
Abstract
The coronavirus disease 2019 pandemic has significantly impacted the world. The sudden decline in electricity load demand caused by strict social distancing restrictions has made it difficult for traditional models to forecast the load demand during the pandemic. Therefore, in this study, a novel transfer deep learning model with reinforcement-learning-based hyperparameter optimization is proposed for short-term load forecasting during the pandemic. First, a knowledge base containing mobility data is constructed, which can reflect the changes in visitor volume in different regions and buildings based on mobile services. Therefore, the sudden decline in load can be analyzed according to the socioeconomic behavior changes during the pandemic. Furthermore, a new transfer deep learning model is proposed to address the problem of limited mobility data associated with the pandemic. Moreover, reinforcement learning is employed to optimize the hyperparameters of the proposed model automatically, which avoids the manual adjustment of the hyperparameters, thereby maximizing the forecasting accuracy. To enhance the hyperparameter optimization efficiency of the reinforcement-learning agents, a new advance forecasting method is proposed to forecast the state-action values of the state space that have not been traversed. The experimental results on 12 real-world datasets covering different countries and cities demonstrate that the proposed model achieves high forecasting accuracy during the coronavirus disease 2019 pandemic.
Introduction
Short-term load forecasting (STLF) refers to the load forecasting from one hour to one week [1]. Forecasted short-term load facilitates efficient dispatching of power systems. Although STLF is challenging owing to the significant uncertainty and volatility of the load demand, it has been well handled by some deep learning models, such as convolutional neural networks (CNNs) [2], long short-term memory networks (LSTMs), and recurrent neural networks (RNNs) [3]. In our previous work [4], an ensemble deep learning model with dynamic error correction method and multi-objective ensemble pruning method was proposed for time series forecasting.
However, the coronavirus disease 2019 (COVID-19) pandemic has severely impacted the daily lives of people worldwide. Relevant policies have been promulgated in many countries and regions, requiring people to obey strict social distancing restrictions because of the high infectiousness of COVID-19. Traditional deep learning models for STLF generally use previous load demand, timing information, and weather data as input features [5]. However, it is difficult for deep learning models to capture the sudden decline in load demand during the pandemic caused by strict social distancing restrictions, because the social and economic information produced by the COVID-19 pandemic is often neglected. It is therefore difficult to achieve the balance between electricity generation and load demand because of the inaccurate load forecasting results, which may lead to large-scale blackouts.
The mobility data provided by Google 1 and Apple 2 reflect the changes in visitor volume in different regions and buildings based on mobile services, which are location specific and aggregated across the population [6]. Le Quéré et al. [7] demonstrated that there is a strong correlation between the mobility data and economic activities. Therefore, a knowledge base comprising mobility data is conducive to improving the forecasting accuracy of the STLF models during the pandemic. However, it is difficult for traditional deep learning models to exploit the knowledge base efficiently because of the limited mobility data associated with the pandemic.
Transfer learning is an approach that utilizes the knowledge accumulated from data in the source domain to solve forecasting problems in the target domain involving different data patterns [8]. The transfer deep learning model can adequately utilize the knowledge base with limited mobility data by combining the data utilization ability of transfer learning with the nonlinear fitting ability of deep learning. However, it is computationally expensive to adjust the hyperparameters of transfer deep learning models to maximize the forecasting accuracy. To the best of our knowledge, there is no effective hyperparameter optimization method for the transfer deep learning models.
Reinforcement learning is an artificial intelligence technology that seeks an optimal strategy and maximizes benefits through continuous interactions with the environment [9]. Reinforcement learning has been widely used to solve diverse optimization problems. However, no research has been reported to optimize the hyperparameters of transfer deep learning models using reinforcement learning algorithms, because it is difficult for the reinforcement-learning agents to completely traverse the large state space composed of different hyperparameters.
To bridge the above research gap and inspired by Chen et al. [6], a novel transfer deep learning model with reinforcement-learning-based hyperparameter optimization and advance forecasting method (TDL-RLHO-AFM) is proposed for STLF during the COVID-19 pandemic. The main contributions of this study are summarized as follows: A knowledge base comprising mobility data is constructed. The socioeconomic behavior changes can be leveraged to analyze the sudden decline in the load during the pandemic, hence improving the load forecasting accuracy during the pandemic. A new transfer deep learning model (TDL) is proposed to solve the problem of limited mobility data associated with the pandemic, which efficiently utilizes the socioeconomic behavior changes across different geographical regions. It also inspires a new insight for load forecasting during some other public emergencies. A new reinforcement-learning-based hyperparameter optimization (RLHO) method is proposed to optimize the hyperparameters of the proposed model automatically and maximize the forecasting accuracy of the proposed model by transforming the hyperparameter optimization problem into a Markov decision process (MDP). A new advance forecasting method (AFM) is proposed to forecast the state-action values of the state space that has not been traversed, which handles the difficulty for the reinforcement-learning agents to completely traverse the large state space comprising different hyperparameters and enhances the hyperparameter optimization efficiency of reinforcement-learning agents. A total of 12 real-world datasets covering different countries and cities are used to verify the effectiveness of the proposed model. The experimental results demonstrate that the proposed model achieves high forecasting accuracy during the COVID-19 pandemic.
