
Abstract
Surrogate modelling techniques such as Kriging are a popular means for cheaply emulating the response of expensive Computational Fluid Dynamics (CFD) simulations. These surrogate models are often used for exploring a parameterised design space and identifying optimal designs. Multi-fidelity Kriging extends the methodology to incorporate data of variable accuracy and costs to create a more effective surrogate. This work recognises that the grid convergence property of CFD solvers is currently an unused source of information and presents a novel method that, by leveraging the data structure implied by grid convergence, could further improve the performance of the surrogate model and the corresponding optimisation process. Grid convergence states that the simulation solution converges to the true simulation solution as the numerical grid is refined. The proposed method is tested with realistic multi-fidelity data acquired with CFD simulations. The performance of the surrogate model is comparable to an existing method, and likely more robust. More research is needed to explore the full potential of the proposed method. Code has been made available online at https://github.com/robertwenink/MFK-Extrapolation.
Introduction
Motivation
Automatic design procedures based on Computational Fluid Dynamics (CFD) simulations are becoming increasingly important in practical ship design [36]. For an efficient optimisation phase of such a design procedure, accurate high-dimensional surrogate modelling is essential [43]. A surrogate model provides a cheap substitute for an expensive (CFD) simulation, enabling us to feasibly approximate and explore the design space. To illustrate the effectiveness and promise of using surrogate models in naval optimisation routines, Scholcz and Veldhuis [37] show that Surrogate-Based Global optimisation (SBGO) of a tanker’s hull reduces the required computational time from two weeks to only a day when compared with a direct optimisation algorithm. This is important since Raven and Scholcz [34] state that the time available for hull shape optimisation with the goal of, for instance, wave resistance minimisation is usually only one to two weeks or even less.
However, SBGO suffers from the curse of dimensionality [27]. Here, the curse of dimensionality refers to the exponential growth of the design-space volume when the number of dimensions or design variables increases, thereby drastically increasing the number of (expensive) simulations required to cover this volume and reliably construct the surrogate model. In other words, if we increase the number of design variables we optimise over, we drastically need to increase the number of CFD simulations, which is costly or even infeasible. Simultaneously, high-dimensional design spaces naturally arise in naval ship design [37], making this curse of dimensionality a limiting problem for using SBGO in practice.
Multi-fidelity modelling can improve the efficiency of SBGO, by using the usual expensive and precise data together with less expensive but less accurate data. Results as early as that of Leifsson et al. [22] show that optimised hull designs can be obtained at over 94% lower computational cost when using multi-fidelity optimisation as compared to a direct high-fidelity optimisation algorithm. However, these results typically do not scale to more design variables.
We want to lessen the effects of the curse of dimensionality even further and enable ourselves to feasibly solve more complex problems of higher dimensionality, or to solve problems less costly and more accurately in general. Shan and Wang [38] survey strategies of solving high-dimensional expensive black-box problems. These strategies include problem decomposition, screening (e.g. Global Sensitivity Analysis), mapping (e.g. lossless projection of high-dimensional spaces onto lower-dimensional spaces; or multi-fidelity approaches that map a lower-fidelity onto a higher-fidelity model (such as considered in this work), and (adaptive) space reduction. From these, Shan and Wang [38] mark mapping as a promising approach and note that research does not take advantage of the characteristics of the underlying expensive functions. Wu and Wang [46] reiterate this conclusion, demonstrating that this research direction still holds relevance today.
In this work, we recognise that the grid convergence property of CFD solvers is currently an unused source of information that could further improve the performance of the surrogate model and the corresponding optimisation process. Grid convergence states that the simulation solution converges to the ‘true’ simulation solution as the grid is refined. CFD simulations reported by for instance Eijk and Wellens [40] show the clear presence of grid convergence. Therefore, this work explores a novel hierarchical multi-fidelity mapping method exploiting this grid convergence information to relieve the effects of the curse of dimensionality at the expensive high fidelity.
Method background
Kriging, also known as a form of Gaussian Process Regression [32], is a particularly popular surrogate modelling technique due to two reasons. First, Kriging provides the best linear unbiased prediction (BLUP) when the assumption of Gaussian correlations between data samples holds [35]. Second, Kriging provides an estimation of the mean squared error corresponding to that prediction [9].
Kriging receives its name from Krige [19,20], who used a precursor method to estimate gold concentrations based on only a few boreholes. It was further mathematically developed by Matheron [25] and has been popularised for use outside the field of geostatistics by Sacks [35]. Jones [14] and Forrester et al. [9] provide a gentle and intuitive introduction to (Ordinary) Kriging.
Kriging and other forms of Gaussian Process Regression are the most popular surrogate models for use in Bayesian optimisation [27], of which the Efficient Global Optimisation (EGO) algorithm [13] is one form. The EGO algorithm adaptively samples additional points based on the Expected Improvement criterion [13], which is formulated using the estimated mean squared error that Kriging provides. Using this criterion, EGO provably converges to the global optimum in an optimisation process [24], although it may exhaustively sample around local optima [8].
In contrast to Gaussian Process Regression, Kriging in principle is an interpolating formulation, which causes problems in the presence of noisy data. To solve this, Forrester et al. [7] show how to introduce regression terms to the Kriging formulation in coherence with the EGO method through a process called re-interpolation. Jones [14] discusses the relation of Kriging with respect to other surrogate modelling methods and explores possible improvements to EGO and the Expected Improvement criterion. As one of the most promising directions for further work, he hinted towards multi-fidelity simulation: using expensive high-precision simulations together with simulations of a lower precision but a much lower cost. This enables us to respectively balance exploitation and exploration of the search space and thereby cut costs while improving the quality of the surrogate.
Since then, Multi-Fidelity Kriging has received significant research effort, see for instance the review papers of Fernández-Godino et al. [10], Peherstorfer et al. [28], Viana et al. [43]. Kennedy and O’Hagan [15] mathematically formulated the fundamentals, while Forrester et al. [8] provides a more transparent overview. Gratiet and Garnier [21] show that the model of Kennedy and O’Hagan [15] can be equivalently but more cheaply formulated as recursively nested independent Kriging problems, one for each fidelity level. Perdikaris et al. [30] improve upon this work by generalising the linear autoregressive1
Meaning that the relations between fidelity levels and the regression parameters are directly solved in the linear system.
Korondi et al. [17], Meliani et al. [26] use the recursive formulation of Gratiet and Garnier [21] to introduce a multi-fidelity approach to the EGO algorithm and formulate level-selection criteria that balance the expected reduction of the prediction variance with the costs of sampling a given level. The combination of Gratiet and Garnier [21] together with the multi-fidelity SBGO method of Meliani et al. [26] will serve as a reference to the method proposed in this work since that combination will feature the so-called nested Design of Experiments (DoE), a sampling strategy that provides the most complete information on the relation between the fidelities [15].
Optimisation methods based on Multi-Fidelity Kriging hold promise in maritime engineering considering the following accounts. Raven [33], Raven and Scholcz [12] apply Multi-Fidelity Kriging in a ship hull form optimisation with a dense set of potential flow results and a coarse set of RANS data, and positively compared the result with the single-fidelity formulation. Korondi et al. [18] performs reliability-based optimisation of a ducted propeller using an EGO-like strategy and a multi-fidelity Kriging surrogate. Although performed under compressible flow conditions, the same techniques are interesting to incompressible flows. Liu et al. [23] uses viscous and potential flow calculations as the high- and low-fidelity respectively and shows the multi-fidelity Kriging approach can obtain a more optimal hydrodynamic hull form than the single-fidelity model alone.
Other than in these accounts, to the authors’ knowledge, Multi-Fidelity Kriging does not seem to have been applied within maritime engineering, presumably because the increased complexity of the computational setup versus the perceived potential benefit. There are still unresolved questions regarding when it is advantageous to use a multi-fidelity over the standard single-fidelity approach [11,17,39] in terms of accuracy, cost, and assumed data characteristics.
