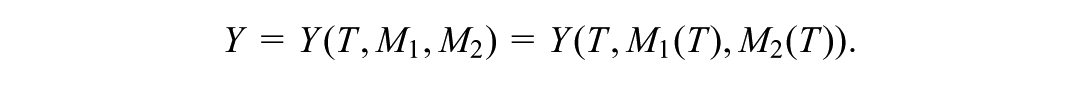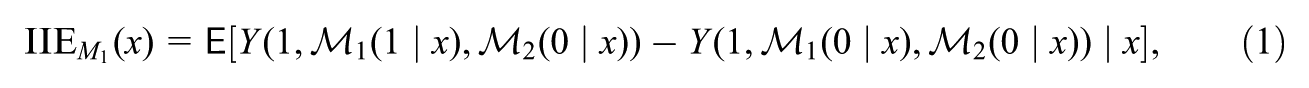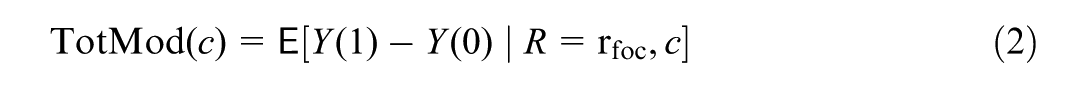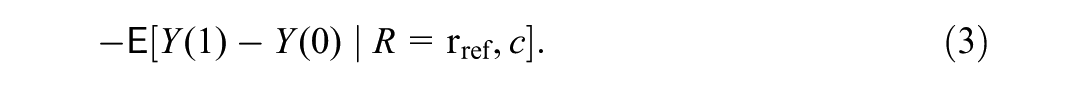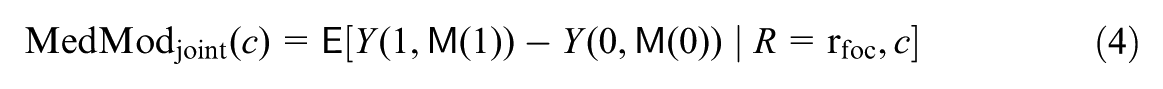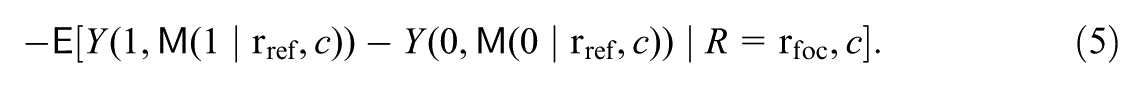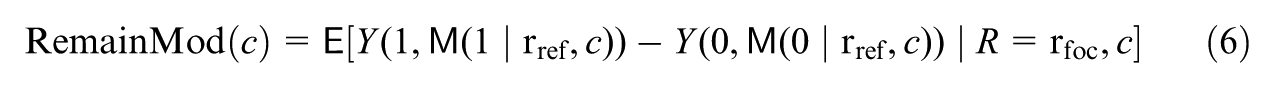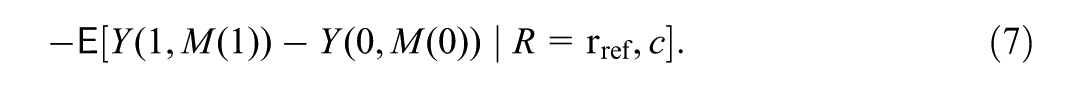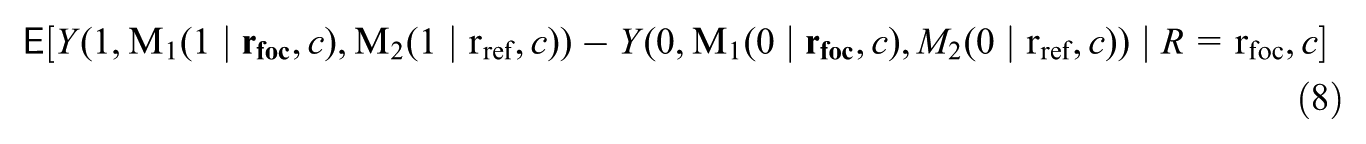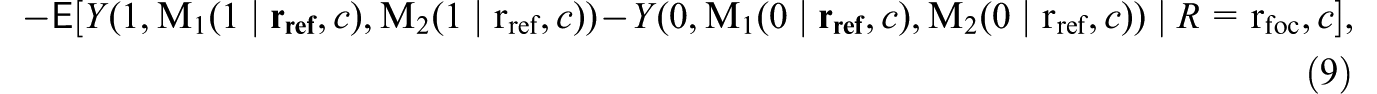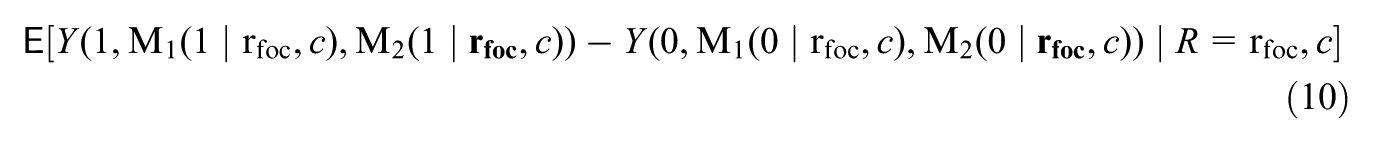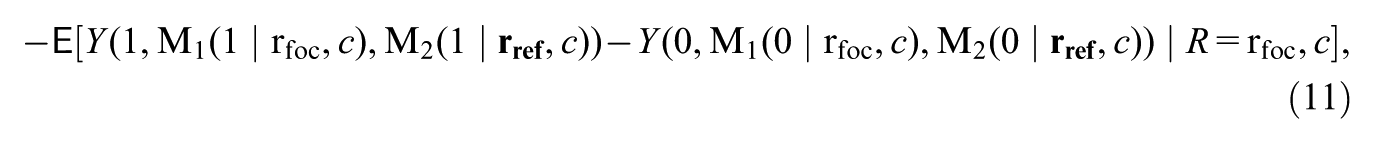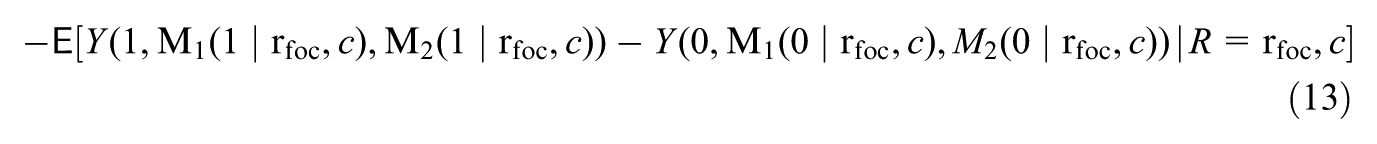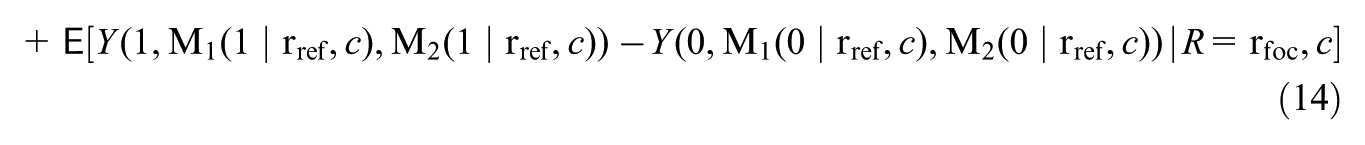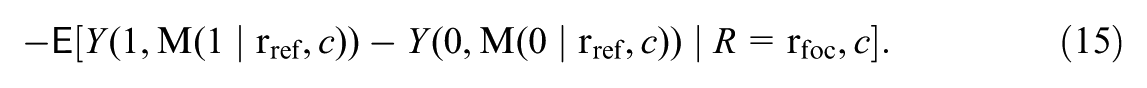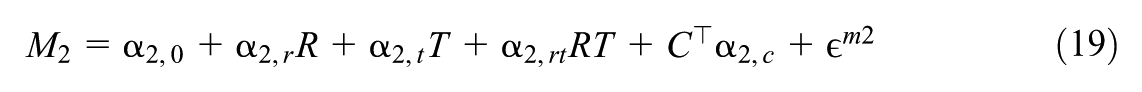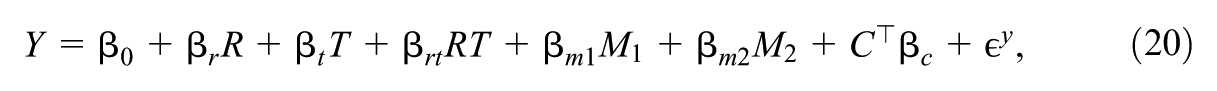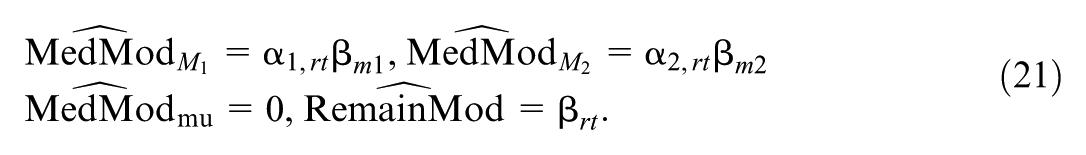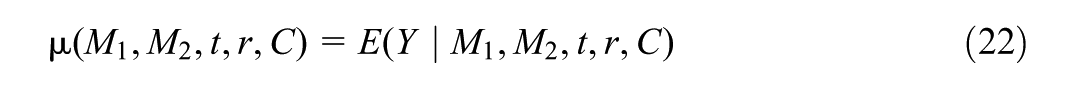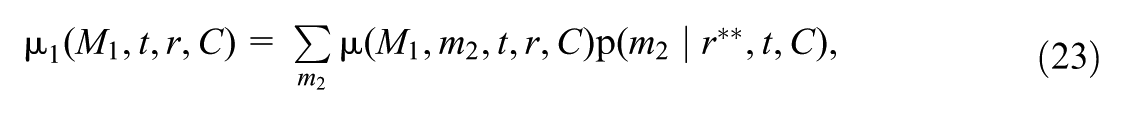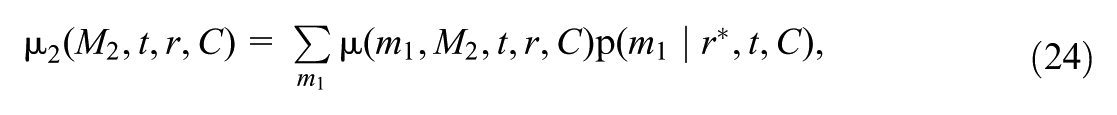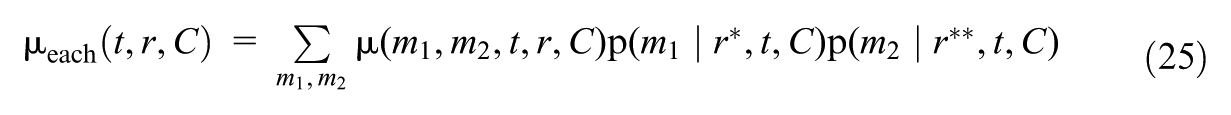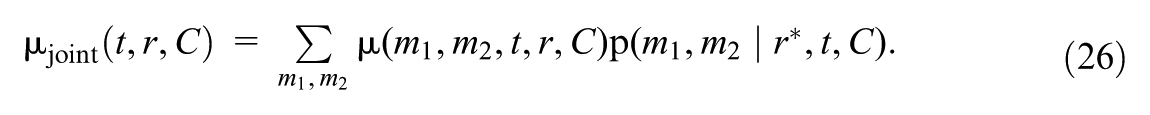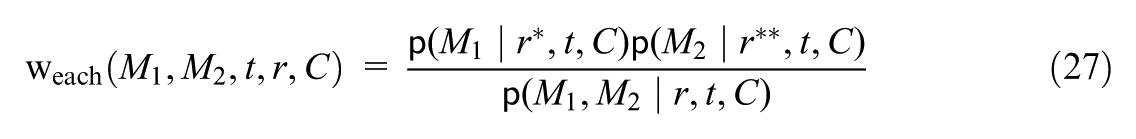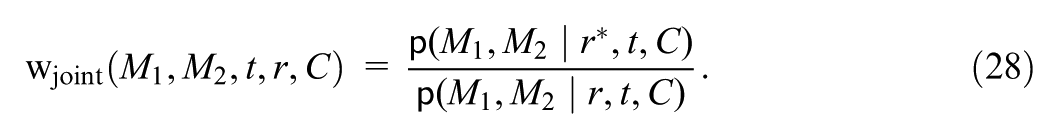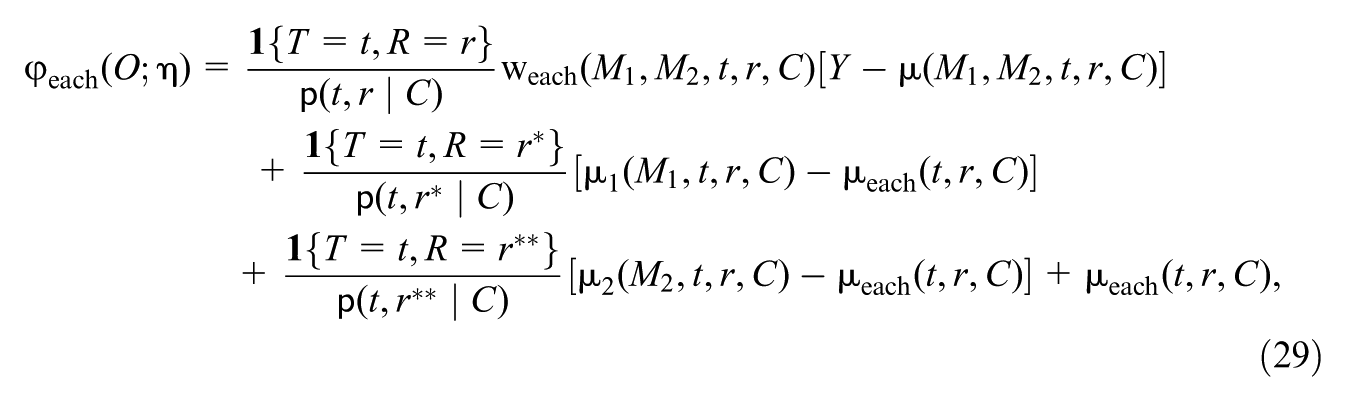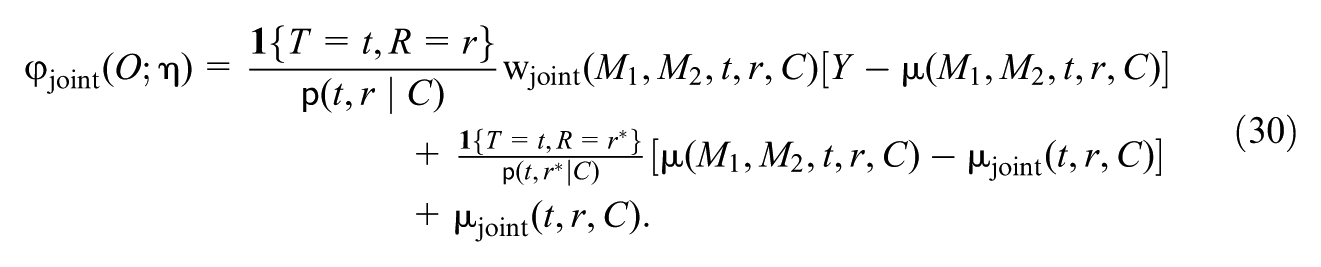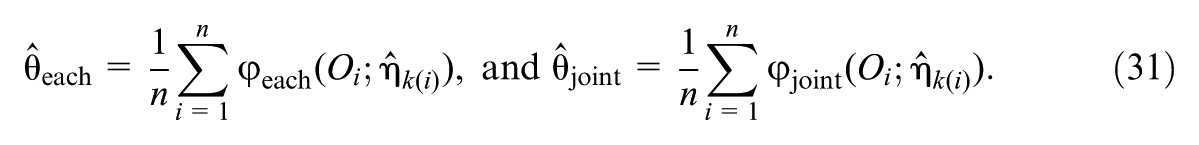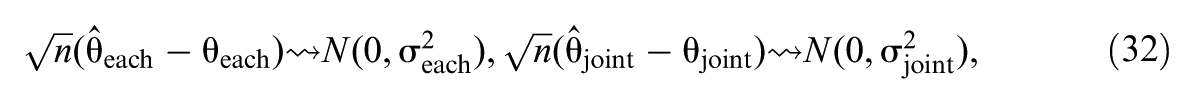Understanding how effect heterogeneity across subgroups is mediated by multiple mediators is important yet under-studied. Despite the growing popularity of causal mediation analysis, existing methods rarely address the mediation of moderated treatment effects, particularly when multiple mediators are of interest. This study develops a causal inference approach for mediated moderation analysis with multiple mediators, decomposing a moderated treatment effect into mediated moderation effects and remaining moderation. We present causal estimands and extend a multiply robust estimator that can incorporate machine learning techniques to relax modeling assumptions. Simulations were conducted to evaluate the method’s performance. An empirical example about adolescent mental health illustrates the application. We hope this study provides a novel causal inference-based approach to understanding multiple mediating mechanisms underlying subgroup heterogeneity in treatment effects.
Mediated moderation analyses are widely used to examine the extent to which a between-subgroup difference in the effect of a treatment on an outcome can be accounted for by between-subgroup differences in effects of the treatment on mediators (Fairchild & MacKinnon, 2009; Morgan-Lopez et al., 2003; Muller et al., 2005). It helps researchers address questions such as “why do treatment effects vary across subgroups” and thereby deepen understandings about effect heterogeneity. For example, mediated moderation analysis was used to investigate how the socioeconomic status (SES) differences in the effect of a stressful exposure on mental health could be accounted by mediators related to psychosocial resources (Miller et al., 2013).
