed us to track neuron activations across layers, revealing that deeper layers can reduce neuron specialisation and lead to class misclassifications. Our findings demonstrate a critical trade-off that increased depth can compromise interpretability without commensurate gains in meaningful semantic learning.
Keywords
Introduction
Graph neural networks (GNNs) (Kipf & Welling, 2016; Yuan & Ji, 2020; ?) have shown remarkable performance in node classification, link prediction, and graph classification tasks. GNNs leverage structural information and node features to capture complex relationships within a graph. However, explaining GNN predictions remains a challenge due to the complex topological nature of graphs and how this is represented in GNN embeddings. Unlike traditional neural networks, GNNs operate on graph structures, which might suggest better interpretability, but understanding how these relationships are learned within the layers remains ambiguous. In current research on the explainability of GNN, most local methods (Yuan et al., 2021) focus on generating small subgraphs and identifying which nodes and edges contribute to a specific prediction. However, they do not explicitly show how information is processed within the network layers. Although useful, they fail to comprehensively understand how the GNN behaves across different layers and do not offer a global understanding of model behaviour.
In our previous work (Raj & Mileo, 2024), we introduced the Functional Semantic Activation Mapping (FSAM) framework to address this gap. FSAM explains how the entire network behaves across its layers by producing, for each layer, a semantic graph whose vertices correspond to neurons and whose edges represent statistically significant coactivation patterns. These graphs are termed semantic because the neuron groups (communities) often correspond to higher-level concepts learned by the model. For example, in a citation network, one community might activate predominantly for papers on machine learning, another for data mining, with connections between them reflecting shared topical structure. By comparing these semantic graphs across layers, FSAM reveals how class-specific or concept-specific representations emerge or merge as network depth increases. In this extended work, we apply FSAM to explore a central question in GNN design: To what extent does increasing the number of layers enhance the model’s ability to represent meaningful patterns? Furthermore, does higher predictive accuracy necessarily imply more faithful or discriminative internal representations?
The oversmoothing phenomenon has been well studied in the literature and is a well-known problem in GNNs (Liu et al., 2020; Rusch et al., 2023; Wu et al., 2020), which occurs when we add more layers of information to a GNN architecture. Our findings indicate that oversmoothing reduces FSAM quality, as evidenced by the degradation of the model’s ability to represent meaningful, class-specific features across layers. Instead of merely confirming that oversmoothing occurs, FSAM provides a better-structured way to detect and quantify the effects of oversmoothing at the neuron level. It tracks when and where neurons begin to lose their class-specific activations, offering a more profound insight into the impact of model depth on representation quality. In this sense, FSAM is more likely to be a diagnostic tool for global-level model behaviour, indicating where oversmoothing might occur. Furthermore, our research has practical implications. We have observed cases where GNN performance improves without a corresponding enhancement in FSAM quality; this suggests that the model may make correct predictions, but not necessarily for the right reasons, as it could rely on less meaningful or oversmoothed features. Therefore, FSAM offers an interpretability driven analysis of oversmoothing which provides insight into the reasons behind the model’s predictions. Our findings elucidate the trade-off between model depth and interpretability, empirically demonstrating how excessive layering can degrade semantic coherence while maintaining superficial accuracy metrics. The FSAM framework emerges as an essential diagnostic tool offering researchers the unprecedented capability to (i) quantify the progressive loss of neuron specialisation across layers, (ii) identify where correct classifications stem from flawed reasoning patterns, and (iii) establish optimal depth thresholds before semantic collapse occurs, establishing a new paradigm for assessing both what GNNs predict and how they derive these predictions – a crucial distinction for deploying graph networks in high-stakes real-world applications.
Since this paper relies on capturing the GNN’s behaviour through activation analysis with FSAM, our first contribution is to extend FSAM validation beyond our previous experiments on CORA (Sen et al., 2008) and CiteSeer (Namata et al., 2012). To achieve this, we conducted additional experiments on four different datasets: PubMed (Botari, 2002), Amazon Computers (McAuley et al., 2015), Amazon Photos (McAuley et al., 2015), and Coauthor (Shchur et al., 2018). These datasets with their distinct topological complexities allow us to comprehensively evaluate FSAM’s approach and determine how well the resulting activation graph reflects the GNN’s behaviour and how effectively the network learns the semantic structure of the input data.