The remainder of this paper is organized as follows. Section 2 provides a review of previous research on the STLF problem, transfer learning, and reinforcement learning. Section 3 introduces the construction of the knowledge base. Section 4 presents the proposed TDL-RLHO-AFM model in detail. Section 5 describes the implementation details and experimental results of TDL-RLHO-AFM on 12 datasets. Section 6 outlines the conclusions and discusses the future work.
Related work
This section briefly presents previous research on the STLF problem, transfer learning, and reinforcement learning.
Short-term load forecasting
Short-term load forecasting models can be categorized into persistence, physical, statistical, and artificial intelligence models [10]. Deep learning models, which belong to artificial intelligence models, are good at STLF, owing to their excellent nonlinear fitting ability on different features, including previous load demand, timing information, and weather data. For example, Qiu et al. [11] proposed a hybrid incremental learning approach for STLF, which was composed of random vector functional link network, discrete wavelet transformation, and empirical mode decomposition. Avatefipour and Nafisian [12] proposed a method based on clonal selection algorithm and artificial neural network for STLF, which used fuzzy set theory to select the most informative and irredundant features from the input feature set. Kim et al. [13] proposed a deep learning model for STLF, which combined RNN and CNN to calibrate the hidden state vector values obtained from different features. Motepe et al. [14] used long short-term memory recurrent neural network to forecast the power consumption of large South African power users, which considered the impact of temperature. Afrasiabi et al. [10] proposed an end-to-end model comprising of CNN and gated recurrent unit for residential load forecasting by utilizing the load consumption information of residents and the meteorological data. Chitalia et al. [15] presented an RNN model to forecast the short-term load in different types of commercial buildings by utilizing the features of different building types and locations. Peng et al. [16] proposed a hybrid RNN model for STLF, which could select the spatial and temporal features that were most relevant to the load demand. However, it is difficult for these deep learning models to forecast the load demand with traditional features during the COVID-19 pandemic because of the massive impact of the pandemic on the power system.
The COVID-19 pandemic has been detected in more than 200 countries, resulting in tens of millions of confirmed cases and hundreds of thousands of deaths worldwide in 2020. The strict social distancing restrictions used to deal with the high infectiousness of COVID-19 have altered load demand tremendously. For example, the average load demand of the New York Independent System Operator (NYISO) area in March fell by 9% than that in the previous year, which was reduced from 17102 watt to 15640 watt [17]. The load demand of New York in April of 2020 was 21% lower than that in the previous year. In Italy, the largest reduction in the observed load demand was 25% [18]. Therefore, the socioeconomic behavior changes associated with the pandemic need to be analyzed to capture the sudden decline in load demand caused by strict social distancing restrictions.
The mobility data provided by Apple and Google reflect the changes in visitor volume in different regions and buildings, which also reflect the socioeconomic behavior changes during the pandemic. In this study, a knowledge base comprising mobility data is constructed for STLF during the pandemic so that the socioeconomic behavior changes can be leveraged to analyze the sudden decline in load during the pandemic. However, only small parts of mobility data are associated with the pandemic, making it difficult for deep learning models to exploit the socioeconomic behavior changes adequately.
To solve the aforementioned problem, a novel TDL model is proposed, which can efficiently utilize the socioeconomic behavior changes by sharing the mobility data across different geographical regions.
Transfer learning
Transfer learning was first introduced in 1996 [19]; however, it did not attract widespread attention until 2018. Transfer learning does not require training and testing data to follow the same distribution [20]. Therefore, it can solve the problem of limited training data by reusing the data from other different but related domains. For example, Laptev et al. [21] proposed a transfer learning model for time series forecasting, which used transfer learning to alleviate the plight of limited training data. Ribeiro et al. [22] proposed a transfer learning model for cross-building energy forecasting, which merged the data from similar buildings with different distributions and solved the problem of small historical datasets. Cai et al. [23] proposed a two-layer transfer-learning-based model for STLF, which solved the problem of limited load data in the target zone. Gupta et al. [24] proposed a transfer learning model for clinical time series forecasting to solve the problem of limited clinically labeled data. Jung et al. [25] proposed a model based on transfer learning to forecast the monthly electric load in cities, by selecting the similar data from other cities to satisfy the required amount of data for model training. Fong et al. [26] combined the transfer learning with RNN to forecast the concentration levels of air pollutants, which solved the problem of limited observed data in air quality monitoring stations. Lee and Rhee [27] adopted transfer learning and meta learning for load forecasting, by taking full advantage of the limited residential dataset collected over just several days.
There are limited mobility data associated with the pandemic, which make it difficult for traditional deep learning models to forecast the load during the pandemic. Inspired by the above studies, a new TDL model is proposed herein to solve the problem of limited mobility data associated with the pandemic. However, the forecasting accuracy is heavily influenced by the hyperparameter optimization of TDL models, which was not considered in the above studies. It is also computationally expensive to optimize the hyperparameters of TDL models to maximize the forecasting accuracy. Therefore, a new RLHO method is proposed in this study to automatically optimize the hyperparameters of the proposed model.
