
Abstract
The performance of Adaboost is highly sensitive to noisy and outlier samples. This is therefore the weights of these samples are exponentially increased in successive rounds. In this paper, three novel schemes are proposed to hunt the corrupted samples and eliminate them through the training process. The methods are: I) a hybrid method based on K-means clustering and K-nearest neighbor, II) a two-layer Adaboost, and III) soft margin support vector machines. All of these solutions are compared to the standard Adaboost on thirteen Gunnar Raetsch’s datasets under three levels of class-label noise. To test the proposed method on a real application, electroencephalography (EEG) signals of 20 schizophrenic patients and 20 age-matched control subjects, are recorded via 20 channels in the idle state. Several features including autoregressive coefficients, band power and fractal dimension are extracted from EEG signals of all participants. Sequential feature subset selection technique is adopted to select the discriminative EEG features. Experimental results imply that exploiting the proposed hunting techniques enhance the Adaboost performance as well as alleviating its robustness against unconfident and noisy samples over Raetsch benchmark and EEG features of the two groups.
Introduction
The performance of conventional classifiers heavily relies on being trained with correctly-labelled datasets. However, in practice, labels of training samples can be corrupted by expert mistakes [20, 26, 45], encoding errors [22, 37], and poor quality of recorded data [8]. To overcome this deficiency, two general solutions have been proposed in the literature. The first approach has focused on making specific supervised learning algorithms robust to mislabelled samples [34] while the other approach has concentrated on finding and removing noisy samples as a pre-processing step prior to learning [7, 31]. The second approach benefits from independence to the type of classifier. In other words, these methods are general and can be used for improving the performance of a wide range of classifiers. Therefore, this study is focused to develop some new techniques within the framework of the second approach.
Contrary to the common belief that having more training data necessarily increases the generalization of all classifiers, studies conducted by [7] showed that the classifiers’ efficacy might be better off when noisy examples are discarded from the training set. To some extent, the quality of training data is more important than its quantity. Therefore, pruning noisy and unconfident samples from training data, is the first necessary step to achieve a better generalization.
Adaptive boosting (Adaboost) is proposed by [16] and has become the most famous ensemble learning algorithm due to its strong statistical background [19]. Adaboost is able to finely handle missing values with minimum information loss, in addition to providing enough flexibility to construct every complex border by linear combination of simple classifiers [12, 25]. These properties along with its fast execution placed it among the top ten machine learning algorithms. However, the main flaw of AdaBoost appears when it boosts the importance of noisy and unconfident samples across its successive weak learners [27]. This boosting is a result of the sample-weighting rule, which increases the weight of hard-to-classify samples continually in a way that learners are biased to the noisy and outlier samples, which are misclassified across successive learners [21].
Several attempts have been made to remove the noisy and outlier samples, as a pre-processing step for Adaboost. [10] used both Gini impurity and one-class SVM methods in order to estimate the best partitioning, in which the percentage of noise filter ratio is maximized. After eliminating the noisy samples, an Adaboost was applied to classify each partition. Nevertheless, this method cannot adaptively set the filtering parameters. In another attempt [48] tried to eliminate the noisy (confusing) samples by a Bayesian-like classifier in an iterative manner. This is done by minimizing the defined average loss of the Bayesian-like classifier. This approach does not need any prior knowledge and covariance matrix estimation. Despite its efficient mathematical derivation, this method eliminates a high portion of samples, which are laid in the margin of classes.
In this study, three novel schemes were proposed to detect induced class-label noises in various datasets using: 1) a hybrid approach based on K-means clustering and K-nearest neighbor, 2) a two-layer AdaBoost, and 3) using soft margin Support Vector Machine (SVM). The effectiveness of the three proposed filtering methods were tested on Adaboost.M1, which is a well-known noise sensitive classifier.
The rest of this paper is structured as follows: Section 2 presents the methodology, including a detailed explanation of AdaBoost and the three proposed methods for the noise filtering. Section 3 presents evaluation criteria and describes the employed data sets. In Section 4, the results of the solutions and their pros and cons are discussed. The paper is finally concluded and some notes, as the future work, are presented in Section 5.
Method
In this section, first, the Adaboost algorithm is described and the reason for its sensitivity to noisy samples/labels is finely explained. Afterward, the proposed filtering methods are introduced.
