
Abstract
Coronavirus is an infectious disease induced by extreme acute respiratory syndrome coronavirus 2. Novel coronaviruses can lead to mild to serious symptoms, like tiredness, nausea, fever, dry cough and breathlessness. Coronavirus symptoms are close to influenza, pneumonia and common cold. So Coronavirus can only be confirmed with a diagnostic test. 218 countries and territories worldwide have reported a total of 59.6 million active cases of the COVID-19 and 1.4 million deaths as of November 24, 2020. Rapid, accurate and early medical diagnosis of the disease is vital at this stage. Researchers analyzed the CT and X-ray findings from a large number of patients with coronavirus pneumonia to draw their conclusions. In this paper, we applied Support Vector Machine (SVM) classifier. After that we moved on to deep transfer learning models such as VGG16 and Xception which are implemented using Keras and Tensor flow to detect positive coronavirus patient using X-ray images. VGG16 and Xception show better performances as compared to SVM. In our work, Xception gained an accuracy of 97.46% with 98% f-score.
Introduction
Coronavirus is a contagious virus that affects respiratory infection and is widely contagious from person to person. The World Health Organization (WHO) noted that many cases of respiratory infection were clinically similar to viral pneumonia, breathlessness, mild fever and cough on December 31, 2019 [1]. The Novel coronavirus (2019-nCoV) was identified in Wuhan providence, China. It refers to a class of viruses including Middle East Respiratory Syndrome (MERS) and Extreme Acute Respiratory Syndrome (SARS) [2]. Coronaviruses may often cause diseases such as pneumonia or bronchitis in the lower respiratory tract. This is much more severe in people with poor immune systems, heart, kidney disease and liver disease [3]. COVID-19 confirmed cases, death cases and recovery cases in Brazil are 6.08, 0.17 and 5.44 million respectively as of November 24, 2020. In India number of coronavirus confirmed cases (9.17 million) is higher than Brazil but the number of death cases (0.13 million) is very less [4, 30–33].
The detection of COVID-19 should be confirmed by gene sequences for respiratory or blood samples as a primary indicator of reverse transcription polymerase chain reaction (RT-PCR), as per the Chinese government. RT-PCR sensitivity is very low. So that it is very difficult to diagnose many COVID- 19 patients [25, 34–35]. The diagnosis currently involves anyone who discovers the popular pneumonia of a COVID-19 chest scan rather than people waiting for positive tests on the virus. This method will allow doctors to quickly isolate and treat the positive COVID-19 patients.
Actually, the COVID-19 check is a difficult task because the diagnostic system is unavailable in certain places. We have to rely on other diagnostic methods to overcome the restricted supply testing kits for COVID-19. Since COVID-19 targets our respiratory tract’s epithelial cells, we may use X-rays to monitor the condition of a patient’s lungs. Doctors used X-ray devices to scan infected body parts for tumors, lung infections, pneumonia and fractures. Computer tomography (CT) is an imaging technique that uses different devices to scan and produce accurate images of areas within the body. It is more advanced as compared to X-ray. Although most hospitals have X-ray scanning technology, it may be essential to use X-rays of the chest to examine COVID-19. As compared to CT scan technology X-ray scan is better. X-ray scan is cheaper, easier, faster and less dangerous to the human body. The disadvantage of X-rays analysis requires a radiology specialist to detect COVID-19 positive patient within short span of time. Some patients may also have symptoms of coronavirus but still they are COVID-19 negative. So, an automated model must be built to save valuable time for medical practitioners to detect COVID-19 patients.
Deep transfer learning has extensive applications in medical image analysis. Various researches have published many research articles to detect brain tumor, breast cancer, and respiratory illness. With the help of deep transfer learning the pediatric pneumonia is identified through chest X-ray images, nature of pulmonary nodules identified through CT images and cystoscopic image processing extracted through videos etc [5]. In this manuscript, we use SVM, VGG16 and Xception pre-trained models on chest X-ray images to detect COVID-19 positive patients.
The rest of the article is arranged as follows. Literature survey is presented in section 2, SVM and deep transfer learning models are described in section 3, section 4 contains the performance matrices and conclusion followed by future works is presented in section 5.
Related works
In this portion, we presented a literature survey on various methodologies proposed by researchers to detect COVID-19 patients.
Shuai Wang et al. [6] suggested a deep learning technique that would retrieve the graphic features of COVID-19, thereby saving crucial time for disease control. They use 1119 COVID-19 positive CT images along with pneumonia images. They modified the existing inception deep learning approaches to detect COVID-19 patients. They got the accuracy as 79.3% and 89.5% for external and internal validations respectively.
Fei Shan et al. [7] proposed deep learning model named “VB-Net” to segment infected COVID-19 CT scans regions. Their model is trained and validated using 249, 300 COVID19 positive patients respectively. Authors have implemented a human-in-the-loop (HITL) procedure to enable radiologists to improve automated annotation. Their model produced dice similarity coefficients between automatic and manual segmentations of 91.6% ±10.0%.
Xiaowei Xu et al. [8] used 3-D deep CNN model from pulmonary CT image set to segment infection regions as Influenza-A, positive COVID-19 and not relevant to infection groups. They use location attention classification model and Bayesian function to calculate the confidence scores. Their model produced the accuracy as 86.7%.
Ophir Gozes et al. [9] developed automatic CT image analysis systems focused on artificial intelligence (AI) to diagnose, analyze and track coronavirus and to differentiate negative COVID-19 patients. Classification results for active COVID-19 versus negative COVID-19 cases were achieved by 0.996 Area under Curve thoracic CT studies with 98% specificity and 94% sensitivity.
Ali Narin et al. [10] proposed InceptionResNetV2, InceptionV3 and ResNet50 model for the identification of positive coronavirus patients utilizing chest X-ray datasets. ResNet50 model offers the best accuracy value as compared to other models.
Prabira et al. [11] proposed coronavirus identification model on X-ray images using different transfer learning models with SVM. They retrieved the deep CNN model features and fed each individually to the SVM classifier. Their proposed COVID-19 classification model was 95.38% accurate.
