
Abstract
Background:
One of the most prestigious competitions in the world is the World Robot Conference. This paper presents the winning solution to the supervised motor imagery (MI) task in the BCI Controlled Robot Contest in World Robot Contest 2021.
Methods:
Data augmentation, preprocessing, feature extraction, and model training are the main components of the solution. The model is based on EEGNet, a popular convolutional neural networks model for classifying electroencephalography data.
Results:
Despite the model’s lack of stability, this solution was the most successful in the task. The channels closest to the vertex were the most helpful in feature extraction.
Conclusion:
This solution is suitable for supervised MI tasks not only in this competition but also in future scenarios.
Keywords
1 Introduction
The BCI Controlled Robot Contest in World Robot Contest 2021 was held in Beijing, China, to promote brain–computer interface (BCI) technology innovation and breakthroughs [1]. The supervised motor imagery (MI) task is one of the tracks of this BCI Controlled Robot Contest. The participants had to build models to recognize the electroencephalography (EEG) signal of a certain motion imagery. We noticed that several methods, such as common spatial pattern (CSP), support vector machine (SVM), neural networks (NNs), linear discriminant analysis, task-related component analysis, and discriminative canonical pattern matching, were well implemented in previous MI-BCI algorithms [2–4]. Recently, these algorithms have made significant progress. However, problems persist in areas such as feature extraction and generalization, as well as the failure to account for the temporal dynamics of the EEG signal when using linear classifiers, such as SVM [5].
Deep NNs (DNNs) are computationally powerful branches of regular artificial NNs that have been increasingly used in MI-BCI in recent years [6]. For an image-like classification, DNNs such as convolutional NNs (CNNs) are very effective. DNNs are representation-learning methods with multiple representation levels and can extract features at different levels, with two or more layers of hidden processing neurons. They have a great potential for solving problems faced by conventional algorithms [7]. For the binary classification of MI tasks, previous research developed a five-layer CNN model. When compared with methods such as SVM and CSP [8], the results indicated that CNN can improve the classification performance even more [8]. CNN also outperforms other classification algorithms in multi-classification problems [9]. For temporal and spatial feature extraction, the shallow CNN method described in MI [10] employs an end-to-end shallow architecture with two convolutional layers. channel-wise convolution with channel mixing (C2CM) is a deep learning model that uses the Hilbert-transformed envelope of an EEG signal as input [5] and has previously been used to classify MI [11].
Our solution to the supervised MI task of the BCI Controlled Robot Contest in the World Robot Contest 2021, using CNN as our basic algorithm, is summarized in this paper.
2 Method
2.1 Contest data and scoring rules
A preliminary contest and a final contest are part of the BCI Controlled Robot Contest in World Robot Contest 2021. The MI task data of the preliminary contest was posted on the organizer’s website, with a total of 10 subjects. Each subject’s data consisted of 15 blocks, each of which contains 8 s’ left-hand MI task data, 8 s’ right-hand MI task data, and 8 s’ foot MI task data. The movements in the dataset were in random order. The data of four subjects were collected on the spot during the final contest. The participants were young people who have been trained to perform well in a variety of tasks. Each subject’s data consisted of 3 blocks, and each block consisted of 12 trials. The participants in the competition must determine the target as soon as possible after the end of each trial. The experimental data were collected using Neuracle’s 64-channel EEG acquisition device, with the 65th lead serving as trigger information. The original sampling rate was 1000 Hz, and the data concentration was reduced to 250 Hz without other filtering processing.
The most common BCI performance evaluation standard simulated information transfer rate (ITR, bit/min) [12, 13], which is defined below, was employed in the contest.
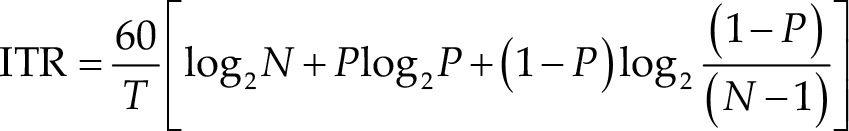
where P denotes the classification accuracy; N is the number of targets for classification (in this study, N was 3); and T (in seconds) is the average target selection time.
2.2 Overview of our solution
The following pipeline is a summary of our solution: (1) data augmentation, (2) data preprocessing, (3) basic model training (seven different models after seven different training runs), (4) update of basic models with new data (these data are augmented and preprocessed), and (5) build ensemble models. Figure 1 presents the entire procedure. Each component will be thoroughly described below.
