
Abstract
Emotion recognition is one of the most important research directions in the field of brain–computer interface (BCI). However, to conduct electroencephalogram (EEG)-based emotion recognition, there exist difficulties regarding EEG signal processing; moreover, the performance of classification models in this regard is restricted. To counter these issues, the 2022 World Robot Contest successfully held an affective BCI competition, thus promoting the innovation of EEG-based emotion recognition. In this paper, we propose the Transformer-based ensemble (TBEM) deep learning model. TBEM comprises two models: a pure convolutional neural network (CNN) model and a cascaded CNN-Transformer hybrid model. The proposed model won the abovementioned affective BCI competition’s final championship in the 2022 World Robot Contest, demonstrating the effectiveness of the proposed TBEM deep learning model for EEG-based emotion recognition.
Keywords
1 Introduction
Emotion recognition, as an emerging research field, has been attracting increasing attention from researchers of various fields in recent years. It has immense potential for applications in the diagnosis and treatment of mental illnesses [1] and is one of the most important research topics in the field of brain–computer interaction (BCI) [2, 3]. Traditional emotion recognition uses human voice [4, 5], and facial expression [6 –8] to identify human emotions; however, these “signals” cannot detect human emotions efficiently, especially when subjects intentionally disguise their voice and facial expressions. Currently, physiological signals have received increasing attention from researchers in the field of emotion recognition [9, 10]. Many research teams have used physiological signals such as breathing modes, body temperature, electromyography (EMG), electrocardiogram (ECG), and electroencephalogram (EEG) to investigate emotion recognition. Among these, EEG is physiological signal produced directly by the body’s central nervous system or brain [11]. Certain brain regions have a high correlation with emotions; for example, amygdala [12 –14] is widely believed to be related to human emotions; further, the prefrontal lobe [15, 16], which is the advanced information processing and processing node of the human brain, is also believed to be related to emotions. Therefore, EEG can reflect human emotions more truly and reliably as compared to other physiological signals.
In recent years, EEG-based emotion recognition has attracted increasing attention from domestic and international research teams; subsequently, a new direction of BCI, namely, affective BCI (aBCI), has been developed [17]. EEG-based aBCI systems mainly include preprocessing, feature extraction, and classification; among these, preprocessing can significantly improve the signal-to-noise ratio of EEG. EEG, as an unsteady signal, is easily affected by noise such as motion artifact, respiration, electrocardiogram, and electroophthalmogram [18]; therefore, appropriate preprocessing is essential. As a physiological signal with high temporal resolution [19], EEG has a relatively wide frequency range [20]. Therefore, extracting information from different frequency bands through filtering are an important part of preprocessing. Because nearby channels receive information from the same region of the brain, they collect similar EEG signals and are affected by the setting of the reference electrodes, resulting in some redundancy of EEG signals. Therefore, it is necessary to remove redundancy through repeated references, such as common mean reference (CAR), etc. In recent years, intensive studies of EEG features used for emotion recognition, including time domain features, frequency domain features, time-frequency domain features, nonlinear features, asymmetric features, brain connectivity features, etc. have been conducted [21, 22]. Time domain features include the Hjorth parameter [23], high-order crossover (HOC) [24], etc. Time-frequency feature extraction methods mainly include short-time Fourier transform (STFT) [25, 26], wavelet analysis [27], etc. The characteristics of the frequency domain include five classical frequency bands: power spectral density of δ (1–3 Hz), θ (4–7 Hz), α (8–13 Hz), β (14–30 Hz), and γ (31-50 Hz), etc. Differential entropy (DE) [28] is a well-known characteristic describing nonlinear dynamical systems. Asymmetric features generally refer to specific phenomena found in cognitive studies [29, 30]. For example, cognitive studies based on brain imaging technologies have found the lateralization of different regions in the brain during emotional processing [31, 32]. Characteristics of connections of adult functional brain networks refer to the analysis of connection density, clustering coefficient, and other indicators through EEG-derived brain network, and considering them as features for emotion recognition [33 –35]. In addition to the above features, pre-processed EEG signals have standalone characteristics. Ding et al. [36] used them to obtain high emotion recognition performance on DEAP dataset.
Classification models, including convolutional neural network (CNN) [37], recurrent neural network (RNN) [38], long short-term memory (LSTM) [39], restricted Boltzmann machine (RBM) [40], etc. have increasingly attracted researchers’ attention in recent years. Deep learning is favored in many tasks due to its self-adaptive task-related features without manual feature extraction. Transformer was introduced by Google in 2017 [41] and has since been used in natural language processing for various tasks, such as machine translation, and text generation, showing high performance [42, 43]. The advent of DETR (DEtection TRansformer) has led to researchers using Transformer on other modes of data. Although Transformer has been successful in many areas, only a few studies have employed it in the area of EEG-based emotion recognition. Wang et al. [44] used a cascade Transformer combined with prior knowledge to determine spatial dependence between different brain regions. Abdallah Tubaishat et al. [45] used a novel architecture based on Transformer to process multimodal neural signals and identify emotions. Arjun et al. [46] divided EEG signals or time-frequency images generated by wavelet transform into patches by using a Vision Transformer, and subsequently using a Transformer encoder for emotion recognition. Although ensemble learning methods have been proposed in the field of EEG-based emotion recognition, most of the ensemble models employed in previous studies are machine learning models.
