
Abstract
Modern computational models have leveraged biological advances in human brain research. This study addresses the problem of multimodal learning with the help of brain-inspired models. Specifically, a unified multimodal learning architecture is proposed based on deep neural networks, which are inspired by the biology of the visual cortex of the human brain. This unified framework is validated by two practical multimodal learning tasks: image captioning, involving visual and natural language signals, and visual-haptic fusion, involving haptic and visual signals. Extensive experiments are conducted under the framework, and competitive results are achieved.
Introduction
Research in multimodal learning has accelerated in recent decades, aiming to bridge gaps when learning from different modalities in order to mine their correlations and make better decisions resulting from their fusion. A common research scheme in multimodal learning is to learn the characteristics of each modality and then combine all the characteristics to inform a final decision. Thus, the premise of multimodal learning relies on the design of learning models for each modality, after which a fusion model must be built to arrive at a final conclusion. For example, image captioning is a task that describes a given image with a sentence. It involves two modalities, the sight of a given image, and natural language, which is the descriptive sentence. Another example is the visual and haptic fusion common in the robotics literature. This is a common task where a robot must make decisions based on visual information, such as images/videos taken by a camera, and haptic information, such as tactile readings from sensors equipped at the end of robot hands. Coping with both modalities gives the robot the ability to make better decisions and improve their function, such as their fine-level grasp of objects. In both of these scenarios, tasks involve two modalities, and thus both belong to the domain of multimodal learning. It is then crucial to design learning algorithms for each modality as well as their fusion.
Brain-inspired learning algorithms have been a leading trend in the learning and comprehension of different modalities. Improved knowledge of the human brain is essential in improving artificial intelligence, and multimodal learning is key. As the understanding of the biology of the human brain improves, models and algorithms centering on multimodal learning have been proposed based on these findings. Such models and algorithms are usually termed brain-inspired learning models. For example, the HMAX model [1] is a biologically inspired vision model based on the simple and complex cells in the visual cortex [2]. Similar vision models also based on such a layered architecture can be found in modern deep neural networks, such as convolutional neural networks [3].
Effectively incorporating brain-inspired learning algorithms for each modality with multimodal learning, which emphasizes the coordination of different modalities, offers interesting research directions. This paper aims at solving multimodal learning problems by leveraging brain-inspired models, primarily deep neural networks. The illustration of the proposed model can be found in
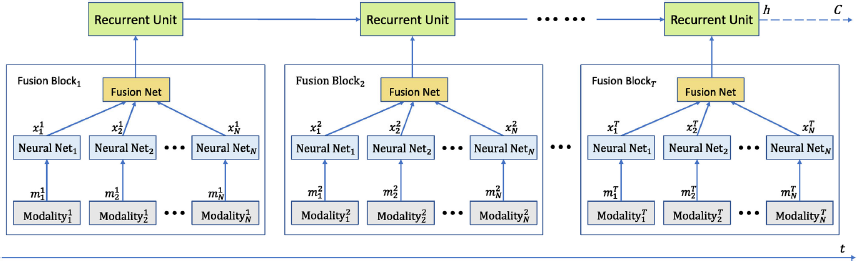
The proposed unified multimodal learning scheme based on brain inspired models. The core of the model is recurrent neural networks, which contains the multimodal inputs at each time step. The multimodal input is a combined feature of each modality. For each modality, the representation is the feature extraction using some neural networks. The final decision is based on the last hidden state of the recurrent neural networks, which contains the information of all the modalities at all time steps.
Define multimodal learning and provide a unified solution architecture.
Based on the unified learning framework, test and validate the model on several single-modality learning problems, then explore multiple modality applications.
Further validate the framework on multimodal learning problems. Specifically, we explore the feasibility of the proposed model on image captioning and visual-haptic fusion. The former involves visual and natural language modalities, and the latter involves visual and haptic modalities.
