
Abstract
Stable states in complex systems correspond to local minima on the associated potential energy surface. Transitions between these local minima govern the dynamics of such systems. Precisely determining the transition pathways in complex and high-dimensional systems is challenging because these transitions are rare events, and isolating the relevant species in experiments is difficult. Most of the time, the system remains near a local minimum, with rare, large fluctuations leading to transitions between minima. The probability of such transitions decreases exponentially with the height of the energy barrier, making the system’s dynamics highly sensitive to the calculated energy barriers. This work aims to formulate the problem of finding the minimum energy barrier between two stable states in the system’s state space as a cost-minimization problem. It is proposed to solve this problem using reinforcement learning algorithms. The exploratory nature of reinforcement learning agents enables efficient sampling and determination of the minimum energy barrier for transitions.
Keywords
Introduction
There are multiple sequential decision-making processes that one comes across in the world, such as control of robots, autonomous driving, and so on. Instead of constructing an algorithm from the bottom up for an agent to solve these tasks, it would be much easier if one could specify the environment and the state in which the task is considered solved and let the agent learn a policy that solves the task [23,29]. Reinforcement learning attempts to address this problem. It is a hands-off approach that provides a feature vector representing the environment and a reward for the actions the agent takes [39]. The objective of the agent is to learn the sequence of steps that maximizes the sum of returns. [38]
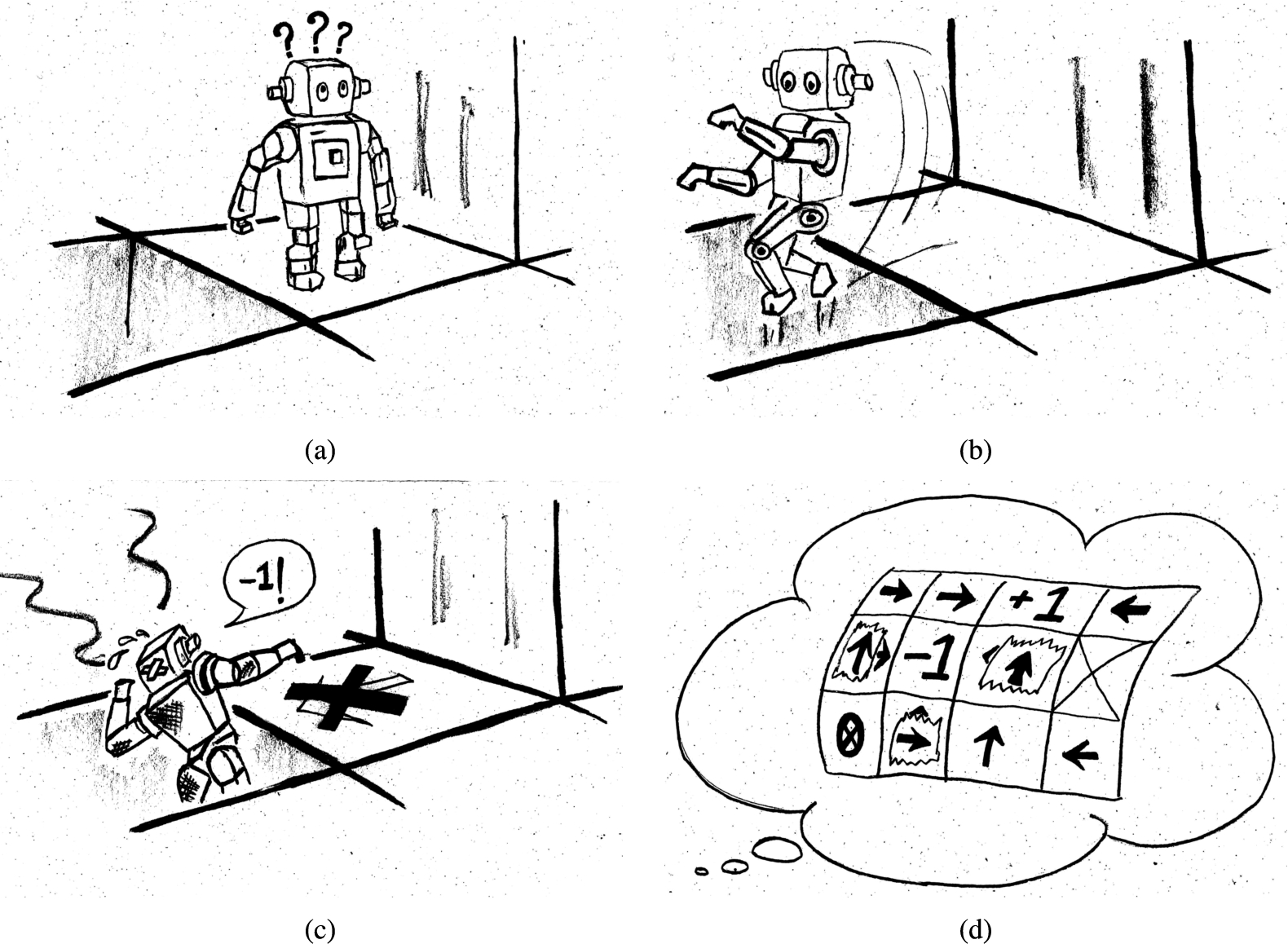
Maze solving using reinforcement learning: (a) the agent is at a state at a particular time step, and takes an action to reaches the next state (b). The agent records the reward obtained by taking the action in that state and (c) continues exploring the environment. After a large number of interactions with the environment, the agent learns a policy (d) that maximizes the rewards collected by the agent. The policy (d) gives the sequence of actions that the agent has to take from the initial state to the final state so that it collects the maximum rewards in an episode.
One widespread example of a sequential decision-making process in which reinforcement learning is utilized is solving mazes [31,35]. The agent, a maze runner, selects a sequence of actions that might have long-term consequences [45]. Since the consequences of immediate actions might be delayed, the agent must evaluate the actions it chooses and learn to select actions that solve the maze. Particularly, in the case of mazes, it might be relevant to sacrifice immediate rewards for possibly larger rewards in the long term. This is the exploitation-exploration trade-off, where the agent has to learn to choose between leveraging its current knowledge to maximize its current gains or further increasing its knowledge for a potential larger reward in the long term, possibly at the expense of short-term rewards [7,36]. The process of learning by an agent while solving a maze is illustrated in Fig. 1.