Currently, many researchers are increasingly focusing on the application of deep learning in the field of emotion recognition. However, because different models have different preferences for parameter adjustment in the training process of deep learning, ensemble learning is an efficient method to set multiple models and make unified decisions. In cases where there are significant differences between different models, ensemble learning is best suited for EEG-based emotion recognition. Li et al. [47] proposed an ensemble learning method based on multi-objective particle swarm optimization, that includes an ensemble of particle swarm including several traditional machine learning classifiers, such as support vector machine (SVM), decision tree (DT), k-nearest neighbor, etc. Awan et al. [48] obtained the most accurate results on the AMIGOS dataset by using a model integrating SVM, random forest, and LSTM. Although ensemble learning methods have been proposed in the field of EEG-based emotion recognition, most of the ensemble models are machine learning models.
As part of the World Robot Contest, the BCI Controlled Robot Contest aims to promote innovative breakthroughs in BCI technology. The affective BCI technology competition is part of the BCI Controlled Robot Contest. The technical competition focuses on the participating team’s ability to create and improve algorithms. The competition is divided into preliminary and final stages. The preliminary rounds are held in the cloud and the finals are held live, with real-time rankings based on the accuracy and efficiency of the calculated results.
This paper outlines the method used by us in the emotion recognition contest of BCI Controlled Robot Contest, and presents a systematic analysis of this method. In the competition, we proposed a deep learning method based on ensemble learning, terming it as Transformer-based ensemble model (TBEM), as shown in Fig. 1. This method integrates two structures: a hybrid model of CNN and Transformer and a pure CNN model. The chapters of the article are planned as follows. Section 2 introduces the models, datasets, preprocessing methods, experimental setup, and training strategies used by us in the competition in detail. Section 3 presents the experimental results and discussion. Finally, Section 4 presents a summary of TBEM.
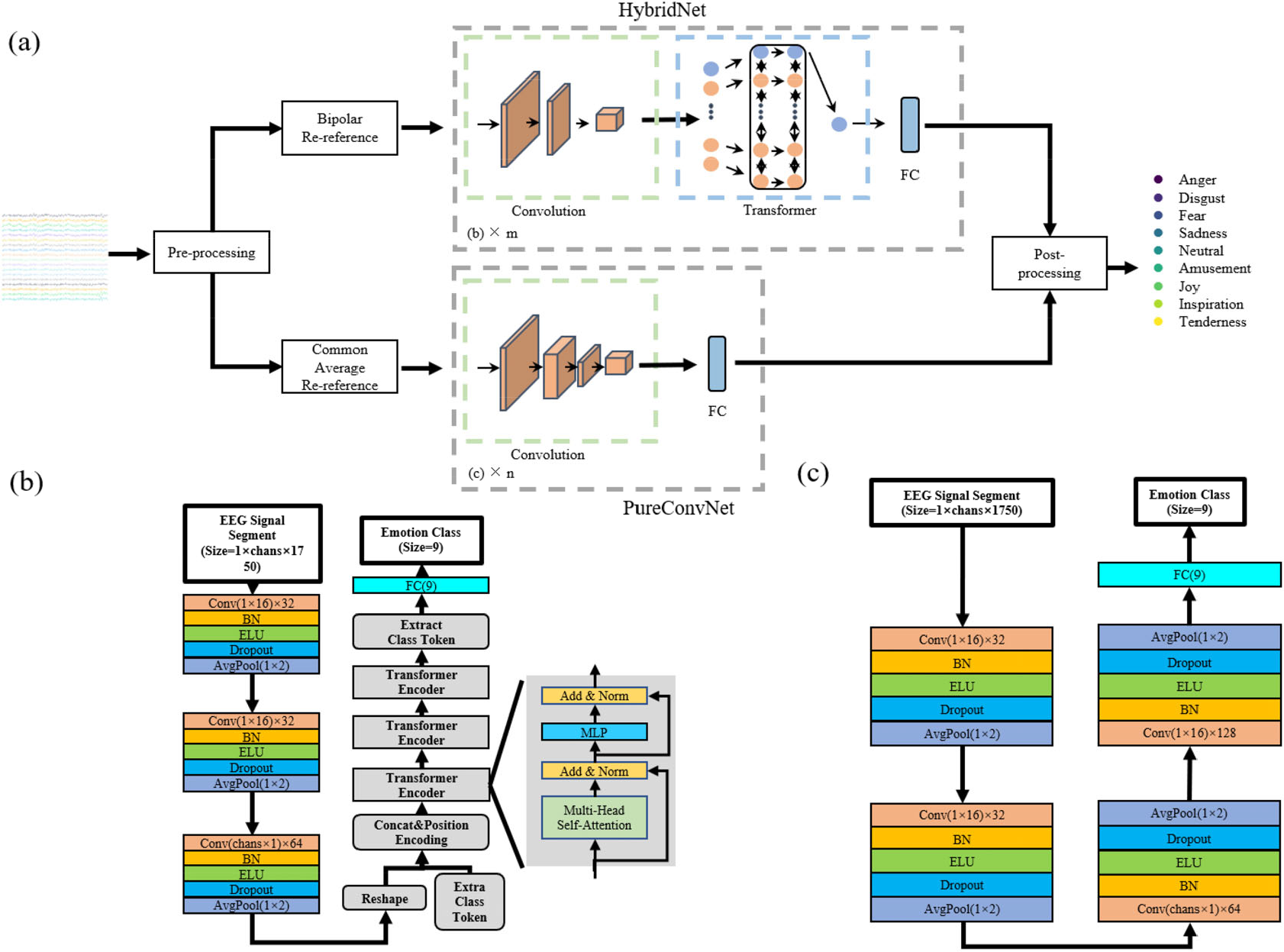
Transformer-based ensemble deep learning model (TBEM) structure. (a) TBEM is composed of two models: a cascaded CNN-Transformer hybrid model (HybridNet) and a pure convolutional neural network model (PureConvNet). (b) HybridNet model architecture: the upper branch of TBEM architecture is a hybrid model of convolutional neural network and Transformer. (c) PureConvNet model architecture: the lower branch of TBEM architecture is a pure convolutional neural network model.
