
Abstract
Objective:
From September 10 to 13, 2021, the finals of the BCI Controlled Robot Contest in World Robot Contest 2021 were held in Beijing, China. Eleven teams participated in the Algorithm Contest of Calibration-free Motor Imagery BCI. The participants employed both traditional electroencephalograph (EEG) analysis methods and deep learning-based methods in the contest. In this paper, we reviewed the algorithms utilized by the participants, extracted the trends and highlighted interesting approaches from these methods to inform future contests and research recommendations.
Method:
First, we analyzed the algorithms in separate steps, including EEG channel and signal segment setup, prepossessing technology, and classification model. Then, we emphasized the highlights of each algorithm. Finally, we compared the competition algorithm with the SOTA algorithm.
Results:
The algorithm employed in the finals performed better than that of the SOTA algorithm. During the final stage of the contest, four of the top five teams used convolutional neural network models, suggesting that with the rapid development of deep learning, convolutional neural network-based models have been the most popular methods in the field of motor imagery BCI.
1 Introduction
The World Robot Contest has been successfully held six times since 2015, attracting more than 150,000 contestants from more than 20 countries worldwide. In the robotics field, it is currently an official professional event with a wide range of influences worldwide, widely acclaimed as the “Olympic Games” in robotics. The World Robot Contest 2021 (WRC2021) focused on the three major competition directions of scientific research, skills, and popular science based on the successful holding of previous competitions. This year, there are four major contests: BCI Controlled Robot Contest, Tri-Co Robot Challenge, Robot Application Contest, and Youth Robot Design Contest [1].
The Information Science Department of the National Natural Science Foundation of China, the Chinese Institute of Electronics, Tsinghua University, and other related institutions organized the BCI Controlled Robot Contest. The brain– computer interface (BCI) refers to the collection, recognition, and transformation of the electrical activity and characteristic signals of the nervous system so that the instructions issued by the human brain can be directly transmitted to the designated machine terminal, thereby making the control and operation of the robot more effective. BCI technology has great innovative significance and use value in the field of communication between humans and robots in terms of efficiency and convenience. The BCI Controlled Robot Contest was organized to promote the innovation and breakthrough of BCI technology, promote technology and industry exchanges and cooperation in various fields, meet people’s diversified livelihood needs, such as medical care, elderly care, and rehabilitation, and realize the development of BCI and various industries.
The BCI Controlled Robot Contest comprises four parts: algorithm contest (technical competition), BCI system control contest (skill competition), application contest (outstanding achievement display), and excellent thesis defense. In the algorithm contest, it included four paradigms: motor imagery BCI (MI-BCI), steady-state visual evoked potential (SSVEP) BCI, event-related potential (ERP) BCI, and emotional BCI.
Motor imagery electroencephalography (MIEEG) is a kind of endogenous spontaneous EEG that is simple, flexible, noninvasive, and has low environmental requirements; thus, becoming an important and widely used branch of BCI. When the subject performs specific motor imagery, the MI-BCI system collects EEG signals, recognizes the motor imagery content according to the EEG signals, and converts the recognition results into control commands to control peripheral devices [2]. Related research works have mainly concentrated on three aspects: the equipment and technology for collecting EEG signals, the method of feature extraction, and the training of the classifier [3].
The existing research is mainly divided into three categories according to the features used: frequency domain feature-based approaches, common spatial pattern (CSP)-based approaches, and deep learning-based approaches.
Frequency domain analysis can be used to extract features in MI-BCI due to the appearance of event-related synchronization (ERS) and event-related desynchronization (ERD) during motor imagery [4, 5]. In motor imagery classification, power spectral density (PSD) techniques, atomic decompositions, time–frequency (t-f) energy distributions, and continuous and discrete wavelet approaches have been used [5]. A feature with a combination of information in the time and frequency domains is preferred, such as short-time Fourier transforms (STFTs) [6] and wavelet transforms [7], because the band power of EEG signals recorded over the motor cortex area changes during motor imagery (ERD/ERS). Feature selection is usually employed before classification after frequency feature extraction.
The CSP algorithm and its variants have been widely applied in MI-BCI [8]. The Filter Bank Common Spatial Pattern (FBCSP) used a filter bank consisting of nine bandpass filters covering the frequency range of 4–40 Hz to process the signal. Then, the discriminative features were extracted by the CSP algorithm, selected for different subjects by the mutual information-based rough set reduction algorithm, and fed to the naive Bayesian Parzen window classifier. The outstanding performance of FBCSP won the champions of BCI Competition IV in 2a and 2b data sets [9]. To select features extracted by the FBCSP algorithm in different EEG frequency bands, Zhang et al. proposed a sparse Bayesian learning algorithm in which they achieved good recognition results [10]. Olivas-Padilla et al. proposed a new interactive method for selecting frequency bands for subsequent feature extraction for the target subject [11]. To solve the problem of frequency band selection for each subject, Luo et al. proposed a dynamic frequency feature selection algorithm [7]. A discriminative subset of frequency band energy features was selected for motor imagery recognition by dynamically adjusting the weight of each sample in the training set.