For pulmonary tuberculosis (PTB), Wei Wu et al. [12] recommended a deep CNN system to automatically generate a CT reports for diagnostic study. They implemented 3D deep learning models to examine lungs and could use the advantages of 3D CT imaging technology to accurately detect different regions and forms of lesions. Among them, v-net backbone with inception-resnet blocks provided the best results for both detection accuracy and classification.
CT imaging features of 2019 novel coronavirus [13–16] are beneficial for the identification and treatment of COVID-19 by the radiologist.
Materials and methods
In this portion we discuss the traditional classification model (SVM) and deep transfer learning models (VGG16 & Xception).
Traditional classification (SVM)
For machine learning classification tasks basically Support Vector Machine (SVM) used. SVM is focused on supervised learning mechanism that classifies points to one of the two disjoint planes. Vapnik [17] proposed the SVM for binary classification. The objective of SVM is to obtain the optimum hyper plane via f (w, x)=w · x + b to distinguish two classes in a particular dataset by maximizing the margin, with features x ∈ Rm.
SVM learns certain parameters W by resolving the problem of optimization mentioned in Equation 1.
Where W
T
W = manhattan norm, y=actual label, C = penalty parameter, W
T
X + b=predictor function. Equation 1 is also called as standard hinge loss (L1-SVM). L2-SVM (Squared hinge loss) [18] provides more stable results represented in equation 2. ∥W ∥ 2 represented as Euclidean norm.
SVM does not do so well whenever the data set has much more noise, i.e. the target classes overlap. So we use deep transfer learning models.
VGG 16 was proposed by Karen Simonyan et al. [19] in 2014. VGG-16 comes from the fact that it has 16 layers. VGG16 contains different layers such as 3 dense layers, 2 fully connected layers, 5 max pooling layers and 13 convolutional layers. All total it contains 16 weight layers out of 21 layers.
AlexNet’s input is a 224x224x3 RGB image that passes through first and second convolutionary layers with 64 filters with size 3x3 and the same pooling with a 14 phase. The dimensions of the images shift to 224x224x64. The VGG16 then applies a maximum layer of pooling or a sub-sampling layer with a filter size 3x3 and a phase of 2. Dimensions of the resulting image are reduced to 112x112x64.
There are two convolutionary layers with 128 size 3x3 feature maps and a phase of 1. Then again there is a maximum layer of pooling with filter size 3x3 and a phase of 2. This layer is the same as the previous pooling layer except it has 128 feature maps which reduce the performance to 56x56x128.
5th and 6th layers are convolutionary filter size layers 3x3 and one phase. Both employed 256 maps of functions. A maximum pooling layer with filter size 3x3, a stage of 2 and 256 feature maps follow the two convolution layers.
These layers contain two sets of three convolutionary layers and a maximum pooling layer. All convolution layers have 512 size 3x3 filters and one phase. The final size is trimmed to 7x7x512.
A fully connected layer (FCL) with a 25088 feature maps each size 1x1 flattens the overall output layer.
These layers contain FCL with 4096 units.
Output layer is called as softmax output layer ŷ with 1000 possible values.
The detail VGG16 architecture is illustrated in Fig. 1.

Basic layout of VGG16 architecture showing its 5 Max Pooling layers, 13 convolutional layers and 2 fully connected layers.
VGG16 model is very slow to train the dataset. The imageNet weights trained by VGG-16 are 528 MB. Therefore, a lot of disk space and bandwidth are required to make it ineffective.
Several important concepts used to develop Xception [20–22] architecture, including depth-wise separable convolution layer, convolutional layer, residual connections and inception module. Xception is the acronym for “extreme inception”. The design of Xception has 36 convolutionary layers which form the network’s extractor base. Xception is an extension of Inception Architecture by deeply separable convolutions for standard Inception modules. Speed and accuracy of Xception model is better as compared to Inception, ImageNet, Inception V3, ResNet-101, ResNet-50, VGGNet. Model. Xception model contains 3 major sections: entry, middle and exit flow. The data goes first through the input flow, then through the eight-fold middle flow, and finally through the exit flow. Batch normalization is accompanied by all the Convolution layers. Xception replaced the conventional starting block by expanding it and changing the various (1x1, 5x5, 3x3) spatial dimensions with a (3x3) single dimension preceded by a (1x1) transition to maintain computational burden.
Xception building block is depicted Fig. 2. Equations 3 and 4 represents the mathematical modeling of Xception.
