
Abstract
Regression models are routinely used in many applied sciences for describing the relationship between a response variable and an independent variable. Statistical inferences on the regression parameters are often performed using the maximum likelihood estimators (MLE). In the case of nonlinear models the standard errors of MLE are often obtained by linearizing the nonlinear function around the true parameter and by appealing to large sample theory. In this article we demonstrate, through computer simulations, that the resulting asymptotic Wald confidence intervals cannot be trusted to achieve the desired confidence levels. Sometimes they could underestimate the true nominal level and are thus liberal. Hence one needs to be cautious in using the usual linearized standard errors of MLE and the associated confidence intervals.
1. INTRODUCTION
Linear and nonlinear statistical models are widely used in many applications to describe the relationship between a response variable Y and an explanatory variable X. A statistical model is said to be linear if the mean response is a linear function of the unknown parameters, otherwise it is said to be a nonlinear model. For example, in the context of fertilizer trials the mean yield of corn is sometimes modeled as a function of dosage X by the quadratic function

The above model is linear in the unknown parameters a, b and c. In animal carcinogenicity studies and risk assessment, often researchers model the mean response to different doses X of a chemical by the following Hill model (Kim et al., 2002, Portier et al., 1996, Walker et al., 1999):

where a represents the baseline response, a + b denotes the maximum response, c denotes the ED 50 (i.e. effective dose corresponding to 50% of the maximum response from the baseline response) and d is the slope parameter. Since some of the parameters enter the above model nonlinearly this is a nonlinear model.
One of the purposes of fitting regression models is to draw inferences on unknown parameters, or their functions, which have some physical interpretation. For example, in the case of fertilizer trials a researcher is often interested in estimating the “optimum dose” which maximizes the corn yield. From the above quadratic function, this parameter is given by b/c, a nonlinear function of the regression parameters b and c. In the case of animal carcinogenicity studies, in addition to estimating a, b, c and d, researchers are often interested in estimating the effective dose corresponding to e % of the maximum response from the baseline response. This parameter is denoted by EDe. Typical parameters of interest are ED 01 and ED 10 (Portier et al., 1996, Walker et al., 1999), which are nonlinear functions of a, b, c and d.
A key step in the statistical inference on unknown parameters of a model is to compute the standard errors of various estimates. If the statistical model is either nonlinear or the parameter of interest in a linear model is a nonlinear function of the regression parameters, then the approximate standard errors are usually derived by using the first order term in a suitable Taylor's series expansion. Once the approximate standard errors are obtained the Wald type confidence intervals such as those given in (3), (4) (see the Appendix) are derived. Such confidence intervals are used very extensively in applications.
Suppose θ is an unknown parameter of interest and suppose  is its MLE with standard error S.E. (
is its MLE with standard error S.E. ( ). The coverage probability of a (1 — α) × 100% confidence interval for a parameter θ, where zα is the suitable critical value, is described as follows. Suppose for each random realization of data one was to construct the above confidence interval, then the coverage probability of the confidence interval is the proportion of all such intervals that contain the true parameter θ. A confidence interval is said to be accurate if (1 — α) × 100% of all such intervals contain θ. A confidence interval formula is said to be liberal if its coverage probability is less than (1 — α) and is said to be conservative if its coverage probability exceeds (1 — α).
). The coverage probability of a (1 — α) × 100% confidence interval for a parameter θ, where zα is the suitable critical value, is described as follows. Suppose for each random realization of data one was to construct the above confidence interval, then the coverage probability of the confidence interval is the proportion of all such intervals that contain the true parameter θ. A confidence interval is said to be accurate if (1 — α) × 100% of all such intervals contain θ. A confidence interval formula is said to be liberal if its coverage probability is less than (1 — α) and is said to be conservative if its coverage probability exceeds (1 — α).
Under some conditions on the linear model the Wald confidence intervals (3) and (4) are accurate when the parameter of interest is a linear function of the regression parameters. However, if the parameter is either a non-linear function of the regression parameters or if the model is a nonlinear model, then they are not necessarily accurate, unless the sample sizes are “very large”. Basically the large sample theory confidence intervals are derived by “linearizing” the nonlinear function. This is accomplished by approximating the function by the first order derivative term in the Taylor series expansion of the nonlinear function. Hence for (3) and (4) to be accurate it is important that the second and higher order terms in the Taylor series expansion are “negligible” in comparison to the first order term. The effect of the second order term is known as the “curvature effect.”