The contributions of this work can be summarised as follows. Firstly, we extend the FSAM approach by conducting experiments on a broader range of datasets to validate that the activation analysis and graphs generated by FSAM consistently reflect the network behaviour. This includes community analysis in different datasets that demonstrates the ability of FSAM to capture the semantic structure between classes reliably. Secondly, we extend our experimental analysis to confirm that the functional activation graph generated by FSAM aligns with the network’s behaviour as the number of layers changes. By testing networks with different depths (from 1 to 4 layers) and comparing the correlation between misclassifications and class similarity, we show that improvements in network accuracy are reflected in the FSAM graph, and the FSAM structure also captures any decline in accuracy. This analysis emphasises FSAM’s ability to represent network behaviour across different layer configurations accurately. Third, we conduct a detailed layer-by-layer analysis to assess how different GNN layer configurations affect the model’s performance in node classification tasks. Specifically, we examine how varying the number of layers influences FSAM and the corresponding community structure and verify whether improvements in accuracy align with better FSAM graphs and, on the other hand, decreases in accuracy correlate with a decline in FSAM quality. This analysis demonstrates that while additional layers may enhance performance, deeper layers can lead to oversmoothing; neuron activation overlap, and ultimately diminish the model’s ability to differentiate between classes. As part of our detailed, comprehensive analysis, we also identify a few interesting cases where accuracy improves without a corresponding improvement in FSAM’s semantic quality. These instances reveal situations where the GNN achieves better predictions, but not necessarily due to a better embedding of the semantic structure in the input data. It highlights FSAM’s potential in identifying cases where a model makes accurate predictions for the wrong reasons.
State of the Art
The interest in neuro-symbolic AI has increased steadily, driven by the need for interpretable and accountable machine learning systems, especially in domains that require transparent decision making. Research has focussed on integrating neural learning with symbolic reasoning, an essential step to enhance the explainability of deep learning models. This integration is crucial for high-stakes domains where accuracy and interpretability are essential. GNNs have shown exceptional performance in handling graph-structured data in a range of fields, such as social networks (Yanardag & Vishwanathan, 2015), molecular structures (Geirhos et al., 2018), and citation networks (Xi et al., 2023). However, despite their success in learning complex relationships, GNNs remain largely opaque with respect to how specific predictions are made, particularly when compared to models in other domains like image and text analysis. The challenge lies in interpreting the internal representations learned by GNNs, particularly about prior knowledge.
Most existing methods for GNN explainability focus on local explanations, identifying key input features, nodes, or edges influencing individual predictions. These techniques are broadly divided into several categories:
In addition to these local approaches, recent research has investigated rule based explanations for GNNs, where the learned model is partially or entirely translated into a set of human interpretable logical rules (Cucala & Grau, 2024). Such methods explicitly connect neural computation with symbolic reasoning, enabling formal reasoning about the model’s predictions. Although promising in their transparency, such approaches often suffer from generating overly complex rules for deeper architectures or large-scale graphs, which can limit practical interpretability. Our FSAM framework addresses a different, yet complementary, aspect of the explainability problem. Instead of enumerating potentially unwieldy rule sets, FSAM provides a global, structured, and layer-wise semantic representation of how neurons interact and form communities throughout the network. This perspective captures overall behaviour and the flow of information across layers. These features are typically absent from both rule-based and local explanation approaches. By offering a consolidated view of the model’s semantic structure, FSAM facilitates reasoning about its behaviour in the context of prior knowledge and domain-specific concepts.
It is worth stating that the use of global explanations is less researched in the context of GNN. One of the methods is
Although these approaches provide some information about the final predictions, they do not explain how the intermediate layers participate in the learned representations, as they are not suitable for explaining the relationship between the internal structure of the model and prior knowledge or domain knowledge, which limits the ability of users to trust and understand the model’s decisions. Furthermore, the related work in SOTA is presented in Table 1.
Comparison of Existing Explainability Methods for GNNs.

Comparison of Existing Explainability Methods for GNNs.