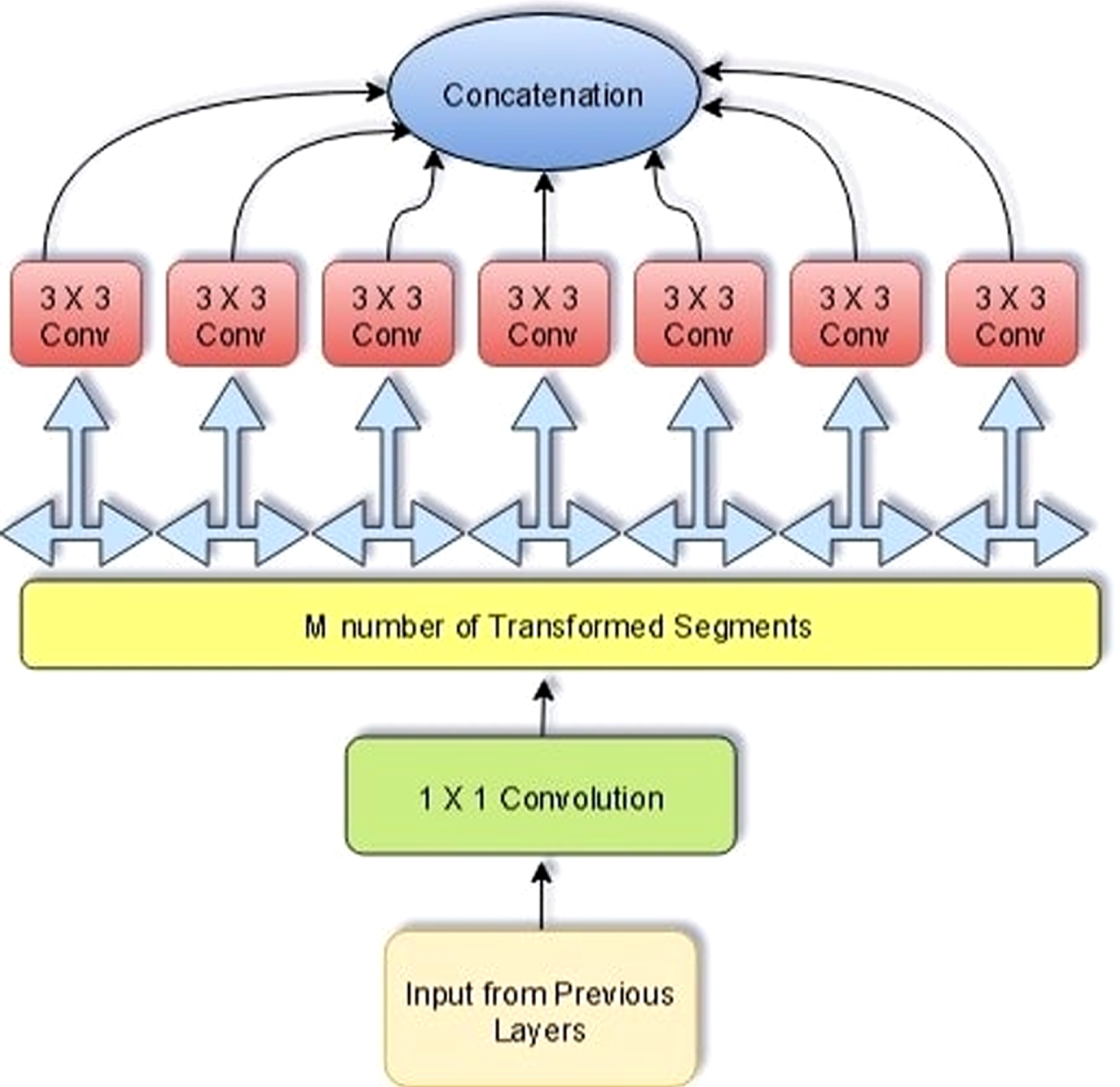
Xception building block architecture.
By decoupling spatial and feature-map correlation, Xception makes a network computationally effective. Using 1x1 convolutions it maps the transformed output to low dimensional embedding. Then it transforms spatially n times, in which n is the cardinality, defining width that defines the number of transformations.
In Equation (4), kl is a kth kernel of lth layer with one depth that is spatially transformed across the kth feature-map
The number of feature-maps is same as of kernels K in depth wise separable convolution. Although in the case of standard convolutionary layers, the number of kernels is not depending on previous layer. On the other hand
Xception enables computation by translating each function map separately around spatial axes, followed by point-specific convolution (1x1 convolutions) for cross-channel correlation. In deep CNN; the number of filters used in Xception is same as the transformation segments. But three transformation segments are used by inception block. Although Xception’s transformation policy does not decrease the parameter numbers, it ensures learning more effective and performs better results. Xception building block is represented in Fig. 2.
Advantages of Xception model
Xception model is lighter due to the less number of connections. It uses depth wise separable convolutions. This model is stronger and robust than the Inception model.
We applied three different algorithms on our covid-19 dataset, which consists of X-RAY images of chest for the prediction of COVID-19, well known VGG16 and Xception transfer learning models have been trained and tested on the available images. Working of VGG16 & Xception models for the detection of COVID-19 positive and negative patients are depicted in Fig. 3.
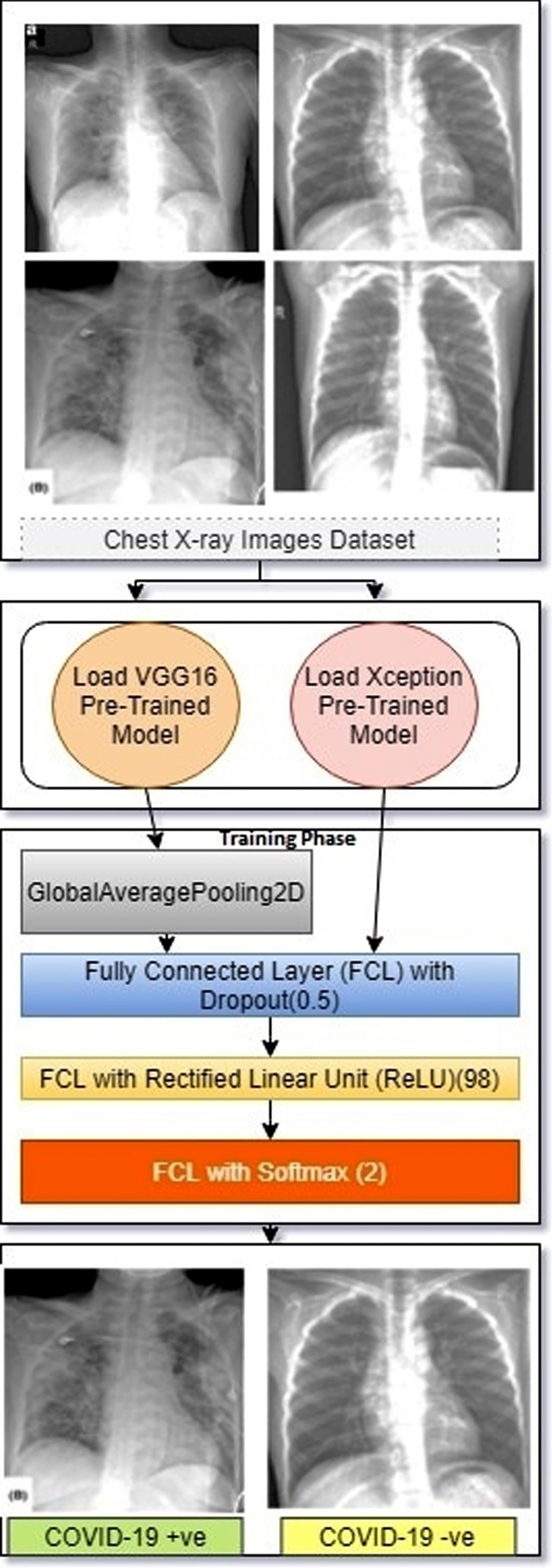
Working principle of VGG16 & Xception pre-trained model for detection of positive and negative coronavirus patients.