With the rapid development of deep learning algorithms in recent years, MI-BCI based on neural network models has also emerged in MI-BCI research [6, 11–15]. The most widely applied is the convolutional neural network (CNN). Using CNNs and stacked autoencoders for feature extraction and classification, Tabar et al. proposed a new input data structure that combined the time, frequency, and space information of EEG signals [6]. Sakhavi used a transfer learning method based on CNNs [13]. To reduce the system calibration time, they pretrained the model with multisubject data and fine-tuned the model with a small amount of new subject data. Specifically, FBCSP-based envelope extraction was used to extract the features that were inputted into the CNN and the linear classifier [13]. Wang et al. proposed two deep learning models based on CNNs and long short-term memory and modeled the frequency domain representation of EEG signals based on a short-time Fourier transform [15]. The experimental results indicated that the CNN showed better results in motor imagery recognition. Olivas-Padilla et al. first proposed a new interactive method to select frequency bands for the target subject and then used the improved discriminative FBCSP to extract features that were inputted into two different CNN structures to make predictions [11]. Schirrmeister et al. proposed a Shallow ConvNet and a Deep ConvNet for end-to-end MI-EEG recognition and showed better performance [16]. In addition, the CNN visualization results showed that the ConvNets learned to use spectral power characteristics from different frequency bands. Lawhern et al. proposed EEGNet to suggest that a compact CNN can be applied and provide robust performance across many BCI paradigms, such as P300 event-related potential, feedback error-related negativity, movement-related cortical potential, and sensory-motor rhythm (motor imagery recognition) [17].
An inconvenient and time-consuming calibration procedure for the subject-dependent MI-BCI is required before the new subject uses the BCI system. Many researchers have recently begun studying calibration-free or subject-independent MI-BCIs. The calibration-free BCI is of great significance for the practical application of MI-BCI because it does not need additional time and cost burden in the calibration stage. Kwon et al. proposed a deep convolutional neural network framework for subject-independent MI-BCI [18]. Mutual information was used to select the best frequency bands for EEG signal preprocessing. The covariance matrix of EEG signals processed by the CSP spatial filter was fed into a convolutional network as a feature map. The experiment showed that the proposed method achieved state-of-the-art subject-independent performance on the OpenBMI dataset. Zhang et al. proposed a convolutional recurrent attention model, which uses convolutional neural networks to encode high-level representations of EEG signals and uses a recurrent attention mechanism to capture the temporal dynamics of EEG [19]. The experimental results verified the effectiveness of each module, showing superior performance compared with a series of the latest research in the subject-independent motor imagery recognition task. MIN2Net is a novel end-to-end multi-task learning framework integrating autoencoder, deep metric learning, and supervised classifiers to learn a compact and discriminative latent representation from EEG [20]. The model was optimized by simultaneously minimizing the reconstruction loss, cross-entropy loss, and triplet loss, resulting in significant performance improvement in the subject-independent motor imagery task.
This study reviewed the algorithms applied in the Algorithm Contest of Calibration-free Motor Imagery BCI in the BCI Controlled Robot Contest in WRC2021. Unlike the subject-dependent motor imagery BCI contest providing a training set for each subject, the calibration-free MI-BCI encouraged the participants to build subject-independent BCI maintaining good performance without additional calibration when new subjects came. Therefore, the submitted algorithms were tested on the new subjects in the contest. There is no limit to the training set used for model training.
2 Experiment data and setup
2.1 Paradigm
Figure 1 shows the experimental procedure of MI-BCI. A motor imagery trial contains a resting stage, a preparation stage, and a motor imagery stage. Each trial contains 8 s of left hand motor imagery task data, 8 s of right hand motor imagery task data, or 8 s of feet motor imagery task data. The sequence of actions is random. In the experiment, the subjects were sitting in a comfortable armchair in front of a computer screen. After a 3 s rest, the screen showed the motor imagery task prompts (left hand, right hand, or feet, as shown in Fig. 2; the subjects were encouraged to prepare for motor imagery for 3 s. Then, the subjects began to execute the motor imagery task for 8 s.

Experiment procedure of MI-BCI.
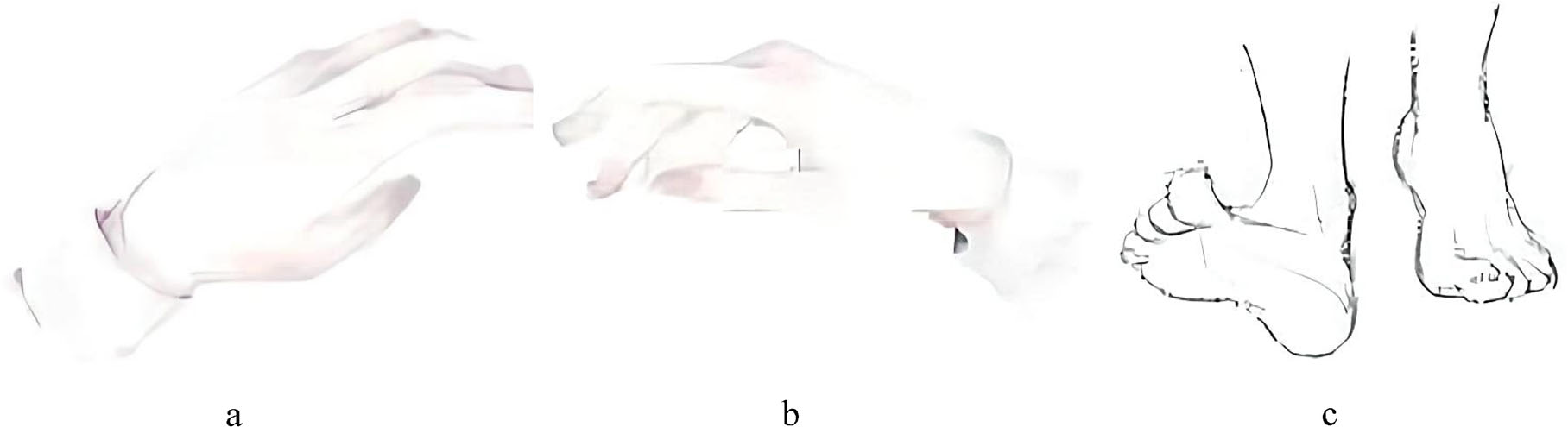
Motor imagery task prompts on the screen. (a) Left hand. (b) Right hand. (c) Feet.
