
Abstract
Current fashion image searching technology based on fine-grained fashion recognition on fashion images has recently achieved great success in online shopping. However, this technique is limited to a single domain—real product images—and thus is inflexible. Recognition and search performance are degraded to a large extent when the distribution of the target data is different from the source training data. To improve the flexibility of fashion image retrieval, we propose multi-domain fashion image recognition in this work. We firstly established Fashion-DA, a large-scale fashion dataset comprising 14 fashion categories and a total of 13,435 images originating from three domains. Then, we propose an unsupervised domain adaption approach based on adaptive feature norm to handle data with different feature distributions. The experiment evaluated the effectiveness of the proposed method.
Keywords
Introduction
Recent studies1–8 in cross-domain fashion image retrieval have achieved satisfying results and been widely applied in our daily life, such as in the “street-to-the-shop” application. Thus, current studies in cross-domain fashion image retrieval (except for some research6–8 that focused on shoe sketch images) focused on real products in different scenarios (e.g., street and online images). However, this method has a limitation: when we do not obtain the desired photo (i.e., it is not always convenient for us to take a picture of other people on the street). In fact, there are many other expression formats, such as hand-drawn and sketch images, that could be used instead of the real photo. As shown in Fig. 1, imagine a scenario: a designer wants to check if his or her new design work already exists or not, or a customer wants to find a fashion item in his or her own mind without any real captured photos, how can a simple hand-drawn image be used to find the real fashion products?
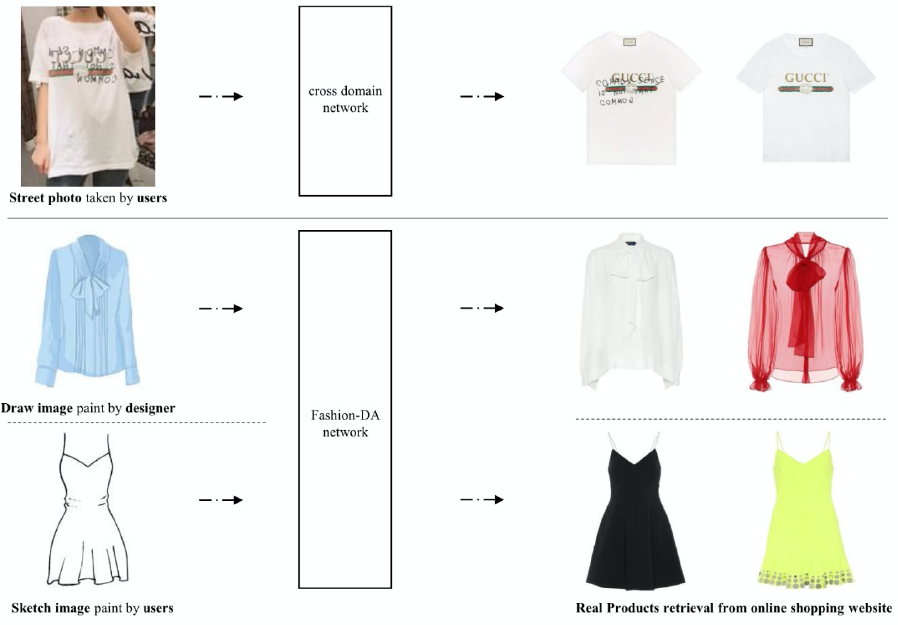
The first line is current mainstream fashion cross-domain network designed for the street-to-the-shop task. The second and third lines are the application scene that the Fashion-DA was built for.
Different from previous cross-domain retrieval (i.e., street-to-the-shop), the aim of this work is to realize fashion image recognition in multiple domains. Since there is no available dataset that could satisfy our interests, we build a fashion dataset, namely Fashion-DA, for fashion recognition in multiple domains.
Dissimilar Domains
Different from previous cross-domain datasets1,4,9 (including online product images and street photos) in fashion, we added hand-drawn (D), sketch (S), and online product images (P) together to build the Fashion-DA dataset.