Adaboost
Ensemble learning refers to training a collection of individual learners, which are connected in a serial, parallel or other structures to map inputs to outputs. The idea behind the ensemble learning is very innovative: the combination of weak learners can act better than a strong single learner [9]. In contrast to the conventional classifiers that use the classification error as their feedback to update their parameters, Adaboost assigns a weight to each sample and defines a pseudo-loss function that plays the role of error [44]. The value of this loss function for each learner is determined by the summation of the weights of misclassified samples. The name of Adaboost stands for “Adaptive Boosting” because it boosts the weight of misclassified samples and decreases the weights of correctly classified samples. In fact, a simple base learner (weak learner) is selected and is sequentially trained by different weighting distribution of samples while in the recall phase, all of the trained weak learners are activated in parallel and their outputs are fused by a linear weighting combination [16]. The distribution of samples’ weight of the
where
The factor in the weight update formula is controlled by the parameter
Final distribution of samples’ weight assigned by AdaBoost on Breath Cancer data samples after 100 iterations.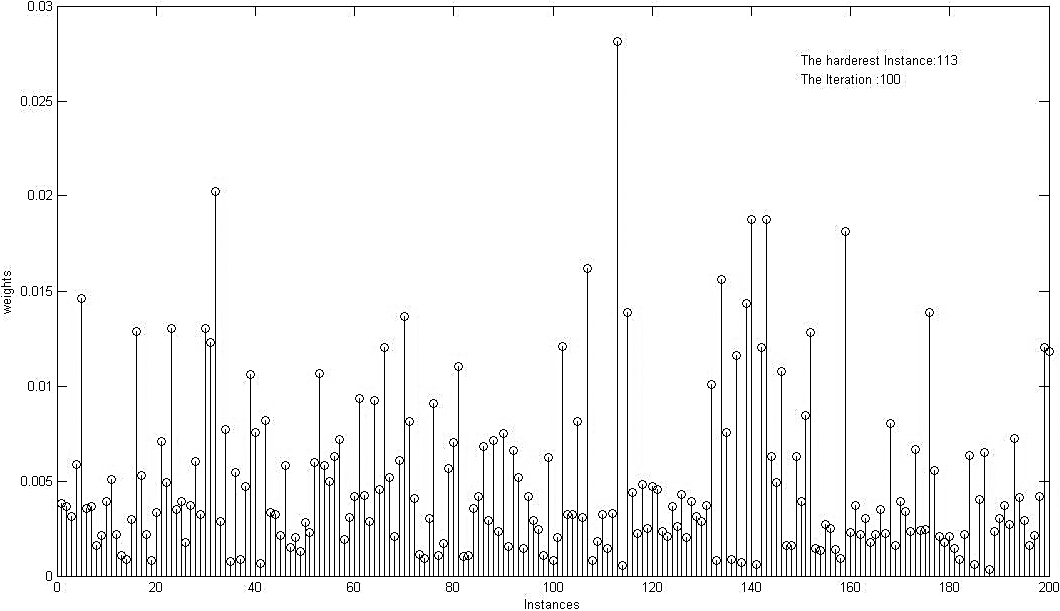
According to Eq. (1), the weight of a noisy or unconfident sample, which is hard-to-classify in essence, would increase repeatedly over the successive iterations. Consequently, the decision boundaries of last base learners would be dragged toward the noisy samples and therefore disturbs the final decision boundary of the overall classifier. An example of the final weight distribution of Adaboost is illustrated Fig. 1. As shown, some samples gain much larger weight compared to others.
In this section, three different solutions are proposed for hunting noisy and unreliable samples. What follows, is the descriptions of these methods in a comprehensive manner.
Combination of K-means & KNN
AApplying a clustering algorithm for outlier detection is a common approach, where outlier samples are defined as those with a low number of neighbors in their vicinity. To enhance the identification of outlier points, the density distribution of all samples (regardless of their labels) is estimated, and samples located far from dense regions are removed. For instance, the K-nearest neighbor (KNN) method is iteratively used to detect noisy samples that assign incorrect labels to the neighbors [31].
On the other hand, the traditional clustering approach for outlier detection suffers from scarifying (e.g., deleting) samples around the hypothetical decision boundary. For instance, the application of KNN to marginal samples enables the detection and deletion of those samples that provide incorrect labels for the neighbors. However, this deletion has the potential to disrupt the hypothetical boundary between classes, leading to an underestimation of classifier parameters [42]. Hence, it is necessary to exclusively apply KNN to specific regions. To achieve this objective, a new concept called “sole sample” is introduced, defined as follows: a sample within a cluster (consisting of at least three samples) is referred to as a sole sample if its label differs from its neighbors within the same cluster.
Illustration of “sole samples” (potential noises) and outliers in a hypothetical two-class classification problem.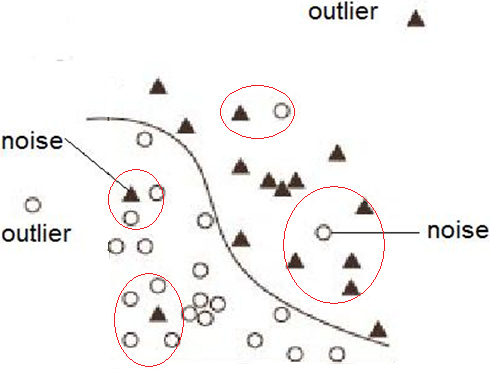
Figure 2 clarifies the concept of sole sample in a two-dimensional space for a hypothetical two-class problem. The underlying assumption is that a sample is less likely to be “sole” when it is close to the decision boundary.