The main research objective that is investigated is how to leverage the grid convergence property of CFD solvers in order to reduce the number of expensive high-fidelity samples required for an accurate (multi-fidelity) Kriging surrogate. Using this property can accelerate surrogate-based global design optimisation in maritime engineering. CFD with a free surface description is used to computed the accelerations for stylized bow shapes of a falling life boat. The main assumption in reaching the objective is that value differences of the objective function that minimized the accelerations, implied by the grid convergence property of a CFD solver, are proportional from one point in the design space to another. To our knowledge the assumption has not been investigated in the context of Kriging or Gaussian Processes for the purpose of Bayesian Optimisation.
Methodology
When we take a look at the results of Forrester et al. [8] in Fig. 1, and later those of Meliani et al. [26] in a fully MF-EGO setting, we notice that although we are only interested in the optimum solution we still need to construct the multi-fidelity surrogate model by sampling the high-fidelity across the full domain. Effectively we need to sample the expensive high-fidelity truth in areas that ultimately are not of interest to an optimisation problem, and therefore will not be directly used. This seems to be a waste of our resources, especially since the high-fidelity per definition is often much more expensive than the low-fidelity while both are generally required to be highly correlated [39].
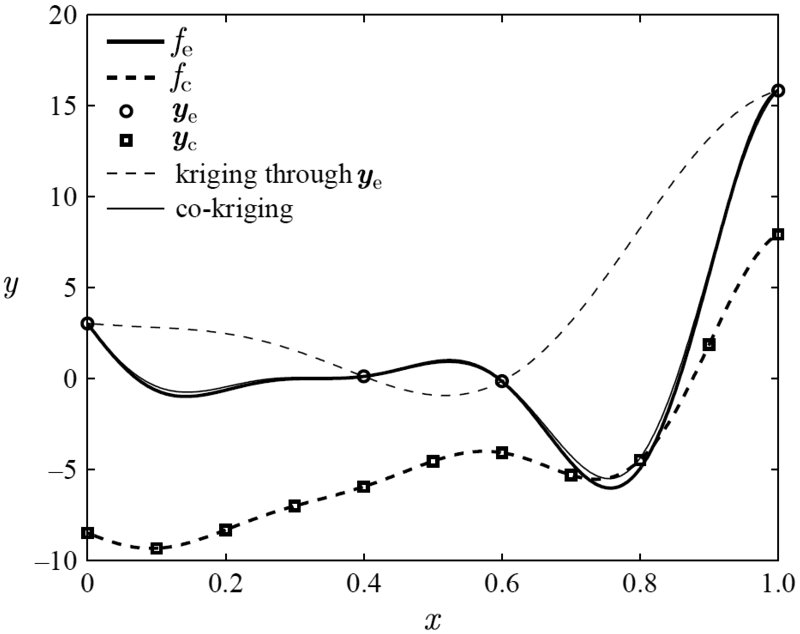
Image from Forrester et al. [8] to showcase multi-fidelity Kriging. Here
Due to the high required correlation between fidelity levels, we implicitly assume to be able to identify regions of interest based on the low fidelity and only sample the high fidelity there. However, this approach presents a problem already observed in the toy case of Forrester et al. [8], where the low-fidelity optimum is only a local optimum of the ‘truth’. Compared to the reference method with two fidelity levels [21,26], our proposed method will feature three fidelity levels, low, medium and high, and will formulate a surrogate model from the combination of samples at these fidelity levels and the assumption of uniform grid convergence, thereby arriving at the formulation of the main assumption as stated together with the objective.
In the following, we exploit this assumption and project the information of as few as a single high-fidelity sample onto the full input domain. We thereby retrieve an approximate Kriging model of the high-fidelity (near) truth, which at the very least should be indicative of areas of interest to an optimisation routine. Then, the adaptive sampling of the EGO algorithm can be performed as usual but at a lower cost of the initial surrogate model in terms of sampling the high-fidelity.
We want to predict an unknown higher fidelity level based on as few samples as possible at that unknown level. To do this, we will estimate the training points of the Kriging model at an unknown level
Incorporating noise and variance
Noise and variance are in principle present in each of the values used in Eq. (1).
Note again that sampling noise of numerical origin can be regressed and estimated by introducing an additional hyperparameter. We can then describe the noise using a Gaussian variance that is fully integrated with the Kriging model prediction variance.
To project this combination of noise and Kriging variance onto our estimation of the high-fidelity, we should thus incorporate them into Eq. (1). Noticing each z in Eq. (1) is actually the mean of a Gaussian, we can alternatively write the corresponding Gaussian as:
The high-fidelity sample
In other words, we assume the sampled (near) truth to be sufficiently precise such that it exhibits relatively little to no noise. In reality however, this is a practical consideration since we will have an insufficient amount of high-fidelity samples to pre-emptively obtain an accurate noise estimate.
At location
As we will see at the end of this section, it only makes sense to sample all three involved levels at location
At location
Although the actual distribution of the expected difference between
Using the notation of Eq. (2) and incorporating the above assumptions into Eq. (1) retrieves the formulation:
Let it be clear that we use each
Sample weighing
Equation (1) retrieves exact predictions (predicted value equals the true value) if:
The response surfaces of each fidelity level are linearly dependent.
We additionally note that Eq. (8a) and (8b) reduces to Eq. (1) in the absence of noise or other variances for each fidelity at input location
Of course, the above conditions in general will not be met exactly. Additionally, we might not know they are not met based on a single high-fidelity sample at location
To detect such events, or simply (locally) improve our response surface, we must be able to retrieve and integrate additional high-fidelity samples. The predictions provided by each high-fidelity sample should therefore be weighed to obtain a weighted prediction
We will determine the coefficients Distance, and Variance.
To retrieve a correct result we enforce that
Before defining
However, although capturing the dimensional scales and relative variability of the objective function per dimension, the medium-fidelity kernel does not necessarily provide an interpolating solution at the high-fidelity samples in the extrapolated surrogate. This is however an absolute requirement.
Therefore, we apply the elementary linear operations of row addition and row multiplication to the correlation matrix to retrieve an interpolating solution while retaining the correlation information. In this form, negative corrected ‘correlations’ indicate that a sample should provide no contribution to an extrapolated point, and are set to zero. Lastly, the columns (with the column consisting of each high-fidelity sample’s contribution to an extrapolated point) of this matrix are rescaled such that the sum equals one. The full procedure that defines

Distance weighing: scaling the correlation matrix
Note that by weighing the contribution of the high-fidelity samples in this way, we implicitly construct a difference model like
To define
A clear example of when such high variances
To resolve this, we define
Please note that the Gaussian-inspired use of a negative exponential is a functioning solution that fits the desired properties. However, other approaches might work as well and the usage of some scaling hyperparameter or constant could improve performance. These considerations are however left to subsequent work.
When there is little convergence or difference between levels, even with little noise the prediction variance
To this end, we introduce prediction weight-factor
Before defining
To solve this problem, we must weigh the contributions of the two fidelities automatically and optimally; which is the very objective of any multi-fidelity surrogate data fusion model. Therefore, we should use the Kriging mean and MSE estimate of a multi-fidelity method such as that of Gratiet and Garnier [21] to define
For three levels, this solution is limited to a minimum of three high fidelity samples for the method of Gratiet and Garnier [21], which is a requirement imposed by the involved GLS solver for the Universal Kriging parameters.
When using the medium-fidelity as an alternative surrogate, the proposed method gains the characteristic of being a hierarchical method. Giselle Fernández-Godino et al. [11] define a multi-fidelity hierarchical method in optimisation as a method that optimizes using the low-fidelity and refines the found extrema using the high-fidelity.
It is important to notice that Eq. (9a) and (9b) and the method of Gratiet and Garnier [21] are both in principle interpolating and exact formulations at the locations of high-fidelity samples, and thus the formulation of Eq. (12a) and (12b) will be too. The medium fidelity, however, inherently is not interpolating.
