
Abstract
Public schools and districts use social media to share announcements and communicate with parents and the community, but alongside such uses run risks to students’ privacy. Using a novel data set of 18 million posts on Facebook by schools and school districts in the United States, we sought to establish how frequently photos of students were shared. Through sequential mixed-methods, we estimated that around 4.9 million posts included identifiable images of students and that approximately 726,000 of these posts also included students’ first and last names and their approximate location. We discuss these findings’ implications from a data ethics perspective.
If you search the web for the school district serving the community in which you live, chances are that one of the first results returned will be that district’s Facebook page, a public page on the most-used social media platform—one used daily by around half of American adults (Gramlich, 2021). Scrolling, you may see announcements, among other posts. You may even notice photos highlighting one or more students alongside their names. Importantly, these public Facebook pages are accessible by anyone on the Internet—with or without a Facebook account.
This study examines the posts on schools’ and districts’ Facebook pages that might reveal the personally identifiable information (PII) of students, information that can be linked to an individual. Guided by the following two research questions (RQs), we focus on how posting this information may inadvertently risk students’ privacy.
RQ #1: To what extent do the public Facebook pages of schools and districts depict one or more students in a photo?
RQ #2: To what extent do they identify one or more students by both name and photo?
The potential sharing of students’ PII is noteworthy for several reasons. Parents have long expressed concerns about others—including teachers (Cino & Vandini, 2020)—sharing the PII of their children (Fox & Hoy, 2019; Plunkett, 2019). These concerns may be heightened by knowing the potential ease with which companies may access the posts of schools and districts for uses not intended to be accessed by those in schools who have posted. For instance, it is increasingly recognized that predictive policing companies (Hill & Dance, 2020) regularly collect and utilize public social media data.
Furthermore, government agencies—including both the United States and other foreign governments (Cadell, 2021)—regularly access public social media data, doing so for purposes ranging from monitoring immigration and predicting crime risk to documenting social connections (Joh, 2016). The potential use of Facebook data by organizations such as the police and government agencies is noteworthy because secondary use of student-related PII data runs counter to the Fair Information Practice standards (FIPs) that undergird Family Educational Rights and Privacy Act (FERPA) protections. Specifically, the FIPs disallows the secondary use of student data (Vance & Waughn, 2021). If schools are aware that third parties access data about students on Facebook, it may run counter to legal protections. We note that media release forms allow parents or guardians to waive protections provided by FERPA. This suggests that even if the sharing we have documented is concerning, it may be legal if a media release form has been signed.
There are broader concerns not about the legality but the ethics of using data found on social media. This matters because even if such access is legally allowable, it could cause harm to those the data is about. For instance, child images shared in public posts have reportedly been found on pedophilia websites. According to Battersby (2015), “Innocent photos of children originally posted on social media and family blogs account for up to half the material found on some pedophile image-sharing sites” (p. 1). The unintended secondary data uses, then, suggest that if student photos and PII are shared on social media platforms, there are ethical questions that indicate the need to use not only legal but also ethical lenses to understand the potential harm to students’ privacy that may result from posts about students on Facebook.
Method
Methodology and Data Source
To access Facebook data, we used CrowdTangle, 1 Facebook’s platform to provide researchers with access to Facebook data. CrowdTangle permits access to the posts of all public pages and open groups. The public internet data mining approach we used to access and record links to Facebook pages from the websites of all of the public districts and schools in the United States (Online Supplementary Material A) allowed us to access 18,004,024 posts via the CrowdTangle API, with 13,870,211 including one or more images (77%). We note that both the number of posts and the proportion of posts, including photos (by year), increase over time (Online Supplementary Material B). Next, we used a sequential mixed-methods design to address the research question. First, we conducted visual content analysis, qualitatively coding posts for the depiction and identification of students, followed by quantitative analyses—namely, logistic regression—to make inferences about the coded sample, described next.