2 Method
2.1 Data
In the preliminary phase of the competition, the organizers provided data containing 80 subjects (50 women and 30 men, with a mean age of 20.16 years, ranging from 17 to 24 years), while the organizers provided data containing 6 subjects (4 women and 2 men) in the final phase. The collection of preliminary and final competition data adopted a similar experimental paradigm, wherein 28 video clips were used as stimuli. The emotions of stimuli included anger, disgust, fear, sadness, amusement, joy, inspiration, tenderness, and neutral emotions. Roughly the same number of stimuli was used for each emotion (anger = 3, disgust = 3, fear = 3, sadness = 3, amusement = 3, joy = 3, inspiration = 3, tenderness = 3, neutral = 4). Each subject was asked to participate in seven experimental blocks, each block contained four trials (one trial containing one stimulus); additionally, the subject was asked to solve 20 arithmetic problems between the two blocks [49]. The experimental paradigm difference between preliminary and final competition data collection is that the experimental paradigm used in the final competition did not include partitioning blocks and did not ask participants to calculate arithmetic problems. Additionally, a 32-channel NeuSen.W32 wireless EEG system was used in the preliminary emotional induction experiment, while a 64-channel wireless EEG equipment was used in the final emotional induction experiment.
2.2 Model
In many competitions on Kaggle, the world’s famous data mining competition platform, participants have adopted the ensemble learning method and achieved more accurate results as compared to those obtained via other methods. Therefore, this paper also adopted the idea of ensemble learning. By combining multiple weak supervised models, ensemble learning aims to obtain a strong supervised model with good generalization. The underlying idea of ensemble learning is that even if a weak classifier makes a wrong prediction, other weak classifiers can correct the error.
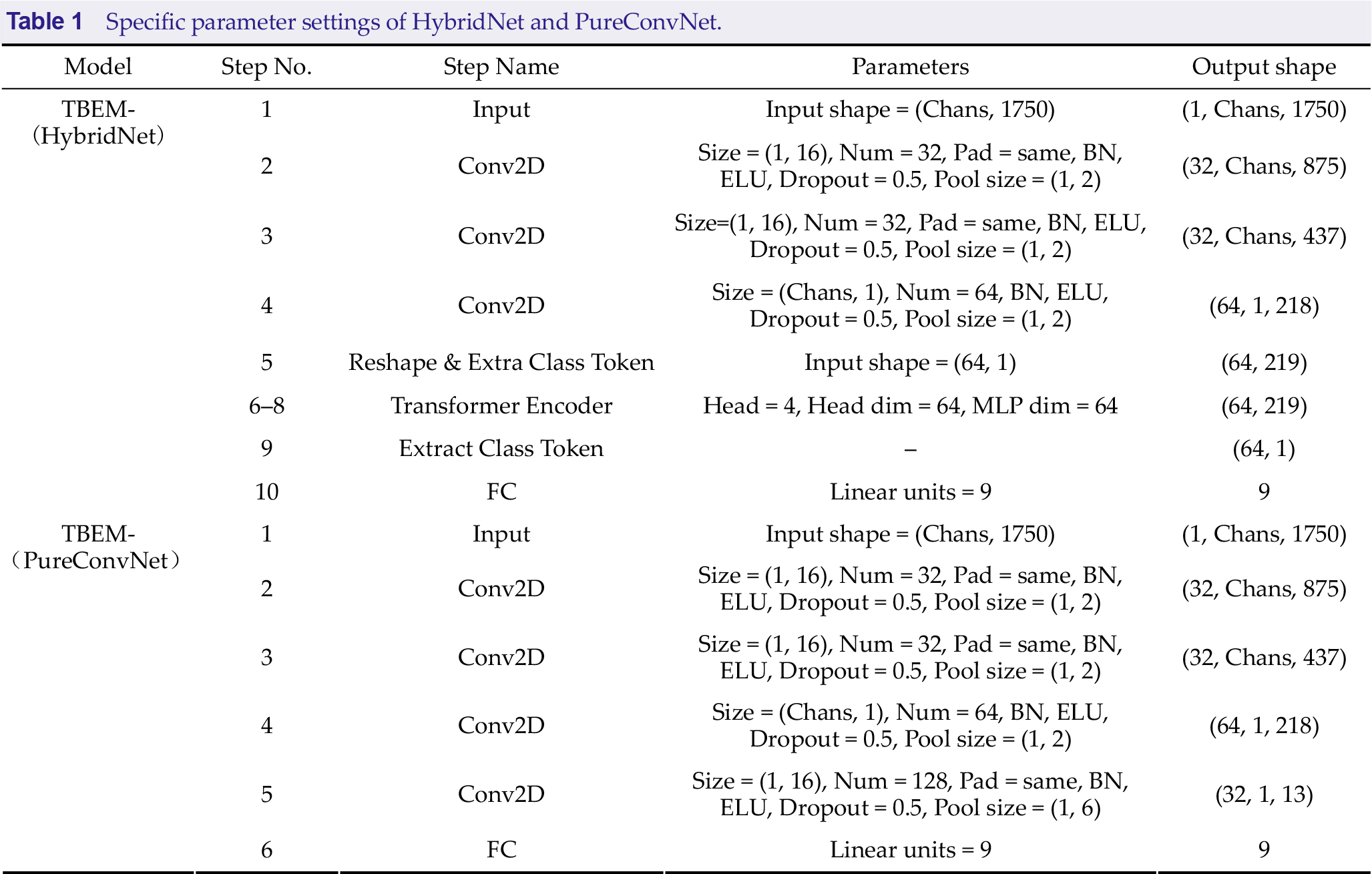
This paper outlines a deep learning method based on ensemble learning called TBEM [Fig. 1(a)] that comprises two models: a HybridNet model, where a CNN is integrated with Transformer [Fig. 1(b)] and PureConvNet, that only comprises CNN [Fig. 1(c)]. Additionally, we show the specific parameter settings for both models in Table 1.
Specific parameter settings of HybridNet and PureConvNet.