Scales
The categories cover all the main products in fashion: tops, trousers, pullovers, dresses, coats, sandals, shirts, sneakers, bags, ankle boots, skirts, and jumpsuits (note that the first ten categories are consistent of those included in Fashion-MNIST 10 ). The whole Fashion-DA dataset contains 13,435 images, of which 5673 images are hand-drawn, 1431 are sketch images, and 6331 are online product images.
Availability
The Fashion-DA database will be openly accessible to the public for research use. We expect that this dataset could serve for benchmarking domain adaptation (DA) algorithms.
Transfer Tasks
Meanwhile, in the Fashion-DA dataset, two new transfer tasks of fashion recognition are proposed:
DTP. A designer creates new design work, and they can see the ready-to-wear version from the retrieved real products.
S → P. A customer does not have the photo of the products he or she wants, but they can search the products by sketch images.
We believe that the two tasks can further enhance the fashion image retrieval systems.
DA Methods
Generally, the ability to generalize across datasets that share similar characteristics, such as classes, but also present different underlying data structures is important. DA11–14 attempts to find an isomorphic latent feature space. The inner sample from this feature space is hard to distinguish from the source domain or the target domain. This approach could solve the domain shift problem in fashion image retrieval, since it enables the model to transfer knowledge from different domains with some shared characteristics, such as categories, but with different distribution features.
Existing DA methods can be roughly divided into three types, including supervised domain adaptation (SDA),15–17 semi-supervised domain adaptation,18–20 and unsupervised domain adaptation (UDA),21–24 based on the label situation in the target source. Generally, SDA outperforms UDA because UDA algorithms do not have any target labeled data (it is possible that the target training samples are not available).
However, the above approaches are performed on general datasets related to animals and transportation office supplies (e.g., Office-31, 25 VisDA2017, 26 and ImageCLEF-DA 27 ). In other words, previous DA methods are not suitable for fashion images. To solve this problem, we propose an unsupervised domain adaptation approach based on the feature norm 28 to perform our proposed application scenes and demonstrate the advantages of Fashion-DA.
Summary
We summarize our contributions as follows:
We built a fashion dataset for fashion recognition in multiple domains with over 13,435 images, namely Fashion-DA. The results of the state-of-the-art DA algorithms as the benchmark in the proposed Fashion-DA dataset are also presented.
We propose an unsupervised DA approach based on feature-norm to deal with the two transfer tasks specifically for fashion.
Related Work
Cross-Domain Datasets
We summarized the cross-domain dataset into two parts: the mainstream datasets that are commonly adopted in testing DA algorithms, and the cross-domain dataset for fashion image retrieval tasks.
The mainstream datasets for object recognition based domain adaptation are COIL, 29 Office-31, 25 Office-Caltech, 21 Office-Home, 30 VisDA2017, 26 and ImageCLEF-DA. 27 Note that these datasets are not related to fashion.
On the other hand, there are some cross-domain datasets for fashion recognition. The most typical are the street- to-the-shop datasets (including two domains: online product images and real-world images), such as Deep Fashion, 9 WITB, 5 and FashionAI. 31 This kind of dataset is large enough, with rich attribute annotations, but only covers two types of domains with similar feature distributions. Additionally, there are some datasets7,32,33 including domains (sketch images and product images) with greater differences. However, all of them are related to shoes and bags.
Unlike the datasets summarized above, we created a dataset with many different domains across more comprehensive fashion categories.
DA Approaches
To mitigate the generalization bottleneck and bridge different distributions, extensive studies have been conducted on DA.12,34–38 Some existing approaches39,40 attempted to align feature spaces by exploiting shift-invariant information to match the target domain with the source domain. Meanwhile, from the perspective of deep learning, some methods18,22,41–44 adopted Maximum Mean Discrepancy (MMD) and association-based losses.
Most recently, major developments45–48 focused on exploring adversarial learning to reveal feature distribution in different domains. Part of adversarial domain adaptation methods was applied to adversarial losses in the feature space. Meanwhile, some methods have introduced adversarial loss in the pixel space. Liu et al. 45 introduced CoGAN to train two generative adversarial networks (GANs) that could generate images as similar as the source and target, respectively. Additionally, Hoffman et al. 49 used the CycleGAN 50 to solve the problem of semantic segmentation.