Experimental setup
The entire experiment was conducted on Google Colaboratory, using Python3 engine and GPU as backend with system RAM 12 GB. Tensor flow 1x is used. For image processing, we loaded the image as color having 3 RGB channels and converted the images to numpy array and rescaled by dividing by 255.The measurement of performance of each pre-trained model (SVM, VGG16, and Xception) is measured in terms of Recall, Precision, F1-Score and Specificity represented in Table 2. The batch size is taken as 32 where the learning rate used in Xception
Dataset description
We collect COVID-19 X-ray image dataset from GitHub uploaded by Joseph Paul Cohen [23], Postdoctoral Fellow, Mila, Universit
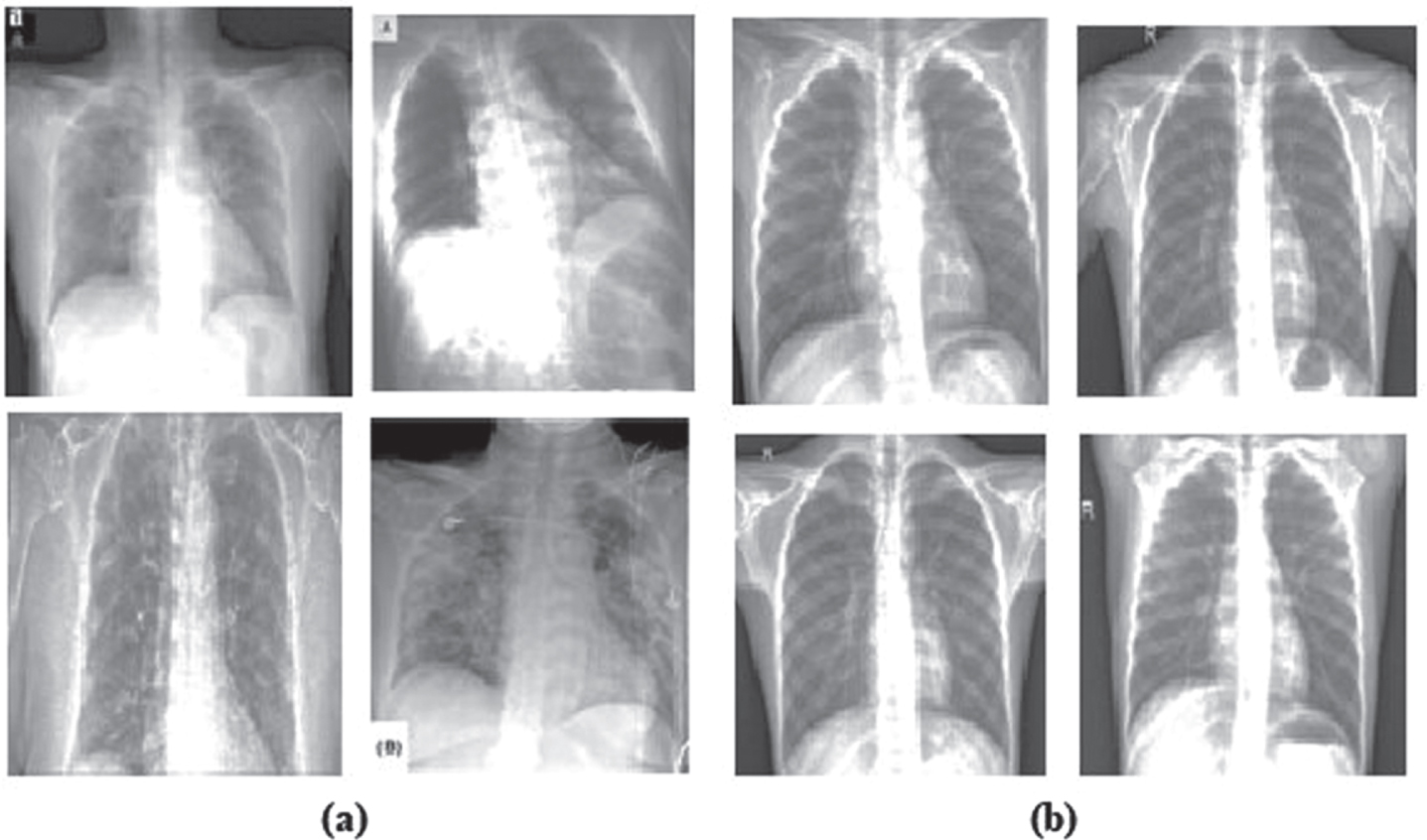
(a) positive (i.e., infected) COVID-19 X-ray images (b) negative samples.
Dataset description
The accuracy and loss graphs of these two models are given in Figs. 5 and 6 respectively.