HybridNet is a model with a large number of parameters; it is designed with reference to Vision Transformer (ViT) [50]. Similar to the original design intention of ViT, Transformer has achieved the performance of SOTA in many pattern recognition tasks, such as BERT [42], GPT3 [43], SwinTransfomer [51], etc. However, because Transformer is not sensitive to the task of processing long sequences, it cannot efficiently process long time series EEG signals in the EEG-based recognition task. Referring to the design of ViT, HybridNet introduces several convolutional modules to compress the sequence and encode the features of EEG signals; thus, the final Transformer module can participate in the processing of data. HybridNet is mainly composed of two sub-blocks: one is a convolutional subblock composed of three convolutional modules, and the other is a Transformer subblock composed mainly of three Transformer encoders (TE).
Each convolutional module contains the same five layers. These include: the convolutional layer, the batch normalization layer (BN), the activation function layer (specifically implemented through the ELU activation function), the dropout layer, and the average pooling layer. While the convolutional layer and pooling layer in the convolutional subblock are both 2-dimensional modules, they realize the functions of one dimension, including time convolution, and space convolution, which is similar to EEGNet [52]. In the convolutional subblock, the first two convolutional modules realize the time perception (or time dimension feature extraction) function, and the third convolutional module realizes the space perception (or space dimension feature extraction) function. The kernel size of each temporal convolution is 1 × 16, while the kernel size of each spatial convolution is chans ×1, which is set to 30 × 1. All the average pooling layers have a pooling size of 1 × 2. The inactivation rate is set to 0.5 for all dropout layers. In addition to TE, the Transformer subblock [Fig. 2(b)] includes the learnable classification marker class token and position-coding, wherein the position-coding adopts the learnable position coding of BERT type instead of the position-coding represented by the sine and cosine functions in ViT. In TE, for MutLI-heads of all multi-head self-attention mechanisms, the number of heads is set to 4; each head processes a sequence dimension of 64, while the fully connected network processes a sequence dimension of 64.
PureConvNet is a lightweight model with fewer parameters as compared to that of HybridNet, designed by referring to EEGNet. The model consists of four convolutional modules, which are similar to the convolutional modules in HybridNet. Each convolutional module consists of a convolutional layer, a BN layer, an ELU activation function layer, a dropout layer, and an average pooling layer. Similarly, the corresponding 1-dimensional feature extraction operation is also implemented through a 2-dimensional convolutional layer. Specifically, PureConvNet adds a convolutional module for time-aware functionality. The kernel size is 1 × 16 for all temporal convolutions; it is chans × 1 for spatial convolutions, and 1 × 2 for the average pooling layer; additionally, the remaining layers remain consistent with HybridNet’s settings.