The purpose of this article is to demonstrate through computer simulations that, in some instances, the standard error of the MLE based on the above linearization process can be a severe underestimate of the true standard error of the MLE. Consequently, (3) and (4) can be liberal and are not trustworthy. As an alternative, we consider confidence intervals based on the sandwich estimator of the covariance matrix of MLE introduced in Zhang (1997) and Zhang et al. (2000a). We notice that, to some extent, the intervals based on Zhang et al. (2000a) methodology correct this problem.
A second problem that is often associated with nonlinear regression analysis is the numerical computation of maximum likelihood estimates. Usually the computation of MLE is based on an iterative process that requires carefully chosen initial starting points to avoid convergence to local optima. Depending upon the nonlinear function this can be a challenging problem. For a good description regarding this issue one may refer to Ratkowsky (1990). Usually it is highly recommended to apply the iterative process by choosing a large number of starting points and choose the best solution among all such solutions. It is important to note that a poor approximation to the true MLE may result in a poor estimate of the standard error, thus compounding the previously mentioned concern regarding the estimation of standard errors.
All notations and formulas are provided in the Appendix of the paper.
2. ESTIMATION OF STANDARD ERRORS AND CONFIDENCE INTERVALS
2.1 Curvature effects and the coverage probability problem
Several authors have noted that the “usual formulas” underestimate (or overestimate) the true standard errors of the estimates of parameters in a nonlinear model. This results in very high (or very low) false positive rates when performing test of hypothesis and liberal (or too conservative) confidence intervals. That is, the confidence intervals could be too narrow or too wide. For example, Simonoff and Tsai (1986) performed extensive simulation studies using three different nonlinear models to demonstrate that the true coverage probability of the confidence regions (3) and (4) can be much below the desired nominal levels. In some cases, when there are no outliers present, the coverage probability can be as low as 0.75 for a 95% nominal level and the coverage probability can drop to about 0.149 when outliers are present. A similar phenomenon was also observed in Zhang (1997) and Zhang et al. (2000a) for several growth and hormone models for boys during puberty. A consequence of these liberal confidence intervals is a very high false positive rate in the context of testing hypotheses. Thus the P values based on such standard errors can be smaller than the true P values and hence a researcher a may declare significance even though there is no significant effect.
Several authors such as Bates and Watts (1988) and Ratkowsky (1990) have discussed the effect of curvature on the accuracy of (3) and (4). A very detailed investigation of these effects is provided in these books. The curvature effects can be decomposed into two components, the intrinsic effect γ N max that is due to the shape of the response function, and the parametric effect γ P max that is due to the functional form of the parameters. Smaller the values of γ N max and γ P max, lower the curvature effects. Estimators for these two parameters along with a simple F test to detect the severity of the two curvature effects can be found in Ratkowsky (1990) and in Seber and Wild (1989). Let

where Fα,p,n– is the (1 — α)th percentile of central F distribution with (p, n — p) degrees of freedom. If the estimated value of γ N max (γ P max) < c* then it suggests that the intrinsic (parametric) curvature effect is not significant.
If the intrinsic curvature is severe then one may want to consider an alternative nonlinear model to describe the dependence of Y on X. On the other hand, if the parametric curvature is severe then one may reparameterize so that the resulting parametric form is subject to less curvature effect. A potential drawback with this solution is that although the parametric curvature may be reduced due to re-parameterization, the experimenter may find the new parameters difficult to interpret. Thus it is often a challenge to analyze data using nonlinear statistical models. Either the parameters have good physical interpretation but hard to perform inferences on or the parameters resulting from re-parameterization are difficult to interpret but easy to perform inferences on!

Based on an experimental data discussed in Seber and Wild (1989) the authors concluded that the intrinsic curvature in the above function is not very severe but the parametric effect curvature is very severe. For this reason they re-parameterized the model as:

Under this re-parameterization it is reasonable to perform statistical inferences on c and d using the standard methods.