To conduct mediated moderation analyses, most existing methods rely on conventional parametric modeling approaches, such as parametric structural equation modeling (Baron & Kenny, 1986; Fairchild & MacKinnon, 2009; Hayes, 2013; Muller et al., 2005). Despite popularity of the parametric modeling-based approaches, they lack formal frameworks to clarify the assumptions under which the estimates have a causal interpretation. Over the past decades, causal inference methods have been fast-growing, which provide frameworks (e.g., potential outcomes; Rubin, 1974, 1978) that enable researchers to define causal effects and explicate the assumptions for identifying causal effects from data. More recently, causal inference methods have been extended to mediation analysis, which contributes various tools to define and identify mediation effects (e.g., the natural indirect effect; Pearl, 2001; Robins & Greenland, 1992) without requiring any parametric models, as well as robust and flexible estimation approaches (e.g., machine learning-based estimators; Benkeser & Ran, 2021) for the defined effects (Hong, 2015; Imai et al., 2010; VanderWeele, 2015).
However, such causal inference-based methods for mediated moderation analysis are underdeveloped. An exception is Liu et al. (2025), which developed causal estimands and robust estimation methods for a single mediator. Despite the contribution of their work, in practice, mediated moderation analyses in behavioral sciences often involve multiple mediators, in which the research questions concern the extent to which each mediator contributes to the effect moderation between different subgroups. To date, no studies have developed methods for addressing multiple mediators in mediated-moderation analysis using causal inference approaches.
To reduce the methodological gap, this study aims to develop causal estimands, identification results, and robust estimation methods that can incorporate machine learning approaches for a common two-mediators scenario in mediated moderation analysis. Specifically, we consider the subgroup status to be an observed pretreatment variable, which is common in studies about effect moderation (Fairchild & MacKinnon, 2009; Qin & Wang, 2023). Furthermore, following the distinction between “effect moderation” (or effect modification) and “interaction” in the causal inference literature (VanderWeele, 2009), our study focuses on the former, that is, we consider that manipulating the subgroup status is of no substantive interest, and the substantive interest concerns how the effect of treatment varies between the subgroups. This focus naturally allows non-manipulable subgroup status (e.g., sex, race/ethnicity) to be used in our methods.
In the rest of this manuscript, we first define causal estimands for mediated moderation with two mediators, based on the interventional effects approach (Liu et al., 2025; Vansteelandt & Daniel, 2017) reviewed in the next section. Then, we present identification results for the defined causal estimands. Subsequently, we develop methods for estimation and inference by extending nonparametric estimators from the causal mediation literature (Benkeser & Ran, 2021; Rudolph et al., 2024). Under achievable conditions, the developed methods provide multiple robustness in consistency and asymptotically proper statistical inferences even with the use of machine learning models. A simulation study is presented in Supplementary Appendix I (available in the online version of this article). To illustrate the application, we provide an empirical example on adolescent mental health. We conclude by discussing limitations of the current study and future research directions.