2.3 Preprocessing
For the offline data (preliminary round data), the abovementioned preprocessing steps were applied to each trial; these included five steps: re-referencing, segmentation, filtering, down-sampling, and normalization. First, re-referencing can be conducted via two methods: bipolar re-reference and common average re-reference (CAR) methods. The bipolar re-reference method subtracts the potential of two adjacent electrodes (according to the location relationship of the 10–20 system). It is important to note that the experiment in the preliminary round employed all 32 electrodes of the NeuSen.W32 wireless EEG system; further, while the device used in the final round does not contain A1 and A2 electrodes, we excluded two channels (N = 30) from the re-reference data in the final round. Additionally, in the preliminary round, we employed a third re-referencing method, namely, mastoid reference (MPR) method, that subtracts the potential of the left mastoid (A1) from the channels located in the left brain, and the potential of the right mastoid (A2) from the channels located on the right side. In the second step, a sliding window method with a window length of 14 s and a step size of 4 s was used for segmentation. In the third step, two filtering operations were performed, namely, a 50 Hz notch filter and a 0.5–45 Hz band-pass filter, both of which were implemented through a 6th order Butterworth filter. In the fourth step, to reduce subsequent computational complexity, the EEG signal was down-sampled to 125 Hz; this reduced the volume of data by half, given that the original sampling rate was relatively high. In the fifth step, Z-score normalization was applied to each down-sampled EEG segment. After implementing the abovementioned five preprocessing steps, due to different trial lengths, the average number of EEG segments obtained was 13.5 (min = 6, max = 29).
These procedures were applied to the online data (finals data), with the exception of differences in data partitioning. Due to the competition’s requirement to report a result every 1 second, the window length for data partitioning remained unchanged, and the step size was updated to 1 second.
2.4 Postprocessing
Similar to many international competitions, in the prediction phase in the affective BCI competition, postprocessing methods were used to integrate the results of multiple classifiers to obtain the final result [53]. The postprocessing method described in this paper includes adding the prediction vectors (i.e., the prediction probabilities for each category) of m HybridNet models to the prediction vectors of n PureConvNet models to obtain the prediction vector of the ensemble model. Finally, the category with the maximum prediction vector is the prediction result of the entire ensemble model. It is important to note that the m HybridNet models are trained by using different subsets of the training set, and the n PureConvNet models are also obtained through different subsets of the training set. However, there may be overlapping training set subsets between the two types of models. In the experiment, both m and n are 3, indicating that the contribution of the two types of models to the results is the same (i.e., the two types of models have the same weight).
2.4 Experimental settings
In the experiment, we used the Adam optimizer with the initial learning rate set to 0.001. The learning rate decay strategy of ReduceOnPlateau was employed [54]; in other words, if the loss did not decrease after seven epochs, then the learning rate decayed to 10% of the original. The batch size was set to 64, the number of epochs was set to 200, and the early stopping strategy was applied. For the accuracy of the results to remain unchanged, the maximum tolerance was 10 epochs. Our model was implemented in the Tensorflow 2.11 framework by using Python 3.10 and run on a GeForce RTX 3090 GPU.
3 Results
In this section, we briefly describe the experimental setup and results.
For the offline analysis in the preliminary round of the affective BCI competition, to evaluate the performance of each algorithm, we used 5-fold cross-validation (CV), with 4-fold CV for training and 1-fold CV for testing. Each fold contained 16 subjects for a total of five cycles. In the online analysis in the final round of the affective BCI competition, when a new continuous EEG signal was obtained, each team needed to provide real-time feedback with an interval of 1 s. Under this requirement, all contestants needed to consider two scenarios of the model. One required adjusting the model according to the existing test data, requiring the real-time data, and light weight of the model. The other required training based on the existing training data and feedback on the results of the new test data. Given that we could fully utilize the existing training data to obtain a model with high performance, and the scenario did not consider model size, we considered using a completely offline approach in the end.
We compared accuracy differences between average and bipolar re-references based on preliminary data (THUR-EP dataset, excluding several subjects online). Among them, PureConvNet obtained the highest accuracy under average re-reference method (31.9 ± 6.9) and HybridNet obtained the highest accuracy under bipolar re-reference method (42.5 ± 6.8). Therefore, in the final round of the competition, we set the following: PureConvNet used an average re-reference method to re-reference, while HybridNet used a bipolar re-reference method to re-reference.
Figure 2 shows the results of the top six teams in the finals. Among them, our team was TJU_TPU. The recognition framework provided by our team won the first place in the final round, and our score was significantly higher than the other teams, showing the effectiveness of the emotion recognition framework proposed by our team.