The approach we propose in this work follows this direction to present a novel learning paradigm from the perspective of an adaptive feature norm which targets the fashion domain.
Fashion-DA Dataset
We developed the Fashion-DA dataset with three types of domains to solve the domain shift problem in fashion recognition and to serve as the benchmarking dataset for testing the performance of DA algorithms.
The proposed dataset embeds several properties. First, it targets the fashion recognition task. Fourteen categories, including tops, trousers, pullovers, dresses, coats, sandals, shirts, sneakers, bags, ankle boots, jumpsuits, skirts, sunglasses, and hats cover all main fashion items. Second, it contains three types of domains with dissimilar feature distributions to provide a more comprehensive dataset for benchmarking.
DA Algorithms
The samples of 14 categories from three domains in the Fashion-DA dataset are shown in Fig. 2 from the three domains, including drawing, sketch, and real product. Meanwhile, each type contains at least 500 images and the total number of images is 13,435. Details can be found in Table I.

Samples of 14 categories in the Fashion-DA dataset from three domains including drawing (1st column), sketch (2nd column), and real product (3rd column).
Image Numbers of the 14 Categories in the Fashion-DA Dataset
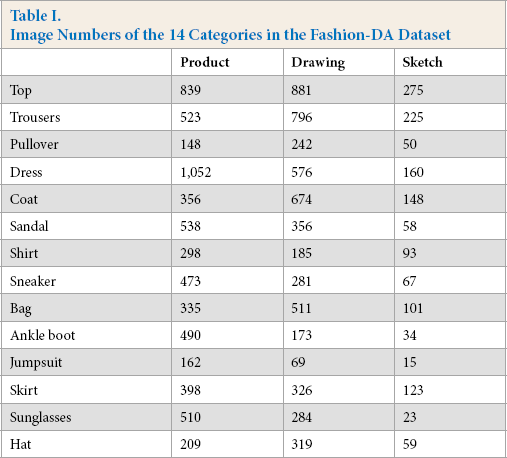
The detailed numbers of images for the 14 categories are shown in Fig. 3. Obviously, the three domains in Fashion-DA are imbalanced. The quality of some collected images in different categories (e.g., trousers, dresses, and coats) was low, which makes categorization more difficult (note that the sketches in this dataset were not asymmetric and were out of proportion).
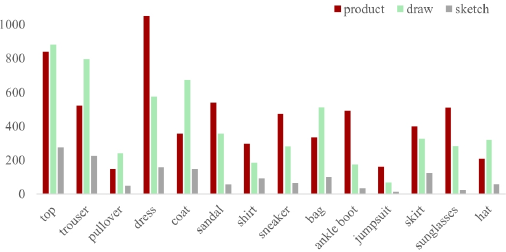
Image numbers of the 14 categories in the Fashion-DA dataset.
Our Approach
To perform the proposed application scenes and demonstrate the advantages of the Fashion-DA database, 28 we used an adaptive unsupervised DA algorithm based on augmented feature norms. Generally, the traditional domain adaptation can be formulated as follows.
Given a source domain
Generally, there are two types of settings, including the vanilla setting (which we focused on in this study) and the partial setting in DA. The partial setting means that the source label space subsumes that C s ⊂ C t . The source labeled data are not related to the target task. The vanilla setting refers to the standard unsupervised DA that has been extensively explored. Specifically, in this setting, the source and target domains share the identical label space (i.e., C s = C t ). Adversarial learning-based methods under the vanilla setting are vulnerable to the negative transfer effect in the disjoint label space C s \C t . Considering the specific target of the fashion domain in this study, the proposed approach is independent of the association between label spaces of the two domains.
Regarding the definition of Maximum Mean Discrepancy, 51 as Norm is a non-negative valued scalar function, we instantiated the function class to be the L2-norm function with deep neural network function and define Maximum Mean Feature Discrepancy (MMFND) between source and target domains in Eq. 1.