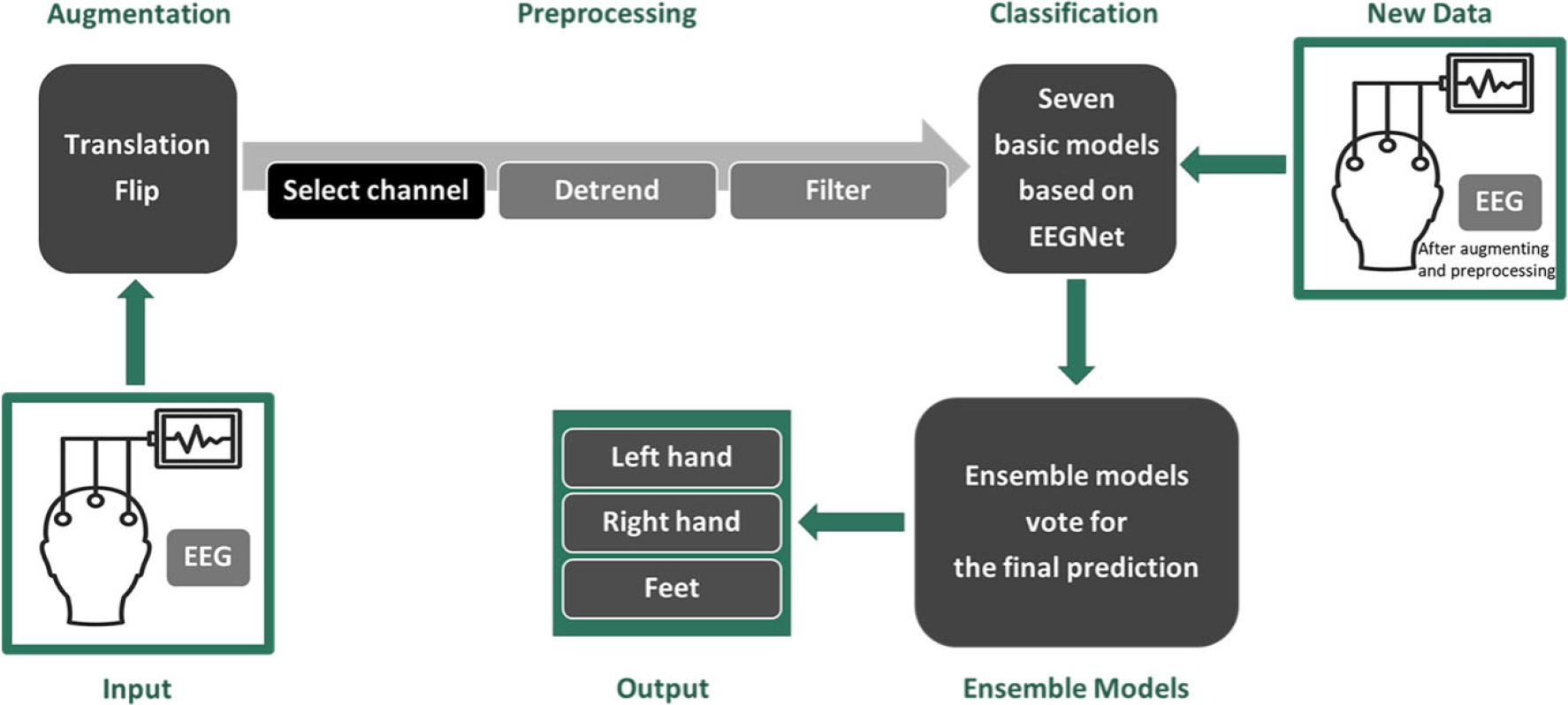
The overview of our solution.
2.3 Data augmentation
We have some data augmentation strategies to address the problem of a small sample size. We used translation to obtain a variety of temporal information as well as vertical flip operations on the data. First, we selected data from 0 to 500 ms after stimulation. Second, we translated data. We selected five time points within the first 200 ms after the stimulus onset randomly and collected data 500 ms later. Using this method, we were able to increase the dataset size by six times. The data was then flipped by taking the augmented data’s opposite value. As a result, we ended up with twelve times as much data as the original.