Reinforcement learning
Reinforcement learning obtains the optimal solution to a specific problem by modeling the problem as an MDP and allowing the agents to continuously interact with the environment. The reinforcement learning models, including Q-learning [28] and state-action-reward-state-action [29], have achieved considerable contributions in the fields of optimization and decision-making. For example, Brandi et al. [30] proposed a reinforcement learning model to control the supply water temperature setpoint of a heating system and obtained promising results for an office building in an integrated simulation environment. Zou et al. [31] used reinforcement learning to solve the dynamic multi-objective optimization problem, which was proven to be effective through the evaluation on a real-world problem.
In recent years, reinforcement learning has gradually been used in the field of hyperparameter optimization, which can efficiently avoid deceptive local optima and handle the high-dimensional parameter vector [32]. For example, Meng et al. [33] used reinforcement learning to optimize the weighting parameters of a dynamic priority scheduling algorithm. Bu et al. [32] proposed a reinforcement learning method to optimize a large number of hyperparameters of a composite load model with distributed generation.
However, reinforcement-learning agents have difficulty in completely traversing the large state space comprising different hyperparameters, resulting in local optimal hyperparameters. In this study, an RLHO combined with a new AFM is proposed to forecast the state-action values of the state space that has not been traversed, which can enhance the hyperparameter optimization efficiency of reinforcement-learning agents.
Construction of knowledge base
The knowledge base constructed in this study includes four types of normalized data: load data, time index, weather data, and mobility data. It covers 12 different geographical regions, including the United Kingdom (UK), Germany, France, the California Independent System Operator (CAISO) area, the NYISO area, Dallas, Houston, San Antonio (SA), Boston, Chicago, Philadelphia, and Seattle. The acquired data range from February 15, 2020 to May 15, 2020, covering the period before and after the policy of strict social distancing restrictions was promulgated to tackle the pandemic. The load data represent the hourly load demand in different geographical regions. The load data of European regions are obtained from the European Network of Transmission System Operators, and the load data of the United States are obtained from the respective independent system operators in the United States. The time index represents the day of the week and hour information through the One-Hot code [34]. The weather data are obtained from World Weather Online, which contain the information on cloud coverage, humidity, precipitation, pressure, and temperature. The mobility data are obtained from Google and Apple, revealing the relative changes in visitor volume in different regions and buildings. The mobility data obtained from Google reveal the relative changes in visitor volume at six different locations: retail and recreation, grocery and pharmacy, parks, transit stations, workplaces, and residential areas. The baseline volumes are the median of the 5-week period from January 3, 2020 to February 6, 2020. The mobility data obtained from Apple reveal the relative changes in visitor volume for three types of movements: driving, transit, and walking. The baseline volumes are the data on January 13, 2020. Google and Apple collect the information based on the location history of the users’ accounts [6]. Take the mobility data at 10 o’clock on March 1, 2020 in Boston as an illustrative example, and the specific values are shown in Table 1.
The values of mobility data provided by Google and Apple
The values of mobility data provided by Google and Apple
As shown in Table 1, the visitor volumes at retail and recreation, grocery and pharmacy, parks, and residential areas are increased by 55.29%, 20.99%, 52.26%, and 21%, respectively. The other values can be self-explainable similarly.