In this study, a hybrid scheme combining both supervised and unsupervised approaches is proposed to better detect the noisy samples. First, a subtractive clustering is applied to the whole data (without considering their label) for estimating the distribution of data. Subtractive clustering is a type of clustering algorithm that uses a density function to determine the number and locations of clusters in a dataset. The main idea behind subtractive clustering is to first find the potential centers of the clusters, and then assign data points to the nearest cluster center based on their distance. The pseudocode for the algorithm can be found following:
Subtractive clustering has some advantages over other clustering algorithms. It can automatically determine the number of clusters in a dataset, which can be useful when the number of clusters is not known in advance. Additionally, it is computationally efficient, as it does not require an iterative optimization process like some other clustering algorithms.
Second, by exploring through the search space, centers of dense regions are considered as initial centers of clusters in the
Estimating both the appropriate number of clusters along with their initial centers plays the key role in the performance of
Subtractive clustering is a fast and one-pass algorithm which has been repeatedly used to estimate the distribution of input data [11]. When appropriate distribution is estimated, as mentioned before, the number of dense regions along with their centers are estimated as the primary centers. This method assumes that the data falls within a unit hypersphere. It has only one user-defined parameter, as the average radius of neighborhood (RADII). This parameter theoretically ranges from 0 to 1 while in practice a value between 0.2 and 0.5 is deployed. Considering small values for RADII results in a high number of small clusters and vice versa. After finding a cluster center in the subtractive clustering, all samples within the RADII around this center are subtracted from the dataset in order to determine the next cluster center. This process is repeated until all of the data is removed.
Defining clusters’ centers with this method has the great advantage of stability compared to conventional random initialization of cluster centers.
As previously defined, sole samples can only be found in clusters with at least three samples. Therefore, over-emphasizing the locality of data (i.e. smaller RADII) produces a large number of small clusters (micro-cluster) with one or two samples. Thus, it leads to a considerable portion of noisy samples. On the other hand, as the size of a potential cluster grows, it is more likely to contain multiple samples from different classes; however, meeting the singularity condition for being a sole sample in a cluster is less likely to be satisfied.
For instance, in a hypothetical 100-sample training dataset, finding a “sole sample” in a cluster containing %10 the all data requires having 9 samples from the same class in a cluster. This scenario would be much less likely than finding a sole sample in a cluster with only %5 of data (i.e. only 4 samples from the same class in a cluster). For this reason, RADII is set to 0.5 in order to hold the maximum size of clusters to %5 of the overall training set.
When a sole sample is detected, two policies can be adopted: deletion and correction. Deletion of the samples means removing some information from the training data which can lead to weakening the learning process. On the other hand, the correction approach has the risk of creating noisy samples in training data, particularly in multi-class problems. However, in the case of having a two-class classification problem, this risk can be managed by setting a low value for the ratio of detected sole samples to the whole training data. In addition, the percentage of noisy samples to sole samples should be acceptable. In Section 4, the achieved experimental results illustrate that the performance of deletion policy can be further improved by “correcting” the labels of “mislabelled” samples and then executing the clustering phase again. Figure 3 illustrates the flowchart of the presented clustering method.
General schema of clustering solution.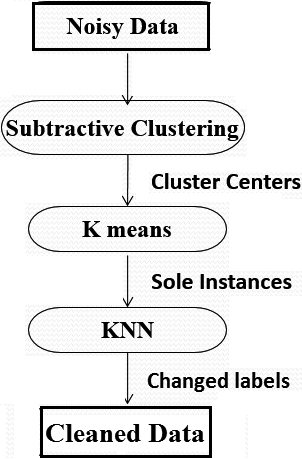
It is intuitive that the most detrimental-to-learning noises are among those samples that have gained highest weights during the Adaboost learning process. Therefore, pruning samples with high weight can be considered as a method for removing noisy samples. Since the Adaboost learning process is a sequential procedure, relying just on the final distribution of weights is misleading [13]. It cannot be ruled out that a noisy sample with a relatively low weight, in the final distribution, exerts its negative effect on first few base learners and then being correctly classified by the last base learners.