2.4 Data preprocessing
Python 3.8 was employed to conduct offline analyses in the MI task. MNE toolbox was used to perform preprocessing. The preprocessing steps for each participant were as follows: we selected EEG data at FT8, Cz, C1, C2, C3, C4, C5, T8, CP1, CP2, CP3, CP4, CP5, CP6, Pz, P3, P4, P5, P6, and P7 present over the motor cortex [14, 15] and then removed the first 45 ms and a linear trend of each data; finally, we band-pass (8–26 Hz) filtered the data with a fifth-order Butterworth filter (BF) [5]. Figure 2 presents the EEG channel layout and channel positions we selected. Figure 3 presents a comparison of example data before and after preprocessing.
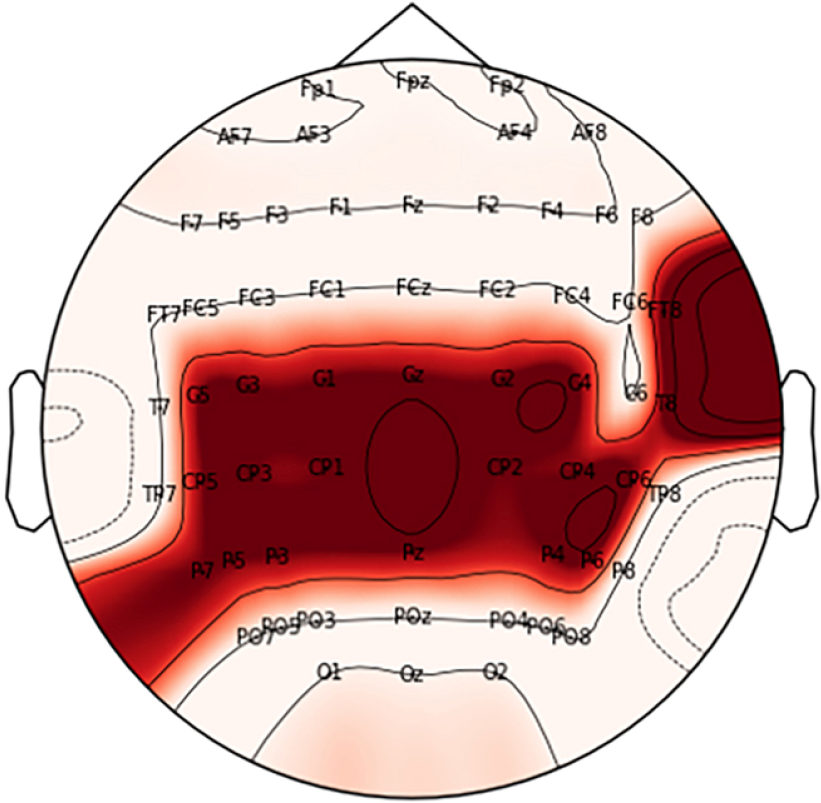
The layout of channels. The red area is the position of the channels we selected.
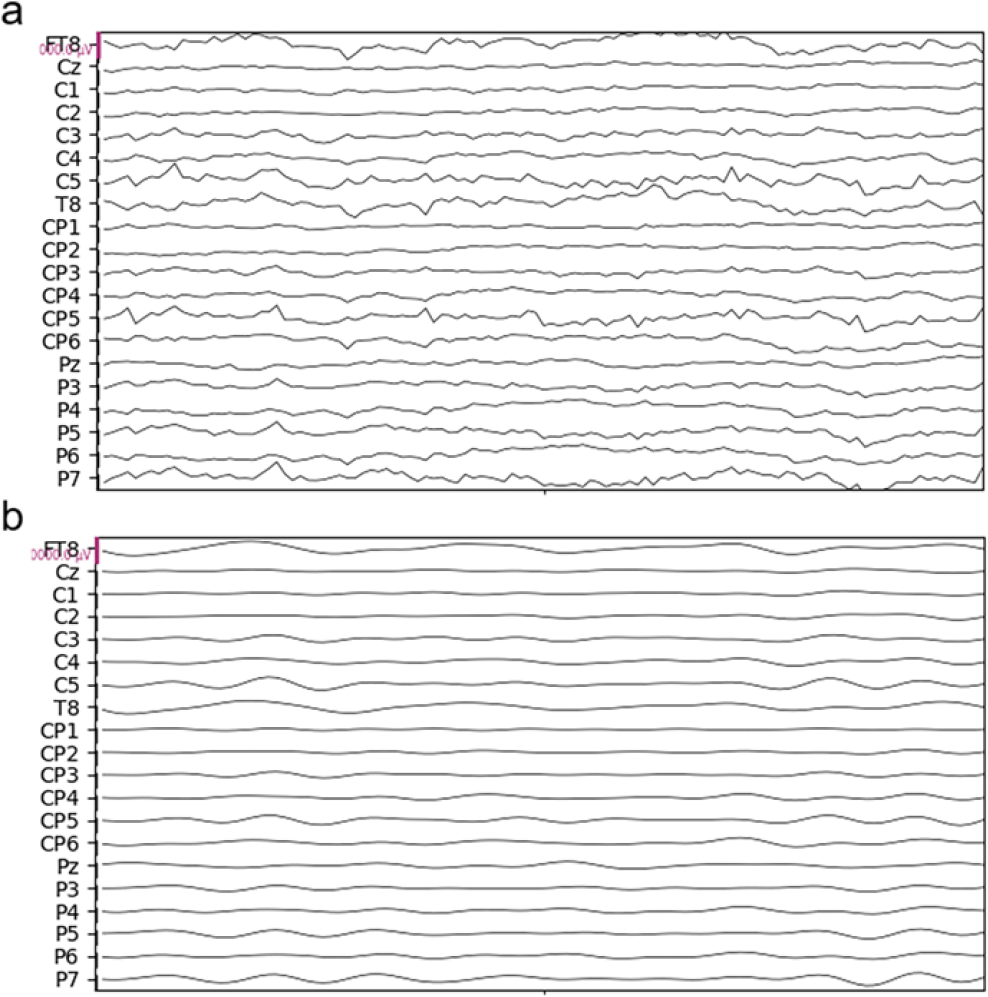
Raw and preprocessed data of the contest. (a) Raw data of an example trial. (b) Preprocessed data of an example trial.
2.5 Basic model training
We trained the basic model based on EEG compact network (EEGNet). EEGNet is a compact CNN architecture that specializes in classification for EEG-based BCI tasks with limited data. EEGNet outperforms both traditional classifications and deep CNNs. Meanwhile, unlike classic classifications, EEGNet does not require manual feature extraction or a long time to fit over 10,000 parameters, as do other deep CNNs. The innovative architecture of EEGNet enables it to extract useful features from raw EEG data in a short amount of time and to perform well in task predictions. As a result, it is an effective, end-to-end, and appropriate tool for the classification of various EEG-based BCI tasks [5].
We tweaked EEGNet hyperparameters such as the kernel length of temporal convolution (kl), number of temporal filters (F1), number of spatial filters (D), and number of point-wise filters (F2), dropout rate, and type to improve the model performance. However, the majority of the time models with default hyperparameters perform worse than those with default hyperparameters. This demonstrates the benefits of EEGNet as well as the rationalization of its default hyperparameters. After several attempts, we finally settled on kl = 128 and D = 16, and other hyperparameters were set by default. The aim of increasing the values of kl and D is to improve feature extraction capability in both the time and spatial domains.
