
Abstract
Nowadays, support vector machines are widely applied to land cover classification although this method is sensitive to parameter selection and noise samples. AdaBoost is an effective approach to find a highly accurate classifier by combining many weak and accurate classifiers. In this article, a novel ensemble support vector machine model that uses AdaBoost approach is proposed to mitigate the influence of noises and error parameters with focus on application on land cover classification. The key characteristics of this approach are that (1) a novel noise filtering scheme that avoids the noisy examples based on fuzzy clustering and principal component analysis algorithm is proposed to remove both attribute noises and class noises to achieve an optimal clean set and (2) support vector machine classifiers, based on the particle swarm optimization algorithm, are seen to component classifiers. We then combined finally individual prediction through AdaBoost algorithm to induce the final classification results on this new training set. A set of experiments is conducted on land cover classification for testing the performance of the proposed algorithm. Experimental results show that the classification accuracy can be increased using our proposed learning model, which results in the smallest generalization error compared with the other learning methods.
Introduction
Land cover can really reflect the information of the earth’s surface coverage, which is closely related with human production and daily life. It is important to extract accurate and timely information from remote sensing imagery for social economy and ecological environment. At present, many machine-learning algorithms are widely used in remote sensing classification, such as neural network,1,2 decision tree,3,4 maximum likelihood method, 5 rough set theory, 6 and support vector machines (SVMs). 7 SVMs are a new research focus in the field of machine learning and pattern recognition. SVMs have been proposed to tackle the problem of remote sensing imagery classification because they can better solve the high-dimensional characteristics and multi-dimensional data classification.8–12 Although SVMs have a very good effect in the extraction of remote sensing information, there are still some problems such as parameter selection and noise sample interference. In real-world datasets, class noises will also confuse a machine-learning algorithm in the training phase.13,14 Usually, noises usually exist in classification problems, including class noises and attribute noises. Class noises are regarded as ineffective samples, namely, misclassification samples and contradictory samples. 15 Attribute noises are produced by introducing erroneous and missing attribute values. The parameters of SVMs mainly include kernel function parameters and penalty parameters.
Inspired by the idea of multi-information fusion approach,16,17 the basis theory of the proposed AdaBoost ensemble learning is to improve the performance of a single classifier by the combining multiple classifiers. Its learning performance depends on the diversity of individual learners and the effective combination of classifiers. Breiman 18 presented the famous Bagging algorithm based on the re-sampling technology. Next, Freund and Schapire 19 improved the boosting algorithm and proposed adaptive boosting (AdaBoost) algorithm. AdaBoost can create a set of component classifiers by maintaining a set of weights on the training samples. In addition, it can adaptively adjust these weights. It has become the most popular ensemble method and been widely used in many fields. Pal introduced finite ensemble approaches, based on boosting and bagging and infinite ensemble created by embedding the infinite hypothesis in the kernel of SVMs. Then, the performance of two different ensemble approaches is used to address land cover classification. The results showed that boosting algorithm can improve the classification performance of SVMs for land cover classification. 20 Maulik and Chakraborty 21 presented semi-supervised ensemble SVMs classifier to tackle remote sensing image classification. SVM-basedIEL was introduced by Yang et al. 22 to significantly improve the accuracy and efficiency of remote sensing classification. Li et al. 23 proposed the AdaBoost that incorporates properly designed radial basis function SVMs (RBFSVM) component classifiers, which it was called AdaBoostSVMs. The results show that it is superior to the single SVMs classification model.
In our work, a novel ensemble SVMs learning scheme based on AdaBoost is proposed to overcome the shortcomings of single SVMs. First, SVMs kernel function parameters and penalty parameters are optimized by particle swarm optimization (PSO) algorithm. Then, the principal component analysis (PCA) method is adopted to eliminate noise features for remote sensing image. At the same time, a fuzzy c-means (FCM) clustering technology is introduced to reduce the class noises. Finally, the improved SVMs is used as a base classifier to train different classifiers for the same training set. Several weak classifiers are generated and combined to form a stronger final classifier using AdaBoost algorithm for further improving the classifier generalization ability. In order to assess the proposed model, experiments are conducted to tackle the problem of the land cover classification.
Study methods
Formulation of SVMs
SVMs, developed by Vapnik 24 , are supervised learning algorithm based on the theory of structural risk minimization. The decision function of SVMs is expressed as formula (1) for a binary classification problem