To address this issue, the weights of samples are investigated through each epoch of AdaBoost, and then a frequency-based approach is employed to define “hard samples”. In other words, a group of “suspected-to-noise” samples is detected regarding their weights’ distribution. To detect these samples, a threshold is defined, and those weights above this value are considered as the suspected ones. The threshold value is defined as follows:
where
General schema of AdaBoost filtering.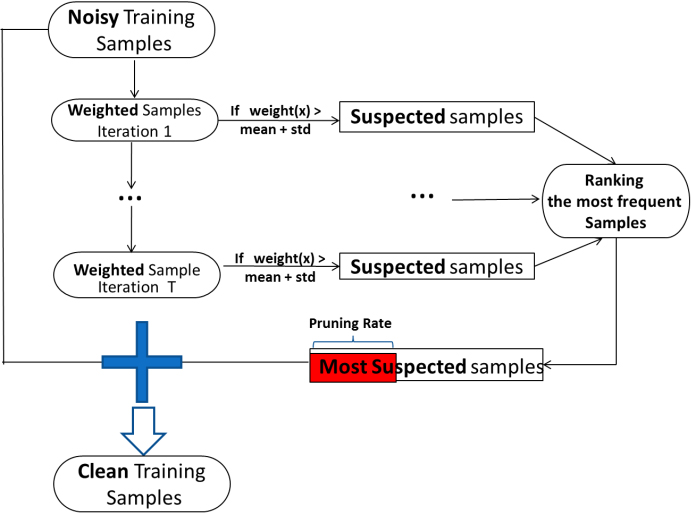
Our preliminary results showed that in the AdaBoost filtering method, unlike cluster-based filtering, a notable percentage of training data is defined as suspected noisy samples. Therefore, flipping the labels of the suspected noises has the risk of inducing new noises into the training set. Nevertheless, there is no way to guarantee that the effect of potential noises induced by the correction policy is less harmful than that of the original random noises. For this reason, the deletion policy was selected as the last stage of this method.
Support vector machine (SVM) method tries to maximize the margin width simultaneously by gaining maximum accuracy over training samples. In general, Margin of a sample is defined as the distance of that sample from the decision boundary. To increase the SVM generalization, its margin should be wide as much as possible while it might damage the train result.
Since the SVM boundary is just adjusted by the support vectors, noisy support vectors deteriorate its boundary. Therefore, train samples should be as clean as possible and then enlarging the margin width to increase its robustness against the remained noisy samples (i.e. Soft Margin) [36]. If the boundary between the classes is nonlinear, a kernel is used to enable SVM to form a flexible boundary [30].
SVM considers a cost, in terms of slack variables
Where
Here
According to the above explanations, two types of soft margin SVMs can be defined: L1-norm (
where
The derivations of Eq. (2.2.3) with respect to
Equation (9) indicates that in a L2-soft margin SVM, the Lagrangian coefficients (
To implement this approach, a SVM model is first trained on the polluted training data to obtain the estimated Lagrangian coefficients of all support vectors. Then, an appropriate threshold is set, and samples with Lagrangian coefficients higher than the threshold are identified as noisy samples. Based on the results of exploratory experiments, the most effective parameter value was found to be the mean of the estimated coefficients plus one standard deviation. Apparently, having a larger threshold can increase the method precision but will reduce its recall (i.e. less number of the noisy samples would be detected).
It should be noted that unlike L1-soft margin SVM, there is no upper bound for Lagrangian coefficients, which facilitates one of our vital requirements, ranking procedure of mislabelled samples. In addition, it is worth mentioning that the C parameter and the Lagrangian coefficients are related through the optimization problem that is solved by the SVM algorithm. The optimization problem is a constrained quadratic programming problem that involves minimizing the error (or loss) function subject to the constraints that the Lagrangian coefficients are non-negative and sum to 1. The C parameter appears in the constraints as an upper bound on the Lagrangian coefficients, meaning that the Lagrangian coefficients cannot exceed the value of C. Therefore, a larger value of C corresponds to a higher penalty for misclassifying training examples, which results in a narrower margin and more support vectors. A smaller value of C corresponds to a lower penalty for misclassification, which results in a wider margin and fewer support vectors.
Codes of all of the presented algorithms were developed using Statistics and Machine Learning Toolbox, MATLAB 2012a. The performance of our proposed methods was tested on a well-known collection of the thirteen benchmark datasets derived from the UCI, DELVE and STATLOG repositories [18]. The dimensions of these data sets vary from 2 to 60, the numbers of training samples are from 140 to 1300 and the numbers of test samples range from 75 to 7000. Covering a wide range of dimensionality and complexity, these datasets have been recommended for model assessment in ensemble and kernel learning methods [36]. Each dataset contains 100 sets of train-tests, except for Splice and Image datasets, which have only 20 splits (see Table 1).
Description of the benchmark datasets
Description of the benchmark datasets
Additionally, EEG signals of twenty schizophrenic patients (mean age 33.3 and standard deviation (std) 9.52) and twenty normal subjects (mean age 33.4 and std 9.29) are considered [38]. The 20-channel EEG signals are partitioned to a number of one-second windows where its dynamics is assumed to be approximately stationary within each window [2, 3]. Successive windows have 50% overlap. Informative features were extracted from all channels in the same window time. In each window, 14 features were extracted that consist of eight autoregressive coefficients, five band power, and Higuchi fractal dimension [39]. Therefore, the data set will have 280 features (20 channel *14 features) for each window. The extracting features are explained in details as follows:
The autoregressive (AR) model, which predicts a sample based on the weighted average of its
where
It has been demonstrated that the EEG has many frequency components that can display various brain states and carry discriminatory data [14]. EEG is typically divided into five frequency ranges: delta (less than 4 Hz), theta (4–8 Hz), alpha (8–13 Hz), beta (13–30 Hz), and gamma (greater than 30 Hz). The power in these five bands at each electrode site is shown by the band power feature. First, a band-pass filter (Butterworth filter of order 5) filters the signal within predetermined frequency ranges. Second, the average of each sample over a one-second period is squared.