The proposed TDL-RLHO-AFM model consists of three parts: a TDL model, an RLHO method, and an AFM. The RLHO method is used to optimize the hyperparameters of neural networks in different layers, which are contained in TDL model. The AFM is used to enhance the hyperparameter optimization efficiency of RLHO method and obtain the better hyperparameters. The framework diagram of the proposed TDL-RLHO-AFM model is shown in Fig. 1 and is detailed in the following sub-sections.
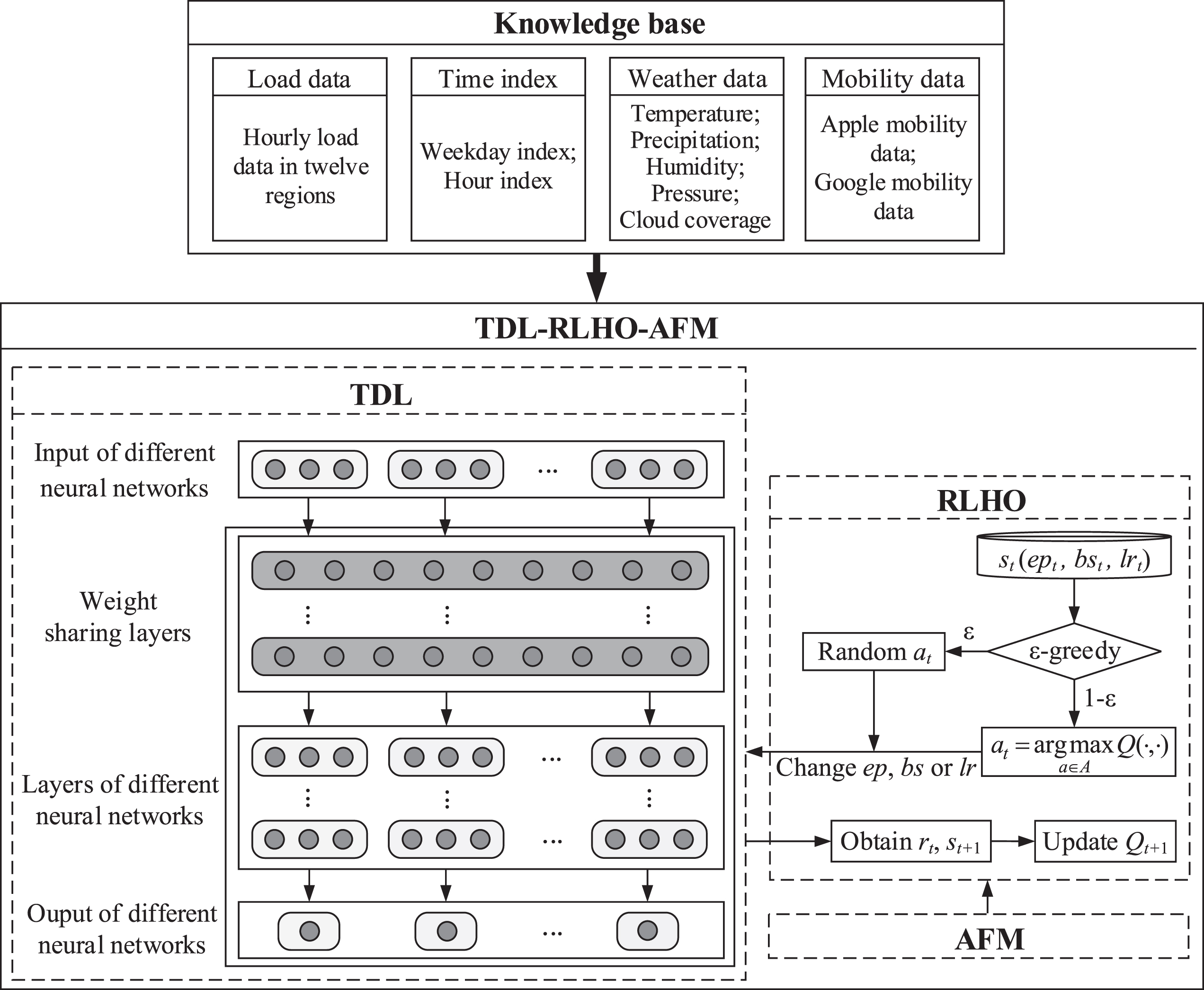
Overview of TDL-RLHO-AFM
In this study, a new TDL model is proposed to solve the problem of limited mobility data associated with the pandemic, which uses the transfer knowledge learned from source domains to solve other target learning tasks. The data covering different source domains include time index, weather data, and mobility data of different geographical regions, and the different learning tasks refer to the STLF in different geographical regions. The definition of TDL is shown as follows.
Definition of transfer deep learning: Given a source domain DS, a source learning task TS, a target domain DT, and a target learning task TT, the TDL model will improve the learning ability of the target forecasting function rT (·) in DT using the transfer knowledge learned from DS and TS, where DS≠DT, and TS≠TT.
According to the definition above, each domain of transfer deep learning is defined as a pair D = {F, P (X)}, where F = {f1, …, fn} is a feature space with n dimensions. X = {x1, …, xn} ∈ F is the learning sample, and P(X) is the marginal probability distribution of X [22]. The feature space and marginal probability distributions differ across different domains. Each learning task is defined as a pair T = {y, r (·)}, where y is the value space of the true load demand, and r(·) is the forecasting function. Referring to Fig. 1, the TDL model includes the following steps: First, the data from different source domains are used as the input of the neural networks for solving different learning tasks. Second, the transfer knowledge is transformed into the weight sharing layers of the proposed model, which can be utilized by all learning tasks. In this study, all weight sharing layers are constructed based on RNN, and the hyperparameters of each weight sharing layer are set to be the same. Finally, the neural networks for different learning tasks are trained, and the forecasting results are output respectively.
Reinforcement-learning-based hyperparameter optimization method
Reinforcement learning models the problem as an MDP, through which, the agents interact with the environment through trial and error over discrete time steps [9]. The goal of the agents is to select an action that maximizes the expected discount reward. In this study, the hyperparameters of the proposed TDL model are optimized through a reinforcement learning method, so as to improve the forecasting accuracy. MDPs are generally defined as < S, A, P, R > [36]: S refers to the set of all possible valid states of the agents, including the different values of epoch, batch size, and learning rate in the proposed TDL model. s refers to the specific state, where ∀s ∈ S. A refers to the set of all possible valid actions of agents. At each time point, the agents take one of the six potential actions and change the value of the epoch, batch size, or learning rate accordingly. a refers to a specific action, where ∀a ∈ A. P refers to the transition probability distribution of the agents in the constructed environment. R is the reward function of the agents,
Q
π (s, a) is defined as the state-action value, which means the expected cumulative discount reward obtained by executing action a under state s following policy π: S⟶A, as shown in Equation (1) [36]:
The Q-learning algorithm [38] is used in this study to continuously estimate the optimal state-action value through the Bellman equation to obtain the optimal policy
The pseudocode of the RLHO method for the TDL model is shown in Algorithm 1, where Q(·,·) refers to the set of state-action values at all time points, and the value of Qt+1 (s t , a t ) is the Q value at time point t + 1. An episode with different number of time steps is one complete play of the agents interacting with the environment in the general reinforcement learning setting [41].