Given a training set of instances {xi, yi}, where i = 1, 2, …, n, x ∈ Rn, y ∈ {–1, +1}, and n is the number of samples.
Minimize

Subject to

where
Maximize

Subject to

where
Next, the nonlinear decision function is written as

The kernel function

The equation of RBF kernel function is

For the SVMs, there are four kernel functions, such as linear, polynomial, RBF, and sigmoid kernels. Among them, the RBF can perform in an excellent way in many practical applications. RBF kernel is used in this article. The performance of SVMs can be affected by the parameter values of
SVMs classification model is constructed through training labeled examples, which can reliably predict the class label for new previously unlabeled examples. Obviously, the model obtained will be negatively affected if the data used to train this model contain noise samples during the learning phase. To better illustrate the effect of noises on SVMs classifiers, we compare the effect of noise samples and noiseless samples on SVMs classifiers, as shown in Figure 1. Two kinds of samples (class A and class B) are randomly generated by MATLAB. We use the traditional SVMs algorithm as classifier and choose the RBF as the kernel function. The values of penalty parameter

Visualization of SVMs classification results,where green dots denote the samples of class A, blue dots denote the samples of class B, red circles denote the support vector, and purple dots denote the noise samples in (b).
Fuzzy clustering algorithm
Clustering problem partitions a given dataset into clusters for detecting clusters and discovering hidden structural distribution and pattern features in the underlying data. In this article, the FCM clustering algorithm is used for obtaining more reliable and non-noisy training samples based on membership values of different clusters. Here, FCM clustering algorithm is described as follows.
FCM clustering algorithm is an unsupervised learning technology. Bezdek 25 used fuzzy set theory to improve the clustering algorithm in order to solve the hard-clustering problem. The algorithm is based on the minimization of an objective function (c-means functional), which can be defined as

where

is a vector of cluster prototypes (centers), and
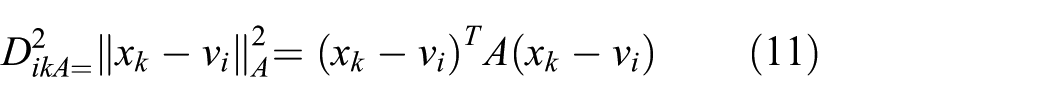
is a squared inner-product distance norm. Formula (9) can be regarded as a measure of the total variance of xk from vi. The minimization of the objective function (equation (9)) represents a nonlinear optimization problem, which can be solved using a variety of available methods, including grouped coordinate minimization, simulated annealing, and genetic algorithms. The stationary points of the objective function (equation (9)) can be found by adjoining the constraint
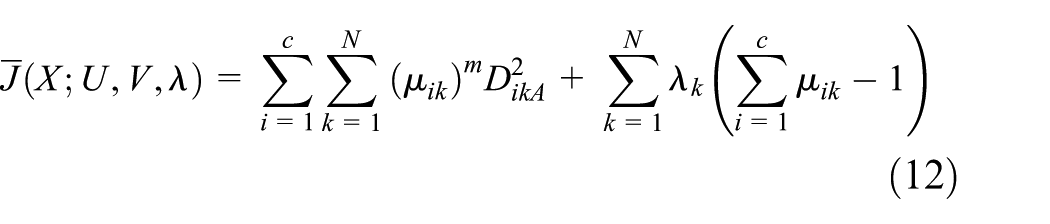
and by setting the gradients of

and

This solution also satisfies the remaining constraints
A novel AdaBoost ensemble SVMs model
Parameters of SVMs optimized based on PSO (PSVMs)
PSO is originated from the study of bird prey behavior, which is similar to genetic algorithms in a way that it is based on particles and fitness function. It also starts from random solution and searches for optimal solution by iteration. Each particle i contains two important characteristics: velocity and position. The position and velocity of each particle can be calculated and updated in each iteration. PSVMs algorithm steps are shown in Table 1.
PSVMs algorithm.

