
Abstract
One of the primary goals of international large-scale assessments in education is the comparison of country means in student achievement. This article introduces a framework for discussing differential item functioning (DIF) for such mean comparisons. We compare three different linking methods: concurrent scaling based on full invariance, concurrent scaling based on partial invariance using the RMSD statistic, and robust and nonrobust linking approaches based on separate scaling. Furthermore, we analytically derive the bias in the country means of different linking methods in the presence of DIF. In a simulation study, we show that the partial invariance and robust linking approaches provide less biased country means than the full invariance approach in the case of biased items.
Keywords
One major goal of large-scale assessment studies in education is to compare cognitive outcomes across many groups. For example, the Program for International Student Assessment (PISA; Organization for Economic Cooperation and Development [OECD], 2017) and the Program for the International Assessment of Adult Competencies (PIAAC; Yamamoto et al., 2013) provide international comparisons of student performance and adult skills for large groups of countries (72 countries in PISA 2015; 38 countries in PIAAC). A major methodological challenge of these comparisons is that the items of the achievement tests show differential item functioning (DIF) in specific countries. Uniform DIF is present if an item is relatively easier or more difficult in a specific country than at the international level (Holland & Wainer, 1993; Penfield & Camilli, 2007). In this case, an item parameter is noninvariant across countries. It has been argued that country DIF has the potential to bias the estimation of country-specific means and standard deviations (Kankaras & Moors, 2014).
In general, three different approaches for conducting cross-national comparisons in the presence of DIF can be distinguished between. First, in the concurrent scaling approach under full invariance, DIF effects are completely ignored, and common item parameters are estimated in a multiple-group item response theory (IRT) model. In this approach, country-specific item parameters are treated as completely invariant across groups when estimating country-specific means and standard deviations. Second, in the concurrent scaling approach under partial invariance, items with noninvariant parameters across countries are identified using country-specific item fit statistics and cutoff values as screening criteria. Based on this screening process, country-specific means and standard deviations are estimated in a multiple-group IRT model in which the parameters of items with no country DIF are constrained to be equal across countries, and the parameters of items with country DIF are allowed to be country-specific. As a third approach, we consider an approach that combines a separate scaling approach with linking methods. In contrast to the concurrent scaling approaches, item parameters are calibrated separately for each country, and no invariance assumptions are made for the group-specific item parameters. In the next step, the group-specific ability distributions are obtained by applying a linking method that places the group-specific item parameters onto a common metric. We extend the linking procedures of Haberman (2009) and Haebara (1980) to the case of many groups and robust linking functions. Robust linking functions have the desirable property that items with large DIF effects are treated as outliers that do not impact country mean comparisons. However, in contrast to concurrent scaling under partial invariance, which removes items with large DIF effects from country comparisons, robust linking methods do not rely on DIF statistics and allow for more principled modeling of DIF effects.
This article is organized as follows. First, we discuss the role that uniform DIF plays in group comparisons in the two-parameter logistic (2PL) model. We argue that it is crucial to differentiate between two group-specific item sets: so-called reference items and biased items. Reference items are group-specific items that allow valid group comparisons. Biased items have DIF effects that have the potential to distort group comparisons. Then, we discuss three different approaches for comparing country means in the presence of DIF: concurrent scaling under full invariance, concurrent scaling under partial invariance, and linking based on separate scaling. We show analytically that these approaches place different constraints on the DIF effects of reference items and biased items. We present the results of a simulation study, which investigated the performance of the different scaling approaches under different conditions for the DIF effects of reference and biased items. Finally, we illustrate the different approaches by reanalyzing the reading domain data of the PISA 2006 assessment.
Uniform DIF in the 2PL Model
In the following, the concept of DIF (Holland & Wainer, 1993; Millsap, 2011) for multiple groups (e.g., countries in large-scale assessments) is discussed. For G groups (g = 1,…, G), items i = 1,…, I are administered. It is assumed that a unidimensional item response model holds in each group with group-specific item response functions (IRF) Pig(θ), indicating the probability of a correct item response conditional on ability θ. According to Mellenbergh (1989; see also Millsap, 2011), there is no DIF for item i (i.e., item i is measurement invariant across groups) if a common IRF Pi(θ) exists so that
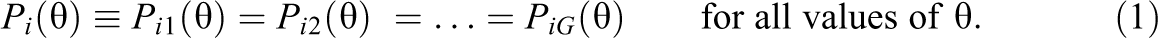
To check whether there is DIF for item i, the ability θ (or its distribution) has to be known in Equation 1. However, this is rarely the case in practice, and item parameters are needed to estimate the ability. This illustrates the circularity in the DIF definition (Camilli, 1993) and highlights that DIF can only be identified at the level of single items if additional assumptions are made.
The IRF in the 2PL model (Birnbaum, 1968) is given as
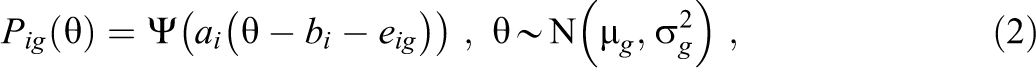
where bi is the common item difficulty for item i and eig are group-specific item difficulty deviations with nonzero values indicating uniform DIF; Ψ denotes the logistic distribution function, and it is assumed that the abilities are normally distributed in group g. The one-parameter logistic (1PL) model arises if item discriminations ai are set to 1 in Equation 2. It has been demonstrated that the 1PL model is not identified. Identification constraints among item parameters are needed to estimate the means µ g and the standard deviations σ g of the ability distributions for the G groups and the DIF effects eig (Bechger & Maris, 2015; Robitzsch & Lüdtke, 2020; Soares et al., 2009). The same principle of nonidentification also applies to the case of uniform DIF in the 2PL model. This can be seen by reparametrizing Equation 2 as follows:
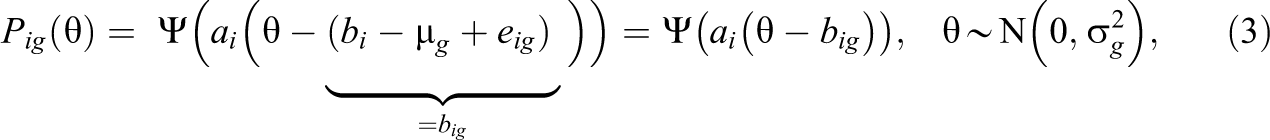
where the group-specific item parameters big are identified without additional constraints and are composed of the common item difficulties bi of item i, the means of the ability distributions µ
g
, and the uniform DIF effects eig. One possible identification constraint is to set the standard deviation
In the following, we denote a test to have balanced DIF if the DIF effects sum to zero for all groups (within each group g), that is,
By distinguishing between reference items and biased items, we highlight the vital role that identification constraints play in estimating the means of the group-specific ability distribution. However, at a more conceptual level, it needs to be emphasized that the decision about whether an item with a DIF effect is classified as a reference item or as a biased item should not be based solely on statistical criteria (see Camilli, 1993; Gomez-Benito et al., 2018; Penfield & Camilli, 2007; Zwitser et al., 2017, for this argument). More specifically, the identification of a mean for group g relies only on items from the set of reference items
It is instructive to relate our definitions of DIF to the terminology of the measurement invariance literature (Meredith, 1993; Vandenberg & Lance, 2000) and to distinguish between the following scenarios of DIF effects. If there are no biased items in all groups and eig = 0 for all items in all groups, there are no DIF effects. This situation is labeled as full invariance. The situation in which there is a set of anchor items in each group (e.g., a subset of items is DIF-free) is labeled as partial invariance (Byrne et al., 1989). It is typically assumed that DIF effects are sparsely distributed (Liang & Jacobucci, 2020); that is, only a minority of items have DIF effects. The situation in which all items have DIF effects is denoted as complete noninvariance. Furthermore, the particular case in which all items serve as reference items (i.e.,
Scaling Approaches for Multiple-Group Comparisons
In the following, we discuss different approaches for comparing group means in the presence of uniform DIF in the 2PL model. We distinguish between three scaling strategies that differ concerning the degree of invariance they assume for the item parameters. First, we discuss concurrent scaling approaches that assume full invariance of item parameters across groups. In this approach, DIF effects are ignored and not modeled (i.e., DIF effects eig are not included as parameters in the statistical model) when estimating group-specific means and standard deviations. Second, we discuss concurrent scaling approaches that assume partial invariance. In this approach, group-specific item parameters only need to be included for a subset of DIF effects (von Davier et al., 2019). Typically, the set of items with modeled DIF effects—which is aimed to match the set of biased items—is allowed to vary from group to group, and a DIF statistic is required to determine the set of biased items for each group. Third, we propose a separate scaling approach that employs linking methods and does not pose invariance assumptions on item parameters (complete noninvariance). All DIF effects are allowed in this approach, and group-specific means and standard deviations are estimated under different types of linking functions.