If the variance
Consequentially, when
If the proposed method above is to be used within a multi-fidelity global optimisation routine, a method is required to select the level at which we will retrieve the sample at a given location
Equation (12b) gives the total variance at Level Level l : Level A strictly increasing expected variance reduction over levels. The variance reductions at level p are of the same order as the Kriging prediction variances The variance reductions at level p are independent of the Kriging prediction variances of the extrapolated surrogate at level p
This formulation adheres to the following requirements we had set:
Especially the last point is important for the stability of the level selection procedure since the variances at the extrapolated level can be spurious. This means the level selection procedures of Korondi et al. [17] and Meliani et al. [26], purely based on the methodology Gratiet and Garnier [21] would not provide correct and stable results.
Although the above variances are calculated point-wise and do not take neighbouring points into account as the Kriging prediction variances do, this difference is of no consequence since we only require an indication of the reducible variance. In fact, the methods of Korondi et al. [17] and Meliani et al. [26] do not correspond with the Kriged variances either, nor do they take irreducible model noise into account. The presence of the second requirement, therefore, is enough to provide us with a reliable level selection methodology.
The level selection procedure is completed by selecting the level that provides the maximum variance reduction
Alternative EI reinterpolation procedure
The Expected Improvement (EI) criterion is used by the (Multi-fidelity) Efficient Global Optimisation algorithm to select the next best location to sample to explore the design space. In the presence of noise, we would reinterpolate the surrogate [7], to ensure the EI converges to zero at sampled locations.
In our case however, we are in principle additionally involved with the extrapolated points of the proposed method. The associated extrapolation variances express the uncertainty of the extrapolation that should ideally remain informative even after reinterpolation. The reinterpolation routine of Forrester et al. [7] would render this information unused. Therefore, this section introduces a reinterpolation strategy that can accommodate both information sources and has the added benefit of being a less costly procedure by not requiring additional training steps. The procedure is given by Algorithm 2.

Alternative implicit EI reinterpolation procedure, fit for the proposed method
Algorithm 2 ensures that the next sampling location does not automatically default to the maximum EI location, but occasionally samples the location of the best extrapolation instead.
It does so either when the EI at the extrapolation location is higher than the maximum EI, or the difference between these two options normalised with the involved maximum expected cost ratio is lower than the criterion
At the best extrapolation, the lower fidelities were already sampled and so the high fidelity will be sampled next. The used cost ratio is therefore calculated as the cost of the high fidelity over the minimal cost of sampling at the location of maximum EI, which in this case is the cost of (nested) sampling the lower fidelities.
Algorithm 2 ensures that we do not sample the lower fidelities at infinitesimally small intervals, but sometimes sample the higher fidelity to lower the actual non-corrected Expected Improvement.
Compared to the original reinterpolation routine of Forrester et al. [7] the surrogate does not have to be retrained. The routine of Algorithm 2 is thereby about half the computational cost.
Algorithm 2 is in effect near identical to the original reinterpolation routine of Forrester et al. [7] if there are no extrapolations present. The Expected Improvement of samples is pushed to a maximum of 0. The primary difference is believed to be found in the evaluation of the Kriging variance, between samples, since the variance at the samples influences the process variance that is solved for during the hyperparameter optimisation. However, in that regard, the procedure proposed here should be regarded as the more accurate method that is more true to the Kriging model.
The proposed method is dependent on accurate noise estimates to provide results as desired. This observation involves some considerations in the method implementation:
The extrapolated high-fidelity surrogate should always be decoupled from the noise estimates on the lower two fidelities. In the proposed method, the high fidelity ‘samples’ include extrapolated values, based on information of the lower fidelities. Thereby the result of the proposed method determines the value of the noise estimates it will use itself at the next timestep. This co-dependency would instigate instability in the surrogate during the course of optimisation. Each fidelity level should be a single-fidelity surrogate. To see why this is, consider that the multi-fidelity Kriging model of Bouhlel et al. and Gratiet and Garnier [4,21] combines the fidelity levels and deducts a single process variance When using a reinterpolation routine for EI calculation, one should take care that the reinterpolation does not affect the lower fidelities. It is beneficial to the proposed method to sample the lower fidelities at locations directly around higher fidelity samples to get better noise estimates and thereby a more stable Kriging mean. Without doing this, it might be that the extrapolated surrogate is quite unstable during optimisation until an area in the design space emerges that is more densely sampled. Doing the same does not provide an advantage to the reference method [21,26], so rather than instigating an unfair advantage, acquiring these additional lower fidelity samples is a disadvantage in terms of costs for the proposed method.
Just as the proposed method benefits from unbiased noise estimates per fidelity level, the same is true for the Kriging means that are used to extrapolate. The Kriging mean should be regarded as the surrogate that is corrected for noise in the input data. This is as well the reason why the extrapolation is based on the Kriging mean and not on the original data, with a clear difference present in the performance of the proposed method.
Code for the proposed method is available at
Design simulation setup
Realistic test scenarios where the data is acquired by means of CFD simulations using the CFD solver described in Eijk and Wellens [40]. The design problem will consist of only two actively controlled variables. This is due to three reasons:
We are verifying a novel method using a CFD evaluation function fit for maritime engineering purposes. Issues are harder to pinpoint for higher-dimensional design problems.
Visualisation of two-variable response surfaces is relatively straightforward and less confusing compared to higher dimensional problems.
The used CFD solver has been under development in 2D until now. Sensible one-to-one 2D design parametrisations with more than two variables were not found.
Since our primary aim is to validate our proposed method, we will not consider multi-objective or constrained formulations. Note that a 3D simulation tool can also be used since the objective output per simulation remains a scalar, see Eq. (18). Furthermore, the proposed method is applicable to higher dimensional design problems, keeping in mind that the effectiveness of the proposed method is primarily dependent on the validity of the main assumption.
In the following the test case and the objective function will be elaborated upon, the parametrisation used to define one-to-one shape variations will be described, and, finally, the filtering procedures to remove errors of numerical origin is discussed.
Case description
The in-house CFD solver that has been used is called EVA [40–42] and developed with a focus on extreme fluid-structure interaction (FSI). EVA is a multiphase flow solver based on the 2D Navier–Stokes equations for the motion of a mixed fluid. The method uses a fixed staggered Cartesian grid on which the free-surface between water and air is described using a geometric Volume-of-Fluid (VoF) method. The interface is represented by piecewise linear line segments and transported using a direction-split scheme.
Examples of extreme FSI are found when waves impact with structures [2,29,42,44,45]. Note that when waves are concerned, simulations benefit from Generating Absorbing Boundary Conditions [5,6], both in terms of accuracy and of computing time. Slamming of an object onto a free water surface constitutes another type of impact simulation, demonstrated by means of a falling cylinder on water in van der Eijk and Wellens [40].
A well-known 2D test case for such impact simulations is the ‘free-falling wedge’ which in our case mimics the collision with water of a free-fall lifeboat: a rescue vessel that drops off an offshore drilling platform into the sea in case of emergency. After the rescue vessel slams the water, constituting the moment with the highest vertical accelerations, flow separation and the generation of a cavity follows. EVA [40] has been validated for the whole entry procedure.
The deformation capacity of the falling object itself, as in Bos and Wellens [3], Xu and Wellens [47,48], is not taken into account, and the object is considered completely impermeable and not porous [44]. We will modify the scenario with a 2D falling wedge to represent a single-objective optimisation problem in which we vary the shape of the falling life boat’s nose or ‘bottom’ in the way that we have set up the simulations.
The optimisation objective is to minimize the maximum acceleration of the wedge as the main indicator for the immediate safety of its hypothetical passengers:
Fixed parameters in this problem will be:
All environmental constants, such as gravitational acceleration Main dimensions of the boat: the size in beam direction Mass or the loaded weight of the boat The height of the boat’s bottom shape variations Design dropping height
All capitalized constants are based upon a real offshore free-fall boat.3
https://www.palfingermarine.com/en/boats-and-davits/life-and-rescue-boats/free-fall-lifeboats#anchorslides_content_contentslides11_5; model: FF 1000 S M2; visited 20/06/2023.