GridWorld is an environment for reinforcement learning that mimics a maze [39]. The agent is placed at the start position in a maze with blocked cells, and the agent tries to reach a stop position with the minimum number of steps possible. One might note an analogy of a maze runner with an agent negotiating the potential energy landscape of a transition event for a system along the saddle point with the minimum height. The start state and the stop state are energy minima on the potential energy surface, separated by an energy barrier for the transition. The agent would have to perform a series of perturbations to the system to take it from one minimum (the start state) to another (the end state) through the located saddle point. In the case of a maze, the (often discrete) action changes the position of the agent (by a fixed measure), but while locating minimum energy pathways, the physical problem demands a continuous action space. However, as in the case of a maze, an action changes the variables describing the system (be it physical coordinates or state variables) by a small measure.
As in the maze-solving problem, the agent tries to identify the pathway with the minimum energy barrier. If the number of steps is considered to be the cost incurred in a normal maze, then it is the energy along the pathway that is the cost of the transition event. Reward maps can vary depending on the maze considered, but in the original GridWorld problem, the agent was given a negative reward if the action led to a wall cell, and a zero reward for all non-terminal states (a discount factor
A comparison is attempted in Fig. 2. A smooth potential energy surface is coarse-grained to construct a maze, where all positions with a negative potential energy are shaded blue (possible move cells), while those with a positive potential energy are shaded red (representing walls). The initial state in the maze is marked yellow, while the final state is marked green. However, instead of classifying a grid cell of the constructed maze either as a wall or as a cell, one can discretize the state space and assign an energy value to a cell. An agent can then be trained to reach the final state starting from the initial state and collect the maximum sum of rewards along its path (minimizing the energy along the pathways requires assigning the negative of the energy as the reward for an action leading the agent to the cell). Since this is an episodic problem, one already runs into the problem where the agent moves back and forth between two adjacent cells, collecting rewards from each move in an attempt to maximize the sum of rewards collected, rather than reaching the final state and terminating the episode. For this simple setting, the problem is solved by rewarding the agent only the first time it visits a cell and terminating the episode after a fixed number of steps (in this case, 15). The energy profile of the pathway followed by the agent (inferred from the rewards collected in an episode) in this maze is plotted as the dashed green line in Fig. 2b. As can be seen, coarse-graining the potential energy surface into an
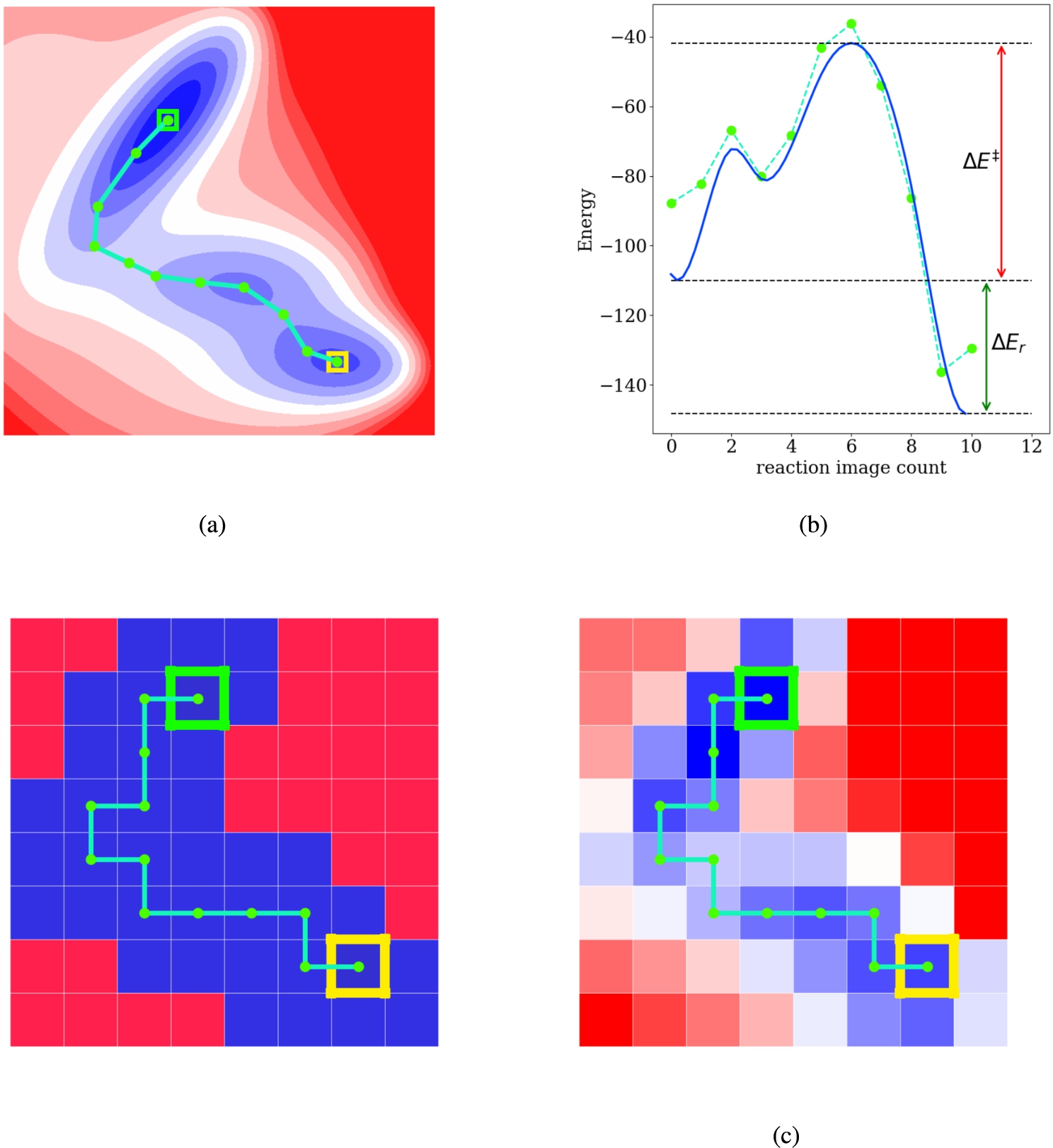
Estimating reaction barriers by modeling the potential energy surface as a maze: (a) the pathway with the lowest energy barrier as determined by a growing string method on the potential energy surface with 9 intermediate images. (b) the reaction profile, plotted as a solid blue line (interpolated to give a smooth curve) from the pathway determined by the growing string method. The reaction barrier is marked as
The problem of locating the minimum energy barrier for a transition has applications in physical phase transitions, synthesis plans for materials, activation energies for chemical reactions, and the conformational changes in biomolecules that lead to reactions inside cells. In most of these scenarios, the dynamics are governed by the kinetics of the system (rather than the thermodynamics) because the thermal energy of the system is much smaller than the energy barrier of the transition. This leads to the system spending most of its time around the minima, and some random large fluctuations in the system lead to a transition. This is precisely why transition events are rare and difficult to isolate and characterize with experimental methods. Moreover, these ultra-fast techniques can be applied to only a limited number of systems. Because transition events are rare, sampling them using Monte Carlo methods requires long simulation times, making them inefficient [6]. To sample the regions of the potential energy surface around the saddle point adequately, a large number of samples have to be drawn. Previous work has been done to identify the saddle point and determine the height of the transition barrier—transition path sampling [22], nudged elastic band [18], growing string method [21], to name a few—which use ideas from gradient descent. However, even for comparatively simple reactions, these methods are not always guaranteed to find the path with the energy barrier that is a global minimum because the initial guess for the pathway might be wrong and lead to a local minimum.