The columns represent various aspects of each method:
Our previous work addresses this gap by introducing the
The primary aim of this paper is to improve the interpretability of GNNs by representing their internal mechanisms as semantic graphs. In our extended study, we hypothesised that adding more layers to GNNs does not necessarily increase their capacity for knowledge representation. Our FSAM method clarifies GNN decisions by focussing on how different layers contribute to, or sometimes reduce, model performance due to oversmoothing. FSAM identifies neuron groups involved in decision-making, termed activation neurons, and constructs a semantic graph to visualise their relationships. FSAM tracks neurone activations and visualises activation relationships across layers, providing valuable information on the network’s decision-making process and semantic coherence. Figure 1 illustrates the proposed system architecture, highlighting the steps to optimise layer depth and improve GNN performance. This section presents the mathematical formulation for generating the semantic graph, integrated with insights from our extended experiments.
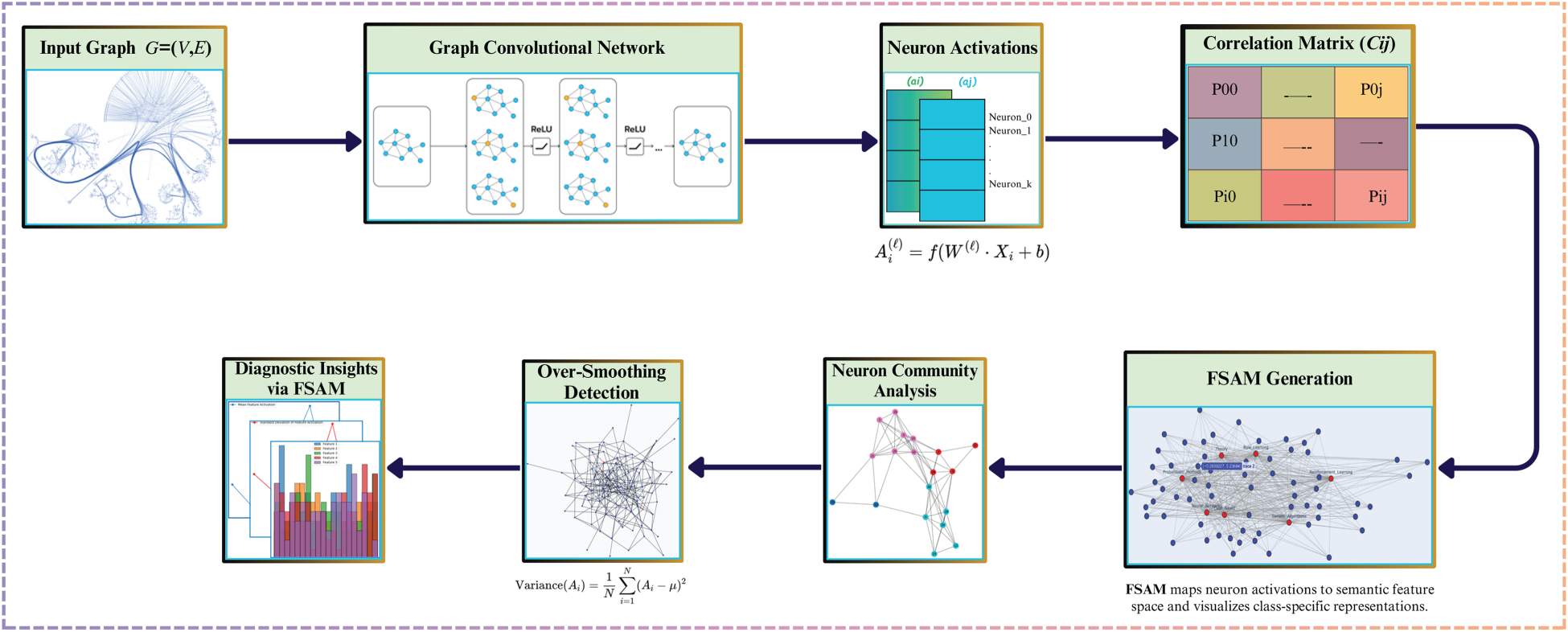
Overall proposed system architecture.
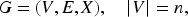
The GNN processes 


This measurement quantifies neuron–neuron relationships independently of the classifier head and will be used in subsequent sections to analyse representation structure across layers.