Concurrent Scaling Under Full Invariance
In concurrent scaling under the assumption of full invariance of item parameters, maximum likelihood (ML) estimation is used to estimate a multiple-group item response model that does not include any DIF effects. More specifically, the following log-likelihood function is maximized with respect to the unknown model parameters
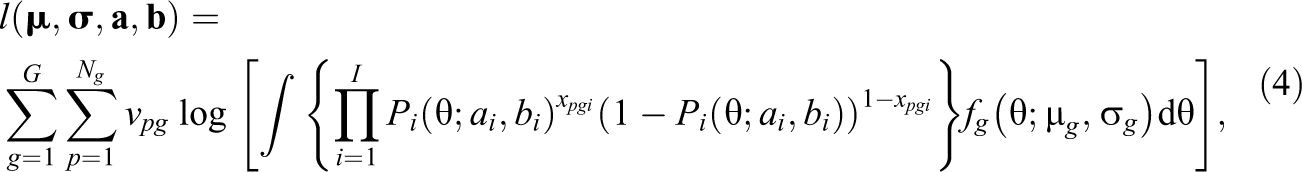
where the ability θ in group g is assumed to be normally distributed (i.e.,
If the item response model is correctly specified, the ML estimator is consistent (White, 1982). However, the model in Equation 4 is misspecified because the true IRF

where the weights
Concurrent Scaling Under Partial Invariance Using DIF Statistics
In contrast to concurrent scaling under full invariance that ignores DIF effects, concurrent scaling under partial invariance allows some of the item parameters with large DIF effects to vary across groups. In this approach, country comparisons are based on a multiple-group IRT model in which, for some of the items, item-by-group interactions are specified (Oliveri & von Davier, 2011; von Davier et al., 2019). The decision about which item parameters obtain group-specific item parameters is based on test statistics for DIF (see Penfield & Camilli, 2007, for an overview). The goal is to determine the set of biased items

where wig are precision weights. If the DIF item set
Many DIF statistics have been proposed in the literature (see Penfield & Camilli, 2007, for an overview). In the following, we use the root mean squared deviation (RMSD) statistic (see Tijmstra et al., 2020), which is now in operation in the ILSA PISA (OECD, 2017; von Davier et al., 2019) and PIAAC (Yamamoto et al., 2013). The RMSD for an item i in country g assesses the distance between a group-specific IRF
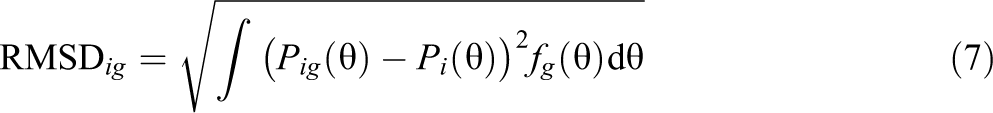
where fg denotes the density of the ability distribution in group g. It should be noted that the RMSD statistic also appears in the literature as the RISE statistic (Sueiro & Abad, 2011) for assessing item misfit. The IRF in Equation 7 involve the unknown functions
Several benchmarks for interpreting DIF effects as large have been proposed for the RMSD statistic for the 1PL or the 2PL model: .055 (Buchholz & Hartig, 2019), .08 (Köhler et al., 2020), .10 (Oliveri & von Davier, 2011), .12 (OECD, 2017, p. 151), .15 (OECD, 2017, p. 174; von Davier et al., 2019), and .20 (OECD, 2015, p. 30). A recent simulation study for the 1PL model suggested that cutoff values of .05 or .08 are to be preferred to .12 (Robitzsch & Lüdtke, 2020). Notably, the RMSD statistic typically increases in smaller sample sizes, making it difficult to apply rules of thumb independent of sample size (Köhler et al., 2020). In small to moderate sample sizes, the detection of DIF items based on statistical significance tests might be preferable (Battauz, 2019; Magis et al., 2010; Millsap, 2011). Overall, the specification of an appropriate cutoff value to identify items with DIF effects is a challenging aspect in applying the partial invariance approach.
Linking With Separate Scaling Under Full Noninvariance
In the third approach, no invariance assumptions are made for the group-specific item parameters. In this approach, group comparisons are based on a two-step procedure that employs linking methods (see Kolen & Brennan, 2014) based on item parameters from a separate scaling within groups. In the first step, a 2PL model is fitted separately for each group (assuming
Haberman linking
In Haberman linking, the group-specific item parameters aig and big are used to simultaneously estimate common item parameters bi, group means µ
g
, and standard deviations σ
g
. Haberman (2009) proposed a regression approach to estimate group means µ, standard deviations σ, and common item parameters
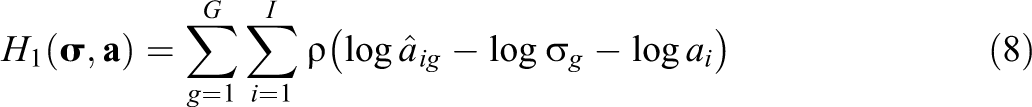
where ρ is a loss function (Fox, 2016), and the identification constraint σ1 = 1 is used. The second regression model for estimating µ and
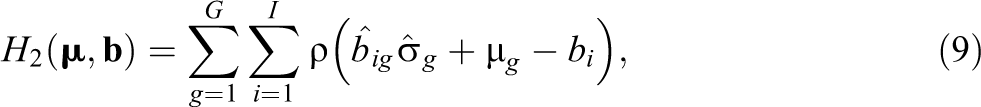
where the identification constraint µ1 = 0 is used. It should be emphasized that the regression models (in Equations 8 and 9) correspond to a two-way ANOVA with main effects and that the presence of DIF effects is equivalent to the presence of interaction effects in the two-way ANOVA (Robitzsch & Lüdtke, 2020).