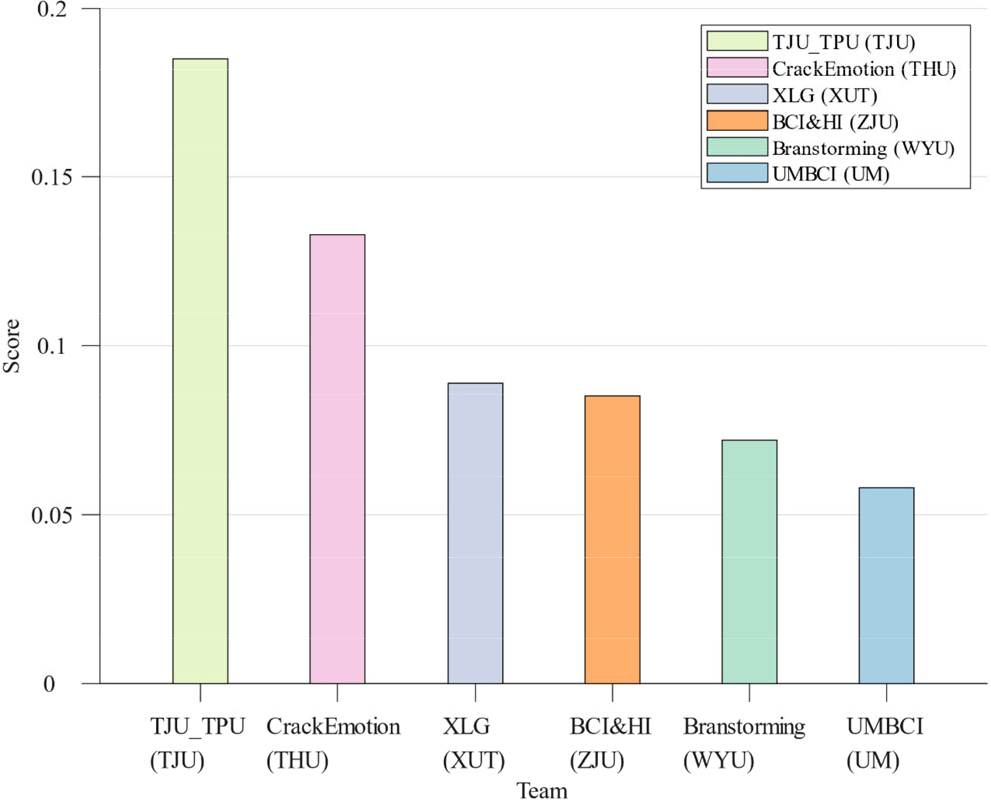
Bar chart of the top six scores in the final phrase of the competition. Note: TJU indicates team from Tianjin University. THU indicates team from Tsinghua University. XUT indicates team from Xi’an University of Technology. ZJU indicates team from Zhejiang University. WYU indicates team from Wuyi University. UM indicates team from University of Macau.
Specifically, Fig. 3 describes the accuracy of the results of the final cross-subject classification of different models (online analysis). As can be seen from Fig. 3(b), the integration model proposed in this paper achieved the highest accuracy regarding three subjects (S1–S3), and the second highest accuracy regarding three subjects S4–S6. Of the two sub-models of the ensemble model, HybridNet exceeded the baseline model EEGNet by a significant extent in the data of multiple subjects (S4–S6); further, even the average accuracy of HybridNet in S3 exceeded that of EEGNet by 23.2%, being twice as high. PureConvNet had a 10% average accuracy advantage regarding S3 and S5. HybridNet and PureConvNet had their own advantages in the test data of different subjects. Regarding S3 and S6, HybridNet had 10% average accuracy advantage, while regarding S1, and S5, PureConvNet had 3% accuracy advantage. It is important to note that the integration model proposed by us achieved the highest average performance among the six participants in the final round [Fig. 3(a)], further proving the efficiency of the proposed integration model.
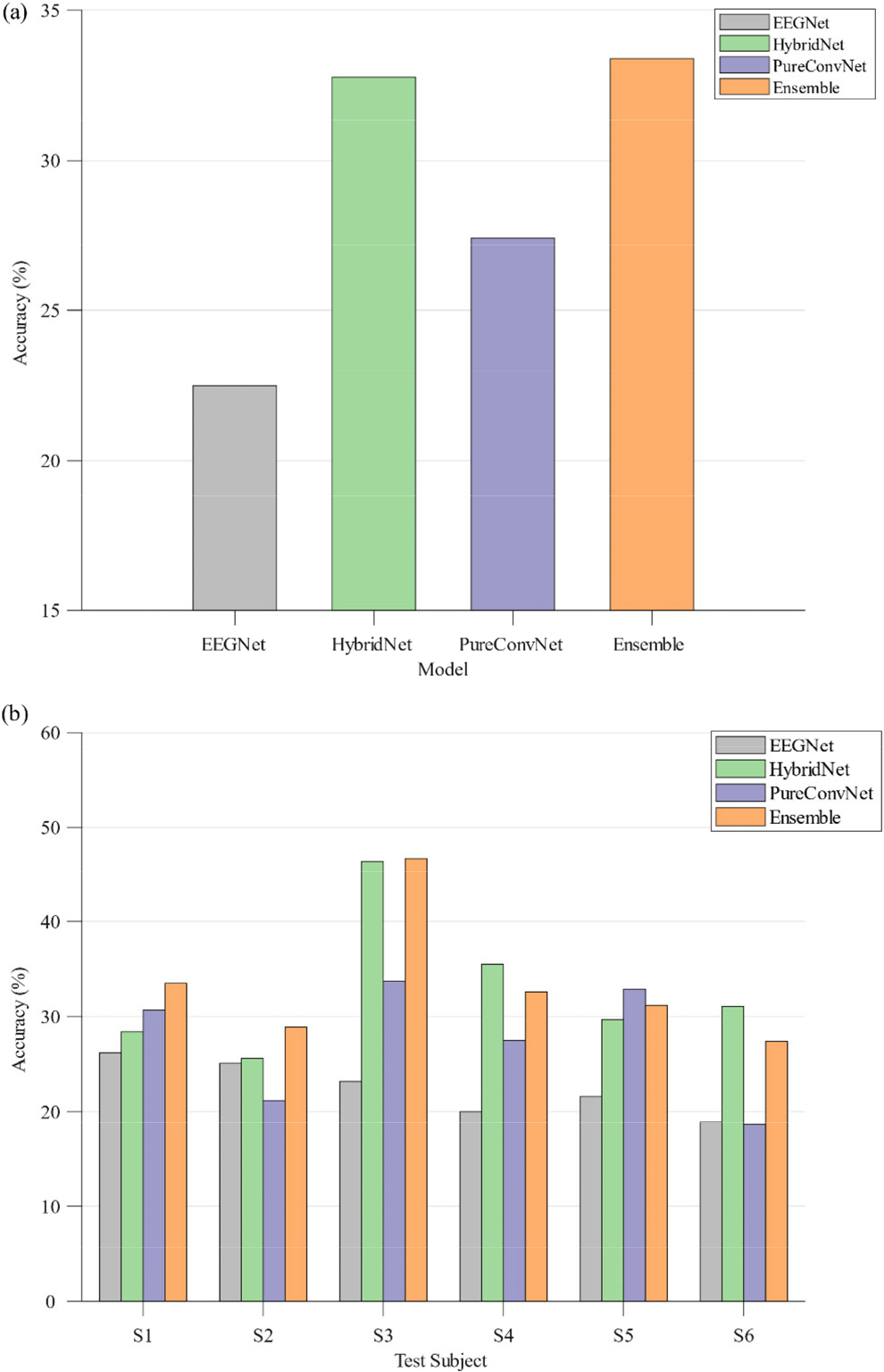
Cross-subject classification accuracy of different models on final data. (a) Average classification accuracy of different models on six subjects. (b) Classification accuracy of different models on six subjects respectively.