Higuchi fractal dimension
The degree of irregularity in a signal can be thought of as the fractal dimension [46]. When the original signal is seen as a geometric figure, it immediately calculates the fractal dimension in the time domain. Following steps outlines the method used to calculate the Higuchi fractal dimension:
Generate
where Compute the average length
Compute total average length
Plot the curve of
To induce classification noise at a rate of r (e.g., %5, %10, and %20), a random selection of r% of samples from each training split was made, and the class labels were flipped. Following the common setup used for AdaBoost, 100 decision stumps (i.e., one-level decision trees) were employed as the base learners. On each split of data, after polluting the training set with %r of class-label noise, AdaBoost was trained by each train set separately and then was applied to the corresponding test set. For evaluation of the EEG data set, leave-one(subject)-out method was used [4, 5, 6, 40]. In other words, each time, the EEG feature vectors of one subject were considered as the test set and the feature vectors of the remaining subjects were considered as the train set. This process was repeated up to the number of subjects [1, 32].
In the next step, the proposed noise-filtering solutions (clustering, AdaBoost and SVM) were applied to the polluted training set to hunt the unconfident samples. These samples were removed from the train set and AdaBoost was trained by the clean data and then applied to the test sets. The final performance on each data set is the average performance over all test sets. Due to the space limitation, standard deviation of accuracies over the subsets was not reported.
To evaluate the performance of the proposed filtering algorithms, three criteria were used, independent of the accuracy of Adaboost.
The first criterion is “Deletion Rate” which is the percent of training data pruned by a filtering method. Clearly, deleting a considerable percentage of training data is neither an efficient nor an elegant way of noise filtering. The upper bound for the deletion rate is considered equal to the rate of induced noise to the training set.
Noise density
The second employed criterion is “Noise Density” which reveals the percentage of true noisy samples among the population of hunted samples by a filtering algorithm. Having a low “Noise Density” suggests a considerable proportion of hunted samples, which are wrongly deleted. The deleted data is one of the sources of inferior classification performance due to the information loss.
Hunting rate
The last used criterion is “Hunting Rate” which indicates the percent of deleted noises. The division of this measure by the “Deletion Rate” provides an indication of the improvement achieved by the algorithm compared to random guessing. The reason stems from the nature of our induced noise that spreads uniformly all over data sets. Therefore, by removing %X of the training data, it is logical to expect the same percent removal of class-label noises. Therefore, having higher percent of the deleted noise means that our filtering methods perform better than random guessing.
Experimental results
In this section, the performance of the proposed filtering methods on improving Adaboost is demonstrated, and the pros and cons of these methods are discussed.
Detecting sole samples by clustering (Radii 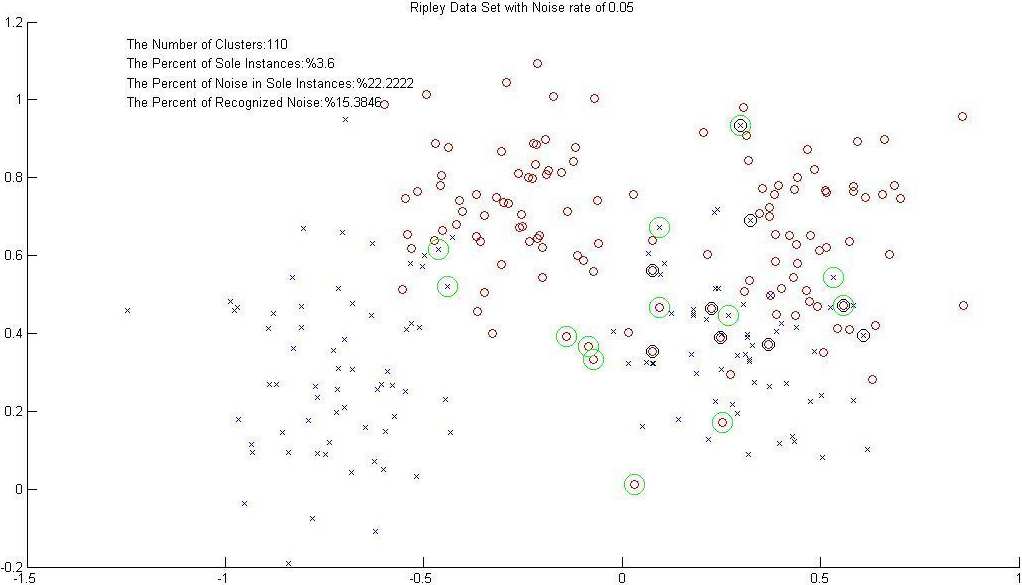
Figure 5 depicts how the sole samples are detected by the cluster-based filtering method on the Ripley dataset, where %20 class-label noises are induced. As seen in Tables 2 and 3, the achieved results on Adaboost reveal that applying this filtering method leads to a higher accuracy compared to the state that no filtering stage is applied.