2.6 Update of basic model with new data
As we all know, the EEG data of different people has different characteristics, and even the data collected from the same person on different dates, places, and devices have different characteristics. Thus, it is difficult to guarantee that a general model trained on data from a small sample size of people will accurately predict a specific individual. However, because a single individual’s data is so small, it is nearly impossible to train a high-performance and generalizable model. To address the issues raised above, we devised a strategy for updating the basic model with new data. The basic model used all data except for a specific individual to ensure that it was robust and generalizable. The basic model was then updated with all of the specific individual’s training data. In this way, we were able to create a personalized model with high robustness and accuracy for a specific individual.
2.7 Ensemble models
We trained all the data we have seven times according to the design above, yielding seven high-performance models. The classification category with the highest votes in the prediction results of the seven models was then determined using the relative majority voting strategy in ensemble learning.
3 Results
In the supervised MI task, our model performed the best. The MI task data of four subjects were collected for the final contest, and all of the teams’ models were tested for real time prediction. The ITR of every subject was updated in real time, and each team’s final score was calculated by averaging the ITR of four subjects. Figure 4 presents the final contest score of the top three models in the final contest using data from four subjects. When compared with other models, ours had a clear advantage in classifying the data from the first three subjects. In the data of the fourth subject, our model performed on par. As described in the discussion section, we speculate that this may be related to our data preprocessing method.