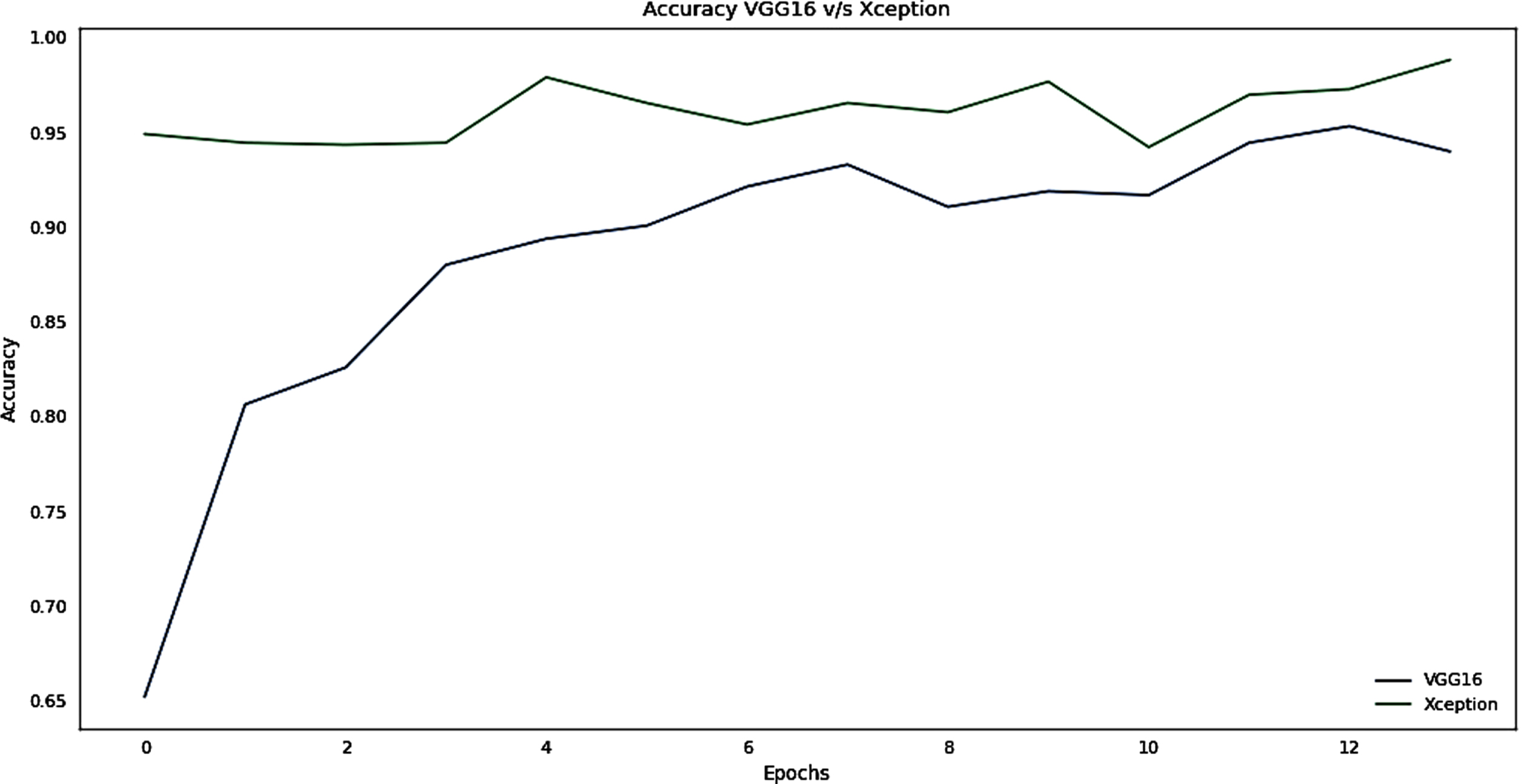
Accuracy graph for the training phase of VGG16 v/s Xception.
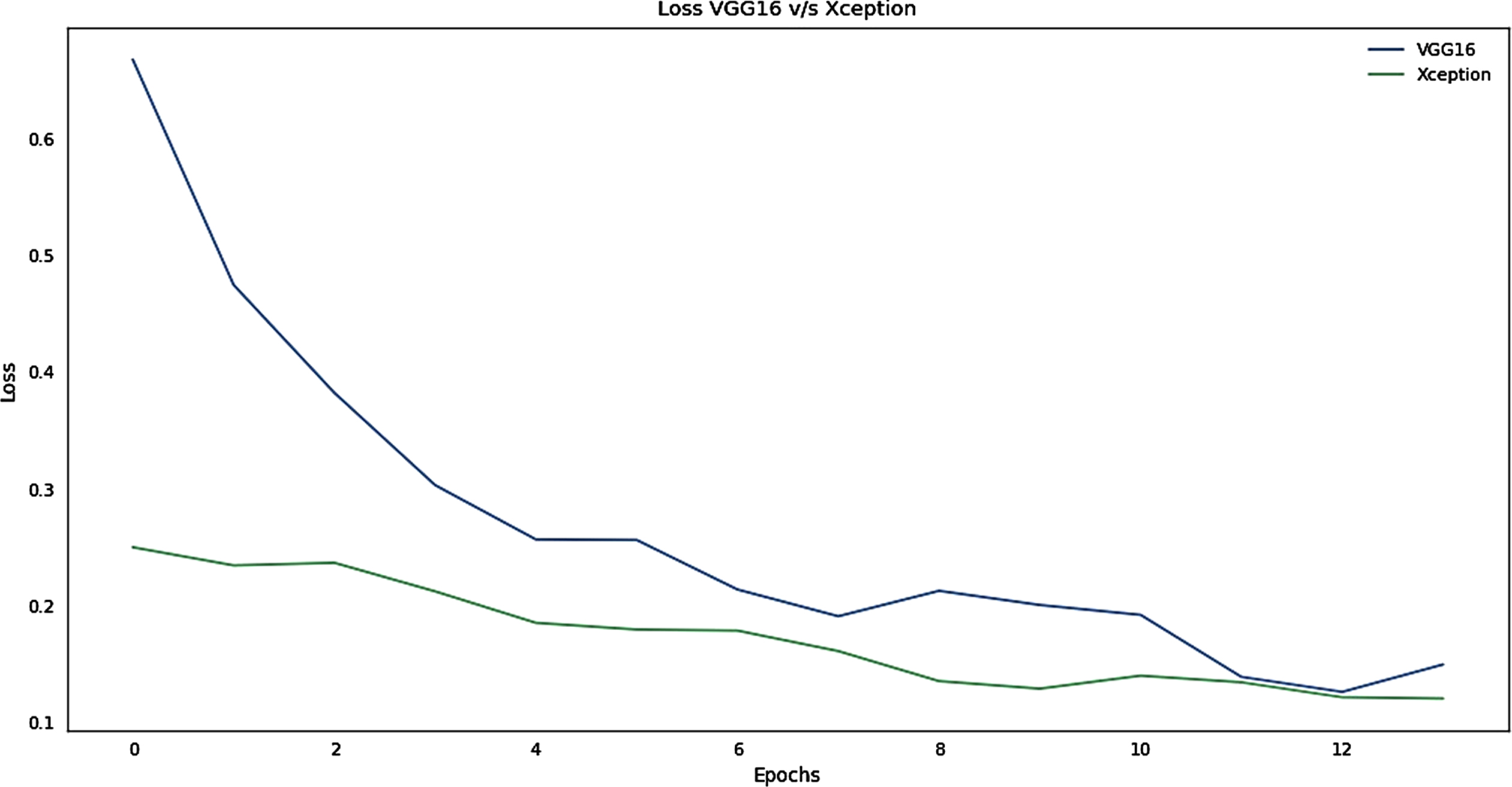
Loss Graph for the Training phase of VGG16 v/s Xception.