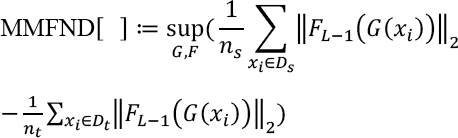
Where n are images from source domain, F l (G(x)) = F(l) (Fl-1(G(x))) and F0(G(x)) = G(x). G and F correspond to the backbone network and classifier in our framework, respectively. Specifically, G is defined as a general feature extraction module inherited from the prevailing neural network architecture. F is presented as a task-specific classifier that has L fully connected layers. p (l) (·) represents the l-th layer operation of the F. The first L - 1 layers of the classifier F we call the bottleneck, noted as FL-1. Those features computed by F depend on the specific domain. Meanwhile, it cannot ensure that it can be transferred to a new domain. Thus, we calculated the class probabilities along the last layer, which was followed with a SoftMax operation.
Next, we considered an FL-1 that can generate the task specific feature embedding. Based on the vector of logits computed by F, we further calculated the class probabilities by applying the SoftMax function. The class probabilities is denoted as p(y|x).
Based on the analysis of the characteristics of the fashion images and testing results of the proposed method, the traditional feature selection method was better than the analysis of feature importance when the dataset obtains non-mass samples. Generally, feature selection is used to preprocess the input. This means it is isolated from the training process. Thus, the number of features selected needs to be artificially set. However, such a situation can easily decrease the models ability to handle overfitting and generalization.
For multi-domains retrieval, we focused more on the generalization ability of the model. Thus, in this work, we augmented the G by combining the traditional feature selection approach with the evaluation of features together into the training process of the deep neural network. Then, similar to the attention mechanism, we forced the neural network to be faster and better focused on information-rich features, which avoid the influence of irrelevant redundancy feature.
To this end, as stated in Eq. 2, we introduced an additional feature selection layer in the traditional neural network model (e.g., AlexNet, 52 GoogleNet, 53 ResNet, 54 and DenseNet). 55
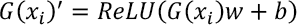
The weight Wm×1 is multiplied by the corresponding input feature Xn×m to multiply the elements. The weight from Eq. 2 is mainly used to scale the input features. Then, we used the ReLU to truncate the scaled feature. And the bias is denoted as the threshold of feature selection.
The deep neural network optimizes w and b, and plays a role as an adaptive selection of input features. Next, we initialize W to the evaluation value of traditional feature selection. The feature selection layer is based on the evaluation value of the featured item. It can enhance or weaken the influence of certain features on the network training by the proposed framework; the traditional feature selection method and the input feature are scaled.
Meanwhile, inspired by the success of GANs, similar to the current mainstream operation, we optimized the upper bound in a two-player adversarial manner. Specifically, we replaced sup in Eq. 1 with the max operator and apply the min operator with respect to F and G respectively and obtained Eq. 3.
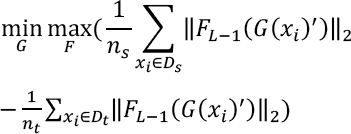
However, in our case, this kind of operation lacks explicit interpretability for adversarial behavior. It may lead to the random walk in the feature space, and then makes it a failure to adapt the source and target samples at the semantic level.
Similar to the idea in a reference, 28 the L2-norm of a vector can be regarded as the radius from the hypersphere origin to the vector point. Based on this, we constructed an equilibrium and a large radius R to bridge the gap between source and target domains. The obtained feature norm objective is given in Eq. 4.
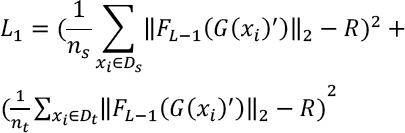
Eq. 4 minimizes the MMFND, since we strictly limited the mean feature norms of source and target domains converging to R. Different from the common alignment method in the adversarial feature, the objective was to optimize Eq. 4 by giving the existing intermediate variable R. This is because the functions class are rich enough to contain substantial positive real-valued functions on the input x. Meanwhile, if there is no restriction on the function, the upper bound would greatly deviate from zero. Specifically, considering the fashion image feature, we replaced the R in Eq. 4 with Δr, which refers to the residual feature norm. This operation is expected to add the instance information into the network. Then, Eq. 4 can be rewritten as Eq. 5.