The mass will be varied between different optimisations (but fixed per optimisation problem) since it is interesting to observe its effect. For instance, a vessel with low mass and thus low specific weight compared to the water might benefit from a more axe-shaped bottom, because buoyancy or added mass effects might de-accelerate the vessel before the primary impact. On the contrary, a vessel with a high mass and thus high specific weight would slow down much less and would benefit from avoiding anything close to flat-plate impacts.
Furthermore, from a design perspective, it makes more sense to fix the mass than for instance to fix the mass-buoyancy ratio or specific weight of the vessel. This is because the main dimensions, required load capacity, and structural weight are more or less already fixed.
We will consider the following two masses in these experiments, where one should note that the 2D CFD solver EVA accepts a mass per meter:
Since we have fixed the mass per design optimization in our experimental setup, the optimization objective acceleration is proportional to the surface-integrated body forces in the vertical y-direction.
The parameters which determine the shape of the wedge’s bottom spline are the parameters that define the domain of the surrogate model. We will use Non-Uniform Rational B-Splines (NURBS) to define this shape, see Piegl and Tiller [31] for extensive information. NURBS are implemented in the geomdl python package [1].
We impose some constraints on the shape endpoints:
The angle of the spline at the bilge is constrained between 10 degrees (horizontally inward) and 90 degrees (vertically down)
The angle of the spline at the keel is constrained between 10 degrees (horizontally outward) and 80 degrees (up).
Both horizontal 10-degree angle restrictions are in place to prevent situations too close to flat-plate impacts, which are numerically hard to simulate. Further, we consider an angle of 90 degrees vertically up at the keel to be unrealistic and not physically constructible and likewise restrict it to (90 −10) = 80 degrees.
We will limit the dimensionality of the design problem to 2. Note that normally by using NURBS, shapes such as the flare bow [50] can be created. Likewise, if we do not impose topological constraints on the vertical location of the control points, we can arrive at catamaran-like shapes. These would provide an interesting class of shapes involving air entrapment. However, proper optimisation requires a one-to-one shape parametrisation, meaning that each input x retrieves a unique shape. Simultaneously, we are limited to 2D shape variations due to the development status of EVA [40]. In 2D, we did not succeed in attaining a one-to-one parametrisation when including the above interesting variations while retaining the simpler but nonetheless important shape variations. Especially triangular bottom shapes were commonly constructed by non-unique and completely different inputs. We choose to retain only the simpler and more interpretable shape variations, defined purely by the angular constraints above.
Because we are interested in the primary impact response and not necessarily in any buoyancy effects after the bilge has submerged, we decrease the freeboard to only 0.5 m to decrease the numerical domain size.
Given a NURBS shape parameterisation, a resulting body is exported to an image. From this image, an SDF (Signed Distance Function) is created, providing the shortest distances to the body boundary where negative values are inside the body and positive values are outside the body. This SDF function is then used to project a body-fraction field upon the simulation grid corresponding to the shape of the provided NURBS image. Lastly, based on this fraction field the body is reconstructed in the grid using the Piecewise Linear Interface Calculation technique.
An example result of the mapping of a NURBS parameterisation to a reconstructed body in-grid is provided in Fig. 2.
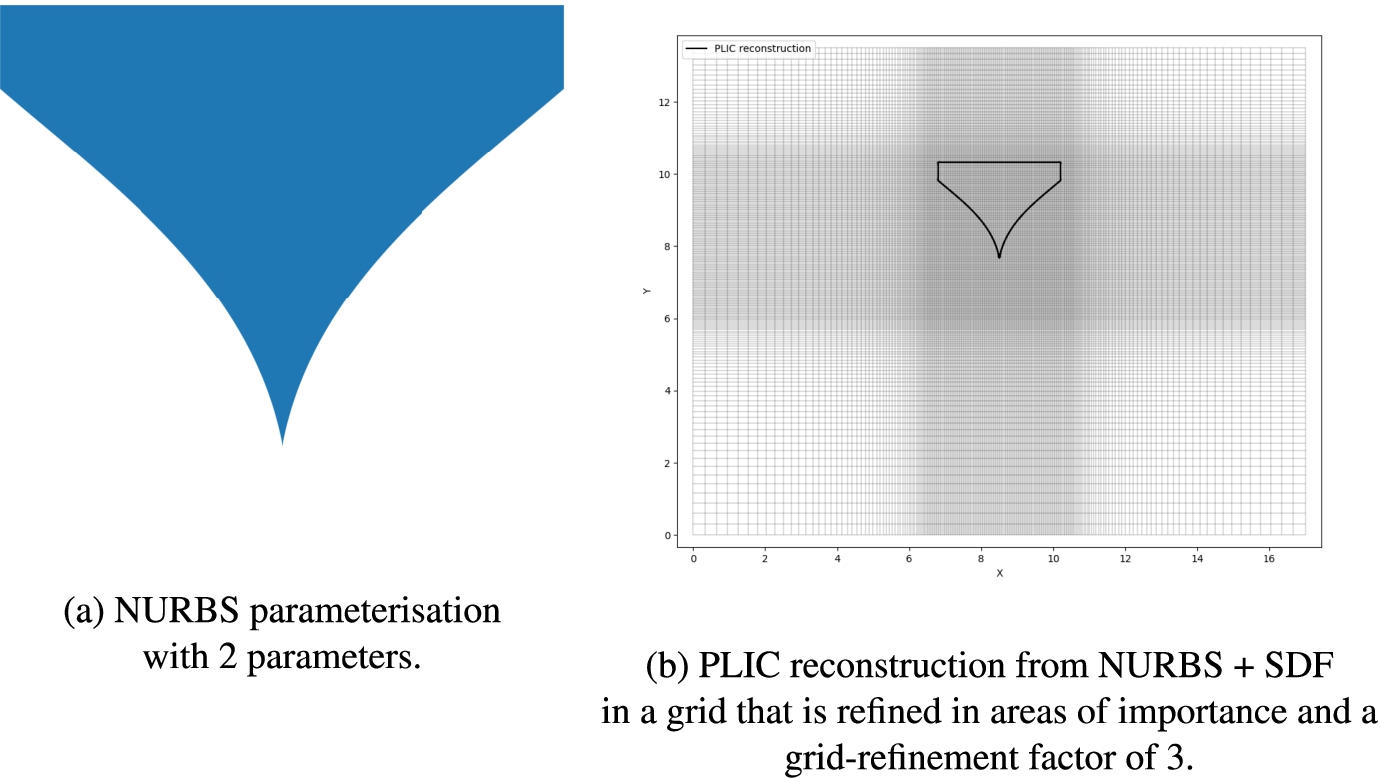
NURBS input image (a) and reconstructed output (b) for X = [06975, 09443].
The definition and coarseness of the numerical grid directly influences the accuracy and costs of the simulation and thereby determine the effective fidelity level. Therefore, first the grid definition is provided, followed by a description of how that grid is refined to create the required fidelities.
The grid definition has to conform to some requirements or preferences:
It has to be symmetric over the body, effectively meaning we require an even number of grid cells for a body defined at the centre of the x-axis.
In height and especially in the width, any grid-cell boundary cannot perfectly overlap with a body boundary. In such a case, PLIC (Piecewise Linear Interface Construction [49]) cannot reconstruct that body boundary, instigating numerical problems. This is true for the definition of the body of water too. It suffices to pick cell spacings that do not exactly divide the body’s main dimensions.
To focus computational effort, the grid is defined such that the grid area that contains the body is of a higher grid density than the surroundings where no direct interactions between body and liquid occur. This area of grid refinement should encompass the whole body from the beginning to the end of the simulation and be somewhat wider to accurately capture, for instance, generated waves. Outside these defined bands of higher cell-density, the dimensional size of each consecutive cell is stretched with a factor of 1.05 as compared to its predecessor.
The standard grid definition in the computational domain resulting from these considerations is given by Table 1.
Numerical domain size, the definition of the focussed grid area per dimension, and the corresponding effective cell-spacing
Numerical domain size, the definition of the focussed grid area per dimension, and the corresponding effective cell-spacing
The definition of ‘refined’ grids and fidelity levels are simple but important, so will be provided separately here.