Haberman (2009) proposed the squared loss function
For the quadratic loss function

where the biasing term Bg is given as the mean of the DIF effects eig for
Haebara linking
It can be expected that Haberman linking can become unstable in small sample sizes because item parameter estimates can be imprecisely estimated. However, estimates of IRF can be quite stable even for unstable item parameters (Ogasawara, 2002). The Haebara linking method relies on linking IRF across groups (Kolen & Brennan, 2014) and can provide more stable group mean estimates than Haberman linking. A generalization of Haebara linking to multiple groups minimizes the summed distances of group-specific IRF and a reference IRF (see Arai & Mayekawa, 2011). More formally, the following criterion is minimized:
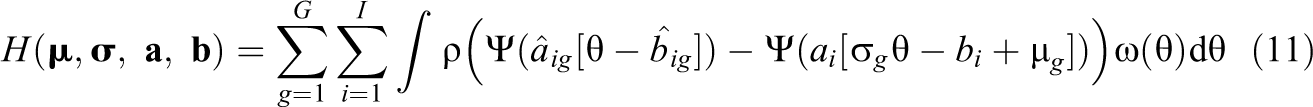
where ρ is a loss function, and
The expected group mean estimate of Haebara linking for the quadratic and the absolute value loss function is of the same form as in Haberman linking (Equation 10; see Appendix C, Equation C4). Each item i in each group g is associated with a weight wig that is a function of ai, bi, µ
g
, and σ
g
. For the loss function
Computation of Standard Errors
The uncertainty in the estimated group means has to be taken into account correctly in statistical inference. In the concurrent scaling approach based on full invariance, standard errors due to the (independent) sampling of persons are readily obtained in ML estimation. Unfortunately, the concurrent scaling approach based on partial invariance does not directly provide valid standard errors because the preliminary step of detecting items with DIF effects is ignored in standard error assessment (Burnham & Anderson, 2002). Standard errors for the linking approaches based on separate scalings rely on the delta formula (Andersson, 2018; Battauz, 2015; Robitzsch, 2020a). The computation of standard errors based on resampling techniques such as balanced repeated replicate weights (used in PISA; OECD, 2009; Kolenikov, 2010) is a viable alternative, particularly in the case of stratified clustered sampling (Andersson, 2018; Battauz, 2017; Haberman et al., 2009). In this article, we are also interested in comparing group mean estimates obtained from different scaling models that were applied to the same sample. Thus, a significance test for a group mean difference evolving from two different models based on the same data set is required because the assumption that the standard errors of the two models are independent is not justified. A simple but effective alternative for computing standard errors consists of applying resampling methods in which the group mean difference between two models is also computed in the replication samples (Burnham & Anderson, 2002; Macaskill, 2008).
Research Questions
The primary research goal of our study is to compare the performance of the linking approach with a separate scaling approach with two concurrent scaling approaches for estimating country means in the presence of uniform country DIF. We expect that the performance of concurrent scaling under partial invariance would depend on the proportion and type of DIF effects of biased items. In the case of balanced DIF (i.e., DIF effects of biased items that sum to zero), efficiency losses of estimated group means are expected when items were removed from country comparisons in concurrent scaling under partial invariance (DeMars, 2020). Furthermore, in this scenario, it could be speculated that concurrent scaling under full invariance and separate scaling with nonrobust linking would be superior to scaling under partial invariance. In the case of unbalanced DIF (i.e., DIF effects of biased items are of the same sign), we expect that robust linking would provide less biased group mean estimates than the full invariance approach and nonrobust linking. The performance of concurrent scaling under partial invariance is expected to strongly depend on selecting an appropriate cutoff value for the RMSD statistic. We also investigate whether the concurrent scaling approaches have some advantages in small samples because they combine information from different groups when estimating item parameters.
Simulation Study
Simulated Conditions
We simulated data from a 2PL model for G = 20 countries. For each country, abilities were normally distributed with mean µ
g
and standard deviation σ
g
. Across all conditions and replications of the simulation, the country means and standard deviations were held fixed and ranged between −0.92 and 0.81 for means (with an average of 0.00) and between 0.82 and 1.06 for standard deviations (with an average of 0.91). The values were chosen to mimic the typical variability of the country means in a PISA study. The total population containing all students in all countries had a mean of zero and a standard deviation of 1. Country-specific item parameters β
ig
were generated according to
In each country, the sets of biased and reference items were held fixed across conditions and replications with a fixed proportion of biased items. For a fixed proportion
For each condition of the simulation design, 500 replications were generated. More specifically, we manipulated the following four factors in our simulation design to mimic typical situations in large-scale assessment studies: the number of persons per country (N = 250, 500, and 1,000), the proportion of biased items (0%, 10%, and 30%; see Magis & De Boeck, 2011), the standard deviation of the DIF effects of the reference items (SDA = 0, and .15; see Monseur et al., 2008), and the type of DIF effects of the biased items (balanced vs. unbalanced). The DIF effect size for the biased items was fixed to δ = 0.6, which corresponds to a large DIF effect size (i.e., C-DIF according to the ETS classification; see Penfield & Camilli, 2007).
Analysis Models and Criteria
We used three different scaling strategies to obtain country means in each replication. First, we specified a multiple-group 2PL model with invariant item parameters across countries (concurrent scaling under full invariance; FI). Second, we implemented concurrent scaling under partial invariance using the RMSD statistic (PI-RMSD) in which items in a country with RMSD values larger than .05, .08, or .12 received country-specific item difficulties while still assuming country-invariant item slopes. Third, we used two linking approaches (Haberman method and Haebara method) that do not rely on invariance assumptions for item parameters. In both approaches, a nonrobust version (HAB and HAE) or a robust version (RHAB and RHAE) was used to link the item parameters that were obtained from a separate scaling within each country. For all analyses, the R software (R Core Team, 2020) and the R packages sirt (Robitzsch, 2020c) and TAM (Robitzsch et al., 2020) were used.
In each scaling strategy, for the first country, the mean was set to zero, and the standard deviation was set to 1 to identify all model parameters. For the country comparisons, country means were linearly transformed so that the total population of students across countries had a mean of zero and a standard deviation of 1. We used two criteria to evaluate the performance of the different approaches: average absolute bias and average root mean square error (RMSE) across countries. Average absolute bias was computed by averaging the absolute biases of all country means. Average absolute biases greater than .03 (i.e., about 3 points in the PISA metric) were considered substantial because standard errors of the country means in ILSA are usually about that size (e.g., OECD, 2017). The average RMSE was calculated by averaging the RMSEs across countries.
Results
Average Absolute Bias (Bias) and Average Root Mean Square Error (RMSE) of Group Means as a Function of Proportion of DIF Items, and Standard Deviation of DIF Effects of Reference Items for a Sample Size of N = 1,000 and for Balanced DIF and Unbalanced DIF
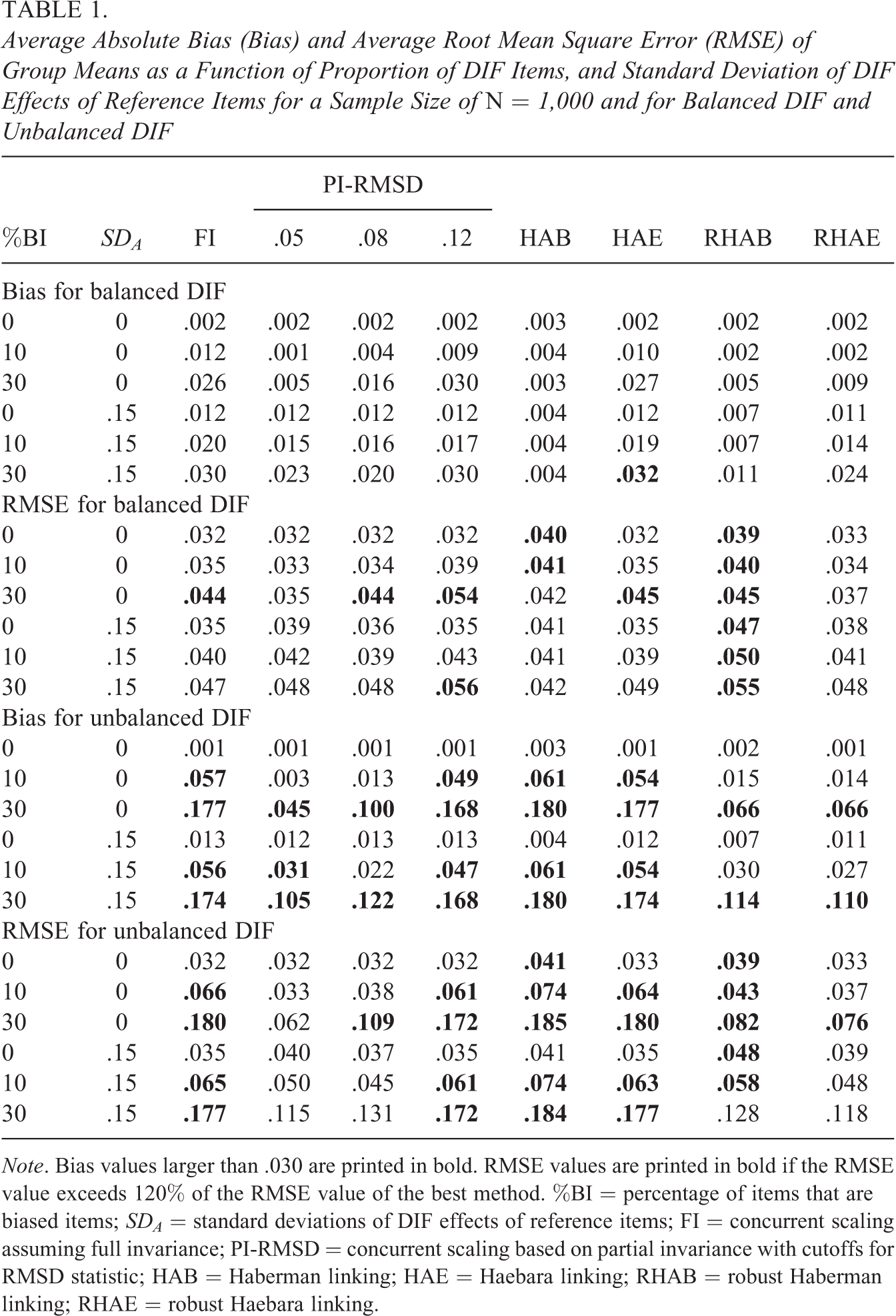
Note. Bias values larger than .030 are printed in bold. RMSE values are printed in bold if the RMSE value exceeds 120% of the RMSE value of the best method. %BI = percentage of items that are biased items; SDA = standard deviations of DIF effects of reference items; FI = concurrent scaling assuming full invariance; PI-RMSD = concurrent scaling based on partial invariance with cutoffs for RMSD statistic; HAB = Haberman linking; HAE = Haebara linking; RHAB = robust Haberman linking; RHAE = robust Haebara linking.