Figure 1 and Algorithm 1 show the main process of the RLHO method, which can be described as follows: At each time point, obtain the action at through the ɛ-greedy algorithm. at is an integer, with different values representing different actions, as listed in Table 2. Run the TDL model with the current values of epoch, batch size, and learning rate at time point t. Then, the forecasting accuracy of the TDL model at time point t is obtained, which is presented by means of the mean absolute percentage error (MAPE) [42] as Equation (3):
Obtain the reward rt at time point t and execute the action at to get the new state st+1, which includes the new values of epoch, batch size, and learning rate at time point t + 1. Update the Q value and the state at time point t + 1, repeat the above procedures until the termination time step is reached. Select the corresponding state with the largest Q value of all time points, representing the optimized hyperparameters.
The values of at and their corresponding actions
The hyperparameters obtained through Q-learning are usually sub-optimal because of the large state space. In this study, an AFM is proposed to forecast the corresponding Q values of the states that have not been traversed at some time points by means of the extreme gradient boosting (XGBoost) [43] algorithm, which is a widely recognized machine learning method. AFM enhances the hyperparameter optimization efficiency of reinforcement-learning agents and obtains the better hyperparameters.
The AFM process is described as follows (Fig. 2). Each Q value represents the state-action value of the state that has or has not been traversed by the agents at different time points. First, in the proposed TDL model with the RLHO method, a part of states are traversed by the agents, with the corresponding Q values obtained. The gray squares in Fig. 2 represent the states that have been traversed by the agents, together with their corresponding Q values. The white squares represent the states that have not been traversed by the agents, together with their corresponding Q values. Second, the states that have been traversed by the agents with their corresponding Q values are divided into the training set and test set, which are used to train the XGBoost. Finally, the trained XGBoost model is used to forecast the Q values of states that have not been traversed by the agents, which are represented by the squares with oblique lines in Fig. 2. Then, the corresponding state with the largest Q value is selected, representing the near optimal hyperparameters.
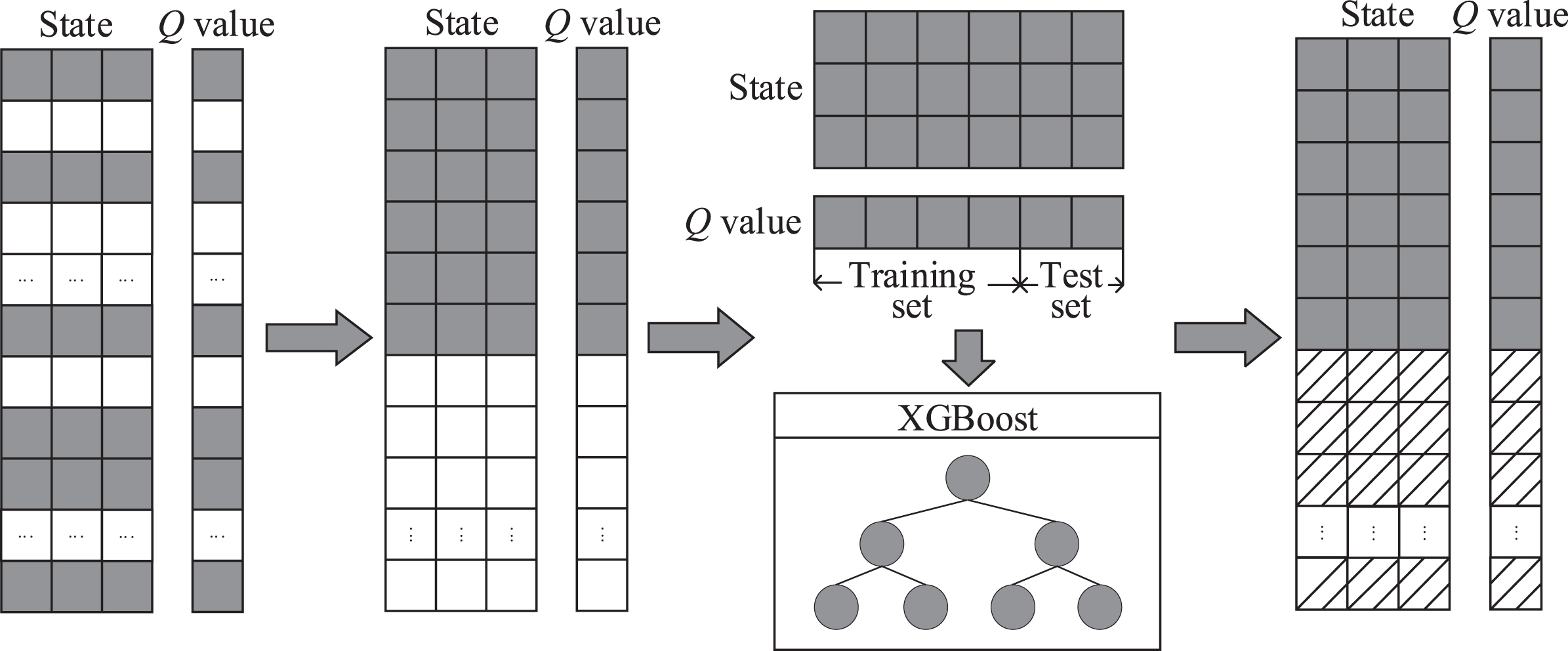
Overview of AFM.