The refined grids or grid refinements adhere to the same rules as the standard grid definition provided earlier. Of particular importance is that the refinement does not break the grid symmetry around the rigid body. The standard grid definition provided above is from hereon referred to as ‘refinement factor 1’.
A refinement factor 2 takes the standard grid definition (refinement factor 1) and multiplies the number of cells within the focussed band of cells by a factor 2. In such a way we would retrieve a number of cells within the focussed grid area as given in Table 2.
Characteristics of the focussed area in the simulation grid for a selection of refinement factors
The seemingly arbitrary usage of refinement steps of 0.5 originates from the fact that the given base grid definition uses a grid coarseness at which the simulation output seemed to be with reasonable levels of noise, provided an appropriate filtering routine and a reasonable cost level. Therefore, this seemed a good medium fidelity level, which is indexed with a 1 using 0-based indexing. The three fidelity levels required by the proposed method could now be constructed using for instance the refinement factors 0.5, 1 and 4.
Given this information, the refinement for the lower fidelity was already fixed too, at
The refinements used to define the fidelities for all experiments are:
These refinement levels, based upon the constant low mass scenario, are consequently applied regardless of what might be best for the other experimental scenarios. The chosen refinement level of the high fidelity is primarily based on the computation time of a CFD run. A CFD run at the lowest fidelity is completed after 1 to 3 minutes, while for the medium fidelity, this is 5 to 9 minutes. At high fidelity, a CFD run takes between 16 and 50 minutes,4
The runtimes are highly dependent on the NURBS shape provided as input. For instance, in simulations where the impact occurs with the (parts of) the body reconstruction comparatively perpendicular to the water (flat-plate impact), the required timestep is much lower and thereby the simulation times longer.
Having described the procedures of mapping the NURBS shape definitions onto the computational grid, we identify the need of filtering either the force signal or, equivalently, the acceleration signal retrieved by EVA such that we can retrieve a more stable objective value with a smaller error. Unfortunately, the force signal retrieved from EVA contains spikes, and these are of a purely numerical origin. Sources of these peaks are for instance the pressure peaks as described in Kleefsman et al. [16], or the PLIC reconstruction.
This custom composite filter consists of:
Filter step 1: Forward + backward time-step compensated exponential moving average. In effect, force peaks of numerical origin, occurring during small time steps, will have almost no influence on the result and thereby the next step will be much more effective. Remove data outliers: removing data that deviates more than 8 per cent of the data mean with respect to the result of step 1, then interpolate again. Filter step 2: Normal forward-backwards emw, with double the span to smooth result.
Filter step 2 is not necessary but improved the smoothness and correctness of the results, especially around where outliers were removed.
The results of this filtering procedure are visualized by means of a force signal in Fig. 3. In the figure, a comparison is made between the original signal and some other filters.
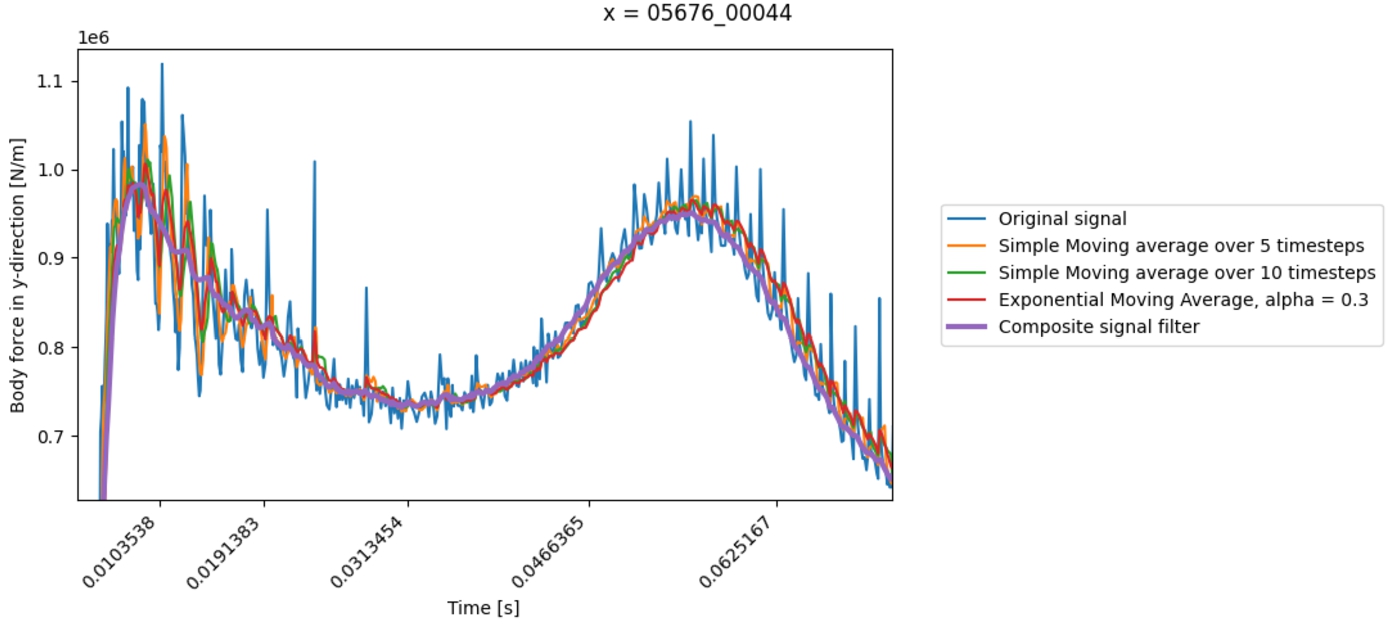
Comparison of filters. Zoom of the signal for the best design of the high mass scenario with
Results will be compared to the surrogate modelling method of Gratiet and Garnier [21], extended with the level selection procedure of Meliani et al. [26] in order to be used in MF-SBGO. As stated above, these methods will jointly be referred to as ‘the reference method’. The reference method has a low-fidelity level and a high-fidelity level. Note that the method proposed here, compared to the reference method, uses an additional fidelity level. A lower fidelity level was added so that that becomes the low-fidelity level in our proposed method. The original fidelity levels in the reference method will hence be referred to as medium-fidelity and high-fidelity levels in the proposed method. The other main difference with the reference method is that the proposed method features the assumption of uniform proportional grid convergence throughout the design space.
To provide a comprehensive comparison, the following metrics will be employed to offer insights into both the surrogate and SBGO methodology in terms of the costs, performance, and other underlying factors:
The best found objective value, together with the corresponding location in the parameter-space, given by the NURBS-parameters
Sampling costs, given as the total sampling cost and the high-fidelity sampling cost.
The number of high-fidelity and low-fidelity samples.
Normalized RMSE of the optimisation’s solution with respect to a fully sampled (initial) DoE at the highest fidelity, see Eq. (20). These are given for the high-fidelity at the start and end of a simulation, and the medium fidelity at the end of the simulation. The medium fidelity is reported as a reference that the (extrapolated) high-fidelity at the very least should outperform.
Performance is measured by comparing the predicted value with the real sampled results by using the Root Mean Squared Error (RMSE) as done in Toal [39]:
Random number generators are used in many aspects of the code:
The initial sampling LHS experimental design within the design space. The LHS used in the EI maximisation sub-routine.
All these random states are set to be constant or structurally varied using counters. Thereby, although semi-random noise is applied, the simulations themselves are completely deterministic. That is, one can re-run the same simulation input and get the same results. This does however not mean that the same input x always retrieves the same result.
Results
Optimisation metrics and evaluation of the main assumption
Optimisation metrics for all the cases are given by Table 3, with the corresponding best-optimised designs reported by Fig. 8. The table compares the outcomes for the proposed optimisation method with the reference method [21,26] for the two main scenarios with different masses. Variations of the methods are made by using a different number, either 1 or 3, of starting high-fidelity samples.