We correlate intermediate layer activations with the predicted class of the final layer to characterise the model’s decision boundary. Let 


This study explores how varying the number of layers in GNNs impacts both model performance and the quality of knowledge representation. Building on our previous research, we employ FSAM to systematically assess how well different layer configurations capture the underlying structure of input data. As our contributions address a central question, Do additional layers enhance the model’s interpretability and accuracy, or do they introduce complexity that impairs representation quality?
The following contributions highlight the key findings of this study:
Overall, these contributions extend our previous work, providing a detailed methodology for assessing GNN layer depth and performance. Our findings position FSAM as a valuable framework for balancing layer depth with interpretability and accuracy, ultimately enhancing the understanding and optimisation of GNN architectures across various datasets.
Experiment
Experimental Set-Up
To evaluate the proposed FSAM framework, we conducted experiments in a setting transductive node classification using six benchmark data sets (Section 5.2). All experiments were implemented in PyTorch Geometric, with the GCNConv layer as the graph convolution operator. The base GCN architecture consisted of multiple graph convolution layers, each followed by a ReLU activation and dropout for regularisation. A final fully connected layer mapped the hidden representations to the
Training and evaluation used the standard
Our aim was to assess whether increasing GCN depth leads to more meaningful internal representations or, conversely, to oversmoothing and loss of discriminative capacity. FSAM was used to generate semantic graphs per layer, allowing a direct visual and quantitative comparison of neuron relationships across depths.
We used six benchmark datasets covering diverse graph domains:
These datasets span a wide range of domains, from academic publications and biomedical research to product co-purchases and academic co-authorships.
Our second contribution involves validating the ability of the FSAM approach to capture GNN behaviour in varying layer configurations reliably. Through systematic experiments on several datasets, as detailed in Section 5.2, we analysed each GNN configuration (from 1 to 4 layers) to assess the alignment between model accuracy, misclassification patterns, and community structures represented by FSAM graphs.
In Table 2, we present the results for the Amazon Photo dataset, illustrating the progression of layerwise accuracy across configurations and highlighting how FSAM captures the relationship between classification errors and community structures.
Final Accuracy and Pearson Correlation of Models with Different Depths (1–4 Layers) Across Three Datasets.

Final Accuracy and Pearson Correlation of Models with Different Depths (1–4 Layers) Across Three Datasets.
Note: Pearson’s correlation is used here to measure the linear association between functional semantic activation mapping (FSAM)-derived metrics and model accuracy in different layer configurations. This differs from the Spearman correlation in Section 3, which is applied to neuron level activation patterns where nonlinear monotonic relationships are expected.
In Layer 1, the model achieves an accuracy of 95% with a Pearson correlation of 0.681. This positive correlation suggests that class-specific representations are moderately well separated, with fewer overlapping nodes in the FSAM graph, leading to lower misclassification rates. The FSAM graph at this layer reveals distinct class representations, demonstrating effective differentiation early in the network. Adding a second layer improves accuracy to 96%, while the Pearson correlation decreases slightly to 0.650. This layer further strengthens class-specific separation without significant overlap in neuron activations. FSAM visualisations at this stage show that, while additional depth aids in correct predictions, it does not compromise the integrity of class distinctions, reflecting the model’s enhanced capacity to maintain semantic coherence. In Layer 3, the accuracy begins to decline, dropping to 94%, while the Pearson correlation rises to 0.752. This increased correlation value indicates a greater overlap in neurone activations, signalling a loss of distinctiveness among class-specific features. Here, FSAM reveals that oversmoothing begins to emerge, with class representations blurring as neuron activations overlap. This finding aligns with our previous work, which observed that classes with high node overlap in the FSAM graph tend to cause more mistakes, highlighting the need for improved class separation strategies. At Layer 4, the accuracy decreases further to 93%, and the Pearson correlation reaches 0.780, confirming substantial activation overlap and diminished distinctiveness in class representations. FSAM visualisations reveal extensive overlap between neuron communities, indicating that deeper layers contribute to oversmoothing. These observations suggest that overlapping nodes between similar classes might be prime targets for tuning, as reducing this overlap could improve the model’s ability to distinguish these classes effectively.
These findings reinforce FSAM’s effectiveness in tracing the network’s behaviour across varying depths. Although initial layers improve accuracy with minimal activation overlap, additional layers increase the correlation between overlapping nodes and misclassification errors. This positive correlation between class similarity and mistake counts underscores FSAM’s diagnostic potential, providing insight into where the network’s performance could be optimised by minimising activation overlaps between similar classes, ultimately aiding in balancing depth and semantic clarity within GNNs.