Compared with offline analysis, the collected EEG signals for the online emotion recognition task had obvious environmental noise because the environment of the subjects was not sufficiently quiet, and the subjects were easily distracted by the surrounding environment; therefore, it was difficult to induce strong emotions in the subjects. The average accuracy of HybridNet in the online results was lower than that of the offline results except for S3 and S4, and the online performance of PureConvNet was also slightly lower than the offline performance.
The computational complexity of the algorithm is one of the most important indexes of an online emotion recognition task. The time required for each method to calculate a single sample (14 s channel EEG signal with a matrix size of 30 × 1750) is shown in Fig. 4. The baseline model EEGNet had the lowest computational complexity (0.217 GFLOPs) due to the low number of parameters. However, the computational complexity of the two models proposed by us is similar. It is important to note that the integration model is derived from the integration of HybridNet and PureConvNet, and that the proportion of the two models is the same; therefore, the computational complexity of the integration model is between these sub-models.
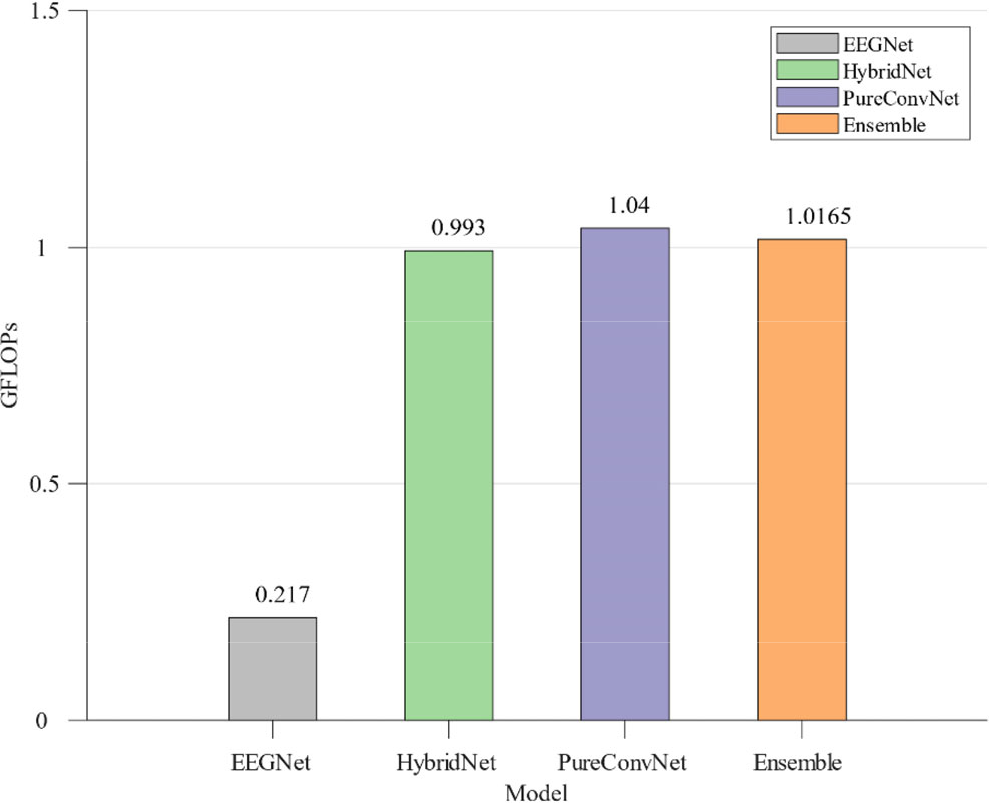
Computational complexity of different models
4 Discussion
Ensemble learning is a highly effective method that can significantly improve a model’s performance in competitions. Thus, we employed ensemble learning to design TBEM. In TBEM, HybridNet generally outperformed PureConvNet in terms of performance, as shown in S2, S3, S4, and S6 [Fig. 3(b)] and for offline data. Moreover, HybridNet’s computational complexity was found to be slightly lower than that of PureConvNet.