Noise detection measures using the proposed clustering-based method. For each dataset, the mean value of the calculated measures over 100 randomly-selected test subsets (except for Splice, Image and raw-EEG datasets that have 40 subsets) is reported
Noise detection measures using the proposed clustering-based method. For each dataset, the mean value of the calculated measures over 100 randomly-selected test subsets (except for Splice, Image and raw-EEG datasets that have 40 subsets) is reported
Error rate of Adaboost (AB) by employing the proposed clustering-based filtering is shown here. For each dataset, the mean values of test error over 100 randomly-selected subsets (except for Splice, Image and raw-EEG datasets that have 40 subsets) are reported for both standard Adaboost and the proposed algorithm (ClustAB). The test error of the proposed algorithm is bolded when it is lower than that of standard Adaboost. HR stands for Hunting Rate and it is calculated by averaging the percentage of hunted noises over all test subsets
In Table 2, it can be observed that for most datasets, the noise density increases as the noise rate increases. This trend is particularly noticeable in the Breast, Diabetes, German, Heart, Thyroid, Two norm, and Real EEG datasets. For example, in the Breast dataset, as the noise rate increases from 5% to 20%, the noise density increases from 20.00% to 37.00%.
However, there are some datasets where the noise density remains constant or decreases as the noise rate increases. For instance, in the FlareSolar and Titanic datasets, the noise density remains constant, regardless of the noise rate. The FlareSolar dataset and the Titanic dataset are both very small in terms of the actual number of instances and most of the training and the test samples were created by replications. Therefore, the number of the clusters, and consequently the number of sole samples, are very small for both datasets. This can explain why the clustering method could not be successful on these dataset for recognizing class label noises.
On Table 3, it is apparent that ClustAB outperformed AdaBoost algorithm on most of the benchmark dataset in particular under higher noise levels. Under %5 noise, ClustAB outperformed AB on 10 out of 14 reported benchmark datasets. Under %10 noise, only on 6 benchmark datasets ClustAB could get better results. Under %20 noise, ClustAB could outperform AB again on 10 out of 14 benchmark datasets.