This section shows the experimental implementation details, presents the results of different comparison experiments, and analyzes the experimental results.
Experimental platforms and parameters
The experimental platforms in this study are described in Table 3.
Hardware and software platforms
Hardware and software platforms
In this study, the sequence length of the input is 24, and the day-ahead load demand are forecasted. The forecasting accuracy of different models is represented by the MAPE. The smaller values of MAPE indicate the more accurate forecasting results. The data are normalized according to Equation (4) [44], and some other data pre-processing techniques, such as outlier detection technique [45], are also used in this study.
All experimental results of the models in this study are obtained by averaging the forecasting results through five runs. The training set of the experiments in this study covers the period from February 15, 2020 to April 30, 2020, and the test set covers the period from May 1, 2020 to May 14, 2020. The proposed TDL-RLHO-AFM model is constructed based on the RNN, and the default hyperparameters are listed in Table 4.
Experimental hyperparameters of different algorithms
Performance of mobility data
This sub-section verifies the effect of the constructed knowledge base containing the mobility data. The forecasting results of the RNN with knowledge base (RNN_KB) and RNN without knowledge base (RNN) are shown in Table 5. The significant values are boldfaced.
Comparison of the forecasting results of RNN with knowledge base and RNN without knowledge base
Comparison of the forecasting results of RNN with knowledge base and RNN without knowledge base
Note: Significant values are boldfaced.
As shown in Table 5, the forecasting accuracy of the RNN with knowledge base is higher than that of the RNN without knowledge base. For France, Germany, UK, NYISO, CAISO, Dallas, Houston, SA, Boston, Chicago, Philadelphia, and Seattle, the forecasting accuracy is improved by 40.5%, 49.2%, 12.5%, 64.9%, 57.5%, 9.1%, 33.8%, 0.2%, 58.5%, 70.6%, 75.1%, and 56.3%, respectively. The experiments in this sub-section demonstrate that the knowledge base, in particular, its contained mobility data, can improve the forecasting accuracy of deep learning model during the pandemic.
This sub-section verifies the effect of the TDL model. The forecasting results of the TDL and the RNN without transfer learning (RNN_KB) are shown in Table 6, and the significant values are boldfaced. Note that the forecasting results of RNN_KB are different from the results in Table 5 because the averaging results are obtained through five runs again.
Comparison of the forecasting results between TDL model and RNN without transfer learning
Comparison of the forecasting results between TDL model and RNN without transfer learning
Note: Significant values are boldfaced.
As shown in Table 6, compared with the RNN without transfer learning, the TDL model has higher forecasting accuracy on eight datasets (i.e., France, Germany, UK, Dallas, Houston, Boston, Philadelphia, and Seattle), and it has lower forecasting accuracy on only four datasets (i.e., NYISO, CAISO, SA, and Chicago). Generally, the TDL model outperforms the RNN without transfer learning because the TDL model can take advantage of the socioeconomic behavior changes contained in the mobility data, demonstrating the effectiveness of transfer learning during the pandemic.
This sub-section verifies the effect of RLHO and AFM. The value scopes of different hyperparameters in this sub-section are shown in Table 7.
Value scopes of different hyperparameters
Value scopes of different hyperparameters
The forecasting results of the proposed TDL-RLHO-AFM model with different episodes and time steps are presented in Table 8. Different combinations of episodes and time steps represent the number of states that can be traversed by the agents. For example, the combination of 5 episodes and 10 time steps means that the agents can traverse up to 50 states. Variables ep, bs, and lr represent the best values of epoch, batch size, and learning rate of the proposed model with different episodes and time steps, respectively. State_num represents the number of states that have been traversed by the agents. Time represents the time cost of training the proposed model with different episodes and time steps. MAPE represents the forecasting accuracy of the proposed model. The significant values of MAPE on all datasets are boldfaced.
The forecasting results of the proposed model with different episodes and time steps
According to the experimental results shown in both Table 6 and Table 8, the following results can be obtained: Referring to both Tables 6 and 8, the forecasting accuracy of the proposed TDL-RLHO-AFM model is higher than that of TDL, which is improved by 14.6%, 13.6%, 26.2%, 24.6%, 21.6%, 64.5%, 53.4%, 71.0%, 20.1%, 17.7%, 30.1%, and 37.2% on the datasets of France, Germany, UK, NYISO, CAISO, Dallas, Houston, SA, Boston, Chicago, Philadelphia, and Seattle, respectively. The results demonstrate the effectiveness of reinforcement learning for optimizing hyperparameters. Referring to Table 8, in 8 of the 12 datasets, the forecasting accuracy of the proposed model with 30 episodes and 30 time steps is higher than that of the proposed model with 10 episodes and 100 steps, indicating that the better hyperparameters are found by the agents in the proposed model with 30 episodes and 30 time steps. This also shows that the agents traversing more states do not always find the better hyperparameters because they may encounter the boundary of the state space more often. Referring to Table 8, the use of AFM significantly enhances the hyperparameter optimization efficiency of the reinforcement-learning agents. For example, on the France dataset, when the episode is 30 and the time step is 30, the agents can traverse up to 900 (30×30) states. However, the agents actually spend 39,765 seconds (i.e., 11.05 hours) to traverse 608 states and obtain the corresponding Q values, because the Q values of the remaining 292 (900–608) states are forecasted using AFM. Because these 292 states are not actually traversed, the time cost of 19,097 (292/608*39,765) seconds (i.e., 5.30 hours) are saved.