Similarly, for the Coauthor CS dataset (Table 2), our findings strongly support the hypothesis that FSAM effectively captures layerwise shifts in network behaviour.
In the first layer, with a high accuracy of 98% and a low Pearson correlation of 0.589, neuron activations remain largely distinct, allowing for clear class separations. As we add layers, accuracy decreases slightly (97% at Layer 2) while correlation increases (0.756), indicating a gradual increase in activation overlap. By the third layer, accuracy drops further to 96%, with a higher Pearson correlation of 0.819, signalling the onset of oversmoothing as neuron activations increasingly overlap, thus blurring class distinctions. In the fourth layer, with an accuracy of 95% and a correlation of 0.834, this trend persists, showing that additional depth now undermines the model’s ability to separate classes effectively.
These findings illustrate that FSAM consistently mirrors the evolving behaviour of the network across layers, accurately capturing the interaction between model accuracy and neuron overlap and confirming its usefulness in diagnosing the point at which further layers no longer benefit performance
In the Amazon Computers dataset (Table 2), we apply the same methodology, analysing how variations in accuracy between layers relate to the structures of the underlying graphs of FSAM. In the first layer, with an accuracy of 90% and a Pearson correlation of 0.683, the FSAM graph captures a balanced representation of the behaviour of the network. This correlation level suggests that neuron activations are distinct enough to preserve class separations effectively, reflecting that the FSAM captures clear distinctions among classes without excessive overlap.
When a second layer is added, the accuracy increases slightly to 91%, while the Pearson correlation decreases to 0.630. This reduction in correlation and improved precision indicate that neuron activations remain well separated, supporting the continued effectiveness of the model in distinguishing between classes. The FSAM graph here effectively aligns with the improved class distinction, reinforcing the model’s structural clarity.
However, in the third layer, accuracy decreases to 88%, and the Pearson correlation increases to 0.785. This shift indicates an increase in the activation of overlapping neurons, suggesting a decline in class distinction, likely attributable to oversmoothing. The FSAM graph reflects this change, capturing the network’s diminished ability to maintain distinct class representations as neuron activations converge.
In the fourth layer, the accuracy slightly recovers to 89%, but the Pearson correlation increases to 0.917. This high correlation signals significant overlap among neuron activations, indicating that further depth contributes little to class separation. Here, the FSAM graph reveals that, despite achieving correct classifications, the model no longer fully preserves the semantic structure of class-specific features. This scenario, where the model’s predictions remain accurate without robust semantic alignment, highlights FSAM’s diagnostic capability in identifying when a network may be ‘right for the wrong reasons’.
These experiments effectively demonstrate FSAM’s capacity to represent network behaviour across diverse configurations. Specifically, the FSAM activation graph tends to exhibit a more substantial alignment with the semantic structure as the accuracy improves. The initial layers, such as the second, achieve higher accuracy with low correlation, showing adequate class distinction. Beyond this point, additional layers lead to diminished accuracy and increased neuron overlap, confirming FSAM’s reliability in capturing the balance between model accuracy and class separation. These findings attest to FSAM’s robustness and consistency in representing GNN behaviour across different depths. Furthermore, these findings support Contribution 4, where we identify instances in which the FSAM graph quality declines even as accuracy improves, underscoring FSAM’s value in diagnosing subtle discrepancies in the network’s semantic coherence with the data. As in the Table 2 it shows raw layer-wise metrics, while Table 3 provides statistical validation. Together, they confirm that: (1) FSAM reliably captures GNN behaviour (all correlations significant,
Layer-wise Analysis with Statistical Validation.

*Significant at
These findings support our mathematical formulation of FSAM, in which we defined layer-wise activation matrices
In our analysis, communities are defined within individual GNN layers, where each neuron is a node in the FSAM coactivation graph and edges are weighted by Spearman’s rank correlation of their activation patterns. Community detection (Louvain method) is applied separately to each layer’s graph, producing clusters of neurons whose activations are strongly correlated for the same input graph. Although detection is performed per layer, we track the corresponding communities across depths by matching neurones with similar activation profiles, enabling us to observe how these clusters evolve. Communities are relevant here because they represent semantically related functional groups of neurons; changes in their size, cohesion, or separation with depth reveal how layer depth influences the organisation of learned representations, class-specific accuracy, and the onset of oversmoothing. This evolution is quantified in Table 4 and supports our findings in Table 2. The structure of the community is delineated in

Layer wise accuracy per class contribution of CoAuthorCs Dataset.