With the advent of deep learning and the use of neural nets as function approximators for complex mappings, there has been increased interest in the use of machine learning [37] to either guess the configuration of the saddle point along the pathway (whose energy can then be determined by standard ab initio methods) or directly determine the height of the energy barrier given the two endpoints of the transition. Graph neural networks [43], generative adversarial networks [30], gated recurrent neural networks [8], transformers [28], machine-learned potentials [17,20], and so on, have been used to optimize the pathway for such transitions.
Noting the superficial similarities between solving a maze and determining the transition pathway with the lowest energy barrier, it is proposed to use standard and tested deep reinforcement learning algorithms used to solve mazes in an attempt to solve the problem of finding minimum energy pathways. The problem is formulated as a min-cost optimization problem in the state space of the system. An actor function approximator suggests the action to be taken by the agent when it is in a particular state. A critic function approximator provides an estimate of the sum of rewards until the end of the episode from the new state after taking the action suggested by the actor. Actor-critic based reinforcement learning techniques have been shown to solve problems effectively, even in higher dimensions [48]. Neural nets are used as the actor and critic function approximators, and a randomly perturbed policy is used to facilitate exploration of the potential energy surface by the agent. Delayed policy updates and target policy averaging are used to stabilize learning, especially during the first few epochs, which are crucial to the optimal performance of the agent. This formulation is used to determine the barrier height of the optimal pathway in the Müller-Brown potential.
Section 2 describes the methods used to formulate the problem as a Markov decision process and the algorithm used to solve it. Section 3 elaborates on the experiments in which the formulated method is used to determine the barrier height of a transition on the Müller-Brown potential. Section 4 contains a short discussion of the work in the context of other similar studies, while Section 5 outlines the conclusions drawn from this work.
To solve the problem of finding a pathway with the lowest energy barrier for a transition using reinforcement learning, one has to model it as a Markov decision process. Any Markov decision process consists of (state, action, next state) tuples. In this case, the agent starts at the initial state (a local minimum) and perturbs the system (action) to reach a new state. Since the initial state was an energy minimum, the current state will have a higher energy. However, as in many sequential control problems, the reward is delayed. A series of perturbations that lead to states with higher energies might enable the agent to climb out of the local minimum into another one that contains the final state. By defining a suitable reward function and allowing the agent to explore the potential energy surface, it is expected that the agent will learn a path from the initial state to the final state that maximizes the rewards. If the reward function is defined properly, it should correspond to the pathway with the lowest energy barrier for the transition.
Once the problem is formulated as a Markov decision process, it can be solved by some reinforcement learning algorithm. In most reinforcement learning algorithms, this (state, action, reward, next state, next action) tuple is stored while the agent is learning. Twin Delayed Deep Deterministic Policy Gradient (TD3) [11] is a good start because it prevents overestimation of the state value function, which often leads the agent to exploit the errors in the value function and learn a suboptimal policy. Soft Actor Critic (SAC) [15] tries to blend the deterministic policy gradient with a stochastic policy optimization, promoting exploration by the agent. In practice, using a stochastic policy to tune exploration often accelerates the agent’s learning.
Markov decision process
The Markov decision process is defined on:
a state space a continuous action space
In a state
To determine the minimum energy barrier for a transition, the reward for an action taking the agent to state
Since both the state space and action space are continuous, an actor-critic based method, specifically the soft actor-critic (SAC), is used. Additionally, since the state space is continuous, the episode is deemed to have terminated when the difference between the current state and the target state is smaller than some tolerance,
Algorithm

Computing minimum energy barrier using SAC in environment
SAC, an off-policy learning algorithm with entropy regularization, is used to solve the formulated Markov Decision process because the inherent stochasticity in its policy facilitates exploration by the agent. Entropy regularization tries to balance maximizing the returns till the end of the episode with randomness in the policy driving the agent. The algorithm learns a behavior policy
The agent chooses an action
A replay buffer with a sufficiently large capacity is employed to increase the probability that independent and identically distributed samples are used to update the actor and two critic networks. The replay buffer (in line 3) is modeled as a deque where the first samples to be enqueued (which are the oldest) are also dequeued first, once the replay buffer has reached its capacity and new samples have to be added. Since an off-policy algorithm is used, the critic net parameters are updated by sampling a mini-batch from the replay buffer at each update step (line 13). Stochastic gradient descent is used to train the actor and the two critic nets.