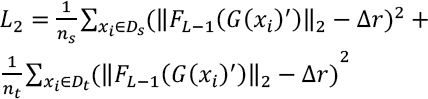
Additionally, the supervised source domain classification loss can be written as Eq. 6.
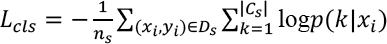
Finally, we obtained the learning objective in Eq. 7, where λ and β are variable weights.
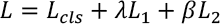
Experiments
To evaluate the effectiveness of our proposed feature norm-based approach (compared with state-of-the-art DA methods), we first conducted experiments on two widely-used domain adaptation benchmark datasets. Then, we listed the results of those approaches (the state-of-the-art methods and our proposed method) on the Fashion-DA datasets as the baselines. The adaptation results are analyzed in detail. Finally, we show a potential application based on the proposed transfer task (i.e., StP) to demonstrate the practical value of this work.
Setup
Along with the Fashion-DA dataset, we also obtained several general datasets for evaluating DA approaches to demonstrate the effectiveness of the proposed method.
Office-31
Office-31 25 comprises 31 categories in an office environment. It contains a total of 4652 images from three domains including: Amazon (A), Digital Simple Lens Reflex (DSLR) (D), and Webcam (W). Those domains contain online website images, digital SLR camera images, and web camera images, respectively. A total of six transfer tasks as A → D, D → A,…, W → A could be conducted.
ImageCLEF-DA
ImageCLEF-DA 27 is a balanced dataset in which each domain obtains the same number of images in the same category. It contains a total of 12 common categories. The images are collected from Caltech-256 (C), ImageNetlLSVR-C2012 (I), and Pascal VOC 2012 (P). A total of six transfer tasks as C → I, I → C,…, C → P could be conducted.
Similar to the literature, 28 we followed the standard protocol42,43,48 with the vanilla setting. All labeled source samples and all unlabeled target images that belong to the corresponding target label space were used.
Method Comparisons
We compared the proposed method with state-of-the-art deep learning and domain adaptation approaches ResNet-50, 54 Domain-Adversarial Neural Networks (DANN), 48 Deep Adaptation Network (DAN), 43 Conditional Domain Adversarial Networks (CDAN), 56 Hard Adaptive Feature Norm (HAFN), and Instance Adaptive Feature Norm (IAFN). 28
We conducted our experiments on the PyTorch platform and fine-tuned ResNet-50 pretrained on ImageNet. 57 The same as the general operation, we adopted a unified set of hyper-parameters throughout the Office-31 and ImageCLEF-DA databases. The mini-batch SGD with a momentum of 0.9 and a learning rate decay of 0.001 was used for the classifier and backbone network. All experiments were repeated three times and the average accuracy with the standard deviation are presented.
Results
The classification results under the vanilla setting for the Office-31, ImageCLEF-DA, and proposed Fashion-DA datasets are presented in Tables II–IV respectively. Reported accuracies of those compared methods (e.g., DAN 43 and DANN 48 ) are directly cited from the corresponding papers. The performance of our proposed models outperformed the other benchmarked methods.