Table 1 shows the average absolute bias and average RMSE for the conditions with a sample size of N = 1,000. In the case of balanced DIF, all scaling strategies were approximately unbiased or showed only small biases. As can be seen, the HAB approach was superior to both the FI approach and the HAE approach. This finding was expected because the HAB linking approach estimated group means under the assumption that DIF effects sum to zero (see Appendix B, Equation B2). This condition exactly resembled the data-generating model. In contrast, the FI and HAE approach employed a different weighting of DIF effects that resulted in small biases (particularly for a large proportion of biased items; see Appendix A, Equation A7, and Appendix C, Equation C4). Furthermore, concurrent scaling under partial invariance (PI-RMSD) slightly outperformed the FI and HAE approaches in many conditions. The robust linking approaches (RHAB and RHAE) performed similarly to the partial invariance approach using the RMSD cutoff of .05 or .08. For the average RMSE, the results were similar to the findings for the bias. First, country mean estimates that were produced by separate scaling with HAE were not less stable than estimates provided by concurrent scaling under FI (see also Andersson, 2018, for similar findings). Second, the performance of concurrent scaling under partial invariance depended on the choice of the specific cutoff to be used for the RMSD statistic. In many conditions, cutoff values of .05 and .08 for the RMSD statistic—which result in using a larger number of country-specific item parameters—outperformed the cutoff value of .12 and produced country mean estimates that were close to the FI approach in terms of RMSE.
Table 1 also shows the average absolute bias and average RMSE for the conditions with a sample size of N = 1,000 in the case of unbalanced DIF (i.e., all DIF effects of biased items were either positive with a value of δ or negative with a value of −δ for each country). The country mean estimates produced by the FI and nonrobust linking approaches (HAB and HAE) were grossly biased in some conditions. This bias was substantially reduced with the partial invariance approaches (PI-RMSD) and robust linking approaches (RHAB and RHAE). The robust linking approaches based on separate scaling (RHAB and RHAE) performed similarly. They even outperformed the partial invariance approaches based on concurrent scaling in many conditions if an optimal cutoff value for the RMSD was not chosen. Considering the dependency of the RMSD on the sample size, it is noteworthy that the choice of an optimal cutoff for the RMSD statistic was either .05 or .08, and there were no conditions in which the cutoff of .12 was preferred.
Figure 1 shows the influence of sample size on the performance of the selected scaling strategies in the case of unbalanced DIF. It can be concluded that the general findings for N = 1,000 also hold for N = 250 and N = 500. The concurrent scaling under FI and nonrobust linking (HAE) approaches were also more biased than the partial invariance and robust linking (RHAE) approaches in smaller samples. The PI-RMSD approach with a cutoff of .08 was always superior to the cutoff of .12. Importantly, the approaches based on separate scaling (HAE, RHAE) were only less stable than the concurrent scaling approaches (FI, PI-RMSD) with a small sample size of N = 250. HAB produced substantially more variable estimates than all other approaches for N = 250. Hence, for sample sizes larger than 500, the different performance of scaling strategies for the average RMSE was mainly determined by average absolute bias.
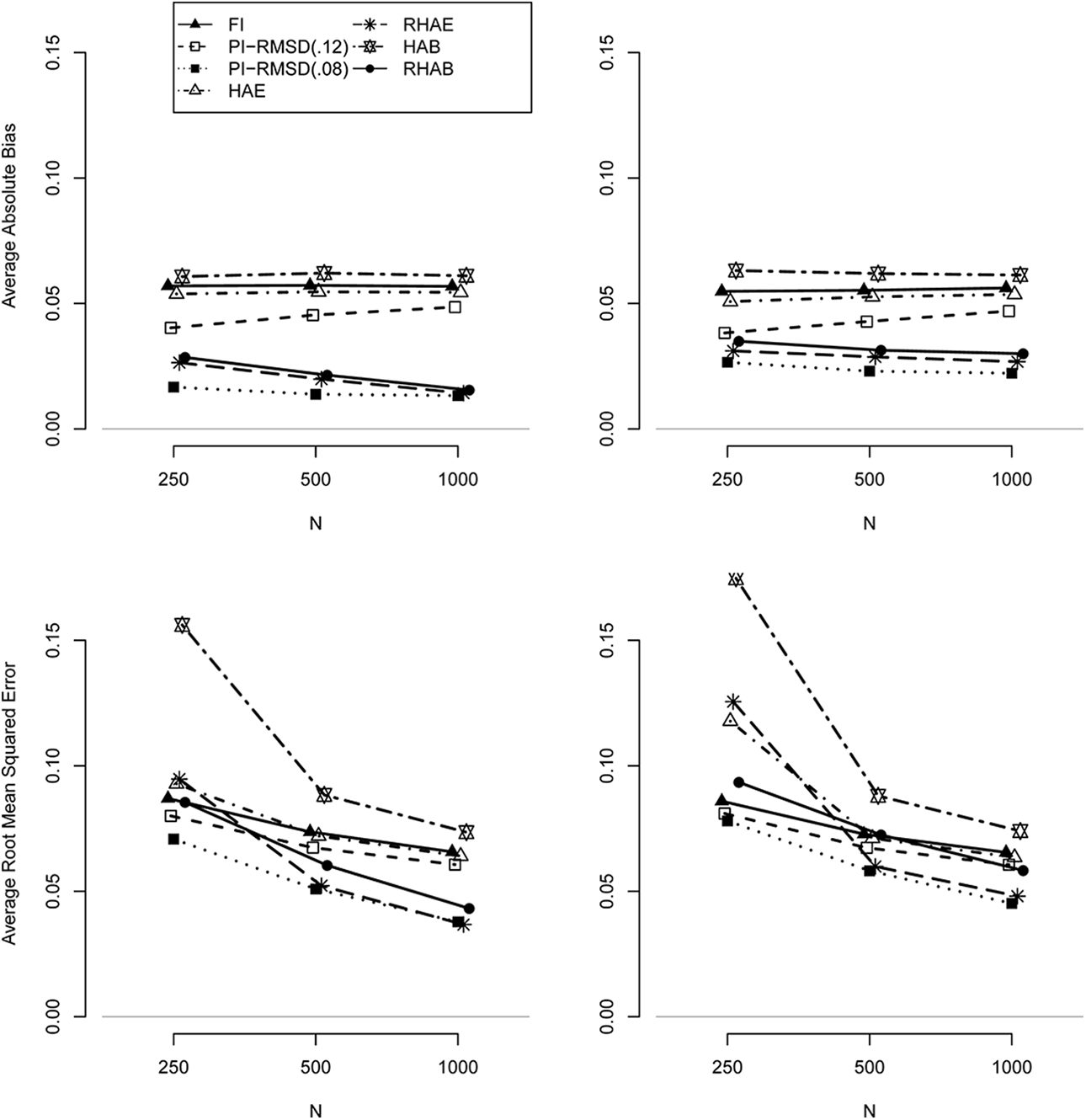
Average absolute bias (upper panels) and average root mean square error (lower panels) for unbalanced differential item functioning (DIF) for 10% biased items with a DIF effect size of .6, I = 20 items, for a standard deviation of DIF effects of reference items of SDA = 0 (left panels) and SDA = 0.15 (right panels) as a function of sample size.