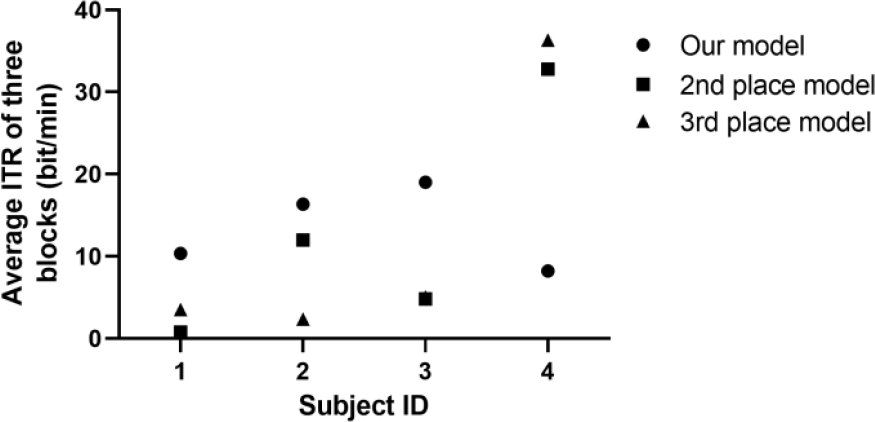
The performance of our model. In the final contest of the supervised MI task, the top three models performed on various subjects. The averaged ITRs of three blocks are as follows: subject 1 (our model = 10.35 bit/min, 2nd place model = 0.79 bit/min, 3rd place model = 3.51 bit/min), subject 2 (our model = 16.35 bit/min, 2nd place model = 11.98 bit/min, 3rd place model = 2.36 bit/min), subject 3 (our model = 19.01 bit/min, 2nd place model = 4.80 bit/min, 3rd place model = 5.06 bit/min), and subject 4 (our model = 8.21 bit/min, 2nd place model = 32.77 bit/min, 3rd place model = 36.31 bit/min).
In addition, we performed a 5-fold cross-validation to compare the performance of our model and CSP + logistic regression (LR). The average accuracy of our model among 10 subjects was 54.72%, which was significantly higher than the chance level of 33.33% (P = 1.16 × 10−5), the CMC2 model of 48.34% (P = 2.09 × 10−4), and the CSP model of 46.12% (P = 0.032). Figure 5 presents the performance of two models in 10 subjects. We also conducted an ablation study, as presented in Table 1, which shows the impact of not augmenting the data and not updating the basic model. The results indicated that our model-building strategy improves the model’s performance in a variety of ways.
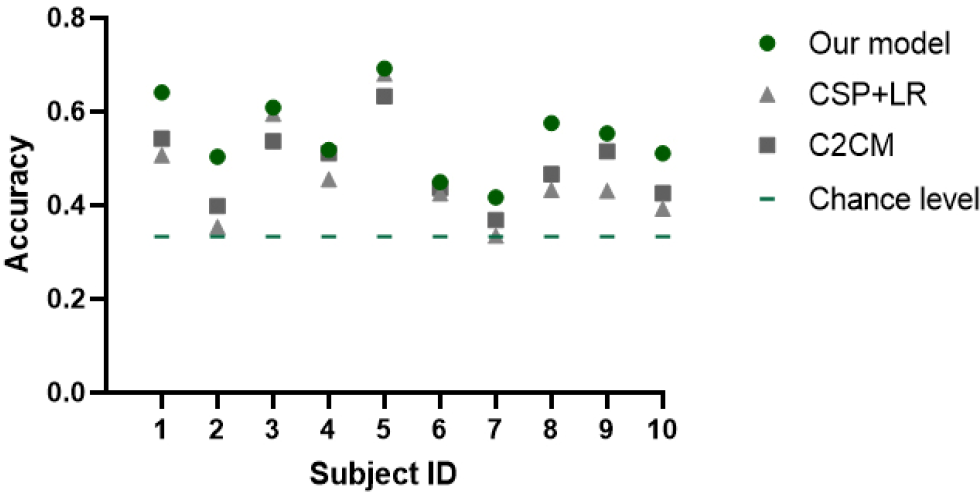
Classification accuracy comparison of our methods, CSP + LR and C2CM, and chance level among the 10 subjects in the preliminary contest.