For both the high mass (
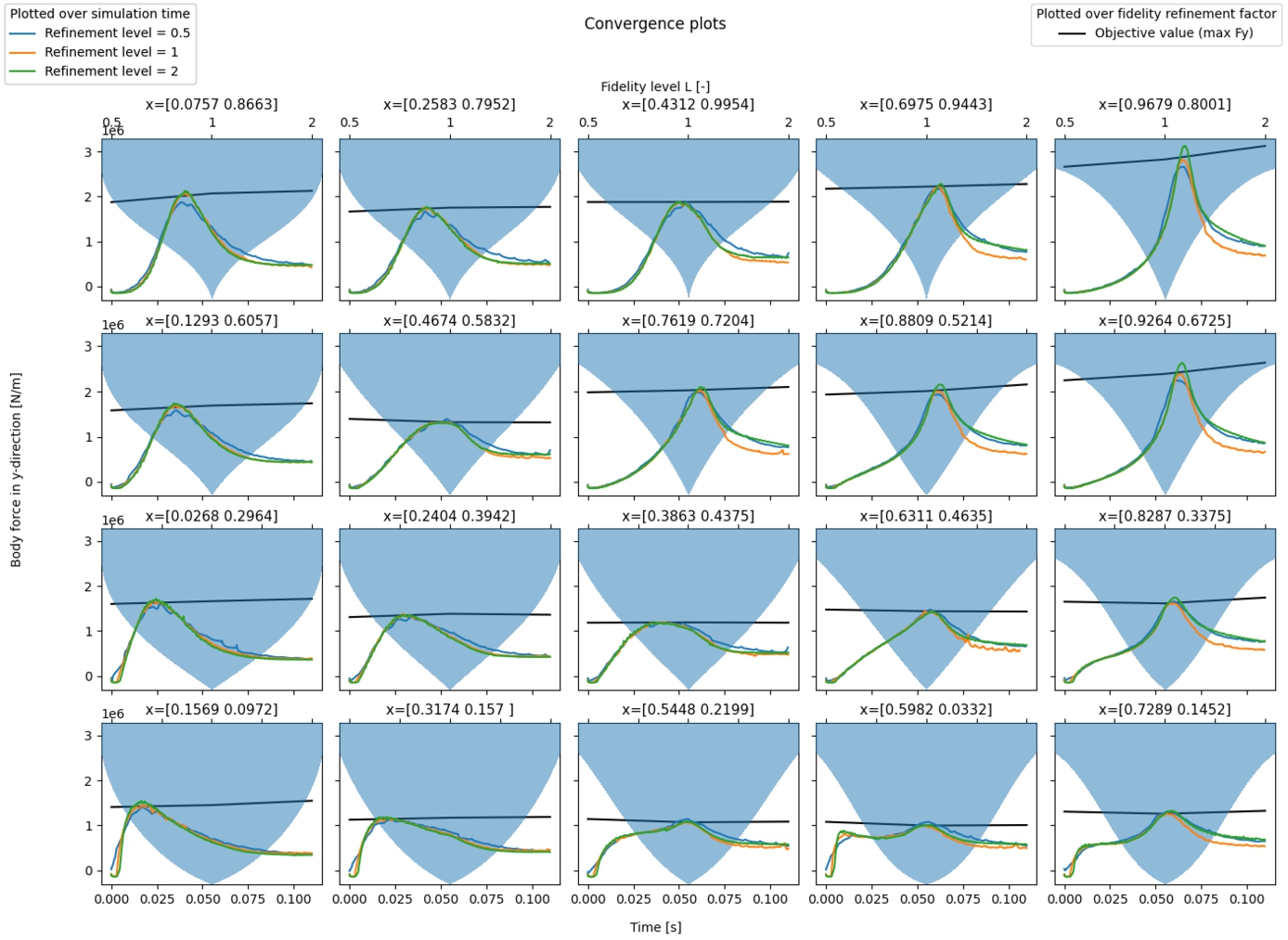
Convergence for the falling wedge experiment with
The proposed method relies on the convergence of the objective value over fidelity levels – as stated in the main assumption. This convergence was assumed to be uniform across the design space. The validity of this assumption is inspected before analysing the optimisation results. When we look at Fig. 4 and Fig. 5 it is seen that there is the anticipated convergence at badly performing designs (large acceleration), but almost no convergence at well-performing designs (low acceleration). The observation is that CFD simulations near the optimum design will encounter less strenuous circumstances with lower forces, pressures, fluid velocities and accelerations present. Because the flow variables for these designs have lower values overall near the optimum designs, good estimates of these flow variables are already achieved at lower grid resolution. Therefore, we observe less convergence of the objective value for better designs.
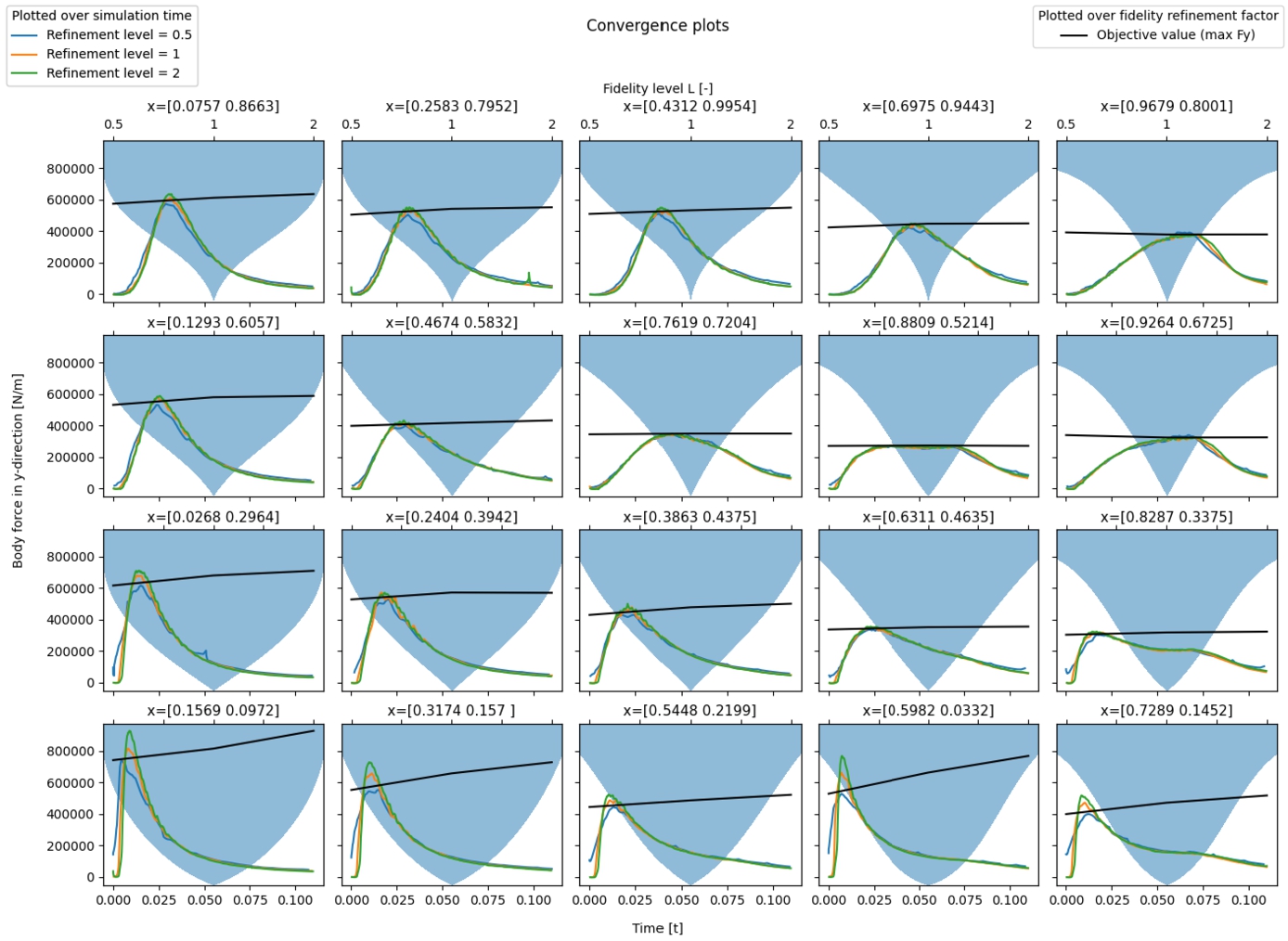
Convergence for the falling wedge experiment with
The end-states of the surrogate of the proposed method and the surrogate of the reference method [21,26] are plotted and visually compared to the ‘truth’ surrogate that is based on a fully sampled DoE at the high-fidelity in Fig. 6 for the high mass case with
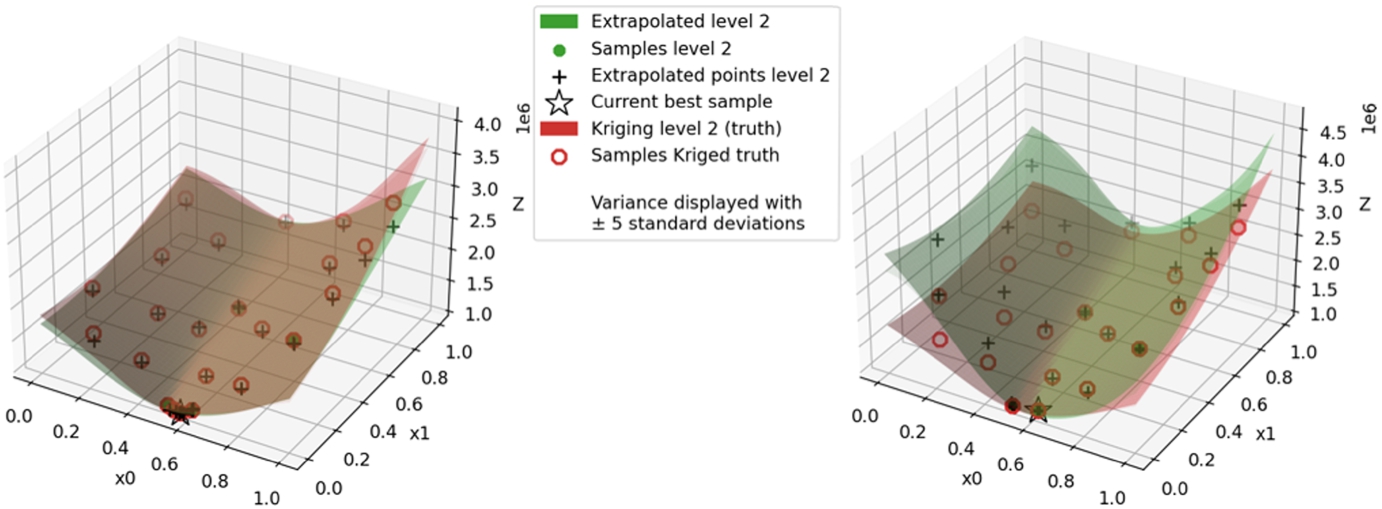
Visualization at the optimisation end of the high mass case with
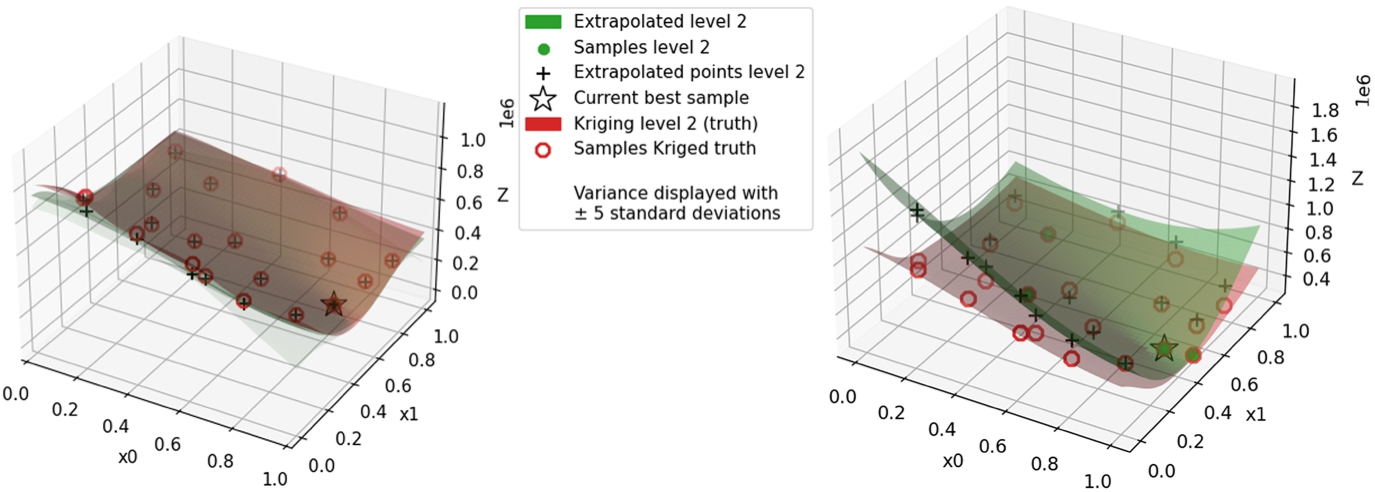
Visualization at the optimisation end of the low mass case with
Figure 6 reveals the following for the high mass case. In testing the method weighing procedure, the medium fidelity is not used if the MFK solution is available, which is from 3 starting high fidelity samples and on. The problem with using the medium fidelity as the alternative surrogate is that it is not principally a solution interpolating with the high-fidelity. Although the high fidelity is forcibly added and there is in this case typically barely any difference between the high and medium fidelity in areas where the proposed method does not work well and so method weighing is used, differences over short distances could be relatively large and thus noise estimates overestimated.
For the case where instead the surrogate modelling method of Gratiet and Garnier [21] provides the alternative surrogate, we are ending with a higher NRMSE, similar to the experiments with the reference method [21,26], even though starting with a very accurate surrogate. When comparing the time traces of the NRMSE together with the weighing variables
Continuing on this, the simulation start of the proposed method with MFK as the alternative surrogate knows a very low NRMSE. This coincides with the reference method having good accuracy at the start too. The proposed method already applies method weighing at the simulation start, and it seems we retrieve a result that takes the best of both worlds. On top of that, this is the only optimisation run that retrieves a better design. This shows the idea of method weighing can be beneficial.