The entropy coefficient α is adjusted over the course of training to encourage the agent to explore more when required and to exploit its knowledge at other times (line 18) [16]. However, some elements from the TD3 algorithm [11] are borrowed to improve the learning of the agent, namely delayed policy updates and target policy smoothing. Due to the delayed policy updates, the critic Q-nets are updated more frequently than the actor and the target Q-nets to allow the critic to learn faster and provide more precise estimates of the returns from the current state. To address the problem of instability in learning, especially in the first few episodes while training the agent, target critic nets are used. Initially, the critic nets are duplicated (line 2), and subsequently soft updates of these target nets are carried out after an interval of a certain number of steps (line 19). This provides more precise estimates for the state-action value function while computing the returns for a particular state in line 14. Adding noise to input during the training of a machine learning model often leads to improved performance because it acts as an
Parameters used while training the RL agen
The proposed algorithm is applied to determine the pathway with the minimum energy barrier on the Müller–Brown potential energy surface [33]. The Müller–Brown potential has been used to benchmark the performance of several algorithms that determine the minimum energy pathways, such as the molecular growing string method [12], Gaussian process regression for nudged elastic bands [25], and accelerated molecular dynamics [42]. Therefore, it is also used in this work to demonstrate the applicability of the proposed method. A custom
Results
The Müller–Brown potential is characterized by the following potential:
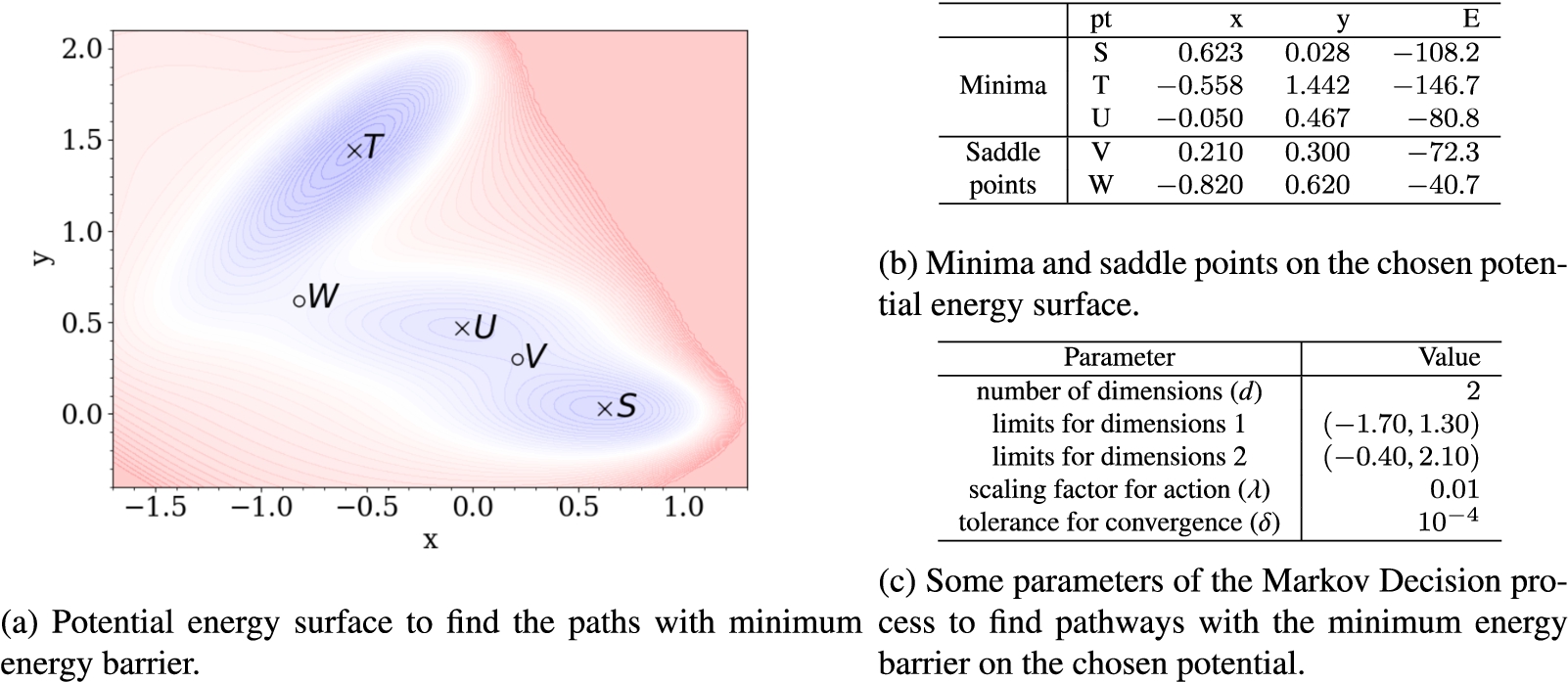
The environment in which the agent learns to find the path with the minimum energy barrier.
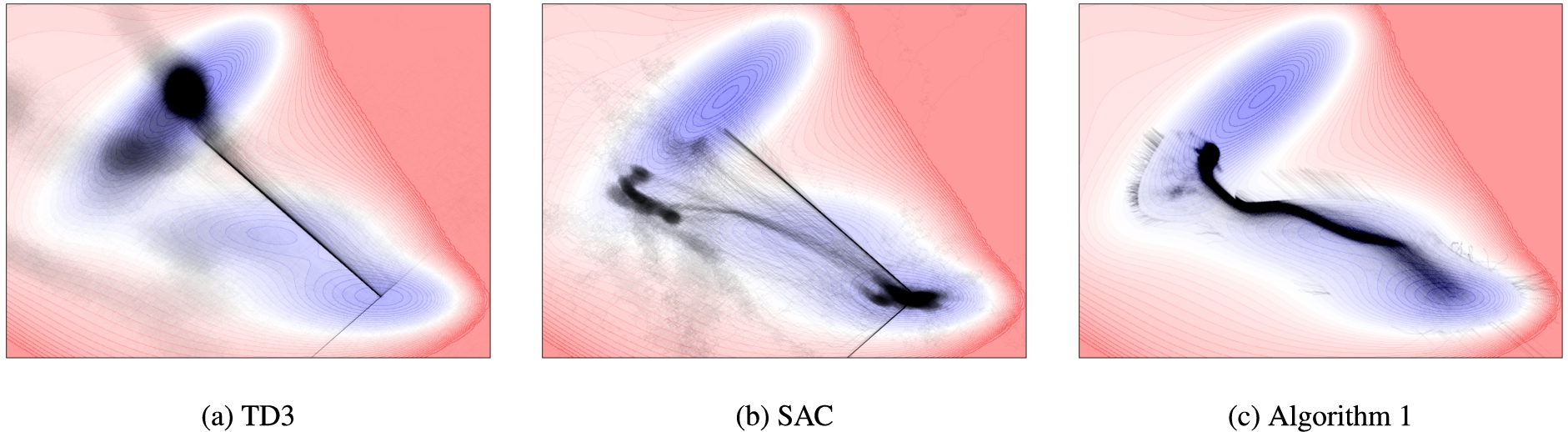
Scatter plot of the regions visited by the reinforcement learning agent during the course of learning while using different algorithms.