The algorithms were tested offline in preliminary stages A and B because the preliminary stage was held on the Internet. However, the algorithms were tested online in the finals. At first, the participants submitted the models to the server before EEG signal collection. When the subject began to conduct motor imagery, the algorithms were tested online and the results were displayed on the other screen simultaneously. Four subjects participated in the final, and the EEG signals collected from each subject consisted of 3 blocks and 36 trials (12 for each of the three possible classes).
We collected the experimental data by a 64-channel EEG acquisition device produced by Neuracle. We used the international 10–20 system of electrode placement, where the electrode index and name were shown in Fig. 3. The 65th dimension of the data was the trigger information. In addition to the trial start trigger, the data also contain other triggers for system control, where the specific trigger definitions are shown in Table 1. The original sampling rate was 1000 Hz, and the raw signal was downsampled to 250 Hz. No other filtering procedure was applied.
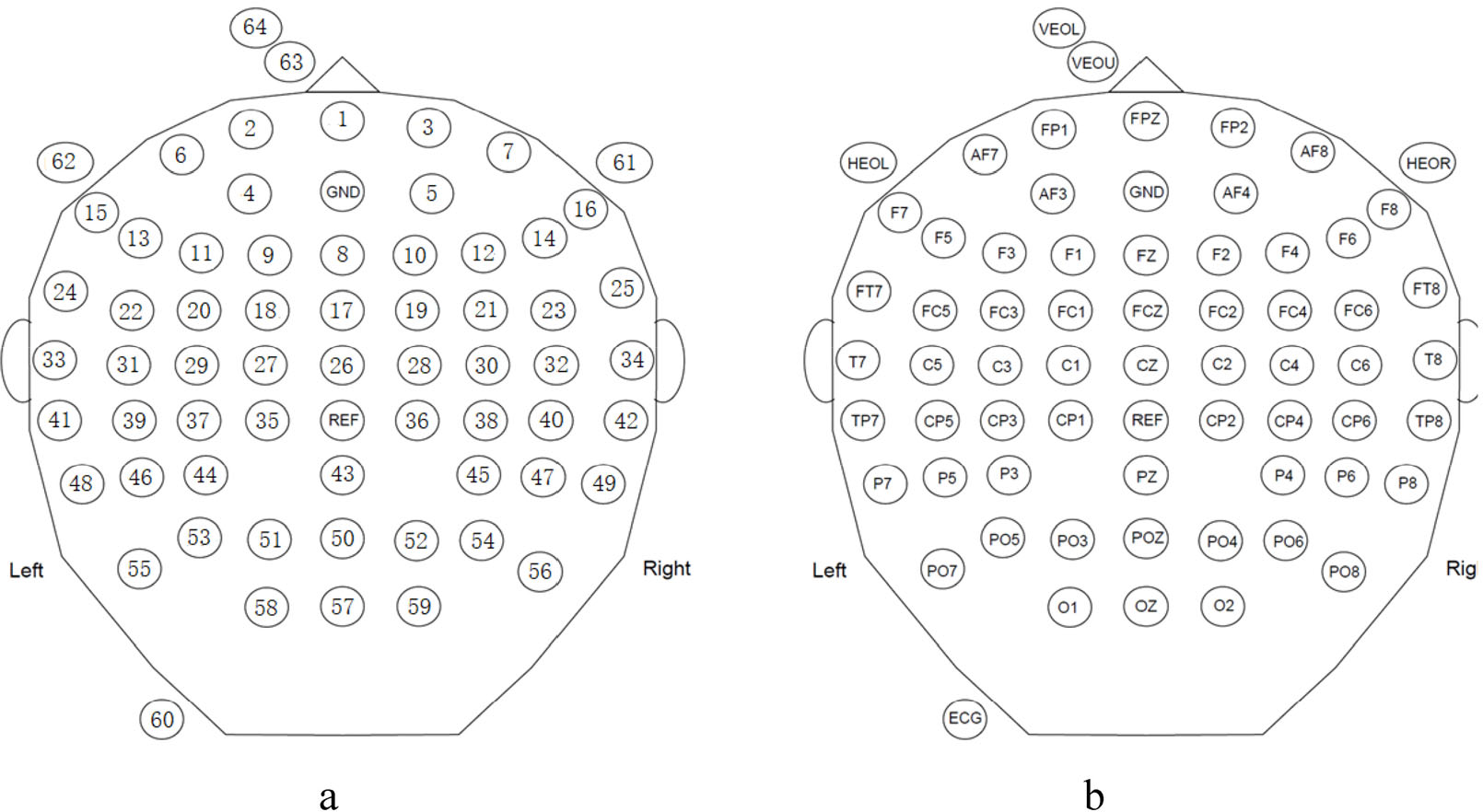
Electrode index and corresponding electrode name. (a) Electrode index. (b) Electrode name.
System trigger definition.