General DA Datasets
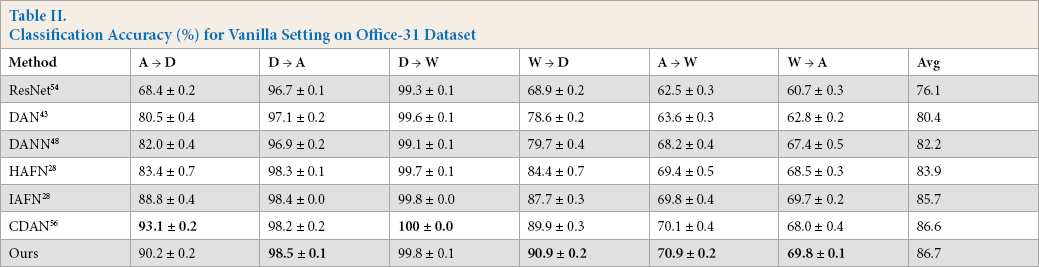
As shown in Table II, the proposed method achieved better performance in most transfer tasks on Office-31 (except A → D and D → W, note that our approach on these two tasks achieved comparable classification performance compared with the state-of-the-art methods). The proposed approach was the highest one on the average of classification accuracy of those six tasks.
Classification Accuracy (%) for Vanilla Setting on Office-31 Dataset
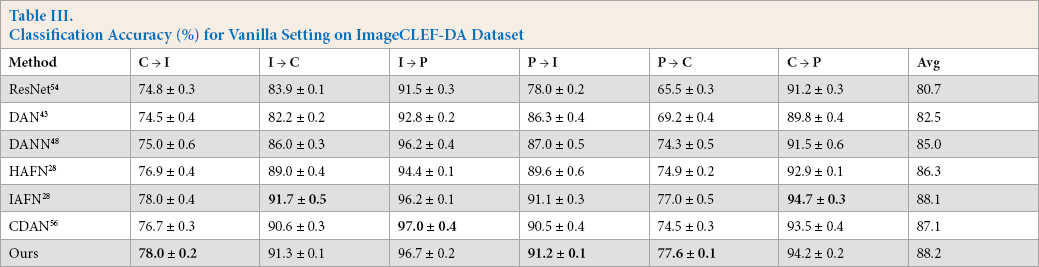
Additionally, as reported in Table III, the proposed method yielded better performance on the standard DA dataset ImageCLEF-DA. However, we can see that accuracy of the proposed method was lower than the highest one on I → C, I → P, and C → P. Specifically, IAFN 28 achieved a higher accuracy on I → C and C → P tasks. The main difference between our approach with IAFN is the defined R. The images in these two domains are more related to the central samples and therefore enjoy more sufficient information.
Classification Accuracy (%) for Vanilla Setting on ImageCLEF-DA Dataset
Application to Fashion-DA Dataset
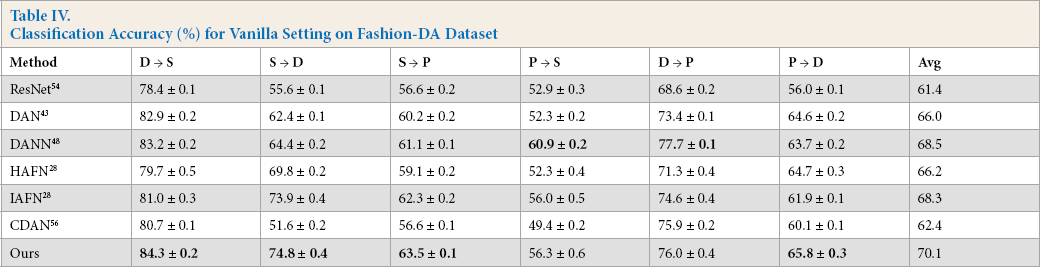
We also applied these approaches to the proposed Fashion-DA dataset. As indicated in Table IV, our method obtained consistently higher accuracy on most transfer tasks. The images in this dataset were specially collected from different fashion domains that were greatly different from the previous DA dataset. It was expected to serve as a benchmark dataset for evaluating DA algorithms from a different perspective.
Classification Accuracy (%) for Vanilla Setting on Fashion-DA Dataset
Feature Visualization
We visualized the t-SNE embeddings 58 of the features learned by HAFN, IAFN, and our approach on the Fashion-DA dataset (including the three transfer tasks: I → C, I → P, and C → P.) in Fig. 4 (with class information). It can be intuitively observed that features in the first row (source only on Fashion-DA) were mixed together. The second row (IAFN on Fashion-DA) and third row (HAFN on Fashion-DA) are indistinguishable, but the fourth row (our method on Fashion-DA) generated better visualization results. In other words, the proposed network obtained a clearer cluster compared with the other two methods.