Community Structure and Mistakes Across Layers for Each Dataset, Where

Mistakes are presented as both absolute counts and percentages.
In
By
These results demonstrate that the CoauthorCS community structure evolves as layers are added, with previously distinct class groupings merging in response to overlapping neuron activations. This trend highlights the limitations of deeper layers in maintaining class specificity and supports FSAM’s capability to capture the network’s shifting behaviour across layers. The increase in misclassification and Pearson’s correlation values illustrates how FSAM serves as a diagnostic tool, accurately reflecting the trade-off between layer depth and community coherence, thus validating the results shown in Table 2.
The analysis of errors between communities in the Amazon Photos dataset, as outlined in Table 2, provides valuable information on how community structures evolve across layers and impact model performance. This breakdown demonstrates FSAM’s capability to capture structural shifts as the network depth increases, highlighting changes in how the model perceives class similarities.
In
As we progress to
However, the model’s performance deteriorates in
By
This layerwise community analysis, as detailed in Table 2, demonstrates that FSAM not only reflects accuracy trends but also captures the nuanced structural shifts within the model as depth increases, reinforcing its utility in diagnosing when additional layers may lead to diminished class coherence.
In Table 4, the Amazon Computers dataset’s analysis effectively captures effective shifts in network behaviour across different layers, especially in cases where accuracy trends diverge from FSAM correlation trends. Changes in community structures and pattern of mistakes in layers demonstrate this.
In
At
Moving to
By
These findings substantiate our hypothesis by demonstrating the ability of FSAM to capture alignment and divergence between accuracy and semantic quality in GNNs. As seen in
Our analysis reveals FSAM’s unique ability to detect discrepancies between accuracy metrics and semantic understanding. In particular, we observe two critical scenarios: (1) Cases where improving accuracy coincides with deteriorating FSAM graph quality, suggesting that the model achieves correct predictions without proper semantic grounding, and (2) situations where reduced accuracy accompanies enhanced FSAM quality, potentially indicating more meaningful learning from misclassifications. These findings demonstrate FSAM’s value in model-level diagnostic tools to identify when models are ‘right for the wrong reasons’, offering crucial insights into the semantic alignment between networks and their training data.
To systematically validate these observations regarding layer depth and class similarity effects, we present multiple visualisation strategies that capture fundamental aspects of model behaviour.

Layer wise accuracy per class contribution of AmazonPhoto Dataset.

Layer wise accuracy per class contribution of Computers Dataset.

Jaccard similarity between different layers for AmazonPhoto dataset.
Our extended analysis revealed a positive correlation between class similarity and the number of mistakes involving them, as illustrated with examples from the datasets
A similar trend appears in the
These findings suggest that adding layers beyond an optimal depth does not necessarily improve knowledge representation. Instead, it introduces an oversmoothing effect in which neuron activations for different classes become increasingly indistinct, reducing the model’s ability to differentiate between them. Our correlation analysis substantiates this effect, which shows that pairs of classes with significant overlap in the FSAM graph tend to experience higher misclassification rates.
Our analysis of community structures aligns with this observation, allowing us to identify classes that the GNN perceives as similar based on FSAM patterns. By examining the Jaccard similarity coefficient, which quantifies the overlap in neuron activations for each pair of classes, we evaluated the impact of these similarities on GNN decision making. In the Amazon Photos dataset, for example, product categories such as Memory Cards and Accessories displayed high Jaccard similarity, leading to frequent misclassifications. For a detailed analysis of the misclassification rates per class pair for each community across different layers, we have presented the results for all layers in Figures 8, 9, 10, and 11. Furthermore, we have conducted more experiments to calculate the time for each layer in different datasets as detailed in Table 5
Execution Times for Different Datasets and Number of Layers.