2.2 Algorithm
The data were provided under a simulated online environment during the testing stage. Every time when the getData function is called, the system will provide a new data packet, including EEG data and trigger information, with a data length of 40 ms (10 sampling points as the sampling rate is 250 Hz). The algorithm can save and process received data packets. In the same block, data packets were sent in order. The algorithm can call the calculation method and report the result to the system when the algorithm detects that the data are enough to make decisions. The system calculates the data length used in the algorithm based on the calling number of the getData function and then calculates the information transfer rate (ITR) according to the data length used to recognize motor imagery and accuracy. The motor imagery content must be recognized within 4 s after the trial begins trigger; otherwise, the system judges that the recognition result is wrong.
2.3 Metric
To evaluate the performance of the algorithms, we used ITR, where the ITR score is calculated for each block and the average ITR score of the 3 blocks is the corresponding subject’s score. The ITR is calculated as follows:
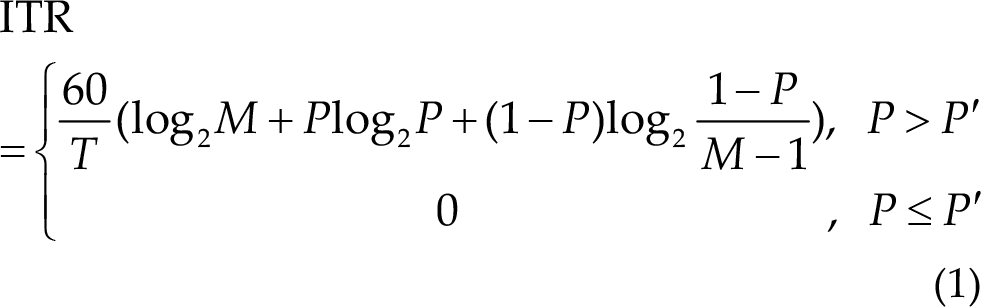
where T (in seconds) denotes the average data length used to recognize motor imagery, M denotes the number of classes (three in this paradigm), P denotes the classification accuracy, and P′ is the accuracy of random prediction (1/3 in three-category classification in this contest). The unit of ITR is bits/min. It should be pointed out that T is an ideal value without resting time and preparation time in contests.
3 Algorithm procedures
3.1 EEG channel and signal segment setup
The participants applied different setups because the provided testing EEG signal has 64 channels, as shown in Fig. 3, and the data length used to recognize motor imagery greatly affects ITR.
3.1.1 EEG channels
The EEG channels where ERD/ERS appears are important basic for motor imagery classification. As the contest is a three-category motor imagery classification task including the left hand, right hand, and feet motor imagery, and 64 electrode signals (0–58 are EEG channels in the international 10–20 system, as shown in Fig. 3) were provided, the EEG channels may be redundant. Many channel selection methods have been proposed for MI-EEG classification. Most teams selected a certain number of EEG channels from all 64 channel signals in the contest. Table 2 summarizes the EEG channels applied by the top 5 teams. We can conclude that three of the top five teams used all 59 EEG channels to accommodate differences in channels between subjects. The other two teams manually selected EEG channels.
EEG channels applied by the top 5 teams.

3.1.2 EEG segments
As ITR was employed as the performance measurement in the contest instead of classification accuracy, the EEG segment length applied directly affects the result. On the one hand, the ITR is higher if the accuracy is higher when the algorithms use the same EEG signal length. On the other hand, the ITR is higher if shorter EEG signals are applied when the algorithms obtain the same accuracy. Therefore, each team should make a trade-off between accuracy and the EEG length required for the algorithm to achieve the highest ITR score. T in Eq. (1) denotes the average data length used to recognize the motor imagery-based on the calling number of the getData function, which is an ideal value without resting time and preparation time in the experiments.
For different EEG signal segment lengths T, the relationship between ITR and accuracy is shown in Fig. 4. Referring to the results of all three stages of the motor imagery paradigm, the test accuracy mainly ranged from 50% to 80%. The figure indicates that the gradients of the ITR trends are small in this range; as a result, the influence of EEG segment length on ITR is usually larger than that of accuracy.
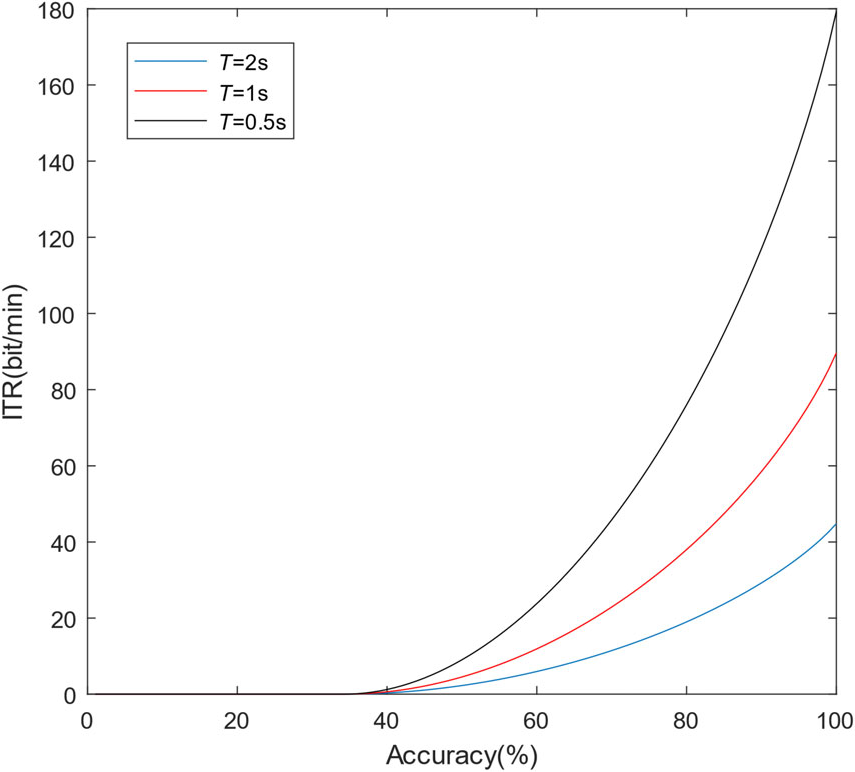
Relationship between ITR and accuracy for different signal segment lengths T.