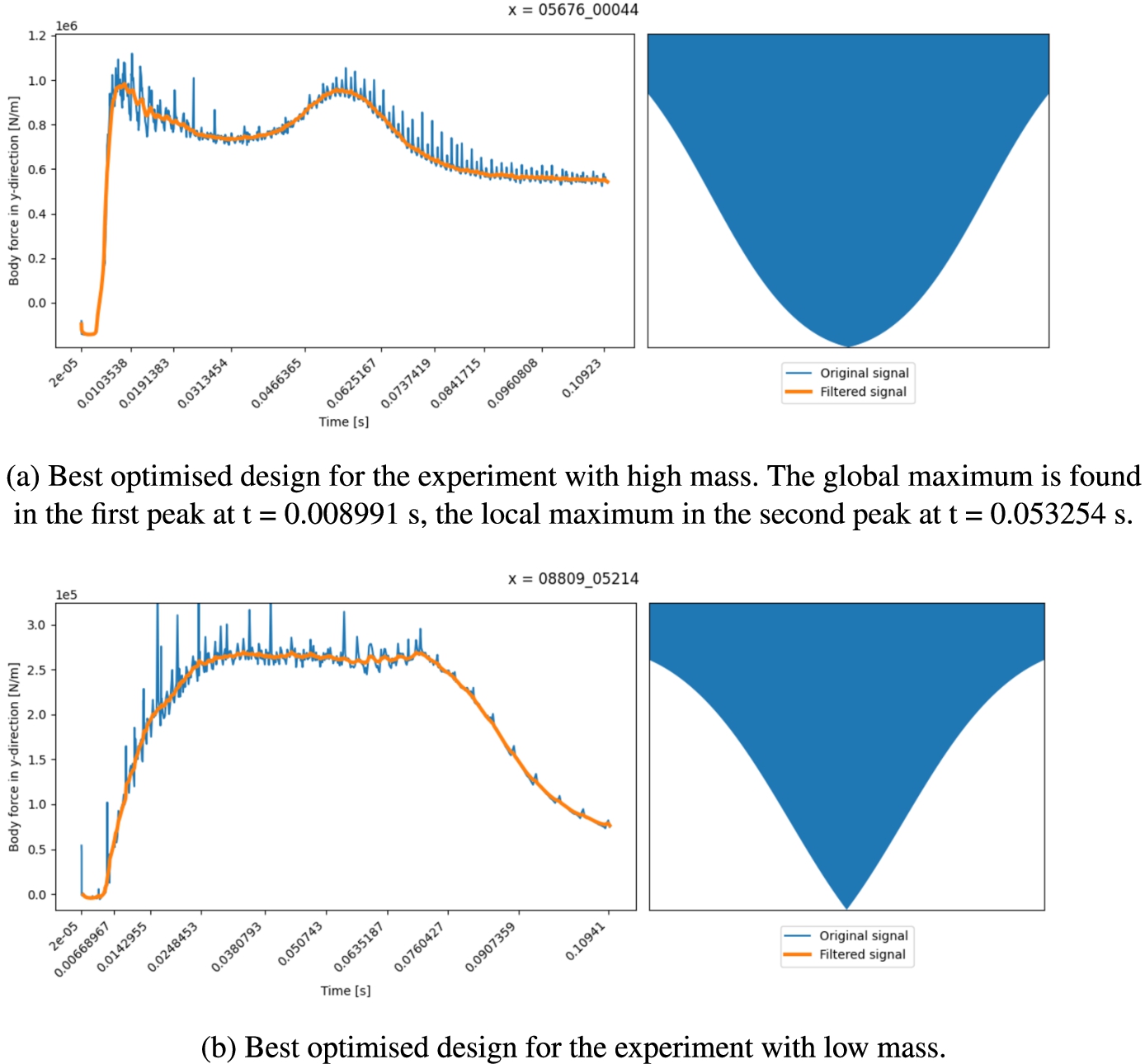
Best results of the wedge optimisations with (a) constant low mass (b) constant high mass. Next to the found optimal shape, the figures provide the body forces in the y-direction for the original acceleration signals and the signals after filtering. Although we minimise the maximum acceleration, the body forces in the y-direction are given because 1) constant body masses are used and so the translation to acceleration is the same for each point in the design space, and 2) this provides insight into how the body mass influences the involved forces whereas Tab. 3 does not.
Figure 8a shows the force on the optimal high mass case design as a function of time, and the optimal design itself. Contrary to expectations, the bottom end of the design is somewhat blunt, starting with a low gradient near the nose, after which the gradient of the cross-section increases before it becomes lower near the sides. Considering the hydrodynamics of water jet formation and jet seperation from the sides of the wedge, that is associated with the force on the wedge becoming lower, this design makes perfect sense: the design tries to avoid a single high force peak by postponing jet separation for as long as possible with a more constant force over time as the outcome.
The body forces of the best-optimised low mass design, given by Fig. 8b, are seen to be stable around the maximum value for most of the impact time, which indicates this is a very good design where we cannot expect to gain more by reducing force peaks. The design maintains a constant deadrise for most of the height of the bottom before tapering off to a more horizontal end at the chine. The peak of the low mass case force is nearly an order of magnitude lower than the high mass case force peak.
While interpreting the objective values of the low mass scenario, one should consider that due to the 2D nature of EVA used the wedge or ‘lifeboat’ effectively drops onto the body of water over its full length at once. This results in much higher forces and accelerations compared to the high mass scenario of
The objective of the proposed method is also to lower the costs of building an accurate surrogate and optimise using it, by lowering the required number of samples at the expensive high fidelity. To assess if successful, Table 3 considers the following main metrics:
Surrogate accuracy, given by the NRMSE of Eq. (20)
Sampling cost
For the sampling cost, it should be taken into account that the ‘low’ fidelity in Table 3 consists of only the medium fidelity for the reference method [21,26] and both the low- and medium-fidelity for the proposed method. Next to this, to improve the proposed method’s stability, extra samples around the high-fidelity samples are acquired to improve the initial noise estimates per fidelity level. Therefore, any gains by the proposed method at the high fidelity need to offset the sampling costs of the complete lowest fidelity to perform better than the reference method. The proposed method is able to do this for the simulations starting with a single high-fidelity sample.
In terms of surrogate accuracy expressed in the NRMSE, the proposed method gives comparable results to the reference method [21,26], but cannot be said to perform better. It is found to be more stable during the course of EGO optimisation. Given the nature of the problem, the reference seems to need more high-fidelity samples in the initial surrogate to perform well.
Because of the instability of the reference method and the corresponding upward parabolic surrogate, the reference might decide earlier than the proposed method to stop the optimisation based on the Expected Improvement criterion. The reference method might therefore seem to be more efficient in costs than it deserves in these scenarios.
As for the optimisation result, only the proposed method has been able to find a better design, for the high-mass case. More investigation is required to determine whether this is due to a structural strength of the method.
Conclusions
The main research objective was to leverage the grid convergence property of CFD solvers to reduce the number of expensive high-fidelity samples required for an accurate (multi-fidelity) Kriging surrogate, thereby accelerating surrogate-based global design optimisation in maritime engineering.
A multi-fidelity method was proposed and tested using computational experiments. The proposed method uses three fidelity levels and assumes that the differences between them are proportional across the design space to extrapolate the high-fidelity data from one point in the design space to another. It then uses the statistics and correlations of the underlying Kriging models to balance or correct the surrogate. An adapted sequential sampling and fidelity-level selection procedure was formulated such that the proposed surrogate can be used in multi-fidelity surrogate-based global design optimisation (MF-SBGO).
To investigate the possible usefulness of the proposed method to SBGO in the field of maritime engineering, the proposed method was tested by optimising the shape of two variations of a falling wedge case as an example of slamming, of which the relevance to maritime engineering is explained by Eijk and Wellens [40], using their CFD solver EVA that is tailored to the problem. The performed optimisations found two different designs of the bottom shape depending on the specific weight of the wedge, where the interplay of hydrodynamic effects resulted in non-trivial designs. In many of the considered cases, the optimal design was also found with fewer high-fidelity samples than the reference method [21,26]. However, the cost of finding the optimal design by means of the proposed method was not lower than that of the reference method in all of the cases. The main explanation is that the grid convergence of EVA was not uniform in magnitude over the design space. Near optimal designs, due to how EVA represents the hydrodynamics of slamming work, good predictions of the wedge’s acceleration were already reached at the low-resolutions, low-fidelity levels, so that information of the grid convergence obtained from other samples farther away from the optimum design was less beneficial than originally assumed. Future work will take this property about grid convergence near optimal designs into account.
Funding
This research was partially supported by Epistemic AI (964505) and by TAILOR (952215), projects funded by EU Horizon 2020 research and innovation programme.
Conflict of interest
P.R. Wellens and M. van der Eijk are Editorial Board Members of this journal, but were not involved in the peer-review process nor had access to any information regarding its peer-review. The authors have no other conflicts of interest to report.
Author contributions
R. Wenink had access to the data and was involved in: conception; performance of work; interpretation of data; writing the article.
M. van der Eijk had access to the data and was involved in: conception; performance of work; interpretation of data; writing the article.
N. Yorke-Smith had access to the data and was involved in: conception; performance of work; interpretation of data; writing the article.
P.R. Wellens had access to the data and was involved in: conception; performance of work; interpretation of data; writing the article.
Footnotes
Acknowledgements
The authors would like to thank Mathieu Pourquie for his feedback to this work.