Table 9 and Fig. 3 present the forecasting accuracies and forecasting results of the proposed model corresponding to different hyperparameter combinations from May 1, 2020 to May 14, 2020 on the NYISO dataset. The significant values of MAPE are boldfaced. The legends of Fig. 3 indicate the different hyperparameter combinations. For example, (30, 30, 0.0001) means the epoch is 30, the batch size is 30, and the learning rate is 0.0001. The unit of load data is megawatt (MW) in Fig. 3.
The forecasting accuracies of the proposed model with different hyperparameter combinations
Note: Significant values are boldfaced.
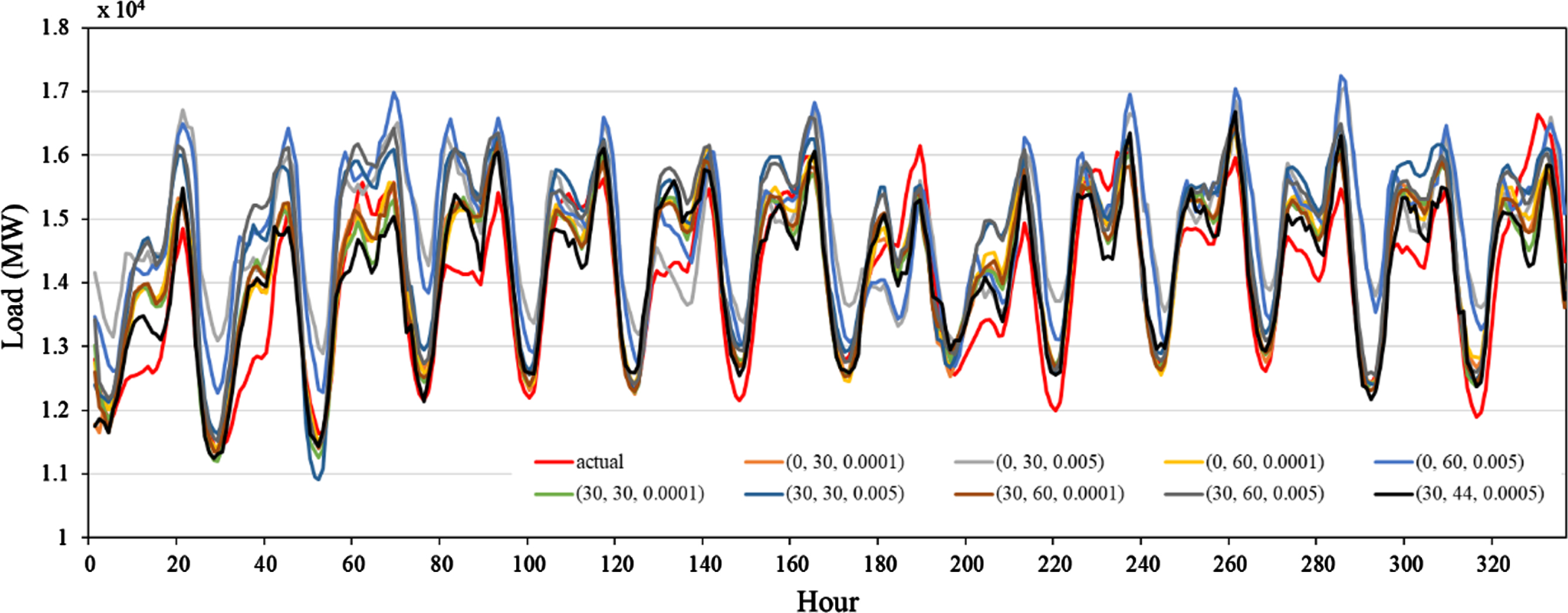
Comparison of forecasting results of the proposed model with different hyperparameter combinations.
As shown in Table 9 and Fig. 3, different hyperparameter values have great influence on the forecasting results of the model, and they are not linearly correlated. The proposed model with the hyperparameters values found by reinforcement learning has the best forecasting accuracy, demonstrating the effectiveness of reinforcement learning.
In order to verify the effect of the proposed model further, CNN and LSTM are used for comparison due to their good ability of feature learning. The forecasting accuracies of the proposed model, CNN and LSTM with knowledge base (CNN_KB and LSTM_KB), and CNN and LSTM without knowledge base (CNN and LSTM) are shown in Table 10. The significant values of MAPE are boldfaced.
Comparison of the forecasting accuracies of the proposed model and other methods
Note: Significant values are boldfaced.
As shown in Table 10, the forecasting accuracy of the proposed TDL-RLHO-AFM model is higher than that of the CNN and LSTM either with or without knowledge base. The experiments in this sub-section demonstrate the effectiveness of the proposed model for load forecasting during the pandemic.