Table 3 shows the EEG signal segments used by the top 5 teams. As the competition organizing committee limited the minimum EEG signal segment length to 0.5 s (125 points as the sampling rate was 250 Hz), most participants applied approximately 0.5-second EEG segments from the trigger of the trial begin. Although the 0.5-second EEG segment is very short for motor imagery classification, increasing the EEG signal length will lead to an obvious ITR drop.
EEG signal segments used by the top 5 teams.

*EEG segment length and range were measured by the sampling point, and the trigger of the trial begin locates at point 0.
In addition, the overall ITR is calculated by summation of ITR for each subject. ITR is nonlinearly related to the accuracy, so the addition may lead to unfairness. In the case of the same average accuracy, the ITR is higher with uneven accuracy. For example, if Algorithm 1 is 70% accurate on all four subjects, then the summation of ITR is 96.8812/T. Suppose that the accuracies of Algorithm 1 on the four subjects are 60%, 60%, 80%, and 80%. In that case, the average accuracy is also 70%, but the summation of ITR is 105.2456/T.
3.2 Preprocessing
Preprocessing is a key procedure in EEG analysis. Common preprocessing methods include detrending, notch filtering, bandpass filtering, and normalization. The detrending removes the linear trend in each channel. A 50-Hz Notch filter can remove power frequency interference. The bandpass filter is a common preprocessing method because the ERD/ERS in the frequency band of 8–30 Hz is considered to be related to motor imagery [9, 21]. Normalization can be applied to ensure that the input is independently identically distributed. Multiplication can enhance the numerical stability of the algorithm. Table 4 summarizes the preprocessing methods used by the top 5 teams.
Preprocessing methods used by the top 5 teams.

Team XAUT-Monster applied an overlapping filter bank before the CNN model. The EEG signal was first filtered through a specific bandpass filter and inputted to independent CNNs. The output probabilities of all nine CNN models based on different bandpass filters were summed to make the final prediction. Other teams employed a single-bandpass filter.
3.3 Classification model
With the rapid development of deep learning, CNNs achieving feature extraction and classification in an end-to-end framework have become the most popular algorithm in the field of MI-EEG classification. Many outstanding methods based on CNNs have been proposed, such as EEGNet [17], Braindecode [16], and FBCNet [22]. In the contest, four of the top five teams used CNNs to recognize motor imagery. The XAUT-Monster team utilized the Deep ConvNet from Braindecode, and the XJTU-Mind reader and USTC-Pikapika teams utilized different versions of EEGNet. The input EEG signals were all organized in the shape of B×1×C ×T , where B is the batch size, C is the number of channels (channel dimension), and T is the number of sampling points (time dimension).
Table 5 summarizes the specific model and parameter numbers applied. The convolution layer is represented as “kernel number × (kernel size)”. ZeroPad pads the input tensor boundaries with zero. CWConv indicates channel-wise convolution performing a convolution over the time dimension. TWConv indicates time-wise convolution performing a convolution over the channel dimension (or spatial dimension). BatchNorm is an operation of batch normalization [23], dropout randomly drops units (along with their connections) from the neural network during training [24], and ELU is the exponential linear unit activation function [25]. AvgPool and MaxPool indicate average pooling and max pooling, respectively. ConvC indicates Conv with constraint regularizing each convolutional kernel by a maximum norm constraint of 2 on its weights [22]. DWConv indicates depthwise convolution, as a spatial convolution performed independently over each feature map of an input, learns a spatial filter, and reduces the number of trainable parameters to fit [26]. PWConv is a convolution layer with a kernel size of 1 × 1. SConv indicates separable convolution consisting of a depthwise convolution and a pointwise convolution [17, 26].
CNN model setups used by 4 of the top 5 teams.

In Table 5, all four CNN models applied a CWConv layer first and a TWConv layer subsequently, which is an important difference between EEG-based CNNs and image-based CNNs. The parameter number ranges from 9440 to 79,450.