Causal Estimands of Mediated Moderation
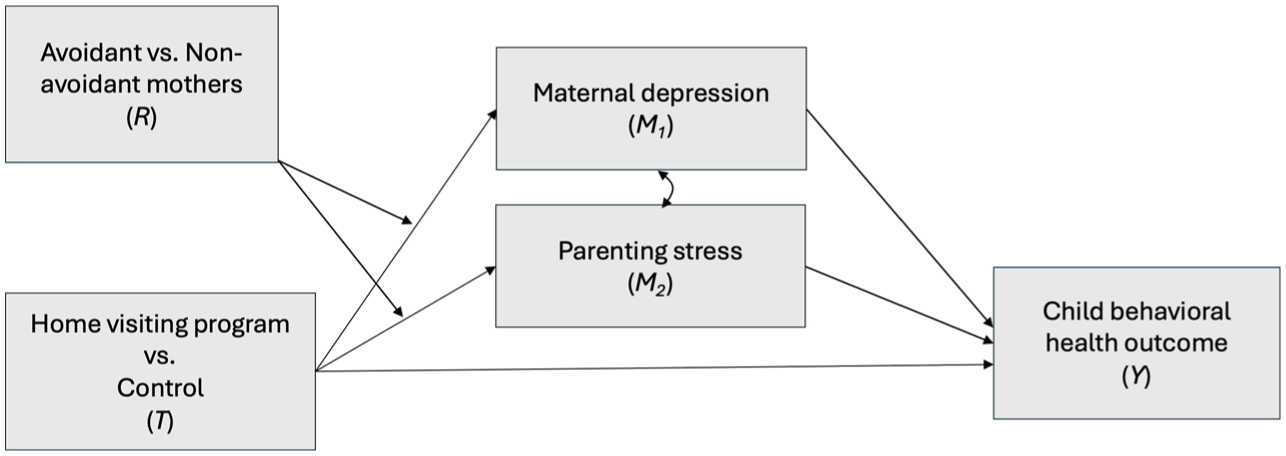
In this section, we define causal estimands of mediated moderation within the potential outcome framework (Rubin, 1974, 1978). To ease presentation, we introduce a toy example (Figure 1) about the moderation of the effect of a home visiting program (treatment : 1 = program, 0 = no program) on child outcome between avoidant and non-avoidant subgroups (Cluxton-Keller et al., 2014). Specifically, in the avoidant subgroup (coded as , our focal subgroup), the mothers showed an avoidant characteristic at baseline (i.e., pretreatment), an attachment characteristic reflecting discomforts with trust; in the non-avoidant subgroup (coded as , our reference subgroup), the mothers had no such characteristic at baseline. While the program effect was beneficial for the non-avoidant subgroup, the avoidant subgroup experienced no such benefits. To investigate potential mediating pathways for extending the program benefits to the avoidant subgroup, two mediators were hypothesized: maternal depression and parenting stress ( and , respectively), which were concurrently measured during follow-up. The hypothesis was that, perhaps, compared with the non-avoidant subgroup, the avoidant subgroup experienced less beneficial (or even adverse) program effects on maternal depression and/or parenting stress, which, in turn, contributed to the less beneficial program effect on the child’s outcome.
Conceptual illustration of the mediated moderation scenario in the toy example.
Let and denote, respectively, the potential mediators for and under treatment value , for example, the maternal depression and parenting stress levels that a mother would experience under the home visiting program () or under no program (). Let denote the potential outcome if the treatment , and mediators and were set to values , , and , respectively. These definitions require the stable unit treatment value assumption (Rubin, 1980, 1986), which assumes that (a) there are no multiple versions of each treatment value and (b) there is no interference among individuals. Under this assumption, the observed mediators equal the potential mediators under the observed value of the treatment variable, and ; the observed outcome equals the potential outcome under the observed values of the treatment and mediators,
A Brief Review of the Interventional Indirect Effects with Multiple Mediatorsand the Decomposition of Total Moderation
To ease introducing our approach, which builds on the interventional effects defined in Vansteelandt and Daniel (2017) and Liu et al. (2025), we briefly review the effect definitions in these prior studies. Then, we define our estimands in the next subsection.
Interventional Indirect Effects with Multiple Mediators
Considering two mediators, Vansteelandt and Daniel (2017) decomposed the total effect of treatment on into four components: the Interventional Indirect Effects (IIEs) via and via , the IIE due to mutual dependence between and , and the interventional direct effect of on not through the mediators. Below, we review the definition of the IIE via , which allows us to illustrate how we build on the definitions in Vansteelandt and Daniel (2017) to define mediated moderation effects with two mediators.
Let denote a set of pretreatment variables (e.g., in Figure 1, , where contains the covariates), and let denote the distribution of in the population. The IIE of treatment on outcome via mediator defined in Vansteelandt and Daniel (2017) can be written as , with
where represents the potential outcome of an individual if the treatment is assigned to value and mediators and are assigned as two independent random draws from, respectively, the potential marginal distribution of under treatment value given covariate value and the potential marginal distribution of under treatment value given covariate value . Similarly, represents the potential outcome if is assigned to value , and and are assigned as two independent random draws from, respectively, the potential marginal distribution of and that of under treatment value given covariate value . Supplementary Appendix A (available in the online version of this article) provides the mathematical definition of that explicitly expresses it in terms of the mediator distributions of interest. Throughout the main text, for notational simplicity, we use summation notation such as (where is a function) to represent the corresponding integral (where is a dominating measure for the distribution of ).
The effect defined above (Equation 1) corresponds to an indirect effect via alone, in the sense that it measures the expected difference in the outcome due to shifting the distribution of from its potential distribution under treatment value to that under treatment value , while the treatment is fixed and the distribution of the other mediator is also fixed. Thus, this effect captures, within strata of covariates, the part of the potential outcome difference between two treatment values ( vs. ) that is attributable to the difference between the potential distributions of under these two different treatment values.
Building on this definition (Equation 1), we define the mediated moderation via each mediator (e.g., ) by instead contrasting the potential distributions of between individuals in different subgroups under each treatment value, while the subgroup status is fixed and the potential distribution of the other mediator is also fixed. Similarly, we extend the other definitions in Vansteelandt and Daniel (2017) and define the mediated moderation via and due to the mediators’ mutual dependence.
As described later, these separate mediated moderation effects via , via , and due to their mutual dependence decompose the mediated moderation defined in Liu et al. (2025) when treating as a single, joint mediator vector; the definition in Liu et al. (2025) is reviewed next.
Decomposition of Total Moderation
Liu et al. (2025) decomposed the total moderation into the mediated moderation via mediator and the remaining moderation. Specifically, the total moderation, , is defined by contrasting the treatment effects for subgroups vs. with balanced distributions of pretreatment covariates : , where represents the distribution of the covariates in the population and, letting denote the potential outcome under treatment value ,
In our example (Figure 1), quantifies the moderation in the home visiting treatment effect between the avoidant versus non-avoidant subgroups ( vs. ), controlling for subgroup differences in pretreatment covariates.
To decompose the total moderation, consider the potential outcomes for the avoidant subgroup if their mediator levels were each set as a random draw from the distribution of potential mediator levels of the non-avoidant subgroup , within covariate stratum . Denote this random draw as for , which is drawn from the distribution with .
The mediated moderation via , , is defined as , where
measures the change in the treatment effect for the focal subgroup if their mediator levels were set to the levels drawn from the reference subgroup , within strata of the covariates. Then, the remaining moderation, , considers the moderation that would remain under this counterfactual scenario, that is: , where
measures the moderation in the treatment effect that would still remain if the potential mediator distributions among the focal subgroup were shifted to the distributions among the reference subgroup , within strata of the covariates. Supplementary Appendix A (available in the online version of this article) provides the mathematical definitions of the above two estimands that explicitly express them in terms of the mediator distributions of interest.
The mediated and remaining moderation decompose the total moderation, . This follows by noticing the equality . Inspecting this decomposition, and captures, respectively, the treatment effect moderation that would reduce and that would remain, if the subgroups were equalized in the potential distributions of mediator within strata of the covariates.
This decomposition in Liu et al. (2025), however, provides little insights into the role of each mediator in mediating the heterogeneity (i.e., moderation).
Mediated Moderation via Each Mediator
To disentangle the role of each mediator, we extend Vansteelandt and Daniel (2017) and decompose the jointly mediated moderation, , into three components: the mediated moderation via , via , and due to the mediators’ mutual dependence.
As described earlier, we define the mediated moderation via (or ) by contrasting the potential distributions of mediator (or ) between the two subgroups. Specifically, for , we use to denote a random draw from , the potential distribution of mediator among individuals in subgroup within the covariate stratum if they were assigned to treatment value . Analogously, for mediator , we use to denote a random draw from .
We define the mediated moderation via as , where
where the highlighted parts (in bold) are contrasted between the first and the second lines. This effect expresses the change in the treatment effect for the focal subgroup , if, under each treatment value, the distribution of mediator were shifted from the mediator’s potential distribution among them to that among the reference subgroup (given covariates), while holding the distribution of at its potential distribution among (given covariates).
captures the moderated treatment effect for the focal (e.g., avoidant) subgroup due to the between-subgroup difference in the potential distribution of mediator (e.g., maternal depression) under each treatment value, while the potential distribution of the other mediator () under each treatment value is fixed. Specifically, in Equation (8) of the definition, the distribution of is kept at its potential distribution among subgroup , by assigning as a random draw from this distribution (i.e., , for }); this is contrasted with Equation (9), where the distribution of is set to its potential distribution among subgroup . In both lines, the potential distribution of under each treatment value is fixed to that among a specific subgroup; similarly, the subgroup among which different potential outcomes are compared is always the focal subgroup.
Corresponding to the definition for , we define the mediated moderation via mediator as , where
where the highlighted parts (in bold) are contrasted between the first and the second lines. Similar to , expresses the change in the treatment effect for the focal subgroup , if the distribution of under each treatment value were shifted from its potential distribution among to that among , while fixing the distribution of under each treatment value at its potential distribution among . Supplementary Appendix A (available in the online version of this article) provides the mathematical definitions of and , which explicitly express them in terms of the mediator distributions of interest.
The above definitions of and consider the two mediators independently; they omit how the dependence between mediators, which may differ between subgroups, contributes to the effect moderation. This contribution is captured by the last estimand, the mediated moderation due to mediators’ mutual dependence, which is defined as , where
expresses the change in the treatment effect for the focal subgroup , if under each treatment value, the dependence of potential levels of and were shifted from the dependence strength among them (as captured by Equations 12–13) to the dependence strength among the reference subgroup (as captured by Equations 14–15), within each stratum of covariates.
The three mediated moderation effects defined here, plus the remaining moderation, achieve a decomposition of the total moderation: . In what follows, we collectively refer to these causal estimands as the “mediated moderation estimands.”