Here, we set up particle components and fitness functions. In this article, SVMs are considered as base classifiers, where RBF kernel function is used in the proposed model. So, the particle comprises penalty parameter

where up denotes the number of false classifications and
Eliminating noise method
The presence of irrelevant features and noises could deteriorate the performance of the assessment model.26,27 In this modeling, we propose an eliminating noise (EN) algorithm to address the noises of datasets. First, PCA is used to form a new subset of attributes and remove ratios which are not useful correlate attributes. Second, the FCM algorithm is introduced to detect the noises based on the movement of the center for clustering in the training dataset. The mean of samples is regarded as the initial center. We calculate the membership function through clustering. The samples of smaller membership, which are suspected to boundary data of containing noises, are eliminated in each iteration. Then, we repeated clustering, until the distance of clustering center for each class satisfies ending condition. The specific steps are shown in Table 2.
Eliminating noises algorithm.

Ensemble SVMs model based on AdaBoost (AdaPSVMs)
AdaBoost can enhance the generalization capability of classifiers by adaptively adjusting the weights of misclassified samples. In this study, PSVMs are seen as component learner. Given a set of training samples, AdaBoost can set a weight distribution
AdaPSVMs algorithm.

Accuracy assessment
The article uses kappa coefficient as evaluation index except the total classification accuracy, and the formula is shown as
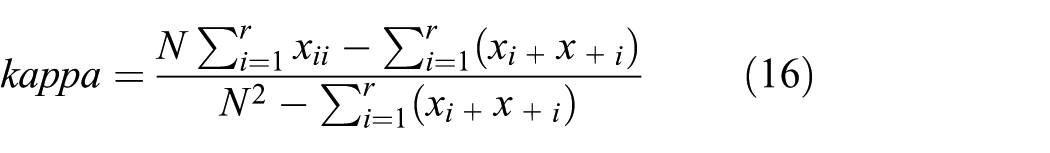
where r is the number of error matrix rows, xii is the value of ith row and ith column, xi + is the sum of the ith row, x + i is the sum of the ith column, and N is the total number of samples.
Results and discussions
Study area
The Tumen River area located in the border areas of China, North Korea, and Russia (41°06′–44°05′ N and 127°39′–131°44′ E) is shown in Figure 2. The region has varied geomorphologic types and rich natural resources, which make the land cover categories diverse. Landsat-5 TM image data, which were acquired on 30 September 2009, are considered here for the experiment. The spectral bands include data in the blue (band 1), green (band 2), red (band 3), near-infrared (band 4), and mid-infrared (bands 5 and 7) regions of the electromagnetic spectrum. Among these bands, thermal band 6 is eliminated because it has a larger pixel size and less information for vegetation classification than the other bands.
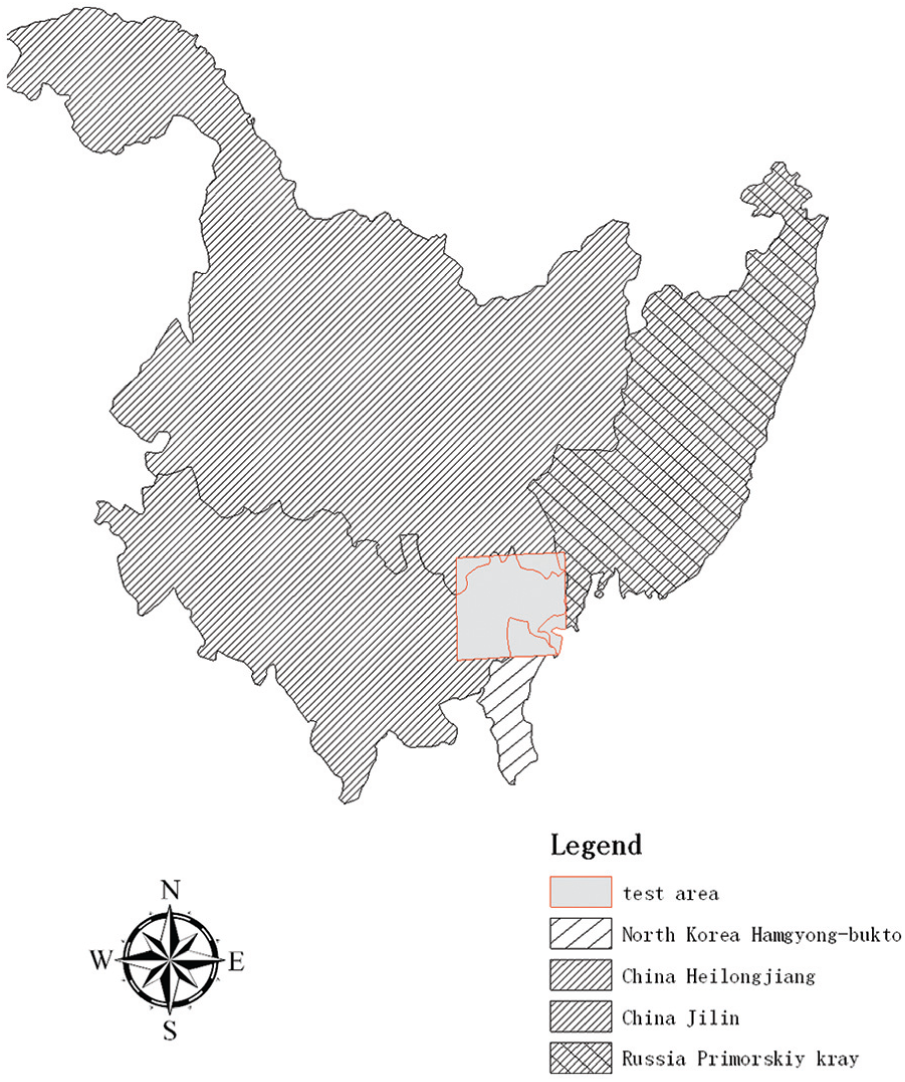
Location of the study area.
Sample set
In the study area, the land use classes include forest, farmland, building land, water, and others, respectively, with the category code ω1–ω5 according to the land cover classification system in Northeast China. The number of samples and land cover types are listed in Table 4. The sample set is formed using random pixel selection strategy, which guarantees maximum variation and representativity for each class. We divided the dataset of 3838 samples into two subsets, one for training (2059 samples) and the other for testing (1779 samples).
Name of classes and number of samples.