Empirical Example: Cross-Sectional Country Comparisons for Reading in PISA 2006
In order to illustrate the different approaches to estimating country means, we analyzed the data from the PISA 2006 assessment (OECD, 2009). In this reanalysis, we included 26 OECD countries that participated in 2006, and we focused on the reading domain, which was a minor domain in PISA 2006. Thus, reading items were only administered to a subset of the participating students, and we included only those students who received a test booklet with at least one reading item. This resulted in a total sample size of 110,236 students (ranging from 2,010 to 12,142 between countries). In total, 28 reading items nested within eight testlets were used in PISA 2006. Six of the 28 items were polytomous and were dichotomously recoded, with only the highest category being recoded as correct. We used six different methods to obtain estimates of country means: a full invariance approach (concurrent scaling with multiple groups; FI); a partial invariance approach with DIF detection based on the RMSD statistic (PI-RMSD) using the cutoffs .05, .08, and the value of .12 that is used in PISA; two nonrobust linking methods (Haberman, HAB; Haebara HAE), and two robust linking methods (RHAB; RHAE). For all analyses, student weights within a country were normalized to a sum of 5,000 so that all countries contributed equally to the analyses. Finally, all estimated country means were linearly transformed so that the distribution containing all (weighted) students in all 26 countries had a mean of 500 (points) and a standard deviation of 100. Note that this transformation is not equivalent to the one used in officially published PISA publications. The 80 balanced repeated replicate weights defined in PISA were used for computing standard errors (OECD, 2009).
In a first exploratory analysis, we fitted the FI model and computed the RMSD statistic for all items and all countries. The average RMSD across items and countries was .060 (SD = .044). For each item, we also computed the average RMSD across countries. These 28 values ranged between .027 and .099 (SD = .020), where the largest value was obtained for item R227Q02T. The average RMSD at the level of countries ranged between .044 and .082 (SD = .010), where the largest values were obtained for Japan (.082) and South Korea (.080). We also specified a variance component model for the RMSD values using items and countries as random effects. We found that the item factor (16.8% of the total variance) was more important than the country factor (2.6%), but the residual effects had the largest variance contribution (80.5%). When using an RMSD cutoff of .12, 9.8% of the item difficulty parameters received country-specific parameters (cutoff of .08: 23.8%; cutoff of .05: 49.1%).
In a second exploratory analysis, we specified the partial invariance approach using RMSD cutoff values from .02 to .20 in increments of .01. We assessed model fit using the information criteria AIC and BIC as well as the log-penalty measure (see van Rijn et al., 2016). In Table 2, these model fit statistics are displayed for the PI-RMSD models with different RMSD cutoff values. The PI-RMSD model with a cutoff of .02 was preferred by the AIC, and the model with a cutoff of .05 was preferred by the BIC. By using differences in log-penalty measures (i.e., ΔPE in Table 2), the difference between the FI model and the PI-RMSD model with a cutoff of .12 was .0071, which could be considered a small difference according to van Rijn et al. (2016, p. 5). The model with a cutoff value of .08 showed a moderate difference of .0103 to the FI model. Overall, the partial invariance approach resulted in a better model fit than the FI model. However, different fit measures prefer different cutoff values for the RMSD statistic.
Model Comparison of 2PL Model under Full Invariance and Partial Invariance With Different Cutoff Values for the RMSD Statistic
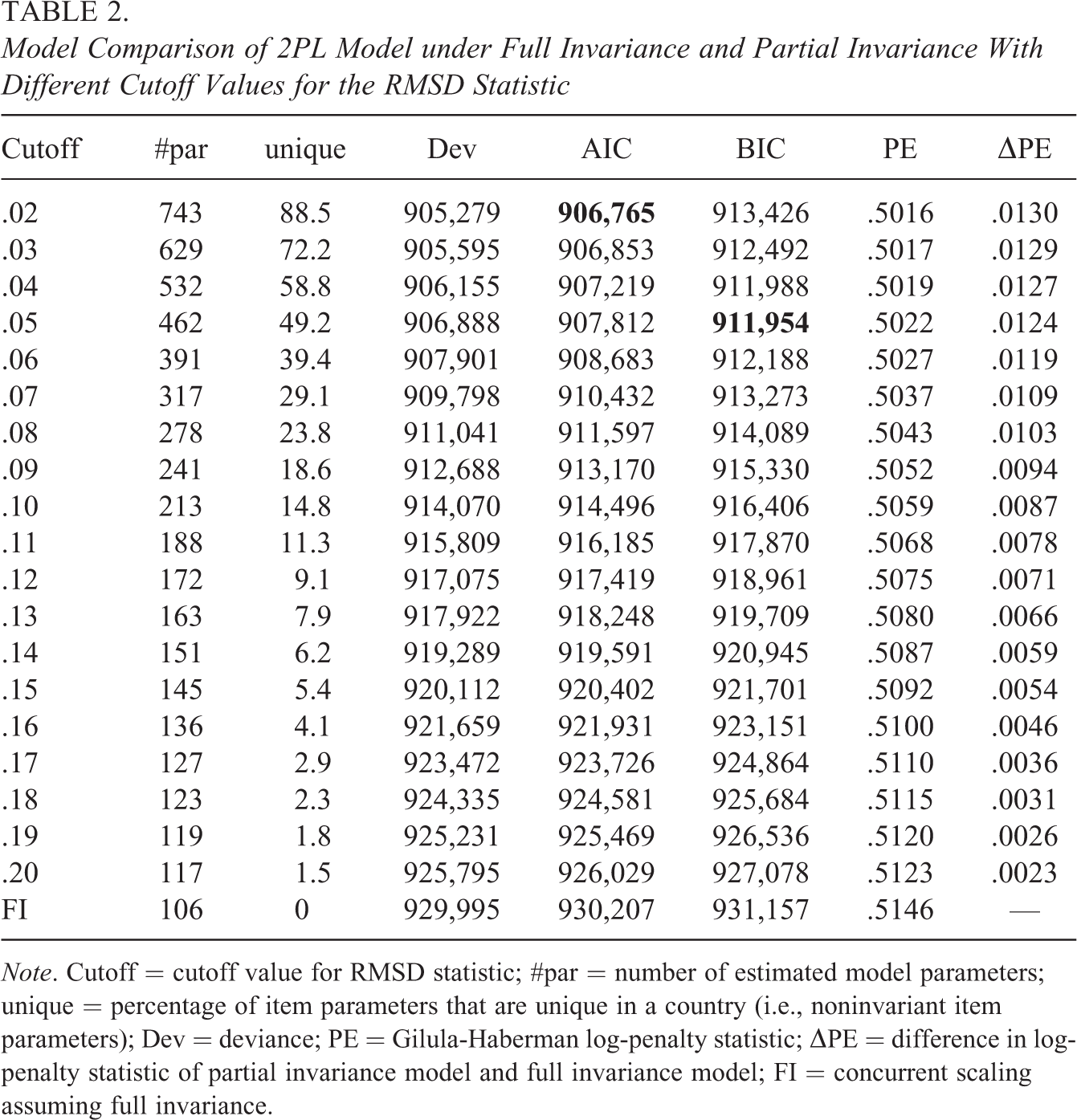
Note. Cutoff = cutoff value for RMSD statistic; #par = number of estimated model parameters; unique = percentage of item parameters that are unique in a country (i.e., noninvariant item parameters); Dev = deviance; PE = Gilula-Haberman log-penalty statistic; ΔPE = difference in log-penalty statistic of partial invariance model and full invariance model; FI = concurrent scaling assuming full invariance.