Features of the Proposed Causal Estimands
The proposed estimands are defined using the interventional effect approach (for review of different approaches to effect definition, see Nguyen et al., 2021; VanderWeele, 2015). That is, our estimands consider potential outcomes if the distributions of mediators are shifted (as if by means of an intervention for the population). This gives our estimands several features, and whether a feature is advantageous or disadvantageous depends on the substantive research context.
First, the proposed approach does not consider subgroup status as a “second” treatment variable for which manipulation is of substantive interest. This feature is misaligned with studies where the interest is not about moderation but rather about the “interaction” effects (VanderWeele, 2009, p. 864) of manipulating both and . This feature, however, would be desirable in studies investigating effect moderation by , especially when subgroup status is considered not manipulable, which is the focus of the current study. Indeed, a motivation for our use of the interventional effect approach is that non-manipulable subgroup variables, such as sex and race/ethnicity, are commonly used moderating variables in empirical studies. Nonetheless, in Supplementary Appendix G (available in the online version of this article), we present analogues of the mediated moderation estimands where is manipulated at an individual level; as described there, these analogues can be identified by the same quantities and estimated using the same methods as the mediated moderation estimands in the main text.
Second, as with the interventional effects in Vansteelandt and Daniel (2017), the identification of our causal estimands (described in the next section) is achievable without imposing any assumptions on the mediators’ causal structure (e.g., causal ordering or the absence of unmeasured common causes of mediators). Concurrent mediators with unknown causal ordering occur frequently in empirical studies. Thus, this feature of our approach offers a practical advantage, in comparison to the natural indirect effect approach in standard causal mediation analysis (Daniel et al., 2015; Valeri & VanderWeele, 2013). The latter approach generally requires making assumptions on the mediators’ causal structure that may or may not be plausible, especially with concurrent mediators (Loh et al., 2022a).
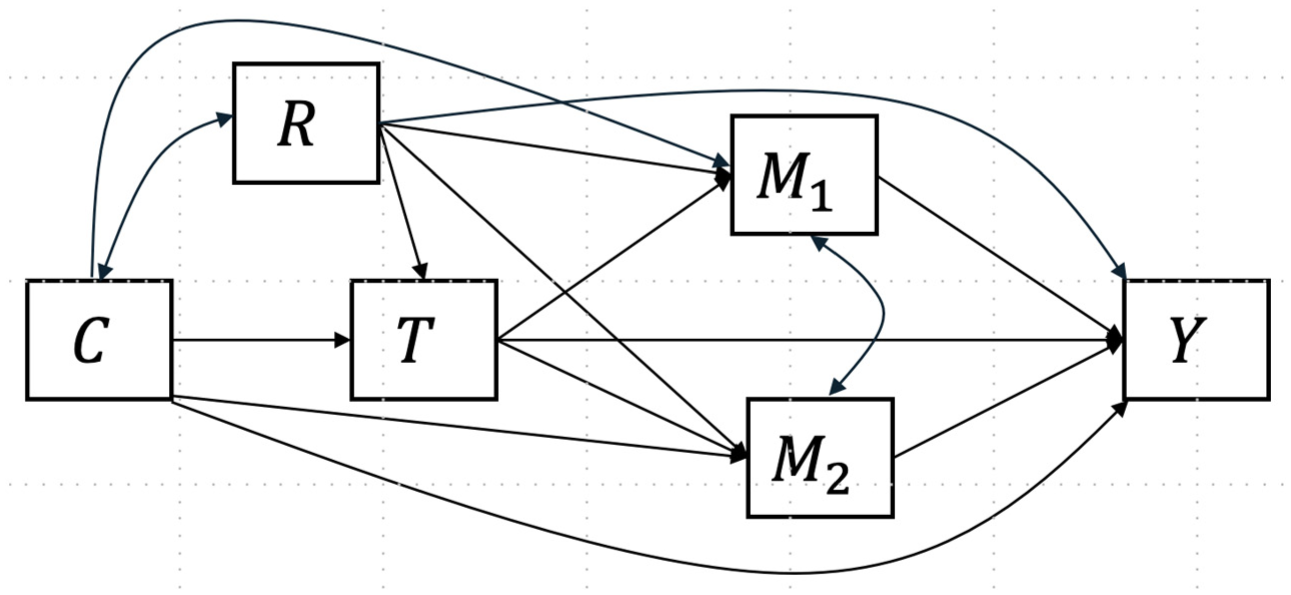
Third, irrespective of the mediators’ causal structure, captures the effect moderation attributable to the subgroup differences in , but not descendants of ; this analogously applies to . To illustrate, suppose the unknown causal structure between mediators is . The subgroup difference in can contribute to the subgroup difference in . captures the effect moderation due to the subgroup differences in the potential distributions of (i.e., vs. )), without distinguishing which part of this difference is due to and which is not. captures the effect moderation due to the subgroup differences in the potential distributions of , and this difference cannot be due to under the assumed causal ordering (i.e., ). Additionally, the subgroups can differ in the strengths of dependence (e.g., covariance) between potential levels of and , which, in turn, can contribute to the effect moderation; this contribution is captured by . This feature is disadvantageous when researchers know the causal ordering between mediators and would like this knowledge to be utilized in the definition of causal estimands. Nonetheless, this feature is advantageous when no knowledge is available for the mediators’ causal structure (i.e., the scenario considered here; see Figure 2) because it allows the interpretations of the causal estimands to hold, regardless of the underlying causal structure between mediators.
Causal diagram of study variables.
Fourth, the proposed causal estimands involve covariates , a feature shared by many interventional effect-based estimands (Nguyen et al., 2021; Vansteelandt & Daniel, 2017). This feature would be disadvantageous if it is undesirable to compare subgroups after controlling for the subgroup differences in the covariates. However, this feature is useful when, as often occurs in mediated moderation analysis, the goal is to decompose a differential (i.e., moderated) treatment effect between subgroups after controlling for the subgroups’ pretreatment differences (Liu et al., 2025). We further discuss this feature and its potential limitations in the “Discussion” section.
Identification
The causal estimands defined above involve potential outcomes that are unobserved. Therefore, assumptions are needed to identify them using the observed data distribution. Identification assumptions have been given for the interventional effects in causal mediation analysis (Vansteelandt & Daniel, 2017) and in mediated moderation analysis with a single mediator (Liu et al., 2025).
For identifying the mediated moderation estimands defined here, we make the following assumptions under the causal diagram in Figure 2: (a) positivity and (b) unconfoundedness. Positivity assumes that within stratum , there are nonzero probabilities for each treatment value , subgroup status , and mediator value , that is, and for all , , , and values.
Unconfoundedness assumes that, given observed pretreatment variables : (A1) the treatment–outcome relationship is unconfounded, ; (A2) the mediators–outcome relationship is unconfounded, ; and (A3) the treatment–mediator relationship is unconfounded, .
The above assumptions have several implications. First, the positivity assumption requires that the subgroups being compared have sufficient overlap in values of covariates . If the overlap is insufficient in the data at hand, the positivity assumption will likely have practical violations, which, in turn, can result in unreliable inferences on any comparisons between the subgroups controlling for (Li et al., 2013), including the mediated moderation estimands. Furthermore, the positivity assumption requires that each value of the treatment and mediators is possible to occur for each subgroup within each covariate stratum.
Second, there is no unconfoundedness assumption for the relations of subgroup status with other variables. This is because no counterfactual manipulation of is considered in the potential outcomes defined above. Rather, the subgroups are compared from a controlled descriptive perspective (J. W. Jackson, 2017; Li et al., 2013), whereby subgroups who are balanced in pretreatment covariates are compared in the potential outcomes and potential mediators. This perspective aligns with substantive interests in mediated moderation analyses, which often concerns why, after controlling for the subgroups’ pretreatment differences, the treatment effects still meaningfully vary between the subgroups (Liu et al., 2025).
Third, the unconfoundedness assumptions (A1) and (A3) require no unmeasured confounders of the treatment–outcome and treatment–mediators relations, and they are satisfied when the treatment is randomized. (A2) is a strong assumption, which requires that conditional on treatment, subgroup status, and covariates, there are no unmeasured confounders of the relation between and . However, (A2) is still achievable by randomizing mediators within strata of , which is weaker than the assumption required in standard causal mediation analyses that assess the nature indirect effects; the latter requires a stringent assumption (referred to as the cross-world counterfactual independence assumption; Moreno-Betancur et al., 2021; Pearl, 2001 that cannot be satisfied even by randomization (Richardson & Robins, 2013).
For and , we define:
Under the identification assumptions, the mean potential outcomes in the causal estimands are identified as , , and . Proofs can be found in Supplementary Appendix B (available in the online version of this article).
Thus, by contrasting and/or , we identify the mediated and remaining moderation as , , , , and .
In the next section, we develop estimation methods. To simplify notation, we write (Equation 17) and (Equation 16) as , and , respectively, when there is no confusion.
Estimation
In this section, we develop methods for estimation and inference of the mediated moderation estimands. We begin by examining the product-of-coefficient approach conventionally used in the parametric modeling framework (Baron & Kenny, 1986). Then, to reduce reliance on modeling assumptions that may be not grounded in prior knowledge, we develop nonparametric methods based on multiply robust estimators in causal mediation literature (Benkeser & Ran, 2021; Rudolph et al., 2024), incorporating the use of machine learning methods.
Connections with the Product-of-Coefficient Approach
The product-of-coefficient approach is typically used with continuous mediators and outcome. It involves specifying models for the mediators’ distribution and the conditional mean outcome . A common specification is the following:
where the mediator residuals are assumed as jointly normally distributed with means of zero and a constant covariance matrix, and the outcome residual is assumed to be independent of the mediator residuals and follows a normal distribution with mean zero and a constant variance.
Plugging the model-implied mediator distributions and conditional mean outcome models (Equations 18–20) into the identification formulas (i.e., and in Equations 17–16), it yields the following estimators for the mediated moderation effects and remaining moderation:
The estimators for and take the form of the product-of-coefficient estimators (Baron & Kenny, 1986; Fairchild & MacKinnon, 2009). This implies that, under the identification assumptions and assuming correct model specification, an estimate of (or ) from the product-of-coefficient approach has a causal interpretation as the mediated moderation via (or ) defined above in the potential outcome framework, and an estimate of can be interpreted as the remaining moderation (), which captures the treatment effect moderation that would still remain after equalizing the potential distributions of both mediators across the subgroups. Lastly, , indicating that the estimator of is restricted to zero . This is because the outcome model (20) assumes no interactions between the mediators; see Loh et al. (2022a) for discussions in the context of causal mediation analysis.