Qualitative Data Analysis
We developed a coding frame for the number of faces depicted (included in a photo) and identified (face depicted with an individual’s first and last name included) in these photos to qualitatively code 400 posts randomly selected from our full sample of around 18 million posts. Coding was performed by two trained coders who assisted with the development of the coding frame. This process involved six rounds of interrater reliability. At the end, coders demonstrated strong agreement for the depiction (80%; Κ = 0.69) and identification of students (100%; Κ = 1.00). See Online Supplementary Material C for additional information on the coding and Online Supplementary Material D for an illustration of the coding process.
Quantitative Data Analysis
Following our qualitative coding, we fit an unconditional logistic regression model to estimate the proportion of photos with one or more students depicted or identified (as separate models). Then, to interpret the models, we examined the estimate and confidence interval for the intercept. Specifically, to better understand the scale of the issue, we used these estimated coefficients and their confidence intervals to estimate the frequency of depicted and identified students in the larger sample of around 18 million posts.
Results
The estimates from the logistic regression (Table 1) indicated that 35.40% (30.43%–40.58%) of photos depicted one or more students, whereas 5.23% (3.25%–7.84%) identified students by first and last name. When extrapolated to the full sample, these estimates suggest that around 4.9 million posts depicted one or more students, and around 726,000 posts identified one or more students.
Log Odds Estimates and Full Sample Extrapolation for the Depiction and Identification of Students in Public Facebook Posts
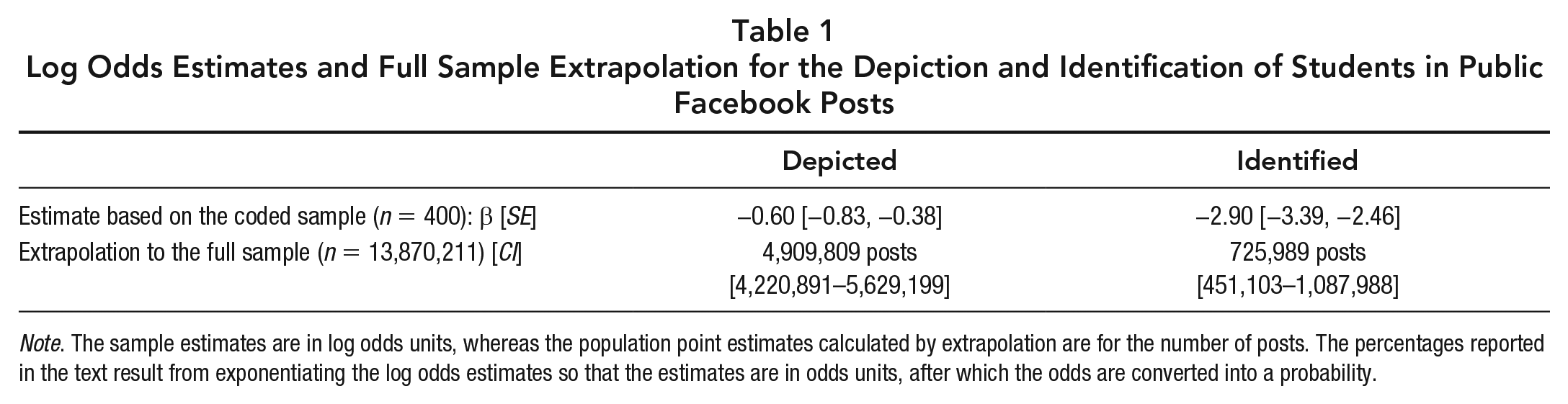
Note. The sample estimates are in log odds units, whereas the population point estimates calculated by extrapolation are for the number of posts. The percentages reported in the text result from exponentiating the log odds estimates so that the estimates are in odds units, after which the odds are converted into a probability.