Country Means for the Reading Domain for PISA 2006 for 26 Selected Organization for Economic Cooperation and Development Countries
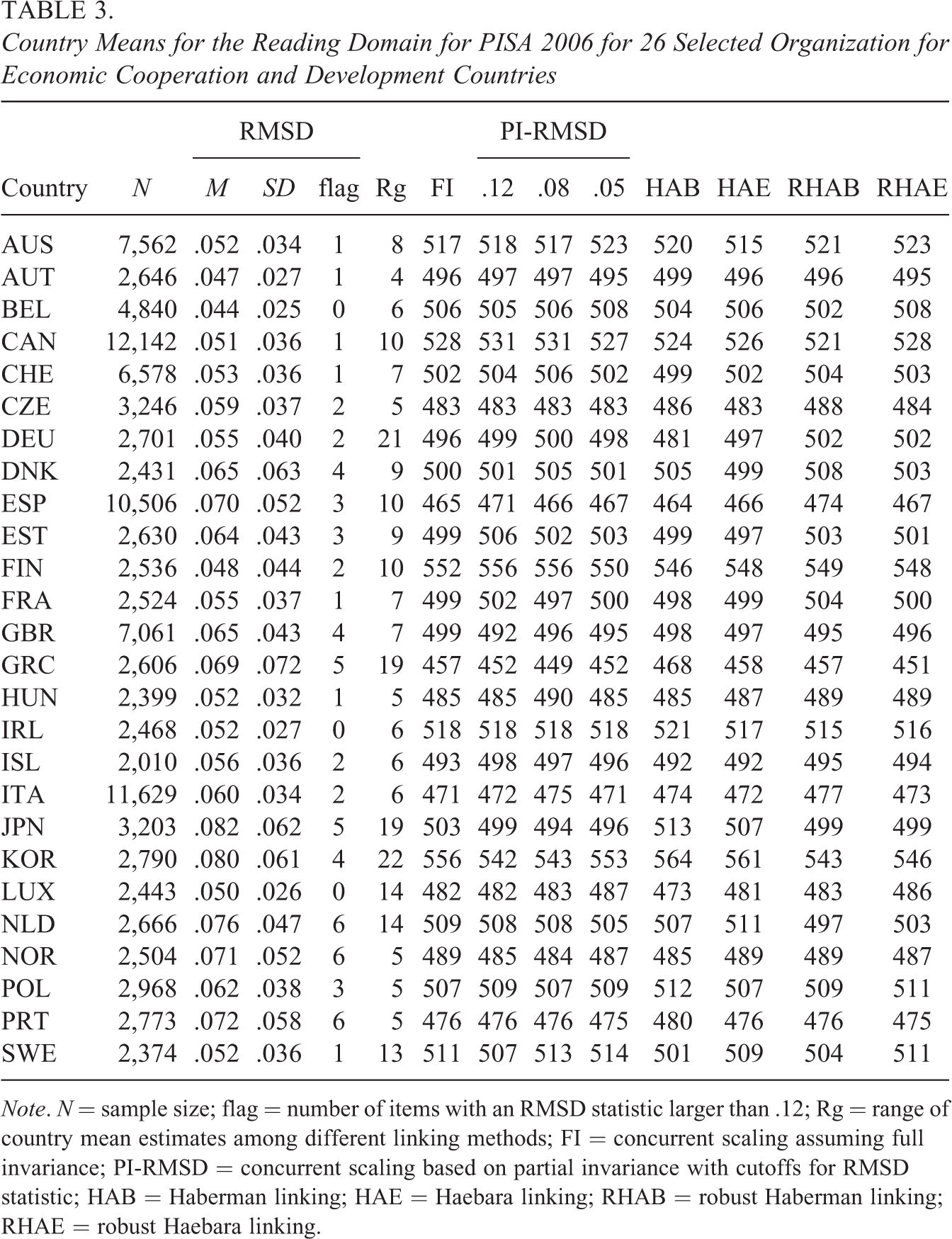
Note. N = sample size; flag = number of items with an RMSD statistic larger than .12; Rg = range of country mean estimates among different linking methods; FI = concurrent scaling assuming full invariance; PI-RMSD = concurrent scaling based on partial invariance with cutoffs for RMSD statistic; HAB = Haberman linking; HAE = Haebara linking; RHAB = robust Haberman linking; RHAE = robust Haebara linking.
In Table 3, the country mean estimates obtained from the six different methods are shown. Within a country, the range of the country’s mean differed between 4 and 22 points (M = 9.7, SD = 5.4) across the different methods. These differences between the methods can be attributed to different amounts of country DIF. It is instructive to first focus on the comparison of country means based on the assumption of full invariance in a concurrent scaling approach that ignores DIF (similar to the PISA method used until 2012) and the partial invariance approach based on the RMSD statistic with a cutoff of .12 (which is the PISA method that has been used since 2015). About 9.8% of all items across countries exceeded an absolute value of .12 for the RMSD statistic. There was an average absolute difference of 3.0 points between the two approaches, with a maximum discrepancy of 22 points (South Korea, KOR). As shown in Table 3, South Korea had four flagged DIF items with an RMSD statistic larger than .12. Those four items received country-specific item parameters in the partial invariance approach, which induced a drop of 14 points in the partial invariance approach (542 points) compared to the full invariance approach (556 points). For all other countries, the absolute differences between the two approaches were at most 7 points (Min = 0, M = 3.0, SD = 3.2). The magnitude of the difference between the full and partial invariance approach with an RMSD cutoff of .12 was, therefore, similar to that of the standard errors caused by person sampling (about 3 points). Hence, the choice of a particular linking method is of practical relevance for at least some countries (but see Jerrim et al., 2018, for a similar analysis with the PISA 2015 data).
Table 4 shows the average absolute differences and correlations of the country mean estimates for the different methods. It needs to be emphasized that even a correlation of country means as high as .996 (FI with HAE) can result in a nonnegligible average absolute difference of 1.3 points (with a maximum of 5 points for South Korea, KOR). The partial invariance approaches based on the RMSD statistic with cutoffs of .08 and .05 performed similarly to the robust Haebara approach (r = .987, .990, .995, respectively). When interpreting the results, it needs to be noted that the observed discrepancies in country means for PISA 2006 could be smaller for more recent PISA assessments as the number of items in a domain has been substantially increased in the recent PISA assessments.