The above regression-based estimation is relatively simple to conduct. However, it has important limitations. First, if the models are misspecified, the resulting estimators for the mediated moderation estimands can be biased, even when the identification assumptions hold. Second, if data-adaptive modeling approaches (e.g., model selection, machine learning) are used to estimate components of the identification formulas (i.e., or ), the resulting estimators’ sampling distributions generally have no established forms and standard nonparametric bootstrapping may not be appropriate (Miles et al., 2020; van der Laan & Rose, 2011), making it difficult to quantify the estimators’ uncertainty and obtain inferences.
Multiply Robust Estimator
To address limitations of the regression-based estimation in the previous subsection, we develop nonparametric estimators based on multiply robust methods in causal mediation literature (Benkeser & Ran, 2021; Liu, 2025; Rudolph et al., 2024). These methods often yield estimators that allow for data-adaptive modeling approaches, while maintaining the ability to provide asymptotically proper inferences (e.g., confidence intervals [CIs]).
Background of Influence Function-Based Estimation and Cross-Fitting
A central tool to develop multiply robust estimators is the influence function (IF) in semiparametric estimation (for review, see Kennedy, 2024; van der Vaart, 2002), which has contributed to many machine learning-based methods for causal inference such as targeted learning (van der Laan & Rose, 2018) and debiased machine learning (Chernozhukov et al., 2018), especially with the use of cross-fitting. To ease introducing our methods, below, we briefly review these techniques (recent tutorials can be found in Kennedy, 2024; Renson et al., 2025; van der Laan & Rose, 2011, 2018).
Intuitively, the IF acts as a first-order derivative of a functional such as (the identification formula, Equation 17) with respect to a model of the data distribution . As a first-order derivative, the IF allows us to express how large a difference between values of (e.g., )) will be produced by small, first-order deviations between two models of the data distribution (e.g., a misspecified model and a correct model ). Thus, using the IF, we can construct estimators by correcting for the part of the estimation error () produced by first-order deviations between the misspecified and correct models.
An important advantage of IF-based estimators is that they can provide asymptotically proper inferences (e.g., CIs), even when components of the data distribution are estimated using data-adaptive machine learning methods. Specifically, for making inferences under the use of machine learning, a key problem is how to handle an overfitting issue related to a term of the estimator’s error (referred to as the empirical process term; Kennedy, 2024). This term would be non-negligible and result in anti-conservative CIs (Naimi et al., 2023), if we use the same data twice, first to estimate components of the data distribution via very complex machine learning models, and then to compute the IF-based estimator. An effective solution, without restricting complexity of the machine learning models, is called “cross-fitting” (or sample splitting), whereby we estimate (or train) the models using a subset of the data, and then compute the estimator using the independent remaining data (Chernozhukov et al., 2018; Zheng & van der Laan, 2011). It has been found that under common conditions, cross-fitted, IF-based estimators provide asymptotically proper inferences even under the use of machine learning (Kennedy, 2024).
Influence Functions
From the above motivation, we construct estimators using the IFs for and . To present them, we introduce some additional notation that represents components of the IFs.
For subgroup status and treatment value , define the following mean outcome functions:
where , . Equations (23) and (24) are partially marginalized mean outcome functions, which average the conditional mean outcome (Equation 22) over one mediator. For example, averages over the “marginal” distribution of given , , and covariates ; this distribution is “marginal” in the sense that it does not depend on the other mediator. In addition, define:
These functions (Equations 25 and 26) are “fully marginalized” mean outcome functions, which average the conditional mean outcome (Equation 22) over both mediators.
Furthermore, define the following functions representing ratios of mediator probabilities:
and provide weights that adjust the observational distribution of mediators to the mediator distributions of interest in the respective estimands and . Similar weights have been used in weighting-based estimators in causal mediation analysis (Hong, 2010; Loh et al., 2020). Lastly, we introduce the “propensity score” (Rosenbaum & Rubin, 1983), , representing the conditional distribution of the treatment and subgroup variables given the covariates.
Let , which comprises all “nuisance” functions of the data distribution that can influence and . Let collect the observed variables of an individual. For and , the IFs are respectively and , where the uncentered IFs and take the following forms:
and
Derivations of the IFs can be found in Supplementary Appendix F (available in the online version of this article). Intuitively, these IFs account for first-order errors of the estimation of nuisance functions. For , in the third line, depends on both the conditional mean outcome and the joint mediator distribution; thus, an estimation error of can arise due to estimation errors in any of these components. Then, the first line corrects for the estimation error of the conditional mean outcome , by adding to a “weighted residual bias correction” (Schafer & Kang, 2008, p. 301), where the weight is the product of the mediator probability ratio (Equation 28) and the inverse propensity score; the second line corrects for the estimation error of the joint mediator distribution, by adding a weighted residual bias correction, with the weight given by the inverse propensity score. Similarly, for , in the fourth line (Equation 25, the expectation of which is the estimand of interest) depends on the conditional mean outcome and the marginal distributions of and . The first line corrects for the estimation error of by adding a weighted residual bias correction, with the weight given by the product of the mediator probability ratio and the inverse propensity score; the second and third lines correct for the estimation errors of the marginal distributions of and , respectively, by adding weighted residual bias corrections with the weights being the inverse of corresponding propensity scores.
Cross-Fitting and Machine Learning for Nuisance Function Estimation
To estimate the nuisance functions, parametric models could be used assuming the correct model specification is available. However, this assumption is often strong in practice. Alternatively, the nuisance functions can be data-adaptively estimated using machine learning methods.
As reviewed above, cross-fitting (Chernozhukov et al., 2018; Zheng & van der Laan, 2012) allows quantifying the estimation uncertainty even when complex machine learning methods are used. Therefore, to avoid restricting the complexity of estimated nuisance functions from machine learning methods, we use cross-fitting to obtain . Specifically, we randomly split the sample index set into (e.g., ) prediction folds of approximately the same size, denoted by ; for each prediction fold , the remaining folds form the training data, denoted as , which is used to estimate (or train) machine learning models for nuisance functions . Let represent the estimated nuisance functions produced using training data . For individual , let indicate the index of the prediction fold that contains . Cross-fitting allows us to obtain the estimated for individual as , which is estimated using only the training data that exclude individual . Then, for the observed data of individual , we compute the value of and .
With obtained via cross-fitting, we compute estimators of and as:
Inference
Examining the estimators’ asymptotic behaviors reveals that they are asymptotically normal and multiply robust in consistency, under achievable assumptions about the estimated nuisance functions and boundedness of the weights. Below, we state these results, which then allows us to obtain inferences on and .
Asymptotic Sampling Distributions
Assume (1) the weights , , and and their estimates are bounded; and (2) nuisance functions are estimated consistently with a sufficient convergence rate, such that for each estimator (or ), the estimator’s second-order error term , where , satisfy the following: . Supplementary Appendix C (available in the online version of this article) presents the expression of the second-order error term, which depends on only products of errors of estimated nuisance functions.
Then, letting convergence in distribution be denoted by ⇝, the estimators are -consistent and asymptotically normal:
where and are variances of the IFs. Proofs can be found in Supplementary Appendix D (available in the online version of this article).
In practice, the assumption in (1) requires the positivity assumption to hold with the data at hand. The assumption in (2) can be satisfied, for example, when the rate of estimating each nuisance function is faster than , a rate achievable by many machine learning methods (e.g., regression trees, random forest, neural networks; Chernozhukov et al., 2018).
The above result enables asymptotically proper uncertainty quantification (standard errors, CIs) for the estimators even when data-adaptive approaches (e.g., model selection, machine learning) are used. It also allows us to obtain asymptotic sampling distributions of the mediated moderation estimands (Equations 8–12) via the delta method and make inferences on them. For example, for , the estimator can be computed as , where is the contrast of function (Equation 29) evaluated with the different values of following the definition of . The variance of the estimator can be estimated as the sample variance of divided by the sample size, represented as . A 95% Wald-type CI for can then be constructed as .
The above asymptotic property, which justifies the use of the Wald-type CIs, requires that all nuisance functions can be estimated consistently at sufficiently fast rates. However, this is not required for the consistency of the estimators. As shown next, the estimators remain consistent under weaker assumptions that allow inconsistent estimation of some nuisance function.
Multiple Robustness
The estimators and are multiply robust in the sense that they are consistent so long as one of multiple subsets of nuisance functions is estimated consistently. Specifically, is consistent when we achieve at least one of the following: (a) the mean outcome (Equation 22), the mediators’ joint distribution , and the marginal mediator distributions and are consistently estimated; or (b) , the propensity score and ’s marginal distribution are consistently estimated; or (c) , , and ’s marginal distribution are consistently estimated; or (d) , and the joint and marginal mediator distributions , , and are consistently estimated.
For , the consistency is achieved when at least one of the following is satisfied: (a′) the mean outcome and the mediators’ joint distribution are consistently estimated; or (b′) and the propensity score are consistently estimated; or (c′) and the joint mediator distribution are consistently estimated. Proofs for the above robustness properties of the estimators and can be found in Supplementary Appendix E (available in the online version of this article).
Together, these robustness properties imply that, for consistent estimation of all the mediated moderation estimands, consistent estimation of the mediators’ joint distribution or either mediator’s marginal distribution is important. Nonetheless, consistent estimation of all the joint or marginal mediator distributions is unnecessary, when either (b) or (c) is achieved. Furthermore, consistent estimation of the mean outcome (or propensity score) is unnecessary, when (d) (or [a]) is achieved.
We provide an R package “multiMedMod,” which implements the developed method (available at https://osf.io/n78kq/?view_only=618e75fab3da4528807c6f743467c17a). In the R package, the nuisance functions are estimated using an ensemble machine learning procedure known as the “super learner” (van der Laan et al., 2007). This procedure allows a user to specify multiple machine learning prediction methods (e.g., parametric regressions, generalized additive models, random forest, neural network) and combines them to optimize cross-validated predictive performance. Tutorials of the super learner ensemble method can be found in, for example, Naimi and Balzer (2018), Polley et al. (2024), and van der Laan and Rose (2011). Our R package accommodates both binary or continuous outcome and mediators. For continuous mediators, we implement the multiply robust estimators by re-parameterizing the nuisance functions such that the estimation of mediator densities is avoided. This re-parameterization follows Rudolph et al. (2024) on causal mediation analysis. Implementation details for handling continuous mediators are provided in Supplementary Appendix H (available in the online version of this article).