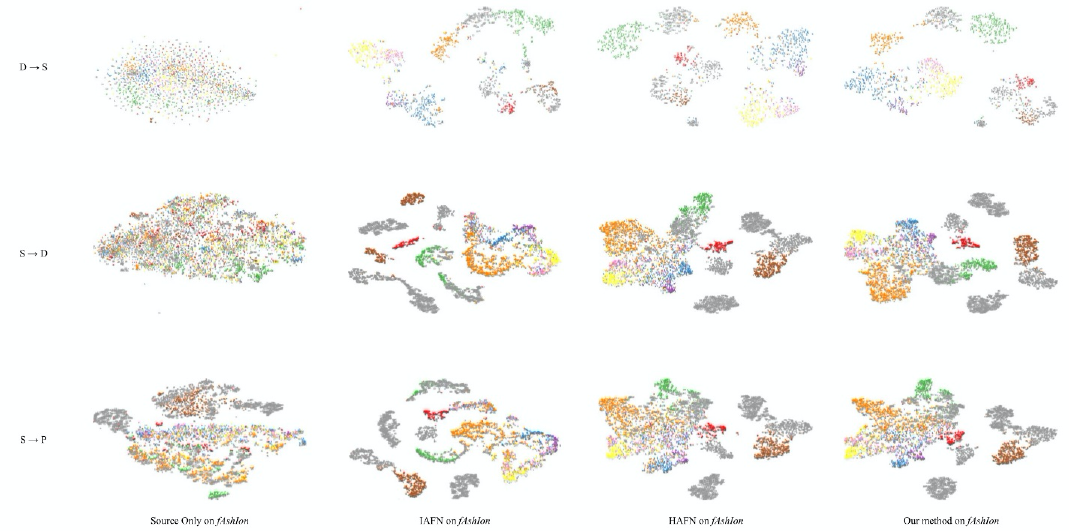
The t-SNE visualization of our proposed model, HFAN and IFAN on the Fashion-DA dataset.
Application
To demonstrate the practical value of the proposed method, we applied our method with a fashion image retrieval task (i.e., sketch-to-the-shop). This application scenario is based on the defined transfer task (i.e., S → P). The images of the retrieval dataset were collected from the Internet. The format of these images was similar to the trained data. Note that our model can recognize the category (but not the specific design attributes) of the trained dataset and, at the same time, achieve consistent performance on the retrieval dataset. As shown in Fig. 5, we present the top ten retrieval results among several categories, including hats, tops, skirts, and sandals. Our model successfully recognized the fashion categories in a different domain. The retrieval results for the same category were randomly ranked. On top of these results, we can further apply other features to conduct more specific retrievals. For example, we adopted the FOCO system 59 to rank the retrieval result by color. As shown in Fig. 6, the retrieval results are ranked according to the color of the fashion items and other pre-labeled attributes can be used as the filter.

Top ten retrieval results based on the proposed method.

Top five retrieval results based on the proposed method and ranked by the black color.
Conclusion
This paper presents Fashion-DA, a fashion recognition dataset in multiple domains. Fashion-DA contains 13,435 images covering 14 main fashion categories. The images have different distributions in three domains including sketch, drawing, and product images. It differs from the current cross-domain fashion dataset, which contains two domains, including street photos and online shopping websites. Our proposed dataset is targeted for application cases, such as from sketch to product and from drawing to product. To demonstrate the advantage of the proposed dataset, we designed a deep model, an adaptive unsupervised DA algorithm based on augmented feature norms, that outperformed state-of-the-art DA approaches among the Fashion-DA dataset and common DA datasets (Office-31 and ImageCLEF-DA). Meanwhile, Fashion-DA is also expected to serve as a benchmark for DA algorithms.
Footnotes
Acknowledgement
This project was supported by the research fund of The Hong Kong Polytechnic University (project code: RUWZ).