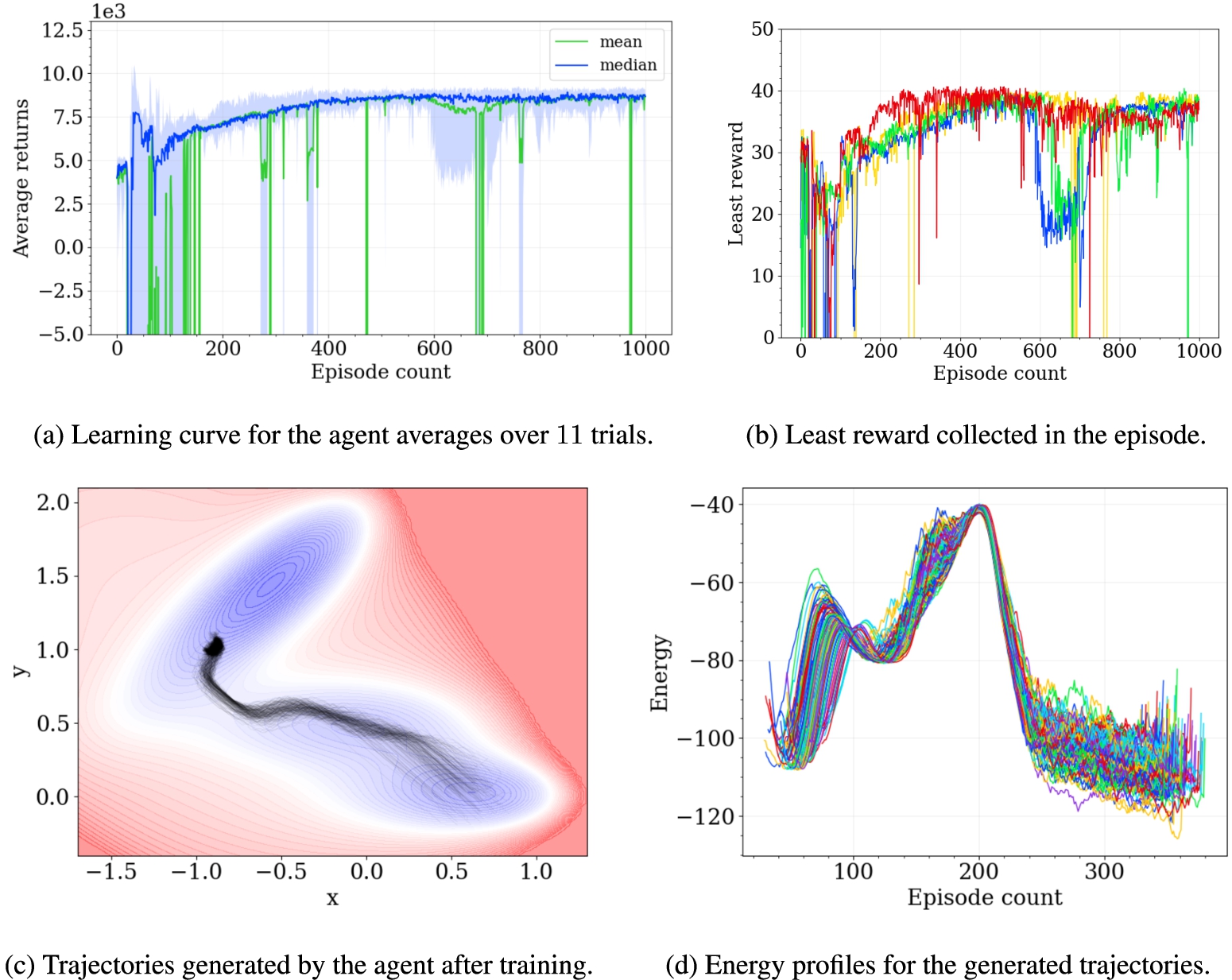
(a) The learning curve for the agent in the reinforcement learning environment. (b) The plot of the variation of the least reward collect by the agent in a step with the validation episode count. (c) Trajectories generated by the trained agent following the learnt policy along with the corresponding energy profiles (d).
Figure 4 shows scatter plots of the trajectories generated by various reinforcement learning algorithms: TD3 in Fig. 4a, SAC in Fig. 4b, and the proposed modified SAC algorithm in Fig. 4c. While the agent trained by the TD3 algorithm does reach the intended target state, it starts to exploit a flaw in the formulation of the MDP by trying to reach the vicinity of the final state quickly and staying near enough to it so that it collects rewards, but does not terminate the episode. This results in a high density in the plot along the straight line connecting the initial and final states and around the final state. It gives a much higher estimate than the correct minimum energy barrier for the transition. The agent trained using SAC shows improved performance, possibly due to the entropy regularizer forcing it to learn a more diverse policy (rather than one that would result in a straight line connecting the initial and final states). However, while generating trajectories in the testing environment, most of the trajectories did not leave the local minima in the vicinity of the start state. Moreover, the learned policy has high variance. The proposed Algorithm 1 learns a much more stable policy and confines itself to exploring the region with lower energies leading to the terminal state (specifically the vicinity of the saddle point) rather than the entire environment. It explores sufficiently and then exploits the state-action values learned appropriately, providing better estimates of the energy barrier for the transition.
The learning curve for the agent under Algorithm 1 is shown in Fig. 5a. The data for this curve were generated by allowing the agent to solve the MDP in evaluation mode once every 10 training episodes, where the neural networks were not updated to monitor the agent’s learning. The ascending learning curve indicates that the agent gradually learns to find a path to the terminal state that maximizes the rewards. The blue line represents the median reward, while the green line shows the mean reward over 11 training iterations, each consisting of
Performance of the trained agent
In Fig. 5c, an ensemble of paths generated by the trained RL agent is plotted on the surface of the potential energy, with the starting points slightly perturbed from
Early stopping during the training of a neural network has often been found to be helpful in scenarios where continued training worsens the performance of the model [1,34]. Borrowing the idea of early stopping, the agent’s training was stopped when the minimum reward collected by the agent (corresponding to the maximum energy along the pathway) started increasing again. This behavior was observed in the case of the agent, as plotted in Fig. 5b. The minimum reward collected by the agent during the episode increases initially (indicating that the agent finds a pathway with a progressively better energy barrier) until the 500th validation step before decreasing slightly. Plots for only 4 of the 11 trials are shown for clarity. This might indicate that the agent does not improve its performance after that step. Furthermore, the learning curve in Fig. 5a shows an increase in spread after 500 iterations. These reasons led to using the model after 500 iterations to generate the final trajectory in test mode to estimate the energy barrier for the reaction. The energy profiles along the generated trajectories are plotted in Fig. 5d aligned by the maximum of the profiles (and not by the start of the trajectories) for better visualization. The energy barrier predicted for the transition of interest is
On the choice of the scaling factor
The scaling factor, λ, scales the action for the agent. In most cases, it is used to adjust the step size for the agent while keeping the action space within some standard interval (
As noted at the end of Section 2.1, the formulated Markov decision process suffers from the drawback that agent might stay at a small distance
For example, if the maximum number of steps for the maze in Fig. 2 is limited to 5, then the agent can never reach the terminal state. As an analogy, decreasing the cell size, resulting in increasing the number of cells in the maze, would be equivalent to decreasing λ in the current case.
Several modifications were made to the standard SAC algorithm to be used in this particular case (highlighted in blue in Algorithm 1). Studies were performed to understand the contribution of each individual component to the working of the algorithm in this particular environment by comparing the performance of the algorithm with different hyperparameters for a component. The parameters for one modification were varied, keeping the parameters for the other two modifications unchanged from the fine-tuned algorithm. Each modification and its contribution to the overall learning of the agent are described in the following sections. The mean and the standard deviation of the returns from the last 100 training steps for each modification of the existing algorithm are listed in Table 6a to compare the performance of the agents. The modification that leads to the highest returns is highlighted.