The paper is organized as follows:
Section 2 reviews the literature of brain-inspired neural networks, as well as the applications of multimodal learning. Section 3 presents the basic mathematical models of neural networks, which forms the basis of subsequent chapters. Section 4 presents the unified architecture of multimodal learning based on neural networks. Sections 5 and 6 focus on two different multimodal learning tasks, image captioning and visual-haptic fusion, respectively, with the purpose of validating the proposed learning algorithms. Section 7 concludes the paper.
Visual cortex and models
Research on the visual cortex of the human brain has advanced computer vision research in multiple ways. This section presents inspiring research on the human visual cortex found in modern multimodal learning settings.
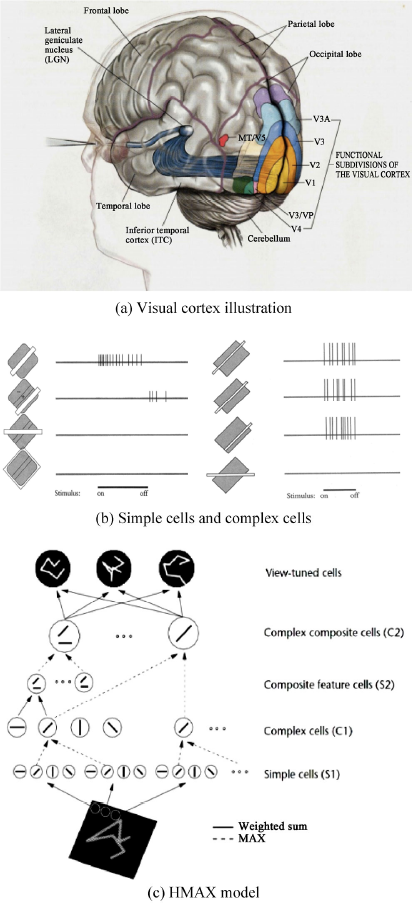
Illustration of visual cortex in brain and the HMAX model inspired by it. (a) The visual cortex model, which has dorsal pathway and ventral pathway. (b) The simple cells and the complex cells in the visual cortex. (c) The HMAX model which is inspired by the simple cells and complex cells in the visual cortex.
Machine learning has shown its effectiveness in many fields, and it has been applied in practical scenarios, such as the application of random forests in Microsoft Kinect [12], in advertising click-through rate prediction, and logistic regression [13]. Traditional machine learning methods are often limited by the original form of natural data [14]. These machine learning techniques generally require the design of appropriate features for specific problems and require significant expert knowledge, system engineering, etc. Cognitively, people do not need to design different feature representations for different tasks, since throughout life, they learn to deal with different tasks from experience. Deep learning is such a “representation learning” method, which is a learning model of more complex multilevel representations by combining simple nonlinear modules [14]. Compared with traditional machine learning methods, deep learning has the advantage of not requiring expert knowledge in a certain field, nor does it need to design features for specific problems. Deep neural networks, as an important research area in deep learning systems, can be considered as a means to deal with modal information by learning hierarchical concepts, with each concept related to other relatively simple concepts. The relationship between the models has been previously described [15]. Common deep neural networks inspired by human brain biology include convolutional neural networks, recurrent neural networks, and deep belief networks.
Multimodal learning
Multimodal learning tasks do not have a standard definition, but can be generally described as observing different phenomena and acquiring data and information from different types of sensors, and then experimenting in different conditions. The information obtained when observing phenomena is termed a “modality” [16]. Multimodal learning refers to feature extraction and integration analysis beyond single-mode data, as well as further decision processes based on these features and analysis [17]. In the context of this paper, multimodal learning refers to multimodal sensor data obtained by analyzing and characterizing the multiple modal sensors of a robot while interacting with its environment, as well as the process of merging these data to make decisions.