Average Absolute Differences (Upper Diagonal) and Correlations (Lower Diagonal) for Different Linking Methods for Reading Domain in PISA 2006 for 26 Selected Organization for Economic Cooperation and Development Countries
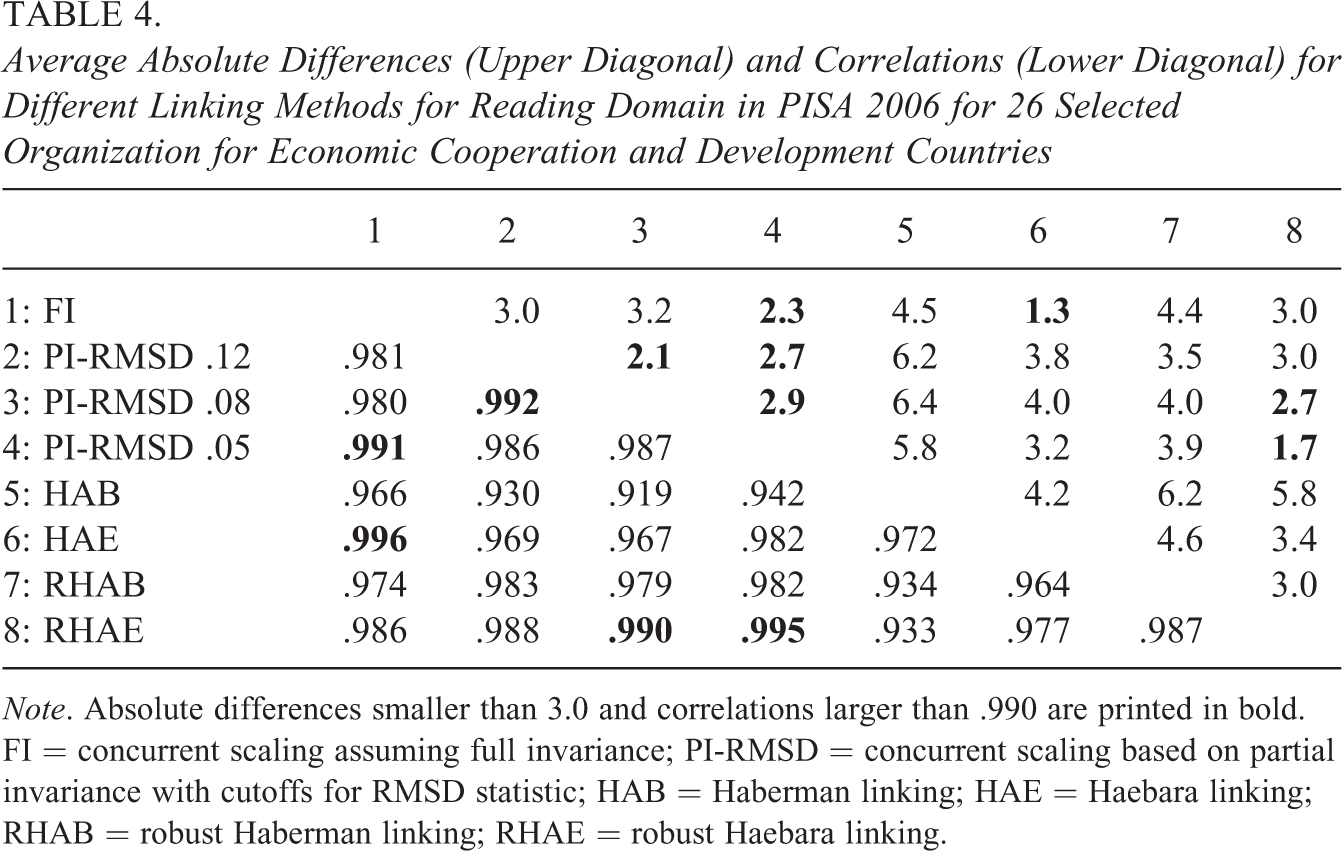
Note. Absolute differences smaller than 3.0 and correlations larger than .990 are printed in bold. FI = concurrent scaling assuming full invariance; PI-RMSD = concurrent scaling based on partial invariance with cutoffs for RMSD statistic; HAB = Haberman linking; HAE = Haebara linking; RHAB = robust Haberman linking; RHAE = robust Haebara linking.
In Table 5, the standard errors for the country means, and the differences between the scaling models and their associated standard errors are displayed. Notably, the country-specific standard errors for the model differences were smaller than the standard errors for the country means because the country means of the different models were strongly dependent as they were obtained from the same data set. For example, the average standard error for the country means under FI was 3.0, while the standard error for the FI and RHAE model difference was 1.9. Notably, 10 out of 26 comparisons between the FI and PI-RMSD(.12) (i.e., the column “FI − PI-RMSD(.12)” in Table 5) turned out to be statistically significant. The difference between the FI (PI-RMSD(.12)) and RHAE models was significant in 6 (or 4, respectively) out of 26 comparisons. To conclude, some model differences are of practical importance.
Standard Errors for Country Means and Differences Between Models for the Reading Domain in PISA 2006 for 26 Selected Organization for Economic Cooperation and Development Countries
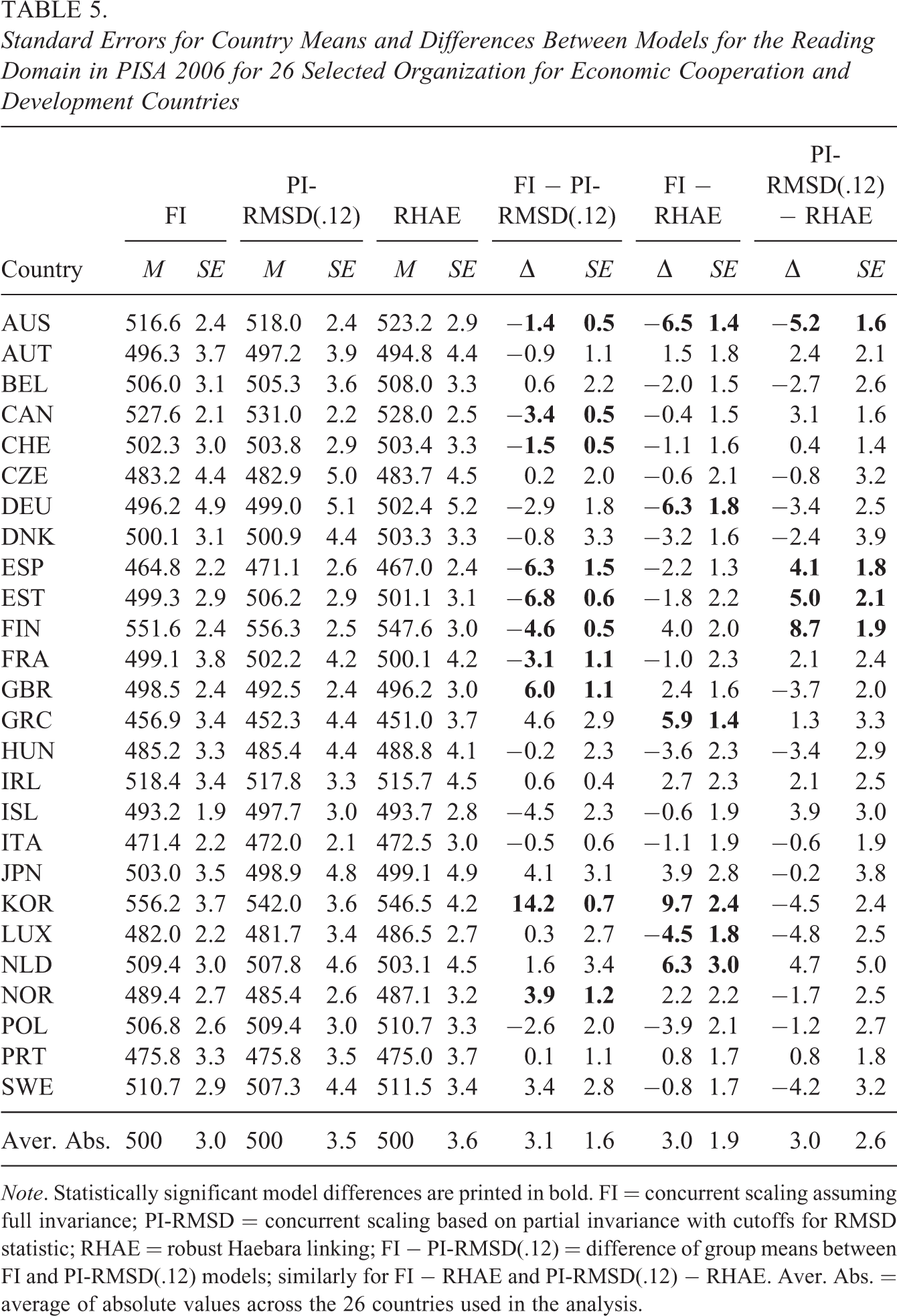
Note. Statistically significant model differences are printed in bold. FI = concurrent scaling assuming full invariance; PI-RMSD = concurrent scaling based on partial invariance with cutoffs for RMSD statistic; RHAE = robust Haebara linking; FI − PI-RMSD(.12) = difference of group means between FI and PI-RMSD(.12) models; similarly for FI − RHAE and PI-RMSD(.12) − RHAE. Aver. Abs. = average of absolute values across the 26 countries used in the analysis.