The preprocessing method also has a significant impact on the model’s performance, and re-referencing is one aspect of it. Studies have found that re-referencing methods can affect the accuracy of EEG electrode placement [55 –58]. By comparing multiple re-referencing methods for EEG, we found that each method has its advantages. Using TBEM, we combined different re-referencing methods with their corresponding models, it resulted in high scores in the EEG emotion recognition task in the affective BCI competition.
It is challenging to build accurate cross-subject emotion recognition models by using traditional machine learning methods because the neural representation of emotion is highly complex and has individual differences [32]. The existing transfer learning method based on domain adaptation provides a possible solution to the problem of individual differences in emotion recognition models [59]. Thus, using transfer learning is an effective choice to obtain a high classification accuracy in future online emotion recognition tasks.
The online task had a high requirement regarding the computational complexity of the model; based on the data in the previous section, it can be seen that since EEGNet had a low computational complexity, its performance is low in the experiment. In general, the performance of a model increases with its computational complexity. However, ensemble learning provides a solution for online tasks with high real-time performance by integrating multiple models with lower computational complexity.
The results of offline and online experiments prove that the performance of the offline experiment is slightly better than that of the online experiment, which may also be related to the lack of inducement of emotions in subjects in online scenes [60]. This finding also highlights the challenge of inducing high-intensity emotions in real situations.
The postprocessing method includes averaging the predictions of each model. Each type of model has the same weight in the final result, rather than focusing on a particular type of model. In some specific test data, poorly performing models may affect the overall performance of the ensemble model [S4 and S6 in Fig. 3(b)], that results in the accuracy of the ensemble model being lower than that of a single branch model. In future, researchers can assign different weights to multiple models to improve the performance of the ensemble model. Furthermore, other postprocessing methods, such as voting, can be attempted.
5 Conclusion
This paper provides a systematic introduction to the approach employed by us, the winning team of the WRC2022 EEG-based emotion recognition competition, to design TBEM, an ensemble deep learning method. We found that ensemble learning is a highly effective method that can significantly improve a model’s performance in EEG-based emotion recognition competitions. TBEM comprises two models: HybridNet, based on a CNN, and Transformer, and the PureConvNet model, which is based solely on a convolutional neural network; it was observed that HybridNet outperformed the PureConvNet model in terms of the accuracy of EEG-based emotion recognition. Moreover, HybridNet’s computational complexity was slightly lower than that of PureConvNet. Thus, the results of the experiments showed that the model combining CNN and Transformer has great potential in the EEG-based emotion recognition task. The proposed method is meaningful for developing effective BCI systems.
Footnotes
Ethical approval
None.
Consent
All the subjects were informed and have signed a written consent to collect their EEG.
Conflict of interests
All contributing authors report no conflict of interests in this work.
Funding
This work was granted by National Key Research and Development Program of China “Biology and Information Fusion” Key Project (Grant No. 2021YFF1200600), National Natural Science Foundation of China (Grant Nos. 61906132 and 81925020), and Key Project & Team Program of Tianjin City (Grant No. XC202020).
Acknowledgements
All authors thank Haolin Wu (Tsinghua University), Dan Zhang (Tsinghua University), and Chengcheng Hong (Beijing University of Posts and Telecommunications) for their support in providing the data for the final competition.
Authors’ contribution
Dong Ming and Xiaopeng Si provided support for this work; Dong Huang and Yulin Sun provided model and analysis; Dong Huang, Shudi Huang and He Huang completed the original draft writing; and Xiaopeng Si reviewed and revised the manuscript. All the authors approved the final manuscript.
Data availability
None.