It can be interpreted from the plot that Xception learns faster than VGG16 from the Fig. 5. Xception has obtained greater Accuracy that VGG16 for the same number of Epochs i.e. 100. To save time and resources early stopping and model checkpoints have been used to save the best model and stop training if there is no significant improvement in the accuracy. The ImageNet weights has been initialized for both the models. However Xception stands out in this race. From Fig. 6, the loss for both the models has been depicted, The VGG16 have initially very high loss rate but there is a gradual decline in the loss whereas Xception have a smooth descent. Almost for both the models, the loss almost approaches within the range < 0.1.
Performance metrics
The measurement of performance of each pre-trained model (SVM, VGG16, Xception) is measured in terms of Recall, Precision, F1-Score, Sensitivity, Specificity and the results are represented in Table 2. Confusion Matrix of all the models is illustrated in Figs. 7–9. Overall performances of models are represented in Fig. 10.
Represents performance metrics of SVM, VGG16 and Xception Models
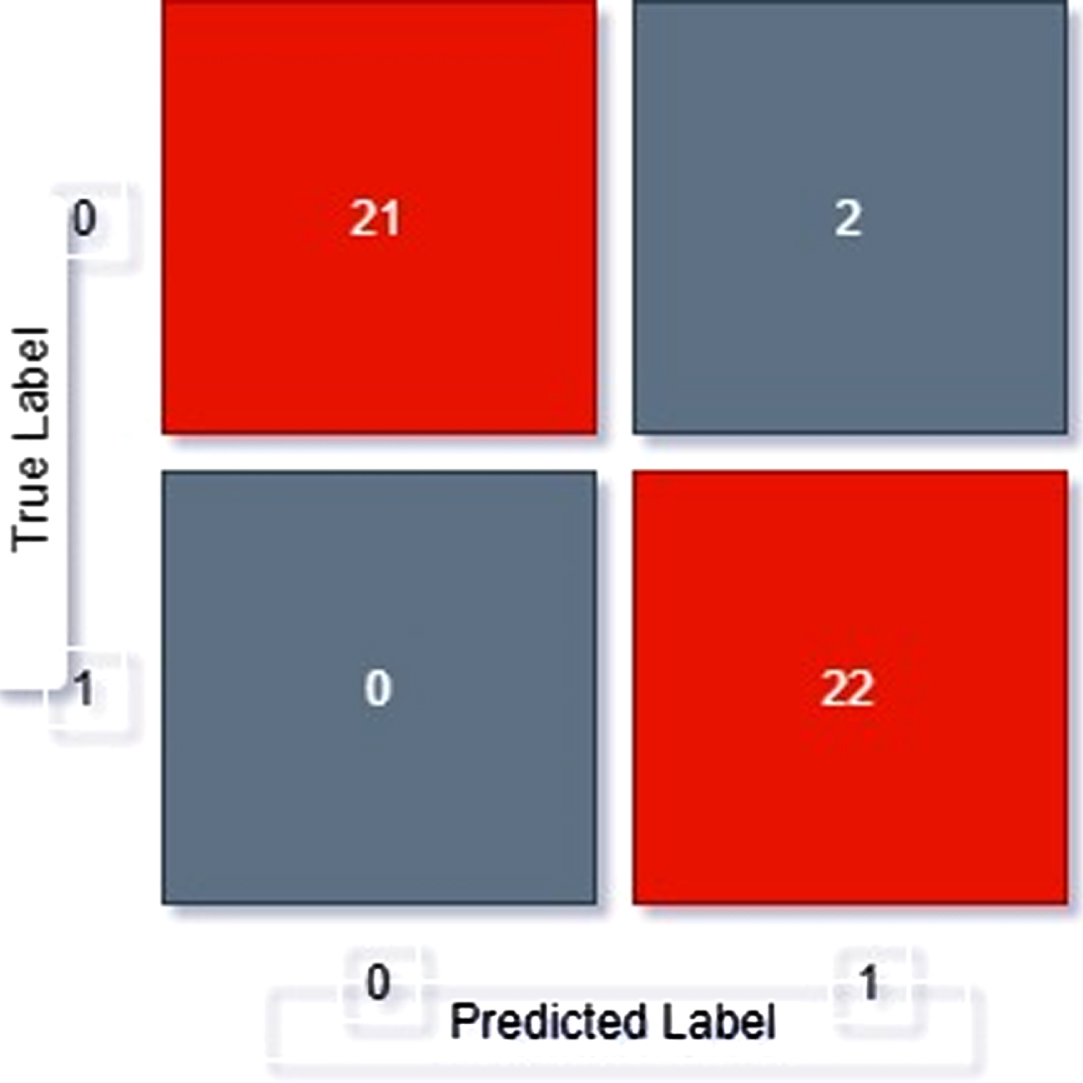
Confusion matrix of SVM.