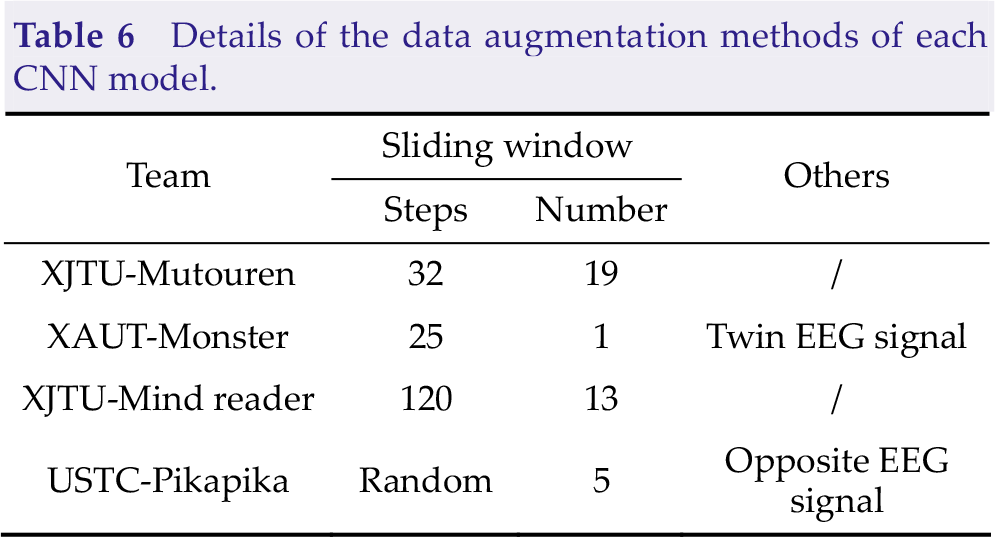
Many parameters in the CNN model need to be learned in the training stage, but the number of EEG trials in the training set is small in MI-BCI. Therefore, data augmentation is a key procedure to help model training and improve the generalization ability. The four teams utilized many different data augmentation methods in the training stage, and the details are presented in Table 6. A sliding window is a simple way to increase the number of training samples. The steps mean that the sampling point gap between adjacent sliding windows and the number indicates the number of sliding windows applied to enlarge the training set. Twin EEG signals are constructed by exchanging EEG channels from the left and right cerebral hemispheres [8]. The value of each sampling point in the opposite EEG signal is opposite to that in the raw EEG signal.
Details of the data augmentation methods of each CNN model.
After preprocessing, THU&BUPT-Jingshenxiaohuo applied PSD features and the SVM classifier framework. The PSD change calculated by Welch’s average periodogram method in the frequency band 13–30 Hz and 30–80 Hz before and after the execution of motor imagery was calculated for each area of the brain, and then the SVM classifier was trained. It was the only non-CNN model in the top 5 teams.
3.4 Inference time and training time
To evaluate the computing complexity of each model, we compared the inference time and training time, as shown in Table 7. The inference time is an average time-consuming of 1000 runs, and the training time is evaluated with a training set with 450 trials. The experiments were conducted based on Intel i5-10400 CPU and NVIDIA GeForce RTX 2060 GPU.
Inference time and training time.
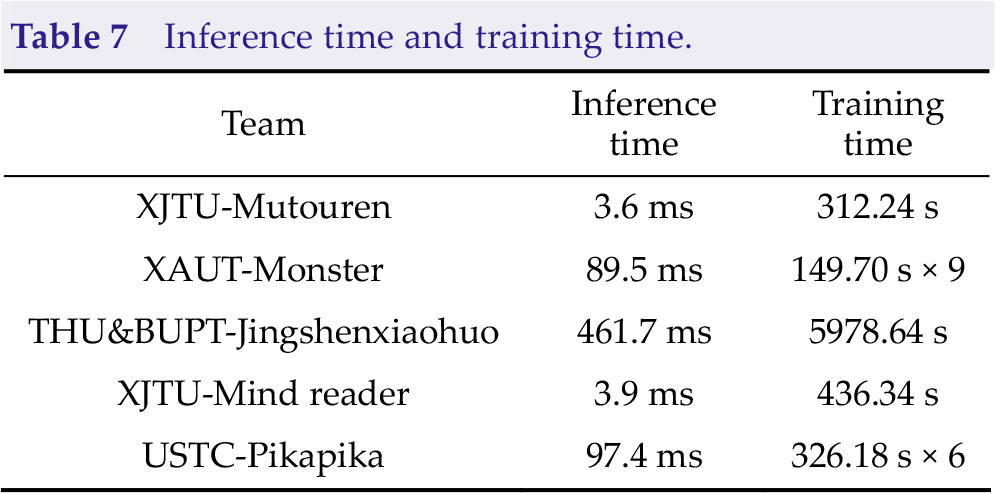
The inference time and training time of XAUT-Monster (9 models) and USTC-Pikapika (6 models) were larger than that of other deep learning-based methods because they both used the model ensemble method. The training time of the single model is mainly depending on the number of samples, which is determined by the data augmentation methods. As the only team to use the traditional EEG analysis method, THU&BUPT-Jingshenxiaohuo needs the longest inference time and training time due to a large amount of time spent on data preprocessing and no GPU acceleration.
4 Results
4.1 Results of the Algorithm Contest of Calibration-free Motor Imagery BCI
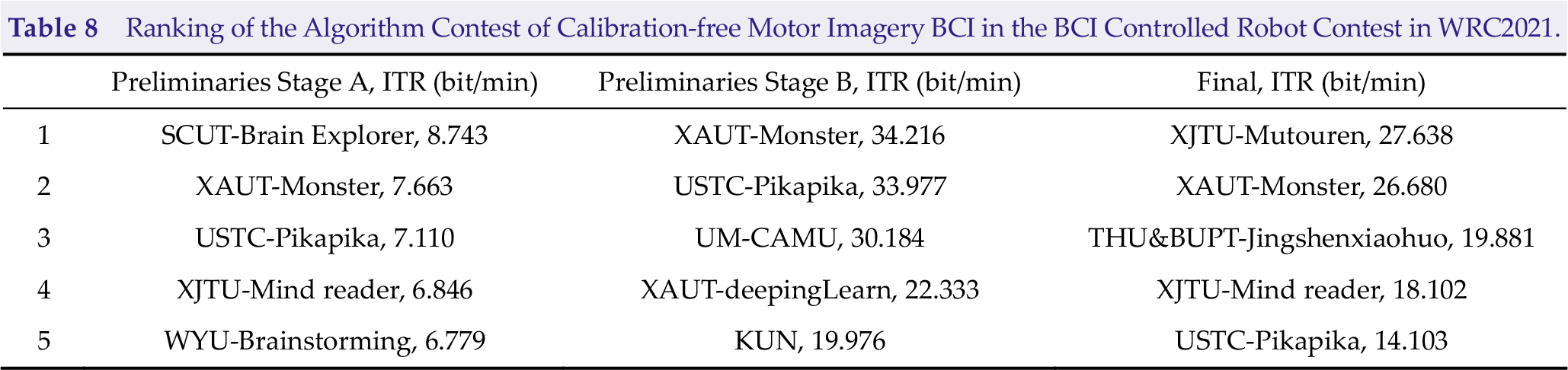
The Algorithm Contest of Calibration-free Motor Imagery BCI includes preliminary stage A, preliminary stage B, and the final stage. Preliminary stages A and B were held online in July and August 2021, and the final stage was held in Beijing, China, from September 10 to 13. Table 8 shows the top 5 teams of each stage. The names of teams are denoted as University-Team/ITR. Team Monster from the Xi’an University of Technology won second place, first place, and second place in each stage, which were the best overall performances in this contest. Team Mutouren from Xi’an Jiaotong University won the championship in the final. Team Pikapika from the University of Science and Technology of China also reached the top five in all three stages.