These insights suggest that tuning efforts should reduce overlap in the coactivation graph for similar classes to enhance the GNN’s ability to differentiate between them. Targeting overlapping nodes can potentially decrease misclassification rates and improve overall model accuracy. This comprehensive evaluation supports our hypothesis that increasing layers does not necessarily yield better performance and, in some instances, may decrease the discriminative power of the model due to overlapping neuron activations. Insights from our FSAM analysis suggest that overlap in coactivations for similar classes is a critical issue that affects the GNN’s ability to differentiate between those classes. By targeting and reducing this overlap, we can improve the model’s ability to distinguish between similar courses, thus reducing misclassification rates and improving overall accuracy. FSAM provides a framework for identifying the overlapping nodes in the coactivation graph. By addressing these overlaps, we can potentially reduce the adverse effects of oversmoothing, thus enhancing model performance and ensuring that the GNN can retain useful discriminative features across layers. Although FSAM does not directly generate explanations, the insights gained from mapping neuron activations and analysing coactivation overlap can pave the way for explanation-generation methods. These insights could ultimately contribute to more human-interpretable explanations of GNN decision making, especially in safety critical applications.
Scalability and Computational Complexity
While FSAM offers valuable insights into GNN’s semantic coherence, its application to large-scale graphs faces computational challenges, particularly in higher-dimensional feature space, as it requires more memory and processing power as it monitors neuronal activations across multiple layers and conducts correlation-based analyses as graph size and model depth increase. The complexity of tracking activations and conducting semantic correlation analysis increases non-linearly with the increase in nodes and edges. More complex GNN architectures exacerbate this issue by introducing additional activation patterns, increasing memory usage and bottleneck, and prolonging the computation duration. Optimisations such as node and edge sampling, parallelisation techniques (e.g., GPU acceleration, distributed computing), and approximate correlation methods can mitigate these challenges by enhancing efficiency. Future research should explore lightweight FSAM variants, such as selective neuronal tracking layerwise approximations, to enhance scalability while preserving interpretability. The practical implementation of FSAM relies on resolving these challenges for large-scale graph datasets.
Conclusion and Future Work
In this extended study, we have worked to deepen the understanding of how GNNs behave using FSAM to examine the link between model depth, performance, and semantic representation. Through experiments on several datasets, we found that FSAM consistently captures meaningful semantic relationships across different contexts, reinforcing its reliability as a tool for interpreting network behaviour. Our findings also indicate that adding more layers to GNNs does not always lead to better performance or richer knowledge representation. In these FSAM graphs, nodes represent neurons, and weighted edges indicate the strength of their coactivation relationships, reflecting correlations in activation patterns across layers. This layered view of the GNN function shows how neurons contribute to specific class predictions and influence overall model decisions. Our experiments confirmed that the FSAM graph structure aligns well with the knowledge stored in GNNs, especially in distinguishing closely related classes. In all data sets, FSAM consistently highlighted key neurons and communities within the GNN that are central to specific class predictions, providing valuable insights into the model decision making process. We used community detection in FSAM graphs to see how the GNN naturally groups classes based on activation patterns. Our analysis showed that courses with high overlap in the FSAM graph are more likely to be misclassified, suggesting that focussing on these overlapping nodes could help fine-tune the model and improve accuracy. This ability to identify cases where accuracy may be achieved ’for the wrong reasons’ where predictions are correct but lack deep semantic alignment highlights the diagnostic power of FSAM. The FSAM graphs and community detection further clarify how the GNN organises knowledge, revealing class groups with high activation overlap that the GNN treats as similar. This overlap is often associated with higher misclassification rates, supporting strategies to reduce this overlap and improve the model’s ability to distinguish between classes.
For future work, we will explore whether similar interpretability degradation occurs when increasing hidden-layer dimensionality rather than depth, and how FSAM patterns evolve throughout training. This includes analysing loss trajectories and probing connections to phenomena such as grokking. We also aim to develop adaptive depth GNN architectures that self-tune based on graph structure, refine FSAM’s class-level evaluation metrics, and integrate FSAM insights with graph topology for richer and context-aware explanations. Advancing FSAM in these directions could transform it from a post hoc diagnostic into a proactive design tool, guiding the creation of GNNs that are not only accurate but also efficient, interpretable, and semantically aligned.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was conducted with the financial support of the Science Foundation, Ireland Centre for Research Training in Artificial Intelligence under Grant No. 18/CRT/622.3.