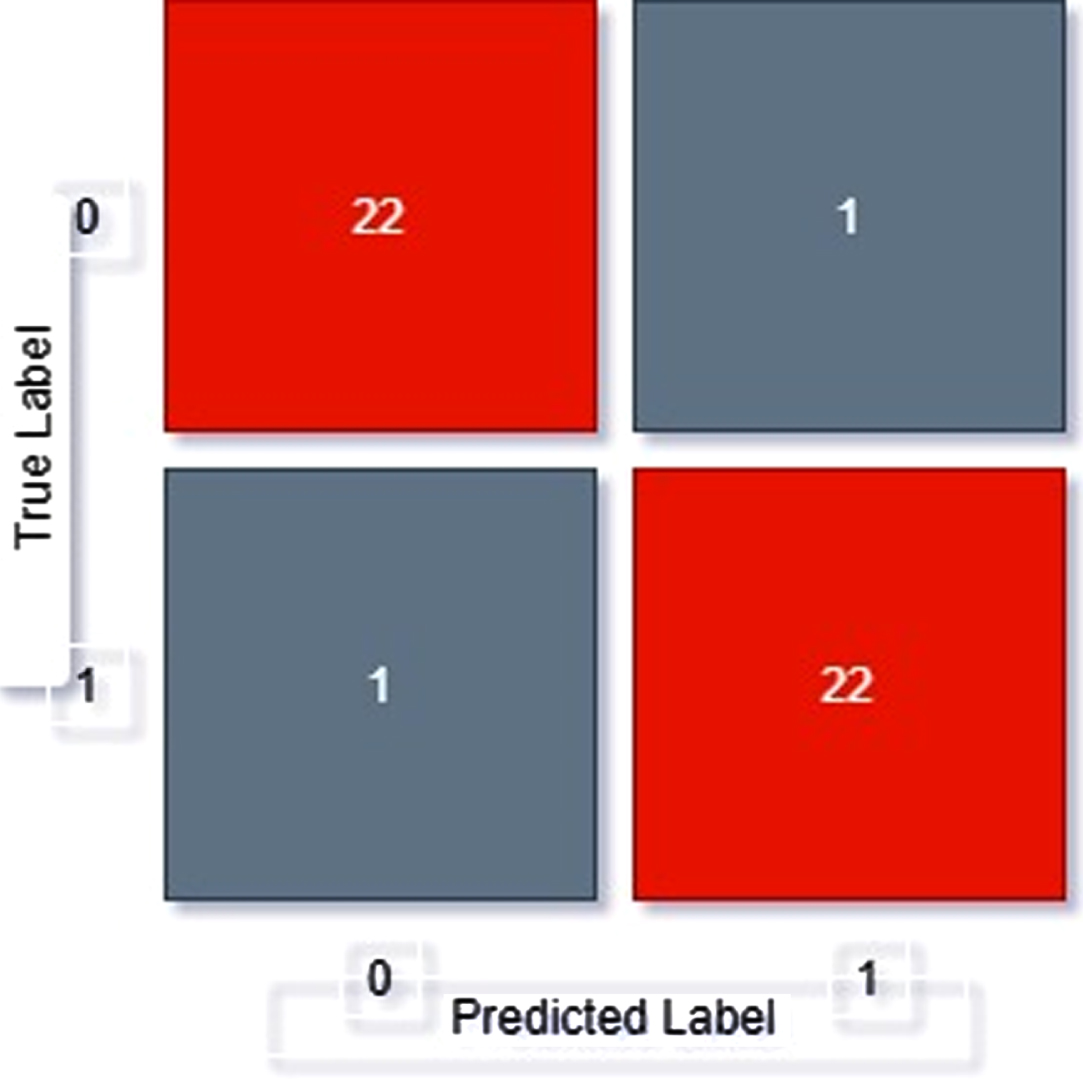
Confusion matrix of VGG16.
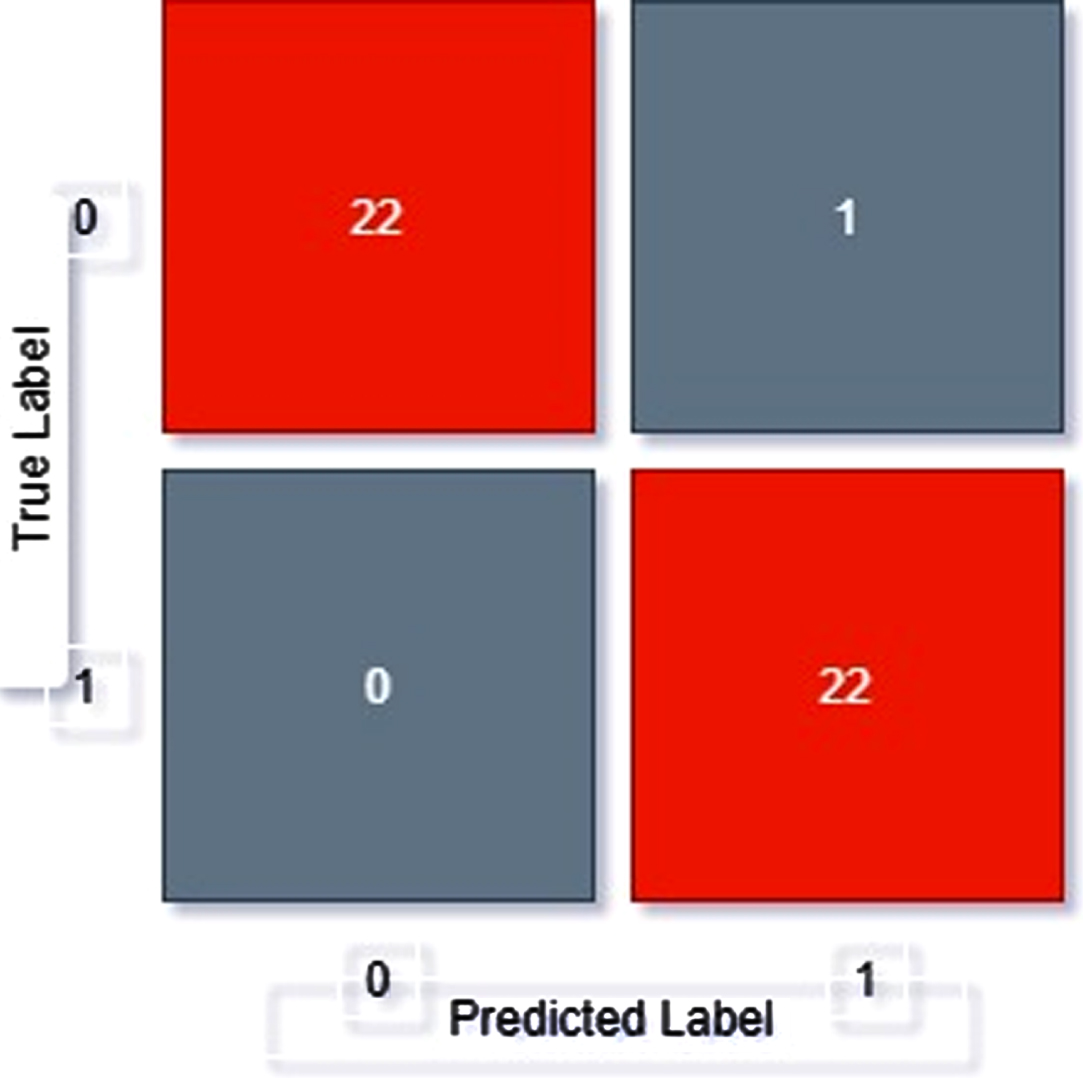
Confusion matrix of Xception.