Histogram of weights in Breath-Cancer database under the noise rate of %20. Dash lines indicate class-label noises over the dataset. Red line and Green line indicate the position of Mean of the weights and Mean 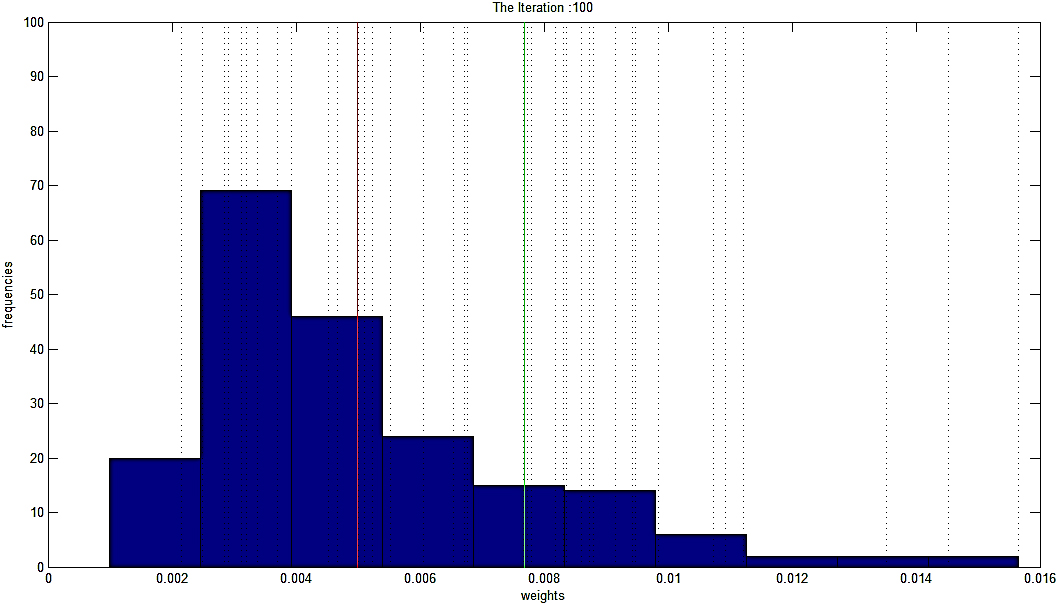
Figure 6 provides an illustration of weight distribution generated by AdaBoost on the Breath-Cancer dataset, where %20 noisy class-label samples are induced. As it can be seen, the majority of the induced noises (pointed out with Dash-lines) are not necessarily located after the threshold (Mean
Results of AdaBoost (AB) solution. For each dataset, the mean values of test error over 100 randomly-selected subsets (except for Splice, Image and raw-EEG datasets that have 40 subsets) are reported for both standard Adaboost and the proposed algorithm (AB-AB). The test error of the proposed algorithm is bolded when it is lower than that of standard Adaboost. HR stands for Hunting Rate and it is calculated by averaging the percentage of hunted noises over all test subsets
Scatter plots of support vectors’ weights (i.e. Lagrangian coefficients) on the two features of the Ripley dataset under %20 class-label noise. The data points surrounded by red circles indicate class-label noises.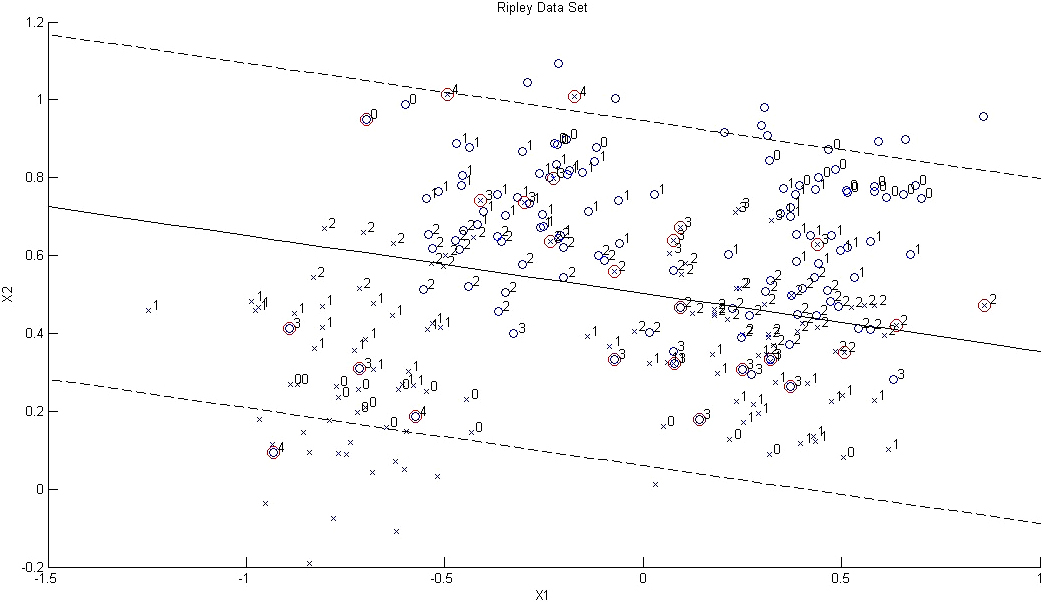
Histogram of support vectors’ weights under the noise rate of %20. Dash lines indicate class-label noises over the dataset. Red line and Green line indicates the position of Mean of the weights and Mean 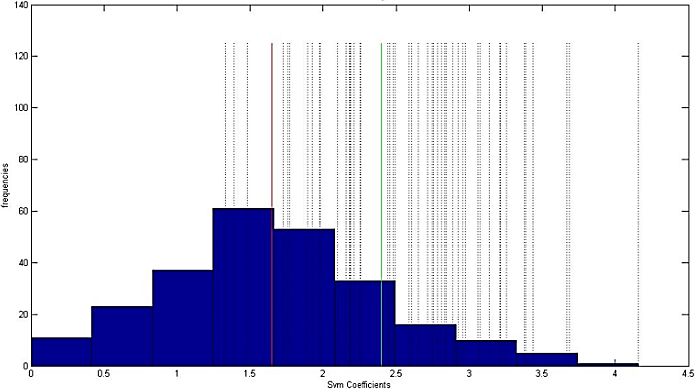
Table 4 shows that the AdaBoost filtering method outperformed the normal AdaBoost algorithm on most of the benchmark dataset. Under %5 noise, AB-AB outperformed AB on 8 out of 14 reported benchmark datasets. Under %10 noise, this number increases to 11 out 14 and under %20 noise, AB-AB could outperform AB on all of the benchmark datasets except one, the Thyroid dataset where it results is on par with AB.
Considering the hunting rate, under %05 noise, the hunting rate ranges from 14.00% (for Banana dataset) to 75.71% (for Thyroid dataset) with a median of 40.10% for all 14 benchmark datasets. Under %10 noise level, the hunting rate ranges from 13.00% (for Breast dataset) to 46.00% (for Two norm dataset) with a median of 29.47%% for all 14 benchmark datasets. For %20 noise level, the hunting rate ranges from 12.03% (FlareSolar dataset) to 24.23% (Image dataset) with a median of 18.83%.