Multimodal learning has wider application than single-mode research, and thus tends to have more practical applications. First, the study of learning can supplement data from single-mode research, which to some extent assists decision-making in original single-mode research. Second, some tasks are by nature multimodal tasks. Often, raw data and related decision-making processes involve more than one mode of data, such as tasks involving image understanding. Such a problem essentially involves visual image or video data, as well as natural language data. Since multimodal learning tasks usually involve time-series data, which are different from static modal information such as images, the context of the modal information must be determined in time to further assist final decision making. In summary, multimodal learning research benefits from more modal and temporal information, and some problems are multimodal problems by nature, offering important research directions and practical applications.
Prerequisites
Prior to describing the proposed unified multi-modal learning architecture, this section presents the prerequisites of the model, providing a basis for understanding the multimodal learning algorithms.
M-P neuron and multilayer perceptron
Neurons are the most basic unit of deep neural networks, which are derived from neuronal models in neuroscience and brain science. By modelling the working mechanism of neurons in the human brain, McCulloch et al. first proposed a concept of artificial neurons [18], the “M-P” neuron model, as shown in
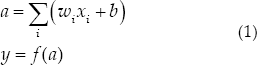
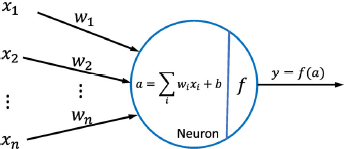
M-P neuron model.
where f is the nonlinear activation function, which is usually one of the following activate functions: sigmoid, tanh, ReLU, or LeakyReLU, as shown in
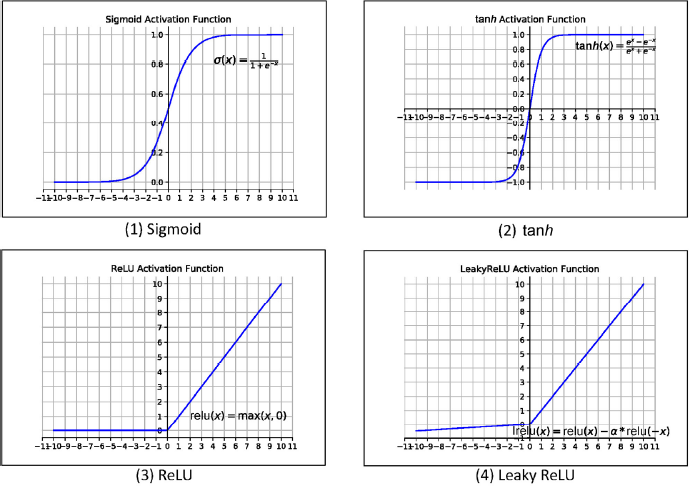
Non-linear activation functions in neuron models.
The multilayer perceptron (MLP) is a hierarchical feedforward artificial neural network, with each unit node of each layer forming a neuron. Take the simplest three-layer multilayer perceptron as an example, which includes an input layer, a hidden layer, and an output layer. More complex multilayer perceptrons essentially add a hidden layer to this three-layer perceptron structure model, so the mathematical expressions are generic. The structure of the three-layer multilayer perceptron is shown in
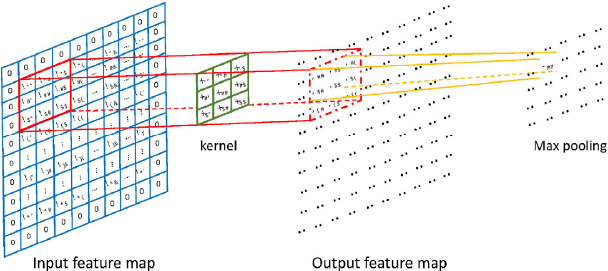
Convolution and max pooling operation in CNNs.
Given sample set D = (x1, y1), (x2, y2), …, (xN,yN), where (x i , y i ) represents the i-th sample of the data set, the output of the MLP model is
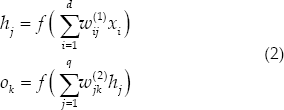
where w ij (1) denotes the weights from the i-th node of the input layer to the j-th node of the hidden layer, and ω ij (2) denotes the weights from the j-th node of the hidden layer to the k-th node of the output layer.