Ablation study of our method on data from the preliminary contest.
4 Discussion
By analyzing the characteristics of the contest data, combining cognitive science and machine learning data processing methods, our EEGNet-based model performed well in the supervised MI task.
Cognitive science agrees that asymmetry in brain function exists. The activation patterns of the left and right hemispheres of the brain in processing complex cognitive and affective tasks are asymmetrical [16]. Thus, in this study, we continuously optimized the channel selection based on the results of offline classification feedback. However, we did not attempt to artificially assign weights to these channels. Weights can be optimized in the following optimization process by combining cognitive science knowledge. In addition, we visualized the temporal features of the model. These channels (C1, C2, C5, T8, CP1, CP2, CP3, CP5, CP6, and Pz) are mainly concentrated in the parietal and occipital lobes (Fig. 6). This is consistent with our understanding of cognitive science [17].
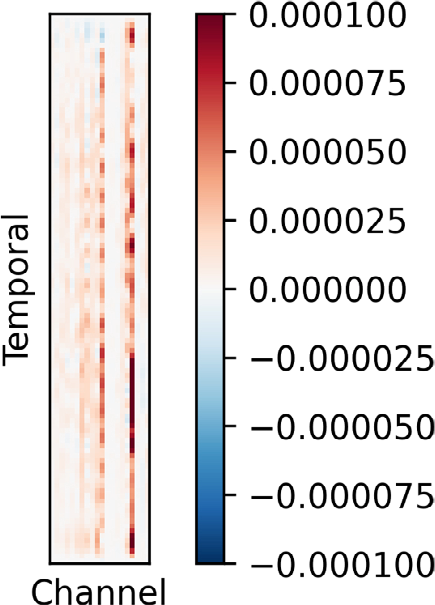
Visualization of the temporal features of our model.
The EEG data samples are typically small due to the difficulty and high cost of EEG data collection. Adding Gaussian noise [18], overlapping time windows, swapping the right- and left-side electrodes, and flipping the time series up and down are all common data argumentation techniques used in EEG-based BCI fields. In the competition, we used data augmentation on raw EEG data. In this way, we increased the sample sizes and made model training and learning easier. Ensemble models consist of more than one different base models. The concept of ensemble models stems from the fact that multiple mutually independent models making the same mistakes is a low-probability event [19]. As a result of basing our final prediction on the classification information generated by seven personalized models, the error rate significantly decreased.
Our solution has some limitations. To begin, we sacrificed the classifier accuracy to achieve a higher ITR in the contest. Furthermore, the data length we employed for model training was less than 500 ms, which was deemed unreasonable by cognitive scientists. Second, EEG data collection has high environmental requirements and is easily disrupted by a variety of factors. When the signal-to-noise ratio (SNR) of data is low, it is critical and difficult to effectively identify and repair data. Our data preprocessing method is simple and struggles to deal with low-data-quality situations. The final contest was held in a noisy environment, which could explain our model’s average performance in the fourth subject’s data. Furthermore, as presented in Fig. 7, data visualization revealed that the SNR of the fourth subject’s data was extremely low. We assumed that the training data for the fourth subject we used was of poor quality due to the short duration of the data we selected. Finally, our solution was created specifically for this competition and may not be applicable to other circumstances.