Simulation Study
A simulation study is presented in Supplementary Appendix I (available in the online version of this article), where we evaluated the performance of the estimation method with binary and continuous mediators and outcomes. We examined sample sizes at n = 200, 300, 500, 800, and 1,000. Key findings are the following. First, the performance was generally better with binary mediators than with continuous mediators. This may be due to the instability of weighting terms when the mediators were continuous. Previous research also found that, owing to instability of the weights, mediation effect estimators involving weights can be prone to finite-sample bias, especially with continuous mediators and not-large sample sizes (Loh et al., 2020). Second, the bias was generally larger when the sample size was small (e.g., 200) and became closer to zero with larger sample sizes (e.g., 800 or above). The mean squared error decreased as the sample size increased. Third, the CI coverage rates ranged from 91% to 97%, which fell within the coverage rate criteria (91%–98%) suggested in Muthén and Muthén (2002). These findings suggest that the multiply robust estimators can work for making inferences on the mediated moderation estimands, but larger sample sizes would be needed, especially when working with continuous mediators.
Illustrative Example
This example is based on studies highlighting the adverse effects of perceived discrimination on adolescent mental health (Maene et al., 2022; Smith & Nicholson, 2022). Studies indicate that these effects could vary by gender, often being more severe for females than males. Additionally, psychosocial resources, such as mastery and perceived family emotional support, could be mediating mechanisms that contribute to this effect heterogeneity by gender (Erving et al., 2022). To illustrate the proposed approach, we examine how these psychosocial resources mediate gender differences in the effects of perceived discrimination on depressive symptoms among adolescents.
Example Data and Analysis
The dataset used in this example consists of = 1,115 African American adolescents in the National Survey of American Life–Adolescent Supplement (J. S. Jackson et al., 2016; Seaton et al., 2008). The analysis includes the following variables. The subgroup status is the adolescent-reported sex, with male as the reference subgroup () and female as the focal subgroup (). The treatment is the adolescent’s perceived discrimination from teacher, coded based on the count of the adolescent-reported perceived teacher discrimination events in day-to-day life (e.g., “your teachers treat you with less respect than other students”; for a zero count, and for one or more counts). The outcome is the adolescent’s depressive symptoms, measured as a composite score of the Epidemiologic Studies Depression Scale (Radloff, 1977). The mediator is a binary indicator of mastery, coded based on the adolescent’s agreement with “having little control over the things that happen to me” (coded as 1 for somewhat or strongly agree, and 0 otherwise). The mediator is a binary indicator of perceived family emotional support, coded based on the adolescent’s response to “how often do your family members make you feel loved and cared for” (coded as 1 for very often, and 0 otherwise). The covariates include background information about the adolescent’s age, family income, school program type (general, academic, vocational, or other), urbanity, whether the adolescent ever repeated a grade, whether ever suspended from school for a day or longer, whether felt family has enough money, number of places ever lived, family composition (numbers of children and adults in the household, whether raised by mother, whether raised by father), and region of the country. The variables were selected based on related substantive literature (Miller et al., 2013).
We used the developed method to estimate the mediated moderation for the two mediators. Specifically, we used four-fold cross-fitting. The nuisance functions were estimated by a super learner ensemble of methods in the R package SuperLearner (Polley et al., 2024; van der Laan et al., 2007), with an ensemble of an intercept-only model, generalized linear model, lasso regression, multivariate adaptive regression splines (Friedman, 1991), random forest (Wright & Ziegler, 2017), and neural network (Ripley et al., 2016). The implementation was done using the R package accompanying this manuscript. The dataset and R code used in this example are available at https://osf.io/n78kq/?view_only=618e75fab3da4528807c6f743467c17a. The results are shown in Table 1 and Figure 3.
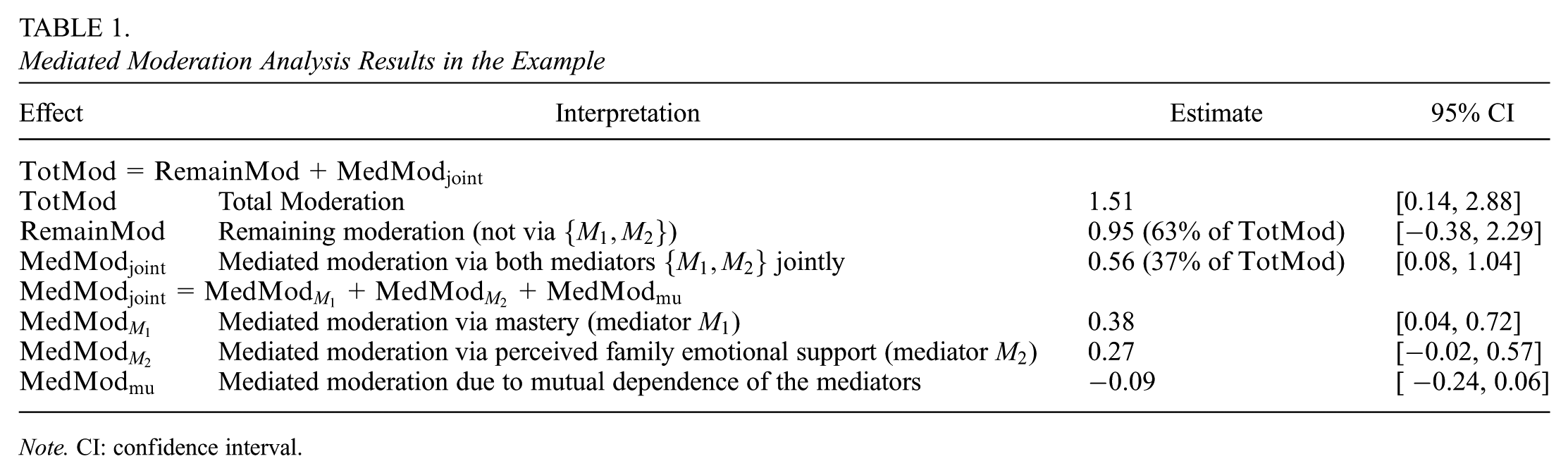
Mediated Moderation Analysis Results in the Example
Effect
Interpretation
Estimate
95% CI
Total Moderation
1.51
[0.14, 2.88]
Remaining moderation (not via )
0.95 (63% of )
[−0.38, 2.29]
Mediated moderation via both mediators jointly
0.56 (37% of )
[0.08, 1.04]
Mediated moderation via mastery (mediator )
0.38
[0.04, 0.72]
Mediated moderation via perceived family emotional support (mediator )
0.27
[−0.02, 0.57]
Mediated moderation due to mutual dependence of the mediators
−0.09
[−0.24, 0.06]
Note. CI: confidence interval.
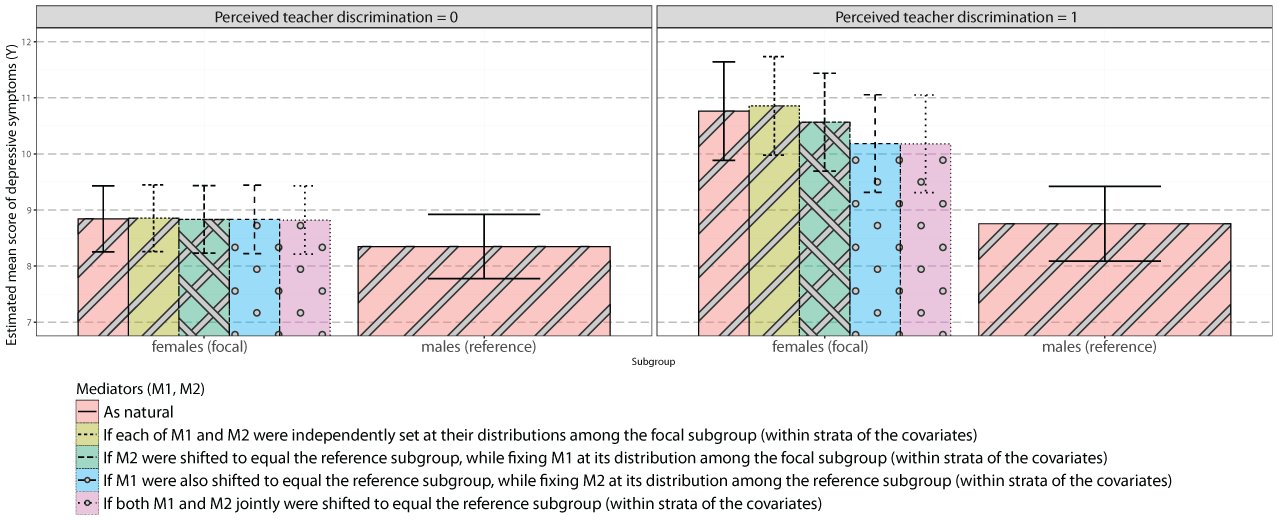
Estimates of expected potential outcomes between the subgroups in the example.
Results of the Illustrative Example
The total moderation (TotMod), quantifying the difference in the impact of perceived teacher discrimination on depressive symptoms between males and females, is estimated at 1.51 (95% CI [0.14, 2.88]). The total moderation is decomposed into the mediated moderation and the remaining moderation, . The remaining moderation (), corresponding to the part of this gender-based moderation not mediated by the two psychosocial resources (i.e., mastery and perceived family emotional support ) is estimated at 0.95 (95% CI [−0.38, 2.29]). This indicates that the gender difference in the impact would become less pronounced (with the CI covering zero), if, within strata of the covariates, the potential levels of both psychosocial resources (i.e., the mediators) were equalized across gender. The jointly mediated moderation (), corresponding to the part of the gender-based moderation attributable both mediators jointly, is estimated at 0.56 (95% CI [0.08, 1.04]), or 37% of the total moderation. This suggests that the adverse impact for females would reduce by 0.56, if, within strata of the covariates, the potential levels of both psychosocial resources among them were jointly made to match those among males.
Next, we further decompose to examine the role of each of the two psychosocial resources (i.e., mastery and perceived family emotional support ) in contributing to the effect moderation by gender. First, we estimate that the mediated moderation via mastery () is 0.38 (95% CI [0.04, 0.72]), accounting for 25% of the total moderation. This suggests that among females, the adverse impact of perceived teacher discrimination on depressive symptoms would decrease by approximately 0.38 if, within strata of the covariates, the potential levels of mastery () among them were made equivalent to those among males, while keeping the potential levels of perceived family emotional support () held at the levels among the males. Second, we estimate that the mediated moderation via perceived family emotional support () is 0.27 (95% CI [−0.02, 0.57]), or 18% of the total moderation. This indicates that compared to mastery (), perceived family emotional support () appears to play a less significant role in contributing to the gender-based moderation. Lastly, we found that, at 0.05 significance level, there is no statistically significant mediated moderation due to mutual dependence of these two psychosocial resources (: estimate = −0.09, 95% CI [−0.24, 0.06]).