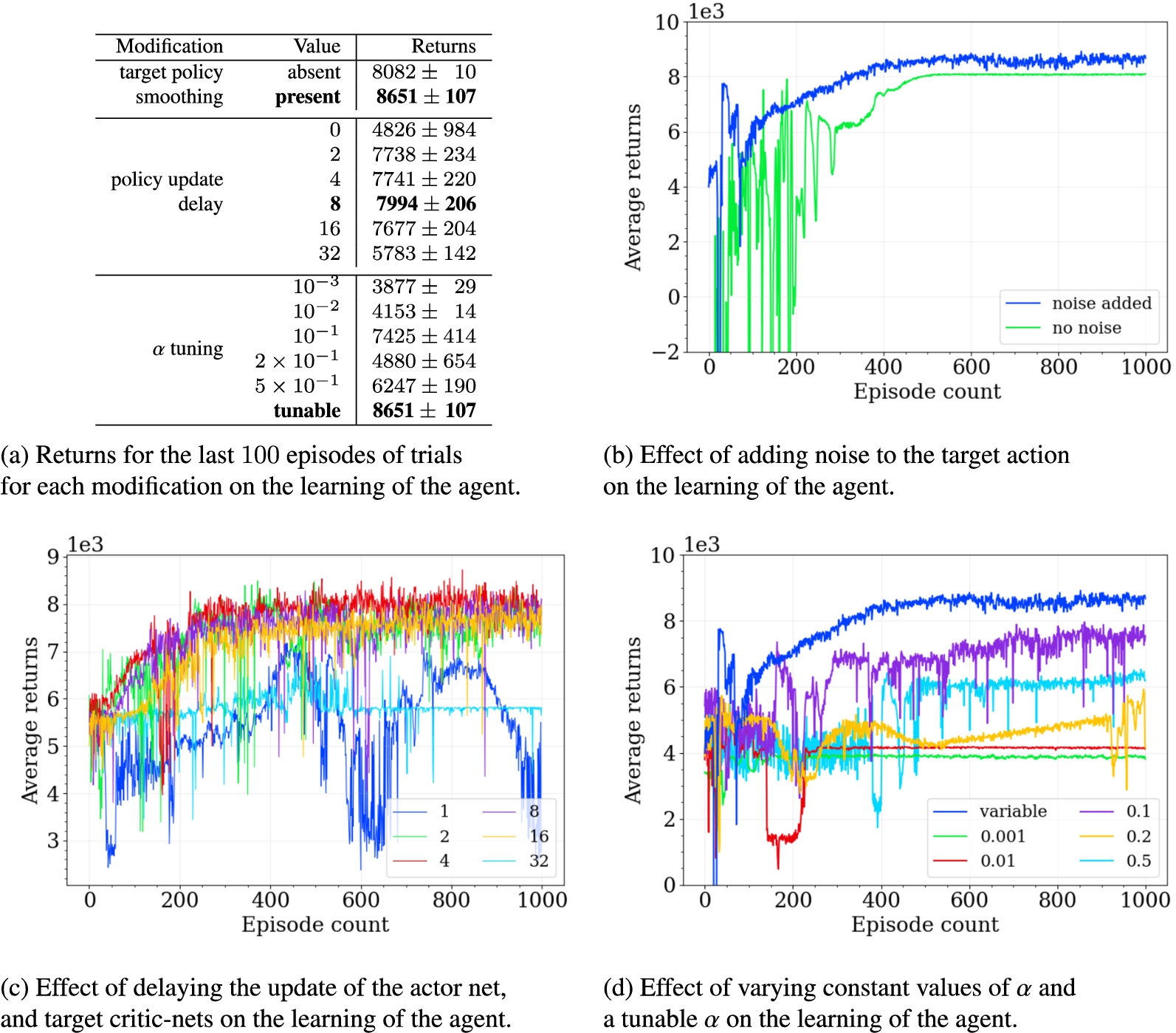
Effect of the various modifications to the SAC algorithm on the learning of the agent.
Injecting random noise (with a standard deviation σ) into the action used in the environment (in line 9 of Algorithm 1) encourages the agent to explore, while adding noise to the actions used to calculate the targets (in line 14 of Algorithm 1) acts as a regularizer, forcing the agent to generalize over similar actions. In the early stages of training, the critic Q-nets can assign inaccurate values to some state-action pairs, and the addition of noise prevents the actor from rote learning these actions based on incorrect feedback. On the other hand, to avoid the actor taking a too random action, the action is clipped by some maximum value for the noise (as done in lines 9 and 14 of Algorithm 1). The effect of adding noise to spread the state-action value over a range of actions is plotted in Fig. 6b. Adding noise leads to the agent learning a policy with less variance in the early learning stages and a more consistent performance.
Delayed policy updates
Delaying the updates for the actor nets and the target Q-nets (in lines 17 and 19 of Algorithm 1) allows the critic Q-nets to update more frequently and learn at a faster rate, so that they can provide a reasonable estimate of the value for a state-action pair before it is used to guide the policy learned by the actor net. The parameters of the critic Q-nets might often change abruptly early on while learning, undoing whatever the agent had learned (catastrophic failure). Therefore, delayed updates of the actor net allow it to use more stable state-action values from the critic nets to guide the policy learned by it. The effect of varying intervals of delay for the actor update on the learning of the agent is plotted in Fig. 6c. Updating the actor net for every update of the critic nets led to a policy with a high variance (blue plot). Delaying the update of the actor net to once every 2 updates of the critic resulted in the agent learning a policy that provided higher returns but still had a high variance (green plot). Delaying the update of the actor further (once every 4 and 8 updates of the critic net plotted as the red and magenta curves, respectively) further improved the performance of the agent. One can notice the lower variance in the policy of the agent during the early stages (first 200 episodes of the magenta curve) for the agent which updates the actor net and target critic nets once every 8 updates of the critic nets. However, delaying the updates for too long intervals would cripple the learning of the actor. The performance of the agent suffers when the update of the actor is delayed to once every 16 updates of the critic nets (yellow curve) and the agent fails to learn when the update of the actor net is further delayed to once every 32 updates of the critic nets (cyan curve).