Feature selection
Feature selection can be regarded as the process of selecting a minimum subset of m features from the original dataset of n features (m < n). Its main purpose is to improve the generalization ability of the classifier and reduce the computational complexity. In this study, we take into account the following three aspects, and finally eight features are adopted, which include TM image band information, PCA principal component, and normalized difference vegetation index (NDVI).
TM band selection: band features include first to fifth bands, seventh band of TM image, and a total of six bands. The deleted sixth band is a thermal infrared band and generally does not participate in band synthesis because its spatial resolution is low (120 m).
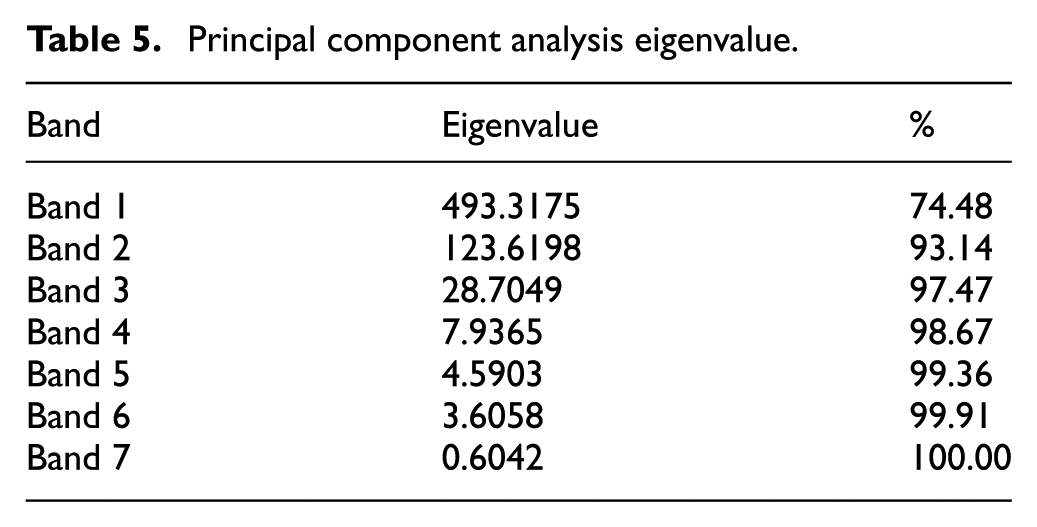
Eliminate redundant features: PCA is used to remove the repetitive and redundant information between the bands of multi-spectral remote sensing images. The TM images obtained in the study area in September 2006 are used in the PCA test, and the results are shown in Figure 3. In Figure 3(a), it is easy to find that band 1 contains the most abundant information. In contrast, band 6 (Figure 3(f)) and band 7 (Figure 3(g)) have very little information and include many noises. In addition, it can also be seen in Table 5 that band 1, band 2, and band 3 feature values are larger in the seven TM bands, and among values, the value of band 1 is the largest, which is 493.3175. Therefore, the article chooses the PCA’s first principal component as one of the classification features.
NDVI: NDVI can well reflect the vegetation growth status and vegetation coverage, which is one of the most effective parameters to evaluate vegetation status. NDVI is selected as the important classification feature, and the result is shown in Figure 3(h)