Simonoff and Tsai (1986) performed very extensive simulations studying eight different jackknife based methods some of which “adjust” for the curvature. They found that the jackknife confidence interval centered at the average of the pseudo-values  (see (9) in the Appendix) for the covariance matrix of MLE. Based on simulation studies involving nonlinear models for growth curve, growth hormone and testosterone for boys during puberty, Zhang (1997) found that the confidence intervals based on (6) perform better than those based on RLQM in terms of the coverage probability.
(see (9) in the Appendix) for the covariance matrix of MLE. Based on simulation studies involving nonlinear models for growth curve, growth hormone and testosterone for boys during puberty, Zhang (1997) found that the confidence intervals based on (6) perform better than those based on RLQM in terms of the coverage probability.
2.2 A simulation study
Since the Hill model (2) is widely used in the context of animal carcinogenicity studies and in the risk assessment of various chemicals we base our simulation studies on this model. In this subsection we demonstrate that the Wald confidence intervals (4), denoted by C MLE , can sometime be liberal for some individual parameters. We only provide simulation results for (4) because in view Simnoff and Tsai (1986) and Zhang (1997) the results are expected to be even worse for (3). We compared the coverage probabilities of C MLE with the coverage probabilities of the confidence intervals introduced in Zhang (1997) and Zhang et al. (2000a), which are denoted as CZ. For simplicity we take the baseline response to be zero and hence consider the following 3-parameter Hill model:

where i = 1, 2, 3, 4, 5, j = 1, 2, …, m, and the random errors ε ij are identically and independently distributed as standard normal variables. To understand the effect of sample size on the coverage probabilities, we considered several different patterns of m, the number of animals at each dose group. In this article we report results corresponding to m = 3 (small sample size), m = 10 (moderately large sample size), and m = 20 (a large sample size). As in Walker et al. (1999) the five dose groups considered in this paper are (0, 3.5, 10.7, 35.7, 125).