Tuning the entropy coefficient
The entropy coefficient α can be tuned as the agent learns (as done in line 18 of Algorithm 1), which overcomes the problem of finding the optimal value for the hyperparameter α [16]. Moreover, simply fixing α to a single value might lead to a poor solution because the agent learns a policy over time: it should still explore regions where it has not learned the optimal action, but the policy should not change much in regions already explored by the agent that have higher returns. In Fig. 6d, the effect of the variation of the hyperparameter α on the learning of the agent is compared. As can be seen, a tunable α allows the agent to learn steadily, encouraging it to explore more in the earlier episodes and exploiting the returns from these explored regions in the latter episodes, resulting in a more stable learning curve (blue curve). A too low value of α, such as
Some more surfaces
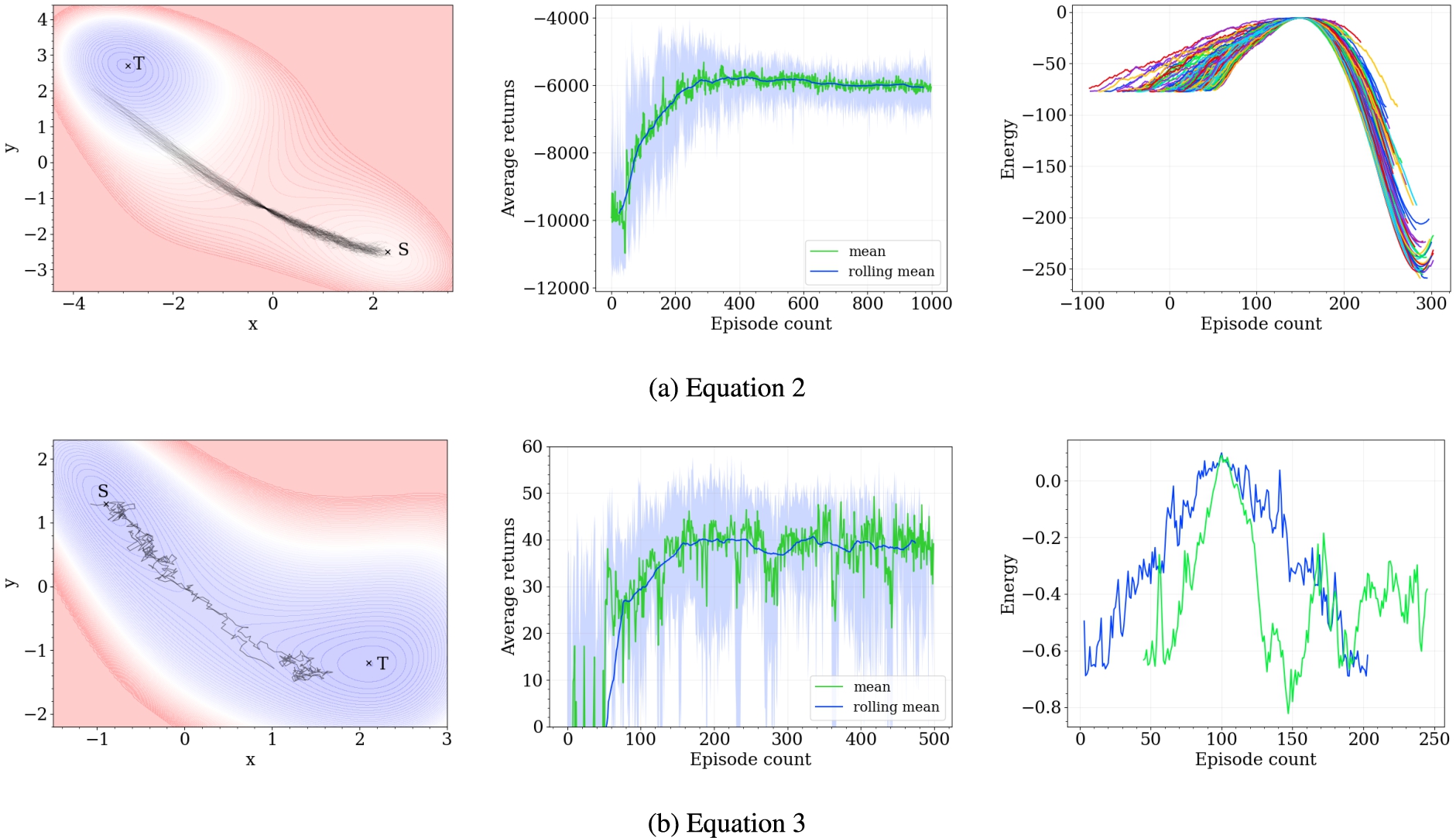
Here we demonstrate the results by an agent trained by Algorithm 1 on some more two-dimensional potential energy surfaces with two potential wells.
Previous work in determining transition pathways using deep learning or reinforcement learning techniques includes formulating the problem as a shooting game solved using deep reinforcement learning [47]. The authors in [47] sample higher energy configurations and shoot trajectories with randomized initial momenta in opposite directions, expecting them to converge at the two desired local minima. In contrast, the method proposed here starts from a minimum on the potential energy surface and attempts to generate a trajectory to another minimum. Additionally, in [19], the problem is formulated as a stochastic optimal control problem, where neural network policies learn a controlled and optimized stochastic process to sample the transition pathway using machine learning techniques. Stochastic diffusion models have also been used to model elementary reactions and generate the structure of the transition state, preserving the required physical symmetries in the process [9]. Furthermore, the problem of finding transition pathways was recast into a finite-time horizon control optimization problem using the variational principle and solved using reinforcement learning in [14]. Moreover, a hybrid-DDPG algorithm was implemented in [32] to identify the global minimum on the Müller–Brown potential, but did not identify pathways between minima as in this work. Recent work [2] used an actor-critic reinforcement learning framework to optimize molecular structures and calculate minimum energy pathways for two reactions.
There has also been previous work [49] to optimize chemical reactions by perturbing the experimental conditions to achieve better selectivity, purity, or cost for the reaction using deep reinforcement learning. While this approach has macroscopic applications in laboratory settings, the method proposed here focuses on a much narrower problem: given a potential energy surface, how well can the minimum energy barrier be estimated for a transition between two minima? Deep reinforcement learning has also been used to find a minimum energy pathway consisting of multiple elementary transitions in catalytic reaction networks [26]. While the free energy barrier for a transition (which is mapped to a reward) between two states is calculated using density functional theory (DFT) with VASP software in [26,27], the objective of the proposed method in this work is to estimate that free energy barrier using an agent trained via deep reinforcement learning, which does not require quantum mechanical calculations. In addition, reinforcement learning techniques are implemented in [46] to minimize the cost of synthesis pathways (consisting of multiple elementary transitions) considering the price of the starting molecules and the atom economy of individual transitions. Furthermore, a reinforcement learning approach is used in [24] to search for process routes that optimize economic profit for a Markov decision process that models the thermodynamic state space as a graph.