Discussion
In this article, we discussed concurrent and separate scaling approaches for comparing group means in the presence of DIF effects. We analytically showed that concurrent scaling under full invariance, concurrent scaling under partial invariance, and separate scaling with linking place different constraints on the DIF effects of reference items and biased items. In a simulation study, we showed that the performance of the different approaches depended on the nature of the DIF effects, particularly for the biased items (balanced vs. unbalanced DIF). In the case of unbalanced DIF, we found that concurrent scaling under full invariance and separate scaling with nonrobust linking produced biased country mean estimates. In contrast, concurrent scaling under partial invariance and separate scaling with robust linking could considerably reduce the bias by removing the impact of items with large DIF effects from the country comparisons. However, the performance of the partial invariance approach strongly depended on the specification of an adequate cutoff value for the RMSD statistic. In most conditions, a cutoff value of .05 performed better than a value of .12. Importantly, with a less than optimal cutoff value for the RMSD statistic, concurrent scaling under partial invariance was outperformed by separate scaling with subsequent robust linking (RHAB, RHAE).
As is the case for all simulation studies, conclusions are limited to the conditions that were investigated in our study. First, we did not consider the case of nonuniform DIF (i.e., DIF that is also present in item slopes) in the data-generating model. It is an interesting topic for future research to examine whether our findings can be generalized to this case. Although one could use similar cutoff values for the RMSD statistics, the linking approaches need further consideration by including item slope parameters. However, it should be noted that uniform DIF is more frequently found in ILSA than nonuniform DIF (Rutkowski & Svetina, 2017). Second, we restricted ourselves to a simulation study involving only 20 items. A linking study for the Rasch model found practically no differences for 20 and 40 items (Robitzsch & Lüdtke, 2020). Further studies could investigate larger numbers of items or could treat items as random instead of as fixed. Third, we assumed that the maximum proportion of biased items was 30%. We believe that the test construction would not have been successful if the majority of items were biased items (Magis & De Boeck, 2011). Third, we only chose two extreme DIF conditions for biased items, namely, the case of balanced DIF in which the DIF effects of biased items sum to zero and the case of unbalanced DIF in which all items either have a joint positive or negative biasing DIF effect δ. In reality, DIF effects of biased items are likely to follow a distribution between these two extreme scenarios. These constellations should be investigated in future simulation studies, providing more practical guidelines for choosing between different scaling approaches.
Our treatment of concurrent and separate scaling approaches for comparing group means in the presence of DIF can be extended in several ways. First, the linking methods could be investigated for polytomous data or the 3PL model, and, again, we would not expect very different findings compared to the 2PL model. However, again, the choice of a cutoff value for the RMSD item fit statistic is crucial for concurrent calibration under partial invariance (Buchholz & Hartig, 2019). Second, different linking functions could be considered. Besides the absolute value loss function
In large-scale assessment studies, the ability distributions are typically estimated using plausible values (von Davier & Sinharay, 2014). Covariates (i.e., background variables) are used in a latent regression model to compute plausible values. Notably, we did not use covariates in our study. However, we expect that our results would also hold if a latent regression model is used. The critical factor is whether the distribution of the ability in a group is correctly specified. In our simulation, we used a normal distribution in each group, and the effect on possible biased estimates would be more significant in short tests. Possible distributional misspecifications in a latent regression model refer only to the regression residuals of the ability variable, so it can be expected that distributional violations are more critical without covariates than with covariates. In future research, the influence of more complex ability distributions (i.e., asymmetric or mixture distributions) on estimated group means could be investigated under a misspecified ability distribution (i.e., assuming a normal distribution).
The linking of multiple groups in the presence of DIF can alternatively be carried out using regularization techniques. In a regularization-based approach to DIF, group-specific item parameters are decomposed into common item parameters and group-specific deviations (e.g., Liang & Jacobucci, 2020; Schauberger & Mair, 2020). Using conventional maximum likelihood estimation would result in a nonidentified model. In the regularization approach, penalty terms for the nonidentifiable group-specific deviations are subtracted from the log-likelihood function to define the optimization function, ensuring the empirical identifiability of model parameters and imposes assumptions about the distribution of the parameters of noninvariance. For example, the lasso penalty function is particularly suited to partial invariance situations (Liang & Jacobucci, 2020).
Furthermore, we believe that conducting a separate estimation with subsequent linking has several advantages over concurrent scaling that relies on full or partial invariance (see Andersson, 2018). Computation times are usually substantially lower with separate estimation. In our empirical example involving 26 countries and 28 items, separate scaling only took about 1 min, and the subsequent Haberman and Haebara linking approaches took at most 3 s, while concurrent scaling assuming full or partial invariance needed 5–10 min by using a multiple-group IRT model. It is often easier to diagnose potential estimation problems with separate estimation (Andersson, 2018). Finally, concurrent scaling can only provide more efficient estimates than separate scaling if model assumptions hold (Kolen & Brennan, 2014). As it cannot be ensured that there are no unmodeled DIF effects or that strict unidimensionality holds, situations in which concurrent scaling should be preferred are not very likely to occur (cf. von Davier et al., 2019, for an alternative view).
In the literature, it is often argued that at least partial invariance for item intercepts is needed to allow meaningful comparisons of group means (e.g., van de Vijver, 2019; Vandenberg & Lance, 2000). However, one critical aspect of the partial invariance approach (as well as other approaches that result in the removal or downweighting of the contribution of particular items, such as robust Haberman or robust Haebara linking) is that comparisons of different groups rely on different sets of items. We regard this feature as a potential threat to validity and find this practice problematic because it compares apples with oranges (see also El-Masri & Andrich, 2020). For example, the comparison of the country means for Germany with those for Italy in PISA does not involve a full set of common item parameters for each country if the sets of country-specific noninvariant items—that receive country-specific item parameters—differ between the two countries. More critically, in the current operational use since PISA 2015, the determination of how a country comparison is conducted (i.e., which items are used as reference items) is solely based on the item misfit in a psychometric model (von Davier et al., 2019). In contrast, approaches using full invariance or complete noninvariance rely on the same set of items for country comparisons. Until PISA 2015, items with DIF effects were only declared as DIF items if translation issues were confirmed (Adams, 2003). In this procedure, items with substantial DIF effects—but without translation issues—remained in a country comparison and were neither removed from scaling nor received country-specific parameters. To conclude, it has to be acknowledged that, in the presence of DIF, country comparisons depend on the particular identification constraint chosen, however arbitrary that choice may be.