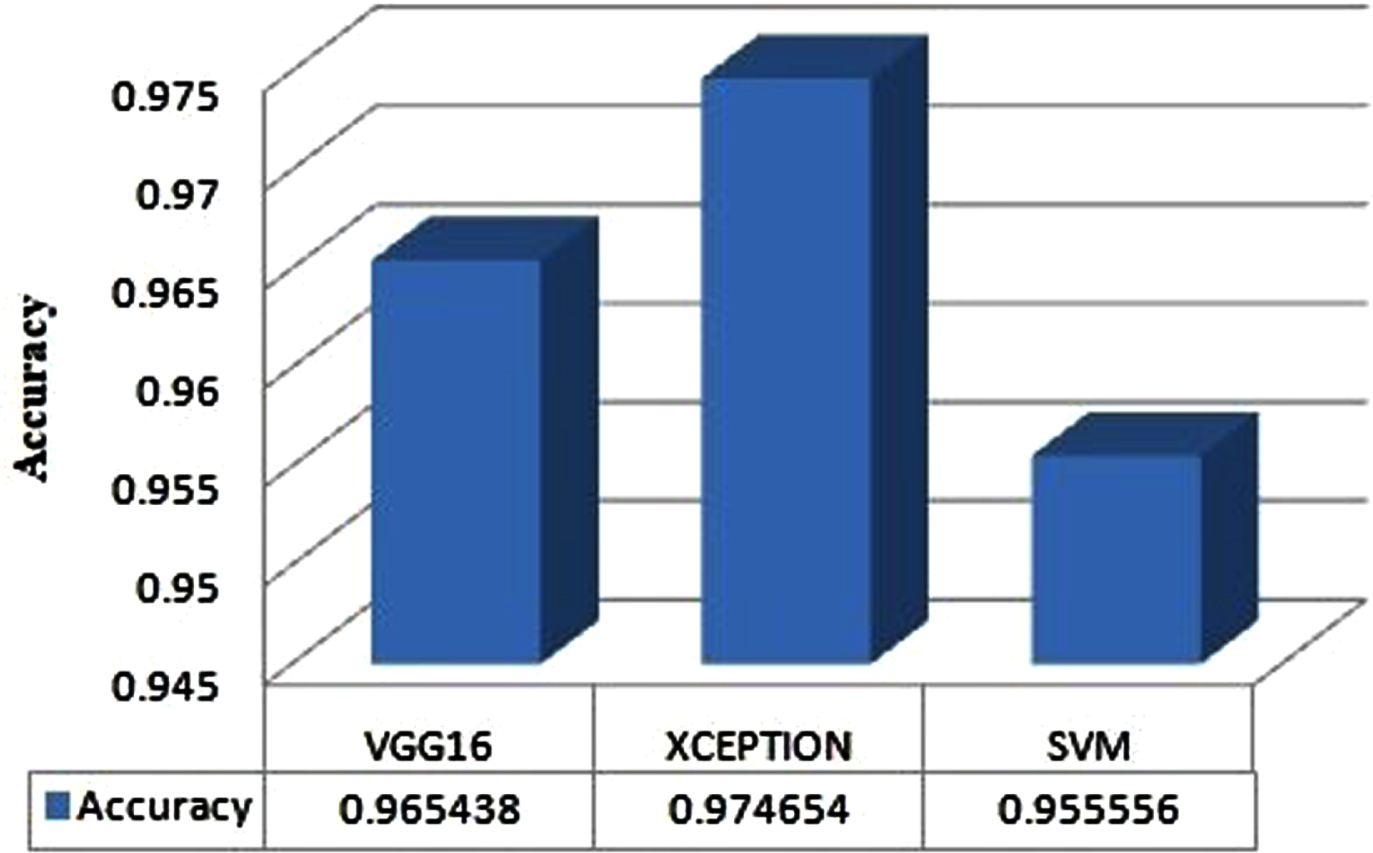
Performance of VGG16, Xception and SVM Models.
Performance Metrics used are:
Confusion Matrix of SVM, VGG16, Xception
From confusion matrix, displayed as Fig. 7, we can see out of 45 samples
21 samples have been correctly classified as positive
22 images have been correctly classified as negative
2 images have been classifies as positive but actually is negative
0 images have been classifies as negative but actually is positive
From confusion matrix, displayed as Fig. 8, we can see out of 45 samples
22 samples have been correctly classified as positive
21 images have been correctly classified as negative
1 images have been classifies as positive but actually is negative
1 images have been classifies as negative but actually is positive
From confusion matrix, displayed as Fig. 9, we can see out of 45 samples
22 samples have been correctly classified as positive
22 images have been correctly classified as negative
1 images have been classifies as positive but actually is negative
0 images have been classifies as negative but actually is positive
Overall performance
It can be observed that among the three models, Xception model is having 97.46% of accuracy as compared to SVM and VGG16. Accuracy can be evaluated as:
Comparative analysis of proposed work with existing work
Early diagnosis and treatment of the COVID-19 patients are necessary to prevent the disease from spreading to others. In this paper, we have applied 3 models namely SVM, VGG16 and Xception. SVM being a traditional machine learning algorithm that works on the maximum margin construction concept for the case of 1 dimensional classification. This comes with some limitations. To resolve this issue, we made use of VGG16 and Xception, both of which are deep transfer learning models, to improve the efficiency of prediction of COVID-19 positive patients. The Xception transfer learning model yields the maximum accuracy of 97.46% with 98% f-score. In future, we plan to detect COVID-19 by using neutrosophical principles with different deep convolutional neural network models by utilizing maximum images in the dataset.