Convolutional neural networks (CNNs) can effectively model more complex structural information by introducing a neural connection that is not fully connected, as is the case for the MLP. In particular, CNNs typically include convolution, pooling, and fully connected operations. The convolution operation of a CNN gives it the characteristics of local connectivity and parameter sharing. Local connectivity refers to the convolution of a kernel and an input feature map. The convolution kernel only operates on a part of the feature map, instead of the full map as would be done with an MLP. With weight sharing, the parameters of the convolution kernels remain the same. With local connectivity and weight sharing, a CNN can effectively reduce the number of model parameters compared to an MLP. An illustration of CNNs is shown in
Recurrent neural networks
Recurrent neural networks (RNNs) are another special artificial neural network that contain self-connected recursive connections between neurons, as shown in
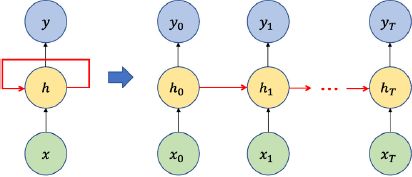
Recurrent neural networks and its unrolled form.
To model multimodal learning, it is essential to define the initial problem. Assume that a multimodal learning task contains N modal raw data, denoted as m1,m2,···, m N . Then the learning task must consider N modalities comprehensively to make decisions. The multimodal learning problem can then be defined in three parts. First, N sets of characterization functions R1, R 2 ··· R N must be found such that each R i characterizes the original data of the i-th modality as Feature x i . Second, the decision function F must be found, which maps the feature representations x1,x2,···, x N of all modalities into the hidden layer space H, denoted as the hidden layer fusion representation h. Then, decision method C performs a final decision task according to the hidden layer fusion representation h. The above procedure is formulated in Eq. (3).
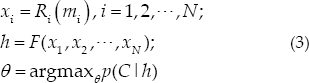
Based on the above definition of the multimodal learning problem, this paper proposes a multimodal time-series data modeling method based on deep neural networks. The input to this model is the raw data for N modalities and the output is the final decision C. This model adopts a general solution to the problem of multimodal learning. With multimodal time-series data modeling, static modal data (such as images) and temporally dynamic data (such as video, natural language data, and haptic data) can be used. Some modal data contain information, and some modes contain information at a single time.
With dynamic and static information in multimodal contexts, the core of the proposed method is a fusion model based on a recurrent neural network, which can effectively model the dynamic data in time, as shown in
In the following sections, we focus on two specific multimodal learning problems in order to validate the proposed learning model. One is image captioning, which involves visual and natural language modalities, and the other is a visual-haptic fusion task, which involves haptic and visual modalities.
In image captioning, an image is input to a computer, which is required to generate a human-level description of the given image. In multimodal learning settings, image captioning tasks require the modeling of visual and natural language modalities. Following the procedure of the proposed unified multimodal learning architecture, image captioning can be divided into three parts. The first represents the visual modality, or the image to be described. The second represents the natural language modality, or the sentence (the words) to generate. The third connects these two modalities and builds the final model.
The proposed image captioning model is presented in
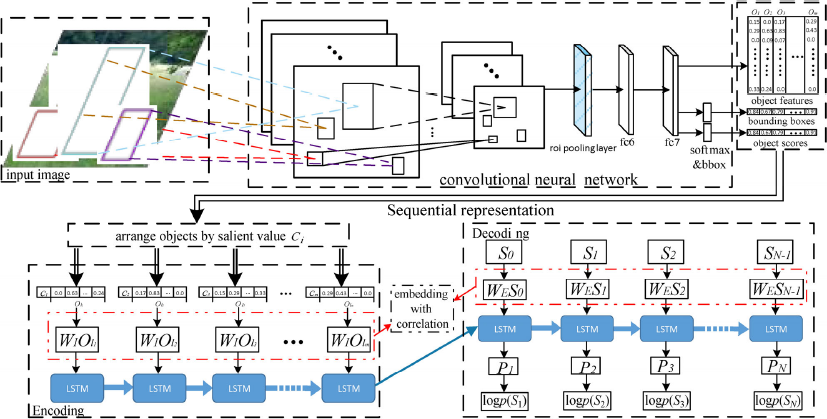
The proposed image captioning model on the basis of the unified multimodal learning architecture.