where B4 and B3 are the near-infrared band reflection value and the red band reflection value, respectively.

Principal component analysis results in some areas of the study area, where (a)–(g) are the results of principal component analysis of bands 1–7, and (h) is the result of NDVI analysis.
Principal component analysis eigenvalue.
Reducing class noises by FCM clustering
Then, we implement the FCM algorithm using the training subset. The optimal dataset will be obtained through several clustering to gradually eliminate class noises.
In order to achieve the integrity and accuracy of test, we follow the two points: (1) the number of class noises is less than 1/10 of each class samples; (2) the number of selected class noises is 0.5% of each class sample in each iteration. When the distance of the two-cluster center is less than 0.0001, clustering is stopped. For FCM clustering algorithm parameters, m is the weighting exponent which determines the fuzziness of the clusters. The default value of m is 2. e is the termination tolerance of the clustering method which is set default as 0.001. The number of original training samples is 2059, and the number of training samples after denoising is 1871. The results are shown in Table 6.
Number of training samples after denoising.

Comparison of the classification models
In this section, we implement the AdaPSVMs to tackle land cover classification for part of subset images with two other classification algorithms, namely, traditional SVMs and PSVMs, for comparison purposes. The classification results obtained by the three algorithms are presented in Table 7, as well as including the parameter values, kappa coefficients, and overall accuracies. Compared with the SVMs model (
Classification results obtained using AdaPSVMs, PSVMs, and SVMs.

Conclusion
Parameter values and noise samples can potentially “corrupt” the model performance of the SVMs learning schemes. In our article, an ensemble SVMs model using an AdaBoost algorithm called as AdaPSVMs is presented to reduce the impact of this issue. PCA is first used to eliminate redundant features of sample set. Then, FCM is presented to search and eliminate class noise. The PSO algorithm is also proposed to search the optimal parameters of SVMs. Our attempt here is to obtain the minimum generalization error through non-noisy dataset and ensemble method. Finally, we implement our model to solve the problem of land cover classification. Experimental results demonstrate that the proposed AdaPSVMs model has better performance than PSVMs and SVMs models.
Footnotes
Handling Editor: Daming Zhou
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a grant from the National Natural Science Foundation of China (no. 61402193), the Foundation of Jilin Provincial Science & Technology Department (no. 20180101337JC), the Science and Technology Bureau of Changchun (no. 17DY009), the National Society Science Foundation of China (no. 15BGL090), the National Natural Science Foundation of China (nos 61572225 and 61806082), and the open foundation of Laboratory of Logistics Industry Economy and Intelligent Logistics in Jilin University of Finance and Economics (no. 201702).