Figure 4 shows the line chart of forecasting results of the proposed TDL-RLHO-AFM model, CNN and LSTM with knowledge base (CNN_KB and LSTM_KB), and CNN and LSTM without knowledge base (CNN and LSTM) from May 1, 2020 to May 14, 2020 on the NYISO dataset. The unit of the load data is megawatt (MW).
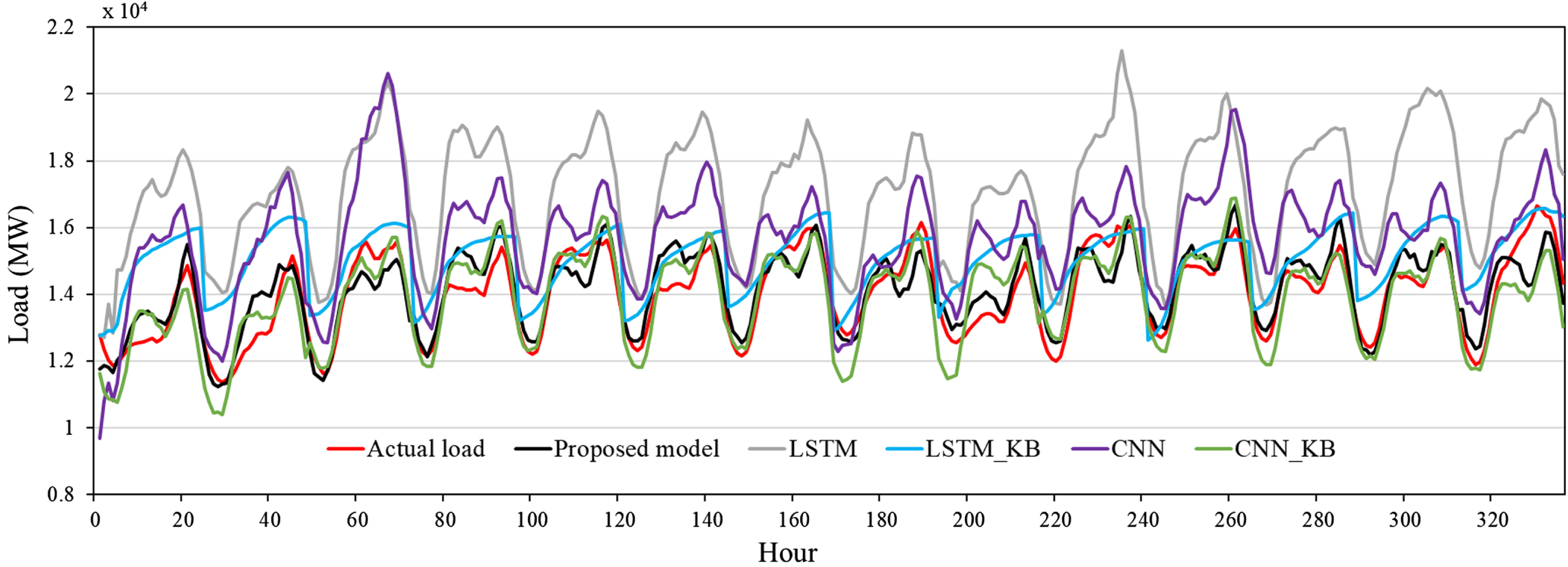
Comparison of forecasting results of the proposed model and other methods.
As shown in Fig. 4, the forecasting results of the proposed TDL-RLHO-AFM model are closer to the actual loads than other methods, visually illustrating the effectiveness of the proposed model for load forecasting during the pandemic.
In this study, a novel TDL model with RLHO and AFM is proposed for STLF during the COVID-19 pandemic. Twelve real-world datasets covering different countries and cities are used to verify the performance of the proposed model. Based on the results of multiple comparison experiments, the following four conclusions are summarized as follows: The socioeconomic behavior changes contained in the knowledge base are beneficial for deep learning models to forecast sudden load decline during the pandemic. It also provides a new direction for load forecasting under other global emergencies. The proposed TDL model can overcome the problem of limited mobility data associated with the pandemic by making full use of the socioeconomic behavior changes in the knowledge base. The proposed RLHO method can automatically optimize the hyperparameters of the TDL model. The proposed AFM can improve the hyperparameter optimization efficiency of the reinforcement-learning agents by forecasting the state-action values of the states that have not been traversed.
Although the proposed model has achieved high forecasting accuracy during the pandemic, it also has some limitations. First, the agents may reach the boundary of the state space, which increases lots of unnecessary time costs, and necessitates a more effective reinforcement learning algorithm that can improve the search efficiency of the agents. Second, generative adversarial networks can expand the limited mobility data [46], therefore, the effectiveness of this technique can be explored in the future work. Finally, various variables affect the forecasting accuracy of deep learning models [47]. However, the study did not explore the influence of various variables except mobility data on load forecasting, which will be considered in the future work.
Conflicts of interest
The authors declare that there is no conflict of interest regarding the publication of this article.
Footnotes
Acknowledgments
The work has been supported by National Natural Science Foundation of China (No. 51875503, No. 51975512), Zhejiang Natural Science Foundation of China (No. LZ20E050001), Zhejiang Key R & D Project of China (No.2021C03153).
Available at https://www.google.com/covid19/mobility
Available at https://www.apple.com/covid19/mobility