Figure 3 displays the expected potential outcomes estimated in the mediated moderation analysis. The estimates show that, under non-exposure to perceived teacher discrimination (; left panel), there is little change in the expected potential depressive symptom outcome among the females, regardless of whether or not shifting the potential levels of the two mediators among them. In contrast, under exposure to perceived teacher discrimination (; right panel), there would be an appreciable reduction in the expected potential depressive symptom outcome among the females, if the potential levels of the psychosocial resources (mastery and perceived family emotional support ) among them were changed to equal those among the males, within strata of the covariates.
Taken together, these results suggest that interventions aimed at improving psychosocial resources (mastery and perceived family emotional support) could help mitigate the adverse impact of perceived teacher discrimination among female adolescents. If the potential levels of both psychosocial resources (mediators) among the females were jointly made to match those among the males (within strata of the covariates), the gender-based difference in the effect of perceived teacher discrimination on depressive symptoms would reduce (by an estimated 37%).
Discussion
Assessing mediated moderation allows addressing important questions about the mechanisms that lead to effect moderation between different subgroups (Fairchild & MacKinnon, 2009; Liu et al., 2025; Muller et al., 2005). However, methods that allow clarifying causal interpretations of mediated moderation estimates formally have been underdeveloped, especially when more than one mediator is of interest. This study reduces this gap by developing causal estimands and identification results for assessing the roles of two mediators in the effect moderation, and by developing robust estimation methods allowing the use of machine learning approaches.
Particularly, this study builds upon and extends three major streams of causal mediation literature. First, the causal estimands defined here extend the counterfactual approach to quantifying mediation (VanderWeele, 2015; Vansteelandt & Daniel, 2017). In doing so, our estimands for mediated moderation do not rely on specific parametric models. This improves upon conventional parametric modeling approaches to defining mediated moderation, as the latter requires modeling assumptions that may or may not be plausible in practice. Second, our decomposition approach builds on recent work on interventional effects (J. W. Jackson & VanderWeele, 2018; Liu et al., 2025; Vansteelandt & Daniel, 2017), and extends this literature by decomposing the effect moderation with respect to two mediators, yielding new interventional effect-based estimands for mediated moderation. The resulting estimands make it possible to test the role of each mediator in generating the subgroup differences in treatment effects. Third, our estimation method extends a fast-growing literature on doubly robust machine learning approaches in causal inference (Chernozhukov et al., 2018; van der Laan & Rose, 2018) to the mediated moderation analysis. The developed method allows relaxing modeling assumptions and improves robustness to the estimation errors from machine learning methods.
Several limitations of the current study present opportunities for future research. First, by the unconfoundedness assumption (A2), we have assumed no posttreatment confounders of the mediators–outcome relation (or known as treatment-induced confounders; VanderWeele et al., 2014), within strata of . To handle posttreatment confounders in the identification, (A2) could be modified by including them in the conditioning set. The corresponding estimation methods would require future developments, which may be built on recent estimation methods considering both posttreatment confounders and multiple mediators (Mittinty et al., 2019). Furthermore, it is important to develop methods for assessing the sensitivity of the mediated moderation results to unmeasured pretreatment or posttreatment confounders. Previous literature has provided parametric and nonparametric sensitivity analysis methods for mediation analysis (Ding & Vanderweele, 2016; Qin & Yang, 2022; Zhang & Ding, 2023), and future studies could examine the feasibility and potential extensions of these methods for mediated moderation.
Second, the interventional effects approach in the current study could have limitations for defining mediation moderation effects. In our current approach, all covariates are used for both the definition and identification of mediation moderation estimands. This essentially treats all pretreatment covariates that serve for confounding control as allowable to be conditioned on for defining the between-subgroup difference in the treatment effect. However, this covariate allowability judgment may not necessarily align with the judgment in all substantive contexts. For example, a healthcare researcher examining effect moderation by race may judge some covariates in (e.g., SES) as non-allowable for defining racial differences (J. W. Jackson, 2021). Therefore, an important future direction could be to distinguish between allowable and non-allowable covariates for defining causal estimands of mediation moderation, such as by incorporating a meaningful causal decomposition perspective (J. W. Jackson, 2021).
Third, in the developed multiply robust method, we have computed the estimators’ variances using empirical values of and , which do not consider uncertainty of estimated nuisance functions . While this is a standard variance estimation approach for IF-based estimators (Benkeser & Ran, 2021; Kennedy, 2024), it could yield anti-conservative variance estimates as sample sizes became smaller or violations of positivity assumptions became severer (Tran et al., 2023; van der Laan & Gruber, 2011). Future research could examine methods (e.g., modified bootstrap-based methods in Tran et al., 2023) to improve the uncertainty quantification (variance estimation, CI construction) for the estimators of the mediated moderation estimands.
Fourth, extending the analysis to more than two mediators could be a valuable direction. For example, Loh et al. (2022b) defined IIEs with high-dimensional mediators, presenting an effect definition approach that may be explored for mediated moderation analyses. Furthermore, accommodating continuous or multivariate moderator variables in the causal estimand definition, identification, and estimation for the mediated moderation analysis awaits future studies. Toward this end, studies could explore methods for continuous or multivariate exposures (Hejazi et al., 2023) and moderators (Valente et al., 2023), as well as approaches for estimating heterogeneous treatment effects given high-dimensional moderators (Athey & Imbens, 2019; Kennedy, 2023). Additionally, we have focused on comparing pretreatment subgroups. Nonetheless, the controlled descriptive perspective (which we adopted for subgroup comparisons) could be extended to the latent subgroups defined using potential status of a posttreatment variable in the principal stratification framework (Frangakis & Rubin, 2002; Page et al., 2015); in that case, a controlled descriptive comparison could entail comparing those latent subgroups, while conditioning on pretreatment covariates.
Conclusion
In conclusion, this study provides a new tool for researchers investigating mediators underlying effect heterogeneity between subgroups. We hope that by enabling the investigation from a causal inference approach, our method can help researchers gain insights on the development or adaptations of interventions for specific subgroups.
Supplemental Material
sj-pdf-1-jeb-10.3102_10769986251410929 – Supplemental material for A Causal Inference Approach for Mediated Moderation with Multiple Mediators
Supplemental material, sj-pdf-1-jeb-10.3102_10769986251410929 for A Causal Inference Approach for Mediated Moderation with Multiple Mediators by Xiao Liu and Monica E. Romero in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
ORCID iD
Xiao Liu
Authors
XIAO LIU is an assistant professor in the Department of Educational Psychology, the University of Texas at Austin. Her research interests include quantitative methods for causal inference, including causal mediation analysis and mediated moderation analysis.
MONICA E. ROMERO is an assistant professor in the Department of Educational Psychology, the University of Texas at Austin. Her research interests include: culturally and linguistically responsive interventions to support academic, social-emotional, and mental health outcomes for emergent bilingual/multilingual Latinx students; multi-tiered system of supports, data-based decision-making, and equitable service delivery in schools; family-school-community partnerships and the well-being of Latinx and newcomer students; and training and supporting bilingual school psychologists while advancing Latinx psychology through strengths-based and advocacy-oriented approaches.
BaronR. M.KennyD. A. (1986). The moderator–mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of Personality and Social Psychology, 51(6), 1173–1882. https://doi.org/10.1037/0022-3514.51.6.1173
3.
BenkeserD.RanJ. (2021). Nonparametric inference for interventional effects with multiple mediators. Journal of Causal Inference, 9(1), 172–189. https://doi.org/10.1515/jci-2020-0018
4.
ChernozhukovV.ChetverikovD.DemirerM.DufloE.HansenC.NeweyW.RobinsJ. (2018). Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal, 21(1), C1–C68. https://doi.org/10.1111/ectj.12097
5.
Cluxton-KellerF.BurrellL.CrowneS. S.McFarlaneE.TandonS. D.LeafP. J.DugganA. K. (2014). Maternal relationship insecurity and depressive symptoms as moderators of home visiting impacts on child outcomes. Journal of Child and Family Studies, 23(8), 1430–1443. https://doi.org/10.1007/s10826-013-9799-x
DingP.VanderweeleT. J. (2016). Sharp sensitivity bounds for mediation under unmeasured mediator-outcome confounding. Biometrika, 103(2), 483–490. https://doi.org/10.1093/biomet/asw012
8.
ErvingC. L.WilliamsT. R.FriersonW.DerisseM. (2022). Gendered racial microaggressions, psychosocial resources, and depressive symptoms among Black women attending a historically black university. Society and Mental Health, 12(3), 230–247. https://doi.org/10.1177/21568693221115766
9.
FairchildA. J.MacKinnonD. P. (2009). A general model for testing mediation and moderation effects. Prevention Science, 10(2), 87–99. https://doi.org/10.1007/s11121-008-0109-6
HongG. (2015). Causality in a social world: Moderation, mediation and spill-over. John Wiley & Sons.
16.
ImaiK.KeeleL.TingleyD. (2010). A general approach to causal mediation analysis. Psychological Methods, 15(4), 309–334. https://doi.org/10.1037/a0020761
17.
JacksonJ. S.CaldwellC. H.AntonucciT. C.OysermanD. R. (2016, July). National Survey of American Life—Adolescent Supplement (NSAL-A), 2001–2004. https://doi.org/10.3886/ICPSR36380.v1
18.
JacksonJ. W. (2017). Explaining intersectionality through description, counterfactual thinking, and mediation analysis. Social Psychiatry and Psychiatric Epidemiology, 52(7), 785–793. https://doi.org/10.1007/s00127-017-1390-0
19.
JacksonJ. W. (2021). Meaningful causal decompositions in health equity research: Definition, identification, and estimation through a weighting framework. Epidemiology, 32(2), 282–290. https://doi.org/https://doi.org/10.1097%2FEDE.0000000000001319
20.
JacksonJ. W.VanderWeeleT. J. (2018). Decomposition analysis to identify intervention targets for reducing disparities. Epidemiology, 29(6), 825–835. https://doi.org/10.1097/EDE.0000000000000901
21.
KennedyE. H. (2023). Towards optimal doubly robust estimation of heterogeneous causal effects. Electronic Journal of Statistics, 17(2), 3008–3049. https://doi.org/10.1214/23-EJS2157
22.
KennedyE. H. (2024). Semiparametric doubly robust targeted double machine learning: A review. In Handbook of Statistical Methods for Precision Medicine. Chapman; Hall/CRC.
23.
LiF.ZaslavskyA. M.BethM. (2013). Propensity score weighting with multilevel data. Statistics in Medicine, 32(19), 3373–3387. https://doi.org/10.1002/sim.5786
24.