We considered 5 different patterns of parameters for the Hill model (see Figure 1) with different amounts of curvature effects. In addition to summarizing the coverage probabilities for the two methods of confidence intervals for each of the parameters, in Table 1 we also provide the median of the estimated curvature effects for each pattern based on 1000 simulation runs and the value of c* for each m. We estimated the two curvature effects using the FORTRAN code provided in Ratkowsky (1990). All minimizations were performed using the subroutine AMOEBA provided in Press et al. (1989) with several initial starting values for performing the minimization.
Comparison of the coverage probabilities of C MLE and C Z .
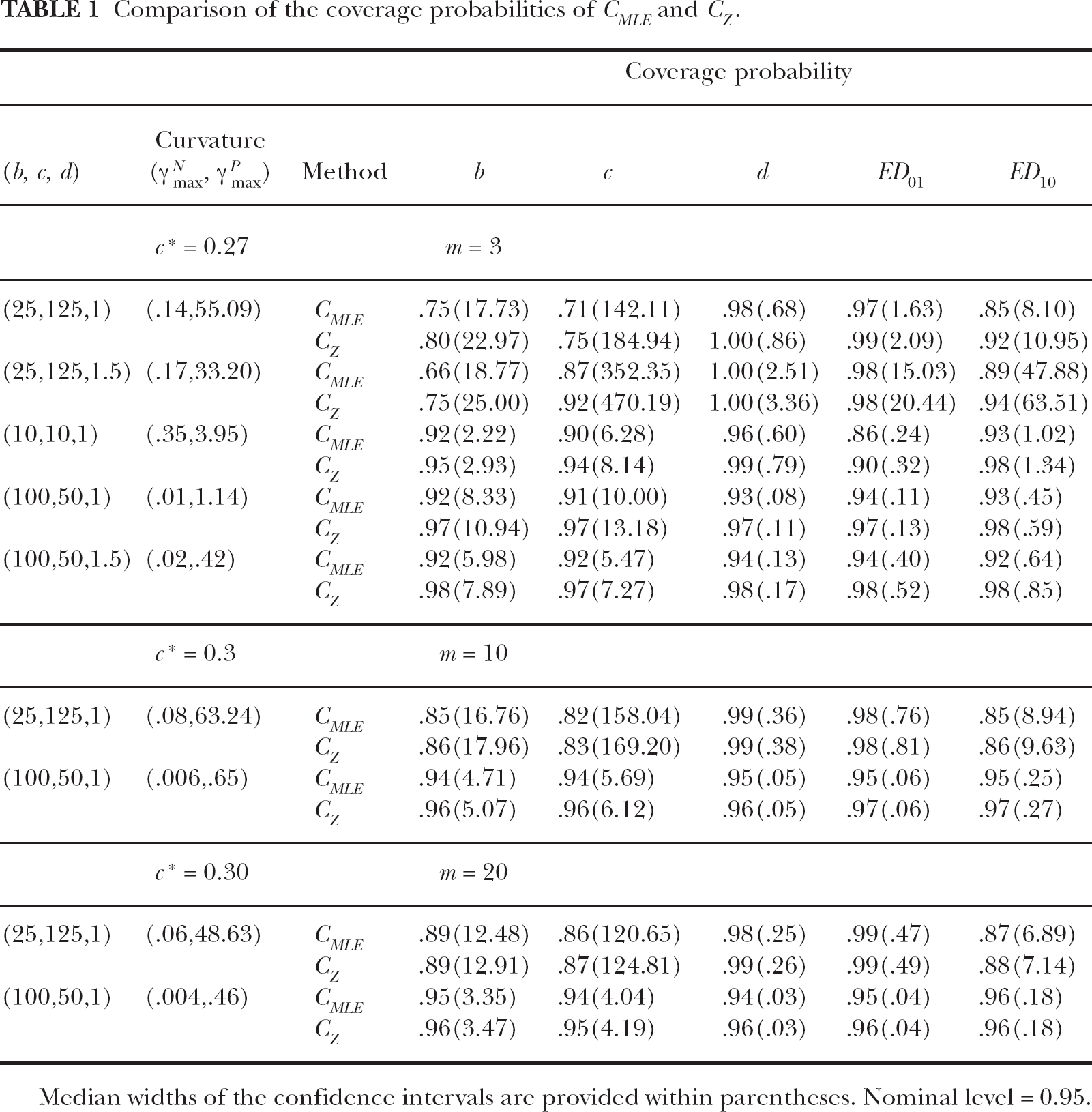
Median widths of the confidence intervals are provided within parentheses. Nominal level = 0.95.

Hill model for different patterns of parameters.
We note from Table 1 that, apart from the case of (b, c, d) = (10, 10, 1), there are no serious intrinsic curvature effects but there can be severe parametric curvature effects. In the case (b, c, d) = (10, 10, 1) the median of the estimated value of γ N max = 0.35 which exceeds c* = 0.27. In this situation we notice that ED01 cannot be estimated with accurate standard error. The coverage probability of MLE is only 0.86, which is much smaller than the nominal level of 0.95. The remaining parameters appear to be estimated reasonably well by the MLE. The method of Zhang et al. (2000a) seems to improve the coverage probability.
Both, MLE as well as Zhang et al. (2000a), procedures are affected by the severity of the parametric curvature effects. Of the two methods, the methodology of Zhang et al. (2000a) performs better. In the worst case when m = 3 and (b, c, d) = (25, 125, 1) both procedures perform very poorly for estimating the parameters b, c and ED10, although the procedure of Zhang et al. (2000a) is better. As the sample size per dose group increases from m = 3 to m = 20 the parametric curvature effects decrease and hence the coverage probabilities tend to improve. When there is very little parametric curvature effect the methods tend to attain the nominal level of 0.95. However, as in the case of (b, c, d) = (25, 125, 1), when the parametric curvature effect is large the convergence to the nominal level is very slow. Even with a sample of size 20 per group we do not seem to attain the nominal level of 0.95. Among the five parameters, the slope parameter d is often estimated conservatively, the coverage probability usually exceeding the nominal level of 0.95. On the other hand the rest of the parameters are often estimated liberally. The worst affected parameters are the maximum of the Hill model, i.e. b, the ED50, i.e. c, and ED10.