Conclusion
Advancements in reinforcement learning algorithms based on the state-action value function have led to their application in diverse sequential control tasks such as Atari games, autonomous driving, robot movement control, and more physical domains [3,4,13,44]. This project formulated the problem of finding the minimum energy barrier for a transition between two local minima as a cost minimization problem, solved using a reinforcement learning setup with neural networks as function approximators for the actor and critics. A stochastic policy was employed to facilitate the exploration by the agent, further perturbed by random noise. Target networks, delayed updates of the actor, and a replay buffer were used to stabilize the learning process for the reinforcement learning agent. While the proposed framework samples the region around the saddle point sufficiently, providing a good estimate of the energy barrier for the transition, there is definitely scope for improvement. The method has been applied only to a two-dimensional system, but as a future work, it could be extended to more realistic and higher-dimensional systems. One promising alternative would be to use max-reward reinforcement learning [41], as it aligns well with the objective of maximizing the minimum reward obtained in an episode. However, a drawback of this method is that the reinforcement learning agent must be trained from scratch if one needs to find minimum energy pathways on a different potential energy surface. In other words, an agent trained on one potential energy surface cannot be used to determine the minimum energy barrier on a different surface, similar to how an agent trained in one
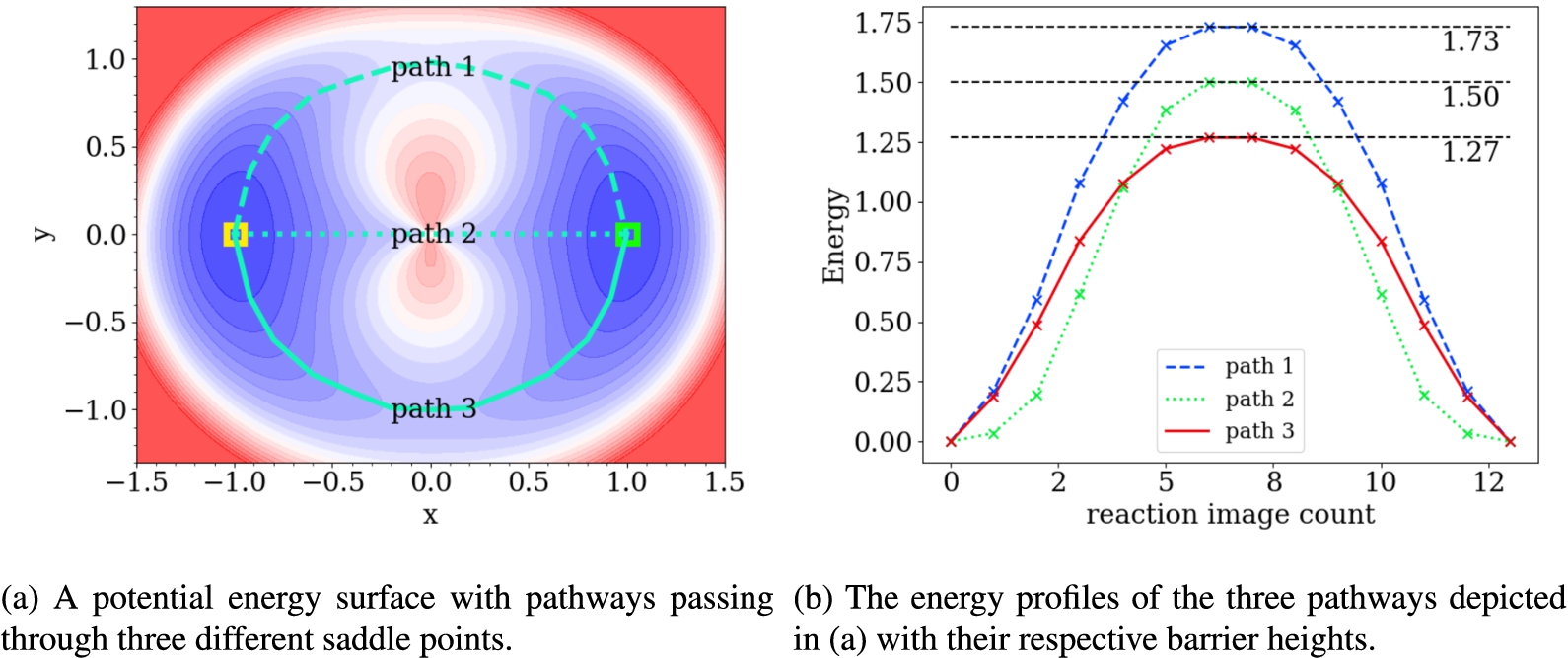
(a) Three possible pathways on a potential energy surface given by equation (4) passing though different saddle points and (b) the energy profile for the three possible transition pathways.
This work differs from previous work that uses reinforcement learning [2,14,19,47] by providing a much simpler formulation of the problem, using the energy of the state directly as the reward while searching for transition pathways with the minimum energy barrier. One of the main advantages of using a reinforcement learning based method is that, unlike traditional methods such as the nudged elastic band or the growing string method, it does not require an initial guess for the trajectory. Traditional methods use energy gradient information along the trajectory to iteratively improve to a trajectory with better energetics. However, the success of these methods depends on the initial guess for the trajectory, and gradient-based methods might get stuck in a local minimum. As shown on the potential energy surface represented by Equation (4) in Fig. 8, there may be multiple saddle points between two minima. The trajectory to which a nudged elastic band or a growing string method converges depends on the initial guess of the starting trajectory. Typically, the initial guess trajectory is a simple linear interpolation between the starting and ending points, which leads to the dotted trajectory (path 2 with a barrier of 1.50 units). Traditional gradient-based methods report this trajectory as the optimal one because the local gradients along the trajectory are minimal and cannot be improved by perturbation. However, the reinforcement learning-based method proposed in this work identifies the trajectory represented by a solid line (Path 3 with a barrier of 1.27 units) as the minimum energy pathway. The suboptimal solution overestimates the energy barrier for the transition by
Footnotes
Acknowledgements
The author would like to gratefully acknowledge the computational resources provided by Institut for Matematik og Datalogi, Syddansk Universitet for this work. The work was also supported by the European Union and supported by the Swiss State Secretariat for Education, Research and Innovation (SERI) under contract numbers 22.00017 and 22.00034 (Horizon Europe Research and Innovation Project CORENET). The author also thanks the two reviewers for their insightful suggestions to improve the manuscript.
Additional heatmap plots
A few experiments by varying the scaling factor for the action, λ, and the number of steps in an episode, n, were performed. The regions of the potential energy surface explored by the agent under those conditions are plotted in Fig. 9. With a small value for λ, the agent does not climb out of the local minima containing the initial state (Fig. 9(a)), while with a large value for λ, the agent jumps over high energy regions of the potential energy surface in the bid to reach a low energy state faster (Fig. 9(f)), giving an incorrect estimate of the energy barrier for the transition.