Discussion
This study revealed how posts about students on Facebook might risk students’ privacy. Nearly five million photos depicting students’ faces have been shared, with more than three-quarters of a million of these photos also identifying one or more students by first and last name. Notably, these findings can be understood in the increasing number of posts and the proportion of posts with images over time (Online Supplementary Material B). This is a potentially urgent topic to consider. These findings suggest the need for three shifts in present discourse and thinking around student privacy and social media.
The first is a broad shift from legal to ethical considerations. As noted earlier, we think there is a likelihood that posts on Facebook are being accessed by a range of actors, including government agencies, predictive policing companies, and those with nefarious intent. We are not legal experts, so the choice to focus on ethical considerations could be seen as a pragmatic one, but we concur with Vance and Waughn (2021). They argue that many questions about ethical data use and student privacy cannot readily be resolved using existing legal protections. Instead, a data ethics perspective is needed. This perspective highlights the importance of asking questions about who uses data and who benefits and is harmed from its use. If it is legally permissible for schools to post the PII of students whose parents have signed a media release form, knowing about who might access this PII as a form of data and how they may use it, is it right to do so? Such questions take on renewed urgency with companies such as Clearview AI applying facial recognition broadly to publicly available media. Even photos without directly attached PII hold the potential to quickly become PII violations in years to come due to expanding facial recognition technology and this technology’s use of publicly available photos (like those we studied) (Smith & Miller, 2022).
The second shift is from data ethics for researchers to data ethics for educators and educational leaders. Mandinach and Gummer (2021) offer a specific definition that is helpful for considering data ethics for educators: individuals’ knowledge, disposition, and skill related to the ethical use of data. This definition emphasizes that these individual characteristics can and must be cultivated. Such a data literacy–focused approach to data ethics could lead to practical benefits, like the revision of media release policies to detail how students’ images and information shared on social media can be accessed by a range of actors.
Lastly, although educators and educational leaders can focus to a greater extent on data ethics regarding student privacy, we also need a shift from individual to social and political responsibility. We should thoughtfully and carefully offer regulations and push platforms to make protecting privacy more practical. For instance, might Facebook have the default setting for school and district pages on Facebook to be private rather than public? More broadly, we agree with scholars who argue that data ethics and protecting privacy are not only the responsibility of those of us in education; it is also the responsibility of social media platforms and the wider society (Krutka et al., 2019). We highlight that at the time of writing this article, the Federal Trade Commission released a policy statement explicitly reminding educational technology companies to comply with the privacy protections included in the Children’s Online Privacy Protection Act (COPPA; Federal Trade Commission, 2022)—protections that some educational technology may not have been followed satisfactorily because COPPA protections have mainly focused on commercial websites.
As social media data and data mining methodologies allow new ways to examine student and family education rights issues and current data use practices, research has the potential to reveal potential harms to students; even relatively low proportions of posts that reveal the PII of students mean that the privacy of hundreds of thousands of students may be risked. Though there are steps educational leaders working in schools and districts can take to mitigate these risks (Rosenberg et al., 2021), we encourage educational researchers to adopt a data ethics perspective to envision how to balance the benefits of social media with the need to honor the privacy of students.
Supplemental Material
sj-pdf-1-edr-10.3102_0013189X221120538 – Supplemental material for Posts About Students on Facebook: A Data Ethics Perspective
Supplemental material, sj-pdf-1-edr-10.3102_0013189X221120538 for Posts About Students on Facebook: A Data Ethics Perspective by Joshua M. Rosenberg, Conrad Borchers, Macy A. Burchfield, Daniel Anderson, Sondra M. Stegenga and Christian Fischer in Educational Researcher
Footnotes
Acknowledgements
We would like to acknowledge Alexa Fox, Maria Hoy, and Tayla Thomas for their contributions to the broader project of which this manuscript was part.
Author Note
The code needed to reproduce the analysis is available at https://github.com/student-privacy/fb-privacy-modeling. The code to access this data is available at https://github.com/student-privacy/download-baseline-data and ![]() .
.
Notes
Authors
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.