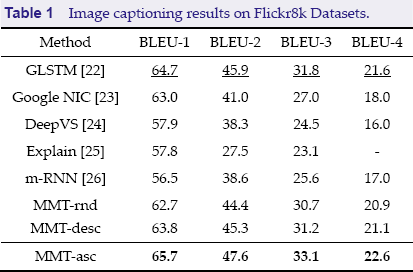
Theoretically, any object detection technique can be leveraged to extract object features, as long as it can achieve a good object coverage rate. In practice, we leverage a state-of-the-art object detection algorithm, R-FCN [19]. The significance of each object is determined by the detection score and the ratio of the area the object takes in the image. The recursive unit LSTM follows the implementation in Ref. [20]. To validate the proposed model, we test our model on the Flickr8k image captioning dataset [21]. The results are shown in
Image captioning results on Flickr8k Datasets.

The example captioning results on Flickr8k datasets. GT means ground truth sentence, BS means baseline sentence, and SIC-asc means our method.
In visual-haptic fusion, a robot must make decisions based on visual and haptic input signals. Generally, decision-making is usually more reliable using multiple modalities rather than one. For example, for object recognition tasks performed in some environments, due to complete or partial occlusion, a robot may not recognize an object through a single visual modality. The robot may visually obtain a position estimate of the object and attempt to grasp it. Then, the grasping posture is further adjusted by tactile feedback, and information on the type of the object may be finally obtained by using the sensing and visual modal information along with the tactile modality. To determine whether to grasp an opaque object such as a plastic bottle, the quality of the liquid in the vessel cannot be determined solely by vision, so it is impossible for the robot to grasp the vessel through its existing grasping experience. Here, the robot can be assisted by tactile sensation, and the tactile feedback used to determine the final grasping force. In other cases, sufficient performance cannot be achieved by relying on a single modality. Sensing information from a single modality can be beset by problems such as excessive error in some environments. Visual sensors are sensitive to light sources, and captured visual sensing information may suffer from issues related to deformation, illumination, or scale change. Likewise, tactile sensing is sensitive to the material, and different types of objects may be similar in material, while the materials on the same type of object may vary greatly. Since single-mode sensor data cannot accurately describe object attributes, processing information from haptic and visual modes can be used to provide a final description of object attributes.
Given this, under the unified multimodal learning framework, a visual-haptic fusion model is proposed, as shown in
Prediction results on PHAC-2.
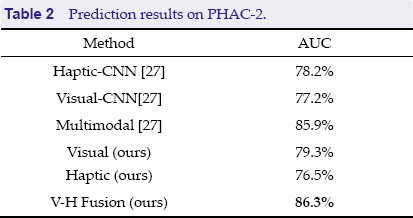
Prediction results on PHAC-2.
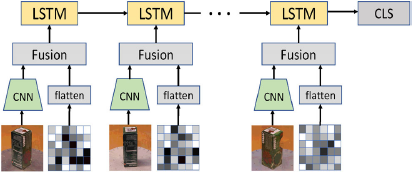
The proposed visual-haptic fusion model.

60 objects that were used in PHAC-2 dataset
This study tackles the problem of multimodal learning using brain-inspired models, specifically leveraging modern deep neural networks to mine the characteristics of each modality. A unified multimodal learning framework is proposed, and the framework is validated through two practical tasks, image captioning and visual-haptic fusion. Experimental results show the feasibility and validity of the model. Future work includes testing the model in more complex experiment settings.
Footnotes
All contributing authors have no conflict of interests.
This paper is jointly supported by National Natural Science Foundation of China (Grant Nos. 61621136008, 61327809,61210013,91420302, and 91520201).