3. CONCLUSIONS
Statistical analysis of nonlinear regression models are routinely performed in applied sciences using the standard asymptotic methods which are based on linearization of the nonlinear model around the unknown parameter. Often data analysts and researchers do not pay attention to the some of the subtle assumptions underlying such analysis. As evidenced in the simulation studies reported in this paper and in Simnoff and Tsai (1986), this may result in underestimation of the standard errors and extremely high false positive rates and liberal or narrow confidence intervals. Consequently, one cannot trust the results obtained from such analyses.
The purpose of this article is to caution researchers and data analysts against the potential problems with nonlinear models. Although at the moment there is no satisfactory methodology for estimating standard errors of MLE, the methodology proposed in Zhang (1997) and in Zhang et al. (2000a) is perhaps an improvement over the existing procedure.
The problem is further complicated if there is heteroscedasticity in the data (i.e. variance of Y is not constant over all observations). In such situations EPA's BMD software (USEPA, 2001) uses the method of maximum likelihood estimation by modeling the variance of Y as a power function of the mean of Y. Although this is a common practice, it can potentially introduce bias due to model mis-specification. As an alternative to this procedure, Zhang (1997) and Zhang et al. (2000a) introduced the sandwich estimator (10) for the covariance matrix of MLE, which is asymptotically consistent. This estimator is based on a procedure developed in Peddada and Smith (1997) for the covariance matrix of the MLE in a linear model with heteroscedastic errors. Some optimality and asymptotic properties of this procedure are discussed in Peddada (1993) and Peddada and Smith (1997). Thus as an alternative to the procedure used in EPA's BMD software [15] one may derive the standard errors of MLE using (10) and obtain the corresponding asymptotic confidence intervals.
Given the extensive usage of nonlinear models in practice we believe there is a need for further methodological work in this field. Perhaps one may want to explore Bayesian methods that do not rely on linearization of the nonlinear model.
Footnotes
ACKNOWLEDGEMENTS
The authors thank Drs. Beth Gladen (NIEHS), David Umbach (NIEHS) and Joanne Zhang (FDA) for carefully reading this manuscript and making several comments that substantially improved the presentation of the manuscript.
APPENDIX
In a nonlinear regression model
Let V̂ denote the standard asymptotic covariance matrix of , V̂′
i
denote the ith row vector of V̂ and let V̂.. be an n×p×p second derivative array where v
ist
= ∂2ƒ (
The standard MLE based asymptotic (1 — α) × 100% confidence region for the parameter is given by (see Seber and Wild, 1989)
where is proportional to the maximum likelihood estimator of σ2, F α,p,n– is the (1 — α)th percentile of central F distribution with (p, n — p) degrees of freedom. The corresponding confidence intervals for individual components θ i are obtained by
where tα/2, n– is the (1 — α/2)th percentile of central t distribution based on n — p degrees of freedom and V̂ ii is the ith diagonal element of V̂.
A variety of jackknife procedures have been considered in the literature (Fox et al., 1980, Simnoff and Tsai, 1986). In particular, Simonoff and Tsai (1986) considered eight different jackknife procedures to construct confidence intervals. Their RLQM procedure, which uses the Box and Coutie (1956) modification of the covariance matrix of MLE for dealing with curvature effects, is based on the following pseudo-values:
where ĥ
ii
= V̂′
Here , and ĥ*
ii
= V̂′
i
and a jackknife point estimator of the covariance matrix is given by
As an alternative to the above methodology, Zhang (1997) and Zhang et al. (2000a) proposed a class of sandwich estimators that are based on the estimators introduced in Peddada (1993), Peddada and Patwardhan (1992), and in Peddada and Smith (1997) for linear models.
For homoscedastic errors, i.e. Var(Y i ) = σ2, Zhang (1997) and Zhang et al. (2000a, 2000b) considered the following sandwich estimator for estimating the covariance matrix of
where
where ε ij are i.i.d. with E(ε ij ) = 0 and Var(ε ij ) = σ2 i. Then Zhang et al. (2000a) proposed the following class of variance estimators:
where δii is some function of TrV̂′ i (V̂′ V̂)−1 V̂ i such that δii → 0 as is a ni × p matrix of partial derivatives of with respect to θ, and with .
Zhang et al. (2000a) deduced the asymptotic properties of the above estimators along the lines of Shao (1990, 1992).