LiuX. (2025). Estimating causal mediation effects in multiple-mediator analyses with clustered data. Journal of Educational and Behavioral Statistics. Advance online publication. https://doi.org/10.3102/10769986251318093
25.
LiuX.EddyJ. M.MartinezC. R. (2025). Causal estimands and multiply robust estimation of mediated-moderation. Multivariate Behavioral Research, 60(3), 460–486. https://doi.org/10.1080/00273171.2024.2444949
26.
LohW. W.MoerkerkeB.LoeysT.VansteelandtS. (2020). Heterogeneous indirect effects for multiple mediators using interventional effect models. Epidemiologic Methods, 9(1), 1–20. https://doi.org/10.1515/em-2020-0023
27.
LohW. W.MoerkerkeB.LoeysT.VansteelandtS. (2022a). Disentangling indirect effects through multiple mediators without assuming any causal structure among the mediators. Psychological Methods, 27(6), 982–999. https://doi.org/10.1037/met0000314
28.
LohW. W.MoerkerkeB.LoeysT.VansteelandtS. (2022b). Nonlinear mediation analysis with high-dimensional mediators whose causal structure is unknown. Biometrics, 78(1), 46–59. https://doi.org/10.1111/biom.13402
29.
MaeneC.D’hondtF.Van LissaC. J.ThijsJ.StevensP. A. J. (2022). Perceived teacher discrimination and depressive feelings in adolescents: The role of national, regional, and heritage identities in Flemish schools. Journal of Youth and Adolescence, 51(12), 2281–2293. https://doi.org/10.1007/s10964-022-01665-7
30.
MilesC. H.ShpitserI.KankiP.MeloniS.TchetgenE. J. (2020). On semiparametric estimation of a path-specific effect in the presence of mediator-outcome confounding. Biometrika, 107(1), 159–172. https://doi.org/10.1093/biomet/asz063
31.
MillerB.RoteS. M.KeithV. M. (2013). Coping with racial discrimination: Assessing the vulnerability of African Americans and the mediated moderation of psychosocial resources. Society and Mental Health, 3(2), 133–150. https://doi.org/10.1177/2156869313483757
32.
MittintyM. N.LynchJ. W.ForbesA. B.GurrinL. C. (2019). Effect decomposition through multiple causally nonordered mediators in the presence of exposure-induced mediator-outcome confounding. Statistics in Medicine, 38(26), 5085–5102. https://doi.org/10.1002/sim.8352
33.
Moreno-BetancurM.MoranP.BeckerD.PattonG. C.CarlinJ. B. (2021). Mediation effects that emulate a target randomised trial: Simulation-based evaluation of ill-defined interventions on multiple mediators. Statistical Methods in Medical Research, 30(6), 1395–1412. https://doi.org/10.1177/0962280221998409
34.
Morgan-LopezA. A.Gonzalez CastroF.ChassinL.MacKinnonD. P. (2003). A mediated moderation model of cigarette use among Mexican American youth. Addictive Behaviors, 28(3), 583–589. https://doi.org/10.1016/s0306-4603(01)00262-3
35.
MullerD.JuddC. M.YzerbytV. Y. (2005). When moderation is mediated and mediation is moderated. Journal of Personality and Social Psychology, 89(6), 852–863. https://doi.org/10.1037/0022-3514.89.6.852
36.
MuthénL. K.MuthénB. O. (2002). How to use a Monte Carlo study to decide on sample size and determine power. Structural Equation Modeling: A Multidisciplinary Journal, 9(4), 599–620. https://doi.org/10.1207/S15328007SEM0904.8
37.
NaimiA. I.BalzerL. B. (2018). Stacked generalization: An introduction to super learning. European journal of epidemiology, 33(5), 459–464. https://doi.org/10.1007/s10654-018-0390-z
38.
NaimiA. I.MishlerA. E.KennedyE. H. (2023). Challenges in obtaining valid causal effect estimates with machine learning algorithms. American Journal of Epidemiology, 192(9), 1536–1544. https://doi.org/10.1093/aje/kwab201
39.
NguyenT. Q.SchmidI.StuartE. A. (2021). Clarifying causal mediation analysis for the applied researcher: Defining effects based on what we want to learn. Psychological Methods, 26(2), 255–271. https://doi.org/http://doi/org/10.1037/met0000299
40.
PageL. C.FellerA.GrindalT.MiratrixL.SomersM.-A. (2015). Principal stratification: A tool for understanding variation in program effects across endogenous subgroups. American Journal of Evaluation, 36(4), 514–531. https://doi.org/10.1177/1098214015594419
41.
PearlJ. (2001). Direct and indirect effects. In BreeseJ.KollerD. (Eds.), UAI’01: Proceedings of the seventeenth conference on uncertainty in artificial intelligence (pp. 411–420). Morgan Kaufmann Publishers. http://dl.acm.org/citation.cfm?id=2074022.2074073
RadloffL. S. (1977). The CES-D Scale: A self-report depression scale for research in the general population. Applied Psychological Measurement, 1(3), 385–401. https://doi.org/10.1177/014662167700100306
46.
RensonA.MontoyaL.GoinD. E.DíazI.RossR. K. (2025, February). Pulling back the curtain: The road from statistical estimand to machine-learning based estimator for epidemiologists (no wizard required) [arXiv:2502.05363 [stat]]. https://doi.org/10.48550/arXiv.2502.05363
47.
RichardsonT. S.RobinsJ. M. (2013). Single world intervention graphs (SWIGs): A unification of the counterfactual and graphical approaches to causality. https://csss.uw.edu/Papers/wp128.pdf
RobinsJ. M.GreenlandS. (1992). Identifiability and exchangeability for direct and indirect effects. Epidemiology, 3(2), 143–155. https://doi.org/https://doi.org/10.1097/00001648-199203000-00013
50.
RosenbaumP. R.RubinD. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika, 70(1), 41–55. https://doi.org/10.1093/biomet/70.1.41
51.
RubinD. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66(5), 688–701. https://doi.org/10.1037/h0037350
52.
RubinD. B. (1978). Bayesian inference for causal effects: The role of randomization. The Annals of Statistics, 6(1), 34–58. https://doi.org/http://www.jstor.org/stable/2958688
53.
RubinD. B. (1980). Randomization analysis of experimental data: The Fisher randomization test comment. Journal of the American Statistical Association, 75(371), 591–593. https://doi.org/10.2307/2287653
54.
RubinD. B. (1986). Statistics and causal inference: Comment, Which ifs have causal answers. Journal of the American Statistical Association, 81(396), 961–962. https://doi.org/10.1080/01621459.1986.10478355
SchaferJ. L.KangJ. (2008). Average causal effects from nonrandomized studies: A practical guide and simulated example. Psychological Methods, 13(4), 279–313. https://doi.org/10.1037/a0014268
57.
SeatonE. K.CaldwellC. H.SellersR. M.JacksonJ. S. (2008). The prevalence of perceived discrimination among African American and Caribbean Black youth. Developmental Psychology, 44(5), 1288–1297. https://doi.org/10.1037/a0012747
58.
SmithN. C.NicholsonH. L. (2022). Perceived discrimination and mental health among African American and Caribbean Black adolescents: Ethnic differences in processes and effects. Ethnicity & Health, 27(3), 687–704. https://doi.org/10.1080/13557858.2020.1814998
59.
TranL.PetersenM.SchwabJ.LaanM. J. V. D. (2023). Robust variance estimation and inference for causal effect estimation. Journal of Causal Inference, 11(1), 1–27. https://doi.org/10.1515/jci-2021-0067
60.
ValenteM. J.RijnhartJ. J. M.GonzalezO. (2023). A novel approach to estimate moderated treatment effects and moderated mediated effects with continuous moderators. Psychological Methods, 30, 1–15. https://doi.org/10.1037/met0000593
61.
ValeriL.VanderWeeleT. J. (2013). Mediation analysis allowing for exposure–mediator interactions and causal interpretation: Theoretical assumptions and implementation with SAS and SPSS macros. Psychological Methods, 18(2), 137–150. https://doi.org/https://doi.org/10.1037/a0031034
62.
van der LaanM. J.GruberS. (2011). Targeted minimum loss based estimation of an intervention specific mean outcome. U.C. Berkeley Division of Biostatistics Working Paper Series. https://biostats.bepress.com/ucbbiostat/paper290
63.
van der LaanM. J.RoseS. (2011). Targeted learning: Causal inference for observational and experimental data (Vol. 4). Springer.
64.
van der LaanM. J.RoseS. (2018). Targeted learning in data science: Causal inference for complex longitudinal studies. Springer International Publishing. http://link.springer.com/10.1007/978-3-319-65304-4
65.
van der LaanM. J.PolleyE. C.HubbardA. E. (2007). Super Learner. Statistical Applications in Genetics and Molecular Biology, 6(1), Article 1309. https://doi.org/10.2202/1544-6115.1309
66.
van der VaartA. W. (2002). Semiparametric statistics. In Lectures on probability theory and statistics (pp. 331–457). Springer.
67.
VanderWeeleT. J. (2009). On the distinction between interaction and effect modification. Epidemiology, 20(6), 863–871. https://www.jstor.org/stable/25662776
68.
VanderWeeleT. J. (2015). Explanation in causal inference: Methods for mediation and interaction. Oxford University Press.
69.
VanderWeeleT. J.VansteelandtS.RobinsJ. M. (2014). Effect decomposition in the presence of an exposure-induced mediator-outcome confounder. Epidemiology, 25(2), 300–306. https://doi.org/10.1097/EDE.0000000000000034
70.
VansteelandtS.DanielR. M. (2017). Interventional effects for mediation analysis with multiple mediators. Epidemiology, 28(2), 258–265. https://doi.org/10.1097/EDE.0000000000000596
71.
WrightM. N.ZieglerA. (2017). Ranger: A fast implementation of random forests for high dimensional data in C++ and R. Journal of Statistical Software, 77, 1–17. https://doi.org/10.18637/jss.v077.i01
72.
ZhangM.DingP. (2023). Interpretable sensitivity analysis for the Baron-Kenny approach to mediation with unmeasured confounding. https://doi.org/10.48550/arXiv.2205.08030
73.
ZhengW.van der LaanM. J. (2011). Cross-validated targeted minimum-loss-based estimation. In van der LaanM. J.RoseS. (Eds.), Targeted learning: Causal inference for observational and experimental data (pp. 459–474). Springer. https://doi.org/10.1007/978-1-4419-9782-1
74.
ZhengW.van der LaanM. J. (2012). Targeted maximum likelihood estimation of natural direct effects. The International Journal of Biostatistics, 8(1), 1–40. https://doi.org/10.2202/1557-4679.1361
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.