Figure 7 shows the results of applying the proposed SVM based filtering method to the Ripley dataset under two noise levels of %0 and %20. In this figure, Lagrangian values of all samples are rounded to their nearest integers. It can be observed that the wrongly classified samples have significantly larger Lagrangian values compared to the correctly classified ones (located near to the boundary). It can be seen that all noises, marked by red circles, gained the largest values except the ones which replaced original mislabelled samples.
Figure 8 shows the histogram of weights assigned to the support vectors. Our threshold, Mean
Noise detection using the proposed SVM filtering is proposed here. For each dataset, the mean values of the calculated measures over 100 randomly-selected subsets (except for Splice, Image and raw-EEG datasets that have 20 subsets) are reported
Noise detection using the proposed SVM filtering is proposed here. For each dataset, the mean values of the calculated measures over 100 randomly-selected subsets (except for Splice, Image and raw-EEG datasets that have 20 subsets) are reported
Results of the SVM solution (SVM-AB). For each dataset, the mean values of test error over 100 randomly-selected subsets (except for Splice, Image and raw-EEG datasets that have 40 subsets) were reported for both standard AdaBoost and the proposed algorithm. The test error of the proposed algorithm is bolded when it is lower than that of the standard AB algorithm. HR stands for Hunting Rate and it is calculated by averaging the percentage of hunted noises over all test subsets
Summary of the average improvement made by the employed filtering methods over all randomly-selected subsets across the benchmark datasets
Table 5 shows that under %05 noise, the hunting rate ranges from 23.5% (for Banana dataset) to 97.5% (for Two norm dataset) with a median of 69.15% for all 14 benchmark datasets. Under %10 noise level, the hunting rate ranges from 25.50% (for Banana dataset) to 94.30% (for Two-norm dataset) with a median of 65.8% for all 14 benchmark datasets. For %20 noise level, the hunting rate ranges from 22.90% (for Banana dataset) to 82.50% (for Two-norm dataset) with a median of 52.90%. Therefore, the SVM method provides the most stable results across all of the proposed filtering methods with always performing worse on the Banana dataset and performing best on (despite being better than the Two-norm dataset. It should be noted that even the hunting rate achieved on the Banada dataset here is better than AdaBoost and Clustering method by a large margin.
Table 6 shows the effect of noise pruning with the SVM method on the performance of the AdaBoost algorithm. As it can be seen, the SVM-AB method outperformed the simple AB method on 8, 10 and 11 datasets out of the 14 benchmarks under %5, %10 and %20 noise level, respectively.
Results of the proposed filtering methods, as a pre-processing stage for Adaboost, are demonstrated in Table 7. The first observation is that the hunting rates of all three algorithms decline as the noise level increases. However, by observing the enhancement of AdaBoost accuracy, the effectiveness of the proposed schemes to hunt the most detrimental noises, under different levels of noise, is empirically proved. The results show that SVM-filtering outperforms the other two methods in terms of higher hunting rate under various noise intensities. Nonetheless, in terms of improving the AdaBoost performance, as might be expected, the AdaBoost-filtering method holds the highest rank. Although the clustering method does not outperform the other counterparts, it is the winner in terms of affecting just less than 5% of data averagely, with one exception of the Breast-Cancer dataset (Table 2). Considering such a minimal effect, the ability of the clustering method on improving the AdaBoost performance over six to ten datasets is of value.
The hunting rate of the SVM filtering was also not largely affected as the noise level increases compared to the other filtering methods. The good match found between Adaboost and SVM is supported by previous studies [35]. Ratsch et al. reported that the decision line constructed by AdaBoost is similar to the one constructed by SVMs and all support vectors also lie within the step part of the margin distribution for AdaBoost.
Conclusion and future work
In this article, three preprocessing methods were introduced for identifying unconfident and noisy samples. To show their effectiveness, they are applied to improve the performance of the AdaBoost classifier, which is famous as a noise sensitive classifier. According to our results, the best presented solution is SVM filtering that employs Lagrangian variables for finding noisy samples. This method shows its strength more and more as the level of noisy data increases from zero to %20 induced noisy samples. The SVM filtering succeeded to hunt more than half of the induced class-label noises as well as to improve the test accuracy over the ten benchmark datasets.
One of our future outlines is extending the SVM filtering method to non-linear kernels. Exploiting the potentials of Lagrangian values in nonlinear kernels can be helpful for developing a more sophisticated noise pruning algorithm. Another idea is to investigate the effect of combining the results of the presented methods for improving the hunting rate. For instance, concentrating on samples found suspected by both AdaBoost and SVM filtering might lead to a better performance in determining class-label noises.
Footnotes
Acknowledgments
No funds, grants, or other support was received.
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Data availability statement
All data generated or analysed during this study are included in this published article and its supplementary information files except the EEG dataset which is not publicly available due privacy concerns but are available from the corresponding author on reasonable request.