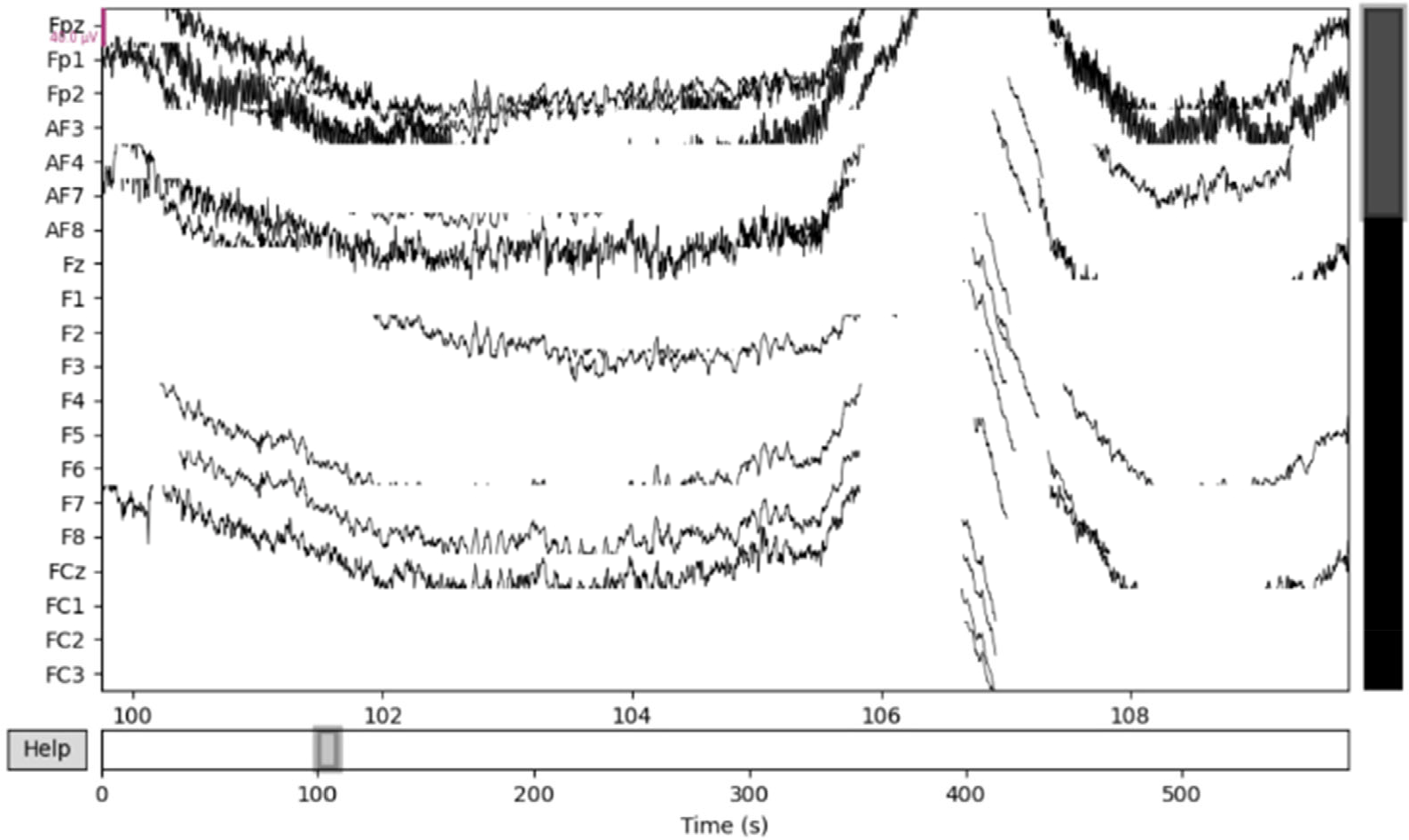
Example trials of data visualization for the fourth subject.
5 Conclusion
We presented the winning solution to the supervised MI task in the BCI Controlled Robot Contest in World Robot Contest 2021 in this paper. This solution’s pipeline and extracted features are impressive. This is a compact and powerful solution that can be used in other supervised MI tasks with limited training data.
Footnotes
Conflict of interests
All contributing authors report no conflict of interests in this work.
Funding
This work was granted by the Chinese National Programs for Brain Science and Brain-like Intelligence Technology (Grant No. 2021ZD0202101), the National Natural Science Foundation of China (Grant Nos. 32171080, 32161143022, 71942003, 31800927, 31900766 and 71874170), Major Project of Philosophy and Social Science Research from Ministry of Education of China (Grant No. 19JZD010), CAS-VPST Silk Road Science Fund 2021 (Grant No. GLHZ202128), Collaborative Innovation Program of Hefei Science Center from CAS (Grant No. 2020HSC-CIP001).
Acknowledgements
We thank the Bioinformatics Center and School of Life Science of the University of Science and Technology of China, School of Life Science, for providing supercomputing resources for this project. We thank the organizers of the BCI Controlled Robot Contest in World Robot Contest for their support.
Authors’ contribution
H Gou, Y Piao, and X Zhang designed this research. All authors reviewed and revised the analysis. H Gou and J Ren wrote the main text of the manuscript. All authors reviewed, revised, and finalized the manuscript.