Ranking of the Algorithm Contest of Calibration-free Motor Imagery BCI in the BCI Controlled Robot Contest in WRC2021.
4.2 Performance comparison with the state-of-the-art methods
We also compared the algorithms in the contest with state-of-the-art methods in the field of calibration-free MI-BCI using the same datasets. MIN2Net is a novel end-to-end multi-task learning framework integrating autoencoder, deep metric learning, and supervised classifiers to learn a compact and discriminative latent representation from EEG. The model optimized by simultaneously minimizing the reconstruction loss, cross-entropy loss, and triplet loss resulted in significant performance improvement in subject-independent motor imagery tasks [20]. As one of the latest publications in the field of calibration-free MI-BCI, MIN2NET is chosen as the SOTA algorithm for algorithm comparison.
Since a three-category classification task is employed in the final, the learning rate of the model is set between [10−4, 10−5], as described in the paper. The time length is set to 1 s because the ITR is time-sensitive. The kernel size in the first convolution layer is adjusted to 16 to accommodate short EEG inputs. The weights of the three loss functions B 1, B 2, and B 3 are respectively set as 0.1, 0.1, and 1. To be fair, the MIN2NET model without data augmentation (MIN2NET-O), MIN2NET using the sliding window method (MIN2NET-W) and MIN2NET using sliding window and twin EEG signal method (MIN2NET-WT) were tested and compared with the ITR scores of the top five algorithms in the final. The comparison results are shown in Fig. 5.
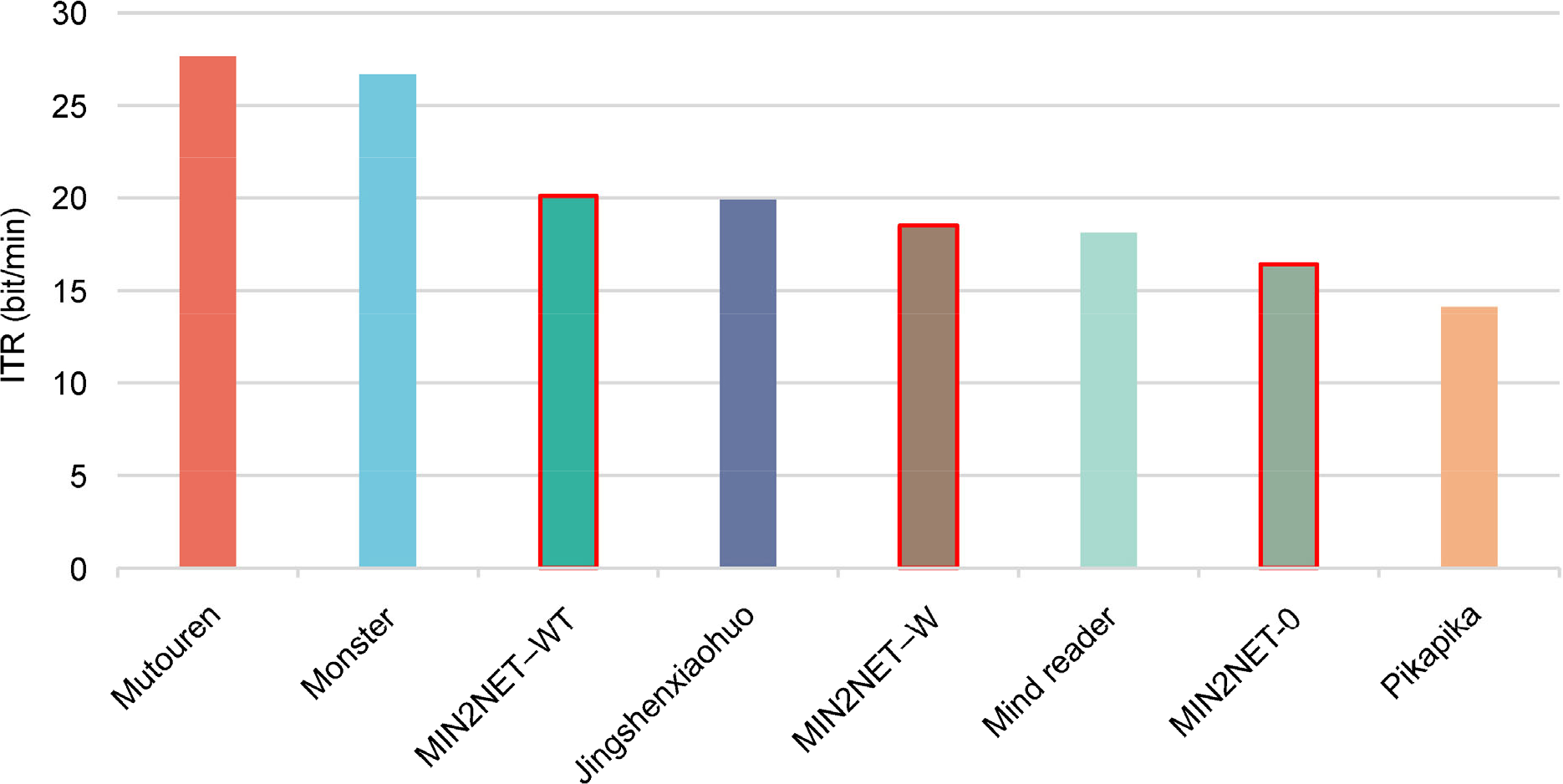
Final scores compare with MIN2NET.
We can conclude from the results that MIN2NET-WT could win third place in the contest. Experiments showed that the top 5 algorithms in the final achieve competitive ITR compared with the state-of-the-art algorithm.
5 Summary of each algorithm
5.1 XJTU-Mutouren
Team XJTU-Mutouren designed a CNN model with four convolution layers, including CWConv, TWConv, CWConv, and PWConv, successively. To suit the model with 0.5-second EEG signal input, ZeroPad padded zeros at the beginning and end of input EEG. A sliding window covering from 0 to 3 s expanded the training set by 20 times to train the model fully. In addition, the input EEG signal was rescaled by the maximum of the absolute values to ensure that the input was independently identically distributed.
5.2 XAUT-Monster
Deep ConvNet from Braindeocde was the basic model in the Team XAUT-Monster algorithm. The size of the convolution kernel in CWConv and pooling is reduced by half to suit the 0.5-second EEG signals input. An overlapping filter bank covering the frequency range 0–36 Hz took advantage of the discriminative information from multiple frequency bands. At the same time, ensembles of CNNs based on different frequency bands implementing model integration further improve the performance. In addition, the twin EEG construction and sliding window enlarged the training set by four times.
5.3 THU&BUPT-Jingshenxiaohuo
THU&BUPT-Jingshenxiaohuo is the only team among the top five teams that used the non-CNN method. The PSD change calculated by Welch’s average periodogram method in the frequency band 13–30 Hz and 30–80 Hz before and after the execution of motor imagery were calculated for each area of the brain, and then the SVM classifier was trained.
5.4 XJTU-Mind reader
EEGNet was modified by a constraint convolution layer [22] in which the kernel was regularized by using a maximum norm constraint of 2 on its weights. Multiplication by 1000 in the preprocessing enhances the numerical stability of the model.
5.5 USTC-Pikapika
Team USTC-Pikapika applied EEGNet in the contest. Sliding windows and opposite EEG signals enlarge the training set by 12 times. The 8–26 Hz bandpass filter is narrower than the other teams.
5.6 Other teams in the final
In the contest, a variety of algorithms were used by the participants. Team ECUST-EastWorld utilized 2 s of 7-channel EEG signals, and classification rules were made based on PSD changes. Team SCUT-BrainExplorer trained a vision transformer model [27] in motor imagery classification. Team HDU-HDUxianfengdui used filter bank common spatial patterns and linear discriminant analysis in classification. Team XDU-ERP employed PSD features and linear discriminant analysis in recognition. Hust-BCI calculated normalized covariance matrices and projected them in the tangent space, and then an SVM classifier was trained. Team WYU-BrainStorming employed max normalization and a 4–40 Hz bandpass filter in preprocessing and EEGNet in classification.
6 Conclusion
In this study, we reviewed the algorithms applied in the Algorithm Contest of Calibration-free Motor Imagery BCI in the BCI Controlled Robot Contest in WRC 2021. Although various methods of feature extraction and classification algorithms for MI-EEG recognition were applied in the contest, four of the top five teams in the final used CNN models. This reveals that with the rapid development of deep learning, convolutional neural network-based models achieving feature extraction and classification in an end-to-end framework have become the most popular methods in the field of MI-BCI. The CNN model usually applies a channel-wise convolution layer first and a time-wise convolution layer subsequently, which is an important difference between EEG-based CNNs and image-based CNNs. The specific data augmentation method of EEG signals is of great help in CNN model training, such as sliding windows, twin EEG signals, and opposite EEG signals.
As mentioned in Section 3.1, the time length of EEG applied in recognition instead of the time length of a whole trial acts as the information transfer time in this contest, leading to ITR being too sensitive to the length of EEG applied. The participants must reduce the length of EEG applied to approximately 0.5 s to gain a higher ITR, which is too short for classification. In addition, the summation or average of ITR for each subject may lead to unfairness. In our opinion, higher precision should be encouraged in MI-BCI, and the actual ITR or kappa value [28] may be a better measurement.
Footnotes
Conflict of interests
All contributing authors report no conflict of interests in this work.
Funding
This work is supported by the National Natural Science Foundation of China (Grant Nos. 61906152 and 62076198), and Key Research and Development Program of Shaanxi (Program Nos. 2021GY-080 and 2020GXLH-Y005)
Authors’ contribution
Jing Luo designed the study, Qi Mao drafted the manuscript, Yaojie Wang performed the experiments, and Zhenghao Shi and Xinhong Hei analysed the results.